Data was extracted from the Center for Systems Science and Engineering (CSSE) at Johns Hopkins University using Python. With this newly created data source, a dashboard was created using the Dash library in Python, then deployed through Heroku.
This project previously utilized PySpark via DataBricks to import COVID-19 daily reports. The data was transformed using Spark SQL through PySpark, then the final products were exported to an S3 bucket (Amazon Web Services). Historic project files are still available to view.
- ETL
Previous Data Flow Diagram:
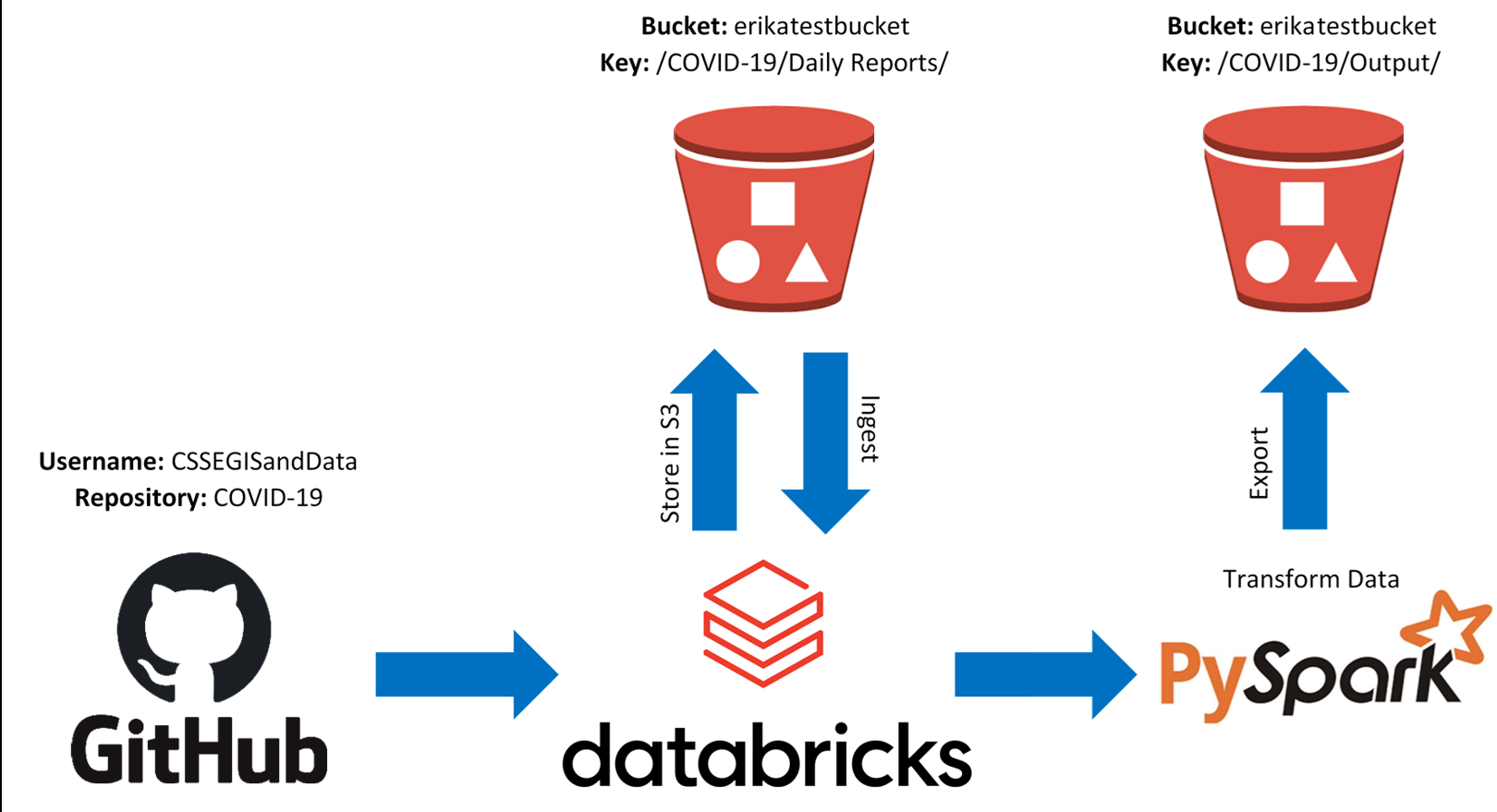
- Python
- DataBricks
- Amazon Web Services (S3)
- Heroku
- Pandas
- Requests
- PySpark
- Boto3
- S3FS
- Dash
On the command line of your operating system, navigate to the repository directory (ideally using a Python virtual environment).
Run the following code on the command line to install requirements:
pip install -r requirements.txt
Run the following code on the command line to run this project:
Python app.py
The code's output should serve the application locally on http://127.0.0.1:8050/, which can be accessed from an internet browser.
app.py- Dashboard Script- Coronavirus Dashboard (Deployed)
- assets
coronavirus.png- Coronavirus image (Courtesy of CDC PHIL)stylesheet.css- CSS Stylesheet for dashboard
- history
COVID-19_Databricks.ipynb- Original ETL data transformation using PySpark and Spark SQL to export to S3app_v1.py- Original Dash app that imported data from S3 to create dashboard
Procfile- Configures Heroku application serverrequirements.txt- Sets Python package requirements for Heroky dynoruntime.txt- Sets Python version in Heroku to Python 3.8.7
{kind=link}