Pytorch Framework learning for deeplearning
- 参考 CNN
- CNN_MINST.ipynb: 使用 torch.nn.RNN 做手写数字书识别
- 其中使用的是
./dataset/MINST文件夹的names_test.csv.gz和names_train.csv.gz数据集
- 其中使用的是
-
需要理解输入维度和隐层维度:
# RNN需要指明输入大小、隐层大小以及层数(默认为1) cell = torch.nn.RNN(input_size, hidden_size, num_layers) # input: (seq_len, batch_size, input_size) 所有时间点的第一层状态 # hidden: (num_layers, batch_size, hidden_size) 第一个时刻所有层的状态 # out: (seq_len, batch_size, hidden_size) 所有时间点的最后一层状态 # hidden: (num_layers, batch_size, hidden_size) 最后时刻的所以层状态 out, hidden = cell(inputs, hidden)
-
自然语言的输入处理需要学会word embedding
-
另外可以参考 RNN
RNNcell.ipynb: 学习使用 torch.nn.RNNcell, 用于hello --> ohlol
- 其实也是一个分类问题
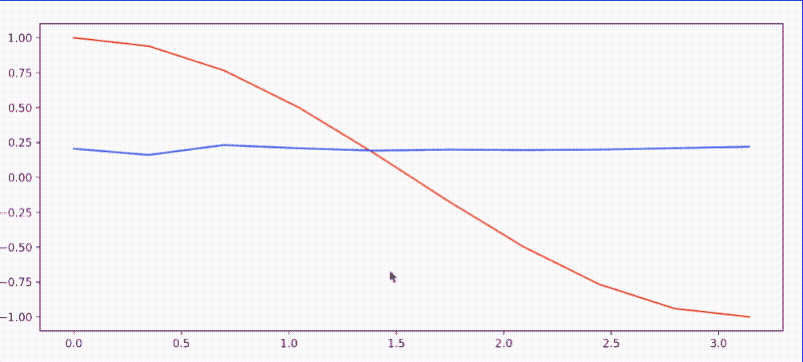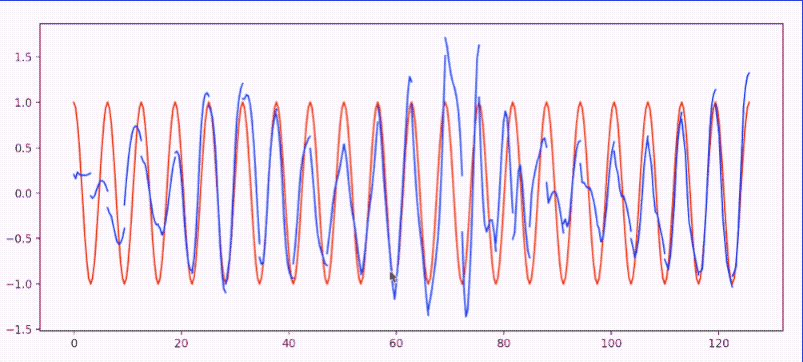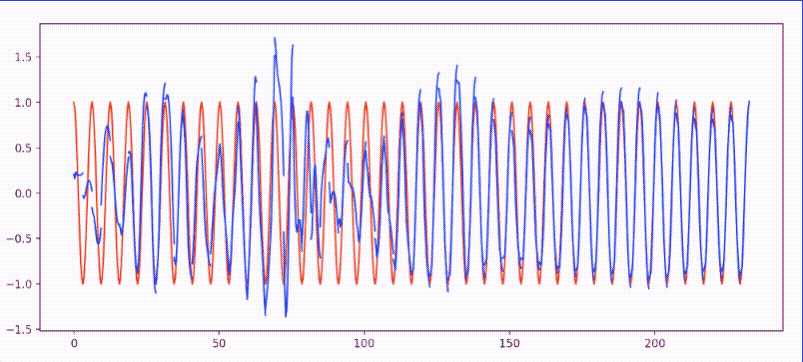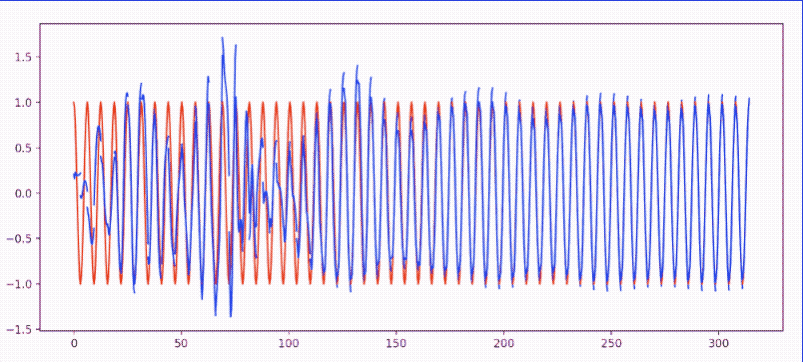
- RNN_Regression.py: 使用 torch.nn.RNN 模拟
