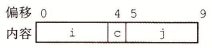
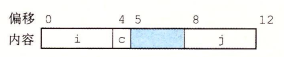
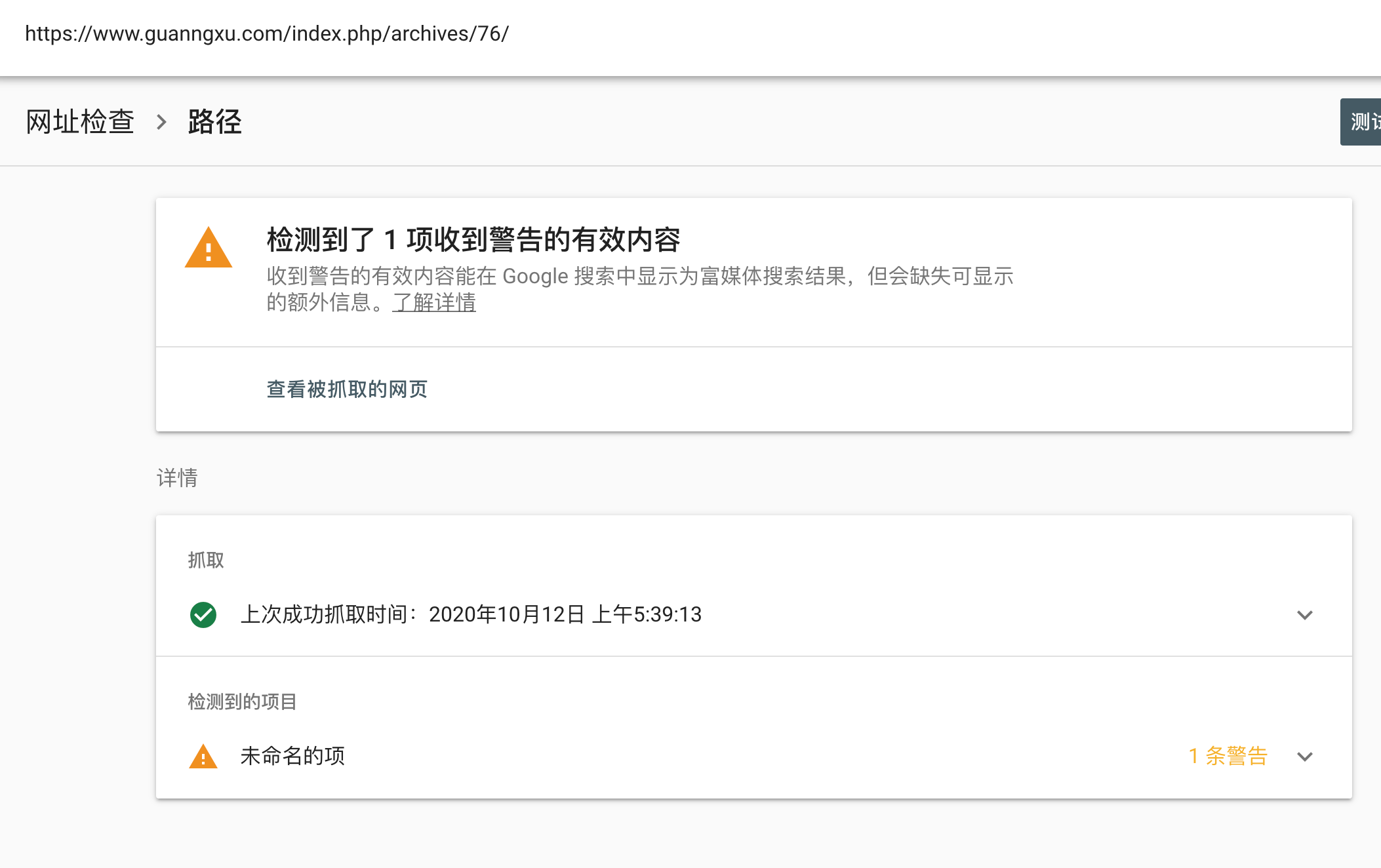
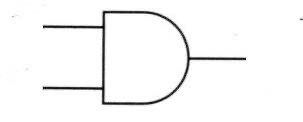
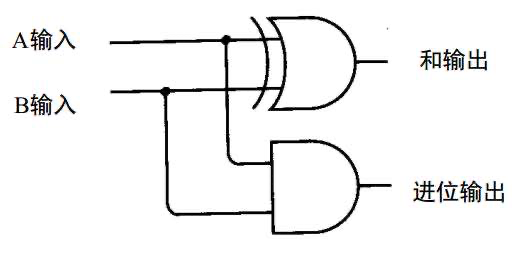
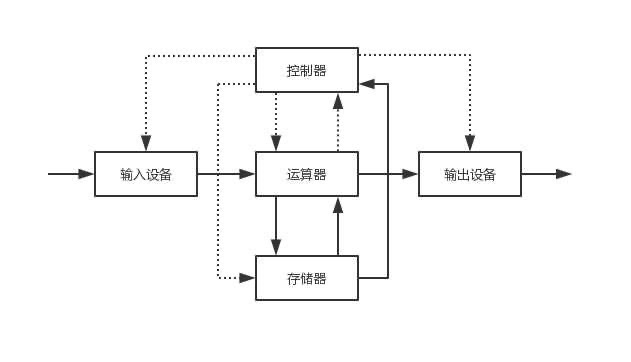
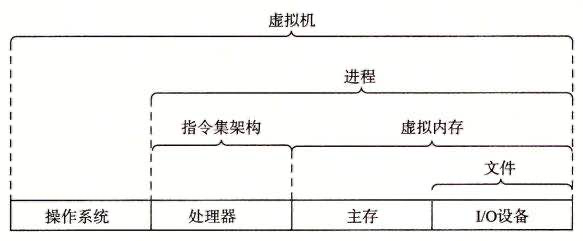
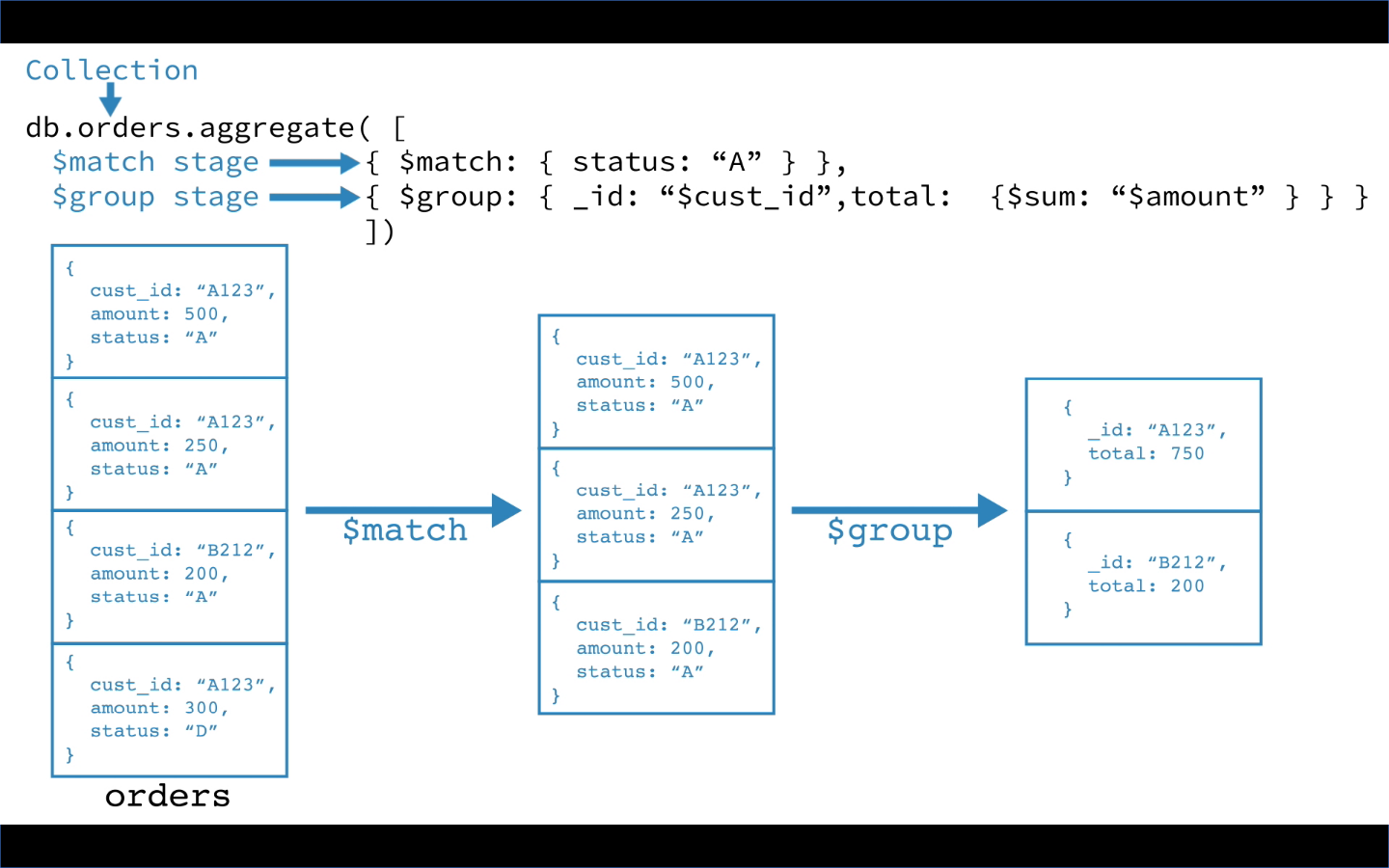
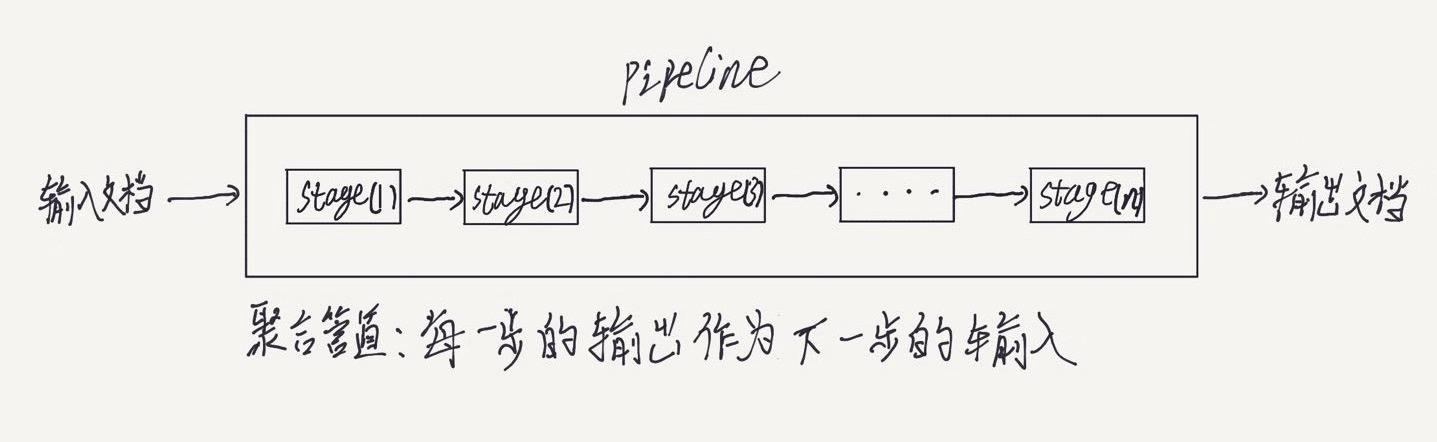
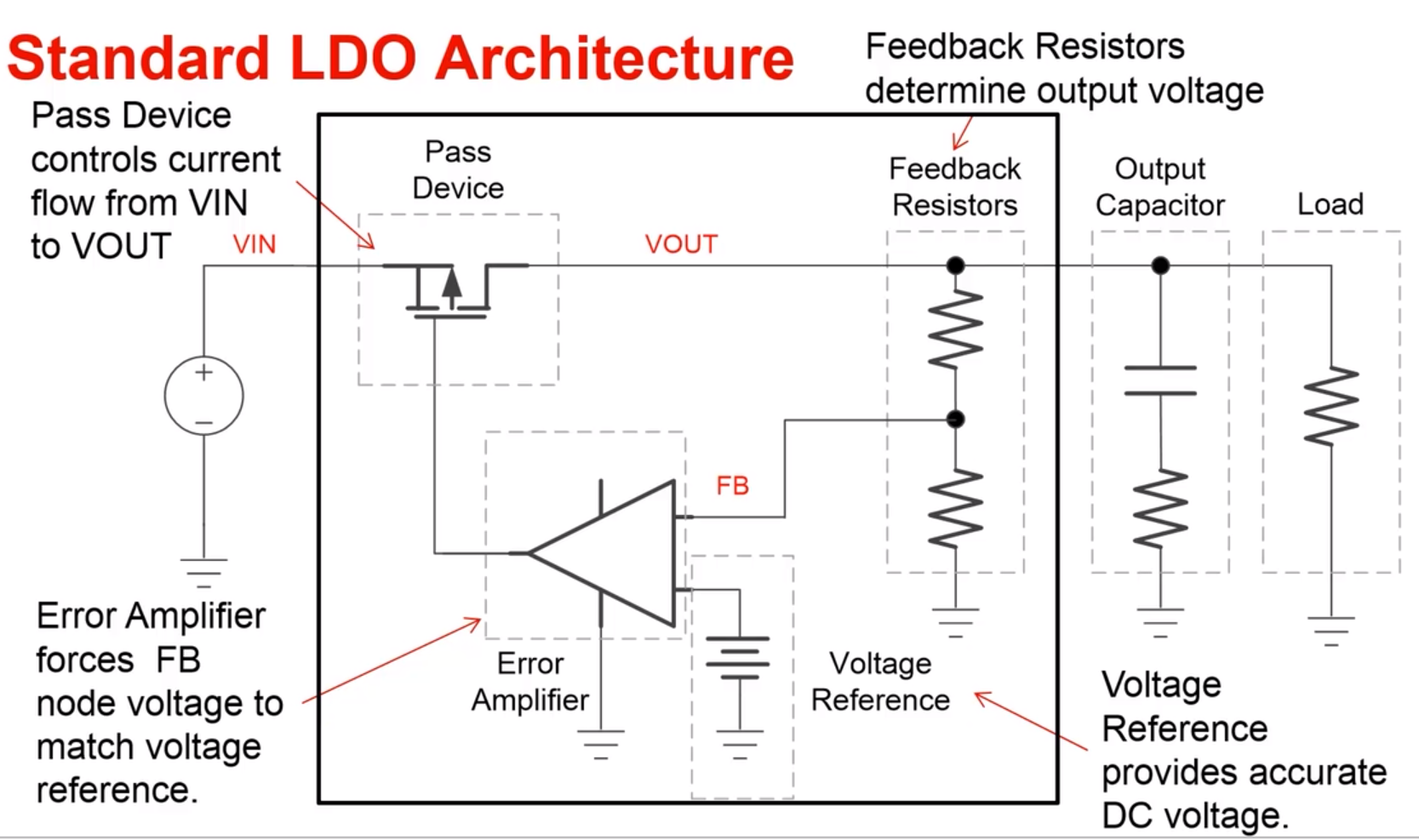
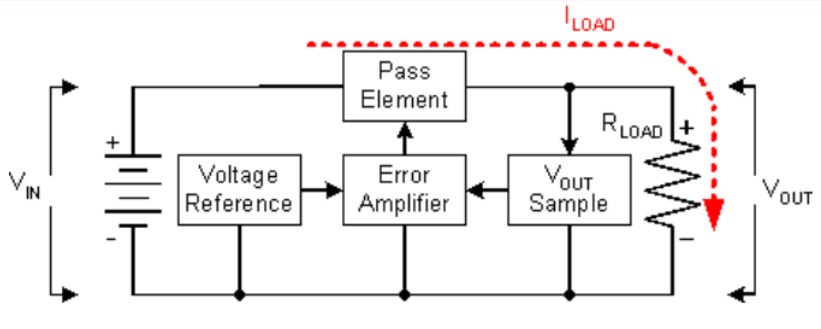
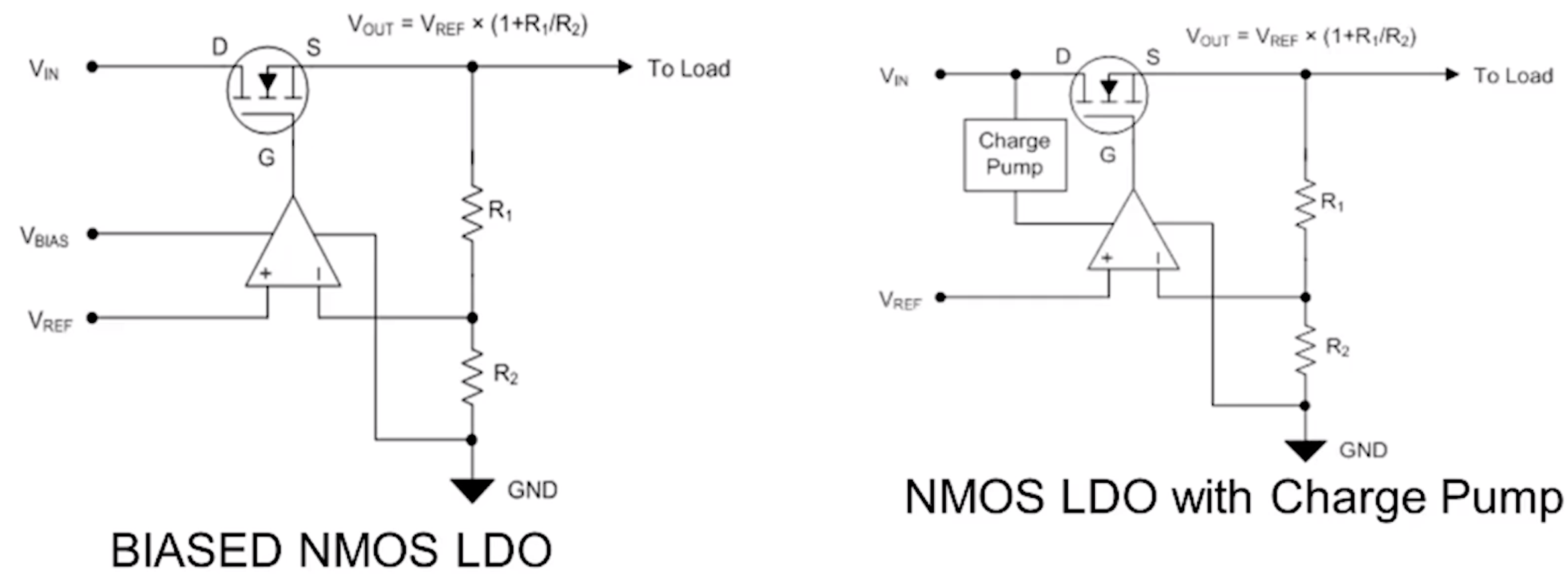
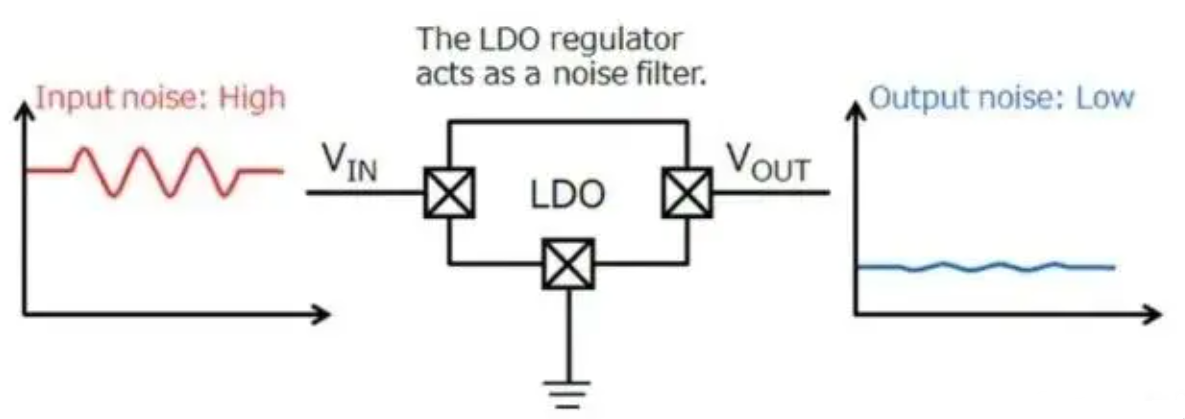
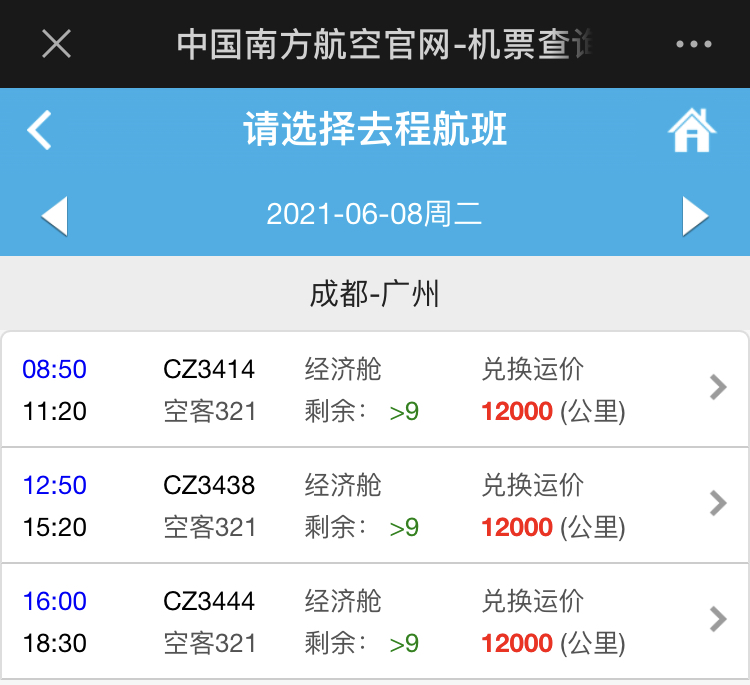
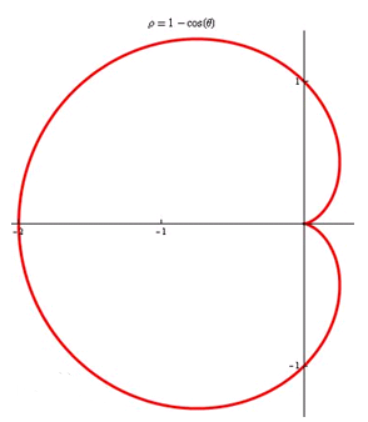
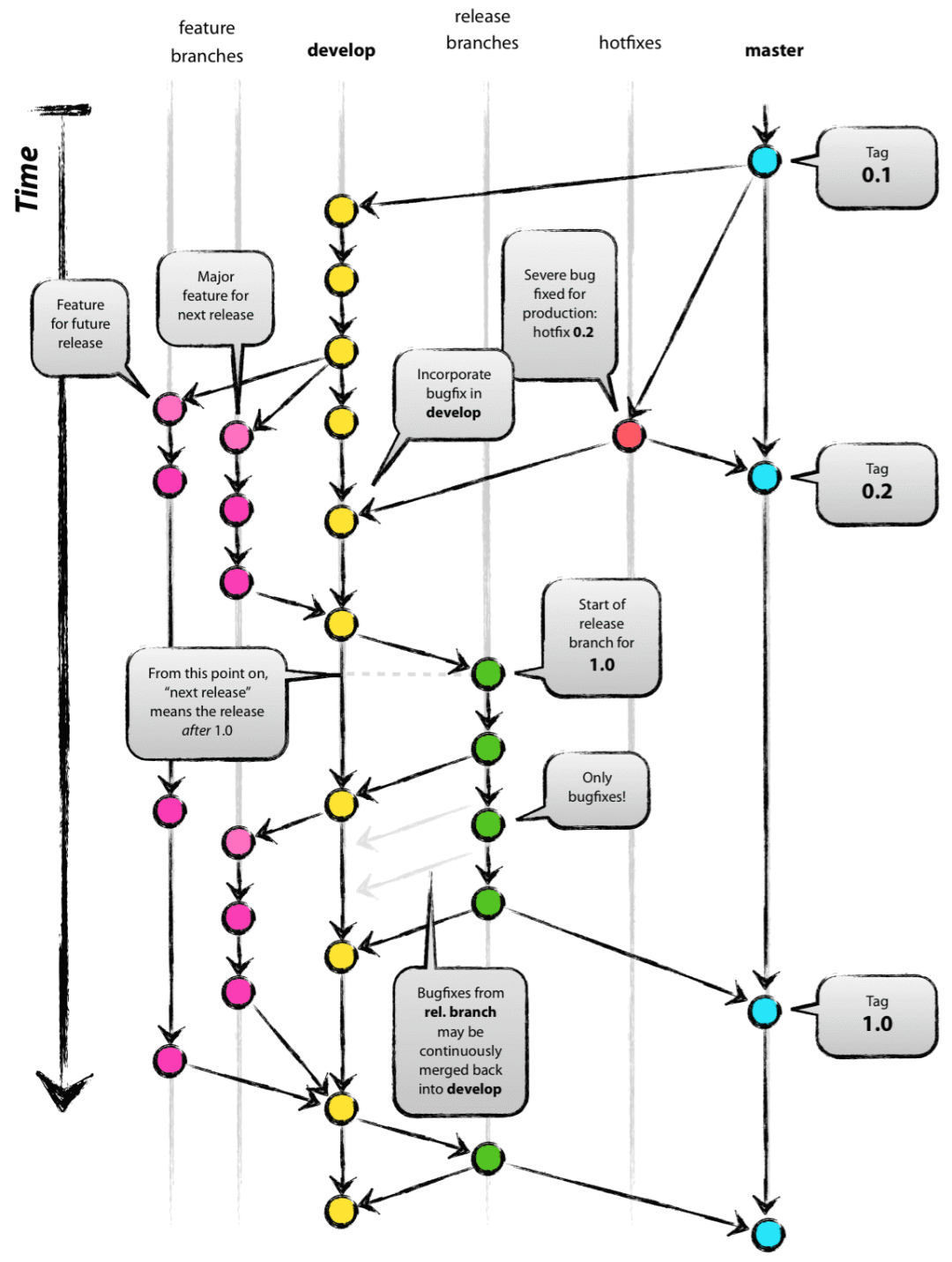
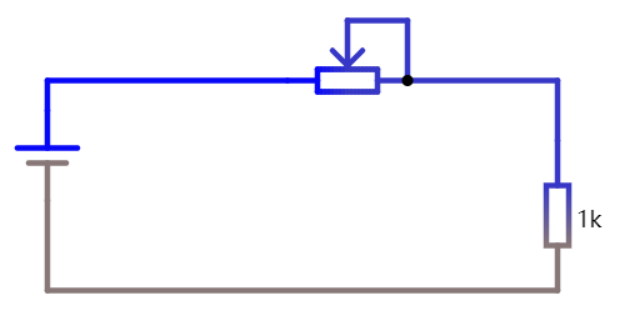
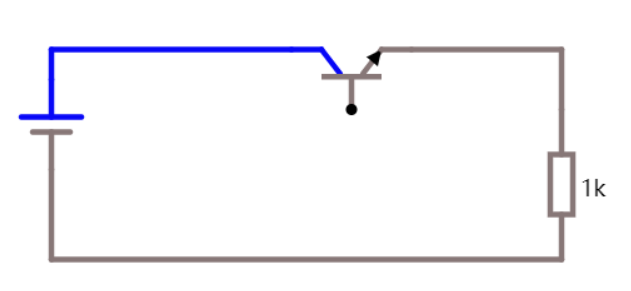
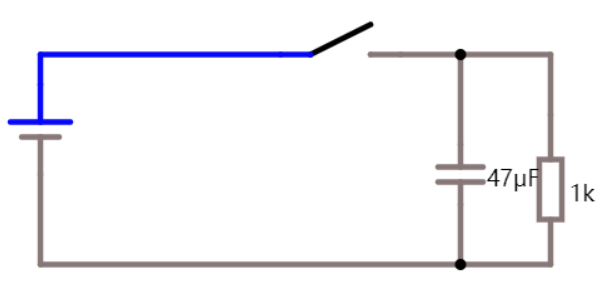
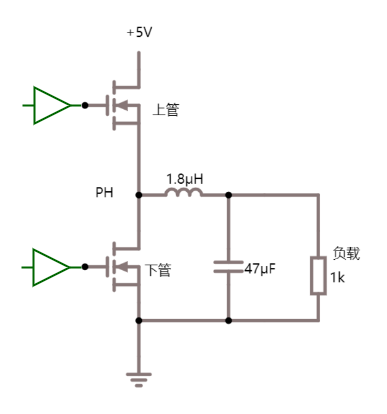
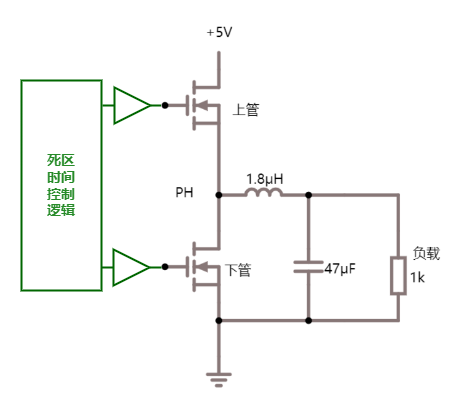
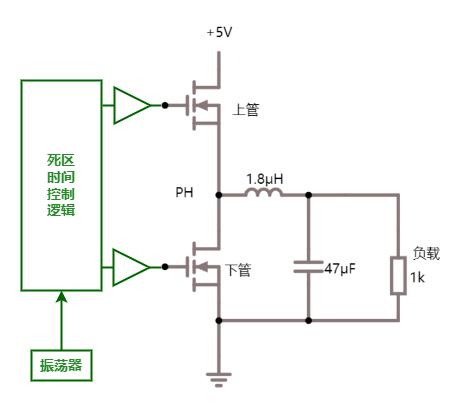
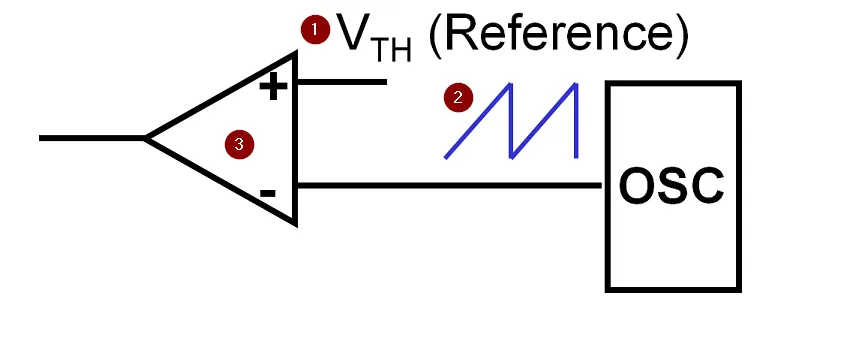
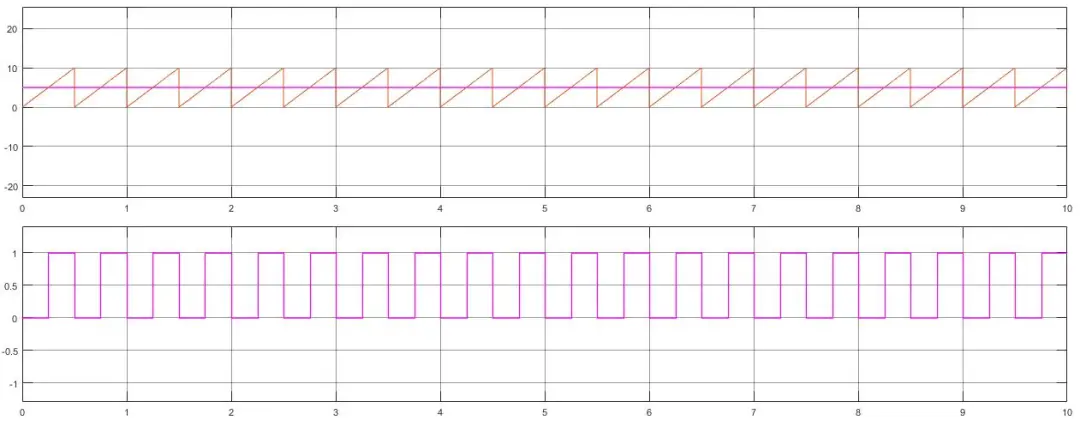
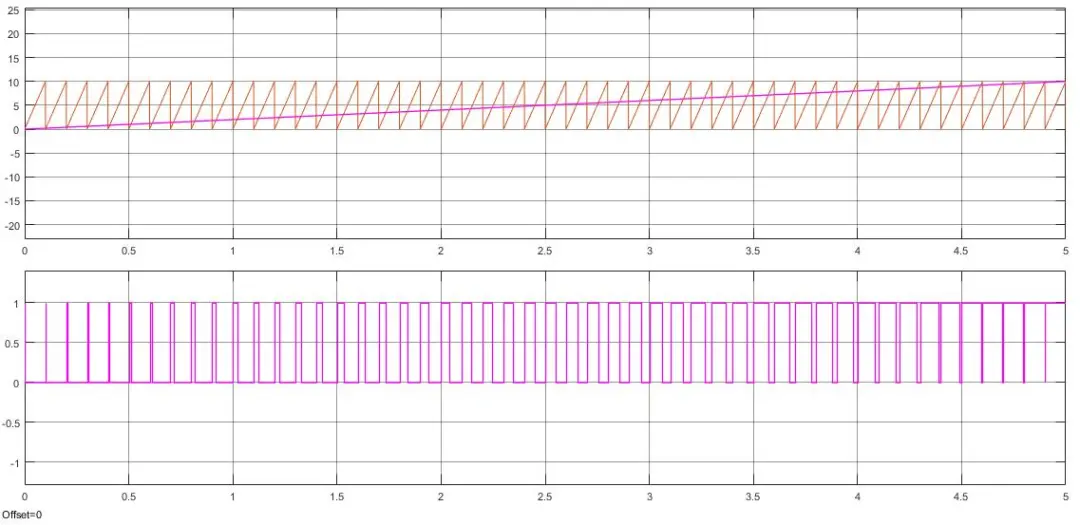
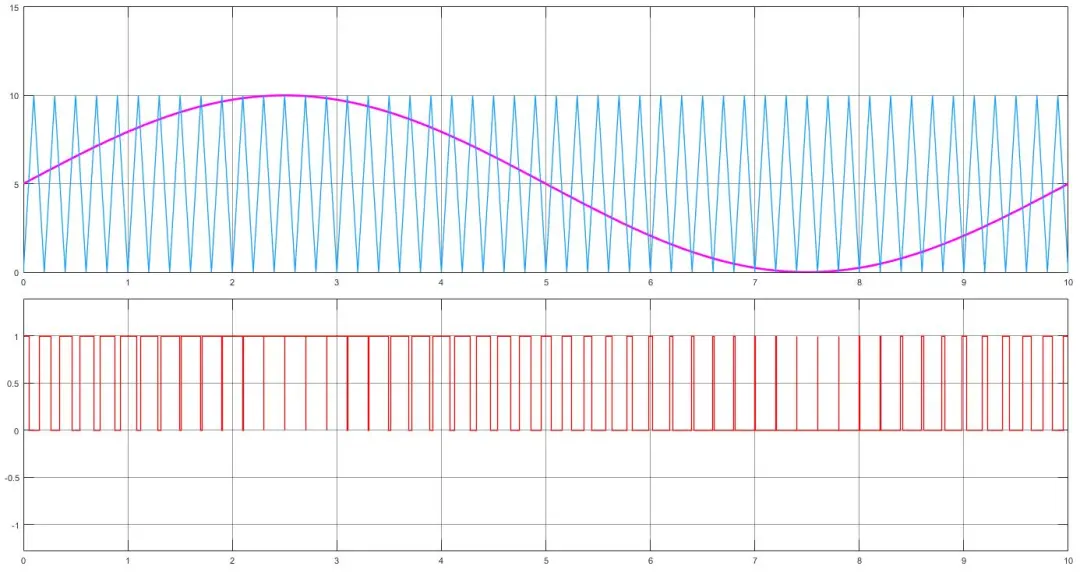
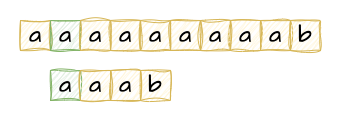
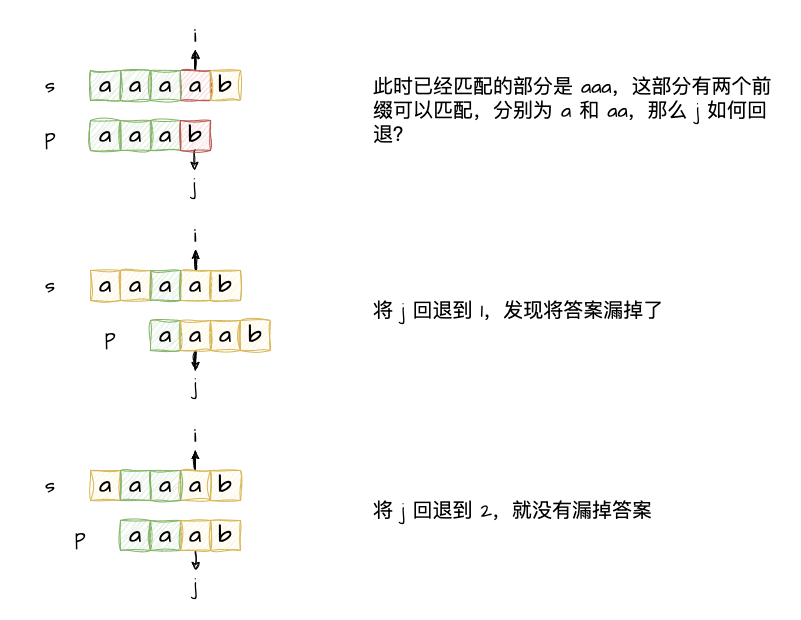
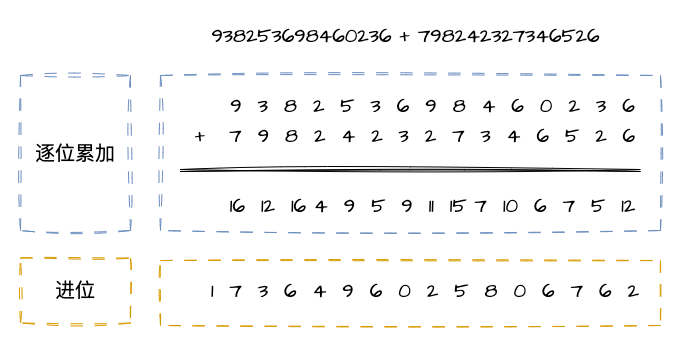
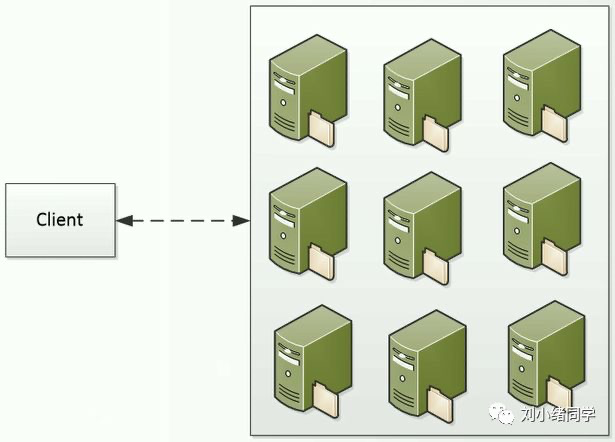
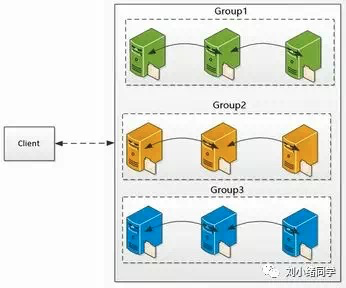
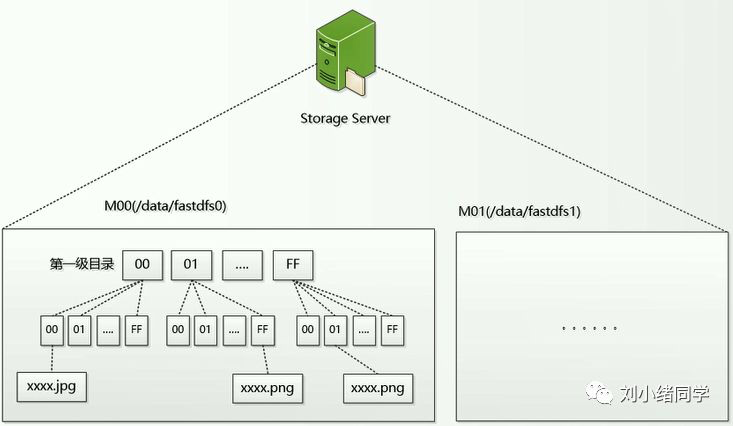
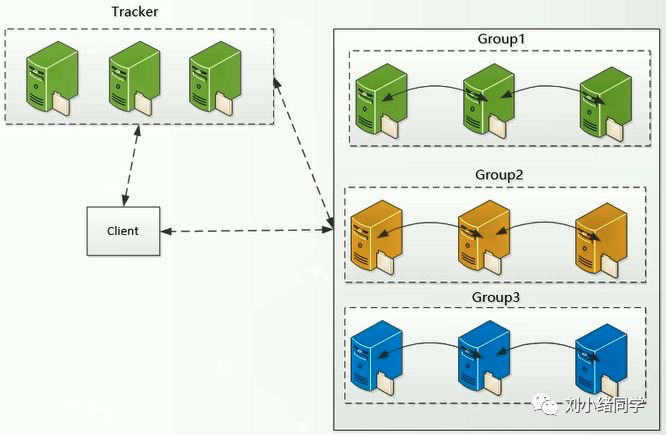
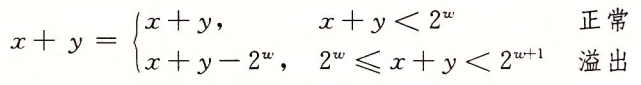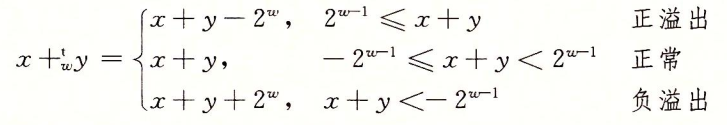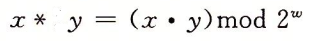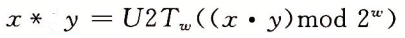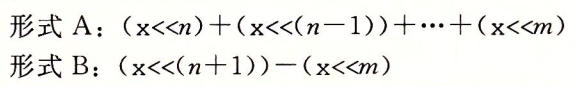比如现在有一个数组A,那么A[i]就等同于表达式* (A + i),这是一个指针运算。C 语言的一大特性就是指针,既是优点也是难点,单操作符&和*可以产生指针和简介引用指针,也就是,对于一个表示某个对象的表达式expr,&expr给出该对象地址的一个指针,而对于一个表示地址的表达式Aexpr,*Aexpr给出该地址的值。
+
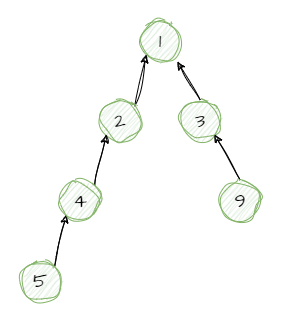
即使我们创建嵌套(多维)数组,上面的一般原则也是成立的,比如下面的例子。
+
int A[5][3];
+
+// 上面声明等价于下面
+typedef int row3_t[3];
+row3_t A[5];
+
alter table gx_comments convert to character set utf8mb4 collate utf8mb4_unicode_ci;
+alter table gx_contents convert to character set utf8mb4 collate utf8mb4_unicode_ci;
+alter table gx_fields convert to character set utf8mb4 collate utf8mb4_unicode_ci;
+alter table gx_metas convert to character set utf8mb4 collate utf8mb4_unicode_ci;
+alter table gx_options convert to character set utf8mb4 collate utf8mb4_unicode_ci;
+alter table gx_relationships convert to character set utf8mb4 collate utf8mb4_unicode_ci;
+alter table gx_users convert to character set utf8mb4 collate utf8mb4_unicode_ci;
+
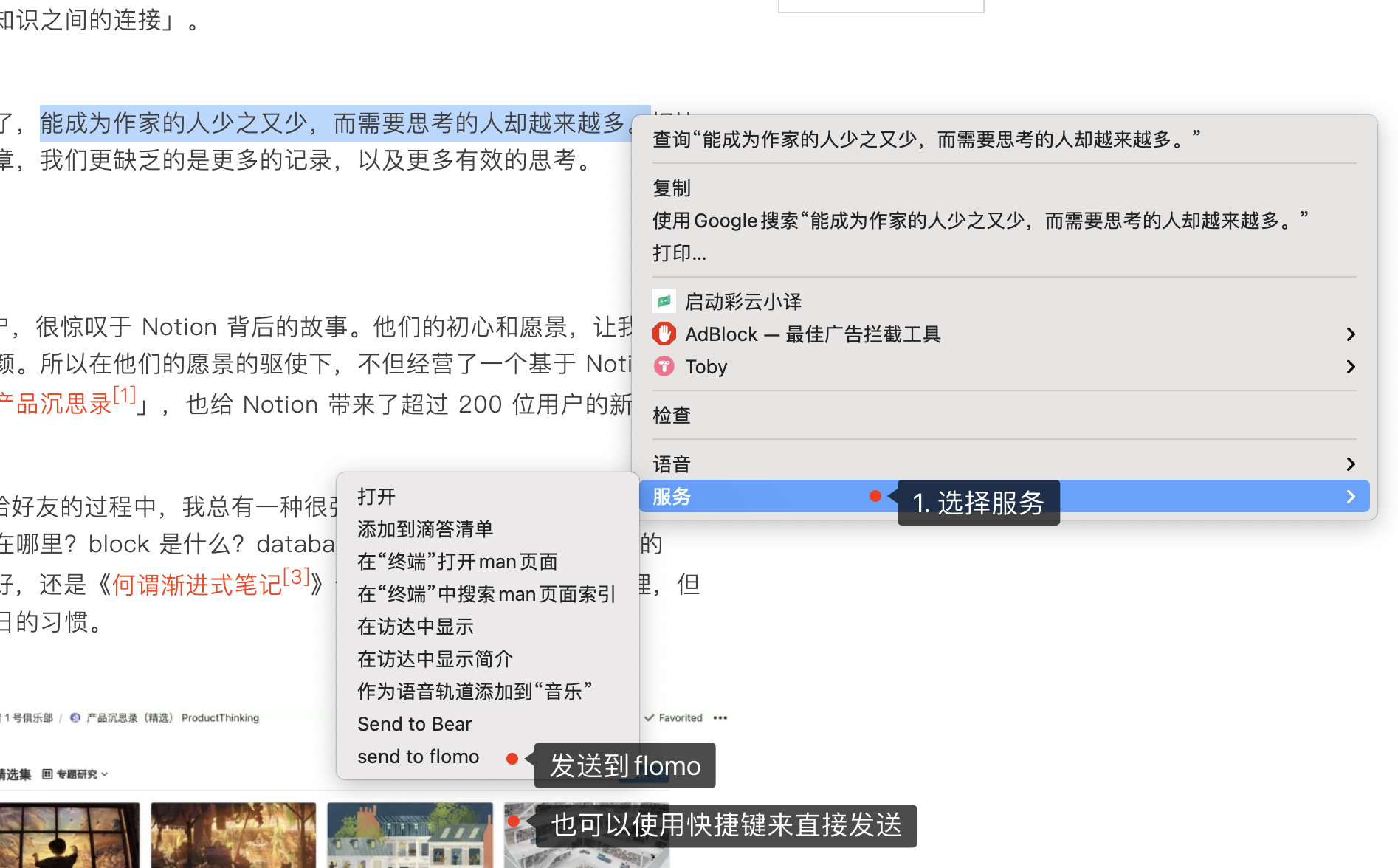
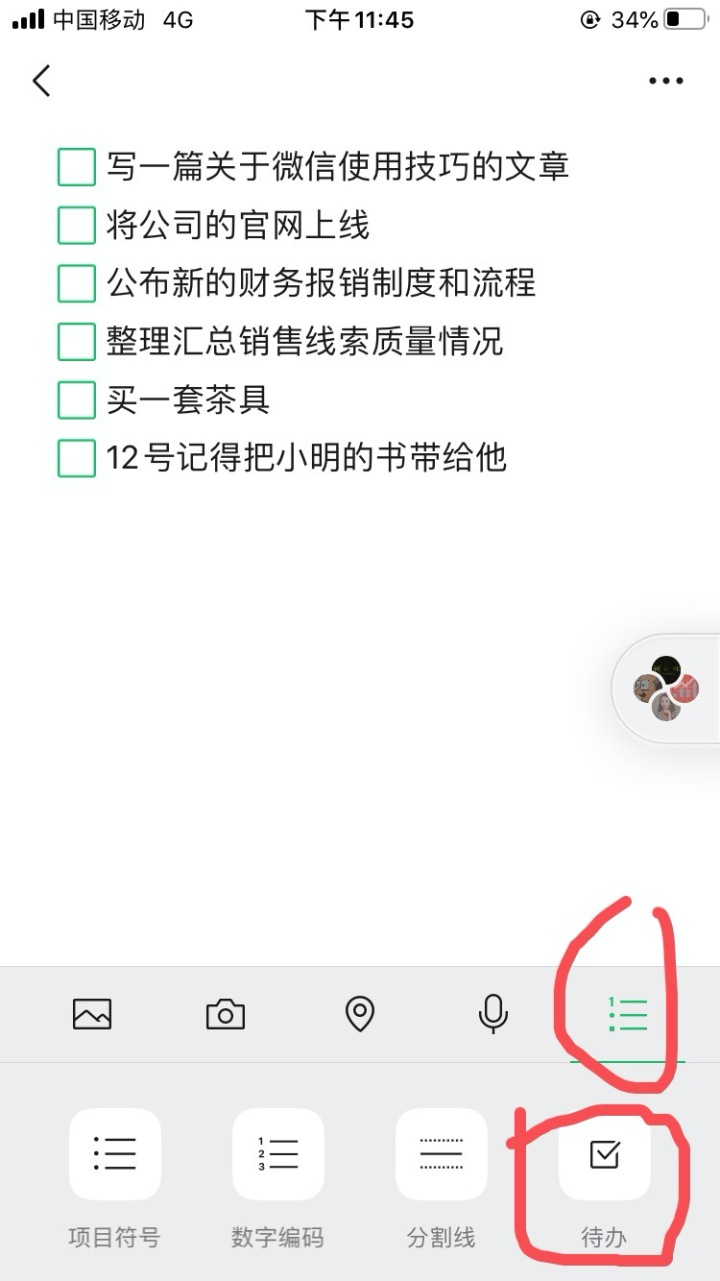
一小段时间使用知识星球做为笔记软件,但是它的搜索功能做的太弱了。一直使用到现在的笔记软件是微信,我建了只有我一个人的群,一些突然冒出来的想法、读书时的思考与摘录、todo things 都直接通过对话框发到群里。我看到有很多朋友也用了我类似的方法,选择发送到文件助手,这种方式的好处是可以借用微信强大的「查找聊天内容」功能,虽然有些鸡肋但用起来也还凑合。
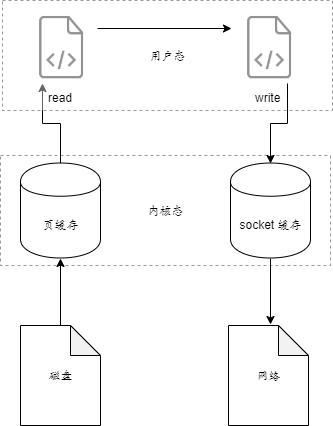
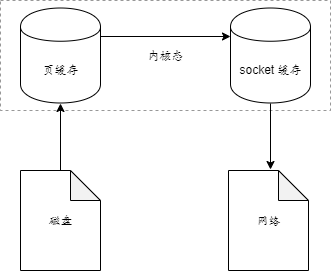
零拷贝就是一种避免 CPU 将一块存储拷贝到另一块存储的技术。它可以减少数据拷贝和共享总线操作的次数,消除传输数据在存储器之间不必要的中间拷贝次数,从而有效的提高数据传输效率,而且零拷贝技术也减少了内核态与用户态之间切换所带来的开销。进行大量的数据拷贝操作是一件简单的任务,从操作系统的角度来看,如果 CPU 一直被占用着去执行这项简单的任务,是极其浪费资源的。如果是高速网络环境下,很可能就出现这样的场景。
+ KK 是凯文·凯利的网名,他曾经担任《连线》杂志的第一任主编,是著名的科技评论家,也是畅销书《失控》的作者。去年的 4 月 28 日是他 68 岁生日,他在个人网站上发表了一篇给年轻人的 68 条建议,文章被翻译成了十几种其它语言,今年 4 月 28 日老爷子又续写了一篇给年轻人的 99 条建议,本文是给年轻人的 68 条建议中文翻译版,翻译除了借助 DeepL 机器翻译工具外,更多参考自KK 在 68 岁生日时给出的 68 条建议。
+Learn how to learn from those you disagree with, or even offend you. See if you can find the truth in what they believe.
+学着从那些你不认可甚至冒犯你的人身上学习,看看能否从他们的信仰中找到真理
+Being enthusiastic is worth 25 IQ points.
+充满热情可以抵得上 25 点智商
+Always demand a deadline. A deadline weeds out the extraneous and the ordinary. It prevents you from trying to make it perfect, so you have to make it different. Different is better.
+做任何事都应该设一个 deadline,它可以帮你排除那些无关紧要的事情,也能避免过分要求自己尽善尽美。努力去做到与众不同,差异比完美更好
+Don’t be afraid to ask a question that may sound stupid because 99% of the time everyone else is thinking of the same question and is too embarrassed to ask it.
+不要害怕自己问的问题看起来很愚蠢,99% 的情况下,其他人和你有一样的问题,只不过他们羞于问而已
+Being able to listen well is a superpower. While listening to someone you love keep asking them “Is there more?”, until there is no more.
+倾听是一种超能力,当听到你喜欢的人说话时,要不时的追问「还有吗」,直到他们没有更多的东西可讲
+A worthy goal for a year is to learn enough about a subject so that you can’t believe how ignorant you were a year earlier.
+一个有意义的年度目标是去充分了解一个学科,这样你就会对一年前的无知感到难以置信
+Gratitude will unlock all other virtues and is something you can get better at.
+感恩可以解锁其它所有的美德,也是你可以继续做的更好的一件事情
+Treating a person to a meal never fails, and is so easy to do. It’s powerful with old friends and a great way to make new friends.
+请一个人吃饭是非常简单的一件事情,不仅仅是老朋友,这也是结交新朋友的有效方式
+Don’t trust all-purpose glue.
+不要相信万能药
+Reading to your children regularly will bond you together and kickstart their imaginations.
+经常给的孩子读书不仅能巩固你们之间的感情,也能帮助孩子开启想象力
+Never use a credit card for credit. The only kind of credit, or debt, that is acceptable is debt to acquire something whose exchange value is extremely likely to increase, like in a home. The exchange value of most things diminishes or vanishes the moment you purchase them. Don’t be in debt to losers.
+永远不要用信用卡去透支。唯一可以接受的透支或负债,应该是那些通过负债有极大可能获得增值的事物,比如房屋。绝大多数事物在你买下它的那一刻就开始贬值了,别为那些没有未来的事物透支
+Pros are just amateurs who know how to gracefully recover from their mistakes.
+专业人士不过是善于从挫折中优雅爬起的菜鸟
+Extraordinary claims should require extraordinary evidence to be believed.
+要想让人相信非同寻常的观点,就需要非同寻常的证据
+Don’t be the smartest person in the room. Hangout with, and learn from, people smarter than yourself. Even better, find smart people who will disagree with you.
+别成为一群人中最聪明的那一个,和那些比你聪明的人待在一起,向他们学习。如果能找到和你观点相反的聪明人,那就更好了
+Rule of 3 in conversation. To get to the real reason, ask a person to go deeper than what they just said. Then again, and once more. The third time’s answer is close to the truth.
+对话中的「数字 3 原则」。想要找到一个人真正的意图,那就请他把刚才说的话再深入一些,如此反复直到第三遍,你就能比较接近真相了
+Don’t be the best. Be the only.
+不做最好的,去做唯一的
+Everyone is shy. Other people are waiting for you to introduce yourself to them, they are waiting for you to send them an email, they are waiting for you to ask them on a date. Go ahead.
+每个人都很害羞,其他人正等着你向他们介绍你自己,等着你给他们发送邮件,等着你约他们见面。大胆的向前走
+Don’t take it personally when someone turns you down. Assume they are like you: busy, occupied, distracted. Try again later. It’s amazing how often a second try works.
+别人拒绝你的时候不要往心里去。假设他们和你一样忙碌、腾不出手、心烦意乱,再试一次,第二次成功的几率超乎你的想象
+The purpose of a habit is to remove that action from self-negotiation. You no longer expend energy deciding whether to do it. You just do it. Good habits can range from telling the truth, to flossing.
+习惯的意义在于无需再为某类行为纠结,不用再消耗精力去觉得是否做这件事。干就完了,讲真话和使用牙线都是很好的习惯
+Promptness is a sign of respect.
+及时回应是表示尊重的一种方式
+When you are young spend at least 6 months to one year living as poor as you can, owning as little as you possibly can, eating beans and rice in a tiny room or tent, to experience what your “worst” lifestyle might be. That way any time you have to risk something in the future you won’t be afraid of the worst case scenario.
+当你年轻的时候,应该至少花半年到一年的时间,过尽可能穷的日子,拥有尽可能少的身外之物,居陋室而箪食瓢饮,体验你可能会经历的最穷困潦倒的生活。这样,在未来任何时候,你都不用担心最坏的情况
+Trust me: There is no “them”.
+相信我,没有「他们」
+
+个人理解,KK 大叔想表达的意思应该是:太阳底下无新事,每个人都是历史的参与者
+
+The more you are interested in others, the more interesting they find you. To be interesting, be interested.
+你越有兴趣了解别人,别人就会发现你越有趣,要成为有趣的人,先要对别人感兴趣
+Optimize your generosity. No one on their deathbed has ever regretted giving too much away.
+常行慷慨之事,没有人会在死的时候后悔给予的太多
+To make something good, just do it. To make something great, just re-do it, re-do it, re-do it. The secret to making fine things is in remaking them.
+想要做好一件事,干就完了。想要做一件值得称赞的事情,那就重做一遍,重做一遍,再重做一遍。制造好东西的秘诀在于不断的重做
+The Golden Rule will never fail you. It is the foundation of all other virtues.
+金科玉律永远不会让你失望,它是所有其他美德的基础
+If you are looking for something in your house, and you finally find it, when you’re done with it, don’t put it back where you found it. Put it back where you first looked for it.
+如果你正在你的房子里寻找什么东西,那么用完后不要放回你找到它的地方,而是放到你最初找它的地方
+Saving money and investing money are both good habits. Small amounts of money invested regularly for many decades without deliberation is one path to wealth.
+存钱和投资是好习惯。几十年如一日的定期进行小额投资(定投),是一条致富之路
+To make mistakes is human. To own your mistakes is divine. Nothing elevates a person higher than quickly admitting and taking personal responsibility for the mistakes you make and then fixing them fairly. If you mess up, fess up. It’s astounding how powerful this ownership is.
+犯错是人之常情,承认错误是神圣的。认错并勇于担责,再认真弥补过错,没有什么比这更可贵了。是自己搞砸的就勇于承担,这反而能彰显你的强大
+Never get involved in a land war in Asia.
+永远不要在亚洲陷入地面战争
+
+KK 大叔这句话没读懂
+
+You can obsess about serving your customers/audience/clients, or you can obsess about beating the competition. Both work, but of the two, obsessing about your customers will take you further.
+你可以专注于你的顾客、听众或客户,也可以沉迷于在竞争中获胜,这两种方法都行之有效,但是专注于服务你的客户会让你走的更远
+Show up. Keep showing up. Somebody successful said: 99% of success is just showing up.
+在场,坚持在场,某个成功人士说过:99% 的成功只不过是因为在场
+Separate the processes of creation from improving. You can’t write and edit, or sculpt and polish, or make and analyze at the same time. If you do, the editor stops the creator. While you invent, don’t select. While you sketch, don’t inspect. While you write the first draft, don’t reflect. At the start, the creator mind must be unleashed from judgement.
+将创造过程与改进过程分开,你不可能在写做的同时进行编辑,也不可能在凿刻的同时进行打磨,更不可能在制造的同时进行分析。如果你这么做,求善之心就会打断创造之意;创新时就要忘掉已有方案;勾勒草图时就不能太着眼于细处;写作时,先打草稿而不要去抠细节。在新事物之初,创意的思想必须得到无拘无束的释放
+If you are not falling down occasionally, you are just coasting.
+如果你从未跌倒过,那么你也就从未努力过
+Perhaps the most counter-intuitive truth of the universe is that the more you give to others, the more you’ll get. Understanding this is the beginning of wisdom.
+也许宇宙中最违反直觉的真理就是,你给予他人越多,你收获的就越多,这是智慧的起点
