- Content
- IR and Search
- Information Acquisition: Web Crawling
- Information Organization and Storage: Indexing and Index
- Information Retrieval
- Personalized Search
- Information Distribution: Search Engine Results Page
- Information Retrieval Evaluation
- Neural Information Retrieval
- Modeling Diverse Ranking with MDP
- Vertical Domain Search: Beyond String and Texts
- MACHINE LEARNING FOR HEALTHCARE
- Knowledge Graphs
- Labs and Resources
- IR and Search
Web search engine is the first big data system in order to collect and organize the data in world wide web. Information retrieval is the extension of the search engine.
- http://pages.cs.wisc.edu/~paris/
- http://yongyuan.name/habir/
- http://www.wisdom.weizmann.ac.il/~ronene/GeomAndDS.html
- http://net.pku.edu.cn/~yangtong/pages/SummerForm18.html
- https://www.mat.univie.ac.at/~neum/clouds.html
- http://yongyuan.name/project/
- https://textprocessing.github.io/ch5.pdf
- Princeton CASS: Content-Aware Search Systems
- http://www.wsdm-conference.org/
- http://www.svcl.ucsd.edu/projects/regularization/
- http://www.svcl.ucsd.edu/projects/crossmodal/
- http://fengzheyun.github.io/
- https://monkeylearn.com/text-analysis/
- RISE: Repository of Online Information Sources Used in Information Extraction Tasks
- Information on Information Retrieval (IR) books, courses, conferences and other resources.
- Recommended Reading for IR Research Students
- AI in Information Retrieval and Language Processing collected by Wlodzislaw Duch
- Marti A. Hearst
- Database Management Systems: Design and Implementation
- Synthesis Lectures on Information Concepts, Retrieval, and Services
- State_of_the_art
- Providing Relevant and Timely Results: Real-Time Search Architectures and Relevance Algorithms
- TREC-2019-Deep-Learning
- The Activate Conference is the world's largest gathering of Solr developers
- Information Retrieval Systems
- https://ntent.com/, https://www.clearquery.io/how, https://www.searchhub.io/, https://etymo.io/, https://searcheo.io/, http://seeknshop.io/, https://constructor.io/, https://www.searchtap.io/, https://lucidworks.com/
If the recommender system is to solve the information overload problem personally, modern information retrieval and search technology is to solve that problem generally at the web-scale. Technically, IR studies the acquisition, organization, storage, retrieval, and distribution of information. Information is in diverse format or form, such as character strings(texts), images, voices and videos so that information retrieval has diverse subfields such as multimedia information retrieval and music information retrival. Search engine is considered as a practical application of information retrieval.
Critical to all search engines is the problem of designing an effective retrieval model that can rank documents accurately for a given query.
A main goal of any IR system is to rank documents optimally given a query so that a highly relevant documents would be ranked above less relevant ones and non-relevant ones.
Relevance, Ranking and Context are three foundation stones of web search. In this section, we focus on relevance more than rank.
If interested in the history of information retrieval, Mark Sanderson and W. Bruce Croft wrote a paper for The History of Information Retrieval Research.

One of the most fundamental and important challenges is to develop a truly optimal retrieval model that is both effective and efficient
and that can learn form the feedback information over time, which will be talked in Rating and Ranking.
- https://en.wikipedia.org/wiki/Information_retrieval
- sease: make research in Information Retrieval more accessible
- search|hub
- Cortical.io
- FreeDiscovery Engine
- Index weblogs, mainstream news, and social media with Datastreamer
- https://www.omnity.io/
- https://www.luigisbox.com/
- Some Tutorilas in IR
- multimedia information retrieval
- Notes on Music Information Retrieval
- https://ntent.com/
- https://www.researchgate.net/scientific-contributions/2118044344_Xiangnan_He
- http://www.somaproject.eu/
- How Search Engines Work: Crawling, Indexing, and Ranking
The first step of information retrieval is to acquise the information itself. The web-scale information brings information overload problem, which search engine or web search attempts to solve.
Web Crawling By Christopher Olston and Marc Najork
A web crawler (also known as a robot or a spider) is a system for the bulk downloading of web pages.
Web crawlers are used for a variety of purposes. Most prominently, they are one of the main components of web search engines, systems that assemble a corpus of web pages, index them, and allow users to issue queries against the index and find the web pages that match the queries.
A related use is web archiving (a service provided by e.g., the Internet archive), where large sets of web pages are periodically collected and archived for posterity. A third use is web data mining, where web pages are analyzed for statistical properties, or where data analytics is performed on them (an example would be Attributor, a company that monitors the web for copyright and trademark infringements). Finally, web monitoring services allow their clients to submit standing queries, or triggers, and they continuously crawl the web and notify clients of pages that match those queries (an example would be GigaAlert).
- https://iorgforum.org/
- http://facweb.cs.depaul.edu/mobasher/classes/ect584/
- https://apify.com/
- Web Crawling By Christopher Olston and Marc Najork
- VII. Information Acquisition
- Automatically modelling and distilling knowledge within AI!
- CH. 3: MODELS OF THE INFORMATION SEEKING PROCESS
- https://zhuanlan.zhihu.com/p/70169130
Index as data structure is to organize the information efficiently in order to search some specific terms.
First, let us consider the case where we do not remember some key terms as reading some references, the appendices may include index recording the places where the terms firstly appear such as the following images shown.

Search engine takes advantage of this idea: it is the best place to store where the terms/words appear in key-value format where the key, values is the terms and their places, respectively.
- Search engine indexing
- Inverted Index versus Forward Index
- https://www.wikiwand.com/en/Inverted_index
- To Index or not to Index: Time-Space Trade-Offs in Search Engines with Positional Ranking Functions
- NSF III-1718680: Index Sharding and Query Routing in Parallel and Distributed Search Engines
Here we introduce some data structure which can speed up the search procedure given a query. Note that index technology is also used in database performance optimization. Index is used to organize and manage the documents. It is the core function of information retrieval system.
- MG4J is a free full-text search engine for large document collections written in Java
- http://www.lemurproject.org/
- http://sphinxsearch.com/
- http://lucene.apache.org/core/
- Terrier IR Platform
- Trinity IR Infrastructure
- Lemur Beginner's Guide, getting started using Lemur
- https://nlp.stanford.edu/IR-book/html/htmledition/index-construction-1.html
- https://zhuanlan.zhihu.com/p/23624390
- Database tutorial
- Inverted file indexing and retrieval optimized for short texts
- https://www2.cs.sfu.ca/CourseCentral/354/zaiane/
- Indexing CS6320 1/29/2018 Shachi Deshpande, Yunhe Liu
A B+ Tree is primarily utilized for implementing dynamic indexing on multiple levels. Compared to B- Tree, the B+ Tree stores the data pointers only at the leaf nodes of the Tree, which makes search more process more accurate and faster.
- https://www.guru99.com/introduction-b-plus-tree.html
- http://pages.cs.wisc.edu/~paris/cs564-f15/lectures/lecture-12.pdf
- https://draveness.me/whys-the-design-mysql-b-plus-tree
In computing, a bitmap is a mapping from some domain (for example, a range of integers) to bits, that is, values which are zero or one. It is also called a bit array or bitmap index.
- https://github.com/hashd/bitmap-elixir
- https://blog.csdn.net/sunnyyoona/article/details/43604387
- https://www.geeksforgeeks.org/bitmap-indexing-in-dbms/
- https://www.oracletutorial.com/oracle-index/oracle-bitmap-index/
To quote the hash function at wikipedia:
A hash function is any function that can be used to map data of arbitrary size to fixed-size values. The values returned by a hash function are called hash values, hash codes, digests, or simply hashes. The values are used to index a fixed-size table called a hash table. Use of a hash function to index a hash table is called hashing or scatter storage addressing.
Hashed indexes use a hashing function to compute the hash of the value of the index field. The hashing function collapses embedded documents and computes the hash for the entire value but does not support multi-key (i.e. arrays) indexes.
- Hash function
- https://github.com/caoyue10/DeepHash-Papers
- https://zhuanlan.zhihu.com/p/43569947
- https://www.tutorialspoint.com/dbms/dbms_hashing.htm
- Indexing based on Hashing
- https://docs.mongodb.com/manual/core/index-hashed/
- https://www.cs.cmu.edu/~adamchik/15-121/lectures/Hashing/hashing.html
- https://www2.cs.sfu.ca/CourseCentral/354/zaiane/material/notes/Chapter11/node15.html
- https://github.com/Pfzuo/Level-Hashing
- https://thehive.ai/insights/learning-hash-codes-via-hamming-distance-targets
- Various hashing methods for image retrieval and serves as the baselines
- http://papers.nips.cc/paper/5893-practical-and-optimal-lsh-for-angular-distance
Locality-Sensitive Hashing (LSH) is a class of methods for the nearest neighbor search problem, which is defined as follows: given a dataset of points in a metric space (e.g., Rd with the Euclidean distance), our goal is to preprocess the data set so that we can quickly answer nearest neighbor queries: given a previously unseen query point, we want to find one or several points in our dataset that are closest to the query point.
- http://web.mit.edu/andoni/www/LSH/index.html
- http://yongyuan.name/blog/vector-ann-search.html
- https://github.com/arbabenko/GNOIMI
- https://github.com/willard-yuan/hashing-baseline-for-image-retrieval
- http://yongyuan.name/habir/
Cuckoo Hashing is a technique for resolving collisions in hash tables that produces a dictionary with constant-time worst-case lookup and deletion operations as well as amortized constant-time insertion operations.
- An Overview of Cuckoo Hashing
- Some Open Questions Related to Cuckoo Hashing
- Practical Survey on Hash Tables
- Elastic Cuckoo Page Tables: Rethinking Virtual Memory Translation for Parallelism
- MinCounter: An Efficient Cuckoo Hashing Scheme for Cloud Storage Systems
- Bloom Filters, Cuckoo Hashing, Cuckoo Filters, Adaptive Cuckoo Filters and Learned Bloom Filters
The fruit fly Drosophila's olfactory circuit has inspired a new locality sensitive hashing (LSH) algorithm, FlyHash. In contrast with classical LSH algorithms that produce low dimensional hash codes, FlyHash produces sparse high-dimensional hash codes and has also been shown to have superior empirical performance compared to classical LSH algorithms in similarity search. However, FlyHash uses random projections and cannot learn from data. Building on inspiration from FlyHash and the ubiquity of sparse expansive representations in neurobiology, our work proposes a novel hashing algorithm BioHash that produces sparse high dimensional hash codes in a data-driven manner. We show that BioHash outperforms previously published benchmarks for various hashing methods. Since our learning algorithm is based on a local and biologically plausible synaptic plasticity rule, our work provides evidence for the proposal that LSH might be a computational reason for the abundance of sparse expansive motifs in a variety of biological systems. We also propose a convolutional variant BioConvHash that further improves performance. From the perspective of computer science, BioHash and BioConvHash are fast, scalable and yield compressed binary representations that are useful for similarity search.
FlyHash
- Bio-Inspired Hashing for Unsupervised Similarity Search
- https://github.com/dataplayer12/Fly-LSH
- https://deepai.org/publication/bio-inspired-hashing-for-unsupervised-similarity-search
- https://science.sciencemag.org/content/358/6364/793/tab-pdf
- https://arxiv.org/abs/1812.01844
By using hash-code to construct index, we can achieve constant or sub-linear search time complexity.
Hash functions are learned from a given training dataset.
- https://cs.nju.edu.cn/lwj/slides/L2H.pdf
- Repository of Must Read Papers on Learning to Hash
- Learning to Hash: Paper, Code and Dataset
- Learning to Hash with Binary Reconstructive Embeddings
- http://zpascal.net/cvpr2015/Lai_Simultaneous_Feature_Learning_2015_CVPR_paper.pdf
- https://cs.nju.edu.cn/lwj/slides/hash2.pdf
- Learning to hash for large scale image retrieval
- http://stormluke.me/learning-to-hash-intro/
- fast library for ANN search and KNN graph construction
- Building KNN Graph for Billion High Dimensional Vectors Efficiently
- https://github.com/aaalgo/kgraph
- https://www.msra.cn/zh-cn/news/features/approximate-nearest-neighbor-search
- https://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/37599.pdf
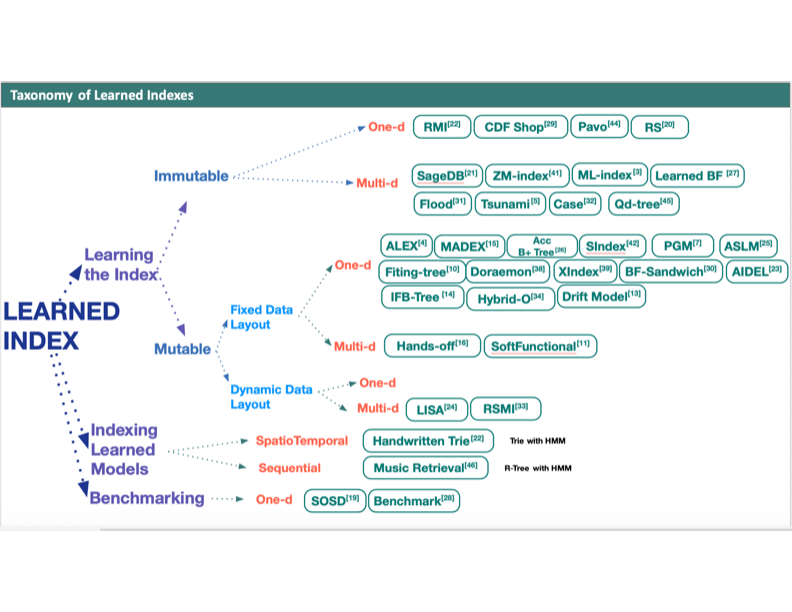
- On Learned Index Structures. Interview with Alex Beutel
- A Tutorial on Learned Multidimensional Indexes
- Learned Indexes for a Google-scale Disk-based Database
- Benchmarking Learned Indexes
- Why Are Learned Indexes So Effective?
- ALEX: An Updatable Adaptive Learned Index
Index compression is one special data compression technology in order to save the storage space. It is necessary to compress the index at the web scale.
- Elasticsearch from the Bottom Up, Part 1
- Intellectual Foundations for Information Organization and Information
- Inverted Index Compression and Query Processing with Optimized Document Ordering
- GIS Introduction by David J. Buckey
- https://nlp.stanford.edu/IR-book/html/htmledition/index-compression-1.html
- https://richardfoote.wordpress.com/category/advanced-index-compression/
- 6 Index Compression
- http://idc.hust.edu.cn/~rxli/teaching/ir/3.2%20Index%20compression.pdf
- https://www.csauthors.net/gang-wang-0001/
Large-scale search engines utilize inverted indexes which store ordered lists of document identifies (docIDs) relevant to query terms, which can be queried thousands of times per second. In order to reduce storage requirements, we propose a dictionarybased compression approach for the recently proposed bitwise data-structure BitFunnel, which makes use of a Bloom filter. Compression is achieved through storing frequently occurring blocks in a dictionary. Infrequently occurring blocks (those which are not represented in the dictionary) are instead referenced using similar blocks that are in the dictionary, introducing additional false positive errors. We further introduce a docID reordering strategy to improve compression.

- Regular Expressions, Text Normalization, Edit Distance
- Introduction to
- solr-vs-elasticsearch
- CH. 4: QUERY SPECIFICATION
- https://homepages.dcc.ufmg.br/~rodrygo/rm-2019-2/
- https://nlp.stanford.edu/IR-book/html/htmledition/computing-scores-in-a-complete-search-system-1.html
- Query Languages
- Operational Database Management Systems
- http://web.stanford.edu/class/cs245/
- NSF III-1117829: Efficient Query Processing in Large Search Engines
Keywords combined with Boolean operators: OR AND BUT
Retrieve documents with a specific phrase (ordered list of contiguous words)
List of words with specific maximal distance constraints between terms Example: “dogs” and “race” within 4 words match “…dogs will begin the race…”
Allow queries that match strings rather than word tokens. Requires more sophisticated data structures and algorithms than inverted indices to retrieve efficiently.
Edit (Levenstein) Distance is defined as minimum number of character deletions, additions, or replacements needed to make two strings equivalent.
Longest Common Subsequence (LCS) is the length of the longest subsequence of characters shared by two strings
Language for composing complex patterns from simpler ones: Union, Concatenation, Repetition.
Assumes documents have structure that can be exploited in search, allow queries for text appearing in specific fields.
Query is often some keywords in natural language such as English or Chinese. We use the search engine when we would like to find some information related with the keywords on the web/internet, which means we do not completely know what the result is. Additionally, all information is digitalized in computer and the computers do not understand the natural language natively.
For example, synonyms are different as character or string data structure in computer.
Natural language processing(NLP) or natural language understanding(NLU) facilitate the computers to comprehend the query.
- Query Understanding
- Exploring Query Parsers
- Query Understanding: An efficient way how to deal with long tail queries
- The Art of Tokenization
- https://jmmackenzie.io/publication/

| Response | Time |
|---|---|
| Query Auto Completion | Before the query input is finished |
| Spelling Correction | When the query input is finished |
| Semantic Analysis | After the query input is finished |
| Query Suggestion | After the query input is finished |
| Intention Analysis | After the query input |
- Query Reformulation:
- Query Expansion: Add new terms to query from relevant documents.
- Term Reweighting: Increase weight of terms in relevant documents and decrease weight of terms in irrelevant documents.
- https://www.cs.bgu.ac.il/~elhadad/nlp18.html
- CH. 6: QUERY REFORMULATION
- Relevance feedback and query expansion
Standard Rochio Method
- https://nlp.stanford.edu/IR-book/html/htmledition/rocchio-classification-1.html
- http://www.cs.cmu.edu/~wcohen/10-605/rocchio.pdf
Ide Regular Method
- https://cs.brynmawr.edu/Courses/cs380/fall2006/Class13.pdf
- http://www1.se.cuhk.edu.hk/~seem5680/lecture/rel-feed-query-exp-2016.pdf
- http://web.eecs.umich.edu/~mihalcea/courses/EECS486/Lectures/RelevanceFeedback.pdf
- https://researchbank.rmit.edu.au/eserv/rmit:9503/Billerbeck.pdf
The auto complete is a drop-down list populated with suggestions of what one can write in the search box.
The auto complete is a list of suggestions of what one can write in the search box to reach different products or categories. These suggestions will also be referred to as query suggestions or completions. After one has written a few letters of the beginning of the query and the list is populated with query suggestions that in some way match the input. In the normal case matching means that the suggestion starts with the input.
- Design and Implementation of an Auto Complete Algorithm for E-Commerce
- https://www.jianshu.com/p/c7bc74d3657d
- https://blog.floydhub.com/gpt2/
- Is Prefix Of String In Table?
For simplicity let us first consider correction of individual misspelled words (e.g., “elefnat” to “elephant”). One simple approach to spelling error correction is to calculate the edit distance between the query word and each of the dictionary words. Dictionary words within a fixed range of edit distance or a variable range of edit distance depending on word length are selected as candidates for correction. There are at least two drawbacks for this approach, however. First, probabilities of word usages as well as word misspellings are not considered in the model. Second, context information of correction is not taken into consideration.
To address the issues, probabilistic approaches, both generative approach and discriminative approach, have been proposed.
Suppose that the query word is represented as
By Bayes’ rule, we can consider finding the correction
The source model can be trained by using the document collection and/or search log. (Due to the wide variety of searches it is better to find the legitimate words from data.) A straightforward way would be to estimate the probabilities of words based on their occurrences in the dataset with a smoothing technique applied. The channel model can be defined based on weighted edit distance, where the model is usually trained by using data consisting of pairs of correct word and misspelled word.
When a user provides a root input, such as a search query, these algorithms dynamically retrieve, curate, and present a list of related inputs, such as search suggestions. Although ubiquitous in online platforms, a lack of research addressing the ephemerality of their outputs and the opacity of their functioning raises concerns of transparency and accountability on where inquiry is steered.

- How Google Instant’s Autocomplete Suggestions Work
- Visual Query Suggestion
- Query Suggestion @https://www.algolia.com
- Incremental Algorithms for Effective and Efficient Query Recommendation
- Auditing Autocomplete: Suggestion Networks and Recursive Algorithm Interrogation
- https://zhuanlan.zhihu.com/p/23693891
- https://github.com/syw2014/query-suggestion
- https://www.cnblogs.com/wangzhuxing/p/9574630.html
- https://elasticsearch-py.readthedocs.io/en/master/api.html
- https://elasticsearch.cn/article/142
- CONQUER: A System for Efficient Context-aware Query Suggestions
Query expansion is a technique studied intensively and widely in IR. The basic idea is to enrich the query with additional terms (words or phrases) and to use the expanded query to conduct search in order to circumvent the query-document mismatch challenge.

- https://blog.csdn.net/baimafujinji/article/details/50930260
- https://www.wikiwand.com/en/Query_expansion
- https://nlp.stanford.edu/IR-book/html/htmledition/query-expansion-1.html
- https://dev.mysql.com/doc/refman/5.5/en/fulltext-query-expansion.html
- Neural Query Expansion for Code Search
- Efficient and Effective Query Expansion for Web Search
Unlike relational databases where the
schema is relatively small and fixed, XML model allows varied/missing structures
and values, which make it difficult for users to ask questions precisely and completely. To address such problems, query relaxation technique enables systems
to automatically weaken, when not satisfactory, the given user query to a less
restricted form to permit approximate answers as well.
Query segmentation is to separate the input query into multiple segments, roughly corresponding to natural language phrases, for improving search relevance.
- https://arxiv.org/abs/1707.07835
- http://ra.ethz.ch/CDstore/www2011/proceedings/p97.pdf
- https://github.com/kchro/query-segmenter
We propose Voronoi scoping, a distributed algorithm to constrain the dissemination of messages from different sinks. It has the property that a query originated by a given sink is forwarded only to the nodes for which that sink is the closest (under the chosen metric). Thus each query is forwarded to the smallest possible number of nodes, and per-node dissemination overhead does not grow with network size or with number of sinks. The algorithm has a simple distributed implementation and requires only a few bytes of state at each node. Experiments over a network of 54 motes confirm the algorithm's effectiveness.
Query understanding: query normalization (encoding, tokenization, spelling); query rewriting (expansion, relaxation, segmentation, scoping)
Levels of Query Understanding:
NTENT’s Search platform choreographs the interpretation of singular query constituents, and the dissemination of relevant answers through a specialized combination of Language Detection, Linguistic Processing, Semantic Processing and Pragmatic Processing.
- Language Detection: The first step is to understand which language the user is using. Sometimes this is obvious, but many things can make this hard. For example, many users find themselves forced to use a keyboard that makes it hard to use accented characters, so they “ascify” their query. Users sometimes use multiple languages within a single query (“code switching”) or proper names that are the same in many languages.
- Linguistic Processing: Every language has its own rules for how text should be broken down into individual words (“tokenized”), whether distinctions of case and accent are significant, how to normalize words to a base form (“lemmatization” or “stemming”), and categorization of words and phrases by parts of speech (“POS tagging”).
- Semantic Processing: A traditional keyword search engine would stop after linguistic processing, but NTENT’s technology goes further, and determines what the user’s words actually mean. Many words have multiple meanings (“homonyms”), and many concepts have multiple ways to express them (“synonyms”). Drawing on many sources of information, such as a large-scale ontology, notability data, and the user’s context (e.g., location), we are able to determine all the possible interpretations of the user’s query, and assign a probability to each one. By distinguishing a particular sense of a word, and by knowing which phrases denote a single concept, we are able to improve the precision of our applications. At the same time, by recognizing that multiple expressions refer to the same concept, and also that broad terms encompass narrower ones (“hyponymy”), we are able to improve recall. Furthermore, NTENT is able to analyze the syntax of how multiple words are combined into composite concepts.
- Intent Detection (Pragmatic Processing): NTENT goes beyond just the surface semantics of the user’s utterance, and develops hypotheses about why they typed what they did: what their information need is; what transactions they intend to perform; what website they’re looking for; or what local facilities they’re trying to find. This inductive reasoning is key to harnessing NTENT’s extensive set of experts to give the user what they want.
| NLP Pipeline of Query Understanding |
|---|
| Tokenization |
| Stop words removal |
| Text Normalization |
| POS Tagging |
| Named Entity Recogition |
- Query Understanding for Search on All Devices
- https://sites.google.com/site/queryunderstanding/
- https://ntent.com/technology/query-understanding/
- 查询理解(Query Understanding)—查询改写总结
- https://www.wikiwand.com/en/Query_understanding
- https://www.luigisbox.com/blog/query-understanding/
- https://github.com/DataEngg/Query-Understanding
- https://docs.microsoft.com/en-us/sharepoint/dev/general-development/customizing-ranking-models-to-improve-relevance-in-sharepoint
Recall the definition of Discounted Cumulative Gain(DCG):
$${DCG}p= \sum{i=1}^{p} \frac{{rel}i}{\log{2}(i+1)}$$
where
However, it is discussed how to compute the relevance of the document and query. The document is always text such as html file so natural language processing plays a lead role in computing the relevances. For other types information retrieval system, it is different to compute the relevance. For example, imagine search engine is to find and return the images similar on the internet with the given image query, where the information is almost in pixel format rather than text/string.
| --- | A part of Ranking Model |
|---|---|
| Query-independent ranking | on-document evidence (retrievability, readability, maliciousness); off-document evidence (centrality, popularity, credibility) |
| Query understanding | query normalization (encoding, tokenization, spelling); query rewriting (expansion, relaxation, segmentation, scoping) |
| Query-dependent ranking | basic models (algebraic models, probabilistic models, information-theoretic models); proximity models (Markov random fields models); structural models (field-based models); semantic models (latent semantics, explicit semantics) |
| Contextual ranking | personalization; diversification; interactivity |
| Machine-learned ranking | query-document representation; loss functions (pointwise, pairwise, listwise loss); optimization strategies; adaptation strategies (intent-awareness, exploration-exploitation) |
| Ranking evaluation | behavioral models; evaluation design; evaluation metrics; offline evaluation; online evaluation |
The Machine-learned ranking and Ranking evaluation is discussed in Rating and Ranking partially.
Contextual ranking does not discuss until now.
- https://homepages.dcc.ufmg.br/~rodrygo/rm-2018-2/
- https://phys.org/news/2011-05-ranking-research.html
- New tools for fair ranking available
- https://github.com/fair-search/fairsearch-deltr-python
- https://github.com/fair-search/fairsearch-deltr-for-elasticsearch
- https://github.com/fair-search
- https://arxiv.org/abs/1805.08716
- https://fair-search.github.io/
Query-independent ranking includes :
- on-document evidence (retrievability, readability, maliciousness);
- off-document evidence (centrality, popularity, credibility)
And it is computed before the query given.
- Microsoft’s UserRank – Query Independent Ranking Based Upon User Logs
- Patent application title: APPLYING QUERY INDEPENDENT RANKING TO SEARCH
- https://hurenjun.github.io/pubs/icde2018-slides.pdf
- Ranking with Query-Dependent Loss for Web Search
- Link Analysis Ranking
- Query-Independent Ranking for Large-Scale Persistent Search Systems
- http://www.seobythesea.com/
- Query independent evidence (QIE)
Centrality of network assigns an importance score based purely on the number of links held by each node.
PageRank is introduced in Graph Algorithms.
HITS algorithm is in the same spirit as PageRank. They both make use of the link structure of the Web graph in order to decide the relevance of the pages. The difference is that unlike the PageRank algorithm, HITS only operates on a small subgraph (the seed SQ) from the web graph. This subgraph is query dependent; whenever we search with a different query phrase, the seed changes as well. HITS ranks the seed nodes according to their authority and hub weights. The highest ranking pages are displayed to the user by the query engine.
Search Engine Optimization(SEO) is a business type to boost the website higher.
- Introduction to Search Engine Theory
- MGT 780/MGT 795 Social Network Analysis
- The Anatomy of a Large-Scale Hypertextual Web Search Engine by Sergey Brin and Lawrence Page
- The Mathematics of Google Search
- HITS Algorithm - Hubs and Authorities on the Internet
- http://langvillea.people.cofc.edu/
- Google PageRank: The Mathematics of Google
- How Google Finds Your Needle in the Web's Haysta
- Dynamic PageRank
- A Replacement for PageRank?
- Beyond PageRank: Machine Learning for Static Ranking
- http://infolab.stanford.edu/~taherh/papers/topic-sensitive-pagerank-tkde.pdf
- CSCE 470 :: Information Storage and Retrieval :: Fall 2017
- Topic-Sensitive PageRank: A Context-Sensitive Ranking Algorithm for Web Search
Query-dependent ranking:
- basic models (algebraic models, probabilistic models, information-theoretic models);
- proximity models (Markov random fields models); structural models (field-based models);
- semantic models (latent semantics, explicit semantics).
| Features/Attributes for ranking |
|---|
| Average Absolute Query Frequency |
| Query Length |
| Average Absolute Document Frequency |
| Document Length |
| Average Inverse Document Frequency |
| Number of Terms in common between query and document |
- https://en.wikipedia.org/wiki/Ranking
- Query Dependent Ranking Using K-Nearest Neighbor∗
- Query-Independent Learning to Rank for RDF Entity Search
- CONTEXTUALIZED WEB SEARCH: QUERY-DEPENDENT RANKING AND SOCIAL MEDIASEARCH
- Query-Independent Ranking for Large-Scale Persistent Search Systems
- Document vector representations for feature extraction in multi-stage document ranking
- Query-dependent ranking and its asymptotic properties
- THE ASYMPTOTICS OF RANKING ALGORITHMS
Term frequency(tf) of a word Inverse document frequency(idf) of a word
The goal of a probabilistic retrieval model is clearly to retrieve the documents with the highest probability of relevance to the given query.
Three random variables- the query
The basic idea is to compute
- http://www.cs.cornell.edu/home/llee/papers/idf.pdf
- http://www.minerazzi.com/tutorials/probabilistic-model-tutorial.pdf
- http://www.cs.cornell.edu/courses/cs6740/2010sp/guides/lec05.pdf
The basic idea of BM25 is to rank documents by the log-odds of their relevance.
Actually BM25 is not a single model, but defines a whole family of ranking models,
with slightly different components and parameters.
One of the popular instantiations of the model is as follows.
Given a query
where
The language model for information retrieval (LMIR) is an application of the statistical language model on information
retrieval. A statistical language model assigns a probability to a sequence of terms.
When used in information retrieval, a language model is associated with a document.
With query
To learn the document’s language model, a maximum likelihood method is used.
As in many maximum likelihood methods, the issue of smoothing the estimate is critical. Usually a background language model estimated using the entire collection is used for this purpose.
Then, the document’s language model can be constructed
as follows:
David Ten wrote a blog on TextRank:
For keyword extraction we want to identify a subset of terms that best describe the text. We follow these steps:
- Tokenize and annotate with Part of Speech (PoS). Only consider single words. No n-grams used, multi-words are reconstructed later.
- Use syntactic filter on all the lexical units (e.g. all words, nouns and verbs only).
- Create and edge if lexical units co-occur within a window of N words to obtain an unweighted undirected graph.
- Run the text rank algorithm to rank the words.
- We take the top lexical words.
- Adjacent keywords are collapsed into a multi-word keyword.
TextRank model is graph-based derived from Google’s PageRank. It constructs a weighted graph
- the node set
$V$ consists of all sentences in the document; - the weight is the similarity of each sentence pair, i.e.,
$w_{i,j}=Similarity (V_i, V_j)$ .
The weight of each sentence depends on the weights of its neighbors: $$WS(V_i)=(1-d)+d\times {\sum}{V_j\in In(V_i)}\frac{w{ij}}{\sum_{V_k\in Out(V_j)}}WS(V_j).$$
- TextRank: Bringing Order into Texts
- Keyword and Sentence Extraction with TextRank (pytextrank)
- https://zhuanlan.zhihu.com/p/41091116
- TextRank for Text Summarization
- https://www.quantmetry.com/tag/textrank/
- Textrank学习
- Gensim: Topic Model for Human
- KISS: Keep It Short and Simple
- NLP buddy
- https://whoosh.readthedocs.io/en/latest/index.html
- https://malaya.readthedocs.io/en/latest/
- Automatic Text Summarization with Python
- http://veravandeseyp.com/ai-repository/
- Text Summarization in Python: Extractive vs. Abstractive techniques revisited
- https://pypi.org/project/sumy/
- 自动文本摘要(Auto Text Summarization)
In the popular open search engine ElasticSearch, the score formula is more complex and complicated.
Document similarity (or distance between documents) is a one of the central themes in Information Retrieval. How humans usually define how similar are documents? Usually documents treated as similar if they are semantically close and describe similar concepts.
w-shingling
- Document Similarity in Machine Learning Text Analysis with ELMo
- Documents similarity
- https://copyleaks.com/
- https://www.wikiwand.com/en/Semantic_similarity
- https://spacy.io/
- https://fasttext.cc/
Vector quantization (VQ) is an efficient coding technique to quantize signal vectors. It has been widely used in signal and image processing, such as pattern recognition and speech and image coding. A VQ compression procedure has two main steps: codebook training (sometimes also referred to as codebook generation) and coding (i.e., codevector matching). In the training step, similar vectors in a training sequence are grouped into clusters, and each cluster is assigned to a single representative vector called a codevector. In the coding step, each input vector is then compressed by replacing it with the nearest codevector referenced by a simple cluster index. The index (or address) of the matched codevector in the codebook is then transmitted to the decoder over a channel and is used by the decoder to retrieve the same codevector from an identical codebook. This is the reconstructed reproduction of the corresponding input vector. Compression is thus obtained by transmitting the index of the codevector rather than the entire codevector itself.
- http://www.mqasem.net/vectorquantization/vq.html
- https://perso.telecom-paristech.fr/cagnazzo/doc/MN910/VQ/mn910_vq.pdf
- Daala: Perceptual Vector Quantization (PVQ)
Latent semantic indexing (LSI) is a concept used by search engines to discover how a term and content work together to mean the same thing, even if they do not share keywords or synonyms.
- https://nlp.stanford.edu/IR-book/html/htmledition/latent-semantic-indexing-1.html
- Probabilistic Latent Semantic Indexing
- Using Latent Semantic Indexing for Information Filtering
- http://edutechwiki.unige.ch/en/Latent_semantic_analysis_and_indexing
- https://www.cse.msu.edu/~cse960/Papers/LSI/LSI.pdf
It is a matching method between query and document at topic level based on matrix factorization, which is scale up to large datasets. The parametric model is expressed in the following form:
$$min_{U, {v_n}}\sum_{n=1}^{N}{|d_n - U v_n|}2^2+\underbrace{\lambda_1\sum{k=1}^K {|u_k|}1}{\text{topics are sparse}} + \underbrace{\lambda_2\sum_{n=1}^{N}{|v_n |}2^2}{\text{documents are smooth}}$$
where
-
$d_n$ is term representation of doc$n$ ; -
$U$ represents topics; -
$v_n$ is the topic representation of doc$n$ ; -
$\lambda_1$ and$\lambda_2$ are regularization parameters.
It is optimized by coordinate descent: $$u_{mk}=\arg\min_{\bar u_m}\sum_{m=1}^M {|\bar d_m - V^T \bar u_m|}2^2+\lambda_1\sum{m=1}^{M}{|\bar u_m|}1,\ v_n^{\ast}=\arg\min{{v_n}}\sum_{n=1}^{N}{|d_n -U v_n|}2^2+\lambda_2\sum{n=1}^N{|v_n|}_2^2=(U^T U + \lambda_2 I)^{-1}U^T {d}_n.$$
- Regularized Latent Semantic Indexing: A New Approach to Large Scale Topic Modeling
- https://www.academia.edu/13253156/Hierarchy-Regularized_Latent_Semantic_Indexing
- https://patents.google.com/patent/US8533195B2/en
- http://cse.msu.edu/~cse960/Papers/LSI/LSI.pdf
- https://github.com/JunXu-ICT/rlsi-java-source
- http://www.bigdatalab.ac.cn/~junxu/publications/SIGIR2011_RLSI.pdf
The input training data set is
It is to optimize the following cost function
Regularized Mapping to Latent Space will change the constraints
- https://stats.idre.ucla.edu/wp-content/uploads/2016/02/pls.pdf
- https://www.microsoft.com/en-us/research/publication/learning-bilinear-model-matching-queries-documents/
- https://www.geeksforgeeks.org/kmp-algorithm-for-pattern-searching/
Query and Indexed Object is similar with Question and Answers.
The user requested a query then a matched response is supposed to match the query in semantics. Before that we must understand the query.
The most common way to model similarity is by means of a distance function. A distance function assigns high values to objects that are dissimilar and small values to objects that are similar, reaching 0 when the two compared objects are the same. Mathematically, a distance function is defined as follows:
Let
-
$\delta(x,x)=0$ (reflexivity) -
$\delta(x,y)=\delta(y,x)$ (symmetry) -
$\delta(x,y)≥0$ (non-negativity)
When it comes to efficient query processing, as we will see later, it is useful if the utilized distance function is a metric.
Let
-
$\delta(x,y)=0\iff x=y$ (identity of indiscernibles) -
$\delta(x,y)\leq \delta(x,z)+\delta(z,y)$ (triangle inequality)

In a similarity-based retrieval model, it is assumed that the relevance status of a document with respect to a query is correlated with the similarity between the query and the document at some level of representation; the more similar to a query, the more relevant the document is assumed to be.
| Similarity matching | Relevance matching |
|---|---|
| Whether two sentences are semantically similar | Whether a document is relevant to a query |
| Homogeneous texts with comparable lengths | Heterogeneous texts (keywords query, document) and very different in lengths |
| Matches at all positions of both sentences | Matches in different parts of documents |
| Symmetric matching function | Asymmetric matching function |
| Representative task: Paraphrase Identification | Representative task: ad-hoc retrieval |
Each search is made up of Matching Problem is to describe the tasks in IR that:
- Deep Semantic Similarity Model
- AI in Information Retrieval and Language Processing collected by Wlodzislaw Duch
- Deep Learning for Information Retrieval
- A Deep Relevance Matching Model for Ad-hoc Retrieval
- Relevance Matching
- DeepMatching: Deep Convolutional Matching
- Quantifying Similarity between Relations with Fact Distribution
- https://www.cnblogs.com/yaoyaohust/p/10642103.html
- https://ekanou.github.io/dynamicsearch/
- http://mlwiki.org/index.php/NLP_Pipeline
- http://www.bigdatalab.ac.cn/tutorial/
- http://lear.inrialpes.fr/src/deepmatching/
- https://github.com/CansenJIANG/deepMatchingGUI
- https://alex.smola.org/workshops/sigir10/index.html
User’s intent is explicitly reflected in query such as keywords, questions. Content is in Webpages, images. Key challenge is query-document semantic gap. Even severe than search, since user and item are two different types of entities and are represented by different features.
Common goal: matching a need (may or may not include an explicit query) to a collection of information objects (product descriptions, web pages, etc.) Difference for search and recommendation: features used for matching!
| --- | Matching | Ranking |
|---|---|---|
| Prediction | Matching degree between a query and a document | Ranking list of documents |
| Model | ||
| Goal | Correct matching between query and document | Correct ranking on the top |
Methods of Representation Learning for Matching:
- DSSM: Learning Deep Structured Semantic Models for Web Search using Click-through Data (Huang et al., CIKM ’13)
- CDSSM: A latent semantic model with convolutional-pooling structure for information retrieval (Shen et al. CIKM ’14)
- CNTN: Convolutional Neural Tensor Network Architecture for Community-Based Question Answering (Qiu and Huang, IJCAI ’15)
- CA-RNN: Representing one sentence with the other sentence as its context (Chen et al., AAAI ’18)
- Text-matching software
- http://staff.ustc.edu.cn/~hexn/papers/www18-tutorial-deep-matching-paper.pdf
- Deep Learning for Matching in Search and Recommendation
- Deep Learning for Recommendation, Matching, Ranking and Personalization
- Tutorials on Deep Learning for Matching in Search and Recommendation
- Framework and Principles of Matching Technologies
- Semantic Matching in Search
We present COBS, a COmpact Bit-sliced Signature index, which is a cross-over between an inverted index and Bloom filters. Our target application is to index k-mers of DNA samples or q-grams from text documents and process approximate pattern matching queries on the corpus with a user-chosen coverage threshold. Query results may contain a number of false positives which decreases exponentially with the query length. We compare COBS to seven other index software packages on 100000 microbial DNA samples. COBS' compact but simple data structure outperforms the other indexes in construction time and query performance with Mantis by Pandey et al. in second place. However, unlike Mantis and other previous work, COBS does not need the complete index in RAM and is thus designed to scale to larger document sets.
- COBS: a Compact Bit-Sliced Signature Index
- https://arxiv.org/abs/1905.09624
- Presentation "COBS: A Compact Bit-Sliced Signature Index" at SPIRE 2019 (Best Paper Award)
- Engineering a Compact Bit-Sliced Signature Index for Approximate Search on Genomic Data
In recent years the Bing search engine has developed and deployed an index based on bit-sliced signatures. This index, known as BitFunnel, replaced an existing production system based on an inverted index.
The key idea of bit-string signatures is that each document in the corpus is represented by
its signature. In BitFunnel, the signature is essentially the sequence
of bits that make up a Bloom filter representing the set of terms in
the document.

- http://bitfunnel.org/strangeloop/
- http://bitfunnel.org/blog-archive/
- https://www.jiqizhixin.com/articles/2019-11-20-15
- https://www.jianshu.com/p/624ac9173d96
- BitFunnel: Revisiting Signatures for Search
- https://github.com/BitFunnel/BitFunnel
- https://github.com/BitFunnel/sigir2017-bitfunnel
- https://github.com/BitFunnelComp/dicComp
- https://github.com/jondgoodwin/bitfunnel-play
- A Hybrid BitFunnel and Partitioned Elias-Fano Inverted Index
- https://dblp.uni-trier.de/pers/hd/z/Zhang:Zhaohua
- https://nbjl.nankai.edu.cn/12126/list.htm
- Index Compression for BitFunnel Query Processing
- https://bitfunnel.org/a-small-query-language/
- BitFunnel: Revisiting Signatures for Search
[Nearest neighbour search is the problem of finding the most similar data-points to a query in a large database of data-points,}(https://learning2hash.github.io/) and is a fundamental operation that has found wide applicability in many fields, from Bioinformatics, through to Natural Language Processing (NLP) and Computer Vision.
- https://github.com/erikbern/ann-benchmarks
- http://ann-benchmarks.com/
- benchmarking-nearest-neighbor-searches-in-python
- New approximate nearest neighbor benchmarks
- Geometric Proximity Problems
- https://yongyuan.name/blog/vector-ann-search.html
- https://yongyuan.name/blog/vector-ann-search.html
- https://yongyuan.name/blog/approximate-nearest-neighbor-search.html
- CS369G: Algorithmic Techniques for Big Data
- ANN: A Library for Approximate Nearest Neighbor Searching
- Randomized approximate nearest neighbors algorithm
- HD-Index: Pushing the Scalability-Accuracy Boundary for Approximate kNN Search in High-Dimensional Spaces
- https://people.csail.mit.edu/indyk/
- Approximate Nearest Neighbor: Towards Removing the Curse of Dimensionality
- Nearest Neighbors for Modern Applications with Massive Data
- https://arxiv.org/pdf/1804.06829.pdf
- https://wiki.52north.org/AI_GEOSTATS/ConfNNWorkshop2008
- Topic: Locality Hashing, Similarity, Nearest Neighbours
- A General and Efficient Querying Method for Learning to Hash (SIGMOD 2018)
- https://people.csail.mit.edu/indyk/slides.html
- https://appsrv.cse.cuhk.edu.hk/~jfli/
- http://www.cse.cuhk.edu.hk/~jcheng/
- https://postgis.net/workshops/postgis-intro/knn.html
- Sublinear Algorithms and Nearest-Neighbor Search
- Bregman proximity queries
- https://cs.nju.edu.cn/lwj/L2H.html
- https://awesomeopensource.com/projects/nearest-neighbor-search
- https://elastiknn.com/
There are some other libraries to do nearest neighbor search. Annoy is almost as fast as the fastest libraries, (see below), but there is actually another feature that really sets Annoy apart: it has the ability to use static files as indexes. In particular, this means you can share index across processes. Annoy also decouples creating indexes from loading them, so you can pass around indexes as files and map them into memory quickly. Another nice thing of Annoy is that it tries to minimize memory footprint so the indexes are quite small.
FALCONN is a library with algorithms for the nearest neighbor search problem. The algorithms in FALCONN are based on Locality-Sensitive Hashing (LSH), which is a popular class of methods for nearest neighbor search in high-dimensional spaces. The goal of FALCONN is to provide very efficient and well-tested implementations of LSH-based data structures.
- https://github.com/falconn-lib/falconn/wiki
- https://libraries.io/pypi/FALCONN
- https://www.ilyaraz.org/
- https://github.com/FALCONN-LIB/FALCONN/wiki/LSH-Primer
- https://github.com/FALCONN-LIB/FALCONN
- https://falconn-lib.org/
SPTAG assumes that the samples are represented as vectors and that the vectors can be compared by L2 distances or cosine distances. Vectors returned for a query vector are the vectors that have smallest L2 distance or cosine distances with the query vector.
SPTAG provides two methods: kd-tree and relative neighborhood graph (SPTAG-KDT) and balanced k-means tree and relative neighborhood graph (SPTAG-BKT). SPTAG-KDT is advantageous in index building cost, and SPTAG-BKT is advantageous in search accuracy in very high-dimensional data.
It explains how SPTAG works:
SPTAG is inspired by the NGS approach [WangL12]. It contains two basic modules:
index builderandsearcher. The RNG is built on the k-nearest neighborhood graph [WangWZTG12, WangWJLZZH14] for boosting the connectivity. Balanced k-means trees are used to replace kd-trees to avoid the inaccurate distance bound estimation in kd-trees for very high-dimensional vectors. The search begins with the search in the space partition trees for finding several seeds to start the search in the RNG. The searches in the trees and the graph are iteratively conducted.
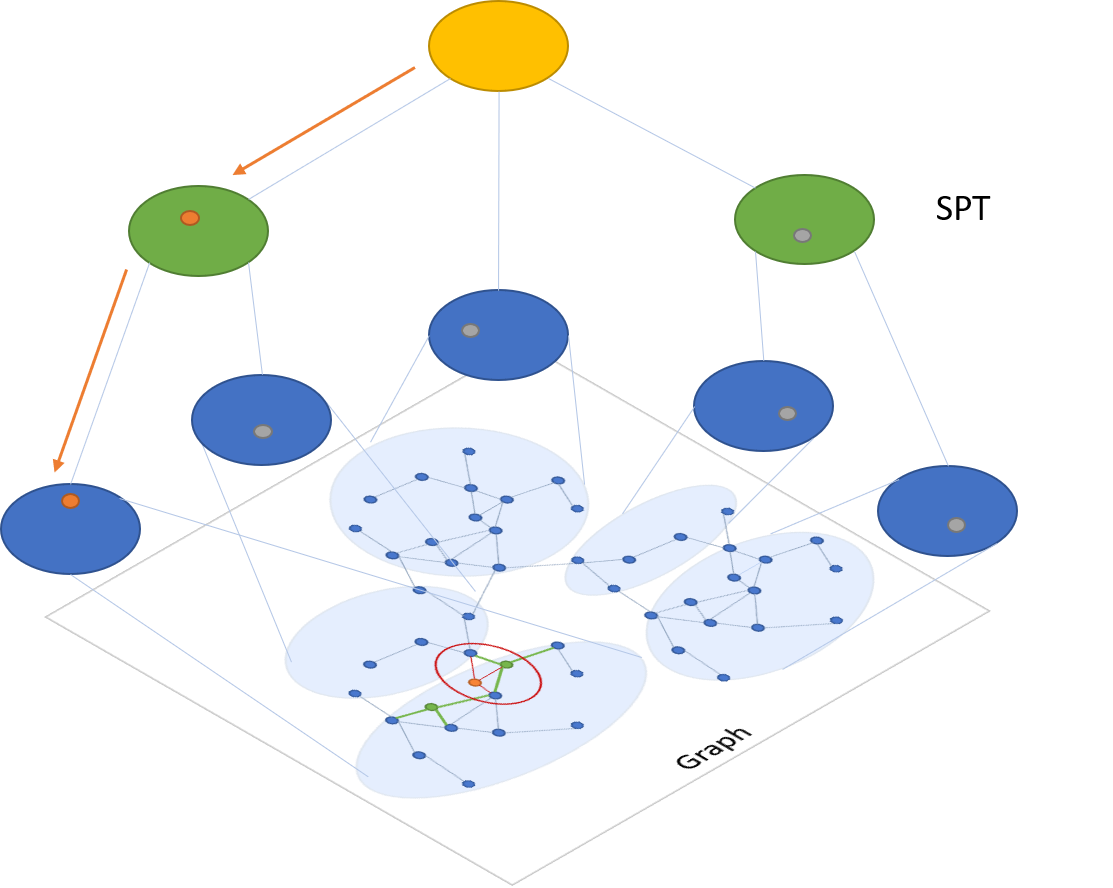
- SPTAG: A library for fast approximate nearest neighbor search
- Query-Driven Iterated Neighborhood Graph Search for Large Scale Indexing
- https://jingdongwang2017.github.io/
Faiss contains several methods for similarity search. It assumes that the instances are represented as vectors and are identified by an integer, and that the vectors can be compared with L2 distances or dot products. Vectors that are similar to a query vector are those that have the lowest L2 distance or the highest dot product with the query vector. It also supports cosine similarity, since this is a dot product on normalized vectors.
Most of the methods, like those based on binary vectors and compact quantization codes, solely use a compressed representation of the vectors and do not require to keep the original vectors. This generally comes at the cost of a less precise search but these methods can scale to billions of vectors in main memory on a single server.
The GPU implementation can accept input from either CPU or GPU memory. On a server with GPUs, the GPU indexes can be used a drop-in replacement for the CPU indexes (e.g., replace IndexFlatL2 with GpuIndexFlatL2) and copies to/from GPU memory are handled automatically. Results will be faster however if both input and output remain resident on the GPU. Both single and multi-GPU usage is supported.
- https://github.com/facebookresearch/faiss
- https://waltyou.github.io/Faiss-Introduce/
- https://github.com/facebookresearch/faiss/wiki
We present a new approach for the approximate K-nearest neighbor search based on navigable small world graphs with controllable hierarchy (Hierarchical NSW, HNSW). The proposed solution is fully graph-based, without any need for additional search structures, which are typically used at the coarse search stage of the most proximity graph techniques. Hierarchical NSW incrementally builds a multi-layer structure consisting from hierarchical set of proximity graphs (layers) for nested subsets of the stored elements. The maximum layer in which an element is present is selected randomly with an exponentially decaying probability distribution. This allows producing graphs similar to the previously studied Navigable Small World (NSW) structures while additionally having the links separated by their characteristic distance scales. Starting search from the upper layer together with utilizing the scale separation boosts the performance compared to NSW and allows a logarithmic complexity scaling. Additional employment of a heuristic for selecting proximity graph neighbors significantly increases performance at high recall and in case of highly clustered data. Performance evaluation has demonstrated that the proposed general metric space search index is able to strongly outperform previous opensource state-of-the-art vector-only approaches. Similarity of the algorithm to the skip list structure allows straightforward balanced distributed implementation.
- https://github.com/nmslib/hnswlib
- https://github.com/nmslib/nmslib
- https://www.itu.dk/people/pagh/
- https://blog.csdn.net/chieryu/article/details/81989920
- http://yongyuan.name/blog/opq-and-hnsw.html
- https://www.ryanligod.com/2018/11/27/2018-11-27%20HNSW%20%E4%BB%8B%E7%BB%8D/
- https://arxiv.org/abs/1707.00143
- https://arxiv.org/abs/1804.09996
- https://arxiv.org/abs/1804.09996
- https://github.com/willard-yuan/cvtk/tree/master/hnsw_sifts_retrieval
- https://github.com/erikbern
- https://github.com/yurymalkov
- https://arxiv.org/abs/1603.09320
- http://sss.projects.itu.dk/
- http://sss.projects.itu.dk/proximity-workshop.html
- http://www.itu.dk/people/jovt/
- http://www.itu.dk/people/rikj/
- http://www.itu.dk/people/maau/
- http://itu.dk/people/pagh/thesis-topics.html
- http://www.itu.dk/people/pagh/
- http://ann-benchmarks.com/
Alexis Sanders as an SEO Account Manager at MERKLE | IMPAQT wrote a blog on semantic search:
The word "semantic" refers to the meaning or essence of something. Applied to search, "semantics" essentially relates to the study of words and their logic. Semantic search seeks to improve search accuracy by understanding a searcher’s intent through contextual meaning. Through concept matching, synonyms, and natural language algorithms, semantic search provides more interactive search results through transforming structured and unstructured data into an intuitive and responsive database. Semantic search brings about an enhanced understanding of searcher intent, the ability to extract answers, and delivers more personalized results. Google’s Knowledge Graph is a paradigm of proficiency in semantic search.

- relevant search
- Learning to rank plugin of Elasticsearch
- MatchZoo's documentation
- http://mlwiki.org/index.php/Information_Retrieval_(UFRT)
- https://en.wikipedia.org/wiki/List_of_search_engines
- Open Semantic Search
- https://www.seekquarry.com/
- http://l-lists.com/en/lists/qukoen.html
- 20款开源搜索引擎介绍与比较
- gt4ireval: Generalizability Theory for Information Retrieval Evaluation
- https://daiwk.github.io/posts/nlp.html
- http://www2003.org/cdrom/papers/refereed/p779/ess.html
- https://blog.alexa.com/semantic-search/
- https://wsdm2019-dapa.github.io/slides/05-YiweiSong.pdf
- https://github.com/semanticvectors/semanticvectors
Personalized Search fetches results and delivers search suggestions individually for each of its users based on their interests and preferences, which is mined from the information that the search engine has about the user at the given time, such as their location, search history, demographics such as the recommenders.
And here search engine and recommender system coincide except the recommender system push some items in order to attract the users' attention while search engine recall the information that the users desire in their mind.
- http://ryanrossi.com/search.php
- https://a9.com/what-we-do/product-search.html
- https://www.algolia.com/
- https://www.cognik.net/
- http://www.collarity.com/
- https://www.wikiwand.com/en/Personalized_search
- The Mathematics of Web Search
- CSAW: Curating and Searching the Annotated Web
- A Gradient-based Framework for Personalization by Liangjie Hong
- Style in the Long Tail: Discovering Unique Interests with Latent Variable Models in Large Scale Social E-commerce
- Personalized Search in Yandex
- Thoughts on Yandex personalized search and beyond
- Yandex filters & algorithms. 1997-2018
- Google's Personalized Search Explained: How personalization works
- A Better Understanding of Personalized Search
- Interest-Based Personalized Search
- Search Personalization using Machine Learning by Hema Yoganarasimhan
- Web Personalization and Recommender Systems
- Scaling Concurrency of Personalized Semantic Search over Large RDF Data
- Behavior‐based personalization in web search
- CH. 9: PERSONALIZATION IN SEARCH
- https://www.jagerman.nl/
- Learn-IR: Learning from User Interactions
- Improving Information Access by Learning from User Interactions
- Efficient, safe and adaptive learning from user interactions
- Learning from User Interactions with Rankings
- Learning from Users’ Interactions with Visual Analytics Systems
- http://www.cs.tufts.edu/~remco/
- https://rishabhmehrotra.com/
- https://staff.fnwi.uva.nl/m.derijke/
- https://personalization.ccs.neu.edu/
- Numerical Algorithms for Personalized Search in Self-organizing Information Networks
- https://cs.stanford.edu/~plofgren/
- https://www.masternewmedia.org/news/2005/04/29/future_pagerank_helps_reputation_and.htm
- http://www.stuntdubl.com/2005/05/18/personalize-search-trustrank/
- https://github.com/actionml/template-personalized-search
Information Distribution Methods – Information distribution is the timely collection, sharing and distribution of information to the project team. Methods can be portals, collaborative work management tools, web conferencing, web publishing, and when all technology is not available, manual filing systems and hard copy distribution.
- SERP: GUIDE TO THE GOOGLE SEARCH ENGINE RESULTS (UPDATED 2019 GUIDE)
- CH. 5: PRESENTATION OF SEARCH RESULTS
- CH. 10: INFORMATION VISUALIZATION FOR SEARCH INTERFACES
- CH. 11: INFORMATION VISUALIZATION FOR TEXT ANALYSIS
- Match Zoo
- https://doc.nuxeo.com/nxdoc/elasticsearch-highlights/
- https://www.the-art-of-web.com/javascript/search-highlight/
Google Cache is normally referred as the copies of the web pages cached by Google. Google crawls the web and takes snapshots of each page as a backup just in case the current page is not available. These pages then become part of Google's cache. These Google cached pages can be extremely useful if a site is temporary down, you can always access these page by visiting Google’s cached version.
Evaluation is used to enhance the performance of the result of the information retrieval.
- http://fire.irsi.res.in/fire/2016/tutorials
- http://informationr.net/ir/18-2/paper582.html#.XW03vih3hPY
- http://sigir.org/awards/best-paper-awards/
Neural networks or deep learning as a subfield of machine learning, is widely applied in information processing.
During the opening keynote of the SIGIR 2016 conference,
Christopher Manningpredicted a significant influx of deep neural network related papers for IR in the next few years. However, he encouraged the community to be mindful of some of the “irrational exuberance” that plagues the field today. The first SIGIR workshop on neural information retrieval received an unexpectedly high number of submissions and registrations. These are clear indications that the IR community is excited by the recent developments in the area of deep neural networks. This is indeed an exciting time for this area of research and we believe that besides attempting to simply demonstrate empirical progress on retrieval tasks, our explorations with neural models should also provide new insights about IR itself. In return, we should also look for opportunities to apply IR intuitions into improving these neural models, and their application to non-IR tasks.
- http://nn4ir.com/
- https://microsoft.github.io/TREC-2019-Deep-Learning/
- Neu-IR: Workshop on Neural Information Retrieval
- Topics in Neural Information Retrieval
- https://frankblood.github.io/
- 5th Workshop on Semantic Deep Learning (SemDeep-5)
- https://www.cs.cornell.edu/~kb/projects/productnet/
- https://github.com/vearch/vearch
- https://github.com/gofynd/mildnet
- https://github.com/Ximilar-com/tf-metric-learning
DSSM stands for Deep Structured Semantic Model, or more general, Deep Semantic Similarity Model. DSSM, developed by the MSR Deep Learning Technology Center(DLTC), is a deep neural network (DNN) modeling technique for representing text strings (sentences, queries, predicates, entity mentions, etc.) in a continuous semantic space and modeling semantic similarity between two text strings (e.g., Sent2Vec).
DSSM can be used to develop latent semantic models that project entities of different types (e.g., queries and documents) into a common low-dimensional semantic space for a variety of machine learning tasks such as ranking and classification. For example, in web search ranking, the relevance of a document given a query can be readily computed as the distance between them in that space. With the latest GPUs from Nvidia, we are able to train our models on billions of words
DSSM: Brief Summary
- Inputs: Bag of letter-trigrams as input for improving the scalability and generalizability
- Representations: mapping sentences to vectors with DNN: semantically similar sentences are close to each other
- Matching: cosine similarity as the matching function
- Problem: the order information of words is missing (bag of letter-trigrams cannot keep the word order information)
Matching Function Learning:
- Step 1: construct basic low-level matching signals
- Step 2: aggregate matching patterns
- https://blog.csdn.net/wangqingbaidu/article/details/79286038
- https://www.microsoft.com/en-us/research/project/dssm/
- Learning to Match Using Local and Distributed Representations of Text for Web Search
- Tensorflow implementations of various Deep Semantic Matching Models
- https://github.com/NTMC-Community/MatchZoo
- https://github.com/shenweichen/DeepMatch
It is asserted that
the ad-hoc retrieval task is mainly about relevance matching while most NLP matching tasks concern semantic matching, and there are some fundamental differences between these two matching tasks. Successful relevance matching requires proper handling of the exact matching signals, query term importance, and diverse matching requirements.
A novel deep relevance matching model (DRMM) for ad-hoc retrieval employs a joint deep architecture at the query term level for relevance matching. By using matching histogram mapping, a feed forward matching network, and a term gating network, we can effectively deal with the three relevance matching factors mentioned above.
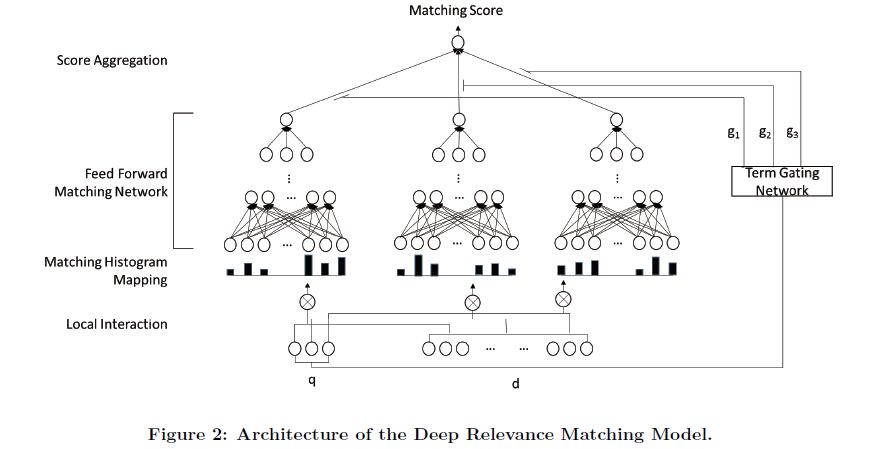
- Matching histogram mapping for summarizing each query matching signals
- Term gating network for weighting the query matching signals
- Lost word order information (during histogram mapping)
- A Deep Relevance Matching Model for Ad-hoc Retrieval
- https://zhuanlan.zhihu.com/p/38344505
- https://frankblood.github.io/2017/03/10/A-Deep-Relevance-Matching-Model-for-Ad-hoc-Retrieval/
Calculate relevance by mimicking the human relevance judgement process
- Detecting Relevance locations: focusing on locations of query terms when scanning the whole document
- Determining local relevance: relevance between query and each location context, using MatchPyramid/MatchSRNN etc.
- Matching signals aggregation
- Deep Relevance Ranking Using Enhanced Document-Query Interactions
- DeepRank: A New Deep Architecture for Relevance Ranking in Information Retrieval
Challenges
- Representation: representing the word level matching signals as well as the matching positions
- Modeling: discovering the matching patterns between two texts
- Our solutions
- Step 1: representing as matching matrix
- Step 2: matching as image recognition
Matching matrix
$$\fbox{MatchPyramid} =\underbrace{Matching,, Matrix}{\text{Bridging the semantic gap between words}}+\underbrace{Hierarchical,, Convolution}{\text{Capturing rich matching patterns}}$$
- http://www.bigdatalab.ac.cn/~junxu/publications/AAAI2016_CNNTextMatch.pdf
- http://www.bigdatalab.ac.cn/~junxu/publications/AAAI2016_BiLSTMTextMatch.pdf
- https://github.com/pl8787/MatchPyramid-TensorFlow
- https://www.cntk.ai/pythondocs/CNTK_303_Deep_Structured_Semantic_Modeling_with_LSTM_Networks.html
The idea of TDM is to predict user interests from coarse to fine by traversing tree nodes in a top-down fashion and making decisions for each user-node pair.
A recommendation tree consists of a set of nodes N, where


- http://www.6aiq.com/article/1565927125584
- https://tianchi.alibabacloud.com/course/video?liveId=41072
- 深度树匹配模型(TDM)@x-deeplearning
- https://www.jianshu.com/p/149467a29b64
- Learning Tree-based Deep Model for Recommender Systems
- Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba
- Joint Optimization of Tree-based Index and Deep Model for Recommender Systems
- 阿里自主创新的下一代匹配&推荐技术:任意深度学习+树状全库检索
- https://dzone.com/articles/breakthroughs-in-matching-and-recommendation-algor
Vector search engine (aka neural search engine or deep search engine) uses deep learning models to encode data sets into meaningful vector representations, where distance between vectors represent the similarities between items.
- https://www.microsoft.com/en-us/ai/ai-lab-vector-search
- https://github.com/textkernel/vector-search-plugin
Weaviate uses vector indexing mechanisms at its core to represent the data. The vectorization modules (e.g., the NLP module) vectorizes the above-mentioned data object in a vector-space where the data object sits near the text ”landmarks in France”. This means that Weaviate can’t make a 100% match, but a very high one to show you the results.
- https://github.com/semi-technologies/weaviate
- https://www.semi.technology/developers/weaviate/current/
As an open source vector similarity search engine, Milvus is easy-to-use, highly reliable, scalable, robust, and blazing fast. Adopted by over 100 organizations and institutions worldwide, Milvus empowers applications in a variety of fields, including image processing, computer vision, natural language processing, voice recognition, recommender systems, drug discovery, etc.
- https://github.com/milvus-io/milvus
- https://milvus.io/docs/v0.6.0/reference/comparison.md
- https://milvus.io/cn/
Jina is a deep learning-powered search framework for building cross-/multi-modal search systems (e.g. text, images, video, audio) on the cloud.
Key points:
- Mimic user top-down browsing behaviors
- Model dynamic information needs with MDP state
States
- sequence of
$t$ preceding documents,$\it Z_t$ and$\it Z_0=\emptyset$ ; - set of candidate documents,
$\it X_t$ and$\it X_0 = \it X$ - latent vector
$\mathrm h_𝑡$ , encodes user perceived utility from preceding documents, initialized with the information needs form the query:$\mathrm h_0=\sigma(V_qq)$
| MDP factors | Corresponding diverse ranking factors |
|---|---|
| Timesteps | The ranking positions |
| States | |
| Policy | |
| Action | Selecting a doc and placing it to rank |
| Reward | Based on evaluation measure nDCG, SRecall etc. |
| State Transition | $s_{t+1}=T(s_t, a_t)=[Z_t\oplus {\mathrm{x}{m(a_t)}}, {X}t\setminus {\mathrm {x}{m(a_t)} }, \sigma(V\mathrm{x}{m(a_t)}+W\mathrm {h}_t)]$ |
Here
Monte-Carlo stochastic gradient ascent is used to conduct the optimization (REINFORCE algorithm)
- http://www.bigdatalab.ac.cn/~gjf/papers/2017/SIGIR2017_MDPDIV.pdf
- Reinforcement Learning to Rank with Markov Decision Process
- Deep and Reinforcement Learning for Information Retrieval
- Improving Session Search Performance with a Multi-MDP Model
- https://github.com/ICT-BDA/EasyML
As we have learned how to handle text, information retrieval is moving on, to projects in sound and image retrieval, along with electronic provision of much of what is now in libraries.
Scholar Search Engine helps to find the digital scholar publication.
Different from general web search engine, scholar search engine does rank the web-page. The citation network is used to evaluate the importance of one scholar article.
- https://scholar.google.com/
- https://academic.microsoft.com/home
- https://www.base-search.net/
- https://www.semanticscholar.org/
- https://xueshu.baidu.com/
- https://www.refseek.com/
- https://dblp.uni-trier.de/
- http://www.jurn.org/
- https://www.plos.org/
- https://www.shortscience.org/
- https://app.dimensions.ai/discover/publication
- https://deepai.org/researchers
- https://scinapse.io/
- http://citeseerx.ist.psu.edu/index
- https://www.semion.io/Home/About
- https://scite.ai/
- https://awesomeopensource.com/
- http://evolutionofmachinelearning.com/
- MACHINE LEARNING FOR HEALTHCARE (MLHC)
- https://ml4health.github.io/2017/
- https://ml4health.github.io/2019/
- BigCHat: Connected Health at Big Data Era
- HEALTH DAY AT KDD
- Microsoft’s focus on transforming healthcare: Intelligent health through AI and the cloud
- https://www.cs.ubc.ca/~rng/
- http://homepages.inf.ed.ac.uk/ckiw/
- http://groups.csail.mit.edu/medg/people/psz/home/Pete_MEDG_site/Home.html
- MIT CSAIL Clinical Decision Making Group
- http://www.cs.ucr.edu/~cshelton/
- http://hst.mit.edu/users/rgmarkmitedu
- http://erichorvitz.com/
- https://www.hms.harvard.edu/dms/neuroscience/fac/Kohane.php
- https://www.khoury.northeastern.edu/people/carla-brodley/
ChartRequest claims that:
Requesting medical records is vital to your operations as a health insurance company. From workers’ compensation claims to chronic-condition care, insurance companies require numerous medical records—daily. Obtain records quickly and accurately with our medical information retrieval software. ChartRequest offers a complete enterprise solution for health insurance companies—facilitating swift fulfillment and secure, HIPAA-compliant records release.
- http://web.cs.ucla.edu/~wwc/course/cs245a/
- http://web.cs.ucla.edu/~wwc/
- http://www.kmed.cs.ucla.edu/
- KMeX: A Knowledge-Based Approach for Scenario-Specific Medical Free Text Retrieval
- https://www.informedhealth.org/
- http://yom-tov.info/publications.html
- http://yom-tov.info/publications.html
- Internet Searches for Medical Symptoms Before Seeking Information on 12-Step Addiction Treatment Programs: A Web-Search Log Analysis
- https://www.webmd.com/
- https://ingemarcox.cs.ucl.ac.uk/?page_id=14
- https://ingemarcox.cs.ucl.ac.uk/?page_id=14
- https://ingemarcox.cs.ucl.ac.uk/
- Using the World Wide Web to answer clinical questions: how efficient are different methods of information retrieval?
- Clinical Digital Libraries Project: design approach and exploratory assessment of timely use in clinical environments.
Biomedical and health informatics (BMHI) is the field concerned with the optimal use of information, often aided by technology, to improve individual health, healthcare, public health, and biomedical research.
- Unified Medical Language System (UMLS)
- Systematized Nomenclature of Medicine--Clinical Terms (SNOMED-CT)
- International Classification of Diseases (ICD)
We focus on ICD10.
- https://dmice.ohsu.edu/hersh//whatis/
- https://www.nlm.nih.gov/research/umls/
- http://www.snomed.org/
- https://icd.who.int/en/
To health professionals, applications providing an easy access to validated and up-to-date health knowledge are of great importance to the dissemination of knowledge and have the potential to impact the quality of care provided by health professionals. On the other side, the Web opened doors to the access of health information by patients, their family and friends, making them more informed and changing their relation with health professionals.
To professionals, one of the main and oldest IR applications is PubMed from the US National Library of Medicine (NLM) that gives access to the world’s medical research literature. To consumers, health information is available through different services and with different quality. Lately, the control over and access to health information by consumers has been a hot topic, with plenty government initiatives all over the world that aim to improve consumer health giving consumers more information and making easier the sharing of patient records.
- http://carlalopes.com/pubs/Lopes_SOA_2008.pdf
- https://www.ncbi.nlm.nih.gov/pubmed/26152963
- https://www.ncbi.nlm.nih.gov/pubmed/25991092
Simply, it is becasue medical information is really professional while critical. It is not easy to understand the semantics of texts with medical terms for patients the ones who need such information.
This can be difficult because health information is constantly changing as a result of new research and because there may be different valid approaches to treating particular conditions.
It is therefore of interest to find out
how well web search engines work for diagnostic queries
and what factors contribute to successes and failures.
Among diseases, rare (or orphan) diseases represent an especially challenging and thus interesting class to diagnose as each is rare, diverse in symptoms
and usually has scattered resources associated with it.
- Specialized tools are needed when searching the web for rare disease diagnoses
- Online Health Information: Is It Reliable?
- https://www.ucsfhealth.org/education/evaluating-health-information
- FindZebra: a search engine for rare diseases.
- Rare disease diagnosis: A review of web search, social media and large-scale data-mining approaches.
- A comparison of world wide web resources for identifying medical information.
- https://slides.com/saeidbalaneshinkordan/medical_information_retrieval#/23
- https://slides.com/saeidbalaneshinkordan/medical_information_retrieval-1-5-6
- http://www0.cs.ucl.ac.uk/staff/ingemar/Content/papers/2015/DMKD2015.pdf
- https://dmice.ohsu.edu/hersh/
- http://www.balaneshin.com/
- https://www.chartrequest.com/
- https://www.a-star.edu.sg/resource
- http://www.bii.a-star.edu.sg/
- Medical Information Retrieval
- Information Retrieval: A Health and Biomedical Perspective
- http://www.khresmoi.eu/
- http://www.imedisearch.com/
- http://everyone.khresmoi.eu/
- https://meshb.nlm.nih.gov/
- http://cbm.imicams.ac.cn/
- Consumer Health Search
- Biomedical Data Science Initiative
- https://dmice.ohsu.edu/hersh/irbook/
- https://www.hon.ch/en/
- https://search.kconnect.eu/beta/
- https://clefehealth.imag.fr/
- http://www.bilegaldoc.com/
- http://www.munmund.net/index.html
- http://2013.digitalhealth.ws/
- http://www.digitalhealth.ws/
- Digital Health 2015
- DIGITAL HEALTH 2018
- https://www.crowdsourcedhealth.com/
- https://www.jmir.org/2019/1/e10179/
- http://yom-tov.info/publications.html
- http://tonghanghang.org/events/KDD_BigChat.htm
- https://www.richgames.org/
- Search Tools Reports: Search Engines for Multimedia: Images, Audio and Video Files
- Building a Content-Based Multimedia Search Engine I: Quantifying Similarity
- Building a Content-Based Multimedia Search Engine II: Extracting Feature Vectors
- Building a Content-Based Multimedia Search Engine III: Feature Signatures
- Building a Content-Based Multimedia Search Engine IV: Earth Mover’s Distance
- Building a Content-Based Multimedia Search Engine V: Signature Quadratic Form Distance
- Building a Content-Based Multimedia Search Engine VI: Efficient Query Processing
- http://www.sonic.net/~rteeter/multimedia.html
- http://www.ee.columbia.edu/~wjiang/
- WebMARS: A Multimedia Search Engine
- https://zhuanlan.zhihu.com/p/93083455
- https://arxiv.org/abs/1907.04476
- http://59.108.48.34/tiki/FGCrossNet/
- https://github.com/PKU-ICST-MIPL/FGCrossNet_ACMMM2019
- https://www.researchgate.net/publication/221368756_NUS-WIDE_A_real-world_web_image_database_from_National_University_of_Singapore
- https://github.com/milvus-io/milvus
- http://www.ifp.illinois.edu/~xzhou2/
- http://fengzheyun.github.io/publications.html
- 关于 Milvus 在线训练营
- https://milvus.io/
- 自制AI图像搜索引擎
- 深度学习表征的不合理有效性——从头开始构建图像搜索服务(一)
- 深度学习表征的不合理有效性——从头开始构建图像搜索服务(二)
Popular sites like Houzz, Pinterest, and LikeThatDecor, have communities of users helping each other answer questions about products in images.
- https://tineye.com/
- https://www.cs.cornell.edu/~kb/projects/productnet/
- https://github.com/awslabs/visual-search
- https://www.pyimagesearch.com/
- https://w3-lab.com/rise-visual-search-seo-trend-2020/
- https://www.bing.com/visualsearch
- https://w3-lab.com/rise-visual-search-seo-trend-2020/
- https://tech.ebayinc.com/research/tips-for-visual-search-at-scale/
- Arista (lARge-scale Image Search To Annotation) Established: January 1, 2006
- International Audio Laboratories Erlangen
- Center for Computer Research in Music and Acoustics
- Exploring deep learning based methods for information retrieval in Indian classical music
- https://keunwoochoi.wordpress.com/
- https://www.music-ir.org/mirex/wiki/MIREX_HOME
- Deep Learning for Music
- https://www.ismir.net/
- Women in Music Information Retrieval
- https://github.com/mozilla/DeepSpeech
- https://github.com/mkanwal/Deep-Music
- https://magenta.tensorflow.org/
- MPATE-GE 2623 Music Information Retrieval
- https://sites.google.com/view/twidale
- Introduction to Mozilla Deep Speech
- The MusArt Music-Retrieval System: An Overview
- SGN-24006 Analysis of Audio, Speech and Music Signals Spring 2017
- Notes on Music Information Retrieval
- https://arxiv.org/abs/1905.13125
- Interactive search in image retrieval: a survey
- Interactive Visual Search
- Give me a hint! Navigating Image Databases using Human-in-the-loop Feedback
- https://www.di.ens.fr/~josef/
According to a recent survey, over 55% of online customers begin their online shopping journey by searching on an E-Commerce website like Amazon as opposed to a generic web search engine like Google. While information retrieval research to date has been primarily focused on optimizing generic search experiences, and search engines in the past decade have improved significantly, not too much attention has been paid to search for E-Commerce. In this talk, I will explore some intrinsic differences between web search and E-Commerce search that makes the direct application of traditional search ranking algorithms to E-Commerce search difficult. In addition, I will present some recent attempts at Etsy to tackle challenges in E-Commerce search.
- https://www.nngroup.com/articles/state-ecommerce-search/
- https://www.nngroup.com/articles/ecommerce-expectations/
- https://sigir-ecom.github.io/
- https://sigir-ecom.github.io/ecom2018/index.html
- http://sigir-ecom.weebly.com/
- NLP for eCommerce Search – Current Challenges and Future Potential
- The Leader in Visual AI for Retail
- https://tooso.ai/
- https://www.904labs.com/en/index.html
- https://choice.ai/
- https://markable.ai/
- https://www.sli-systems.com/blog/putting-ai-work-e-commerce.html
- https://www.nosto.com/
- https://adeptmind.ai/
- https://www.kdd.org/kdd2015/program.html#ig02
A multilingual, multimodal search and access system for biomedical information and documents. The system allows access to biomedical data:
- from many sources,
- analyzing and indexing multi-dimensional (2D, 3D) medical images, with improved search capabilities due to the integration of technologies to link the texts and images to facts in a knowledge base,
- in a multilingual environment,
- providing trustable results at a level of understandability adapted to the users.
- DeepStyle: Multimodal Search Engine for Fashion and Interior Design
- What Looks Good with my Sofa: Ensemble Multimodal Search for Interior Design
- http://www.khresmoi.eu/overview/
- http://www.ee.columbia.edu/~wjiang/publications.html
- Multi-Task Learning with Neural Networks for Voice Query Understanding on an Entertainment Platform
The Content-Aware Similarity Search (CASS) project investigates research issues in searching, clustering, and classification, and management for feature-rich, non-text data types.
Search is not only on string but also things. Knowledge graphs are large networks of entities and their semantic relationships. They are a powerful tool that changes the way we do data integration, search, analytics, and context-sensitive recommendations. Knowledge graphs have been successfully utilized by the large Internet tech companies, with prominent examples such as the Google Knowledge Graph. Open knowledge graphs such as Wikidata make community-created knowledge freely accessible.

- The First Workshop on Knowledge Graphs and Semantics for Text Retrieval and Analysis
- The Second Workshop on Knowledge Graphs and Semantics for Text Retrieval, Analysis, and Understanding
- Open Knowledge Network.
- https://twiggle.com/
- https://www.clearquery.io/how
- The Entity & Language Series: Translation and Language APIs Impact on Query Understanding & Entity Understanding (4 of 5)
- https://etymo.io/
- https://www.omnity.io/
- https://scholar.etymo.io/
- https://cayley.io/
- https://grakn.ai/
- TUTORIAL: GETTING STARTED WITH KNOWLEDGE GRAPHS
- Mining Knowledge Graphs from Text
- Open knowledge mining and graph builder
- WordAtlas — the next-generation multilingual knowledge graph based on BabelNet
- https://www.openacademic.ai/
- ConceptNet An open, multilingual knowledge graph
- Knowledge Graphs and Knowledge Networks: The Story in Brief
- Renlifang/EntityCube
- http://www.ecmlpkdd2018.org

Any opinions, findings, and conclusions or recommendations expressed in this material are those of the creators of WordNet and do not necessarily reflect the views of any funding agency or Princeton University.
- https://www.peak-labs.com/
- https://www.peak-labs.com/docs/zh/magi/intro
- https://magi.com/
- https://www.peak-labs.com/#technology
- Search and information retrieval@Microsoft
- Search and information retrieval@Google
- Web search and mining @Yandex
- The Information Engineering Lab
- Information Retrieval Lab: A research group @ University of A Coruña (Spain)
- BCS-IRSG: Information Retrieval Specialist Group
- 智能技术与系统国家重点实验室信息检索课题组
- Web Information Retrieval / Natural Language Processing Group (WING)
- The Cochrane Information Retrieval Methods Group (Cochrane IRMG)
- SOCIETY OF INFORMATION RETRIEVAL & KNOWLEDGE MANAGEMENT (MALAYSIA)
- Quantum Information Access and Retrieval Theory)
- Center for Intelligent Information Retrieval (CIIR)
- InfoSeeking Lab situated in School of Communication & Information at Rutgers University.
- http://nlp.uned.es/web-nlp/
- http://mlwiki.org/index.php/Information_Retrieval
- information and language processing systems
- information retrieval facility
- Center for Information and Language Processing
- Summarized Research in Information Retrieval for HTA
- IR Lab
- IR and NLP Lab
- CLEF 2018 LAB
- QANTA: Question Answering is Not a Trivial Activity
- SIGIR
- http://cistern.cis.lmu.de/
- http://hpc.isti.cnr.it/
- http://trec-car.cs.unh.edu/
- http://www.cs.wayne.edu/kotov/index.html
- http://www.isp.pitt.edu/research/nlp-info-retrieval-group
- LETOR: Learning to Rank for Information Retrieval
- A Lucene toolkit for replicable information retrieval research
- Information Overload Research Group
- National Information Standards Organization by ANSI
- International Society of Music Information Retrieval
- Open Clinical information retrieval
- Medical Library Association
- AMIA
- INternational Medical INformatics Association
- Association of Directors of Information System
- Ivory: A Hadoop Toolkit for Distributed Text Retrieval
- https://ciir.cs.umass.edu/
- https://cs.uwaterloo.ca/~jimmylin/index.html
- https://ischool.illinois.edu/research/areas/design-and-evaluation-information-systems-and-services
- https://datanatives.io/conference/
- sigir2019
- Natural Language Processing in Information Retrieval
- HE 3RD STRATEGIC WORKSHOP ON INFORMATION RETRIEVAL IN LORNE (SWIRL)
- Text Retrieval COnference(TREC)
- European Conference on Information Retrieval (ECIR 2018)
- ECIR 2019
- IR @wikiwand
- Algorithm Selection and Meta-Learning in Information Retrieval (AMIR)
- The ACM SIGIR International Conference on the Theory of Information Retrieval (ICTIR)2019
- KDIR 2019
- Advances in Semantic Information Retrieval (ASIR’19)
- Music Information Retrieval Evaluation eXchange (MIREX 2019)
- 20th annual conference of the International Society for Music Information Retrieval (ISMIR)
- 8th International Workshop on Bibliometric-enhanced Information Retrieval
- ICMR 2019
- 3rd International Conference on Natural Language Processing and Information Retrieval
- FACTS-IR Workshop @ SIGIR 2019
- ACM Conference of Web Search and Data Mining 2019
- SMIR 2014
- 2018 PRS WORKSHOP: Personalization, Recommendation and Search (PRS)
- Neu-IR: The SIGIR 2016 Workshop on Neural Information Retrieval
- Neu-IR 2017: Workshop on Neural Information Retrieval
- NeuIR Group
- TREC 2019 Fair Ranking Track
- LEARNING FROM LIMITED OR NOISY DATA FOR INFORMATION RETRIEVAL
- DYNAMIC SEARCH: Develop algorithms and evaluation methodologies with the user in the search loop
- European Summer School in Information Retrieval ’15
- SEA: Search Engines Amsterdam
- HE 3RD STRATEGIC WORKSHOP ON INFORMATION RETRIEVAL IN LORNE (SWIRL)
- 2nd International Workshop on Conversational Approaches to Information Retrieval (CAIR'18)
- CS 276 / LING 286: Information Retrieval and Web Search
- LING 289: History of Computational Linguistics Winter 2011
- Introduction to Information Retrieval
- CS 371R: Information Retrieval and Web Search
- CS 242: Information Retrieval & Web Search, Winter 2019
- Winter 2017 CS293S: Information Retrieval and Web Search
- CS 276 / LING 286: Information Retrieval and Web Search
- Information Retrieval and Web Search 2015
- 信息检索与数据挖掘 2019 USTC
- Data and Web Mining
- Neural Networks for Information Retrieval
- Introduction to Search Engine Theory
- INFORMATION RETRIEVAL FOR GOOD
- Search user interfaces
- Modern Information Retrieval
- Search Engine: Information Retrieval in Practice
- Information Retrieval 潘微科
- Information Organization and Retrieval: INFO 202
- Music Information Retrieval @ NYU
- Intelligent Information Retrieval
- CSc 7481 / LIS 7610 Information Retrieval Spring 2008
- Winter 2016 CSI4107: Information Retrieval and the Internet
- Information Retrieval 2017 Spring
- Ranking Model
- TEXT TECHNOLOGIES FOR DATA SCIENCE
- EPL 660 - Information Retrieval and Search Engines
- https://searchpatterns.org/
- http://widodo.com/lecturer/IR/
- https://www.cl.cam.ac.uk/teaching/1516/InfoRtrv/materials.html
- Information Retrieval
- https://www.jianshu.com/p/a133f54222cb
- http://ir.cs.georgetown.edu/
- http://people.cs.georgetown.edu/~nazli/
- http://ir.cs.georgetown.edu/publications/