第 8 章 著名数据集及基准
作者: 张伟 (Charmve)
日期: 2021/06/06
- 第 8 章 著名数据集及基准
本节将介绍PyTorch中数据集相关知识,包括常见数据集的介绍,如何自定义数据集,数据的读取以及扩充等内容。只有清晰理解了数据集构建和使用方法,才能够为后续CV学习铺平道路。本节涵盖的主要内容如下:
- CV中常见数据集简介
- pytorch中图像数据集制作及读取方式
- 数据增强简介
- 总结:读取数据并进行数据扩增的完整示例
学习CV,最重要的就是先有图像数据集,现在互联网中也已经有很多开源的图像数据集供我们学习选择。在CV中较为“出名”,使用频率较高的几个数据集有:MNIST、CIFAR、PASCAL VOC、ImageNet、MS COCO、Open Image Dataset等。这些数据集都是根据具体的应用场景(如分类、检测、分割等),为了更好的促进学术研究的进展,耗费大量人力进行标注的。除此之外,当然还有很多特定领域的数据集,这里不再一一罗列,感兴趣的读者可以自行检索。下面将对分类任务常见的数据集进行介绍。
8.1.1.1 ImageNet
简介
ImageNet项目是一个大型计算机视觉数据库,它按照WordNet层次结构(目前只有名词)组织图像数据,其中层次结构的每个节点都由成百上千个图像来描述,用于视觉目标识别软件研究。该项目已手动注释了1400多万张图像,以指出图片中的对象,并在至少100万张图像中提供了边框。ImageNet包含2万多个典型类别(synsets),例如大类别包括:amphibian、animal、appliance、bird、covering、device、fabric、fish等,每一类包含数百张图像。尽管实际图像不归ImageNet所有,但可以直接从ImageNet免费获得标注的第三方图像URL。2010年以来,ImageNet项目每年举办一次软件竞赛,即ImageNet大规模视觉识别挑战赛(ILSVRC)。
目前,ImageNet已广泛应用于图像分类(Classification)、目标定位(Object localization)、目标检测(Object detection)、视频目标检测(Object detection from video)、场景分类(Scene classification)、场景解析(Scene parsing)。
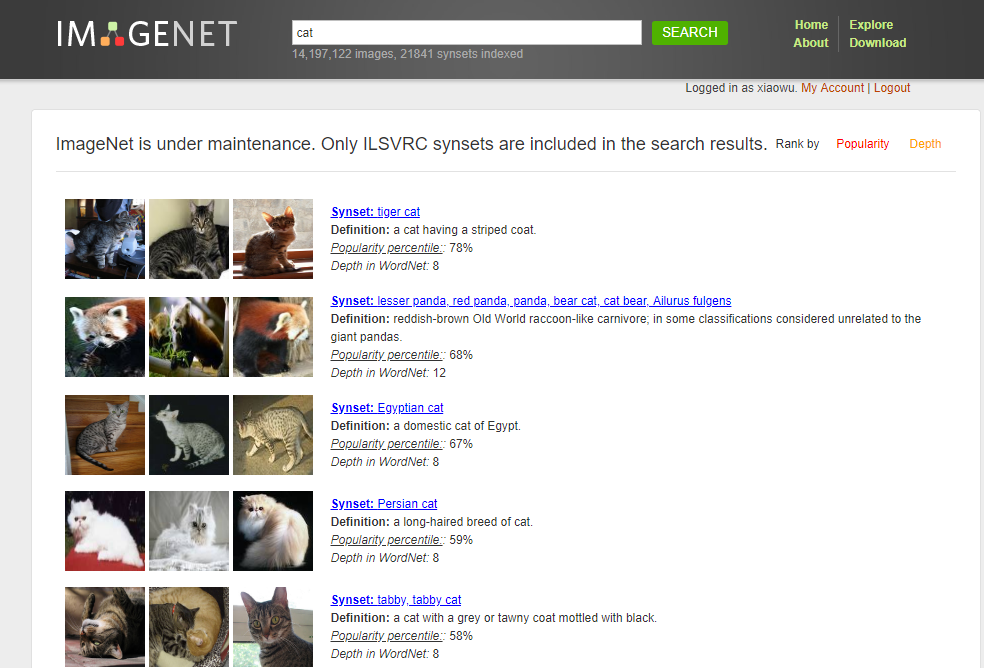
图8.1 ImageNet数据集
总览
- Total number of non-empty synsets: 21841
- Total number of images: 14,197,122
- Number of images with bounding box annotations: 1,034,908
- Number of synsets with SIFT features: 1000
- Number of images with SIFT features: 1.2 million
层次结构及下载方式
如图8.2所示,展示了ImageNet的层次结构:
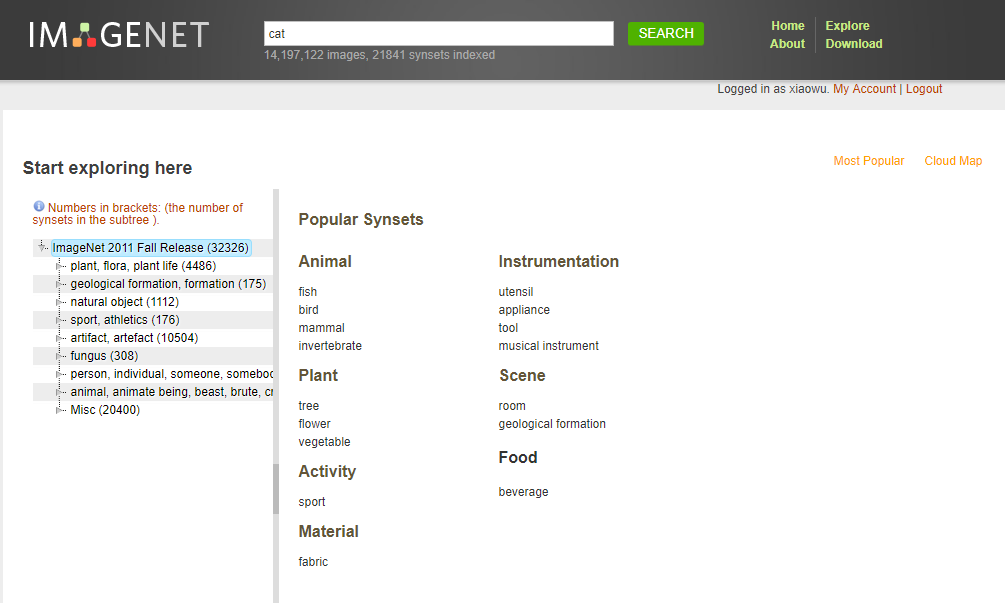
图8.2 层次结构及下载方式
ImageNet有5种下载方式,如下图8.3所示:
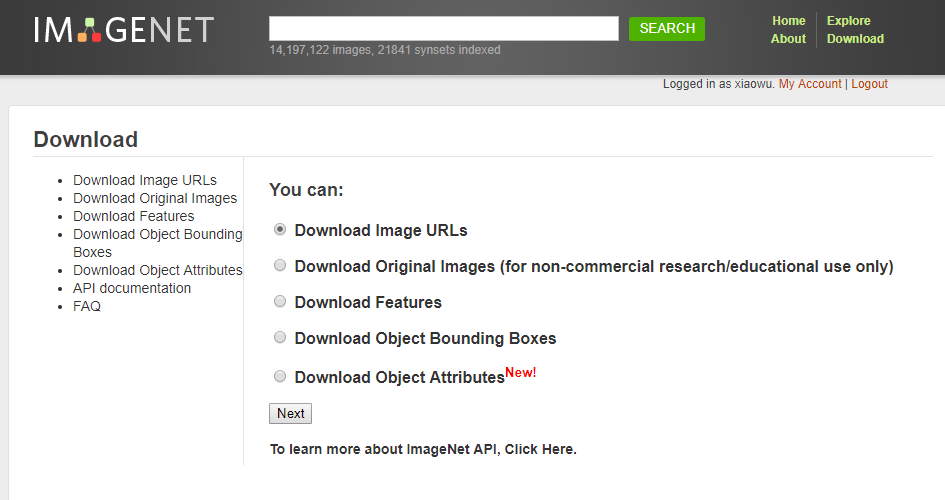
图8.3 ImageNet下载方式
- 所有原始图像可通过url下载:http://image-net.org/download-imageurls
- 直接下载原始图像:需要自己申请注册一个账号,然后登录访问,普通邮箱(非组织和学校)无法获取权限。对于希望将图像用于非商业研究或教育目的的研究人员,可以在特定条件下通过ImageNet网站提供访问权限。
- 下载图像sift features:http://image-net.org/download-features
- 下载Object Bounding Boxes:http://image-net.org/download-bboxes
- 下载Object Attributes: http://image-net.org/download-attributes
- 官网:http://image-net.org/download-attributes
8.1.1.2 MNIST
简介
MNIST数据集(Mixed National Institute of Standards and Technology database)是美国国家标准与技术研究院收集整理的大型手写数字数据库,如图8.4所示。包含60,000个示例的训练集以及10,000个示例的测试集,其中训练集 (training set) 由来自 250 个不同人手写的数字构成, 其中 50% 是高中学生, 50% 来自人口普查局 (the Census Bureau) 的工作人员,测试集(test set) 也是同样比例的手写数字数据。可以说,完成MNIST手写数字分类和识别是计算机视觉领域的"Hello World"(第1章 实战项目 1 - 手写字分类)。

图8.4 MNIST数据集
如下图8.5所示,MNIST数据集的图像尺寸为28 * 28,且这些图像只包含灰度信息,灰度值在0~1之间。
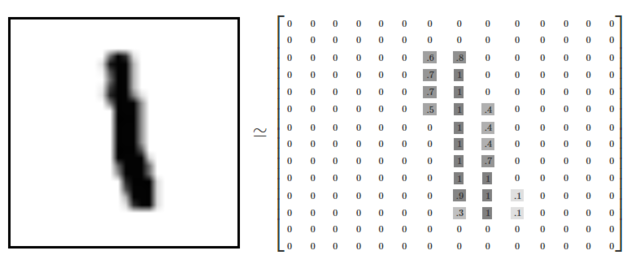
图8.5 MNIST数据集举例
下载
- train-images-idx3-ubyte.gz: training set images (9912422 bytes)
- train-labels-idx1-ubyte.gz: test set images (1648877 bytes)
- t10k-images-idx3-ubyte.gz: test set images (1648877 bytes)
- t10k-labels-idx1-ubyte.gz: test set labels (4542 bytes)
8.1.1.3 COCO
COCO数据集是微软团队获取的一个可以用来图像recognition+segmentation+captioning 数据集,其官方说明网址:https://cocodataset.org/。
该数据集主要有的特点如下:
- 目标分割
- 上下文中的识别
- 每类图像多个对象
- 超过 300,000 张图像
- 超过 200 万个实例
- 80个对象类别
- 每张图片 5 个标题
- 100,000 人的关键点
为了更好的介绍这个数据集,微软在ECCV Workshops里发表这篇文章:Microsoft COCO: Common Objects in Context。从这篇文章中,我们了解了这个数据集以scene understanding为目标,主要从复杂的日常场景中截取,图像中的目标通过精确的segmentation进行位置的标定。图像包括91类目标,328,000影像和2,500,000个label。
该数据集主要解决3个问题:目标检测,目标之间的上下文关系,目标的2维上的精确定位。数据集的对比示意图,如图8.12所示。

图8.6 COCO 数据集。虽然以前的对象识别数据集专注于 (a) 图像分类、(b) 对象边界框定位或 (c) 语义像素级分割,但该数据集专注于 (d) 分割单个对象实例,引入了一个大型的、注释丰富的数据集,其中包含描绘自然环境中常见物体的复杂日常场景的图像。
- 图像分类
分类需要二进制的标签来确定目标是否在图像中。早期数据集主要是位于空白背景下的单一目标,如MNIST手写数据库,COIL household objects。在机器学习领域的著名数据集有CIFAR-10 and CIFAR-100,在32*32影像上分别提供10和100类。最近最著名的分类数据集即ImageNet,22,000类,每类500-1000影像。
- 目标检测