+Friends are better than money. Almost anything money can do, friends can do better. In so many ways a friend with a boat is better than owning a boat.
+朋友胜过金钱。金钱几乎可以做任何事情,但朋友可以做得更好。很多时候,自己有条船不如有个有船的朋友
+This is true: It’s hard to cheat an honest man.
+相信我,你很难欺骗一个诚实的人
+When an object is lost, 95% of the time it is hiding within arm’s reach of where it was last seen. Search in all possible locations in that radius and you’ll find it.
+当一件物品丢失时,95% 的情况下,它都藏在人们最后一次看到它时触手可及的地方。在这个半径范围内搜索所有可能的地点,你就能找到它
+You are what you do. Not what you say, not what you believe, not how you vote, but what you spend your time on.
+你做什么就是什么。不是你说什么,不是你相信什么,更不是你支持什么,而是你把时间花在了什么上
+If you lose or forget to bring a cable, adapter or charger, check with your hotel. Most hotels now have a drawer full of cables, adapters and chargers others have left behind, and probably have the one you are missing. You can often claim it after borrowing it.
+如果你遗失或忘记带电缆、适配器或充电器,不妨去问问你的酒店。大多数酒店都会有满满一抽屉的电源线、适配器和充电器,这些东西都是别人留下的,没准儿其中就有你的,酒店也并不介意你借用后随身带走
+Hatred is a curse that does not affect the hated. It only poisons the hater. Release a grudge as if it was a poison.
+仇恨是一种诅咒,但它不会影响被仇恨的人。它只会毒害仇恨者,把你的怨恨当作毒药一样丢掉吧
+There is no limit on better. Talent is distributed unfairly, but there is no limit on how much we can improve what we start with.
+没有最好,只有更好。个人的天分有高有低,但不论高低,自身的提升都永无止境
+Be prepared: When you are 90% done any large project (a house, a film, an event, an app) the rest of the myriad details will take a second 90% to complete.
+任何一项大工程(修房子、拍电影、开发 app)完成度为 90% 的时候,你都要做好心理准备:剩余的大量细节工作同样需要 90% 的时间来完成
+When you die you take absolutely nothing with you except your reputation.
+当你死的时候,除了你的名誉,你什么都无法带走
+Before you are old, attend as many funerals as you can bear, and listen. Nobody talks about the departed’s achievements. The only thing people will remember is what kind of person you were while you were achieving.
+在你年老之前,尽可能多地参加葬礼并听听别人的谈话,没有人会谈论逝者的成就,人们能记住的只有逝者在成功时是什么样的人
+For every dollar you spend purchasing something substantial, expect to pay a dollar in repairs, maintenance, or disposal by the end of its life.
+你每花一美元在实体店购买一件东西,将来都要再花一元钱去维修、保养,或是在它报废后处理掉它
+Anything real begins with the fiction of what could be. Imagination is therefore the most potent force in the universe, and a skill you can get better at. It’s the one skill in life that benefits from ignoring what everyone else knows.
+任何真实的东西都来源于虚构的想法,想象是宇宙中最强大的力量,也是你可以做的更好的一种能力,生命中可以因不知众人所知而获利
+When crisis and disaster strike, don’t waste them. No problems, no progress.
+当危机和灾难来临时,不要错过他们,没有问题就没有进步
+On vacation go to the most remote place on your itinerary first, bypassing the cities. You’ll maximize the shock of otherness in the remote, and then later you’ll welcome the familiar comforts of a city on the way back.
+度假时,先绕过城市去行程中最偏远的地方。这样你就能最大程度地体验到异域风情带给你的冲击,而在返程的路上,又可以享受熟悉的城市所带给你的舒适
+When you get an invitation to do something in the future, ask yourself: would you accept this if it was scheduled for tomorrow? Not too many promises will pass that immediacy filter.
+当你被邀请在未来的某个时间点做某件事情时,问问自己:如果是明天,你会接受邀请吗?绝大多数邀约都经不住这种迫切性检验
+Don’t say anything about someone in email you would not be comfortable saying to them directly, because eventually they will read it.
+如果一些话你不能当面对某人说出口,那么就不要在邮件中对他评头论足,因为他们最终会看到邮件
+If you desperately need a job, you are just another problem for a boss; if you can solve many of the problems the boss has right now, you are hired. To be hired, think like your boss.
+如果你只是迫切需要一份工作,那你只是老板的另一个问题;如果你能解决许多老板眼下的问题,那你自然能得到这份工作。要想得到一份工作,就要像老板一样去思考
+Art is in what you leave out.
+艺术藏身于你遗忘的地方
+Acquiring things will rarely bring you deep satisfaction. But acquiring experiences will.
+获得物品很少能给你带来深刻的满足感,但是经验却能做到
+Rule of 7 in research. You can find out anything if you are willing to go seven levels. If the first source you ask doesn’t know, ask them who you should ask next, and so on down the line. If you are willing to go to the 7th source, you’ll almost always get your answer.
+研究的「数字 7 原则」。当你愿意就一个问题深入七层时,总能找到你想要的答案。如果你问的第一层人不知道,那么就问问他们应该去找谁,如此追索下去,你几乎总能得到你的答案
+How to apologize: Quickly, specifically, sincerely.
+如何道歉:迅速、具体、真诚
+Don’t ever respond to a solicitation or a proposal on the phone. The urgency is a disguise.
+永远不要在电话上面答应一个请求或提议,所谓的急迫不过是一种假象
+When someone is nasty, rude, hateful, or mean with you, pretend they have a disease. That makes it easier to have empathy toward them which can soften the conflict.
+当有人对你粗鄙、无礼、刻薄,甚至是下流时,当他们有病就好了,这使得我们更容易对他们产生同情心,进而缓和冲突
+Eliminating clutter makes room for your true treasures.
+清理杂物,为真正重要的东西腾出空间
+You really don’t want to be famous. Read the biography of any famous person.
+你绝对不会想出名,不信的话可以随便找本名人传记读读
+Experience is overrated. When hiring, hire for aptitude, train for skills. Most really amazing or great things are done by people doing them for the first time.
+经验往往被高估了,招聘时应该多看资质,技能是可以培训的。许多令人惊奇和赞叹的事情,都是新手做出来的
+A vacation + a disaster = an adventure.
+度假 + 灾难 = 冒险
+Buying tools: Start by buying the absolute cheapest tools you can find. Upgrade the ones you use a lot. If you wind up using some tool for a job, buy the very best you can afford.
+购买工具:从最便宜的开始,升级那些使用频次高的。如果你的工具是用于工作,那么买你能买得起的最好的
+Learn how to take a 20-minute power nap without embarrassment.
+学会毫不尴尬的打 20 分钟小盹儿
+Following your bliss is a recipe for paralysis if you don’t know what you are passionate about. A better motto for most youth is “master something, anything”. Through mastery of one thing, you can drift towards extensions of that mastery that bring you more joy, and eventually discover where your bliss is.
+如果你不知道自己热爱什么,追寻心之所向往往会带你误入歧途,对年轻人来说,更好的格言是:master something, anything,在精通一件事的过程中,你可以顺着带给你更多快乐的方向继续深入,并最终发现你热爱的东西
+I’m positive that in 100 years much of what I take to be true today will be proved to be wrong, maybe even embarrassingly wrong, and I try really hard to identify what it is that I am wrong about today.
+我敢肯定,我今天认为正确的许多东西在 100 年后将被证明是错误的,甚至可能是令人尴尬的错误。而我非常努力在做的事情,就是去识别我对今天的错误认知
+Over the long term, the future is decided by optimists. To be an optimist you don’t have to ignore all the many problems we create; you just have to imagine improving our capacity to solve problems.
+从长远来说,未来由乐观主义者决定。作为一个乐观主义者并非要对我们制造的问题视而不见,而是要想象如何提升我们解决问题的能力
+The universe is conspiring behind your back to make you a success. This will be much easier to do if you embrace this pronoia.
+整个宇宙在背后密谋让你成功,要相信,天助人愿
+
+
+
+若没有在段落文字后面做特别标注,那该段落即摘录自The Almanack of Naval Ravikant: A Guide to Wealth and Happiness
+
+There’s no shortcut to smart.
+聪明没有捷径可走
+The fundamental delusion: There is something out there that will make me happy and fulfilled forever.
+最基本的错觉: 有些东西会让我永远快乐和满足
+Hard work is really overrated. How hard you work matters a lot less in the modern economy. What is underrated? Judgment. Judgment is underrated.
+在现代经济中,努力工作的重要性大大降低了。什么被低估了?判断,判断被低估了
+Spend more time making the big decisions. There are basically three really big decisions you make in your early life: where you live, who you’re with, and what you do.
+花更多的时间做重大决定。在你的早期生活中,基本上有三个真正重大的决定: 你住在哪里,你和谁在一起,你做什么
+Stay out of things that could cause you to lose all of your capital, all of your savings. Don’t gamble everything on one go. Instead, take rationally optimistic bets with big upsides.
+远离那些可能导致你失去所有资本、所有储蓄的事情。不要一次性赌光所有的东西。取而代之的是,理性乐观地下注,并从中获得巨大的好处
+Don’t partner with cynics and pessimists. Their beliefs are self-fulfilling.
+不要和愤世嫉俗者和悲观主义者合作,他们的信仰是自我实现的
+You’re not going to get rich renting out your time. You must own equity—a piece of a business—to gain your financial freedom.
+出租你的时间是不会致富的。你必须拥有股权,一项业务,才能获得财务自由
+Follow your intellectual curiosity more than whatever is “hot” right now. If your curiosity ever leads you to a place where society eventually wants to go, you’ll get paid extremely well.
+比起现在所谓的「热门」 ,应该更多地追随你的求知欲。如果你的好奇心曾经引导你到一个社会最终想要去的地方,那么你会得到非常好的报酬
+The less you want something, the less you’re thinking about it, the less you’re obsessing over it, the more you’re going to do it in a natural way.
+你想要的东西越少,你对它的思考就越少,你对它的困扰就越少,你就会越自然地去做它
+Learn to sell. Learn to build. If you can do both, you will be unstoppable.
+学会销售,学会建设,如果你能同时做到这两点,你将不可阻挡
+If you secretly despise wealth, it will elude you.
+如果你私下里鄙视财富,它就会躲避你
+Arm yourself with specific knowledge, accountability, and leverage. Specific knowledge is found by pursuing your genuine curiosity and passion rather than whatever is hot right now. Specific knowledge is knowledge you cannot be trained for.
+用具体的知识、责任感和影响力武装自己。具体的知识是通过追求你真正的好奇心和激情而不是任何现在热门的东西找到的。具体的知识是你不能被训练的知识
+If they can train you to do it, then eventually they will train a computer to do it.
+如果他们能训练你做一件事,那么最终他们会训练一台电脑来做这件事
+Apply specific knowledge, with leverage, and eventually you will get what you deserve.
+运用特定的知识,利用杠杆作用,最终你会得到你应得的东西
+You should be too busy to “do coffee” while still keeping an uncluttered calendar.
+你应该忙得没时间“喝咖啡” ,同时保持日程表整洁
+There are no get-rich-quick schemes. Those are just someone else getting rich off you.
+没有快速致富的计划,那些只是别人从你身上赚钱而已
+Code and media are permissionless leverage.
+代码和媒体是未经许可的杠杆
+People who live far below their means enjoy a freedom that people busy upgrading their lifestyles can’t fathom.
+那些生活水平远远低于自己收入的人们享受着一种自由,这是忙于提升自己的生活方式的人们所无法企及的
+By the time people realize they have enough money, they’ve lost their time and their health.
+当人们意识到他们有足够的钱时,他们已经失去了时间和健康
+To have peace of mind, you have to have peace of body first.
+为了拥有内心的平静,你必须首先拥有身体的平静
+The more secrets you have, the less happy you’re going to be.
+你的秘密越多,你就越不快乐
+No exceptions—all screen activities linked to less happiness, all non-screen activities linked to more happiness.
+毫无例外,所有的屏幕活动都与较少的快乐有关,所有的非屏幕活动都与较多的快乐有关
+Inspiration is perishable—act on it immediately.
+灵感是易逝的,所以立即付诸行动
+To make an original contribution, you have to be irrationally obsessed with something
+为了做出原创性的贡献,你必须非理性地沉迷于某些东西
+If there’s something you want to do later, do it now. There is no “later.”
