{kind=link}
SenTrEv (Sentence Transformers Evaluator) is a python package that is aimed at running simple evaluation tests to help you choose the best embedding model for Retrieval Augmented Generation (RAG) with your PDF documents.
SenTrEv works with:
- Text encoders/embedders loaded through the class
SentenceTransformerin the python packagesentence_transformers - PDF documents (single and multiple uploads supported)
- Qdrant vector databases (both local and on cloud)
You can install the package using pip (easier but no customization):
python3 -m pip install sentrevOr you can build it from the source code (more difficult but customizable):
# clone the repo
git clone https://github.com/AstraBert/SenTrEv.git
# access the repo
cd SenTrEv
# build the package
python3 -m build
# install the package locally with editability settings
python3 -m pip install -e .SenTrEv applies a very simple evaluation workflow:
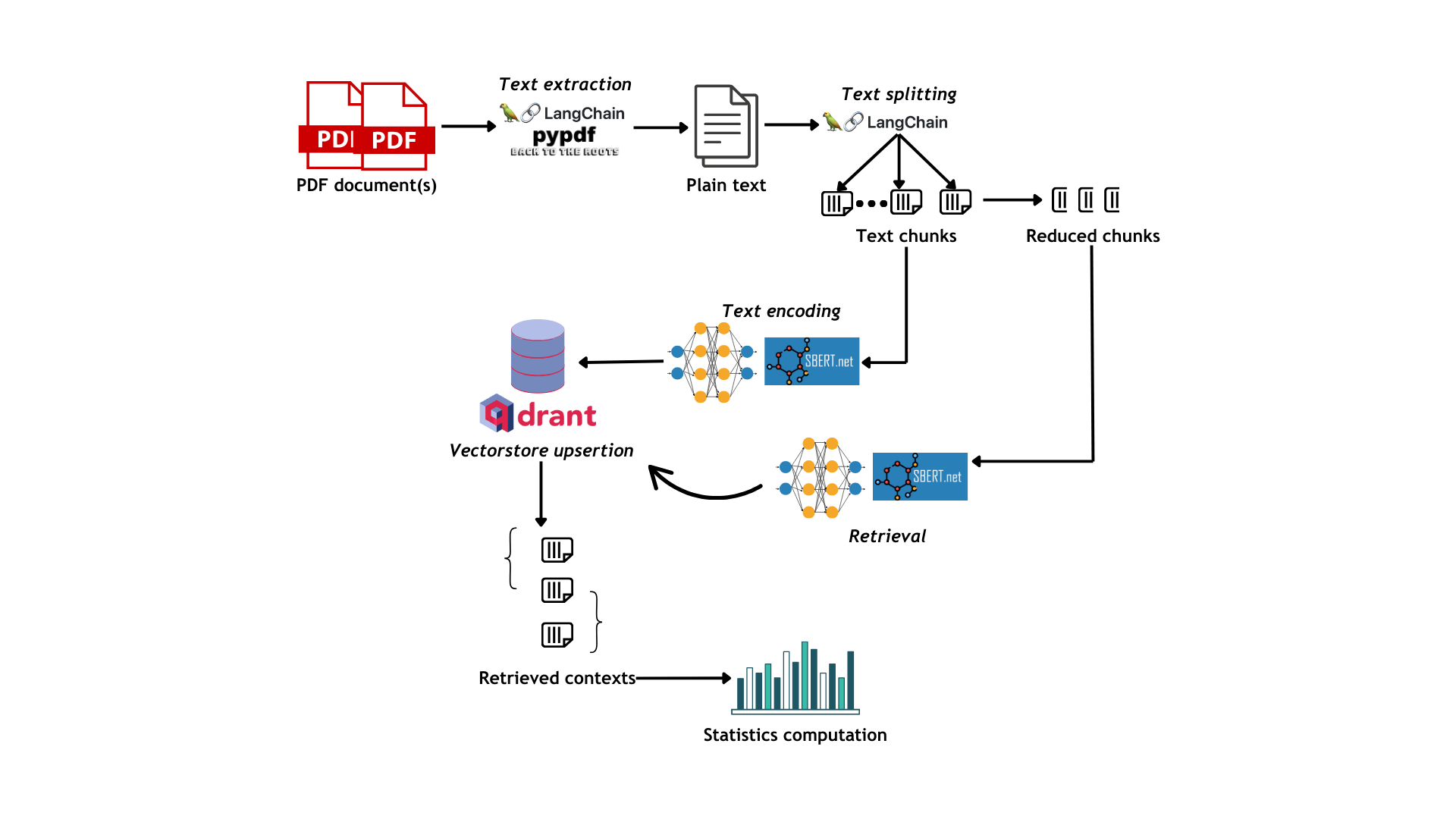
- After the PDF text extraction and chunking (cfr. supra) phase, the chunks are reduced according to a (optionally) user-defined percentage (default is 25%), which is randomly extracted at any point of each chunk.
- The reduced chunks are mapped to their original ones in a dictionary
- Each model encodes the original chunks and uploads the vectors to the Qdrant vector storage
- The reduced chunks are then used as queries for dense retrieval
- Starting from retrieval results, accuracy, time and carbon emissions statistics are calculated and plotted.
