 `,
+ want: &mdImage{src: "img.png", isHTML: true},
+ }, {
+ in: `
`,
+ want: &mdImage{src: "img.png", isHTML: true},
+ }, {
+ in: ` `,
+ want: &mdImage{
+ src: "./a.png", alt: "alt", widthPx: "700", isHTML: true,
+ },
+ }, {
+ in: `
`,
+ want: &mdImage{
+ src: "./a.png", alt: "alt", widthPx: "700", isHTML: true,
+ },
+ }, {
+ in: ` `,
+ want: &mdImage{
+ src: "a.jpeg",
+ style: "height: 300px; width: 500px",
+ isHTML: true,
+ },
+ }, {
+ // concating "px" and "/>"
+ // this is technically invalid html, but we should handle it.
+ in: `
`,
+ want: &mdImage{
+ src: "a.jpeg",
+ style: "height: 300px; width: 500px",
+ isHTML: true,
+ },
+ }, {
+ // concating "px" and "/>"
+ // this is technically invalid html, but we should handle it.
+ in: ` `,
+ "some more random text",
+ "",
+ }, "\n")
+
+ imgs, err := parseMdImages([]byte(md))
+ if err != nil {
+ t.Fatalf("parseMdImages: %v", err)
+ }
+
+ want := []*mdImage{
+ {src: "img.png", alt: "first image"},
+ {src: "img2.png", alt: "second image", widthPx: "200", isHTML: true},
+ {src: "img3.png", alt: "third image"},
+ }
+
+ wantLens := []int{23, 50, 24}
+
+ if len(imgs) != len(want) {
+ t.Errorf("got %d images, want %d", len(imgs), len(want))
+ } else {
+ for i, img := range imgs {
+ want := want[i]
+ if img.src != want.src {
+ t.Errorf("img %d, got src %q, want %q", i, img.src, want.src)
+ }
+ if img.alt != want.alt {
+ t.Errorf("img %d, got alt %q, want %q", i, img.alt, want.alt)
+ }
+ if img.widthPx != want.widthPx {
+ t.Errorf(
+ "img %d, got width %q, want %q",
+ i, img.widthPx, want.widthPx,
+ )
+ }
+ if img.isHTML != want.isHTML {
+ t.Errorf(
+ "img %d, got isHTML %t, want %t",
+ i, img.isHTML, want.isHTML,
+ )
+ }
+
+ lenOfImg := img.end - img.start
+ if lenOfImg != wantLens[i] {
+ t.Errorf(
+ "img %d, got length %d, want %d",
+ i, lenOfImg, wantLens[i],
+ )
+ }
+ }
+
+ if imgs[0].start != 0 {
+ t.Errorf("first image start is %d, want 0", imgs[0].start)
+ }
+ }
+}
+
+func TestMdImage_writeInto(t *testing.T) {
+ imageFile := []byte("fakeimg")
+ tmp := t.TempDir()
+
+ img := filepath.Join(tmp, "img.png")
+ if err := os.WriteFile(img, imageFile, 0o644); err != nil {
+ t.Fatalf("write fake png: %v", err)
+ }
+
+ tests := []struct {
+ img *mdImage
+ opt *writeImgOptions
+ want string
+ }{{
+ img: &mdImage{src: "img.png"},
+ opt: &writeImgOptions{},
+ want: `
`,
+ "some more random text",
+ "",
+ }, "\n")
+
+ imgs, err := parseMdImages([]byte(md))
+ if err != nil {
+ t.Fatalf("parseMdImages: %v", err)
+ }
+
+ want := []*mdImage{
+ {src: "img.png", alt: "first image"},
+ {src: "img2.png", alt: "second image", widthPx: "200", isHTML: true},
+ {src: "img3.png", alt: "third image"},
+ }
+
+ wantLens := []int{23, 50, 24}
+
+ if len(imgs) != len(want) {
+ t.Errorf("got %d images, want %d", len(imgs), len(want))
+ } else {
+ for i, img := range imgs {
+ want := want[i]
+ if img.src != want.src {
+ t.Errorf("img %d, got src %q, want %q", i, img.src, want.src)
+ }
+ if img.alt != want.alt {
+ t.Errorf("img %d, got alt %q, want %q", i, img.alt, want.alt)
+ }
+ if img.widthPx != want.widthPx {
+ t.Errorf(
+ "img %d, got width %q, want %q",
+ i, img.widthPx, want.widthPx,
+ )
+ }
+ if img.isHTML != want.isHTML {
+ t.Errorf(
+ "img %d, got isHTML %t, want %t",
+ i, img.isHTML, want.isHTML,
+ )
+ }
+
+ lenOfImg := img.end - img.start
+ if lenOfImg != wantLens[i] {
+ t.Errorf(
+ "img %d, got length %d, want %d",
+ i, lenOfImg, wantLens[i],
+ )
+ }
+ }
+
+ if imgs[0].start != 0 {
+ t.Errorf("first image start is %d, want 0", imgs[0].start)
+ }
+ }
+}
+
+func TestMdImage_writeInto(t *testing.T) {
+ imageFile := []byte("fakeimg")
+ tmp := t.TempDir()
+
+ img := filepath.Join(tmp, "img.png")
+ if err := os.WriteFile(img, imageFile, 0o644); err != nil {
+ t.Fatalf("write fake png: %v", err)
+ }
+
+ tests := []struct {
+ img *mdImage
+ opt *writeImgOptions
+ want string
+ }{{
+ img: &mdImage{src: "img.png"},
+ opt: &writeImgOptions{},
+ want: ` `,
+ }, {
+ img: &mdImage{src: "img.png", alt: "alt"},
+ opt: &writeImgOptions{},
+ want: `
`,
+ }, {
+ img: &mdImage{src: "img.png", alt: "alt"},
+ opt: &writeImgOptions{},
+ want: ` `,
+ }, {
+ img: &mdImage{src: "./img.png"},
+ opt: &writeImgOptions{inlineSrc: true},
+ want: `
`,
+ }, {
+ img: &mdImage{src: "./img.png"},
+ opt: &writeImgOptions{inlineSrc: true},
+ want: ` `,
+ "some extra text",
+ }, "\n")
+
+ path := filepath.Join(tmp, "README.md")
+ if err := os.WriteFile(path, []byte(content), 0600); err != nil {
+ t.Fatal("write readme: ", err)
+ }
+
+ readme, err := readReadmeFile(path)
+ if err != nil {
+ t.Fatal("read readme: ", err)
+ }
+
+ output := filepath.Join(tmp, "README.github.md")
+ if err := readme.writeGitHubMD(output); err != nil {
+ t.Fatal("write github md: ", err)
+ }
+
+ got, err := os.ReadFile(output)
+ if err != nil {
+ t.Fatal("read output: ", err)
+ }
+
+ want := strings.Join([]string{
+ "# example",
+ "",
+ `
`,
+ "some extra text",
+ }, "\n")
+
+ path := filepath.Join(tmp, "README.md")
+ if err := os.WriteFile(path, []byte(content), 0600); err != nil {
+ t.Fatal("write readme: ", err)
+ }
+
+ readme, err := readReadmeFile(path)
+ if err != nil {
+ t.Fatal("read readme: ", err)
+ }
+
+ output := filepath.Join(tmp, "README.github.md")
+ if err := readme.writeGitHubMD(output); err != nil {
+ t.Fatal("write github md: ", err)
+ }
+
+ got, err := os.ReadFile(output)
+ if err != nil {
+ t.Fatal("read output: ", err)
+ }
+
+ want := strings.Join([]string{
+ "# example",
+ "",
+ ` `,
+ `
`,
+ ` `,
+ `
`,
+ ` `,
+ `extra text`,
+ }, ""),
+ }, "\n")
+
+ if string(got) != want {
+ t.Errorf("got:\n---\n%s\n---\nwant:\n---\n%s\n---\n", got, want)
+ }
+}
+
+func findJupyter() (bool, error) {
+ if _, err := exec.LookPath("jupyter"); err != nil {
+ if errors.Is(err, exec.ErrNotFound) {
+ return false, nil
+ }
+ return false, err
+ }
+ return true, nil
+}
+
+func checkJupyterOrSkipOnLocal(t *testing.T) {
+ t.Helper()
+
+ if ok, err := findJupyter(); err != nil {
+ t.Fatal(err)
+ } else if !ok {
+ if os.Getenv("CI") == "" {
+ t.Skip("jupyter not found; skip the test as it is not on CI.")
+ } else {
+ t.Fatal("jupyter not found")
+ }
+ }
+}
+
+func TestReadmeFromNotebook(t *testing.T) {
+ checkJupyterOrSkipOnLocal(t)
+
+ tmp := t.TempDir()
+
+ f, err := readmeFromNotebook("testdata/reefy-ray/README.ipynb")
+ if err != nil {
+ t.Fatal("read readme from notebook: ", err)
+ }
+
+ output := filepath.Join(tmp, "README.github.md")
+ if err := f.writeGitHubMD(output); err != nil {
+ t.Fatal("write github md: ", err)
+ }
+
+ got, err := os.ReadFile(output)
+ if err != nil {
+ t.Fatal("read output: ", err)
+ }
+
+ want := strings.Join([]string{
+ "# Test example",
+ "",
+ `
`,
+ `extra text`,
+ }, ""),
+ }, "\n")
+
+ if string(got) != want {
+ t.Errorf("got:\n---\n%s\n---\nwant:\n---\n%s\n---\n", got, want)
+ }
+}
+
+func findJupyter() (bool, error) {
+ if _, err := exec.LookPath("jupyter"); err != nil {
+ if errors.Is(err, exec.ErrNotFound) {
+ return false, nil
+ }
+ return false, err
+ }
+ return true, nil
+}
+
+func checkJupyterOrSkipOnLocal(t *testing.T) {
+ t.Helper()
+
+ if ok, err := findJupyter(); err != nil {
+ t.Fatal(err)
+ } else if !ok {
+ if os.Getenv("CI") == "" {
+ t.Skip("jupyter not found; skip the test as it is not on CI.")
+ } else {
+ t.Fatal("jupyter not found")
+ }
+ }
+}
+
+func TestReadmeFromNotebook(t *testing.T) {
+ checkJupyterOrSkipOnLocal(t)
+
+ tmp := t.TempDir()
+
+ f, err := readmeFromNotebook("testdata/reefy-ray/README.ipynb")
+ if err != nil {
+ t.Fatal("read readme from notebook: ", err)
+ }
+
+ output := filepath.Join(tmp, "README.github.md")
+ if err := f.writeGitHubMD(output); err != nil {
+ t.Fatal("write github md: ", err)
+ }
+
+ got, err := os.ReadFile(output)
+ if err != nil {
+ t.Fatal("read output: ", err)
+ }
+
+ want := strings.Join([]string{
+ "# Test example",
+ "",
+ ` `,
+ "",
+ "and some text",
+ "",
+ "",
+ "```python",
+ `print("this is just an example")`,
+ "```",
+ "",
+ }, "\n")
+
+ if string(got) != want {
+ t.Errorf("got:\n---\n%s\n---\nwant:\n---\n%s\n---\n", got, want)
+ }
+}
diff --git a/ci/maketmpl/template_meta.go b/ci/maketmpl/template_meta.go
new file mode 100644
index 000000000..89d1a8718
--- /dev/null
+++ b/ci/maketmpl/template_meta.go
@@ -0,0 +1,11 @@
+package maketmpl
+
+type templateMeta struct {
+ Name string `json:"name"`
+
+ // Base64 encoded cluster environment.
+ ClusterEnvBase64 string `json:"cluster_env_base64,omitempty"`
+
+ // Base64 encoded compute config for different cloud types.
+ ComputeConfigBase64 map[string]string `json:"compute_config_base64,omitempty"`
+}
diff --git a/ci/maketmpl/testdata/BUILD.yaml b/ci/maketmpl/testdata/BUILD.yaml
new file mode 100644
index 000000000..d748f313a
--- /dev/null
+++ b/ci/maketmpl/testdata/BUILD.yaml
@@ -0,0 +1,21 @@
+- name: reefy-ray
+ emoji: 🪸
+ title: Reefy Ray
+ description: The fastest Ray lives around coral reefs.
+ dir: reefy-ray
+ cluster_env:
+ build_id: anyscaleray2370-py311
+ compute_config:
+ GCP: configs/gcp.yaml
+ AWS: configs/aws.yaml
+
+- name: fishy-ray
+ emoji: 🐠
+ title: Fishy Ray
+ description: Ray that swims with the other fishes.
+ dir: fishy-ray
+ cluster_env:
+ build_id: anyscaleray2370-py311
+ compute_config:
+ GCP: configs/gcp.yaml
+ AWS: configs/aws.yaml
diff --git a/ci/maketmpl/testdata/configs/aws.yaml b/ci/maketmpl/testdata/configs/aws.yaml
new file mode 100644
index 000000000..458ee023e
--- /dev/null
+++ b/ci/maketmpl/testdata/configs/aws.yaml
@@ -0,0 +1,10 @@
+head_node_type:
+ name: head
+ instance_type: m5.2xlarge
+
+worker_node_types:
+- name: cpu_worker
+ instance_type: m5.2xlarge
+ min_workers: 0
+ max_workers: 2
+ use_spot: false
diff --git a/ci/maketmpl/testdata/configs/gcp.yaml b/ci/maketmpl/testdata/configs/gcp.yaml
new file mode 100644
index 000000000..3b2701bc0
--- /dev/null
+++ b/ci/maketmpl/testdata/configs/gcp.yaml
@@ -0,0 +1,10 @@
+head_node_type:
+ name: head
+ instance_type: n2-standard-8
+
+worker_node_types:
+- name: cpu_worker
+ instance_type: n2-standard-8
+ min_workers: 0
+ max_workers: 2
+ use_spot: false
diff --git a/ci/maketmpl/testdata/fishy-ray/README.md b/ci/maketmpl/testdata/fishy-ray/README.md
new file mode 100644
index 000000000..34d7b17ef
--- /dev/null
+++ b/ci/maketmpl/testdata/fishy-ray/README.md
@@ -0,0 +1,5 @@
+# Fishy Ray
+
+[Batoidea][ray] is a superorder of cartilaginous fishes, commonly known as rays.
+
+[ray]: https://en.wikipedia.org/wiki/Batoidea
diff --git a/ci/maketmpl/testdata/reefy-ray/README.ipynb b/ci/maketmpl/testdata/reefy-ray/README.ipynb
new file mode 100644
index 000000000..dc6aa3221
--- /dev/null
+++ b/ci/maketmpl/testdata/reefy-ray/README.ipynb
@@ -0,0 +1,31 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Test example\n",
+ "\n",
+ "
`,
+ "",
+ "and some text",
+ "",
+ "",
+ "```python",
+ `print("this is just an example")`,
+ "```",
+ "",
+ }, "\n")
+
+ if string(got) != want {
+ t.Errorf("got:\n---\n%s\n---\nwant:\n---\n%s\n---\n", got, want)
+ }
+}
diff --git a/ci/maketmpl/template_meta.go b/ci/maketmpl/template_meta.go
new file mode 100644
index 000000000..89d1a8718
--- /dev/null
+++ b/ci/maketmpl/template_meta.go
@@ -0,0 +1,11 @@
+package maketmpl
+
+type templateMeta struct {
+ Name string `json:"name"`
+
+ // Base64 encoded cluster environment.
