Mapping
- Open Source Application: uReport (https://github.com/City-of-Bloomington/uReport)
- Author: Quan Zhang (quanzhang@acm.org)
- Mentor: Cliff Ingham (inghamn@bloomington.in.gov)
- Sponsor: Google Inc. (Google Summer of Code)
- Focus Area: GIS, Clustering, Big Data
- When: June - September, 2013
- Where: Bloomington City Hall, IT services Dept.
- Address: 401 N Morton St, Suite 150, Bloomington IN 47402
- Tools: Solr, Apache, Tomcat, MySQL, Google Map API V3, YUI
- Languages: PHP, Javascript, SQL
- Main Achievement: Clustered up to 1M tickets on the map within one second.
The city of Bloomington has a web application uReport to receive the issues reported by citizens. Once received, the issue will be stored into the database as a ticket. A ticket has many properties like category, status, date, township, latitude, longitude and etc. These properties are set when the citizen report the issue. Now the city's database stored more than 70,000 tickets. In the main page of the web application, the users need to see the tickets on the map. Also they can filter tickets by choosing properties as search parameters. However, a problem rose. If we show all the tickets as markers on the map at a time, the map will be full of markers. Also, displaying the markers will take a long time. What's worse, the client will receive tickets from Solr server. The time to transmit tickets data from server to client will also be too long to accept. We need to cluster markers on server side and transmit the clusters instead of tickets to the map of the client.
Solr[1] has a feature to facet query and return any number of results back. The query results will be transmitted as JSON or XML data. The more tickets results returned, the larger the data will be. By setting "start" and "rows" parameters in Solr query string, we can get small number of tickets of the query results, and display the tickets on the map immediately. The Solr query strings are sent by Javascript whenever the map stops to pan or zoom. Since this design cannot show all the query results at a time. I also added an HTML option to dynamically display the chosen number of tickets and used OverlappingMarkerSpiderfier [5] to display overlapping markers separately. Later I tried to cluster tickets on the client side. Google provided some samples to cluster on client side [3]. Gary Little [4] implemented the client side clustering and released it as an API. Also, the officially posted article "Too Many Markers!" [2] summarized solutions to deal with marker clustering on client side. I borrowed some ideas from this article in later server side clustering design. However, no matter how efficient the clustering algorithm is, since transmitting large data from server to client is not acceptable, we still need to implement clustering on server side.
As far as my mentor and I can find, there is no released API or build-in component of Solr can do clustering on server side. However I got idea from a thesis posted by Josef Dabernig [9], even though that was implemented on Drupal. The basic idea is pre-cluster the tickets into grids using Base 32 Geohash [8]. Austin White provided an open source API to convert a lat-lng pair to a base 32 geohash code [7]. The earth firstly will be divided into 32 grids, the first digit of geohash code represents the grid the lat-lng belongs to. Further, the represented grid will be divided into another 32 sub-grids. The second digit of geohash code represents the sub-grid the lat-lng belongs to, and so forth. The more digits we use in geohash code, the smaller the grid will be [10]. In this way, we can pre-cluster the tickets into grids based on current zoom level. I also designed a geohash length to zoom level corresponding relationship to display appropriate number of clusters on the map when zoom in and out. Since what we need is the number of tickets of clusters and the centroids of clusters rather than lat-lngs of individual tickets. We need to calculate them on Solr server. Fortunately, we don’t need to add any plug-in into Solr. The Solr’s Stats Component [6] can count the number of tickets, get the average latitude and longitude of tickets in clusters very fast. For example, the following Solr query can do statistics within a bounding box and group by geohash code.
localhost/solr/quan/select?q=*:*&stats=true&stats.field=latitude&stats.field=longitude&stats.facet=geohash_lv8&fq=coordinates:[39.169000,-86.550000 TO 39.170000,-86.549000]&rows=0
In this way, we can display the clusters with count on the centroid very fast. However, the view is bad, the clusters are always like standing in a queue when the real tickets distribution is even. Also, in some part of map, two clusters are too close to each other, but since they belong to different grids, they will be shown in different clusters no matter how close they really are.

