{kind=link}

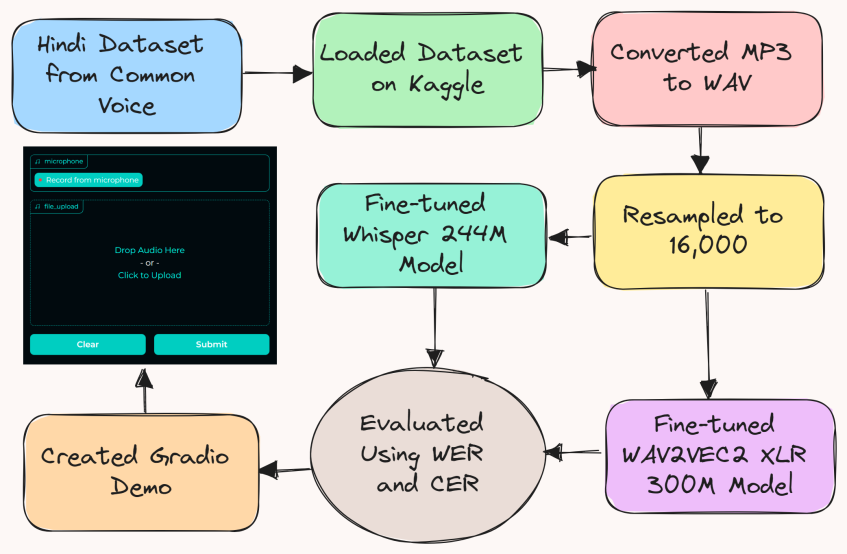
The project,being part of Kagglex BIPOC Mentorship Program final project, aims to train two separate Hindi ASR models using the Facebook Wav2Vec2 (300M parameters) and OpenAI Whisper-Small models, respectively. The goal is to compare their performance, with a target WER of less than 13%, across various Hindi accents and dialects. Additionally, an evaluation framework will be established to assess real-time processing capabilities, including latency, throughput, and computational efficiency. The project intends to provide insights into the strengths and weaknesses of each model, enabling the selection of the most suitable ASR system for specific application requirements and deployment environments, thereby enhancing technological accessibility for Hindi speakers.
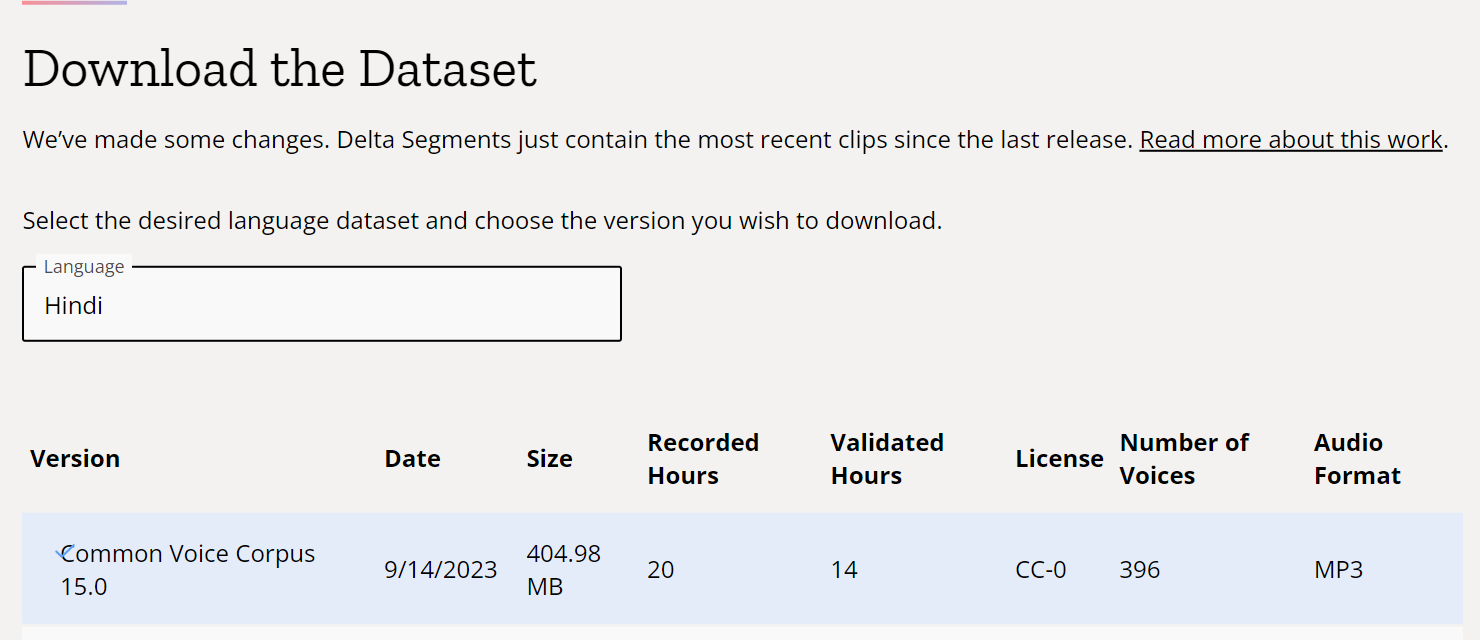
The Common Voice Corpus 15.0 Hindi dataset is a part of Mozilla's Common Voice project, which is known for being a multi-language dataset and is one of the largest publicly available voice datasets of its kind1. The Common Voice Corpus 15.0 was released on 9/13/2023, and the dataset size is 1.74 GB.
Wav2Vec2-XLS-R-300M is a representation of Facebook AI's large-scale multilingual pre-trained model for speech, which is part of the XLS-R model series, often referred to as "XLM-R for Speech".
This model comprises 300 million parameters and is pre-trained on a massive 436,000 hours of unlabeled speech data from various datasets including VoxPopuli, MLS, CommonVoice, BABEL, and VoxLingua10723. The training encompasses 128 different languages and employs the wav2vec 2.0 objective. It's crucial to note that the audio input for this model should be sampled at 16kHz1.
For practical utilization, Wav2Vec2-XLS-R-300M requires fine-tuning on a downstream task like Automatic Speech Recognition (ASR), Translation, or Classification14. The model, when fine-tuned, has shown significant performance improvements in speech recognition tasks.

