
NoSQL (от англ. Not Only SQL — не только SQL) — термин, обозначающий ряд подходов, направленных на реализацию
систем
управления базами данных, имеющих существенные отличия от моделей, используемых в традиционных реляционных СУБД с
доступом к данным средствами языка SQL. Применяется к базам данных, в которых делается попытка решить проблемы
масштабируемости и доступности за счёт атомарности (англ. atomicity) и согласованности данных (англ. consistency).
Все NoSQL решения принято делить на 4 типа (их больше, но эти 4 являются основными):
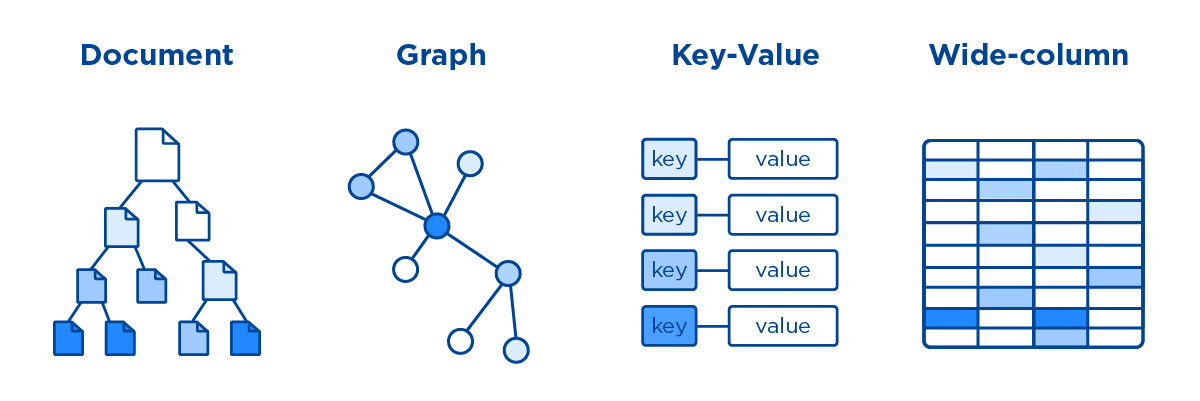
Базы данных типа "ключ-значение" (Key-Value stores) представляют собой простейшую форму хранения данных. Они работают по принципу ассоциативного массива или словаря, где каждому ключу соответствует определенное значение.
-
Ключ (Key): Уникальный идентификатор, по которому можно получить доступ к значению. Ключи могут быть строками, числами или другими простыми типами данных.
-
Значение (Value): Данные, связанные с ключом. Значение может быть простым (например, строка или число) или сложным объектом (например, JSON, XML).
В отличие от реляционных баз данных, где данные организованы в таблицы, в базе данных типа "ключ-значение" данные организованы в виде пары "ключ-значение". Такой подход позволяет быстро получать данные по ключу без необходимости проведения сложных запросов.
-
Высокая производительность: Базы данных типа "ключ-значение" оптимизированы для быстрых операций чтения и записи. Это делает их идеальными для приложений, требующих низкой задержки.
-
Масштабируемость: Эти базы данных легко масштабируются горизонтально (добавлением новых серверов). Они могут обрабатывать большие объемы данных, распределенные по множеству узлов.
-
Гибкость: Нет жесткой схемы данных, что позволяет легко изменять структуру хранимых данных.
-
Ограниченные возможности запросов: В отличие от реляционных баз данных, в базах данных типа "ключ-значение" нет возможности выполнять сложные запросы, такие как объединения или фильтрация данных.
-
Отсутствие транзакционности: В большинстве таких баз данных отсутствует поддержка транзакций, что может быть критично для некоторых приложений.
-
Проблемы с консистентностью: В распределенных системах возможно нарушение консистентности данных, особенно в сценариях, где нужно выбрать между консистентностью и доступностью (CAP-теорема).
-
Redis
- Redis — это популярная база данных типа "ключ-значение" с открытым исходным кодом. Она часто используется как кэш, брокер сообщений или даже в качестве базы данных для хранения временных данных.
- Особенности: поддержка множества структур данных (списки, множества, хеши), встроенная репликация, скриптинг на Lua, поддержка Pub/Sub.