(The markers are actually clusters, I didn't use image to represent marker at that time)
The distance based clustering [12] on server side can solve the problems in grid based one. The distribution of clusters will never be orderly and the distance between the clusters are guaranteed. The distance based algorithm performs in SQL. In the tickets table, we added new fields “cluster_id_lv0”, “cluster_id_lv1”, …, “cluster_id_lv6”. The clustering level is similar to that of geohash, clustering levels are corresponding to zoom level in Google Map. We only need to care the zoom level from 21 to 10, since we are only handling data in Bloomington Area. For a particular clustering level, we assign the cluster id to each ticket. When calculating distance, we used Haversine formula [11].
begin
for t ∈ tickets do
select the tickets tics within r distance to t;
get all the clusters clus containing at least one ticket in tics
and calculate the centroids of the clus;
if the centroid of the closest cluster c is within r distance to t
assign c’s cluster id to t;
else
assign a new cluster id to t;
end
end
end
(Cluster ID assigning pseudo code)
SELECT id,x(center) as longitude, y(center) as latitude,
( SELECT
(ACOS(SIN(RADIANS(y(center))) * SIN(RADIANS($lat))
+ COS(RADIANS(y(center))) * COS(RADIANS($lat))
* COS(RADIANS(x(center) - $lng))) * 6371.0)
) as distance
FROM geoclusters
WHERE level=?
and (ACOS(SIN(RADIANS(y(center))) * SIN(RADIANS($lat))
+ COS(RADIANS(y(center))) * COS(RADIANS($lat))
* COS(RADIANS(x(center) - $lng))) * 6371.0) < $dist
order by distance
LIMIT 1(SQL query embedded in PHP)
To cluster in this way, The displaying effect becomes much better, no matter how many tickets are there, the server can calculate the centroid of clusters and the number of tickets in the clusters instantaneously. But the time to assign cluster id for each tickets for each cluster level is very long. It takes up to 18 hours to finish assigning cluster id. However it is acceptable, because this calculation will only happen once. Later when the user add more tickets into existed database, it just need to calculate for that one ticket, which is very fast.
But to make it perfect, we still spent some time to improve this cluster id assigning process. In the previous calculation, the centroid data is not stored. When assigning cluster id for each ticket, we need to do calculation to get the centroids of clusters around the ticket. We improved this by creating a new table “clusters”. The centroids will be stored. When a new ticket comes in, it only needs to get the closest cluster centroid. If the cluster is close enough for the ticket to join, it only needs to assign the cluster's id to the new ticket and update the centroid for that cluster. This improvement boosted the cluster id assigning process from 18 hours to 45 mins.
In addition, for the clusters with less than 5 tickets, it’d better show the individual tickets rather than clusters. To display both clusters and tickets on the same map. We will query to Solr twice. The first query gets all the clusters within current bounding box but only displays the clusters with more than 5 tickets. For the small clusters, we record their cluster ids, and query to Solr again using “OR” operation. For example:
localhost/solr/quan/select?q=*:*&fq=cluster_id_lv0(2518 OR 2618 OR 12509)&fq=coordinates: :[39.169000,-86.550000 TO 39.170000,-86.549000]&rows=100
Finally, I displayed the clusters in colorful pictures[13]. To do so, I overwrote the OverlayView[14] class of Google Map API, so that the new custom overlay can show both the colorful pictures and numbers on it.
