



It is a project of MUST course LP104-Oriented Object Programming, whose purpose is to develop an auxiliary tool to solve crossword puzzles. This tool can read the text, record the words and their frequency, search for matches when you give specific conditions, and sort them according to the frequency.
- Development Environment
- Install
- Usage
- Highlights
- Data Structure
- Algorithms
- Releases
- Maintainers
- Contributing
- License
| System | Windows 10 x64 |
| Language | C++ |
| IDE | Qt Creator 4.8.0 Enterprise (GUI) / Visual Studio 2017 Community (CLI) |
-
Install the Qt.
-
Clone the repos:
git clone https://github.com/MUST-SCSE-SE-2018/Crossword-Helper.git
-
GUI
- Download the latest GUI version.
- Run TextSearch_GUI.exe.
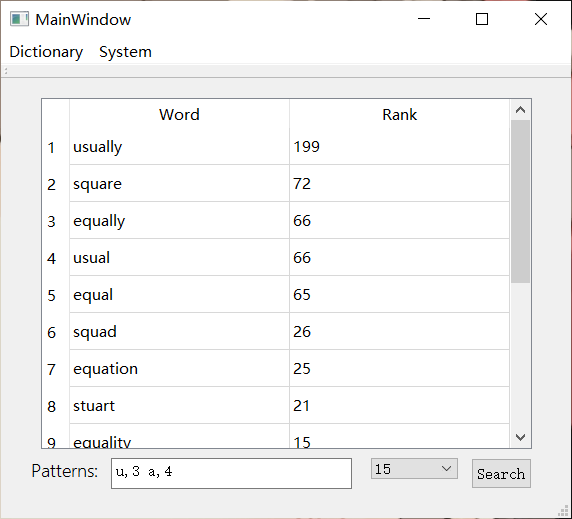
- Import .txt or .csv file to generate a new dictionary. All file directories must be in English!
- After that, it will generate a newDict.csv file. For the next time, users can use this dictionary by importing directly.
- It can also be browsed by the Open CSV Dict function.
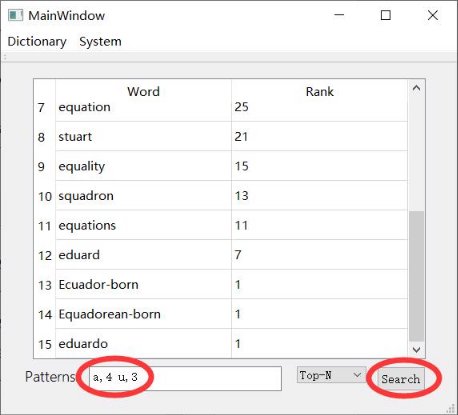
- Please enter a query string in a fixed format for search. Patterns are separated by space, for each pattern, please use a character and an integer number to represent which character is in which position, and use a comma to split it. For example, if you want to find words like "XXuaXXX" ( "u" is the 3rd character, "a" is the 4th character, and "X" means unknown character ), you need to write "u,3 a,4" ( regardless of order between 2 patterns ) in the text field, and click the search button.
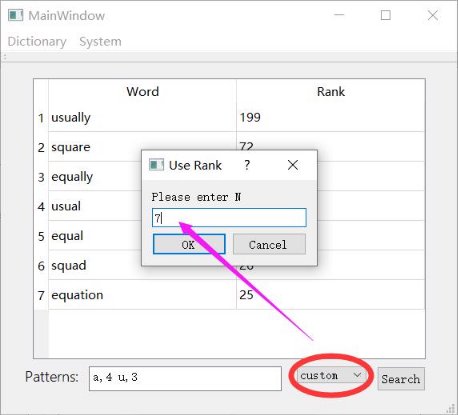
- For the Top-N rank search, users can select to display the Top N results of all the searched words, and Custom means users can determine any number N by themselves.
- Click Exit to end up the program.
- The display window will be cleared if the query operation is incorrect. But do not worry, the content is still alive if importing the data file and not quitting the program. Please enter the query operation again and it will manifest.
-
CLI
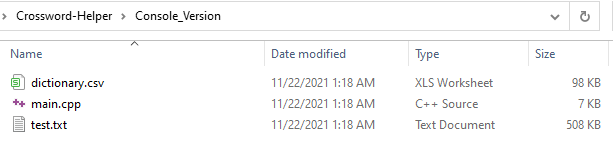
- Please put the test file ( test.txt and dictionary.csv ) into the folder Console_Version.
- Open source code via IDE ( Recommend Visual Studio 2017 ).
- Run it and enter the text file with the .txt suffix.
- Enter CSV dictionary with .csv suffix, and please add two files ( 1 .txt and 1 .csv ) to continue.
- Please input again if the directory is incorrect.
- Please search words in fixed patterns. Use particular characters, position numbers, and a comma between them, and do not use space. If wanting to input more than one pattern, users can type Y/y to continue.
- The result will be ordered by rank.








-
GUI
- Friendly to users (without using commands). All the functions are implemented by the mouse and keyboard event.
- Most normal dictionaries are in ASCII order. Compared to the console version, this version has implemented this feature at a very low time cost.
- Implement an open file function to let users browse the dictionary. When importing, a real-time newDict will be displayed when importing a new dictionary to combine with the old one.
- Users can choose to display results with N-top rank or without N-top rank, or in custom. However, if the total number is less than N, it will display all the results. If there are no results, the program will prompt with a message dialogue.
- A message dialogue will show up to help you while you are doing an incorrect operation.
-
CLI
- Based on the OOP concept, I design a class and encapsulate the correlated method into it. To solve the sustainable problem, I prefer to use the "kit class" concept. The class is regarded as a kit, the operation to object could be executed by calling class methods, which does not define function parameters and the main function will look briefly, too.
- The total complexity is N x O(1) [read file] + N x O(1) [insert key] + N x O(1) [write dictionary] + O(N) [search] + O(0.01N^2) [sort] ~= O(0.01N^2). Although, I do not use a fast sort algorithm such as Merge Sort, Heap Sort, Quick Sort, etc, as well as the Binary Search Tree algorithm, the high efficiency will be revealed most by the "First Search Last Sort" algorithm. Compared to this, I think using faster sort or search algorithms only manifests a few advantages.
- We retain all the words with hyphen (-) and we also parse most abbreviations to words. For example, "'re" will be regarded as "are", and "'s" will be read as "is".
- A timer will show the records after each process ends up.
- Implement a try-catch method in the main function, and the program will continue to run even if entering a wrong file directory, and then the while loop will ask users to enter again.
-
GUI
-
UI
Variable / Function Name Modifier Element Type Function Return Type Function Parameter Description MainWindow() public / / Qwidget *parent Constructor ~MainWindow() public / / / Destructor displayCSVFile() private / void void Slot: display the content of newDict.csv openFile() private / void string suff Slot: open file with corresponding suffix ( If the suff is CSV, then open .csv file ) on_actionOpen_triggered() private / void void Slot: Execute openFile("csv") on_actionExit_triggered() private / void void Slot: End up the program on_actionImport_TXT_file_triggered() private / void void Slot: read .txt file into the new dictionary and display the newDict on_actionImport_CSV_File_triggered() private / void void Slot: read .csv file into the new dictionary and display the newDict displayDict() private / void unsigned int topN Slot: display the final result of searched words On_pushButton_clicked() private / void void Slot: confirm to search ui private Ui:MainWindow* / / UI pointer, can be used to point to any components of the UI -
Original Class
