This repository contains (1) the data-agnostic validation methodology of expert-annotated datasets in terms of consistency and completeness and (2) the crowdsourcing annotations for events and time expressions referenced in the following paper:
- Oana Inel and Lora Aroyo: Validation Methodology for Expert-Annotated Datasets: Event Annotation Case Study. Language, Data and Knowledge (LDK), 2019.
If you find this data useful in your research, please consider citing:
@inproceedings{inel2019validation,
title={Validation Methodology for Expert-Annotated Datasets: Event Annotation Case Study},
author={Inel, Oana and Aroyo, Lora},
booktitle={To Appear in the Proceedings of the 2nd International Conference on Language, Data and Knowledge (LDK)},
year={2019}
}
If you want to run and regenerate the results on your own, you need to install the stable version of the crowdtruth package from PyPI using:
pip install crowdtruth
The notebooks to regenerate the results are found in the following folders: notebooks/Main Crowdsourcing Experiments and notebooks/Pilot Crowdsourcing Experiments (for main and respectively, pilot experiments).
The raw crowdsourced data is found in the folders data/main_crowd_data/raw_data and data/pilot_crowd_data/raw_data (for main and respectively, pilot experiments).
The data aggregated with CrowdTruth metrics and the evaluation against the expert annotations is available in the folders data/main_crowd_data/results and data/pilot_crowd_data/results (for main and respectively, pilot experiments).
The TempEval-3 data is found in the folder data/TempEval3-data.
The training and evaluation data, for each event-sentence threshold is found in the folder: data/Train-and-Test.
