This is a project repo for group 11 in the course of Stat 547. Here I will be working with student survey data from a Portugese school. This project is broken down into 6 milestones and there will be two major themes, the first is an analysis pipeline and the second is the creation of a dashboard using the same dataset.
The link to the dataset is found in data/student_port_survey.csv. Another public repository that has this data (as of April 2020) is here. This dataset was manually unzipped data taken from : UCL ML Repository
Link to Heroku App
https://portugese-stu-survey-app.herokuapp.com/
- data: contains all the relevant data in .csv format (raw and processed), as well as metadata in .txt format
- docs: contains .Rmd scripts and the draft report
- images: contains the figures created by the R scripts in png format
- scripts: contains the relevant R scripts
- app.R: found in root directory, for DashR dashboard.
Below is my table of contents for the milestones:
| Name of milestone | Description | Status | Date completed |
|---|---|---|---|
| Milestone 1 | Dataset EDA, and research | completed | March 3,2020 |
| Milestone 2 | Basic Draft Report and R scripts | completed | March 9,2020 |
| Final Report-HTML | Final Report HTML doc | completed | March 17/20 |
| Milestone_4 | Includes Draft of dash app and description of it | completed | March 24/20 |
| Dash Script-V2 | Updated Dash script with all components and tabs | completed | March 31/20 |
To Run this app in your terminal run Rscript app.R
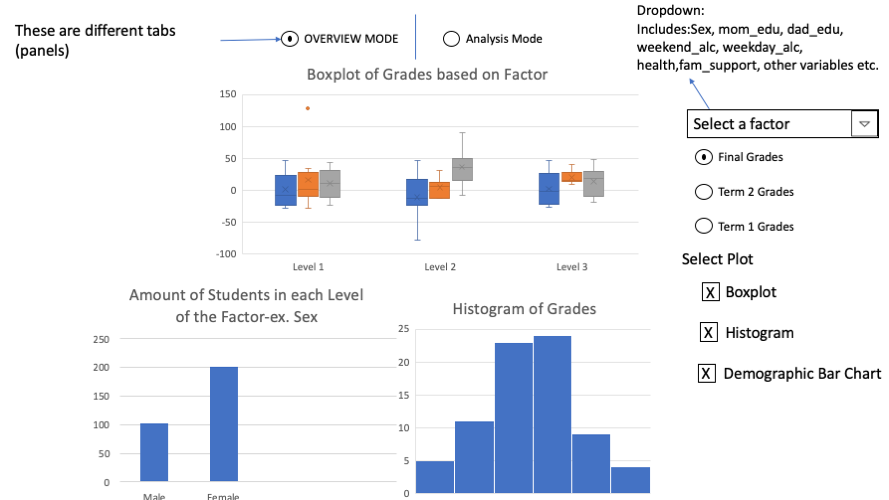
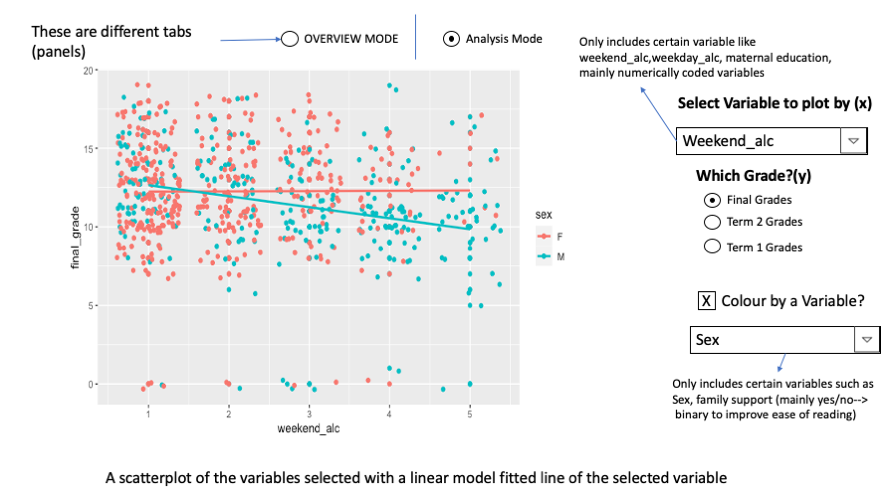
This app will have 2 tabs, the first being as the overview tab and the second one being the analysis tab. The first tab will include a boxplot that shows the spread of the selected grade and the selected factor chosen by the user from a dropdown provided(ex. Sex, weekend alcohol, workday alcohol, mother's education, family support, etc). The user also has the option to view a histogram of the grade chosen. Additionally, they can look at the number of students in each level of the factor they select through a demographic boxplot. For the second tab, the user can view a linear regression plot to get a better understanding of the effect of certain factors on grades.The user has the option to select which of the numeric factors to plot, these include workday alcohol, weekend alcohol, mother's education, number of absences, etc.They then select which grade to plot and include up to one binary covariable represented by the colour to look at interaction terms. In this example, sex is coloured and it is plotted by weekend alcohol and its effect on grades (here there is an obvious interaction with the crossing of the lines). I am potentially thinking of including the ability for users to hover over the plot to get the p value of the factor or interaction term which is the smallest.