- Применение: кэширование данных, управление сессиями пользователей, очереди задач, обработка временных данных.
-
Memcached
- Memcached — это еще одна популярная система кэширования типа "ключ-значение". Она используется для ускорения динамических веб-приложений за счет снижения нагрузки на базу данных.
- Особенности: чрезвычайно быстрая и легкая система, поддерживает кэширование в памяти.
- Применение: кэширование результатов запросов к базе данных, кэширование объектов веб-приложений, временное хранение данных.
-
DynamoDB (AWS)
- DynamoDB — это облачная база данных типа "ключ-значение", предоставляемая Amazon Web Services (AWS). DynamoDB обеспечивает автоматическое масштабирование и высокую производительность.
- Особенности: полное управление Amazon, поддержка серверов без состояния, возможность настроек доступа, встроенная поддержка бэкапов и репликации.
- Применение: управление пользовательскими профилями, обработка заказов в реальном времени, анализ логов, поддержка игровых приложений.
-
Кэширование данных: Веб-приложения могут использовать базы данных типа "ключ-значение" для кэширования часто запрашиваемых данных. Это снижает нагрузку на основную базу данных и ускоряет ответы пользователю.
-
Управление сессиями: Веб-приложения часто используют такие базы данных для хранения информации о сессиях пользователей, что позволяет сохранять состояние между запросами.
-
Временные данные: Временные данные, такие как результаты вычислений, временные файлы или, например, содержание корзины в интернет магазине
Redis - практически универсальная вещь, которая требуется практически на каждом проекте. Часто редис добавляют еще до того, как в нем появляется необходимость, опытные разработчики знают, что редис может понадобиться, практически когда угодно. Плюс приятный бонус, что редис умеет в управление очередями, что мы будем использовать дальше по курсу.
Memcached - очень часто используется для хранения кеша. Что это дальше по лекции.
Документные базы данных (Document-oriented databases) предназначены для хранения, извлечения и управления данными в форме документов. Документы обычно хранятся в формате JSON, BSON (бинарный JSON), XML или других подобных форматах, что позволяет сохранять сложные данные с вложенной структурой.

-
Документ: Основной единицей данных в такой базе является документ, представляющий собой структурированный объект, например, в формате JSON. Документ содержит поля и значения, которые могут включать вложенные объекты и массивы.
-
Коллекции: Документы группируются в коллекции, которые аналогичны таблицам в реляционных базах данных. Однако в отличие от таблиц, документы в коллекции могут иметь разные структуры (например, различные поля и типы данных).
-
Гибкость схемы: Документные базы данных не требуют предварительного определения схемы. Это позволяет разработчикам изменять структуру данных без необходимости миграции базы.
-
Естественное отображение данных: Структура документа может точно соответствовать объектам в коде, что делает работу с данными более интуитивной для разработчиков.
-
Удобство работы с данными: Возможность хранения сложных структур данных, включая вложенные объекты и массивы, делает документные базы данных идеальными для многих современных приложений.
-
Поддержка сложных запросов: Документные базы данных, как правило, поддерживают мощные механизмы запросов, которые позволяют фильтровать, сортировать и агрегировать данные.
-
Повышенные требования к памяти: Хранение данных в виде документов может требовать больше памяти по сравнению с реляционными базами данных, особенно при наличии дублирования данных.
-
Ограниченная поддержка транзакций: Хотя многие современные документные базы данных поддерживают транзакции, их возможности часто ограничены по сравнению с реляционными системами.
-
Проблемы с согласованностью данных: Как и в случае с другими NoSQL базами данных, возможно нарушение согласованности данных в распределенных системах.
-
MongoDB
- MongoDB — одна из самых популярных документных баз данных с открытым исходным кодом. Она широко используется благодаря своей гибкости и поддержке мощных запросов.
- Особенности: хранение данных в формате BSON, поддержка индексации, агрегация данных, репликация и шардинг для масштабирования.
- Применение: хранение пользовательских данных, ведение логов, управление контентом, e-commerce.
-
CouchDB
- CouchDB — это документная база данных, которая использует HTTP/JSON для хранения данных. Она фокусируется на обеспечении высокой доступности и автономности.
- Особенности: поддержка формата JSON, встроенные RESTful API, возможность работы в автономном режиме с последующей синхронизацией данных.
- Применение: распределенные системы, мобильные приложения, приложения с офлайн-доступом.
-
RavenDB
- RavenDB — это документная база данных, разработанная для работы с большим объемом данных и обеспечивающая высокую производительность.
- Особенности: встроенная поддержка полного текста поиска, ACID-транзакции на уровне документа, гибкие механизмы индексации.
- Применение: системы управления контентом, финансовые приложения, аналитика данных.
-
Управление контентом: Документные базы данных идеально подходят для систем управления контентом, где различные типы контента могут иметь разные структуры. Например, статьи блога, комментарии, и медиафайлы могут быть представлены разными структурами документов.
-
Хранение данных пользователей: В веб-приложениях информация о пользователях, профилях, настройках и активности может храниться в виде документов. Это упрощает процесс добавления новых полей или изменения структуры данных без необходимости миграции.
-
Системы рекомендаций: В системах, где требуется хранение и анализ большого количества разнообразных данных, например, предпочтений пользователей, документные базы данных могут обеспечить эффективное управление этими данными.
Колонночные базы данных (Column-family stores) — это системы управления базами данных, в которых данные организованы по столбцам, а не по строкам, как в реляционных базах данных. Каждый столбец хранится отдельно, что позволяет эффективно обрабатывать и запрашивать большие объемы данных, особенно в случае агрегации данных по столбцам.
-
Семейства столбцов (Column Families): Основной единицей хранения в колонночных базах данных является "семейство столбцов", которое аналогично таблице в реляционной базе данных. Каждое семейство столбцов содержит набор столбцов, объединенных по определенному признаку.
-
Ключи строк (Row Keys): Данные внутри семейства столбцов организованы по строкам, каждая из которых идентифицируется уникальным ключом строки. Однако, в отличие от реляционных баз данных, все значения одного столбца хранятся вместе, что позволяет быстрее выполнять операции чтения и записи.
-
Гибкость в структуре: Разные строки в одном семействе столбцов могут содержать разные наборы столбцов. Это означает, что колонночные базы данных не требуют жесткой схемы и позволяют хранить данные с разной структурой.
-
Высокая производительность при аналитических запросах: Колонночные базы данных особенно эффективны для аналитических запросов, которые требуют агрегации данных по столбцам, так как данные одного столбца хранятся вместе и могут быть быстро извлечены.
-
Масштабируемость: Колонночные базы данных легко масштабируются горизонтально, что делает их идеальными для работы с большими объемами данных в распределенных системах.
-
Гибкость схемы: Возможность хранения различных наборов столбцов для разных строк делает такие базы данных гибкими в плане структуры данных.
-
Оптимизация по дисковому пространству: Данные одного столбца могут быть сжаты, что позволяет экономить дисковое пространство и ускорять операции чтения.
-
Сложность управления: Колонночные базы данных могут быть сложнее в управлении и настройке по сравнению с реляционными базами данных.
-
Ограниченная поддержка транзакций: В отличие от реляционных баз данных, транзакции в колонночных базах данных, как правило, ограничены в своих возможностях.
-
Меньшая гибкость для операций записи: В некоторых случаях, особенно при частых изменениях данных, производительность колонночных баз данных может снижаться.
-
Apache Cassandra
- Apache Cassandra — это распределенная колонночная база данных с открытым исходным кодом, которая обеспечивает высокую доступность и отказоустойчивость.
- Особенности: поддержка масштабирования на уровне центра обработки данных, консистентность по принципу "в конечном итоге", отказоустойчивость, высокая скорость записи и чтения.
- Применение: управление журналами событий, аналитика данных в реальном времени, хранение временных рядов данных.
-
Apache HBase
- Apache HBase — это распределенная база данных, основанная на Hadoop и Bigtable от Google. Она предназначена для обработки больших объемов данных в режиме реального времени.
- Особенности: интеграция с Hadoop, поддержка больших таблиц (миллионы строк и столбцов), быстрая обработка данных, поддержка ACID-транзакций на уровне строки.
