Asuransi kesehatan adalah kontrak yang mengharuskan perusahaan asuransi membayar sebagian atau seluruh biaya perawatan terkait masalah kesehatan yang kamu alami. Untuk mendapatkannya, pengguna asuransi harus membayar iuran dalam periode yang telah ditentukan, disebut dengan premi.
Layanan yang diberikan tergantung dari fitur dan skema yang dipilih. umumnya, asuransi kesehatan mengcover biaya pemeriksaan medis, bedah, obat resep, perawatan gigi, perawatan rumah sakit, hingga kejadian tak terduga seperti kecelakaan.
Dalam praktiknya, pembayaran premi asuransi kesehatan bisa langsung dipotong dari gaji bulanan yang didapat. maka dari itu buatlah sebuah algoritma prediksi biaya medis yang dikeluarkan per individu dengan menggunakan perbandingan 4 algoritma yaitu KNN , Random Forest, Adaboost dan SVM dengan dataset yang diambil dari wilayah Amerika Serikat ( USA ) dengan dataset ini disusun berdasarkan kolom usia, jenis Kelamin , kemudian indeks Massa Tubuh ( BMI ), jumlah anak dalam satu keluarga , apakah individu tersebut perokok atau tidak lalu wilayah tempat tinggal penerima asuransi kesehatan di USA , terakhir kolom biaya medis yang ditanggung oleh asuransi kesehatan.
Berdasarkan latar belakang di atas, berikut ini batasan masalah yang dapat diselesaikan dengan proyek ini :
- Bagaimana cara melakukan pra- pemrosesan data agar dapat digunakan untuk membuat model ?
- Bagaimana cara membuat model prediksi berdasarkan dari 4 algoritma yaitu KNN, Random Forest, Adaboost, dan SVM ?
- Bagaimana prosedur melakukan perbandingan model prediksi berdasarkan dari 3 algoritma yaitu KNN, Random Forest, Adaboost, dan SVM ?
- Bagaimana cara membuat model dengan akurasi yang baik ?
- Melakukan pra- pemrosesan data dengan baik agar dapat digunakan dalam pembuatan model.
- Mengetahui cara membuat model machine learning untuk memprediksi biaya medis yang ditanggung asuransi kesehatan per individu
- Mengetahui bagaimana prosedur pembuatan algoritma untuk melakukan perbandingan dengan model machine learning untuk memprediksi biaya medis yang ditanggung asuransi kesehatan per individu dari 4 algoritma yaitu KNN , Random Forest , Adaboost dan SVM
- Mengetahui bagaimana langkah langkah dalam membuat model dengan akurasi yang baik
Solusi yang dapat dilakukan sebagai berikut :
- Membandingkan hasil dari empat algoritma machine learning, yaitu KNN, Random Forest, Adaboost, dan SVM
- Menggunakan Mean squared error masing-masing algoritma pada data train dan test
Untuk membuat model , menggunakan 4 model yaitu KNN , Random Forest, Adaboost dan SVM

Gambar 1 . Cover Dataset Kaggle
Dataset ini dapat diakses menggunakan Kaggle
Informasi dari dataset dapat dirangkum sebagai berikut :
Tabel 1 . Rangkuman informasi Dataset
| Jenis | Keterangan |
|---|---|
| Sumber | Kaggle Dataset : Medical cost personal datasets |
| Lisensi | Database contents license (DbCL) v1.0 |
| Kategori | Medical |
| Jenis & Ukuran Berkas | CSV (16 KB) |
Pada berkas yang diunduh yakni insurance.csv berisi 1338 baris dan 7 kolom. Kolom-kolom tersebut terdiri dari 3 buah kolom bertipe objek dan 4 buah kolom bertipe numerik (tipe data int64 dan tipe data float64) .Untuk penjelasan mengenai variabel-variable pada dataset insurance ini dapat dilihat sebagai berikut:
- Age : Usia penerima asuransi kesehatan
- Jenis kelamin : Jenis kelamin penerima asuransi kesehatan , Yaitu perempuan atau laki-Laki
- BMI : Indeks massa tubuh, memberikan pemahaman tentang tubuh, bobot yang relatif tinggi atau rendah relatif terhadap tinggi, indeks objektif berat badan (kg / m^ 2) menggunakan rasio tinggi terhadap berat, idealnya 18,5 hingga 24,9
- anak-anak: Jumlah anak yang ditanggung oleh asuransi kesehatan / jumlah tanggungan
- perokok: Merokok
- wilayah: daerah perumahan penerima di AS, timur laut, tenggara, barat daya, barat laut.
- biaya: Biaya medis individu ditagih oleh asuransi kesehatan
Langkah - Langkah pra-pemrosesan data
- Memasukkan dataset ke dalam dataframe menggunakan pandas
- Menampilkan informasi dari dataset
- Menampilkan deskripsi statistik dataset
- Menemukan dan menangani missing values di dataset
- Menangani outliers dataset
- Visualisasikan hubungan antar fitur numerik dengan fungsi pairplot
Dataframe dataset dengan pandas
Pada proyek digunakan fungsi read di pandas untuk memasukkan dataset insurance.csv ke dalam bentuk dataframe menggunakan pandas dan dataframe itu akan tersimpan dalam variabel df lalu untuk menampilkan 10 data pertama dalam dataset yaitu menggunakan df.head(10), lalu tampilannya akan seperti pada tabel 2.
Tabel 2 : Tampilan dataset dalam bentuk dataframe dengan pandas
| age | sex | bmi | children | smoker | region | charges | |
|---|---|---|---|---|---|---|---|
| 0 | 19 | female | 27.900 | 0 | yes | southwest | 16884.92400 |
| 1 | 18 | male | 33.770 | 1 | no | southeast | 1725.55230 |
| 2 | 28 | male | 33.000 | 3 | no | southeast | 4449.46200 |
| 3 | 33 | male | 22.705 | 0 | no | northwest | 21984.47061 |
| 4 | 32 | male | 28.880 | 0 | no | northwest | 3866.85520 |
| 5 | 31 | female | 25.740 | 0 | no | southeast | 3756.62160 |
| 6 | 46 | female | 33.440 | 1 | no | southeast | 8240.58960 |
| 7 | 37 | female | 27.740 | 3 | no | northwest | 7281.50560 |
| 8 | 37 | male | 29.830 | 2 | no | northeast | 6406.41070 |
| 9 | 60 | female | 25.840 | 0 | no | northwest | 28923.13692 |
Menampilkan informasi dari dataset
Pada proyek ini digunakan fungsi info() di pandas yang digunakan untuk menampilkan informasi dari dataset, informasi seperti tipe data yang terdapat di masing masing kolom dataset, hasil dari fungsi info() dapat dilihat dari gambar 2