经典的情况下通过bounding box确定目标位置,期初主要用于人脸检测与行人检测,数据集如Caltech Pedestrian Dataset包含350,000个bounding box标签。PASCAL VOC数据包括20个目标超过11,000图像,超过27,000目标bounding box。最近还有ImageNet数据下获取的detection数据集,200类,400,000张图像,350,000个bounding box。由于一些目标之间有着强烈的关系而非独立存在,在特定场景下检测某种目标是是否有意义的,因此精确的位置信息比bounding box更加重要。
- 语义场景标注
这类问题需要pixel级别的标签,其中个别目标很难定义,如街道和草地。数据集主要包括室内场景和室外场景的,一些数据集包括深度信息。其中,SUN dataset包括908个场景类,3,819个常规目标类(person, chair, car)和语义场景类(wall, sky, floor),每类的数目具有较大的差别(这点COCO数据进行改进,保证每一类数据足够)。

图8.7 (a) 标志性对象图像、(b) 标志性场景图像和 (c) 非标志性图像的示例。
- 其他视觉数据集
一些数据集如Middlebury datasets,包含立体相对,多视角立体像对和光流;同时还有Berkeley Segmentation Data Set (BSDS500),可以评价segmentation和edge detection算法。
该数据集标记流程,如图8.8所示。

图8.8 标记流程分为 3 个主要任务:(a)标记图像中存在的类别,(b)定位和标记标记类别的所有实例,以及(c)分割每个对象实例。
COCO数据集有91类,虽然比ImageNet和SUN类别少,但是每一类的图像多,这有利于获得更多的每类中位于某种特定场景的能力,对比PASCAL VOC,其有更多类和图像。
COCO数据集分两部分发布,前部分于2014年发布,后部分于2015年,2014年版本:82,783 training, 40,504 validation, and 40,775 testing images,有270k的segmented people和886k的segmented object;2015年版本:165,482 train, 81,208 val, and 81,434 test images。
其性能对比和一些例子,如图8.9所示。

图8.9 MS COCO 和 PASCAL VOC 的每个类别的注释实例数。 (b,c) 分别为 MS COCO、ImageNet 检测、PASCAL VOC 和 SUN 的每张图像的注释类别和注释实例的数量(类别和实例的平均数量显示在括号中)。 (d) 对于许多流行的对象识别数据集,类别数量与每个类别的实例数量。 (e) MS COCO、ImageNet Detection、PASCAL VOC 和 SUN 数据集的实例大小分布。
如图8.10所示,数据集中带注释的图像样本。

图8.10 MS COCO 数据集中带注释的图像样本
官网链接:The CIFAR-10 dataset

图8.11 CIFAR-10数据集
CIFAR-10是一个更接近普适物体的彩色图像数据集。CIFAR-10 是由Hinton 的学生Alex Krizhevsky 和Ilya Sutskever 整理的一个用于识别普适物体的小型数据集。一共包含10 个类别的RGB 彩色图片:飞机( airplane )、汽车( automobile )、鸟类( bird )、猫( cat )、鹿( deer )、狗( dog )、蛙类( frog )、马( horse )、船( ship )和卡车( truck )。 每个图片的尺寸为32 × 32 ,每个类别有6000个图像,数据集中一共有50000 张训练图片和10000 张测试图片。
(1) 与MNIST 数据集中目比, CIFAR-10 真高以下不同点:
- CIFAR-10 是3 通道的彩色RGB 图像,而MNIST 是灰度图像。
- CIFAR-10 的图片尺寸为**32 × 32 **, 而MNIST 的图片尺寸为28 × 28 ,比MNIST 稍大。
- 相比于手写字符, CIFAR-10 含有的是现实世界中真实的物体,不仅噪声很大,而且物体的比例、特征都不尽相同,这为识别带来很大困难。直接的线性模型如Softmax 在CIFAR-10 上表现得很差。
(2) TensorFlow 官方示例的CIFAR-10 代码文件
表8.1 TensorFlow官方示例的CIFAR-10代码文件
| 文件 | 用途 |
|---|---|
| cifar10.py | 建立CIFAR-10预测模型 |
| cifar10_input.py | 在TensorFlow 中读入CIFAR-10 训练文件 |
| cifar10_input_test.py | cifar10_input.py 的测试用例文件 |
| cifar10_train.py | 使用单个 GPU 或 CPU 训练模型 |
| cifar10_train_mutil_gpu.py | 使用多个 GPU 训练模型 |
| cifar10_cval.py | 在测试集上测试模型的性能 |
(3) CIFAR-10 数据集的数据文件名及用途
在CIFAR-10 数据集中,文件data_batch_1.bin、data_batch_2.bin 、··data_batch_5.bin 和test_ batch.bin 中各有10000 个样本。一个样本由3073 个字节组成,第一个字节为标签label ,剩下3072 个字节为图像数据。样本和样本之间没高多余的字节分割, 因此这几个二进制文件的大小都是30730000 字节。
表8.2 CIFAR-10 数据集的数据文件名及用途
| 文件名 | 文件用途 |
|---|---|
| batches.meta. bet | 文件存储了每个类别的英文名称。可以用记事本或其他文本文件阅读器打开浏览查看 |
| data batch 1.bin、data batch 2.bin 、……、data batch 5.bin | 这5 个文件是CIFAR- 10 数据集中的训练数据。每个文件以二进制格式存储了10000 张32 × 32 的彩色图像和这些图像对应的类别标签。一共50000 张训练图像 |
| test batch.bin | 这个文件存储的是测试图像和测试图像的标签。一共10000 张。 |
| readme.html | 数据集介绍文件 |
下载CIFAR-10 数据集的全部数据。
FLAGS = tf.app.flags.FLAGS
cifar10.maybe_download_and_extract()
>> Downloading cifar-10-binary.tar.gz 0.0%
……
>> Downloading cifar-10-binary.tar.gz 0.0%
>> Downloading cifar-10-binary.tar.gz 0.1%
……
>> Downloading cifar-10-binary.tar.gz 0.1%
>> Downloading cifar-10-binary.tar.gz 0.2%
……
>> Downloading cifar-10-binary.tar.gz 0.2%
>> Downloading cifar-10-binary.tar.gz 0.3%
……
>> Downloading cifar-10-binary.tar.gz 98.9%
……
>> Downloading cifar-10-binary.tar.gz 99.0%
……
>> Downloading cifar-10-binary.tar.gz 100.0%
Successfully downloaded cifar-10-binary.tar.gz 170052171 bytes.使用TF读取CIFAR-10 数据。
- 用
tf.train.string_ input producer建立队列。 - 通过
reader.read读数据。一个文件就是一张图片,因此用的 reader 是tf.WholeFileReader()。CIFAR-10 数据是以固定字节存在文件中的,一个文件中含再多个样本,因此不能使用tf. WholeFileReader(),而是用tf.FixedLengthRecordReader()。 - 调用