The following crowdsourcing templates have been used in the aforementioned article. We use the same experiment notation as in the article. To check each crowdsourcing annotation template, click on the small template icon. The image will open in a new tab.
| EXP. TYPE | ENTITY TYPE | CROWDSOURCING ANNOTATION TEMPLATE (click to enlarge) | INPUT ENTITY VALUES | ANNOTATION GUIDELINES | TARGET ANNOTATION |
|---|---|---|---|---|---|
| P1 | Event | 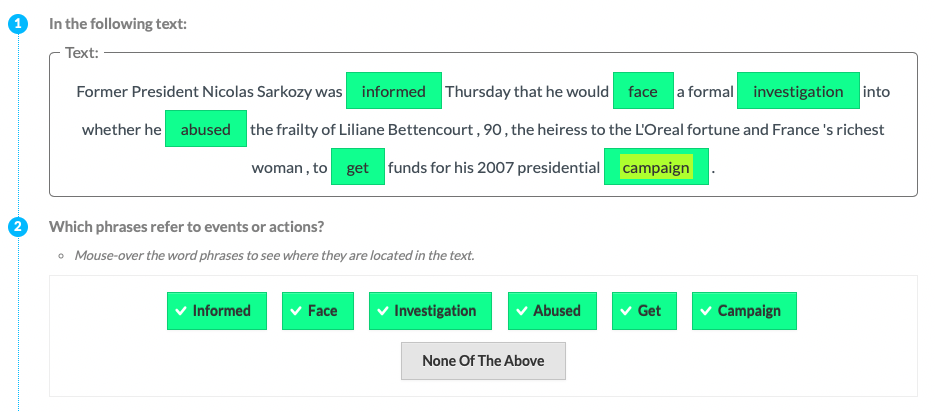 |
Experts (P) & Tools | Explicit Definition | Entities |
