-
Notifications
You must be signed in to change notification settings - Fork 2
/
06_datentransformation.Rmd
631 lines (508 loc) · 30.3 KB
/
06_datentransformation.Rmd
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
519
520
521
522
523
524
525
526
527
528
529
530
531
532
533
534
535
536
537
538
539
540
541
542
543
544
545
546
547
548
549
550
551
552
553
554
555
556
557
558
559
560
561
562
563
564
565
566
567
568
569
570
571
572
573
574
575
576
577
578
579
580
581
582
583
584
585
586
587
588
589
590
591
592
593
594
595
596
597
598
599
600
601
602
603
604
605
606
607
608
609
610
611
612
613
614
615
616
617
618
619
620
621
622
623
624
625
626
627
628
629
630
631
## **Datentransformation**
[](https://creativecommons.org/licenses/by/4.0/deed.de)
*"Datentransformation" von Zoé Wolter und Jonas Lorenz in "R Lernen - der Datenkurs von und für die Zivilgesellschaft" von CorrelAid e.V. Lizensiert unter [Creative Commons Attribution 4.0 International](https://creativecommons.org/licenses/by/4.0/deed.de).*

### **Kernaussagen**
#### Das Tidyverse
<left>
{#id .class width=20% height=100%}
</left>
<br>
- Das Tidyverse ist eine **Sammlung von verschiedenen R-Packages**, die aufeinander abgestimmt sind und dabei derselben Logik folgen ([tidyverse.org](https://www.tidyverse.org/){target="_blank"}).
- Voraussetzung für die Arbeit mit dem Tidyverse sind "tidy" Datensätze:
{#id .class width=60% height=60%}
*Illustrations from the Openscapes blog Tidy Data for reproducibility, efficiency, and collaboration by Julia Lowndes and Allison Horst*
- Einige der Packages und Funktionen kennt Ihr bereits aus den letzten Wochen!
- Die Packages können einzeln installiert und aufgerufen werden, aber auch gesammelt über `install_packages('tidyverse')` bzw. `library(tidyverse)`.
#### Die wichtigsten Funktionen des Tidyverse
| Funktion | Wofür? |
|:----------------|:--------------------------------------------------------|
| `dplyr::arrange()` | **Sortierung** von Zeilen im Datensatz nach bestimmten Kriterien |
| `dplyr::filter()` | **Auswahl von Zeile**n bzw. Beobachtungen nach bestimmten Kriterien |
| `dplyr::select()` | **Auswahl von Spalten** bzw. Variablen |
| `dplyr::mutate()` | **Erstellung neuer Spalten/Variablen** auf Basis bereits vorhandener Spalten/Variablen bzw. **Veränderung von Variablen** |
| `dplyr::group_by()` | **Gruppierung** von Beobachtungen |
| `dplyr::summarise()` | **Zusammenfassen** von Beobachtungen mit statistischen Kennzahlen |
<br>
### **Quiz**
```{r 07quiz_datenbereinigung1}
quiz(caption = NULL,
question("Was macht einen Datensatz tidy?",
answer("Jede Variable hat eine eigene Spalte", correct = TRUE),
answer("Jede Beobachtung hat eine eigene Zeile", correct = TRUE),
answer("Jeder Wert hat eine eigene Zelle", correct = TRUE),
correct = "Richtig!",
incorrect = "Leider falsch: Versuche es einfach nochmal oder schau im Video nach!",
allow_retry = TRUE,
try_again_button = "Nochmal versuchen"
),
question("Was ist der Pipe-Operator (%>%)?",
answer("Eine Funktion", correct = TRUE),
answer("Ein Werkzeug zur Strukturierung von mehrfachen Operationen in R", correct = TRUE),
answer("Ein Werkzeug zur verbesserten Lesbarkeit von Code in R", correct = TRUE),
answer("Syntax des ggplot2-Packages"),
answer("Eine Besonderheit des dplyr-Packages", correct = TRUE),
correct = "Richtig!",
incorrect = "Leider falsch: Versuche es einfach nochmal oder schau im Video nach!",
allow_retry = TRUE,
try_again_button = "Nochmal versuchen"
),
question("Wofür steht NA?",
answer("Not accessible"),
answer("Not available", correct = TRUE),
answer("Not attainable"),
correct = "Richtig!",
incorrect = "Leider falsch: NA steht für not available (nicht verfügbar).",
allow_retry = TRUE,
try_again_button = "Nochmal versuchen"
)
)
```
<br>
### **Interaktive Übung**
#### Wiederholung: Die Pipe `%>%`
Bei der ersten Einführung in R habt Ihr Euch die Funktion `nrow()` angeschaut, mit der Ihr herausfinden könnt, wie viele Zeilen ein Datensatz hat. Damals habt Ihr das mit `nrow(data_raw)` gemacht, also `base R`, in der Zwischenzeit habt Ihr aber auch die **Pipe (%>%)** aus dem `tidyverse` kennengelernt. So könnten wir anstatt mit `ncol(plastics)` mit dem Pipe-Operator die Anzahl an Spalten bestimmen:
``` {r 07pipebeispiel, exercise = TRUE}
# Berechnung der Spaltenanzahl
data_raw %>%
ncol()
```
Nutzt nun die Pipe, um Euch die Anzahl der Beobachtungen (`nrow()`) im Datensatz ausgeben zu lassen:
``` {r exercise_07pipe, exercise = TRUE}
# Hier Euer Code!
```
```{r exercise_07pipe-solution}
# Berechnung der Zeilenanzahl
data_raw %>%
nrow()
```
```{r exercise_07pipe-check}
grade_this_code()
```
Die Pipe wird Euch in dieser Lektion überall begegnen. So bleibt die langwidrige Datenbereinigung nämlich schön übersichtlich.
<br>
#### Import der Rohdaten
Zuerst laden wir - wie immer - den Datensatz. Das kennt Ihr ja bereits! Hier ziehen wir uns über den Hyperlink einen ziemlich unordentlichen Rohdatensatz, aus dem wir gemeinsam zwei bereinigte Datentabellen (`community` und `audit`) generieren.
``` {r 07load_data, exercise = TRUE}
# Laden des Datensatzes
data_raw <- rio::import('https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2021/2021-01-26/plastics.csv')
```
#### Bereinigungsschritte definieren
Nun überlegen wir uns, welche Datensätze am Ende des Bereinigungsprozesses existieren sollen und wie wir dorthin kommen.
Das Ziel sind zwei verschiedene Datensätze:<br>
- **Community** (2019):
- Eine Zeile = Ein Land
- Variablen: Kontinent, Land, Countrycode, Anzahl Plastikstücke, Events und Freiwillige
- **Audit** (2019):
- Eine Zeile = Eine einzigartige Kombination aus Hersteller und Plastiktyp pro Land
- Variablen: Kontinent, Land, Countrycode, Hersteller, Anzahl Plastikstücke
Das heißt um diese beiden Datensätze zu erstellen, müssen wir folgende Schritte machen:
1. Zeilen, in denen das Land "EMPTY" ist, Sammelzeilen und Beobachtungen aus dem Jahr 2020 aussortieren. <br>
2. Ländernamen bereinigen und übersetzen. <br>
3. Entsprechende Variablen auswählen und ggf. Datensatz umformen. <br>
<br>
#### Die Funktion `dplyr::filter()`
{#id .class width=60% height=60%}
Für die Analyse des Datensatzes planen wir einen **Ländervergleich** und sortieren deshalb Beobachtungen aus, für die das Land nicht hinterlegt wurde. Es handelt sich hierbei vermutlich um ein einziges Land, da die Anzahl an Freiwilligen und Events über alle Zeilen konstant ist. Daneben sortieren wir Summenzeilen aus, die unsere Ergebnisse verfälschen würden, und schließen 2020 auf Grund der COVID-19-Pandemie aus. Zum **Filtern von Zeilen bzw. Beobachtungen** nutzen wir die `dplyr::filter()`-Funktion, wobei die Zeilen beibehalten werden, die die Bedingung(en) erfüllen, die Ihr definiert. Im Kapitel "Einführung in (R)Studio" im Exkurs "Syntax R" könnt Ihr nachschauen, wie Ihr die Bedingungen für die Filterfunktion definieren könnt.