tf. train.start_ queue_ runners。 - 最后,通过
sess.run()取出图片结果。
我们已经了解了部分分类任务的常用数据集,下面我们来介绍在pytorch中是如何定义和读取这些数据集的。在pytorch中已经包含了部分常用数据集的定义,可以直接使用,但在实际工程应用中仅仅使用pytorch自带的数据集远远不够,有时还需要自定义数据集来满足需求。下面内容中,我们将从pytorch自带数据集和自定义数据集两部分介绍数据集制作和读取方法。
pytorch中所有的数据集均继承自torch.utils.data.Dataset,它们都需要实现了 __getitem__ 和 __len__ 两个接口,因此,实现一个数据集的核心也就是实现这两个接口。
Pytorch的torchvision中已经包含了很多常用数据集以供我们使用,如Imagenet,MNIST,CIFAR10、VOC等,利用torchvision可以很方便地读取。对于pytorch自带的图像数据集,它们都已经实现好了上述的两个核心接口。因此这里先忽略这部分细节,先介绍用法,关于 __getitem__ 和 __len__ 两个方法,我们将在后面的自定义数据集读取方法中详细介绍。
pytorch支持哪些常用数据加载呢?可以参见:torchvision.datasets
本节以读取pytorch自带的CIFAR10数据集为例进行介绍,建议将数据集下载在'Dive-into-CV-PyTorch/dataset/'目录下。
CIFAR10数据集的定义方法如下:
dataset_dir = '../../../dataset/'
torchvision.datasets.CIFAR10(dataset_dir, train=True, transform=None, target_transform=None, download=False) 参数:
- dataset_dir:存放数据集的路径。
- train(bool,可选)–如果为True,则构建训练集,否则构建测试集。
- transform:定义数据预处理,数据增强方案都是在这里指定。
- target_transform:标注的预处理,分类任务不常用。
- download:是否下载,若为True则从互联网下载,如果已经在dataset_dir下存在,就不会再次下载
为了直观地体现数据读取方法,给出以下两个示例:
读取示例1:从网上自动下载
from PIL import Image
import torch
import torchvision
from torch.utils.data.dataset import Dataset
import torchvision.transforms as transforms
# 读取训练集
train_data = torchvision.datasets.CIFAR10('../../../dataset',
train=True,
transform=None,
target_transform=None,
download=True)
# 读取测试集
test_data = torchvision.datasets.CIFAR10('../../../dataset',
train=False,
transform=None,
target_transform=None,
download=True) 读取示例2:示例1基础上附带数据增强
在使用API读取数据时,API中的transform参数指定了导入数据集时需要对图像进行何种变换操作。对于图像进行各种变换来增加数据的丰富性称为数据增强,是一种常用操作,在下一小节将有更详细的说明。
一般的,我们使用torchvision.transforms中的函数来实现数据增强,并用transforms.Compose将所要进行的变换操作都组合在一起,其变换操作的顺序按照在transforms.Compose中出现的先后顺序排列。在transforms中有很多实现好的数据增强方法,在这里我们尝试使用缩放,随机颜色变换、随机旋转、图像像素归一化等组合变换。
from PIL import Image
import torch
import torchvision
from torch.utils.data.dataset import Dataset
import torchvision.transforms as transforms
# 读取训练集
custom_transform=transforms.transforms.Compose([
transforms.Resize((64, 64)), # 缩放到指定大小 64*64
transforms.ColorJitter(0.2, 0.2, 0.2), # 随机颜色变换
transforms.RandomRotation(5), # 随机旋转
transforms.Normalize([0.485,0.456,0.406], # 对图像像素进行归一化
[0.229,0.224,0.225])])
train_data=torchvision.datasets.CIFAR10('../../../dataset',
train=True,
transform=custom_transforms,
target_transform=None,
download=False) 数据集定义完成后,我们还需要进行数据加载。Pytorch提供DataLoader来完成对于数据集的加载,并且支持多进程并行读取。
DataLoader使用示例
from PIL import Image
import torch
import torchvision
from torch.utils.data.dataset import Dataset
import torchvision.transforms as transforms
# 读取数据集
train_data=torchvision.datasets.CIFAR10('../../../dataset', train=True,
transform=None,
target_transform=None,
download=True)
# 实现数据批量读取
train_loader = torch.utils.data.DataLoader(train_data,
batch_size=2,
shuffle=True,
num_workers=4) 这里batch_size设置了批量大小,shuffle设置为True在装载过程中为随机乱序,num_workers>=1表示多进程读取数据,在Win下num_workers只能设置为0,否则会报错。
除了pytorch自带的数据集外,在实际应用中,我们可能还需要从其他各种不同的数据集或自己构建的数据集(将其统称为自定义数据集)中读取图像,这些图像可能来自于开源数据集网站,也可能是我们自己整理得到的。对于这样的图像数据:首先,我们要确定是否包含标签文件,如果没有就要自己先创建标签文件;然后,我们就可以使用pytorch来读取数据集了。道理是不是很简单?接下来,该小节我们将着重讲解pytorch自定义数据集的制作和读取方法。
在上一节中,我们已经能够使用Dataset和DataLoader两个类实现pytorch自带数据集的读写。其实,我们完全可以将上节的内容看作是pytorch读取数据“通用解”中的一种特殊情况,只不过它满足了一些特殊的条件——pytorch帮你下载好了数据并制作了数据标签,然后通过使用Dataset和DataLoader两个类完成了数据集的构建和读取。简单的对pytorch读取数据一般化pipeline的描述,就是下面的这个流程:
图像数据 ➡ 图像索引文件 ➡ 使用Dataset构建数据集 ➡ 使用DataLoader读取数据
图像数据不必多说,就是训练测试模型使用的图片。这里的索引文件指的就是记录数据标注信息的文件,我们必须有一个这样的文件来充当“引路人”,告诉程序哪个图片对应哪些标注信息,例如图片img_0013.jpg对应的类别为狗。之后便可以像套公式一样使用Dataset和DataLoader两个类完成数据读取。下面我们会根据这个流程用实例指引你实现自制数据集的构建和读取。
