English | 中文
VisionLAN: From Two to One: A New Scene Text Recognizer with Visual Language Modeling Network
Visual Language Modeling Network (VisionLAN) [1] is a text recognion model that learns the visual and linguistic information simultaneously via character-wise occluded feature maps in the training stage. This model does not require an extra language model to extract linguistic information, since the visual and linguistic information can be learned as a union.
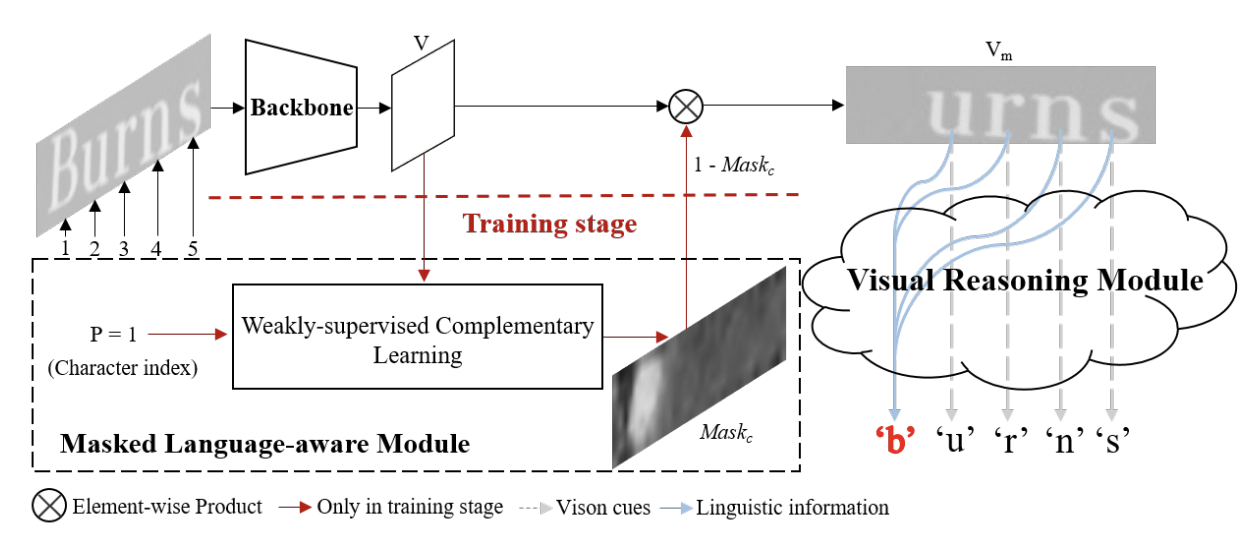
Figure 1. The architecture of visionlan [1]
As shown above, the training pipeline of VisionLAN consists of three modules:
-
The backbone extract visual feature maps from the input image;
-
The Masked Language-aware Module (MLM) takes the visual feature maps and a randomly selected character index as inputs, and generates position-aware character mask map to create character-wise occluded feature maps;
-
Finally, the Visual Reasonin Module (VRM) takes occluded feature maps as inputs and makes prediction under the complete word-level supervision.
While in the test stage, MLM is not used. Only the backbone and VRM are used for prediction.
According to our experiments, the evaluation results on ten public benchmark datasets is as follow:
| Model | Context | Backbone | Train Dataset | Model Params | Avg Accuracy | Train Time | Per Step Time | FPS | Recipe | Download |
|---|---|---|---|---|---|---|---|---|---|---|
| visionlan | D910x4-MS2.0-G | resnet45 | MJ+ST | 42.2M | 90.61% | 7718 s/epoch | 417 ms/step | 1,840 img/s | yaml(LF_1) yaml(LF_2) yaml(LA) | ckpt files | mindir(LA) |
Detailed accuracy results for ten benchmark datasets
| Model | Context | IC03_860 | IC03_867 | IC13_857 | IC13_1015 | IC15_1811 | IC15_2077 | IIIT5k_3000 | SVT | SVTP | CUTE80 | Average |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| visionlan | D910x4-MS2.0-G | 96.16% | 95.16% | 95.92% | 94.19% | 84.04% | 77.46% | 95.53% | 92.27% | 85.74% | 89.58% | 90.61% |
Notes:
- Context: Training context denoted as
{device}x{pieces}-{MS version}-{MS mode}. Mindspore mode can be eitherG(graph mode) orF(pynative mode). For example,D910x4-MS2.0-Gdenotes training on 4 pieces of 910 NPUs using graph mode based on MindSpore version 2.0.0. - Train datasets: MJ+ST stands for the combination of two synthetic datasets, SynthText(800k) and MJSynth.
- To reproduce the result on other contexts, please ensure the global batch size is the same.
