- Audio Source Separation
- Reference
- WaveNet
- A Universal Music Translation Network
- U-Wave-Net
- DeepConvSep
- Obtain accompaniment and vocals from mix music
- WAVENET
- A Universal Music Translation Network
- WAVE-U-NET
- https://github.com/MTG/DeepConvSep
- https://github.com/ShichengChen/WaveUNet

- Encode audio by mu-law and then quantize it to 256 possible values
- Input is a quantized audio array, for example, input.shape = L. L is the length of the audio.
- Causal Conv is a norm convolutional layer
- Dilated Conv is shown as above figure.
- Left yellow circle is a tanh fuction and right yellow circle is sigmoid
- Red circle denotes an element-wise multiplication operator Tanh(DilatedConv0(x)) * sigmoid(DilatedConv1(x))
- Green square are two norm convolutional layers with 1 * 1 kernel size
- One convolutional layer's output is followed by the residual summation, and the other convolutional layer's output is skip connections
- K is the layer
- Each block has a skip connection, red circle sums these skip connections up
- And then relu function, 1 * 1 kernel conv layer, relu, 1 * 1 conv layer and a softmax
- Output is quantized audio array, for example, output shape is 256 * L. 256 is 256 possible quantized values and L is the length of the audio.
- Map output to [-1,1] and then decode it to raw audio array.

- A is mix audio, B is vocals and C is accompaniment.
- The deepmind wavenet's input and label are only A
- I use A as input and B as label
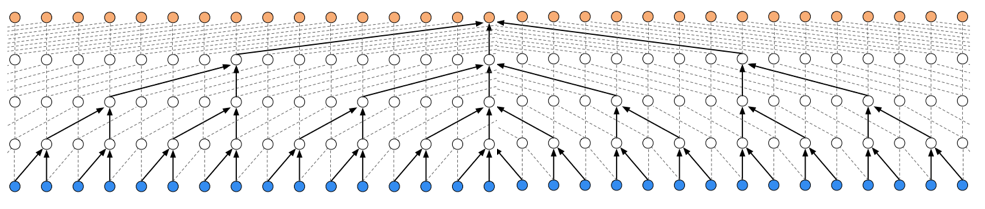
- As shown in above figure, I slightly changed the dilated conv layers
- I use A[0:100] to predict B[50] instead of using A[0:50] to predict A[50]