``` {r 07overview_data, exercise = TRUE}
# Ihr nehmt Euren Datensatz...
data_raw %>%
# ..filtert "EMPTY" und "Grand Total" heraus
dplyr::filter(country != "EMPTY",
parent_company != "Grand Total")
```
Angenommen Ihr möchtet nun nur die Daten aus dem Jahr 2019. Filtert den Datensatz so, dass er nur die Daten aus dem Jahr 2019 enthält:
``` {r exercise_07filter_data_exercise, exercise = TRUE}
# Ihr nehmt Euren Datensatz...
data_raw %>%
# ..filtert "EMPTY", "Grand Total" und alle Jahre außer 2019 heraus
dplyr::filter(country != "EMPTY",
parent_company != "Grand Total",
# Hier Euer Code!
)
```
```{r exercise_07filter_data_exercise-solution}
# Ihr nehmt Euren Datensatz...
data_raw %>%
# ..filtert "EMPTY", "Grand Total" und alle Jahre außer 2019 heraus
dplyr::filter(country != "EMPTY",
parent_company != "Grand Total",
year == 2019
)
```
```{r exercise_07filter_data_exercise-check}
grade_this_code()
```
*Anmerkung: Wenn Ihr sicher seid, dass nur 2019 und 2020 enthalten sind, könnt Ihr auch mit `year != 2020` filtern.*
<br>
#### Die Funktion `dplyr::mutate()`
{#id .class width=60% height=60%}
Nun sollten wir die Variable `country` (zu dt. Land) bereinigen. Wie so oft sind die Bezeichnungen für Großbritannien und die USA **nicht standardisiert** und die **Groß- und Kleinschreibung** ist vollkommen durcheinander geraten. Außerdem möchten wir die **deutschen Bezeichnungen** nutzen und den Kontinent und Countrycode ergänzen. Mit `dplyr::case_when()` können wir einen bestimmten Wert in einen anderen Wert transformieren (WENN-DANN), mit `stringr::str_to_title()` wird nur noch der Anfangsbuchstabe großgeschrieben und mit dem Package `countrycode` können wir Ländernamen in verschiedene Sprachen übersetzen und kodieren. Welche Funktionen Ihr für Eure Bereinigungsschritte braucht, hängt immer vom Datensatz ab. Mit etwas mehr Erfahrung und einer Googlerecherche lassen sich für die meisten Herausforderungen tolle Hilfsmittel finden!
De Code ist für Euch schon geschrieben. Könnt Ihr die fehlenden Funktionen und Variablennamen an Stelle der ??? ergänzen? Um alle Stellen zu finden, müsst Ihr etwas scrollen.
```{r exercise_07mutate_data_exercise, exercise = TRUE}
# Ihr nehmt Euren Datensatz...
data_raw %>%
# ..filtert "EMPTY", "Grand Total" und Jahr 2020 heraus
dplyr::???(
country != "EMPTY",
parent_company != "Grand Total",
year == 2019
) %>%
# ..bereinigt die Ländernamen, indem Ihr...
dplyr::???(
# ..die UK und USA umbenennt
country =
dplyr::case_when(
country == "United Kingdom of Great Britain & Northern Ireland" ~ "United Kingdom",
country == "United States of America" ~ "United States",
TRUE ~ country # falls keine der beiden Zeilen zutrifft, dann nehmen wir diese Zeile und schreiben wieder den Wert aus `country` in die neue Variable
),
# ..nur den Anfangsbuchstaben der Länder großschreibt
??? = stringr::str_to_title(country),
# ..Kontinent und Land übersetzt
continent = countrycode::countrycode(country,
origin = "country.name",
destination = "continent"),
??? = dplyr::case_when(continent == "Africa" ~ "Afrika",
continent == "Americas" ~ "Amerika",
continent == "Asia" ~ "Asien",
continent == "Europe" ~ "Europa",
continent == "Oceania" ~ "Ozeanien"),
countrycode = countrycode::countrycode(country,
origin = "country.name",
destination = "iso3c"),
country = countrycode::countrycode(country,
origin = "country.name",
destination = "country.name.de")
)
```
```{r exercise_07mutate_data_exercise-solution}
# Ihr nehmt Euren Datensatz...
data_raw %>%
# ..filtert "EMPTY", "Grand Total" und Jahr 2020 heraus
dplyr::filter(
country != "EMPTY",
parent_company != "Grand Total",
year == 2019
) %>%
# ..bereinigt die Ländernamen, indem Ihr...
dplyr::mutate(
# ..die UK und USA umbenennt
country =
dplyr::case_when(
country == "United Kingdom of Great Britain & Northern Ireland" ~ "United Kingdom",
country == "United States of America" ~ "United States",
TRUE ~ country
),
# ..nur den Anfangsbuchstaben der Länder großschreibt
country = stringr::str_to_title(country),
# ..Kontinent und Land übersetzt
continent = countrycode::countrycode(country,
origin = "country.name",
destination = "continent"),
continent = dplyr::case_when(continent == "Africa" ~ "Afrika",
continent == "Americas" ~ "Amerika",
continent == "Asia" ~ "Asien",
continent == "Europe" ~ "Europa",
continent == "Oceania" ~ "Ozeanien"),
countrycode = countrycode::countrycode(country,
origin = "country.name",
destination = "iso3c"),
country = countrycode::countrycode(country,
origin = "country.name",
destination = "country.name.de")
)
```
```{r exercise_07mutate_data_exercise-check}
grade_this_code()
```
Der Hauptteil der Bereinigung ist nun abgeschlossen. Das Ergebnis steht Euch unter `plastics_processed` zur Verfügung. Wir können die Daten nun in zwei Tabellen aufteilen.