- The models are trained from scratch without any pre-training. For more dataset details of training and evaluation, please refer to 3.2 Dataset preparation section.
- The input Shape of MindIR of VisionLAN is (1, 3, 64, 256).
Please refer to the installation instruction in MindOCR.
Training sets
The authors of VisionLAN used two synthetic text datasets for training: SynthText(800k) and MJSynth. Please follow the instructions of the original VisionLAN repository to download the training sets.
After download SynthText.zip and MJSynth.zip, please unzip and place them under ./datasets/train. The training set contain 14,200,701 samples in total. More details are as follows:
Validation sets
The authors of VisionLAN used six real text datasets for evaluation: IIIT5K Words (IIIT5K_3000) ICDAR 2013 (IC13_857), Street View Text (SVT), ICDAR 2015 (IC15), Street View Text-Perspective (SVTP), CUTE80 (CUTE). We used the sum of the six benchmarks as validation sets. Please follow the instructions of the original VisionLAN repository to download the validation sets.
After download evaluation.zip, please unzip this zip file, and place them under ./datasets. Under ./datasets/evaluation, there are seven folders:
- IIIT5K: 50M, 3000 samples
- IC13: 72M, 857 samples
- SVT: 2.4M, 647 samples
- IC15: 21M, 1811 samples
- SVTP: 1.8M, 645 samples
- CUTE: 8.8M, 288 samples
- Sumof6benchmarks: 155M, 7248 samples
During training, we only used the data under ./datasets/evaluation/Sumof6benchmarks as the validation sets. Users can delete the other folders ./datasets/evaluation optionally.
Test Sets
We choose ten benchmarks as the test sets to evaluate the model's performance. Users can download the test sets from here (ref: deep-text-recognition-benchmark). Only the evaluation.zip is required for testing.
After downloading the evaluation.zip, please unzip it, and rename the folder name from evaluation to test. Please place this folder under ./datasets/.
The test sets contain 12,067 samples in total. The detailed information is as follows:
- CUTE80: 8.8 MB, 288 samples
- IC03_860: 36 MB, 860 samples
- IC03_867: 4.9 MB, 867 samples
- IC13_857: 72 MB, 857 samples
- IC13_1015: 77 MB, 1015 samples
- IC15_1811: 21 MB, 1811 samples
- IC15_2077: 25 MB, 2077 samples
- IIIT5k_3000: 50 MB, 3000 samples
- SVT: 2.4 MB, 647 samples
- SVTP: 1.8 MB, 645 samples
In the end of preparation, the file structure should be like:
datasets
├── test
│ ├── CUTE80
│ ├── IC03_860
│ ├── IC03_867
│ ├── IC13_857
│ ├── IC13_1015
│ ├── IC15_1811
│ ├── IC15_2077
│ ├── IIIT5k_3000
│ ├── SVT
│ ├── SVTP
├── evaluation
│ ├── Sumof6benchmarks
│ ├── ...
└── train
├── MJSynth
└── SynText
If the datasets are placed under ./datasets, there is no need to change the train.dataset.dataset_root in the yaml configuration file configs/rec/visionlan/visionlan_L*.yaml.
Otherwise, change the following fields accordingly:
...
train:
dataset_sink_mode: False
dataset:
type: LMDBDataset
dataset_root: dir/to/dataset <--- Update
data_dir: train <--- Update
...
eval:
dataset_sink_mode: False
dataset:
type: LMDBDataset
dataset_root: dir/to/dataset <--- Update
data_dir: evaluation/Sumof6benchmarks <--- Update
...Optionally, change
train.loader.num_workersaccording to the cores of CPU.
Apart from the dataset setting, please also check the following important args: system.distribute, system.val_while_train, common.batch_size. Explanations of these important args:
system:
distribute: True # `True` for distributed training, `False` for standalone training
amp_level: 'O0'
seed: 42
val_while_train: True # Validate while training
common:
...
batch_size: &batch_size 192 # Batch size for training
...
loader:
shuffle: False
batch_size: 64 # Batch size for validation/evaluation
...Notes:
- As the global batch size (batch_size x num_devices) is important for reproducing the result, please adjust
batch_sizeaccordingly to keep the global batch size unchanged for a different number of GPUs/NPUs, or adjust the learning rate linearly to a new global batch size.
The training stages include Language-free (LF) and Language-aware (LA) process, and in total three steps for training:
LF_1: train backbone and VRM, without training MLM
LF_2: train MLM and finetune backbone and VRM
LA: using the mask generated by MLM to occlude feature maps, train backbone, MLM, and VRM
We used distributed training for the three steps. For standalone training, please refer to the recognition tutorial.
mpirun --allow-run-as-root -n 4 python tools/train.py --config configs/rec/visionlan/visionlan_resnet45_LF_1.yaml
mpirun --allow-run-as-root -n 4 python tools/train.py --config configs/rec/visionlan/visionlan_resnet45_LF_2.yaml
mpirun --allow-run-as-root -n 4 python tools/train.py --config configs/rec/visionlan/visionlan_resnet45_LA.yamlThe training result (including checkpoints, per-epoch performance and curves) will be saved in the directory parsed by the arg ckpt_save_dir in yaml config file. The default directory is ./tmp_visionlan.
After all three steps training, change the system.distribute to False in configs/rec/visionlan/visionlan_resnet45_LA.yaml before testing.
To evaluate the model's accuracy, users can choose from two options:
- Option 1: Repeat the evaluation step for all individual datasets: CUTE80, IC03_860, IC03_867, IC13_857, IC131015, IC15_1811, IC15_2077, IIIT5k_3000, SVT, SVTP. Then take the average score.
An example of evaluation script fort the CUTE80 dataset is shown below.
model_name="e8"
yaml_file="configs/rec/visionlan/visionlan_resnet45_LA.yaml"
training_step="LA"
python tools/eval.py --config $yaml_file --opt eval.dataset.data_dir=test/CUTE80 eval.ckpt_load_path="./tmp_visionlan/${training_step}/${model_name}.ckpt"
- Option 2: Given that all the benchmark datasets folder are under the same directory, e.g.
test/. And use the scripttools/benchmarking/multi_dataset_eval.py. The example evaluation script is like:
model_name="e8"
yaml_file="configs/rec/visionlan/visionlan_resnet45_LA.yaml"
training_step="LA"
python tools/benchmarking/multi_dataset_eval.py --config $yaml_file --opt eval.dataset.data_dir="test" eval.ckpt_load_path="./tmp_visionlan/${training_step}/${model_name}.ckpt"Please download the MINDIR file from the table above, or you can use tools/export.py to manually convert any checkpoint file into a MINDIR file:
# For more parameter usage details, please execute `python tools/export.py -h`
python tools/export.py --model_name_or_config visionlan_resnet45 --data_shape 64 256 --local_ckpt_path /path/to/visionlan-ckptThis command will save a visionlan_resnet45.mindir under the current working directory.
Learn more about Model Export.
If you haven't downloaded MindSpore Lite, please download it via this link. More details on how to use MindSpore Lite in Linux Environment refer to this document.
converter_lite tool is an executable program under mindspore-lite-{version}-linux-x64/tools/converter/converter. Using converter_lite, we can convert the MindIR file to MindSpore Lite MindIR file.
Run the following command:
converter_lite \
--saveType=MINDIR \
--fmk=MINDIR \
--optimize=ascend_oriented \
--modelFile=path/to/mindir/file \
--outputFile=visionlan_resnet45_liteRunning this command will save a visionlan_resnet45_lite.mindir under the current working directory. This is the MindSpore Lite MindIR file that we can run inference with on the Ascend310 or 310P platform. You can also define a different file name by changing the --outputFile argument.
Learn more about Model Conversion.
Taking SVT test set as an example, the data structure under the dataset folder is:
svt_dataset
├── test
│ ├── 16_16_0_ORPHEUM.jpg
│ ├── 12_13_4_STREET.jpg
│ ├── 17_08_TOWN.jpg
│ ├── ...
└── test_gt.txt
We run inference with the visionlan_resnet45_lite.mindir file with the command below:
python deploy/py_infer/infer.py \
--input_images_dir=/path/to/svt_dataset/test \
--rec_model_path=/path/to/visionlan_resnet45_lite.mindir \
--rec_model_name_or_config=configs/rec/visionlan/visionlan_resnet45_LA.yaml \
--res_save_dir=rec_svtRunning this command will create a folder rec_svt under the current working directory, and save a prediction file rec_svt/rec_results.txt. Some examples of prediction in this file are shown below:
16_16_0_ORPHEUM.jpg "orpheum"
12_13_4_STREET.jpg "street"
17_08_TOWN.jpg "town"
...
Then, we can compute the prediction accuracy using:
python deploy/eval_utils/eval_rec.py \
--pred_path=rec_svt/rec_results.txt \
--gt_path=/path/to/svt_dataset/test_gt.txtThe evaluation results are shown below:
{'acc': 0.9227202534675598, 'norm_edit_distance': 0.9720136523246765}
[1] Yuxin Wang, Hongtao Xie, Shancheng Fang, Jing Wang, Shenggao Zhu, Yongdong Zhang: From Two to One: A New Scene Text Recognizer with Visual Language Modeling Network. ICCV 2021: 14174-14183