Migrate MDs to SoA+PortableCollection #101
Conversation
|
Let's see if there are timing issues here too. /run standalone |
|
There was a problem while building and running in standalone mode. The logs can be found here. |
|
/run standalone |
|
The PR was built and ran successfully in standalone mode. Here are some of the comparison plots.
The full set of validation and comparison plots can be found here. Here is a timing comparison: |
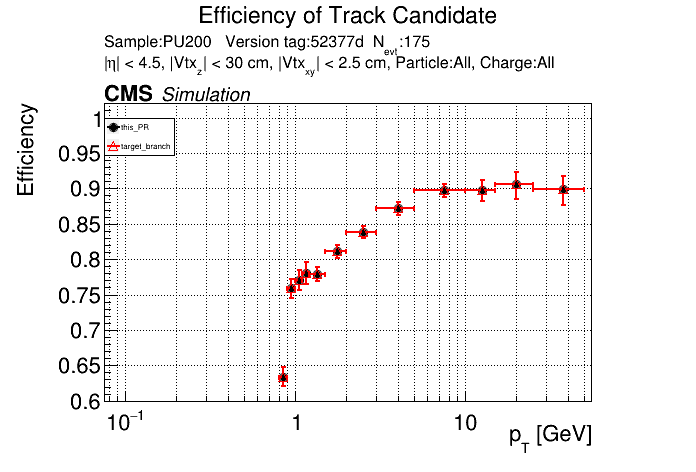
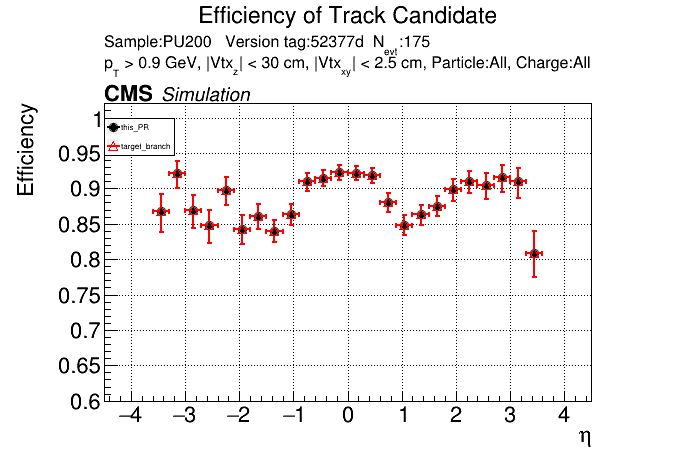
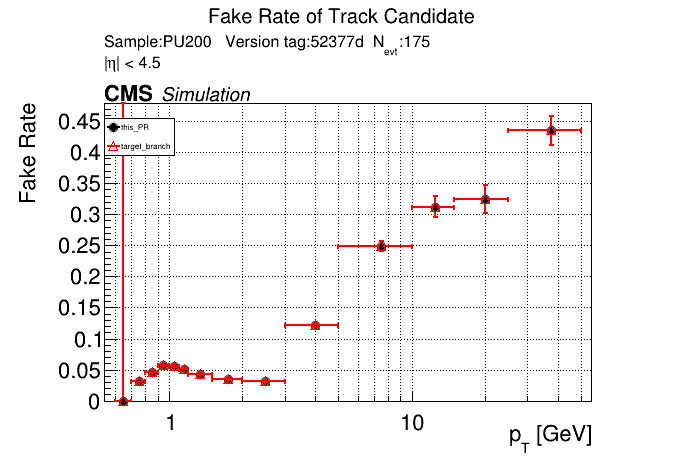
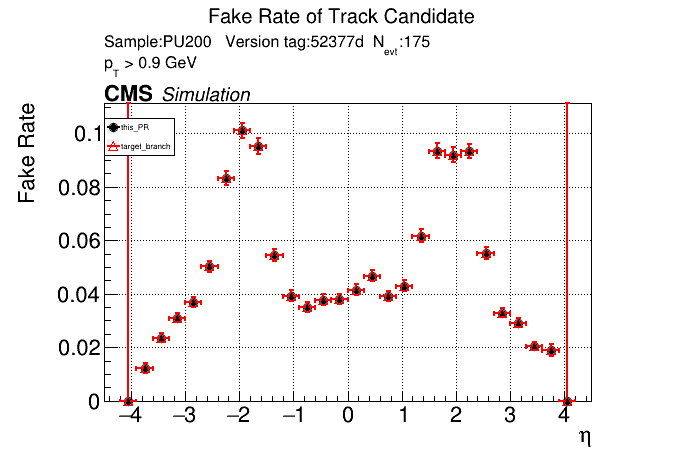
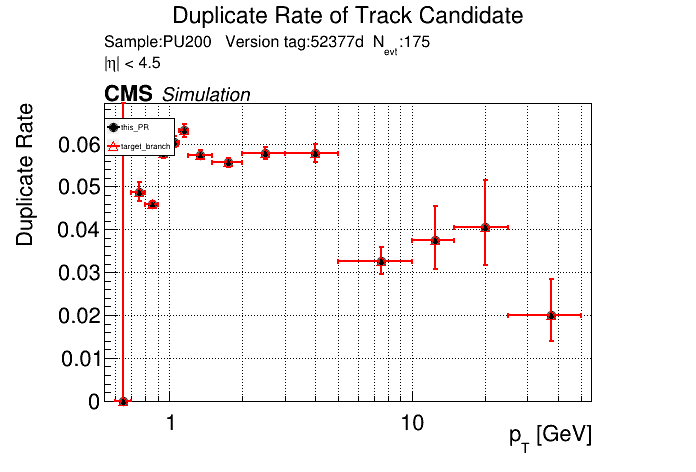
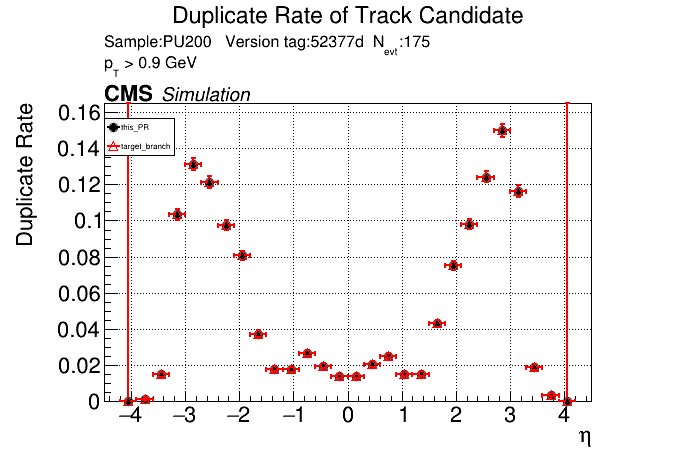
That doesn't look great. I'll investigate more. I've been having some issues with the profiler included in CMSSW, so I haven't profiled it yet. |
|
|
||
| template <typename TAcc> | ||
| ALPAKA_FN_ACC ALPAKA_FN_INLINE void addMDToMemory(TAcc const& acc, | ||
| MiniDoublets& mdsInGPU, | ||
| MiniDoublets mds, |
There was a problem hiding this comment.
Are the view copies relatively free or should we pass by ref?
There was a problem hiding this comment.
I tried with references and it doesn't make a difference
| CXXFLAGS_ROCM = -O3 -g -Wall -Wshadow -Woverloaded-virtual -fPIC -I${ROCM_ROOT}/include -I.. | ||
| CXXFLAGS_CPU = -march=native -mtune=native -Ofast -fno-reciprocal-math -fopenmp-simd -g -Wall -Woverloaded-virtual -fPIC -fopenmp -I.. | ||
| CXXFLAGS_CUDA = -O3 -g --compiler-options -Wall --compiler-options -Woverloaded-virtual --compiler-options -fPIC --compiler-options -fopenmp -dc -lineinfo --ptxas-options=-v --cudart shared $(GENCODE_CUDA) --use_fast_math --default-stream per-thread -I.. | ||
| CXXFLAGS_ROCM = -O3 -g -Wall -Woverloaded-virtual -fPIC -I${ROCM_ROOT}/include -I.. |
There was a problem hiding this comment.
these changes are showing up in multiple PRs.
Should we make a small update and merge these in the main realfiles branch
|
Did you have much success with igprof? For the column access I checked in my TC PR that e.g. |
@fwyzard @makortel |
Yesterday I didn't have time, but I got it to work now. I'm looking into it. I'll also look at the assembly to see if there are clear differences. |