gambar 2: output tampilan informasi dari dataset
dari output pada gambar, dapat dilihat bahwa :
- Terdapat 3 kolom dengan tipe objek yaitu : sex, smoker, region. kolom ini merupakan categorical features (fitur non-numerik)
- Terdapat 2 kolom bertipe numerik dengan tipe data int64 yaitu age dan children
- Terdapat 2 kolom bertipe numerik dengan tipe data float64 yaitu bmi dan charges. kolom charges akan dijadikan kolom target pada proyek ini
Menampilkan statistik dataset
Pada proyek ini digunakan fungsi describe() yang berfungsi untuk menampilkan statistik dari dataset,dan output dari fungsi describe() tersebut dapat dilihat di tabel 3
Tabel 3: tampilan statistik dataset
| age | bmi | children | charges | |
|---|---|---|---|---|
| count | 1338.000000 | 1338.000000 | 1338.000000 | 1338.000000 |
| mean | 39.207025 | 30.663397 | 1.094918 | 13270.422265 |
| std | 14.049960 | 6.098187 | 1.205493 | 12110.011237 |
| min | 18.000000 | 15.960000 | 0.000000 | 1121.87390 |
| 25% | 27.000000 | 26.296250 | 0.000000 | 4740.287150 |
| 50% | 39.000000 | 30.400000 | 1.000000 | 9382.033000 |
| 75% | 51.000000 | 34.693750 | 2.000000 | 16639.912515 |
| max | 64.000000 | 53.130000 | 5.000000 | 63770.428010 |
Fungsi describe() memberikan informasi statistik pada masing-masing kolom, antara lain:
- Count adalah jumlah sampel pada data.
- Mean adalah nilai rata-rata
- Std adalah standar deviasi
- Min yaitu nilai minimum setiap kolom
- 25% adalah kuartil pertama. Kuartil adalah nilai yang menandai batas interval dalam empat bagian sebaran yang sama.
- 50% adalah kuartil kedua, atau biasa juga disebut median (nilai tengah).
- 75% adalah kuartil ketiga
- Max adalah nilai maksimum.
Mencari missing value
Pada proyek ini digunakan fungsi isnull().sum() yang berfungsi untuk menemukan nilai missing value di masing masing kolom dataset. missing value sendiri dapat diartikan sebagai nilai atribut yang kosong pada objek data. kemudian hasil dari fungsi isnull().sum() diatas dapat dilihat di gambar 3