- The encoder is a fully convolutional network
- The encode part has three blocks of 10 residual-layers as shwon in the first above figure.
- the NC Dilated Conv layer is Dilated Conv layer
- After the three blocks, there is an additional 1 * 1 layer
- An average pooling with a kernel size of 800(if sample size for one second is 16000) follows
- And then domain confusion loss, I re-implemented a domain confusion in there.
- Upsampled to the original audio rate using nearest neighbor interpolation
- The above figure is new version wavenet
- The encoding audio is used to condition a WaveNet decoder. The conditioning signal is passed through a 1 × 1 layer that is different for each WaveNet layer
- The WaveNet decoder has 4 blocks of 10 residual-layers
- The input and output are quantized using 8-bit mu-law encoding
- Loss fuction is softmax
- Uniformly select a segment of length between 0.25 and 0.5 seconds
- Modulate its pitch by a random number between -0.5 and 0.5 of half-steps
- Structure A, I made the decoding part to be same as encoding, removed downsample and upsample, removed confusion loss.
- I used data augmentation strategy from u-wave-net paper. For example, A is mix audio, B is vocals and C is accompaniment. B * factor0 + C * factor1 = newA, I used newA as input and C*factor1 as label. Factor0 and factor1 is chosen uniformly from the interval [0.7, 1.0].
- I used Ccmixter as dataset. Ccmixter has 3 Children's songs, two songs as training data and the other as testing data, the result on testing data is also very good even though is slightly worse than training data.
- Three rap songs can also generalize well.
- Two songs have different background music and same lyrics(two same voice), generalization is also ok, but worse than above two situations
- First 45 songs for training and last 5 songs for testing, the results is still not good.
- If I chose 9 different types of music, even in training set, the result is not good. I am trying to solve this problem.
- Add downsample and upsample, add confusion loss, use short time fourier transform to preprocess the raw audio. The results are worse than structure A.
- I implemented a domain confusion loss in there.
- My result is better than original paper's result, but when I add to structure A, the result became very bad. Because I think that I need the domain information when I generate the music without voice. I should keep the original music and accompaniment having same type.
- Try to add decoding part to structure A. The bottleneck during inference is the autoregressive process done by the WaveNet, try to use dedicated CUDA kernels code by NVIDIA
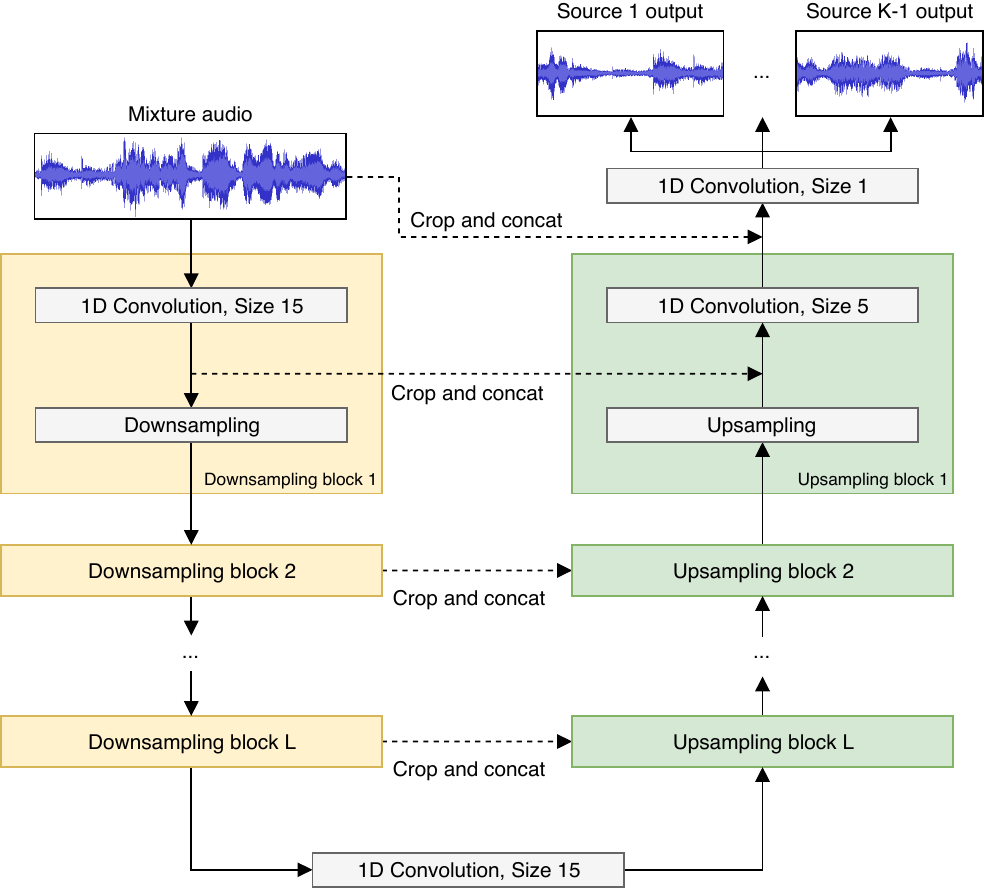
- Use LeakyReLU activation except for the final one, which uses tanh
- Downsampling discards features for every other time step to halve the time resolution
- Concat concatenates the current high-level features with more local features x
- Since they do not padding zeros and so they need to crop for concatenating.
- Input and output are raw audio.
- Loss function is mean squared error
- A is mix audio, B is vocals and C is accompaniment.
- B * factor0 + C * factor1 = newA
- A as input and C*factor1 as label
- Factor0 and factor1 is chosen uniformly from the interval [0.7, 1.0].
Result for the UWaveNet
- The result is better than mine results