| P1 | Time | 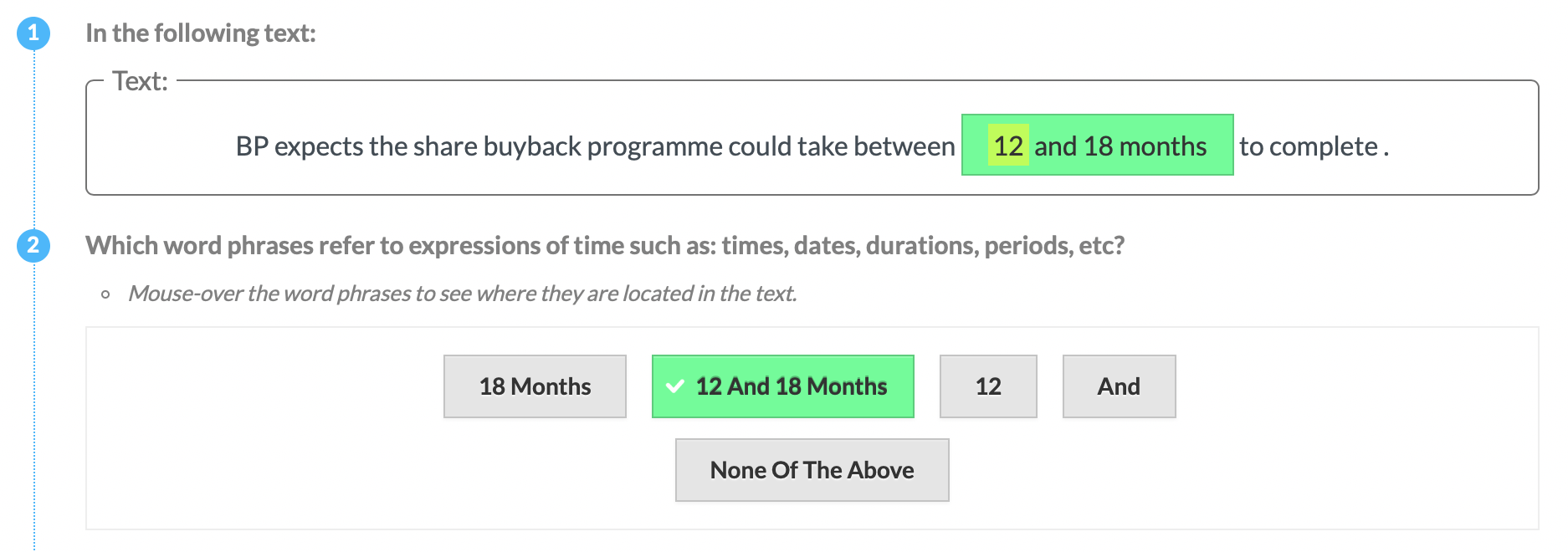 |
Experts (P) & Tools | Explicit Definition | Entities |
| P2 | Event | 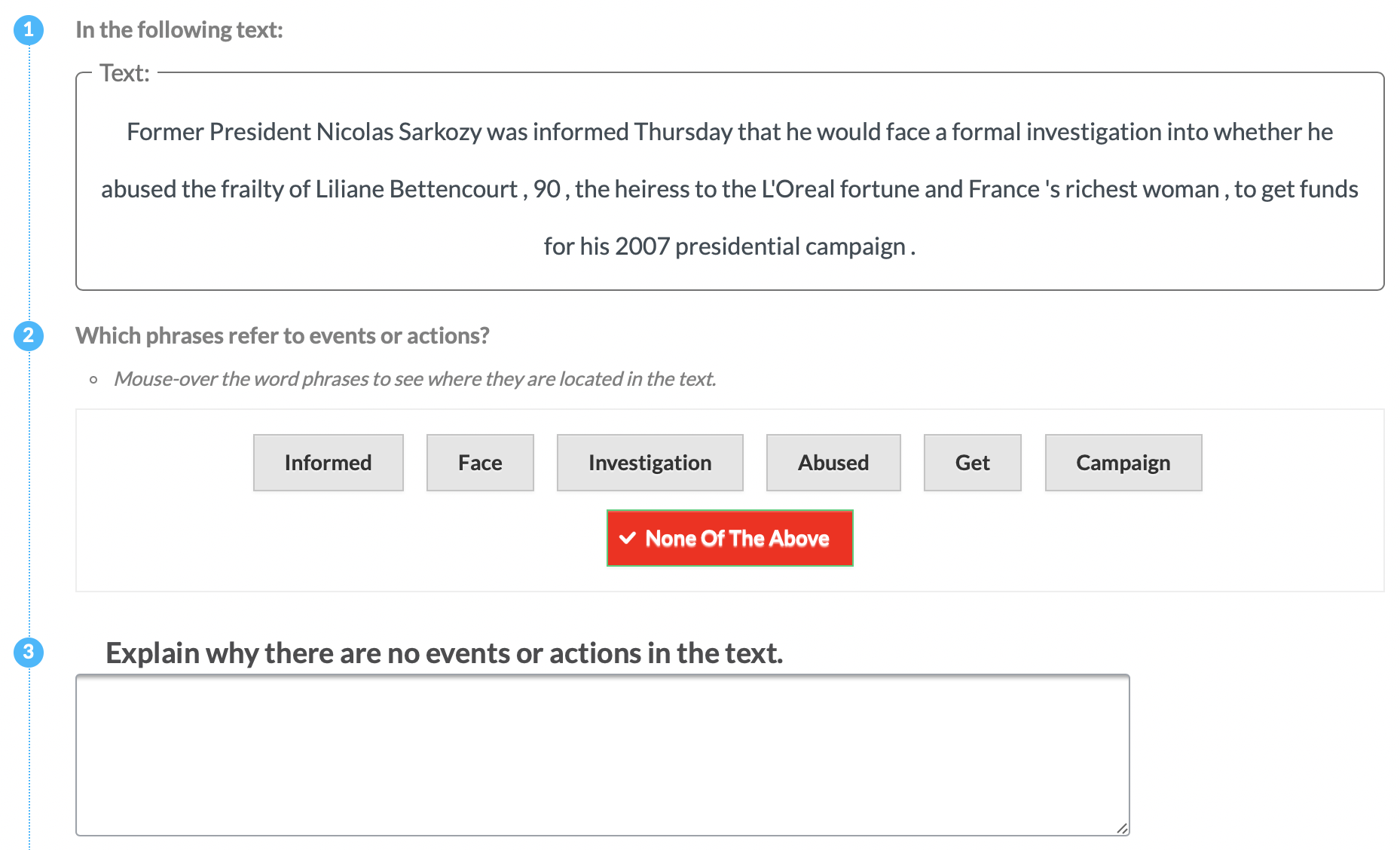 |
Experts (P) & Tools | Explicit Definition | Entities + Motivation (NONE) |
| P2 | Time | 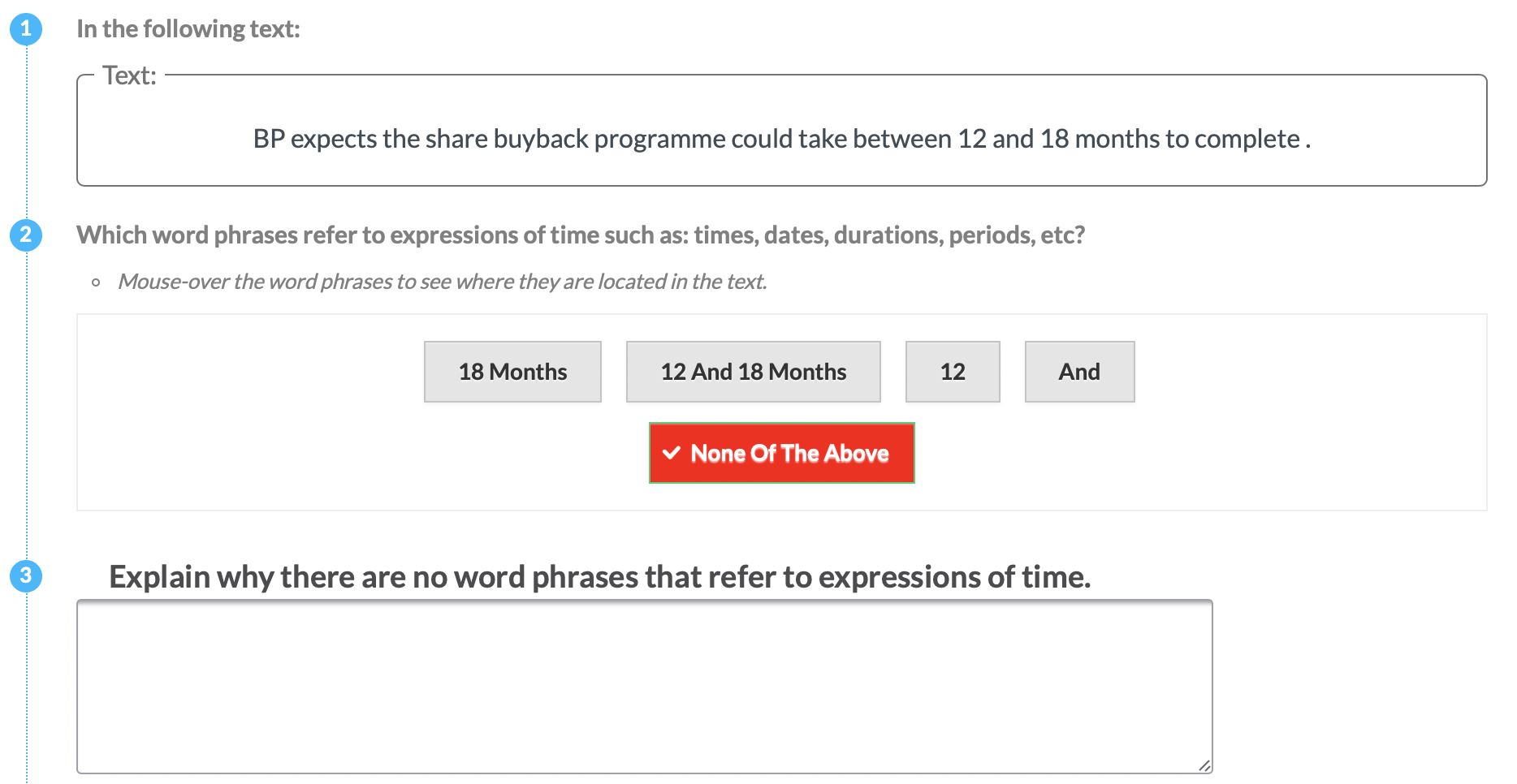 |
Experts (P) & Tools | Explicit Definition | Entities + Motivation (NONE) |
| P3 | Event | 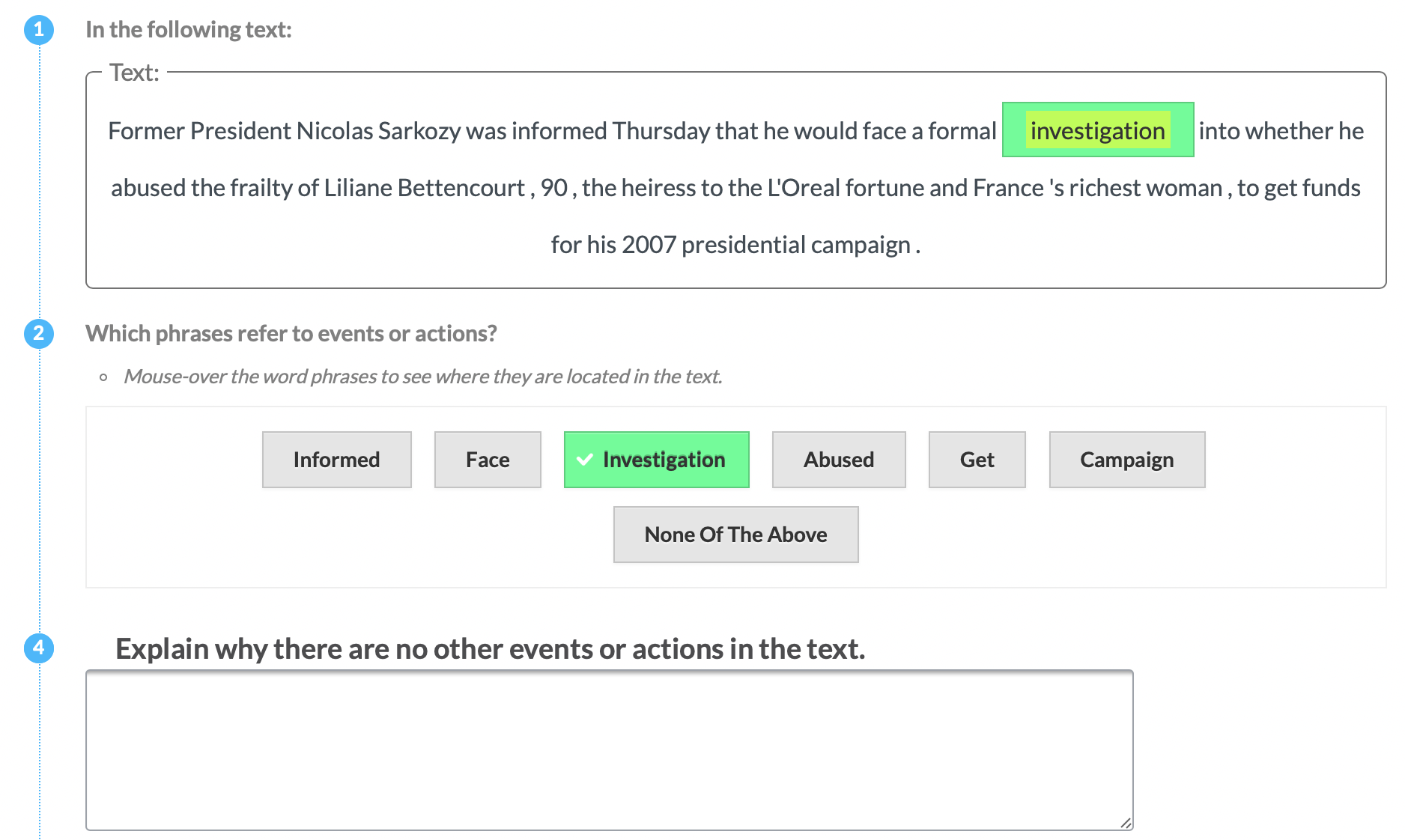 |
Experts (P) & Tools | Explicit Definition | Entities + Motivation (ALL) |
| P3 | Time | 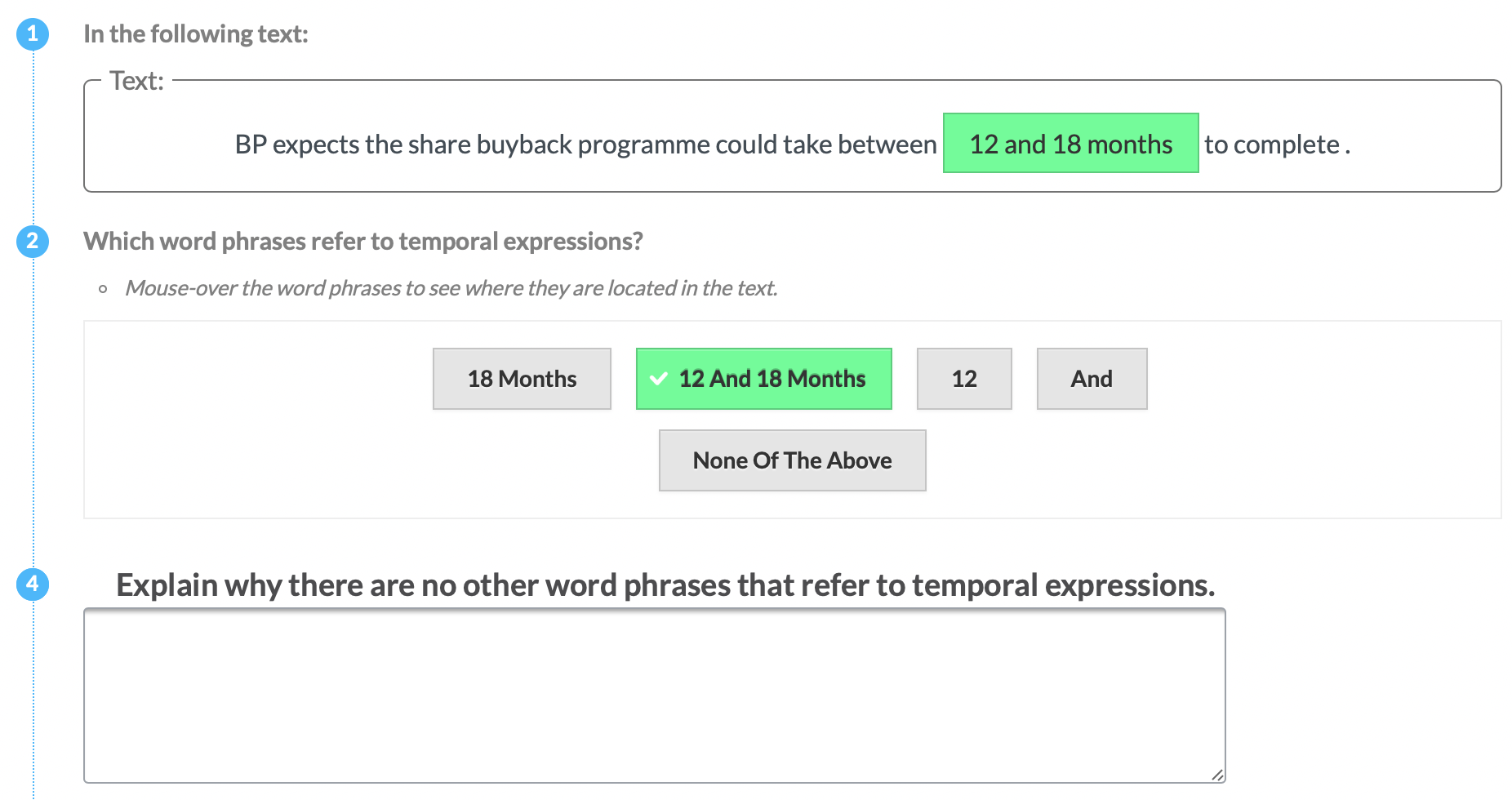 |