Gambar 3: output hasil pencarian missing value
Berdasarkan output pada gambar 3 dapat dilihat bahwa tidak ditemukan missing value pada masing masing kolom di dataset
Adalah sampel yang nilainya sangat jauh dari cakupan umum data utama. outliers sendiri adalah hasil pengamatan yang kemunculannya sangat jarang dan berbeda dari data hasil pengamatan lainnya
Ada beberapa teknik untuk menangani outliers, antara lain:
- Hypothesis Testing
- Z-score method
- IQR Method
Untuk mengecek apakah ada outliers atau tidak, dapat menggunakan teknik visualisasi, yaitu boxplot.
Berikut adalah ilustrasi dan penjelasan nilai statistik pada boxplot.
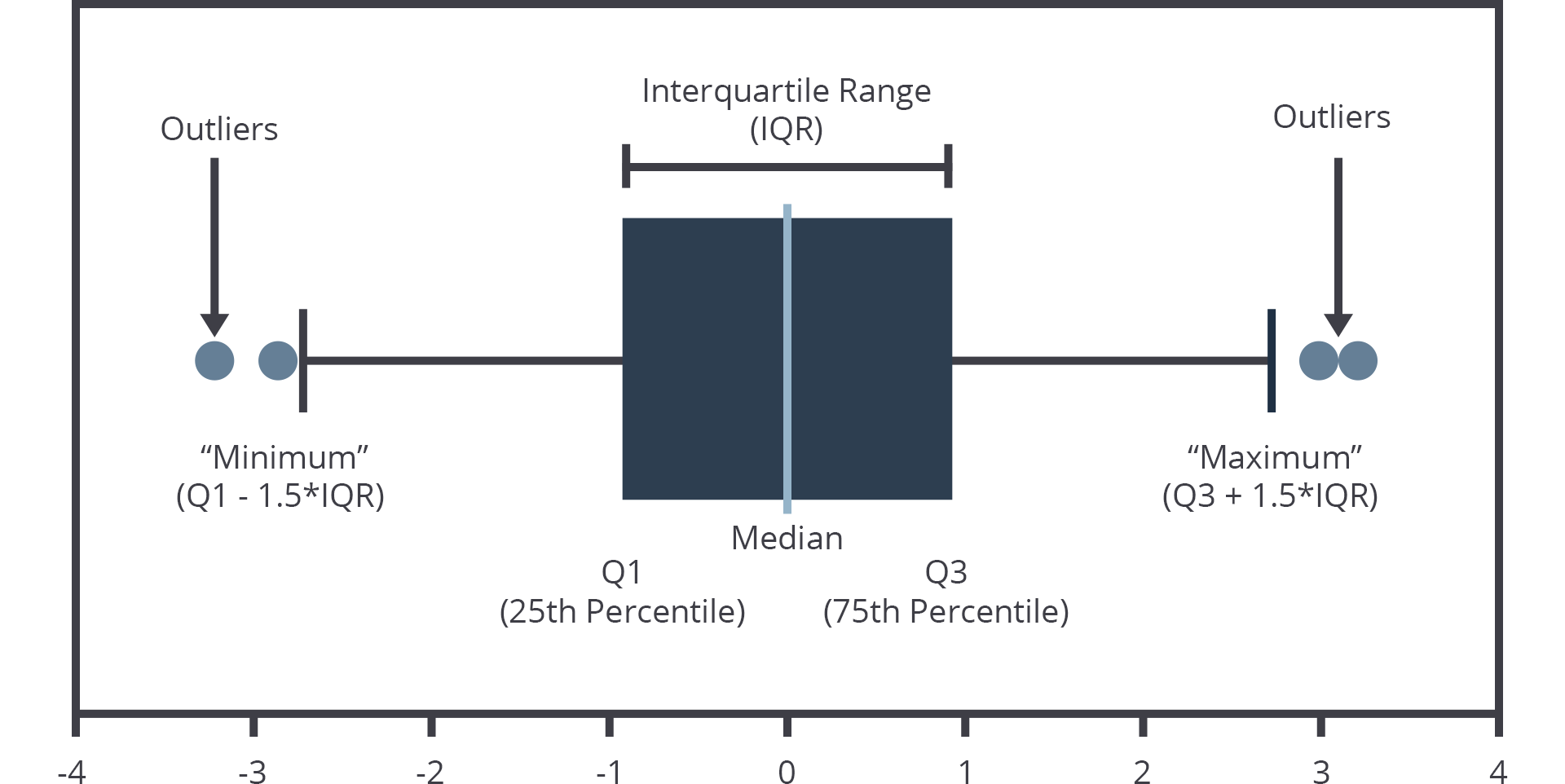
Gambar 4 . Ilustrasi dan penjelasan nilai statistik pada boxplot
Pada gambar 4 merupakan ilustrasi bagaimana boxplot memvisualisasikan outliers, dapat diperhatikan outliers ada jika letaknya diluar diluar nilai Q1 ( minimum ) dan diluar nilai Q3 (maximum)
boxplot dapat diartikan untuk menunjukkan ukuran lokasi dan penyebaran, serta memberikan informasi tentang simetri dan outliers. Boxplot bisa digambarkan secara vertikal maupun horizontal.
Visualisasi boxplot outliers pada fitur numerik
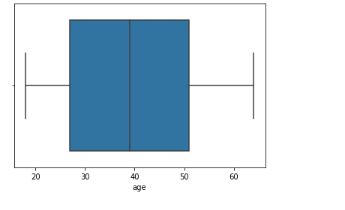
Gambar 5. Visualisasi boxplot variabel age
Pada gambar 5 dapat diperhatikan boxplot pada variabel age tidak terdapat indikasi outliers

Gambar 6. Visualisasi boxplot variabel bmi
Pada gambar 6 dapat diperhatikan pada variabel bmi terdapat indikasi outliers
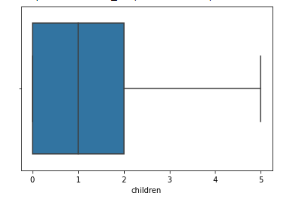
Gambar 7. Visualisasi boxplot variabel children
Pada gambar 7 dapat diperhatikan pada variabel children tidak terdapat indikasi outliers
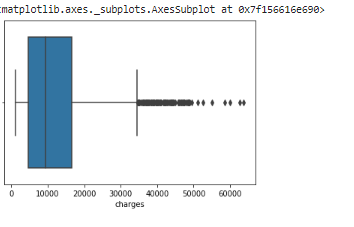
Gambar 8. Visualisasi boxplot variabel charges
Pada gambar 8 dapat diperhatikan pada variabel charges terdapat indikasi outliers
Pada proyek ini , terdapat outliers variabel bmi dan charges, untuk menangani outliers kita dapat menggunakan teknik IQR method. IQR adalah singkatan dari Interquartile Range. untuk memahami apa itu IQR, mari kita ingat lagi konsep kuartil. Kuartil dari suatu populasi adalah tiga nilai yang membagi distribusi data menjadi empat sebaran. Seperempat dari data berada di bawah kuartil pertama (Q1), setengah dari data berada di bawah kuartil kedua (Q2), dan tiga perempat dari data berada di kuartil ketiga (Q3). Dengan demikian interquartile range atau IQR = Q3 - Q1, untuk lebih jelasnya dapat diperhatikan pada bagian potongan code dibawah ini :
Pada proyek ini digunakan IQR method untuk menangani outliers yang pertama definisikan dulu outliers pada Q1 atau batas bawah yaitu 0.25 lalu outliers pada Q3 atau batas atas yaitu 0.75 kemudian hasil Q3 akan dikurangi dengan hasil Q1 setelah itu buat variabel baru yaitu insurance untuk menampung hasil batas bawah dari pengurangan Q1 dengan 1,5 * IQR. lalu untuk hasil batas atas digunakan penambahan 1.5 * IQR dengan Q3
dan jika dibuat persamaan dapat dilihat sebagai berikut :
Batas bawah = Q1 - 1.5 * IQR
Batas atas = Q3 + 1.5 * IQR
setelah itu untuk melihat ukuran hasil penanganan outliers, variabel insurance dapat dipanggil dengan insurance.shape lalu akan ditampilkan hasil penanganan outliers seperti pada gambar 9.

