{kind=link}
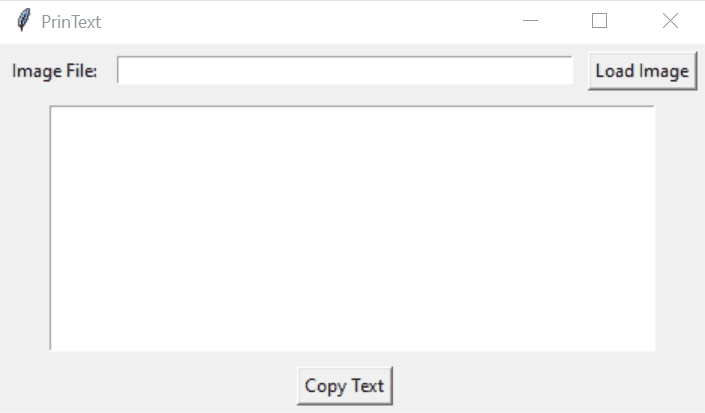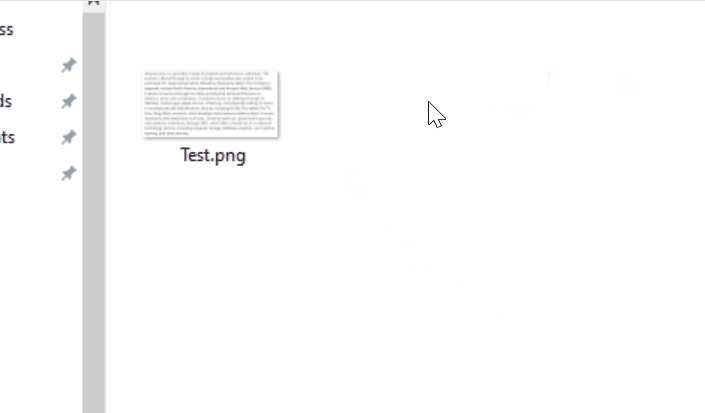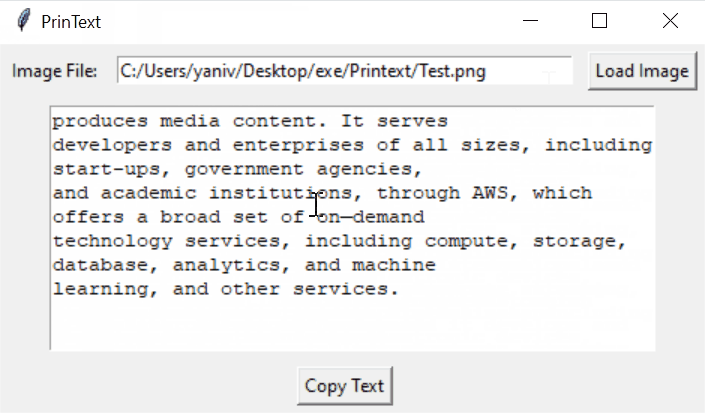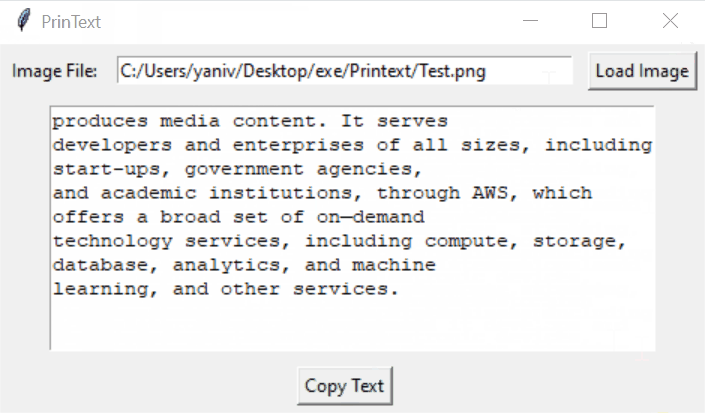
Printext is a lightweight, user-friendly desktop application that extracts text from images using Optical Character Recognition (OCR) technology. Built with Python, it provides a simple graphical interface for users to load images, extract text, and easily copy the results to their clipboard.
- Load images through a file dialog
- Extract text from various image formats (JPEG, PNG, BMP)
- Display extracted text in a text area
- Copy extracted text to clipboard with one click
- Simple and intuitive graphical user interface
- Python 3.x
- tkinter
- Pillow (PIL)
- pytesseract
- pyperclip
-
Ensure you have Python 3.x installed on your system.
-
Install the required libraries:
pip install pillow pytesseract pyperclip -
Install Tesseract-OCR on your system:
- For Windows: Download and install from GitHub
- For macOS: Use Homebrew:
brew install tesseract - For Linux: Use your distribution's package manager, e.g.,
sudo apt-get install tesseract-ocr
-
Download the
printext.pyfile.
-
Run the script:
python printext.py -
Click "Load Image" to select an image file.
-
The extracted text will appear in the text area.
-
Click "Copy Text" to copy the extracted text to your clipboard.
PrinText uses the following libraries:
tkinterfor the graphical user interfacePIL(Python Imaging Library) for image processingpytesseractfor OCR (Optical Character Recognition)pyperclipfor clipboard operations
The application loads an image, processes it using Tesseract-OCR, and displays the extracted text. Users can then easily copy the text for use in other applications.
Contributions, issues, and feature requests are welcome! Feel free to check the issues page.
- This project uses Tesseract-OCR for text extraction.