Variable / Function Name Modifier Element Type Function Return Type Function Parameter Description / private struct Word / / / display private vector<Word> / / / c_dict private map<string,int> / / Use map data structure: dictionary will be ordered by alphabet of key splitStr() public / string* string str, string token / splitQuery() public / vector<string> string str, string token Used for separating multi-word string like query string line modifyStr() public / void string &str Dealing with problems of unsigned integer: replace -1 with UINT_MAX fill_completions() public / void string fd / importCSV() public / void string fd / findWord() public / map<string,int> string str According to query string ( more than one patterns ) to search correct words rankSort() public / int map<string,int> hash / fileWrite() public / void void / main() / / int void Execute program and show the main window
-
-
CLI
Variable / Function Name Modifier Element Type Function Return Type Function Parameter Description / private struct Word / / Defined struct with 2 members: string word & int rk display private vector<Word> / / Used for displaying both words and its rank c_dict private hash_map<string,int> / / Dictionary, used to store word data askForFile() public / string void Read the file directory users have entered splitStr() public / string* string str, string token Split a string to a string array by token modifyStr() public / void string &str Modify string words by trimming redundant prefix & suffix and transform abbreviation to full word. Change Upper case character to lower case character fill_completions() public / void string fd Read text file through given file directory, then modify them and store in the dictionary importCSV() public / void string fd Read CSV dictionary through given file directory, then modify them and store in the dictionary findWord() public / hash_map<string,int> void According to inputted pattern to search correct words from dictionary and return these words rankSort() public / int hash_map<string,int> hash Rearrange those words searched by findWord() in rank order, then push them into vector display and output them fileWrite() public / void void Generate new dictionary based on c_dict main() / / int void Test function
-
GUI
Similar to Console Version, replace hash_map with map<string,int> because map uses Red-Black Tree to sort keys in ASCII order automatically. The complexity of N-word insertion is O(NlogN), still less than sort O(0.01N^2). The overall complexity is N x O(1) [read file] + O(NlogN) [insert key] + N x O(1) [write dictionary] + O(N) [search] + O(0.01N^2) [sort] ~= O(0.01N^2).
-
CLI
-
Storage Use hash_map<string,int> c_dict as a dictionary, this data structure could record key-value pair without duplicating. It is based on hash value and linked list, which means the insertion procedure is very fast. When a new word comes in, we compute the hash value of the key, and then link the key-value pair to the corresponding node, so the complexity is O(1).
-
Word Search We let users input fixed patterns including characters and their exact position. Like "u,3", which means we expect the word whose 3rd character is "u". Sequential Search is used here, which has O(N) complexity average (O(1) for the best case, O(N) for the worst case).
-
Rank Sort Complexity (First Search Last Sort) We know that Selection Sort & Insertion Sort has a complexity of O(N^2), while Merge Sort & Heap Sort has a complexity of O(NlogN), and the complexity of Quick Sort is O(NlnN). All in all, time consumption is correlated to sort complexity, also based on the size of N. The smaller N is, the faster the program will be. If we search words first, it will be faster because we know the accurate position of some characters and exclude most cases of words.
-
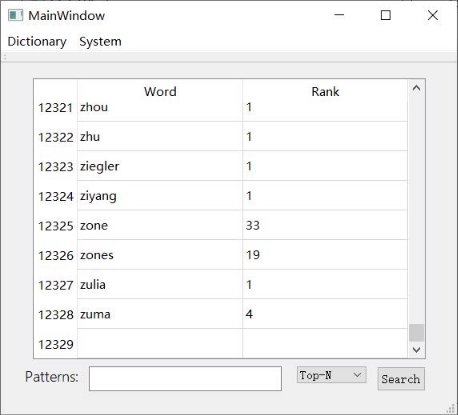
Experiment We know that "E" has the highest appearance rate (12.25%) in English words, so we assume we know the exact position of "E" and count how many words (repetition is allowed).
Position of E 1 2 3 4 5 6 7 8 9 Total words 12328 550 (4.46%) 1925 (15.6%) 875 (7.1%) 1542 (12.5%) 1714 (13.9%) 1134 (9.2%) 1027 (8.3%) 756 (6.13%) 527 (4.27%) The result demonstrates clearly that the percentage of matching words has decreased to 10% around. We can compute the overall complexity is O(N) [search] + O(0.01N^2) [use selection sort]. However, if we use the original algorithm, the complexity will be O(N^2) [sort] + O(N) [search]. When N ~= 10000, our new algorithm is nearly 99 times faster than the old one.
-
Feel free to open an issue or submit PRs.