Gambar 9. Output Hasil penanganan outlier
Visualisasi Category Fitur
- Dataset tipe Categorical
Sex


Gambar 10. Hasil visualisasi chart bar Sex di Fitur category
Pada gambar 10 merupakan visualisasi chart bar Sex dapat dilihat bahwa jumlah jenis kelamin laki laki lebih banyak daripada jumlah jenis kelamin perempuan dalam penerima asuransi kesehatan.
Smoker

Gambar 11. Hasil visualisasi chart bar Smoker di Fitur category
Pada gambar 11 merupakan visualisasi chart bar Smoker dapat dilihat bahwa jumlah perokok lebih sedikit sekitar 200 orang daripada non perokok sekitar 1000 orang dalam penerima asuransi kesehatan.
Region

Gambar 12. Hasil visualisasi chart bar Region di Fitur category
Pada gambar 12 merupakan visualisasi chart bar Region dapat dilihat wilayah southeast lebih banyak orang yang penerima asuransi kesehatan tinggal disana . kemudian untuk wilayah southwest, northwest dan northeast memiliki chart yang rata dan berarti jumlah penerima asuransi kesehatan tersebar merata tinggal di wilayah southwest, northwest dan northeast
Visualisasi Fitur Numerik
- Dataset Tipe Numerical


Gambar 13. Visualisasi chart pada Fitur Numerik
Pada gambar 13 merupakan visualisasi histogram untuk variabel " charges" yang merupakan fitur target ( label ) pada data kita. Dari histogram "charges", kita bisa memperoleh beberapa informasi, antara lain:
- Peningkatan biaya medis yang ditanggung per individu sebanding dengan penurunan jumlah sampel, Hal ini dapat kita lihat jelas dari histogram "charges" yang grafiknya mengalami penurunan seiring dengan semakin banyaknya jumlah sampel (sumbu x).
- Rentang biaya medis yang perlu ditanggung per individu cukup tinggi yaitu dari skala $ 1000 hingga $ 6000
- Setengah biaya medis dapat ditanggung di bawah $1000.
- Distribusi charges miring ke kanan (right-skewed). Hal ini akan berimplikasi pada model.
Visualisasi korelasi charges terhadap categorical data


Gambar 14. Visualisasi korelasi charges terhadap categorical data
Pada gambar 14 merupakan Visualisasi korelasi charges terhadap categorical data dan pada gambar 14 terdapat chart masing masing rata-rata "charges" relatif terhadap fitur kategori di atas, kita memperoleh insight sebagai berikut:
- Pada fitur Sex rata rata charges cenderung mirip rentangnya berada antara 1200 hingga 14000. grade tertinggi yaitu grade ideal memiliki harga rata-rata terendah diantara grade lainnya. sehingga, fitur Sex memiliki pengaruh atau dampak yang kecil terhadap rata-rata charges
- Pada fitur Smoker rata rata charges memiliki perbedaan yang cukup signifikan terhadap jumlah perokok di rentang 300000 dengan non perokok yang hanya berada di rentang 5000, sehingga fitur Smoker memiliki pengaruh atau dampak yang besar terhadap rata rata charges
- Pada fitur Region rata rata charges cenderung mirip rentangnya berada antara 1200 hingga 14000. grade tertinggi yaitu grade Ideal memiliki harga rata-rata terendah diantara grade lainnya. Sehingga, fitur Region memiliki pengaruh atau dampak yang kecil terhadap rata-rata charges
- Kesimpulan akhir, fitur kategori memiliki pengaruh yang rendah terhadap charges pada Fitur sex dan region tetapi memiliki pengaruh tinggi terhadap Smoker
Visualisasi hubungan antar fitur numerik dengan fungsi pairplot

Gambar 15. visualisasi hubungan antar fitur numerik dengan fungsi pairplot
Pada gambar 15 merupakan visualisasi hubungan antar fitur numerik dengan fungsi pairplot dan pada gambar 15 terdapat fungsi pairplot dari library seaborn menunjukkan relasi pasangan dalam dataset. Dari grafik, kita dapat melihat plot relasi masing-masing fitur numerik pada dataset.
Pada kasus ini, kita akan melihat relasi antara semua fitur numerik dengan fitur target kita yaitu ‘charges’. Untuk membacanya, perhatikan fitur pada sumbu y, temukan fitur target ‘charges’, dan lihatlah grafik relasi antara semua fitur pada sumbu x dengan fitur price pada sumbu y. Dalam hal ini, kita cukup melihat relasi antar fitur numerik dengan fitur target ‘charges’ pada baris tersebut saja.
Pada pola sebaran data grafik pairplot sebelumnya, terlihat ‘age','children' memiliki korelasi yang tinggi dengan fitur "charges". Sedangkan fitur lainnya yaitu 'bmi' terlihat memiliki korelasi yang lemah karena sebarannya tidak membentuk pola. Untuk mengevaluasi skor korelasinya, gunakan fungsi corr().
Correlation Matriks Fitur Numerik

Gambar 16. Correlation Matriks Fitur Numerik
Pada gambar 16 merupakan visualisasi Correlation Matriks Fitur Numerik. fungsi Correlation Matriks terdapat Koefisien korelasi berkisar antara -1 dan +1. Ia mengukur kekuatan hubungan antara dua variabel serta arahnya (positif atau negatif). Mengenai kekuatan hubungan antar variabel, semakin dekat nilainya ke 1 atau -1, korelasinya semakin kuat. Sedangkan, semakin dekat nilainya ke 0, korelasinya semakin lemah.
Arah korelasi antara dua variabel bisa bernilai positif (nilai kedua variabel cenderung meningkat bersama-sama) maupun negatif (nilai salah satu variabel cenderung meningkat ketika nilai variabel lainnya menurun).
dan pada gambar 16 Jika kita amati lagi terdapat fitur ‘age’, ‘children', ‘bmi' memiliki skor korelasi yang besar dengan fitur target ‘charges’. Artinya, fitur 'charges' berkorelasi tinggi dengan keempat fitur tersebut. Sementara itu, fitur 'bmi’ memiliki korelasi yang sangat kecil (0.2). Sehingga, fitur tersebut dapat di-drop.
- menangani dataset categorical dengan data yang dapat dimengerti oleh mesin yaitu angka menggunakan teknik One-Hot-Encoding pada dataset categorical yaitu sex, smoker dan region
- Melakukan Reduksi menggunakan teknik PCA
- Melakukan data splitting menjadi data latih dan data test dengan perbandingan 80:20
- Melakukan normalisasi data numerical sehingga memiliki mean 0 dan standard deviation 1
One Hot Encoding
Tabel 4. Hasil Pengolahan One Hot Encoding pada Fitur Kategori
| age | children | charges | sex_female | sex_male | smoker_no | smoker_yes | region_northeast | region_northwest | region_southeast | region_southwest | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 19 | 0 | 16884.92400 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| 1 | 18 | 1 | 1725.55230 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 0 |
| 2 | 28 | 3 | 4449.46200 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 0 |
| 3 | 33 | 0 | 21984.47061 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 0 |
| 4 | 32 | 0 | 3866.85520 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 0 |
Pada Tabel 4 merupakan visualisasi One Hot Encoding pada Fitur Kategori dan pada tabel 4 terdapat proses untuk melakukan proses encoding fitur kategori, salah satu teknik yang umum dilakukan adalah teknik one-hot-encoding.
Library scikit-learn menyediakan fungsi ini untuk mendapatkan fitur baru yang sesuai sehingga dapat mewakili variabel kategori. Kita memiliki tiga variabel kategori dalam dataset kita, yaitu ‘Sex’, ‘Smoker’, dan ‘Region'. Mari kita lakukan proses encoding ini dengan fitur get_dummies.
TEKNIK PCA Teknik reduksi (pengurangan) dimensi adalah prosedur yang mengurangi jumlah fitur dengan tetap mempertahankan informasi pada data. Teknik pengurangan dimensi yang paling populer adalah Principal Component Analysis atau disingkat menjadi PCA. Ia adalah teknik untuk mereduksi dimensi, mengekstraksi fitur, dan mentransformasi data dari “n-dimensional space” ke dalam sistem berkoordinat baru dengan dimensi m, dimana m lebih kecil dari n.
PCA bekerja menggunakan metode aljabar linier. Ia mengasumsikan bahwa sekumpulan data pada arah dengan varians terbesar merupakan yang paling penting (utama). PCA umumnya digunakan ketika variabel dalam data memiliki korelasi yang tinggi. Korelasi tinggi ini menunjukkan data yang berulang atau redundant.
Karena hal inilah, teknik PCA digunakan untuk mereduksi variabel asli menjadi sejumlah kecil variabel baru yang tidak berkorelasi linier, disebut komponen utama (PC). Komponen utama ini dapat menangkap sebagian besar varians dalam variabel asli. Sehingga, saat teknik PCA diterapkan pada data, ia hanya akan menggunakan komponen utama dan mengabaikan sisanya.
Berikut ini akan ditampilkan Hasil PCA :
Tabel 5. Hasil Pengolahan PCA pada fitur Numerik
| age | children | charges | sex_female | sex_male | smoker_no | smoker_yes | region_northeast | region_northwest | region_southeast | region_southwest | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 19 | 0 | 16884.92400 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| 1 | 18 | 1 | 1725.55230 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 0 |
| 2 | 28 | 3 | 4449.46200 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 0 |
| 3 | 33 | 0 | 21984.47061 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 0 |
| 4 | 32 | 0 | 3866.85520 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 1333 | 50 | 3 | 10600.54830 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 0 |
| 1334 | 18 | 0 | 2205.98080 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 |
| 1335 | 18 | 0 | 1629.83350 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
| 1336 | 21 | 0 | 2007.94500 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
| 1337 | 61 | 0 | 29141.36030 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 |
Pada tabel 5 menunjukkan hasil dari reduksi dimensi menggunakan PCA pada age,children dan charges dengan mempertahankan komponen PC Pertama saja karena bersumber dari gambar dibawah :
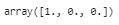
gambar 17. proporsi informasi Komponen PCA
Pada gambar 17 dapat diartikan yaitu 100 % informasi pada kedua fitur yaitu age dan children berada di komponen PC Pertama
Pada proyek ini digunakan teknik split dataset, split dataset sangat penting dilakukan sebelum tahap modelling. dan untuk melakukan, kita perlu mengimport library split data yaitu train_test_split, kemudian buat 2 variabel yaitu X yang berfungsi untuk menghapus kolom charges dan y untuk menampilkan kolom charges lalu bagi dataset menjadi 4 variabel baru yaitu X_train, X_test, y_train, y_test dengan library train_test_split dengan parameter yang digunakan yaitu :
- X berfungsi untuk menghapus kolom charges
- y berfungsi menampilkan kolom charges
- test_size adalah ukuran pembagian dataset yaitu sekitar 80 % untuk training dan 20 % untuk testing, data testing ini bertujuan untuk mengukur kinerja model pada data baru.
- random_state: digunakan untuk mengontrol random number generator yang digunakan, di proyek ini menggunakan random_state = 123
Setelah dilakukan split dataset, kita bisa mengetahui jumlah seluruh dataset menggunakan fungsi print len pada variabel X kemudian jika ingin mengetahui hasil jumlah dataset setelah dilakukan split dataset pada data training dapat menggunakan fungsi len data X_train dan jika ingin mengetahui hasil jumlah dataset setelah dilakukan split dataset pada data testing dapat menggunakan fungsi len data X_test dan untuk mengetahui hasil split dataset dapat dilihat dari gambar 18.