图像索引文件只要能够合理记录标注信息即可,内容可以简单也可以复杂,但有一条要注意:内容是待读取图像的名称(或路径)及标签,并且读取后能够方便实现索引。该文件可以是txt文件,csv文件等多种形式,甚至是一个list都可以,只要是能够被Dataset类索引到即可。
我们以读取MNIST数据为例,构建分类任务的图像索引文件,对于其他任务的索引文件,我相信你在学过分类任务的索引文件制作后将会无师自通。
通过 https://www.cs.utoronto.ca/~kriz/cifar.html 我们下载MNIST的图像和标签数据到Dive-into-CV-PyTorch/dataset/MNIST/目录下,得到下面的压缩文件并解压暂存,以用来充当自己的图像数据集。
train-images-idx3-ubyte.gz: training set images (9912422 bytes) ➡ train-images-idx3-ubyte(解压后)
train-labels-idx1-ubyte.gz: training set labels (28881 bytes) ➡ train-labels-idx1-ubyte(解压后)
t10k-images-idx3-ubyte.gz: test set images (1648877 bytes) ➡ t10k-images-idx3-ubyte(解压后)
t10k-labels-idx1-ubyte.gz: test set labels (4542 bytes) ➡ t10k-labels-idx1-ubyte(解压后)
我们运行如下代码,实现图像数据的本地存储和索引文件的制作,我们将图像按照训练集和测试集分别存放,并且分别制作训练集和测试集的索引文件,在索引文件中将记录图像的文件名和标签信息。
import os
from skimage import io
import torchvision.datasets.mnist as mnist
# 数据文件读取
root = r'./MNIST/' # MNIST解压文件根目录
train_set = (
mnist.read_image_file(os.path.join(root, 'train-images-idx3-ubyte')),
mnist.read_label_file(os.path.join(root, 'train-labels-idx1-ubyte'))
)
test_set = (
mnist.read_image_file(os.path.join(root, 't10k-images-idx3-ubyte')),
mnist.read_label_file(os.path.join(root, 't10k-labels-idx1-ubyte'))
)
# 数据量展示
print('train set:', train_set[0].size())
print('test set:', test_set[0].size())
def convert_to_img(save_path, train=True):
'''
将图片存储在本地,并制作索引文件
@para: save_path 图像保存路径,将在路径下创建train、test文件夹分别存储训练集和测试集
@para: train 默认True,本地存储训练集图像,否则本地存储测试集图像
'''
if train:
f = open(save_path + 'train.txt', 'w')
data_path = save_path + '/train/'
if (not os.path.exists(data_path)):
os.makedirs(data_path)
for i, (img, label) in enumerate(zip(train_set[0], train_set[1])):
img_path = data_path + str(i) + '.jpg'
io.imsave(img_path, img.numpy())
int_label = str(label).replace('tensor(', '')
int_label = int_label.replace(')', '')
f.write(str(i)+'.jpg' + ',' + str(int_label) + '\n')
f.close()
else:
f = open(save_path + 'test.txt', 'w')
data_path = save_path + '/test/'
if (not os.path.exists(data_path)):
os.makedirs(data_path)
for i, (img, label) in enumerate(zip(test_set[0], test_set[1])):
img_path = data_path + str(i) + '.jpg'
io.imsave(img_path, img.numpy())
int_label = str(label).replace('tensor(', '')
int_label = int_label.replace(')', '')
f.write(str(i)+'.jpg' + ',' + str(int_label) + '\n')
f.close()
# 根据需求本地存储训练集或测试集
save_path = r'./MNIST/mnist_data/'
convert_to_img(save_path, True)
convert_to_img(save_path, False)上面的代码虽然笨重,但是能够清晰的展示图像和我们索引文件内容的对应关系,也实现图像本地存储和索引文件构建。我们在索引文件中记录了每张图像的文件名和标签,并且每一行对应一张图像的信息,这也是为了方便数据的索引。其实我们在索引文件中可以直接记录每一张图像的路径和标签信息,但考虑数据的可移植性,便只记录了图像的名称。如下图8.12所示。
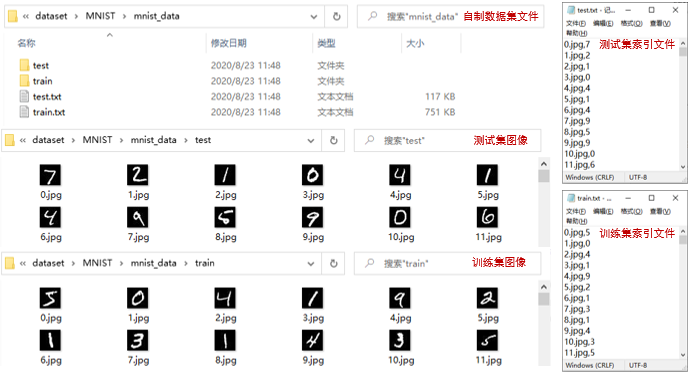
图8.12 在索引文件中记录了每张图像的文件名和标签
通过上面的示例,其实是为了展示自制分类数据集的数据形式与索引文件之间的关系,以方便后续构建自己的Dataset。
想要读取我们自己数据集中的数据,就需要写一个Dataset的子类来定义我们的数据集,并必须对 __init__、__getitem__ 和 __len__ 方法进行重载。下面我们看一下构建Dataset类的基本结构:
from torch.utils.data.dataset import Dataset
class MyDataset(Dataset): # 继承Dataset类
def __init__(self):
# 初始化图像文件路径或图像文件名列表等
pass
def __getitem__(self, index):
# 1.根据索引index从文件中读取一个数据(例如,使用numpy.fromfile,PIL.Image.open,cv2.imread)
# 2.预处理数据(例如torchvision.Transform)
# 3.返回数据对(例如图像和标签)
pass
def __len__(self):
return count # 返回数据量
- __init__() : 初始化模块,初始化该类的一些基本参数
- __getitem__() : 接收一个index,这个index通常指的是一个list的index,这个list的每个元素就包含了图片数据的路径和标签信息,返回数据对(图像和标签)
- __len__() : 返回所有数据的数量
重点说明一下 __getitem__() 函数,该函数接收一个index,也就是索引值。只要是具有索引的数据类型都能够被读取,如list,Series,Dataframe等形式。为了方便,我们一般采用list形式将文件代入函数中,该list中的每一个元素包含了图片的路径或标签等信息,以方便index用来逐一读取单一样本数据。在__getitem__() 函数内部,我们可以选择性的对图像和标签进行预处理等操作,最后返回图像数据和标签。
