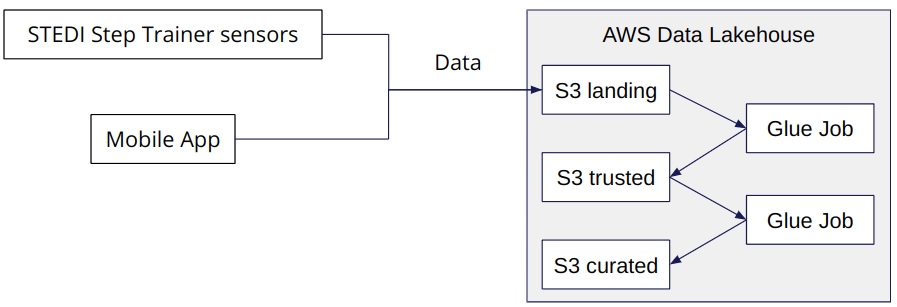
The STEDI startup team has launched on the market Step Trainers which are being adopted by a growing number of customers; the team has been working on IoT sensor data and ML to continuously exceed the expectations of its customers. In order to support the STEDI team, as data engineers, we have been asked to build an ETL pipeline that extracts the data from STEDI Step Trainer sensors and the mobile app, and curate them into a data lakehouse solution on AWS so that data scientists can train a learning model. This lakehouse implementation provides a more versatile and powerful data management solution to embrace modern businesses for data storage, processing, and analytics. For this job we have adopted: Python and Spark, Glue, Athena, and S3.