- Применение: аналитика больших данных, системы управления пользователями, работа с временными рядами.
-
Google Bigtable
- Google Bigtable — это управляемая колонночная база данных от Google, которая используется для обработки больших объемов структурированных данных.
- Особенности: полностью управляемая облачная база данных, поддержка горизонтального масштабирования, интеграция с экосистемой Google Cloud.
- Применение: хранение и анализ веб-индексов, обработка временных рядов, работа с IoT-данными.
-
Анализ больших данных: Колонночные базы данных идеально подходят для аналитических задач, где требуется обработка больших объемов данных и выполнение сложных запросов, таких как агрегации и вычисления по столбцам.
-
Обработка временных рядов: В задачах, связанных с временными рядами (например, мониторинг, IoT), колонночные базы данных позволяют эффективно хранить и анализировать данные благодаря возможности оптимизации хранения по столбцам.
-
Хранение данных для приложений с высокой нагрузкой: Колонночные базы данных часто используются в приложениях с высокой нагрузкой, таких как социальные сети, аналитические платформы и системы управления пользователями, где требуется быстрая обработка и хранение больших объемов данных.
Графовые базы данных (Graph databases) — это системы управления базами данных, которые используют структуру графа для хранения и представления данных. Граф состоит из вершин (узлов) и ребер (связей), что делает графовые базы данных особенно эффективными для моделирования и анализа взаимосвязей между объектами.
-
Узел (Node): Узел представляет объект или сущность. Например, это может быть человек, место, продукт или другой объект. Каждый узел может иметь определенные атрибуты, которые описывают его свойства.
-
Ребро (Edge): Ребро связывает два узла и представляет отношение между ними. Например, "друг", "работает в", " покупает" и т.д. Ребра могут быть направленными (обозначая направление отношения) или недиректными.
-
Свойства (Properties): Как узлы, так и ребра могут иметь свойства, которые предоставляют дополнительную информацию. Например, узел "Человек" может иметь свойства "имя" и "возраст", а ребро "Друг" может иметь свойство "дата начала дружбы".
-
Метки (Labels): Узлы и ребра могут быть помечены для обозначения их типа. Это упрощает фильтрацию и поиск нужных данных.
-
Эффективное управление сложными связями: Графовые базы данных оптимизированы для работы с сильно взаимосвязанными данными. Это делает их идеальными для задач, где важно быстро и эффективно анализировать связи между объектами.
-
Гибкость и динамичность: В отличие от реляционных баз данных, графовые базы данных позволяют легко добавлять новые типы узлов и ребер без необходимости изменения схемы данных.
-
Высокая производительность при запросах на связи: Операции поиска и анализа связей между узлами выполняются значительно быстрее по сравнению с реляционными базами данных, особенно когда речь идет о многократных переходах между узлами.
-
Интуитивное моделирование данных: Графовые базы данных позволяют моделировать данные в виде графа, что часто более естественно и интуитивно по сравнению с таблицами и строками реляционных баз данных.
-
Сложность масштабирования: Масштабирование графовых баз данных может быть сложнее по сравнению с другими типами NoSQL баз данных, особенно если граф становится очень большим и сильно взаимосвязанным.
-
Относительная новизна: Графовые базы данных менее распространены и зрелы по сравнению с реляционными базами данных, что может привести к ограниченному выбору инструментов и меньшему количеству специалистов.
-
Специфичность применения: Графовые базы данных не всегда подходят для задач, не связанных с анализом связей или сетевыми структурами.
-
Neo4j
- Neo4j — одна из самых популярных графовых баз данных с открытым исходным кодом. Она широко используется для моделирования сложных сетей и анализа данных.
- Особенности: поддержка языка запросов Cypher, ACID-транзакции, встроенные инструменты для визуализации графов.
- Применение: социальные сети, системы рекомендаций, управление знаниями, сетевые графы.
-
Amazon Neptune
- Amazon Neptune — это управляемая графовая база данных от AWS, поддерживающая несколько моделей графов, включая Property Graph и RDF (Resource Description Framework).
- Особенности: высокая доступность, автоматическое масштабирование, поддержка нескольких API, включая Gremlin и SPARQL.
