A pythonic solution for calculating predictive r-squared
This function will calculate the value of Predictive R-Squared. It is used as a means of evaluating the R-Squared/Adj-R-Squared value of the training model, by providing evidence suggestive of model under/overfitting.
This function takes three arguments - y_test, y_pred, X. y_test should be a pandas series of the observed dependent variable in the test set. numpy's train_test_split function will automatically create this series. y_pred should the the result of using the fitted model (I use statsmodels) on x_test. This, too, should be output automatically in a series. Note that the indices will be the same for both of these files. It is always good to check, though. X should be a pandas dataframe of numeric values (after feature engineering for dummy encoding). You can pass the entire X dataframe (before the train/test split), as the function will match up the the appropriate indices for the hat matrix. A later version of this may require X_test as a means of optimization for runtime.
In an RPubs blog post, Predictive R-Squared is discussed in terms of h ow it was implemented by Tom Hopper. This program uses the following general formula from that post to calculate Predictive R-Squared:
predictive R-squared = [1 - (PRESS / SST)] * 100
This formula requires the calculation of the Predicted Residual Error Sum of Squares (PRESS) statistic, and the Sum of Squares Total (SST). The function first calculates the PRESS statistic. According to Kutner et al, the formula for PRESS is as follows:
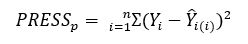
In this formula, Y-hat is obtained by deleting the i-th observation and refitting the model. Naturally, it would be computationally expensive to refit a model for all n observations in the test set, deleting each observation per run. Luckily, there is another way to calculate the Deleted Residual (the Y minus Y-hat part of the PRESS formula):
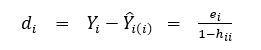
Here e is the ordinary residual for the ith case, and h is the ith diagonal element in the hat matrix (Kutner et al). More plainly, calculating the Deleted Residual requires calculating two variables. The first is the ordinary residual, which is simply the observed dependent variable in the test set minus the predicted value. The hat matrix, denoted as H = X(X'X)^-1 (X') can be calculated with a couple of NumPy functions, and the diagonal of the matrix retrieved as a vector.
With the calculations for the Deleted Residual satisfied, the resulting scalar can be passed into the PRESS formula, where each element is squared and the resulting vector reduced to a scalar by summation. Now, SST must be calculated:
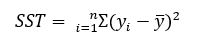
y-bar is simply the mean of the predictive variable of the test set. This scalar can then be used to calculate SST by taking each element of the predicted values of the test set, subtracting them by y-bar, squaring the result, and taking the summation of the resulting vector.
With PRESS and SST calculated, the Predictive R-Squared value can be realized. For the purposes of this function, I have chosen to ignore putting this value in percentage form, opting to leave it as a decimal, and so the resulting formula is as follows:
predictive R-squared = [1 - (PRESS / SST)]
I would love any comments/feedback about the function, particularly as they pertain to the accuracy of my interpretation of the formulas used herein.
As mentioned above, pandas and numpy should keep the indices for y_test and y_pred, but do a double check before running this function.
Kutner, Michael H., et al. Applied Linear Regression Models. Fourth, McGraw-Hill Irwin, pp. 360, 361, 395.
numpy hat matrix code - https://stackoverflow.com/questions/23926496/computing-the-trace-of-a-hat-matrix-from-and-independent-variable-matrix-with-a
Additional resources for PRESS statistic - https://online.stat.psu.edu/stat501/lesson/10/10.5, https://en.wikipedia.org/wiki/PRESS_statistic
Additional resources on Predictive R-Squared - https://blog.minitab.com/en/adventures-in-statistics-2/multiple-regession-analysis-use-adjusted-r-squared-and-predicted-r-squared-to-include-the-correct-number-of-variables
Additional resources on the Hat Matrix from a mathematical standpoint - https://www.jstor.org/stable/2683469 , https://stats.stackexchange.com/questions/208242/hat-matrix-and-leverages-in-classical-multiple-regression