A concurrent schedule on a set of tx's TT is serialisable if:
- It produces the same effect as a serial schedule on
TT.
A goal of isolation mechanisms is:
- To arrange execution of individual operations in tx's in
TT. - To ensure that a serializable schedule is produced.
Serialisability is a property of a schedule focusing on isolation. Other properties focus on recovering from failures.
Producing a serialisable schedule:
- Eliminates all update anomalies (GOOD).
- May reduce opportunity for concurrency (BAD).
- May reduce overall throughput of system (BAD).
If DB programmers know update anomalies are unlikely/tolerable:
- Serialisable schedules may not be necessary.
- Some DBMSs offer less strict isolation levels (e.g. repeatable read).
- Allowing opportunity for more concurrency.
Problems arise when transactions abort. Consider the following schedule where T1 fails:
T1: R(X) W(X) A
T2: R(X) W(X) C
There are 3 places where the rollback might occur:
T1: R(X) W(X) A [1] [2] [3]
T2: R(X) W(X) C
Case 1 (GOOD):
- All effects of
T1vanish; final effect is simply fromT2.
Case 2 (BAD):
- Some of
T1's effects persist, even thoughT1aborted.
Case 3 (BAD):
T2's effects are lost, even thoughT2committed.
Consider the serialisable schedule:
T1: R(X) W(Y) C
T2: W(X) A
(where final value of Y is dependent on X value)
Notes:
- Final value of
Xis valid (change fromT2rolled back). T1reads/usesXvalue that is eventually rolled-back.- Even though
T2is correctly aborted, it has produced an effect.
This produces an invalid database state, even though serialisable.
Recoverable schedules:
- Have transactions commit only AFTER all transactions whose changes they read commit.
- Formally: All tx's
T_ithat write values used byT_jmust commit BEFORET_jcommits.
- Formally: All tx's
- Ensures a transaction does not commit a value written/updated by another transaction that is eventually rolled-back.
- Note: does NOT prevent dirty reads.
In order to make schedules recoverable, may need to abort multiple transactions.
Recall the non-recoverable schedule:
T1: R(X) W(Y) C
T2: W(X) A
To make it recoverable requires:
- Delaying
T1's commit untilT2commits. - If
T2aborts, cannot allowT1to commit.
T1: R(X) W(Y) ... C? A!
T2: W(X) A
This is known as cascading aborts.
Another example:
T1: R(Y) W(Z) A
T2: R(X) W(Y) A
T3: W(X) A
T3 aborts, causing T2 to abort, causing T1 to abort even though T1 has no shared data with T3.
This kind of problem:
- Can potentially affect very many concurrent transactions.
- Could have significant impact on system throughput.
Cascading aborts can be avoided if:
- Tx's can only read values written by committed transactions.
- Alternatively: no tx can read data items written by an uncommitted tx.
Effectively: eliminate the possibility of reading dirty data.
Downside: reduces opportunity for concurrency.
These are known as ACR (avoid cascading rollback) schedules. All ACR schedules are also recoverable.
Strict schedules also eliminate the chance of writing dirty data.
A schedule is strict if:
- No tx can read values written by another uncommitted tx (ACR).
- No tx can write a data item written by another uncommitted tx.
Strict schedules simplify rolling back after aborts.
T1: W(X) A
T2: W(X) A
Problems with handling rollback after aborts:
- When
T1aborts, don't rollback (need to retain value written byT2). - When
T2aborts, need to rollback to pre-T1(not just pre-T2, as this would have the effect ofT1).
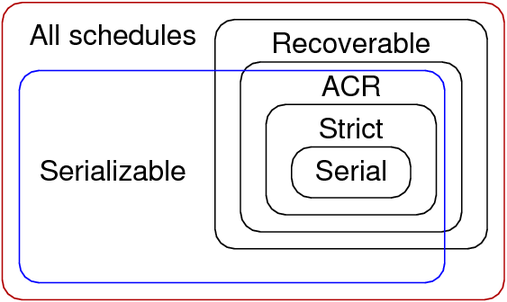
DBMSs allow users to trade off "safety" (seralisability and strictness) against performance.