{kind=link}
Build a Search Engine with gensim using Topic Modeling: Latent Dirichlet Allocation and Latent Semantic Indexing
SEE: https://en.wikipedia.org/wiki/Latent_Dirichlet_allocation
SEE: https://radimrehurek.com/gensim/
REQUIRED: Python 3.6+
preprocess.pyaccepts a local CSV file as input- The CSV file can contain any number of documents or strings of arbitary length in a given column
preprocess.pywill automatically locate the column with the largest amount of text in terms of average words per cell in a given column- The 'largest' text column from the CSV is converted to a Pandas Series object and then passed through text preprocessing steps, including:
- stopword removal, using any number of custom stopwords, as well as the set of stopwords from:
sklearnnltkspacygensim
- lemmatization and stemming
- tokenization
- stopword removal, using any number of custom stopwords, as well as the set of stopwords from:
- The result of the preprocessing step is a pickled Pandas Series object: 'processed_docs.pkl'
- As an example, you can use a collection of Wikipedia articles. Download an example set here (10,000+ articles).
- Use
get_wiki.pyto download your own set of articles from Wikipedia, changing the list of top-level URLs from which to scrape articles (and those of articles linked within each of these documents). NOTE: Choosing ~24 generic topics, and recursing down one level to all linked articles, results in ~10,000 articles being downloaded.
train_model.pyaccepts a pickle-formatted file representing the preprocessed text- If you wish you can use the preprocessed
.pklfile produced from the samplewiki_df.csvfile linked above. Download this preprocessed set of Wikipedia articles here. - Example command:
python3 train_model.py 30 0.7 100000 20 2 2 processed_docs.pkl - This is loaded into memory and a dictionary is created using Gensim
- Subsequently, Topic Model training is initialized
- Hyperparameters can be defined by passing command-line arguments to
train_model.py, for example:dict_no_below = 30- no words appearing less than {n} times in the corpusdict_no_above = 0.70- no words appearing in more than {n}% of all documents in the corpusdict_keep_n = 100000- dictionary to be comprised of a maximum of {n} featuresnum_topics = 20- create a model with {n} topicsnum_passes = 2- perform {n} passes through the corpus during model trainingworkers = 2- use {n} CPU cores during model training- Recommended formula for
workers:$ echo "$(nproc) - 1" | bc - Using 2 or more CPU cores allows you to take advantage of LdaMulticore in Gensim.
- Recommended formula for
processed_docs = pd.read_pickle('processed_docs.pkl')- provide the name of a pickle-formatted file containing a Pandas Series object with preprocessed text
- The output of
train_model.pyis a list of topics that have been derived from the corpus of preprocessed documents. - The Gensim model files, state, and dictionary are saved to the current directory, as well as backed up to
./models/saved-model/, using the accompanying bash script:tar_model.sh.
- If you wish you can use the preprocessed
Example of Gensim LDA & TF-IDF model trained with 20 topics:
- Parameters used:
dict_no_below=30 dict_no_above=0.70 dict_keep_n=100000 num_passes=2 workers=2 - Filtered dictionary contains 13034 features
Topic #0: 0.005*"law" + 0.004*"confucian" + 0.004*"philosophi" + 0.003*"polit" + 0.003*"social" + 0.003*"liber" + 0.003*"legal" + 0.003*"capit" + 0.003*"moral" + 0.003*"philosoph"
Topic #1: 0.007*"particl" + 0.007*"newton" + 0.004*"gravit" + 0.004*"einstein" + 0.004*"quantum" + 0.004*"motion" + 0.003*"atom" + 0.003*"bertalanffi" + 0.003*"frame" + 0.003*"graviti"
Topic #2: 0.006*"manifold" + 0.005*"transistor" + 0.004*"circuit" + 0.004*"pythagorean" + 0.004*"socrat" + 0.004*"semiconductor" + 0.003*"voltag" + 0.003*"electron" + 0.003*"mosfet" + 0.003*"pythagora"
Topic #3: 0.009*"bu" + 0.006*"brahman" + 0.006*"yoga" + 0.005*"vedanta" + 0.004*"tram" + 0.004*"hinduism" + 0.004*"advaita" + 0.003*"piaget" + 0.003*"krishna" + 0.003*"upanishad"
Topic #4: 0.011*"softwar" + 0.006*"game" + 0.006*"user" + 0.004*"window" + 0.004*"digit" + 0.004*"app" + 0.003*"program" + 0.003*"download" + 0.003*"microsoft" + 0.003*"web"
Topic #5: 0.009*"manag" + 0.006*"market" + 0.006*"busi" + 0.005*"product" + 0.004*"custom" + 0.004*"sale" + 0.003*"compani" + 0.003*"cost" + 0.003*"servic" + 0.003*"process"
Topic #6: 0.006*"axiom" + 0.004*"proof" + 0.004*"hilbert" + 0.003*"zfc" + 0.003*"philosophi" + 0.003*"librari" + 0.003*"congress" + 0.002*"provabl" + 0.002*"foundation" + 0.002*"catalog"
Topic #7: 0.002*"bu" + 0.002*"energi" + 0.002*"passeng" + 0.002*"transport" + 0.002*"citi" + 0.002*"countri" + 0.001*"nation" + 0.001*"servic" + 0.001*"land" + 0.001*"compani"
Topic #8: 0.007*"philosophi" + 0.005*"philosoph" + 0.004*"logic" + 0.004*"tourism" + 0.003*"scienc" + 0.003*"theori" + 0.003*"knowledg" + 0.003*"truth" + 0.003*"epistemolog" + 0.002*"social"
Topic #9: 0.005*"nokia" + 0.003*"nihil" + 0.003*"parson" + 0.002*"luhmann" + 0.002*"nuclear" + 0.002*"financi" + 0.002*"tax" + 0.002*"nasa" + 0.002*"social" + 0.002*"reactor"
Topic #10: 0.007*"displaystyl" + 0.007*"mathemat" + 0.005*"comput" + 0.004*"algebra" + 0.004*"engin" + 0.004*"theorem" + 0.003*"theori" + 0.003*"system" + 0.003*"topolog" + 0.003*"model"
Topic #11: 0.007*"rail" + 0.006*"engin" + 0.006*"electr" + 0.005*"transport" + 0.005*"railway" + 0.004*"heat" + 0.004*"passeng" + 0.004*"car" + 0.004*"vehicl" + 0.003*"steam"
Topic #12: 0.009*"water" + 0.004*"soil" + 0.004*"ship" + 0.003*"transport" + 0.003*"fuel" + 0.003*"iron" + 0.003*"miner" + 0.002*"cargo" + 0.002*"chemic" + 0.002*"marin"
Topic #13: 0.014*"parser" + 0.009*"doi" + 0.007*"svg" + 0.007*"output" + 0.004*"lock" + 0.004*"url" + 0.004*"background" + 0.003*"kern" + 0.003*"png" + 0.003*"alt"
Topic #14: 0.005*"church" + 0.003*"christian" + 0.003*"cathol" + 0.003*"jain" + 0.002*"hebrew" + 0.002*"aleph" + 0.002*"canon" + 0.002*"jewish" + 0.002*"stoic" + 0.002*"raphael"
Topic #15: 0.005*"hotel" + 0.004*"art" + 0.003*"hors" + 0.003*"ski" + 0.003*"mathemat" + 0.002*"carriag" + 0.002*"freight" + 0.002*"ca" + 0.002*"hous" + 0.002*"paint"
Topic #16: 0.004*"mathbf" + 0.003*"compani" + 0.003*"law" + 0.003*"displaystyl" + 0.002*"dictionari" + 0.002*"quantum" + 0.002*"momentum" + 0.002*"chemistri" + 0.002*"angular" + 0.002*"energi"
Topic #17: 0.004*"oil" + 0.004*"asset" + 0.004*"playstat" + 0.003*"risk" + 0.003*"forest" + 0.003*"cash" + 0.003*"plantinga" + 0.002*"fish" + 0.002*"equiti" + 0.002*"emiss"
Topic #18: 0.009*"glossari" + 0.009*"milki" + 0.005*"galaxi" + 0.004*"award" + 0.004*"wikipedia" + 0.003*"displaystyl" + 0.003*"hardi" + 0.003*"eso" + 0.003*"mathemat" + 0.002*"star"
Topic #19: 0.002*"ticket" + 0.002*"confucian" + 0.002*"philosoph" + 0.002*"bicycl" + 0.002*"yang" + 0.002*"court" + 0.002*"rope" + 0.002*"fallibil" + 0.002*"law" + 0.002*"pharmaci"
evaluate.py:
- Requires model, corpus, and dictionary files in the current working directory
- Loads the above and calculates Model Perplexity and Model Coherence scores
- A higher score is better
- e.g. for log perplexity: -13.5 is better than -15.5
- e.g. for coherence
u_mass: -1.5 is better than -3.5 - e.g. for coherence
c_v: 0.65 is better than 0.55
c_vhas been found to have the highest correlation with human-evaluated topic model coherence:- Use
grid_train.pyto compare multiple models using these metrics. - You can use these metrics along with your own best judgment to select the best model to use for topic inference
- Good metrics alone won't necessarily lead to a useful or interpretable set of topics for your model
grid_train.py:
- Requires a corpus (dataframe) in
.pklformat, including a 'tokens' column of preprocessed text. - Download an example corpus here containing all the expected columns: 'title', 'raw', 'tokens'.
- Prompts user for min and max
n_topicvalues, along with other hyperparameters. - Includes evaluation step (log perplexity, cohesion: u_mass, and cohesion: c_v) and logging of model performance metrics after each training loop.
- NOTE: On systems with fewer resources,
LdaMulticoremay stall or fail to continue after the first training loop. In such cases, it is advisable to try instead withLdaModel(single-core version).- default:
lda_model = gensim.models.LdaMulticore(corpus_tfidf, num_topics=n_topics, id2word=dictionary, passes=n_passes, workers=n_workers) - alternative:
lda_model = gensim.models.LdaModel(corpus_tfidf, num_topics=n_topics, id2word=dictionary, passes=n_passes)
- default:
Example Metrics Plot: Performance of Models Trained using from 5 to 20 Topics
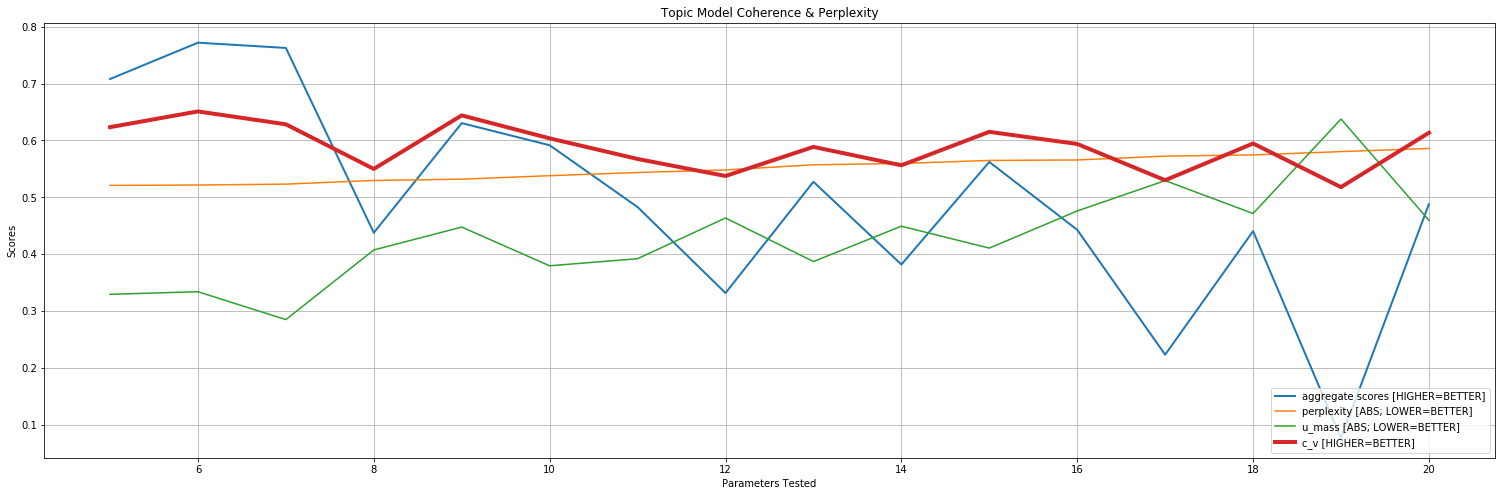
infer_topics.py:
- Requires a text string as input
- Requires that saved gensim model and dictionaries be present in the same directory
tf-lda.modelandtf-lda.dict
jsd_topics.py:
- Requires two text strings as input (ex. use
"$(cat doc1.txt)" "$(cat doc2.txt)")- These are
sys.argv[2]andsys.argv[3](second and third arguments)
- These are
- Requires the Gensim LDA model files and stopword files be available on the local filesystem
- Provide the PATH for:
tf-lda.model,tf-lda.dict,stop.txt,unstop.txtassys.argv[1](first argument) stop.txtandunstop.txtcan be empty, but must exist in the PATH specified
- Provide the PATH for:
- Returns a Jensen-Shannon Distance score indicating how similar or different the two documents are from each other
- A lower score (closer to 0) means the two documents are similar
- A higher score (closer to 1) means the documents are different
pairwise_jsd.py:
Example output:
z_topics: [[4, 6, 15], [4, 9, 11, 15], [4, 6, 9, 11], [2, 9, 11, 18], [15, 18, 19], [1, 2, 4, 6, 15, 18], [9, 12, 17], [2, 9, 17, 18]]
all topics present: [1, 2, 4, 6, 9, 11, 12, 15, 17, 18, 19]
all topics missing: [0, 3, 5, 7, 8, 10]
interpolating missing topic probabilities...
[(1, 0.0), (2, 0.0), (4, 0.7161293), (6, 0.02428288), (9, 0.0), (11, 0.0), (12, 0.0), (15, 0.24149476), (17, 0.0), (18, 0.0), (19, 0.0)]
[(1, 0.0), (2, 0.0), (4, 0.5708665), (6, 0.0), (9, 0.053239796), (11, 0.024362523), (12, 0.0), (15, 0.34636793), (17, 0.0), (18, 0.0), (19, 0.0)]
[(1, 0.0), (2, 0.0), (4, 0.14515485), (6, 0.058119595), (9, 0.23094778), (11, 0.5552489), (12, 0.0), (15, 0.0), (17, 0.0), (18, 0.0), (19, 0.0)]
[(1, 0.0), (2, 0.014619733), (4, 0.0), (6, 0.0), (9, 0.38259736), (11, 0.57920164), (12, 0.0), (15, 0.0), (17, 0.0), (18, 0.011559188), (19, 0.0)]
[(1, 0.0), (2, 0.0), (4, 0.0), (6, 0.0), (9, 0.0), (11, 0.0), (12, 0.0), (15, 0.3889571), (17, 0.0), (18, 0.3415453), (19, 0.24018)]
[(1, 0.10456503), (2, 0.013440372), (4, 0.23529643), (6, 0.097215556), (9, 0.0), (11, 0.0), (12, 0.0), (15, 0.46182993), (17, 0.0), (18, 0.084769495), (19, 0.0)]
[(1, 0.0), (2, 0.0), (4, 0.0), (6, 0.0), (9, 0.6103957), (11, 0.0), (12, 0.05248777), (15, 0.0), (17, 0.29461083), (18, 0.0), (19, 0.0)]
[(1, 0.0), (2, 0.058049496), (4, 0.0), (6, 0.0), (9, 0.72442913), (11, 0.0), (12, 0.0), (15, 0.0), (17, 0.19779378), (18, 0.014589181), (19, 0.0)]
Jensen-Shannon Distance Matrix:
[0. 0. 0.05021582 0. 0.04815683 0.
0.09937985 0. 0.05021582 0. 0.04815683 0.
0.09937985 0.05021582 0. 0.04815683 0. 0.09937985
0.05021582 0.00247222 0.05021582 0.05797268 0.04815683 0.
0.09937985 0.04815683 0.06027675 0.09937985]
- Loads a pretrained model and launches a Flask server with a '
/search' route on the local machine at port5000 - Run
search_infer.pywith Python and then navigate to http://127.0.0.1:5000/search in your browser - You will be presented with a search form; Enter a query and hit submit
- The query is combined with a random query_id, source, and timestamp and returned in JSON format after Topic Inference
- Inferred Query Topics, and the Original Model Topics List, are presented back to the user once this is complete
- Loads pretrained model and dictionary
- Removes duplicate rows based on 'title' and 'raw' columns
- Infers topics of all candidate documents, saving output "compare_docs" corpus as '
{save_docs}.pkl'
- Set hostname/IP address and port prior to running.
- Run
search_app.pyusing Python 3.6+. - Loads a model and set of candidate documents of your choosing.
- User input query is processed, modeled, and compared to candidate documents. Distance between the query and a given candidate's topic probability distributions is measured using Jensen-Shannon Distance.
- The top 1% of candidate documents are returned to the user as search results.
Cosine similarity is used to measure the similarity between two documents:
- Range: -1 to 1; the greater the score, the more similar: e.g. 0.9981 is very similar
- LSI is another means to find similar documents even when the words in the query are not present in the potentially relevant documents.
- See:
LSI_test_example.py(WIP)