In this lab, we import the following Jupyter notebooks into IBM Watson Studio within the IBM Cloud Pak for Data:
- The FHIR API
- FHIR in Spark
- Predictive Modeling
Notebook 1 is configured to use an instance of the IBM FHIR Server (running on IBM Cloud) which has been loaded with sample data generated from the Synthea™️ Patient Generator.
Notebook 2 requires access to a Cloud Object Store with FHIR R4 resources from SyntheticMass.
Notebook 3 builds a predictive model from Parquet files that are built in notebook 2 from features extracted from the FHIR resources.
Notebook 1 should work from almost any Jupyter notebook environment, but notebooks 2 and 3 use Apache Spark to process bulk FHIR resources into a dataframe and therefor must run in a Jupyter environment with access to Spark.
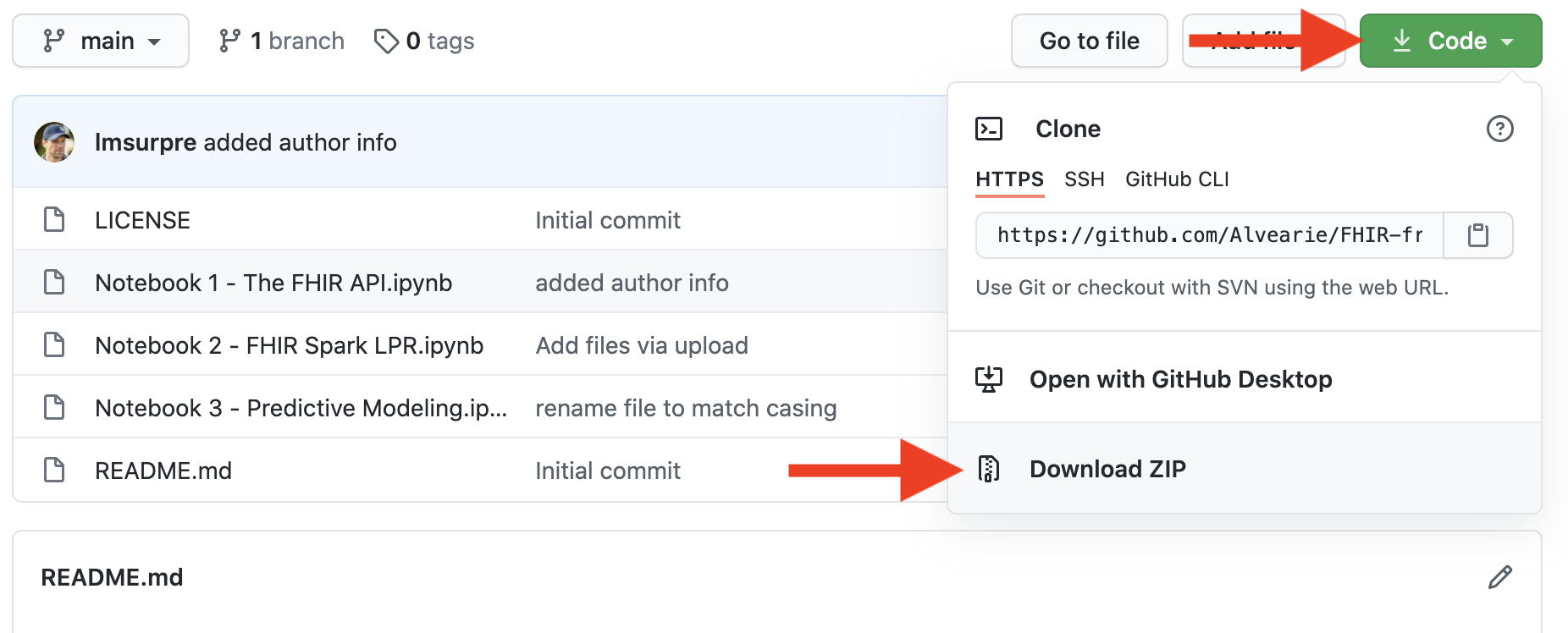
Clone or download the notebooks from this repo to your local system.