我们延续上一小节自制MNIST索引文件,构建自己的Dataset类,以便通过该类读取特定图像数据。
import pandas as pd
import numpy as np
from PIL import Image
import torch
from torch.utils.data import Dataset
from torchvision import transforms
class MnistDataset(Dataset):
def __init__(self, image_path, image_label, transform=None):
super(MnistDataset, self).__init__()
self.image_path = image_path # 初始化图像路径列表
self.image_label = image_label # 初始化图像标签列表
self.transform = transform # 初始化数据增强方法
def __getitem__(self, index):
"""
获取对应index的图像,并视情况进行数据增强
"""
image = Image.open(self.image_path[index])
image = np.array(image)
label = float(self.image_label[index])
if self.transform is not None:
image = self.transform(image)
return image, torch.tensor(label)
def __len__(self):
return len(self.image_path)
def get_path_label(img_root, label_file_path):
"""
获取数字图像的路径和标签并返回对应列表
@para: img_root: 保存图像的根目录
@para:label_file_path: 保存图像标签数据的文件路径 .csv 或 .txt 分隔符为','
@return: 图像的路径列表和对应标签列表
"""
data = pd.read_csv(label_file_path, names=['img', 'label'])
data['img'] = data['img'].apply(lambda x: img_root + x)
return data['img'].tolist(), data['label'].tolist()
# 获取训练集路径列表和标签列表
train_data_root = './dataset/MNIST/mnist_data/train/'
train_label = './dataset/MNIST/mnist_data/train.txt'
train_img_list, train_label_list = get_path_label(train_data_root, train_label)
# 训练集dataset
train_dataset = MnistDataset(train_img_list,
train_label_list,
transform=transforms.Compose([transforms.ToTensor()]))
# 获取测试集路径列表和标签列表
test_data_root = './dataset/MNIST/mnist_data/test/'
test_label = './dataset/MNIST/mnist_data/test.txt'
test_img_list, test_label_list = get_path_label(test_data_root, test_label)
# 测试集sdataset
test_dataset = MnistDataset(test_img_list,
test_label_list,
transform=transforms.Compose([transforms.ToTensor()]))上面的代码通过构建 MnistDataset 类,完成了数据集的定义。
首先通过 get_path_label() 函数获得图像的路径和标签列表,并通过 MnistDataset 类中 __init__() 的 self.image_path 和 self.image_label 进行存储,我们能够看到此处的图像列表中的数据和标签列表中的数据是一一对应的关系,同时我们在初始化中还初始化了 transform ,以实现后续中图像增强操作。
MnistDataset 类的 __getitem__() 函数完成了图像读取和增强。该函数的前三行,我们通过 index 读取了 self.image_path 和 self.image_label (两个list,也是前文中提到的list)中的图像和标签。第四、五行,对图像进行处理,在 transform 中可以实现旋转、裁剪、仿射变换、标准化等等一系列操作。最后返回处理好的图像数据和标签。
通过 MnistDataset 类的定义,pytorch就知道了如何获取一张图片并完成相应的预处理工作。这里我们尝试从数据集中读取一些数据,打印下输出结果进行观察:
>>> train_iter = iter(train_dataset)
>>> next(train_iter)
(tensor([[[0.0000, 0.0000, 0.0039, 0.0039, 0.0118, 0.0196, 0.0118, 0.0000,
0.0000, 0.0000, 0.0000, 0.0039, 0.0039, 0.0000, 0.0000, 0.0039,
0.0000, 0.0000, 0.0157, 0.0314, 0.0000, 0.0667, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
...,
[0.0667, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0510, 0.0471, 0.0078, 0.0118, 0.0000, 0.0157, 0.0000, 0.0196,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000]]]),
tensor(5.))
>>> next(train_iter)
(tensor([[[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0392, 0.0039, 0.0000, 0.0157, 0.0000, 0.0000, 0.0314,
0.0000, 0.0157, 0.0314, 0.0039, 0.0000, 0.0431, 0.0039, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
...,
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000]]]),
tensor(0.))每一张图像及标签都被封装成了一个二元元组,第一个元素为图像矩阵,第二个元素为图像标签。下面我们尝试打印每张图片的尺寸和标签信息来看下结果:
>>> for i in train_dataset:
img, label = i
print(img.size(), label)
torch.Size([1, 28, 28]) tensor(5.)
torch.Size([1, 28, 28]) tensor(0.)
torch.Size([1, 28, 28]) tensor(4.)
...
torch.Size([1, 28, 28]) tensor(5.)
torch.Size([1, 28, 28]) tensor(6.)
torch.Size([1, 28, 28]) tensor(8.)