Bia Almeda is a local principal in Portugal, who is concerned with the dropping grades in her school.She interested in [exploring] factors that could affect student performance in order to come up with school policies and campaigns that could better support student learning. She wants to [compare] different factors that affect student learning in order to [identify] some variables that the school team could target. When Bia visits the Portugese high school survey app, she chooses to look at a number of different factors that seem to affect the spread of final grades. She notices that workday alcohol has a negative effect on the final grades of students. Additionally, she finds an interaction between alcohol use and sex of the individual. Through this, she decides to conduct a follow-up survey to look at the ways students cope and potentially bring in better supports for student mental health,with a more targetted strategy aimed at each gender.
To completely reproduce the steps for analysis do the following:
-
Clone this repo
-
Ensure the following packages are installed:
- ggplot - dplyr - docopt - purrr - corrplot - tidyverse - here - glue - broom - devtools --> for Dash App - install_github("plotly/dashR", upgrade = TRUE) --> for Dash App
-
With a clean repository, to run the whole pipeline
make all
-
Clean up the results from the scripts and start fresh:
make clean
# Download the data:
make data/student_port_survey.csv
# Clean and wrangle the data
make data/cleaned_data.csv
# Perform Basic EDA and generate some interesting plots
make images/Correllogram.png images/Final_Grade_vs_Workday_Alcohol.png images/Final_Grade_vs_Weekend_Alcohol.png images/Final_Grade_vs_Health.png images/Final_Grade_vs_Maternal_Education.png images/Final_Grade_vs_Family_Support.png images/Final_Grade_vs_Parental_Status.png images/Final_Grade_vs_Sex.png images/density_plot_grades.png
# Run linear regression and generate some plots
make images/residual_fitted_plot.png images/residual_plot_qq.png images/Linear_Reg_Plot_Final_Grade_vs_Weekend_Alcohol_and Workday_Alcohol.png data/lm_model_alc.RDS
docs/filtered_cleaned.csv
#Knit the final report
make docs/Final_report.html docs/Final_report.pdf
Run the following scripts (in order) with the appropriate arguments specified:
# Download data
Rscript scripts/load.r --data_url="https://github.com/STAT547-UBC-2019-20/data_sets/raw/master/student-por.csv"
# Clean and wrangle the data
Rscript scripts/clean.R --data_input="data/student_port_survey.csv" --filename="cleaned_data"
# Perform Basic EDA and generate some interesting plots
Rscript scripts/EDA.R --folder_path="images"
# Run linear regression and generate some plots
Rscript scripts/linear_regression.R --filename="cleaned_data.csv"
#Knit the final report
Rscript scripts/knit.R --finalreport_name="docs/Final_report.Rmd"
As stated above:
#To Run this app in your terminal run `Rscript app.R`