A powerful and comprehensive deepfake detection system implementing multiple deep learning architectures, all packed into a user-friendly web interface! 🚀
🌐 Live Web Application: Deepfake Detection Web App
This project integrates cutting-edge deep learning architectures to detect deepfakes:
- 🤖 Xception
- ⚡ EfficientNet
- 🌀 Swin Transformer
- 🔗 Cross Attention
- 🧠 CNN-Transformer
Each model is independently trained but seamlessly combined in the web app for ensemble predictions.
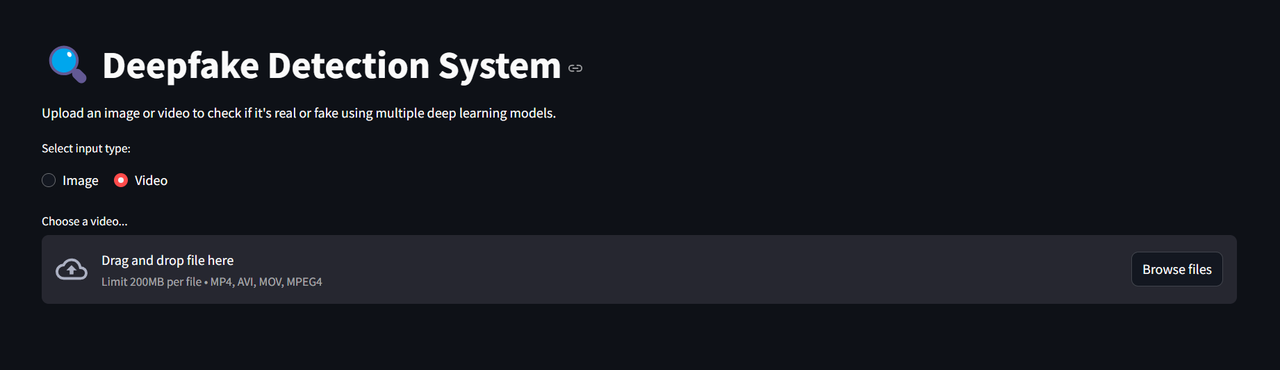
Example of the interactive web app interface
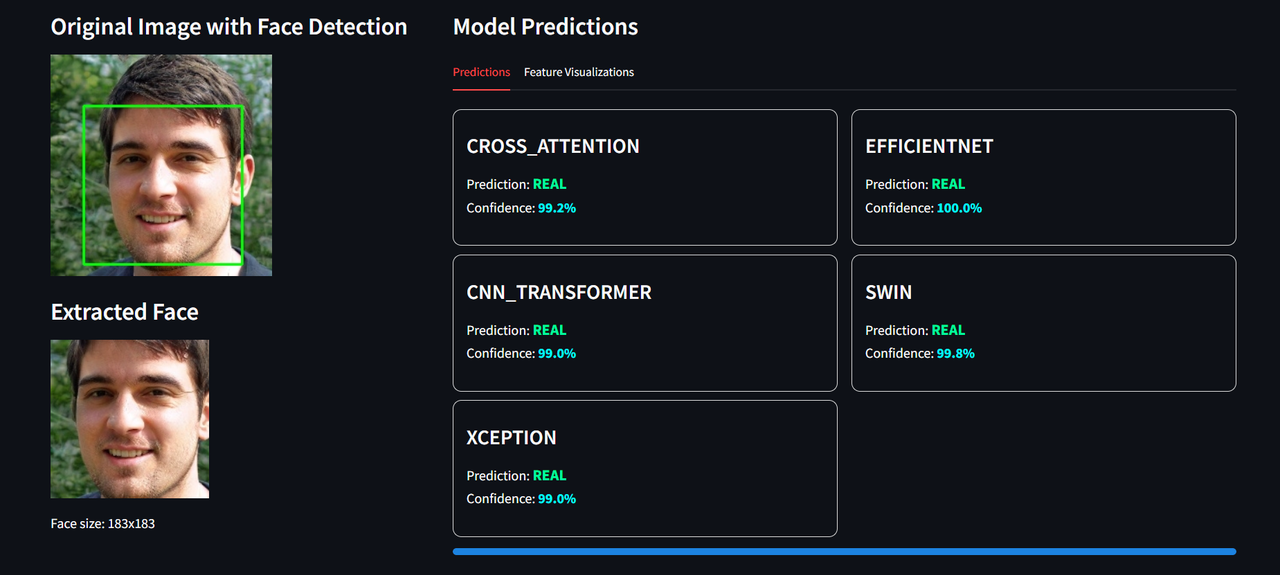
Results from multiple models displayed together

Image mode with face detection visualization
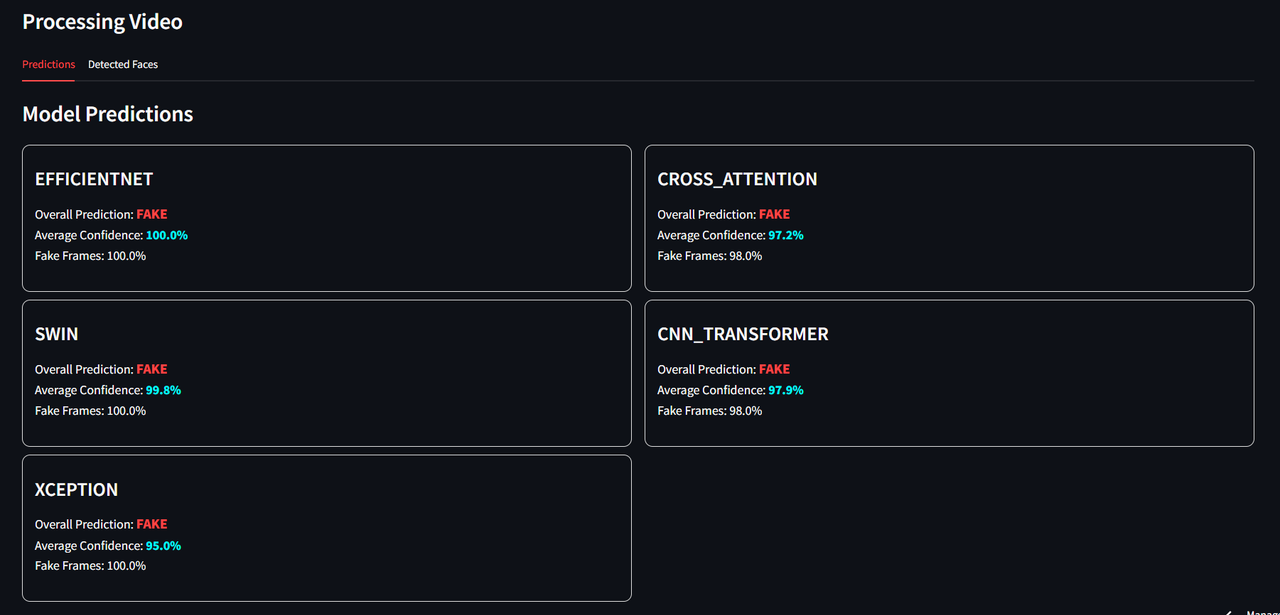
Video mode displaying prediction results
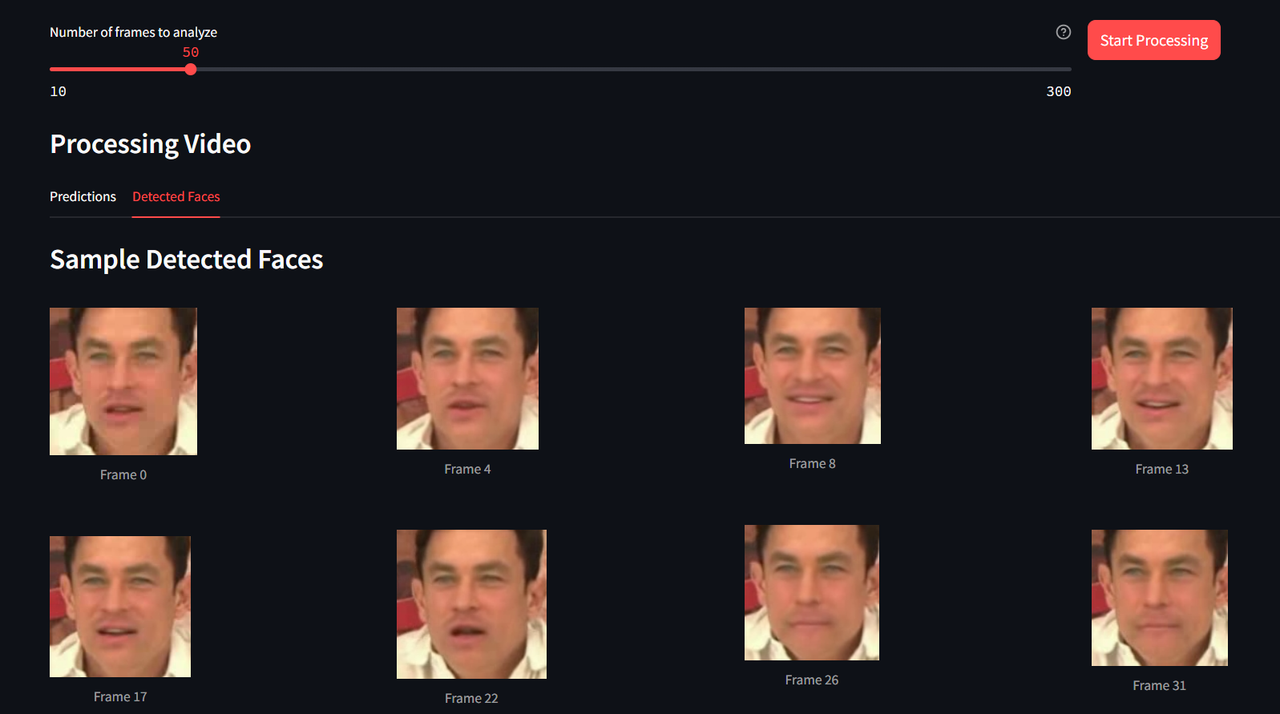
Cropped face samples from video
This project is licensed under the Apache License 2.0. You are free to use, modify, and distribute the code, provided that the following conditions are met:
- Attribution: Proper credit must be given to the original authors, along with a copy of the license.
- State of Derivative Works: Any modifications or derivative works must be clearly identified as such.
- No Liability: The software is provided "as is," without any warranties or guarantees. The authors are not liable for any damages arising from its use.
For full terms and conditions, refer to the official LICENSE.md file.
The project utilizes a balanced dataset of 20,000 face-cropped images:
- 🟢 10,000 Real Images
- 🔴 10,000 Fake Images
- 📚 Sourced from DFDC, FF++, and CelebDF-v2
📥 Dataset Link: 3body-filtered-v2-10k
- A Kaggle account with GPU access
- Add the dataset to your Kaggle account
- Use the provided
train_*.pyfiles in Kaggle notebooks - Each model has a unique training configuration
- General training parameters:
NUM_EPOCHS = 30 # Default BATCH_SIZE = 32 IMAGE_SIZE = 224 # Varies by model
- Key configurations:
- Optimizer: AdamW with weight decay
- Scheduler: ReduceLROnPlateau
- Experiment tracking: MLflow integration
Models are converted for CPU compatibility:
- Use the notebook: DDP-V4-Converter
- Download pre-converted models: DDP-V4-Models
- Create a virtual environment:
python -m venv venv source venv/bin/activate # Linux/Mac venv\Scripts\activate # Windows
- Install dependencies:
pip install -r requirements.txt
deepfake-detection-project-v4/
├── app.py # Main Streamlit app
├── video_processor.py # Video utilities
├── feature_visualization.py # Visualize CNN features
├── data_handler.py # Data processing
├── train_*.py # Training scripts
└── converted_models/ # Directory for pre-trained models
- Add converted models to the
converted_models/folder - Start the app:
streamlit run app.py
- Upload an image containing a face
- View:
- 📸 Face detection visualization
- 📊 Predictions from each model
- 🧠 Feature maps (CNN models only)
- Upload a video file
- Choose the number of frames to analyze (10–300)
- View:
- 🔍 Frame-by-frame predictions
- 😃 Detected faces
- 📈 Confidence scores and stats
- 🔗 Multi-model ensemble predictions
- 🕵️♂️ Real-time face detection
- 🖼️ Feature map visualization
- 📊 Confidence tracking
- 🌑 Dark theme UI
- Specialized in texture analysis
- Input size: 299x299
- B3 variant: Efficiency-accuracy balance
- Input size: 300x300
- Hierarchical feature learning
- Input size: 224x224
- Focuses on enhanced feature interaction
- Input size: 224x224
- Hybrid model: Combines local & global feature learning
- Input size: 224x224
- Python 3.8+
- CUDA-compatible GPU (for training)
- CPU with 8GB+ RAM (for inference)
⚠️ Models must be converted before use in the web app- 🖼️ Feature visualization is limited to CNN-based models
- ⏳ Video processing speed depends on frame count