English | 中文
由于部分无良商家销售WebUI,捆绑本插件做卖点收取智商税,本仓库的许可证已修改为 CC BY-NC-SA,任何人都可以自由获取、使用、修改、以相同协议重分发本插件。
自许可证修改之日(AOE 2023.3.28)起,之后的版本禁止用于商业贩售 (不可贩售本仓库代码,但衍生的艺术创作内容物不受此限制)。
如果你喜欢这个项目,请给作者一个 star!⭐

本插件通过以下三种技术实现了 在有限的显存中进行大型图像绘制:
- 两种 SOTA diffusion tiling 算法:Mixture of Diffusers 和 MultiDiffusion
- 原创的 Tiled VAE 算法。
- 原创混合放大算法生成超高清图像
=> 快速入门教程: Tutorial for multidiffusion upscaler for automatic1111, 感谢由 @PotatoBananaApple 提供 🎉
高质量图像放大,产生清晰且整洁的细节。
- 本插件的 Tiled Noise Inversion 功能可以与 ControlNet v1.1 Tile模型 (简称 CN Tile) 协同工作,产出细节合适的高质量大图。示例
- 高重绘幅度下(>= 0.4)CN Tile 倾向于产生过多的细节,使图像看起来脏乱。
- MultiDiffusion Noise Inversion 倾向于产生整洁但过度磨皮的图像,缺乏足够的细节。
- 然而把这两个功能结合,就能同时消除两者的缺陷
- 能产生整洁清晰的线条、边缘和颜色
- 能产生适当和合理的细节,不显得怪异或凌乱
- 推荐的设置:
- 重绘幅度 >= 0.75,采样步数25步
- Method = Mixture of Diffusers,overlap = 8
- Noise Inversion Steps >= 30
- Renoise strength = 0
- CN Tile 预处理器 = tile_resample,下采样率 = 2
- 如果您的结果模糊:
- 尝试增加 Noise Inversion Steps
- 尝试降低重绘幅度
- 尝试换一个模型
- 与纯 CN Tile 对比,画面更加整洁:
- 高重绘幅度下画面颜色会变,这是CN Tile的已知bug,我们无法修复
适用于不想改变作画结构的 Img2Img
- 超高分辨率高质量图像放大,8k图仅需12G显存
- 尤其适用于人像放大,当你不想大幅改变人脸时
- 4x放大效果,去噪强度0.4:对比图1,对比图2
- 对比Ultimate SD Upscale, 这一的算法更加忠实于原图,且产生更少的奇怪结果。与Ultimate SD Upscale(实测最佳去噪强度0.3),对比如下 对比图1,对比图2
⚠ 请不要一上来就放的非常大,建议先在小图上用1.5x测试。通常需要denoise小于0.6,CFG敏感度不大,可自行尝试。
极大降低 VAE 编解码大图所需的显存开销
- 几乎无成本的降低显存使用。
- 您可能不再需要 --lowvram 或 --medvram。
- 以 highres.fix 为例,如果您之前只能进行 1.5 倍的放大,则现在可以使用 2.0 倍的放大。
- 通常您可以使用默认设置而无需更改它们。
- 但是如果您看到 CUDA 内存不足错误,请相对降低两项 tile 大小。
通过融合多个区域进行大型图像绘制。
⚠ 我们建议您使用自定义区域来填充整个画布。
-
参数:
- 模型:Anything V4.5, 高度 = 1920, 宽度 = 1280 (未使用highres.fix), 方法(Method) = Mixture of Diffusers
- 全局提示语:masterpiece, best quality, highres, extremely clear 8k wallpaper, white room, sunlight
- 全局负面提示语:ng_deepnegative_v1_75t EasyNegative
- ** 块大小(tile size)参数将不起效,可以忽略它们。**
-
区域:
- 区域 1:提示语 = sofa,类型 = Background
- 区域 2:提示语 = 1girl, gray skirt, (white sweater), (slim) waist, medium breast, long hair, black hair, looking at viewer, sitting on sofa,类型 = Foreground,羽化 = 0.2
- 区域 3:提示语 = 1girl, red silky dress, (black hair), (slim) waist, large breast, short hair, laughing, looking at viewer, sitting on sofa,类型 = Foreground,羽化 = 0.2
-
区域布局:

-
结果 (4张中的2张)





ℹ 通常情况下,以高分辨率绘制全身人物会比较困难(例如可能会将两个身体连接在一起)。 ℹ 通过将你的角色置入背景中,可以轻松的做到这一点。
-
参数:
- 模型:Anything V4.5,宽度 = 1280,高度 = 1600 (未使用highres.fix),方法(Method) = MultiDiffusion
- 全局提示语:masterpiece, best quality, highres, extremely clear 8k wallpaper, beach, sea, forest
- 全局负面提示语:ng_deepnegative_v1_75t EasyNegative
-
区域:
- 区域 1:提示语 = 1girl, black bikini, (white hair), (slim) waist, giant breast, long hair,类型(Type) = Foreground,羽化(Feather) = 0.2
- 区域 2:提示语 = (空),类型(Type) = Background
-
区域布局:

-
结果: NVIDIA V100 使用 4729 MB 显存用了 32 秒生成完毕。我很幸运的一次就得到了这个结果,没有进行任何挑选。

-
也适用于 2.5D 人物。例如,1024 * 1620像素的图像生成
-
特别感谢 @辰熙 的所有设置。点击此处查看更多她的作品:https://space.bilibili.com/179819685
-
从20次生成结果中精选而出。



利用 Tiled Diffusion 来放大或重绘图像
-
参数:
- 降噪 = 0.4,步数 = 20,采样器 = Euler a,放大器 = RealESRGAN++,负面提示语=EasyNegative,
- 模型:Gf-style2 (4GB 版本), 提示词相关性(CFG Scale) = 14, Clip 跳过层(Clip Skip) = 2
- 方法(Method) = MultiDiffusion, 分块批处理规模(tile batch size) = 8, 分块高度(tile size height) = 96, 分块宽度(tile size width) = 96, 分块重叠(overlap) = 32
- 全局提示语 = masterpiece, best quality, highres, extremely detailed 8k wallpaper, very clear, 全局负面提示语 = EasyNegative.
-
放大前

-
4倍放大后:无精选,在 NVIDIA Tesla V100 上使用1分12秒生成完毕(如果只放大2倍,10秒即可生成完毕)



ℹ 请在页面顶部使用简单的正面提示语,因为它们将应用于每个区域。 ℹ 如果要将对象添加到特定位置,请使用区域提示控制并启用绘制完整的画布背景

- 22020 x 1080 超宽图像转绘


- ControlNet (canny edge)


⚪ 方法 1: 官方市场
- 打开Automatic1111 WebUI -> 点击“扩展”选项卡 -> 点击“可用”选项卡 -> 找到“[MultiDiffusion 放大器(TiledDiffusion with Tiled VAE)]” -> 点击“安装”
⚪ 方法 2: URL 安装
- 打开Automatic1111 WebUI -> 点击“扩展”选项卡 -> 点击“从网址安装”选项卡 -> 输入 https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111.git -> 点击“安装”
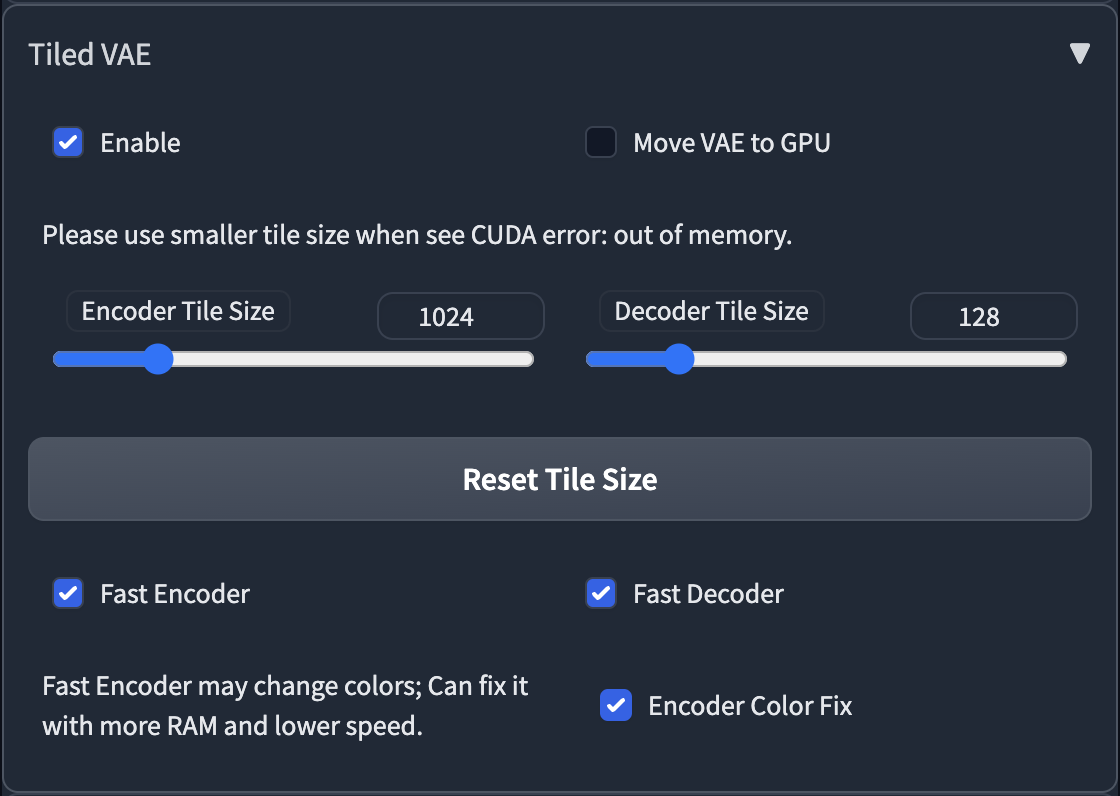
- 在第一次使用时,脚本会为您推荐设置。
- 因此,通常情况下,您不需要更改默认参数。
- 只有在以下情况下才需要更改参数:
- 当生成之前或之后看到CUDA内存不足错误时,请降低 tile 大小
- 当您使用的 tile 太小且图片变得灰暗和不清晰时,请启用编码器颜色修复。

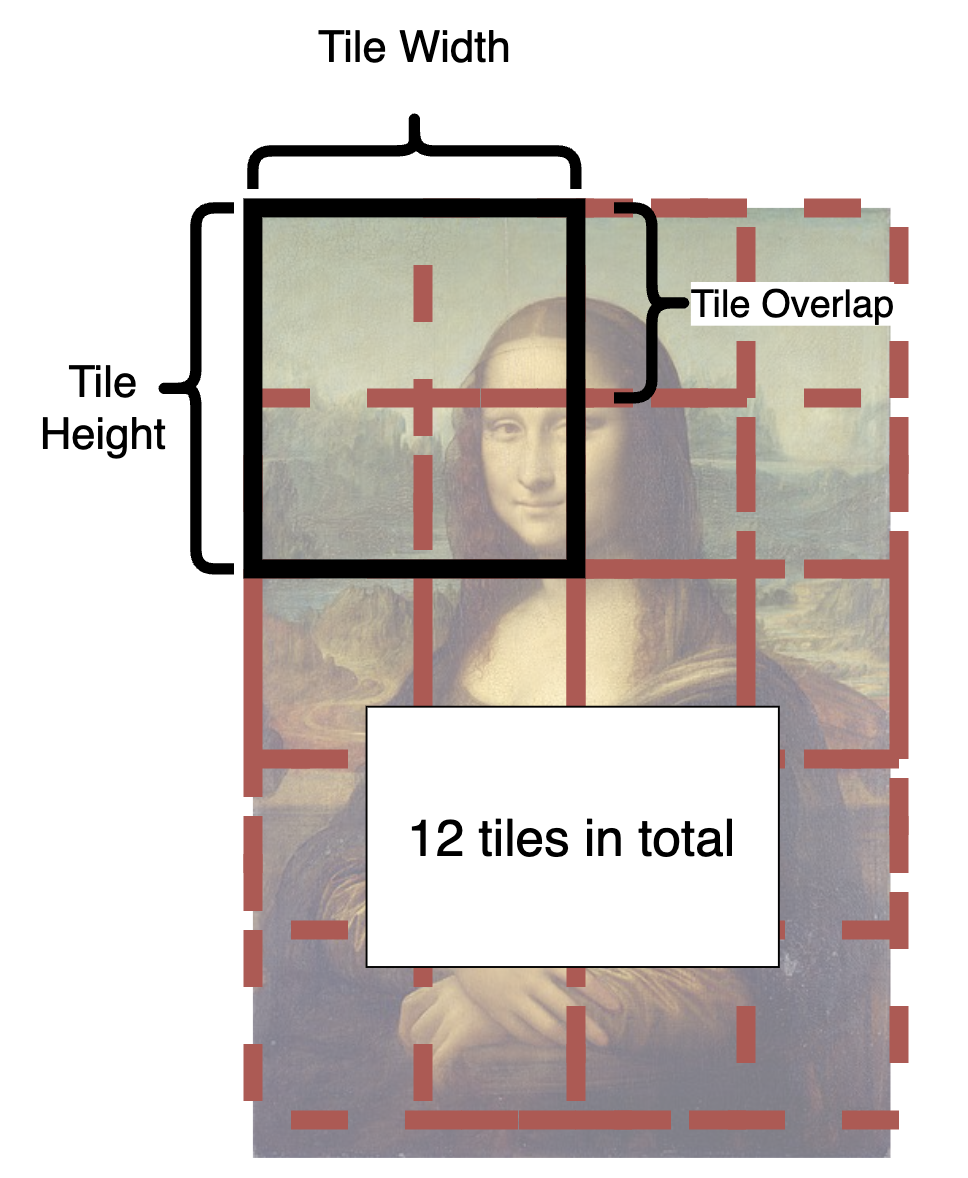
- 从图中可以看到如何将图像分割成块。
- 在每个步骤中,潜在空间中的每个小块都将被发送到 Stable Diffusion UNet。
- 小块一遍遍地分割和融合,直到完成所有步骤。
- 块要多大才合适?
- 较大的块大小将提升处理速度,因为小块数量会较少。
- 然而,最佳大小取决于您的模型。SD1.4仅适用于绘制512 * 512图像(SD2.1是768 * 768)。由于大多数模型无法生成大于1280 * 1280的好图片。因此,在潜在空间中将其除以8后,你将得到64-160。
- 因此,您应该选择64-160之间的值。
- 个人建议选择96或128以获得更快的速度。
- 重叠要多大才合适?
- 重叠减少了融合中的接缝。显然,较大的重叠值意味着更少接缝,但会显著降低速度,因为需要重新绘制更多的小块。
- 与 MultiDiffusion 相比,Mixture of Diffusers 需要较少的重叠,因为它使用高斯平滑(因此可以更快)。
- 个人建议使用 MultiDiffusion 时选择32或48,使用 Mixture of Diffusers 选择16或32
- 放大算法(Upscaler) 选项将在图生图(img2img)模式中可用,你可选用一个合适的前置放大器。
ℹ 通常情况下,所有小块共享相同的主提示语。因此,您不能使用主提示语绘制有意义的对象,它会在整个图像上绘制您的对象并破坏您的图像。 ℹ 为了处理这个问题,我们提供了强大的区域提示语控制工具。
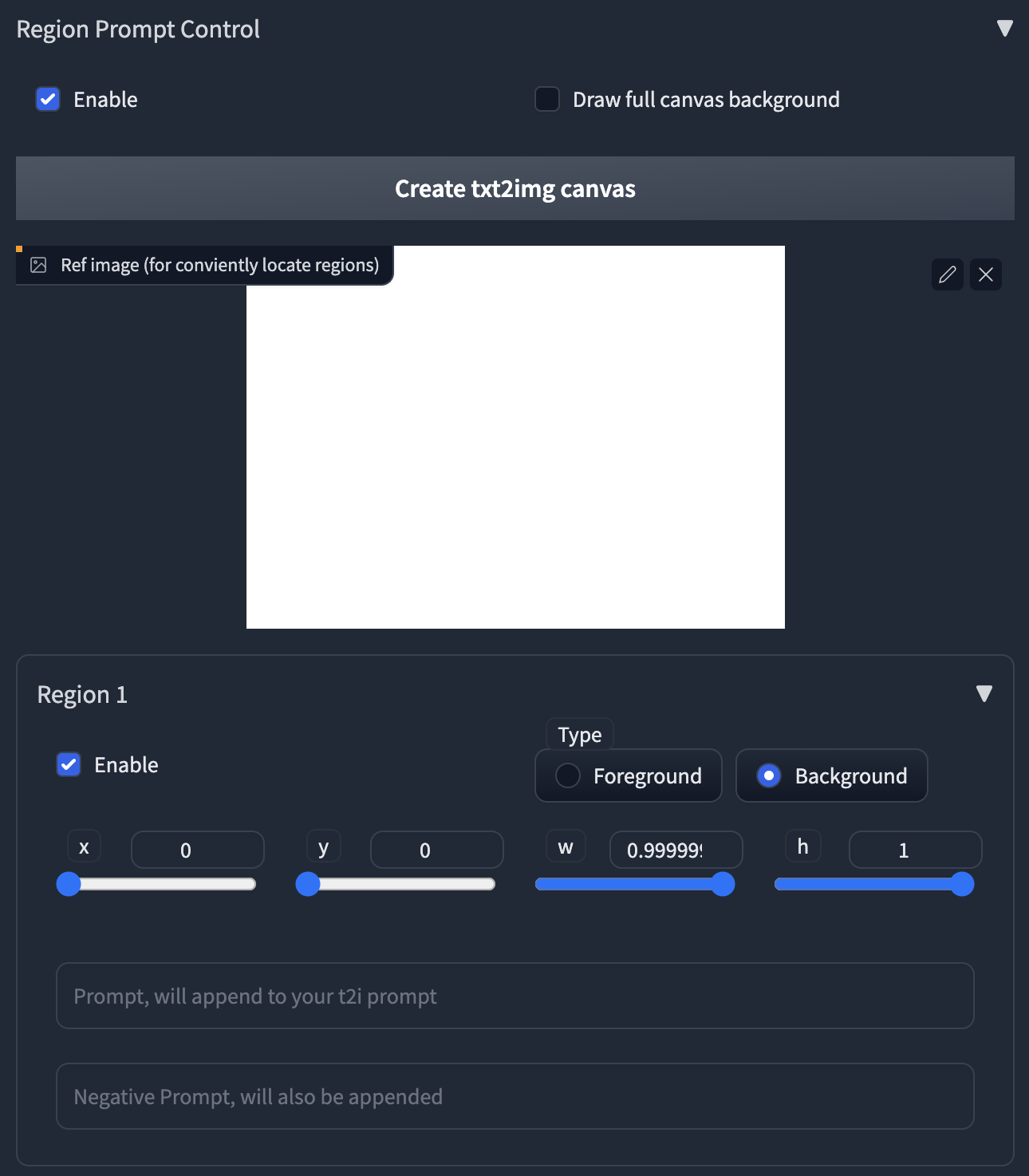
- 首先,启用区域提示语控制。
- 注意:启用区域控制时,默认的小块分割功能将被禁用。
- 如果您的自定义区域不能填满整个画布,它将在这些未覆盖的区域中产生棕色(MultiDiffusion)或噪声(Mixture of Diffusers)。
- 我们建议您使用自己的区域来填充整个画布,因为在生成时速度可能会更快。
- 如果您懒得绘制,您也可以启用绘制完整的画布背景。但是,这将显著降低生成速度。
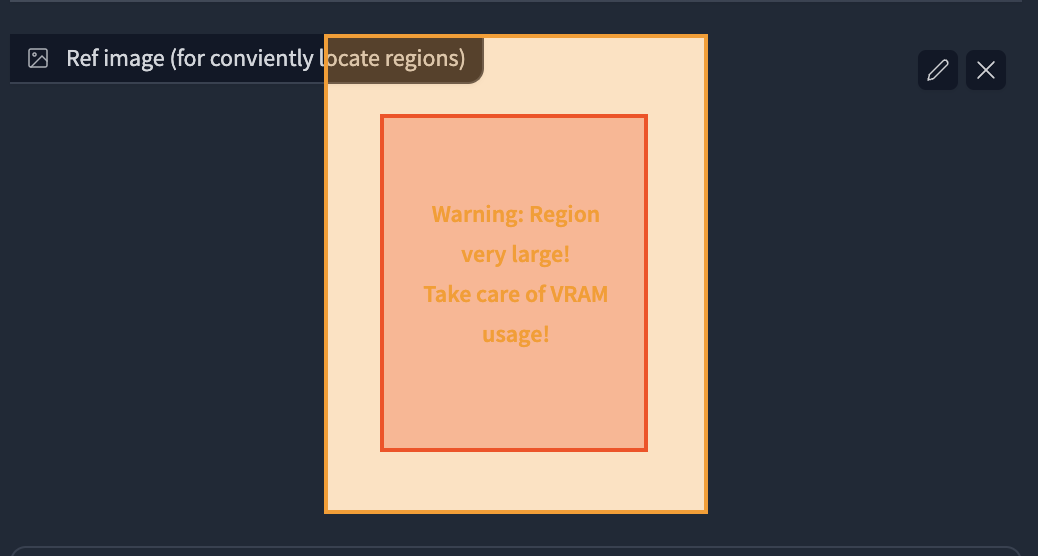
- 上传一张图片,或点击按钮创建空白图像作为参考。
- 点击区域1的启用,您将在图像中看到一个红色的矩形。
- 在区域中点击并拖动鼠标以移动和调整区域大小。
- 选择区域类型。如果您想绘制对象,请选择前景。否则选择背景。
- 如果选择前景,则会出现羽化。
- 较大的值将为您提供更平滑的边缘。
- 输入区域的提示语和负面提示语。
- 注意:您的提示将附加到页面顶部的主提示语中。
- 您可以利用此功能来节省你的词条,例如在页面顶部使用使用常见的提示语(如“masterpiece, best quality, highres...”)并使用“EasyNegative”之类的 embedding 。
- 您也可以在提示语中使用 Textual Inversion 和 LoRA
- 提高分辨率的推荐参数
- 采样器(Sampler) = Euler a,步数(steps) = 20,去噪强度(denoise) = 0.35,方法(method) = Mixture of Diffusers,潜变量块高和宽(Latent tile height & width) = 128,重叠(overlap) = 16,分块批处理规模(tile batch size)= 8(如果 CUDA 内存不足,请减小块批量大小)。
- 支持蒙版局部重绘(mask inpaint)
- 如果你想保留某些部分,或者 Tiled Diffusion 给出的结果很奇怪,只需对这些区域进行蒙版。
- 所用的模型很重要
- MultiDiffusion 与 highres.fix 的工作方式非常相似,因此结果非常取决于你所用的模型。
- 一个能够绘制细节的模型可以为你的图像添加惊人的细节。
- 使用完整的模型而不是剪枝版(pruned)模型可以产生更好的结果。
- 不要在主提示语中包含任何具体对象,否则结果会很糟糕。
- 只需使用像“highres, masterpiece, best quality, ultra-detailed 8k wallpaper, extremely clear”之类的词语。
- 如果你喜欢,可以使用区域提示语控制来控制具体对象。
- 不需要使用太大的块大小、过多的重叠和过多的降噪步骤,否则速度会非常慢。
- 提示词相关性(CFG scale)可以显著影响细节
- 较大的提示词相关性(例如 14)可以提供更多的细节。
- 你可以通过0.1 - 0.6 的降噪强度来控制你想要多大程度地改变原始图像.
- 如果你的结果仍然不如我的满意,可以在这里查看我们的讨论。
This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.

{kind=link}
{kind=link}
感谢阅读!