Spring、Netty、Mybatis 等框架的代码中大量运用了 Java 多线程编程技巧。并发编程处理的恰当与否,将直接影响架构的性能。本章通过对 这些框架源码 的分析,结合并发编程的常用技巧,来讲解多线程编程在这些主流框架中的应用。
JVM规范 定义了 Java内存模型 来屏蔽掉各种操作系统、虚拟机实现厂商和硬件的内存访问差异,以确保 Java 程序 在所有操作系统和平台上能够达到一致的内存访问效果。
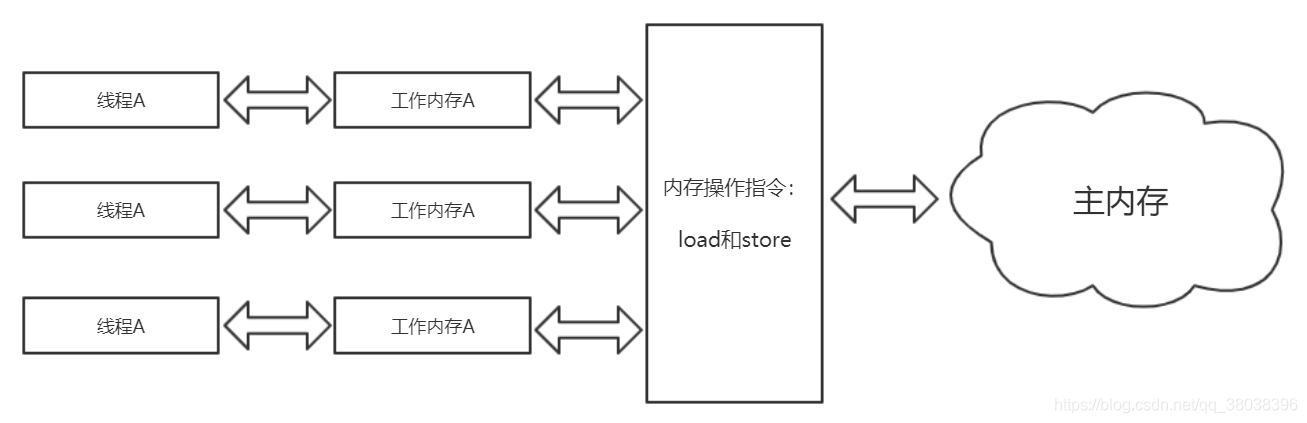
Java内存模型 规定所有的变量都存储在主内存中,每个线程都有自己独立的工作内存,工作内存保存了 对应该线程使用的变量的主内存副本拷贝。线程对这些变量的操作都在自己的工作内存中进行,不能直接操作主内存 和 其他工作内存中存储的变量或者变量副本。线程间的变量传递需通过主内存来完成,三者的关系如下图所示。
Java内存模型定义了8种操作来完成主内存和工作内存的变量访问,具体如下。
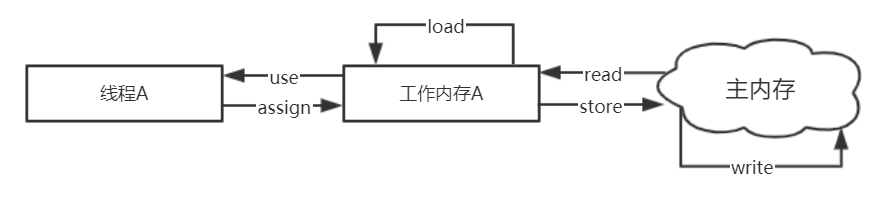
- read:把一个变量的值从主内存传输到线程的工作内存中,以便随后的 load 动作使用。
- load:把从主内存中读取的变量值载入工作内存的变量副本中。
- use:把工作内存中一个变量的值传递给 Java 虚拟机执行引擎。
- assign:把从执行引擎接收到的变量的值赋值给工作内存中的变量。
- store:把工作内存中一个变量的值传送到主内存中,以便随后的write操作。
- write:工作内存传递过来的变量值放入主内存中。
- lock:把主内存的一个变量标识为某个线程独占的状态。
- unlock:把主内存中 一个处于锁定状态的变量释放出来,被释放后的变量才可以被其他线程锁定。
这个概念与事务中的原子性大概一致,表明此操作是不可分割,不可中断的,要么全部执行,要么全部不执行。 Java内存模型直接保证的原子性操作包括read、load、use、assign、store、write、lock、unlock这八个。
可见性是指当一个线程修改了共享变量的值,其他线程能够立即得知这个修改。Java内存模型 是通过在变量修改后将新值同步回主内存,在变量读取前从主内存刷新变量值这种依赖主内存作为传递媒介的方式来实现可见性的,无论是普通变量还是 volatile变量 都是如此,普通变量与 volatile变量 的区别是,volatile 的特殊规则保证了新值能立即同步到主内存,以及每次使用前立即从主内存刷新。因此,可以说 volatile 保证了多线程操作时变量的可见性,而普通变量则不能保证这一点。除了 volatile 外,synchronized 也提供了可见性,synchronized 的可见性是由 “对一个变量执行 unlock操作 之前,必须先把此变量同步回主内存中(执行 store、write 操作)” 这条规则获得。
单线程环境下,程序会 “有序的”执行,即:线程内表现为串行语义。但是在多线程环境下,由于指令重排,并发执行的正确性会受到影响。在 Java 中使用 volatile 和 synchronized 关键字,可以保证多线程执行的有序性。volatile 通过加入内存屏障指令来禁止内存的重排序。synchronized 通过加锁,保证同一时刻只有一个线程来执行同步代码。
打开 NioEventLoop 的代码中,有一个控制 IO操作 和 其他任务运行比例的,用 volatile 修饰的 int类型字段 ioRatio,代码如下。
private volatile int ioRatio = 50;这里为什么要用 volatile 修饰呢?我们首先对 volatile 关键字进行说明,然后再结合 Netty 的代码进行分析。
关键字 volatile 是 Java 提供的最轻量级的同步机制,Java 内存模型对 volatile 专门定义了一些特殊的访问规则。下面我们就看它的规则。当一个变量被 volatile 修饰后,它将具备以下两种特性。
- 线程可见性:当一个线程修改了被 volatile 修饰的变量后,无论是否加锁,其他线程都可以立即看到最新的修改(什么叫立即看到最新的修改?感觉这句话太口语化且模糊,搞不太懂!),而普通变量却做不到这点。
- 禁止指令重排序优化:普通的变量仅仅保证在该方法的执行过程中所有依赖赋值结果的地方都能获取正确的结果,而不能保证变量赋值操作的顺序与程序代码的执行顺序一致。举个简单的例子说明下指令重排序优化问题,代码如下。
public class ThreadStopExample {
private static boolean stop;
public static void main(String[] args) throws InterruptedException {
Thread workThread = new Thread(new Runnable() {
public void run() {
int i= 0;
while (!stop) {
i++;
try{
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
});
workThread.start();
TimeUnit.SECONDS.sleep(3);
stop = true;
}
}我们预期程序会在 3s 后停止,但是实际上它会一直执行下去,原因就是虚拟机对代码进行了指令重排序和优化,优化后的指令如下。
if (!stop)