<br>
#### Die Funktionen `dplyr::group_by()` und `dplyr::summarise()`
{#id .class width=60% height=60%}
{#id .class width=60% height=60%}
Um den `community`- Datensatz zu erstellen, in dem eine Beobachtung pro Land vorhanden sein soll, müssen wir die bereinigten Daten pro Land gruppieren und entscheiden, wie die anderen Variablen zusammengefasst werden sollen. Mit `dplyr::group_by()` und `dplyr::summarise()` steht uns die **Gruppierung und Zusammenfassung** der Variablen offen. Wir addieren die Plastikstücke und wählen für die Anzahl der Events und Freiwilligen genau einen Wert aus. Diese sind im Originaldatensatz mehrfach vorhanden - etwas, das typischerweise beim Zusammenfügen von Datensätzen entsteht.
``` {r 07group_by_summarise1, exercise = TRUE}
# Ihr nehmt Euren Datensatz,...
community <- plastics_processed %>%
# ..gruppiert die Beobachtungen pro Land
dplyr::group_by(continent, country, countrycode) %>% # Pro Kontinent und Land gruppieren
# ..entscheidet, wie die anderen Variablen zusammengefasst werden sollen
dplyr::summarise(
n_pieces = sum(grand_total, na.rm = TRUE), # Summe
n_volunteers = unique(volunteers), # Einzigartige Werte (da Duplikate)
n_events = unique(num_events) # Einzigartige Werte (da Duplikate)
)
```
Berechnet nun zur Übung mit den Funktionen `dplyr::group_by()` und `dplyr::summarise()` die Gesamtzahl der Plastikstücke, die pro Kontinent gesammelt wurden. Nutzt dafür den `community`-Datensatz.
```{r 07group_by_summarise2, exercise = TRUE}
# Hier Euer Code
```
```{r 07group_by_summarise2-solution}
# Ihr nehmt Euren Datensatz,...
community %>%
# ..gruppiert die Beobachtungen pro Kontinent
dplyr::group_by(continent) %>%
#..entscheidet, wie die anderen Variablen zusammengefasst werden sollen
dplyr::summarise(n_pieces = sum(n_pieces, na.rm = TRUE)) # Summe
```
```{r 07group_by_summarise2-check}
grade_this_code()
```
---
<details>
<summary><h4>➡ Exkurs: Pivoting</h4></summary>
<br>
Über die Bereinigung von Werten im Datensatz und das Filtern von Werten hinaus, könnt Ihr auch die Form des gesamten Datensatzes über `tidyr::pivot_longer()` und `tidyr::pivot_wider()` verändern. Um den `audit`-Datensatz zu bereinigen, müsst Ihr beispielsweise noch die Plastikarten so transformieren, dass sie als eine Variable im Datensatz vorkommen:
``` {r 07pivot_wider, exercise = TRUE}
# Ihr nehmt Euren Datensatz...
plastics_processed %>%
#..pivotiert die Plastikarten
tidyr::pivot_longer(
cols = c(hdpe, ldpe, o, pet, pp, ps, pvc), # Betroffene Variablen
names_to = "plastic_type", # Zielspalte
values_to = "n_pieces" # Wertspalte
) %>%
# ..und faktorisiert sicherheitshalber die anderen Variablen (nicht immer notwendig)
dplyr::mutate(dplyr::across( # Zu Faktor konvertieren
.cols = c(country, continent, year, plastic_type),
.fns = as_factor
))
```
Mit `dyplr::pivot_wider()` könnt Ihr den Datensatz auch wieder in das breite Format bringen. Wir empfehlen aber die lange Form zu nutzen.
