En el siguiente documento se detallarán las tareas realizadas en clase, apuntes, etc.
[EN CONTRUCCIÓN]
- Definir variables variables que almacenen los siguiente datos: Un nombre: “pepe”
- Una edad: 25
- Un precio: $99.90
- Los nombres de mis series favoritas: “Dark”, “Mr Robot”, “Castlevania”
- Mis películas favoritas, en donde cada película detalla su nombre, el año de estreno, y una lista con los nombres de sus protagonistas.
-
Mostrar todos esos valores por consola.
-
Incrementar la edad en 1 y volver a mostrarla.
-
Agregar una serie a la lista y volver a mostrarla.
Solución:
const name = "pepe";
let age = "25";
const price = 99.99;
const mySeries = ["Dark", "Mr Robot", "Castlevania"];
const myFavoriteFilm = [
{
name: "a",
year: 2000,
protagonists: ["a", "b", "c"],
},
{
name: "b",
year: 2000,
protagonists: ["a", "b", "c"],
},
{
name: "c",
year: 2000,
protagonists: ["a", "b", "c"],
},
]
console.log("name", name);
console.log("age", age);
console.log("price", price);
console.log("mySeries", mySeries);
console.log("myFavoriteFilm", myFavoriteFilm);
age++;
console.log(age);
mySeries.push("nueva serie");
console.log(mySeries);
-
Definir la función mostrarLista que reciba una lista de datos y muestre su contenido, si no está vacía, o de lo contrario muestre el mensaje: “lista vacía”. Luego, invocarla con datos de prueba para verificar que funciona bien en ambos casos.
-
Definir una función anónima que haga lo mismo que la del punto 1, e invocarla inmediatamente, pasando una lista con 3 números como argumento.
-
Definir la función crearMultiplicador que reciba un número y devuelva una función anónima que reciba segundo número y dé como resultado el producto de ambos. Luego, a partir de la función definida, crear dos funciones duplicar y triplicar, y probarlas con diferentes valores
Solución:
const mostrarLista = (lista) => lista || "lista vacia";
console.log(mostrarLista(["a","b","c"]));
console.log(mostrarLista());
function crearMultiplicador(n1){
return (n2) => n1*n2;
}
const duplicar = crearMultiplicador(2);
const triplicar = crearMultiplicador(3);
console.log (duplicar(4));
console.log(triplicar(3));
En este ejercicio construiremos una herramienta que permita que diferentes personas puedan llevar cuentas individuales sobre algo que deseen contabilizar, al mismo tiempo que nos brinde una contabilidad general del total contado. Para ello:
- Definir la clase Contador.
- Cada instancia de contador debe ser identificada con el nombre de la persona responsable de ese conteo.
- Cada instancia inicia su cuenta individual en cero.
- La clase en sí misma posee un valor estático con el que lleva la cuenta de todo lo contado por sus instancias, el cual también inicia en cero.
- Definir un método obtenerResponsable que devuelva el nombre del responsable de la instancia.
- Definir un método obtenerCuentaIndividual que devuelva la cantidad contada por la instancia.
- Definir un método obtenerCuentaGlobal que devuelva la cantidad contada por todos los contadores creados hasta el momento.
- Definir el método contar que incremente en uno tanto la cuenta individual como la cuenta general.
Solución:
class Contador {
constructor(name) {
this.name = name;
this.count = 0;
}
static totalCount = 0;
obtenerResponsable() {
return this.name;
}
obtenerCuentaIndividual() {
return this.count;
}
obtenerCuentaGlobal() {
return Contador.totalCount;
}
contar() {
this.count++;
Contador.totalCount++;
}
}
const contador1 = new Contador(`Gastón`);
console.log(contador1.obtenerResponsable());
console.log(`Cuenta individual`, contador1.obtenerCuentaIndividual());
contador1.contar();
console.log(`Cuenta individual`, contador1.obtenerCuentaIndividual());
contador1.contar();
console.log(`Cuenta individual`, contador1.obtenerCuentaIndividual());
console.log(`Conteo obtenerCuentaGlobal`, contador1.obtenerCuentaGlobal());
- Funciones en variables:
const mostrarMensaje = function (params){
console.log(`mensaje: ${params}`);
}
- Convirtiendo a funciones flecha...
const mostrarMensaje = (params) =>{
console.log(`mensaje: ${params}`);
}
- Cuando la funcion flecha posee una sola linea, automáticamente se retorna el valor, tener en cuenta si no se desea realizar un retorno: return implícito
- las llaves {} se vuelven opcionales.
const mostrarMensaje = (params) => console.log(`mensaje: ${params}`);
- Si la función recibe un único parámetro se pueden quitar los paréntesis ()
const mostrarMensaje = params => console.log(`mensaje: ${params}`);
- Si se desea retornar un objeto, el mismo debe estar entre paréntesis:
const getPersona = (name, age) => ({nombre: name, edad:age});
- Con return:
const getPersona = (name, age) => {
return {nombre: name, edad:age}
}
Los callbacks se utilizan para retomar el flujo de ejecución del programa en caso de que se haya perdido.
- El callback siempre es el último parámetro.
- El callback suele ser una función que recibe dos parámetros: error & resultado.
- La función llama al callback al terminar de ejecutar todas sus operaciones.
- Si la operación fue exitosa, la función llamará al callback pasando null como primer parámetro y si generó algun resutlado este se pasará como segundo parámetro.
- Si la operación resulto en un error, la función llamará al callback pasando el error obtenido como primer parámetro.
Ejemplo:
const operacion = (a, b, accion, callback) => {
return setTimeout(() => {
const resultado = accion(a, b);
callback(null, resultado);
}, 1000);
}
const suma = (a, b) => a + b;
const resta = (a, b) => a - b;
const multiplicacion = (a, b) => a * b;
const division = (a, b) => a / b;
const modulo = (a, b) => a % b;
operacion(2, 4, suma, (err, resultado) => {
if (err != null) {
console.error(err);
return
} else {
console.log(`resultado`, resultado);
console.log(`A partir de aqui retomo el flujo de ejecución de mi programa`)
}
});
console.log(resultado);
-
Los callbacks fueron una buena práctica adoptada por la comunidad, no era un método de resolución propiamente del lenguaje, actualmente para resolver el problema de los callback of hell surgen las promesas, que si son propios del lenguaje.
-
El estado inicial de una promesa es: pendiente (pending)
Una vez que la operación contenida se resuelva, el estado de la promesa pasa a ser:
-
Cumplida (resolve): la operación salió bien, y su resultado será manejado por el callback asignado mediante el metodo .then()
-
Rechazada (rejected): la operación fallo, y su error será manejado por el callback asignado mediante el metodo .catch()
Veamos un simple ejemplo:
function dividir (dividendo, divisor){
return new Promise ((resolve, reject) => {
if (divisor == 0){
reject (`No se puede dividir entre cero`);
} else {
resolve (dividendo / divisor);
}
})
}
Veamos el mismo ejemplo manejando el resultado de la función dividir, agregando .then y .catch con su correspondiente callback:
const dividir = (dividendo, divisor) => {
return new Promise((resolve, reject) => {
if (divisor == 0) {
reject(`No se puede dividir entre cero`);
} else {
resolve(dividendo / divisor);
}
})
}
dividir(10, 2)
.then((resultado) => {
console.log(`El resultado de la division es: ${resultado}`);
})
.catch((err) => {
console.log(err);
})
Desarrollar una función ‘mostrarLetras’ que reciba un string como parámetro y permita mostrar una vez por segundo cada uno de sus caracteres. Al finalizar, debe invocar a la siguiente función que se le pasa también como parámetro: const fin = () => console.log('terminé') Realizar tres llamadas a ‘mostrarLetras’ con el mensaje ‘¡Hola!’ y demoras de 0, 250 y 500 mS verificando que los mensajes de salida se intercalen.
//Asincronismo y callback
const fin = () => console.log (`Termine`);
const mostrarLetra = (palabra , callback) =>{
let i = 0;
const interval = setInterval (() => {
const letra = palabra[i];
i++;
if (letra){
console.log(letra)
}else{
clearInterval(interval);
callback();
}
}, 1000)
}
setTimeout(() => {
mostrarLetra (`primeraPalabra`, fin);
}, 700);
setTimeout(() => {
mostrarLetra (`segundaPalabra`, fin);
}, 1500);
setTimeout(() => {
mostrarLetra (`terceraPalabra`, fin);
}, 2000);
Realizar un programa que: A) Guarde en un archivo llamado fyh.txt la fecha y hora actual. B) Lea nuestro propio archivo de programa y lo muestre por consola. C) Incluya el manejo de errores con try catch (progresando las excepciones con throw new Error).