While(true)
......workThread线程 在执行重排序后的代码时,是无法发现 变量stop 被其它线程修改的,因此无法停止运行。要解决这个问题,只要将 stop 前增加 volatile 修饰符即可。volatile 解决了如下两个问题。第一,主线程对 stop 的修改在 workThread线程 中可见,也就是说 workThread线程 立即看到了其他线程对于 stop变量 的修改。第二,禁止指令重排序,防止因为重排序导致的并发访问逻辑混乱。
一些人认为使用 volatile 可以代替传统锁,提升并发性能,这个认识是错误的。volatile 仅仅解决了可见性的问题,但是它并不能保证互斥性,也就是说多个线程并发修改某个变量时,依旧会产生多线程问题。因此,不能靠 volatile 来完全替代传统的锁。根据经验总结,volatile 最适用的场景是 “ 一个线程写,其他线程读 ”,如果有多个线程并发写操作,仍然需要使用锁或者线程安全的容器或者原子变量来代替。下面我们继续对 Netty 的源码做分析。上面讲到了 ioRatio 被定义成 volatile,下面看看代码为什么要这样定义。
final long ioTime = System.nanoTime() - ioStartTime;
runAllTasks(ioTime * (100 - ioRatio) / ioRatio);通过代码分析我们发现,在 NioEventLoop线程 中,ioRatio 并没有被修改,它是只读操作。既然没有修改,为什么要定义成 volatile 呢?继续看代码,我们发现 NioEventLoop 提供了重新设置 IO 执行时间比例的公共方法。
public void setIoRatio(int ioRatio) {
if (ioRatio <= 0 || ioRatio > 100) {
throw new IllegalArgumentException("ioRatio: " + ioRatio + " (expected: 0 < ioRatio <= 100)");
}
this.ioRatio = ioRatio;
}首先,NioEventLoop线程 没有调用该 set方法,说明调整 IO执行时间比例 是外部发起的操作,通常是由业务的线程调用该方法,重新设置该参数。这样就形成了一个线程写、一个线程读。根据前面针对 volatile 的应用总结,此时可以使用 volatile 来代替传统的 synchronized关键字,以提升并发访问的性能。
ThreadLocal 又称为线程本地存储区(Thread Local Storage,简称为TLS),每个线程都有自己的私有的本地存储区域,不同线程之间彼此不能访问对方的 TLS区域。使用 ThreadLocal变量 的 set(T value)方法 可以将数据存入 该线程本地存储区,使用 get() 方法 可以获取到之前存入的值。
不使用 ThreadLocal。
public class SessionBean {
public static class Session {
private String id;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
}
public Session createSession() {
return new Session();
}
public void setId(Session session, String id) {
session.setId(id);
}
public String getId(Session session) {
return session.getId();
}
public static void main(String[] args) {
//没有使用ThreadLocal,在方法间共享session需要进行session在方法间的传递
new Thread(() -> {
SessionBean bean = new SessionBean();
Session session = bean.createSession();
bean.setId(session, "susan");
System.out.println(bean.getId(session));
}).start();
}
}上述代码中,session需要在方法间传递才可以修改和读取,保证线程中各方法操作的是一个。下面看一下使用 ThreadLocal 的代码。
public class SessionBean {
//定义一个静态ThreadLocal变量session,就能够保证各个线程有自己的一份,并且方法可以方便获取,不用传递
private static ThreadLocal<Session> session = new ThreadLocal<>();
public static class Session {
private String id;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
}
public void createSession() {
session.set(new Session());
}
public void setId(String id) {
session.get().setId(id);
}
public String getId() {
return session.get().getId();
}
public static void main(String[] args) {
new Thread(() -> {
SessionBean bean = new SessionBean();
bean.createSession();
bean.setId("susan");
System.out.println(bean.getId());
}).start();
}
}在方法的内部实现中,直接可以通过 session.get() 获取到当前线程的 session,省掉了参数在方法间传递的环节。
一般,类属性中的数据是多个线程共享的,但 ThreadLocal类型的数据 声明为类属性,却可以为每一个使用它(通过set(T value)方法)的线程存储 线程私有的数据,通过其源码我们可以发现其中的原理。
public class ThreadLocal<T> {
/**
* 下面的 getMap()方法 传入当前线程,获得一个ThreadLocalMap对象,说明每一个线程维护了
* 自己的一个 map,保证读取出来的value是自己线程的。
*
* ThreadLocalMap 是ThreadLocal静态内部类,存储value的键值就是ThreadLocal本身。
*
* 因此可以断定,每个线程维护一个ThreadLocalMap的键值对映射Map。不同线程的Map的 key值 是一样的,
* 都是ThreadLocal,但 value 是不同的。
*/
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
}Spring事务处理的设计与实现中大量使用了 ThreadLocal类,比如,TransactionSynchronizationManager 维护了一系列的 ThreadLocal变量,用于存储线程私有的 事务属性及资源。源码如下。
/**
* 管理每个线程的资源和事务同步的中心帮助程序。供资源管理代码使用,但不供典型应用程序代码使用。
*
* 资源管理代码应该检查线程绑定的资源,如,JDBC连接 或 Hibernate Sessions。
* 此类代码通常不应该将资源绑定到线程,因为这是事务管理器的职责。另一个选项是,
* 如果事务同步处于活动状态,则在首次使用时延迟绑定,以执行跨任意数量资源的事务。
*/
public abstract class TransactionSynchronizationManager {
/**
* 一般是一个线程持有一个 独立的事务,以相互隔离地处理各自的事务。
* 所以这里使用了很多 ThreadLocal对象,为每个线程绑定 对应的事务属性及资源,
* 以便后续使用时能直接获取。
*/
private static final ThreadLocal<Map<Object, Object>> resources =
new NamedThreadLocal<Map<Object, Object>>("Transactional resources");
private static final ThreadLocal<Set<TransactionSynchronization>> synchronizations =
new NamedThreadLocal<Set<TransactionSynchronization>>("Transaction synchronizations");
private static final ThreadLocal<String> currentTransactionName =
new NamedThreadLocal<String>("Current transaction name");
private static final ThreadLocal<Boolean> currentTransactionReadOnly =
new NamedThreadLocal<Boolean>("Current transaction read-only status");
private static final ThreadLocal<Integer> currentTransactionIsolationLevel =
new NamedThreadLocal<Integer>("Current transaction isolation level");
private static final ThreadLocal<Boolean> actualTransactionActive =
new NamedThreadLocal<Boolean>("Actual transaction active");
/**
* 为当前线程 绑定 对应的resource资源
*/
public static void bindResource(Object key, Object value) throws IllegalStateException {
Object actualKey = TransactionSynchronizationUtils.unwrapResourceIfNecessary(key);
Assert.notNull(value, "Value must not be null");
Map<Object, Object> map = resources.get();
// 如果当前线程的 resources中,绑定的数据map为空,则为 resources 绑定 map
if (map == null) {
map = new HashMap<Object, Object>();
resources.set(map);
}
Object oldValue = map.put(actualKey, value);
if (oldValue instanceof ResourceHolder && ((ResourceHolder) oldValue).isVoid()) {
oldValue = null;
}
if (oldValue != null) {
throw new IllegalStateException("Already value [" + oldValue + "] for key [" +
actualKey + "] bound to thread [" + Thread.currentThread().getName() + "]");
}
if (logger.isTraceEnabled()) {
logger.trace("Bound value [" + value + "] for key [" + actualKey + "] to thread [" +
Thread.currentThread().getName() + "]");
}
}
/**
* 返回当前线程绑定的所有资源
*/
public static Map<Object, Object> getResourceMap() {
Map<Object, Object> map = resources.get();
return (map != null ? Collections.unmodifiableMap(map) : Collections.emptyMap());
}
}Mybatis 的 SqlSession对象 也是各线程私有的资源,所以对其的管理也使用到了 ThreadLocal类。源码如下。
public class SqlSessionManager implements SqlSessionFactory, SqlSession {
private final ThreadLocal<SqlSession> localSqlSession = new ThreadLocal<>();
public void startManagedSession() {
this.localSqlSession.set(openSession());
}
public void startManagedSession(boolean autoCommit) {
this.localSqlSession.set(openSession(autoCommit));
}
public void startManagedSession(Connection connection) {
this.localSqlSession.set(openSession(connection));
}
public void startManagedSession(TransactionIsolationLevel level) {
this.localSqlSession.set(openSession(level));
}
public void startManagedSession(ExecutorType execType) {
this.localSqlSession.set(openSession(execType));
}
public void startManagedSession(ExecutorType execType, boolean autoCommit) {
this.localSqlSession.set(openSession(execType, autoCommit));
}
public void startManagedSession(ExecutorType execType, TransactionIsolationLevel level) {
this.localSqlSession.set(openSession(execType, level));
}
public void startManagedSession(ExecutorType execType, Connection connection) {
this.localSqlSession.set(openSession(execType, connection));
}
public boolean isManagedSessionStarted() {
return this.localSqlSession.get() != null;
}
@Override
public Connection getConnection() {
final SqlSession sqlSession = localSqlSession.get();
if (sqlSession == null) {
throw new SqlSessionException("Error: Cannot get connection. No managed session is started.");
}
return sqlSession.getConnection();
}
@Override
public void clearCache() {
final SqlSession sqlSession = localSqlSession.get();
if (sqlSession == null) {
throw new SqlSessionException("Error: Cannot clear the cache. No managed session is started.");
}
sqlSession.clearCache();
}
@Override
public void commit() {
final SqlSession sqlSession = localSqlSession.get();
if (sqlSession == null) {
throw new SqlSessionException("Error: Cannot commit. No managed session is started.");
}
sqlSession.commit();
}
@Override
public void commit(boolean force) {
final SqlSession sqlSession = localSqlSession.get();
if (sqlSession == null) {
throw new SqlSessionException("Error: Cannot commit. No managed session is started.");
}
sqlSession.commit(force);
}
@Override
public void rollback() {
final SqlSession sqlSession = localSqlSession.get();
if (sqlSession == null) {
throw new SqlSessionException("Error: Cannot rollback. No managed session is started.");
}
sqlSession.rollback();
}
@Override
public void rollback(boolean force) {
final SqlSession sqlSession = localSqlSession.get();
if (sqlSession == null) {
throw new SqlSessionException("Error: Cannot rollback. No managed session is started.");
}
sqlSession.rollback(force);
}
@Override
public List<BatchResult> flushStatements() {
final SqlSession sqlSession = localSqlSession.get();
if (sqlSession == null) {
throw new SqlSessionException("Error: Cannot rollback. No managed session is started.");
}
return sqlSession.flushStatements();
}
@Override
public void close() {
final SqlSession sqlSession = localSqlSession.get();
if (sqlSession == null) {
throw new SqlSessionException("Error: Cannot close. No managed session is started.");
}
try {
sqlSession.close();
} finally {
localSqlSession.set(null);
}
}
}首先通过 ThreadPoolExecutor 的源码 看一下线程池的主要参数及方法。
public class ThreadPoolExecutor extends AbstractExecutorService {
/**
* 核心线程数
* 当向线程池提交一个任务时,若线程池已创建的线程数小于corePoolSize,即便此时存在空闲线程,
* 也会通过创建一个新线程来执行该任务,直到已创建的线程数大于或等于corePoolSize
*/
private volatile int corePoolSize;
/**
* 最大线程数
* 当队列满了,且已创建的线程数小于maximumPoolSize,则线程池会创建新的线程来执行任务。
* 另外,对于无界队列,可忽略该参数
*/
private volatile int maximumPoolSize;
/**
* 线程存活保持时间
* 当线程池中线程数 超出核心线程数,且线程的空闲时间也超过 keepAliveTime时,
* 那么这个线程就会被销毁,直到线程池中的线程数小于等于核心线程数
*/
private volatile long keepAliveTime;
/**
* 任务队列
* 用于传输和保存等待执行任务的阻塞队列
*/
private final BlockingQueue<Runnable> workQueue;
/**
* 线程工厂
* 用于创建新线程。threadFactory 创建的线程也是采用 new Thread() 方式,threadFactory
* 创建的线程名都具有统一的风格:pool-m-thread-n(m为线程池的编号,n为线程池中线程的编号
