This repository contains the code for ACL2020 paper: The Summary Loop: Learning to Write Abstractive Summaries Without Examples.
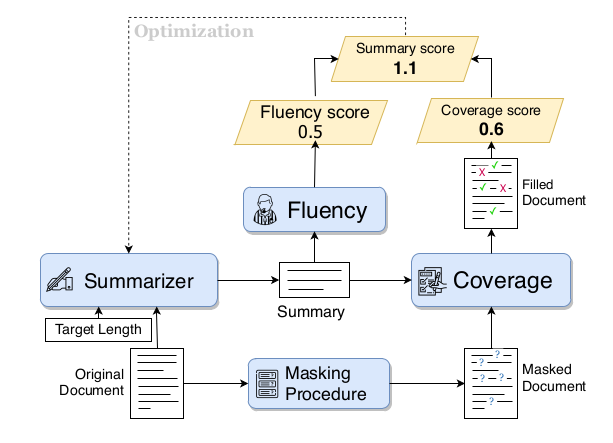
We provide pre-trained models for each component needed in the Summary Loop Release:
keyword_extractor.joblib: An sklearn pipeline that will extract can be used to compute tf-idf scores of words according to the BERT vocabulary, which is used by the Masking Procedure,bert_coverage.bin: A bert-base-uncased finetuned model on the task of Coverage for the news domain,fluency_news_bs32.bin: A GPT2 (base) model finetuned on a large corpus of news articles, used as the Fluency model,gpt2_copier23.bin: A GPT2 (base) model that can be used as an initial point for the Summarizer model.
In the release, we also provide:
pretrain_coverage.pyscript to train a coverage model from scratch,train_generator.pyto train a fluency model from scratch (we recommend Fluency model on domain of summaries, such as news, legal, etc.)
Once all the pretraining models are ready, training a summarizer can be done using the train_summary_loop.py:
python train_summary_loop.py --experiment wikinews_test --dataset_file data/wikinews.db
We provide the 11,490 summaries produces by the Summary Loop models on the test portion of the CNN/Daily Mail dataset. The release is available here. This is intended to facilitate comparison to future work, and analysis work, such as analysis of abstractiveness and factuality.
[New January 2022] The model card for Summary Loop 46 has been added to the HuggingFace model hub, working with the latest version of the HuggingFace library. See the model card here for usage: https://huggingface.co/philippelaban/summary_loop46
The model can be loaded in the following way:
from transformers import GPT2LMHeadModel, GPT2TokenizerFast
model = GPT2LMHeadModel.from_pretrained("philippelaban/summary_loop46")
tokenizer = GPT2TokenizerFast.from_pretrained("philippelaban/summary_loop46")
Usage examples in the model card.
The Coverage and Fluency model and Guardrails scores can be used separately for analysis, evaluation, etc.
They are respectively in model_coverage.py and model_guardrails.py, each model is implemented as a class with a score(document, summary) function.
The Fluency model is a Language model, which is also the generator (in model_generator.py).
Examples of how to run each model are included in the class files, at the bottom of the files.
Want to test out the Summary Loop on a different language/type of text?
A Jupyter Notebook can help you bring your own data into the SQLite format we use in the pre-training scripts. Otherwise you can modify the scripts' data loading (DataLoader) and collate function (collate_fn).
If you make use of the code, models, or algorithm, please cite our paper:
@inproceedings{laban2020summary,
title={The Summary Loop: Learning to Write Abstractive Summaries Without Examples},
author={Laban, Philippe and Hsi, Andrew and Canny, John and Hearst, Marti A},
booktitle={Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics},
volume={1},
year={2020}
}
If you'd like to contribute, or have questions or suggestions, you can contact us at phillab@berkeley.edu. All contributions welcome! For example, if you have a type of text data on which you want to apply the Summary Loop.