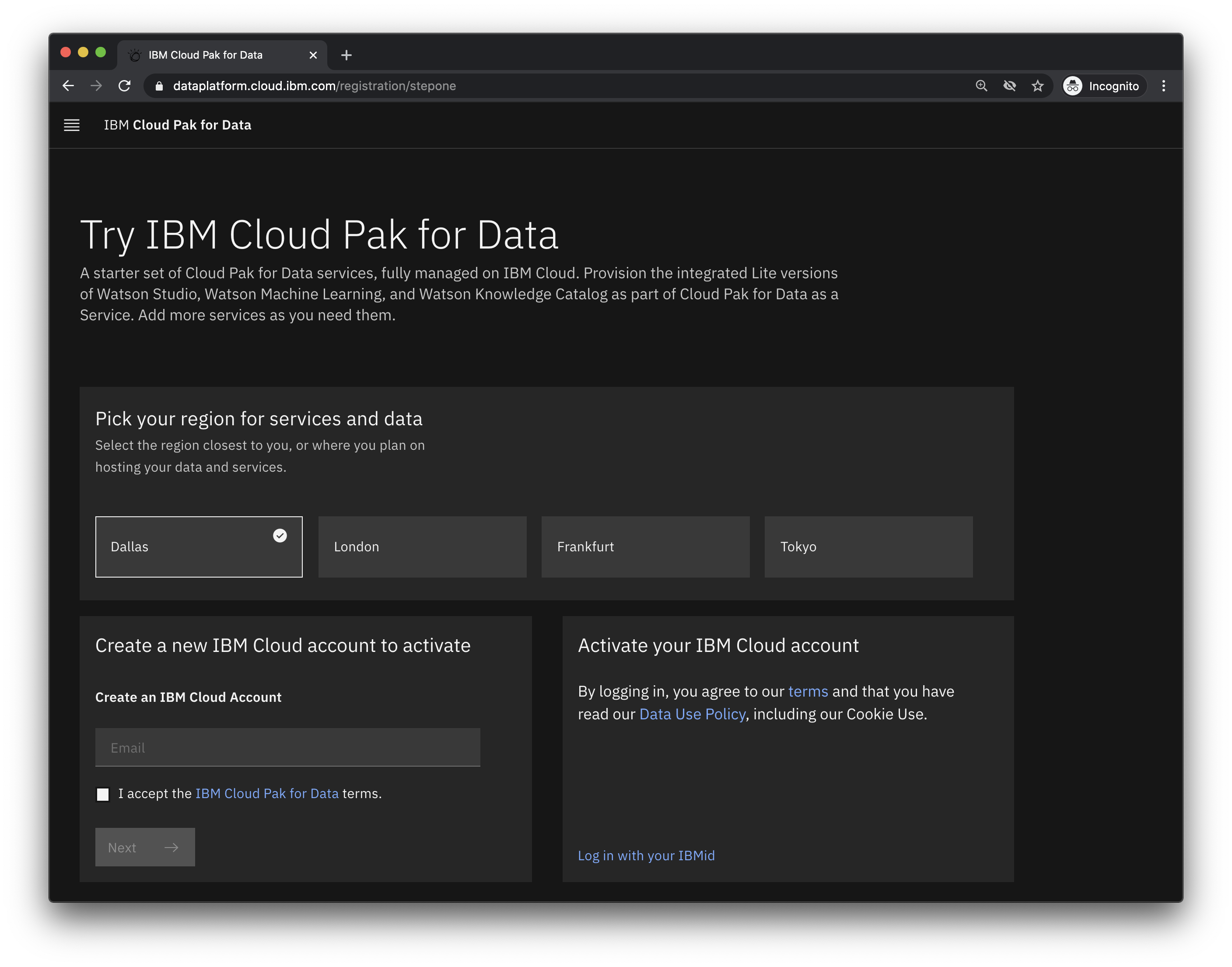
- Navigate to https://dataplatform.cloud.ibm.com/registration/stepone
- Choose
Dallasto be nearest to the data for this lab
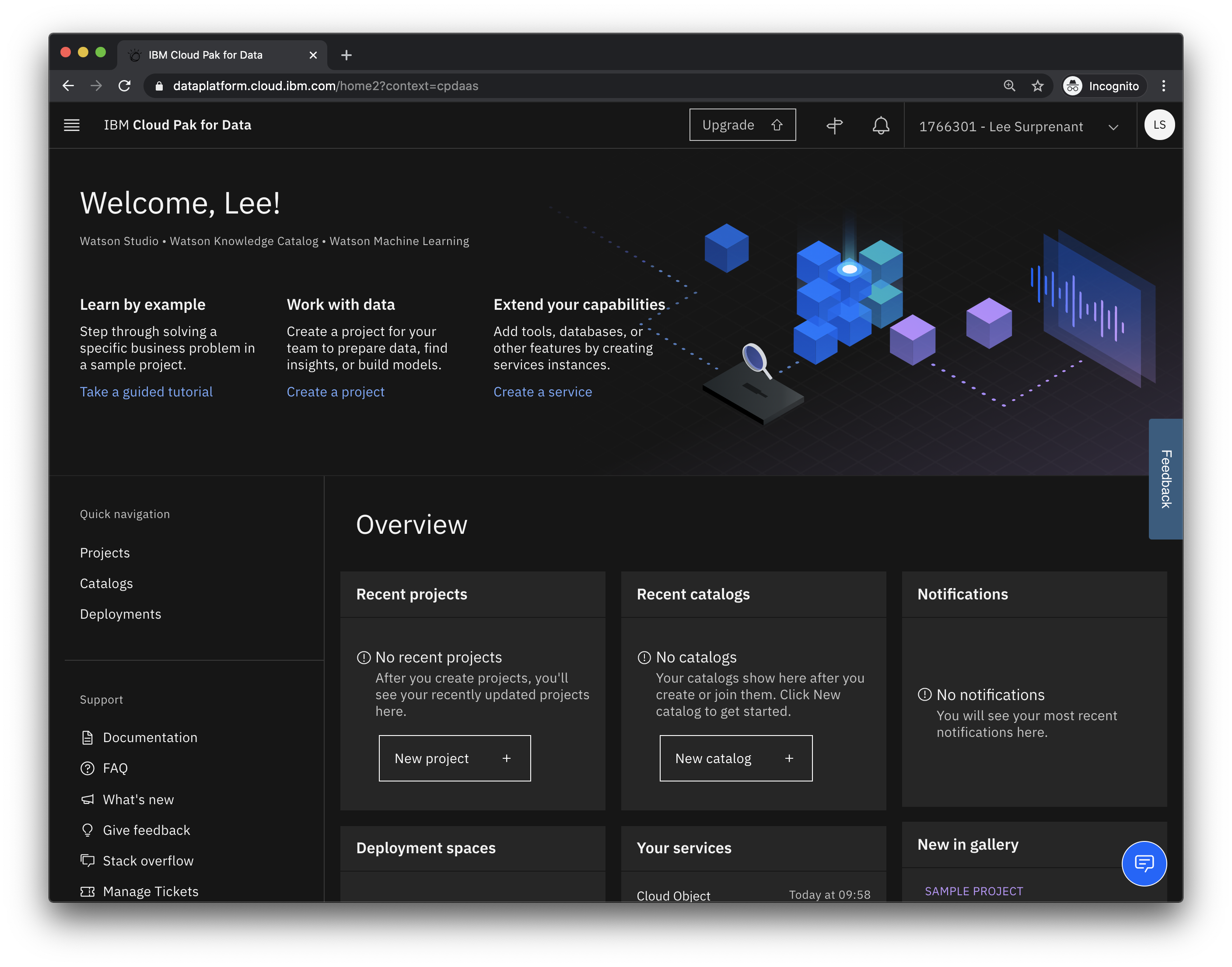
If you already have an IBMid, enter it on the right. If not, enter a valid email address on the left, agree to the terms, click Next, and check your email to complete the registration process.
Once registered and logged in, continue to the Watson Studio dashboard.