+ ClusterEnvBase64 string `json:"cluster_env_base64,omitempty"`
+
+ // Base64 encoded compute config for different cloud types.
+ ComputeConfigBase64 map[string]string `json:"compute_config_base64,omitempty"`
+}
diff --git a/ci/maketmpl/testdata/BUILD.yaml b/ci/maketmpl/testdata/BUILD.yaml
new file mode 100644
index 000000000..d748f313a
--- /dev/null
+++ b/ci/maketmpl/testdata/BUILD.yaml
@@ -0,0 +1,21 @@
+- name: reefy-ray
+ emoji: 🪸
+ title: Reefy Ray
+ description: The fastest Ray lives around coral reefs.
+ dir: reefy-ray
+ cluster_env:
+ build_id: anyscaleray2370-py311
+ compute_config:
+ GCP: configs/gcp.yaml
+ AWS: configs/aws.yaml
+
+- name: fishy-ray
+ emoji: 🐠
+ title: Fishy Ray
+ description: Ray that swims with the other fishes.
+ dir: fishy-ray
+ cluster_env:
+ build_id: anyscaleray2370-py311
+ compute_config:
+ GCP: configs/gcp.yaml
+ AWS: configs/aws.yaml
diff --git a/ci/maketmpl/testdata/configs/aws.yaml b/ci/maketmpl/testdata/configs/aws.yaml
new file mode 100644
index 000000000..458ee023e
--- /dev/null
+++ b/ci/maketmpl/testdata/configs/aws.yaml
@@ -0,0 +1,10 @@
+head_node_type:
+ name: head
+ instance_type: m5.2xlarge
+
+worker_node_types:
+- name: cpu_worker
+ instance_type: m5.2xlarge
+ min_workers: 0
+ max_workers: 2
+ use_spot: false
diff --git a/ci/maketmpl/testdata/configs/gcp.yaml b/ci/maketmpl/testdata/configs/gcp.yaml
new file mode 100644
index 000000000..3b2701bc0
--- /dev/null
+++ b/ci/maketmpl/testdata/configs/gcp.yaml
@@ -0,0 +1,10 @@
+head_node_type:
+ name: head
+ instance_type: n2-standard-8
+
+worker_node_types:
+- name: cpu_worker
+ instance_type: n2-standard-8
+ min_workers: 0
+ max_workers: 2
+ use_spot: false
diff --git a/ci/maketmpl/testdata/fishy-ray/README.md b/ci/maketmpl/testdata/fishy-ray/README.md
new file mode 100644
index 000000000..34d7b17ef
--- /dev/null
+++ b/ci/maketmpl/testdata/fishy-ray/README.md
@@ -0,0 +1,5 @@
+# Fishy Ray
+
+[Batoidea][ray] is a superorder of cartilaginous fishes, commonly known as rays.
+
+[ray]: https://en.wikipedia.org/wiki/Batoidea
diff --git a/ci/maketmpl/testdata/reefy-ray/README.ipynb b/ci/maketmpl/testdata/reefy-ray/README.ipynb
new file mode 100644
index 000000000..dc6aa3221
--- /dev/null
+++ b/ci/maketmpl/testdata/reefy-ray/README.ipynb
@@ -0,0 +1,31 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Test example\n",
+ "\n",
+ " \n",
+ "\n",
+ "and some text"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(\"this is just an example\")"
+ ]
+ }
+ ],
+ "metadata": {
+ "language_info": {
+ "name": "python"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 2
+}
diff --git a/ci/maketmpl/testdata/reefy-ray/README.md b/ci/maketmpl/testdata/reefy-ray/README.md
new file mode 100644
index 000000000..0dae8a771
--- /dev/null
+++ b/ci/maketmpl/testdata/reefy-ray/README.md
@@ -0,0 +1,12 @@
+# Test example
+
+
\n",
+ "\n",
+ "and some text"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(\"this is just an example\")"
+ ]
+ }
+ ],
+ "metadata": {
+ "language_info": {
+ "name": "python"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 2
+}
diff --git a/ci/maketmpl/testdata/reefy-ray/README.md b/ci/maketmpl/testdata/reefy-ray/README.md
new file mode 100644
index 000000000..0dae8a771
--- /dev/null
+++ b/ci/maketmpl/testdata/reefy-ray/README.md
@@ -0,0 +1,12 @@
+# Test example
+
+ \n",
+ "\n",
+ "Built on top of Ray Core, the Ray AI Libraries inherit all the performance and scalability benefits offered by Core while providing a convenient abstraction layer for machine learning. These Python-first native libraries allow ML practitioners to distribute individual workloads, end-to-end applications, and build custom use cases in a unified framework.\n",
+ "\n",
+ "The Ray AI Libraries bring together an ever-growing ecosystem of integrations with popular machine learning frameworks to create a common interface for development.\n",
+ "\n",
+ "|
\n",
+ "\n",
+ "Built on top of Ray Core, the Ray AI Libraries inherit all the performance and scalability benefits offered by Core while providing a convenient abstraction layer for machine learning. These Python-first native libraries allow ML practitioners to distribute individual workloads, end-to-end applications, and build custom use cases in a unified framework.\n",
+ "\n",
+ "The Ray AI Libraries bring together an ever-growing ecosystem of integrations with popular machine learning frameworks to create a common interface for development.\n",
+ "\n",
+ "| |\n",
+ "|:-:|\n",
+ "|Ray AI Libraries enable end-to-end ML development and provides multiple options for integrating with other tools and libraries form the MLOps ecosystem.|\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 2. Quick end-to-end example\n",
+ "\n",
+ "|Ray AIR Component|NYC Taxi Use Case|\n",
+ "|:--|:--|\n",
+ "|Ray Data|Ingest and transform raw data; perform batch inference by mapping the checkpointed model to batches of data.|\n",
+ "|Ray Train|Use `Trainer` to scale XGBoost model training.|\n",
+ "|Ray Tune|Use `Tuner` for hyperparameter search.|\n",
+ "|Ray Serve|Deploy the model for online inference.|\n",
+ "\n",
+ "For this classification task, you will apply a simple [XGBoost](https://xgboost.readthedocs.io/en/stable/) (a gradient boosted trees framework) model to the June 2021 [New York City Taxi & Limousine Commission's Trip Record Data](https://www1.nyc.gov/site/tlc/about/tlc-trip-record-data.page). This dataset contains over 2 million samples of yellow cab rides, and the goal is to predict whether a trip will result in a tip greater than 20% or not.\n",
+ "\n",
+ "**Dataset features**\n",
+ "* **`passenger_count`**\n",
+ " * Float (whole number) representing number of passengers.\n",
+ "* **`trip_distance`** \n",
+ " * Float representing trip distance in miles.\n",
+ "* **`fare_amount`**\n",
+ " * Float representing total price including tax, tip, fees, etc.\n",
+ "* **`trip_duration`**\n",
+ " * Integer representing seconds elapsed.\n",
+ "* **`hour`**\n",
+ " * Hour that the trip started.\n",
+ " * Integer in the range `[0, 23]`\n",
+ "* **`day_of_week`**\n",
+ " * Integer in the range `[1, 7]`.\n",
+ "* **`is_big_tip`**\n",
+ " * Whether the tip amount was greater than 20%.\n",
+ " * Boolean `[True, False]`."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "__Import libraries__"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "import json\n",
+ "import pandas as pd\n",
+ "import requests\n",
+ "import xgboost\n",
+ "from starlette.requests import Request\n",
+ "\n",
+ "import ray\n",
+ "from ray import tune\n",
+ "from ray.train import ScalingConfig, RunConfig\n",
+ "from ray.train.xgboost import XGBoostTrainer\n",
+ "from ray.tune import Tuner, TuneConfig\n",
+ "from ray import serve"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "__Read, preprocess with Ray Data__"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# Read the dataset\n",
+ "dataset = ray.data.read_parquet(\"s3://anonymous@anyscale-training-data/intro-to-ray-air/nyc_taxi_2021.parquet\")\n",
+ "\n",
+ "# Split the dataset into training and validation sets\n",
+ "train_dataset, valid_dataset = dataset.train_test_split(test_size=0.3)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "__Fit model with Ray Train__"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# Define the trainer\n",
+ "trainer = XGBoostTrainer(\n",
+ " label_column=\"is_big_tip\",\n",
+ " scaling_config=ScalingConfig(num_workers=4, use_gpu=False),\n",
+ " params={\"objective\": \"binary:logistic\"},\n",
+ " datasets={\"train\": train_dataset, \"valid\": valid_dataset},\n",
+ " run_config=RunConfig(storage_path=\"/mnt/cluster_storage/\"),\n",
+ ")\n",
+ "\n",
+ "# Fit the trainer\n",
+ "result = trainer.fit()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "__Optimize hyperparameters with Ray Tune__"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# Define the tuner\n",
+ "tuner = Tuner(\n",
+ " trainer,\n",
+ " param_space={\"params\": {\"max_depth\": tune.randint(2, 12)}},\n",
+ " tune_config=TuneConfig(num_samples=3, metric=\"valid-logloss\", mode=\"min\"),\n",
+ " run_config=RunConfig(storage_path=\"/mnt/cluster_storage/\"),\n",
+ ")\n",
+ "\n",
+ "# Fit the tuner and get the best checkpoint\n",
+ "checkpoint = tuner.fit().get_best_result().checkpoint"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "__Batch inference with Ray Data__"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "class OfflinePredictor:\n",
+ " def __init__(self):\n",
+ " # Load expensive state\n",
+ " self._model = xgboost.Booster()\n",
+ " self._model.load_model(checkpoint.path + \"/model.ubj\")\n",
+ "\n",
+ " def __call__(self, batch: dict) -> dict:\n",
+ " # Make prediction in batch\n",
+ " dmatrix = xgboost.DMatrix(pd.DataFrame(batch))\n",
+ " outputs = self._model.predict(dmatrix)\n",
+ " return {\"prediction\": outputs}"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# Apply the predictor to the validation dataset\n",
+ "valid_dataset_inputs = valid_dataset.drop_columns(['is_big_tip'])\n",
+ "predicted_probabilities = valid_dataset_inputs.map_batches(OfflinePredictor, concurrency=2)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# Materialize a batch\n",
+ "predicted_probabilities.take_batch()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "__Online prediction with Ray Serve__"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "@serve.deployment\n",
+ "class OnlinePredictor:\n",
+ " def __init__(self, checkpoint):\n",
+ " # Load expensive state\n",
+ " self._model = xgboost.Booster()\n",
+ " self._model.load_model(checkpoint.path + \"/model.ubj\")\n",
+ "\n",
+ " async def __call__(self, request: Request) -> dict:\n",
+ " # Handle HTTP request\n",
+ " data = await request.json()\n",
+ " data = json.loads(data)\n",
+ " return {\"prediction\": self.predict(data)}\n",
+ "\n",
+ " def predict(self, data: list[dict]) -> list[float]:\n",
+ " # Make prediction\n",
+ " dmatrix = xgboost.DMatrix(pd.DataFrame(data))\n",
+ " return self._model.predict(dmatrix)\n",
+ "\n",
+ "# Run the deployment\n",
+ "handle = serve.run(OnlinePredictor.bind(checkpoint=checkpoint))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# Form payload\n",
+ "valid_dataset_inputs = valid_dataset.drop_columns([\"is_big_tip\"])\n",
+ "sample_batch = valid_dataset_inputs.take_batch(1)\n",
+ "data = pd.DataFrame(sample_batch).to_json(orient=\"records\")\n",
+ "\n",
+ "# Send HTTP request\n",
+ "requests.post(\"http://localhost:8000/\", json=data).json()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# Shutdown Ray Serve\n",
+ "serve.shutdown()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Cleanup\n",
+ "!rm -rf /mnt/cluster_storage/XGBoostTrainer*"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 4
+}
diff --git a/templates/ray-summit-ai-libraries/2_Intro_Train.ipynb b/templates/ray-summit-ai-libraries/2_Intro_Train.ipynb
new file mode 100644
index 000000000..09252990d
--- /dev/null
+++ b/templates/ray-summit-ai-libraries/2_Intro_Train.ipynb
@@ -0,0 +1,976 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Introduction to Ray Train\n",
+ "\n",
+ "This notebook will walk you through the basics of distributed training with Ray Train and PyTorch.\n",
+ "\n",
+ "
|\n",
+ "|:-:|\n",
+ "|Ray AI Libraries enable end-to-end ML development and provides multiple options for integrating with other tools and libraries form the MLOps ecosystem.|\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 2. Quick end-to-end example\n",
+ "\n",
+ "|Ray AIR Component|NYC Taxi Use Case|\n",
+ "|:--|:--|\n",
+ "|Ray Data|Ingest and transform raw data; perform batch inference by mapping the checkpointed model to batches of data.|\n",
+ "|Ray Train|Use `Trainer` to scale XGBoost model training.|\n",
+ "|Ray Tune|Use `Tuner` for hyperparameter search.|\n",
+ "|Ray Serve|Deploy the model for online inference.|\n",
+ "\n",
+ "For this classification task, you will apply a simple [XGBoost](https://xgboost.readthedocs.io/en/stable/) (a gradient boosted trees framework) model to the June 2021 [New York City Taxi & Limousine Commission's Trip Record Data](https://www1.nyc.gov/site/tlc/about/tlc-trip-record-data.page). This dataset contains over 2 million samples of yellow cab rides, and the goal is to predict whether a trip will result in a tip greater than 20% or not.\n",
+ "\n",
+ "**Dataset features**\n",
+ "* **`passenger_count`**\n",
+ " * Float (whole number) representing number of passengers.\n",
+ "* **`trip_distance`** \n",
+ " * Float representing trip distance in miles.\n",
+ "* **`fare_amount`**\n",
+ " * Float representing total price including tax, tip, fees, etc.\n",
+ "* **`trip_duration`**\n",
+ " * Integer representing seconds elapsed.\n",
+ "* **`hour`**\n",
+ " * Hour that the trip started.\n",
+ " * Integer in the range `[0, 23]`\n",
+ "* **`day_of_week`**\n",
+ " * Integer in the range `[1, 7]`.\n",
+ "* **`is_big_tip`**\n",
+ " * Whether the tip amount was greater than 20%.\n",
+ " * Boolean `[True, False]`."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "__Import libraries__"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "import json\n",
+ "import pandas as pd\n",
+ "import requests\n",
+ "import xgboost\n",
+ "from starlette.requests import Request\n",
+ "\n",
+ "import ray\n",
+ "from ray import tune\n",
+ "from ray.train import ScalingConfig, RunConfig\n",
+ "from ray.train.xgboost import XGBoostTrainer\n",
+ "from ray.tune import Tuner, TuneConfig\n",
+ "from ray import serve"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "__Read, preprocess with Ray Data__"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# Read the dataset\n",
+ "dataset = ray.data.read_parquet(\"s3://anonymous@anyscale-training-data/intro-to-ray-air/nyc_taxi_2021.parquet\")\n",
+ "\n",
+ "# Split the dataset into training and validation sets\n",
+ "train_dataset, valid_dataset = dataset.train_test_split(test_size=0.3)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "__Fit model with Ray Train__"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# Define the trainer\n",
+ "trainer = XGBoostTrainer(\n",
+ " label_column=\"is_big_tip\",\n",
+ " scaling_config=ScalingConfig(num_workers=4, use_gpu=False),\n",
+ " params={\"objective\": \"binary:logistic\"},\n",
+ " datasets={\"train\": train_dataset, \"valid\": valid_dataset},\n",
+ " run_config=RunConfig(storage_path=\"/mnt/cluster_storage/\"),\n",
+ ")\n",
+ "\n",
+ "# Fit the trainer\n",
+ "result = trainer.fit()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "__Optimize hyperparameters with Ray Tune__"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# Define the tuner\n",
+ "tuner = Tuner(\n",
+ " trainer,\n",
+ " param_space={\"params\": {\"max_depth\": tune.randint(2, 12)}},\n",
+ " tune_config=TuneConfig(num_samples=3, metric=\"valid-logloss\", mode=\"min\"),\n",
+ " run_config=RunConfig(storage_path=\"/mnt/cluster_storage/\"),\n",
+ ")\n",
+ "\n",
+ "# Fit the tuner and get the best checkpoint\n",
+ "checkpoint = tuner.fit().get_best_result().checkpoint"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "__Batch inference with Ray Data__"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "class OfflinePredictor:\n",
+ " def __init__(self):\n",
+ " # Load expensive state\n",
+ " self._model = xgboost.Booster()\n",
+ " self._model.load_model(checkpoint.path + \"/model.ubj\")\n",
+ "\n",
+ " def __call__(self, batch: dict) -> dict:\n",
+ " # Make prediction in batch\n",
+ " dmatrix = xgboost.DMatrix(pd.DataFrame(batch))\n",
+ " outputs = self._model.predict(dmatrix)\n",