Word Error Rate (WER): 32.85%
Character Error Rate (CER): 8.75%

import torch
from datasets import load_dataset, Audio
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import evaluate
import librosa
test_dataset = load_dataset("mozilla-foundation/common_voice_13_0", "hi", split="test")
wer = evaluate.load("wer")
cer = evaluate.load("cer")
processor = Wav2Vec2Processor.from_pretrained("SakshiRathi77/wav2vec2-large-xlsr-300m-hi-kagglex")
model = Wav2Vec2ForCTC.from_pretrained("SakshiRathi77/wav2vec2-large-xlsr-300m-hi-kagglex").to("cuda")
# Preprocessing the datasets.
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = librosa.load(batch["path"], sr=16_000)
batch["speech"] = speech_array
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids, skip_special_tokens=True)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
print("CER: {}".format(100 * cer.compute(predictions=result["pred_strings"], references=result["sentence"])))WER: 55.95676839620688
CER: 19.123313671430792
Whisper is an automatic speech recognition (ASR) system developed by OpenAI, trained on 680,000 hours of multilingual and multitask supervised data collected from the web. This extensive training on a large and diverse dataset has led to improved robustness to accents, background noise, and technical language, making it a general-purpose speech recognition model capable of multilingual speech recognition, speech translation, and language identification