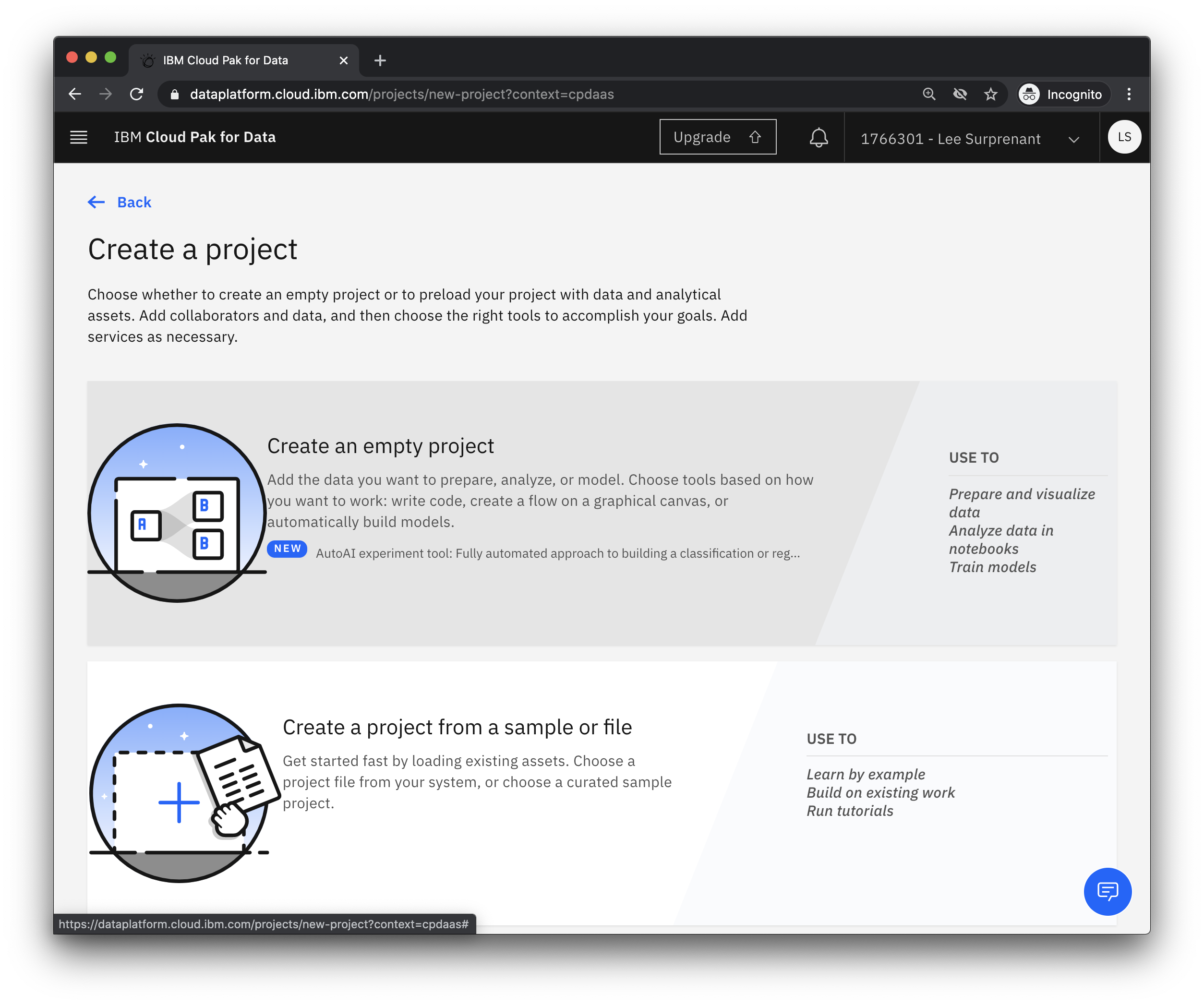
- From the IBM Cloud Pak for Data dashboard, click
New project +
- Select
Create an empty project
- Give the project a name (e.g. FHIR from Jupyter) and click
