Deep Learning has been applied successfully to Automatic Speech Recognition (ASR) and Speech Emotion Recognition (SER), where the main focus of research has been designing better network architectures, for example, DNNs, CNNs, RNNs and end-to-end models. However, these models tend to overfit easily and require large amounts of training data.
Let's check some open source, Speech Emotion datasets.
- TESS (Toronto emotional speech set)
A set of 200 target words were spoken in the carrier phrase "Say the word _____' by two actresses (aged 26 and 64 years) and recordings were made of the set portraying each of seven emotions (anger, disgust, fear, happiness, pleasant surprise, sadness, and neutral). There are 2800 stimuli in total.
- RAVDESS (The Ryerson Audio-Visual Database of Emotional Speech and Song)
The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS) contains 7356 files (total size: 24.8 GB). The database contains 24 professional actors (12 female, 12 male), vocalizing two lexically-matched statements in a neutral North American accent. Speech includes calm, happy, sad, angry, fearful, surprise, and disgust expressions, and song contains calm, happy, sad, angry, and fearful emotions.
- CREMA -d (crema_d)
This data set consists of facial and vocal emotional expressions in sentences spoken in a range of basic emotional states (happy, sad, anger, fear, disgust, and neutral). 7,442 clips of 91 actors with diverse ethnic backgrounds were collected.
- SAVEE (Surrey Audio-Visual Expressed Emotion)
This consists of recordings from 4 male actors in 7 different emotions, 480 British English utterances in total
- IEMOCAP (Interactive Emotional Dyadic Motion Capture)
IEMOCAP database is annotated by multiple annotators into categorical labels, such as anger, happiness, sadness, neutrality, as well as dimensional labels such as valence, activation and dominance. The dataset contains useful 5531 utterances.
The main problem we saw here, is the lack of training data in each dataset. Maximum number of training data available are 7422 and with such a small number of dataset, it is very difficult to implement a deep learning model without overfitting and that's why, implementation of different data augmentation techniques are necessary.
In the absence of an adequate volume of training data, it is possible to increase the effective size of existing data through the process of data augmentation, which has contributed to significantly improving the performance of deep networks in the domain of image classification. In the case of speech emotion recognition, augmentation traditionally involves deforming the audio waveform used for training in some fashion (e.g., by speeding it up or slowing it down), or adding background noise. This has the effect of making the dataset effectively larger, as multiple augmented versions of a single input is fed into the network over the course of training, and also helps the network become robust by forcing it to learn relevant features. However, existing conventional methods of augmenting audio input introduces additional computational cost and sometimes requires additional data.
A recent paper from Google Brain, “SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition”, thay took a new approach to augmenting audio data, treating it as a visual problem rather than an audio one. Instead of augmenting the input audio waveform as is traditionally done, SpecAugment applies an augmentation policy directly to the audio spectrogram (i.e., an image representation of the waveform). This method was simple, computationally cheap to apply, and does not require additional data. It is also surprisingly effective in improving the performance of ASR
SpecAugment modifies the spectrogram by warping it in the time direction, masking blocks of consecutive frequency channels, and masking blocks of utterances in time. As shown in below picture, First Picture is a typical representation of Audio file and the second picture is a log mel spectrogram of given audio.

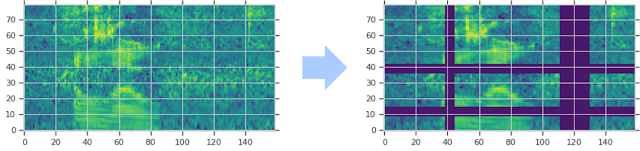
From our experimental data,

In contrast to SpecAugment, we came up with another data augmentation technique, Codec Augmentation.
Audio encoding is used to expand the training data set. Audio encoding is typically used to reduce the data bandwidth for storage and especially for transmission. Audio is compressed to enable efficient storage and to simplify transmission. Compression can be lossless or lossy in audio encoding. It automatically removes certain information not needed to fulfill the purpose of the application used. For music transmission, the compression is optimized to remove certain parts of the original sound signal that go beyond the auditory resolution ability. Voice quality and intelligibility are of interest for voice data transmission. Losing information while compressing audio without drastically changing it is an essential aspect of the audio augmentation method at the data level. Such loss of data later affects feature extraction and enables data variation in the training set. Several studies investigated the impact of compression on spectral quality and acoustic features but without analyzing the possibility of using these altered features for data augmentation. Although there are many ways to change the acoustic information, we have focused on the bit rate and code type as parameters.
For the codec type, we have chosen Opus, as it is an audio codec that can be of high quality and low delay with the capability of incorporating multiple channels. It supports several audio-frequency bandwidths and is suitable for various real-time audio signals, including speech and music also it is an open source and royalty free software. Furthermore, Opus achieves an outstanding quality of experience across multiple listening tests, especially in the higher bands. For bitrates, OPUS codec gives us 3 variations.
- Low Pass (Nerrow band) from 8 to 16 Kbps
- Hybrid mode (Wide band) from 16 to 64 Kbps
- MDCT (Wide band/ psychoacoustics) above 64Kbps
We took one or two bitrates from each variations i.e. 8 Kbps, 16Kbps, 32 Kbps, 48 Kbps, 64 Kbps and 128 Kbps.
Let's check out how Codec Augment works.