sin(x)逼近cos(x)- 效果图:
- GRU_Classifier.ipynb: 使用 torch.nn.RNN 训练名字到国家的分类,即输入名字输出其属于哪个国家的
- 其中使用的数据集在
./dataset文件夹中 - 对应的Python脚本文件可以参考: GRU_Classifier.py
- 其中使用的数据集在
- LSTM_Regression.py: 使用 torch.nn.LSTM 模拟
sin(x)逼近cos(x)- 效果图:
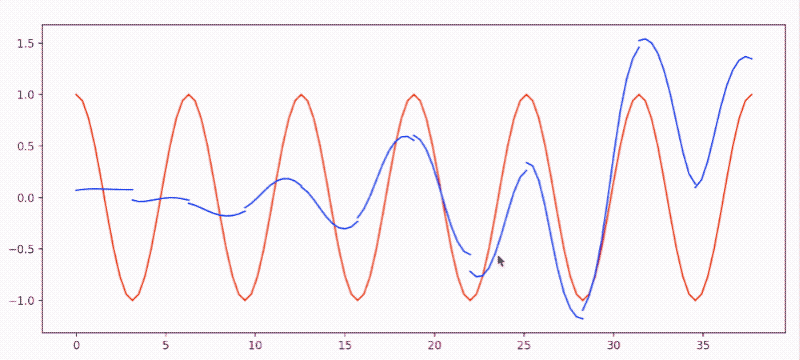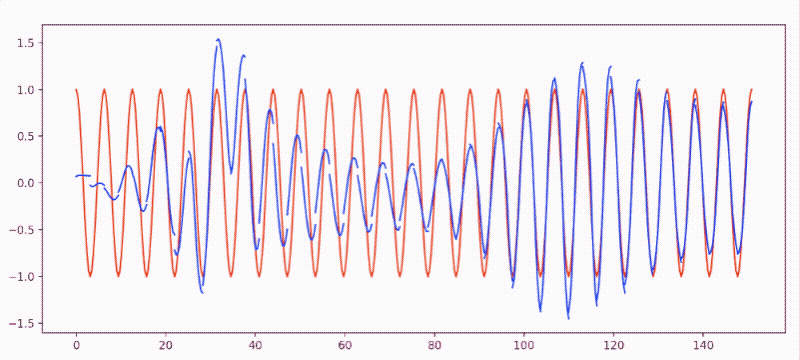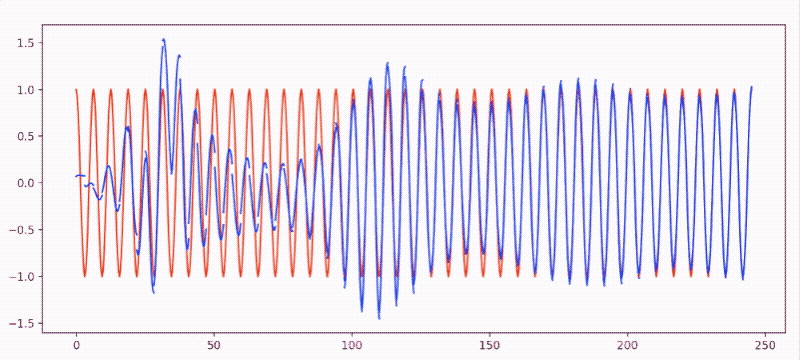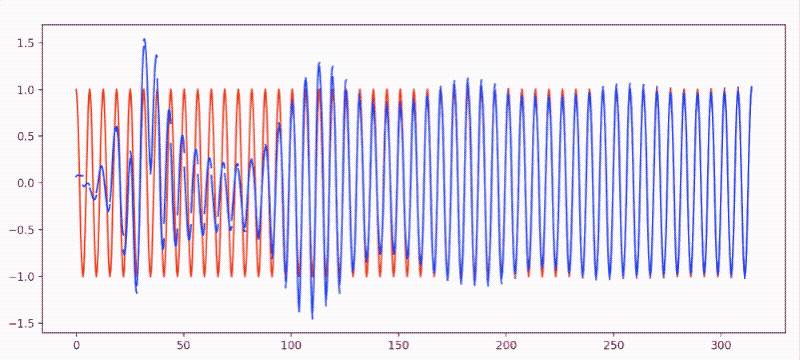
-
LSTM_airplane_forcast.ipynb: 根据前9年的数据预测后3年的客流, 这个为了训练过程简单使用的数据是:
./dataset/airplane_data.csv,只有144条数据,所以训练效果不是那么好,只是为了简单理解LSTM做回归分析的方法- 这个例子好像是有点问题的:根据简书的评论
- Data leakage的问题:数据的预处理放在了数据集分割之前,测试集的信息泄露给了训练集
- 下面讨论最多的input_size和seq_len的问题:若本例目的是"以t-2,t-1的数据预测t的数据"的话 根据Pytorch的DOC定义“input of shape (seq_len, batch, input_size)” 而本例的输入维度从这可以看出来了train_X = train_X.reshape(-1, 1, 2) 说明input_size=2 batch=1 seq_len=?(我没算),不过这似大概没能用到LSTM的特性,或者说没法用"以t-2,t-1的数据预测t的数据"来解释本结构的目的。 我比较同意上面讨论的人的看法,即特征数(input_size)为1,seq_len为2,应该是比较合理的