>>> print(train_dataset.__len__())
train num: 60000需要注意的是,当 Dataset 创建好后并没有将数据生产出来,我们只是定义了数据及标签生产的流水线,只有在真正使用时,如手动调用 next(iter(train_dataset)),或被 DataLoader调用,才会触发数据集内部的 __getitem__() 函数来读取数据,通常CV入门者对于这一块会存在困惑。
在构建好自己的 Dataset 之后,就可以使用 DataLoader 批量的读取数据,相当于帮我们完成一个batch的数据组装工作。Dataloader 为一个迭代器,最基本的使用方法就是传入一个 Dataset 对象,在Dataloader中,会触发Dataset对象中的 __gititem__() 函数,逐次读取数据,并根据 batch_size 产生一个 batch 的数据,实现批量化的数据读取。
Dataloader 内部参数如下:
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, num_workers=0, collate_fn=default_collate, pin_memory=False, drop_last=False)
- dataset:加载的数据集(Dataset对象)
- batch_size:一个批量数目大小
- shuffle::是否打乱数据顺序
- sampler: 样本抽样方式
- num_workers:使用多进程加载的进程数,0代表不使用多进程
- collate_fn: 将多个样本数据组成一个batch的方式,一般使用默认的拼接方式,可以通过自定义这个函数来完成一些特殊的读取逻辑。
- pin_memory:是否将数据保存在pin memory区,pin memory中的数据转到GPU会快一些
- drop_last:为True时,dataset中的数据个数不是batch_size整数倍时,将多出来不足一个batch的数据丢弃
承接上一节中的 train_dataset 和 test_dataset,使用 DataLoader 进行批量化读取,此处仅使用了常用的几个参数。
from torch.utils.data import DataLoader
# 训练数据加载
train_loader = DataLoader(dataset=train_dataset, # 加载的数据集(Dataset对象)
batch_size=3, # 一个批量大小
shuffle=True, # 是否打乱数据顺序
num_workers=4) # 使用多进程加载的进程数,0代表不使用多进程(win系统建议改成0)
# 测试数据加载
test_loader = DataLoader(dataset=test_dataset,
batch_size=3,
shuffle=False,
num_workers=4)如上面的代码,为方便展示加载后的结果,我们定义了一个批量大小为 3 的 DataLoader 来加载训练集,并且打乱了数据顺序,在测试集的加载中,我们并没有打乱顺序,这都可以根据自己的需求进行调整。现在,train_loader 已经将原来训练集中的60000张图像重新“洗牌”后按照每3张一个batch划分完成(test_loader同理),进一步查看划分后的数据格式。
>>> loader = iter(train_loader)
>>> next(loader)
[tensor([[[[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0157, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0157, 0.0000, ..., 0.0000, 0.0000, 0.0000],
...,
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000]]],
[[[0.0000, 0.0000, 0.0118, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0039, ..., 0.0000, 0.0000, 0.0000],
[0.0118, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
...,
[0.0510, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0157, 0.0196, ..., 0.0000, 0.0000, 0.0000]]],
[[[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
...,
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000]]]]),
tensor([2., 3., 9.])]
>>> next(loader)
[tensor([[[[0.0118, 0.0000, 0.0275, ..., 0.0000, 0.0000, 0.0000],
[0.0039, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.0118, 0.0039, 0.0000, ..., 0.0000, 0.0000, 0.0000],
...,
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000]]],
[[[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0275, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.0078, 0.0078, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0118, 0.0275],
...,
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000]]],
[[[0.0196, 0.0000, 0.0118, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0510, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0392, ..., 0.0000, 0.0000, 0.0000],
...,
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000]]]]),
tensor([3., 8., 3.])]经过DataLoader的封装,每3(一个batch_size数量)张图像数据及对应的标签被封装为一个二元元组,第一个元素为四维的tensor形式,第二个元素为对应的图像标签数据。按照如下方式将所有train_loader中的数据进行展示。
>>> for i, img_data in enumerate(train_loader, 1):
images, labels = img_data
print('batch{0}:images shape info-->{1} labels-->{2}'.format(i, images.shape, labels))
batch1:images shape info-->torch.Size([3, 1, 28, 28]) labels-->tensor([2., 3., 9.])
batch2:images shape info-->torch.Size([3, 1, 28, 28]) labels-->tensor([3., 8., 3.])
batch3:images shape info-->torch.Size([3, 1, 28, 28]) labels-->tensor([4., 7., 6.])
...
batch19998:images shape info-->torch.Size([3, 1, 28, 28]) labels-->tensor([0., 7., 7.])
batch19999:images shape info-->torch.Size([3, 1, 28, 28]) labels-->tensor([3., 7., 0.])
batch20000:images shape info-->torch.Size([3, 1, 28, 28]) labels-->tensor([9., 7., 5.])
>>> len(train_loader)
20000我们将DataLoader与Dataset分别处理后的数据比较可以发现出两者的不同:Dataset是对本地数据读取逻辑的定义;而DataLoader是对Dataset对象的封装,执行调度,将一个batch size的图像数据组装在一起,实现批量读取数据。
我们已经学会了通过构建自己的Dataset类来读取数据,这是具有一般性的数据读取方式,无论是分类、检测等等都能够通过这种方式读取图像及标签。但对于图像分类问题,torchvision还提供了一种文件目录组织形式可供调用,即ImageFolder,因为利用了分类任务的特性,此时就不用再另行创建一份标签文件了。这种文件目录组织形式,要求数据集已经自觉按照待分配的类别分成了不同的文件夹,一种类别的文件夹下面只存放同一种类别的图片。
我们以具有cat、dog、duck、horse四类图像的数据为例进行说明,数据结构形式如下。
.
└── sample # 根目录
├── train # 训练集
│ ├── cat # 猫类
│ │ ├── 00001.jpg # 具体所属类别图片
| | └── ...
│ ├── dog # 狗类
│ │ ├── 00001.jpg
| | └── ...
│ ├── duck # 鸭类
│ │ ├── 00001.jpg
| | └── ...
│ └── horse # 马类
│ ├── 00001.jpg
| └── ...
└── test # 测试集
├── cat
│ ├── 00001.jpg
| └── ...
├── dog
│ ├── 00001.jpg
| └── ...
├── duck
│ ├── 00001.jpg
| └── ...
└── horse
├── 00001.jpg
└── ...
