diff --git a/README.md b/README.md
index 9872aa1..c3b9b3b 100644
--- a/README.md
+++ b/README.md
@@ -1,5 +1,7 @@
# Flake8-pyspark-with-column
+[](https://github.com/SemyonSinchenko/flake8-pyspark-with-column/actions/workflows/python-publish.yml) 
+
## Getting started
```sh
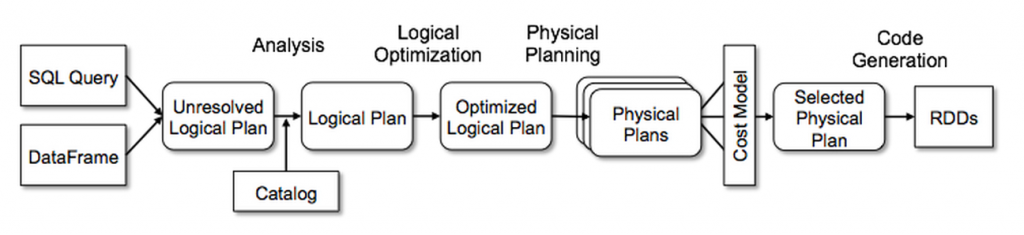
@@ -32,11 +34,17 @@ When you run a PySpark application the following happens:
2. Spark do analysis of this plan to create an `Analyzed Logical Plan`
3. Spark apply optimization rules to create an `Optimized Logical Plan`
-
+
+  +
+
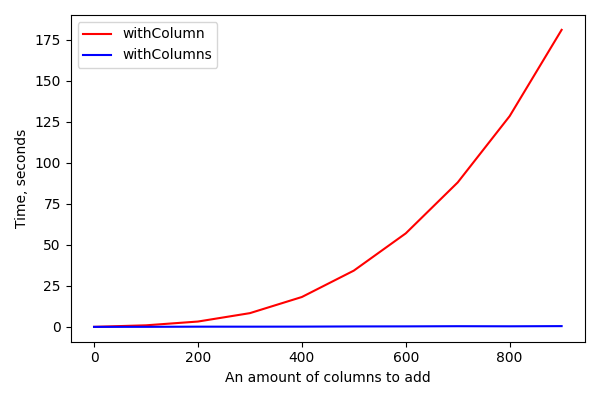
What is the problem with `withColumn`? It creates a single node in the unresolved plan. So, calling `withColumn` 500 times will create an unresolved plan with 500 nodes. During the analysis Spark should visit each node to check that column exists and has a right data type. After that Spark will start applying rules, but rules are applyed once per plan recursively, so concatenation of 500 calls to `withColumn` will require 500 applies of the corresponding rule. All of that may significantly increase the amount of time from `Unresolved Logical Plan` to `Optimized Logical Plan`:
-
+
+  +
+
+
+From the other side, both `withColumns` and `select(*cols)` create only one node in the plan doesn't matter how many columns we want to add.
## Rules
This plugin contains the following rules:
@@ -77,4 +85,6 @@ def cast_to_double(df: DataFrame) -> DataFrame:
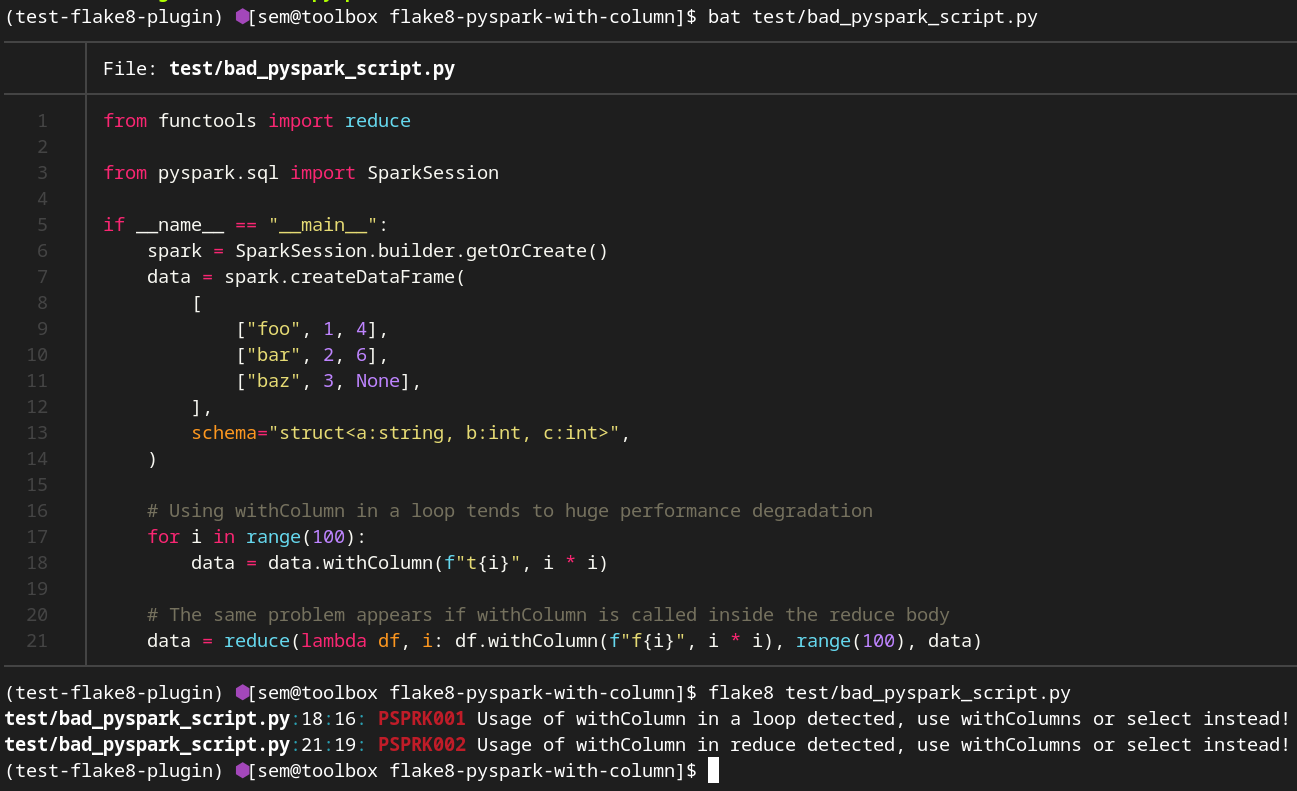
`flake8 %your-code-here%`
-
+
+  +
+