Addto define a storage service
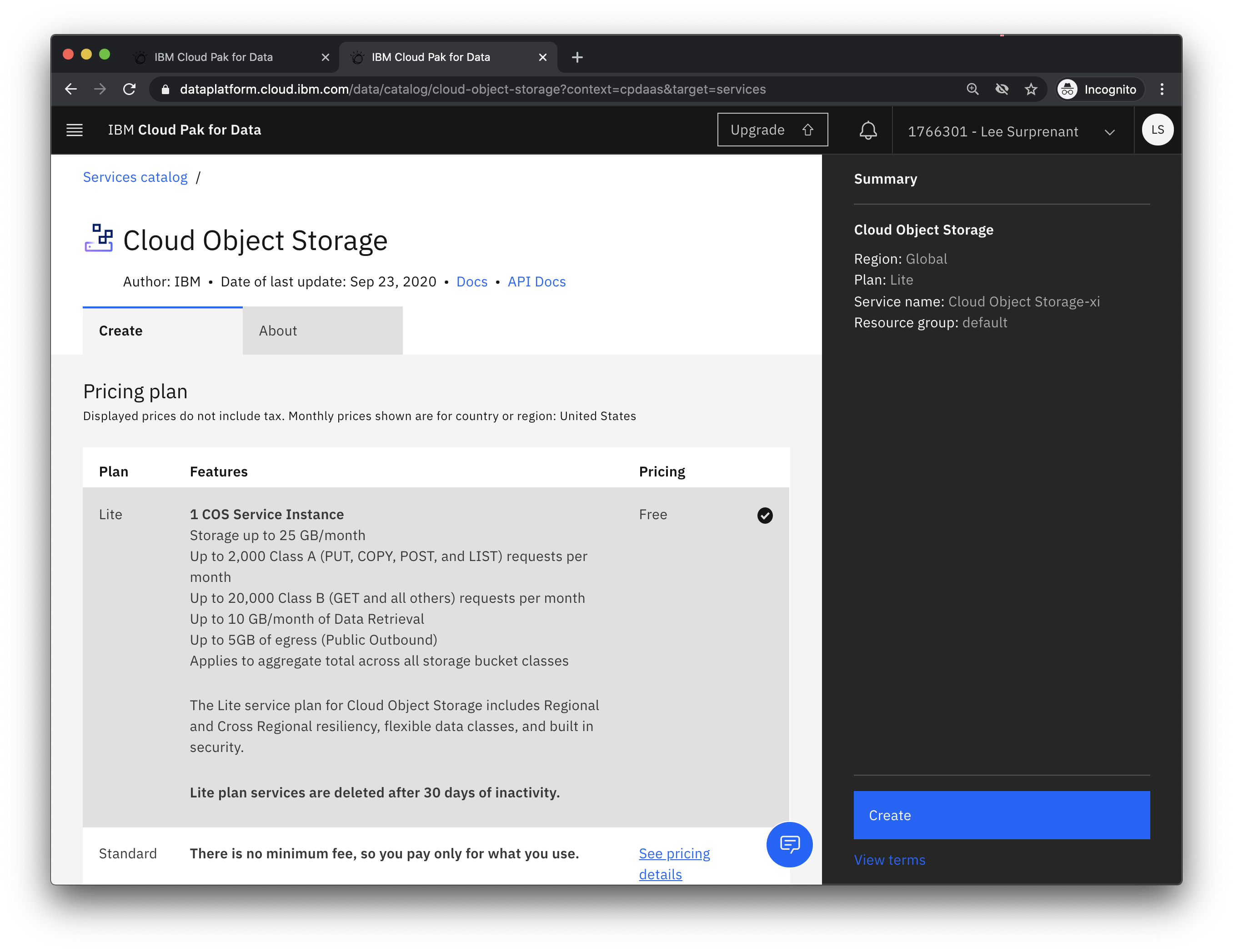
- Select a plan (the free
Liteplan should be fine) and clickCreate - Click