- Customer Records: s3://cd0030bucket/customers/
- Step Trainer Records: s3://cd0030bucket/step_trainer/
- Accelerometer Records: s3://cd0030bucket/accelerometer/
stedi-spark
└--cli
| abreu-stedi.txt # Content of S3 bucket
└--graphics
└--curated # folder: Athena screenshots: curated data - count of customers & machine learning curated readings
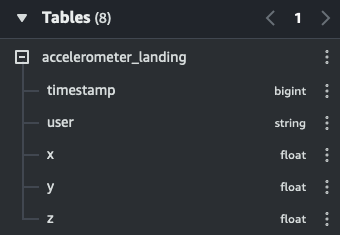
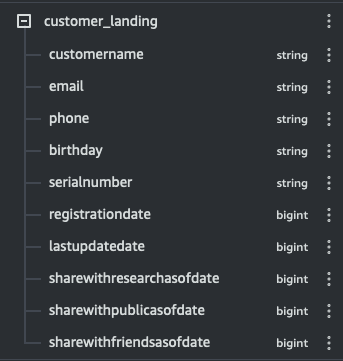
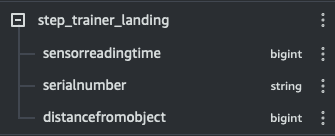
└--landing # folder: screenshots: raw data - preview + count of customers, sensor readings & table schemas + data types
└--trusted # folder: Athena screenshots: filtered data - data preview + count of customers & sensor readings
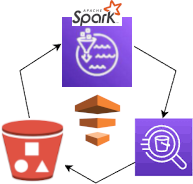
| aws_pipeline.png # AWS stack: S3, Glue/Spark, Athena
| database.png # Glue database