Aclaración: utilizar las funciones sincrónicas de lectura y escritura de archivos del módulo fs de node.js
const fs = require(`fs`);
const date = Date().toLocaleString();
try {
fs.writeFileSync(`./fyh.txt`, date);
} catch (err) {
console.error(err);
}
try {
const date = fs.readFileSync(`./fyh.txt`, `utf-8`);
console.log(`La fecha actual es ${date}`);
} catch (err) {
console.error(err);
}
- Se ejecutan una por una, desde la primera a la última.
- Se si ejecuta una llamada a otra función, la ejecución se pausa y se procede a ejecutar esa función, al terminar retoma la siguiente instrucción.
Ejemplo:
const funA = () => {
console.log(1);
funB();
console.log(2);
}
const funB = () => {
console.log(3);
funC();
console.log(4);
}
const funC = () => {
console.log(5);
}
funA();
Se imprime:
1
3
5
4
2
- Es muy importante entender y aprender a utilizar las funciones no bloqueantes para no generar nuevos problemas.
- Cuando hablamos de ejecución no bloqueante (asincrónica) solo sabemos en que orden comenzará la ejecución de las intrucciones, pero no sabemos en que momento ni en que orden terminarán de ejecutarse.
La misma puede ser bloqueante o no-bloqueante, si alguna de las instrucciones dentro de una función intente acceder a un recurso que se encuentre fuera del programa se observará dicho comportamiento.
Es muy importante saber como va a funcionar el programa, conocer que características tienen las funciones para poder utilizar el mejor mecanismo a la hora de controlar el flujo del programa. Que una función sea bloqueante no es algo negativo, puede ser necesario que el sistema necesite esperar por ello, o no, lo importante es conocer las características y utilizar el mejor mecanismo para controlar el flujo del programa.
Ejemplo: programa bloqueante / síncrono:
const delay = ret => {for(let i=0; i<ret*3e6; i++);}
function hacerTarea(num) {
console.log('haciendo tarea ' + num)
delay(100)
}
console.log('inicio de tareas');
hacerTarea(1)
hacerTarea(2)
hacerTarea(3)
hacerTarea(4)
console.log('fin de tareas')
console.log('otras tareas ...')
Se imprime:
Inicio de tareas
Haciendo tarea 1
Haciendo tarea 2
Haciendo tarea 3
Haciendo tarea 4
Fin de tareas
Otras tareas …
Como se puede ver, es un programa bloqueante
Recordar que en los métodos asincrónicos (no bloqueante) se pierde el flujo del programa, para recuperar y controlar el mismo se utilizan los callback.
- try / catch
- Callback: callback manejamos el error, entonces no se utiliza try & catch.
- Promesas: resolve / reject -> then / catch
- Async / await : se manejan promesas de forma bloqueantes, para ello se agrega try & catch
- Protocolo utilizado en internet para tranferrir datos.
- HTTP = Hypertext Transfer Protocol.
- Protocolo de estructura cliente-servidor: Cliente realiza una petición, el servidor responde.
- HTTP establece varios tipos de peticiones, siendo las principales: POST, GET, PUT, DELETE.
- En Node.js existe un módulo nativo.
Cada mensaje de respuesta HTTP tiene un código de estado numérico de tres cifras que indica el resutlado de la petición:
- 1xx(informativo): la petición fue recibida, y continúa su procesamiento.
- 2xx (Éxito): la petición fue recibida con éxito, comprendida y procesada.
- 3xx (Redirección): más acciones con requeridas para completar la petición. Utiliza la información que tenía previamente.
- 4xx (Erro del cliente): la petición tiene algún error, y no puede ser procesada.
- 5xx (Error del servidor): el servidor falló al intentar procesar una petición aparentemenete válida.
Desarrollar un servidor en node.js que escuche peticiones en el puerto 8080 y responda un mensaje de acuerdo a la hora actual:
- Si la hora actual se encuentra entre las 6 y las 12 hs será 'Buenos días!'.
- Entre las 13 y las 19 hs será 'Buenas tardes!'.
- De 20 a 5 hs será 'Buenas noches!'. Se mostrará por consola cuando el servidor esté listo para operar y en qué puerto lo está haciendo.
const http = require (`http`);
const server = http.createServer((req, res) =>{
const date = (new Date()).getHours();
date >= 6 && date <12 ? res.end(`Buenos días!`) : null;
date >= 12 && date <19 ? res.end(`Buenos tardes!`) : null;
date >= 20 ? res.end(`Buenos noches!`) : null;
})
const connectedServer = server.listen(8080, () =>{
console.log(`Servidor HTTP escuchando en el puerto ${connectedServer.address().port}`);
})
NodeJS cuenta con módulos nativos para manejar el envío y recepción de peticiones de tipo http/s, sin embargo, usaremos para nuestra aplicación un módulo externo llamado express Características:
- Muy utilizado por la comunidad, facil de utilizar.
- Facilita la tarea de crear los distintos puntos de entrada de nuestro servidor.
- Permite personalizar la manera en que se maneja cada petición en forma más simple y rápida.
- Express nos permite definir, para cada tipo de petición HTTP que llegue a una determinada URL, qué acciones debe tomar, mediante la definición de un callback para cada caso que consideremos necesario incluir en nuestra API.
Instalación:
npm install express
- Requerimos la librería express:
const express = require(`express`);
const app = express();
- configuramos el servidor, para que escuche un puerto:
const PORT = 8080;
const server = app.listen(PORT, () => {
console.log(`Servidor HTTP escuchando puerto ${PORT}`);
});
- configuramos el error:
server.on(`error`, err => {
console.log(`error en el servidor: ${err}`)
})
[EN CONTRUCCIÓN]
Las API son conjuntos de definiciones y protocolos que se utilizan para diseñar e integrar el software de las aplicaciones.Suele considerarse como el contrato entre el proveedor de información y el usuario, donde se establece el contenido que se necesita por parte del consumidor (la llamada) y el que requiere el productor (la respuesta).Por ejemplo, el diseño de una API de servicio meteorológico podría requerir que el usuario escribiera un código postal y que el productor diera una respuesta en dos partes: la primera sería la temperatura máxima y la segunda, la mínima.
- En resumen: funcionalidad de un sistema que esta expuesta para ser consumida por otro componente.
- REpresentational State Transer = Transferencia de Estado Representacional.
- Representación -> nos referimos a un modelo o estructura con la que representamos algo.
- Estado -> nos referimos a los datos que contiene ese modelo estructura.
- Transferir un Estado de Representación implica el envío de datos (con una determinada estructura) entre dos partes.
- Los dos formatos más utilizados: XML y JSON.
Cuando hablamos de aplicaciones RESTFul, nos referimos a aplicaicones que operan en forma de servicios web, respondiendo consultas a otros sistemas a través de internet. Dichas aplicaciones lo hacen respetando algunas reglas y convenciones.
- Tipo de API que no dispone de interfaz gráfica.
- Se utiliza exclusivamente para comunicación entre sistemas, mediante el protocolo HTTP. Para que una API se considere REST debe cumplir con las siguientes características:
- Arquitectura cliente - servidor sin estado.
- Cacheable.
- Operaciones comunes.
- Interfaz uniforme.
- Utilización de hipermedios.
A continuación, explicaremos lo anteriormente nombrado.
- Cada mensaje HTTP contiene toda la información necesaria para comprender la petición.
- Ni el cliente ni el servidor necesitan recordar ningún estado de las comunicaciones entre mensajes.
- El cliente y el servidor se encuentran débilmente acoplados ya que el cliente no necesita conocer los detalles de implementaciñon del servidor y el servidor se "despreocupa" de cómo son usados los datos que envía al cliente.
- Debe admitir un sistema de almacenamiento en caché.
- Dicho almacenamiento evita repetir varias conexiones entre el servidor y el cliente en caso de que la peticiones idénticas fueran a generar la msima respuesta. Lo informa mediante HTTP status, código: 304.
- Todos los recursos detrás de una API seben poder ser consumidos mediante peticiones HTTP, las principales: POST, GET, PUT y DELETE.
- Operaciones CRUD: Create, Read, Update, Delete.
- Se devolverá el código de estado para informar el resultado de la operación.
- Cada acción debe contar con una URI: identificador único.
- URI nos facilitará el acceso a la información para consultar, modificar, eliminar.
- ejemplo de URI: http://servicio/api/usuario/1
- Cada vez que se hace una petición al servidor y este devuelve una respuesta, parte de la información devuelta pueden ser hipervínculos de navegación a otro recurso del cliente.
- Se puede navegar de un recurso REST a muchos otros.
- Peticiones: get(), post(), felete() y put().
- Todos reciben como primer argumento la ruta (URI), y el segundo parámetro un callback con el que maneja la petición. La petición posee dos parámetros: primero la petición (request) y el segundo la respuesta (response).
