In this Code Pattern, we will use German Credit data to train, create, and deploy a machine learning model using Watson Machine Learning. We will create a data mart for this model with Watson OpenScale and configure OpenScale to monitor that deployment, and inject seven days' worth of historical records and measurements for viewing in the OpenScale Insights dashboard.
When the reader has completed this Code Pattern, they will understand how to:
- Create and deploy a machine learning model using the Watson Machine Learning service
- Setup Watson OpenScale Data Mart
- Bind Watson Machine Learning to the Watson OpenScale Data Mart
- Add subscriptions to the Data Mart
- Enable payload logging and performance monitor for subscribed assets
- Enable Quality (Accuracy) monitor
- Enable Fairness monitor
- Enable Drift montitor
- Score the German credit model using the Watson Machine Learning
- Insert historic payloads, fairness metrics, and quality metrics into the Data Mart
- Use Data Mart to access tables data via subscription

- The developer creates a Jupyter Notebook on Watson Studio.
- The Jupyter Notebook is connected to a PostgreSQL database, which is used to store Watson OpenScale data.
- The notebook is connected to Watson Machine Learning and a model is trained and deployed.
- Watson OpenScale is used by the notebook to log payload and monitor performance, quality, and fairness.
- An IBM Cloud Account
- IBM Cloud CLI
- IBM Cloud Object Storage (COS)
- An account on IBM Watson Studio.
- Clone the repository
- Use free internal DB or Create a Databases for PostgreSQL DB
- Create a Watson OpenScale service
- Create a Watson Machine Learning instance
- Create a notebook in IBM Watson Studio on Cloud Pak for Data
- Run the notebook in IBM Watson Studio
- Setup OpenScale to utilize the dashboard
git clone https://github.com/IBM/monitor-wml-model-with-watson-openscale
cd monitor-wml-model-with-watson-openscaleIf you wish, you can use the free internal Database with Watson OpenScale. To do this, make sure that the cell for KEEP_MY_INTERNAL_POSTGRES = True remains unchanged.
Note: Services created must be in the same region, and space, as your Watson Studio service.
- Using the IBM Cloud Dashboard catalog, search for PostgreSQL and choose the
Databases for Postgresservice. - Wait for the database to be provisioned.
- Click on the
Service Credentialstab on the left and then clickNew credential +to create the service credentials. Copy them or leave the tab open to use later in the notebook. - Make sure that the cell in the notebook that has:
KEEP_MY_INTERNAL_POSTGRES = Trueis changed to:
KEEP_MY_INTERNAL_POSTGRES = FalseCreate Watson OpenScale, either on the IBM Cloud or using your On-Premise Cloud Pak for Data.
On IBM Cloud
-
If you do not have an IBM Cloud account, register for an account
-
Create a Watson OpenScale instance from the IBM Cloud catalog
-
Select the Lite (Free) plan, enter a Service name, and click Create.
-
Click Launch Application to start Watson OpenScale.
-
Click Auto setup to automatically set up your Watson OpenScale instance with sample data.

-
Click Start tour to tour the Watson OpenScale dashboard.

On IBM Cloud Pak for Data platform
Note: This assumes that your Cloud Pak for Data Cluster Admin has already installed and provisioned OpenScale on the cluster.
-
In the Cloud Pak for Data instance, go the (☰) menu and under
Servicessection, click on theInstancesmenu option.
-
Find the
OpenScale-defaultinstance from the instances table and click the three vertical dots to open the action menu, then click on theOpenoption.
-
If you need to give other users access to the OpenScale instance, go the (☰) menu and under
Servicessection, click on theInstancesmenu option. -
Find the
OpenScale-defaultinstance from the instances table and click the three vertical dots to open the action menu, then click on theManage accessoption.
-
To add users to the service instance, click the
Add usersbutton.
-
For all of the user accounts, select the
Editorrole for each user and then click theAddbutton.