- Применение: рекомендации продуктов, управление знаниями, построение графов данных для интернета вещей (IoT).
-
OrientDB
- OrientDB — это многомодельная база данных, которая поддерживает графы, документы, ключ-значение и объектные модели данных.
- Особенности: встроенная поддержка графов и документов, высокая производительность, поддержка распределенных архитектур.
- Применение: управление пользовательскими профилями, аналитика данных, управление логистикой и цепочками поставок.
-
Социальные сети: В социальных сетях пользователи связаны друг с другом различными типами отношений (дружба, подписка и т.д.). Графовые базы данных позволяют легко моделировать и анализировать эти связи, а также предлагать рекомендации на основе общих друзей или интересов.
-
Системы рекомендаций: Графовые базы данных используются для создания систем рекомендаций, где важно учитывать связи между пользователями, продуктами и интересами. Например, можно рекомендовать книги или фильмы на основе предпочтений пользователей с похожими интересами.
-
Управление знаниями: В организациях графовые базы данных могут использоваться для построения графов знаний, где объекты связаны с определенными концепциями, документами или другими объектами. Это упрощает поиск информации и установление взаимосвязей между различными знаниями.
-
Фрод-менеджмент (управление мошенничеством): В банковской сфере и страховании графовые базы данных помогают выявлять сложные мошеннические схемы, анализируя связи между транзакциями, счетами и пользователями.
У SQL и NoSQL баз данных свои преимущества и недостатки, и необходимо понимать, когда и что использовать.
Понятие "сессий" основано на том, что состояние пользователя каким-то образом сохраняется, когда он переходит с одной страницы на другую. Вспомните, что HTTP не сохраняет состояний, поэтому только браузер или ваше приложение может "запомнить" то, что нужно запомнить.

Куки — это пары данных по типу "ключ-значение", которые сохраняются в браузере пользователя до истечения какого-то определенного срока. Они применимы практически для любой задачи, но чаще всего их используют, чтобы сохранить пользователя в том же месте веб-страницы, если он потеряет интернет-соединение, или, чтобы хранить простые настройки отображения сайта. Например, корзины интернет магазинов чаще всего делают именно через куки, ведь вы не теряете данные, при переходе со страницы на страницу, а хранить данные о том, что вы набираете в корзину, в базе данных, слишком избыточно. Вы можете также хранить в них данные пользователя или даже пароли, но это не очень хорошая идея, не стоит хранить в обычных куках браузера информацию, которая должна быть защищенной или сохраняться между сессиями браузера. Пользователь может легко потерять данные, очистив кэш, или украсть/использовать незащищенные данные из куков.

Куки добавляются в request/response для хранения совершенно разных данных. Например, стандартная Django авторизация добавляет куку с данными о пользователя, чтобы можно было определить, кто именно делает запрос. Поэтому там и нужны CSRF токены в формах или просто токены в REST запросах. Так как перехватить значение куки при запросе очень просто, а мы должны быть уверены, что запрос пришел именно от авторизированного пользователя. Куки хранит информацию, кто это, а токены позволяют проверить, что это был именно этот пользователь.
Задумайтесь о том, каким образом браузеры следят, что пользователь залогинен, когда страница перезагружается. HTTP запросы не имеют состояний, так как же вы определите, что запрос пришел именно от залогиненного пользователя? Вот почему важны куки — они позволяют вам отслеживать пользователя от запроса к запросу, пока не истечет их срок действия.
Особый случай — это когда нужно отслеживать данные пользовательской "сессии", которая включает все, что пользователь делает, пока вы хотите "запоминать" это, обычно до тех пор, пока пользователь не закроет окно браузера. В этом случае каждая страница, которую пользователь посетил до закрытия браузера, будет частью одной сессии.
Если упростить, сессия - это набор запросов от одного и того же пользователя (или от разных в рамках одного процесса).
