The game environment of MarioKart 64 runs on the Bizhawk emulator which provides features for joypad support, recording functions of the gameplay as well as several debugging tools. Via Lua scripting it is possible to access and manipulate the game environment such that one can load and save the current state and subsequently take screenshots for learning abstract features of the environment.
In order to establish real time learning AI, we used a python server on which the lua environments connect to. The agent which acts on the environment is then solely implemented in python.
https://polybox.ethz.ch/index.php/s/XH9sq6kOYkKxPZG
Check out our youtube videos!
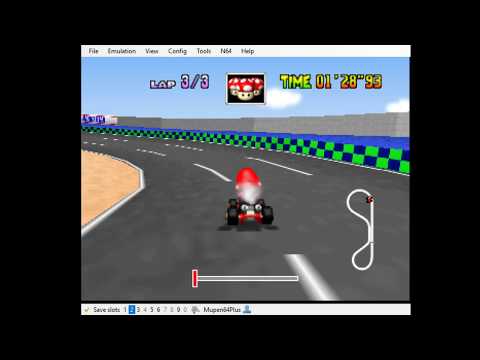
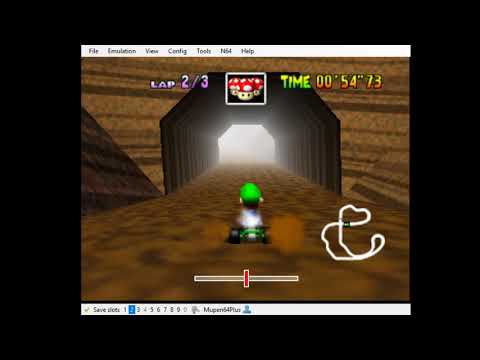
To see how things work in the big picture we provide the following example. Here is an example of an agent that executes random actions provided by the action space.
from mario_env import MarioEnv
"""
Random agent. Executes random actions provided by the action space
"""
def main():
# num_steering_dir divides the continuous steering direction into discrete action space of steering directions. Should be a odd number.
# if jump = true the bot has the ability to jump, too
env = MarioEnv(num_steering_dir=11, jump=False)
# returns all possible actions that can be executed on the environment
action_space = env.action_space
# sets the agent back to start and returns current printscreen
state = env.reset()
done = False
while not done:
# samples some action uniformly from action space
new_action = action_space.sample()
# executes the action on the environment
# returns new printscreen, current reward and if were done, info is empty
new_state, reward, done, info = env.step(new_action)
# closes the bizhawk client and the socket
env.close()
if __name__ == '__main__':
main()To get started, you can have a look at the simple random action agent which executes random actions.
Based on the gym environment from https://github.com/openai/gym, each mario environment starts its own python server. Then, we start via some environment variables that point to the path of the bizhawk client. For each environment we establish a connection with the python servers. This results in a 1 to 1 socket between the mario environments on the python side and the Mario clients on the bizhawk side. Via this socket we have a primitive text based communication with a few commands e.g. "RESET, 0.1234:1, ..".
The whole communication is basically encapsulated into the class MarioConnection and the agent only interacts with the MarioEnvironment. The MarioEnv implements the proposed Gym methods from openai:
- Reset -> State: Resets the environment and gets the initial status back.
- Act(action) -> State,Reward,Done: Executes an action and gets the reward back and if we're done or not.
- Close -> closes the environment. The rest of the provided methods are not relevant for us . In our case the state is defined as the current screenshot. The reward is some value in the range [0,1].
MarioConnection encapsulates the byte communication between bizhawk and python.
Since bizhawk can't currently accept some number to indicate which python server to connect. We had to create a script for each specific port to connect. This is the reason for the numerous new_mario_env0.lua, new_mario_env1.lua etc. Since everything starts automatically.
When bizhawk is loaded it loads the state saved on state 2. http://tasvideos.org/Bizhawk/SavestateFormat.html You can save a state in-game via: shift + F2 on 2. It is advised to save the state at the beginning of the track such that the agent can directly start to cruise.
mkdl holds all the python code. Short summary:
- random_agent.py: Example agent
- start_bizhawk.py : responsible for starting bizhawk automatically
- utils.py: some util functions
- run_bizhawk.py: starts bizhawk from python console
- policy.py: holds our used NeuralNetworks. Mostly used is OurCNN2 which is a CNN with 2 additional non-linear relu layers.
- mario_env.py: holds the MarioEnv which the agent can act on. And also the MarioConnection which communicates with the Bizhawk
- ppo2_agent.py: executes the ppo agent. openai ppo implementation
- a2c_agent.py
- a3c_agent.py
- just some additional agents we tried out and rejected again for our problem.
- windows only (thanks to bizhawk)
- python 3.6
- Install python 3.6.4 (https://www.python.org/downloads/release/python-364/)
- install some relevant modules:
- pip install gym --no-dependencies
- pip install tensorflow (cpu version) / pip install tensorflow-gpu (gpu version)
- pip install bench
- pip install logger
- pip install cloudpickle
- install openai baselines but our extended ones: pip install --no-dependencies git+https://github.com/SimiPro/baselines.git
- Install Microsoft MPI https://www.microsoft.com/en-us/download/details.aspx?id=55494
- Install Bizhawk https://github.com/TASVideos/BizHawk/releases
- Set the system environment variables:
- BIZHAWK = "Path/To/BizHawkEmulator"
- MKDL_LUA = "Path/To/MKDL_LUA/Folder"
- Create folder "isos" in the Bizhawk Emulator folder and place the rom file ('mario.z64') in the folder
OPTIONAL:
- Install Pycharm https://www.jetbrains.com/pycharm/download/#section=windows
- Open Pycharm and select the python interpreter we just installed in 1
- Install package gym under File -> Project:mkdl -> Project Interpreter -> Green Plus symbol -> Add gym
Before running environment we have to create a save state which is loaded when bizhawk is started. This is normally at the start line of a track.
- Run the Bizhawk emulator and select the rom mario.z64
- Choose Timetrial mode, choose a Player, choose a Kart and Track (e.g. Luigi Raceaway)
- Press Shift + F1 to create a save state at slot 2, close the application
- Run python random_agent.py
How to use PPO2_agent.py
To run the agent with precomputed weights:
- ppo2_agent.py, Line 103 change to run(..)
- Go to site-packages -> baselines -> PPO2 -> ppo2.py -> Line 153 Make sure load_path = "Path\To\Model\Model_no"
The weights can be downloaded here and are thought to be used with the track of luigi raceaway: https://polybox.ethz.ch/index.php/s/FUgZ7cWQ7BVd2Kv
- ppo2_agent.py, Line 103 change to train(..)
- Go to site-packages -> baselines -> PPO2 -> ppo2.py -> Line 153 Make sure load_path = None
- Simon Huber
- Huy Cao Tri Do
- Samuel Andermatt
- Quentin Auzepy
This project is licensed under the MIT License
- big thanks to https://github.com/rameshvarun/NeuralKart which was basically our inspiration for doing this.