+ " return {\"prediction\": outputs}"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# Apply the predictor to the validation dataset\n",
+ "valid_dataset_inputs = valid_dataset.drop_columns(['is_big_tip'])\n",
+ "predicted_probabilities = valid_dataset_inputs.map_batches(OfflinePredictor, concurrency=2)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# Materialize a batch\n",
+ "predicted_probabilities.take_batch()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "__Online prediction with Ray Serve__"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "@serve.deployment\n",
+ "class OnlinePredictor:\n",
+ " def __init__(self, checkpoint):\n",
+ " # Load expensive state\n",
+ " self._model = xgboost.Booster()\n",
+ " self._model.load_model(checkpoint.path + \"/model.ubj\")\n",
+ "\n",
+ " async def __call__(self, request: Request) -> dict:\n",
+ " # Handle HTTP request\n",
+ " data = await request.json()\n",
+ " data = json.loads(data)\n",
+ " return {\"prediction\": self.predict(data)}\n",
+ "\n",
+ " def predict(self, data: list[dict]) -> list[float]:\n",
+ " # Make prediction\n",
+ " dmatrix = xgboost.DMatrix(pd.DataFrame(data))\n",
+ " return self._model.predict(dmatrix)\n",
+ "\n",
+ "# Run the deployment\n",
+ "handle = serve.run(OnlinePredictor.bind(checkpoint=checkpoint))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# Form payload\n",
+ "valid_dataset_inputs = valid_dataset.drop_columns([\"is_big_tip\"])\n",
+ "sample_batch = valid_dataset_inputs.take_batch(1)\n",
+ "data = pd.DataFrame(sample_batch).to_json(orient=\"records\")\n",
+ "\n",
+ "# Send HTTP request\n",
+ "requests.post(\"http://localhost:8000/\", json=data).json()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# Shutdown Ray Serve\n",
+ "serve.shutdown()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Cleanup\n",
+ "!rm -rf /mnt/cluster_storage/XGBoostTrainer*"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 4
+}
diff --git a/templates/ray-summit-ai-libraries/2_Intro_Train.ipynb b/templates/ray-summit-ai-libraries/2_Intro_Train.ipynb
new file mode 100644
index 000000000..09252990d
--- /dev/null
+++ b/templates/ray-summit-ai-libraries/2_Intro_Train.ipynb
@@ -0,0 +1,976 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Introduction to Ray Train\n",
+ "\n",
+ "This notebook will walk you through the basics of distributed training with Ray Train and PyTorch.\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "At a high level, here is how our training loop in PyTorch looks like: "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def train_loop_torch(num_epochs: int = 2, batch_size: int = 128, local_path: str = \"./checkpoints\"):\n",
+ " # Model, Loss, Optimizer\n",
+ " criterion = CrossEntropyLoss()\n",
+ " model = load_model_torch()\n",
+ " optimizer = Adam(model.parameters(), lr=1e-5)\n",
+ "\n",
+ " # Initialize the metric \n",
+ " acc = torchmetrics.Accuracy(task=\"multiclass\", num_classes=10).to(\"cuda\")\n",
+ "\n",
+ " # Load the data loader\n",
+ " data_loader = build_data_loader_torch(batch_size=batch_size)\n",
+ "\n",
+ " # Training loop\n",
+ " for epoch in range(num_epochs):\n",
+ " for images, labels in data_loader:\n",
+ " # Move the data to the GPU\n",
+ " images, labels = images.to(\"cuda\"), labels.to(\"cuda\")\n",
+ "\n",
+ " # Forward pass\n",
+ " outputs = model(images)\n",
+ "\n",
+ " # Compute the loss\n",
+ " loss = criterion(outputs, labels)\n",
+ " \n",
+ " # Backward pass\n",
+ " optimizer.zero_grad()\n",
+ " loss.backward()\n",
+ "\n",
+ " # Update the weights\n",
+ " optimizer.step()\n",
+ "\n",
+ " # Update the metric\n",
+ " acc(outputs, labels)\n",
+ " \n",
+ " # Report the metrics\n",
+ " metrics = report_metrics_torch(loss=loss, accuracy=acc.compute(), epoch=epoch)\n",
+ " \n",
+ " # Reset the metric\n",
+ " acc.reset()\n",
+ "\n",
+ " # Save the checkpoint and metrics\n",
+ " Path(local_path).mkdir(parents=True, exist_ok=True)\n",
+ " save_checkpoint_and_metrics_torch(metrics=metrics, model=model, local_path=local_path)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We first start by defining how to build and load our model on a single GPU."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "def build_resnet18():\n",
+ " model = resnet18(num_classes=10)\n",
+ " model.conv1 = torch.nn.Conv2d(\n",
+ " in_channels=1, # grayscale MNIST images\n",
+ " out_channels=64,\n",
+ " kernel_size=(7, 7),\n",
+ " stride=(2, 2),\n",
+ " padding=(3, 3),\n",
+ " bias=False,\n",
+ " )\n",
+ " return model\n",
+ "\n",
+ "\n",
+ "def load_model_torch() -> torch.nn.Module:\n",
+ " model = build_resnet18()\n",
+ " # Move to the single GPU device\n",
+ " model.to(\"cuda\")\n",
+ " return model"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Here is our dataset"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "dataset = MNIST(root=\"./data\", train=True, download=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's display the first 10 images, with the corresponding labels:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig, axs = plt.subplots(1, 10, figsize=(20, 2))\n",
+ "\n",
+ "for i in range(10):\n",
+ " axs[i].imshow(dataset.train_data[i], cmap=\"gray\")\n",
+ " axs[i].axis(\"off\")\n",
+ " axs[i].set_title(dataset.train_labels[i].item())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We will also define a data loader to load our data in batches and apply transformations."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 30,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def build_data_loader_torch(batch_size: int) -> DataLoader:\n",
+ " transform = Compose([ToTensor(), Normalize((0.5,), (0.5,))])\n",
+ " dataset = MNIST(root=\"./data\", train=True, download=True, transform=transform)\n",
+ " train_loader = DataLoader(dataset, batch_size=batch_size, shuffle=True, drop_last=True)\n",
+ " return train_loader"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We will compute and report metrics via a simple print statement."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def report_metrics_torch(loss: torch.Tensor, accuracy: torch.Tensor, epoch: int) -> None:\n",
+ " metrics = {\"loss\": loss.item(), \"epoch\": epoch, \"accuracy\": accuracy.item()}\n",
+ " print(metrics)\n",
+ " return metrics"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "To save the checkpoint we will make use of a local directory."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def save_checkpoint_and_metrics_torch(metrics: dict[str, float], model: torch.nn.Module, local_path: str) -> None:\n",
+ " # Save the metrics\n",
+ " with open(os.path.join(local_path, \"metrics.csv\"), \"a\") as f:\n",
+ " writer = csv.writer(f)\n",
+ " writer.writerow(metrics.values())\n",
+ "\n",
+ " # Save the model\n",
+ " checkpoint_path = os.path.join(local_path, \"model.pt\")\n",
+ " torch.save(model.state_dict(), checkpoint_path)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Now we can schedule the training loop on a single GPU"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "timestamp = datetime.datetime.now(datetime.UTC).strftime(\"%Y-%m-%d_%H-%M-%S\")\n",
+ "local_path = f\"/mnt/local_storage/single_gpu_mnist/torch_{timestamp}/\"\n",
+ "\n",
+ "train_loop_torch(\n",
+ " num_epochs=2, \n",
+ " local_path=local_path\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's inspect the produced checkpoints and metrics"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!ls -l {local_path}"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "metrics = pd.read_csv(\n",
+ " os.path.join(local_path, \"metrics.csv\"),\n",
+ " header=None,\n",
+ " names=[\"loss\", \"epoch\", \"accuracy\"],\n",
+ ")\n",
+ "\n",
+ "metrics"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can also load our produced model checkpoint"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "loaded_model = build_resnet18()\n",
+ "loaded_model.load_state_dict(torch.load(os.path.join(local_path, \"model.pt\")))\n",
+ "loaded_model.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can the proceed to generate predictions on the first 10 images of the MNIST dataset."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig, axs = plt.subplots(1, 10, figsize=(20, 2))\n",
+ "for i in range(10):\n",
+ " axs[i].imshow(dataset.train_data[i], cmap=\"gray\")\n",
+ " axs[i].axis(\"off\")\n",
+ " with torch.no_grad():\n",
+ " normalized = Normalize((0.5,), (0.5,))(ToTensor()(dataset[i][0]))\n",
+ " prediction = loaded_model(normalized.unsqueeze(0)).argmax()\n",
+ " axs[i].set_title(prediction.item())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Distributed Data Parallel Training with Ray Train and PyTorch\n",
+ "\n",
+ "Let's now consider the case where we have a very large dataset of images that would take a long time to train on a single GPU. \n",
+ "\n",
+ "We would now like to scale this training job to run on multiple GPUs. \n",
+ "\n",
+ "Here is a diagram visualizing the desired distributed data-parallel training process:\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "At a high level, here is how our training loop in PyTorch looks like: "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def train_loop_torch(num_epochs: int = 2, batch_size: int = 128, local_path: str = \"./checkpoints\"):\n",
+ " # Model, Loss, Optimizer\n",
+ " criterion = CrossEntropyLoss()\n",
+ " model = load_model_torch()\n",
+ " optimizer = Adam(model.parameters(), lr=1e-5)\n",
+ "\n",
+ " # Initialize the metric \n",
+ " acc = torchmetrics.Accuracy(task=\"multiclass\", num_classes=10).to(\"cuda\")\n",
+ "\n",
+ " # Load the data loader\n",
+ " data_loader = build_data_loader_torch(batch_size=batch_size)\n",
+ "\n",
+ " # Training loop\n",
+ " for epoch in range(num_epochs):\n",
+ " for images, labels in data_loader:\n",
+ " # Move the data to the GPU\n",
+ " images, labels = images.to(\"cuda\"), labels.to(\"cuda\")\n",
+ "\n",
+ " # Forward pass\n",
+ " outputs = model(images)\n",
+ "\n",
+ " # Compute the loss\n",
+ " loss = criterion(outputs, labels)\n",
+ " \n",
+ " # Backward pass\n",
+ " optimizer.zero_grad()\n",
+ " loss.backward()\n",
+ "\n",
+ " # Update the weights\n",
+ " optimizer.step()\n",
+ "\n",
+ " # Update the metric\n",
+ " acc(outputs, labels)\n",
+ " \n",
+ " # Report the metrics\n",
+ " metrics = report_metrics_torch(loss=loss, accuracy=acc.compute(), epoch=epoch)\n",
+ " \n",
+ " # Reset the metric\n",
+ " acc.reset()\n",
+ "\n",
+ " # Save the checkpoint and metrics\n",
+ " Path(local_path).mkdir(parents=True, exist_ok=True)\n",
+ " save_checkpoint_and_metrics_torch(metrics=metrics, model=model, local_path=local_path)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We first start by defining how to build and load our model on a single GPU."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "def build_resnet18():\n",
+ " model = resnet18(num_classes=10)\n",
+ " model.conv1 = torch.nn.Conv2d(\n",
+ " in_channels=1, # grayscale MNIST images\n",
+ " out_channels=64,\n",
+ " kernel_size=(7, 7),\n",
+ " stride=(2, 2),\n",
+ " padding=(3, 3),\n",
+ " bias=False,\n",
+ " )\n",
+ " return model\n",
+ "\n",
+ "\n",
+ "def load_model_torch() -> torch.nn.Module:\n",
+ " model = build_resnet18()\n",
+ " # Move to the single GPU device\n",
+ " model.to(\"cuda\")\n",
+ " return model"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Here is our dataset"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "dataset = MNIST(root=\"./data\", train=True, download=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's display the first 10 images, with the corresponding labels:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig, axs = plt.subplots(1, 10, figsize=(20, 2))\n",
+ "\n",
+ "for i in range(10):\n",
+ " axs[i].imshow(dataset.train_data[i], cmap=\"gray\")\n",
+ " axs[i].axis(\"off\")\n",
+ " axs[i].set_title(dataset.train_labels[i].item())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We will also define a data loader to load our data in batches and apply transformations."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 30,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def build_data_loader_torch(batch_size: int) -> DataLoader:\n",
+ " transform = Compose([ToTensor(), Normalize((0.5,), (0.5,))])\n",
+ " dataset = MNIST(root=\"./data\", train=True, download=True, transform=transform)\n",
+ " train_loader = DataLoader(dataset, batch_size=batch_size, shuffle=True, drop_last=True)\n",
+ " return train_loader"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We will compute and report metrics via a simple print statement."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def report_metrics_torch(loss: torch.Tensor, accuracy: torch.Tensor, epoch: int) -> None:\n",
+ " metrics = {\"loss\": loss.item(), \"epoch\": epoch, \"accuracy\": accuracy.item()}\n",
+ " print(metrics)\n",
+ " return metrics"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "To save the checkpoint we will make use of a local directory."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def save_checkpoint_and_metrics_torch(metrics: dict[str, float], model: torch.nn.Module, local_path: str) -> None:\n",
+ " # Save the metrics\n",
+ " with open(os.path.join(local_path, \"metrics.csv\"), \"a\") as f:\n",
+ " writer = csv.writer(f)\n",
+ " writer.writerow(metrics.values())\n",
+ "\n",
+ " # Save the model\n",
+ " checkpoint_path = os.path.join(local_path, \"model.pt\")\n",
+ " torch.save(model.state_dict(), checkpoint_path)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Now we can schedule the training loop on a single GPU"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "timestamp = datetime.datetime.now(datetime.UTC).strftime(\"%Y-%m-%d_%H-%M-%S\")\n",
+ "local_path = f\"/mnt/local_storage/single_gpu_mnist/torch_{timestamp}/\"\n",
+ "\n",
+ "train_loop_torch(\n",
+ " num_epochs=2, \n",
+ " local_path=local_path\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's inspect the produced checkpoints and metrics"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!ls -l {local_path}"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "metrics = pd.read_csv(\n",
+ " os.path.join(local_path, \"metrics.csv\"),\n",
+ " header=None,\n",
+ " names=[\"loss\", \"epoch\", \"accuracy\"],\n",
+ ")\n",
+ "\n",
+ "metrics"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can also load our produced model checkpoint"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "loaded_model = build_resnet18()\n",
+ "loaded_model.load_state_dict(torch.load(os.path.join(local_path, \"model.pt\")))\n",
+ "loaded_model.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can the proceed to generate predictions on the first 10 images of the MNIST dataset."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig, axs = plt.subplots(1, 10, figsize=(20, 2))\n",
+ "for i in range(10):\n",
+ " axs[i].imshow(dataset.train_data[i], cmap=\"gray\")\n",
+ " axs[i].axis(\"off\")\n",
+ " with torch.no_grad():\n",
+ " normalized = Normalize((0.5,), (0.5,))(ToTensor()(dataset[i][0]))\n",
+ " prediction = loaded_model(normalized.unsqueeze(0)).argmax()\n",
+ " axs[i].set_title(prediction.item())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Distributed Data Parallel Training with Ray Train and PyTorch\n",
+ "\n",
+ "Let's now consider the case where we have a very large dataset of images that would take a long time to train on a single GPU. \n",
+ "\n",
+ "We would now like to scale this training job to run on multiple GPUs. \n",
+ "\n",
+ "Here is a diagram visualizing the desired distributed data-parallel training process:\n",
+ "\n",
+ " \n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Given it is the same model across all workers, we can instead only build the checkpoint on worker of rank 0. Note that we will still need to call `ray.train.report` on all workers to ensure that the training loop is synchronized."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def save_checkpoint_and_metrics_ray_train(\n",
+ " model: torch.nn.Module, metrics: dict[str, float]\n",
+ ") -> None:\n",
+ " with tempfile.TemporaryDirectory() as temp_checkpoint_dir:\n",
+ " checkpoint = None\n",
+ " if ray.train.get_context().get_world_rank() == 0:\n",
+ " torch.save(\n",
+ " model.module.state_dict(), os.path.join(temp_checkpoint_dir, \"model.pt\")\n",
+ " )\n",
+ " checkpoint = ray.train.Checkpoint.from_directory(temp_checkpoint_dir)\n",
+ "\n",
+ " ray.train.report(\n",
+ " metrics,\n",
+ " checkpoint=checkpoint,\n",
+ " )"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "For an in-depth guide on saving checkpoints and metrics, see the [docs](https://docs.ray.io/en/latest/train/user-guides/checkpoints.html)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 6. Launching the distributed training job\n",
+ "\n",
+ "Here is the desired data-parallel training diagram, but now using Ray Train.\n",
+ "\n",
+ "
\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Given it is the same model across all workers, we can instead only build the checkpoint on worker of rank 0. Note that we will still need to call `ray.train.report` on all workers to ensure that the training loop is synchronized."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def save_checkpoint_and_metrics_ray_train(\n",
+ " model: torch.nn.Module, metrics: dict[str, float]\n",
+ ") -> None:\n",
+ " with tempfile.TemporaryDirectory() as temp_checkpoint_dir:\n",
+ " checkpoint = None\n",
+ " if ray.train.get_context().get_world_rank() == 0:\n",
+ " torch.save(\n",
+ " model.module.state_dict(), os.path.join(temp_checkpoint_dir, \"model.pt\")\n",
+ " )\n",
+ " checkpoint = ray.train.Checkpoint.from_directory(temp_checkpoint_dir)\n",
+ "\n",
+ " ray.train.report(\n",
+ " metrics,\n",
+ " checkpoint=checkpoint,\n",
+ " )"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "For an in-depth guide on saving checkpoints and metrics, see the [docs](https://docs.ray.io/en/latest/train/user-guides/checkpoints.html)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 6. Launching the distributed training job\n",
+ "\n",
+ "Here is the desired data-parallel training diagram, but now using Ray Train.\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "Let's proceed to launch the distributed training job."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Configure persistent storage\n",
+ "Create a `RunConfig` object to specify the path where results (including checkpoints and artifacts) will be saved.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "storage_path = \"/mnt/cluster_storage/ray-summit-2024-training/\"\n",
+ "run_config = RunConfig(storage_path=storage_path, name=\"distributed-mnist-resnet18\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can now launch a distributed training job with a `TorchTrainer`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "trainer = TorchTrainer(\n",
+ " train_loop_ray_train,\n",
+ " scaling_config=scaling_config,\n",
+ " run_config=run_config,\n",
+ " train_loop_config={\"num_epochs\": 2, \"global_batch_size\": 128},\n",
+ ")\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Calling `trainer.fit()` will start the run and block until it completes."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "result = trainer.fit()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 7. Access the training results"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "After training completes, a `Result` object is returned which contains information about the training run, including the metrics and checkpoints reported during training."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "result"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can check the metrics produced by the training job."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "result.metrics_dataframe"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can also take the latest checkpoint and load it to inspect the model."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ckpt = result.checkpoint\n",
+ "with ckpt.as_directory() as ckpt_dir:\n",
+ " model_path = os.path.join(ckpt_dir, \"model.pt\")\n",
+ " loaded_model_ray_train = build_resnet18()\n",
+ " state_dict = torch.load(model_path, map_location=torch.device('cpu'), weights_only=True)\n",
+ " loaded_model_ray_train.load_state_dict(state_dict)\n",
+ " loaded_model_ray_train.eval()\n",
+ "\n",
+ "loaded_model_ray_train"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "To learn more about the training results, see this [docs](https://docs.ray.io/en/latest/train/user-guides/results.html) on inspecting the training results."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can then proceed to generate predictions using the loaded model:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig, axs = plt.subplots(1, 10, figsize=(20, 2))\n",
+ "\n",
+ "for i in range(10):\n",
+ " axs[i].imshow(dataset.train_data[i], cmap=\"gray\")\n",
+ " axs[i].axis(\"off\")\n",
+ " with torch.no_grad():\n",
+ " normalized = Normalize((0.5,), (0.5,))(ToTensor()(dataset[i][0]))\n",
+ " prediction = loaded_model_ray_train(normalized.unsqueeze(0)).argmax()\n",
+ " axs[i].set_title(prediction.item())\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "Let's proceed to launch the distributed training job."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Configure persistent storage\n",
+ "Create a `RunConfig` object to specify the path where results (including checkpoints and artifacts) will be saved.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "storage_path = \"/mnt/cluster_storage/ray-summit-2024-training/\"\n",
+ "run_config = RunConfig(storage_path=storage_path, name=\"distributed-mnist-resnet18\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can now launch a distributed training job with a `TorchTrainer`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "trainer = TorchTrainer(\n",
+ " train_loop_ray_train,\n",
+ " scaling_config=scaling_config,\n",
+ " run_config=run_config,\n",
+ " train_loop_config={\"num_epochs\": 2, \"global_batch_size\": 128},\n",
+ ")\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Calling `trainer.fit()` will start the run and block until it completes."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "result = trainer.fit()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 7. Access the training results"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "After training completes, a `Result` object is returned which contains information about the training run, including the metrics and checkpoints reported during training."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "result"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can check the metrics produced by the training job."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "result.metrics_dataframe"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can also take the latest checkpoint and load it to inspect the model."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ckpt = result.checkpoint\n",
+ "with ckpt.as_directory() as ckpt_dir:\n",
+ " model_path = os.path.join(ckpt_dir, \"model.pt\")\n",
+ " loaded_model_ray_train = build_resnet18()\n",
+ " state_dict = torch.load(model_path, map_location=torch.device('cpu'), weights_only=True)\n",
+ " loaded_model_ray_train.load_state_dict(state_dict)\n",
+ " loaded_model_ray_train.eval()\n",
+ "\n",
+ "loaded_model_ray_train"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "To learn more about the training results, see this [docs](https://docs.ray.io/en/latest/train/user-guides/results.html) on inspecting the training results."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can then proceed to generate predictions using the loaded model:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig, axs = plt.subplots(1, 10, figsize=(20, 2))\n",
+ "\n",
+ "for i in range(10):\n",
+ " axs[i].imshow(dataset.train_data[i], cmap=\"gray\")\n",
+ " axs[i].axis(\"off\")\n",
+ " with torch.no_grad():\n",
+ " normalized = Normalize((0.5,), (0.5,))(ToTensor()(dataset[i][0]))\n",
+ " prediction = loaded_model_ray_train(normalized.unsqueeze(0)).argmax()\n",
+ " axs[i].set_title(prediction.item())\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 8. Ray Train in Production\n",
+ "\n",
+ "Here are some use-cases of using Ray Train in production:\n",
+ "1. Canva uses Ray Train + Ray Data to cut down Stable Diffusion training costs by 3.7x. Read this [Anyscale blog post here](https://www.anyscale.com/blog/scalable-and-cost-efficient-stable-diffusion-pre-training-with-ray) and the [Canva case study here](https://www.anyscale.com/resources/case-study/how-canva-built-a-modern-ai-platform-using-anyscale)\n",
+ "2. Anyscale uses Ray Train + Deepspeed to finetune language models. Read more [here](https://github.com/ray-project/ray/tree/master/doc/source/templates/04_finetuning_llms_with_deepspeed).\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Run this cell for file cleanup \n",
+ "!rm -rf /mnt/cluster_storage/single_gpu_mnist"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.8"
+ },
+ "orphan": true,
+ "vscode": {
+ "interpreter": {
+ "hash": "a8c1140d108077f4faeb76b2438f85e4ed675f93d004359552883616a1acd54c"
+ }
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 4
+}
diff --git a/templates/ray-summit-ai-libraries/3_Intro_Tune.ipynb b/templates/ray-summit-ai-libraries/3_Intro_Tune.ipynb
new file mode 100644
index 000000000..29b254274
--- /dev/null
+++ b/templates/ray-summit-ai-libraries/3_Intro_Tune.ipynb
@@ -0,0 +1 @@
+{"cells":[{"cell_type":"markdown","metadata":{},"source":["# Intro to Ray Tune\n","\n","This notebook will walk you through the basics of hyperparameter tuning with Ray Tune.\n","\n","Click here to see the solution
\n", + "\n", + "```python\n", + "def print_metrics_ray_train(loss, accuracy, auroc):\n", + " metrics = {\n", + " \"loss\": loss.item(),\n", + " \"accuracy\": accuracy.item(),\n", + " \"auroc\": auroc.item(),\n", + " }\n", + " if ray.train.get_context().get_world_rank() == 0:\n", + " print(\n", + " f\"Loss: {loss.item()}, Accuracy: {accuracy.item()}, AUROC: {auroc.item()}\"\n", + " )\n", + " return metrics\n", + "\n", + "\n", + "def train_loop_ray_train(config):\n", + " criterion = CrossEntropyLoss()\n", + " model = load_model_ray_train()\n", + " optimizer = Adam(model.parameters(), lr=1e-5)\n", + "\n", + " global_batch_size = config[\"global_batch_size\"]\n", + " batch_size = global_batch_size // ray.train.get_context().get_world_size()\n", + " data_loader = build_data_loader_ray_train(batch_size=batch_size)\n", + "\n", + " acc = torchmetrics.Accuracy(task=\"multiclass\", num_classes=10).to(model.device)\n", + " # Add AUROC metric\n", + " auroc = torchmetrics.AUROC(task=\"multiclass\", num_classes=10).to(model.device)\n", + "\n", + " for epoch in range(config[\"num_epochs\"]):\n", + " data_loader.sampler.set_epoch(epoch)\n", + "\n", + " for images, labels in data_loader:\n", + " outputs = model(images)\n", + " loss = criterion(outputs, labels)\n", + " optimizer.zero_grad()\n", + " loss.backward()\n", + " optimizer.step()\n", + " acc(outputs, labels)\n", + " auroc(outputs, labels)\n", + "\n", + " metrics = print_metrics_ray_train(\n", + " loss, acc.compute(), auroc.compute()\n", + " )\n", + " save_checkpoint_and_metrics_ray_train(model, metrics)\n", + " acc.reset()\n", + " auroc.reset()\n", + "\n", + "trainer = TorchTrainer(\n", + " train_loop_ray_train,\n", + " scaling_config=scaling_config,\n", + " run_config=run_config,\n", + " train_loop_config={\"num_epochs\": 2, \"global_batch_size\": 128},\n", + ")\n", + "result = trainer.fit()\n", + "print(result.metrics_dataframe)\n", + "```\n", + "\n", + "\n","
\n"]},{"cell_type":"markdown","metadata":{},"source":["## Imports"]},{"cell_type":"code","execution_count":null,"metadata":{},"outputs":[],"source":["from typing import Any\n","\n","import matplotlib.pyplot as plt\n","import numpy as np\n","import torch\n","from torchvision.datasets import MNIST\n","from torchvision.transforms import Compose, ToTensor, Normalize\n","from torchvision.models import resnet18\n","from torch.utils.data import DataLoader\n","from torch.optim import Adam\n","from torch.nn import CrossEntropyLoss\n","\n","import ray\n","from ray import tune, train\n","from ray.tune.search import optuna"]},{"cell_type":"markdown","metadata":{},"source":["## 1. Loading the data\n","\n","Our Dataset is the MNIST dataset\n","\n","The MNIST dataset consists of 28x28 pixel grayscale images of handwritten digits (0-9).\n","\n","**Dataset details:**\n","- Training set: 60,000 images\n","- Test set: 10,000 images\n","- Image size: 28x28 pixels\n","- Number of classes: 10 (digits 0-9)\n","\n","**Data format:**\n","Each image is represented as a 2D array of pixel values, where each pixel is a grayscale intensity between 0 (black) and 255 (white).\n","\n"]},{"cell_type":"code","execution_count":null,"metadata":{},"outputs":[],"source":["def build_data_loader(batch_size: int) -> torch.utils.data.DataLoader:\n"," transform = Compose([ToTensor(), Normalize((0.5,), (0.5,))])\n"," train_data = MNIST(root=\"./data\", train=True, download=True, transform=transform)\n"," data_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True, drop_last=True)\n"," return data_loader"]},{"cell_type":"markdown","metadata":{},"source":["Let's visualize a batch"]},{"cell_type":"code","execution_count":null,"metadata":{},"outputs":[],"source":["fig, axs = plt.subplots(1, 10, figsize=(20, 2))\n","\n","data_loader = build_data_loader(batch_size=10)\n","\n","for (images, labels) in data_loader:\n"," \n"," for i, (image, label) in enumerate(zip(images, labels)):\n"," axs[i].imshow(image.squeeze(), cmap=\"gray\")\n"," axs[i].set_title(label.item())\n"," axs[i].axis(\"off\")\n"," break"]},{"cell_type":"markdown","metadata":{},"source":["## 2. Starting out with vanilla PyTorch\n","\n","Here is a high level overview of the model training process:\n","\n","- **Objective**: Classify handwritten digits (0-9)\n","- **Model**: Simple Neural Network using PyTorch\n","- **Evaluation Metric**: Accuracy\n","- **Dataset**: MNIST\n","\n","We'll start with a basic PyTorch implementation to establish a baseline before moving on to more advanced techniques. This will give us a good foundation for understanding the benefits of hyperparameter tuning and distributed training in later sections."]},{"cell_type":"code","execution_count":null,"metadata":{},"outputs":[],"source":["def train_loop_torch(num_epochs: int = 2, batch_size: int = 128, lr: float = 1e-5):\n"," criterion = CrossEntropyLoss()\n","\n"," model = resnet18()\n"," model.conv1 = torch.nn.Conv2d(\n"," 1, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False\n"," )\n"," model.to(\"cuda\")\n"," data_loader = build_data_loader(batch_size)\n"," optimizer = Adam(model.parameters(), lr=lr)\n","\n"," for epoch in range(num_epochs):\n"," for images, labels in data_loader:\n"," images, labels = images.to(\"cuda\"), labels.to(\"cuda\")\n"," outputs = model(images)\n"," loss = criterion(outputs, labels)\n"," optimizer.zero_grad()\n"," loss.backward()\n"," optimizer.step()\n","\n"," # Report the metrics\n"," print(f\"Epoch {epoch}, Loss: {loss}\")"]},{"cell_type":"markdown","metadata":{},"source":["We fit the model by submitting it onto a GPU node using Ray Core"]},{"cell_type":"code","execution_count":null,"metadata":{},"outputs":[],"source":["train_loop_torch(num_epochs=2)"]},{"cell_type":"markdown","metadata":{},"source":["**Can we do any better ?** let's see if we can tune the hyperparameters of our model to get a better loss.\n","\n","But hyperparameter tuning is a computationally expensive task, and it will take a long time to run sequentially.\n","\n","[Ray Tune](https://docs.ray.io/en/master/tune/) is a distributed hyperparameter tuning library that can help us speed up the process!"]},{"cell_type":"markdown","metadata":{},"source":["## 3. Hyperparameter tuning with Ray Tune"]},{"cell_type":"markdown","metadata":{},"source":["### Intro to Ray Tune\n","\n","Here is the roadmap for this notebook:
\n","- \n","
- Part 1: Loading the data \n","
- Part 2: Starting out with vanilla PyTorch \n","
- Part 3: Hyperparameter tuning with Ray Tune \n","
- Part 4: Ray Tune in production \n","
 \n","\n","Tune is a Python library for experiment execution and hyperparameter tuning at any scale.\n","\n","Let's take a look at a very simple example of how to use Ray Tune to tune the hyperparameters of our XGBoost model."]},{"cell_type":"markdown","metadata":{},"source":["### Getting started\n","\n","We start by defining our training function"]},{"cell_type":"code","execution_count":null,"metadata":{},"outputs":[],"source":["def my_simple_model(distance: np.ndarray, a: float) -> np.ndarray:\n"," return distance * a\n","\n","# Step 1: Define the training function\n","def train_my_simple_model(config: dict[str, Any]) -> None: # Expected function signature for Ray Tune\n"," distances = np.array([0.1, 0.2, 0.3, 0.4, 0.5])\n"," total_amts = distances * 10\n"," \n"," a = config[\"a\"]\n"," predictions = my_simple_model(distances, a)\n"," rmse = np.sqrt(np.mean((total_amts - predictions) ** 2))\n","\n"," train.report({\"rmse\": rmse}) # This is how we report the metric to Ray Tune"]},{"cell_type":"markdown","metadata":{},"source":["
\n","\n","Tune is a Python library for experiment execution and hyperparameter tuning at any scale.\n","\n","Let's take a look at a very simple example of how to use Ray Tune to tune the hyperparameters of our XGBoost model."]},{"cell_type":"markdown","metadata":{},"source":["### Getting started\n","\n","We start by defining our training function"]},{"cell_type":"code","execution_count":null,"metadata":{},"outputs":[],"source":["def my_simple_model(distance: np.ndarray, a: float) -> np.ndarray:\n"," return distance * a\n","\n","# Step 1: Define the training function\n","def train_my_simple_model(config: dict[str, Any]) -> None: # Expected function signature for Ray Tune\n"," distances = np.array([0.1, 0.2, 0.3, 0.4, 0.5])\n"," total_amts = distances * 10\n"," \n"," a = config[\"a\"]\n"," predictions = my_simple_model(distances, a)\n"," rmse = np.sqrt(np.mean((total_amts - predictions) ** 2))\n","\n"," train.report({\"rmse\": rmse}) # This is how we report the metric to Ray Tune"]},{"cell_type":"markdown","metadata":{},"source":["\n","Note: how the training function needs to accept a config argument. This is because Ray Tune will pass the hyperparameters to the training function as a dictionary.\n","
"]},{"cell_type":"markdown","metadata":{},"source":["Next, we define and run the hyperparameter tuning job by following these steps:\n","\n","1. Create a `Tuner` object (in our case named `tuner`)\n","2. Call `tuner.fit`"]},{"cell_type":"code","execution_count":null,"metadata":{},"outputs":[],"source":["# Step 2: Set up the Tuner\n","tuner = tune.Tuner(\n"," trainable=train_my_simple_model, # Training function or class to be tuned\n"," param_space={\n"," \"a\": tune.randint(0, 20), # Hyperparameter: a\n"," },\n"," tune_config=tune.TuneConfig(\n"," metric=\"rmse\", # Metric to optimize (minimize)\n"," mode=\"min\", # Minimize the metric\n"," num_samples=5, # Number of samples to try\n"," ),\n",")\n","\n","# Step 3: Run the Tuner and get the results\n","results = tuner.fit()"]},{"cell_type":"code","execution_count":null,"metadata":{},"outputs":[],"source":["# Step 4: Get the best result\n","best_result = results.get_best_result()\n","best_result"]},{"cell_type":"code","execution_count":null,"metadata":{},"outputs":[],"source":["best_result.config"]},{"cell_type":"markdown","metadata":{},"source":["So let's recap what actually happened here ?\n","\n","```python\n","tuner = tune.Tuner(\n"," trainable=train_my_simple_model, # Training function or class to be tuned\n"," param_space={\n"," \"a\": tune.randint(0, 20), # Hyperparameter: a\n"," },\n"," tune_config=tune.TuneConfig(\n"," metric=\"rmse\", # Metric to optimize (minimize)\n"," mode=\"min\", # Minimize the metric\n"," num_samples=5, # Number of samples to try\n"," ),\n",")\n","\n","results = tuner.fit()\n","```\n","\n","A Tuner accepts:\n","- A training function or class which is specified by `trainable`\n","- A search space which is specified by `param_space`\n","- A metric to optimize which is specified by `metric` and the direction of optimization `mode`\n","- `num_samples` which correlates to the number of trials to run\n","\n","`tuner.fit` then runs multiple trials in parallel, each with a different set of hyperparameters, and returns the best set of hyperparameters found.\n"]},{"cell_type":"markdown","metadata":{},"source":["### Diving deeper into Ray Tune concepts\n","\n","You might be wondering:\n","- How does the tuner allocate resources to trials?\n","- How does it decide how to tune - i.e. which trials to run next?\n"," - e.g. A random search, or a more sophisticated search algorithm like a bayesian optimization algorithm.\n","- How does it decide when to stop - i.e. whether to kill a trial early?\n"," - e.g. If a trial is performing poorly compared to other trials, it perhaps makes sense to stop it early (successive halving, hyperband)\n","\n","It turns out that by default: \n","- Each trial will run in a separate process and consume 1 CPU core.\n","- Ray Tune uses a search algorithm to decide which trials to run next.\n","- Ray Tune uses a scheduler to decide if/when to stop trials, or to prioritize certain trials over others."]},{"cell_type":"markdown","metadata":{},"source":["Here is the same code with the default settings for Ray Tune *explicitly* specified."]},{"cell_type":"code","execution_count":null,"metadata":{},"outputs":[],"source":["tuner = tune.Tuner(\n"," # This is how to specify resources for your trainable function\n"," trainable=tune.with_resources(train_my_simple_model, {\"cpu\": 1}),\n"," param_space={\"a\": tune.randint(0, 20)},\n"," tune_config=tune.TuneConfig(\n"," mode=\"min\",\n"," metric=\"rmse\",\n"," num_samples=5, \n"," # This search algorithm is a basic variation (i.e random/grid search) based on parameter space\n"," search_alg=tune.search.BasicVariantGenerator(), \n"," # This scheduler is very simple: no early stopping, just run all trials in submission order\n"," scheduler=tune.schedulers.FIFOScheduler(), \n"," ),\n",")\n","results = tuner.fit()"]},{"cell_type":"markdown","metadata":{},"source":["Below is a diagram showing the relationship between the different Ray Tune components we have discussed.\n","\n"," \n","\n","\n","To learn more about the key tune concepts, you can visit the [Ray Tune documentation here](https://docs.ray.io/en/master/tune/key-concepts.html)."]},{"cell_type":"markdown","metadata":{},"source":["Here is the same experiment table annotated \n","\n","
\n","\n","\n","To learn more about the key tune concepts, you can visit the [Ray Tune documentation here](https://docs.ray.io/en/master/tune/key-concepts.html)."]},{"cell_type":"markdown","metadata":{},"source":["Here is the same experiment table annotated \n","\n"," \n","\n","\n"]},{"cell_type":"markdown","metadata":{},"source":["#### Exercise\n","\n","
\n","\n","\n"]},{"cell_type":"markdown","metadata":{},"source":["#### Exercise\n","\n","\n"," \n","__Lab activity: Finetune a linear regression model.__\n"," \n","\n","Given the below code to train a linear regression model from scratch: \n","\n","```python\n","def train_linear_model(lr: float, epochs: int) -> None:\n"," x = np.array([0, 1, 2, 3, 4])\n"," y = x * 2\n"," w = 0\n"," for _ in range(epochs):\n"," loss = np.sqrt(np.mean((w * x - y) ** 2))\n"," dl_dw = np.mean(2 * x * (w * x - y)) \n"," w -= lr * dl_dw\n"," print({\"rmse\": loss})\n","\n","# Hint: Step 1 update the function signature\n","\n","# Hint: Step 2 Create the tuner object\n","tuner = tune.Tuner(...)\n","\n","# Hint: Step 3: Run the tuner\n","results = tuner.fit()\n","```\n","\n","Use Ray Tune to tune the hyperparameters `lr` and `epochs`. \n","\n","Perform a search using the optuna.OptunaSearch search algorithm with 5 samples over the following ranges:\n","- `lr`: loguniform(1e-4, 1e-1)\n","- `epochs`: randint(1, 100)\n","\n","
\n"]},{"cell_type":"code","execution_count":null,"metadata":{},"outputs":[],"source":["# Write your code here\n"]},{"cell_type":"markdown","metadata":{},"source":["\n","
"]},{"cell_type":"markdown","metadata":{},"source":["### Hyperparameter tune the PyTorch model using Ray Tune\n","\n","The first step is to move in all the PyTorch code into a function that we can pass to the `trainable` argument of the `tune.run` function."]},{"cell_type":"code","execution_count":null,"metadata":{},"outputs":[],"source":["def train_pytorch(config): # we change the function so it accepts a config dictionary\n"," criterion = CrossEntropyLoss()\n","\n"," model = resnet18()\n"," model.conv1 = torch.nn.Conv2d(\n"," 1, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False\n"," )\n"," model.to(\"cuda\")\n","\n"," optimizer = Adam(model.parameters(), lr=config[\"lr\"])\n"," transform = Compose([ToTensor(), Normalize((0.5,), (0.5,))])\n"," train_data = MNIST(root=\"./data\", train=True, download=True, transform=transform)\n"," data_loader = DataLoader(train_data, batch_size=config[\"batch_size\"], shuffle=True, drop_last=True)\n","\n"," for epoch in range(config[\"num_epochs\"]):\n"," for images, labels in data_loader:\n"," images, labels = images.to(\"cuda\"), labels.to(\"cuda\")\n"," outputs = model(images)\n"," loss = criterion(outputs, labels)\n"," optimizer.zero_grad()\n"," loss.backward()\n"," optimizer.step()\n","\n"," # Report the metrics using train.report instead of print\n"," train.report({\"loss\": loss.item()})"]},{"cell_type":"markdown","metadata":{},"source":["The second and third steps are the same as before. We define the tuner and run it by calling the fit method."]},{"cell_type":"code","execution_count":null,"metadata":{},"outputs":[],"source":["tuner = tune.Tuner(\n"," trainable=tune.with_resources(train_pytorch, {\"gpu\": 1}), # we will dedicate 1 GPU to each trial\n"," param_space={\n"," \"num_epochs\": 1,\n"," \"batch_size\": 128,\n"," \"lr\": tune.loguniform(1e-4, 1e-1),\n"," },\n"," tune_config=tune.TuneConfig(\n"," mode=\"min\",\n"," metric=\"loss\",\n"," num_samples=2,\n"," search_alg=tune.search.BasicVariantGenerator(),\n"," scheduler=tune.schedulers.FIFOScheduler(),\n"," ),\n",")\n","\n","results = tuner.fit()"]},{"cell_type":"markdown","metadata":{},"source":["Finally, we can get the best result and its configuration:"]},{"cell_type":"code","execution_count":null,"metadata":{},"outputs":[],"source":["best_result = results.get_best_result()\n","best_result.config"]},{"cell_type":"markdown","metadata":{},"source":["## 4. Ray Tune in Production\n","\n","Here are some use-cases of using Ray Train in production:\n","1. The Uber internal autotune service uses Ray Tune. See the uber blog post [here](https://www.uber.com/blog/from-predictive-to-generative-ai/).\n","2. How Spotify makes use of Ray Tune for hyperparameter tuning. See the spotify blog post [here](https://engineering.atspotify.com/2023/02/unleashing-ml-innovation-at-spotify-with-ray/)"]}],"metadata":{"kernelspec":{"display_name":"base","language":"python","name":"python3"},"language_info":{"codemirror_mode":{"name":"ipython","version":3},"file_extension":".py","mimetype":"text/x-python","name":"python","nbconvert_exporter":"python","pygments_lexer":"ipython3","version":"3.11.8"}},"nbformat":4,"nbformat_minor":2}
diff --git a/templates/ray-summit-ai-libraries/4_Intro_Data.ipynb b/templates/ray-summit-ai-libraries/4_Intro_Data.ipynb
new file mode 100644
index 000000000..03315a097
--- /dev/null
+++ b/templates/ray-summit-ai-libraries/4_Intro_Data.ipynb
@@ -0,0 +1,589 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Intro to Ray Data\n",
+ "\n",
+ "This notebook will provide an overview of Ray Data and how to use it to load, and transform data in a distributed manner.\n",
+ "\n",
+ "\n","
\n","Click here to view the solution
\n","\n","```python\n","def train_linear_model(config) -> None:\n"," epochs = config[\"epochs\"]\n"," lr = config[\"lr\"]\n"," x = np.array([0, 1, 2, 3, 4])\n"," y = x * 2\n"," w = 0\n"," for _ in range(epochs):\n"," loss = np.sqrt(np.mean((w * x - y) ** 2))\n"," dl_dw = np.mean(2 * x * (w * x - y)) \n"," w -= lr * dl_dw\n"," train.report({\"rmse\": loss})\n","\n","tuner = tune.Tuner(\n"," trainable=train_linear_model, # Training function or class to be tuned\n"," param_space={\n"," \"lr\": tune.loguniform(1e-4, 1e-1), # Hyperparameter: learning rate\n"," \"epochs\": tune.randint(1, 100), # Hyperparameter: number of epochs\n"," },\n"," tune_config=tune.TuneConfig(\n"," metric=\"rmse\", # Metric to optimize (minimize)\n"," mode=\"min\", # Minimize the metric\n"," num_samples=5, # Number of samples to try\n"," search_alg=optuna.OptunaSearch(), # Use Optuna for hyperparameter search\n"," ),\n",")\n","\n","results = tuner.fit()\n","```\n","\n","\n",
+ " Here is the roadmap for this notebook:\n",
+ "
\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Imports"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import numpy as np\n",
+ "import torch\n",
+ "from torchvision.transforms import Compose, ToTensor, Normalize\n",
+ "\n",
+ "import ray"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 1. When to use Ray Data\n",
+ "\n",
+ "Use Ray Data to load and preprocess data for distributed ML workloads. Compared to other loading solutions, Datasets are more flexible and provide [higher overall performance](https://www.anyscale.com/blog/why-third-generation-ml-platforms-are-more-performant). Ray Data is especially performant when needing to run pre-processing in a **streaming fashion** across a **large dataset** on a **heterogeneous cluster of CPUs and GPUs**.\n",
+ "\n",
+ "\n",
+ "Use Datasets as a last-mile bridge from storage or ETL pipeline outputs to distributed applications and libraries in Ray. \n",
+ "\n",
+ "- \n",
+ "
- Part 1: When to use Ray Data \n", + "
- Part 2: Loading Data \n", + "
- Part 3: Transforming Data \n", + "
- Part 4: Materializing Data \n", + "
- Part 5: Data Operations: Grouping, Aggregation, and Shuffling \n", + "
- Part 6: Persisting Data \n", + "
- Part 7: Ray Data in Production \n", + "
 \n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 2. Loading Data\n",
+ "\n",
+ "Datasets uses Ray tasks to read data from remote storage. When reading from a file-based datasource (e.g., S3, GCS), it creates a number of read tasks proportional to the number of CPUs in the cluster. Each read task reads its assigned files and produces an output block:\n",
+ "\n",
+ "
\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 2. Loading Data\n",
+ "\n",