+如果你以后有什么想做的事情,现在就应该去做,没有「以后」
+Courage isn’t charging into a machine gun nest. Courage is not caring what other people think.
+勇气不是冲进机关枪的巢穴,而是不在乎别人的看法
+Happiness is a choice you make and a skill you develop.
+幸福是你的选择,是你发展的一项技能
+Your brain is overvaluing the side with the short-term happiness and trying to avoid the one with short-term pain.
+你的大脑高估了短期的幸福,却试图避免短期的痛苦
+Envy is the enemy of happines.
+嫉妒是幸福的敌人
+Honesty is a core, core, core value.
+诚信是一个非常,非常,非常核心的价值观
+where you build a unique character, a unique brand, a unique mindset, which causes luck to find you.
+你要建立一个独特的个性,一个独特的品牌,一个独特的心态,这会让好运气找到你
+Figure out what you’re good at, and start helping other people with it.
+找出你擅长的东西,然后去帮助他人
+If you are a trusted, reliable, high-integrity, long-term-thinking dealmaker, when other people want to do deals but don’t know how to do them in a trustworthy manner with strangers, they will literally approach you and give you a cut of the deal just because of the integrity and reputation you’ve built up.
+如果你是一个值得信赖的、可靠的、正直的、有长远眼光的交易者,当其他人想做交易,但不知道如何以值得信赖的方式与陌生人做交易时,他们会真正地接近你,并和你进行交易,仅仅因为你已经建立起的诚信和声誉
+All benefits in life come from compound interest, whether in money, relationships, love, health, activities, or habits.
+生活中所有的好处都来自于复利,无论是在金钱、人际关系、爱情、健康、活动还是习惯上
+Productize yourself
+将自己产品化
+It’s only after you’re bored you have the great ideas. It’s never going to be when you’re stressed, or busy, running around or rushed.
+只有当你感到无聊的时候,你才会有好的想法。当你感到压力,或者忙碌,到处跑或者匆忙的时候,这些都不会发生
+Play stupid games, win stupid prizes.
+玩愚蠢的游戏,赢得愚蠢的奖品
+Clear accountability is important. Without accountability, you don’t have incentives. Without accountability, you can’t build credibility. But you take risks. You risk failure. You risk humiliation.
+明确的问责制很重要。没有责任感,你就没有动力。没有责任感,你就无法建立可信度。但是你要冒险,要冒着失败的风险,冒着被羞辱的风险
+The best jobs are neither decreed nor degreed. They are creative expressions of continuous learners in free markets.
+最好的工作既没有规定也没有程度,它们是自由市场中不断学习者的创造性表现
+Reading is faster than listening. Doing is faster than watching.
+读比听快,做比看快
+Explain what you learned to someone else. Teaching forces learning.
+向别人解释你学到了什么。教学是学习的动力
+Read what you love until you love to read.
+读你喜欢的东西,直到你喜欢阅读
+Better is the enemy of done.
+完成比完美更重要
+
+Angela Zhu 摘抄
+
+If you did not make yourself well understood, it is your problem.
+如果别人没有听懂你在说什么,一定是你的问题
+
+Angela Zhu 摘抄
+
+Inspire your people do things, not tell your people do things.
+不断激烈启发你的组员做事,而不是告诉他们做什么
+
+Angela Zhu 摘抄
+
+It does not matter what was your motivation, it only matters how this make your direct reports feel.
+你的出发点不重要,重要的是你让别人感觉你想干什么
+
+Angela Zhu 摘抄
+
+尽可能帮助和服务别人,建立信任,赢得资本
+
+Angela Zhu
+
+To learn something, you should do not reread, summarize and teach it out loud.
+要想学点东西,你不应该重读、总结和大声教出来
+
+http://www.toolkiit.com/
+
+在人生最好的年纪,应该少一点算计,多一点洒脱。遇到喜欢的人就去相处,去恋爱,不要辜负自己的时光,然后人生就会给出你更多的可能性
+
+Fenng
+
+你心里应该有爱,应该有为了爱去放弃一些东西的勇气。如果你做不到这样,那我觉得你很可悲。或者,会成为一个精致的利己主义者,体会不到人生的幸福,和真正的生活的勇气
+
+Fenng
+
+电话、视频会议,线下会议、面对面交流的时候,这是同步事件,需要一定程度上近乎实时反馈。而短信、微信消息、语音消息、留言、邮件,这些都是异步事件,用固定的节奏批量处理就是了
+
+Fenng
+
+When you are old and gray, and look back on your life, you will want to be proud of what you have done. The source of that pride won’t be the things you have acquired or the recognition you have received. It will be the lives you have touched and the difference you have made.
+当你白发苍苍、垂垂老矣、回首人生时,你需要为自己做过的事感到自豪。物质生活和满足的占有欲,都不会产生自豪。只有那些受你影响、被你改变过的人和事,才会让你产生自豪感
+
+Steven Chu 2009 年哈佛大学毕业演讲
+
+In your collaborations, always remember that “credit” is not a conserved quantity. In a successful collaboration, everybody gets 90 percent of the credit.
+合作中,不要把功劳都归在自己身上,在一场成功的合作中,每个人都应该获得 90% 的荣誉
+
+Steven Chu 2009 年哈佛大学毕业演讲
+
+
+
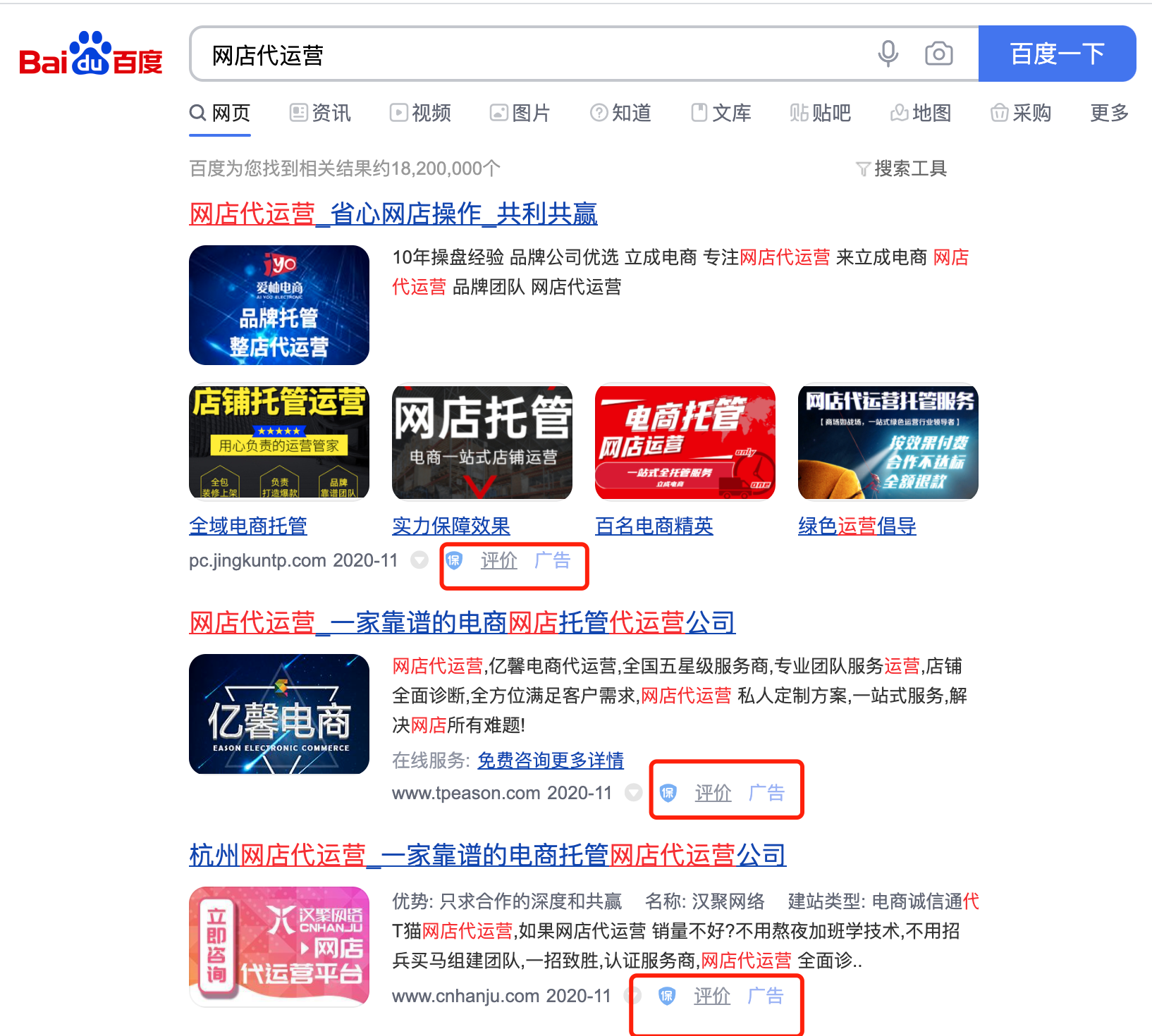
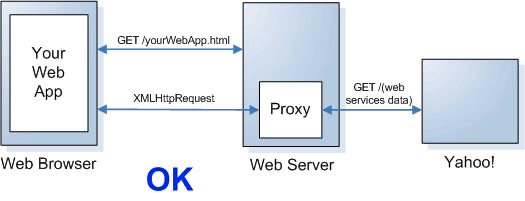
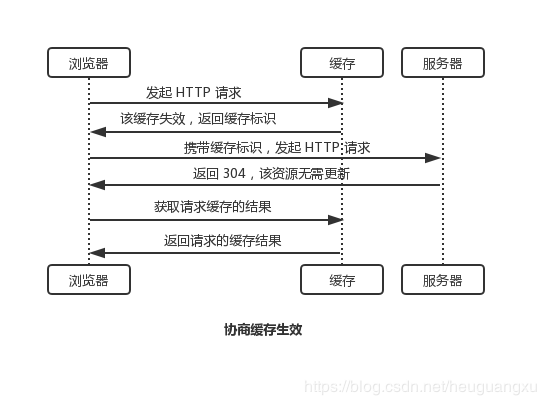
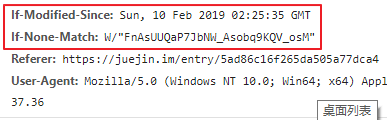
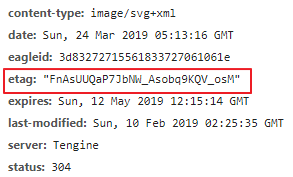
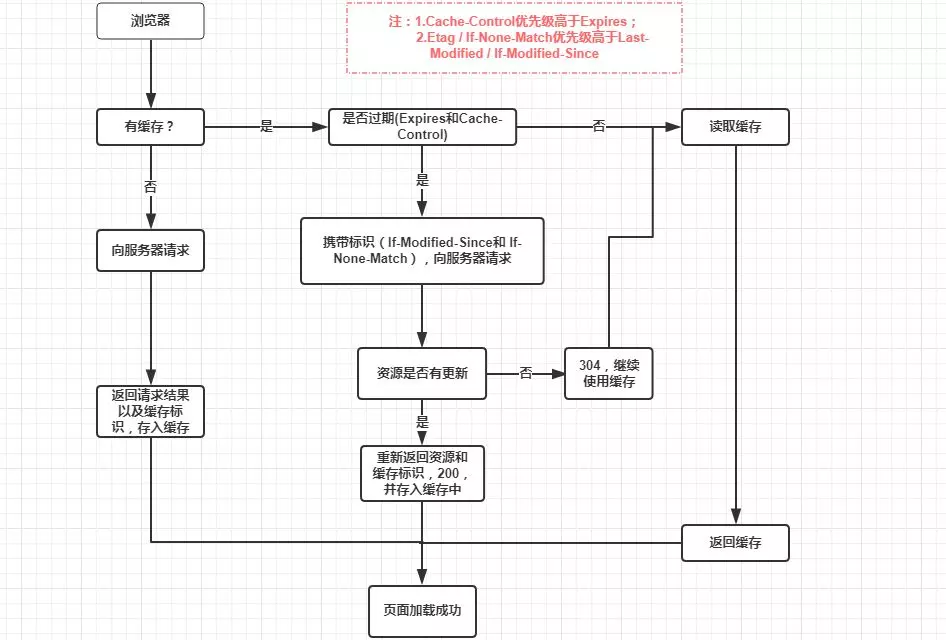
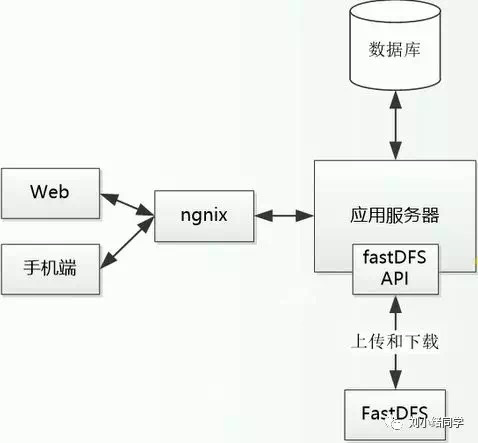
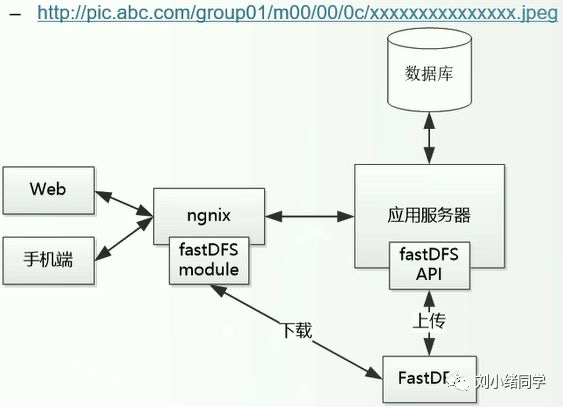
跨域请求问题是浏览器的同源策略造成的,该策略不允许执行其它网站的脚本,是浏览器施加的安全限制。什么是同源?最初是指网页 A 设置的 Cookie 不能被网页 B 打开,包括三个相同:协议、域名、端口。这个同源是从 URL 判断的,不是从 IP 判断的,如果同一个服务器对应连个域名,这两个域名是不同源的。
所有的现代浏览器都对网络连接进行了安全限制,包括 XMLHttpRequest,如果你的 web 应用程序和其使用的数据在同一个服务器,你不会遇到跨域请求问题。但是当你的 web 应用程序和 web 服务数据不在同一个服务器时,就会被浏览器限制连接了。
+
常用解决方案
+
对于跨域请求有很多的解决方案,最常用的解决方案是在你的 web 服务器上面设置代理。在设置代理之前就通过,应用程序直接去请求另一个服务器下的数据;设置代理之后,应用程序从自己的 web 服务器中请求数据,再由代理去请求数据,这样 web 服务器拿到数据之后返回给应用程序即可。从浏览器角度看,就是从同一个服务器拿的数据,并没有进行跨域请求。
我囤课最严重的时间段是也是 14 年和 15 年,网上有不少干货资源,什么 Linux、各种项目实战、计算机网络等等培训视频不计其数。那时候干的第一件事就是,上百度云把这些资源下下来,而且一个资源往往要下一周甚至更久;然后告诉自己,下周开始每天看一段视频,但是最终的结果是过去了 N 个下周,依然没有去处理这些资源。
+
现在博客、公众号也有一些不知道是为了获取更多人的关注,还是仅仅是做公益,文章末尾会标注:关注公众号,回复“XXXXX”,即可获得多少多少G的资源,这个「多少」一般是在 500 以上。我个人现在是对这类文章没有什么兴趣的,因为几百 G 甚至上千 G 的东西,我是不可能看完的,我清楚自己的能力,我也不否认可能有人有毅力能看完,那肯定是凤毛菱角了,我一个普通人不与凤毛菱角对比。
+
+参考文章:
+聊一聊契约测试 —— ThoughtWorks洞见
+契约测试
+前后端分离了,然后呢?
+
+契约测试全称为:消费者驱动契约测试,最早由 Martin Fowler 提出。契约这个词从字面上很容易理解,就是双方(多方)达成的共同协议,那又为什么需要契约测试这个东西呢?
+在当前微服务大行其道的行业背景下,越来越多的团队采用了前后端分离和微服务架构,我们知道微服务是由单一程序构成的小服务,与其它服务使用 HTTP API 进行通讯,服务可以采用不同的编程语言与数据库,微服务解决了单体应用团队协作开发成本高、系统高可用性差等等问题。
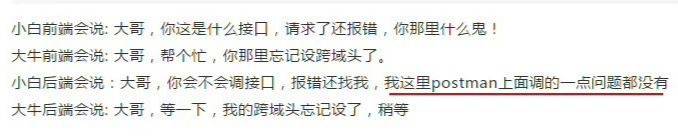
+但是微服务也引入了新的问题,假设 A 团队开发某服务并提供对应的 API,B 团队也在开发另一个服务,但是他们需要调用 A 团队的 API,为了产品的尽快发布,两个团队都争分夺秒,已经进入联调阶段了,然而出现了下面这样的尴尬情况。
+
+随着越来越多的微服务加入,它们的调用关系开始变得越来越复杂,如果每次更改都需要和所有调用该 API 的团队协商,那沟通成本也未免太大了,试想下图的沟通成本。
+
+为了保证 API 调用的准确性,我们会对外部系统的 API 进行测试,如果外部系统稳定性很差,或者请求时间很长的时候,就会导致我们的测试效率很低,当调用 API 失败时,你甚至无法确定是因为 API 被更改而导致的失败还是运行环境不稳定导致的失败。
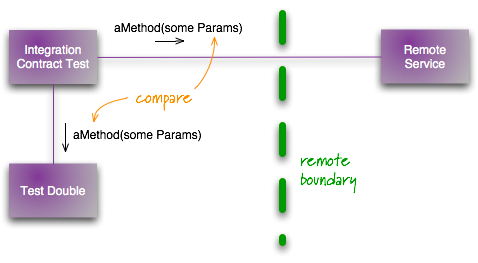
+A 团队提供的 API 不稳定,肯定会导致 B 团队效率低下,为了不影响 B 团队的进度,所以构建了测试替身,通过模拟外部 API 的响应行为来增强测试的稳定性和反应速度。
+
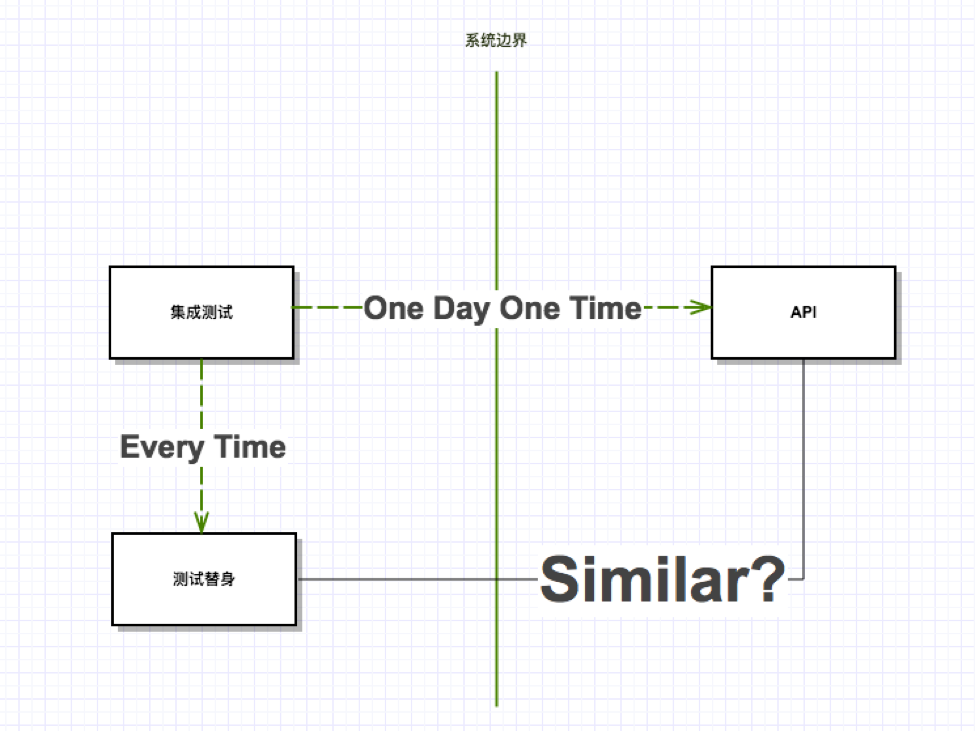
+但是这样做真的就解决问题了吗?当所有内部测试都通过时,能拍着胸脯说真正的外部 API 就一定没有变化?很简单的一个解决方案就是:部分测试使用测试替身,另一部分测试定期使用真实的外部 API,这样既保证了测试的运行效率、调用端的准确性,又能确保当真实外部系统API改变时能得到反馈。
+
+感觉剧情到这里就差不多该结束了,实际上真正的高潮部分开刚刚开始。如果外部 API 的反馈周期很长,那增加真实 API 测试间隔时间就又回到了最初的起点。现在我们回顾一下上面的方案。
+在上面的场景中,我们都是已知外部 API 功能来编写相应的功能测试,并且使用直接调用外部 API 的方式来达到测试的目的,如此就不可避免的带来了两个问题:
+
+API 调用者(消费者)对服务提供方(生产者)的更改是通过对 API 的测试来感知的;
+直接依赖于真实 API 的测试效果受限于 API 的稳定性和反映速度。
+
+解决方案首先是依赖关系解耦,去掉直接对外部 API 的依赖,而是内部和外部系统都依赖于一个双方共同认可的约定—“契约”,并且约定内容的变化会被及时感知;其次,将系统之间的集成测试,转换为由契约生成的单元测试,例如通过契约描述的内容,构建测试替身。这样,同时契约替代外部 API 成为信息变更的载体。
+前后照应一下,我们现在再来看一下消费者驱动契约测试。它有两个不可或缺的角色:消费者是服务使用方;生产者(提供者)是服务提供方。采用需求驱动(消费者驱动)的思想。契约文件(比如 json 文件)由双方共同定义规范,一般由消费者生成,生产者根据这份契约去实现。
+契约测试其中一个的典型应用场景是内外部系统之间的测试,另一个典型的例子是前后端分离后的 API 测试。行业内比较成熟的解决方案是 Swagger Specification 和 Pact Specification,这里不做展开讨论。
+我们同样可以把契约测试的思想用到代码的编写中,契约测试通过一个契约文件来解耦依赖,那么对于需要用户定义很多规则的场景,我们同样可以将这些规则像契约文件一样抽取出来,这样就降低了代码之间的耦合度。
+最后敲敲黑板,契约测试不是替代 E2E 测试的终结者,更不是单元测试的升级换代,它更偏向于服务和服务之间的 API 测试,通过解耦服务依赖关系和单元测试来加快测试的运行效率。
+
+
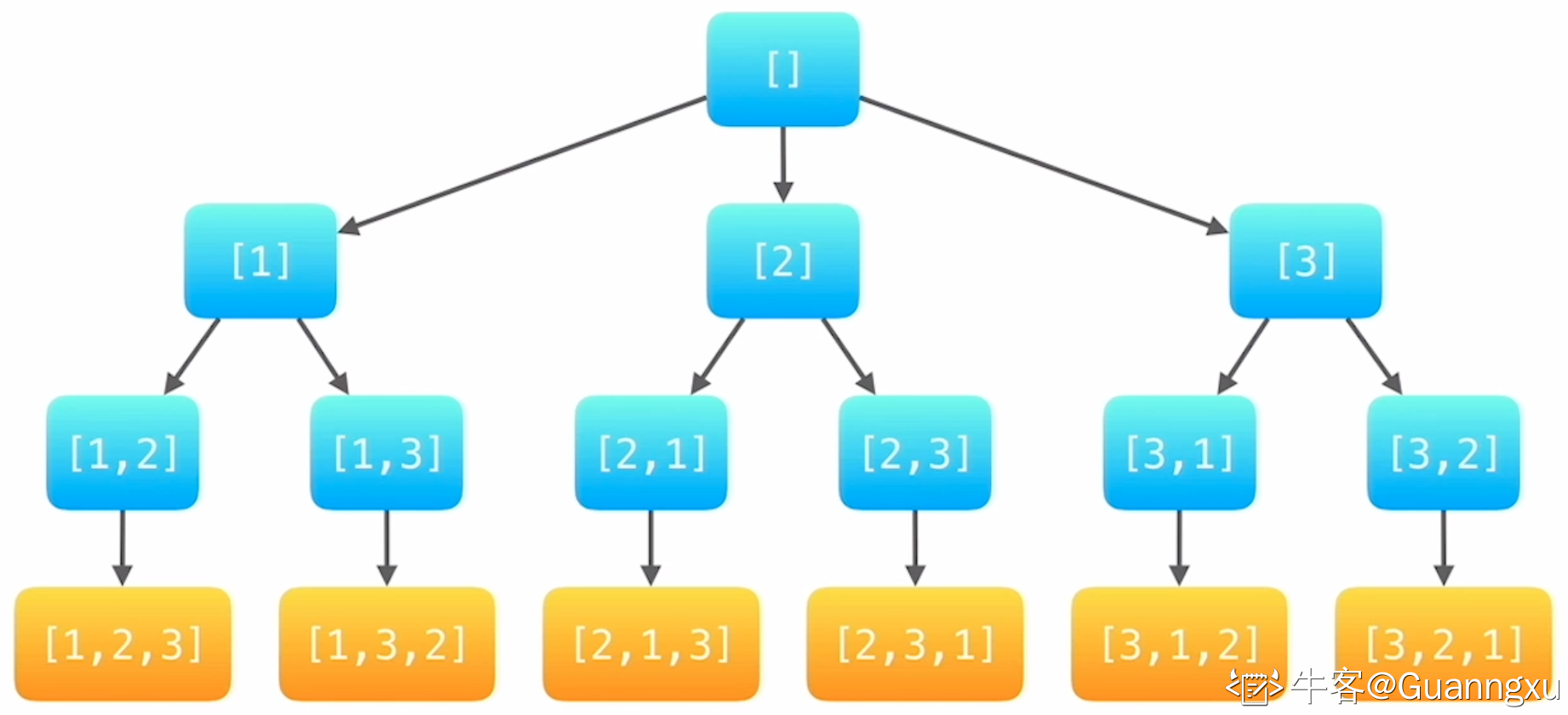
Today is Ignatius' birthday. He invites a lot of friends. Now it's dinner time. Ignatius wants to know how many tables he needs at least. You have to notice that not all the friends know each other, and all the friends do not want to stay with strangers.
+
One important rule for this problem is that if I tell you A knows B, and B knows C, that means A, B, C know each other, so they can stay in one table.
+
For example: If I tell you A knows B, B knows C, and D knows E, so A, B, C can stay in one table, and D, E have to stay in the other one. So Ignatius needs 2 tables at least.
+
输入格式
+
The input starts with an integer T(1<=T<=25) which indicate the number of test cases. Then T test cases follow. Each test case starts with two integers N and M(1<=N,M<=1000). N indicates the number of friends, the friends are marked from 1 to N. Then M lines follow. Each line consists of two integers A and B(A!=B), that means friend A and friend B know each other. There will be a blank line between two cases.
+
输出格式
+
For each test case, just output how many tables Ignatius needs at least. Do NOT print any blanks.
小希设计了一个迷宫让 Gardon 玩,首先她认为所有的通道都应该是双向连通的,就是说如果有一个通道连通了房间 A 和 B,那么既可以通过它从房间 A 走到房间 B,也可以通过它从房间 B 走到房间 A,为了提高难度,小希希望任意两个房间有且仅有一条路径可以相通(除非走了回头路)。小希现在把她的设计图给你,让你帮忙判断她的设计图是否符合她的设计思路。比如下面的例子,前两个是符合条件的,但是最后一个却有两种方法从 5 到达 8。
从产品角度讲,不得不佩服头条对人性的洞察,为了“懂你”,在自己的产品上加入推荐算法,但实际上是让你把时间花在他们产品的身上,把产品做到这种程度,不得不承认是很牛的。最近奈飞出了一步很棒的纪录片,叫做监视资本主义:智能陷阱 The Social Dilemma,片中将科技的负面清楚的呈现给我们,网络科技在某些方面已经逐渐演变为操纵社会的巨兽。
"I'm a string"本身是一个字面量,并且是一个不可变的值,如果要在这个字面量上执行一些操作,比如获取长度、访问某个字符等,那就需要将其转换为String类型,在必要的时候 js 会自动帮我们完成这种转换,也就是说我们并不需要用new String('I'm a string')来显示的创建一个对象。类似的像使用42.359.toFixed(2)时,引擎也会自动把数字转换为Number对象。
window.color = "red";
+var o = {color: "blue"};
+function sayColor() {
+ console.info(this.color);
+}
+sayColor(); // red
+sayColor.call(this); // red
+sayColor.call(window); // red
+sayColor.call(o); // blue
+sayColor.apply(o); // blue
+
设 gcd(a, b) = x,a > b;
+则有 a = mx,b = nx,m,n 均为正整数且 m > n;
+c = a - b = mx - nx = (m - n)x;
+因为 a 和 b 均为正整数,所以 c 也能被 x 整除;
+所以 gcd(a, b) = gcd(b, a-b)
+
+
具体的算法实现步骤在第一段已经有一个比较清晰的例子了,这里可以直接给出实现代码。
+
// 递归写法
+int gcd(int a, int b){
+ if(a == b){
+ return a;
+ }
+ return a > b ? gcd(a-b, b) : gcd(a, b-a);
+}
+
+// 迭代写法
+int gcd(int a, int b){
+ while(a != b){
+ a > b ? a = a - b : b = b - a;
+ }
+ return a;
+}
+
export let mergeCellsByFields = function (data: Object[], target, fields) {
+ for (let i = 0; i < fields.length; i++) {
+ let field = fields[i];
+ // 保证 field 与 i 是相对应的
+ let preMergeMap = getMergeMap(data, i);
+ let table = target.bootstrapTable();
+ mergeCells(preMergeMap, table, field);
+ }
+}
+
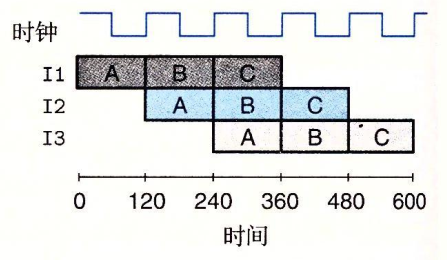
switch语句可以根据一个整数索引值进行多重分支,在处理具有多种可能结果的测试时,这种语句特别有用。为了让switch的实现更加高效,使用了一种叫做跳转表的数据结构(Radis 也是用的跳表)。跳转表是一个数组,表项 i 是一个代码段的地址,当开关情况数量比较多的时候,就会使用跳转表。
+
我们举个例子,还是采用 C 语言的形式表是控制流,要理解的是执行switch语句的关键步骤就是通过跳转表来访问代码的位置。
+
void switch_eg(long x, long n, long *dest){
+ long val = x;
+ switch(n){
+ case 100:
+ val *= 13;
+ break;
+ case 102:
+ val += 10;
+ case 103:
+ val += 11;
+ break;
+ case 104:
+ case 105:
+ val *= val;
+ break;
+ default:
+ val = 0;
+ }
+ *dest = val;
+}
+
小花是博冠古今的人,这怎么能难倒她呢。他们彼此约定,每次写信都加上密码,让信鸽传送的信件是用密文书写的。他们约定的密码是把每个字母的位置向后移动三位,比如 A → D 、 B → E ,如果他们要给对方写一句 "I love you" ,那么实际上信件上面写的就是 "L oryh brx" 。现在就算父亲把信件拦截了,他也不知道里面的内容是什么,而且也没办法修改为有效的内容,因为他不知道密码,现在小花和小明又能给对方写情书了。
Regular expression \d took 00:00:00.2141226 result: 5077/10000
+Regular expression [0-9] took 00:00:00.1357972 result: 5077/10000 63.42 % of first
+Regular expression [0123456789] took 00:00:00.1388997 result: 5077/10000 64.87 % of first
+
// Create an example of how to test for correctly formed URLs
+const tester = VerEx()
+ .startOfLine()
+ .then('http')
+ .maybe('s')
+ .then('://')
+ .maybe('www.')
+ .anythingBut(' ')
+ .endOfLine();
+
+// Create an example URL
+const testMe = 'https://www.google.com';
+
+// Use RegExp object's native test() function
+if (tester.test(testMe)) {
+ alert('We have a correct URL'); // This output will fire
+} else {
+ alert('The URL is incorrect');
+}
+
+console.log(tester); // Outputs the actual expression used: /^(http)(s)?(\:\/\/)(www\.)?([^\ ]*)$/
+
+ 以前在朋友圈提到过这样一个现象,重庆人和四川人说的都是四川话,但是大部分重庆人会说他们说的是重庆话,说「川渝是一家」的通常也都是四川人。
+在深圳也有一个很怪的现象,两个客家人谈话会用客家话,两个潮汕人谈话会用潮汕话,两个广东人谈话会用粤语,反正就是尽可能用更小众的语言。
+想了一下,故意用第三方听不懂的语言,实际上是很欠考虑的,如果是刚见面用方言寒暄几句我觉得还行,但是后面谈话就应该使用大家都能听懂的语言了。
+疫情期间大家都没法出去玩,我和老叔倒是出去爬了爬山,村里的荔枝山别人进不去,整座山就我和叔两个人,单从疫情这个角度讲,荔枝山是比大部分地方都要安全的。
+我自己可以在疫情期间爬爬山,结合我自己的感受,加上前段时间的「大奔进故宫」事件。我发现人们并不是痛恨特权,而是痛恨自己没有特权。大部人痛恨的不是腐败,痛恨的是自己没有腐败的机会。
+上面四川和深圳两个例子也差不多是出于这样的优越感,鉴于四川除了成都外,其它地方投资的回报率太低,穷地方的人总会羡慕富有的地方,说川渝一家的人大概率不是成都人。
+
+春节期间看了一本《断舍离》,它讲究的是内部的自觉自省,虽然整本书挺啰嗦的,完完全全可以用一篇几千字的文章代替,但是它传达的人生整理理念很值得参考,感兴趣的读者大人可以在微信读书中阅读此书。下面是一段摘自书中的内容。
+
+我们习惯于思考「有效性」,却往往忽略了作为「有效性」前提的「必要性」,对物品也常常陷入这样的定式思维,导致家里各种杂物堆积,这些杂物给人的压迫感,以及狭窄空间给人的阻塞感,会让人的思维变得迟钝、行动变得迟缓!
+
+借助「断舍离」的理念,我删了 400 多个微信好友,处理了一些不会再使用的家具和书籍,才发现之前一直舍不得扔的那些东西扔了对我的积极作用更大,以前写过的一篇你如果只是一直囤干货,那永远也不可能进步,核心思想和断舍离基本一致,遗憾的是自己当时写下这篇文章后,竟然不懂得延伸到其它领域。
+可能一部分人有读书摘抄语录的习惯,我个人在阅读技术书籍或是扫除我知识盲点的时候,我也会通过记笔记来加深自己的理解。想想自己强迫症式的记笔记面面俱到其实也是在浪费时间,大部分笔记自己都不会再去看第二遍的,舍弃一些不必要的形式会让自己的阅读更有收获。
+还发现自己另外一个错误观点,我不管是写字还是看书都比大部分人慢,一直都认为是自己看书的方法不对,现在才发现问题的根本原因。是因为我对具体的领域不熟悉,所以看这个领域的书籍才会速度很慢,如果对这个领域熟悉了,那一目十行甚至几十行的速度应该都可以达到。结论就是书读的少了导致读书的速度慢。
+
+推荐一部美剧——《良医》,全剧的场景基本是在医院,但有深度的内容基本都和医院无关,除了最基本的医疗科普外,更多的是对家庭、爱、职场、心理等的探讨,下面是我摘的两句台词。
+
+Whenever people want you to do someting they think is wrong, they say it’s “reality”.
+当人们想让你做他们认为错误的事时,他们总会说这就是现实。
+
+
+Very few things that are worthwhile in life come without a cost.
+人生中那些有意义的事大多是有代价的。
+
+
+
Learn how to learn from those you disagree with, or even offend you. See if you can find the truth in what they believe.
+学着从那些你不认可甚至冒犯你的人身上学习,看看能否从他们的信仰中找到真理
+
Being enthusiastic is worth 25 IQ points.
+充满热情可以抵得上 25 点智商
+
Always demand a deadline. A deadline weeds out the extraneous and the ordinary. It prevents you from trying to make it perfect, so you have to make it different. Different is better.
+做任何事都应该设一个 deadline,它可以帮你排除那些无关紧要的事情,也能避免过分要求自己尽善尽美。努力去做到与众不同,差异比完美更好
+
Don’t be afraid to ask a question that may sound stupid because 99% of the time everyone else is thinking of the same question and is too embarrassed to ask it.