- URI: /api/mensajes/
- Método: get.
app.get(`/api/mensajes/`, (req, res) => {
});
const express = require(`express`);
const app = express();
const messages = [
{
id: 1,
title: `OK`,
message: ``
},
{
id: 2,
title: `NOK`,
message: ``
},
];
app.get(`/api/mensajes/`, (req, res) => {
console.log(`Request recibido`);
if (!req.query.title) {
return res.json(messages);
}
const messageFilttered = messages.filter(message => message.title === req.query.title);
return res.json(messageFilttered);
});
const PORT = 8080;
const server = app.listen(PORT, () => {
console.log(`Servidor HTTP escuchando puerto ${PORT}`);
});
server.on(`error`, err => {
console.log(`error en el servidor: ${err}`)
})
En caso de que se quiera acceder a un recurso en particular ya conocido, es necesario enviar un identificador unívoco en la URL:
- Agregamos en el código anterior:
app.get(`/api/mensajes/:id`, (req, res) => {
console.log(`Request recibido /api/mensajes/:id`);
const id = Number(req.params.id);
console.log(`id: ${id}`);
const messageFilttered = messages.find(message => message.id === id);
if (!messageFilttered) {
return res.status(404).json({
error: `mensaje no encontrado`
});
};
return res.json(messageFilttered);
});
Dada la siguiente constante: const frase = 'Hola mundo cómo están' Realizar un servidor con API Rest usando node.js y express que contenga los siguientes endpoints get:
- '/api/frase' -> devuelve la frase en forma completa en un campo ‘frase’.
- '/api/letras/:num -> devuelve por número de orden la letra dentro de esa frase (num 1 refiere a la primera letra), en un campo ‘letra’.
- '/api/palabras/:num -> devuelve por número de orden la palabra dentro de esa frase (num 1 refiere a la primera palabra), en un campo ‘palabra’.
// EJERCICIO APIRest
const express = require(`express`);
const app = express();
const frase = `Hola como estas`;
const PORT = 8080;
const server = app.listen(PORT, () => {
console.log(`Servidor escuchando puerto: ${PORT}`);
});
//1)
app.get(`/api/frase`, (req, res) => {
return res.json(frase);
});
//2)
app.get(`/api/letras/:num`, (req, res) => {
if (req.params.num > frase.length - 1) {
return res.status(404).json({
error: `letra no encontrada`
});
}
if (isNaN (req.params.num)) {
return res.status(404).json({
error: `El parámetro ingresado debe ser un número`
});
}
const letra = frase.charAt(req.params.num);
console.log(letra);
return res.json(letra);
})
//3
app.get(`/api/palabras/:num`, (req, res)=>{
const num = req.params.num;
const palabrasArray = frase.split(` `);
if (req.params.num > palabrasArray.length - 1) {
return res.status(404).json({
error: `Palabra no encontrada, excede la cantidad máxima`
});
}
if (isNaN (req.params.num)) {
return res.status(404).json({
error: `El parámetro ingresado debe ser un número`
});
}
return res.json(`la palabra seleccionada es: ${palabrasArray[num]}`);
});
Para que nuestro servidor pueda interpretar mensajes JSON se debe indicar de forma explícita, para ello agregamos las siguientes lineas de código:
app.use(express.json()); -> req.body contendra el contenido.
app.use(express.urlencoded({ extended: true }));
Se utiliza para realizar todo tipo de peticiones HTTP a una API, desde el navedador solo podremos arealizar (de forma simple) peticiones get.
Sumemos el siguiente código al ejemplo de clase:
app.post(`/api/mensajes`, (req, res) => {
console.log(`POST request recibido`);
console.log({ body: req.body })
const newMessage = req.body;
newMessage.id = messages.length + 1;
messages.push(newMessage);
return res.status(201).json(newMessage);
});
app.put(`/api/mensajes/:id`, (req, res) => {
console.log(`PUT request recibido`);
const id= Number(req.params.id);
const messageIndex = messages.findIndex(message => message.id === id);
if (messageIndex < 0){
return res.status(401).json({
error: "mensaje no encontrado"
});
}
const body = req.body;
messages[messageIndex].title = body.title;
messages[messageIndex].message = body.message;
return res.json(messages[messageIndex]);
});
En este caso filtraremos el array, dejando afuera el elemento a borrar y retornaremos status 204 (sin contenido).
app.delete(`/api/mensajes/:id`, (req, res) => {
console.log(`DELETE request recibido`);
const id= Number(req.params.id);
const messageIndex = messages.findIndex(message => message.id === id);
if (messageIndex < 0){
return res.status(401).json({
error: "mensaje no encontrado"
});
}
messages = messages.filter(message => message.id != id);
return res.status(204).json({});
});
Conceptos para ordenar dentro de las clases anteriores:
¿Qué es ruta absoluta y relativa? Ruta absoluta: se indica toda la ruta del archivo incluyendo el directorio raíz. Por ejemplo, C:\carpeta1\carpeta2\archivo1. doc. Ruta relativa: se indica la ruta a partir de donde este en ese momento situado.
middleware Un Un middleware es un bloque de código que se ejecuta entre la petición que hace el usuario (request) hasta que la petición llega al servidor. Es inevitable utilizar middlewares en una aplicación en Node. es un bloque de código que se ejecuta entre la petición que hace el usuario (request) hasta que la petición llega al servidor. Es inevitable utilizar middlewares en una aplicación en Node.
APIRest Sistema para proporcionar informaciòn mediante endpoints, devolvemos json
Resumen de puntos dictados:
- Ruteo en Express: nos sirve para asociar un ruteo a entidades que poseen el mismo nombre.
- Ruteo: contenido estático(imagenes, txt, videos, documentos, JavaScript, etc) y dinámico.
- Ruta relativa & ruta absoluta: __dirname.
- Middleware: un middleware es un bloque de código que se ejecuta entre la petición que hace el usuario (request) hasta que la petición llega al servidor. Es inevitable utilizar middlewares en una aplicación en Node. Se puede relacionar con .then de la promesas, el then equivale al next, permitiendo pasar al siguiente middleware. Existen muchos tipos de middleware: a nivel de aplicación, router, manejod de errores, incorporado, de terceros. En resumen: se utilizan para dirigir el flujo del programa.
- Multer: middleware de express, nos permite subir archivos a un servidor.
Resumen de puntos dictados:
- Motor de plantilla: herramienta que nos permite transformar pseudo codigo HTML en HTML-
- MVC: modelo vista controlador, se trata de separar los datos de su presentación. Separar el front del back. Las plantillas (templates) son una aproximación más para resolver este problema.
- MVC es una forma de separar nuestro codigo en capas, haciendo que cada capa se ocupe de una sola cosa, para que este mas organizado y sea mas legible.
- MVC vs API: un cliente HTTP puede consumir la API, MVC posee vista la API no.
- Los motores de plantillas hoy en dia no se utilizan tanto.
- Template + input data = templating Engine, templating Engine entrega el Output
- Ventajas y desventajas de utilizar motores de plantillas.
- Instalar npm i -g http-server para correr servidor. Para correr desde nodeJs: http-server . .=propia carpeta del proyecto.
- Creación de motor de plantilla custom para express.
- Handlebars: lenguaje de plantillas simples, tienen aspecto de texto normal con expresiones de Handlebars se componen de {{ + algunos contenidos +}}. Se puede utilizar del lado del servidor y del cliente.
- Para utilizar handlebars --> npm install express-handlebars
Resumen de puntos dictados:
- Pug es un motor de plantillas
- Para instalar pug: npm install pug
- Pug se basa en la tabulación para interpretar etiquetas.
- EJs es un motor de plantilla, es el más utilizado. Se puede utilizar en el servidor o en el cliente. Instalar npm install ejs.
- Se deben utilizar sintáxis básicas propias de Ejs.
- Para instalar EJs: npm install ejs
- Sintaxis básica de Ejs: <%= incrusta en la plantilla el valor tal cual está, <%- incrusta en la plantilla el valor renderizado como HTML, <% Scriptlet admite instrucciones en JS para declaración de variables y control de flujo.
- El modelo MVC es muy utilizado para realizar el front desde el back.
Resumen de puntos dictados:
- Comunicaciòn entre el back y el front: API --> el cliente se encarga 100% en mostrar los datos que enviamos por Json, MVC--> se encuentra todo integrado en el mismo sistema.
- Websockets: protocolo para intercambiar información mediante TCP, en HTPP contabamos con arquitectura cliente servidor, aqui tendremos tambien arquitectura cliente servidor pero en forma de red, red de clientes conectados a un servidor de websockets. La comunicación entre servidor y cliente es bidireccional, a diferencia de HTTP.
- Con Websocket se obtienen los datos de una forma mas rápida, comunicación directa y en tiempo real. Se genera una única comunicación, una vez que se realizó la primer conexión el cliente y el servidor quedan enlazados, no deben inicializar nuevamente.
- Las notificaciones push --> se recomienda utilizar websockets, por ejemplo chat, información en tiempo real.
- Recordar: HTTP esta limitado a la petición del cliente, con websocket tenemos mayor flexibilidad para determinadas aplicaciones.
- microservicio: Backend pequeño que se encarga de una tarea. Los microservicios estan separados, comparten información entre ellos.
- Librería para trabajar con websocket: socket.io
Resumen de puntos dictados:
- Un websocket es solo una conexión TCP que permite la comunicación full-duplex, lo que significa que cualquier lado de la conexión puede enviar datos al otro, incluso al mismo tiempo.
- Envio de mensaje: socket.emit
- Envio de mensaje a todos los clientes conectados: io.sockets.emit
- Envio de mensaje a todos los clientes a excepción de quien envió el mensaje original: socket.broadcast.emit
- typeScript
- Webpack es un empaquetador, nos reduce al minimo el código fuente que vamos a colocar en producción.
- La DB es un repositorio persistente que nos permite almacenar gran numero de información de forma organizada.
- Tipo de clientes de base de datos: CLI, GUI, cliente web y cliente de aplicación.
- CLI: command Line interface - es un cliente que interactua con la base de datos mediante el uso de una consola.
- GUI: graphical user interface, es un cliente que interactua con la base de datos mediante el uso de una aplicación gráfica.
- Cliente web: accedemos a ellos mediante una URL.
- Cliente de aplicación: es un cliente que está implementado dentro de nuestra aplicacon backend y sire para que nuestro programa se conecte e interactue con la DB.
- En el perfil desarrollador backend se utiliza mucho "cliente de aplicación", ya que realizaremos CRUD desde nuestra aplicación.
- CRUD: crear, leer, actualizar, borrar, son las tareas que se realizan con una DB.
- SQL: lenguaje de consulta estructurado, structured query language. Es un tipo de lenguaje vinculado con la gestion de DB. SQL es una DB RELACIONAL.
- MySQL & MariaDB: sistemas de gestion de DB relacionales.
- Instalación: MySQL Workbench (Cliente), XAMPP
- MySQL cheatsheet: https://devhints.io/mysql
- Para acceder al CLI de MySQL: C:\xampp\mysql\bin : abrir la terminal desde XAMPP, luego escribir "mysql -u root"
- Listar DB
SHOW DATABASES;
- Crear DB
CREATE DATABASE ecommerce;
- Usar DB
USE ecommerce;
- Listar tablas
SHOW TABLES;
- Crear tabla
CREATE TABLE Productos (
id INT NOT NULL auto_increment,
name VARCHAR(30),
price FLOAT,
description VARCHAR(255),
stock INT,
PRIMARY KEY (id)
);
CREATE TABLE Categorias(
id INT NOT NULL auto_increment,
name VARCHAR(30),
PRIMARY KEY (id)
);
- Detalle de una tabla
DESCRIBE productos;
- Insertar información en una tabla
INSERT INTO Productos(name, price, description, stock) VALUES ("Producto1", 20, "Producto numero 1", 100);
- Visualizar todos los datos de una tabla:
SELECT * FROM Productos;
- Visualizar determinados datos:
SELECT name,stock FROM Productos;
- Insertar columna en tabla existente y agregar la llave foranea
ALTER TABLE Productos
ADD COLUMN categoria_id INT NULL,
ADD FOREIGN KEY (categoria_id) REFERENCES categorias(id);
- Actualizar productos
UPDATE Productos SET categoria_id = 1 WHERE id= 2;
- Borrar
DELETE FROM Productos WHERE id = 2;
- Utilización de node como cliente de MySQL mediante la libreria knex.js
- knex es un generador de consultas SQL.
- Cuenta con una interfaz basada en callbacks y en promesas.
- Instalar knex: npm install knex.
- Instalar mysql: npm install mysql.
- IMPORTANTE: con knex no podremos crear una DB, lo utilizaremos para CRUD.
- El objetivo de esta clase es realizar lo mismo que la anterior pero con knex desde el ciente de aplicación.
- DEBUG=knex:query node createTable.js --> aqui podremos ejecutar y saber las query que se ejecutan
- ¿Qué es SQLite3? es una biblioteca en lenguaje C que implementa un motor de base de datos SQL pequeña, rapida, autónoma.
- Knex & SQLite3 : se debe instalar la dependencia de SQL, npm install sqlite3
- Pare realizar la conexión no es necesario un usuario & pass, ya que utiliza un archivo, ese archivo contendra toda la DB.
- MongoDB es una base de datos No relacional, NoSQL, orientada a documentos que ofrece una gran escalabilidad y flexibilidad, y un modelo de consulta e indexacion avanzado.
- MongoDB es una DB orientada a documentos. No se basa en el concepto de tabla, fila y registro, sino que se apoya en el concepto de colección, docuemnto y propiedad.

- En mongoDB se almacena en colecciones, similar a JSON.
- Se puede utilizar de forma loca o remota (MongoDB Atlas)
- Ejemplo DB:
[
{
"id": 1,
"nombre": "Coca cola",
"precio": 10,
"descripcion": "refresco de cola",
"stock": 100,
"categoria_id": 1
},
{
"id": 2,
"nombre": "Agua",
"precio": 10,
"descripcion": "Botella de 1L",
"stock": 100,
"categoria_id": 1
},
{
"id": 3,
"nombre": "Galletas",
"precio": 10,
"descripcion": "Paquete de 20",
"stock": 100,
"categoria_id": 1
}
]
[
{
"name": "Alvaro"
},
{
"name": "Martha",
"estudios": "Ingeniero",
"ingles": "alto",
"address": {
"calle": "xxxx",
"numero": 44,
"ciudad": "Montevideo",
"pais": "uy"
},
"cursos": [
{
"name": "Desarrollo Web",
"asistencia": 80
},
{
"name": "React js",
"asistencia": 90
},
{
"name": "Programación Backend",
"asistencia": 100
}
]
}
]
-
Instalación de MongoDB --> https://www.mongodb.com/try/download/community
-
Video ayuda --> https://www.youtube.com/watch?v=kPKwJWr_9TM
-
Comandos:
mongosh;
show collections;
use nombreDB;
nombreDB> db.users.find()
nombreDB> db.users.insertOne({"name": "Gastón"})
nombreDB> db.dropDatabase();
nombreDB> db.users.drop();
nombreDB> db.nombreDB.estimatedDocumentCount()
nombreDB> db.nombreDB.estimatedDocumentCount({precio:10})
- CRUD: create, read, update y delete.
- Campo _id: ObjectId --> identificador único en la colección
- Desafio:
db.clientes.insertOne({ name: 'Jaime', edad: 34 })
const clientes = [
{ name: 'Adrian', edad: 23 },
{ name: 'Javier', edad: 40 },
{ name: 'Carlos', edad: 34 }
]
db.clientes.insertMany(clientes)
const articulos = [
{
name: 'Coca Cola',
precio: 12.21,
stock: 100
},
{
name: 'Fanta',
precio: 14.24,
stock: 80
},
{
name: 'Sprinte',
precio: 11.21,
stock: 200
},
{
name: 'Agua natural',
precio: 9.21,
stock: 100
}
]
db.articulos.insertMany(articulos)
db.articulos.countDocuments()
- Filtros de búsqueda: nombreDB> db.nombreCollecion.find($and: [{name:"jaime}, {edad:40}])
- Operadores para los filtros de búsqueda: $and, $or, $it, $gt, $gte, $ne, $eq.