+ "Datasets uses Ray tasks to read data from remote storage. When reading from a file-based datasource (e.g., S3, GCS), it creates a number of read tasks proportional to the number of CPUs in the cluster. Each read task reads its assigned files and produces an output block:\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's load some `MNIST` data from s3."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Here is our dataset it contains 50 images per class\n",
+ "!aws s3 ls s3://anyscale-public-materials/ray-ai-libraries/mnist/50_per_index/"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We will use the `read_images` function to load the image data."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds = ray.data.read_images(\"s3://anyscale-public-materials/ray-ai-libraries/mnist/50_per_index/\", include_paths=True)\n",
+ "ds"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Refer to the [Input/Output docs](https://docs.ray.io/en/latest/data/api/input_output.html) for a comprehensive list of read functions."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Dataset\n",
+ "\n",
+ "A Dataset consists of a list of Ray object references to *blocks*. Having multiple blocks in a dataset allows for parallel transformation and ingest.\n",
+ "\n",
+ "The following figure visualizes a tabular dataset with three blocks, each block holding 1000 rows each:\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's load some `MNIST` data from s3."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Here is our dataset it contains 50 images per class\n",
+ "!aws s3 ls s3://anyscale-public-materials/ray-ai-libraries/mnist/50_per_index/"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We will use the `read_images` function to load the image data."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds = ray.data.read_images(\"s3://anyscale-public-materials/ray-ai-libraries/mnist/50_per_index/\", include_paths=True)\n",
+ "ds"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Refer to the [Input/Output docs](https://docs.ray.io/en/latest/data/api/input_output.html) for a comprehensive list of read functions."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Dataset\n",
+ "\n",
+ "A Dataset consists of a list of Ray object references to *blocks*. Having multiple blocks in a dataset allows for parallel transformation and ingest.\n",
+ "\n",
+ "The following figure visualizes a tabular dataset with three blocks, each block holding 1000 rows each:\n",
+ "\n",
+ " \n",
+ "\n",
+ "Since a Dataset is just a list of Ray object references, it can be freely passed between Ray tasks, actors, and libraries like any other object reference. This flexibility is a unique characteristic of Ray Datasets."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 3. Transforming Data\n",
+ "\n",
+ "Ray Data can use either Ray tasks or Ray actors to transform datasets. Using actors allows for expensive state initialization (e.g., for GPU-based tasks) to be cached.\n",
+ "\n",
+ "Ray Data simplifies general purpose parallel GPU and CPU compute in Ray. \n",
+ "\n",
+ "Here is a sample data pipeline for streaming image data across a classification and segmentation model on a heterogenous cluster of CPUs and GPUs.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "Since a Dataset is just a list of Ray object references, it can be freely passed between Ray tasks, actors, and libraries like any other object reference. This flexibility is a unique characteristic of Ray Datasets."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 3. Transforming Data\n",
+ "\n",
+ "Ray Data can use either Ray tasks or Ray actors to transform datasets. Using actors allows for expensive state initialization (e.g., for GPU-based tasks) to be cached.\n",
+ "\n",
+ "Ray Data simplifies general purpose parallel GPU and CPU compute in Ray. \n",
+ "\n",
+ "Here is a sample data pipeline for streaming image data across a classification and segmentation model on a heterogenous cluster of CPUs and GPUs.\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "To transform data, we can use the `map_batches` API. This API allows us to apply a transformation to each batch of data."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def normalize(\n",
+ " batch: dict[str, np.ndarray], min_: float, max_: float\n",
+ ") -> dict[str, np.ndarray]:\n",
+ " transform = Compose([ToTensor(), Normalize((0.5,), (0.5,))])\n",
+ " batch[\"image\"] = [transform(image) for image in batch[\"image\"]]\n",
+ " return batch\n",
+ "\n",
+ "\n",
+ "ds_normalized = ds.map_batches(normalize, fn_kwargs={\"min_\": 0, \"max_\": 255})\n",
+ "ds_normalized"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Execution mode\n",
+ "\n",
+ "Most transformations are **lazy**. They don't execute until you write a dataset to storage or decide to materialize/consume the dataset.\n",
+ "\n",
+ "To materialize a very small subset of the data, you can use the `take_batch` method."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "normalized_batch = ds_normalized.take_batch(batch_size=10)\n",
+ "\n",
+ "for image in normalized_batch[\"image\"]:\n",
+ " assert image.shape == (1, 28, 28) # channel, height, width\n",
+ " assert image.min() >= -1 and image.max() <= 1 # normalized to [-1, 1]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "To transform data, we can use the `map_batches` API. This API allows us to apply a transformation to each batch of data."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def normalize(\n",
+ " batch: dict[str, np.ndarray], min_: float, max_: float\n",
+ ") -> dict[str, np.ndarray]:\n",
+ " transform = Compose([ToTensor(), Normalize((0.5,), (0.5,))])\n",
+ " batch[\"image\"] = [transform(image) for image in batch[\"image\"]]\n",
+ " return batch\n",
+ "\n",
+ "\n",
+ "ds_normalized = ds.map_batches(normalize, fn_kwargs={\"min_\": 0, \"max_\": 255})\n",
+ "ds_normalized"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Execution mode\n",
+ "\n",
+ "Most transformations are **lazy**. They don't execute until you write a dataset to storage or decide to materialize/consume the dataset.\n",
+ "\n",
+ "To materialize a very small subset of the data, you can use the `take_batch` method."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "normalized_batch = ds_normalized.take_batch(batch_size=10)\n",
+ "\n",
+ "for image in normalized_batch[\"image\"]:\n",
+ " assert image.shape == (1, 28, 28) # channel, height, width\n",
+ " assert image.min() >= -1 and image.max() <= 1 # normalized to [-1, 1]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "### Activity: Add the ground truth label using the image path.\n",
+ "\n",
+ "In this activity, you will add the ground truth label using the image path.\n",
+ "\n",
+ "The image path is in the format of `s3://anyscale-public-materials/ray-ai-libraries/mnist/50_per_index/{label}/{image_id}.png`.\n",
+ "\n",
+ "See the suggested code below:\n",
+ "\n",
+ "```python\n",
+ "# Hint: define the add_label function\n",
+ "\n",
+ "ds_labeled = ds_normalized.map_batches(add_label)\n",
+ "labeled_batch = ds_labeled.take_batch(10)\n",
+ "print(labeled_batch[\"ground_truth_label\"])\n",
+ "```\n",
+ "\n",
+ "\n",
+ "
\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Write your solution here"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Stateful transformations with actors\n",
+ "\n",
+ "In cases like batch inference, you want to spin up a number of actor processes that are initialized once with your model and reused to process multiple batches.\n",
+ "\n",
+ "To implement this, you can use the `map_batches` API with a \"Callable\" class method that implements:\n",
+ "\n",
+ "- `__init__`: Initialize any expensive state.\n",
+ "- `__call__`: Perform the stateful transformation.\n",
+ "\n",
+ "For example, we can implement a `MNISTClassifier` that:\n",
+ "- loads a pre-trained model from a local file\n",
+ "- accepts a batch of images and generates the predicted label"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "class MNISTClassifier:\n",
+ " def __init__(self, local_path: str):\n",
+ " self.model = torch.jit.load(local_path)\n",
+ " self.model.to(\"cuda\")\n",
+ " self.model.eval()\n",
+ "\n",
+ " def __call__(self, batch: dict[str, np.ndarray]) -> dict[str, np.ndarray]:\n",
+ " images = torch.tensor(batch[\"image\"]).float().to(\"cuda\")\n",
+ "\n",
+ " with torch.no_grad():\n",
+ " logits = self.model(images).cpu().numpy()\n",
+ "\n",
+ " batch[\"predicted_label\"] = np.argmax(logits, axis=1)\n",
+ " return batch"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# We download the model from s3 to an EFS storage\n",
+ "!aws s3 cp s3://anyscale-public-materials/ray-ai-libraries/mnist/model/model.pt /mnt/cluster_storage/model.pt"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can now use the `map_batches` API to apply the transformation to each batch of data."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds_preds = ds_normalized.map_batches(\n",
+ " MNISTClassifier,\n",
+ " fn_constructor_kwargs={\"local_path\": \"/mnt/cluster_storage/model.pt\"},\n",
+ " num_gpus=0.1,\n",
+ " concurrency=1,\n",
+ " batch_size=100,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "
\n",
+ "Click to view solution
\n", + "\n", + "```python\n", + "def add_label(batch: dict[str, np.ndarray]) -> dict[str, np.ndarray]:\n", + " batch[\"ground_truth_label\"] = [int(path.split(\"/\")[-2]) for path in batch[\"path\"]]\n", + " return batch\n", + "\n", + "ds_labeled = ds_normalized.map_batches(add_label)\n", + "labeled_batch = ds_labeled.take_batch(10)\n", + "print(labeled_batch[\"ground_truth_label\"])\n", + "```\n", + "\n", + "\n",
+ "\n",
+ "Note: We pass in the Callable class uninitialized. Ray will pass in the arguments to the class constructor when the class is actually used in a transformation.\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "batch_preds = ds_preds.take_batch(100)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "batch_preds"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 4. Materializing Data\n",
+ "\n",
+ "You can choose to materialize the entire dataset into the ray object store which is distributed across the cluster, primarily in memory and secondarily spilling to disk.\n",
+ "\n",
+ "To materialize the dataset, we can use the `materialize()` method.\n",
+ "\n",
+ "Use this **only** when you require the full dataset to compute downstream outputs."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds_preds.materialize()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 5. Data Operations: Grouping, Aggregation, and Shuffling\n",
+ "\n",
+ "Let's look at some more involved transformations.\n",
+ "\n",
+ "#### Custom batching using `groupby`. \n",
+ "\n",
+ "In case you want to generate batches according to a specific key, you can use `groupby` to group the data by the key and then use `map_groups` to apply the transformation.\n",
+ "\n",
+ "For instance, let's compute the accuracy of the model by \"ground truth label\"."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def add_label(batch: dict[str, np.ndarray]) -> dict[str, np.ndarray]:\n",
+ " batch[\"ground_truth_label\"] = [int(path.split(\"/\")[-2]) for path in batch[\"path\"]]\n",
+ " return batch\n",
+ "\n",
+ "\n",
+ "def compute_accuracy(group: dict[str, np.ndarray]) -> dict[str, np.ndarray]:\n",
+ " return {\n",
+ " \"accuracy\": [np.mean(group[\"predicted_label\"] == group[\"ground_truth_label\"])],\n",
+ " \"ground_truth_label\": group[\"ground_truth_label\"][:1],\n",
+ " }\n",
+ "\n",
+ "\n",
+ "ds_preds.map_batches(add_label).groupby(\"ground_truth_label\").map_groups(compute_accuracy).to_pandas()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "Note: ds_preds is not re-computed given we have already materialized the dataset.\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Aggregations\n",
+ "\n",
+ "Ray Data also supports a variety of aggregations. For instance, we can compute the mean accuracy across the entire dataset."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds_preds.map_batches(add_label).map_batches(compute_accuracy).mean(on=\"accuracy\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "As of version 2.34.0, Ray Data provides the following aggregation functions:\n",
+ "\n",
+ "- `count`\n",
+ "- `max`\n",
+ "- `mean`\n",
+ "- `min`\n",
+ "- `sum`\n",
+ "- `std`\n",
+ "\n",
+ "See relevant [docs page here](https://docs.ray.io/en/latest/data/api/grouped_data.html#ray.data.aggregate.AggregateFn)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Shuffling data \n",
+ "\n",
+ "There are different options to shuffle data in Ray Data of varying degrees of randomness and performance."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### File based shuffle on read\n",
+ "\n",
+ "To randomly shuffle the ordering of input files before reading, call a read function that supports shuffling, such as `read_images()`, and use the shuffle=\"files\" parameter."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ray.data.read_images(\"s3://anyscale-public-materials/ray-ai-libraries/mnist/50_per_index/\", shuffle=\"files\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Shuffling block order\n",
+ "This option randomizes the order of blocks in a dataset. Blocks are the basic unit of data chunk that Ray Data stores in the object store. Applying this operation alone doesn’t involve heavy computation and communication. However, it requires Ray Data to materialize all blocks in memory before applying the operation. Only use this option when your dataset is small enough to fit into the object store memory.\n",
+ "\n",
+ "To perform block order shuffling, use `randomize_block_order`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds_randomized_blocks = ds_preds.randomize_block_order()\n",
+ "ds_randomized_blocks.materialize()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Shuffle all rows globally\n",
+ "To randomly shuffle all rows globally, call `random_shuffle()`. This is the slowest option for shuffle, and requires transferring data across network between workers. This option achieves the best randomness among all options.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds_randomized_rows = ds_preds.random_shuffle()\n",
+ "ds_randomized_rows.materialize()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 6. Persisting Data\n",
+ "\n",
+ "Finally, you can persist a dataset to storage using any of the \"write\" functions that Ray Data supports.\n",
+ "\n",
+ "Lets write our predictions to a parquet dataset."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds_preds.write_parquet(\"/mnt/cluster_storage/mnist_preds\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Refer to the [Input/Output docs](https://docs.ray.io/en/latest/data/api/input_output.html) for a comprehensive list of write functions."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# cleanup\n",
+ "!rm -rf /mnt/cluster_storage/mnist_preds"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 7. Ray Data in Production\n",
+ "\n",
+ "1. Runway AI is using Ray Data to scale its ML workloads. See [this interview with Runway AI](https://siliconangle.com/2024/10/02/runway-transforming-ai-driven-filmmaking-innovative-tools-techniques-raysummit/) to learn more.\n",
+ "2. Netflix is using Ray Data for multi-modal inference pipelines. See [this talk at the Ray Summit 2024](https://raysummit.anyscale.com/flow/anyscale/raysummit2024/landing/page/sessioncatalog/session/1722028596844001bCg0) to learn more."