Experts (P) & Tools | Explicit Definition | Entities + Motivation (ALL) |
| P4 | Event | 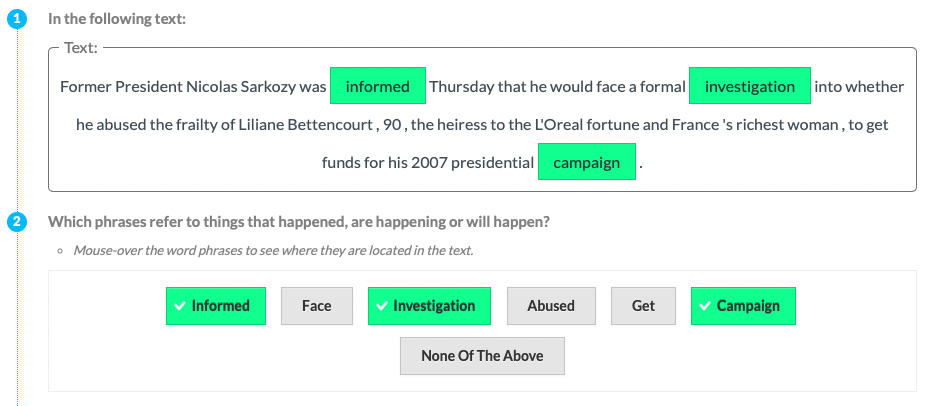 |
Experts (P) & Tools | Implicit Definition | Entities |
| P4 | Time | 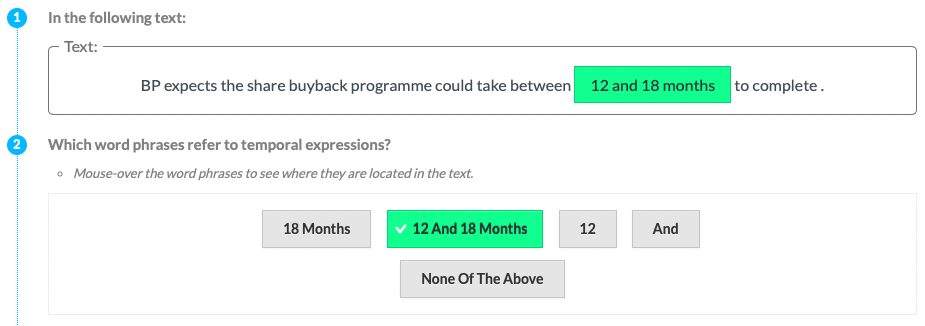 |
Experts (P) & Tools | Implicit Definition | Entities |
| P5 | Event | 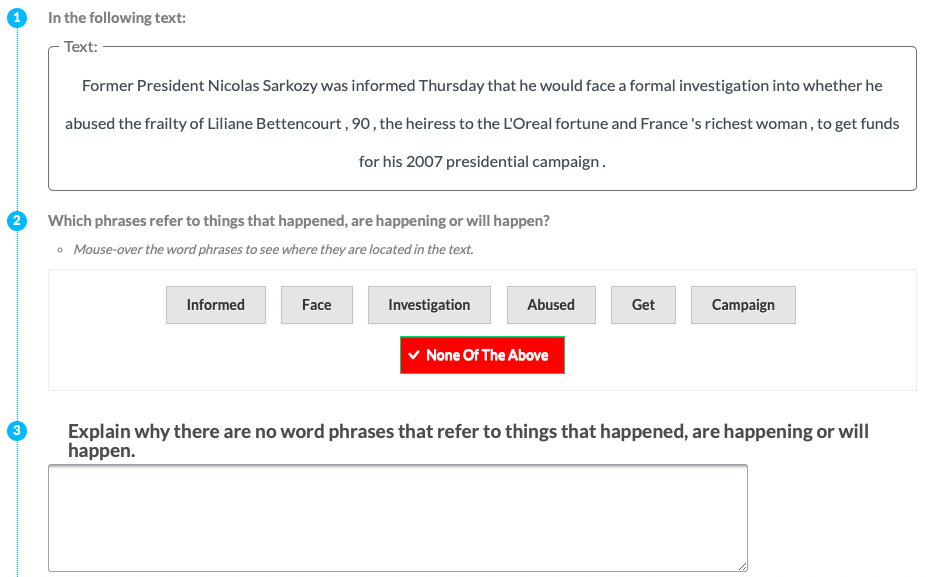 |
Experts (P) & Tools | Implicit Definition | Entities + Motivation (NONE) |
| P5 | Time | 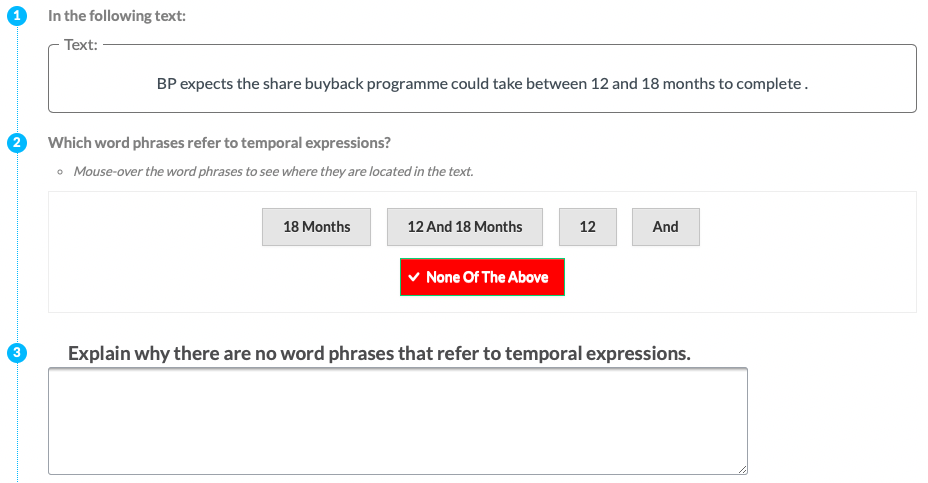 |
Experts (P) & Tools | Implicit Definition | Entities + Motivation (NONE) |