В случае с Django, при стандартных настройках сессия хранит набор куки, которые хранятся в формате JSON. (А значит, что данные можно сериализовать)
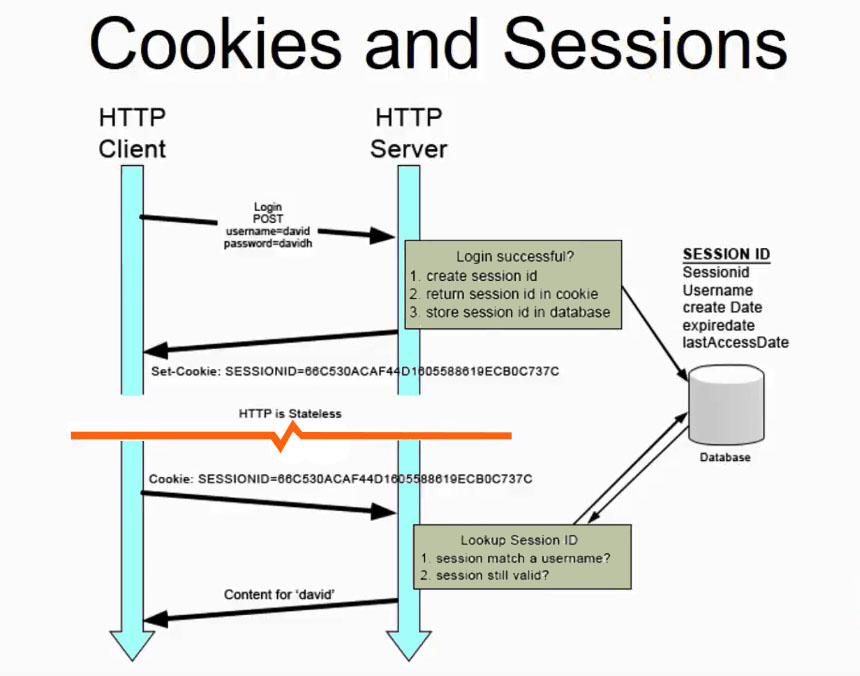
С точки зрения протокола HTTP, сессия является абстракцией. То есть физически её не существует. Если разобрать любой запрос, там вы сможете увидеть только куки, схему использования можно изучить на картинке.
Сессиями можно пользоваться только для залогиненных пользователей, иначе это не имело бы смысла.
При отправке успешного запроса на логин, на уровне бекенда, в нашем случае Django создаёт в базе данных объект сессии, для которого генерируется уникальный идентификатор (id), и уже он добавляется к каждому последующему реквесту и респонсу в качестве куки.
Как именно это значение попадает в каждый реквест, мы рассмотрим на следующем занятии, а пока давайте разберёмся, как мы можем это использовать?
В Django сессия всегда хранится в реквесте, а значит, вы можете использовать сессию как временное хранилище в любом
месте, где у вас есть доступ к реквесту. request.session в виде словаря.
Рассмотрим несколько примеров.
request.session[0] = 'bar'
# subsequent requests following serialization & deserialization
# of session data
request.session[0] # KeyError
request.session['0']
'bar'Данные хранятся в формате JSON, а значит ключи будут преобразованы в строки.
Допустим, вам нужно "запомнить", комментировал ли этот пользователь только что статью, чтобы не позволить написать большое количество комментариев подряд. Конечно, можно сохранить эти данные в базе, но зачем? Проще воспользоваться сессией:
def post_comment(request, new_comment):
if request.session.get('has_commented', False):
return HttpResponse("You've already commented.")
c = comments.Comment(comment=new_comment)
c.save()
request.session['has_commented'] = True
return HttpResponse('Thanks for your comment!')Сохраним это состояние в сессии и будем перепроверять именно его.
Допустим, вам нужно хранить, сколько времени назад пользователь последний раз совершал действие после логина.
request.session['last_action'] = timezone.now()Теперь мы можем проверить, когда было выполнено последнее действие, и добавить любую нужную нам логику.
Если нам нужно воспользоваться сессией вне мест, где есть доступ к реквесту (никогда не пользовался, но мало ли):
from django.contrib.sessions.backends.db import SessionStore
s = SessionStore()
# stored as seconds since epoch since datetimes are not serializable in JSON.
s['last_login'] = 1376587691
s.create()
s.session_key
'2b1189a188b44ad18c35e113ac6ceead'
SessionStore(session_key='2b1189a188b44ad18c35e113ac6ceead')
s['last_login']
1376587691Мы можем получить сессию по ключу (любая созданная Django сессия автоматически хранит переменную session_key), по
которой можно получить нужные нам данные.
