Demo: Youtube
Try at: Streamlit
- This is a Streamlit based tool to train and develop a Few Shot Classification ML model very rapidly.
- It uses Prototypical Networks with Resnet18 as the backbone network.
- During training, model parameters are also saved on disk.
- PyTorch - An open source machine learning framework that accelerates the path from research prototyping to production deployment.
- Resnet18 CNN
- Loading datasets
- Image transformations
- Omniglot Data set - for Demo - It is designed for developing more human-like learning algorithms. It contains 1623 different handwritten characters from 50 different alphabets. Each of the 1623 characters was drawn online via Amazon's Mechanical Turk by 20 different people.
- Streamlit - for GUI - Streamlit is an open-source app framework for Machine Learning and Data Science teams.
- Matplotlib - for plotting loss function - Matplotlib is a comprehensive library for creating static, animated, and interactive visualizations in Python. Matplotlib makes easy things easy and hard things possible.
-
Download this GitHub repository
- Either Clone the repository
git clone https://github.com/Kunal-Attri/Few-Shot-Classification-GUI-based-Training.git - Or download and extract the zip archive of the repository.
- Either Clone the repository
-
Download & Install requirements
- Ensure that you have Python 3 installed.
- Open terminal in the Repository folder on your local machine.
- Run the following command to install requirements.
pip3 install -r requirements.txt
-
Run the Program
streamlit run train.pyExpected Interface:

-
Preparing the Data set
- To try: Download omniglot_dataset: It has the full Omniglot Data set which has characters of 30 different languages.
- Create a folder, then sub-folders(which will essentially represent different classes), and then put images for those classes in those sub-folders.
- It's a good idea to keep no. of images for N classes to be almost equal if not exactly equal. They must be quality images as per ML standards.
- Then, zip the main folder!
-
Training model on the data set
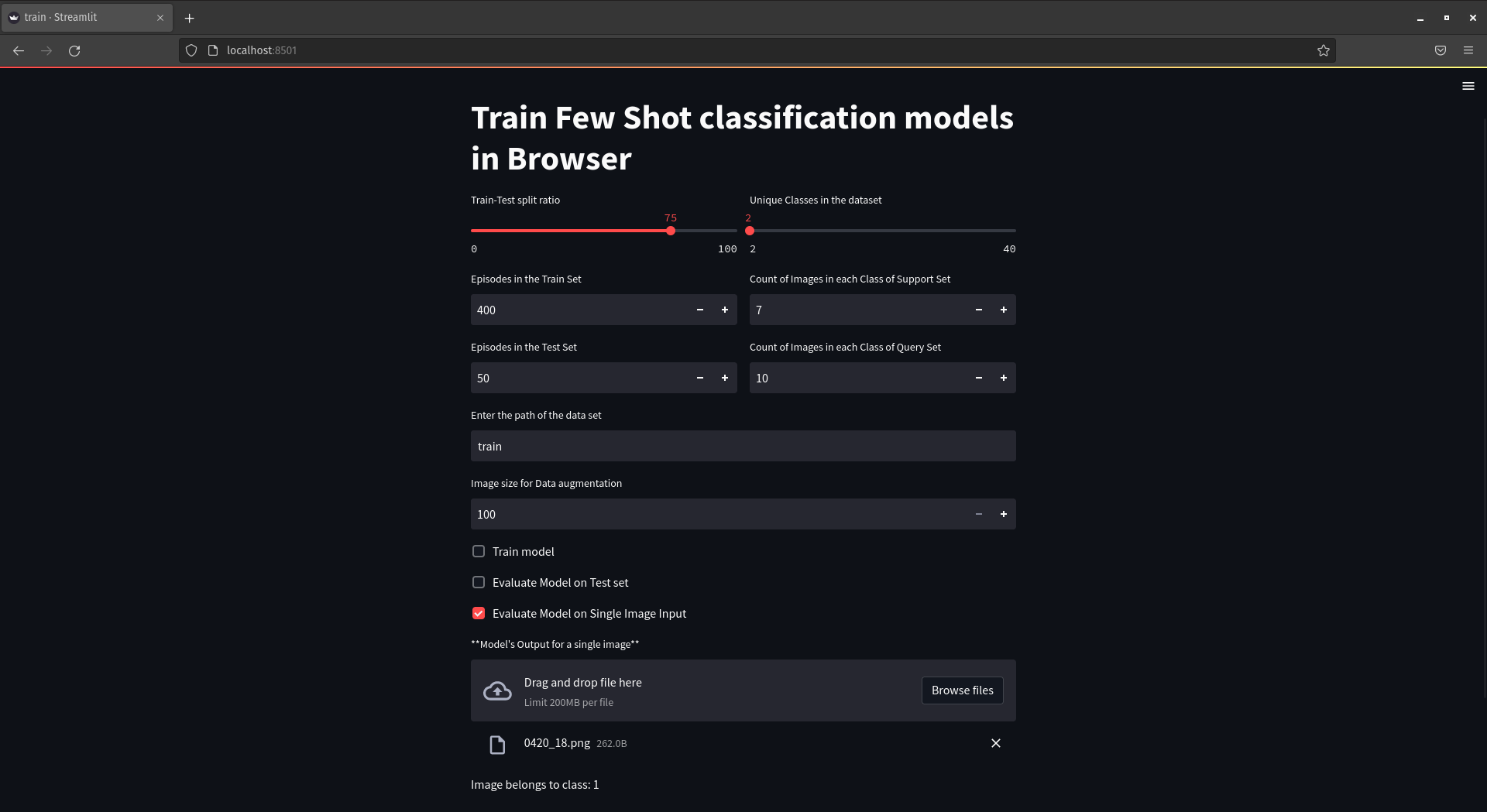
- Set parameters. Unless, you have your own data set, you can try demo values.
- Train-test split ratio: That is the ratio in which you want to divide your data set for training and testing phases. Generally 60 to 90 percent is a good ratio. For demo: 75 %
- Unique Classes in Data set: No of different classes in the data. For demo: 2 classes
- Episodes in Train set: It's like the Epoch in ML. More complex the data set, higher episodes will benefit. Generally, 200-600 is a good number for training. For demo: 400
- Episodes in Test set: Generally, 20-200 is a good number for testing. For demo: 50
- Images in each class of Support Set: These are the no. of images that will be supplied in each support set during training phase. Generally, 3-10 is a good choice. For demo: 7
- Images in each class of Query Set: No. of images that will be supplied in each set during testing phase. Generally 5-20 is good value. For demo: 10
- Data set Path: It refers to the location at which data set is located. It can be either relative or absolute path. For demo: train
- Image size for Data augmentation: That refers to the transformed size of images for training and testing. Low data -> Low res, else higher res. For demo: 100
- Demo Parameters:

- Then check the Train Model checkbox. It will now train the model. Should take 3-7 minutes. Model is saved every 25 % of model training progress, and we also get the Training Loss plot vs Episodes.
- Trained Model:

- NOTE: While setting parameters Don't set too high values or too low values, as it can cause Overfitting or Underfitting respectively.
- Set parameters. Unless, you have your own data set, you can try demo values.
-
Testing Model on Test Set
- Uncheck the Train Model checkbox.
- And, check the Evaluate Model on Test Set checkbox. This will now test the model on Test set from the data set.
- After evaluation, it will give the Accuracy on test set as the output. Here, our model has 97.6% accuracy!!!
- Evaluation on Test set:

-
Testing Model on Custom Image Input
- Uncheck all checkboxes.
- Check the Evaluate Model on Single Image Input checkbox. This will enable a image upload bar.
- You can now drag-n-drop a image or upload one, to get predicted output from the model.
- Evaluation on Image: