The project is part of the 'Introduction to Computer Vision' course.
Submission by Tomer Dwek and Guy Kabiri
 Plant pathology investigates the biotic and abiotic factors behind the failure of plants to reach their genetic potential and develops interventions to protect plants, reduce crop losses and improve food security.
Plant pathology investigates the biotic and abiotic factors behind the failure of plants to reach their genetic potential and develops interventions to protect plants, reduce crop losses and improve food security.
The biotic disease is caused when virulent pathogens infect susceptible plants under favorable environmental conditions. Plants are protected from most microbes by passive physical and chemical barriers and invoke active defense responses when these barriers are breached by invasive pathogens.
However, virulent pathogens suppress these responses and engage in an arms race with host plants. Plant disease management depends on accurate diagnosis, a complete understanding of the disease cycle and biology of disease, and potential interventions that include genetic resistance, quarantine, sanitation and hygiene, soil and water management, and fungicides.
In this competition, apple leaves are being inspected. Apples are among the most important temperate fruits grown worldwide. A major threat to apple orchard productivity and quality is leaf disease. At present, apple orchard disease diagnosis is performed by humans using manual scouting, which can be tedious and expensive. Therefore, computer vision implementation can be very helpful in identifying diseases on apples' leaves.
The data in this competition is on a huge scale.
Performing training on this data may take a significant amount of time, so we decided to train our models with resized data which was uploaded to Kaggle.
By using the 256 X 170 and 384 X 256 datasets, we were able to reduce training time from about 40 minutes per epoch to 8 or 15 minutes, respectively.
df.head()| image | labels | |
|---|---|---|
| 0 | 800113bb65efe69e.jpg | healthy |
| 1 | 8002cb321f8bfcdf.jpg | scab frog_eye_leaf_spot complex |
| 2 | 80070f7fb5e2ccaa.jpg | scab |
| 3 | 80077517781fb94f.jpg | scab |
| 4 | 800cbf0ff87721f8.jpg | complex |
All unique labels are listed above.
list(df['labels'].value_counts().keys())['scab',
'healthy',
'frog_eye_leaf_spot',
'rust',
'complex',
'powdery_mildew',
'scab frog_eye_leaf_spot',
'scab frog_eye_leaf_spot complex',
'frog_eye_leaf_spot complex',
'rust frog_eye_leaf_spot',
'rust complex',
'powdery_mildew complex']
There are 12 unique labels, which are a combination of different classes.
array(['complex', 'frog_eye_leaf_spot', 'healthy', 'powdery_mildew',
'rust', 'scab'], dtype='<U18')
The actual unique labels are shown here.
There are five disease classes, as well as the healthy class, in the dataset, which means that there is a power of 2 to 5 possible combination.
Despite the fact that not all combinations are possible, this training set contains only 11 of them.
There may be other combinations in the test set that are not in the training set.
Therefore, we deal with the problem in a multi-label manner.
Let's look at the balancing of each.
| label | count | |
|---|---|---|
| 0 | complex | 2151 |
| 1 | frog_eye_leaf_spot | 4352 |
| 2 | healthy | 4624 |
| 3 | powdery_mildew | 1271 |
| 4 | rust | 2077 |
| 5 | scab | 5712 |

Leaves those who do not suffer from any diseases.

Scab is a bacterial or fungal plant disease characterized by crusty lesions on fruits, leaves, and stems.
The term is also used for the symptom of the disease.

Rust is a fungus-caused plant disease. Often appearing on leaves and fruits as yellow, orange, red, rust, brown, or black powdery pustules, rust affects many economically important plant species.

Many species of fungi in the order Erysiphales cause powdery mildew diseases.
The symptoms of powdery mildew are quite distinct, making it one of the easiest diseases to identify.
Infected plants have white powdery spots on their leaves and stems.

Frogeye leaf spot is caused by the fungus Cercospora sojina.
The disease occurs across the United States and in Ontario, Canada. When widespread within a field, frogeye leaf spot can cause significant yield losses.
Lesions on the leaves are small, irregular to circular in shape, gray with reddish brown borders.

As described in the competition:
Unhealthy leaves with too many diseases to classify visually will have the
complexclass, and may also have a subset of the diseases identified.

Data Augmentation reduces over-fitting. Our dataset may have images taken in a limited set of conditions but we might fall short in a variety of conditions that we don’t account for. Here the modified/augmented data helps deal with such scenarios.
Albumations' image augmentation for classification provides a way to define an augmentation pipeline through which the data will pass through.
This process is done by calling to Compose class of Albumentations, which gets all the transform functions to load into the pipeline, and returns a callable object, that by calling it, will return an augmented image. Each transform function provided to the pipeline has a probability attribute to determine if the current image should be processed by that transform or not. In that way, we can create a bunch of different augmented images and increase our dataset's size.
Eventually, the following were used:
Randomly changes the hue saturation in the input image.

The image may be flipped horizontally, vertically, or both.

An image may only be horizontally flipped.

The image may be rotated and its scale may be changed by shifting.
In case the image goes beyond its own borders, some of the image will be duplicated to the black borders..

Change the brightness and contrast of the input image at random.

Blur the input image using a random-sized kernel.

Apply gaussian noise to the input image.

Apply motion blur to the input image using a random-sized kernel.

Apply camera sensor noise to the input image.

Apply a grid of dropouts to the input image.

Produces random-sized dropouts across an image.

-
Resizing:
As the dataset contains images of different sizes, all the images are resized to the same size before being input into the model. -
Normalization:
Data normalization is an important step that ensures that each input parameter (pixel, in this case) has a similar data distribution. This makes convergence faster while training the network.
Data normalization is done by subtracting the mean from each pixel and then dividing the result by the standard deviation. The distribution of such data would resemble a Gaussian curve centered at zero. -
ToTensor:
Convert image totorch.Tensor. The NumPy HWC image is converted to PyTorch CHW tensor.
Preparing the data is a major focus in machine learning.
PyTorch provides an API to load and handle the data before using it in our algorithms.
PyTorch's Dataset class provides a unified way to represent data. All that needs to be done is to create a class that inherits from Dataset and overrides the __len__ method that returns the size of the dataset, and the __getitem__ method that returns a specific item from the dataset by an index.
By self-implementing __getitem__, we may perform some transformations on the data before returning it back. It might be useful when handling datasets with unintended size variations among images, for example.
Dataset stores the samples and their corresponding labels, and DataLoader wraps an iterable around the Dataset to enable easy access to the samples.
Training set contains 15837 images which is 84.9989% of the data
Validation set contains 2795 images which is 15.0011% of the data

The Asymmetric Loss For Multi-Label Classification function is used, which is discussed in this article and suggested here (10th place).
Compared to Multilabel Soft Margin Loss and BCE with Logits Loss, this loss function is mote effective at classifying multilabel problems.
Mean-F1 is calculated from the F1 score. F1 scores are calculated separately for each label, and the sum is then divided by the number of labels.
An average picture contains few positive labels and many negative ones in a multi-label setting.
It can lead to under-emphasizing gradients from positive labels during training, which results in poor accuracy due to the positive-negative imbalance that dominates the optimization process.
The paper presents a novel asymmetric loss ("ASL"), which operates differently on positive and negative samples.
The loss enables dynamically down-weights and hard-thresholds easy negative samples, while also discarding possibly mislabeled samples.

Focal Loss (FL) is a revised version of Cross-Entropy Loss (CE) that attempts to handle the problem of class imbalance by adjusting the weights assigned to hard and easily misclassifiable examples, and to down-weight easy examples.
Focal Loss thus reduces the loss contribution from easy examples and emphasizes the importance of correcting misclassified examples.
A focal loss function is simply an extension of the cross-entropy loss function that decreases the weight of easy examples and emphasizes training on hard negatives.

The focal loss has the following properties:
- When an example is misclassified and pt is small, the modulating factor is near 1 and the loss is not affected.
- As
pt→1, the factor is 0 and the loss for well-classified examples is downweighed. - By adjusting focusing parameter
γ, easy examples are down-weighted at a smooth rate.
According to intuition, the modulating factor reduces the loss contribution from easy examples and extends the range in which the example receives the low loss.
By decreasing the slope of the function, focal loss contributes to backpropagating (or weighing down) the loss.
Measures of the accuracy of a model on a dataset. It is used to evaluate binary classification systems that classify examples as 'positive' or 'negative'.
It is defined as the harmonic mean of the model's precision and recall, and it is a way to combine precision and recall.

Optimizers are algorithms or methods used to change the attributes of your neural network such as weights and learning rate in order to reduce the losses.
The Adam optimizer is one of the most commonly used optimizers for deep learning. When training with Adam the model usually converges a lot faster than when using regular stochastic gradient descent (SGD), and Adam often requires less tuning of the learning rate compared to SGD with momentum.
Adam improves on SGD with momentum by (in addition to momentum) also computing adaptive learning rates for each parameter that is tuned.
This means that when using Adam there is less need to modify the learning rate during the training than when using SGD.
In the common weight decay implementation in the Adam optimizer the weight decay is implicitly bound to the learning rate.
This means that when optimizing the learning rate you will also need to find a new optimal weight decay for each learning rate you try. The AdamW optimizer decouples the weight decay from the optimization step.
This means that the weight decay and learning rate can be optimized separately, i.e. changing the learning rate does not change the optimal weight decay.
The result of this fix is a substantially improved generalization performance.

Learning rate scheduler provides a method to adjust the learning rate based on the number of epochs, or based on time.
In the training section, we have used K-Fold Cross Validation (k=5).
Cross-Validation is a statistical method of evaluating and comparing learning algorithms by dividing data into two segments: one used to learn or train a model and the other used to validate the model.
In typical cross-validation, the training and validation sets must cross-over in successive rounds such that each data point has a chance of being validated against.
In k-fold cross-validation, the data is first partitioned into k equally (or nearly equally) sized segments or folds.
Subsequently k iterations of training and validation are performed such that within each iteration a different fold of the data is held-out for validation while the remaining k − 1 folds are used for learning.

As a first step, we'll train some pre-trained CNN's that others extensively used in the competition.
The networks are:
- EfficientNet-B4
- ResNext50
- SEResNeXt50
In machine learning, transfer learning refers to storing knowledge gained while solving one problem and applying it to another, related problem.
The pre-trained model is trained on a different task than the one at hand, but provides a very useful starting point since the features learned while training on the old task are useful when training for the new one.
- Better initial model: Transfer learning is a better starting point for building a model without any knowledge, and can perform tasks at a certain level even without training.
- Higher accuracy after training: Transfer learning allows a machine learning model to converge at a higher performance level, resulting in more accurate output.
- Faster training: By using a pre-trained model, the training can achieve the desired performance faster than traditional methods.
- Fighting Overfitting: Transfer learning's main advantage is that it mitigates the problems associated with insufficient training data. This is one of the causes of overfitting.
Freezing a layer in the context of neural networks is about controlling the way the weights are updated. Layers that are frozen cannot be modified further.
The idea with this technique, as obvious as it may sound, is to shorten the training time while maintaining accuracy.
By gradually freezing hidden layers, you can accelerate the training process of neural networks.
In our models, we used batch-noramalization freeze:
On a standard GPU, the batch size is typically quite small due to the memory requirements. Batch normalization will be difficult (as it requires a large batch size).
A freeze of the weights is a good solution since the network is pre-trained based on ImageNet. (This approach is taken in faster-CNN and similar projects).
train_cv(model, folds=CFG.n_folds, epochs=CFG.n_epochs)Fold 1 of 5
This running path is: `drive/My Drive/Colab Notebooks/Computer Vision/Final Assignment/models/efficientnet_b4 24-07-21 11:18/efficientnet_b4_1kfold.pth`
Epoch 1:
train: 100%|██████████| 466/466 [08:46<00:00, 1.13s/it]
valid: 100%|██████████| 117/117 [00:30<00:00, 3.86it/s]
train loss: 0.061967 train accuracy: 0.963716 train f1: 0.865167
valid loss: 0.023500 valid accuracy: 0.985303 valid f1: 0.913560
Epoch 2:
train: 100%|██████████| 466/466 [08:49<00:00, 1.14s/it]
valid: 100%|██████████| 117/117 [00:30<00:00, 3.87it/s]
train loss: 0.056407 train accuracy: 0.966476 train f1: 0.873489
valid loss: 0.032076 valid accuracy: 0.983106 valid f1: 0.907314
Epoch 3:
train: 100%|██████████| 466/466 [08:49<00:00, 1.14s/it]
valid: 100%|██████████| 117/117 [00:30<00:00, 3.87it/s]
train loss: 0.058895 train accuracy: 0.965689 train f1: 0.872497
valid loss: 0.039120 valid accuracy: 0.977443 valid f1: 0.895985
Epoch 4:
train: 100%|██████████| 466/466 [08:49<00:00, 1.14s/it]
valid: 100%|██████████| 117/117 [00:30<00:00, 3.87it/s]
train loss: 0.053252 train accuracy: 0.968158 train f1: 0.879021
valid loss: 0.040885 valid accuracy: 0.984929 valid f1: 0.910278
Epoch 5:
train: 100%|██████████| 466/466 [08:49<00:00, 1.14s/it]
valid: 100%|██████████| 117/117 [00:30<00:00, 3.89it/s]
train loss: 0.053612 train accuracy: 0.969020 train f1: 0.882872
valid loss: 0.046363 valid accuracy: 0.976033 valid f1: 0.893861
Epoch 6:
train: 100%|██████████| 466/466 [08:49<00:00, 1.14s/it]
valid: 100%|██████████| 117/117 [00:30<00:00, 3.90it/s]
train loss: 0.051505 train accuracy: 0.969133 train f1: 0.884350
valid loss: 0.047163 valid accuracy: 0.979580 valid f1: 0.891807
Epoch 7:
train: 100%|██████████| 466/466 [08:49<00:00, 1.14s/it]
valid: 100%|██████████| 117/117 [00:30<00:00, 3.88it/s]
train loss: 0.049465 train accuracy: 0.970344 train f1: 0.882810
valid loss: 0.048639 valid accuracy: 0.974758 valid f1: 0.884553
Epoch 8:
train: 100%|██████████| 466/466 [08:49<00:00, 1.14s/it]
valid: 100%|██████████| 117/117 [00:30<00:00, 3.88it/s]
train loss: 0.050965 train accuracy: 0.969111 train f1: 0.882738
valid loss: 0.048853 valid accuracy: 0.979006 valid f1: 0.894323
Epoch 9:
train: 100%|██████████| 466/466 [08:49<00:00, 1.14s/it]
valid: 100%|██████████| 117/117 [00:30<00:00, 3.87it/s]
train loss: 0.048620 train accuracy: 0.972199 train f1: 0.886350
valid loss: 0.054831 valid accuracy: 0.974498 valid f1: 0.886659
Epoch 10:
train: 100%|██████████| 466/466 [08:49<00:00, 1.14s/it]
valid: 100%|██████████| 117/117 [00:30<00:00, 3.86it/s]
train loss: 0.045387 train accuracy: 0.974010 train f1: 0.894559
valid loss: 0.056839 valid accuracy: 0.974865 valid f1: 0.885647

When performing cross validation, in the process, we generate K similar models, which each one is trained over a bit different data. Therefore, in each of these folds, we generate a bit different models.
We can use each of these models and generate an ensemble classifier, which as explained above, is better than using a single model.
EfficientNet is a convolutional neural network architecture and scaling method that uniformly scales all dimensions of depth/width/resolution using a compound coefficient.
Unlike conventional practice that arbitrary scales these factors, the EfficientNet scaling method uniformly scales network width, depth, and resolution with a set of fixed scaling coefficients.
The compound scaling method is justified by the intuition that if the input image is bigger, then the network needs more layers to increase the receptive field and more channels to capture more fine-grained patterns on the bigger image.
Compound Model Scaling: A Better Way to Scale Up CNNs
In order to understand the effect of scaling the network, we systematically studied the impact of scaling different dimensions of the model.
While scaling individual dimensions improves model performance, we observed that balancing all dimensions of the network—width, depth, and image resolution—against the available resources would best improve overall performance.
(B – number of iterations)

ResNeXt is based on ResNet architecture, but with another dimentional called cardinality.
It aggregates a set of transformations to the image.
Instead of using linear function in a simple neuron that wi times xi in each path, a nonlinear function is performed for each path.
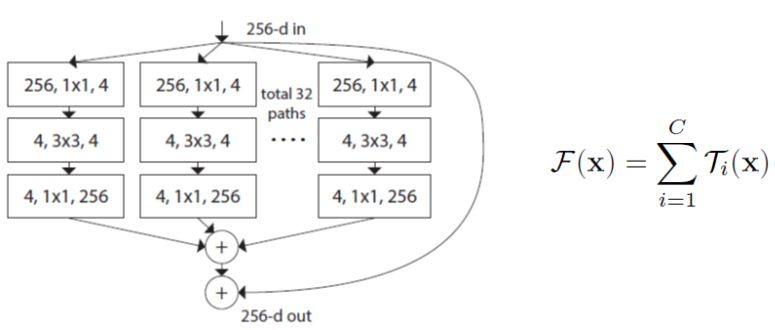
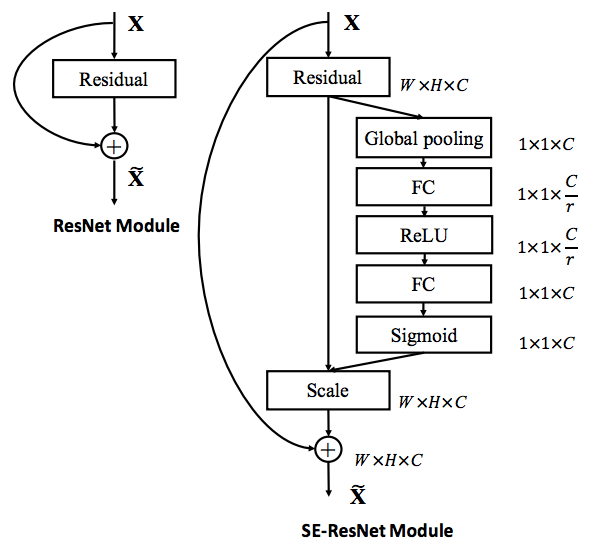
SEResNext is ResNext-50 with Squeeze-and-Excitation blocks.
Squeeze-and-Excitation Networks (SENets) introduce a building block for CNNs that improves channel interdependencies at almost no computational cost.
Besides this huge performance boost, they can be easily added to existing architectures.







In our final project, we participated in Kaggle's competition of classifying images of apple leaves disease.
We had to implement the knowledge gained during the Computer Vision course:
- Dataset and Dataloader.
- Image Augmentations.
- Training CNN models.
- Optimizers, Loss functions, and Learning Rate Schedulers.
- Cross-Validation.
- Transfer Learning.
- Ensemble.
Moreover, we had to acquire knowledge from other sources in order to achieve better results:
- Layer Freeze.
- Batch-Normalization.
- Multi-Label Classification.
- Voting Classifier.
- Synchronize Colab's notebooks with Kaggle's.
Combining all of these methods, we were able to achieve an F1 score of 0.8353 in the Private Score and 0.8241 in the Public Score.


- https://github.com/clcarwin/focal_loss_pytorch/blob/master/focalloss.py
- https://www.kaggle.com/buinyi/understanding-the-evaluation-metric-cv?scriptVersionId=57391136
- https://www.kaggle.com/c/plant-pathology-2021-fgvc8/discussion/243042
- https://www.kaggle.com/c/plant-pathology-2021-fgvc8/discussion/242843
- https://www.kaggle.com/c/plant-pathology-2021-fgvc8/discussion/242454
- https://www.kaggle.com/c/plant-pathology-2021-fgvc8/discussion/242275
- https://www.kaggle.com/c/plant-pathology-2021-fgvc8/discussion/227032
- https://github.com/facebookresearch/ResNeXt