This project aims to create a data pipeline for WIKIHOW website. The most important parts of this pipeline are as follows:
1- Crawler
2- ETL
3- Data Analysis
4- REST API
In this project, I employ the following technologies to design my pipeline:
1- Apache Airflow: to crawl data, do ETL on raw data and extract funny information
2- Postgresql: to save information.
3- Flask API: to send a request to server to ger information
In this project, just trend articles will be crawled from the main page of this website.
To extract raw data day to day you just need to turn the wikihow_trend_crawler dag on!
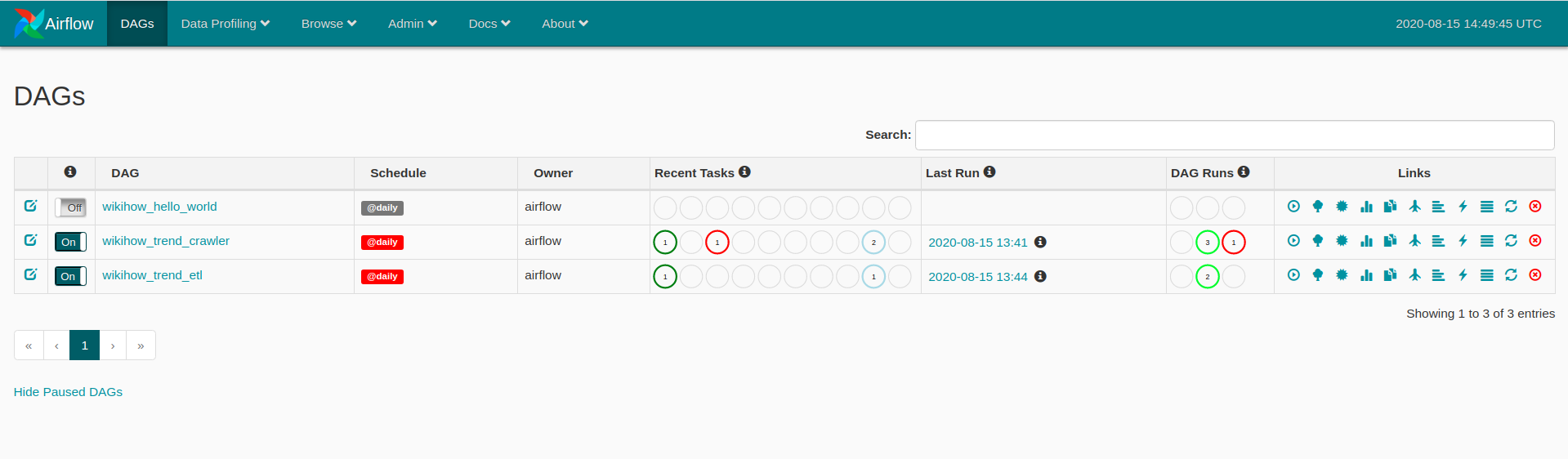
In order to prepare a structured dataset for data scientists, we turn wikihow_trend_etls dag on which convert all html files in a specific day to CSV file. Each processed CSV file contains the following columns:
- title
- last update date
- date of publishing
- date of crawling
- number of views
- number of votes
- mean votes
- main description
- steps (json)
under development
under development
You just need to run the following command to make everything done. note that you should install docker before.
`docker-compose up --build`