See the figure below for a visualization of the workflow
The metrics used to evaluate performance were:
-
Success rate: defined as the number retrieval operation in which the correct context was retrieved ranking top among all the retrieved contexts, out of the total retrieval operations:
$SR = \frac{Ncorrect}{Ntot}$ (eq.1) -
Mean Reciprocal Ranking (MRR): MRR defines how high in ranking the correct context is placed among the retrieved results. MRR@10 was used, meaning that for each retrieval operation 10 items were returned and an evaluation was carried out for the ranking of the correct context, which was then normalized between 0 and 1 (already implemented in SenTrEv). An MRR of 1 means that the correct context was ranked first, whereas an MRR of 0 means that it wasn't retrieved. MRR is calculated with the following general equation:
$MRR = \frac{ranking + Nretrieved - 1}{Nretrieved}$ (eq.2)When the correct context is not retrieved, MRR is automatically set to 0. MRR is calculated for each retrieval operation, then the average and standard deviation are calculated and reported.
-
Time performance: for each retrieval operation the time performance in seconds is calculated: the average and standard deviation are then reported.
-
Carbon emissions: Carbon emissions are calculated in gCO2eq (grams of CO2 equivalent) through the Python library
codecarbonand were evaluated for the Austrian region. They are reported for the global computational load of all the retrieval operations.
You can easily run Qdrant locally with Docker:
docker pull qdrant/qdrant:latest
docker run -p 6333:6333 -p 6334:6334 qdrant/qdrant:latestNow your vector database is listening at http://localhost:6333
Let's say we have three PDFs (~/pdfs/instructions.pdf, ~/pdfs/history.pdf, ~/pdfs/info.pdf ) and we want to test retrieval with three different encoders sentence-transformers/all-MiniLM-L6-v2 , sentence-transformers/sentence-t5-base, sentence-transformers/all-mpnet-base-v2.
We can do it with this very simple code:
from sentrev.evaluator import evaluate_rag
from sentence_transformers import SentenceTransformer
from qdrant_client import QdrantClient
# load all the embedding moedels
encoder1 = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
encoder2 = SentenceTransformer('sentence-transformers/sentence-t5-base')
encoder3 = SentenceTransformer('sentence-transformers/all-mpnet-base-v1')
# create a list of the embedders and a dictionary that map each one with its name for the stats report which will be output by SenTrEv
encoders = [encoder1, encoder2, encoder3]
encoder_to_names = {encoder1: 'all-MiniLM-L6-v2', encoder2: 'sentence-t5-base', encoder3: 'all-mpnet-base-v1'}
# set up a Qdrant client
client = QdrantClient("http://localhost:6333")
# create a list of your PDF paths
pdfs = ['~/pdfs/instructions.pdf', '~/pdfs/history.pdf', '~/pdfs/info.pdf']
# Choose a path for the CSV where the evaluation stats will be saved
csv_path = '~/eval/stats.csv'
# evaluate retrieval
evaluate_rag(pdfs=pdfs, encoders=encoders, encoder_to_name=encoder_to_names, client=client, csv_path=csv_path, distance='euclid', chunking_size=400, mrr=10,carbon_tracking="USA", plot=True)You can play around with the chunking of your PDF by setting the chunking_size argument or with the percentage of text used to test retrieval by setting text_percentage or with the distance metric used for retrieval by setting the distance argument or with the mrr settings by tuning the number of retrieved items (in this case 10); you can also pass plot=True if you want plots for the evaluation: plots will be saved under the same folder of the CSV file; if you want to turn on carbon emissions tracking, you can use the carbon_tracking option followed by the three-letters ISO code of the State you are in.
You can also exploit Qdrant on-cloud database solutions (more about it here). You just need your Qdrant cluster URL and the API key to access it:
from qdrant_client import QdrantClient
client = QdrantClient(url="YOUR-QDRANT-URL", api_key="YOUR-API-KEY")This is the only change you have to make to the code provided in the example before.
You can use SenTrEv also to chunk, vectorize and upload your PDFs to a Qdrant database.
from sentrev.evaluator import upload_pdfs
encoder = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
pdfs = ['~/pdfs/instructions.pdf', '~/pdfs/history.pdf', '~/pdfs/info.pdf']
client = QdrantClient("http://localhost:6333")
upload_pdfs(pdfs=pdfs, encoder=encoder, client=client)As for before, you can also play around with the chunking_size argument (default is 1000) and with the distance argument (default is cosine).
You can also search already-existent collections in a Qdrant database with SenTrEv:
from sentrev.utils import NeuralSearcher
encoder = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
collection_name = 'customer_help'
client = QdrantClient("http://localhost:6333")
searcher = NeuralSearcher(client=client, model=encoder, collection_name=collection_name)
res = searcher.search("Is it possible to pay online with my credit card?", limit=5)The results will be returned as a list of payloads (the metadata you uploaded to the Qdrant collection along with the vector points).
If you used SenTrEv upload_pdfs function, you should be able to access the results in this way:
text = res[0]["text"]
source = res[0]["source"]
page = res[0]["page"]You can refer to the test case reported here
Find a reference for all the functions and classes here
- Add support for Markdown, HTML, Word and CSV data types
- Add support for Chroma, Pinecone, Weaviate, Supabase and MongoDB as vector databases
Contributions are always welcome!
Find contribution guidelines at CONTRIBUTING.md
This project is open-source and is provided under an MIT License.
If you used SenTrEv to evaluate your retrieval models, please consider citing it:
Bertelli, A. C. (2024). Evaluation of the performance of three Sentence Transformers text embedders - a case study for SenTrEv (v0.1.0). Zenodo. https://doi.org/10.5281/zenodo.14503887
If you found it useful, please consider funding it .