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 4
+}
diff --git a/templates/ray-summit-ai-libraries/5_Intro_Serve.ipynb b/templates/ray-summit-ai-libraries/5_Intro_Serve.ipynb
new file mode 100644
index 000000000..e7fa8cb09
--- /dev/null
+++ b/templates/ray-summit-ai-libraries/5_Intro_Serve.ipynb
@@ -0,0 +1,881 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "682e224e-1bb9-470c-b363-386ede0785a4",
+ "metadata": {},
+ "source": [
+ "# Intro to Ray Serve\n",
+ "\n",
+ "This notebook will introduce you to Ray Serve, a framework for building and deploying scalable ML applications.\n",
+ "\n",
+ "\n",
+ " \n",
+ "Here is the roadmap for this notebook:\n",
+ "\n",
+ "
\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1060aea0",
+ "metadata": {},
+ "source": [
+ "## Imports"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "099b7710",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from typing import Any\n",
+ "from torchvision import transforms\n",
+ "\n",
+ "import json\n",
+ "import numpy as np\n",
+ "import ray\n",
+ "import requests\n",
+ "import torch\n",
+ "from ray import serve\n",
+ "from matplotlib import pyplot as plt\n",
+ "from fastapi import FastAPI\n",
+ "from starlette.requests import Request"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7250cc03-e52c-4e30-a262-8d8e0a5a0837",
+ "metadata": {},
+ "source": [
+ "## 1. Overview of Ray Serve\n",
+ "\n",
+ "Serve is a framework for serving ML applications. \n",
+ "\n",
+ "Here is a high-level overview of the architecture of a Ray Serve Application.\n",
+ "\n",
+ "- \n",
+ "
- Part 1: Overview of Ray Serve \n", + "
- Part 2: Implement an MNISTClassifier service \n", + "
- Part 3: Advanced features of Ray Serve \n", + "
- Part 4: Ray Serve in Production \n", + "
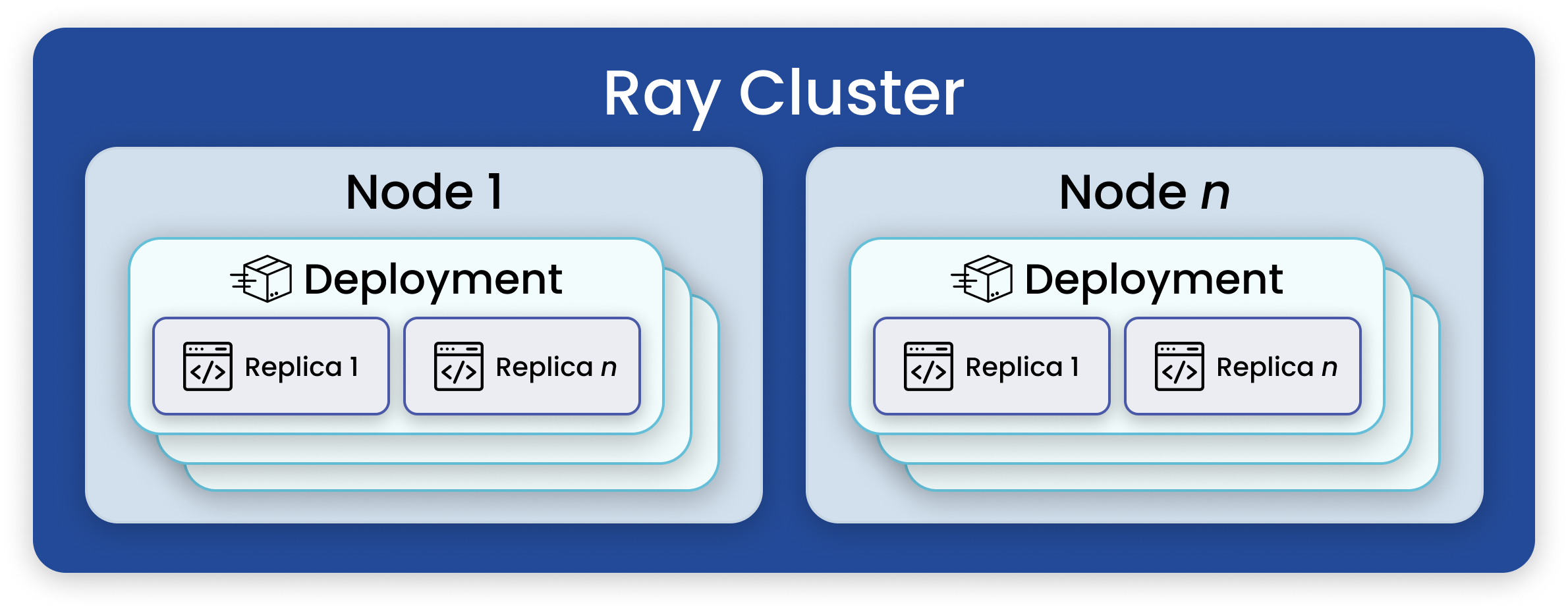 \n",
+ "\n",
+ "An Application is a collection of one or more Deployments that are deployed together.\n",
+ "\n",
+ "### Deployments\n",
+ "\n",
+ "`Deployment` is the fundamental developer-facing element of serve.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "An Application is a collection of one or more Deployments that are deployed together.\n",
+ "\n",
+ "### Deployments\n",
+ "\n",
+ "`Deployment` is the fundamental developer-facing element of serve.\n",
+ "\n",
+ "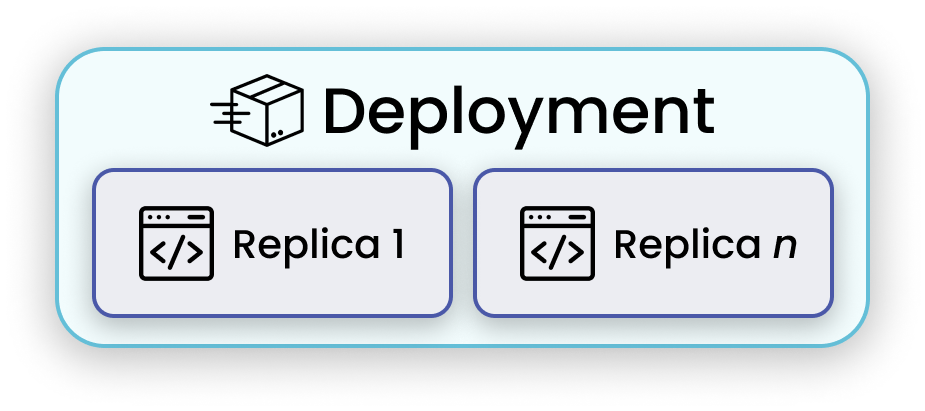 \n",
+ "\n",
+ "Each deployment can have multiple replicas. \n",
+ "\n",
+ "A replica is implemented as a Ray actor with a queue to process incoming requests.\n",
+ "\n",
+ "Each replica can be configured with a set of compute resources. "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6380b141",
+ "metadata": {},
+ "source": [
+ "### When to use Ray Serve?\n",
+ "\n",
+ "Ray Serve is designed to be used in the following scenarios:\n",
+ "- Build end-to-end ML applications with a flexible and programmable python API\n",
+ "- Flexibly scale up and down your compute resources to meet the demand of your application\n",
+ "- Easy to develop on a local machine, and scale to a multi-node GPU cluster\n",
+ "\n",
+ "#### Key Ray Serve Features\n",
+ "Ray Serve provides the following key features and optimizations:\n",
+ "- [response streaming](https://docs.ray.io/en/latest/serve/tutorials/streaming.html)\n",
+ "- [dynamic request batching](https://docs.ray.io/en/latest/serve/advanced-guides/dyn-req-batch.html)\n",
+ "- [multi-node/multi-GPU serving](https://docs.ray.io/en/latest/serve/tutorials/vllm-example.html)\n",
+ "- [model multiplexing](https://docs.ray.io/en/latest/serve/model-multiplexing.html)\n",
+ "- [fractional compute resource usage](https://docs.ray.io/en/latest/serve/configure-serve-deployment.html)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a43da1a6",
+ "metadata": {},
+ "source": [
+ "## 2. Implement an MNISTClassifier service\n",
+ "\n",
+ "Let’s jump right in and get a simple ML service up and running on Ray Serve. \n",
+ "\n",
+ "Recall the `MNISTClassifier` we built to perform batch inference on the `MNIST` dataset."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "14fb17a6-a71c-4a11-8ea8-b1b350a5fa1c",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "class OfflineMNISTClassifier:\n",
+ " def __init__(self, local_path: str):\n",
+ " self.model = torch.jit.load(local_path)\n",
+ " self.model.to(\"cuda\")\n",
+ " self.model.eval()\n",
+ "\n",
+ " def __call__(self, batch: dict[str, np.ndarray]) -> dict[str, np.ndarray]:\n",
+ " return self.predict(batch)\n",
+ " \n",
+ " def predict(self, batch: dict[str, np.ndarray]) -> dict[str, np.ndarray]:\n",
+ " images = torch.tensor(batch[\"image\"]).float().to(\"cuda\")\n",
+ "\n",
+ " with torch.no_grad():\n",
+ " logits = self.model(images).cpu().numpy()\n",
+ "\n",
+ " batch[\"predicted_label\"] = np.argmax(logits, axis=1)\n",
+ " return batch"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "48d148b8",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# We download the model from s3 to the EFS storage\n",
+ "!aws s3 cp s3://anyscale-public-materials/ray-ai-libraries/mnist/model/model.pt /mnt/cluster_storage/model.pt"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e1a79961",
+ "metadata": {},
+ "source": [
+ "Here is how we can use the `OfflineMNISTClassifier` to perform batch inference on a dataset of random images."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "41b16400",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Create a dataset of random images\n",
+ "ds = ray.data.from_items([{\"image\": np.random.rand(1, 28, 28)} for _ in range(100)])\n",
+ "\n",
+ "# Map the OfflineMNISTClassifier to the dataset\n",
+ "ds = ds.map_batches(\n",
+ " OfflineMNISTClassifier,\n",
+ " fn_constructor_kwargs={\"local_path\": \"/mnt/cluster_storage/model.pt\"},\n",
+ " concurrency=1,\n",
+ " num_gpus=1,\n",
+ " batch_size=10\n",
+ ")\n",
+ "\n",
+ "# Take a look at the first 10 predictions\n",
+ "ds.take_batch(10)[\"predicted_label\"]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fbb1a687",
+ "metadata": {},
+ "source": [
+ "Now, if want to migrate to an online inference setting, we can transform this into a Ray Serve Deployment by applying the `@serve.deployment` decorator \n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c68888dd",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@serve.deployment() # this is the decorator to add\n",
+ "class OnlineMNISTClassifier:\n",
+ " def __init__(self, local_path: str):\n",
+ " self.model = torch.jit.load(local_path)\n",
+ " self.model.to(\"cuda\")\n",
+ " self.model.eval()\n",
+ "\n",
+ " async def __call__(self, request: Request) -> dict[str, Any]: # __call__ now takes a Starlette Request object\n",
+ " batch = json.loads(await request.json()) # we will need to parse the JSON body of the request\n",
+ " return await self.predict(batch)\n",
+ " \n",
+ " async def predict(self, batch: dict[str, np.ndarray]) -> dict[str, np.ndarray]:\n",
+ " # same code as OfflineMNISTClassifier.predict except we added async to the method\n",
+ " images = torch.tensor(batch[\"image\"]).float().to(\"cuda\")\n",
+ "\n",
+ " with torch.no_grad():\n",
+ " logits = self.model(images).cpu().numpy()\n",
+ "\n",
+ " batch[\"predicted_label\"] = np.argmax(logits, axis=1)\n",
+ " return batch"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2cf85ff1",
+ "metadata": {},
+ "source": [
+ "We can now instantiate the `OnlineMNISTClassifier` as a Ray Serve Application using `.bind`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "df46ddd7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "mnist_deployment = OnlineMNISTClassifier.options(\n",
+ " num_replicas=1,\n",
+ " ray_actor_options={\"num_gpus\": 1},\n",
+ ")\n",
+ "\n",
+ "mnist_app = mnist_deployment.bind(local_path=\"/mnt/cluster_storage/model.pt\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "098e8ac4",
+ "metadata": {},
+ "source": [
+ "
\n",
+ "\n",
+ "Each deployment can have multiple replicas. \n",
+ "\n",
+ "A replica is implemented as a Ray actor with a queue to process incoming requests.\n",
+ "\n",
+ "Each replica can be configured with a set of compute resources. "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6380b141",
+ "metadata": {},
+ "source": [
+ "### When to use Ray Serve?\n",
+ "\n",
+ "Ray Serve is designed to be used in the following scenarios:\n",
+ "- Build end-to-end ML applications with a flexible and programmable python API\n",
+ "- Flexibly scale up and down your compute resources to meet the demand of your application\n",
+ "- Easy to develop on a local machine, and scale to a multi-node GPU cluster\n",
+ "\n",
+ "#### Key Ray Serve Features\n",
+ "Ray Serve provides the following key features and optimizations:\n",
+ "- [response streaming](https://docs.ray.io/en/latest/serve/tutorials/streaming.html)\n",
+ "- [dynamic request batching](https://docs.ray.io/en/latest/serve/advanced-guides/dyn-req-batch.html)\n",
+ "- [multi-node/multi-GPU serving](https://docs.ray.io/en/latest/serve/tutorials/vllm-example.html)\n",
+ "- [model multiplexing](https://docs.ray.io/en/latest/serve/model-multiplexing.html)\n",
+ "- [fractional compute resource usage](https://docs.ray.io/en/latest/serve/configure-serve-deployment.html)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a43da1a6",
+ "metadata": {},
+ "source": [
+ "## 2. Implement an MNISTClassifier service\n",
+ "\n",
+ "Let’s jump right in and get a simple ML service up and running on Ray Serve. \n",
+ "\n",
+ "Recall the `MNISTClassifier` we built to perform batch inference on the `MNIST` dataset."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "14fb17a6-a71c-4a11-8ea8-b1b350a5fa1c",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "class OfflineMNISTClassifier:\n",
+ " def __init__(self, local_path: str):\n",
+ " self.model = torch.jit.load(local_path)\n",
+ " self.model.to(\"cuda\")\n",
+ " self.model.eval()\n",
+ "\n",
+ " def __call__(self, batch: dict[str, np.ndarray]) -> dict[str, np.ndarray]:\n",
+ " return self.predict(batch)\n",
+ " \n",
+ " def predict(self, batch: dict[str, np.ndarray]) -> dict[str, np.ndarray]:\n",
+ " images = torch.tensor(batch[\"image\"]).float().to(\"cuda\")\n",
+ "\n",
+ " with torch.no_grad():\n",
+ " logits = self.model(images).cpu().numpy()\n",
+ "\n",