- Ejemplo de filtros con operadores:
// METODO DE BUSQUEDA : FIND
db.clientes.find({ edad: 28 }) // obtengo todos los clientes (colección) con edad = 28
db.clientes.find({ $and: [{ name: 'Jaime' }, { edad: 40 }] }); // obtengo los clientes que posean el nombre = jaime y edad = 40
db.clientes.find({ name: 'jaime' }, { edad: 40 }); // and implícito, es el único operador que podremos utilizar de forma implícito
db.clientes.find({ $or: [{ name: 'Pepe' }, { edad: 28 }] });
db.clientes.find({ edad: { $gt: 34 } }); //edad > 34
db.clientes.find({ edad: { $gte: 34 } }); //edad >= 34
db.clientes.find({ edad: { $lt: 34 } }); //edad < 34
db.clientes.find({ edad: { $lte: 34 } }); //edad <= 34
db.clientes.find({ name: { $ne: 'Carlos' } }); // name != "carlos"
db.clientes.find({ name: { $eq: 'Carlos' } }); // name == "carlos"
db.clientes.find({ name: 'Carlos' }); // name == "carlos"
db.articulos.articulos.find({ inStore: { $exists: true } }); // filtramos los articulos en donde exista el campo "inStore"
db.articulos.articulos.find({ inStore: { $exists: false } }); // filtramos los articulos en donde NO existe el campo "inStore"
db.clientes.find({ name: { $in: ['Jaime', 'Carlos'] } }); // obtenemos todo la info de los clientes que posean los nombres: Jaime, Carlos.
db.clientes.find({ name: { $nin: ['Jaime', 'Carlos'] } }); // lo inverso a $in
const newClients = [
{
name: 'Joaquin',
edad: 23,
cursos: [
'Desarrollo Web',
'React JS',
'Programaciòn Backend'
]
},
{
name: 'Alma',
edad: 23,
cursos: [
'Desarrollo Web',
'Programaciòn Backend'
]
},
{
name: 'Sofia',
edad: 23,
cursos: [
'React JS',
'Programaciòn Backend'
]
},
{
name: 'Jorge',
edad: 23,
cursos: [
'Desarrollo Web',
'React JS',
'Programaciòn Backend'
]
},
];
db.clientes.find({ cursos: { $size: 3 } });
db.clientes.find({ cursos: { $all: ['Desarrollo Web', 'React JS', 'Programaciòn Backend'] } });
db.clientes.distinct('edad'); // Nos devuelve un array con el valor de las edades.
db.clientes.distinct('name'); // Nos devuelve un array con el valor de los nombres.
db.clientes.find({ name: /^J/ }); // Nos los clientes que su nombre comience con la letra A.
db.clientes.find({ name: /^J/ }, { name: true }); // Filtro por proyección.
db.clientes.find({ name: /^J/ }, { name: true, _id: false }); // Filtro por proyección.
db.clientes.find().sort({ name: 1 }); //Obtengo todos los clientes y los ordeno de forma ascendente.
db.clientes.find().sort({ name: -1 }); //Obtengo todos los clientes y los ordeno de forma descendente.
db.clientes.find().sort({ name: 1, edad: -1 }); // Filtro y obteengo con criterio de orden concatenado.
db.clientes.find().sort({ name: 1, edad: -1 }).limit(2); // Filtro y obteengo con criterio de orden concatenado, también limito la cantidad de elementos que obtengo.
// METODO DE ACTUALIZACIÓN Y DELET:
// Se utilizan los mismos métodos explicados anteriormente
//update
db.clientes.updates({ name: 'Alma' }, { $set: { 'direccion': 'asd123' } }); // db.clientes.updates({ COMANDO DE BUSQUEDA}, { $set: { 'direccion': 'asd123' } });
db.clientes.update({ cursos: { $elemMatch: { $eq: 'Desarrollo Web' } } }, { $push: { cursos: 'HTML' } }) // buscar y agregar en uno
db.clientes.updateMany({ cursos: { $elemMatch: { $eq: 'Desarrollo Web' } } }, { $push: { cursos: 'HTML' } }) // buscar y agregar en todos.
//delete
db.clientes.deleteOne({ name: /^J/ });
b.clientes.deleteMany({ name: /^J/ }) ;
-
Mongoose es una librería que nos permitirá conectarnos a MongoDB mediante Node. Como vimos en las clases anteriores, existen distintos tipos de clientes para acceder a la DB, en este caso veremos la libreria que nos permite acceder mediante una aplicación.
-
La aplicación Backend se convierte en el cliente y la DB en el servidor:
-
MERN Stack: cuatro tecnologías muy utilizadas en conjunto, M=MongoDB, E=Express, R=React Js, N=Node Js
-
Mongoose es una dependencia JS que realiza la conexión a la instancia de MongoDB. Crea una capa que nos permite interactuar con la DB en forma de esquema.
-
Integración de Mongoose con proyecto de Node:
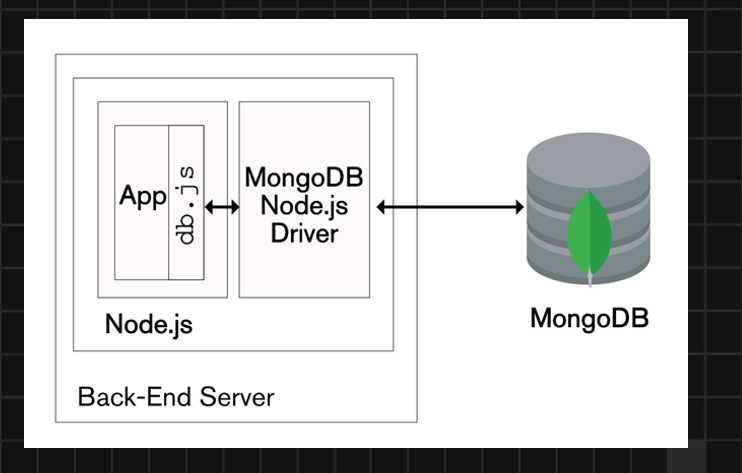
- Creamos un proyecto Node.js con npm init -y
- Instalamos la dependencia mongoose con npm i mongoose
- Describimos nuestro modelo de datos ( Schema + Model ) con las validaciones necesarias.
- Levantamos el motor de base de datos MongoDB.
- Creamos la función de conexión mediante mongoose, con las opciones configuradas.
- Con mongoose realizamos las operaciones CRUD hacia MongoDB: Read, Create, Update y Delete.
- Mostramos consultas con distintos filtros de Query y con el uso de projection, funciones sort, limit y skip
- DBaaS: plataforma que nos permite tener una DB en la nube. DBaaS = DB as a Service.
- Podemos definir dos modalidades de servicio: modelo clásico y ajomaniento gestionado. Clasico hace referencia al uso de la infraestructura fisica del proveedor para alojar sus DB. Con alojamiento gestionado hace referencia a que el cliente se desentiende de cualquier tarea de mantenimiento y gestión avanzada de la DB, esto lo asume el proveedor.
- MongoDB Atlas: es un servicio cloud de mongoDB. Se desarrollo con el objetivo de aliviar el trabajo de los desarrolladores, al quitar la necesidad de instalar, adminitrar etc la DB.
- https://www.mongodb.com/atlas/database
- TDD: PRUEBAS UNITARIAS : desarrollo dirigido por test, desarrollo orientado a pruebas, es una práctica de programación que consiste en escribir primero las pruebas, despues el código fuente que pase la prueba satifactoriamente, y por último, refactorizar el código escrito.
- El mocking es una técnica utilizada para simular objetos en memoria con la finalidad de poder ejecutar pruebas unitarias.
- Mocking & mock: mocking es la técnica para simular objetos en memoria.
- De esta manera generamos un sistema en donde no falle la DB ( creamos una DB fake) y nos olvidamos de posibles problemas con la misma, entonces, de esta manera podemos garantizar el funcionamiebto de la app --> mock & mocking.
- Mocks en TDD: trabajando con TDD y mocks podremos probar nuestro códio y garantizar el correcto funcionamiento al entregar un proyecto.
- Faker.js: nos da la opción de generar valores random de muchos datos. Actualmente se encuentra en desuso. Este tipo de librerías es muy utilizada cuando queremos mostrar un proyecto y simular valores, etc.
- El proyecto tiene cinco rutas:
- POST /api/users/popular?cant=n : si no específico cant me genera 50 objetos mock
- GET /api/users/:id? : con id me trae un mock; sin id devuelve todos los mocks
- POST /api/users : incorpora un nuevo mock
- PUT /api/users/:id : actualiza un mock total o parcialmente por campo
- DELETE /api/users/:id : borra un mock específico
- Los usuarios tienen: nombre, email, website, e imagen.
- Cada una puede generar, listar, incorporar, actualizar y borrar mocks.
- Los datos son persistentes en memoria.
- Es un proceso de estandarización y validación de datos que consiste en eliminar las redundacias o inconsistencias, completando datos mediante una serie de reglas que actualizan la información.
- La normalización de datos es útil cuando un repositorio de datos es demasiado grande, contiene redundancia, tiene información profundamente anidada y/o es difícil de usar.
- Al normalizar los datos, debemos seguir algunas reglas: la lectura de datos debe ser plana, cada entidad debe almacenarse como propiedad de objeto diferente, las relaciones con otras entidades deben crearse basadas en identificadores: "id".
- Para poder realizar la normalización podremos utilizar la libreria Normalizr.
- Conclusión: al normalizar datos se obtiene un paquete menor en peso, de esta manera se puede enviar ocupando menos capacidad, desde front se puede recibir y nuevamente denormalizar para trabajar con la información original.
- Información que el BE envia al cliente y se guarda en el cliente.