I tried to look at calls related to Perhaps there are some extra diagnostic flags to add to gcc to get more detail. |
Could the range checks (that are presently enabled by default) |
|
If I remember how they are implemented, the range checks should come into play only when one uses a syntax like view.column(i)or view[i].column()while the changes in #93 (I looked at those, not a this PR) seem to use the syntax which first takes the raw pointer ( But I may be wrong in my recollection :-) So a couple of related suggestions:
Note that if you access many elements using the same index, like view.x()[i] = ...;
view.y()[i] = ...;
view.z()[i] = ...;you can also use auto item = view[i];
item.x() = ...;
item.y() = ...;
item.z() = ...;The only performance improvement should be that the range check is applied only once. |
|
@fwyzard I tried disabling range checking and using the other syntax (separately and together), but nothing changed. By the way, I noticed that range checking is enabled by default for SoALayouts, but not for views. I'm not sure if this is intentional, but I thought it was unexpected. @slava77 I'm seeing the same thing you saw from igprof, but the other way around. On the base branch the call stack makes sense, but in this PR I'm seeing some weird intertwined function calls. I haven't been able to make sense of this. |
Just to be sure, did you run the igprof-analyse consistently on the current compilation variant (in case both were tested in the same area) |
What I see in both cases is that the calls are a part of in the baseline: in mds_soa: however, the order of other computations around/following this load is different. |
Oh, I messed up that part. I'm checking again |
|
I didn't find anything insightful from the profiling or from (briefly) looking at the assembly. However, just like in #93, it seems like it is only affecting the performance on CPU. Here is a more complete timing comparison for CPU on cgpu-1. Here is a comparison for GPU on cgpu-1. |
I have a feeling that plain gcc is less capable in optimizing the code (we've seen it in mkFit) |
This PR migrates MDs to SoA+PortableCollection.