Gambar 18 : Hasil Split dataset
Proses scaling dan standarisasi membantu untuk membuat fitur data menjadi bentuk yang lebih mudah diolah oleh algoritma.
Standarisasi adalah teknik transformasi yang paling umum digunakan dalam tahap persiapan pemodelan. Untuk fitur numerik, kita tidak akan melakukan transformasi dengan one-hot-encoding seperti pada fitur kategori. kita akan menggunakan teknik StandarScaler dari library Scikit learn,
Standard Scaler melakukan proses standarisasi fitur dengan mengurangkan mean (nilai rata-rata) kemudian membaginya dengan standar deviasi untuk menggeser distribusi. Standard Scaler menghasilkan distribusi dengan standar deviasi sama dengan 1 dan mean sama dengan 0. Sekitar 68% dari nilai akan berada di antara -1 dan 1.
Untuk menghindari kebocoran informasi pada data uji, kita hanya akan menerapkan fitur standarisasi pada data latih. Kemudian, pada tahap evaluasi, kita akan melakukan standarisasi pada data uji. Untuk lebih jelasnya, mari kita terapkan Standard Scaler pada data.
Berikut ini akan ditampilkan Hasil dari Standarisasi Pada X_train dan X_test :
Tabel 6. Hasil standarisasi pada X_train
| age | children | |
|---|---|---|
| 67 | 0.062072 | -0.067366 |
| 736 | -0.150575 | -0.886479 |
| 310 | 0.770896 | -0.886479 |
| 963 | 0.487366 | 1.570860 |
| 680 | -1.284694 | -0.067366 |
Pada tabel 6 menunjukkan hasil proses standarisasi yang dilakukan pada variabel 'age' dan 'children' di X_train
Tabel 7: Hasil standarisasi pada Describe X_train
| age | children | |
|---|---|---|
| 67 | 0.062072 | -0.067366 |
| 736 | -0.150575 | -0.886479 |
| 310 | 0.770896 | -0.886479 |
| 963 | 0.487366 | 1.570860 |
| 680 | -1.284694 | -0.067366 |
Seperti yang telah disebutkan sebelumnya, proses standarisasi mengubah nilai rata-rata (mean) menjadi 0 dan nilai standar deviasi menjadi 1. Untuk mengecek nilai mean dan standar deviasi
Perhatikan tabel 7 menunjukkan hasil nilai mean = 0 dan standar deviasi = 1. Sampai di tahap ini, data kita telah siap untuk dilatih menggunakan model machine learning.
Penulis menerapkan 4 Algoritma model machine learning yang berbeda yaitu :
- KNN
- RANDOM FOREST
- ADABOOST
- SVM
Semua model dilatih menggunakan parameter default yang disediakan library sklearn.
Merupakan model prediksi yang termasuk teknik bagging dengan terdiri dari beberapa model dan bekerja secara bersama-sama. Ide dibalik model ensemble adalah sekelompok model yang bekerja bersama menyelesaikan masalah. Sehingga, tingkat keberhasilan akan lebih tinggi dibanding model yang bekerja sendirian. Pada model ensemble, setiap model harus membuat prediksi secara independen. kemudian, prediksi dari setiap model ensemble ini digabungkan untuk membuat prediksi akhir.
Algoritma yang cocok untuk teknik bagging ini adalah decision tree. Nah, random forest pada dasarnya adalah versi bagging dari algoritma decision tree. Bayangkan Anda memiliki satu bag (tas) random forest yang berisi beberapa model decision tree. Model decision tree masing-masing memiliki hyperparameter yang berbeda dan dilatih pada beberapa bagian (subset) data yang berbeda juga. Teknik pembagian data pada algoritma decision tree adalah memilih sejumlah fitur dan sejumlah sampel secara acak dari dataset yang terdiri dari n fitur dan m sampel.
alasan inilah mengapa algoritma ini disebut sebagai random forest. Karena algoritma ini disusun dari banyak algoritma pohon (decision tree) yang pembagian data dan fiturnya dipilih secara acak.
Tahapan Umum Cara kerja Random Forest
- Diawali dengan pemilihan k pada sampel dataset yang diambil secara acak dengan pengembalian
- Gunakan dataset untuk membangun decision tree ke-i
- Ulangi langkah kedua langkah di atas sebanyak k.
Pada kasus proyek ini bertipe regresi maka dari itu yang digunakan adalah Random Forest Regressor dari library scikit-learn.dengan beberapa nilai parameter. Berikut adalah parameter-parameter yang digunakan:
- n_estimator: jumlah trees (pohon) di forest. Di sini kita set n_estimator=50.
- max_depth: kedalaman atau panjang pohon. Ia merupakan ukuran seberapa banyak pohon dapat membelah (splitting) untuk membagi setiap node ke dalam jumlah pengamatan yang diinginkan. di proyek ini menggunakan max_depth = 16 sebagai ukuran panjang banyaknya pohon yang dapat membelah (splitting) untuk membagi setiap node ke dalam jumlah pengamatan
- random_state: digunakan untuk mengontrol random number generator yang digunakan, di proyek ini menggunakan random_state = 55.
- n_jobs: jumlah job (pekerjaan) yang digunakan secara paralel. Ia merupakan komponen untuk mengontrol thread atau proses yang berjalan secara paralel. n_jobs=-1 artinya semua proses berjalan secara paralel.
Kelebihan & Kekurangan Random Forest
- Kelebihannya yaitu dapat mengatasi noise dan missing value serta dapat mengatasi data dalam jumlah yang besar.
- Kekurangan pada algoritma Random Forest yaitu interpretasi yang sulit dan membutuhkan tuning model yang tepat untuk data.
KNN bekerja dengan membandingkan jarak satu sampel ke sampel pelatihan lain dengan memilih sejumlah k tetangga terdekat (dengan k adalah sebuah angka positif). Nah, itulah mengapa algoritma ini dinamakan K-nearest neighbor (sejumlah k tetangga terdekat).
Tahapan Umum Cara Kerja KNN
- Menentukan jumlah tetangga terdekat K
- Menghitung jarak dokumen testing ke dokumen training
- Urutkan data berdasarkan data yang mempunyai jarak Euclidean terkecil
- Tentukan kelompok testing berdasarkan label pada K.