 (Large clusters in upper zoom level)
(Large clusters in upper zoom level)
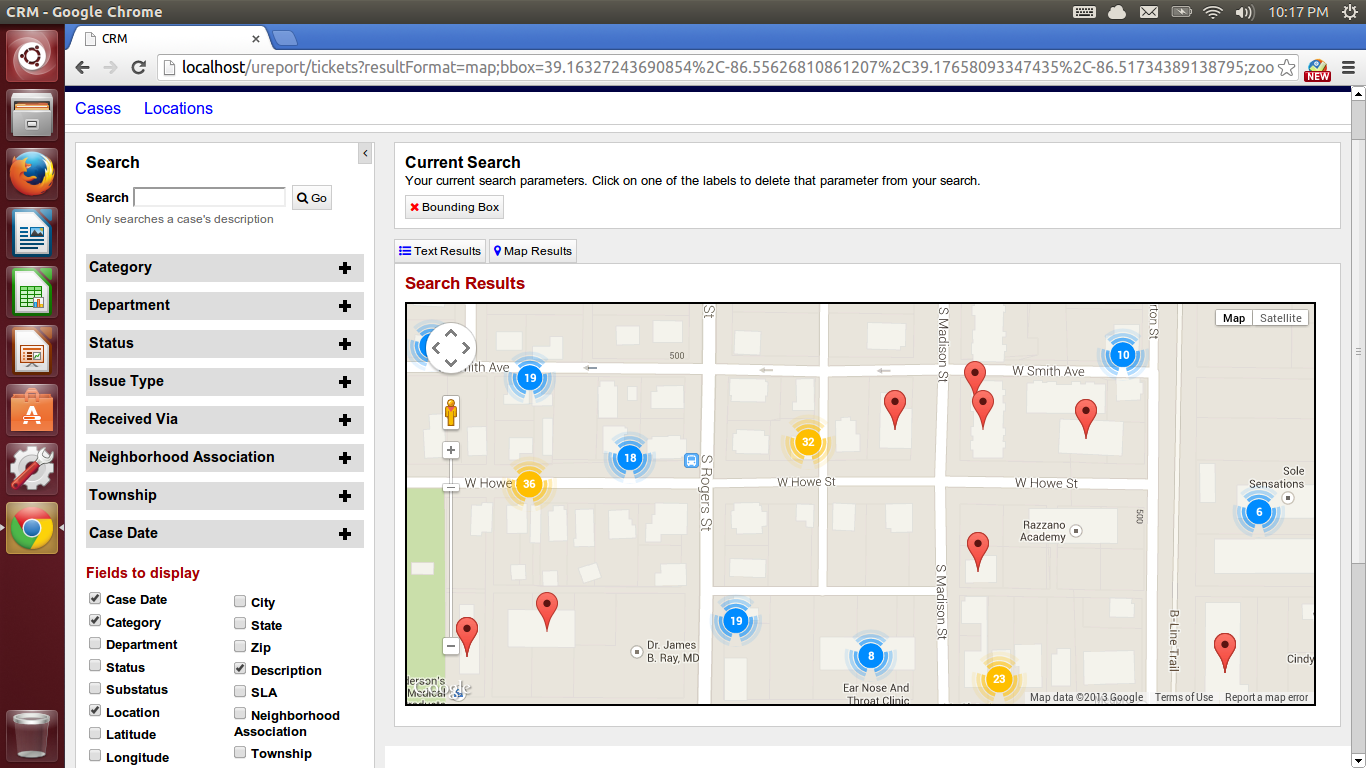 (Small clusters and individual tickets in lower zoom level)
(Small clusters and individual tickets in lower zoom level)
The main idea of this server side clustering is to calculate as much as possible when storing the tickets in Solr. When doing the clustering on Solr server, it only needs to use the Solr Stats Component to group tickets by cluster id and calculate the centroid. This designing idea can apply to many GIS applications with huge point data.
[1] Solr 4.0 Spatial Search: http://wiki.apache.org/solr/SolrAdaptersForLuceneSpatial4
[2] Too Many Markers! https://developers.google.com/maps/articles/toomanymarkers
[3] Solutions to the Too Many Markers problem with the Google Maps JavaScript API V3: http://gmaps-samples-v3.googlecode.com/svn/trunk/toomanymarkers/toomanymarkers.html
[4] Client side marker clusterer: https://code.google.com/p/google-maps-utility-library-v3/source/browse/trunk/markerclustererplus/src/markerclusterer.js?r=360
[5] OverlappingMarkerSpiderfier: https://github.com/jawj/OverlappingMarkerSpiderfier
[6] Solr Stats Component: http://wiki.apache.org/solr/StatsComponent
[7] Base 32 Geohash API: https://github.com/asonge/php-geohash/blob/master/geohash.php
[8] Base 32 Geohash Definition: http://en.wikipedia.org/wiki/Geohash#Decode_from_base_32
[9] Geocluster: Server-side clustering for mapping in Drupal based on Geohash: https://groups.drupal.org/node/296238
[10] Slides to show how the geohash code work: http://www.slideshare.net/LucidImagination/spatial-search-with-geohashes
[11] Haversine formula: http://en.wikipedia.org/wiki/Haversine_formula
[12] Distance based marker clustering using Haversine algorithm: http://www.appelsiini.net/2008/11/introduction-to-marker-clustering-with-google-maps
[13] clustermap -- Visualizing Clusters of Markers on Google Maps (v3): https://code.google.com/p/clustermap/source/browse/trunk/clustermap.js
[14] Custom Overlays: https://developers.google.com/maps/documentation/javascript/overlays#CustomOverlays