Refreshto see your Cloud Object Storage instance appear and then clickCreate
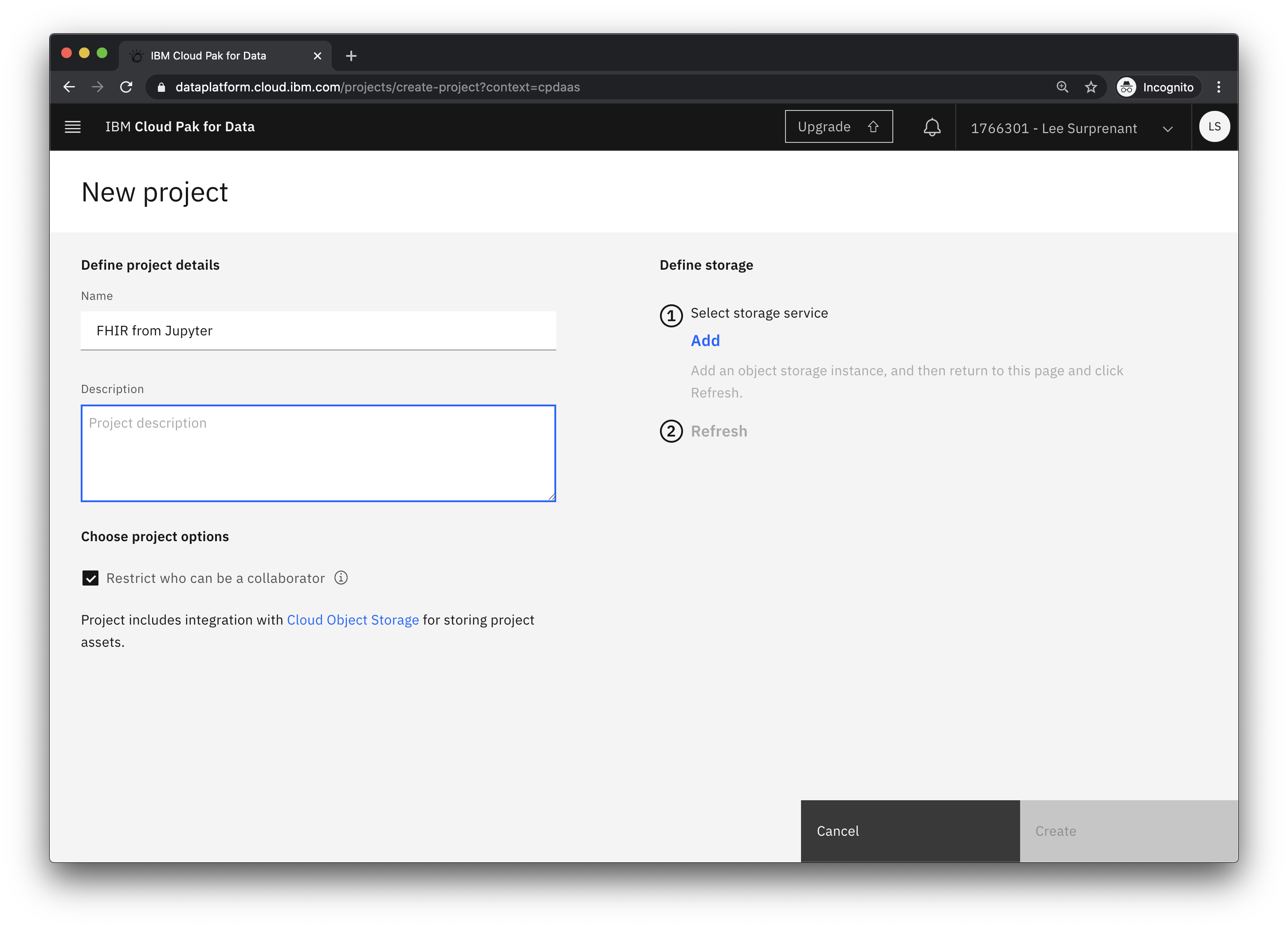

From the Project dashboard, click Add to project + and choose the Notebook asset type.