Pada kasus proyek ini menggunakan n_neighbors = 10 tetangga dengan catatan Pemilihan nilai k sangat penting dan berpengaruh terhadap performa model. kemudian metric Euclidean untuk mengukur jarak antara titik. Pada tahap ini kita hanya melatih data training dan menyimpan data testing untuk tahap evaluasi yang akan dibahas di Modul Evaluasi Model.
Kelebihan & Kekurangan KNN
- KNN memiliki beberapa kelebihan yaitu bahwa algoritmanya tangguh terhadap training data yang noisy dan efektif apabila data latihnya besar.
- Kekurangan pada algoritma KKN yaitu perlu menentukan nilai dari parameter K (jumlah dari tetangga terdekat), Pembelajaran berdasarkan jarak tidak jelas mengenai jenis jarak apa yang harus digunakan dan atribut mana yang harus digunakan untuk mendapatkan hasil yang terbaik dan Biaya komputasi cukup tinggi karena diperlukan perhitungan dari jarak tiap sample uji pada keseluruhan sample latih.
algoritma ini bertujuan untuk meningkatkan performa atau akurasi prediksi. Caranya adalah dengan menggabungkan beberapa model sederhana dan dianggap lemah (weak learners) sehingga membentuk suatu model yang kuat (strong ensemble learner). Algoritma boosting muncul dari gagasan mengenai apakah algoritma yang sederhana seperti linear regression dan decision tree dapat dimodifikasi untuk dapat meningkatkan performa.
Algoritma ini sangat powerful dalam meningkatkan akurasi prediksi. Algoritma boosting sering mengungguli model yang lebih sederhana seperti logistic regression dan random forest. Beberapa pemenang kompetisi di platform Kaggle menyatakan bahwa mereka menggunakan algoritma boosting atau kombinasi beberapa algoritma boosting dalam modelnya. Meskipun demikian, hal ini tetap bergantung pada kasus per kasus, ruang lingkup masalah, dan dataset yang digunakan.
Dilihat dari caranya memperbaiki kesalahan pada model sebelumnya, algoritma boosting terdiri dari dua metode:
- Adaptive boosting
- Gradient boosting
Pada proyek ini , kita akan menggunakan metode adaptive boosting. Salah satu metode adaptive boosting yang terkenal adalah AdaBoost, dikenalkan oleh Freund and Schapire (1995) Pertanyaannya adalah, bagaimana AdaBoost bekerja ?
Cara Kerja AdaBOOST Awalnya, semua kasus dalam data latih memiliki weight atau bobot yang sama setelah itu model akan memeriksa apakah observasi yang dilakukan sudah benar? lalu Bobot yang lebih tinggi kemudian diberikan pada model yang salah sehingga mereka akan dimasukkan ke dalam tahapan selanjutnya. Proses iteratif ini berlanjut sampai model mencapai akurasi yang diinginkan kemudian membangun model pada dataset pelatihan, kemudian model kedua dibangun untuk memperbaiki kesalahan yang ada pada model pertama. Prosedur ini dilanjutkan sampai dan kecuali kesalahan diminimalkan, dan kumpulan data diprediksi dengan benar.
Berikut merupakan parameter-parameter yang digunakan pada proyek ini :
- learning_rate: bobot yang diterapkan pada setiap regressor di masing-masing proses iterasi boosting, pada proyek ini digunakan learning_rate = 0.05
- random_state: digunakan untuk mengontrol random number generator yang digunakan, pada proyek ini digunakan random_state = 55
- Kelebihan dari metode AdaBoost yaitu relatif lebih mudah untuk diimplementasikan dan waktu pengujian yang relatif cepat sehingga cocok dipakai dalam implementasi kondisi real time.
- Kekurangan dari metode AdaBoost yaitu membutuhkan hypertuning yang tepat untuk tuning model yang tepat untuk data
Cara Kerja SVM Support Vector Machine adalah model ML multifungsi yang dapat digunakan untuk menyelesaikan permasalahan klasifikasi, regresi, dan pendeteksian outlier. Termasuk ke dalam kategori supervised learning, SVM adalah salah satu metode yang paling populer dalam machine learning. Siapa pun yang tertarik untuk masuk ke dalam dunia ML, perlu mengetahui SVM.
Tujuan dari algoritma SVM adalah untuk menemukan hyperplane terbaik dalam ruang berdimensi-N (ruang dengan N-jumlah fitur) yang berfungsi sebagai pemisah yang jelas bagi titik-titik data input.
Kelebihan & Kekurangan SVM
Kelebihan dari metode SVM
- yaitu SVM efektif pada data berdimensi tinggi (data dengan jumlah fitur atau atribut yang sangat banyak).
- SVM efektif pada kasus di mana jumlah fitur pada data lebih besar dari jumlah sampel.
- SVM menggunakan subset poin pelatihan dalam fungsi keputusan (disebut support vector) sehingga membuat penggunaan memori menjadi lebih efisien.
Kekurangan dari metode SVM yaitu Sulit dipakai dalam problem berskala besar. Skala besar dalam hal ini dimaksudkan dengan jumlah sample yang diolah
tapi pada kasus ini SVM yang digunakan bertipe Regresi yaitu SVR
Cara Kerja SVR Support Vector Regression (SVR) menggunakan prinsip yang sama dengan SVM pada kasus klasifikasi. Perbedaannya adalah jika pada kasus klasifikasi, SVM berusaha mencari ‘jalan’ terbesar yang bisa memisahkan sampel-sampel dari kelas berbeda, maka pada kasus regresi SVR berusaha mencari jalan yang dapat menampung sebanyak mungkin sampel di ‘jalan’ dan , pada SVR support vector adalah sampel yang menjadi pembatas jalan yang dapat menampung seluruh sampel pada data. Pada proyek ini digunakan SVR tanpa parameter
Pada Proyek ini menggunakan model machine learning bertipe regresi yang berarti Jika prediksi mendekati nilai sebenarnya, performanya baik. Sedangkan jika tidak, performanya buruk. Secara teknis, selisih antara nilai sebenarnya dan nilai prediksi disebut eror. Maka, semua metrik mengukur seberapa kecil nilai error tersebut.
Metrik yang akan kita gunakan pada prediksi ini adalah MSE atau Mean Squared Error yang menghitung jumlah selisih kuadrat rata-rata nilai sebenarnya dengan nilai prediksi. MSE didefinisikan dalam persamaan berikut