Данные в любой сессии хранятся в кодированном виде, чтобы получить все данные сессии, не зная конкретного ключа, их
можно получить через метод .get_decoded()
s.session_data
'KGRwMQpTJ19hdXRoX3VzZXJfaWQnCnAyCkkxCnMuMTExY2ZjODI2Yj...'
s.get_decoded()
{'user_id': 42}Сохранение данных в сессии происходит только тогда, когда меняется значение request.session:
# Session is modified.
request.session['foo'] = 'bar'
# Session is modified.
del request.session['foo']
# Session is modified.
request.session['foo'] = {}
# Gotcha: Session is NOT modified, because this alters
# request.session['foo'] instead of request.session.
request.session['foo']['bar'] = 'baz'В последнем случае данные не будут сохранены, т. к. модифицируется не request.session, а request.session['foo']
Это поведение можно изменить, если добавить настройку в settings.py SESSION_SAVE_EVERY_REQUEST = True, тогда запись
в сессию будет происходить при каждом запросе, а не только в момент изменения.
.
Так как сессии хранятся в базе данных, то теоретически может произойти так, что через какое-то длительное время сессии
будут занимать большой объем в базе. Если нам они не нужны, то необходимо их периодически очищать. Если мы хотим
удалить все данные, то мы можем воспользоваться manage-командой python manage.py clearsessions.
Если же нужно удалить только часть сессии, то можно воспользоваться тем, что сессия - это такая же модель, как и все остальные. Значит, мы можем импортировать её, отфильтровать и удалить необходимые нам данные.
Некоторые настройки можно поменять и перенастроить, как и полностью кастомизировать любые действия с сессиями. Подробнее об этом Тут
По умолчанию сессии пишутся в вашу обычную базу данных, но можно легко перенастроить на то, что бы хранить сессии в Redis, и это довольно часто делается

Официальная документация Тут
Что такое кеш?
Кеш — промежуточный буфер с быстрым доступом к нему, содержащий информацию, которая может быть запрошена с наибольшей вероятностью. Доступ к данным в кэше осуществляется быстрее, чем выборка исходных данных из более медленной памяти или удалённого источника, однако её объём существенно ограничен по сравнению с хранилищем исходных данных.
Если упростить, то это хранилище для часто запрашиваемых данных.

Предположим, мы разрабатываем новостной сайт, и знаем, что новости у нас обновляются раз в час.
В течение часа, пока новости не обновятся, абсолютно каждый заходящий на сайт пользователь будет видеть один и тот же набор статей, а значит, нам необязательно каждый раз доставать этот набор из базы данных, мы можем закешировать его!
Для использования кеша мы можем воспользоваться огромным количеством заранее заготовленных решений для кеша.
Два основных используемых в реальности вида кеша - это Memcached и redis.
Как можно догадаться, всё настраивается через settings.py.
Способ хранения данных в виде хеш-таблицы (словаря) в оперативной памяти.
Требует предварительной установки!
Как и с большинством необходимых сторонних приложений очень легко ставится на Linux и с определёнными сложностями на Windows, изучите это самостоятельно.
Memcached запускается как отдельный сервис или служба, и стандартным портом для доступа к нему является 11211.
Хранение данных с использованием Memcached на практике:
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.memcached.MemcachedCache',
'LOCATION': '127.0.0.1:11211',
}
}Хранение в файле сокета (временный файл хранилища в UNIX системах):
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.memcached.MemcachedCache',
'LOCATION': 'unix:/tmp/memcached.sock',
}
}Хранение на нескольких серверах для уменьшения нагрузки:
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.memcached.MemcachedCache',
'LOCATION': [
'172.19.26.240:11211',
'172.19.26.242:11211',
]
}
}Для использования кеша через Redis необходимо знать, что такое Redis.
Мы будем изучать целый вид баз данных среди, которых будет и Redis. На данном этапе нам нужно знать, что Redis - это специальная база данных, которая может хранить данные в виде хеш-таблицы (ключ-значение).
Для использования такого кеша нам необходимо, установить Redis, стандартный порт 6379.
И установить сторонние библиотеки для работы с ним:
pip install django-redis
После чего прописать настройки в settings.py и держать сервис Redis запущенным:
CACHES = {
"default": {
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": "redis://127.0.0.1:6379/1",
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient"
},
"KEY_PREFIX": "example"
}
}Можно хранить кеш прям в базе данных, для этого нужно указать таблицу, в которую складывать кеш:
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.db.DatabaseCache',
'LOCATION': 'my_cache_table',
}
}Для использования кеша через базу таблицу нужно предварительно создать, сделать это можно при помощи manage-команды:
python manage.py createcachetable
Можно хранить кеш в обычном файле:
Linux\MacOS:
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.filebased.FileBasedCache',
'LOCATION': '/var/tmp/django_cache',
}
}Windows:
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.filebased.FileBasedCache',
'LOCATION': 'c:/foo/bar',
}
}Есть упрощенная схема кеширования для разработки:
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.dummy.DummyCache',
}
}Как и всё остальное, кеш можно кастомизировать, написав собственные классы для управления кешем:
CACHES = {
'default': {
'BACKEND': 'path.to.backend',
}
}Любой тип кеширования поддерживает большое количество дополнительных настроек, подробно о которых в документации.
Существует два основных способа использовать кеш.
Кешировать весь сайт или кешировать конкретную вью.
Чтобы кешировать весь сайт, нужно добавить две middleware (как это работает, на следующем занятии) до и
после CommonMiddleware (это важно, иначе работать не будет):
В settings.py
MIDDLEWARE = [
...
'django.middleware.cache.UpdateCacheMiddleware',
'django.middleware.common.CommonMiddleware',
'django.middleware.cache.FetchFromCacheMiddleware',
...
]Время кеширования или ограничения на кеш выставляются через переменные settings.py, подробно в документации.
Для того чтобы кешировать отдельный метод или класс, используется декоратор cache_page
from django.views.decorators.cache import cache_page
@cache_page(60 * 15)
def my_view(request):
...В скобках указывается время, которое кеш должен храниться, обычно записывается в виде умножения на секунды\минуты для простоты чтения (15*60 - это 15 минут, никакой разницы от того, чтобы записать 900, но так проще воспринимать на вид).
Чаще всего декоратор используется в URL:
from django.views.decorators.cache import cache_page
urlpatterns = [
path('foo/<int:code>/', cache_page(60 * 15)(my_view)),
]Для кеширования class-based view кешируется весь класс:
from django.views.decorators.cache import cache_page
url(r'^my_url/?$', cache_page(60 * 60)(MyView.as_view())),Также можно закешировать часть темплейта при помощи темплейт тега cache:
{ % load cache %}
{ % cache 500 sidebar %}
..sidebar..
{ % endcache %}В кеш можно записать любые кастомные данные, если это необходимо
from django.core.cache import cache
cache.set('my_key', 'hello, world!', 30)
cache.get('my_key')
'hello, world!'
# Wait 30 seconds for 'my_key' to expire...
cache.get('my_key')
None
cache.set('add_key', 'Initial value')
cache.add('add_key', 'New value')
# .add() сработает, только если в указанном ключе ничего не было
cache.get('add_key')
'Initial value'
cache.get_or_set('my_new_key', 'my new value', 100)
'my new value'
import datetime
cache.get_or_set('some-timestamp-key', datetime.datetime.now)
datetime.datetime(2014, 12, 11, 0, 15, 49, 457920)
cache.set('a', 1)
cache.set('b', 2)
cache.set('c', 3)
cache.get_many(['a', 'b', 'c'])
{'a': 1, 'b': 2, 'c': 3}
cache.set_many({'a': 1, 'b': 2, 'c': 3})
cache.get_many(['a', 'b', 'c'])
{'a': 1, 'b': 2, 'c': 3}
cache.delete('a')
cache.delete_many(['a', 'b', 'c'])
cache.clear()
cache.touch('a', 10) # обновить время храненияИ многие другие тонкости и особенности, например, декоратор from django.views.decorators.cache import never_cache,
который можно использовать, чтобы не кешировать данные, если вы уже кешируете весь сайт. И многое другое, подробности в
документации.