
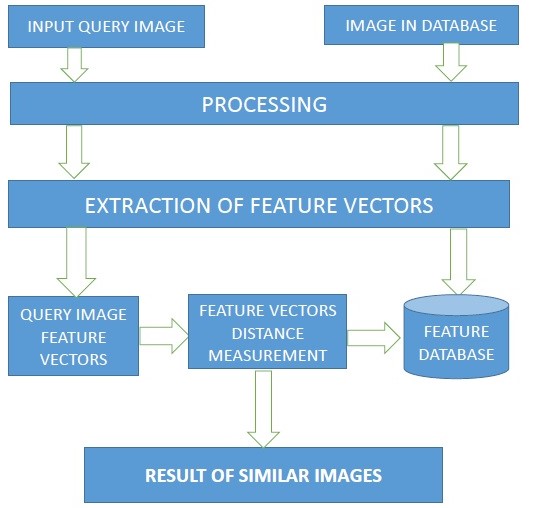
This is a Content Based Image Retrieval System(CBIR) where the program takes some input images and extracts the image feature vectors and stores them. When another image is given as a query image to the program it searches for all similar images that are given as input
“A picture is worth a thousand words”. A picture provides a lot of information that a human may not always be able to perceive all the very minute details that the image contains. Feature extraction is the process of obtaining the most relevant information from the original image and represent it in a reduced set of features like texture, shape in a way the user can easily interact with. The main objective is to design an interface that offers an intuitive way of interaction for the user to use the data of the image for various applications. Feature extraction and representing the analyzed and interpreted data is a very challenging task hence various innovative and effective algorithms should be used to process and collect the image data. Applications of feature extraction from images are limitless. The user can edit the various components of the image to his needs like patching an overexposed image. Since users usually work with a huge number of images, this data can be used in the classification and recognition of images. This can be very much useful to the user as he can remove obsolete images that are similar to save storage and for better organization of data. Holds significant applications in security systems as it is the basis in biometric systems.
The huge collection of digital images is collected due to the improvement in the digital storage media, image capturing devices like scanners, web cameras, digital cameras and rapid development in internet. Due to these reasons there is a need of an efficient and effective retrieval system to retrieve these images for visual information. Image retrieval is achieved through low level features that are extracted from the images by the algorithm and then these features are represented in a form called feature vector. These feature vectors are calculated statistical values like standard deviation. These feature vectors of all images are stored in a database. Similarity is measured to rank the images by calculating the distance between the query image feature vector and feature vectors of database images. The algorithm is such that it describes the contents of image in the form of certain features which will be represented to get a vector of these features. The aim and objective of the feature vector is to select those images that will give more accuracy in result.
- Receive input query image from user to be retrieved from image database.
- Extraction of raw RGB data from input image.
- Convert this greyscale image into histogram data.
- Extraction of feature vectors from this histogram data.
- Distance measurement between query vector and database vectors for similarity.
- Result of similar images.
PROS
- Images can be retrieved based on color, contrast and brightness of images.
- This algorithm is very efficient.
- It is very good retrieval accuracy.
- Sensitive to contrast and brightness of images.
- Retrieval time is very less and doesn’t increases exponentially with dimensions of image but remains almost the same.
- Time taken can be even more optimized by adjusting the number of bins in the histogram.
- Consumes very less memory space.
- Retrieved images can be ranked based on their similarity with query image.
- Can handle image retrieval in large image databases.
CONS
- Sometimes different images can have the same histogram. Example: Grey pixels concentrated in an image produces a similar histogram to a image in the same number grey pixels are distributed randomly.
- Similarity measurement and image retrieval perform two times, so it increases calculations and overhead.
- Feature vector sets sometimes might be insufficient.
- The format of images used are
BMP imagesand this program doesn't function for other image formats. - Images should be natively stored in the
C Drive for Windowsand for images in other directories ,Pathshould be explicitly mentioned. - Only the image name can be given as input since the image extension
.bmpwill concatenated automatically