</details>
---
#### Die Funktion `dplyr::select()`
{#id .class width=60% height=60%}
Neben Zeilen bzw. Beobachtungen könnt Ihr natürlich auch **Spalten bzw. Variablen filtern**. Auch hier hilft Euch das `dplyr` Package mit der Funktion `dplyr::select()` weiter. Mit `dplyr::select()` könnt Ihr entweder die Variablen auswählen, die im Datensatz enthalten sein sollen oder aber mit einem `-` die Variablen auswählen, die aus Eurem Datensatz gelöscht werden sollen. Der folgende Code löscht so zum Beispiel die Variable `grand_total` aus dem `data_raw`-Datensatz:
``` {r 07select_data1, exercise = TRUE}
# Spalte "grand total" NICHT auswählen
data_raw %>%
dplyr::select(-grand_total) %>%
head()
```
Um den `audit`-Datensatz zu finalisieren, wählen wir in einem letzten Schritt die relevanten Variablen aus:
```{r 07select_data2, exercise = TRUE}
# Ihr nehmt Euren Datensatz...
audit <- plastics_processed %>%
#..pivotiert die Plastikarten
tidyr::pivot_longer(
cols = c(hdpe, ldpe, o, pet, pp, ps, pvc), # Betroffene Variablen
names_to = "plastic_type", # Zielspalte
values_to = "n_pieces" # Wertspalte
) %>%
# ..faktorisiert sicherheitshalber die anderen Variablen (nicht immer notwendig)
dplyr::mutate(dplyr::across( # Zu Faktor konvertieren
.cols = c(country, continent, countrycode, year, plastic_type),
.fns = as_factor
)) %>%
# und wählt die richtigen Spalten aus, da manche Variablen mit der Pivotierung nicht aussagekräftig sind.
dplyr::select(continent, country, countrycode, parent_company, plastic_type, n_pieces)
```
Wir sind soweit: Die beiden bereinigten Datensätze stehen. Sind die enthaltenen Werte richtig? Wir machen eine **Qualitätsprüfung** und schauen uns für beide Datensätze einige Informationen an:
```{r sanitycheck, exercise = TRUE}
# Anzahl Plastikstücke
sum(community$n_pieces, na.rm = TRUE) == sum(plastics_processed$grand_total)
sum(audit$n_pieces, na.rm = TRUE) == sum(plastics_processed$grand_total)
# Länder
sort(unique(community$country)) == sort(unique(audit$country))
```
Check! Das habt Ihr wirklich gut gemacht!
<br>
#### Die Funktion `dplyr::arrange()`
{#id .class width=60% height=60%}
Eine Funktion, die wir Euch nicht vorenthalten möchten und die oft eher für Transformation als Bereinigung genutzt wird, z.B. um **Ranglisten** auszugeben, ist `dplyr::arrange()`. Sie **sortiert Datensätze** für Euch. Wir interessieren uns für die Top10 der Firmen, deren Plastikverpackung gefunden wurde:
```{r arrange, exercise = TRUE}
# Ihr nehmt Euren Datensatz...
audit %>%
# ..wählt relevante Spalten aus
dplyr::select(parent_company, n_pieces) %>%
# ..gruppiert pro Hersteller
dplyr::group_by(parent_company) %>%
# ..berechnet die Zusammenfassung (hier: Summe)
dplyr::summarise(total_pieces = sum(n_pieces, na.rm = TRUE)) %>%
# ..filtert unnütze Werte heraus
dplyr::filter(! parent_company %in% c("Unbranded", "Inconnu", "Assorted")) %>%
# ..begrenzt die Anzahl auf 10
dplyr::slice_max(total_pieces, n = 10) %>%
# ..und sortiert die Werte absteigend
dplyr::arrange(desc(total_pieces))
```
Das gefundene Plastik kann Herstellern direkt zugeordnet werden: La Doo (4 Prozent) und Coca-Cola (2,7 Prozent). Vielleicht ist das etwas für die nächste Kampagne?
Nun kennt Ihr alle `dplyr`-Verben und seid fit für die Datentransformation! Bevor Ihr in die Übung geht: Auf einige Themen sind wir hier nur am Rande eingegangen - den Umgang mit fehlenden Werte (NAs), die Umformung von Textdaten und das (in der `countrycode`-Funktion versteckte) Zusammenfügen von Datensätzen. Wenn Ihr Euch für diese Themen interessiert, dann macht gerne die Exkurse.
---
<details>
<summary><h3>➡ Exkurs: Umgang mit fehlenden Werten (NAs)</h3></summary>
<br>
Nachdem Ihr nun Variablen und Beobachtungen auswählen und filtern könnt, schaut Ihr Euch nun den Umgang mit fehlenden Werten, also NAs (**n**ot **a**vailable) an. Versucht zuerst einmal, die Summe für die Variable `n_pieces` im Datensatz `community` zu berechnen.
``` {r 07mean_na1, exercise = TRUE}
# Berechnung der Summe
sum(community$n_pieces)
```
Klappt! Im Datensatz `community` sind keine NAs enthalten, die bei der Berechnung der Summe stören könnten. Versucht das gleiche jetzt mal für den `audit`-Datensatz in folgendem Codeblock:
``` {r exercise_07mean_na2, exercise = TRUE}
# Hier Euer Code!
```
```{r exercise_07mean_na2-solution}
# Berechnung de Summe
sum(audit$n_pieces)
```
```{r exercise_07mean_na2-check}
grade_this_code()
```
Ups - Ihr erhaltet ein NA? R kann den Wert nicht berechnen, da **in der Variable NAs** enthalten sind. Versucht hier zu berechnen, wie viele NAs die Variable hat. <br>
*Tipp: Experimentiert mit der Funktion `summary()`)!*
``` {r exercise_07mean_na3, exercise = TRUE}
# Hier Euer Code!
```
``` {r exercise_07mean_na3-solution}
# NAs bestimmen
summary(audit)
```
``` {r exercise_07mean_na3-check}
grade_this_code()
```
Trotzdem wollt Ihr in solchen Fällen manchmal statistische Kennzahlen berechnen. Dafür könnt Ihr R explizit sagen, dass die **NAs bei der Berechnung ignoriert** werden sollen. Das funktioniert über das Argument `na.rm = TRUE`, das Ihr schon aus vorherigen Übungen kennt:
``` {r 07mean_na4, exercise = TRUE}
# Berechnung der Summe unter Ausschluss der NAs
sum(audit$n_pieces, na.rm = TRUE)
```
Perfekt, jetzt könnt Ihr R schon mitteilen, **NAs zu ignorieren**! Natürlich gibt es noch viele weitere Möglichkeiten, NA's in Datensätzen zu entdecken und zu filtern - versucht dafür mal den folgenden Codeblock zu verstehen:
``` {r 07mean_na5, exercise = TRUE}
# Anzahl an fehlenden Werten (is.na gibt für eine Beobachtung TRUE (1) oder FALSE (0) zurück, deshalb können wir das hier aufsummieren)
na_count <- sum(is.na(audit$n_pieces))
# Auflisten von Beobachtungen, die fehlende Werte haben
na_rows <- audit[!complete.cases(audit$n_pieces), ]
na_rows <- which(is.na(audit$n_pieces))
# Neuer Datensatz ohne fehlende Werte
new_df <- na.omit(audit)
```
**Achtung:** Nicht immer können fehlende Werte einfach so ausgeschlossen werden. Manchmal beeinträchtigt dieser Ausschluss die **Aussagekraft unserer Analysen**. Bei [Allison 2010](https://statisticalhorizons.com/wp-content/uploads/Allison_MissingData_Handbook.pdf){target="_blank"} findet Ihr eine gute Übersicht gängiger Herausforderungen und Lösungen. Unser Tipp: Schon bei der Datenerhebung ansetzen und während der Datenerhebung beständig auf genau solche Vorkommnisse prüfen, sodass Ihr rechtzeitig reagieren könnt.
Häufig kommt es zudem vor, dass **NAs nicht als NAs codiert** sind: Wie Ihr vielleicht schon mal gesehen habt, werden fehlende Werte häufig auch als **“N/A”, “N A”, und “Not Available”, oder -99, oder -1** (oder wie bei uns mit etwas ganz anderem wie "EMPTY") angegeben. Schaut deshalb immer ins **Codebuch**, bevor Ihr die Daten bereinigt und analysiert - sonst berechnet Ihr beispielsweise einen Mittelwert, in den fälschlicherweise diese Zahlen einfließen! Hier hat dann auch das `dplyr`-Package wieder eine einfache Lösung parat: die Funktion `dplyr::na_if()`. Diese wenden wir mithilfe von `dplyr::mutate_all()` auf alle Spalten an:
``` {r 07mean_na6, exercise = TRUE}
# Erstellung eines Beispieldataframes mit NAs als "NA" und "-99"
df <- tibble::tribble(
~name, ~x, ~y, ~z,
"Person 1", 1, -99, 6.7,
"Person 2", 3, NA, -99,
"Person 3", NA, 0.76, -1.6
)
# Definition der NAs
df2 <- df %>%
dplyr::mutate_all(dplyr::na_if, -99)
# Erste fünf Zeilen anzeigen
head(df2)
```
</details>
---
---
<details>
<summary><h3>➡ Exkurs: Datensätze zusammenfügen</h3></summary>
<br>
Häufig ist es auch der Fall, dass mehrere Datensätze zu einem zusammengefügt werden sollen. Letzte Woche habt Ihr bereits den Datensatz der Weltbank zu Naturschutzgebieten (`wb_areas`) heruntergeladen. Verschafft Euch zuerst nochmal einen kleinen Überblick über den Datensatz `wb_areas`:
``` {r 07gdppc, exercise = TRUE}
# Hier Euer Code!
```
Den Datensatz `wb_areas` wollt Ihr nun mit dem Datensatz `community` zusammenfügen. Um die Datensätze zusammenzuführen, braucht Ihr eine **gemeinsame Variable**, anhand der R die Länder einander zuordnen kann. Die Variable muss den **gleichen Namen** in beiden Datensätzen haben oder von Euch zugeordnet werden und die Kodierung (hier ISO2C) muss übereinstimmen. Da Ländernamen fehleranfällig sind, fokussieren wir uns auf die **Country Codes**:
``` {r 07wb_clean, exercise = TRUE}
# Umbennung der Spalten
wb_areas %>%
dplyr::select(countrycode = 'iso2c', protected_area = 'ER.PTD.TOTL.ZS')
```
Versucht jetzt einmal herauszufinden, wie viele Länder in beiden Datensätzen `community` und `wb_areas` vorhanden sind (hier führen viele Wege zum Ziel!):
``` {r 07nrow_ex, exercise = TRUE}
# Hier Euer Code!
```
```{r 07quiz_datenbereinigung5}
quiz(caption = NULL,
question("Wie viele Länder sind im Datensatz der World Bank enthalten?",
answer("3"),
answer("266", correct = TRUE),
answer("51"),
answer("4084"),
correct = "Gut gemacht!",
incorrect = "Das ist leider nicht ganz richtig. Probiert es nochmal!",
allow_retry = TRUE,
try_again_button = "Nochmal versuchen"
)
)
```
```{r 07quiz_datenbereinigung6}
quiz(caption = NULL,
question("Wie viele Länder sind in Community enthalten?",
answer("51", correct = TRUE),
answer("4"),
answer("9296"),
answer("4084"),
correct = "Gut gemacht!",
incorrect = "Das ist leider nicht ganz richtig. Probiert es nochmal!",
allow_retry = TRUE,
try_again_button = "Nochmal versuchen"
)
)
```
Jetzt könnt Ihr die beiden Datensätze zusammenfügen. Dabei gibt es verschiedene Möglichkeiten, denn in dem einen Datensatz kommen viel mehr Länder vor als im anderen:
- `inner_join`: nur die Länder werden beibehalten, die **in beiden Datensätzen** enthalten sind
- `full_join`: **alle Länder** aus beiden Datensätzen sind enthalten
- `left_join`/`right_join`: nur die **Länder aus dem zuerst bzw. zuletzt genannten Datensatz** bleiben enthalten
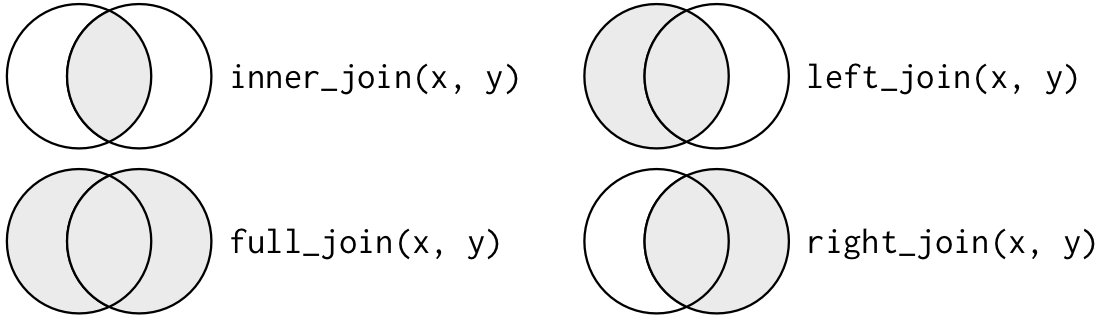{#id .class width=80% height=100%}
Führt die folgenden Codeblöcke nacheinander aus und schaut Euch an, wie diese verschiedenen Joins für Euren Datensatz in der Praxis funktionieren:
``` {r 07inner_join, exercise = TRUE}
# Ihr nehmt Euren ersten Datensatz...
community %>%
# ...und führt den Join aus
dplyr::inner_join(wb_processed, by = "countrycode")
```
``` {r 07full_join, exercise = TRUE}
# Ihr nehmt Euren ersten Datensatz...
community %>%
# ...und führt den Join aus
dplyr::full_join(wb_processed, by = "countrycode")
```
``` {r 07left_join, exercise = TRUE}
# Ihr nehmt Euren ersten Datensatz...
community %>%
# ...und führt den Join aus
dplyr::left_join(wb_processed, by = "countrycode")
```
``` {r 07right_join, exercise = TRUE}
# Ihr nehmt Euren ersten Datensatz...
community %>%
# ...und führt den Join aus
dplyr::right_join(wb_processed, by = "countrycode")
```
```{r 07quiz_datenbereinigung8}
quiz(
caption = NULL,
question("Wie Ihr sehen könnt, führt der full_join natürlich zu den meisten Zeilen im Datensatz und der inner_join zur geringsten Anzahl an Ländern. Welcher der beiden anderen Joins führt zu einer höheren Anzahl an Ländern im Datensatz?",
answer("left_join"),
answer("right_join", correct = TRUE),
correct = "Gut gemacht!",
incorrect = "Das ist leider nicht ganz richtig. Probiert es nochmal!",
allow_retry = TRUE,
try_again_button = "Nochmal versuchen"
),
question("Welche der folgenden Aussagen sind wahr?",
answer("Beim Inner Join bleiben nur Zeilen bestehen, die in beiden Datensätzen vorhanden sind (n = 50)", correct = TRUE),
answer ("Beim Full Join bleiben alle Zeilen bestehen, passende werden zusammengefügt (n = 267)", correct = TRUE),
answer ("Beim Left Join bleiben alle Zeilen des links referenzierten Datensatzes (community) bestehen, passende werden zusammengefügt (n = 51)", correct = TRUE),
answer ("Beim Right Join bleiben alle Zeilen des rechts referenzierten Datensatzes (wb_areas) bestehen, passende werden zusammengefügt (n = 266)", correct = TRUE),
correct = "Gut gemacht!",
incorrect = "Das ist leider nicht ganz richtig. Probiert es nochmal!",
allow_retry = TRUE,
try_again_button = "Nochmal versuchen"
)
)
```
</details>
---
### **Und jetzt Ihr**
Wenn Ihr einen **eigenen Datensatz** habt - den Ihr letzte Woche bereits in R importiert habt - dann könnt Ihr jetzt versuchen, diesen zu bereinigen. Wenn Ihr nicht genug von Datenbereinigung bekommen könnt oder Ihr keinen eigenen Datensatz habt, dann schaut Euch das **R Markdown: 06_datentransformation-uebung.Rmd** (im [Übungsordner](https://download-directory.github.io/?url=https://github.com/CorrelAid/lernplattform/tree/main/uebungen){target="_blank"} unter 06_datentransformation) an und versucht die Aufgaben darin zu bearbeiten.
### **Zusätzliche Ressourcen**
- [Schummelblatt: dplyr](https://github.com/CorrelAid/lernplattform/blob/main/cheatsheets/06_cheatsheet-dplyr.pdf){target="_blank"} (engl.)
- [Schummelblatt: stringr](https://github.com/CorrelAid/lernplattform/blob/main/cheatsheets/06_cheatsheet-stringr.pdf){target="_blank"} (engl.)
- [Schummelblatt: tidyr](https://github.com/CorrelAid/lernplattform/blob/main/cheatsheets/06_cheatsheet-tidyr.pdf){target="_blank"} (engl.)
- [Data Cleaning in R](https://app.dataquest.io/course/r-data-cleaning){target="_blank"} auf DataQuest (engl.)
- [Advanced Data Cleaning in R](https://app.dataquest.io/course/r-data-cleaning-advanced){target="_blank"} auf DataQuest (engl.)
- Eine noch etwas holpriger Spielplatz, der zeigt, wie Eure Schritte in der Datenbereinigung aussehen: [Tidy Data Tutor](https://tidydatatutor.com){target="_blank"} (engl.)
- [Tidyverse: Tidy data](https://tidyr.tidyverse.org/articles/tidy-data.html){target="_blank"} (engl.)