我们可以清楚看出在训练集和测试集中分别包含有cat、dog、duck、horse四类图像的子文件夹,在子文件夹中就是所属类别的具体图像。在笔者电脑中,数据集的图片路径如下图8.13所示。
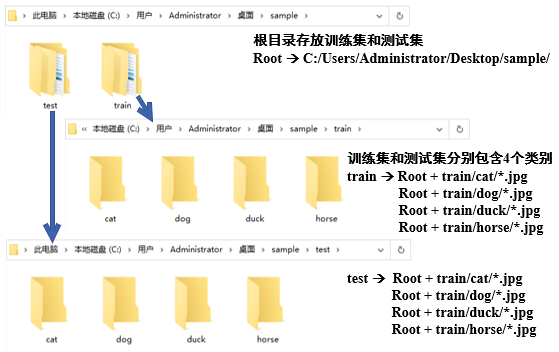
图8.13 数据集的图片路径
使用torchvision包中的ImageFolder类针对上述的文件目录组织形式快速创建dataset。
from torchvision.datasets import ImageFolder
import torchvision.transforms as transforms
from torch.utils.data import DataLoade
# train & test root
train_root = r'./sample/train/'
test_root = './sample/test/'
# transform
train_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
test_transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# train dataset
train_dataset = torchvision.datasets.ImageFolder(root=train_root,
transform=train_transform)
train_loader = DataLoader(train_dataset, batch_size=1, shuffle=True, num_workers=0)
# test dataset
test_dataset = torchvision.datasets.ImageFolder(root=test_root,
transform=test_transform)
test_loader = DataLoader(test_dataset, batch_size=1, shuffle=False, num_workers=0)
图像的增广是通过对训练图像进行一系列变换,产生相似但不同于主体图像的训练样本,来扩大数据集的规模的一种常用技巧。另一方面,随机改变训练样本降低了模型对特定数据进行记忆的可能,有利于增强模型的泛化能⼒,提高模型的预测效果,因此可以说数据增强已经不算是一种优化技巧,而是CNN训练中默认要使用的标准操作。在常见的数据增广方法中,一般会从图像颜色、尺寸、形态、亮度/对比度、噪声和像素等角度进行变换。当然不同的数据增广方法可以自由进行组合,得到更加丰富的数据增广方法。
在torchvision.transforms中,提供了Compose类来快速控制图像增广方式:我们只需将要采用的数据增广方式存放在一个list中,并传入到Compose中,便可按照数据增广方式出现的先后顺序依次处理图像。如下面的样例所示:
from torchvison import transforms
# 数据预处理
transform = transforms.Compose([transforms.CenterCrop(10),
transforms.ToTensor()])同时torchvision.transforms提供了大量的图像数据处理方式,不仅含有图像增广方法,还有数据类型转换等预处理方法。对于torchvision.transforms中各种图像预处理方法的详细参数解释,参见本章附录部分,也可以通过官方torchvision.transforms教程进行学习。
部分图像变换的代码示例和效果展示如下:
首先import相关的包并读入原始图像,如图8.14所示。
from PIL import Image
from matplotlib import pyplot as plt
import torchvision.transforms as transforms
# 原始图像
im = Image.open('./cat.png')
plt.figure('im')
plt.imshow(im) 
图8.14 读入原始图像
裁剪效果示例
对上述原图进行中心裁剪、随机裁剪和随机长宽比裁剪,得到裁剪效果展示如图8.15所示。
## 中心裁剪
center_crop = transforms.CenterCrop([200, 200])(im)
## 随机裁剪
random_crop = transforms.RandomCrop([200,200])(im)
## 随机长宽比裁剪
random_resized_crop = transforms.RandomResizedCrop(200,
scale=(0.08, 1.0),
ratio=(0.75, 1.55),
interpolation=2)(im)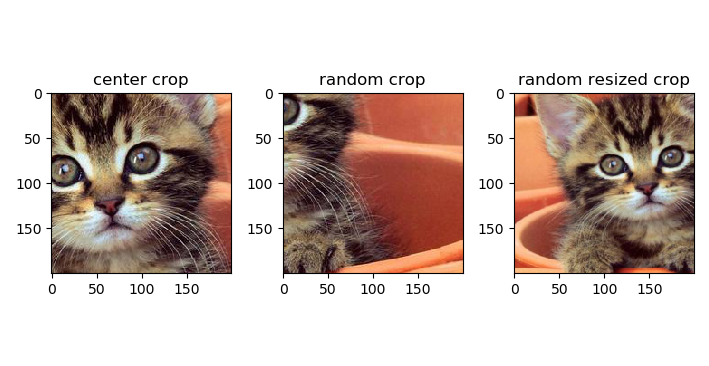
图8.15 裁剪效果示例
翻转和旋转效果示例
对上述原图进行水平翻转、垂直翻转和随机旋转,得到裁剪效果展示如图8.16所示。
## 依概率p水平翻转
h_flip = transforms.RandomHorizontalFlip(0.7)(im)
## 依概率p垂直翻转
v_flip = transforms.RandomVerticalFlip(0.8)(im)
## 随机旋转
random_rotation = transforms.RandomRotation(30)(im)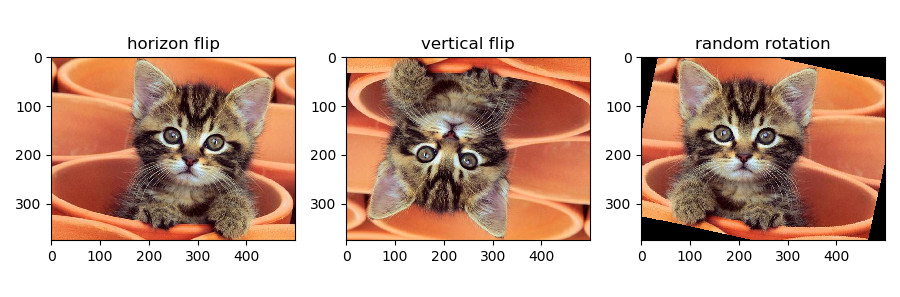
图8.16 翻转和旋转效果示例
其他图像变换效果示例
对上述原图进行图像填充、调整亮度、对比度和饱和度、灰度图处理、仿射变换、尺寸缩放、转Tensor、标准化和转换为PILImage操作,如图8.17所示。
## 图像填充
pad = transforms.Pad(10, fill=0, padding_mode='constant')(im)
## 调整亮度、对比度和饱和度
color_jitter = transforms.ColorJitter(brightness=1,
contrast=0.5,
saturation=0.5,
hue=0.4)(im)
## 转成灰度图
gray = transforms.Grayscale(1)(im)
## 仿射变换
random_affine = transforms.RandomAffine(45,(0.5,0.7),(0.8,0.5),3)(im)
## 尺寸缩放
resize = transforms.Resize([100,200])(im)
## 转Tensor、标准化和转换为PILImage
mean = [0.45, 0.5, 0.5]
std = [0.3, 0.6, 0.5]
transform = transforms.Compose([transforms.ToTensor(), #转Tensor
transforms.Normalize(mean, std),
transforms.ToPILImage() # 这里是为了可视化,故将其再转为 PIL
])
img_tansform = transform(im)![]()
图8.17 其他图像变换效果示例
前文对数据读取和数据增广方法分别进行了详细介绍,篇幅很长,最后这部分做个小小的总结。
我们仍以 CIFAR10 数据集为例,将数据读取和数据增广整合到一起,给出一个综合示例作为复习强化记忆。
import os, sys, glob, shutil, json
import numpy as np
import cv2
from PIL import Image
import torch
import torchvision
from torch.utils.data.dataset import Dataset
import torchvision.transforms as transforms
transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ColorJitter(0.3, 0.3, 0.2),
transforms.RandomRotation(10),
transforms.RandomAffine(10, (0.5,0.7), (0.8,0.5), 0.2),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
train_data = torchvision.datasets.CIFAR10('../../../dataset', train=True,
transform= transform,
target_transform=None,
download=False)
test_data = torchvision.datasets.CIFAR10('../../../dataset', train=False,
transform= transform,
target_transform=None,
download=False)
train_loader = torch.utils.data.DataLoader(train_data,
batch_size=64,
shuffle=True,
num_workers=4)
test_loader = torch.utils.data.DataLoader(train_data,
batch_size=64,
shuffle=False,
num_workers=4)本文第一部分对常用数据集进行了简单介绍,第二部分讲解了pytorch中的各种数据集读取方法,包括torchvision自带数据集的读取方法,ImageFolder格式数据集读取方法和任意数据集的一般化自定义读取方案。第三部分介绍了常见的数据增强方法且展示了可视化效果,最后给出了一个数据加载的完整示例。
下面我们来解读一下 pycocoDemo.ipynb。由于 COCO API 对 Windows 不是那么友好,为了避免去调试各种 Bug,下面我们先在 Linux 系统下来使用 COCO API。下面我是在 Jupyter Notebook 下运行代码的。
%matplotlib inline
import zipfile
import os
import numpy as np
import skimage.io as io
import matplotlib.pyplot as plt
import pylab
pylab.rcParams['figure.figsize'] = (8.0, 10.0)
# -------------------
try: # pycocotools 已经加入了全局环境变量中
from pycocotools.coco import COCO
except ModuleNotFoundError:
import sys
# 加载 COCO API 环境
sys.path.append('D:\API\cocoapi\PythonAPI')
from pycocotools.coco import COCO
root = 'E:/Data/coco' # 你下载的 COCO 数据集所在目录
# 查看 images 下的图片
os.listdir(f'{root}/images')['test2014.zip',
'test2015.zip',
'test2017.zip',
'train2014.zip',
'train2017.zip',
'unlabeled2017.zip',
'val2014.zip',
'val2017.zip']
下面我以 val2017.zip 图片数据集为例,来说明下面的一些问题。
Z = zipfile.ZipFile(f'{root}/images/val2017.zip')
Z.namelist()[7] # 查看一张图片的文件名
val2017/000000463918.jpg'
由于 Z.read 函数返回的是 bytes,所以,我们需要借助一些其他模块来将图片数据转换为 np.uint8 形式。