-
Under the
Settingstab, scroll down toAssociated services, click+ Add serviceand chooseWatson:
-
Search for
Machine Learning, Verify this service is being created in the same space as the app in Step 1, and clickCreate.
-
Alternately, you can choose an existing Machine Learning instance and click on
Select. -
The Watson Machine Learning service is now listed as one of your
Associated Services. -
In a different browser tab go to https://cloud.ibm.com/ and log in to the Dashboard.
-
Click on your Watson Machine Learning instance under
Services, click onService credentialsand then onView credentialsto see the credentials.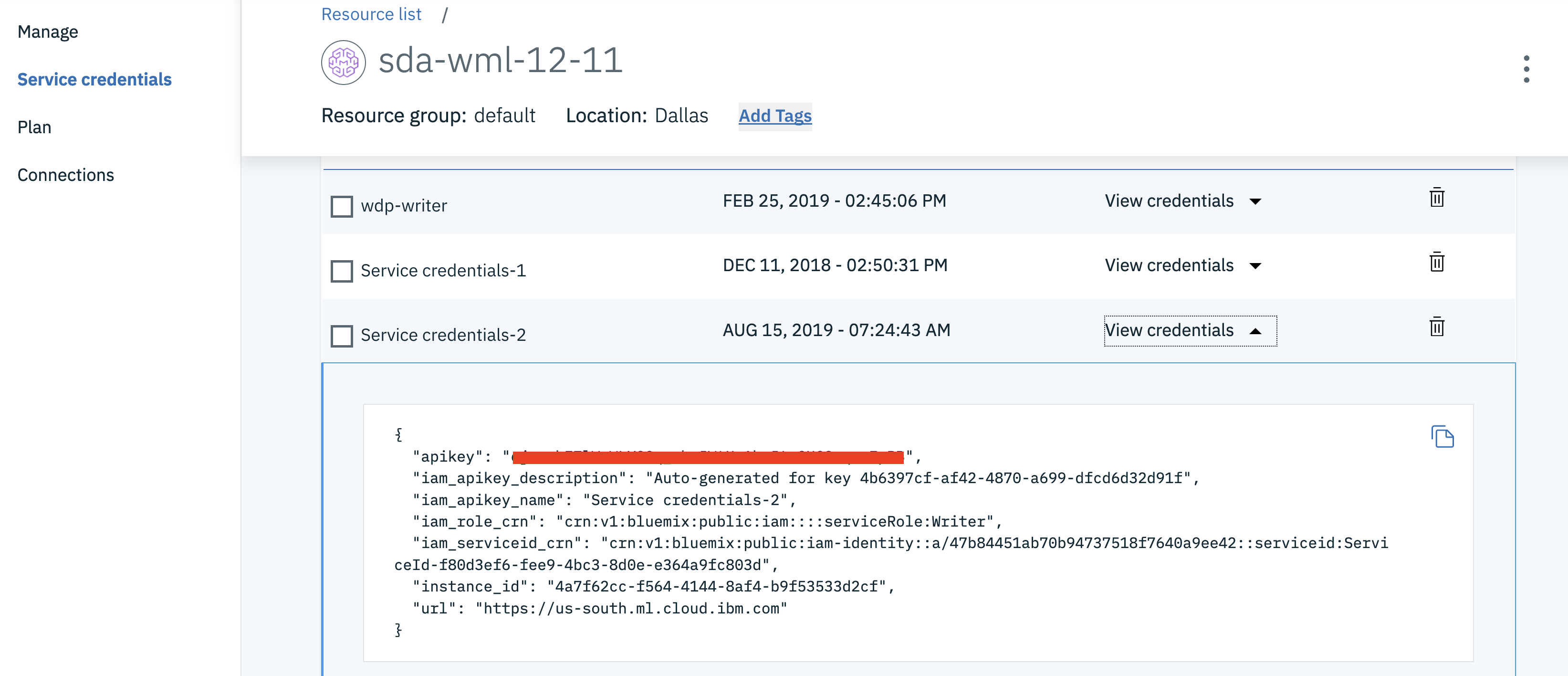
-
Save the credentials in a file. You will use them inside the notebook.