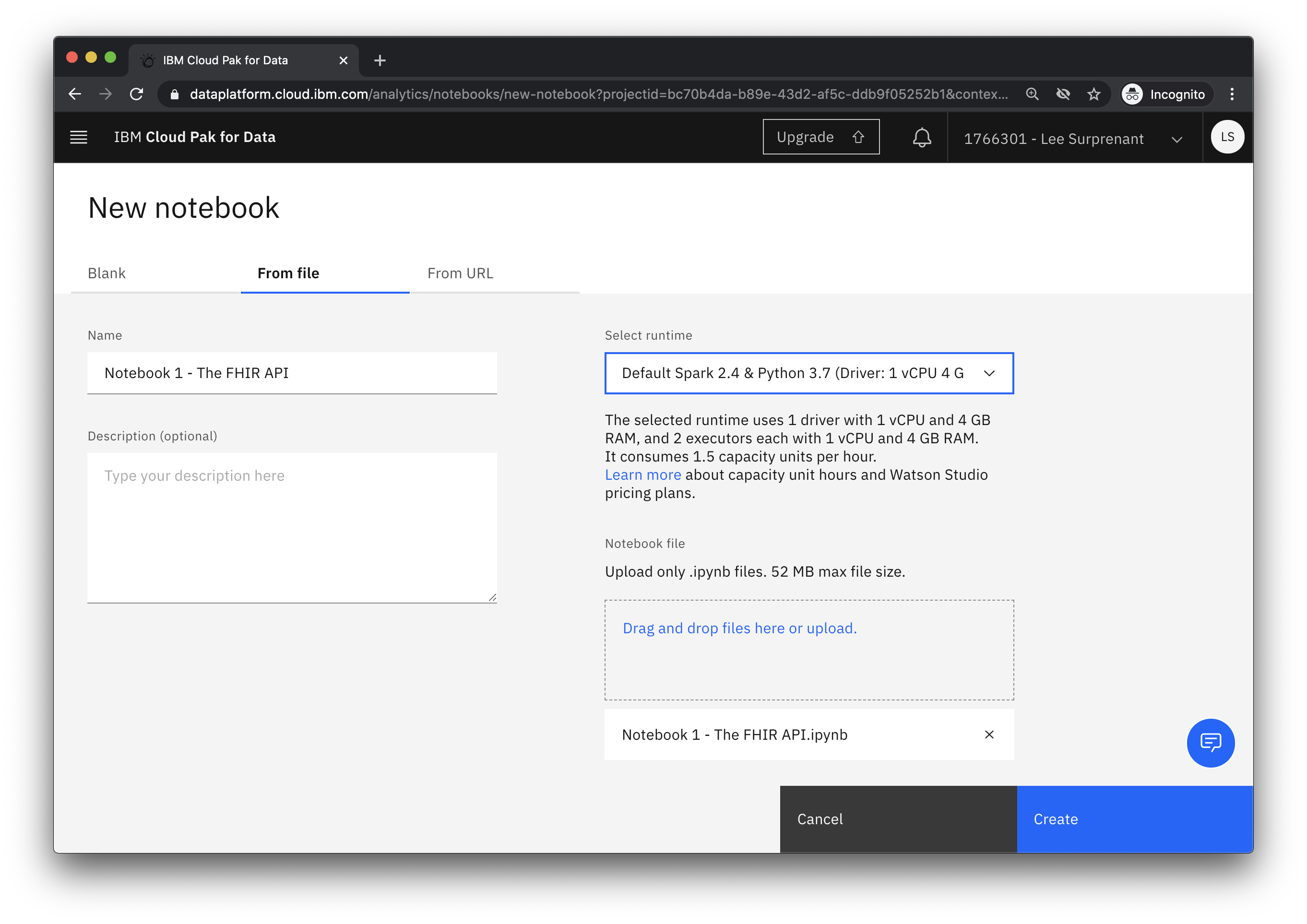
Select the From file tab and select the Default Spark 2.4 & Python 3.7 environment.
Then, upload one of the notebook files that was downloaded in the Download the notebooks section and click Create.
Repeat this process for the other notebooks that you desire to load.