+不要害怕自己问的问题看起来很愚蠢,99% 的情况下,其他人和你有一样的问题,只不过他们羞于问而已
+
Being able to listen well is a superpower. While listening to someone you love keep asking them “Is there more?”, until there is no more.
+倾听是一种超能力,当听到你喜欢的人说话时,要不时的追问「还有吗」,直到他们没有更多的东西可讲
+
A worthy goal for a year is to learn enough about a subject so that you can’t believe how ignorant you were a year earlier.
+一个有意义的年度目标是去充分了解一个学科,这样你就会对一年前的无知感到难以置信
+
Gratitude will unlock all other virtues and is something you can get better at.
+感恩可以解锁其它所有的美德,也是你可以继续做的更好的一件事情
+
Treating a person to a meal never fails, and is so easy to do. It’s powerful with old friends and a great way to make new friends.
+请一个人吃饭是非常简单的一件事情,不仅仅是老朋友,这也是结交新朋友的有效方式
+
Don’t trust all-purpose glue.
+不要相信万能药
+
Reading to your children regularly will bond you together and kickstart their imaginations.
+经常给的孩子读书不仅能巩固你们之间的感情,也能帮助孩子开启想象力
+
Never use a credit card for credit. The only kind of credit, or debt, that is acceptable is debt to acquire something whose exchange value is extremely likely to increase, like in a home. The exchange value of most things diminishes or vanishes the moment you purchase them. Don’t be in debt to losers.
+永远不要用信用卡去透支。唯一可以接受的透支或负债,应该是那些通过负债有极大可能获得增值的事物,比如房屋。绝大多数事物在你买下它的那一刻就开始贬值了,别为那些没有未来的事物透支
+
Pros are just amateurs who know how to gracefully recover from their mistakes.
+专业人士不过是善于从挫折中优雅爬起的菜鸟
+
Extraordinary claims should require extraordinary evidence to be believed.
+要想让人相信非同寻常的观点,就需要非同寻常的证据
+
Don’t be the smartest person in the room. Hangout with, and learn from, people smarter than yourself. Even better, find smart people who will disagree with you.
+别成为一群人中最聪明的那一个,和那些比你聪明的人待在一起,向他们学习。如果能找到和你观点相反的聪明人,那就更好了
+
Rule of 3 in conversation. To get to the real reason, ask a person to go deeper than what they just said. Then again, and once more. The third time’s answer is close to the truth.
+对话中的「数字 3 原则」。想要找到一个人真正的意图,那就请他把刚才说的话再深入一些,如此反复直到第三遍,你就能比较接近真相了
+
Don’t be the best. Be the only.
+不做最好的,去做唯一的
+
Everyone is shy. Other people are waiting for you to introduce yourself to them, they are waiting for you to send them an email, they are waiting for you to ask them on a date. Go ahead.
+每个人都很害羞,其他人正等着你向他们介绍你自己,等着你给他们发送邮件,等着你约他们见面。大胆的向前走
+
Don’t take it personally when someone turns you down. Assume they are like you: busy, occupied, distracted. Try again later. It’s amazing how often a second try works.
+别人拒绝你的时候不要往心里去。假设他们和你一样忙碌、腾不出手、心烦意乱,再试一次,第二次成功的几率超乎你的想象
+
The purpose of a habit is to remove that action from self-negotiation. You no longer expend energy deciding whether to do it. You just do it. Good habits can range from telling the truth, to flossing.
+习惯的意义在于无需再为某类行为纠结,不用再消耗精力去觉得是否做这件事。干就完了,讲真话和使用牙线都是很好的习惯
+
Promptness is a sign of respect.
+及时回应是表示尊重的一种方式
+
When you are young spend at least 6 months to one year living as poor as you can, owning as little as you possibly can, eating beans and rice in a tiny room or tent, to experience what your “worst” lifestyle might be. That way any time you have to risk something in the future you won’t be afraid of the worst case scenario.
+当你年轻的时候,应该至少花半年到一年的时间,过尽可能穷的日子,拥有尽可能少的身外之物,居陋室而箪食瓢饮,体验你可能会经历的最穷困潦倒的生活。这样,在未来任何时候,你都不用担心最坏的情况
+
Trust me: There is no “them”.
+相信我,没有「他们」
+
+
个人理解,KK 大叔想表达的意思应该是:太阳底下无新事,每个人都是历史的参与者
+
+
The more you are interested in others, the more interesting they find you. To be interesting, be interested.
+你越有兴趣了解别人,别人就会发现你越有趣,要成为有趣的人,先要对别人感兴趣
+
Optimize your generosity. No one on their deathbed has ever regretted giving too much away.
+常行慷慨之事,没有人会在死的时候后悔给予的太多
+
To make something good, just do it. To make something great, just re-do it, re-do it, re-do it. The secret to making fine things is in remaking them.
+想要做好一件事,干就完了。想要做一件值得称赞的事情,那就重做一遍,重做一遍,再重做一遍。制造好东西的秘诀在于不断的重做
+
The Golden Rule will never fail you. It is the foundation of all other virtues.
+金科玉律永远不会让你失望,它是所有其他美德的基础
+
If you are looking for something in your house, and you finally find it, when you’re done with it, don’t put it back where you found it. Put it back where you first looked for it.
+如果你正在你的房子里寻找什么东西,那么用完后不要放回你找到它的地方,而是放到你最初找它的地方
+
Saving money and investing money are both good habits. Small amounts of money invested regularly for many decades without deliberation is one path to wealth.
+存钱和投资是好习惯。几十年如一日的定期进行小额投资(定投),是一条致富之路
+
To make mistakes is human. To own your mistakes is divine. Nothing elevates a person higher than quickly admitting and taking personal responsibility for the mistakes you make and then fixing them fairly. If you mess up, fess up. It’s astounding how powerful this ownership is.
+犯错是人之常情,承认错误是神圣的。认错并勇于担责,再认真弥补过错,没有什么比这更可贵了。是自己搞砸的就勇于承担,这反而能彰显你的强大
+
Never get involved in a land war in Asia.
+永远不要在亚洲陷入地面战争
+
+
KK 大叔这句话没读懂
+
+
You can obsess about serving your customers/audience/clients, or you can obsess about beating the competition. Both work, but of the two, obsessing about your customers will take you further.
+你可以专注于你的顾客、听众或客户,也可以沉迷于在竞争中获胜,这两种方法都行之有效,但是专注于服务你的客户会让你走的更远
+
Show up. Keep showing up. Somebody successful said: 99% of success is just showing up.
+在场,坚持在场,某个成功人士说过:99% 的成功只不过是因为在场
+
Separate the processes of creation from improving. You can’t write and edit, or sculpt and polish, or make and analyze at the same time. If you do, the editor stops the creator. While you invent, don’t select. While you sketch, don’t inspect. While you write the first draft, don’t reflect. At the start, the creator mind must be unleashed from judgement.
+将创造过程与改进过程分开,你不可能在写做的同时进行编辑,也不可能在凿刻的同时进行打磨,更不可能在制造的同时进行分析。如果你这么做,求善之心就会打断创造之意;创新时就要忘掉已有方案;勾勒草图时就不能太着眼于细处;写作时,先打草稿而不要去抠细节。在新事物之初,创意的思想必须得到无拘无束的释放
+
If you are not falling down occasionally, you are just coasting.
+如果你从未跌倒过,那么你也就从未努力过
+
Perhaps the most counter-intuitive truth of the universe is that the more you give to others, the more you’ll get. Understanding this is the beginning of wisdom.
+也许宇宙中最违反直觉的真理就是,你给予他人越多,你收获的就越多,这是智慧的起点
+
Friends are better than money. Almost anything money can do, friends can do better. In so many ways a friend with a boat is better than owning a boat.
+朋友胜过金钱。金钱几乎可以做任何事情,但朋友可以做得更好。很多时候,自己有条船不如有个有船的朋友
+
This is true: It’s hard to cheat an honest man.
+相信我,你很难欺骗一个诚实的人
+
When an object is lost, 95% of the time it is hiding within arm’s reach of where it was last seen. Search in all possible locations in that radius and you’ll find it.
+当一件物品丢失时,95% 的情况下,它都藏在人们最后一次看到它时触手可及的地方。在这个半径范围内搜索所有可能的地点,你就能找到它
+
You are what you do. Not what you say, not what you believe, not how you vote, but what you spend your time on.
+你做什么就是什么。不是你说什么,不是你相信什么,更不是你支持什么,而是你把时间花在了什么上
+
If you lose or forget to bring a cable, adapter or charger, check with your hotel. Most hotels now have a drawer full of cables, adapters and chargers others have left behind, and probably have the one you are missing. You can often claim it after borrowing it.
+如果你遗失或忘记带电缆、适配器或充电器,不妨去问问你的酒店。大多数酒店都会有满满一抽屉的电源线、适配器和充电器,这些东西都是别人留下的,没准儿其中就有你的,酒店也并不介意你借用后随身带走
+
Hatred is a curse that does not affect the hated. It only poisons the hater. Release a grudge as if it was a poison.
+仇恨是一种诅咒,但它不会影响被仇恨的人。它只会毒害仇恨者,把你的怨恨当作毒药一样丢掉吧
+
There is no limit on better. Talent is distributed unfairly, but there is no limit on how much we can improve what we start with.
+没有最好,只有更好。个人的天分有高有低,但不论高低,自身的提升都永无止境
+
Be prepared: When you are 90% done any large project (a house, a film, an event, an app) the rest of the myriad details will take a second 90% to complete.
+任何一项大工程(修房子、拍电影、开发 app)完成度为 90% 的时候,你都要做好心理准备:剩余的大量细节工作同样需要 90% 的时间来完成
+
When you die you take absolutely nothing with you except your reputation.
+当你死的时候,除了你的名誉,你什么都无法带走
+
Before you are old, attend as many funerals as you can bear, and listen. Nobody talks about the departed’s achievements. The only thing people will remember is what kind of person you were while you were achieving.
+在你年老之前,尽可能多地参加葬礼并听听别人的谈话,没有人会谈论逝者的成就,人们能记住的只有逝者在成功时是什么样的人
+
For every dollar you spend purchasing something substantial, expect to pay a dollar in repairs, maintenance, or disposal by the end of its life.
+你每花一美元在实体店购买一件东西,将来都要再花一元钱去维修、保养,或是在它报废后处理掉它
+
Anything real begins with the fiction of what could be. Imagination is therefore the most potent force in the universe, and a skill you can get better at. It’s the one skill in life that benefits from ignoring what everyone else knows.
+任何真实的东西都来源于虚构的想法,想象是宇宙中最强大的力量,也是你可以做的更好的一种能力,生命中可以因不知众人所知而获利
+
When crisis and disaster strike, don’t waste them. No problems, no progress.
+当危机和灾难来临时,不要错过他们,没有问题就没有进步
+
On vacation go to the most remote place on your itinerary first, bypassing the cities. You’ll maximize the shock of otherness in the remote, and then later you’ll welcome the familiar comforts of a city on the way back.
+度假时,先绕过城市去行程中最偏远的地方。这样你就能最大程度地体验到异域风情带给你的冲击,而在返程的路上,又可以享受熟悉的城市所带给你的舒适
+
When you get an invitation to do something in the future, ask yourself: would you accept this if it was scheduled for tomorrow? Not too many promises will pass that immediacy filter.
+当你被邀请在未来的某个时间点做某件事情时,问问自己:如果是明天,你会接受邀请吗?绝大多数邀约都经不住这种迫切性检验
+
Don’t say anything about someone in email you would not be comfortable saying to them directly, because eventually they will read it.
+如果一些话你不能当面对某人说出口,那么就不要在邮件中对他评头论足,因为他们最终会看到邮件
+
If you desperately need a job, you are just another problem for a boss; if you can solve many of the problems the boss has right now, you are hired. To be hired, think like your boss.
+如果你只是迫切需要一份工作,那你只是老板的另一个问题;如果你能解决许多老板眼下的问题,那你自然能得到这份工作。要想得到一份工作,就要像老板一样去思考
+
Art is in what you leave out.
+艺术藏身于你遗忘的地方
+
Acquiring things will rarely bring you deep satisfaction. But acquiring experiences will.
+获得物品很少能给你带来深刻的满足感,但是经验却能做到
+
Rule of 7 in research. You can find out anything if you are willing to go seven levels. If the first source you ask doesn’t know, ask them who you should ask next, and so on down the line. If you are willing to go to the 7th source, you’ll almost always get your answer.
+研究的「数字 7 原则」。当你愿意就一个问题深入七层时,总能找到你想要的答案。如果你问的第一层人不知道,那么就问问他们应该去找谁,如此追索下去,你几乎总能得到你的答案
+
How to apologize: Quickly, specifically, sincerely.
+如何道歉:迅速、具体、真诚
+
Don’t ever respond to a solicitation or a proposal on the phone. The urgency is a disguise.
+永远不要在电话上面答应一个请求或提议,所谓的急迫不过是一种假象
+
When someone is nasty, rude, hateful, or mean with you, pretend they have a disease. That makes it easier to have empathy toward them which can soften the conflict.
+当有人对你粗鄙、无礼、刻薄,甚至是下流时,当他们有病就好了,这使得我们更容易对他们产生同情心,进而缓和冲突
+
Eliminating clutter makes room for your true treasures.
+清理杂物,为真正重要的东西腾出空间
+
You really don’t want to be famous. Read the biography of any famous person.
+你绝对不会想出名,不信的话可以随便找本名人传记读读
+
Experience is overrated. When hiring, hire for aptitude, train for skills. Most really amazing or great things are done by people doing them for the first time.
+经验往往被高估了,招聘时应该多看资质,技能是可以培训的。许多令人惊奇和赞叹的事情,都是新手做出来的
+
A vacation + a disaster = an adventure.
+度假 + 灾难 = 冒险
+
Buying tools: Start by buying the absolute cheapest tools you can find. Upgrade the ones you use a lot. If you wind up using some tool for a job, buy the very best you can afford.
+购买工具:从最便宜的开始,升级那些使用频次高的。如果你的工具是用于工作,那么买你能买得起的最好的
+
Learn how to take a 20-minute power nap without embarrassment.
+学会毫不尴尬的打 20 分钟小盹儿
+
Following your bliss is a recipe for paralysis if you don’t know what you are passionate about. A better motto for most youth is “master something, anything”. Through mastery of one thing, you can drift towards extensions of that mastery that bring you more joy, and eventually discover where your bliss is.
+如果你不知道自己热爱什么,追寻心之所向往往会带你误入歧途,对年轻人来说,更好的格言是:master something, anything,在精通一件事的过程中,你可以顺着带给你更多快乐的方向继续深入,并最终发现你热爱的东西
+
I’m positive that in 100 years much of what I take to be true today will be proved to be wrong, maybe even embarrassingly wrong, and I try really hard to identify what it is that I am wrong about today.
+我敢肯定,我今天认为正确的许多东西在 100 年后将被证明是错误的,甚至可能是令人尴尬的错误。而我非常努力在做的事情,就是去识别我对今天的错误认知
+
Over the long term, the future is decided by optimists. To be an optimist you don’t have to ignore all the many problems we create; you just have to imagine improving our capacity to solve problems.
+从长远来说,未来由乐观主义者决定。作为一个乐观主义者并非要对我们制造的问题视而不见,而是要想象如何提升我们解决问题的能力
+
The universe is conspiring behind your back to make you a success. This will be much easier to do if you embrace this pronoia.
+整个宇宙在背后密谋让你成功,要相信,天助人愿
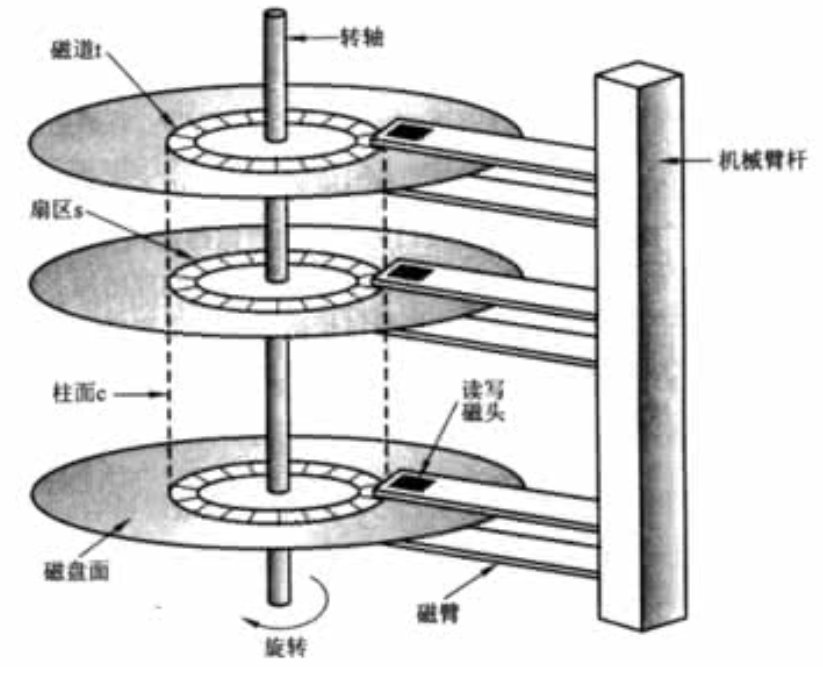
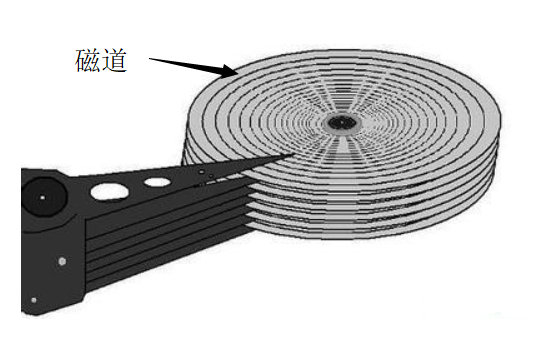
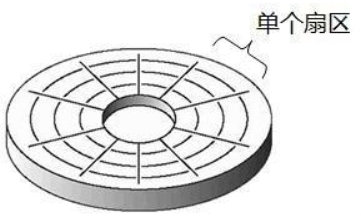
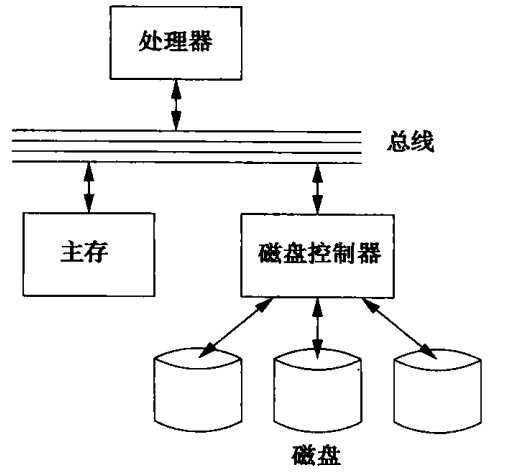
尽管校验和几乎能正确检测出介质故障或读写故障的存在,但是它却不能帮助我们纠正错误。为了处理这个问题,我们可以在一个或多个磁盘中执行一个被称为稳定存储的策略。通常的思想是,扇区时成对的,每一对代表一个扇区内容 X。我们把代表 X 的扇区对分别称为左拷贝 XL和右拷贝XR。这样实际上就是每个扇区的内容都存储了两份,操作XL失败,那么去操作XR就可以了,更何况我们还在每个扇区中有校验和,把错误的概率就大大降低了。
我是快毕业时开始接触公众号的,那时候的环境很单纯,很多作者都把公众号当博客用。认识的一个和我同龄的作者,为了能把某个算法讲清楚经常熬夜 P 图。那时候的程序员小灰还叫玻璃猫,刘欣大大的文章标题比现在也要朴素。我自己那段时间写文章尤其认真,因此也认识了许许多多网友,收到了博文视点和另一家出版社的出版邀请。那时大部分人还不懂什么是 IP,流量一词更普遍的含义还是电话卡用的那个上网流量,10 万+偶有出现但频率不高。
导致电脑宕机的原因竟然是 Janet Jackson 的一首歌。微软资深工程师 Raymond Chen 披露 WinXP 发布早期,一些用户报告电脑系统会意外崩溃。起初他们以为是 Windows 的 bug,但很欣慰的是发现同行也存在这个问题,最终定位到这个问题的根源竟然是 Janet Jackson 1989 年发行的歌曲《Rhythm Nation》。歌曲中一些旋律会和当时一款 5400 转硬盘发生共振,进而导致电脑崩溃。
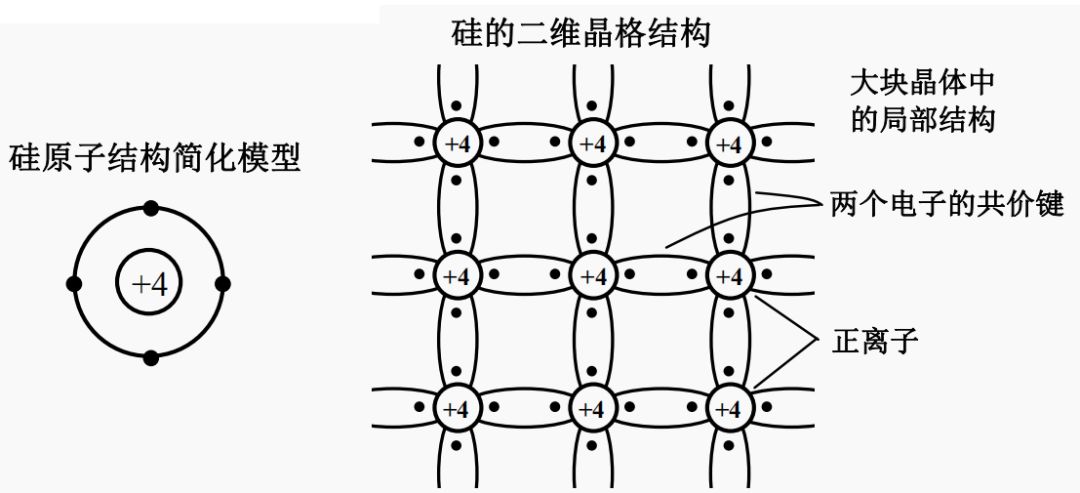
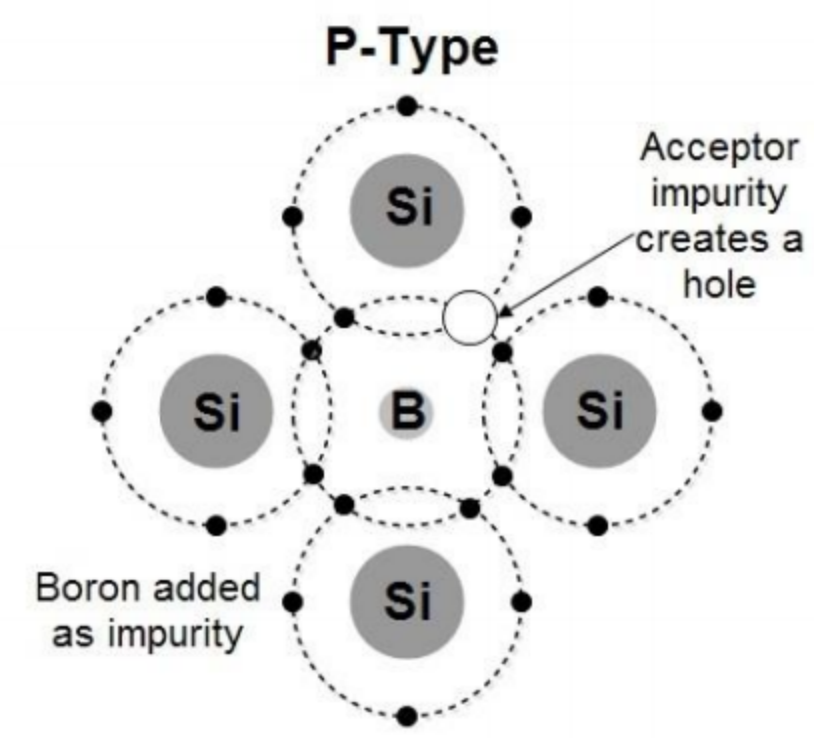
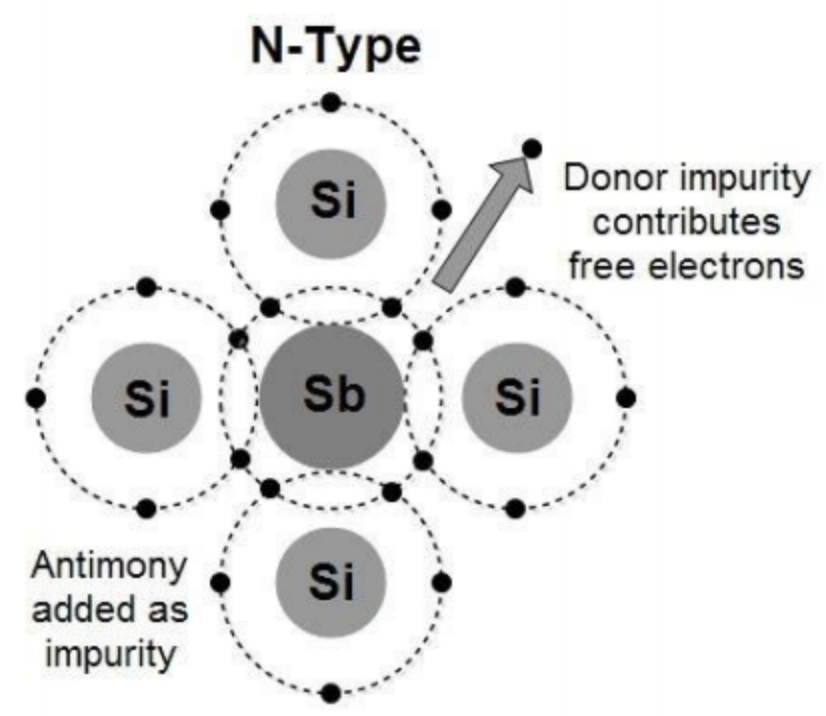
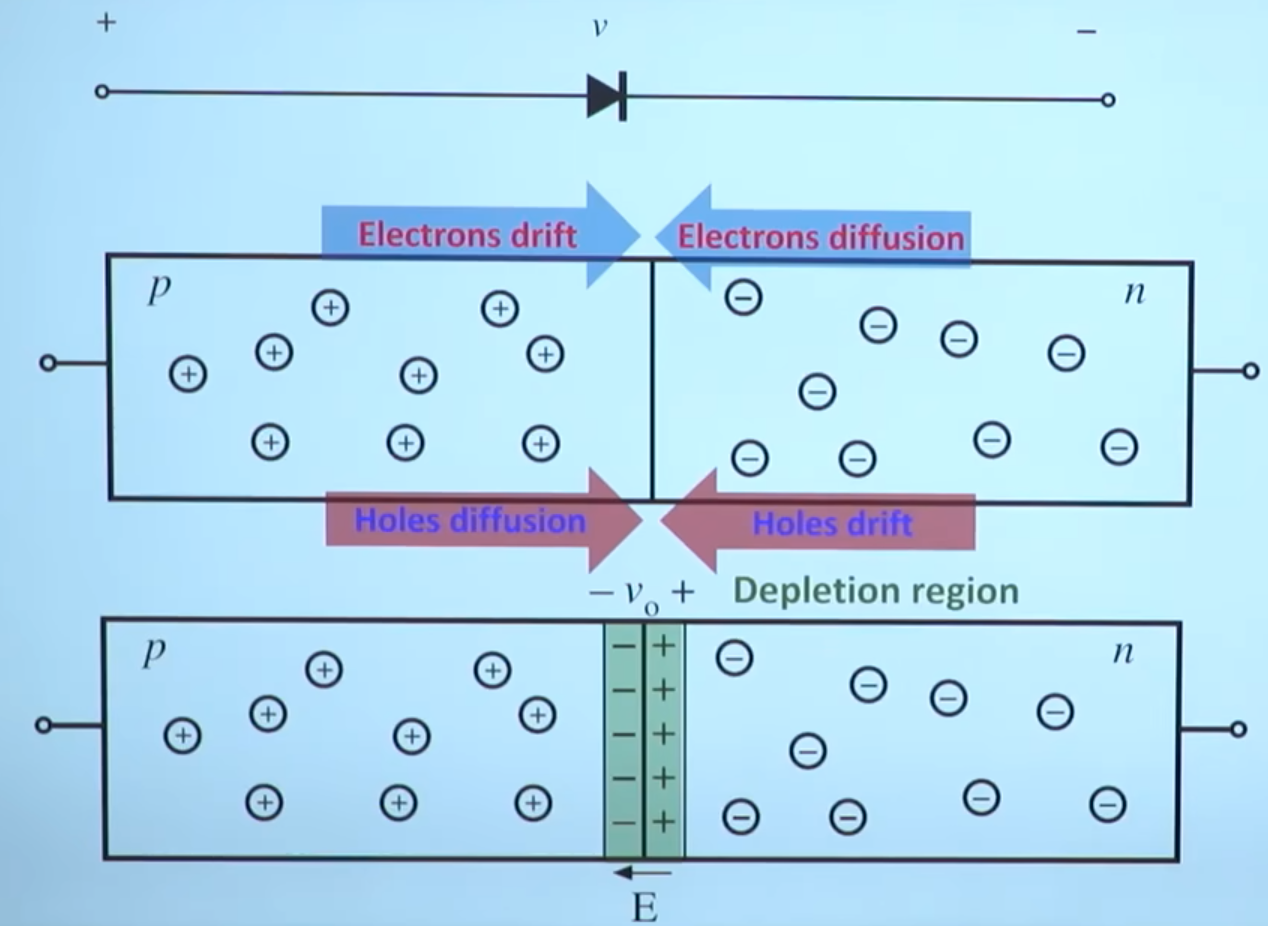
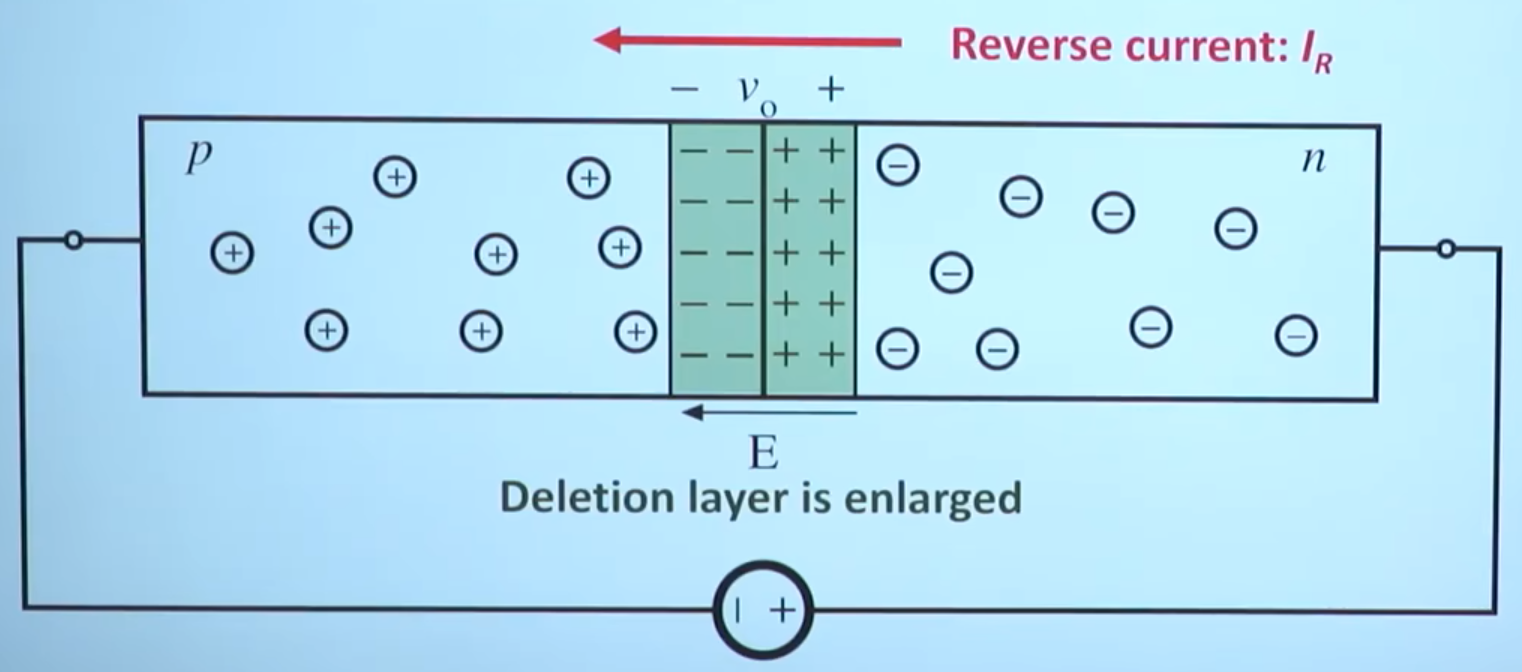
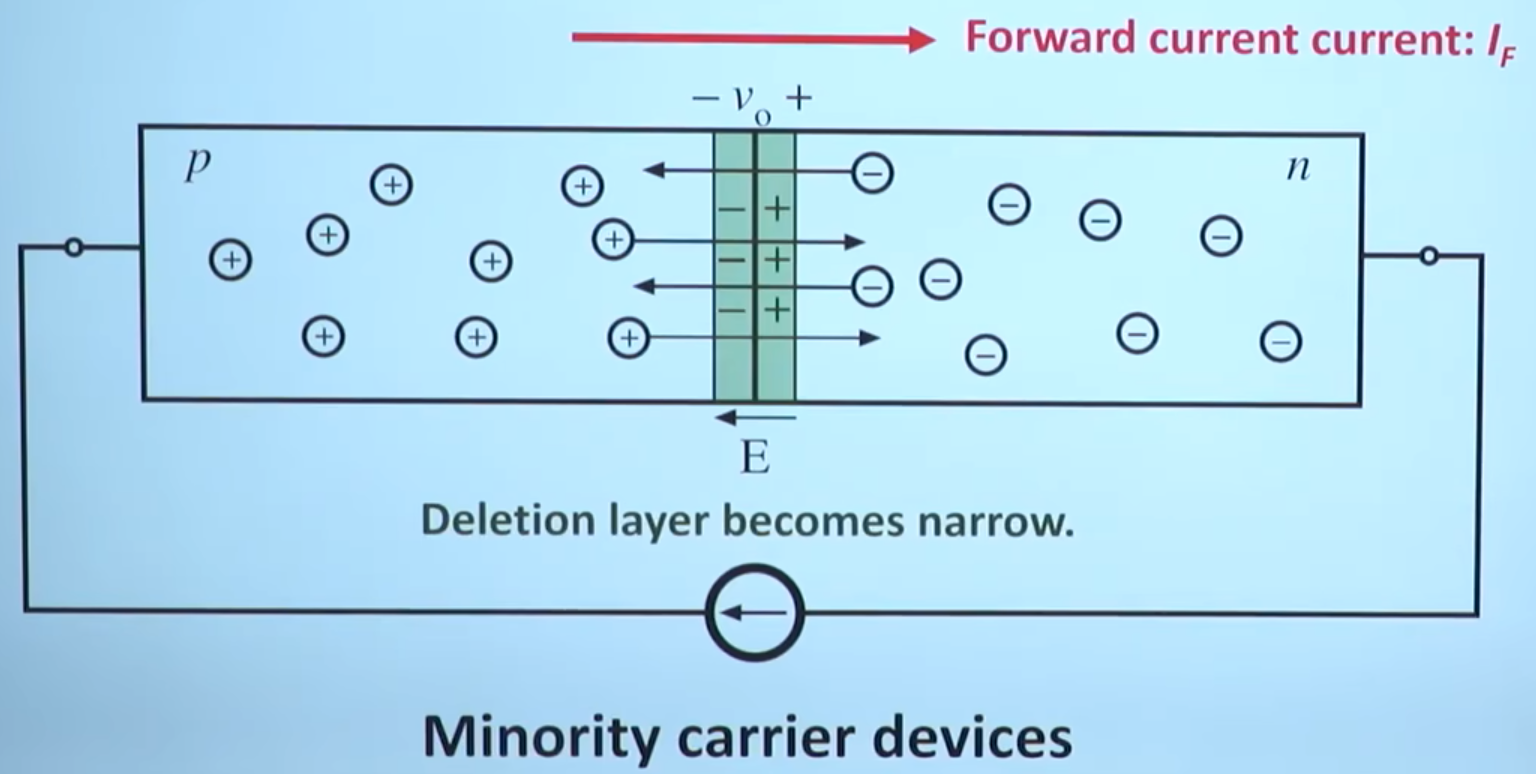
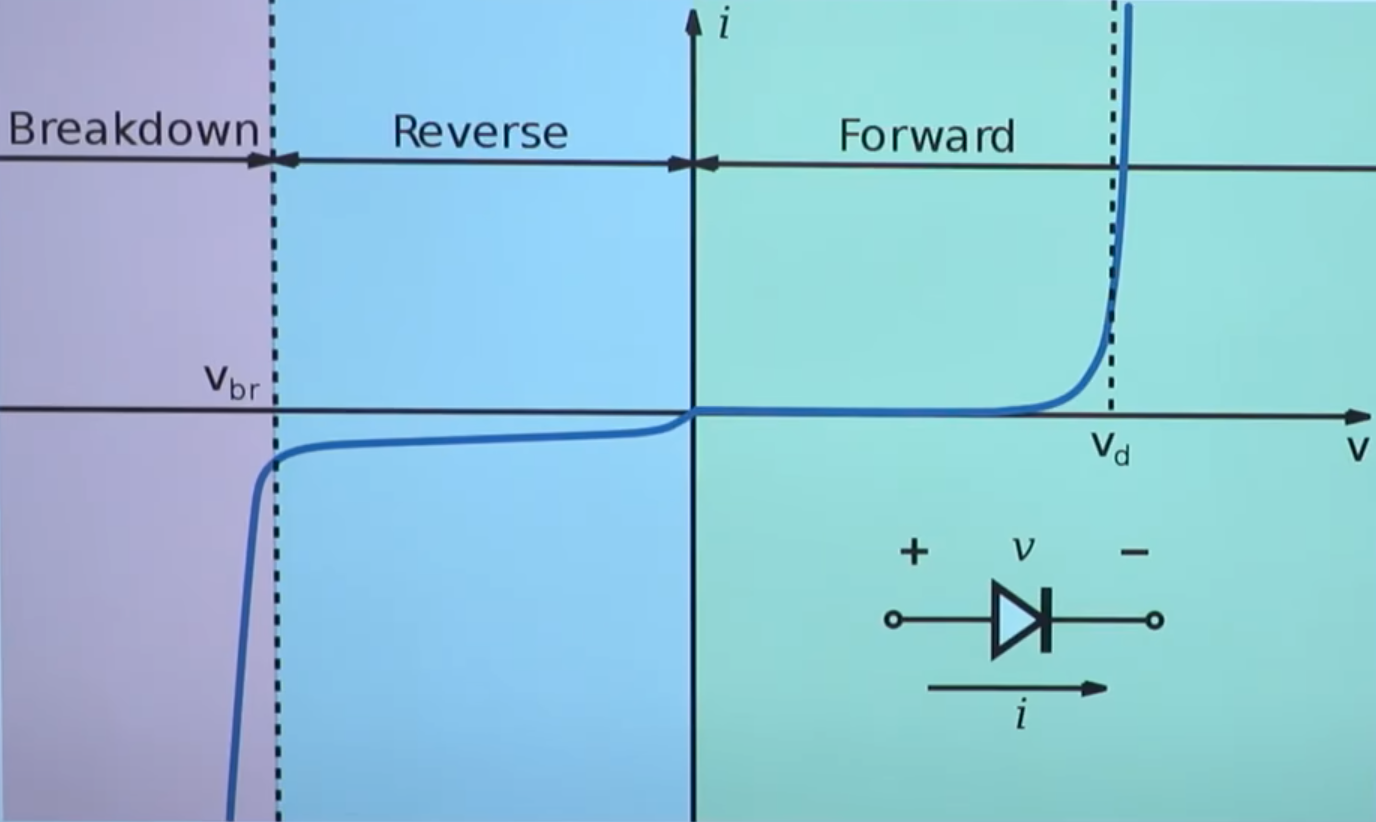
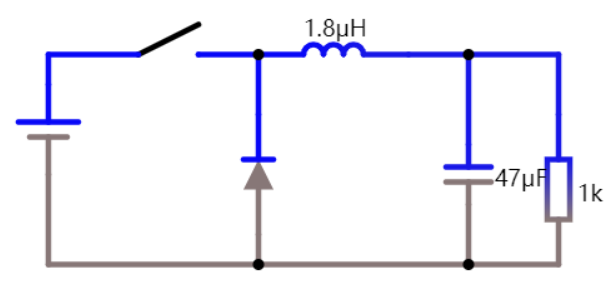
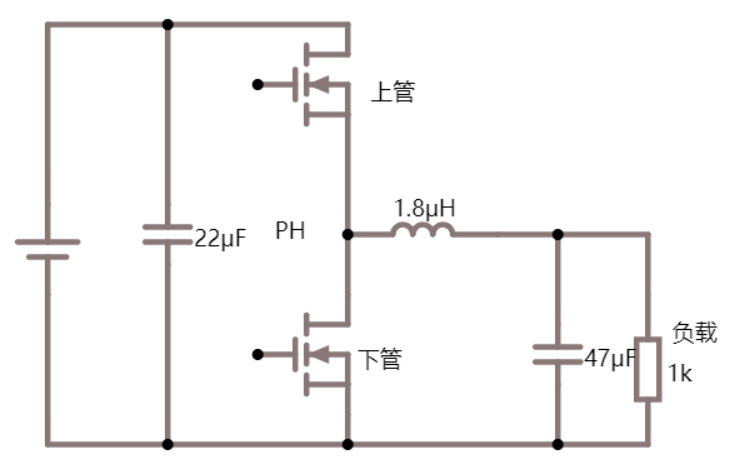
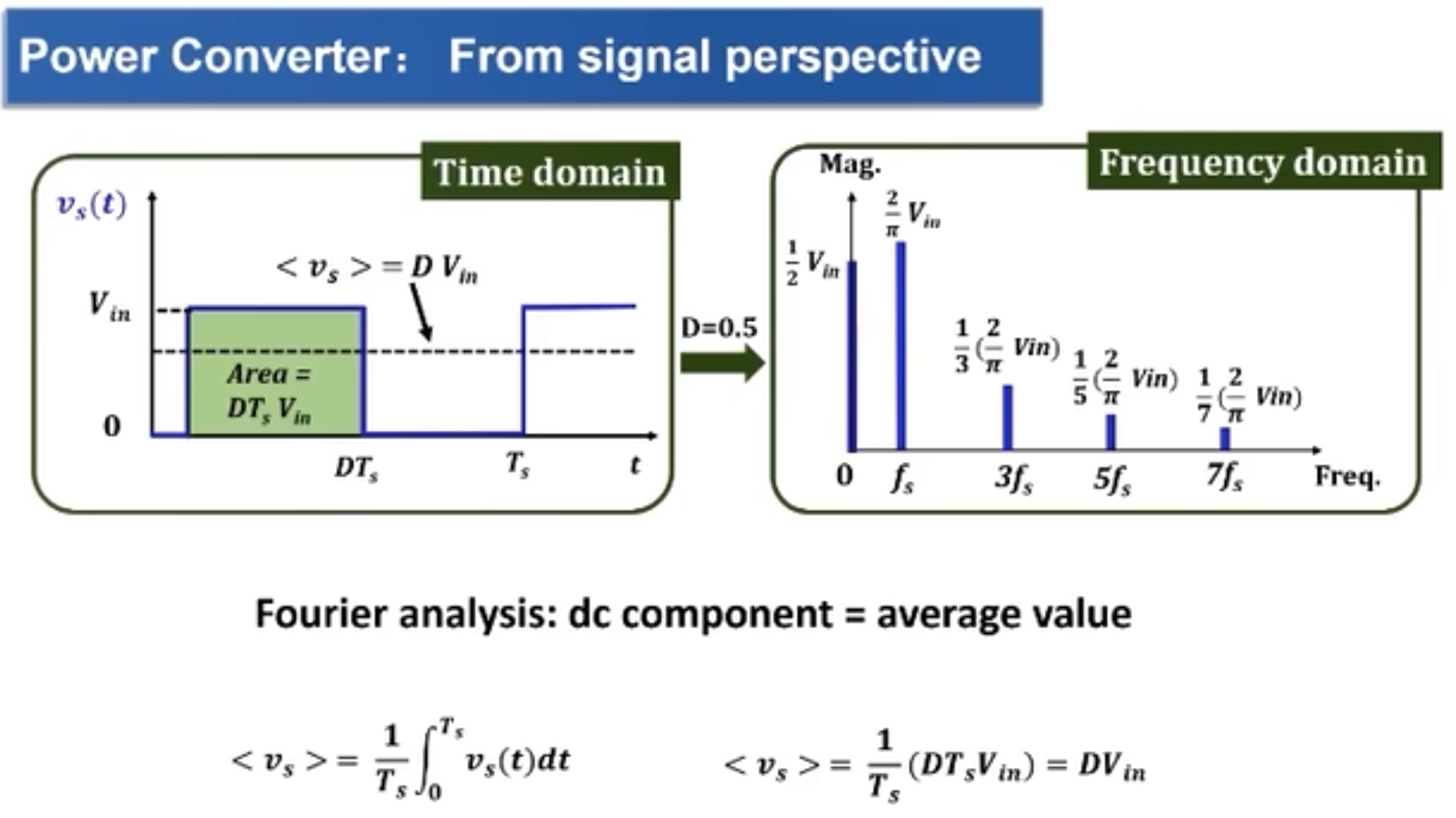
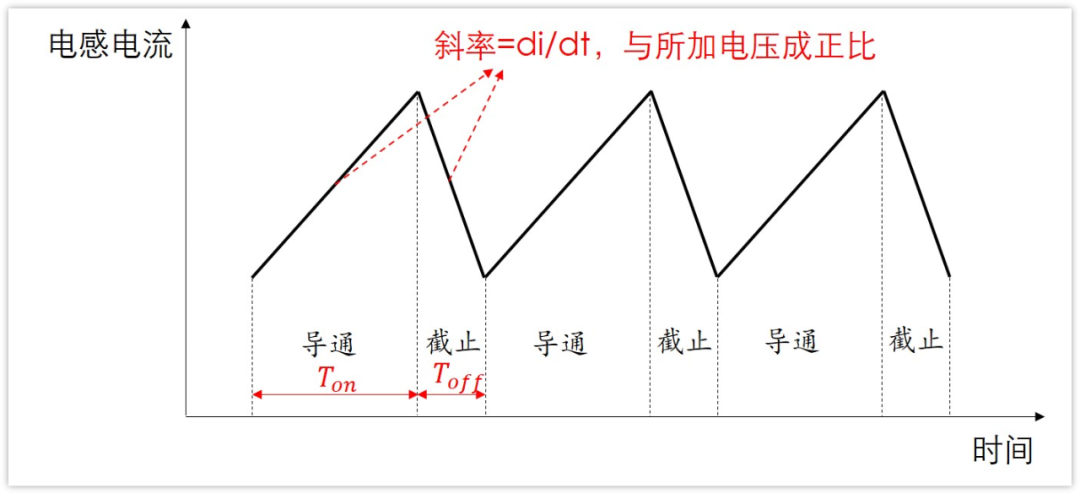
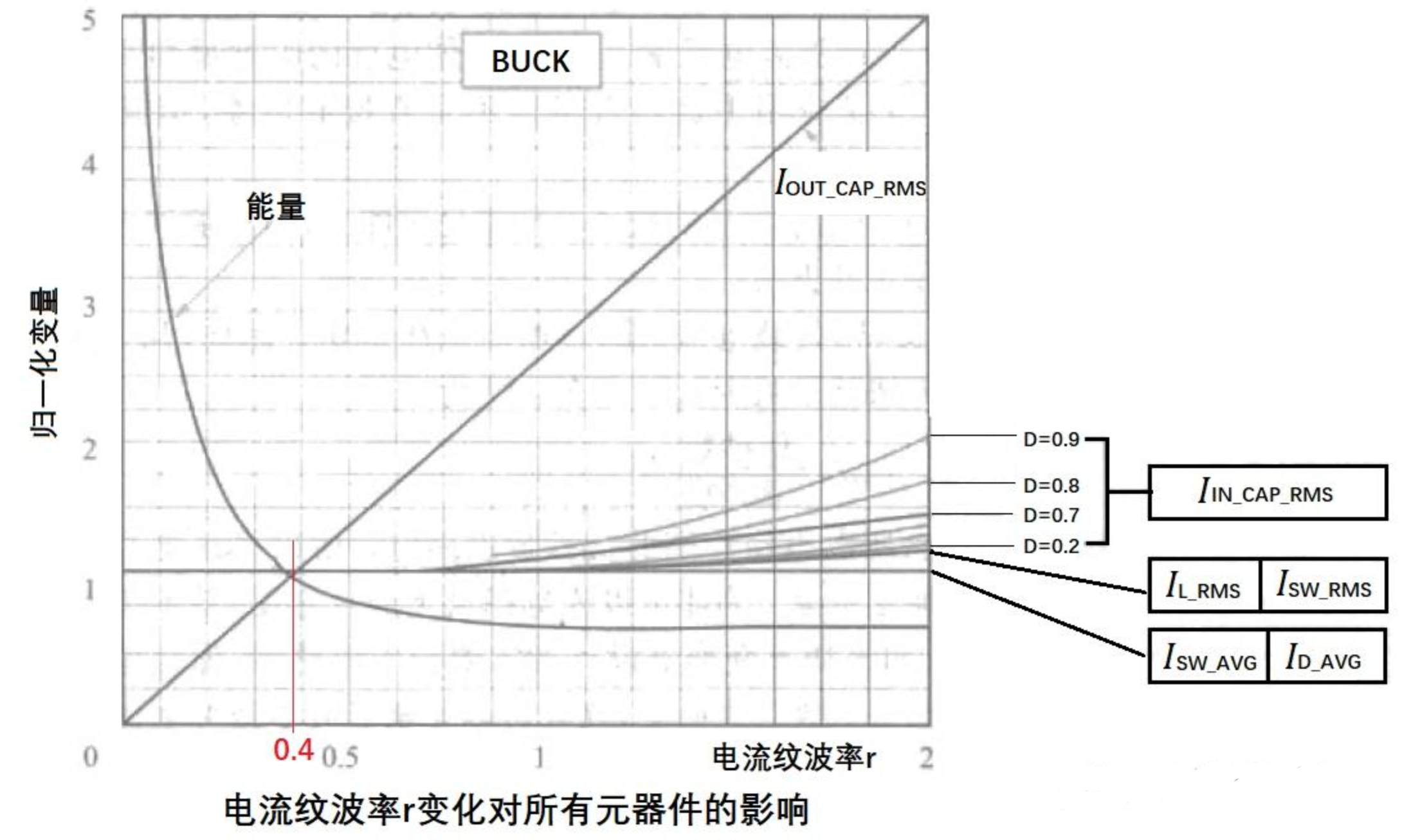
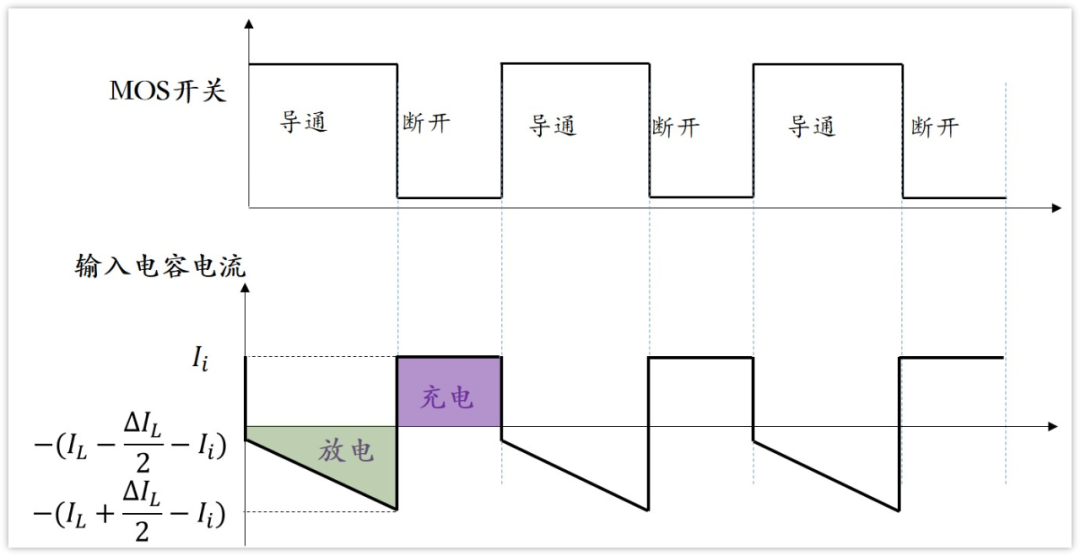
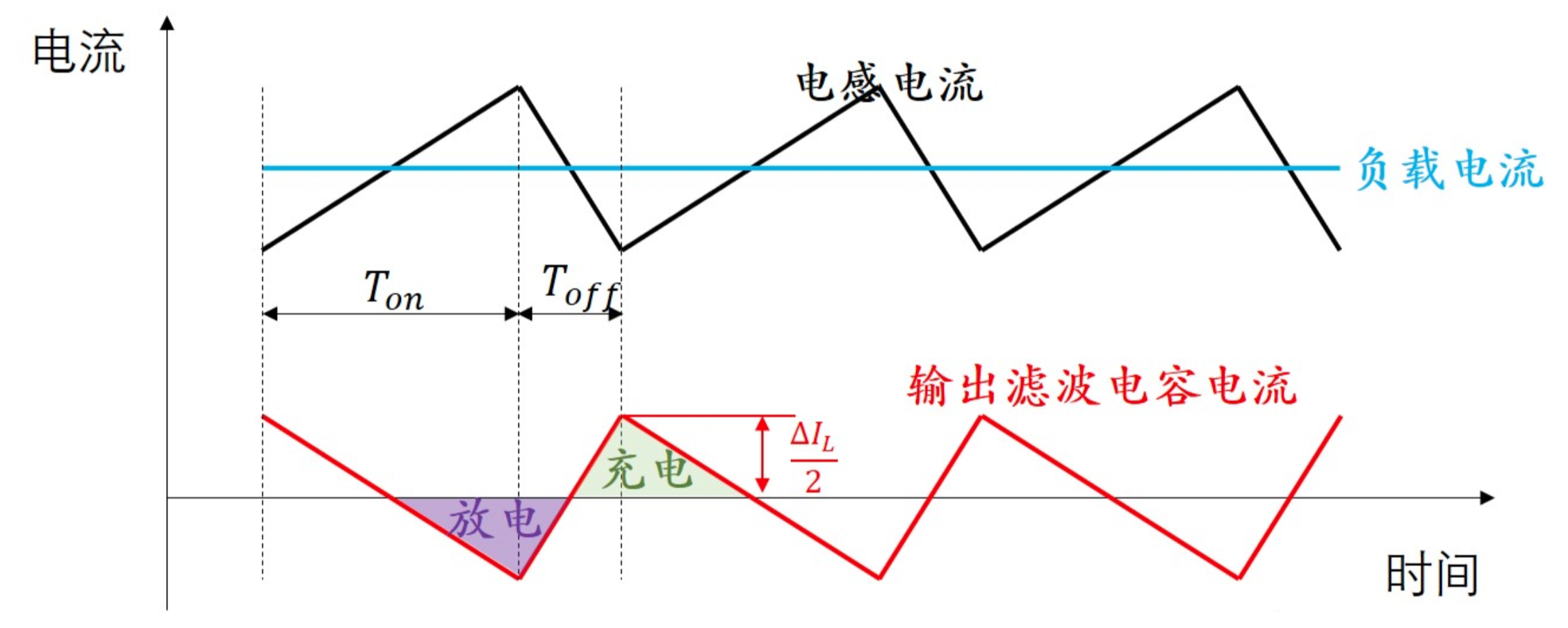
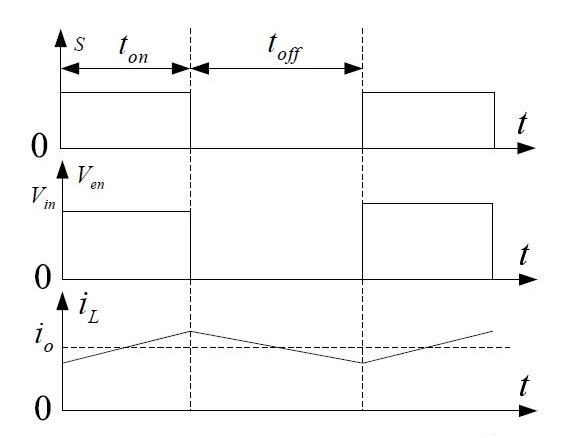
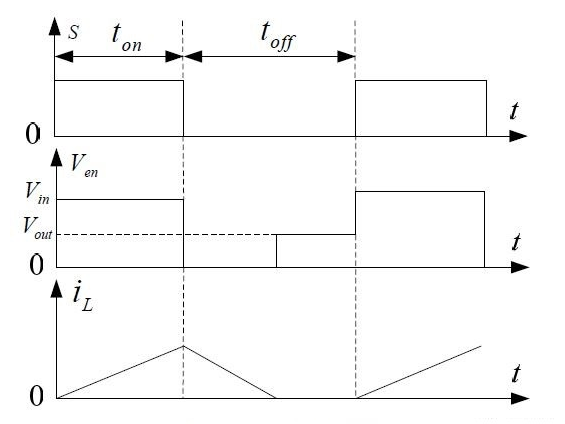
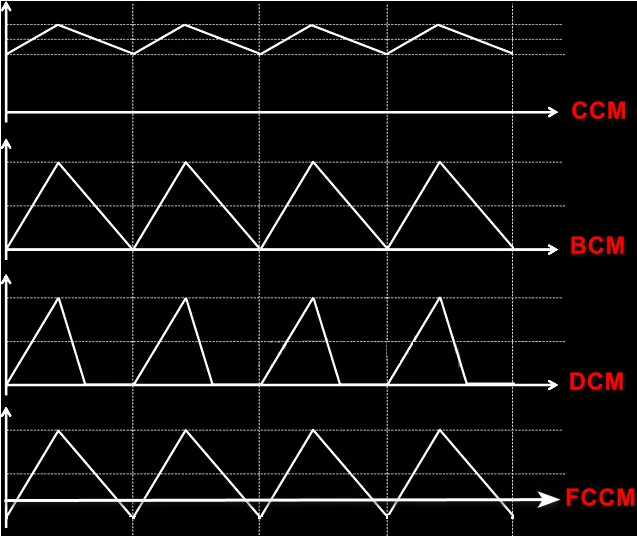
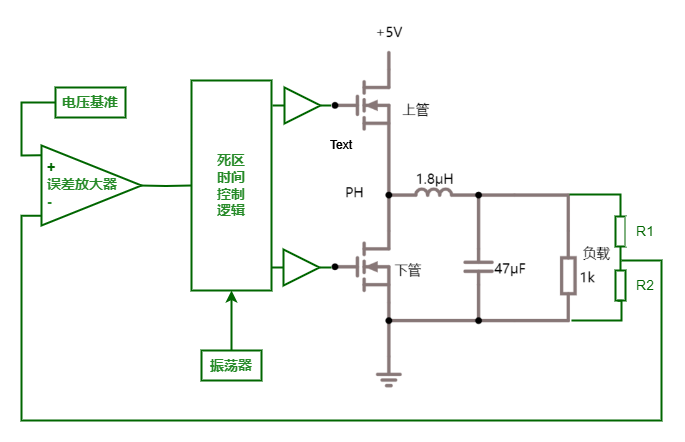
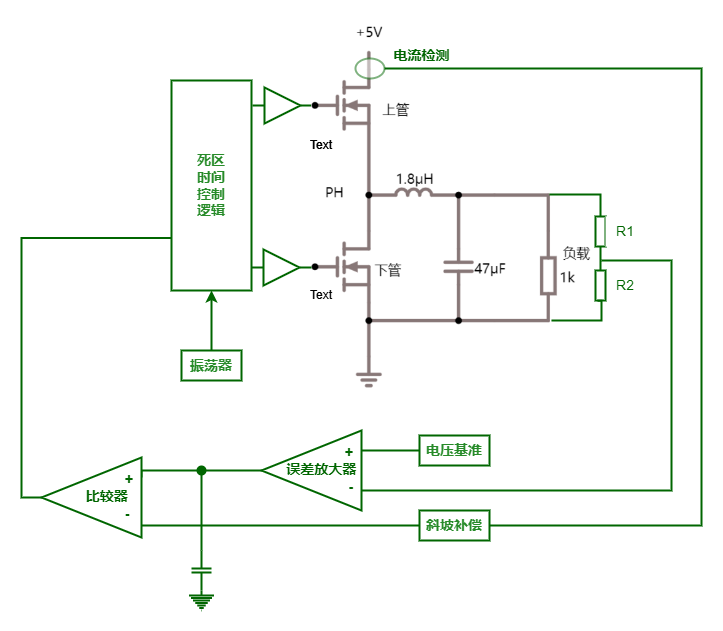
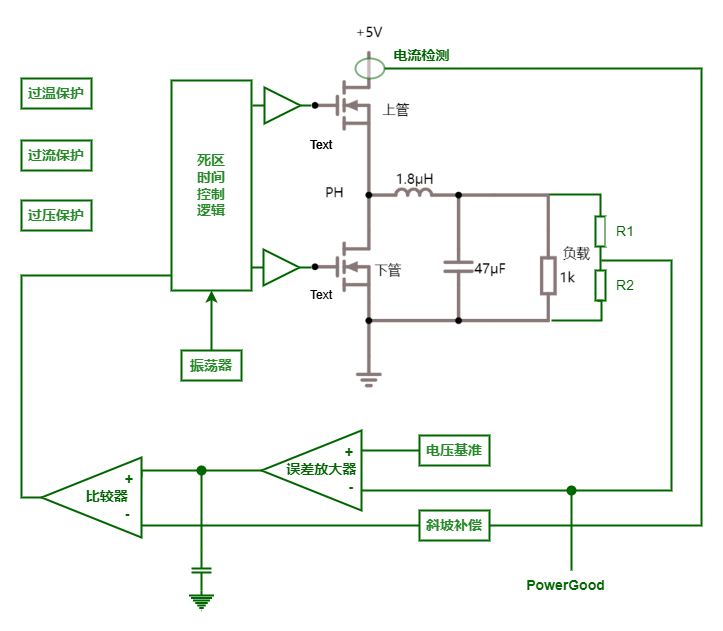
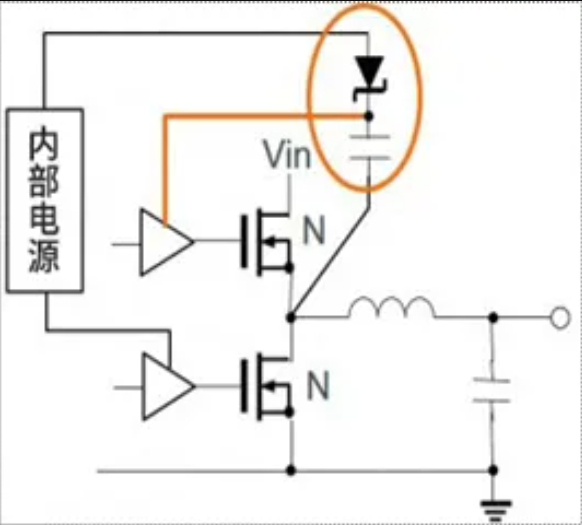
图中(4)处伴随系统从通到断的状态变化,大规模载流子需要进行重新分配,这个重新分配表现出来就是电流,而且这个电流与主电流相反,所以会看到一个反向的电流,而且这个反向电流会施加在主电路里面。这一段反向电流又分为两部分,下降阶段是之前外加电压时,PN 结中从 P 区域移动到 N 区域的载流子移除(恢复)过程,即从正偏到反偏的过程,正偏时空间电荷区非常非常窄,此时要进入反偏状态,空间电荷区需要加强,载流子需要重新分配,外部激励会移除不必要的空间电荷。电流上升的过程,即二极管又变成一个耐压器件了,也就是空间电荷区加宽,更多的载流子会不均匀的分布在两端。整个过程不可避免的需要移动电荷,而电荷的聚集效应可以认为就是一个电容的效应,当我们需要施加电压时,电压的增加就会需要额外的电荷,电荷不断聚集提供相反电荷,使其电压不断增加,以致增加到刚好截止输出电压为止。
+
+
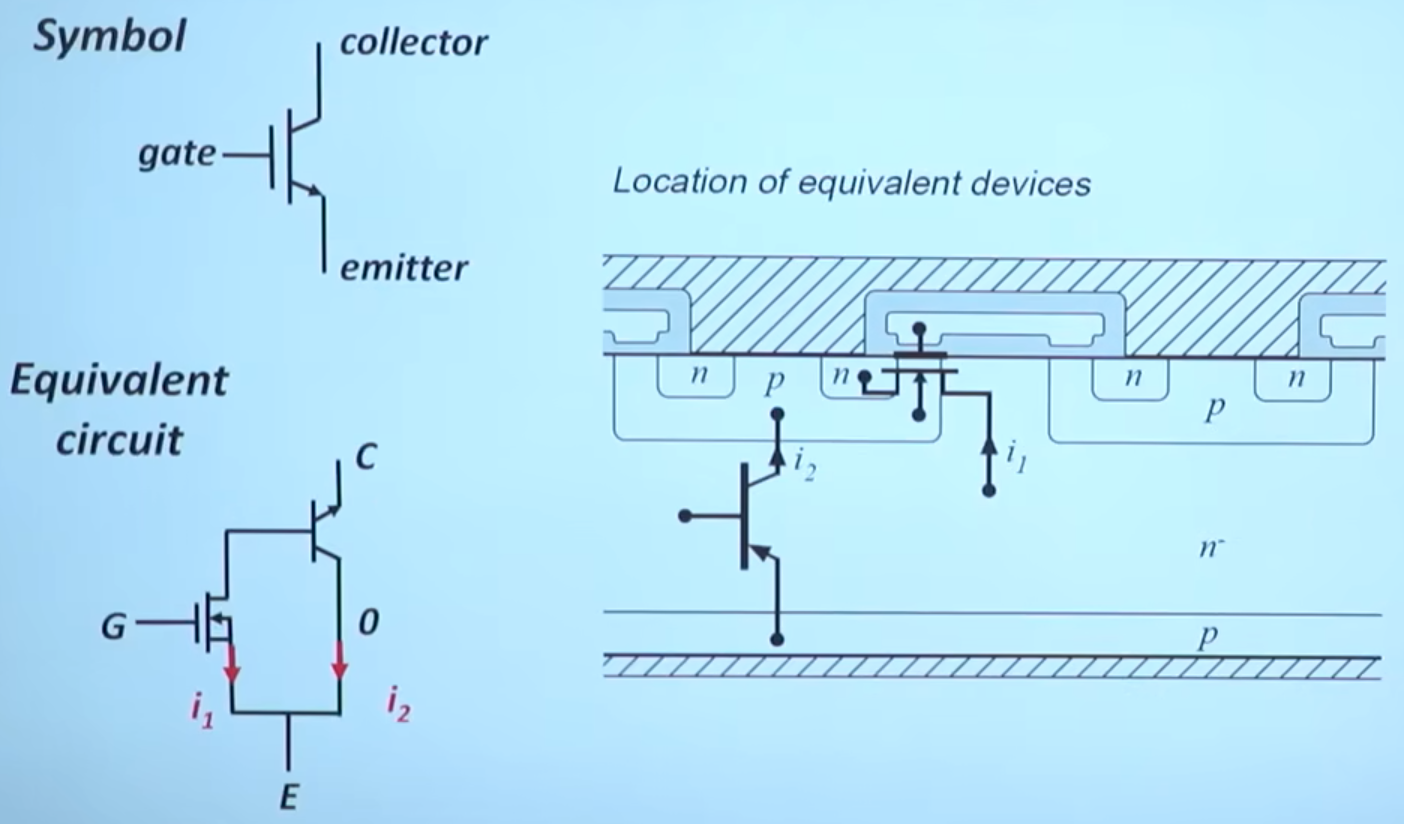
MOS 管
+
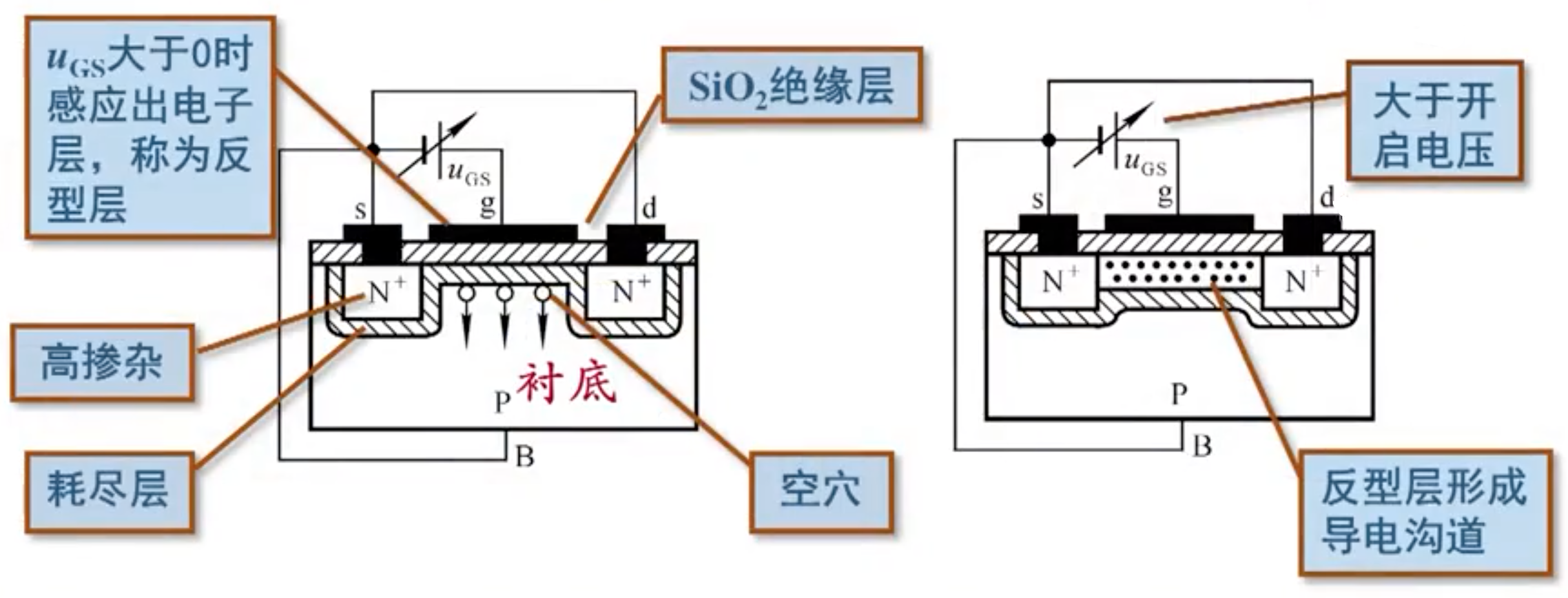
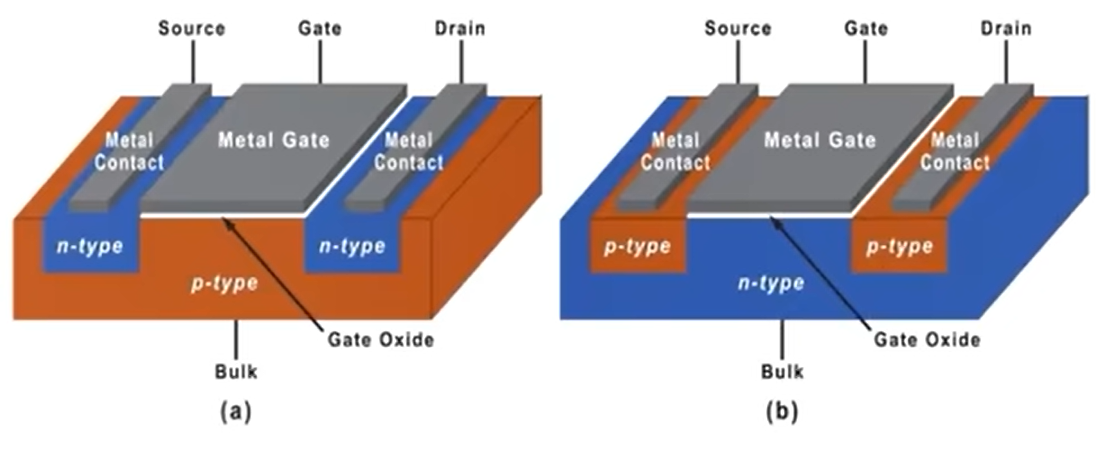
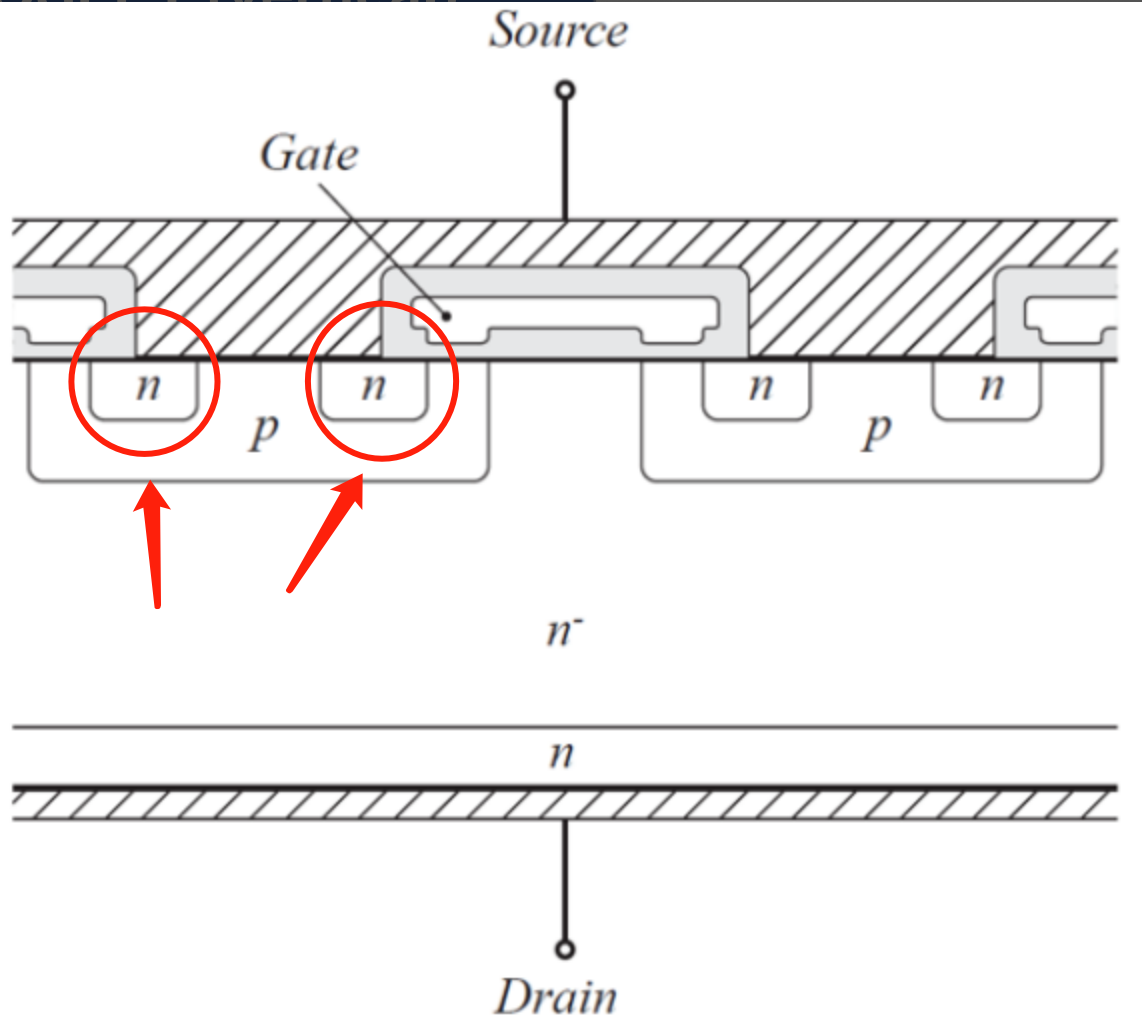
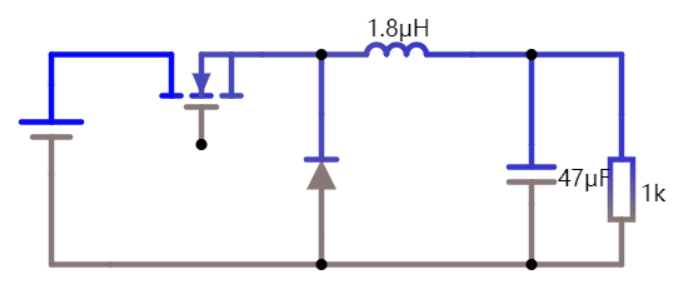
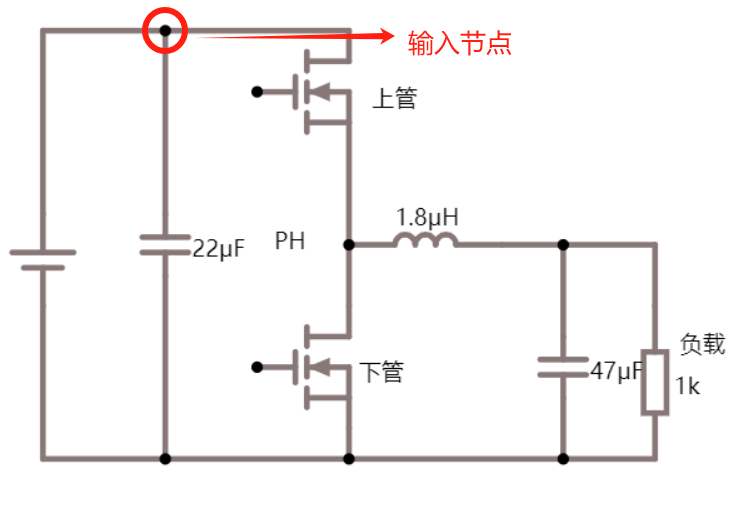
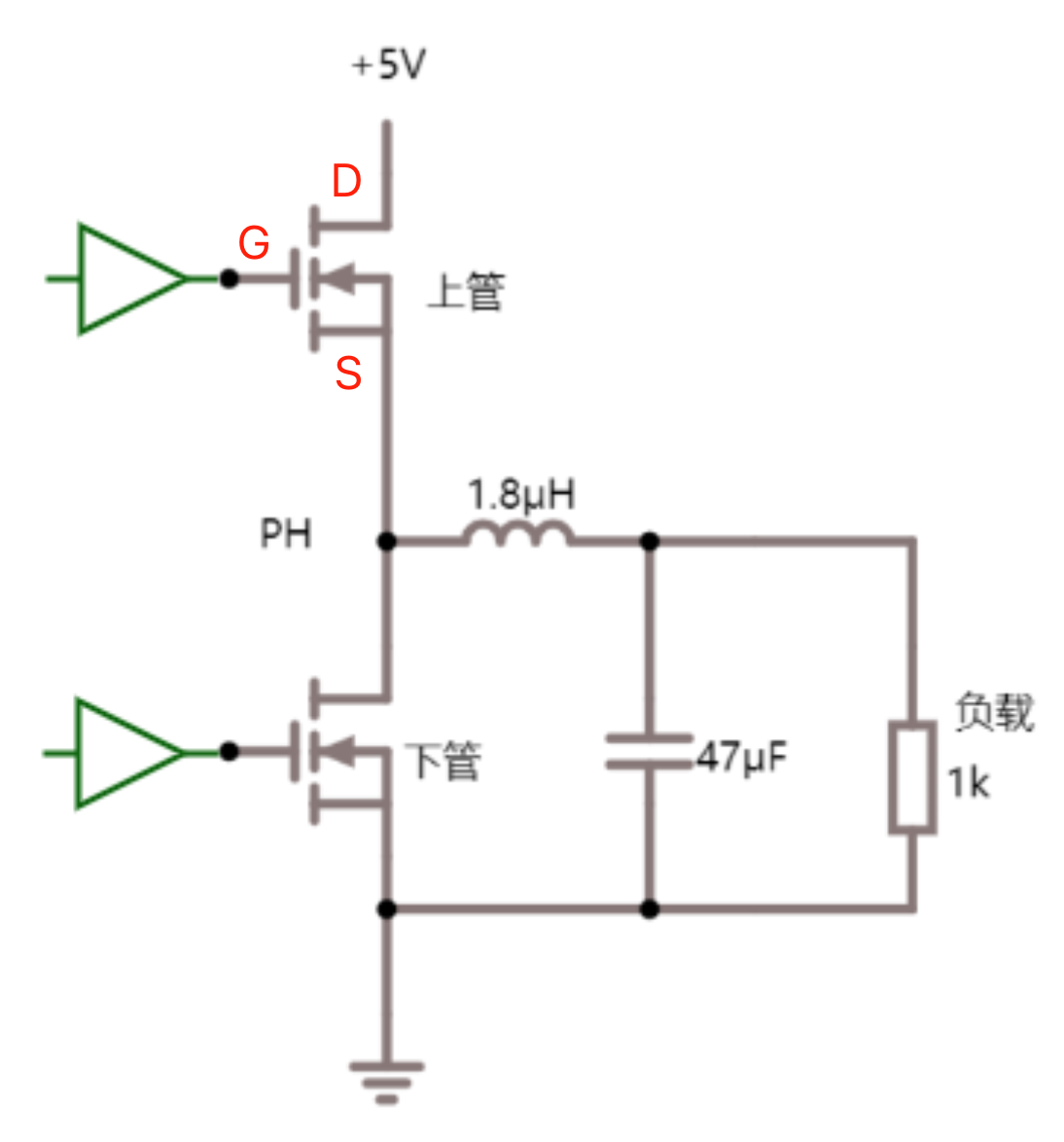
以 NMOS 为例,它以 P 型半导体衬底,以 N 型半导体作为导电沟道,金属部分作为栅极(Gate),氧化部分(SiO2)作为绝缘层,两端分别为源极(Source)和漏极(Drain),从物理结构可以看出 MOS 管的源极和漏极是可以互换的,不像三极管有严格的顺序。
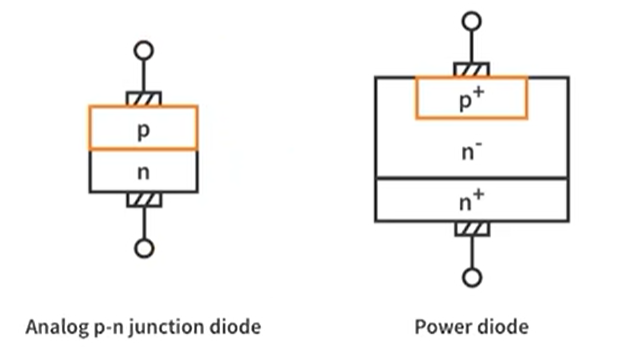
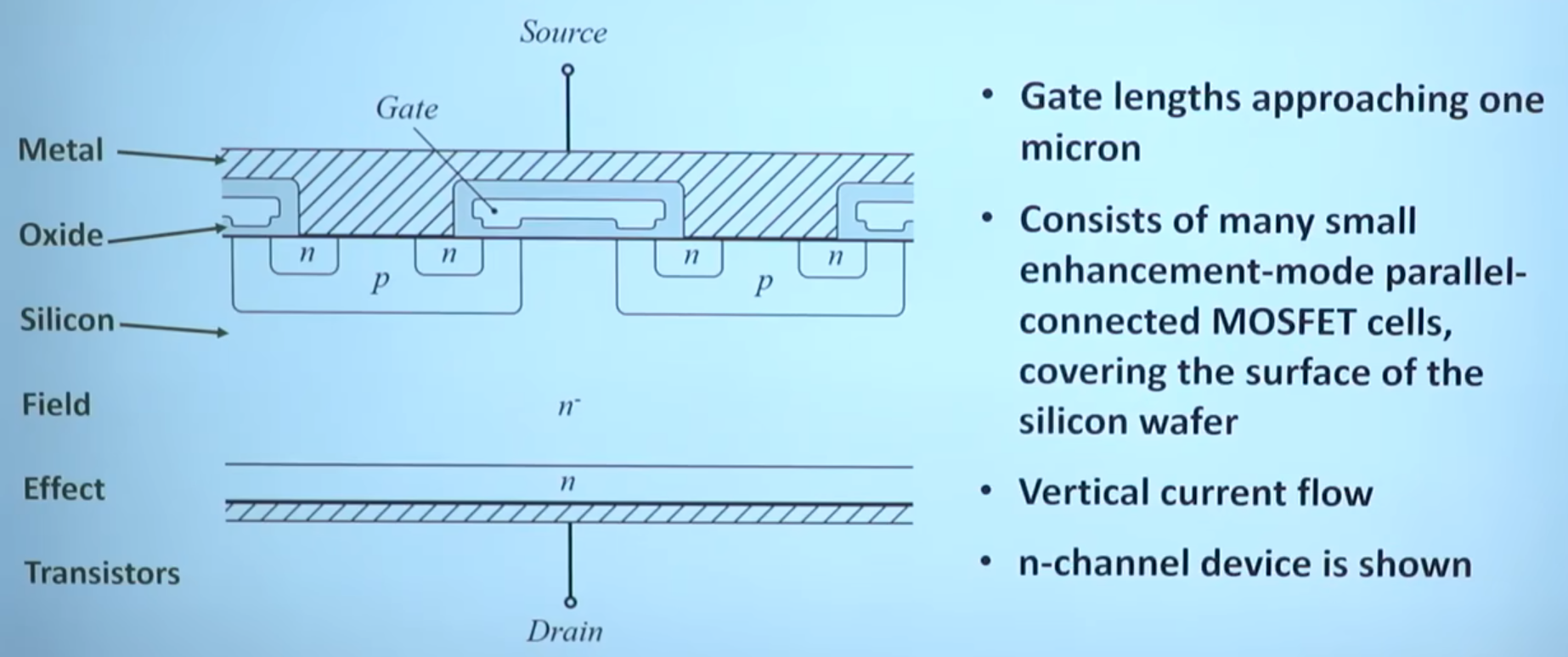
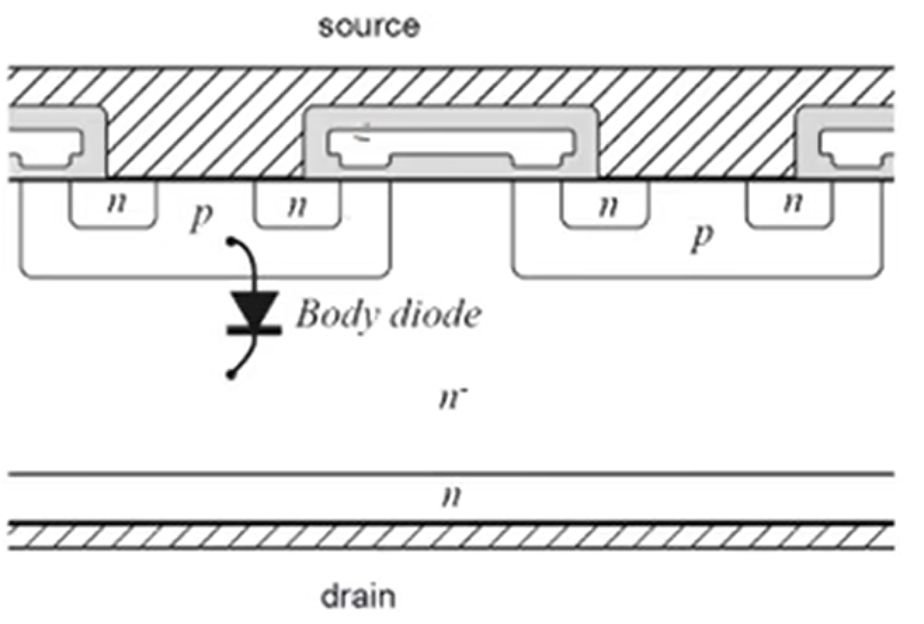
对比前文普通 MOS 管,可以看到源极、栅极、漏极是分开的,顶上那个灰色的板子是金属板。而功率 MOS 管在这个基础上做了一点创新,下图中的阴影部分就是金属板,可以发现总共只有两个金属板,上面的金属板把 N 区和 P 区都给连起来了,所以即使在栅极没有加电压的时候,也会存在一个天然的二极管通道,但是普通 MOS 管是没有体二极管通道存在的。同时由于是功率 MOS 管,所以也会想办法将耗尽层加宽,以增加其耐压能力。
+
+
体二极管和耐压能力的加强是功率 MOS 和普通 MOS 的区别。
+
+
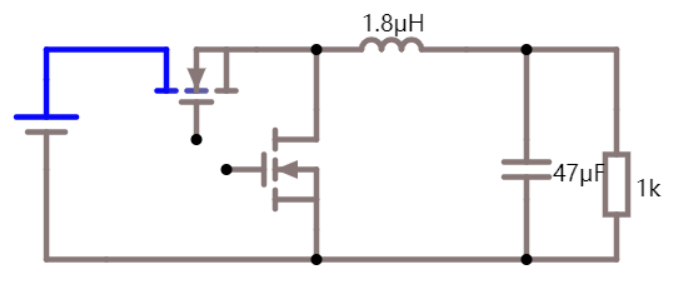
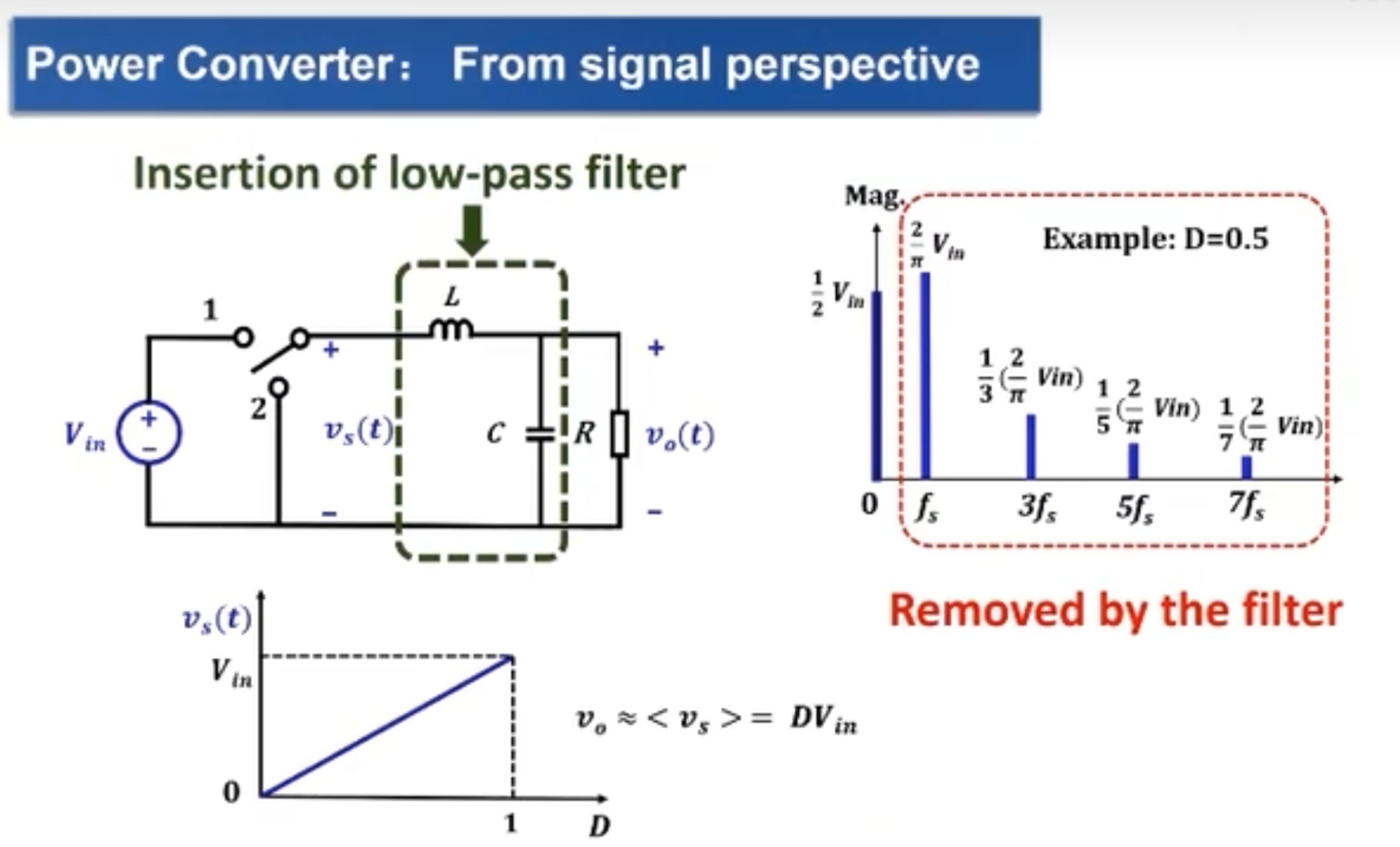
功率 MOS 管的正向导通能力就是涉及「场效应」了,所谓的场效应即意味着外部可以通过电场来控制其内部载流子的浓度,在栅极施加正电压时就会产生一个电子的导电沟道,由于整体是 N 型半导体衬底,所以整体也就形成了一个电子的导电沟道,并且该沟道支持电子的双向移动。
+
+
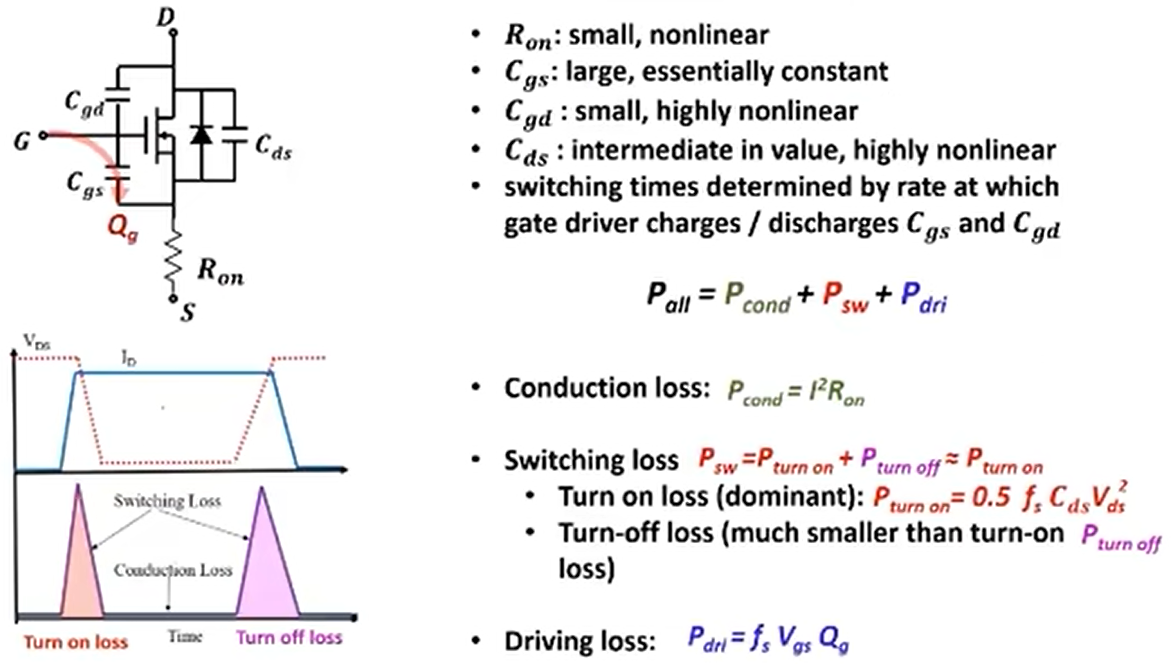
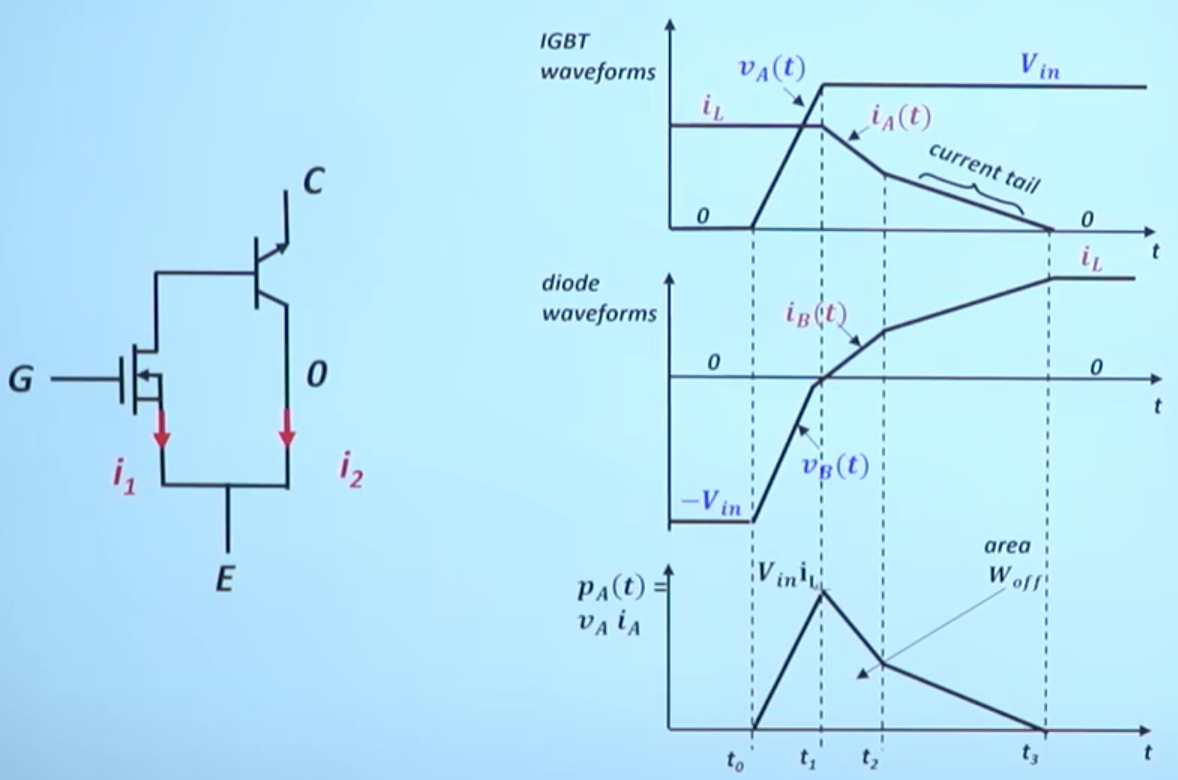
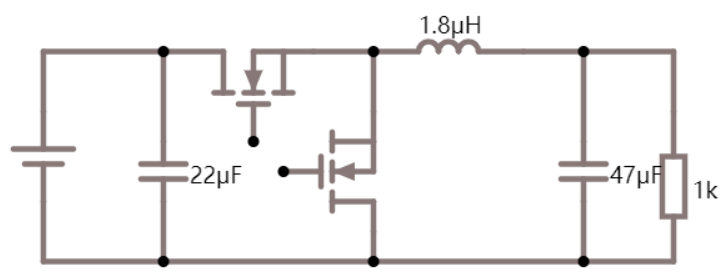
如下图所示是功率 MOS 管的等效电路模型。其主要损耗由三部分组成,分别为导通损耗、开关损耗(开通损耗和关断损耗)、驱动损耗。其中导通损耗与开关损耗容易理解,驱动损耗作何理解呢?MOS 并不像二极管是一个被动型器件,MOS 管开或关的行为都需要能量作为代价,就好比要打开机械开关需要用手去按压,这个过程所消耗的能量就是驱动损耗。
+
+
晶体管
+
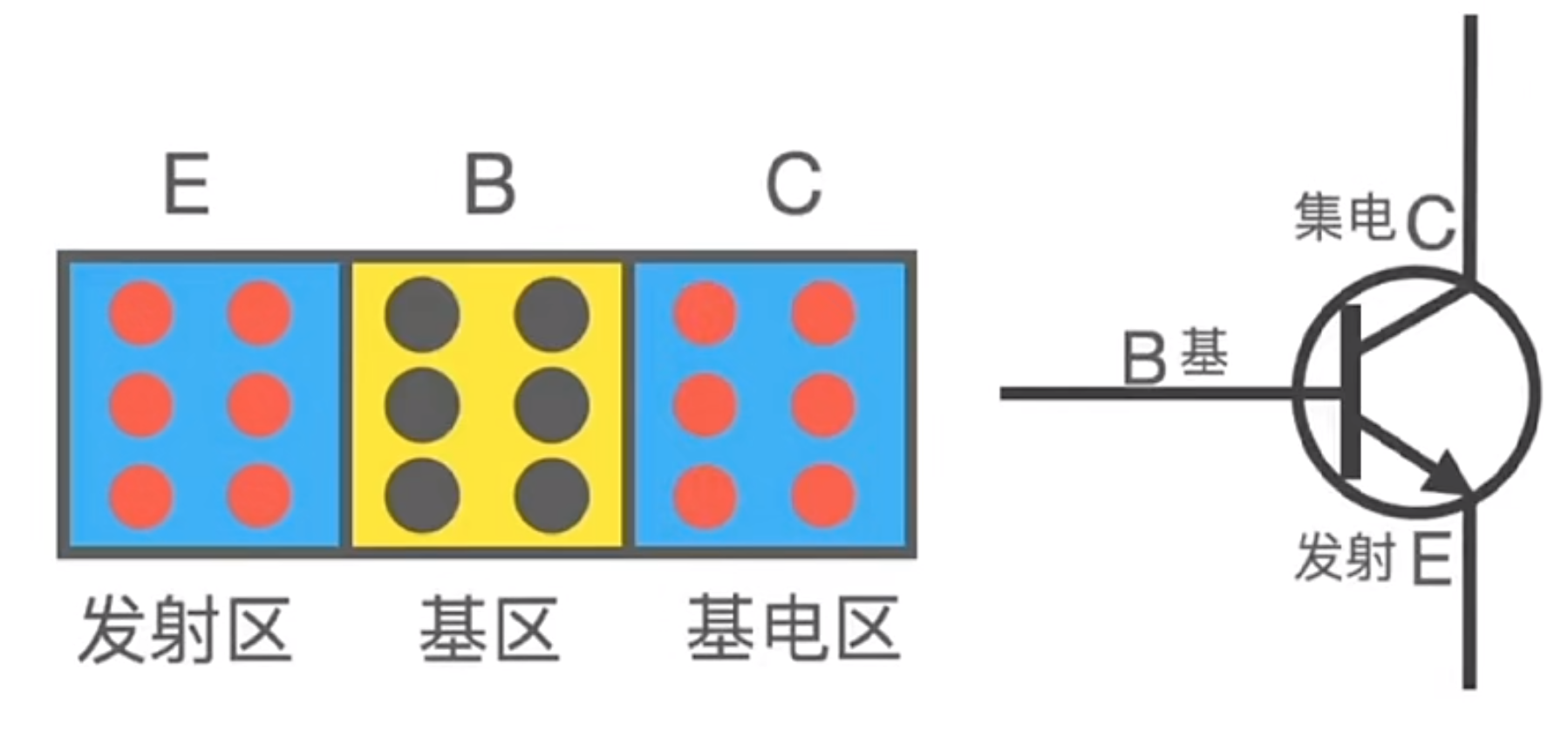
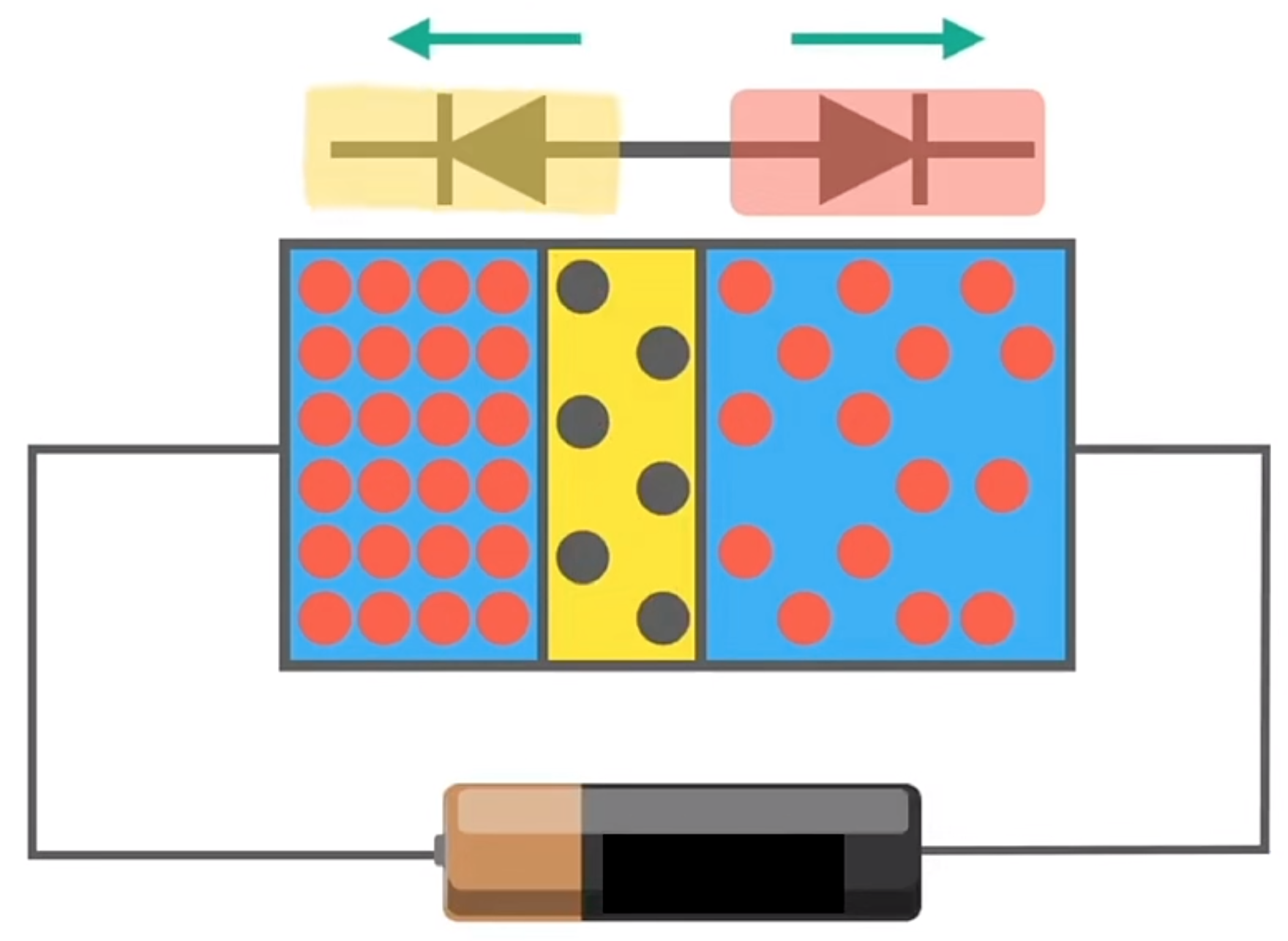
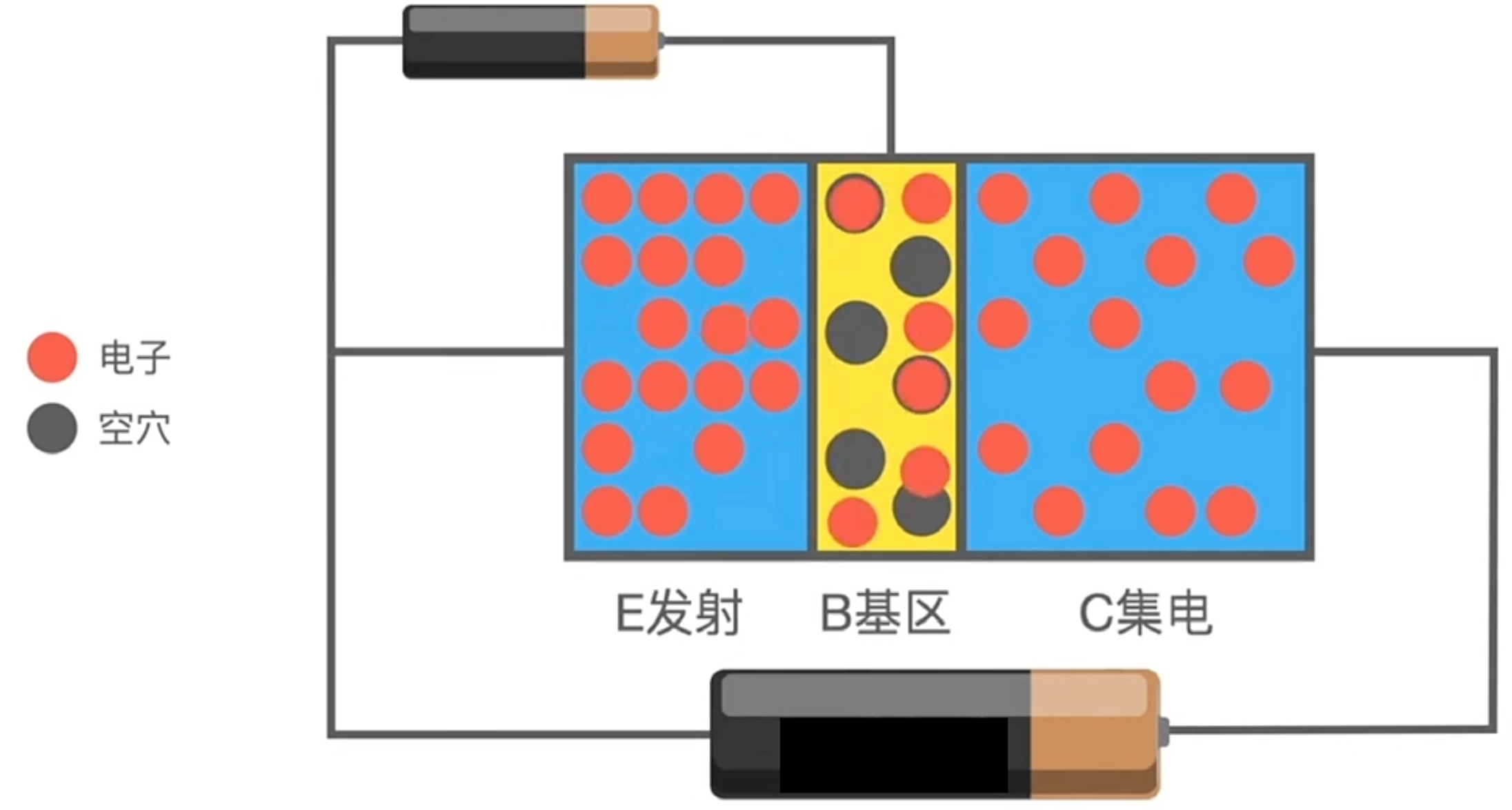
二极管只有一个 P 型半导体和一个 N 型半导体结合,如果再加一个 N 型半导体(或 P 型半导体)即构成了晶体管(三极管),晶体管有集电极、发射极、基极三个极。
Today is Ignatius' birthday. He invites a lot of friends. Now it's dinner time. Ignatius wants to know how many tables he needs at least. You have to notice that not all the friends know each other, and all the friends do not want to stay with strangers.