-
In Watson Studio or your on-premise Cloud Pak for Data, click
New Project +under Projects or, at the top of the page click+ Newand choose the tile forData Scienceand thenCreate Project. -
Using the project you've created, click on
+ Add to projectand then choose theNotebooktile, OR in theAssetstab underNotebookschoose+ New notebookto create a notebook. -
Select the
From URLtab. [1] -
Enter a name for the notebook. [2]
-
Optionally, enter a description for the notebook. [3]
-
For
Runtimeselect theDefault Spark Python 3.7option. [4] -
Under
Notebook URLprovide the following url: https://raw.githubusercontent.com/IBM/monitor-wml-model-with-watson-openscale/master/notebooks/WatsonOpenScaleMachineLearning.ipynb
Note: The current default (as of 8/11/2021) is Python 3.8. This will cause an error when installing the
pyspark.sql SparkSessionlibrary, so make sure that you are using Python 3.7
- Click the
Create notebookbutton. [6]

Follow the instructions for Provision services and configure credentials:
Your Cloud API key can be generated by going to the Users section of the Cloud console.
-
From that page, click your name, scroll down to the API Keys section, and click Create an IBM Cloud API key.
-
Give your key a name and click Create, then copy the created key and paste it below.
Alternately, from the IBM Cloud CLI :
ibmcloud login --sso
ibmcloud iam api-key-create 'my_key'- Enter the
CLOUD_API_KEYin the cell1.1 Cloud API key.
-
In your IBM Cloud Object Storage instance, create a bucket with a globally unique name. The UI will let you know if there is a naming conflict. This will be used in cell 1.3.1 as BUCKET_NAME.
-
In your IBM Cloud Object Storage instance, get the Service Credentials for use as
COS_API_KEY_ID,COS_RESOURCE_CRN, andCOS_ENDPOINT:
-
Add the COS credentials in cell 1.2 Cloud object storage details.
-
Insert your BUCKET_NAME in the cell 1.2.1 Bucket name.
-
Either use the internal Database, which requires No Changes or Add your
DB_CREDENTIALSafter reading the instructions preceeding that cell and change the cellKEEP_MY_INTERNAL_POSTGRES = Trueto becomeKEEP_MY_INTERNAL_POSTGRES = False. -
Move your cursor to each code cell and run the code in it. Read the comments for each cell to understand what the code is doing. Important when the code in a cell is still running, the label to the left changes to In [*]:. Do not continue to the next cell until the code is finished running.

Now that you have created a machine learning model, you can utilize the OpenScale dashboard to gather insights.
You can find a sample notebook with output for WatsonOpenScaleMachineLearning-with-outputs.ipynb.
- Go to the instance of Watson OpenScale for an IBM Cloud deployment, or to your deployed instance on Cloud Pak for Data on-premise version. Choose the
Insightstab to get an overview of your monitored deployments, Accuracy alerts, and Fairness alerts.

- Click on the tile for the
Spark German Risk Deploymentand you can see tiles for theFairness,Accuracy, andPerformance monitors.

- Click on one of the tiles, such as Drift to view details. Click on a point on the graph for more information on that particular time slice.

- You will see which types of drift were detected. Click on the number to bring up a list of transactions that led to drift.

- Click on the
Explainicon on the left-hand menu and you'll see a list of transactions that have been run using an algorithm to provide explainability. Choose one and clickExplain.

- You will see a graph showing all the most influential features with the relative weights of contribution to the Predicted outcome.

- Click the
Inspecttab and you can experiment with changing the values of various features to see how that would affect the outcome. Click theRun analysisbutton to see what changes would be required to change the outcome.
