“I don’t want a full report, just give me a summary of the results”. I have often found myself in this situation – both in college as well as my professional life. We prepare a comprehensive report and the teacher/supervisor only has time to read the summary.
Sounds familiar? Well, I decided to do something about it. Manually converting the report to a summarized version is too time taking, right? Could I lean on Natural Language Processing (NLP) techniques to help me out?
This is where the awesome concept of Text Summarization using Deep Learning really helped me out. It solves the one issue which kept bothering me before – now our model can understand the context of the entire text. It’s a dream come true for all of us who need to come up with a quick summary of a document!
“Automatic text summarization is the task of producing a concise and fluent summary while preserving key information content and overall meaning”
-Text Summarization Techniques: A Brief Survey, 2017
There are broadly two different approaches that are used for text summarization:
Extractive Summarization Abstractive Summarization
The name gives away what this approach does. We identify the important sentences or phrases from the original text and extract only those from the text. Those extracted sentences would be our summary.
This is a very interesting approach. Here, we generate new sentences from the original text. This is in contrast to the extractive approach we saw earlier where we used only the sentences that were present. The sentences generated through abstractive summarization might not be present in the original text.
We can build a Seq2Seq model on any problem which involves sequential information. This includes Sentiment classification, Neural Machine Translation, and Named Entity Recognition – some very common applications of sequential information. Our objective is to build a text summarizer where the input is a long sequence of words (in a text body), and the output is a short summary (which is a sequence as well). So, we can model this as a Many-to-Many Seq2Seq problem.
There are two major components of a Seq2Seq model:
Encoder
Decoder
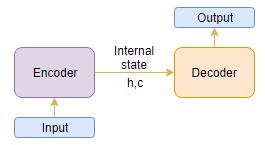
The Encoder-Decoder architecture is mainly used to solve the sequence-to-sequence (Seq2Seq) problems where the input and output sequences are of different lengths.
Let’s understand this from the perspective of text summarization. The input is a long sequence of words and the output will be a short version of the input sequence.
Generally, variants of Recurrent Neural Networks (RNNs), i.e. Gated Recurrent Neural Network (GRU) or Long Short Term Memory (LSTM), are preferred as the encoder and decoder components. This is because they are capable of capturing long term dependencies by overcoming the problem of vanishing gradient.
We can set up the Encoder-Decoder in 2 phases:
firstly, Training phase
secondly, Inference phase
In the training phase, we will first set up the encoder and decoder. We will then train the model to predict the target sequence offset by one timestep. Let us see in detail on how to set up the encoder and decoder.
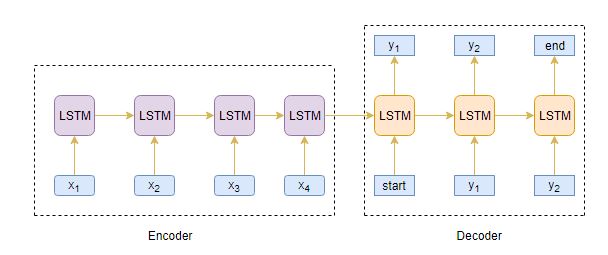
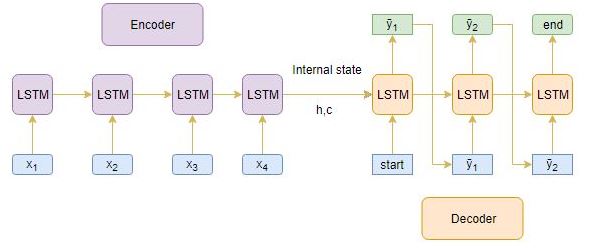
An Encoder Long Short Term Memory model (LSTM) reads the entire input sequence wherein, at each timestep, one word is fed into the encoder. It then processes the information at every timestep and captures the contextual information present in the input sequence.
I’ve put together the below diagram which illustrates this process:
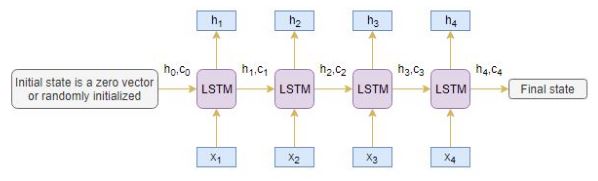
The hidden state (hi) and cell state (ci) of the last time step are used to initialize the decoder. Remember, this is because the encoder and decoder are two different sets of the LSTM architecture.
The decoder is also an LSTM network which reads the entire target sequence word-by-word and predicts the same sequence offset by one timestep. The decoder is trained to predict the next word in the sequence given the previous word.
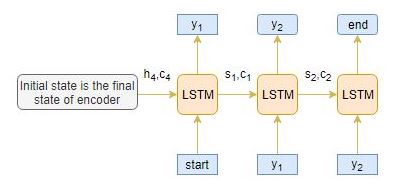
and are the special tokens which are added to the target sequence before feeding it into the decoder. The target sequence is unknown while decoding the test sequence. So, we start predicting the target sequence by passing the first word into the decoder which would be always the token. And the token signals the end of the sentence.
After training, the model is tested on new source sequences for which the target sequence is unknown. So, we need to set up the inference architecture to decode a test sequence:
How does the inference process work?
Here are the steps to decode the test sequence:
Encode the entire input sequence and initialize the decoder with internal states of the encoder Pass token as an input to the decoder Run the decoder for one timestep with the internal states The output will be the probability for the next word. The word with the maximum probability will be selected Pass the sampled word as an input to the decoder in the next timestep and update the internal states with the current time step Repeat steps 3 – 5 until we generate token or hit the maximum length of the target sequence
So, basically here I have used three stacked bidirectional LSTM layers as encoder and a single unidirentional LSTM layer as my decoder.
Hope, this was quite informative . :)