一般来说CNN可以提取图片的空间特征,LSTM可以提取时间特征,如果有时间序列的图片场景,我们可以使用 Convolutional LSTM (ConvLSTM) 提取时空特征(Spatio-temporal features),该网络由香港科技大学的 Shi Xingjian 等人提出,具体的论文可以参考:Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting
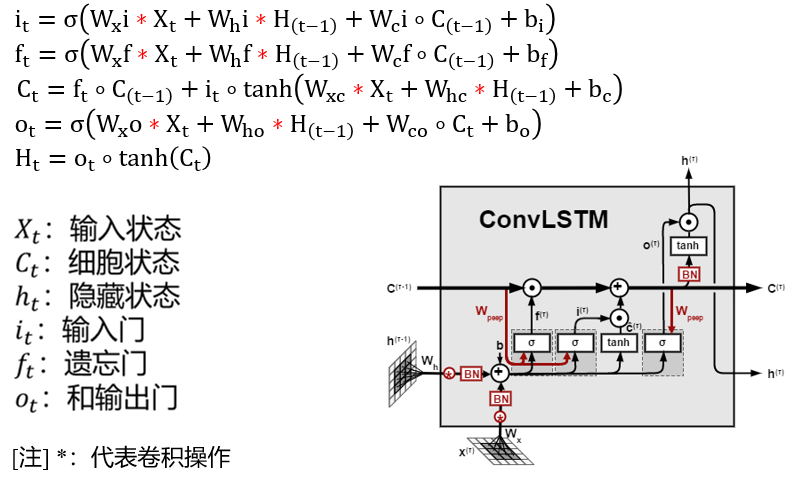
代码参考:ConvLSTM.py,其中主要有四个类:
ConvLSTMCell是卷积LSTM的细胞单元:通过卷积操作计算之后返回LSTM中隐层状态和细胞状态;ConvLSTM是实现卷积LSTM提取时空特征的一个模型:输入格式为$(B, T, C, H, W)$ 或者$(T, B, C, H, W)$ ,B是batchSize,T是timeLength或seqLen,CHW分别是图片的channel、height和widthoutputCNN:一个简单的CNN网络处理ConvLSTM的输出
- 一般LSTM的输出后面都会接一个Linear层处理,这里ConvLSTM的输出就是使用CNN处理
ConvLSTM_model:使用ConvLSTM以及outputCNN的混合网络
-
multiple_dimension_diabetes.ipynb: 学习处理多维特征输入,使用二分类交叉熵 torch.nn.BCELoss
- 使用的
./dataset文件夹中的diabetes.csv.gz数据集
- 使用的
-
softmax_classifier.ipynb: 学习处理多维特征分类,使用交叉熵 torch.nn.CrossEntropyLoss
- 使用的是
./dataset/MINST数据集
- 使用的是