表格是图像之外另一个非常重要的数据类型,某种意义上,科研图像分析的结果最终都会归到表格。ImagePy对表格类型数据有很好的支持,其核心数据结构是pandas.DataFrame。
from imagepy.core.engine import Free
from imagepy import IPy
import numpy as np
import pandas as pd
class Score(Free):
title = 'Student Score'
def run(self, para=None):
index = ['Stutent%s'%i for i in range(1,6)]
columns = ['Math', 'Physics', 'Biology', 'History']
score = (np.random.rand(20)*40+60).reshape((5,4)).astype(np.uint8)
IPy.show_table(pd.DataFrame(score, index, columns), 'Scores')我们通过一个Free插件生成表格,表格是一个pandas.DataFrame对象,通过IPy.show_table(df, title)来展示。
from imagepy.core.engine import Table
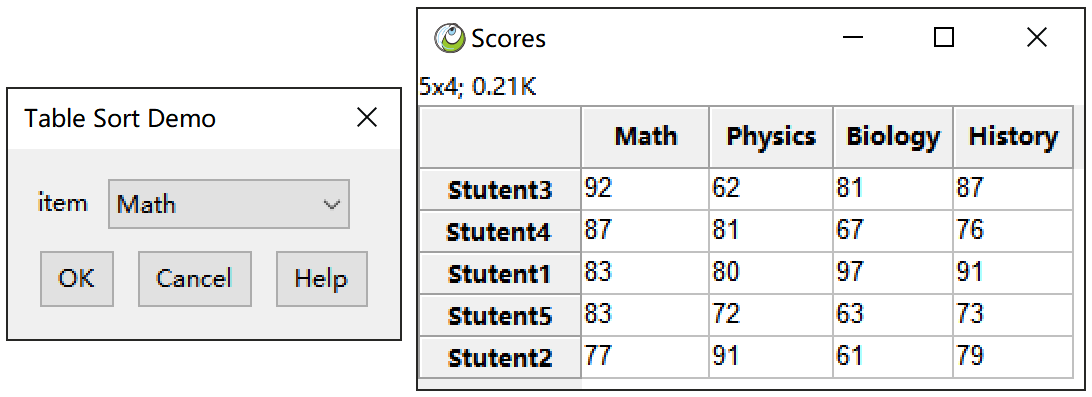
class Sort(Table):
title = 'Table Sort Demo'
para = {'by':'Math'}
view = [('field', 'by', 'item', '')]
def run(self, tps, data, snap, para=None):
tps.data.sort_values(by=para['by'], inplace=True)这里用到了一种新的参数类型,field,这种参数类型其实是一个单选类型,但是不需要我们提供选项,会自动从当前表格的columns中获取。run中通过inplace参数直接改变DataFrame本身,一些操作无法修改本身,可以将结果return。
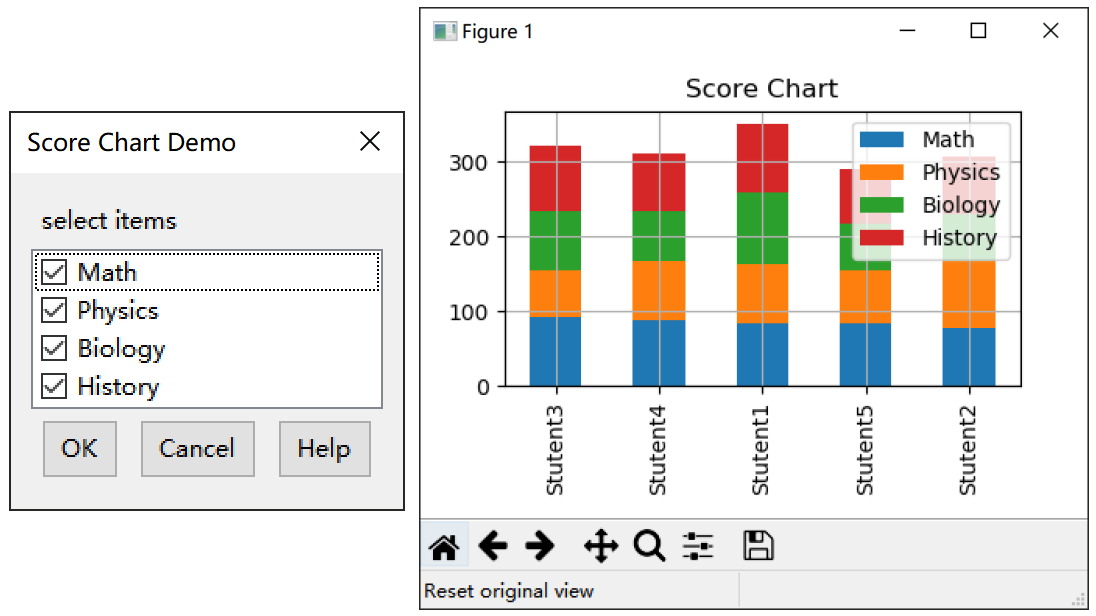
class Bar(Table):
title = 'Score Chart Demo'
asyn = False
para = {'item':[]}
view = [('fields', 'item', 'select items')]
def run(self, tps, data, snap, para = None):
data[para['item']].plot.bar(stacked=True, grid=True, title='Score Chart')
plt.show()这里又遇到了一种参数类型,fields,这种参数类型其实是一个多选类型,但是不需要我们提供选项,会自动从当前表格的columns中获取。当表格从界面上被选中若干列,参数对话框里对应的项也会被默认勾上。我们用pandas自带的绘图函数,但值得一提的是,插件中加入了asyn = False,这个标识告诉ImagePy不要启用异步执行run,因为这个插件涉及了UI,必须在主线程进行。
note:
note选项是行为控制标识,用于控制插件执行的流程,比如让框架进行类型兼容检测,如不满足自动中止,与Filter和simple的note有所区别。
req_sel:需要选区req_row:需要选中行req_col:需要选中列auto_snap:处理前框架自动对数据进行缓冲row_msk:snap时只缓冲选中的行col_msk:snap时只缓冲选中的列num_only:snap时只缓冲数值列preview:是否显示预览选项
para, view:
参数字典,具体用法参阅start入门。
run:
tps:表格封装类,我们可以通过tps对rowmsk,colmsk等进行访问或操作snap:表格缓冲,如果有auto_snap标识,则可以生效。data:当前表格,对其进行操作。
load:
def load(self, tps) 最先执行,如果return结果为False,插件将中止执行。默认返回True,如有必要,可以对其进行重载,进行一系列条件检验,如不满足,IPy.alert弹出提示,并返回False。
preview:
def preview(self, tps, para) ,默认情况下会自动执行run并更新,有需要可以重载。