*/
private volatile ThreadFactory threadFactory;
/**
* 线程饱和策略
* 当线程池和队列都满了,再加入的线程会执行此策略
*/
private volatile RejectedExecutionHandler handler;
/**
* 构造方法提供了多种重载,但实际上都使用了最后一个重载 完成了实例化
*/
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
threadFactory, defaultHandler);
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
RejectedExecutionHandler handler) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), handler);
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
/**
* 执行一个任务,但没有返回值
*/
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}
/**
* 提交一个线程任务,有返回值。该方法继承自其父类 AbstractExecutorService,有多种重载,这是最常用的一个。
* 通过future.get()获取返回值(阻塞直到任务执行完)
*/
public <T> Future<T> submit(Callable<T> task) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task);
execute(ftask);
return ftask;
}
/**
* 关闭线程池,不再接收新的任务,但会把已有的任务执行完
*/
public void shutdown() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
advanceRunState(SHUTDOWN);
interruptIdleWorkers();
onShutdown(); // hook for ScheduledThreadPoolExecutor
} finally {
mainLock.unlock();
}
tryTerminate();
}
/**
* 立即关闭线程池,已有的任务也会被抛弃
*/
public List<Runnable> shutdownNow() {
List<Runnable> tasks;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
advanceRunState(STOP);
interruptWorkers();
tasks = drainQueue();
} finally {
mainLock.unlock();
}
tryTerminate();
return tasks;
}
public boolean isShutdown() {
return ! isRunning(ctl.get());
}
}线程池执行流程,如下图所示。

Executors类 通过 ThreadPoolExecutor 封装了 4 种常用的线程池:CachedThreadPool,FixedThreadPool,ScheduledThreadPool 和 SingleThreadExecutor。其功能如下。
- CachedThreadPool:用来创建一个几乎可以无限扩大的线程池(最大线程数为 Integer.MAX_VALUE),适用于执行大量短生命周期的异步任务。
- FixedThreadPool:创建一个固定大小的线程池,保证线程数可控,不会造成线程过多,导致系统负载更为严重。
- SingleThreadExecutor:创建一个单线程的线程池,可以保证任务按调用顺序执行。
- ScheduledThreadPool:适用于执行 延时 或者 周期性 任务。
-
CPU密集型任务
尽量使用较小的线程池,一般为 CPU核心数+1。 因为 CPU密集型任务 使得 CPU使用率 很高,若开过多的线程数,会造成 CPU 过度切换。 -
IO密集型任务
可以使用稍大的线程池,一般为 2*CPU核心数。 IO密集型任务 CPU使用率 并不高,因此可以让 CPU 在等待 IO 的时候有其他线程去处理别的任务,充分利用 CPU时间。
Tomcat 在分发 web请求 时使用了线程池来处理。
public interface BlockingQueue<E> extends Queue<E> {
// 将给定元素设置到队列中,如果设置成功返回true, 否则返回false。如果是往限定了长度的队列中设置值,推荐使用offer()方法。
boolean add(E e);
// 将给定的元素设置到队列中,如果设置成功返回true, 否则返回false. e的值不能为空,否则抛出空指针异常。
boolean offer(E e);
// 将元素设置到队列中,如果队列中没有多余的空间,该方法会一直阻塞,直到队列中有多余的空间。
void put(E e) throws InterruptedException;
// 将给定元素在给定的时间内设置到队列中,如果设置成功返回true, 否则返回false.
boolean offer(E e, long timeout, TimeUnit unit)
throws InterruptedException;
// 从队列中获取值,如果队列中没有值,线程会一直阻塞,直到队列中有值,并且该方法取得了该值。
E take() throws InterruptedException;
// 在给定的时间里,从队列中获取值,时间到了直接调用普通的 poll()方法,为null则直接返回null。
E poll(long timeout, TimeUnit unit)
throws InterruptedException;
// 获取队列中剩余的空间。
int remainingCapacity();
// 从队列中移除指定的值。
boolean remove(Object o);
// 判断队列中是否拥有该值。
public boolean contains(Object o);
// 将队列中值,全部移除,并发设置到给定的集合中。
int drainTo(Collection<? super E> c);
// 指定最多数量限制将队列中值,全部移除,并发设置到给定的集合中。
int drainTo(Collection<? super E> c, int maxElements);
}-
ArrayBlockingQueue
基于数组的阻塞队列实现,在 ArrayBlockingQueue 内部,维护了一个定长数组,以便缓存队列中的数据对象,这是一个常用的阻塞队列,除了一个定长数组外,ArrayBlockingQueue 内部还保存着两个整形变量,分别标识着队列的头部和尾部在数组中的位置。
ArrayBlockingQueue 在生产者放入数据 和 消费者获取数据时,都是共用同一个锁对象,由此也意味着两者无法真正并行运行,这点尤其不同于 LinkedBlockingQueue。ArrayBlockingQueue 和 LinkedBlockingQueue 间还有一个明显的不同之处在于,前者在插入或删除元素时不会产生或销毁任何额外的对象实例,而后者则会生成一个额外的 Node对象。这在长时间内需要高效并发地处理大批量数据的系统中,其对于 GC 的影响还是存在一定的区别。而在创建 ArrayBlockingQueue 时,我们还可以控制对象的内部锁是否采用公平锁,默认采用非公平锁。 -
LinkedBlockingQueue
基于链表的阻塞队列,同 ArrayListBlockingQueue 类似,其内部也维持着一个数据缓冲队列(该队列由一个链表构成),当生产者往队列中放入一个数据时,队列会从生产者手中获取数据,并缓存在队列内部,而生产者立即返回;只有当队列缓冲区达到最大值缓存容量时(LinkedBlockingQueue可以通过构造函数指定该值),才会阻塞生产者队列,直到消费者从队列中消费掉一份数据,生产者线程会被唤醒,反之对于消费者这端的处理也基于同样的原理。而 LinkedBlockingQueue 之所以能够高效的处理并发数据,还因为其对于生产者端和消费者端分别采用了独立的锁来控制数据同步,这也意味着在高并发的情况下生产者和消费者可以并行地操作队列中的数据,以此来提高整个队列的并发性能。
需要注意的是,如果构造一个 LinkedBlockingQueue对象,而没有指定其容量大小,LinkedBlockingQueue 会默认一个类似无限大小的容量(Integer.MAX_VALUE),这样的话,如果生产者的速度一旦大于消费者的速度,也许还没有等到队列满阻塞产生,系统内存就有可能已被消耗殆尽了。 -
PriorityBlockingQueue
基于优先级的阻塞队列(优先级的判断通过构造函数传入的Compator对象来决定),但需要注意的是PriorityBlockingQueue并不会阻塞数据生产者,而只会在没有可消费的数据时,阻塞数据的消费者。因此使用的时候要特别注意,生产者生产数据的速度绝对不能快于消费者消费数据的速度,否则时间一长,会最终耗尽所有的可用堆内存空间。在实现PriorityBlockingQueue时,内部控制线程同步的锁采用的是公平锁。
互斥同步最主要的问题就是进行线程阻塞和唤醒所带来的性能的额外损耗,因此这种同步被称为阻塞同步,它属于一种悲观的并发策略,我们称之为悲观锁。随着硬件和操作系统指令集的发展和优化,产生了非阻塞同步,被称为乐观锁。简单地说,就是先进行操作,操作完成之后再判断操作是否成功,是否有并发问题,如果有则进行失败补偿,如果没有就算操作成功,这样就从根本上避免了同步锁的弊端。
目前,在Java中应用最广泛的非阻塞同步就是 CAS。从 JDK1.5 以后,可以使用 CAS 操作,该操作由 sun.misc.Unsafe 类里的 compareAndSwapInt() 和 compareAndSwapLong() 等方法实现。通常情况下 sun.misc.Unsafe类 对于开发者是不可见的,因此,JDK 提供了很多 CAS包装类 简化开发者的使用,如 AtomicInteger。使用 Java 自带的 Atomic原子类,可以避免同步锁带来的并发访问性能降低的问题,减少犯错的机会。