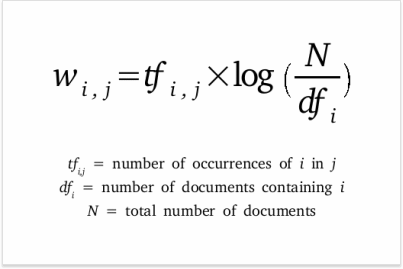- Machine learning algorithms usually deal with numbers, and natural language is, well, text. So we need to transform that text into numbers, otherwise known as text vectorization.
- Text Vectorization is the process of converting text into numerical representation. Here is some popular methods to accomplish text vectorization:
- Binary Term Frequency
- Bag of Words (BoW) Term FrequencY
- Normalized TF-IDF
- Word2Vec
- Different vectorization algorithms will affect end results in a different way, so we need to choose one that will deliver the results we’re hoping for.
- Once we’ve transformed words into numbers, in a way that’s machine learning algorithms can understand, the TF-IDF score can be fed to algorithms such as Naive Bayes and Support Vector Machines.
- TF-IDF enables us to gives us a way to associate each word in a document with a number that represents how relevant each word is in that document. Then, documents with similar, relevant words will have similar vectors, which is what we are looking for in a machine learning algorithm.
- TF-IDF is a statistical measure that evaluates how relevant a word is to a document in a collection of documents. This is done by multiplying two metrics:
-
TERM FREQUENCY(TF), which measures how frequently a term occurs in a document. Since every document is different in length, it is possible that a term would appear much more times in long documents than shorter ones. Thus, the term frequency is often divided by the document length (the total number of terms in the document) as a way of normalization:
- TF(w,d) = (Number of times word d appears in a document) / (Total number of words in the document).
-
IDF: Inverse Document Frequency, which measures how important a term is. While computing TF, all terms are considered equally important. However it is known that certain terms, such as "is", "of", and "that", may appear a lot of times but have little importance. Thus we need to weigh down the frequent terms while scale up the rare ones, by computing the following:
- IDF(w) = log_e(Total number of documents / Number of documents with word w in it).
-
- Formula for calculating TF-IDF: