-
Chromedriver实现JSfinder,支持动态渲染页面,避免遗漏接口
-
根据给出的域名,调用Jsfinder去爬取每个页面的api接口、标签,并判断爬取的接口/标签是否属于域名下资产:同域名下资产则入库后队列继续递归爬取,否则直接入库。
-
获取每个域名主页相应的title、状态码、html大小并入库存储
-
携带cookie去递归爬取页面接口,针对单点登陆的情况,或者页面权鉴的情况
-
支持爬取单页面的接口,可以选择一层/深度爬取
-
把数据库所有结果导出到txt,以便转存数据&进一步扫描器测试接口
pip3 install requests pymongo bs4 selenium urllib
下载chromedriver后放入python根目录或加入全局环境变量 下载地址:http://npm.taobao.org/mirrors/chromedriver/ 注:必须要与当前chrome浏览器的版本匹配
[server]
ip: 127.0.0.1
port: 65530
database: Baidu
account:
password:
- -u:指定url爬取
- -i:深度爬取flag标志
- -d:指定域名,深度爬取/携带cookie的时候必须存在的参数
- -c:指定cookie文件
需要在脚本同目录下的cookies.txt中填入自己的cookie,形式如下

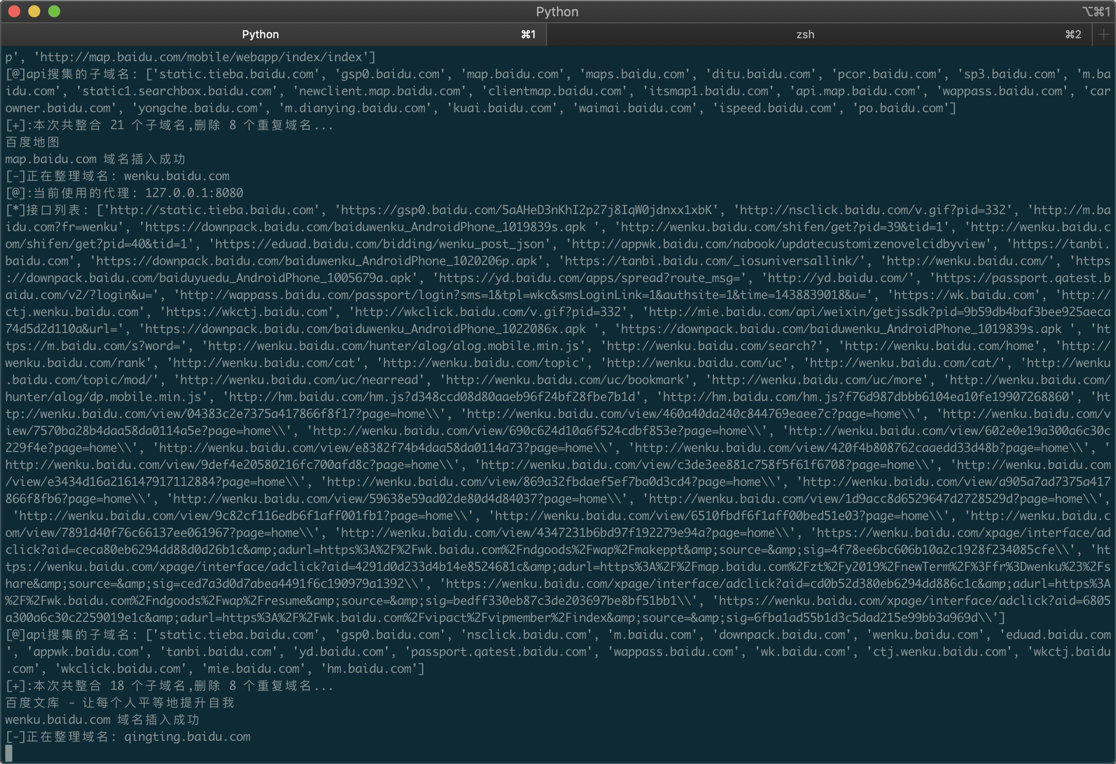
- 只爬取单个页面,不携带cookie,以爬取asrc为例
python3 SubdoaminUp.py -u https://security.alibaba.com//leak/profile.htm
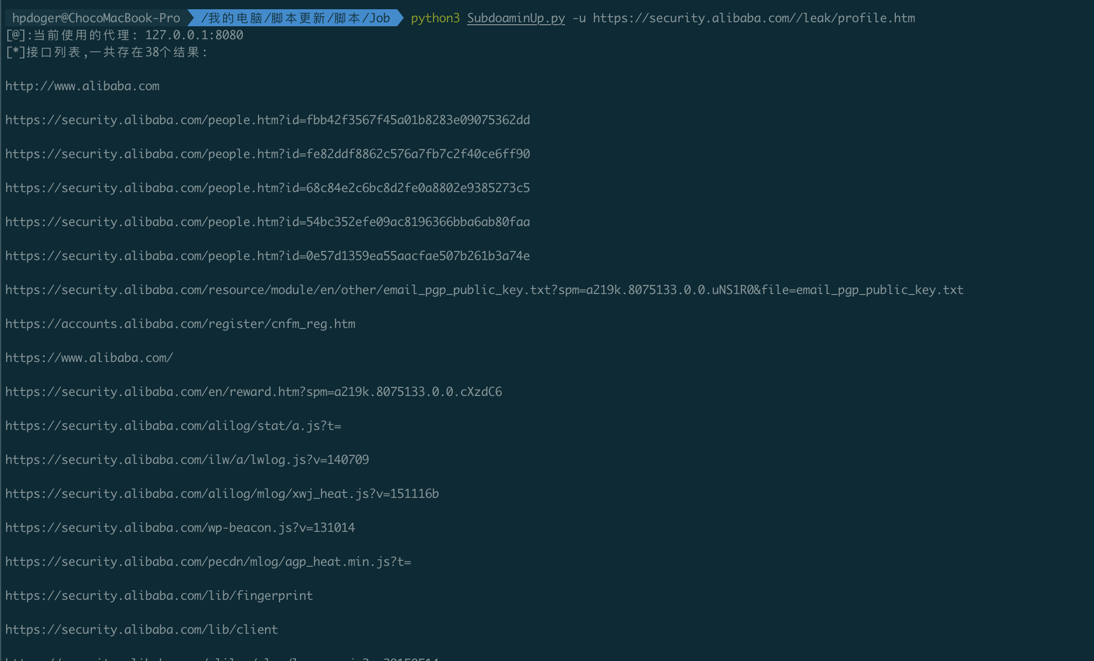
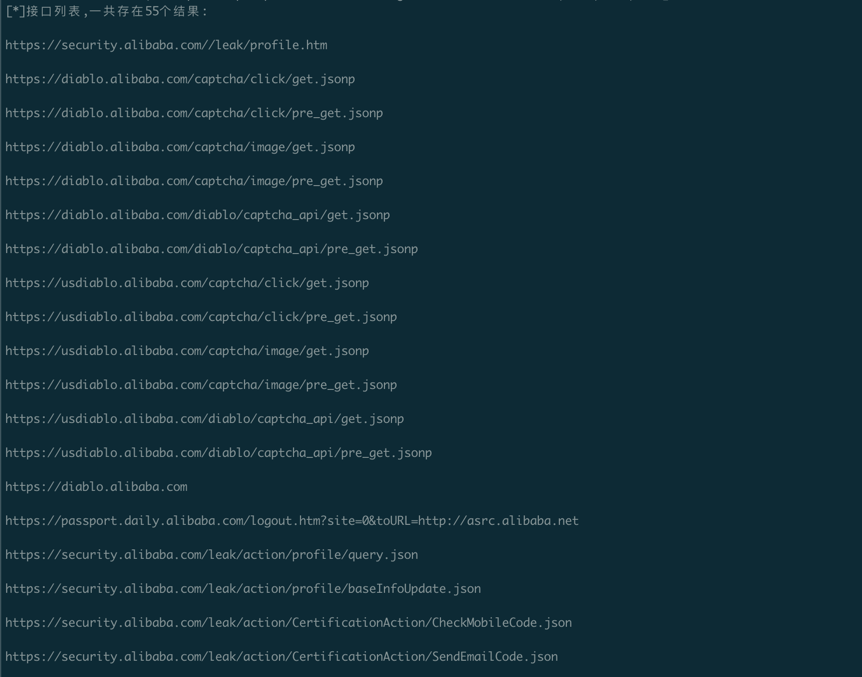
- 携带cookie进行深度爬取
python3 SubdoaminUp.py -u https://security.alibaba.com//leak/profile.htm -c cookies.txt -d alibaba.com
在subdomain.txt中加入域名
union.baidu.com
mssp.baidu.com
yingxiao.baidu.com
baiyi.baidu.com
developer.baidu.com
bes.baidu.com
tongji.baidu.com
dmp.baidu.com
jianyi.baidu.com
absample.baidu.com
- 跟单页面爬取一样,可以选择深度爬取/单页面爬取&是否携带cookie
python3 InFoCollecter.py -d baidu.com -i