This project demonstrates a sophisticated search engine that leverages vector databases and machine learning models to find visually similar images and extract information from PDFs. Utilizing Qdrant for storage and OpenAI for processing, it allows users to search images by visual similarity, interact with PDFs via chat, and generate images from text descriptions.
To run this project, you need to have the following installed on your machine:
- Docker: Install Docker by following the instructions provided on the official Docker documentation.
- Python: Install Python by following the instructions on the official Python website.
- Node.js: Install Node.js by following the instructions on the official Node.js website.
- OPENAI_API_KEY: You will need an OpenAI API key to access GPT-3. You can create a free account and get access to GPT-3 with free credits. Visit the OpenAI website for more information.
Note: Currently, due to some backend issues, I couldn't dockerize the project. Therefore, to run the project, please follow the steps below. Additionally, the dependency on OpenAI's APIs will soon be removed and replaced with open-source models like LLaMA-7B by Meta AI.
-
Clone the repository:
git clone https://github.com/Prathap-Chandra/vector-search-blog-code
-
Start the React app:
- Navigate to the frontend folder:
cd frontend - Install the dependencies:
npm i
- Run the React app using Vite on port 5173:
npm run dev
- Navigate to the frontend folder:
-
Start the Qdrant - Vector Database:
- Pull the Qdrant Docker image:
docker pull qdrant/qdrant
- Run the Qdrant Docker image with the specified port mappings and volume mounts. Replace
$(pwd)with your host path, such as/home/prathap/Desktop/Codebase/Personal/docker-volumes/qdrant_storage:docker run -d --name vector-database -p 6333:6333 -p 6334:6334 -v $(pwd)/qdrant_storage:/qdrant/storage:z qdrant/qdrant - That's it. Your database should be up and running; you can confirm this by visiting http://localhost:6333/dashboard in your browser.
- Pull the Qdrant Docker image:
-
Start the Python Server:
- Navigate to the backend folder:
cd backend - Create and activate a virtual environment:
# For macOS (and Linux/Ubuntu) python3 -m venv venv source venv/bin/activate pip install -r requirements.txt # For Windows python -m venv venv .\venv\Scripts\activate pip install -r requirements.txt
- Now create a .env file in your backend folder and add
OPENAI_API_KEY. - Before starting the server, let's seed some data into the database. Please note that executing this script can take anywhere from 5 to 15 minutes, depending on your hardware and the number of images and PDFs you're uploading to Qdrant.
- Inside backend folder, you'll find an
appfolder inside which there is aseed_datafolder. Inside theseed_datafolder, you can find images and pdfs folders. Copy all your images and pdfs to their respective folders. - I've added few test images and pdf's for your understanding. feel free to replace them with yours. Additionaly you can use https://www.kaggle.com/datasets/vikashrajluhaniwal/fashion-images this kaggle dataset. Once copied, run the below command to extract the embeddings of images and pdfs and store them in Qdrant:
python3 -m app.script.py
- Once the script is executed you can start the server.
python3 run.py
- Navigate to the backend folder:
- Please note that this is a temporary solution, and eventually, the project will be dockerized. Once dockerized, you will only need to run the compose file to start the servers.
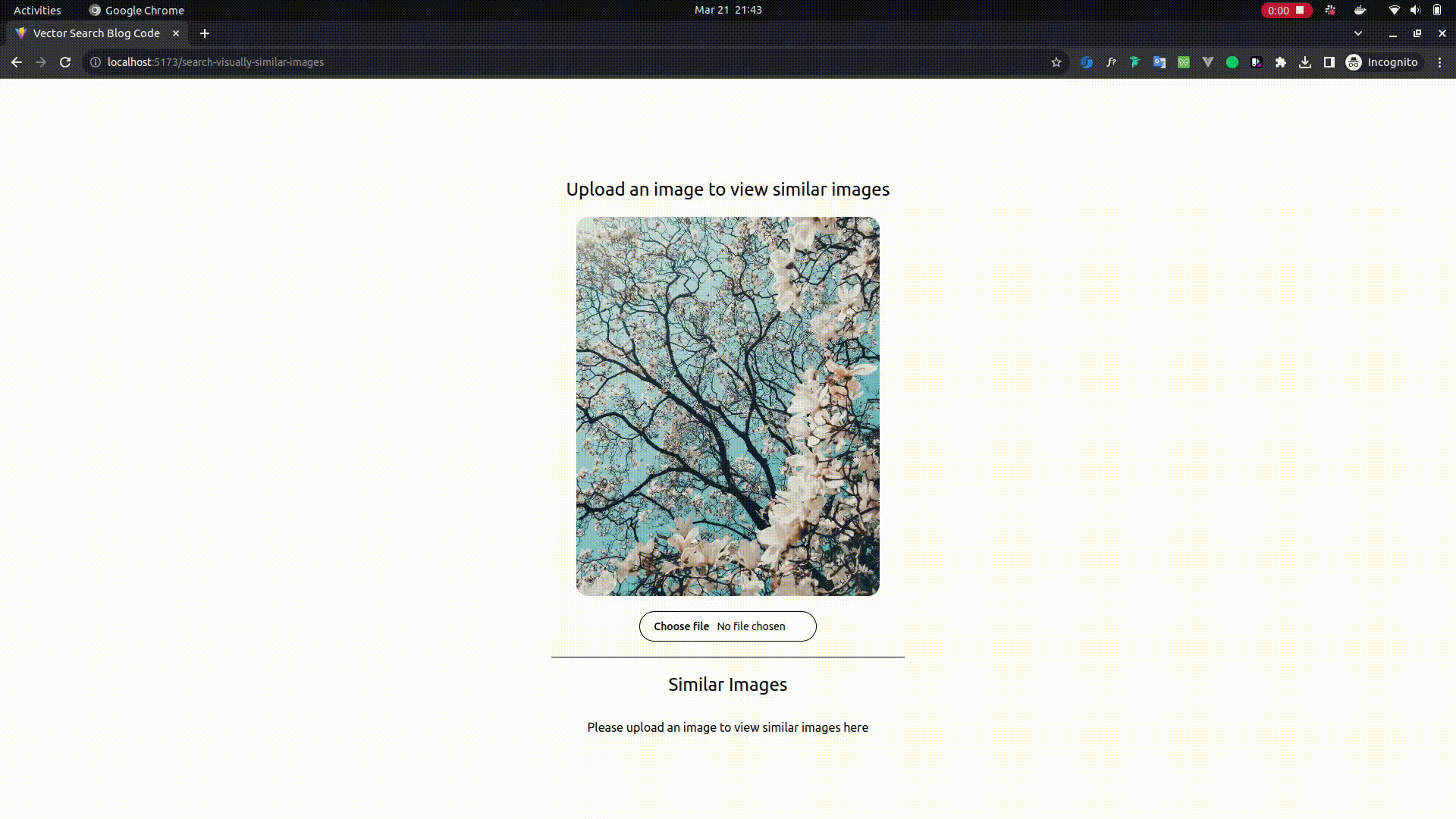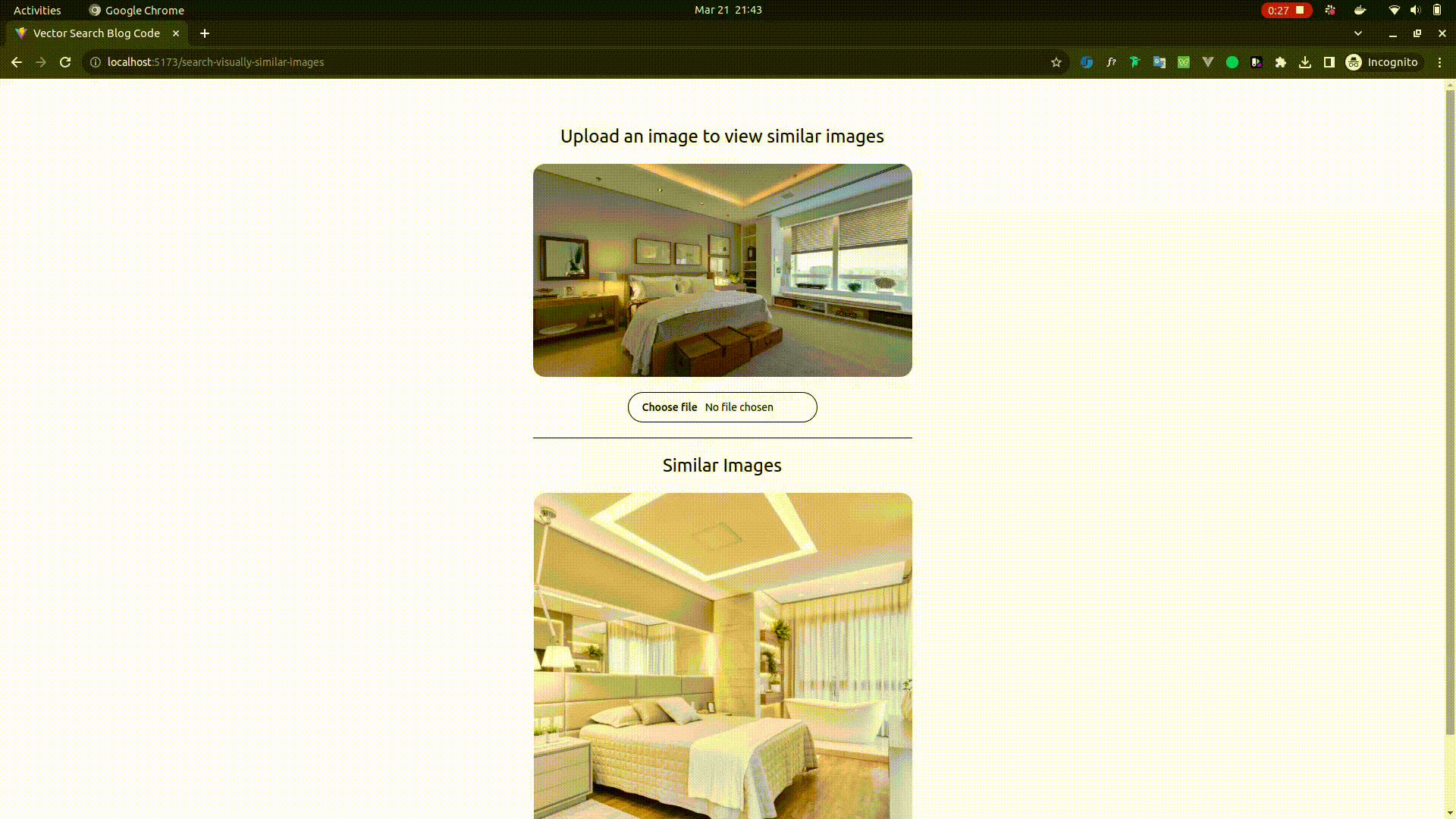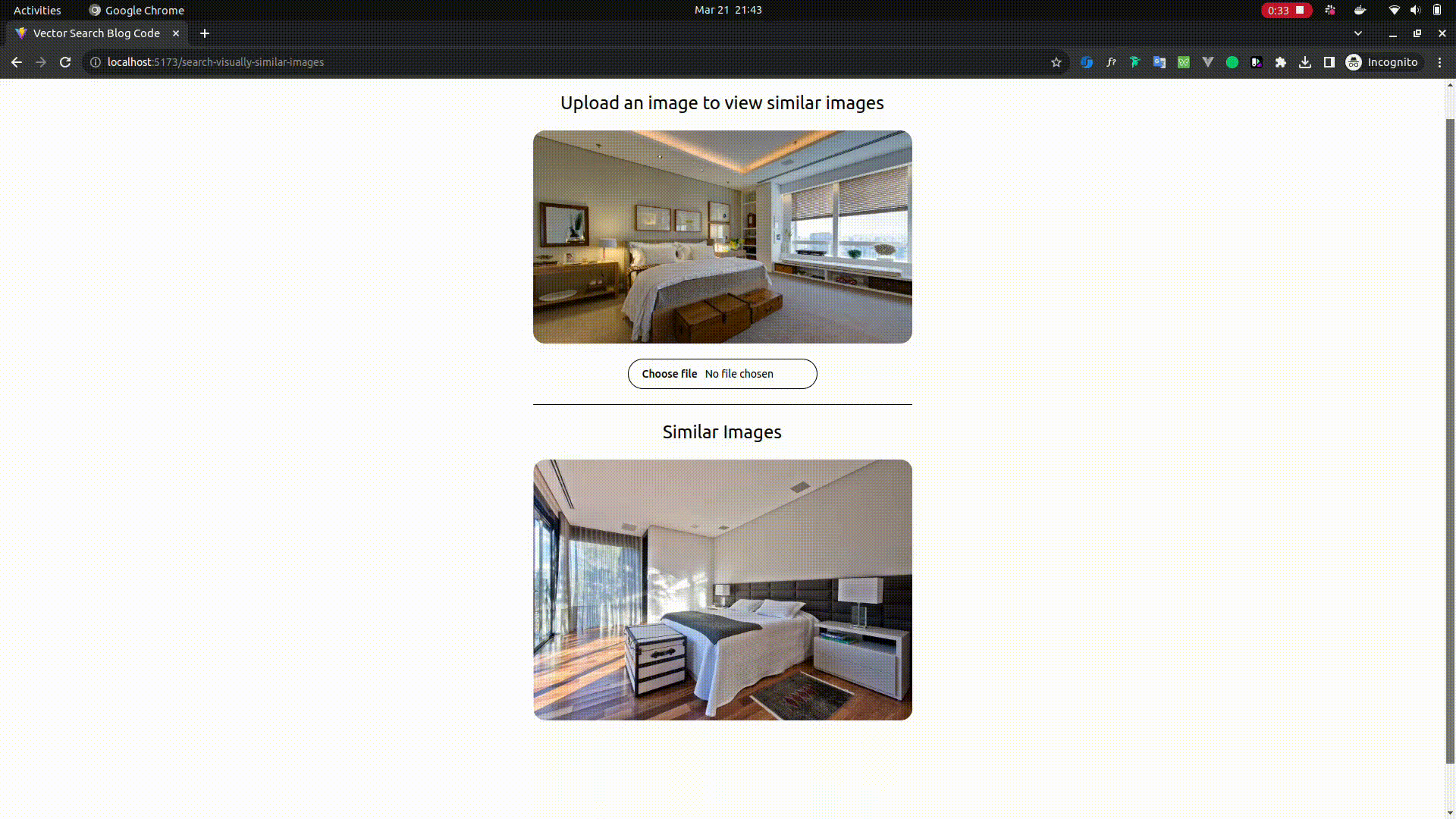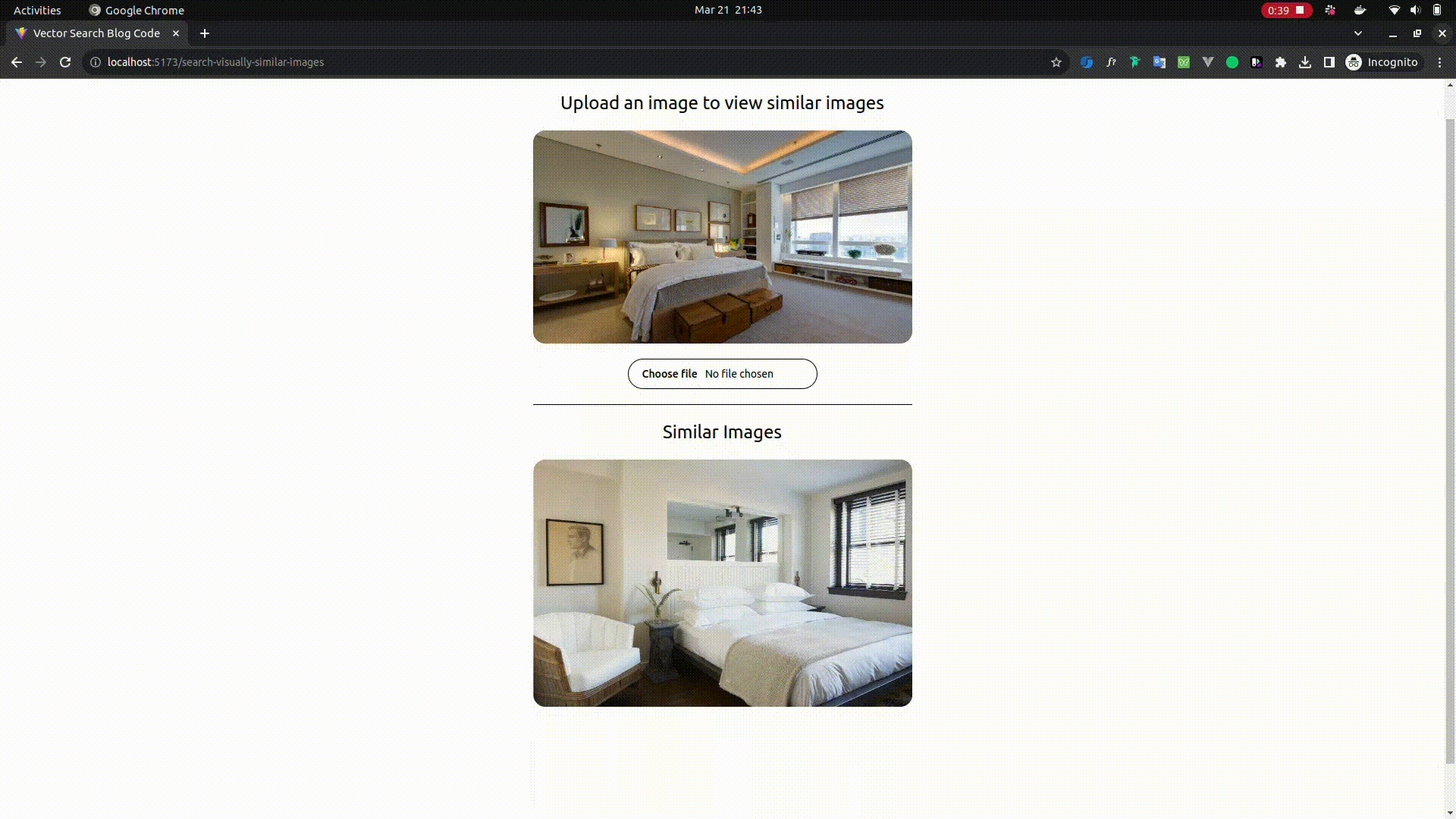
Searching Visually Similar Images
- Open
http://localhost:5173/search-visually-similar-imagesin your browser - Upload an image of your choice and wait for few seconds and you should be able to see the similar images
Chat With PDF
- Open
http://localhost:5173/chat-with-your-pdfin your browser - Upload a pdf of your choice and wait for few seconds till its uploaded to qdrant. Once done shoot a question from that PDF and you should be able to see the corresponding answer
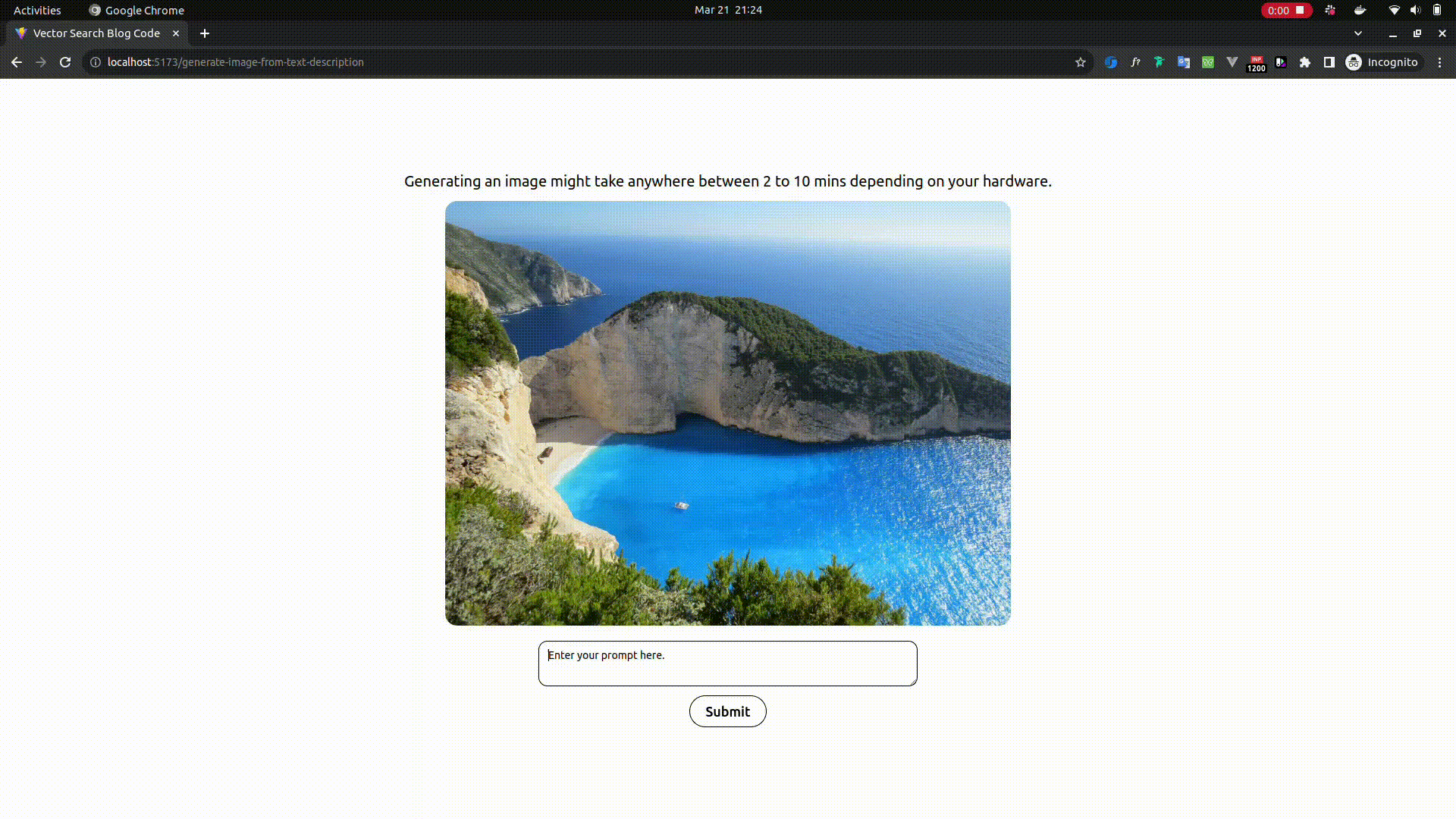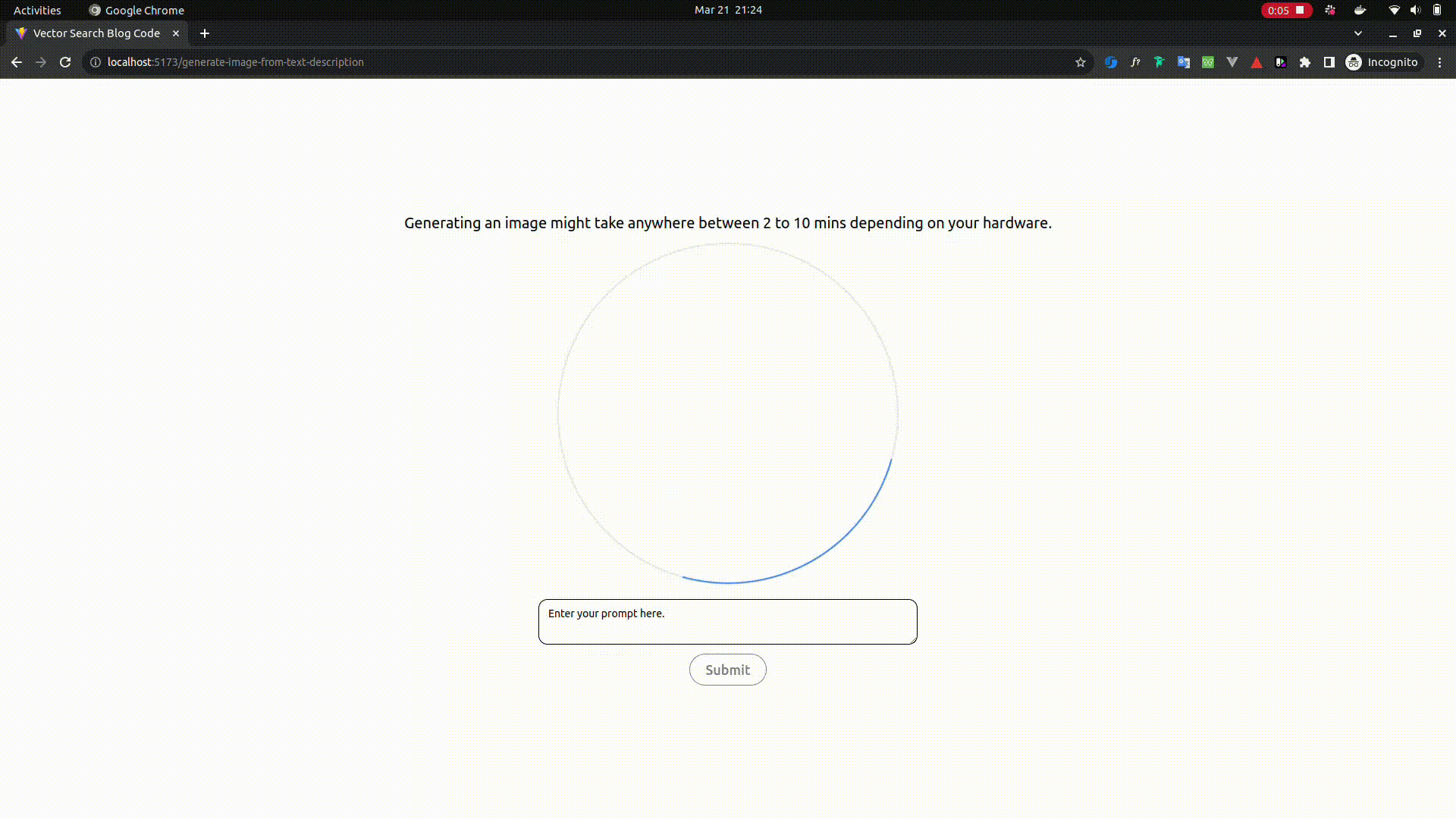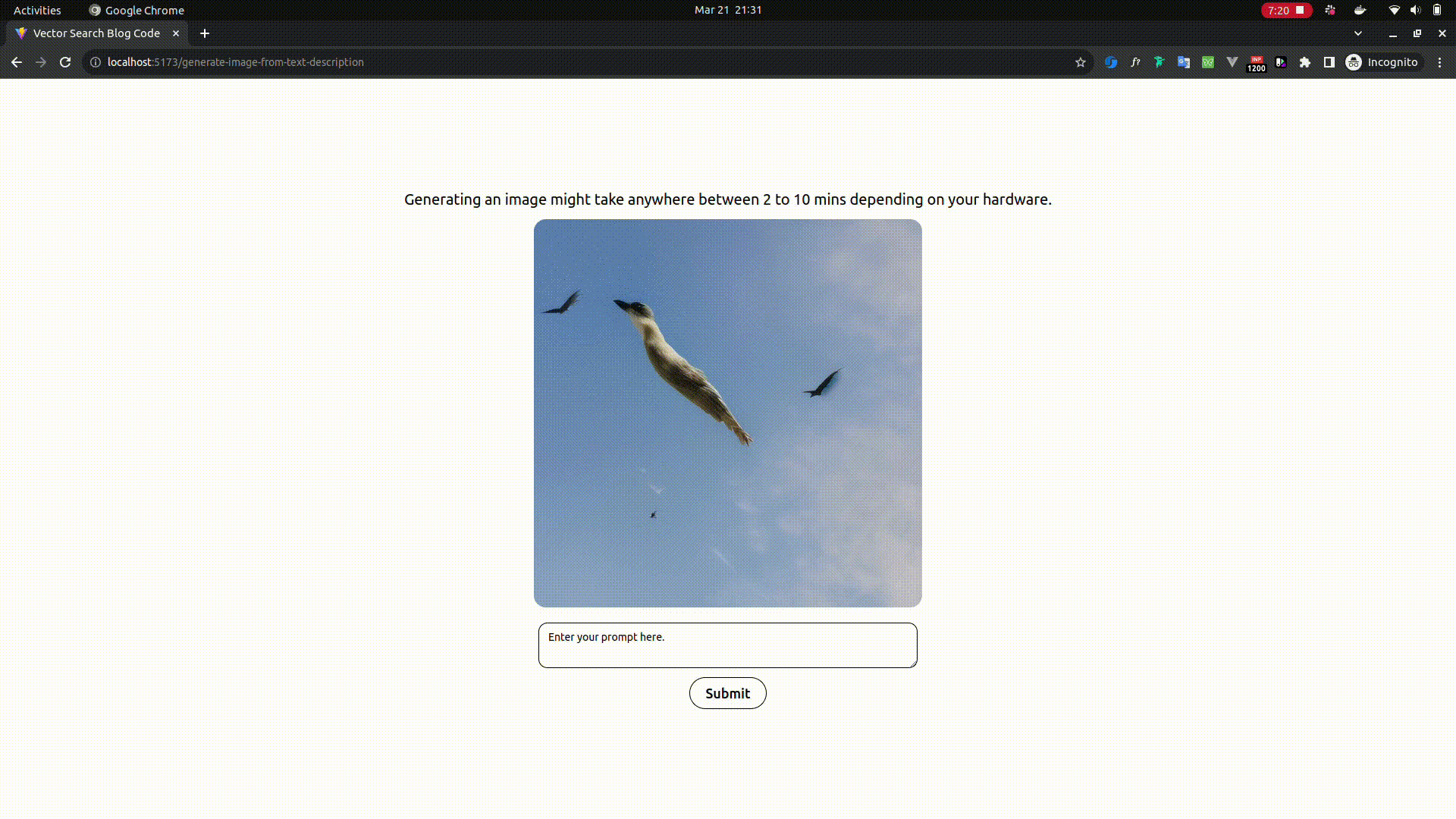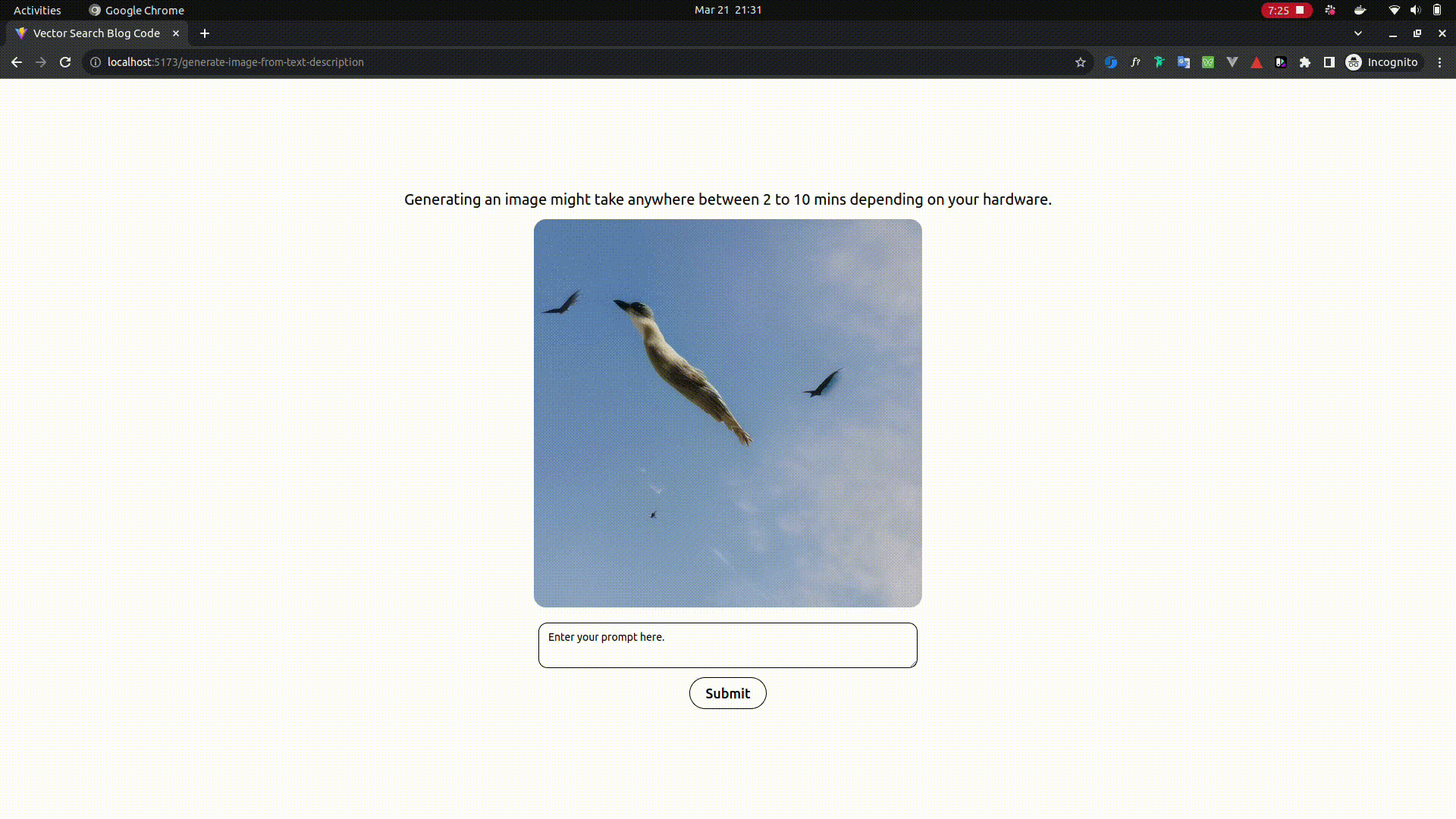
Image generation from text prompt - Poor man's Dall-E and MidJourney
- Open
http://localhost:5173/generate-image-from-text-descriptionin your browser - Enter any text prompt like a man in a pool or a bird flying in sky etc., and see your imagination coming to life in the lowest image resolution possible.