For experiment we choose 2 datasets.
- IEMOCAP (Interactive Emotional Dyadic Motion Capture)
IEMOCAP has 12 hours of audio-visual data from 10 actors where the recordings follow dialogues between a male and a female actor in both scripted or improvised topics. After the audio-visual data has been collected it is divided into small utterances of length between 3 to 15 seconds which are then labelled by evaluators. Each utterance is evaluated by 3-4 assessors. The evaluation form contained 10 options (neutral, happiness, sadness, anger, surprise, fear, disgust frustration, excited, other). We consider only 4 of them anger, excitement (happiness), neutral and sadness so as to remain consistent with the prior research. Also to resolve the problem of unbalanced classes we, added happiness and excitement category into a single category.
We performed experiment two times, 1st by taking a simple sequential model and considering all seasons and all actors and then, randomly splitting 80% of dataset as training data and rest 20% of dataset as testing data.
On the other hand, we also performed the experiment by taking first 4 season and 8 different actors as a training dataset and last season 5 and actors 9 and 10 as in testing dataset. During this process, we also used Keras tuner as Hyperparameter Optimizer.
- TESS (Toronto emotional speech set)
TESS is very cleaned dataset, having 2800 utterances, and 14 different classes namely, male and female 7 difference utterances. i.e. Happy, Sad, Excited, Fear, Frustration, Anger, and Disgust. We randomly took 80% of total dataset for training data and 20% as testing data.
The reason behind going for these 2 datasets is, TESS is very cleaned and balanced and IEMOCAP is comparitively rough and very unbalanced, and we can get clear idea about data augmentation techniques.
We considered 4 different cases. Let's understand like this. We have X = training data, Y = testing data, Z = total data (whole dataset)
- Single Dataset (X = training data, Y = testing data)
- Double Dataset (2X = training data, Y = testing data)
- SpecAgumentation (X = training + X = SpecAugmented training, Y = testing data)
- Codec Augment (X = training + X = codecAugmented training, Y = testing data)
In Codec Augmentation we took 6 different bitrates and take experimental results, 6 times for each bitrate i.e. 8,16,32,48,64 and 128kbps.

We also used Keras Tuner for hyper parameter optimization. The tuning summery is as below.
Search space summary
Default search space size: 13
filters_1 (Int)
{'default': 256, 'conditions': [], 'min_value': 32, 'max_value': 512, 'step': 32, 'sampling': None}
kernel_size_1 (Int)
{'default': 8, 'conditions': [], 'min_value': 2, 'max_value': 10, 'step': 2, 'sampling': None}
filters_2 (Int)
{'default': 256, 'conditions': [], 'min_value': 32, 'max_value': 512, 'step': 32, 'sampling': None}
kernel_size_2 (Int)
{'default': 8, 'conditions': [], 'min_value': 2, 'max_value': 10, 'step': 2, 'sampling': None}
dropout_1 (Float)
{'default': 0.05, 'conditions': [], 'min_value': 0.0, 'max_value': 0.5, 'step': 0.05, 'sampling': None}
n_layers (Int)
{'default': None, 'conditions': [], 'min_value': 1, 'max_value': 5, 'step': 1, 'sampling': None}
filters_3_0 (Int)
{'default': 256, 'conditions': [], 'min_value': 32, 'max_value': 512, 'step': 32, 'sampling': None}
kernel_size_3_0 (Int)
{'default': 8, 'conditions': [], 'min_value': 2, 'max_value': 10, 'step': 2, 'sampling': None}
dropout_2 (Float)
{'default': 0.05, 'conditions': [], 'min_value': 0.0, 'max_value': 0.5, 'step': 0.05, 'sampling': None}
filters_4_0 (Int)
{'default': 256, 'conditions': [], 'min_value': 32, 'max_value': 512, 'step': 32, 'sampling': None}
kernel_size_4_0 (Int)
{'default': 8, 'conditions': [], 'min_value': 2, 'max_value': 10, 'step': 2, 'sampling': None}
learning_rate (Choice)
{'default': 0.01, 'conditions': [], 'values': [0.01, 0.001, 0.0001], 'ordered': True}
momentum (Choice)
{'default': 0.0, 'conditions': [], 'values': [0.0, 0.25, 0.5, 0.7, 0.9, 0.99], 'ordered': True}
For the experimental results in IEMOCAP, we considered Accuracy, Precision, Recall, F1 score and Confusion Metrix as our evaluation metrics.
The below results are with randomly choosing train test split and without use of HPO.




For the experimental results in TESS, we considered Accuracy as our evaluation metrics. As dataset has equal number of data for each category. The results are as below.

It can be seen from confusion metrics and other evaluation metrics values, we can say that, the best results can be get with Codec Augmentation if we augment original audio file at 32Kbps or 64Kbps. At this bitrates, the experimental results are even better than SpecAugment. We are experimenting more and taking more results, but these are initial results and they seem promising as of now.