Word Error Rate (WER): 13.4129%
Character Error Rate (CER): 5.6752%

from datasets import load_dataset, Audio
from transformers import WhisperForConditionalGeneration, WhisperProcessor
import torch
import torchaudio
import evaluate
test_dataset = load_dataset("mozilla-foundation/common_voice_13_0", "hi", split="test")
wer = evaluate.load("wer")
cer = evaluate.load("cer")
processor = WhisperProcessor.from_pretrained("SakshiRathi77/whisper-hindi-kagglex")
model = WhisperForConditionalGeneration.from_pretrained("SakshiRathi77/whisper-hindi-kagglex").to("cuda")
test_dataset = test_dataset.cast_column("audio", Audio(sampling_rate=16000))
def map_to_pred(batch):
audio = batch["audio"]
input_features = processor(audio["array"], sampling_rate=audio["sampling_rate"], return_tensors="pt").input_features
batch["reference"] = processor.tokenizer._normalize(batch['sentence'])
with torch.no_grad():
predicted_ids = model.generate(input_features.to("cuda"))[0]
transcription = processor.decode(predicted_ids)
batch["prediction"] = processor.tokenizer._normalize(transcription)
return batch
result = test_dataset.map(map_to_pred)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["prediction"], references=result["reference"])))
print("CER: {:2f}".format(100 * cer.compute(predictions=result["prediction"], references=result["reference"])))WER: 23.1361
CER: 10.4366
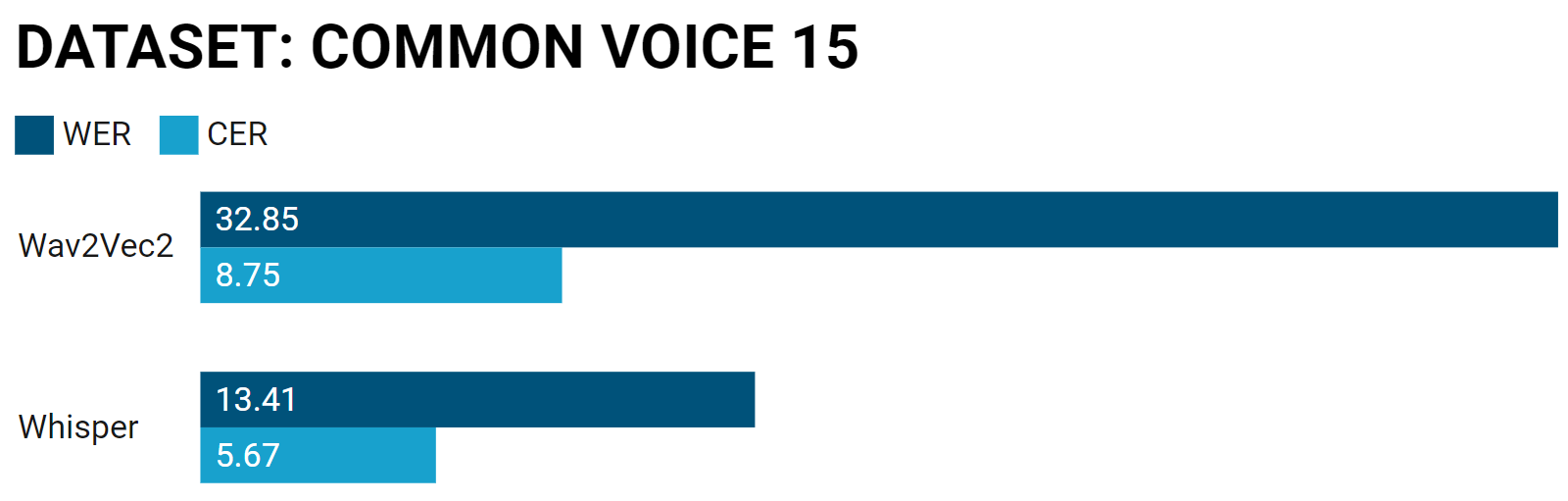
- Sequence Modeling With CTC
- Wav2Vec 2.0: A Framework for Self-Supervised Learning of Speech Representations
- Illustrated Wav2Vec 2.0
- Fine-tune Wav2Vec2 (English)
- Wav2Vec2 with N-Gram
- Attention is All You Need: Discovering the Transformer Paper
- Whisper: A Speech-to-Text Model with Exceptional Accuracy and Robustness
- MP3 to WAV Dataset-kagglex
- Wav2Vec2 XLSR Kagglex Fine-tuning
- Whisper Kagglex Fine-tuning (
⚠️ The notebook was not able to complete the task and the last saved checkpoint was at 3000.) - Wav2Vec2 Evaluation
- Whisper Evaluation
We can improve our model performace by:
-
Cleaning the text:
- Pre-processing textual data for uniformity and consistency.
- Manually improve mistakes in dataset if any.
-
Removing the noise from audio:
- Applying techniques to filter out unwanted background noise.
- Enhancing the quality of the speech signal for improved transcription accuracy.
-
Training on the full dataset:
- Using the complete dataset for comprehensive model training.
- Capturing various nuances and complexities in the data for improved performance.
-
Adding Language model Boosting Wav2Vec2 with n-grams in 🤗 Transformers:
- Enhancing the Wav2Vec2 model's performance with n-grams.
- Integrating language models to provide contextual information for more accurate transcriptions.
-
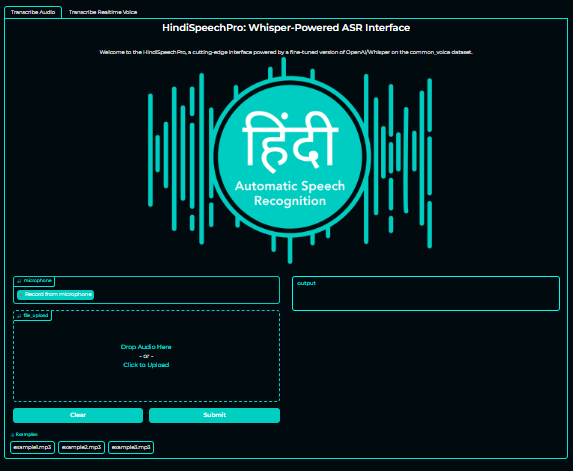
Advancements in the Demo:
- Incorporating an English language translator to enhance accessibility on a global scale.
Made with ❤️ by Sakshi Rathi