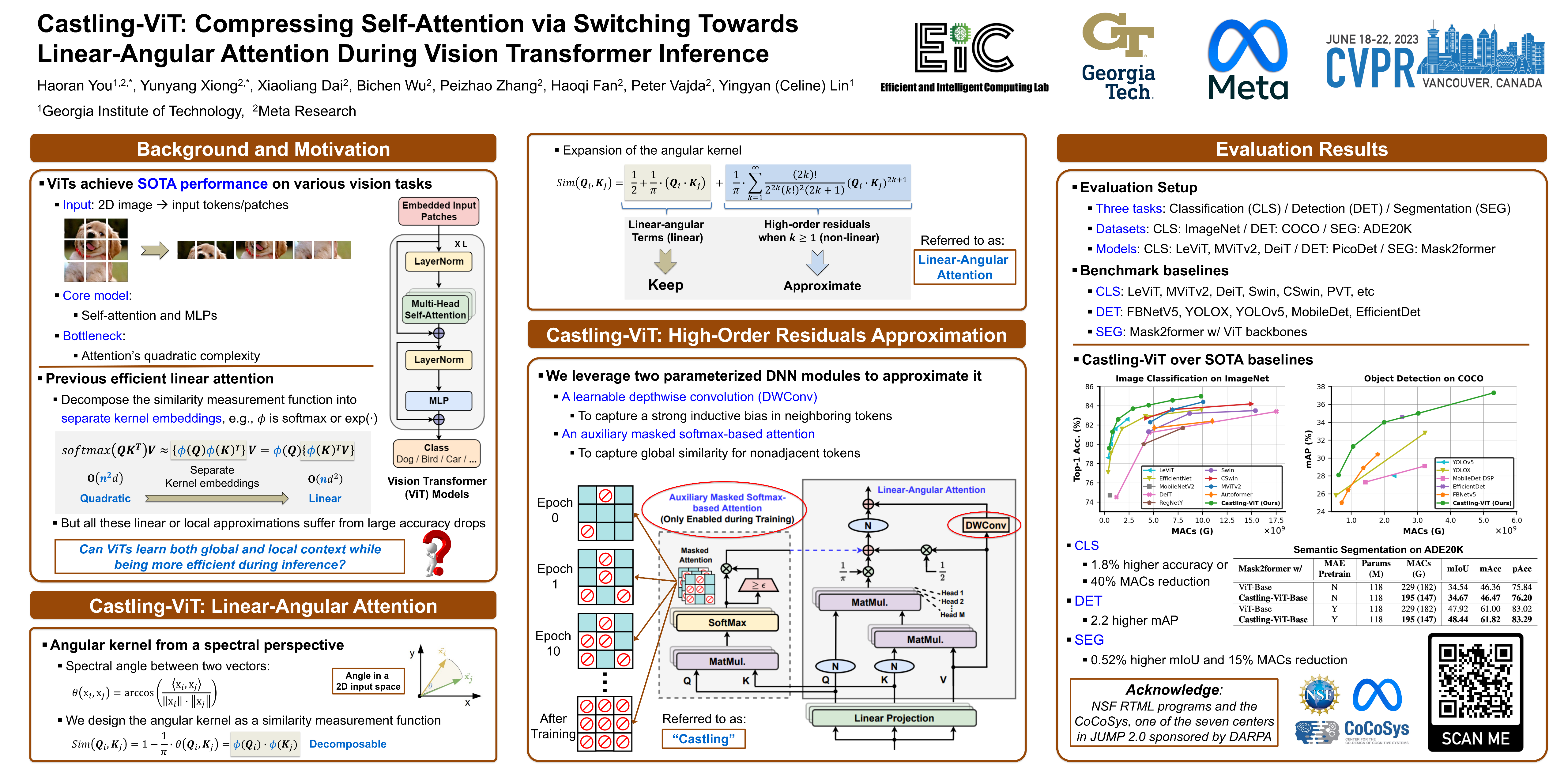
Castling-ViT: Compressing Self-Attention via Switching Towards Linear-Angular Attention During Vision Transformer Inference
Haoran You, Yunyang Xiong, Xiaoliang Dai, Bichen Wu, Peizhao Zhang, Haoqi Fan, Peter Vajda, Yingyan Lin
Accepted by CVPR 2023. More Info: [ Paper | Slide | Youtube | Poster | Github ]
{kind=link}
This is supposed to be an unofficial release of miniature code to reveal the core implementation of our attention block. The final adopted attention block is in a MultiScaleAttention format.
python attention.py

Here are some general guidances for reproducing results reported in our paper.
-
For classification task, we build our codebase on top of MobileVision@Meta.
-
For segmentation task, we build our codebase on top of Mask2Former, where the unsupervised pretrained models are trained using the MAE framework.
-
For detection task, we build our codebase on top of PicoDet@PaddleDet and its PyTorch version. The supervised pretrained models are trained using the LeViT framework.
To facilitate the usage in our research community, I am working on translating some of the highly coupled codes to standalone version. Ideally, the detection codebase can be exptected later, stay tuned.
If you find this codebase is useful for your research, please cite:
@inproceedings{you2023castling,
title={Castling-ViT: Compressing Self-Attention via Switching Towards Linear-Angular Attention During Vision Transformer Inference},
author={You, Haoran and Xiong, Yunyang and Dai, Xiaoliang and Wu, Bichen and Zhang, Peizhao and Fan, Haoqi and Vajda, Peter and Lin, Yingyan},
booktitle={The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2023)},
year={2023}
}