| flowchart.png # Flow of data (source: Udacity)
| glue_jobs.png # screenshot from Glue Studio: Glue ETL jobs
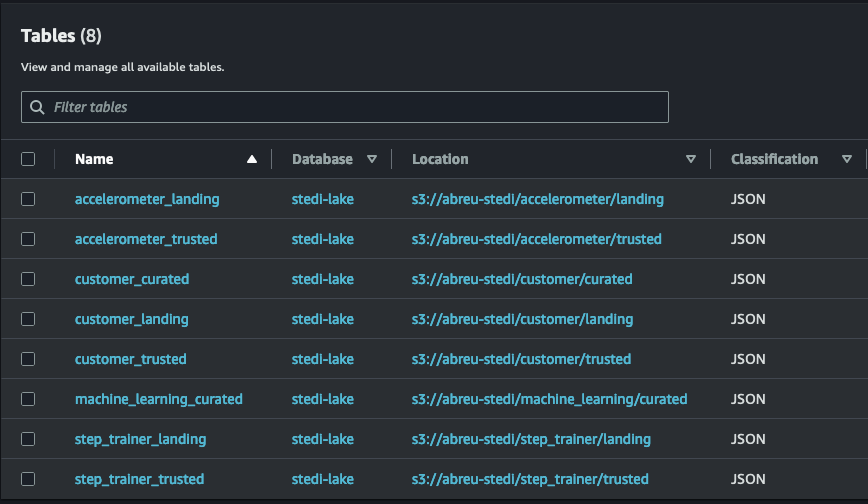
| tables.png # screenshot from Data Catalog: Glue tables
└--sql # folder: sql ddl scripts source of Glue tables
└--src # folder: python scripts source of Glue jobs
| README.md # Repository description
Create S3 gateway endpoint:
$ aws ec2 create-vpc-endpoint --vpc-id vpc-0f184f2e87eba239a --service-name com.amazonaws.us-east-1.s3 --route-table-ids rtb-0852aa5316bd66cc6
Create IAM role:
$ aws iam create-role --role-name my-glue-service-role --assume-role-policy-document '{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "glue.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}'
Grant AWS Glue privileges to access S3 bucket:
$ aws iam put-role-policy --role-name my-glue-service-role --policy-name S3Access --policy-document '{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "ListObjectsInBucket",
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::abreu-stedi"
]
},
{
"Sid": "AllObjectActions",
"Effect": "Allow",
"Action": "s3:*Object",
"Resource": [
"arn:aws:s3:::abreu-stedi/*"
]
}
]
}'
- Download/clone the repository with the project data (accelerometer, customer, step trainer)
- Create a new S3 bucket (ex. $ aws s3 mb s3://abreu-stedi --region us-east-1)
- Copy individually the JSON data of the 3 categories to the new S3 bucket, creating a sub-folder "landing" for each of the 3 different locations (ex. bucket path: s3://abreu-stedi/accelerometer/landing/).
$ aws glue create-database --database-input '{"Name": "stedi-lake"}'
A Glue database allows us to manage the data directly from the S3 bucket.
Disclosure: The results of each operation are summarized & presented as graphics. The source code of Glue tables & Glue ETL jobs are included in the project folders.
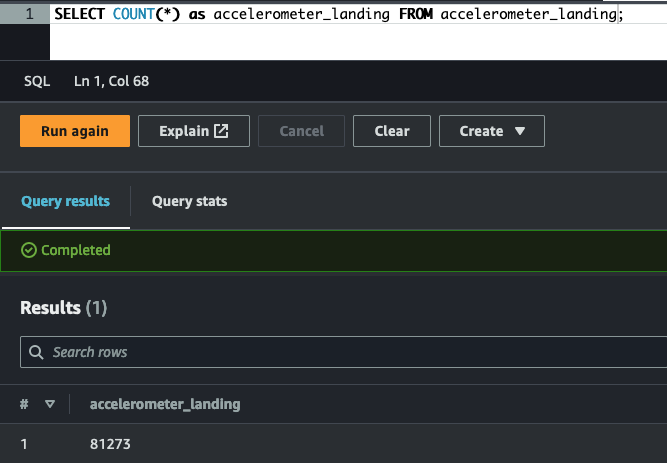
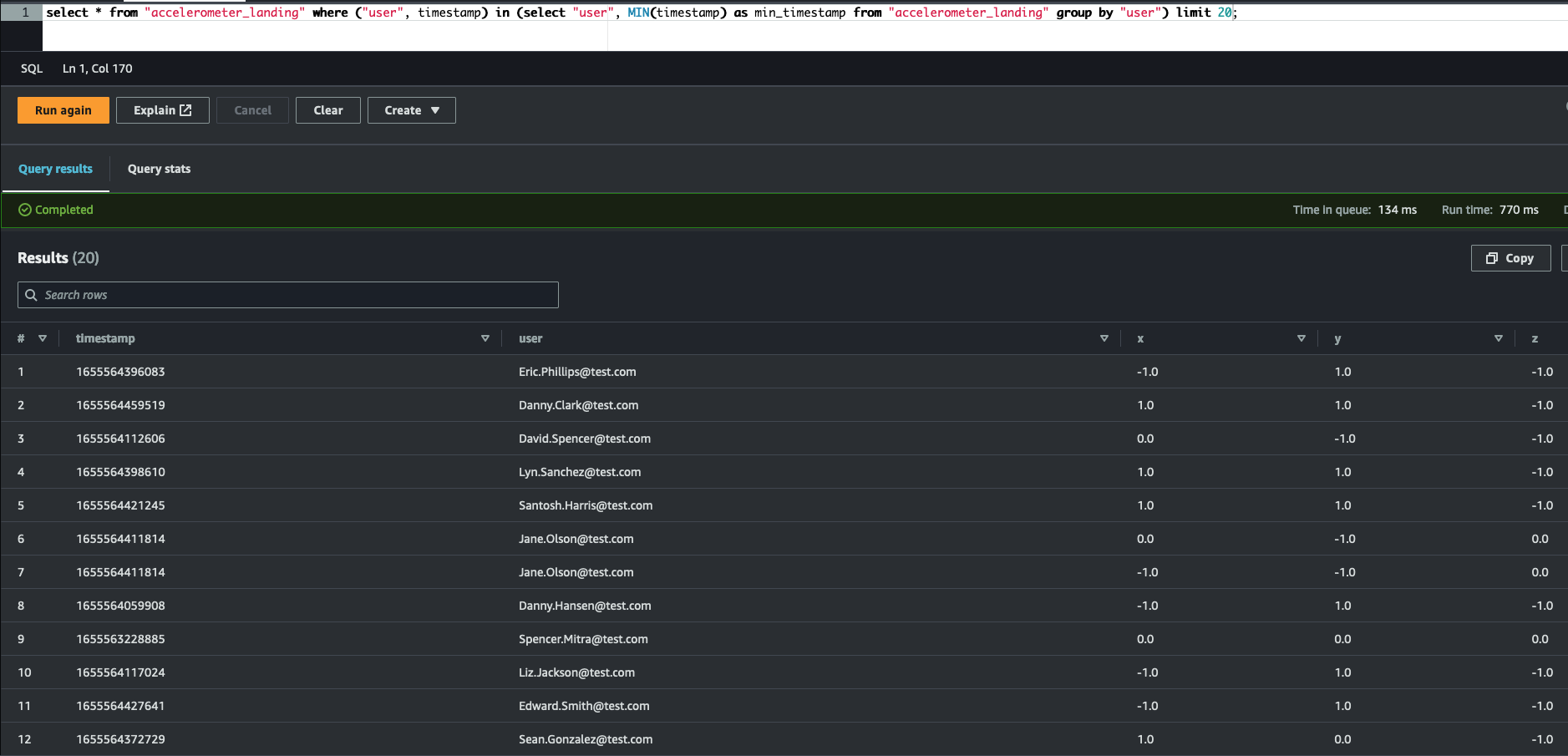
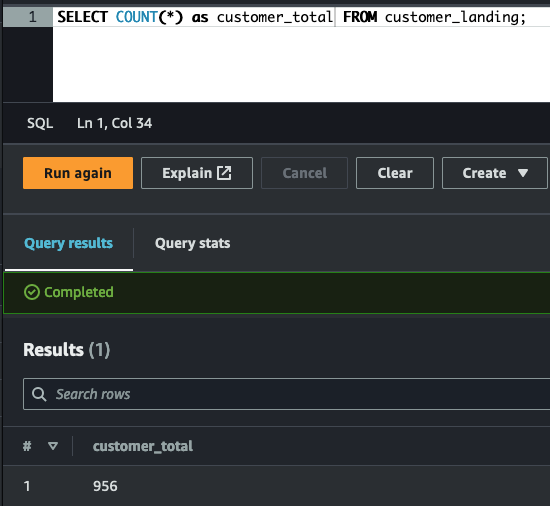
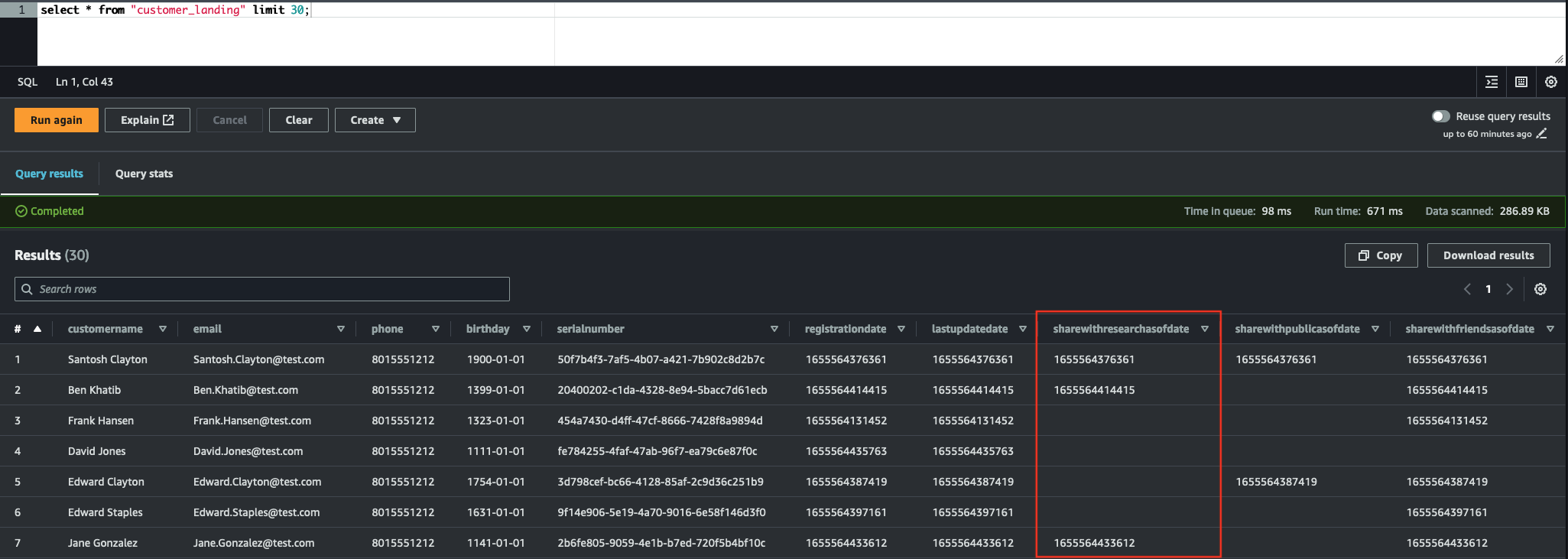
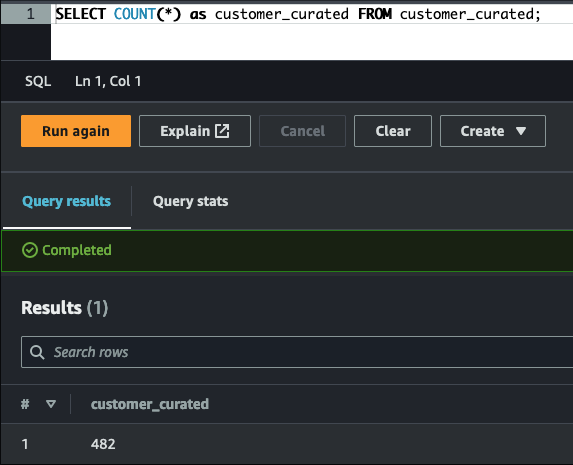
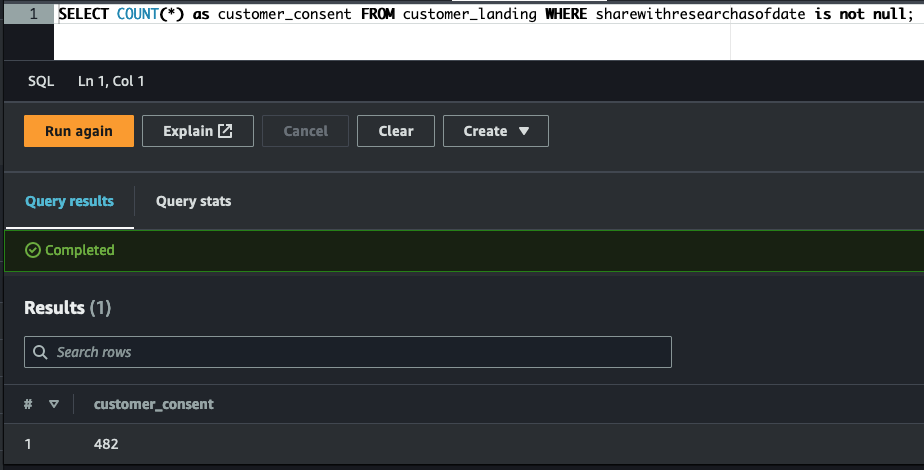
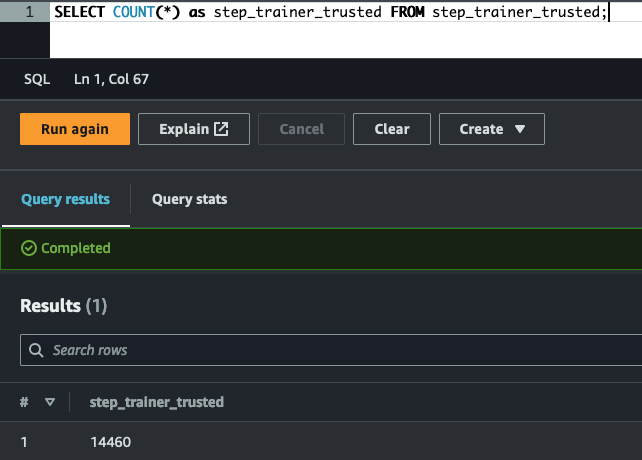
Filter the data that can be used for research/analytics (customers gave their consensus):
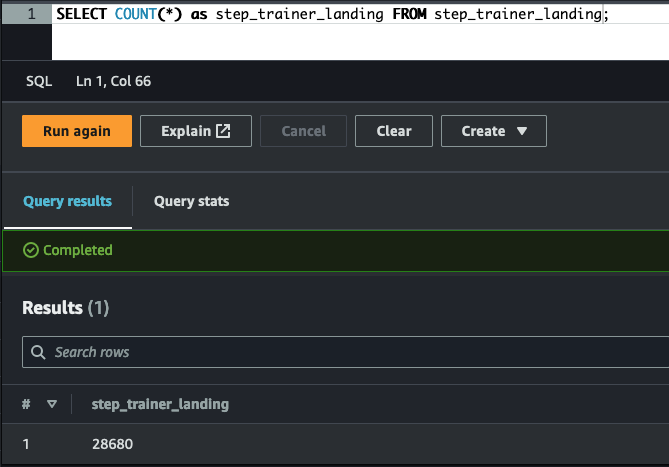
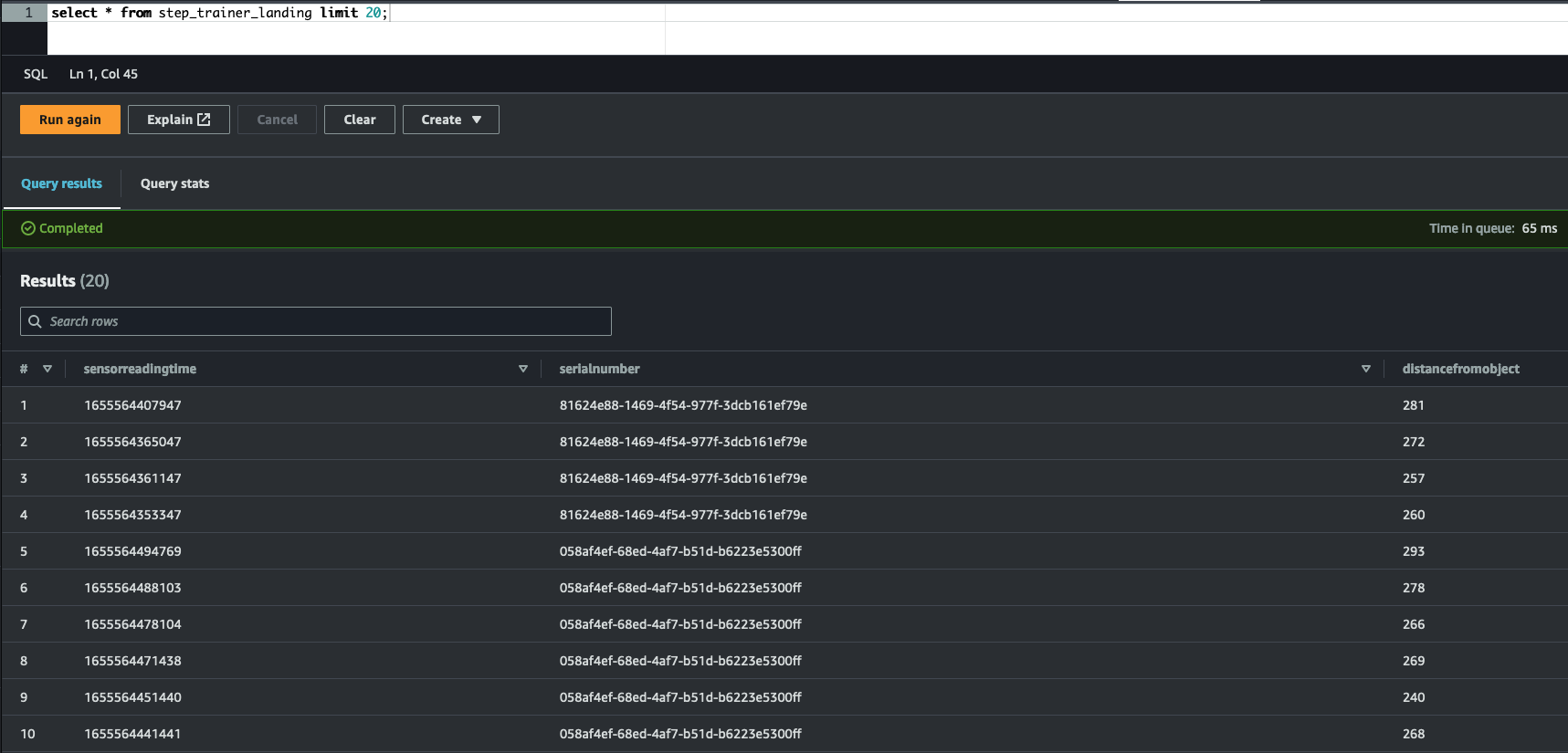
The sql folder contains the source code (DDL) to create each of the tables.
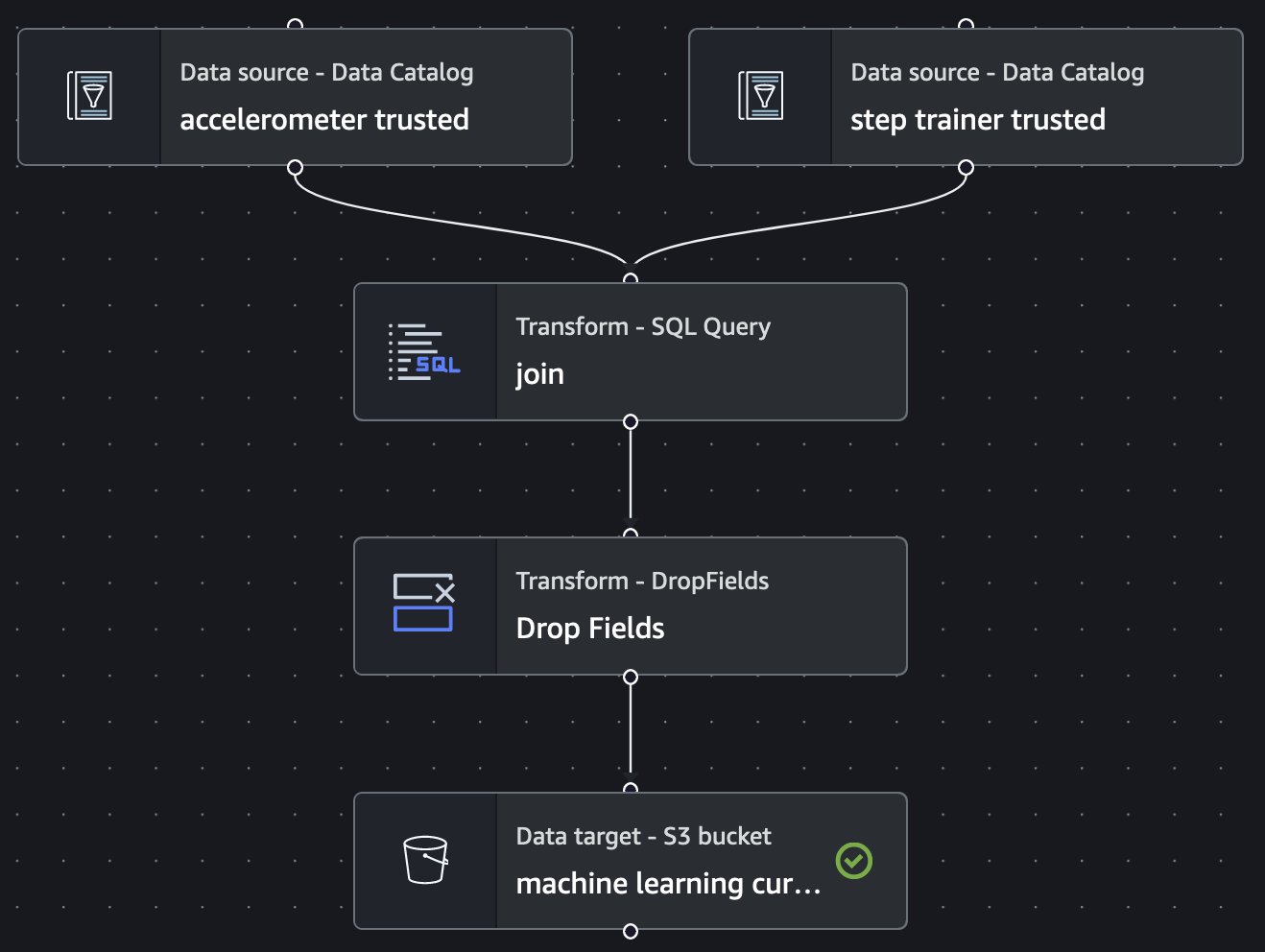
Use Glue Studio to build ETL jobs that extract, transform, and load the data from the origin (using source type: Data source - Data Catalog), transform/munge/clean/filter the data using SQL, and loading it into the target S3 bucket.
The following Glue jobs were created:
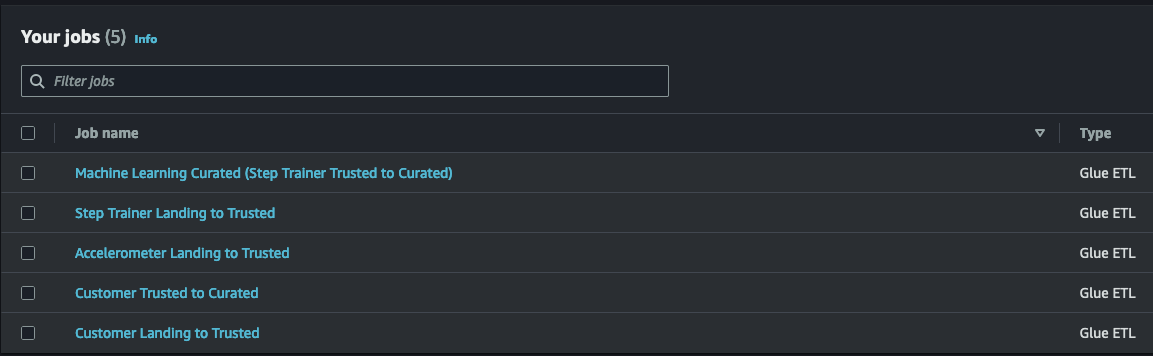
The src folder contains the source code (python) to create each of the Glue jobs. The name of each file is self-explanatory.
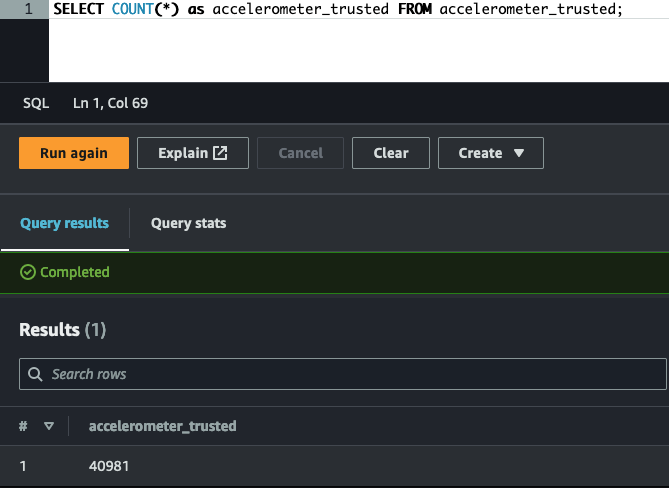
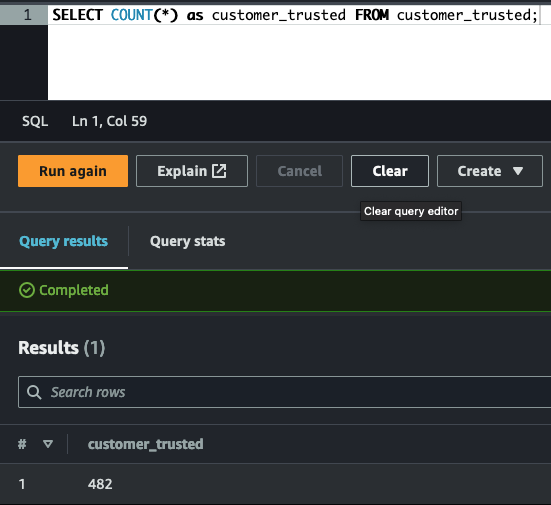
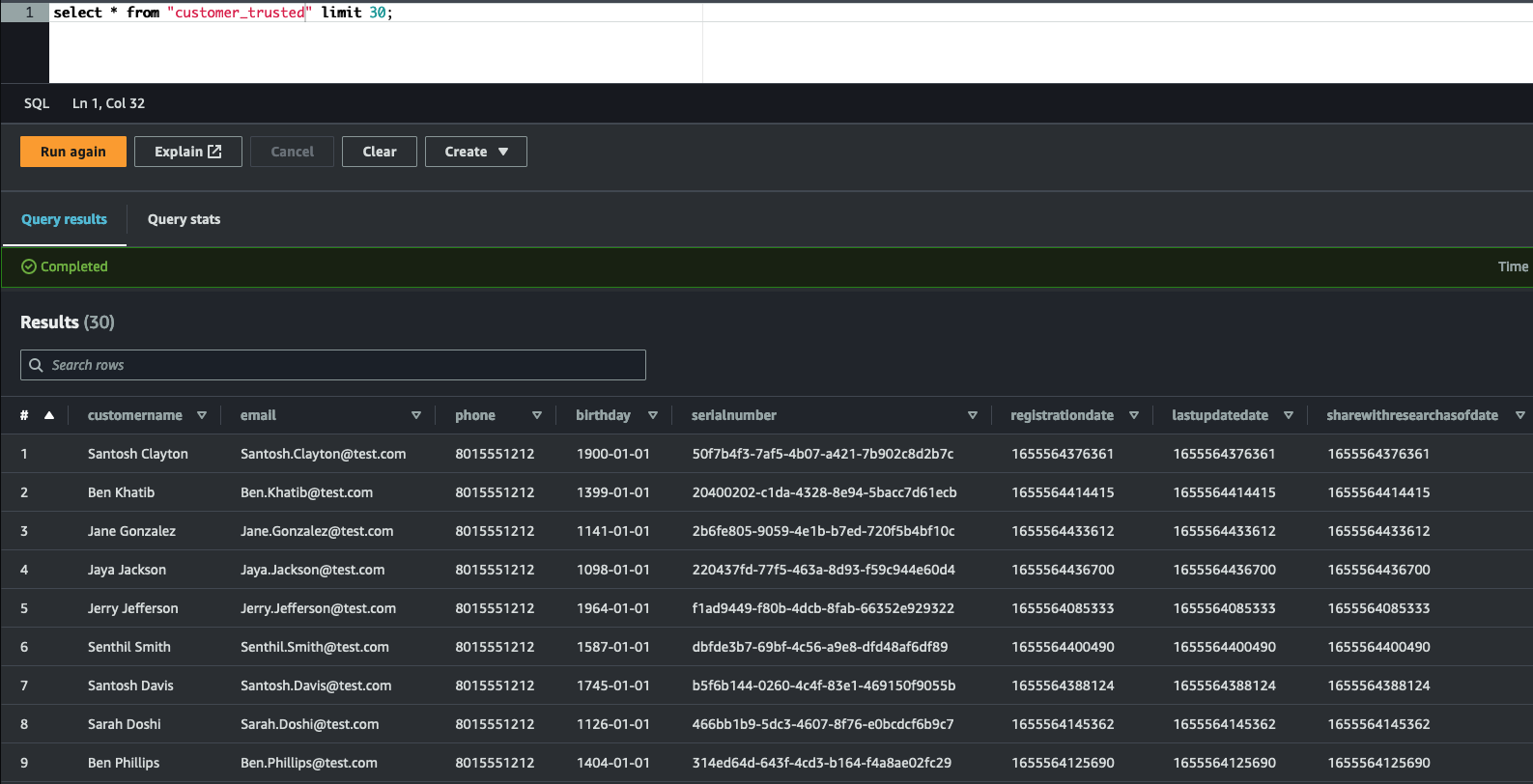
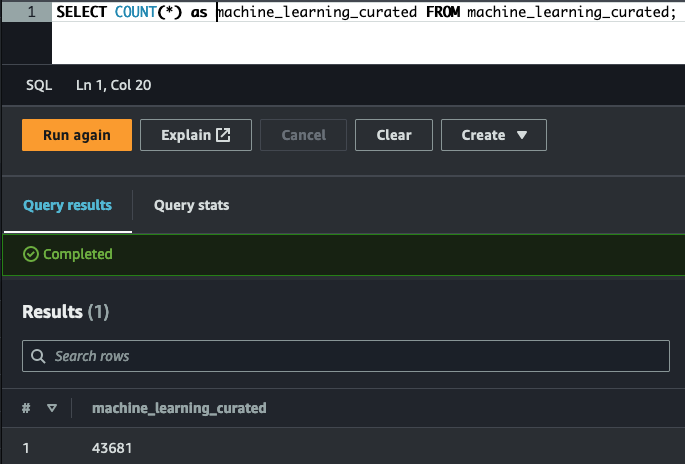
ETL showing accelerometer and step trainer readings in trusted area being transformed (aggregated) into a glue table machine_learning_curated in the curated zone.