Approach:
- Sort both relations on join attribute.
- Scan together using merge to form result
(r, s)tuples.
Advantages:
- No need to deal with all
Stuples for eachrtuples. - Deal with runs of matching
RandStuples.
Disadvantages:
- Cost of sorting both relations.
- Some rescanning required when long runs of
Stuples.
Merging for join requires 3 cursors to scan sorted relations:
r= current record inRrelation.s= current record inSrelation.ss= start of current run inSrelation.
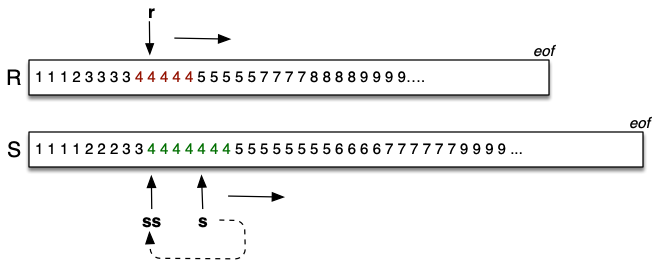
ri: Query = startScan("SortedR")
si: Query = startScan("SortedS")
while (r := nextTuple(ri)) is not None \
and (s := nextTuple(si)) is not None:
# aligns cursors to start of next common run
while r is not None and r.i < s.j:
r = nextTuple(ri)
if r is None:
break
while s is not None and r.i > s.i:
s = nextTuple(si)
if s is None:
break
# must have r.i == s.i here
startRun: TupleId = scanCurrent(si)
x
while r is not None and r.i == s.j:
while s is not None and s.j = r.i:
addTuple(outBuf, combine(r, s))
if isFull(outBuf):
writePage(outFile, outp, outBuf)
outp += 1
clearBuf(outBuf)
s = nextTuple(si)
r = nextTuple(ri)
setScan(si, startRun)Sort phase:
- As many as possible (cost is
O(log(N))). - If insufficient buffers, sorting cost can dominate.
Merge phase:
- 1 output buffer for result.
- 1 input buffer for relation
R. - (Preferably) enough buffers for longest run in
S.
Step 1: sort each relation (if not already sorted):
- Cost =
2 * b_r * (1 + ceil(log_{N - 1}(b_R / N))) + 2 * b_s * (1 + ceil(log_{N - 1}(b_RS/ N))) Nis number of memory buffers.
Step 2: merge sorted relations:
- If every run of values in
Sfits completely in buffers, merge requires single scan.- Cost =
b_R + b_S.
- Cost =
- If some runs in
Sare larger than buffers, need to re-scan run for each corresponding value fromR.- Need to re-scan old values of
Sfor new value ofR.
- Need to re-scan old values of