- Las cookies pueden tener un tiempo de vida, una vez finalizada la misma se elimina del navegador.
- El espacio es limitado, y se debe tener cuidado con datos sensibles. La información existente en las cookies es pública.
- Para integrarlo desde BE, y desde express --> npm i cookie-parser, es un middleware que se requiere a nivel de aplicación.
- Las cookies se pueden proteger, consiste en encriptar el contenido.
- Existen dos tipos de proeyctos: modelo vista controlador (MVC) y API Rest (sistemas que intercambian información en formato Json), la principal diferencia entre estos sistemas es que las API Rest no manejan vistas, las resuelve otro sistemas, mientras que el MVC posee las vistas incorporadas en el mismo sistema que el back. Las cookie storage se suelen utilizar para las MVC ya que las API Rest no poseen estados, cada endpint se debe comportar de forma independiente a otro.
- Proteger cookies: se puede encriptar el contenido de la cookie, esto se realiza mediante la palabra clave "secreto" definida del lado del servidor y desconocida por los cloentes. El seridor es capaz de verificar si la cookie que se recibe desde el cliente ha sido adulterada o no, chqueando contra la versión enciptada.
- Session: permite que una variable sea accesible desde cualquier lugar del sitio. Se almacena del lado del servidor, del lado del cliente se crea un identificador único para acceder a esa informaciòn desde el navegador. Los datos almacenados en session se borran al cerrar la ventana del navegador.
- Session --> npm i express-session
- Persistencia de sessiones en file-store, mongo.
- Session con redis, redislab
- Autenticación: proceso de identificaión de usuario para asegurarse su identidad.
- Autorización: define la información, los servicios y recursos del sistema a los que podrá acceder el usuarioautenticado. Usuario común / administrador. Existen distintos métodos para autorizar usuarios: se suele utiliuzar middleware.
- Méotodos de autenticación: usuario y contraseña, sin contraseña, por redes sociales, datos biométricos, JWT (JSON Web Token), OAuth 2.0.
- Passport - Strategies: es un middleware de autenticación de NodeJS. Cumple únicamente la función de autenticar solicitudes, por lo que delega todas las demás funciones a la aplicación ( esto mantiene el código limpio).
- Passport-local: ingreso mediante usuario y contraseña, passport-openid: autenticación mediante OpenId, passport-oauth: autenticar mediante API de otros proveedores como de redes sociales (facebook, instagram, etc.).
- npm install passport
- npm install passport-local
- npm install bcrypt
- npm install connect-flash
- Passport es la librería que nos permitirá realizar autenticación desde el back: local, facebook, twitter.
- Para realizar el login desde facebook, debemos registrarnos como developers dentro de facebook: https://developers.facebook.com/
- passport-facebook
- Twitter: npm install passport-twitter, realizar también el registro como developers.
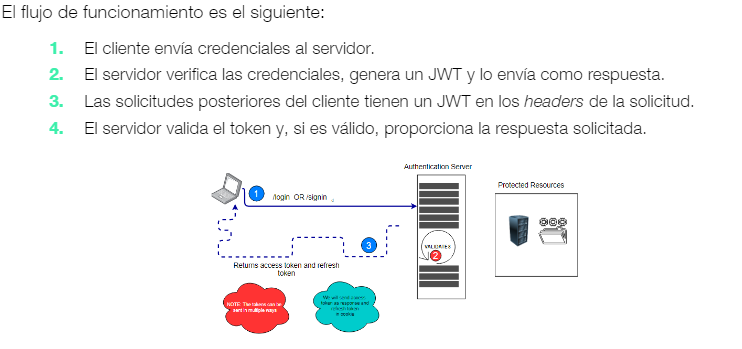
- JWT: JSON web token. Muy utilizado en las API Rest, para solucionar la falta de cookies. Son cadenas de datos que se pueden utilizar oara autenticar e intercambiar información entre un servidor y un cliente.
- https://jwt.io/
- npm install jsonwebtoken
- Flujo de funcionamiento del JWT:
- iniciar redis: redis-cli
- mostrar todas las key: KEYS *
- obtener info de la key: GET ..... --> ejemplo: GET user:10229798612374820
- Los argumentos de la línea de comandos son cadena de texto que se utilizan para pasar información adicional a un programa, cuando se ejecuta una aplicación a través del interfaz de linea de comandos (CLI) de un sistema operativo.
- Variables de entorno: son variables externas a nuestra aplicación que residen en el sistema operativo o en el contenedor de la aplicación que se está ejecutando. Una variable de entorno es simplemente un nombre asignado a un valor.
- El acceso a las variables de entonro en Node es compatible desde que inicia nuestra aplicación.
- Cuando el proceso Node se inicia, proporciona automáticamente el acceso a todas las variables de entorno existentes mediante el objeto process.env. En el archivo config.js.
- ¿Cómo setear variables de entorno? --> set variable1=valor1 && variable2=valor2 && nodemon server --> set PORT=3001 && nodemon server
- .env --> es un módulo de node que carga variables de entorno desde un archivo .env a process.env al momento de levantar la aplicación
- npm install dotenv
- minimist
- Objeto process: es una variable global disponible en Node. Cotiene diversos métodos, eventos y propiedades que nos sirve paa obtener datos.
- Variables de argumento vs variables de proceso: las variables de argumento se setean al correr el programa, por ejemplo: //nodemon repaso 1 2 abc -name gaston, las variables de proceso estan en el sistema.
- La mayor funcionalidad de process está contenida en la función ".on". Dicha función esta escuchando durante todo el proceso que se ejecuta, es por eso que solo se puede actuar sobre su callback.
- Dentro de la funcion ".on" nos encontramos con diferentes eventos: "beforeExit", "exit", "uncaughtException".
- Child process: Cuando ponemos en marcha un programa escrito en nodejs se dispone de un único hilo de ejecución. Child process es un nódulo de node que nos permite ejecutar procesos en segundo plano, de esta manera podremos tratar los sistemas bloqueantes.
- Podemos crear procesos hijo de 4 formas diferentes: exec(), spawn(), execFile(), fork().
- Proceso secundario con exe(): primer argumento se coloca el argumento que queremos ejecutar, segundo
- Proceso secundario execFile(): la diferencia principal entre las funciones execFile() y exec() es que el primer argumento de execFile() es ahora una ruta a un archivo ejecutable en vez de un comando.
- Proceso secundario spawn(): los datos se procesan y transfieren en pequeños trozos. Entonces, puede procesar una gran cantidad de datos sin usar demasiada memoria en un momento dado.
- Proceso secundario fork(): nos permite ejecutar otro script de node evitando el bloqueo.
- Cluster: Nos referimos al uso de subprocesos que permite aprovechar la capacidad del procesador del servidor donde se ejecuta la aplicación.
- Node se ejecuta en un solo proceso (single thread), y entonces no aprovechamos la máxima capacidad que nos puede brindar un proocesador multicore (múltiple núcleos).
- Al usar cluster, lo que hacemos es, en el caso de estar ejecutando sobre un servidor multicore, hacer uso de todos los núcleos del mismo, aprovechando al máximo su capacidad.
- Node nos provee un módulo llamado cluster para hacer uso de esto. Permite crear facilmente procesos hijo. Lo que hace es clonar el worker maestro y delegarle la carga de trabajo a cada uno de ellos, de esa manera se evita la sobrecarga a un solo núcleo del procesador. Un mñetodo similar al que vimos con Fork, se crea una copia del proceso actual. Etnonces, el primer proceso se convierte en maestro y la copia en un trabajador o worker.
- npm install cluster
- Módulo forever: Cuando ejecutamos un proyecto de Node en un servidor en el que lo tengamos desplegadom dejamos la consola "ocupada" con esa aplicación. Si queremos seguir haciendo cosas o arrancar otro proyecto no podemos, ya que tendríamos que detener la aplicación pulsando Ctrl+C quedando la consola libre nuevamente. Por otro lado, si el servidor se parara por un fallo, nuestra aplicación no se arrancaría de nuevo. Ambos problemas se pueden resolver con el módulo Forever de node.
- Nodemon nos reinicia el servidor cuando realizamos cambios, pero no sirve para producción, esta es la ventaja de Forever.
- Forever no es un código invasivo, no necesitamos incorporar en el código.
- npm install forever.
- forever start serverForever.js --> correr servidor
- forever start serverForever.js 8081 --> correr servidor
- forever stopall --> detener todos.
- PM2: es un gestor de procesos, es decir, un programa que controla la ejecución de otro proceso. Permite chequear si el proceso se está ejecutando, reiniciar el servidor si este se detiene por alguna razón, gestionar los logs, etc. PM2 simplifica las aplicaciones de Node para ejecutar como cluster, pero de forma no invasiva ya que se encarga el mismo módulo de PM2 de resolver.
- npm isntall -g pm2npm ins
- pm2 start nombreDelServer.js
- pm2 start nombreDelServer.js --watch --> idem nodemon
- pm2 delete all --> bajar todos los servidores activos.
- pm2 logs --> observamos los logs que esten corriendo.
- pm2 list --> tabla que ofrece que proceso de pm2 estan corriendo.
- pm2 start nombreDelServer.js -i max --> levante el maximo de procesos posible asociado a nuestro nucleo. en mi caso levanta 8 procesos del (0-7) correspondiente a los nucleos del PC, levanta los server en modo cluster
- pm2 stop numeroDelProceso --> ejemplo: pm2 stop 0
- pm2 restart numeroDelProceso --> levanta nuevamente el proceso. --> ejemplo: pm2 restart 0
- pm2 describe numeroDelProceso --> describe el proceso --> ejemplo: pm2 describe 0
- pm2 monit --> nos da una ventana en tiempo real para monitorizar los procesos.
- Proxy: hace de intermediario entre las conexiones de un cliente y un servidor, filtrando todos los paquetes entre ambos. Sin el proxy la conexiòn entre el cliente y el servidor es directa. Se utiliza para navegar por internet de forma más anónima ya que oculta las IP, sea del cliente o del servidor. Ofrece funcionalidades como control de acceso, registro de tráfico, mejora de rendimiento, etc.
- Forward proxy vs reverse proxy.
- Proxy directo ( forward): se coloca entre el cliente y la web. Recibe la peticion del cliente para acceder a un sitio web. Lo utiliza un cliente cuando quiere anonimizar su IP. Es útil para mejorar la privacidad, y para evitar restricciones de contenido geográfico ( contenido bloqueado en ciierta región)
- Proxy invero (reverse): el que nos interesará en esta clase, el servidor proxy se coloca entre la web y el servidor de origen. El que se mantiene en el anonimato es el servidor de origen. Garantiza que ningún cliente se conecte directo con él y por ende mejore sus eguridad. También, es útil para distribuir la carga entre varios servidores web.
- Ambos pueden trabajar juntos, ya que no se superponen.
- Los clientes/usuarios pueden utilizar un proxy directo y los servidores de origen un proxy inverso.
- Proxy inverso en backend: existen varios beneficios, como: balancear la carga, seguirdad mejorada, potente caching (acelerador de web, cache), compresió superior, cifrado optimizado, monitoreo y registro del tráfico.
- Nginx: lo utilizaremos en un servicio que ofrece AWS - Servicio: EC2.
- https://portal.aws.amazon.com/billing/signup --> registro en AWS
- Primero debemos abrir la consola de comandos.
- Conexión con PC virtual (instancia) de AWS:
Nos posicionamos en la carpeta que tiene la key:
Ejecutamos:
cd download
Ejecutamos:
ssh -i "coderhouse-clase30.pem" ubuntu@ec2-54-175-66-113.compute-1.amazonaws.com
- actualizar de forma general del sistema
Ejecutamos:
sudo apt update && sudo apt upgrade -->
-
Reiniciamos la instancia desde la plataforma web de AWS
-
Instalamos nginx:
Ejecutamos:
sudo apt install nginx -y
- Revisamos el status de ngnix
Ejecutamos:
systemctl status nginx
- Detener ngnix:
Ejecutamos:
sudo systemctl stop nginx
- Run ngnix:
Ejecutamos:
sudo systemctl start nginx
- Restart ngnix:
Ejecutamos:
sudo systemctl restart nginx
-Realizar peticion http desde comando:
Ejecutamos:
sudo curl http://localhost
-
Esta peticion la podremos ver desde la IP publica de la instancia (ver plataforma AWS)
-
Existen dos archivos importantes para la configuración de nginx:
Ejecutamos:
cat /etc/nginx/nginx.conf
- Abrimos sites-available:
Ejecutamos:
cat /etc/nginx/sites-available/default
- Instalamos Node en su version V18, primero descargamos el paquete:
Ejecutamos:
curl -fsSL https://deb.nodesource.com/setup_18.x | sudo -E bash -
- Instalamos node:
Ejecutamos:
sudo apt-get install -y nodejs
- Verificamos la correcta instalación:
Ejecutamos:
node -v
- Creamos una carpeta, creamos proyecto, etc.:
Ejecutamos:
mkdir code
ls
cd code/
mkdir node_app
cd node_app/
npm init -y
- Ejecución de getProducts:
- instalamos express:
Ejecutamos:
npm install express
- creamos archivo y editamos, mediante el edito vim podremos realizar esto:
Ejecutamos:
vim index.js
Precionamos "y" para editar:
y
- Comenzamos a escribir el programa:
const express = require('express');
const app = express();
app.get('/', (req,res) =>{
return res.json({
return res.json({
status: `ok`
});
});
});
const PORT = process.argv[2] || 8080;
app.listen(PORT, () => console.log(`Servidor corriendo en el puerto ${PORT}`));
- Para guardar precionamos "esc", luego ejecutamos:
:wq
- Instalamos pm2:
sudo npm install -g pm2
- Levantamos con pm2
pm2 start index.js --name="node app 1"-- 8081
- Para verificar que el servidor esta corriendo correctamente:
Ejecutamos:
curl http://localhost:8081
- Para realizar esto deberemos modificar el archivo de configuración de nginx, entonces:
Ejecutamos:
sudo vim /etc/nginx/sites-available/default
- Comentamos la linea, ya que utilizaremos otra
root /var/www/html;
- Al tener problemas con el editor vim, instalamos nano
sudo apt install nano
Ejecutamos:
sudo nano /etc/nginx/sites-available/default
- Para salir del editor: ctrl + o
-Siempre que realicemos una modificacion en nginx, debemos reiniciar.
- Realizar aplicaciones operativas, tener cuidado con la complejidad.
- Optimización de código:
-
Compresión con gzip: es un middleware de compresiòn de node para la compresión en aplicaciones express. No resulta la mejor opción con tráfico elevado en producción. Si realizamos un ejemplo sin usar compresión, supongamos que enviamos 100 veces la palabra "bienvenido", podremos ver un size = 11.2 kB --> se visualiza en chrome + F12. Al agregar compression como middleware, se puede ver claramente como disminuye el tiempo y el tamaño, entonces estamos optimizando. Recordar que es bloqueante, esto puede generar latencias.
-
Tratar de no utilizar funciones síncronas, buscar estrategias para evitar el bloqueo cuando se presentan estas funciones, por ejemplo con fork, cluster, pm2, etc.
-
Realizar un registro correcto en la app. No usar console.log(), console.error(). Se recomienda utilizar logs.
-
Manejar las excepciones de forma correcta. Las aplicaciones node se bloquean cuando encuentran una excepción no capturada. Para manejar las epciones se utiliza try/catch, promises, async/await.
- Buenas practicas: entorno/configuración:
- Variable de entorno, NODE_ENV.
- App se reinicia automáticamente: en producción no es deseable que la app se encuentre fuera de linea, entonces debemos asegurar la continuidad, y la misma se puede lograr reiniciando la app en caso de que se caiga --> utilizar pm2, forever.
- Ejecutar la app en un Cluster: en un sistema multinúcreo, podemos multiplicar el rendimiento de una aplicación Node iniciando un cluster de procesos. El cluster ejecuta varias instancias de la aplicación, idealmente una instancia en cada núcleo de CPU, lo que permite distribuir la carga y las tareas entre las instancias.
- Utilizar almacenamiento en memoria caché como nginx, mejora significativamente la velocidad y el rendimiento de la aplicación.
- Utilizar balanceador de cargas.
- Utilizar un proxy inverso para única entrada a la app.
-
Logs: cuando llevamos un sistema a producción, uno de los elementos mas importantes a la hora de detectar cualquier problema o anomalía son los logs. Son librerias para facilitar la impresión de un identificador único.
-
Log4js: es una de las librería de loggers más utilizada. --> npm install log4js
-
Winston: es una librería con soporte para múltiples transportes diseñada para el registro simple y universal. Un transporte es esencialmente un dispositivo que nos permite almacenar mensajes personalizados de seguimiento (al igual que console.log) en un archivo plano o desplegado por consola. --> npm install winston.
-
Pino: librería moderna. --> npm install pino. Solo se puede loggear por consola, no por file.
- Artillery: se utiliza para realizar test de carga a servidores. Se utiliza para el backend. --> npm install artillery.
- Con artillery podremos hacer prueba de cargas, ejecutando el comando:
artillery quick –-count 50 -n 40 http://localhost:8080?max=100000 > result_fork.txt
- Prueba en midi fork:
artillery quick –-count 50 -n 40 http://localhost:8080?max=100000 > result_fork.txt
- Prueba en midi cluster:
artillery quick –-count 50 -n 40 http://localhost:8080?max=100000 > result_cluster.txt
- En el ejemplo anterior estaremos enviando 50 peticiones con 40 rafagas, el resultado será guardado en "result.fork"
- Comparando los resultados del server en modo fork y modo closter podremos analizar la prueba de carga.
-
Profiling: analisis de rendimiento. Es la investigación del comportamiento de un programa. Desde google chrome podremos realizar este análisis. Desde node : npm install crypto
-
Curl: es una herramienta en línea de comandos y librería para transferir datos con URL. Se usa en linea de comandos o scripts para transferir datos.
-
prof: podemos prender el servidor en modo profiler, ejecutamos el server en modo prof --> --prof. Ejecuta y guarda información para analizar el funcionamiento.
-
inspect: para realizar este análisis desde google chrome, ejecutamos en modo inspect:
node --inspect profiler.js
-
Abrimos en chrome --> chrome://inspect/#devices
-
Autocannon: es una dependencia de Node (similar a Artillery) que nos ayuda a realizar los test de carga. --> npm install autocannon
-
0x: es una dependenica que perfila y genera un gráfico de flama (flame graph) interactivo para un proceso Node en un solo comando. --> npm install -g 0x
- Control de versiones: forma de registrar los cambios realizados sobre archivos a lo largo del tiempo, permitiendo recuperar versiones más adelante.
- Git: es una herramienta para llevar a cabo el control de versiones. Existen diferentes conceptos: remoto, local, working directory, versio, commit, tag, push, pull, conflictos, resolución de conflicto, branch, merge.
- Paas: plataforma como servicio, es un entorno de desarrollo e implementación completo en la nube. Cuenta con recursos que permiten generar "de todo": desde aplicaciones sencillas basadas en la nube, hasta aplicaciones empresariales sofisiticadas habilitadas para la nube.
- Heroku: plataforma como servicio --> paas. Las aplicaciones se corren desde un servidor Heroku usando Heroku DNS
- Para utilizar Heroku desde comandos, instalamos --> Install the Heroku CLI
- AWS: plataforma en la nuve muy adoptada y completa.
- Ofrece más de 200 servicios.
- Creación de cuenta --> https://aws.amazon.com/es/getting-started/hands-on/deploy-nodejs-web-app/
- En esta clase utilizaremos la plataforma Elastic Beanstalk de AWS para implementar aplicaciones NodeJS en la nube.
- Nodemailer: es un módulo para aplicaciones Node que permite el envìo de correos electrónicos de forma sencilla. Posee gran foco en la seguridad. Proxies para conexiones SMTP. --> npm install nodemailer
- doppler: correo electrónico masivo --> desde web, uso administrativo, marketing.
- Ethereal: https://ethereal.email/ : utilizaremos un correo ficticio para enviar e-mails.
- Twilio whatsapp: intermediario entre API de wsp
- https://www.twilio.com/es-mx/docs/whatsapp/quickstart/node
- Es un patrón que se utiliza en desarrollo de software donde los roles y responsabilidades dentro de la aplicación (app) son separadas en capas.
- Una app pequeña suele contener 3 apas. Luego, el número de capas puede ir aumentando con la complejización de la app. Las mismas son: capa de ruteo, capa de servicio, capa de persistencia.
- Aplicaremos los patrones de la capa de persistencia DAO, DTO y Repository, en conjunto con Factory.
- Presentar ORM y ODM como técnicas para la conversión de datos.
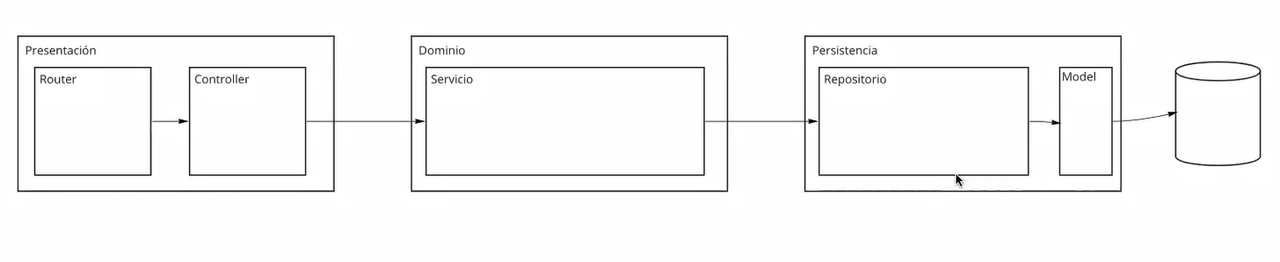
- Hasta ahora tenemos 3 capas: presentaciñon, dominio y persistencia.
- Presentaciòn: Router, controller.
- Dominio: servicio.
- Persistencia: Repositorio, Model
- DB
- En resumen: la capa de Router se comunica con la de controller. La capa de controller se comunica con la capa de servicio. La capa de Servicio se comunica con la de Repositorio, la de Repositorio con Model, y Model con DB. En esta clase nos centraremos en la capa de Persistencia. La idea es generar transparencia a la hora de cambiar la persistencia, que no afecte la información de interés. En el siguiente esquema, podremos ver un correcto funcionamiento desde el punto de vista teórico, pero en la practica no funcionará como pensamos.
- Para poder corregir este problema, debemos integrar un tratamiento de la data. Utilizaremos nuevas capas para solucionar esto.
- DAO: Data access object - permite separar la lógica de acceso a datos de los Business Objects u objetos de negocios. El DAO es la capa mas abstracta de la persistencia.
- El DAO nos es útil cuando tenemos una sola fuente de datos, sin importar de qué tipo sea.
- Es común contar con varias fuentes de datos. Entonces, necesitamos usar el patron Abstract Factory.
- Mediante el patrón Abstract Factory vamos a poder definir una serie de familias de clases que permitan conectarnos a las diferentes fuentes de datos.
- En resumen: tendremos un DAO por cada fuente de datos diferente que tengamos, de modo de poder usarlo de "traductor" en cada una de ellas y no tener que modificar la lógica de negocio si alguna cambia.

- 00:46:49
- Para poder utilizar la misma data al cambiar la DB debemos concurrir a DTO (data transfer object).
- Una de las problemáticas más comunes cuando desarrollamos aplicaciones, es diseñar la forma en que la información debe viajar desde la capa de servicios a as aplicaciones o capa de presentación.
- El patrón DTO tiene como finalidad crear un objeto plano con una serie de atributos que puedan ser enviados o recuperados del servidor en una sola invocación, de tal forma que un DTO puede contener información de múltiples fuentes o tablas y concentrarlas en una única clase simple.
- El DTO es un objeto plano, pero debe cumplir on las siguientes reglas: 1- no posee lógica: se utiliza para trnsferir data entre el cliente y el servidor. 2- Serializable: como los objetos viajan por la red, entonces, deben ser serializables. En javascript serializar se refiere convertir a sctring y luego al objeto nativo.
- min 56:15 --> implementar DTO

- 01:24:00
- Patrón genérico, se aplica sin importar el lenguaje de programación.
- Herramienta utilizada para limpiar el código.
- Nos permite centralizar la lógica de crear objetos en un único lugar. Esto nos permite olvidarnos de esa parte y concentrarnos en simplemente solicitar el objeto que necesitamos y luego usarlo.
- 01:20:40
- En ingeniería de software, singleton o instancia única es un patrón de diseño que permite restringir la creación de objetos pertenecientes a una clase o el valor de un tipo a un único objeto.
- Su intención consiste en garantizar que una clase solo tenga una instancia y proporcionar un punto de acceso global a ella.
- Uitlizar el backend como cliente para realizar peticiones, algo muy utilizado en las web scraping.
- Existen librerias propias de node, y externas como Axios.
- Es el encargado de abrir una sesión HTTP y de enviar la solicitud de conexión al servidor.
- Existen dos tipos principales de clientes: interno - módulo HTTP o HTTPS estandar de node. Externos - paquete de NPM como Axios o Got
- Clientes con implementación mucho mas simple que la nativa.
- Se utilizan con promesas.
..
[EN CONTRUCCIÓN]
git add .
git commit -m "mensaje"
git push -u origin master
Para generar la dependencia package.json, iniciaizar el proyecto: node_modules:
npm init -y
Relanzado de la ejecución de Node.js cuando algún archivo cambia en el proyecto.
Instalación:
npm i -g nodemon
Ejecutar proyecto de interés:
nodemon nombreArchivo.js
Group: 30975.
Teach: Iram Gutierrez
Tutor: Gonzalo Moure.
Gastón Barlocco.
Email: barlocco@hotmail.es