img_b = Z.read(Z.namelist()[7])
print(type(img_b))
<class 'bytes'>
方式1:np.frombuffer(img_b, 'B')
import numpy as np
import cv2
img_flatten = np.frombuffer(img_b, 'B')
img_cv = cv2.imdecode(img_flatten, cv2.IMREAD_ANYCOLOR)
print(img_cv.shape)
(359, 500, 3)
方式2:imageio.imread
import imageio
img_io = imageio.imread(img_b)
print(img_io.shape)
(359, 500, 3)
方式3:mxnet.image.imdecode
import mxnet as mx
img_mx = mx.image.imdecode(img_b)
下面我们来看看这张图片张什么样?如图8.18所示。
from matplotlib import pyplot as plt
plt.subplot(231)
plt.imshow(cv2.cvtColor(img_cv, cv2.COLOR_BGR2RGB))
plt.title('OpenCV')
plt.axis('off')
plt.subplot(232)
plt.imshow(img_io)
plt.title('imageio')
plt.axis('off')
plt.subplot(233)
plt.imshow(img_io)
plt.title('MXNet')
plt.axis('off')
plt.show()
图8.18 读取一张图片显示
考虑到 OpenCV 的高效性,我们采用方式1 来处理 images 下的图片数据。
def buffer2array(Z, image_name):
'''
无需解压,直接获取图片数据
参数
===========
Z:: 图片数据是 ZipFile 对象
'''
buffer = Z.read(image_name)
image = np.frombuffer(buffer, dtype="B") # 将 buffer 转换为 np.uint8 数组
img = cv2.imdecode(image, cv2.IMREAD_COLOR)
return img
img = buffer2array(Z, Z.namelist()[8])
print('图片的尺寸:', img.shape)
图片的尺寸: (480, 640, 3)
这里有一个坑 (由 PIL 引发) import skimage.io as io 在 Windows 下可能会报错,我的解决办法是:
-
先卸载 Pillow,然后重新安装即可。
-
插曲:PIL(Python Imaging Library)是Python一个强大方便的图像处理库,名气也比较大。Pillow 是 PIL 的一个派生分支,但如今已经发展成为比 PIL 本身更具活力的图像处理库。
dataDir = cocox.root
dataType = 'val2017'
annFile = '{}/annotations/instances_{}.json'.format(dataDir, dataType)
# initialize COCO api for instance annotations
coco=COCO(annFile)
loading annotations into memory...
Done (t=0.93s)
creating index...
index created!
COCO??
COCO 是一个类:
Constructor of Microsoft COCO helper class for reading and visualizing annotations.
:param annotation_file (str): location of annotation file
:param image_folder (str): location to the folder that hosts images.
cats = coco.loadCats(coco.getCatIds())
nms = [cat['name'] for cat in cats]
print('COCO categories: \n{}\n'.format(' '.join(nms)))
nms = set([cat['supercategory'] for cat in cats])
print('COCO supercategories: \n{}'.format(' '.join(nms)))
COCO categories:
person bicycle car motorcycle airplane bus train truck boat traffic light fire hydrant stop sign parking meter bench bird cat dog horse sheep cow elephant bear zebra giraffe backpack umbrella handbag tie suitcase frisbee skis snowboard sports ball kite baseball bat baseball glove skateboard surfboard tennis racket bottle wine glass cup fork knife spoon bowl banana apple sandwich orange broccoli carrot hot dog pizza donut cake chair couch potted plant bed dining table toilet tv laptop mouse remote keyboard cell phone microwave oven toaster sink refrigerator book clock vase scissors teddy bear hair drier toothbrush
COCO supercategories:
appliance sports person indoor vehicle food electronic furniture animal outdoor accessory kitchen
# get all images containing given categories, select one at random
catIds = coco.getCatIds(catNms=['person', 'dog', 'skateboard'])
imgIds = coco.getImgIds(catIds=catIds)
imgIds = coco.getImgIds(imgIds=[335328])
img = coco.loadImgs(imgIds[np.random.randint(0, len(imgIds))])[0]
img
{'license': 4,
'file_name': '000000335328.jpg',
'coco_url': 'http://images.cocodataset.org/val2017/000000335328.jpg',
'height': 640,
'width': 512,
'date_captured': '2013-11-20 19:29:37',
'flickr_url': 'http://farm3.staticflickr.com/2079/2128089396_ddd988a59a_z.jpg',
'id': 335328}
官方给的这个代码需要将图片数据集解压:
# load and display image
# use url to load image
# I = io.imread(img['coco_url'])
I = io.imread('%s/images/%s/%s' % (dataDir, dataType, img['file_name']))
plt.axis('off')
plt.imshow(I)
plt.show()
我们可以使用 zipfile 模块直接读取图片,而无须解压,如图8.19所示。
image_names[-1]
'E:/Data/coco/images/val2017.zip'
val_z = zipfile.ZipFile(image_names[-1])
I = image.imdecode(val_z.read('%s/%s' % (dataType, img['file_name']))).asnumpy()
# 或者直接使用 I = buffer2array(val_z, val_z.namelist()[8])
plt.axis('off')
plt.imshow(I)
plt.show()

图8.19 读取一张图片
plt.imshow(I)
plt.axis('off')
annIds = coco.getAnnIds(imgIds=img['id'], catIds=catIds, iscrowd=None)
anns = coco.loadAnns(annIds)
coco.showAnns(anns)

图8.20 载入和展示:实例注解
初始化人体关键点标注(person keypoints annotations)的 COCO api。
annFile = '{}/annotations/person_keypoints_{}.json'.format(dataDir, dataType)
coco_kps = COCO(annFile)
loading annotations into memory...
Done (t=0.43s)
creating index...
index created!
展示,如图8.21所示。
plt.imshow(I)
plt.axis('off')
ax = plt.gca()
annIds = coco_kps.getAnnIds(imgIds=img['id'], catIds=catIds, iscrowd=None)
anns = coco_kps.loadAnns(annIds)
coco_kps.showAnns(anns)

图8.21 人体关键点
annFile = '{}/annotations/captions_{}.json'.format(dataDir, dataType)
coco_caps = COCO(annFile)
loading annotations into memory...
Done (t=0.06s)
creating index...
index created!
展示,结果如图8.22所示。
annIds = coco_caps.getAnnIds(imgIds=img['id'])
anns = coco_caps.loadAnns(annIds)
coco_caps.showAnns(anns)
plt.imshow(I)
plt.axis('off')
plt.show()
A couple of people riding waves on top of boards.
a couple of people that are surfing in water
A man and a young child in wet suits surfing in the ocean.
a man and small child standing on a surf board and riding some waves
A young boy on a surfboard being taught to surf.
caption

图8.22 载入和展示:标题注释
小武, 阿水, 袁明坤,安晟. @datawhalechina/dive-into-cv-pytorch. 数据读取与数据扩增.md