+
One important rule for this problem is that if I tell you A knows B, and B knows C, that means A, B, C know each other, so they can stay in one table.
+
For example: If I tell you A knows B, B knows C, and D knows E, so A, B, C can stay in one table, and D, E have to stay in the other one. So Ignatius needs 2 tables at least.
+
输入格式
+
The input starts with an integer T(1<=T<=25) which indicate the number of test cases. Then T test cases follow. Each test case starts with two integers N and M(1<=N,M<=1000). N indicates the number of friends, the friends are marked from 1 to N. Then M lines follow. Each line consists of two integers A and B(A!=B), that means friend A and friend B know each other. There will be a blank line between two cases.
+
输出格式
+
For each test case, just output how many tables Ignatius needs at least. Do NOT print any blanks.
小希设计了一个迷宫让 Gardon 玩,首先她认为所有的通道都应该是双向连通的,就是说如果有一个通道连通了房间 A 和 B,那么既可以通过它从房间 A 走到房间 B,也可以通过它从房间 B 走到房间 A,为了提高难度,小希希望任意两个房间有且仅有一条路径可以相通(除非走了回头路)。小希现在把她的设计图给你,让你帮忙判断她的设计图是否符合她的设计思路。比如下面的例子,前两个是符合条件的,但是最后一个却有两种方法从 5 到达 8。
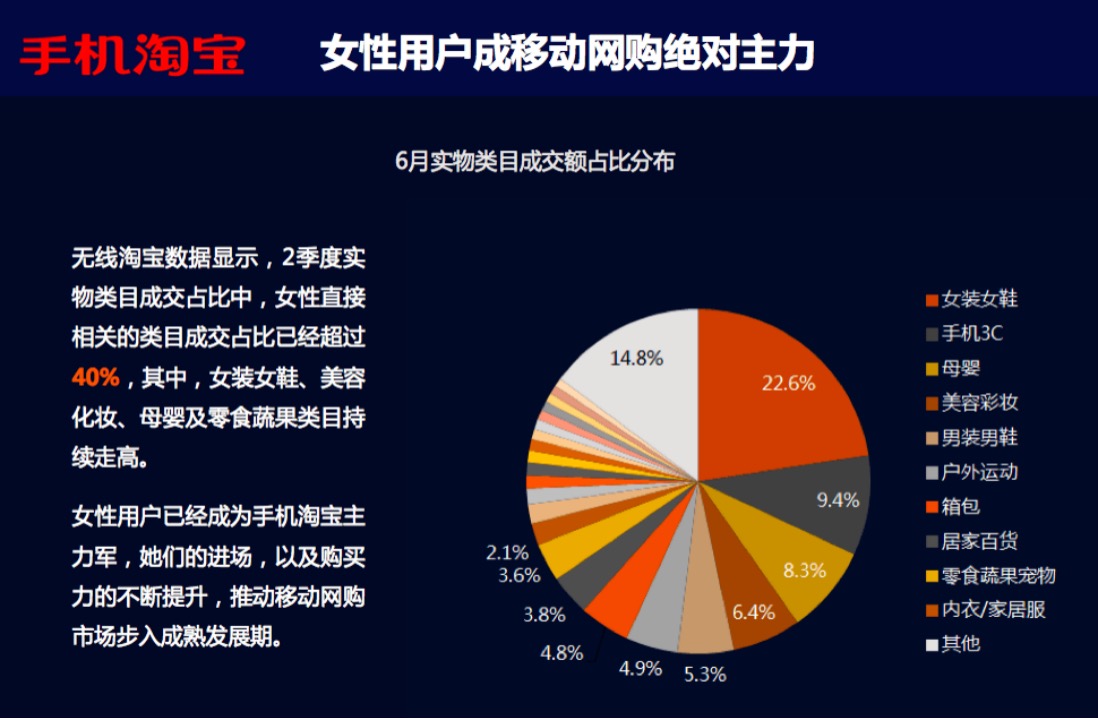
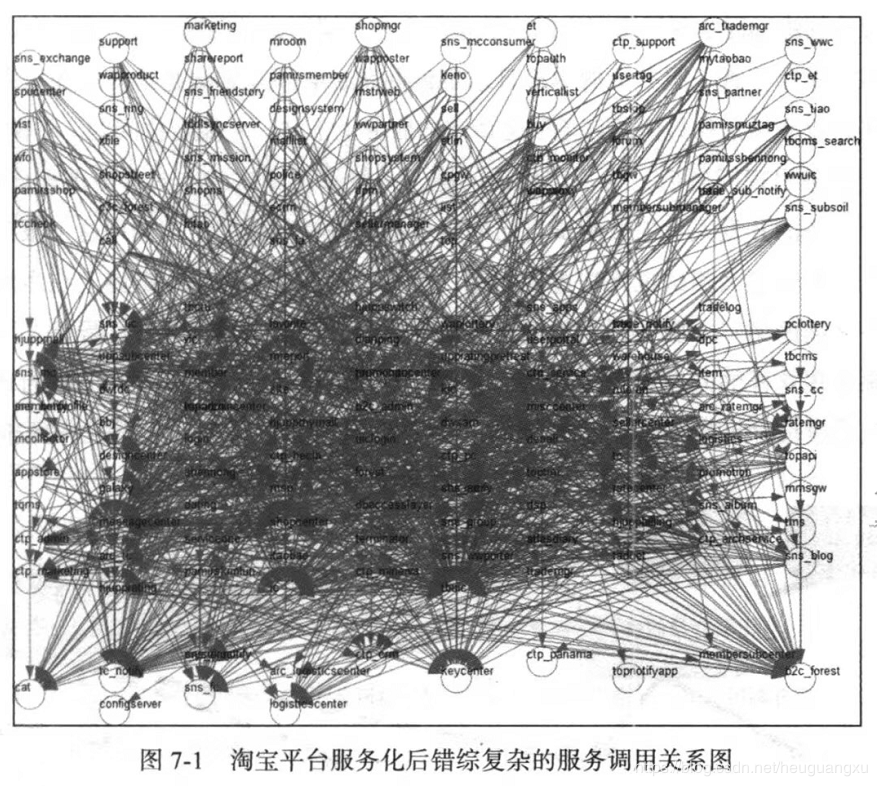
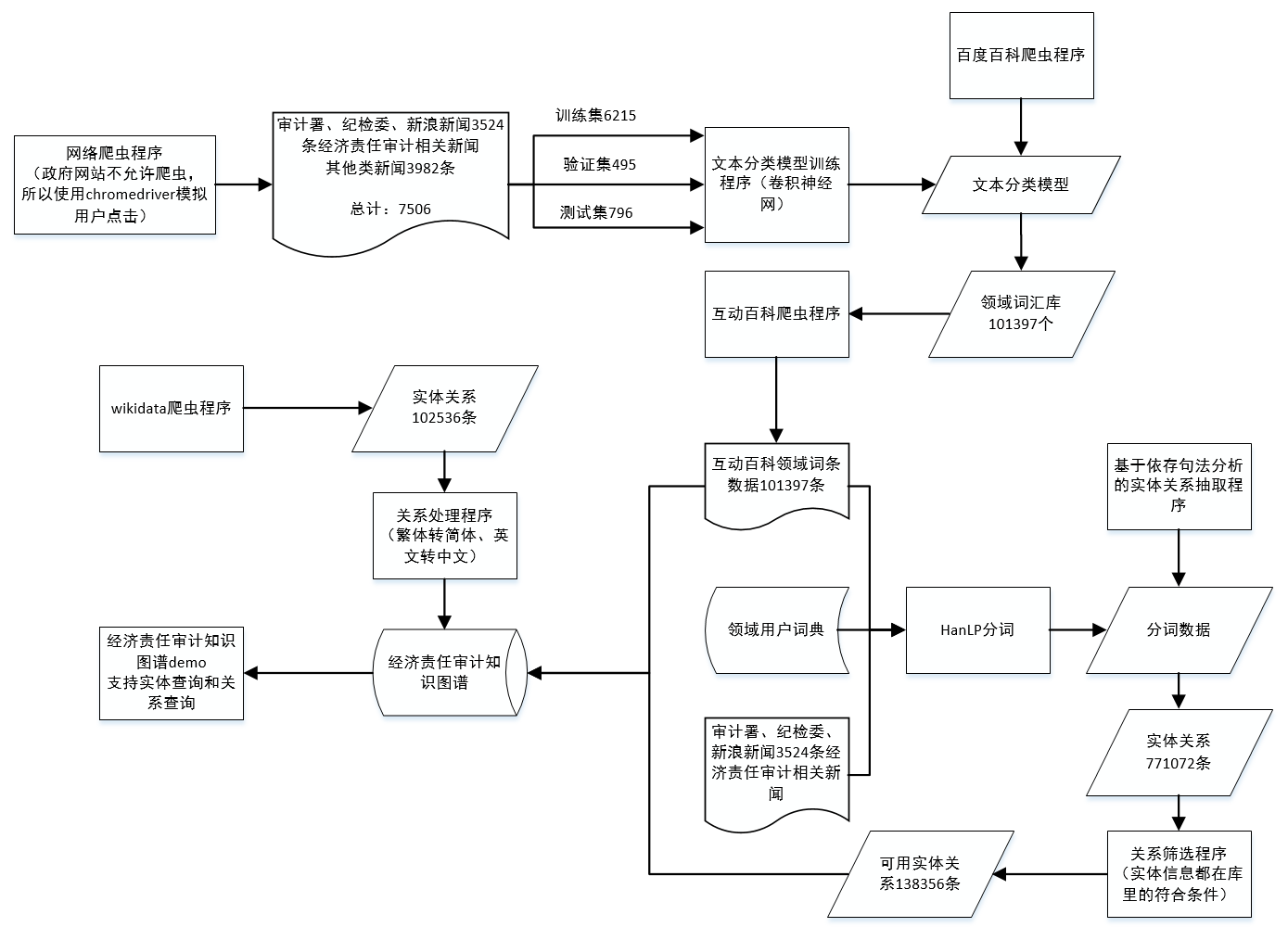
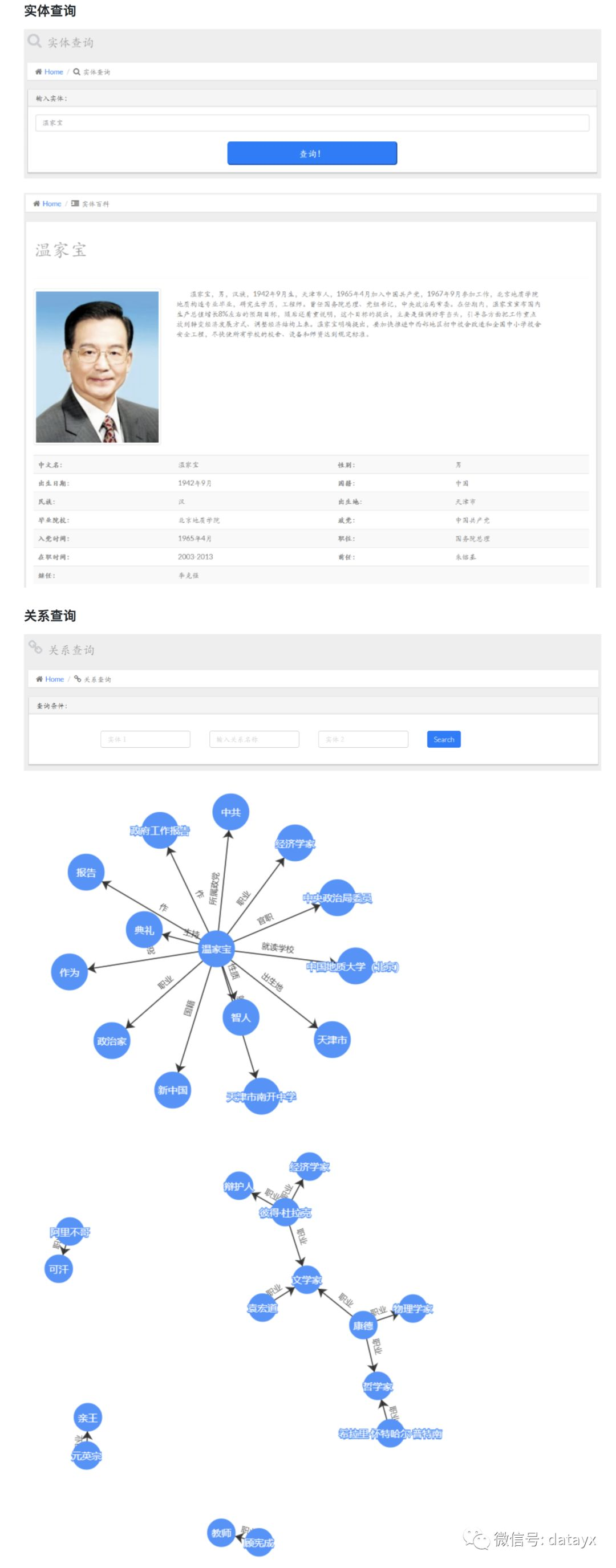
自 2012 年 Google 提出“知识图谱”的概念以来,知识图谱就一直是学术研究的重要方向,现在有很多高校、企业都致力于将这项技术应用到医疗、教育、商业等领域,并且已经取得了些许成果。Google 也宣布将以知识图谱为基础,构建下一代智能搜索引擎。
+
现在已经可以在谷歌、百度、搜狗等搜索引擎上面看到知识图谱的应用了。比如在 Google 搜索某个关键词时,会在其结果页面的右边显示该关键字的详细信息。在几个常用的搜索引擎中搜索知识时,返回的答案也变得更加精确,比如搜索“汪涵的妻子”,搜索引擎会直接给出答案“杨乐乐”,方便了用户快速精准的获取想要的信息。不过目前的搜索引擎只有少部分搜索问题能达到这种效果。
当然你也可以选择使用关系型数据库,因为我做的经济责任审计知识图谱不够深入,所以做到最后展示的时候,发现其实用我比较熟悉的 MySql 更好,相比 NOSql 我更熟悉关系型数据库,而且 MySql 有更大的社区在维护,它的 Bug 少、性能也更好。
+
最后放几张效果图
+
+
+
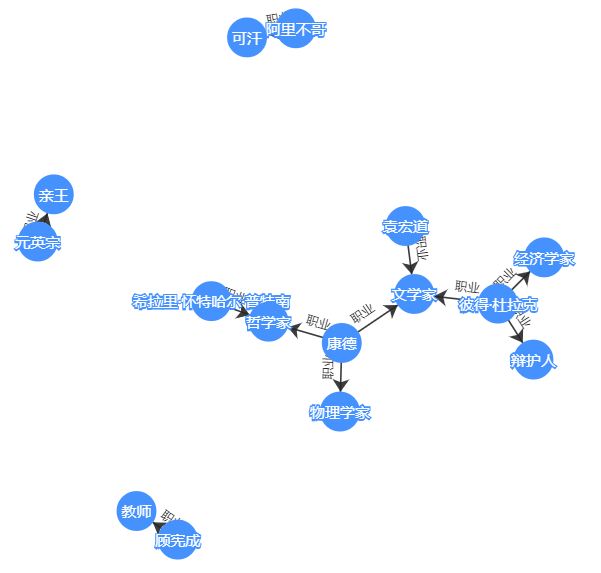
下面是以“职业”为关系查询条件所得出的结果。
+
+
总结一下
+
只是对几个月工作的梳理,大多数核心代码都改自现有的代码,所有的数据都来自于网络,与知识图谱相关的公开技术较少,我也只是尝试着做了一下,虽然很菜,也可以对大致的技术路线、流程有一个简单的了解,主要工作都是自然语言处理的内容。后期可以利用现在的知识图谱构建智能问答系统,实现从 what 到 why 的转换。
至此,微信公众号历史文章的爬虫已经实现,其实整个过程只不过是用程序来模拟的了人类的操作。需要注意的是,程序不能设置太快,因为微信做了相关限制,所以设太快会在一段时间内无法使用文章查找功能;另外一点是使用选择器选择页面元素的时候,会有一些坑,而且我发现不同账号登录,有很少部分的页面元素虽然直观上是一样的,但是它的 html 代码有细微的差别。
The fundamental delusion: There is something out there that will make me happy and fulfilled forever.
+最基本的错觉: 有些东西会让我永远快乐和满足
+
Hard work is really overrated. How hard you work matters a lot less in the modern economy. What is underrated? Judgment. Judgment is underrated.
+在现代经济中,努力工作的重要性大大降低了。什么被低估了?判断,判断被低估了
+
Spend more time making the big decisions. There are basically three really big decisions you make in your early life: where you live, who you’re with, and what you do.
+花更多的时间做重大决定。在你的早期生活中,基本上有三个真正重大的决定: 你住在哪里,你和谁在一起,你做什么
+
Stay out of things that could cause you to lose all of your capital, all of your savings. Don’t gamble everything on one go. Instead, take rationally optimistic bets with big upsides.
+远离那些可能导致你失去所有资本、所有储蓄的事情。不要一次性赌光所有的东西。取而代之的是,理性乐观地下注,并从中获得巨大的好处
+
Don’t partner with cynics and pessimists. Their beliefs are self-fulfilling.
+不要和愤世嫉俗者和悲观主义者合作,他们的信仰是自我实现的
+
You’re not going to get rich renting out your time. You must own equity—a piece of a business—to gain your financial freedom.
+出租你的时间是不会致富的。你必须拥有股权,一项业务,才能获得财务自由
+
Follow your intellectual curiosity more than whatever is “hot” right now. If your curiosity ever leads you to a place where society eventually wants to go, you’ll get paid extremely well.
+比起现在所谓的「热门」 ,应该更多地追随你的求知欲。如果你的好奇心曾经引导你到一个社会最终想要去的地方,那么你会得到非常好的报酬
+
The less you want something, the less you’re thinking about it, the less you’re obsessing over it, the more you’re going to do it in a natural way.
+你想要的东西越少,你对它的思考就越少,你对它的困扰就越少,你就会越自然地去做它
+
Learn to sell. Learn to build. If you can do both, you will be unstoppable.
+学会销售,学会建设,如果你能同时做到这两点,你将不可阻挡
+
If you secretly despise wealth, it will elude you.
+如果你私下里鄙视财富,它就会躲避你
+
Arm yourself with specific knowledge, accountability, and leverage. Specific knowledge is found by pursuing your genuine curiosity and passion rather than whatever is hot right now. Specific knowledge is knowledge you cannot be trained for.
+用具体的知识、责任感和影响力武装自己。具体的知识是通过追求你真正的好奇心和激情而不是任何现在热门的东西找到的。具体的知识是你不能被训练的知识
+
If they can train you to do it, then eventually they will train a computer to do it.
+如果他们能训练你做一件事,那么最终他们会训练一台电脑来做这件事
+
Apply specific knowledge, with leverage, and eventually you will get what you deserve.
+运用特定的知识,利用杠杆作用,最终你会得到你应得的东西
+
You should be too busy to “do coffee” while still keeping an uncluttered calendar.
+你应该忙得没时间“喝咖啡” ,同时保持日程表整洁
+
There are no get-rich-quick schemes. Those are just someone else getting rich off you.
+没有快速致富的计划,那些只是别人从你身上赚钱而已
+
Code and media are permissionless leverage.
+代码和媒体是未经许可的杠杆
+
People who live far below their means enjoy a freedom that people busy upgrading their lifestyles can’t fathom.
+那些生活水平远远低于自己收入的人们享受着一种自由,这是忙于提升自己的生活方式的人们所无法企及的
+
By the time people realize they have enough money, they’ve lost their time and their health.
+当人们意识到他们有足够的钱时,他们已经失去了时间和健康
+
To have peace of mind, you have to have peace of body first.
+为了拥有内心的平静,你必须首先拥有身体的平静
+
The more secrets you have, the less happy you’re going to be.
+你的秘密越多,你就越不快乐
+
No exceptions—all screen activities linked to less happiness, all non-screen activities linked to more happiness.
+毫无例外,所有的屏幕活动都与较少的快乐有关,所有的非屏幕活动都与较多的快乐有关
+
Inspiration is perishable—act on it immediately.
+灵感是易逝的,所以立即付诸行动
+
To make an original contribution, you have to be irrationally obsessed with something
+为了做出原创性的贡献,你必须非理性地沉迷于某些东西
+
If there’s something you want to do later, do it now. There is no “later.”
+如果你以后有什么想做的事情,现在就应该去做,没有「以后」
+
Courage isn’t charging into a machine gun nest. Courage is not caring what other people think.
+勇气不是冲进机关枪的巢穴,而是不在乎别人的看法
+
Happiness is a choice you make and a skill you develop.
+幸福是你的选择,是你发展的一项技能
+
Your brain is overvaluing the side with the short-term happiness and trying to avoid the one with short-term pain.
+你的大脑高估了短期的幸福,却试图避免短期的痛苦
+
Envy is the enemy of happines.
+嫉妒是幸福的敌人
+
Honesty is a core, core, core value.
+诚信是一个非常,非常,非常核心的价值观
+
where you build a unique character, a unique brand, a unique mindset, which causes luck to find you.
+你要建立一个独特的个性,一个独特的品牌,一个独特的心态,这会让好运气找到你
+
Figure out what you’re good at, and start helping other people with it.
+找出你擅长的东西,然后去帮助他人
+
If you are a trusted, reliable, high-integrity, long-term-thinking dealmaker, when other people want to do deals but don’t know how to do them in a trustworthy manner with strangers, they will literally approach you and give you a cut of the deal just because of the integrity and reputation you’ve built up.
+如果你是一个值得信赖的、可靠的、正直的、有长远眼光的交易者,当其他人想做交易,但不知道如何以值得信赖的方式与陌生人做交易时,他们会真正地接近你,并和你进行交易,仅仅因为你已经建立起的诚信和声誉
+
All benefits in life come from compound interest, whether in money, relationships, love, health, activities, or habits.
+生活中所有的好处都来自于复利,无论是在金钱、人际关系、爱情、健康、活动还是习惯上
+
Productize yourself
+将自己产品化
+
It’s only after you’re bored you have the great ideas. It’s never going to be when you’re stressed, or busy, running around or rushed.
+只有当你感到无聊的时候,你才会有好的想法。当你感到压力,或者忙碌,到处跑或者匆忙的时候,这些都不会发生
+
Play stupid games, win stupid prizes.
+玩愚蠢的游戏,赢得愚蠢的奖品
+
Clear accountability is important. Without accountability, you don’t have incentives. Without accountability, you can’t build credibility. But you take risks. You risk failure. You risk humiliation.
+明确的问责制很重要。没有责任感,你就没有动力。没有责任感,你就无法建立可信度。但是你要冒险,要冒着失败的风险,冒着被羞辱的风险
+
The best jobs are neither decreed nor degreed. They are creative expressions of continuous learners in free markets.
+最好的工作既没有规定也没有程度,它们是自由市场中不断学习者的创造性表现
+
Reading is faster than listening. Doing is faster than watching.
+读比听快,做比看快
+
Explain what you learned to someone else. Teaching forces learning.
+向别人解释你学到了什么。教学是学习的动力
+
Read what you love until you love to read.
+读你喜欢的东西,直到你喜欢阅读
+
Better is the enemy of done.
+完成比完美更重要
+
+
Angela Zhu 摘抄
+
+
If you did not make yourself well understood, it is your problem.
+如果别人没有听懂你在说什么,一定是你的问题
+
+
Angela Zhu 摘抄
+
+
Inspire your people do things, not tell your people do things.
+不断激烈启发你的组员做事,而不是告诉他们做什么
+
+
Angela Zhu 摘抄
+
+
It does not matter what was your motivation, it only matters how this make your direct reports feel.
+你的出发点不重要,重要的是你让别人感觉你想干什么
+
+
Angela Zhu 摘抄
+
+
尽可能帮助和服务别人,建立信任,赢得资本
+
+
Angela Zhu
+
+
To learn something, you should do not reread, summarize and teach it out loud.
+要想学点东西,你不应该重读、总结和大声教出来
When you are old and gray, and look back on your life, you will want to be proud of what you have done. The source of that pride won’t be the things you have acquired or the recognition you have received. It will be the lives you have touched and the difference you have made.
+当你白发苍苍、垂垂老矣、回首人生时,你需要为自己做过的事感到自豪。物质生活和满足的占有欲,都不会产生自豪。只有那些受你影响、被你改变过的人和事,才会让你产生自豪感
+
+
Steven Chu 2009 年哈佛大学毕业演讲
+
+
In your collaborations, always remember that “credit” is not a conserved quantity. In a successful collaboration, everybody gets 90 percent of the credit.
+合作中,不要把功劳都归在自己身上,在一场成功的合作中,每个人都应该获得 90% 的荣誉
近期参与的项目属于嵌入式软件领域,自然而然就得用 C 语言进行开发,开发过程中发现引入的第三方库里面有一些奇奇怪怪的写法,比如大佬们都喜欢使用do {...} while(0)的宏定义,在 Stack Overflow 上也有人提出了这个问题。之前从事 Linux 内核开发的谷歌大佬 Robert Love 给出了如下的解释:
+
+
do {…} while(0) is the only construct in C that lets you define macros that always work the same way, so that a semicolon after your macro always has the same effect, regardless of how the macro is used (with particularly emphasis on the issue of nesting the macro in an if without curly-brackets).
+
do {...} while(0) 在 C 中是唯一的构造程序,让你定义的宏总是以相同的方式工作,这样不管怎么使用宏(尤其在没有用大括号包围调用宏的语句),宏后面的分号也是相同的效果。
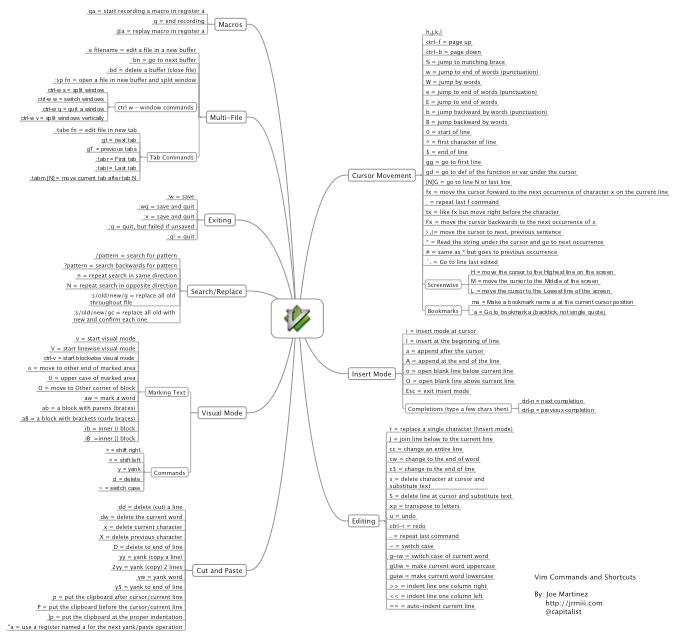
Vim 可以认为是 Vi 的高级版本,Vim 可以用颜色或下划线的方式来显示一些特殊信息,您可以认为 Vi 是一个文本处理工具,而 Vim 是一个程序开发工具,现在大部分 Linux 的发行版都以 Vim 替换 Vi 了。在 Linux 命令行模式下有很多编辑器,但是 Vi 文本编辑器是所有 Unix-like 系统都会内置的,因此学会 Vi/Vim 的使用时非常有必要的,对于 Vi 的三种模式(命令模式、编辑模式、命令行模式)这里就不在做说明了,下面是一些比较常用的命令。
+
一般命令模式下
+
+
+
+
命令
+
说明
+
+
+
+
+
h、j、k、l
+
与键盘的方向键一一对应,分别为左、下、上、右,在键盘上着几个字母是排在一起的
+
+
+
Ctrl+f、Ctrl+b
+
分别对应键盘的「Page Down」、「Page Up」,我更习惯于这两个键,而不是前面的组合键
+
+
+
0、$
+
分别对应键盘的「Home」、「End」,即移动到该行的最前面/后面字符处
+
+
+
n<Enter>
+
n 为数字,光标向下移动 n 行
+
+
+
/word、?word
+
向光标之上/下寻找一个字符串名称为 word 的字符串
+
+
+
n、N
+
如果我们刚刚执行了上面上面的 /word 或 ?word 查找操作,那么 n 则表示重复前一个查找操作,可以简单理解为向下继续查找下一个名称为 word 的字符串,N 则与 n 刚好相反
《The Almanack of Naval Ravikant:A Guide to Wealth and Happiness》、《原则》、《奈飞文化手册》几本书介绍了很多人生应该践行的准则。前面两本算是创始人的人生原则清单, 指出不少我们应该避免的事情,也列出来了很多我们应该坚持的东西,比如写作、用计算机节省人力等等。《奈飞文化手册》我觉得算是集体智慧,虽然内容是站在企业角度写的,但对个人也有很大的人生指导意义。
+
+最后再推荐一本《你是你吃出来的》吧,我们中国人的饮食基本是不健康的。身体所必须的营养一定要注意均衡摄入,不能因为不想吃饭或是学校的饭难吃就不吃,吃东西不仅要关注能量,更要注重七大营养素(碳水化合物、脂类、蛋白质、维生素、矿物质、水、膳食纤维)。鸡蛋、牛奶、蔬菜、水果、坚果、肉类、(深海)鱼、动物肝脏、米饭/面食等,都需要均衡摄入。《你是你吃出来的》里面做了大量苦口婆心的讲解,也纠正了大家平时的一些错误观点,比如很多人生病了不舒服就喝喝粥打发,觉得粥里面很有营养,实际上粥是没有什么营养的;粉条、土豆、红薯这些都是算作主食这一类的,尤其很多人把粉条当做菜来吃是绝对错误的,某一餐有粉条话就应该主动减少米饭的摄入量;很多地方晚上都习惯吃面食,觉得面食容易消化,但面食里面的主要要成分是碳水化合物,碳水化合物摄入过多的结果只会让你越来越胖。
+
+「一席」上的大部分演讲是值得听的,让您对中国社会有一个更好的了解;「TED」、「网易公开课」上国外高校的视频可以多看看,讲的真心不错;国内出观众、大部分二流学校的演讲能不去就不去,还不如把这种时间拿去睡睡觉,补充补充精力。
做过一段的信息流广告,真真切切体会到了「如果你没有花钱买产品,那你就是被卖的产品」,这是纪录片《监视资本主义:智能陷阱 The Social Dilemma》中的一句话,以前在阅读高于自己的作品,远离精神毒品中批评过抖音、快手一类的产品,但现在我得改一点这个观念,50 岁以上的人没事时候刷刷抖音挺不错的,年轻人还是别去当被卖的产品了。
+ KK 是凯文·凯利的网名,他曾经担任《连线》杂志的第一任主编,是著名的科技评论家,也是畅销书《失控》的作者。去年的 4 月 28 日是他 68 岁生日,他在个人网站上发表了一篇给年轻人的 68 条建议,文章被翻译成了十几种其它语言,今年 4 月 28 日老爷子又续写了一篇给年轻人的 99 条建议,本文是给年轻人的 68 条建议中文翻译版,翻译除了借助 DeepL 机器翻译工具外,更多参考自KK 在 68 岁生日时给出的 68 条建议。
+Learn how to learn from those you disagree with, or even offend you. See if you can find the truth in what they believe.
+学着从那些你不认可甚至冒犯你的人身上学习,看看能否从他们的信仰中找到真理
+Being enthusiastic is worth 25 IQ points.
+充满热情可以抵得上 25 点智商
+Always demand a deadline. A deadline weeds out the extraneous and the ordinary. It prevents you from trying to make it perfect, so you have to make it different. Different is better.
+做任何事都应该设一个 deadline,它可以帮你排除那些无关紧要的事情,也能避免过分要求自己尽善尽美。努力去做到与众不同,差异比完美更好
+Don’t be afraid to ask a question that may sound stupid because 99% of the time everyone else is thinking of the same question and is too embarrassed to ask it.
+不要害怕自己问的问题看起来很愚蠢,99% 的情况下,其他人和你有一样的问题,只不过他们羞于问而已
+Being able to listen well is a superpower. While listening to someone you love keep asking them “Is there more?”, until there is no more.
+倾听是一种超能力,当听到你喜欢的人说话时,要不时的追问「还有吗」,直到他们没有更多的东西可讲
+A worthy goal for a year is to learn enough about a subject so that you can’t believe how ignorant you were a year earlier.
+一个有意义的年度目标是去充分了解一个学科,这样你就会对一年前的无知感到难以置信
+Gratitude will unlock all other virtues and is something you can get better at.
+感恩可以解锁其它所有的美德,也是你可以继续做的更好的一件事情
+Treating a person to a meal never fails, and is so easy to do. It’s powerful with old friends and a great way to make new friends.
+请一个人吃饭是非常简单的一件事情,不仅仅是老朋友,这也是结交新朋友的有效方式
+Don’t trust all-purpose glue.
+不要相信万能药
+Reading to your children regularly will bond you together and kickstart their imaginations.
+经常给的孩子读书不仅能巩固你们之间的感情,也能帮助孩子开启想象力
+Never use a credit card for credit. The only kind of credit, or debt, that is acceptable is debt to acquire something whose exchange value is extremely likely to increase, like in a home. The exchange value of most things diminishes or vanishes the moment you purchase them. Don’t be in debt to losers.
+永远不要用信用卡去透支。唯一可以接受的透支或负债,应该是那些通过负债有极大可能获得增值的事物,比如房屋。绝大多数事物在你买下它的那一刻就开始贬值了,别为那些没有未来的事物透支
+Pros are just amateurs who know how to gracefully recover from their mistakes.
+专业人士不过是善于从挫折中优雅爬起的菜鸟
+Extraordinary claims should require extraordinary evidence to be believed.
+要想让人相信非同寻常的观点,就需要非同寻常的证据
+Don’t be the smartest person in the room. Hangout with, and learn from, people smarter than yourself. Even better, find smart people who will disagree with you.
+别成为一群人中最聪明的那一个,和那些比你聪明的人待在一起,向他们学习。如果能找到和你观点相反的聪明人,那就更好了
+Rule of 3 in conversation. To get to the real reason, ask a person to go deeper than what they just said. Then again, and once more. The third time’s answer is close to the truth.
+对话中的「数字 3 原则」。想要找到一个人真正的意图,那就请他把刚才说的话再深入一些,如此反复直到第三遍,你就能比较接近真相了
+Don’t be the best. Be the only.
+不做最好的,去做唯一的
+Everyone is shy. Other people are waiting for you to introduce yourself to them, they are waiting for you to send them an email, they are waiting for you to ask them on a date. Go ahead.
+每个人都很害羞,其他人正等着你向他们介绍你自己,等着你给他们发送邮件,等着你约他们见面。大胆的向前走
+Don’t take it personally when someone turns you down. Assume they are like you: busy, occupied, distracted. Try again later. It’s amazing how often a second try works.
+别人拒绝你的时候不要往心里去。假设他们和你一样忙碌、腾不出手、心烦意乱,再试一次,第二次成功的几率超乎你的想象
+The purpose of a habit is to remove that action from self-negotiation. You no longer expend energy deciding whether to do it. You just do it. Good habits can range from telling the truth, to flossing.
+习惯的意义在于无需再为某类行为纠结,不用再消耗精力去觉得是否做这件事。干就完了,讲真话和使用牙线都是很好的习惯
+Promptness is a sign of respect.
+及时回应是表示尊重的一种方式
+When you are young spend at least 6 months to one year living as poor as you can, owning as little as you possibly can, eating beans and rice in a tiny room or tent, to experience what your “worst” lifestyle might be. That way any time you have to risk something in the future you won’t be afraid of the worst case scenario.
+当你年轻的时候,应该至少花半年到一年的时间,过尽可能穷的日子,拥有尽可能少的身外之物,居陋室而箪食瓢饮,体验你可能会经历的最穷困潦倒的生活。这样,在未来任何时候,你都不用担心最坏的情况
+Trust me: There is no “them”.
+相信我,没有「他们」
+
+个人理解,KK 大叔想表达的意思应该是:太阳底下无新事,每个人都是历史的参与者
+
+The more you are interested in others, the more interesting they find you. To be interesting, be interested.
+你越有兴趣了解别人,别人就会发现你越有趣,要成为有趣的人,先要对别人感兴趣
+Optimize your generosity. No one on their deathbed has ever regretted giving too much away.
+常行慷慨之事,没有人会在死的时候后悔给予的太多
+To make something good, just do it. To make something great, just re-do it, re-do it, re-do it. The secret to making fine things is in remaking them.
+想要做好一件事,干就完了。想要做一件值得称赞的事情,那就重做一遍,重做一遍,再重做一遍。制造好东西的秘诀在于不断的重做
+The Golden Rule will never fail you. It is the foundation of all other virtues.
+金科玉律永远不会让你失望,它是所有其他美德的基础
+If you are looking for something in your house, and you finally find it, when you’re done with it, don’t put it back where you found it. Put it back where you first looked for it.
+如果你正在你的房子里寻找什么东西,那么用完后不要放回你找到它的地方,而是放到你最初找它的地方
+Saving money and investing money are both good habits. Small amounts of money invested regularly for many decades without deliberation is one path to wealth.
+存钱和投资是好习惯。几十年如一日的定期进行小额投资(定投),是一条致富之路
+To make mistakes is human. To own your mistakes is divine. Nothing elevates a person higher than quickly admitting and taking personal responsibility for the mistakes you make and then fixing them fairly. If you mess up, fess up. It’s astounding how powerful this ownership is.
+犯错是人之常情,承认错误是神圣的。认错并勇于担责,再认真弥补过错,没有什么比这更可贵了。是自己搞砸的就勇于承担,这反而能彰显你的强大
+Never get involved in a land war in Asia.
+永远不要在亚洲陷入地面战争
+
+KK 大叔这句话没读懂
+
+You can obsess about serving your customers/audience/clients, or you can obsess about beating the competition. Both work, but of the two, obsessing about your customers will take you further.
+你可以专注于你的顾客、听众或客户,也可以沉迷于在竞争中获胜,这两种方法都行之有效,但是专注于服务你的客户会让你走的更远
+Show up. Keep showing up. Somebody successful said: 99% of success is just showing up.
+在场,坚持在场,某个成功人士说过:99% 的成功只不过是因为在场
+Separate the processes of creation from improving. You can’t write and edit, or sculpt and polish, or make and analyze at the same time. If you do, the editor stops the creator. While you invent, don’t select. While you sketch, don’t inspect. While you write the first draft, don’t reflect. At the start, the creator mind must be unleashed from judgement.
+将创造过程与改进过程分开,你不可能在写做的同时进行编辑,也不可能在凿刻的同时进行打磨,更不可能在制造的同时进行分析。如果你这么做,求善之心就会打断创造之意;创新时就要忘掉已有方案;勾勒草图时就不能太着眼于细处;写作时,先打草稿而不要去抠细节。在新事物之初,创意的思想必须得到无拘无束的释放
+If you are not falling down occasionally, you are just coasting.
+如果你从未跌倒过,那么你也就从未努力过
+Perhaps the most counter-intuitive truth of the universe is that the more you give to others, the more you’ll get. Understanding this is the beginning of wisdom.
+也许宇宙中最违反直觉的真理就是,你给予他人越多,你收获的就越多,这是智慧的起点
+Friends are better than money. Almost anything money can do, friends can do better. In so many ways a friend with a boat is better than owning a boat.
+朋友胜过金钱。金钱几乎可以做任何事情,但朋友可以做得更好。很多时候,自己有条船不如有个有船的朋友
+This is true: It’s hard to cheat an honest man.
+相信我,你很难欺骗一个诚实的人
+When an object is lost, 95% of the time it is hiding within arm’s reach of where it was last seen. Search in all possible locations in that radius and you’ll find it.
+当一件物品丢失时,95% 的情况下,它都藏在人们最后一次看到它时触手可及的地方。在这个半径范围内搜索所有可能的地点,你就能找到它
+You are what you do. Not what you say, not what you believe, not how you vote, but what you spend your time on.
+你做什么就是什么。不是你说什么,不是你相信什么,更不是你支持什么,而是你把时间花在了什么上
+If you lose or forget to bring a cable, adapter or charger, check with your hotel. Most hotels now have a drawer full of cables, adapters and chargers others have left behind, and probably have the one you are missing. You can often claim it after borrowing it.
+如果你遗失或忘记带电缆、适配器或充电器,不妨去问问你的酒店。大多数酒店都会有满满一抽屉的电源线、适配器和充电器,这些东西都是别人留下的,没准儿其中就有你的,酒店也并不介意你借用后随身带走
+Hatred is a curse that does not affect the hated. It only poisons the hater. Release a grudge as if it was a poison.
+仇恨是一种诅咒,但它不会影响被仇恨的人。它只会毒害仇恨者,把你的怨恨当作毒药一样丢掉吧
+There is no limit on better. Talent is distributed unfairly, but there is no limit on how much we can improve what we start with.
+没有最好,只有更好。个人的天分有高有低,但不论高低,自身的提升都永无止境
+Be prepared: When you are 90% done any large project (a house, a film, an event, an app) the rest of the myriad details will take a second 90% to complete.
+任何一项大工程(修房子、拍电影、开发 app)完成度为 90% 的时候,你都要做好心理准备:剩余的大量细节工作同样需要 90% 的时间来完成
+When you die you take absolutely nothing with you except your reputation.
+当你死的时候,除了你的名誉,你什么都无法带走
+Before you are old, attend as many funerals as you can bear, and listen. Nobody talks about the departed’s achievements. The only thing people will remember is what kind of person you were while you were achieving.
+在你年老之前,尽可能多地参加葬礼并听听别人的谈话,没有人会谈论逝者的成就,人们能记住的只有逝者在成功时是什么样的人
+For every dollar you spend purchasing something substantial, expect to pay a dollar in repairs, maintenance, or disposal by the end of its life.
+你每花一美元在实体店购买一件东西,将来都要再花一元钱去维修、保养,或是在它报废后处理掉它
+Anything real begins with the fiction of what could be. Imagination is therefore the most potent force in the universe, and a skill you can get better at. It’s the one skill in life that benefits from ignoring what everyone else knows.
+任何真实的东西都来源于虚构的想法,想象是宇宙中最强大的力量,也是你可以做的更好的一种能力,生命中可以因不知众人所知而获利
+When crisis and disaster strike, don’t waste them. No problems, no progress.
+当危机和灾难来临时,不要错过他们,没有问题就没有进步
+On vacation go to the most remote place on your itinerary first, bypassing the cities. You’ll maximize the shock of otherness in the remote, and then later you’ll welcome the familiar comforts of a city on the way back.
+度假时,先绕过城市去行程中最偏远的地方。这样你就能最大程度地体验到异域风情带给你的冲击,而在返程的路上,又可以享受熟悉的城市所带给你的舒适
+When you get an invitation to do something in the future, ask yourself: would you accept this if it was scheduled for tomorrow? Not too many promises will pass that immediacy filter.
+当你被邀请在未来的某个时间点做某件事情时,问问自己:如果是明天,你会接受邀请吗?绝大多数邀约都经不住这种迫切性检验
+Don’t say anything about someone in email you would not be comfortable saying to them directly, because eventually they will read it.
+如果一些话你不能当面对某人说出口,那么就不要在邮件中对他评头论足,因为他们最终会看到邮件
+If you desperately need a job, you are just another problem for a boss; if you can solve many of the problems the boss has right now, you are hired. To be hired, think like your boss.
+如果你只是迫切需要一份工作,那你只是老板的另一个问题;如果你能解决许多老板眼下的问题,那你自然能得到这份工作。要想得到一份工作,就要像老板一样去思考
+Art is in what you leave out.
+艺术藏身于你遗忘的地方
+Acquiring things will rarely bring you deep satisfaction. But acquiring experiences will.
+获得物品很少能给你带来深刻的满足感,但是经验却能做到
+Rule of 7 in research. You can find out anything if you are willing to go seven levels. If the first source you ask doesn’t know, ask them who you should ask next, and so on down the line. If you are willing to go to the 7th source, you’ll almost always get your answer.
+研究的「数字 7 原则」。当你愿意就一个问题深入七层时,总能找到你想要的答案。如果你问的第一层人不知道,那么就问问他们应该去找谁,如此追索下去,你几乎总能得到你的答案
+How to apologize: Quickly, specifically, sincerely.
+如何道歉:迅速、具体、真诚
+Don’t ever respond to a solicitation or a proposal on the phone. The urgency is a disguise.
+永远不要在电话上面答应一个请求或提议,所谓的急迫不过是一种假象
+When someone is nasty, rude, hateful, or mean with you, pretend they have a disease. That makes it easier to have empathy toward them which can soften the conflict.
+当有人对你粗鄙、无礼、刻薄,甚至是下流时,当他们有病就好了,这使得我们更容易对他们产生同情心,进而缓和冲突
+Eliminating clutter makes room for your true treasures.
+清理杂物,为真正重要的东西腾出空间
+You really don’t want to be famous. Read the biography of any famous person.
+你绝对不会想出名,不信的话可以随便找本名人传记读读
+Experience is overrated. When hiring, hire for aptitude, train for skills. Most really amazing or great things are done by people doing them for the first time.
+经验往往被高估了,招聘时应该多看资质,技能是可以培训的。许多令人惊奇和赞叹的事情,都是新手做出来的
+A vacation + a disaster = an adventure.
+度假 + 灾难 = 冒险
+Buying tools: Start by buying the absolute cheapest tools you can find. Upgrade the ones you use a lot. If you wind up using some tool for a job, buy the very best you can afford.
+购买工具:从最便宜的开始,升级那些使用频次高的。如果你的工具是用于工作,那么买你能买得起的最好的
+Learn how to take a 20-minute power nap without embarrassment.
+学会毫不尴尬的打 20 分钟小盹儿
+Following your bliss is a recipe for paralysis if you don’t know what you are passionate about. A better motto for most youth is “master something, anything”. Through mastery of one thing, you can drift towards extensions of that mastery that bring you more joy, and eventually discover where your bliss is.
+如果你不知道自己热爱什么,追寻心之所向往往会带你误入歧途,对年轻人来说,更好的格言是:master something, anything,在精通一件事的过程中,你可以顺着带给你更多快乐的方向继续深入,并最终发现你热爱的东西
+I’m positive that in 100 years much of what I take to be true today will be proved to be wrong, maybe even embarrassingly wrong, and I try really hard to identify what it is that I am wrong about today.
+我敢肯定,我今天认为正确的许多东西在 100 年后将被证明是错误的,甚至可能是令人尴尬的错误。而我非常努力在做的事情,就是去识别我对今天的错误认知
+Over the long term, the future is decided by optimists. To be an optimist you don’t have to ignore all the many problems we create; you just have to imagine improving our capacity to solve problems.
+从长远来说,未来由乐观主义者决定。作为一个乐观主义者并非要对我们制造的问题视而不见,而是要想象如何提升我们解决问题的能力
+The universe is conspiring behind your back to make you a success. This will be much easier to do if you embrace this pronoia.
+整个宇宙在背后密谋让你成功,要相信,天助人愿
+
+
+
+若没有在段落文字后面做特别标注,那该段落即摘录自The Almanack of Naval Ravikant: A Guide to Wealth and Happiness
+
+There’s no shortcut to smart.
+聪明没有捷径可走
+The fundamental delusion: There is something out there that will make me happy and fulfilled forever.
+最基本的错觉: 有些东西会让我永远快乐和满足
+Hard work is really overrated. How hard you work matters a lot less in the modern economy. What is underrated? Judgment. Judgment is underrated.
+在现代经济中,努力工作的重要性大大降低了。什么被低估了?判断,判断被低估了
+Spend more time making the big decisions. There are basically three really big decisions you make in your early life: where you live, who you’re with, and what you do.
+花更多的时间做重大决定。在你的早期生活中,基本上有三个真正重大的决定: 你住在哪里,你和谁在一起,你做什么
+Stay out of things that could cause you to lose all of your capital, all of your savings. Don’t gamble everything on one go. Instead, take rationally optimistic bets with big upsides.
+远离那些可能导致你失去所有资本、所有储蓄的事情。不要一次性赌光所有的东西。取而代之的是,理性乐观地下注,并从中获得巨大的好处
+Don’t partner with cynics and pessimists. Their beliefs are self-fulfilling.
+不要和愤世嫉俗者和悲观主义者合作,他们的信仰是自我实现的
+You’re not going to get rich renting out your time. You must own equity—a piece of a business—to gain your financial freedom.
+出租你的时间是不会致富的。你必须拥有股权,一项业务,才能获得财务自由
+Follow your intellectual curiosity more than whatever is “hot” right now. If your curiosity ever leads you to a place where society eventually wants to go, you’ll get paid extremely well.
+比起现在所谓的「热门」 ,应该更多地追随你的求知欲。如果你的好奇心曾经引导你到一个社会最终想要去的地方,那么你会得到非常好的报酬
+The less you want something, the less you’re thinking about it, the less you’re obsessing over it, the more you’re going to do it in a natural way.
+你想要的东西越少,你对它的思考就越少,你对它的困扰就越少,你就会越自然地去做它
+Learn to sell. Learn to build. If you can do both, you will be unstoppable.
+学会销售,学会建设,如果你能同时做到这两点,你将不可阻挡
+If you secretly despise wealth, it will elude you.
+如果你私下里鄙视财富,它就会躲避你
+Arm yourself with specific knowledge, accountability, and leverage. Specific knowledge is found by pursuing your genuine curiosity and passion rather than whatever is hot right now. Specific knowledge is knowledge you cannot be trained for.
+用具体的知识、责任感和影响力武装自己。具体的知识是通过追求你真正的好奇心和激情而不是任何现在热门的东西找到的。具体的知识是你不能被训练的知识
+If they can train you to do it, then eventually they will train a computer to do it.
+如果他们能训练你做一件事,那么最终他们会训练一台电脑来做这件事
+Apply specific knowledge, with leverage, and eventually you will get what you deserve.
+运用特定的知识,利用杠杆作用,最终你会得到你应得的东西
+You should be too busy to “do coffee” while still keeping an uncluttered calendar.
+你应该忙得没时间“喝咖啡” ,同时保持日程表整洁
+There are no get-rich-quick schemes. Those are just someone else getting rich off you.
+没有快速致富的计划,那些只是别人从你身上赚钱而已
+Code and media are permissionless leverage.
+代码和媒体是未经许可的杠杆
+People who live far below their means enjoy a freedom that people busy upgrading their lifestyles can’t fathom.
+那些生活水平远远低于自己收入的人们享受着一种自由,这是忙于提升自己的生活方式的人们所无法企及的
+By the time people realize they have enough money, they’ve lost their time and their health.
+当人们意识到他们有足够的钱时,他们已经失去了时间和健康
+To have peace of mind, you have to have peace of body first.
+为了拥有内心的平静,你必须首先拥有身体的平静
+The more secrets you have, the less happy you’re going to be.
+你的秘密越多,你就越不快乐
+No exceptions—all screen activities linked to less happiness, all non-screen activities linked to more happiness.
+毫无例外,所有的屏幕活动都与较少的快乐有关,所有的非屏幕活动都与较多的快乐有关
+Inspiration is perishable—act on it immediately.
+灵感是易逝的,所以立即付诸行动
+To make an original contribution, you have to be irrationally obsessed with something
+为了做出原创性的贡献,你必须非理性地沉迷于某些东西
+If there’s something you want to do later, do it now. There is no “later.”
+如果你以后有什么想做的事情,现在就应该去做,没有「以后」
+Courage isn’t charging into a machine gun nest. Courage is not caring what other people think.
+勇气不是冲进机关枪的巢穴,而是不在乎别人的看法
+Happiness is a choice you make and a skill you develop.
+幸福是你的选择,是你发展的一项技能
+Your brain is overvaluing the side with the short-term happiness and trying to avoid the one with short-term pain.
+你的大脑高估了短期的幸福,却试图避免短期的痛苦
+Envy is the enemy of happines.
+嫉妒是幸福的敌人
+Honesty is a core, core, core value.
+诚信是一个非常,非常,非常核心的价值观
+where you build a unique character, a unique brand, a unique mindset, which causes luck to find you.
+你要建立一个独特的个性,一个独特的品牌,一个独特的心态,这会让好运气找到你
+Figure out what you’re good at, and start helping other people with it.
+找出你擅长的东西,然后去帮助他人
+If you are a trusted, reliable, high-integrity, long-term-thinking dealmaker, when other people want to do deals but don’t know how to do them in a trustworthy manner with strangers, they will literally approach you and give you a cut of the deal just because of the integrity and reputation you’ve built up.
+如果你是一个值得信赖的、可靠的、正直的、有长远眼光的交易者,当其他人想做交易,但不知道如何以值得信赖的方式与陌生人做交易时,他们会真正地接近你,并和你进行交易,仅仅因为你已经建立起的诚信和声誉
+All benefits in life come from compound interest, whether in money, relationships, love, health, activities, or habits.
+生活中所有的好处都来自于复利,无论是在金钱、人际关系、爱情、健康、活动还是习惯上
+Productize yourself
+将自己产品化
+It’s only after you’re bored you have the great ideas. It’s never going to be when you’re stressed, or busy, running around or rushed.
+只有当你感到无聊的时候,你才会有好的想法。当你感到压力,或者忙碌,到处跑或者匆忙的时候,这些都不会发生
+Play stupid games, win stupid prizes.
+玩愚蠢的游戏,赢得愚蠢的奖品
+Clear accountability is important. Without accountability, you don’t have incentives. Without accountability, you can’t build credibility. But you take risks. You risk failure. You risk humiliation.
+明确的问责制很重要。没有责任感,你就没有动力。没有责任感,你就无法建立可信度。但是你要冒险,要冒着失败的风险,冒着被羞辱的风险
+The best jobs are neither decreed nor degreed. They are creative expressions of continuous learners in free markets.
+最好的工作既没有规定也没有程度,它们是自由市场中不断学习者的创造性表现
+Reading is faster than listening. Doing is faster than watching.
+读比听快,做比看快
+Explain what you learned to someone else. Teaching forces learning.
+向别人解释你学到了什么。教学是学习的动力
+Read what you love until you love to read.
+读你喜欢的东西,直到你喜欢阅读
+Better is the enemy of done.
+完成比完美更重要
+
+Angela Zhu 摘抄
+
+If you did not make yourself well understood, it is your problem.
+如果别人没有听懂你在说什么,一定是你的问题
+
+Angela Zhu 摘抄
+
+Inspire your people do things, not tell your people do things.
+不断激烈启发你的组员做事,而不是告诉他们做什么
+
+Angela Zhu 摘抄
+
+It does not matter what was your motivation, it only matters how this make your direct reports feel.
+你的出发点不重要,重要的是你让别人感觉你想干什么
+
+Angela Zhu 摘抄
+
+尽可能帮助和服务别人,建立信任,赢得资本
+
+Angela Zhu
+
+To learn something, you should do not reread, summarize and teach it out loud.
+要想学点东西,你不应该重读、总结和大声教出来
+
+http://www.toolkiit.com/
+
+在人生最好的年纪,应该少一点算计,多一点洒脱。遇到喜欢的人就去相处,去恋爱,不要辜负自己的时光,然后人生就会给出你更多的可能性
+
+Fenng
+
+你心里应该有爱,应该有为了爱去放弃一些东西的勇气。如果你做不到这样,那我觉得你很可悲。或者,会成为一个精致的利己主义者,体会不到人生的幸福,和真正的生活的勇气
+
+Fenng
+
+电话、视频会议,线下会议、面对面交流的时候,这是同步事件,需要一定程度上近乎实时反馈。而短信、微信消息、语音消息、留言、邮件,这些都是异步事件,用固定的节奏批量处理就是了
+
+Fenng
+
+When you are old and gray, and look back on your life, you will want to be proud of what you have done. The source of that pride won’t be the things you have acquired or the recognition you have received. It will be the lives you have touched and the difference you have made.
+当你白发苍苍、垂垂老矣、回首人生时,你需要为自己做过的事感到自豪。物质生活和满足的占有欲,都不会产生自豪。只有那些受你影响、被你改变过的人和事,才会让你产生自豪感
+
+Steven Chu 2009 年哈佛大学毕业演讲
+
+In your collaborations, always remember that “credit” is not a conserved quantity. In a successful collaboration, everybody gets 90 percent of the credit.
+合作中,不要把功劳都归在自己身上,在一场成功的合作中,每个人都应该获得 90% 的荣誉
+
+Steven Chu 2009 年哈佛大学毕业演讲
+
+
+
+ 以前在朋友圈提到过这样一个现象,重庆人和四川人说的都是四川话,但是大部分重庆人会说他们说的是重庆话,说「川渝是一家」的通常也都是四川人。
+在深圳也有一个很怪的现象,两个客家人谈话会用客家话,两个潮汕人谈话会用潮汕话,两个广东人谈话会用粤语,反正就是尽可能用更小众的语言。
+想了一下,故意用第三方听不懂的语言,实际上是很欠考虑的,如果是刚见面用方言寒暄几句我觉得还行,但是后面谈话就应该使用大家都能听懂的语言了。
+疫情期间大家都没法出去玩,我和老叔倒是出去爬了爬山,村里的荔枝山别人进不去,整座山就我和叔两个人,单从疫情这个角度讲,荔枝山是比大部分地方都要安全的。
+我自己可以在疫情期间爬爬山,结合我自己的感受,加上前段时间的「大奔进故宫」事件。我发现人们并不是痛恨特权,而是痛恨自己没有特权。大部人痛恨的不是腐败,痛恨的是自己没有腐败的机会。
+上面四川和深圳两个例子也差不多是出于这样的优越感,鉴于四川除了成都外,其它地方投资的回报率太低,穷地方的人总会羡慕富有的地方,说川渝一家的人大概率不是成都人。
+
+春节期间看了一本《断舍离》,它讲究的是内部的自觉自省,虽然整本书挺啰嗦的,完完全全可以用一篇几千字的文章代替,但是它传达的人生整理理念很值得参考,感兴趣的读者大人可以在微信读书中阅读此书。下面是一段摘自书中的内容。
+
+我们习惯于思考「有效性」,却往往忽略了作为「有效性」前提的「必要性」,对物品也常常陷入这样的定式思维,导致家里各种杂物堆积,这些杂物给人的压迫感,以及狭窄空间给人的阻塞感,会让人的思维变得迟钝、行动变得迟缓!
+
+借助「断舍离」的理念,我删了 400 多个微信好友,处理了一些不会再使用的家具和书籍,才发现之前一直舍不得扔的那些东西扔了对我的积极作用更大,以前写过的一篇你如果只是一直囤干货,那永远也不可能进步,核心思想和断舍离基本一致,遗憾的是自己当时写下这篇文章后,竟然不懂得延伸到其它领域。
+可能一部分人有读书摘抄语录的习惯,我个人在阅读技术书籍或是扫除我知识盲点的时候,我也会通过记笔记来加深自己的理解。想想自己强迫症式的记笔记面面俱到其实也是在浪费时间,大部分笔记自己都不会再去看第二遍的,舍弃一些不必要的形式会让自己的阅读更有收获。
+还发现自己另外一个错误观点,我不管是写字还是看书都比大部分人慢,一直都认为是自己看书的方法不对,现在才发现问题的根本原因。是因为我对具体的领域不熟悉,所以看这个领域的书籍才会速度很慢,如果对这个领域熟悉了,那一目十行甚至几十行的速度应该都可以达到。结论就是书读的少了导致读书的速度慢。
+
+推荐一部美剧——《良医》,全剧的场景基本是在医院,但有深度的内容基本都和医院无关,除了最基本的医疗科普外,更多的是对家庭、爱、职场、心理等的探讨,下面是我摘的两句台词。
+
+Whenever people want you to do someting they think is wrong, they say it’s “reality”.
+当人们想让你做他们认为错误的事时,他们总会说这就是现实。
+
+
+Very few things that are worthwhile in life come without a cost.
+人生中那些有意义的事大多是有代价的。
+
+
+
+
+参考文章:
+聊一聊契约测试 —— ThoughtWorks洞见
+契约测试
+前后端分离了,然后呢?
+
+契约测试全称为:消费者驱动契约测试,最早由 Martin Fowler 提出。契约这个词从字面上很容易理解,就是双方(多方)达成的共同协议,那又为什么需要契约测试这个东西呢?
+在当前微服务大行其道的行业背景下,越来越多的团队采用了前后端分离和微服务架构,我们知道微服务是由单一程序构成的小服务,与其它服务使用 HTTP API 进行通讯,服务可以采用不同的编程语言与数据库,微服务解决了单体应用团队协作开发成本高、系统高可用性差等等问题。
+但是微服务也引入了新的问题,假设 A 团队开发某服务并提供对应的 API,B 团队也在开发另一个服务,但是他们需要调用 A 团队的 API,为了产品的尽快发布,两个团队都争分夺秒,已经进入联调阶段了,然而出现了下面这样的尴尬情况。
+
+随着越来越多的微服务加入,它们的调用关系开始变得越来越复杂,如果每次更改都需要和所有调用该 API 的团队协商,那沟通成本也未免太大了,试想下图的沟通成本。
+
+为了保证 API 调用的准确性,我们会对外部系统的 API 进行测试,如果外部系统稳定性很差,或者请求时间很长的时候,就会导致我们的测试效率很低,当调用 API 失败时,你甚至无法确定是因为 API 被更改而导致的失败还是运行环境不稳定导致的失败。
+A 团队提供的 API 不稳定,肯定会导致 B 团队效率低下,为了不影响 B 团队的进度,所以构建了测试替身,通过模拟外部 API 的响应行为来增强测试的稳定性和反应速度。
+
+但是这样做真的就解决问题了吗?当所有内部测试都通过时,能拍着胸脯说真正的外部 API 就一定没有变化?很简单的一个解决方案就是:部分测试使用测试替身,另一部分测试定期使用真实的外部 API,这样既保证了测试的运行效率、调用端的准确性,又能确保当真实外部系统API改变时能得到反馈。
+
+感觉剧情到这里就差不多该结束了,实际上真正的高潮部分开刚刚开始。如果外部 API 的反馈周期很长,那增加真实 API 测试间隔时间就又回到了最初的起点。现在我们回顾一下上面的方案。
+在上面的场景中,我们都是已知外部 API 功能来编写相应的功能测试,并且使用直接调用外部 API 的方式来达到测试的目的,如此就不可避免的带来了两个问题:
+
+API 调用者(消费者)对服务提供方(生产者)的更改是通过对 API 的测试来感知的;
+直接依赖于真实 API 的测试效果受限于 API 的稳定性和反映速度。
+
+解决方案首先是依赖关系解耦,去掉直接对外部 API 的依赖,而是内部和外部系统都依赖于一个双方共同认可的约定—“契约”,并且约定内容的变化会被及时感知;其次,将系统之间的集成测试,转换为由契约生成的单元测试,例如通过契约描述的内容,构建测试替身。这样,同时契约替代外部 API 成为信息变更的载体。
+前后照应一下,我们现在再来看一下消费者驱动契约测试。它有两个不可或缺的角色:消费者是服务使用方;生产者(提供者)是服务提供方。采用需求驱动(消费者驱动)的思想。契约文件(比如 json 文件)由双方共同定义规范,一般由消费者生成,生产者根据这份契约去实现。
+契约测试其中一个的典型应用场景是内外部系统之间的测试,另一个典型的例子是前后端分离后的 API 测试。行业内比较成熟的解决方案是 Swagger Specification 和 Pact Specification,这里不做展开讨论。
+我们同样可以把契约测试的思想用到代码的编写中,契约测试通过一个契约文件来解耦依赖,那么对于需要用户定义很多规则的场景,我们同样可以将这些规则像契约文件一样抽取出来,这样就降低了代码之间的耦合度。
+最后敲敲黑板,契约测试不是替代 E2E 测试的终结者,更不是单元测试的升级换代,它更偏向于服务和服务之间的 API 测试,通过解耦服务依赖关系和单元测试来加快测试的运行效率。
+
+
但是需要注意的是,这样拆分小文件之后引入了另外一个新的问题,因为客户端会缓存这些编译后的 js 文件,如果功能 A 同时依赖了a.js和b.js两个文件,但用户在使用其它功能时已经把a.js缓存到本地了,使用功能 A 时需要请求b.js文件,这时程序就很容易报错,因为此时在客户端这两个文件不是同一个版本,所以可能导致a.js调用b.js中的方法已经被删了,进而导致客户端页面异常。
不管你认可还是不认可,同时给 A 和 B 抛出同样的一个问题,A 能把问题解决而 B 不能解决问题,那 A 就是要比 B 牛逼。我越来越相信实力是赢得别人认可的基石,能独立解决问题在一定程度上也说明你是个靠谱的人。能解决小问题人家才会把更大的问题交给你,不要嫌弃那些小事情,把小事情做到精致别人就会给你更大的成长机会。
+ 以前在朋友圈提到过这样一个现象,重庆人和四川人说的都是四川话,但是大部分重庆人会说他们说的是重庆话,说「川渝是一家」的通常也都是四川人。
+在深圳也有一个很怪的现象,两个客家人谈话会用客家话,两个潮汕人谈话会用潮汕话,两个广东人谈话会用粤语,反正就是尽可能用更小众的语言。
+想了一下,故意用第三方听不懂的语言,实际上是很欠考虑的,如果是刚见面用方言寒暄几句我觉得还行,但是后面谈话就应该使用大家都能听懂的语言了。
+疫情期间大家都没法出去玩,我和老叔倒是出去爬了爬山,村里的荔枝山别人进不去,整座山就我和叔两个人,单从疫情这个角度讲,荔枝山是比大部分地方都要安全的。
+我自己可以在疫情期间爬爬山,结合我自己的感受,加上前段时间的「大奔进故宫」事件。我发现人们并不是痛恨特权,而是痛恨自己没有特权。大部人痛恨的不是腐败,痛恨的是自己没有腐败的机会。
+上面四川和深圳两个例子也差不多是出于这样的优越感,鉴于四川除了成都外,其它地方投资的回报率太低,穷地方的人总会羡慕富有的地方,说川渝一家的人大概率不是成都人。
+
+春节期间看了一本《断舍离》,它讲究的是内部的自觉自省,虽然整本书挺啰嗦的,完完全全可以用一篇几千字的文章代替,但是它传达的人生整理理念很值得参考,感兴趣的读者大人可以在微信读书中阅读此书。下面是一段摘自书中的内容。
+
+我们习惯于思考「有效性」,却往往忽略了作为「有效性」前提的「必要性」,对物品也常常陷入这样的定式思维,导致家里各种杂物堆积,这些杂物给人的压迫感,以及狭窄空间给人的阻塞感,会让人的思维变得迟钝、行动变得迟缓!
+
+借助「断舍离」的理念,我删了 400 多个微信好友,处理了一些不会再使用的家具和书籍,才发现之前一直舍不得扔的那些东西扔了对我的积极作用更大,以前写过的一篇你如果只是一直囤干货,那永远也不可能进步,核心思想和断舍离基本一致,遗憾的是自己当时写下这篇文章后,竟然不懂得延伸到其它领域。
+可能一部分人有读书摘抄语录的习惯,我个人在阅读技术书籍或是扫除我知识盲点的时候,我也会通过记笔记来加深自己的理解。想想自己强迫症式的记笔记面面俱到其实也是在浪费时间,大部分笔记自己都不会再去看第二遍的,舍弃一些不必要的形式会让自己的阅读更有收获。
+还发现自己另外一个错误观点,我不管是写字还是看书都比大部分人慢,一直都认为是自己看书的方法不对,现在才发现问题的根本原因。是因为我对具体的领域不熟悉,所以看这个领域的书籍才会速度很慢,如果对这个领域熟悉了,那一目十行甚至几十行的速度应该都可以达到。结论就是书读的少了导致读书的速度慢。
+
+推荐一部美剧——《良医》,全剧的场景基本是在医院,但有深度的内容基本都和医院无关,除了最基本的医疗科普外,更多的是对家庭、爱、职场、心理等的探讨,下面是我摘的两句台词。
+
+Whenever people want you to do someting they think is wrong, they say it’s “reality”.
+当人们想让你做他们认为错误的事时,他们总会说这就是现实。
+
+
+Very few things that are worthwhile in life come without a cost.
+人生中那些有意义的事大多是有代价的。
+
+
+
年龄 25 岁,喜欢数码、宅男、喜欢听歌,在互联网行业,是不是给别人的亲切感也比较强?更容易让人信服?而且这样的基础资料也比较符合我上面提到的转卖 Airpods Pro 的形象,总的来说就是信息越完善越容易让人信服。
+
当然这属于比较简单的套利方式,一个人最多能注册 3 个账号,如果不是工作室的话维护起更多的账号也会费时费力,我在公司客户里面看到了一个比较 NB 的操作,去淘宝联盟去采集那些有优惠券的商品,就是做淘宝客店铺,去找那些有淘宝返利的商品,然后批量上架到自己的淘宝店铺,淘宝对那些下架前的商品会提高权重,有机会显示到前面,相对来说引流成本就能降低一些!听说还有些工作室直接利用软件批量采集淘宝联盟的商品,然后批量上架到京东商铺去赚返利。
图中(4)处伴随系统从通到断的状态变化,大规模载流子需要进行重新分配,这个重新分配表现出来就是电流,而且这个电流与主电流相反,所以会看到一个反向的电流,而且这个反向电流会施加在主电路里面。这一段反向电流又分为两部分,下降阶段是之前外加电压时,PN 结中从 P 区域移动到 N 区域的载流子移除(恢复)过程,即从正偏到反偏的过程,正偏时空间电荷区非常非常窄,此时要进入反偏状态,空间电荷区需要加强,载流子需要重新分配,外部激励会移除不必要的空间电荷。电流上升的过程,即二极管又变成一个耐压器件了,也就是空间电荷区加宽,更多的载流子会不均匀的分布在两端。整个过程不可避免的需要移动电荷,而电荷的聚集效应可以认为就是一个电容的效应,当我们需要施加电压时,电压的增加就会需要额外的电荷,电荷不断聚集提供相反电荷,使其电压不断增加,以致增加到刚好截止输出电压为止。
+
+
MOS 管
+
以 NMOS 为例,它以 P 型半导体衬底,以 N 型半导体作为导电沟道,金属部分作为栅极(Gate),氧化部分(SiO2)作为绝缘层,两端分别为源极(Source)和漏极(Drain),从物理结构可以看出 MOS 管的源极和漏极是可以互换的,不像三极管有严格的顺序。
对比前文普通 MOS 管,可以看到源极、栅极、漏极是分开的,顶上那个灰色的板子是金属板。而功率 MOS 管在这个基础上做了一点创新,下图中的阴影部分就是金属板,可以发现总共只有两个金属板,上面的金属板把 N 区和 P 区都给连起来了,所以即使在栅极没有加电压的时候,也会存在一个天然的二极管通道,但是普通 MOS 管是没有体二极管通道存在的。同时由于是功率 MOS 管,所以也会想办法将耗尽层加宽,以增加其耐压能力。
+
+
体二极管和耐压能力的加强是功率 MOS 和普通 MOS 的区别。
+
+
功率 MOS 管的正向导通能力就是涉及「场效应」了,所谓的场效应即意味着外部可以通过电场来控制其内部载流子的浓度,在栅极施加正电压时就会产生一个电子的导电沟道,由于整体是 N 型半导体衬底,所以整体也就形成了一个电子的导电沟道,并且该沟道支持电子的双向移动。
+
+
如下图所示是功率 MOS 管的等效电路模型。其主要损耗由三部分组成,分别为导通损耗、开关损耗(开通损耗和关断损耗)、驱动损耗。其中导通损耗与开关损耗容易理解,驱动损耗作何理解呢?MOS 并不像二极管是一个被动型器件,MOS 管开或关的行为都需要能量作为代价,就好比要打开机械开关需要用手去按压,这个过程所消耗的能量就是驱动损耗。
+
+
晶体管
+
二极管只有一个 P 型半导体和一个 N 型半导体结合,如果再加一个 N 型半导体(或 P 型半导体)即构成了晶体管(三极管),晶体管有集电极、发射极、基极三个极。