| P6 | Event | 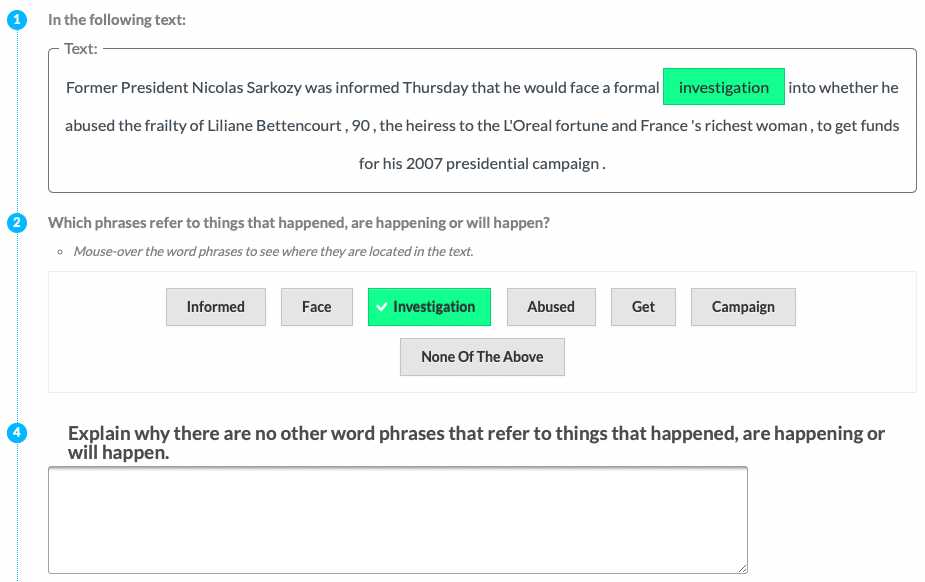 |
Experts (P) & Tools | Implicit Definition | Entities + Motivation (ALL) |
| P6 | Time |  |
Experts (P) & Tools | Implicit Definition | Entities + Motivation (ALL) |
| P7 | Event |  |
Experts (G&P) & Tools & Missing | Explicit Definition | Entities + Motivation (ALL) |
| P7 | Time | 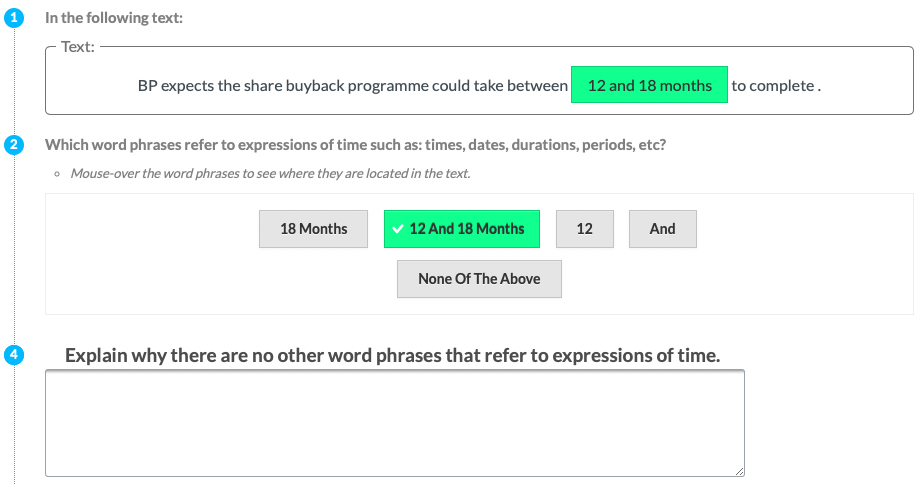 |
Experts (G&P) & Tools & Missing | Explicit Definition | Entities + Motivation (ALL) |
| P8 | Event | 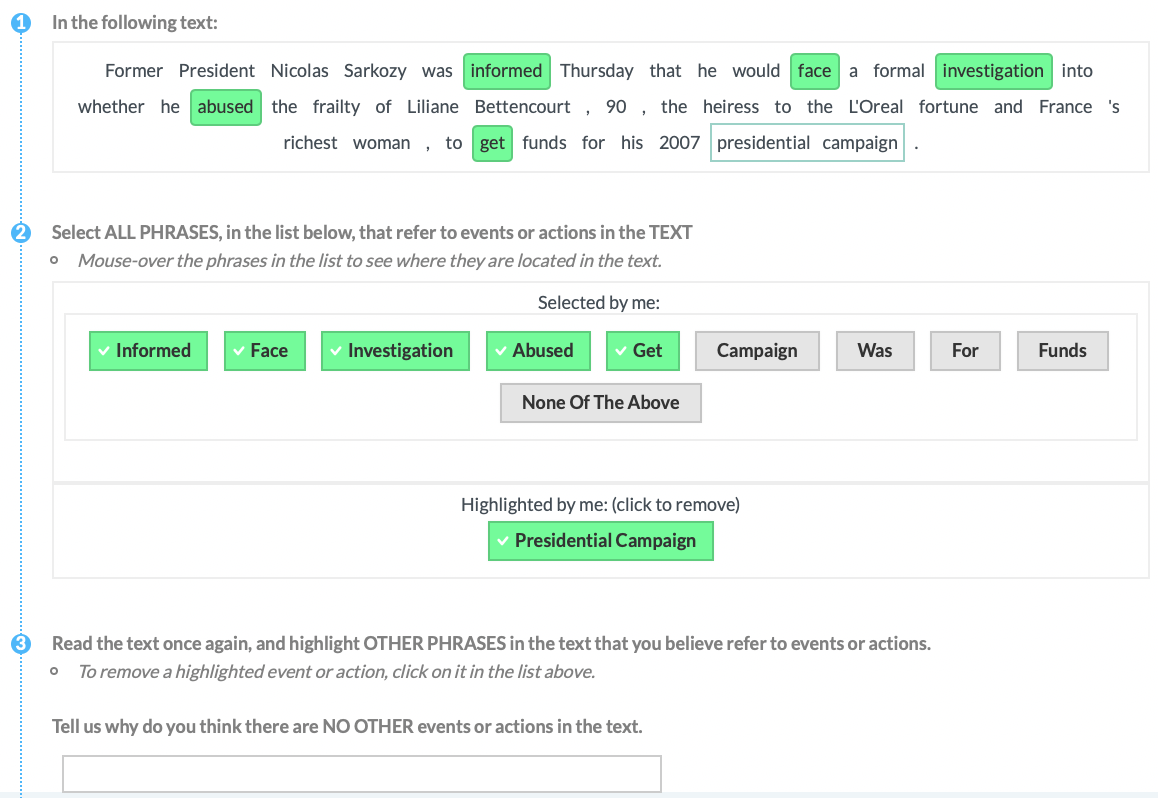 |
Experts (G&P) & Tools & Missing | Explicit Definition | Entities + Motivation (ALL) + Highlight |
| P8 | Time | 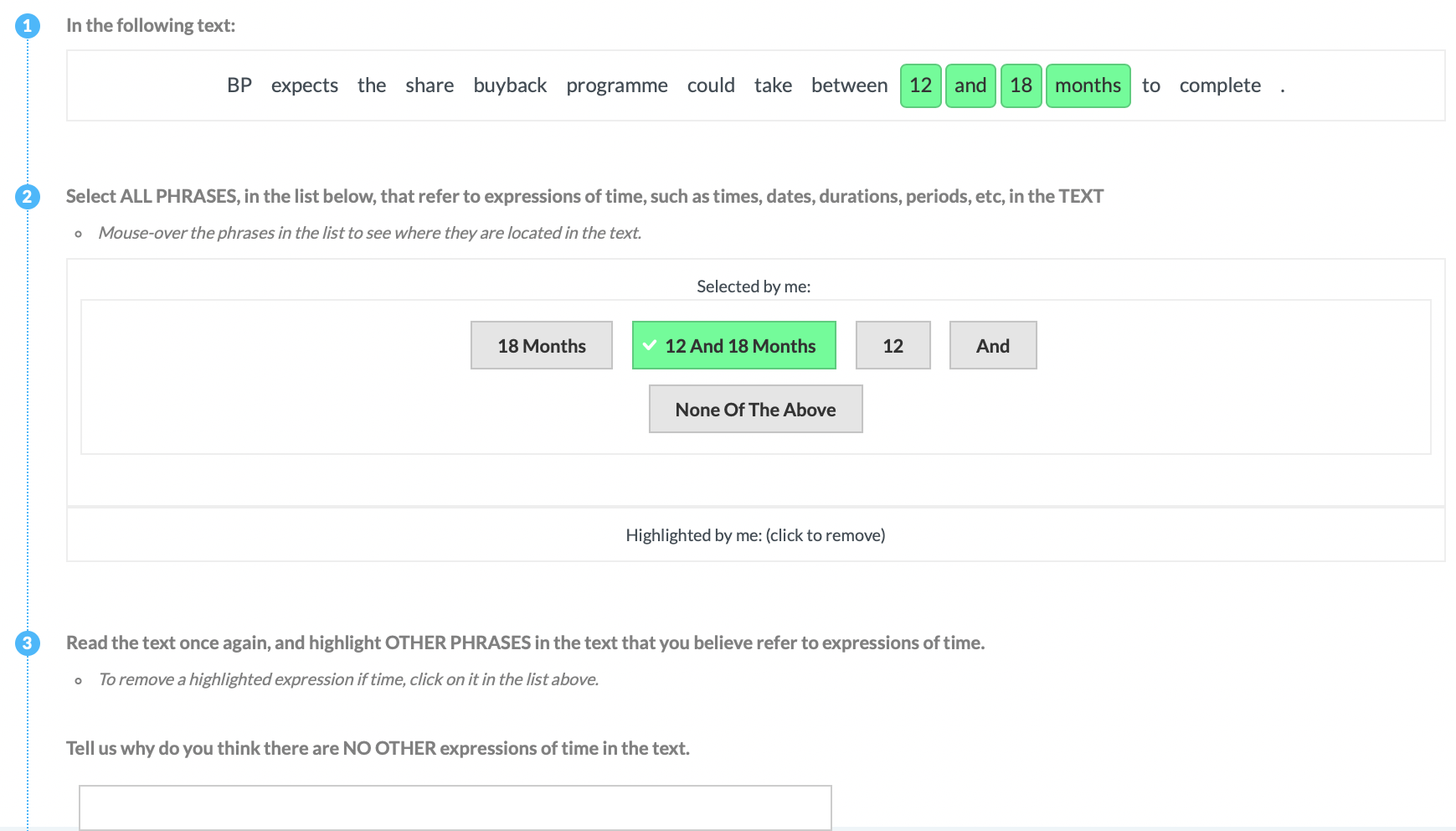 |
Experts (G&P) & Tools & Missing | Explicit Definition | Entities + Motivation (ALL) + Highlight |
| M1 | Event | 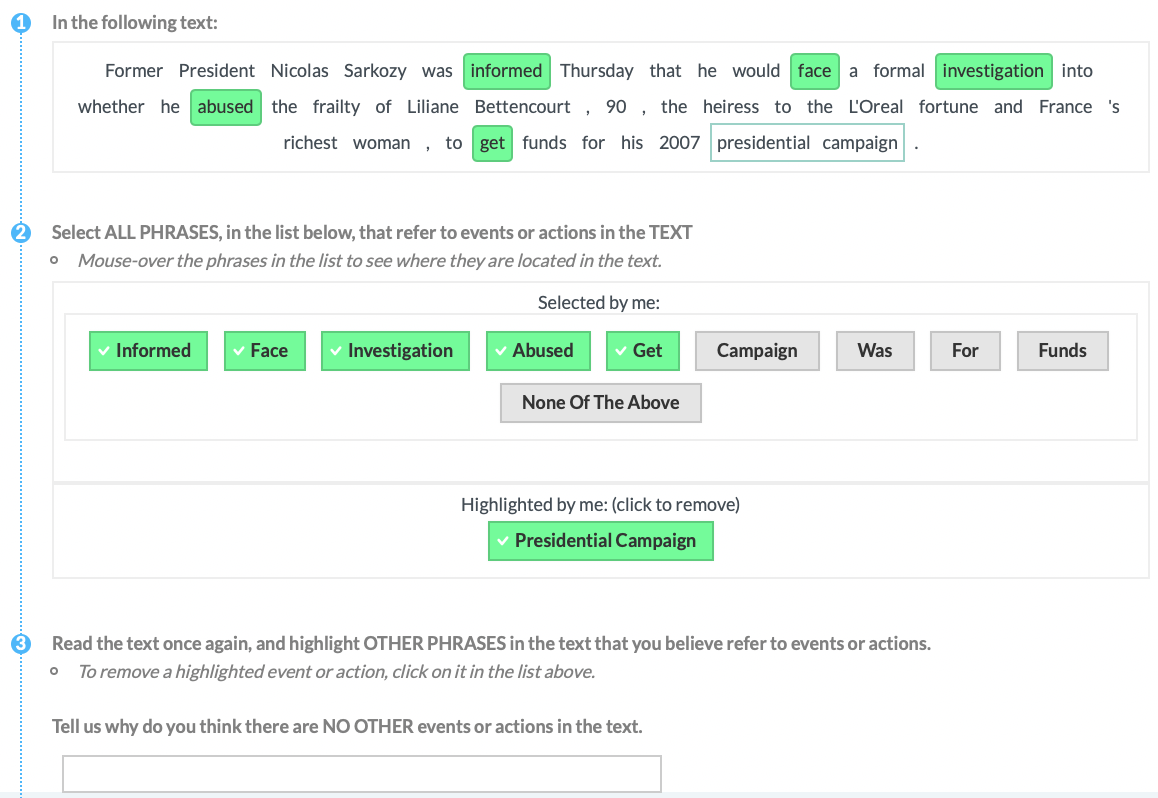 |
Experts (G&P) & Tools & Missing | Explicit Definition | Entities + Motivation (ALL) + Highlight |
| M2 | Time | 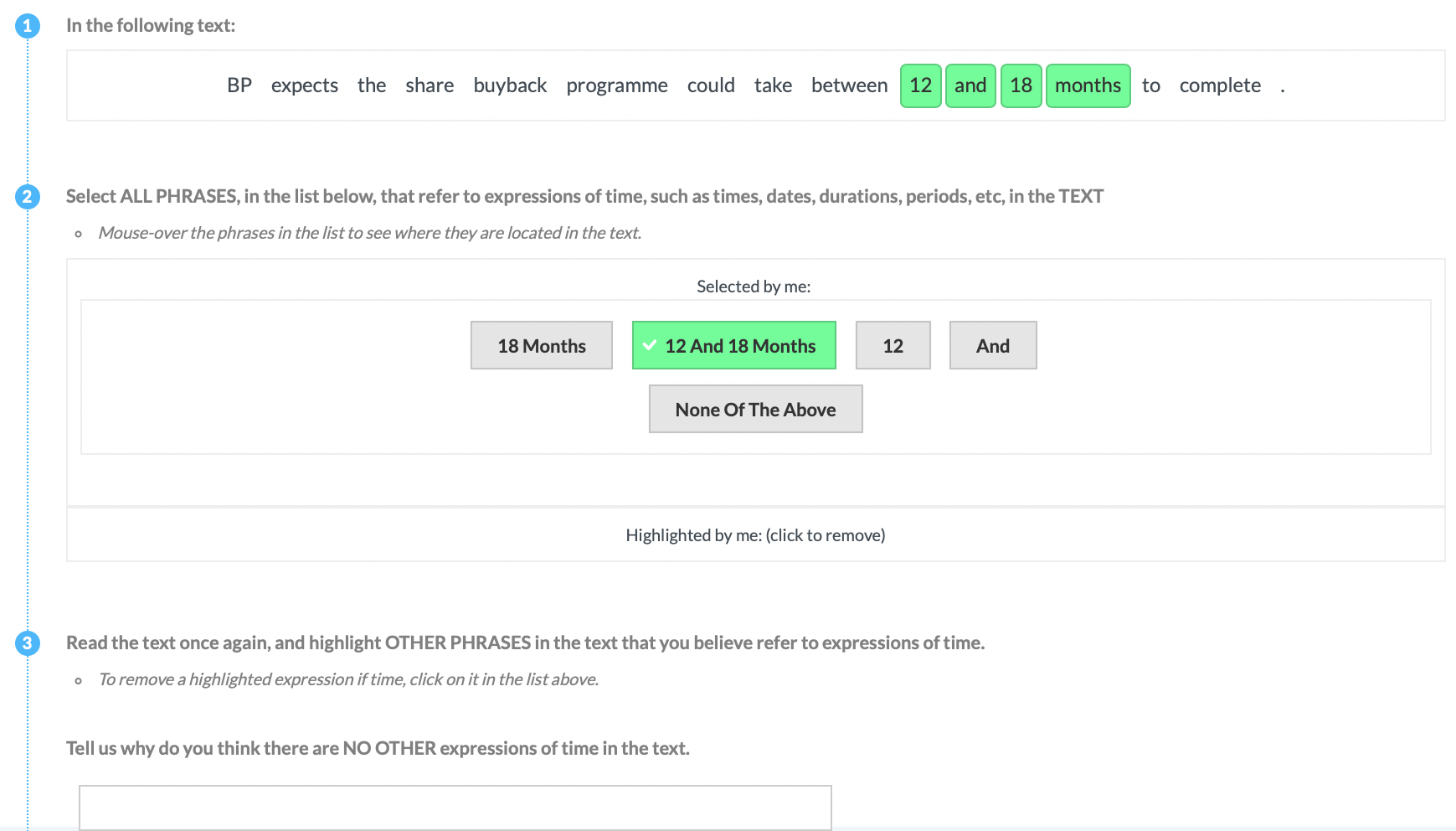 |
Experts (G&P) & Tools & Missing | Explicit Definition | Entities + Motivation (ALL) + Highlight |