Gambar 19 . Perhitungan MSE
Keterangan:
N = jumlah dataset
yi = nilai sebenarnya
y_pred = nilai prediksi
Tabel 8 . Hasil Perhitungan MSE 4 Algoritma
| train | test | |
|---|---|---|
| KNN | 38190666.934227 | 45165701.590825 |
| RF | 12361073.677352 | 50698016.090074 |
| Boosting | 41173600.411401 | 37804782.197369 |
| svm | 159381957.446801 | 170699957.447317 |
Perhatikan pada tabel 8 menunjukkan hasil penghitungan nilai Mean squared error pada data train dan test setelah membaginya dengan nilai 1e3. Hal ini bertujuan agar nilai mse berada dalam skala yang tidak terlalu besar.
Untuk memudahkan, mari kita plot matrik tersebut dengan bar chart
Visualisasi MSE 4 Algoritma

Gambar 20. Visualisasi Hasil MSE dari 4 Algoritma
Dari gambar 20 , terlihat bahwa, model boosting memiliki nilai error pada data test yang paling kecil kemudian model dengan knn memiliki nilai error yang sedikit lebih banyak daripada model boosting sedangkan model random forest miliki lebih banyak nilai error dibandingkan boosting dan knn namum model svm memiliki nilai error paling banyak dari ketiga model boosting, kkn, dan random forest Model inilah yang akan kita pilih sebagai model terbaik untuk melakukan prediksi biaya medis yang ditanggung per individu .
Untuk mengujinya, mari kita buat prediksi menggunakan beberapa harga dari data test.
Hasil Perbandingan Prediksi 4 Algoritma

Gambar 21. Hasil Prediksi MSE dari 4 Algoritma
Pada gambar 21 adalah hasil prediksi "charges" dari 4 algoritma yaitu KNN, Random Forest dan berdasarkan Gambar 20 terlihat Terlihat bahwa prediksi dengan Boosting memberikan hasil yang paling mendekati. dan berdasarkan gambar 21 dapat dijabarkan bahwa algoritma KNN memiliki nilai prediksi MSE (Mean Squared Error) sebesar 9651.5, algoritma Random Forest(RF) memiliki nilai prediksi MSE (Mean Squared Error) sebesar 9755.4, algoritma Boosting memiliki nilai prediksi MSE (Mean Squared Error) sebesar 12167.0 sedangkan algoritma svm memiliki nilai prediksi MSE (Mean Squared Error) sebesar 9312.6
Dapat dilihat dari Empat model Algoritma yang dikembangkan, dapat disimpulkan dari hasil perbandingan serta visualisasi perbandingan prediksi 4 Algoritma yaitu KNN, Random Forest, AdaBoost , dan SVM. dapat disimpulkan model boosting memiliki nilai error pada data test yang paling kecil kemudian model dengan knn memiliki nilai error yang sedikit lebih banyak daripada model boosting sedangkan model random forest miliki lebih banyak nilai error dibandingkan boosting dan knn namum model svm memiliki nilai error paling banyak dari ketiga model boosting, kkn, dan random forest
[2] [R.Rakhmat Sani, J.Zeniarja, A.Luthfiartha."Penerapan Algoritma K- Nearest Neighbor pada Information Retrieval dalam Penentuan Topik Referensi Tugas Akhir. Journal of Applied Intelligent System, Vol. 1, No. 2, Juni 2016: 123 – 133]