+ " batch[\"predicted_label\"] = np.argmax(logits, axis=1)\n",
+ " return batch"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "48d148b8",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# We download the model from s3 to the EFS storage\n",
+ "!aws s3 cp s3://anyscale-public-materials/ray-ai-libraries/mnist/model/model.pt /mnt/cluster_storage/model.pt"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e1a79961",
+ "metadata": {},
+ "source": [
+ "Here is how we can use the `OfflineMNISTClassifier` to perform batch inference on a dataset of random images."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "41b16400",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Create a dataset of random images\n",
+ "ds = ray.data.from_items([{\"image\": np.random.rand(1, 28, 28)} for _ in range(100)])\n",
+ "\n",
+ "# Map the OfflineMNISTClassifier to the dataset\n",
+ "ds = ds.map_batches(\n",
+ " OfflineMNISTClassifier,\n",
+ " fn_constructor_kwargs={\"local_path\": \"/mnt/cluster_storage/model.pt\"},\n",
+ " concurrency=1,\n",
+ " num_gpus=1,\n",
+ " batch_size=10\n",
+ ")\n",
+ "\n",
+ "# Take a look at the first 10 predictions\n",
+ "ds.take_batch(10)[\"predicted_label\"]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fbb1a687",
+ "metadata": {},
+ "source": [
+ "Now, if want to migrate to an online inference setting, we can transform this into a Ray Serve Deployment by applying the `@serve.deployment` decorator \n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c68888dd",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@serve.deployment() # this is the decorator to add\n",
+ "class OnlineMNISTClassifier:\n",
+ " def __init__(self, local_path: str):\n",
+ " self.model = torch.jit.load(local_path)\n",
+ " self.model.to(\"cuda\")\n",
+ " self.model.eval()\n",
+ "\n",
+ " async def __call__(self, request: Request) -> dict[str, Any]: # __call__ now takes a Starlette Request object\n",
+ " batch = json.loads(await request.json()) # we will need to parse the JSON body of the request\n",
+ " return await self.predict(batch)\n",
+ " \n",
+ " async def predict(self, batch: dict[str, np.ndarray]) -> dict[str, np.ndarray]:\n",
+ " # same code as OfflineMNISTClassifier.predict except we added async to the method\n",
+ " images = torch.tensor(batch[\"image\"]).float().to(\"cuda\")\n",
+ "\n",
+ " with torch.no_grad():\n",
+ " logits = self.model(images).cpu().numpy()\n",
+ "\n",
+ " batch[\"predicted_label\"] = np.argmax(logits, axis=1)\n",
+ " return batch"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2cf85ff1",
+ "metadata": {},
+ "source": [
+ "We can now instantiate the `OnlineMNISTClassifier` as a Ray Serve Application using `.bind`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "df46ddd7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "mnist_deployment = OnlineMNISTClassifier.options(\n",
+ " num_replicas=1,\n",
+ " ray_actor_options={\"num_gpus\": 1},\n",
+ ")\n",
+ "\n",
+ "mnist_app = mnist_deployment.bind(local_path=\"/mnt/cluster_storage/model.pt\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "098e8ac4",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "**Note:** `.bind` is a method that takes in the arguments to pass to the Deployment constructor.\n",
+ "\n",
+ "
\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e3e70529",
+ "metadata": {},
+ "source": [
+ "We can then run the application "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e96056cd",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "mnist_deployment_handle = serve.run(mnist_app, name='mnist_classifier', blocking=False)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5f4a0cdb-822a-4439-aeab-9916dd8d059c",
+ "metadata": {},
+ "source": [
+ "We can test it as an HTTP endpoint"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1c0a80e9-c26f-48d2-8985-ef4eab4dc580",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "images = np.random.rand(2, 1, 28, 28).tolist()\n",
+ "json_request = json.dumps({\"image\": images})\n",
+ "response = requests.post(\"http://localhost:8000/\", json=json_request)\n",
+ "response.json()[\"predicted_label\"]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7cd2cb01",
+ "metadata": {},
+ "source": [
+ "We can also test it as a gRPC endpoint"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "342928ea",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "batch = {\"image\": np.random.rand(10, 1, 28, 28)}\n",
+ "response = await mnist_deployment_handle.predict.remote(batch)\n",
+ "response[\"predicted_label\"]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4e170084",
+ "metadata": {},
+ "source": [
+ "## 3. Advanced features of Ray Serve"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "da2b22a2",
+ "metadata": {},
+ "source": [
+ "### Using fractions of a GPU\n",
+ "\n",
+ "With Ray we can specify fractional compute resources for each deployment's replica. \n",
+ "\n",
+ "This is useful to help us fully utilize a GPU especially when running small models like our `MNISTClassifier` model.\n",
+ "\n",
+ "Here is how to specify only 10% of a GPU's compute resources for our `MNISTClassifier` model."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "230f9ff2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "mnist_app = OnlineMNISTClassifier.options(\n",
+ " num_replicas=4, # we can scale to up to 10 replicas on a single GPU\n",
+ " ray_actor_options={\"num_gpus\": 0.1}, \n",
+ ").bind(local_path=\"/mnt/cluster_storage/model.pt\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b35a8d83",
+ "metadata": {},
+ "source": [
+ "Next we update the running application by running serve.run with the new options."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9e9ad6fa",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "mnist_deployment_handle = serve.run(mnist_app, name='mnist_classifier', blocking=False)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b196a535",
+ "metadata": {},
+ "source": [
+ "We can test the new application by sending a sample request."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c5aad97c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "images = np.random.rand(2, 1, 28, 28).tolist()\n",
+ "json_request = json.dumps({\"image\": images})\n",
+ "response = requests.post(\"http://localhost:8000/\", json=json_request)\n",
+ "response.json()[\"predicted_label\"]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "05041234",
+ "metadata": {},
+ "source": [
+ "### Customizing autoscaling\n",
+ "\n",
+ "Ray Serve provides a simple way to autoscale the number of replicas in a deployment. It is primarily based on the target number of ongoing requests per replica.\n",
+ "\n",
+ "i.e. here is how we can set the autoscaling config for our `OnlineMNISTClassifier` deployment."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e356f749",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "mnist_app = OnlineMNISTClassifier.options(\n",
+ " ray_actor_options={\"num_gpus\": 0.1}, \n",
+ " autoscaling_config={\n",
+ " \"target_ongoing_requests\": 10,\n",
+ " },\n",
+ ").bind(local_path=\"/mnt/cluster_storage/model.pt\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1ae8a244",
+ "metadata": {},
+ "source": [
+ "We can also control more granularly the autoscaling logic by setting:\n",
+ "- the upscale and downscale delays\n",
+ "- the intervals at which the replica sends metrics reports about the current number of ongoing requests\n",
+ "- the look-back period used to evaluate the current number of ongoing requests\n",
+ "\n",
+ "Here is an example of how to set these options:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6e5594d5",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "mnist_app = OnlineMNISTClassifier.options(\n",
+ " ray_actor_options={\"num_gpus\": 0.1}, \n",
+ " autoscaling_config={\n",
+ " \"target_ongoing_requests\": 10,\n",
+ " \"upscale_delay_s\": 10,\n",
+ " \"downscale_delay_s\": 10,\n",
+ " \"metrics_interval_s\": 10,\n",
+ " \"look_back_period_s\": 10, \n",
+ " },\n",
+ ").bind(local_path=\"/mnt/cluster_storage/model.pt\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e8a643b4",
+ "metadata": {},
+ "source": [
+ "We can additionally control the minimum and maximum number of replicas that can be scaled up and down. \n",
+ "\n",
+ "We can even specify to start scaling up from 0 replicas."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ebea6c15",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "mnist_app = OnlineMNISTClassifier.options(\n",
+ " ray_actor_options={\"num_gpus\": 0.1}, \n",
+ " autoscaling_config={\n",
+ " \"target_ongoing_requests\": 10,\n",
+ " \"initial_replicas\": 0, # scale up from 0 replicas\n",
+ " \"min_replicas\": 0,\n",
+ " \"max_replicas\": 10,\n",
+ " # extreme upscale speeds\n",
+ " \"upscale_delay_s\": 0,\n",
+ " \"metrics_interval_s\": 0.1,\n",
+ " \"look_back_period_s\": 0.1,\n",
+ " },\n",
+ ").bind(local_path=\"/mnt/cluster_storage/model.pt\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e040d6ac",
+ "metadata": {},
+ "source": [
+ "Let's run the application with the new autoscaling config."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "fbe684a4",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "mnist_deployment_handle = serve.run(mnist_app, name='mnist_classifier', blocking=False)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "75be6e25",
+ "metadata": {},
+ "source": [
+ "Looking at the Ray Serve dashboard, we can see we are currently at 0 replicas - i.e. no GPU resources are being used.\n",
+ "\n",
+ "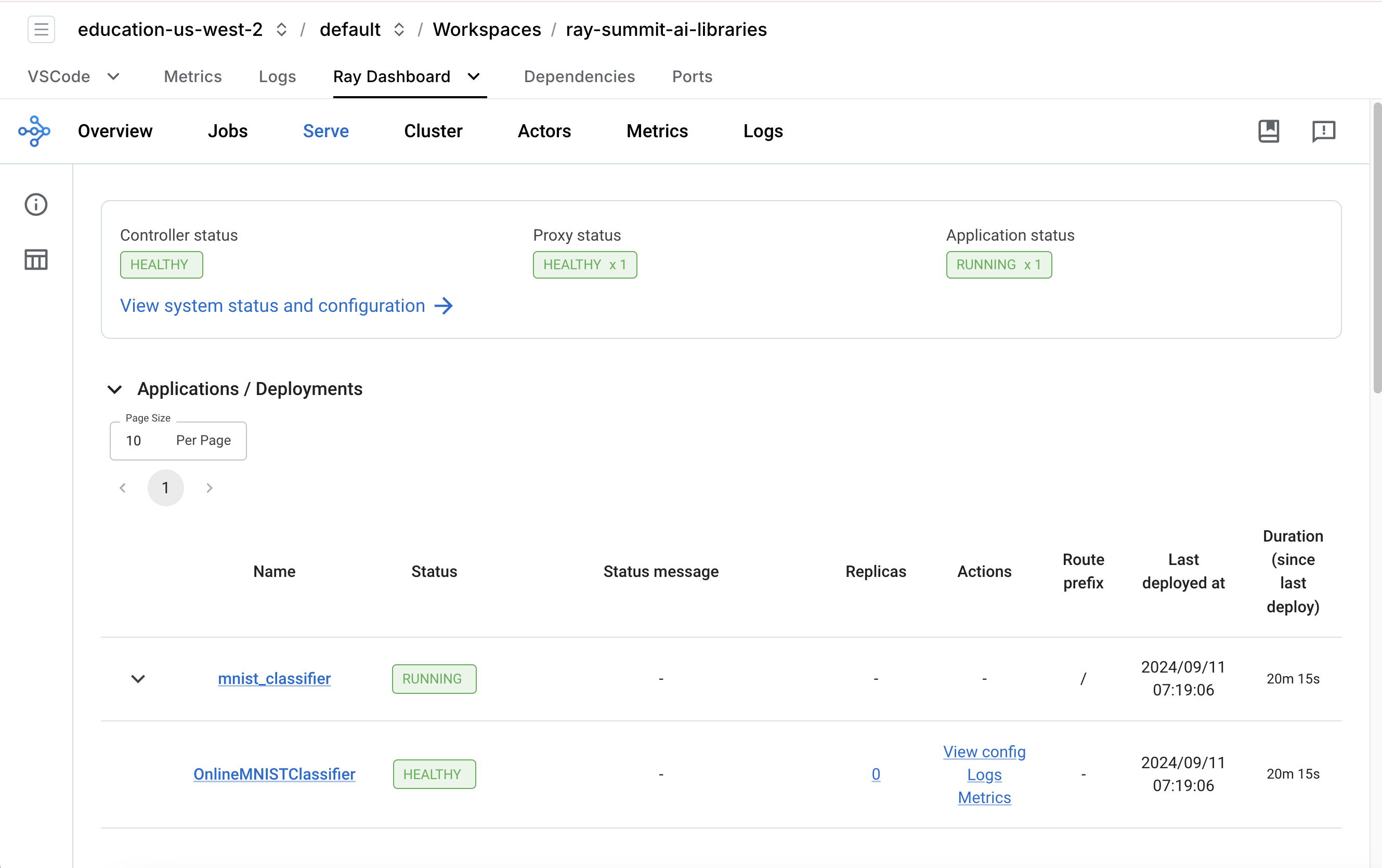 "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "761fd6a6",
+ "metadata": {},
+ "source": [
+ "We can send out a larger number of requests to the `OnlineMNISTClassifier` deployment to see the autoscaling in action."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7a7a834f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "batch = {\"image\": np.random.rand(10, 1, 28, 28)}\n",
+ "[\n",
+ " mnist_deployment_handle.predict.remote(batch)\n",
+ " for _ in range(100)\n",
+ "]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "91a4e5e9",
+ "metadata": {},
+ "source": [
+ "Looking at the Ray Serve dashboard, we can see that the number of replicas has scaled up to 10 as expected.\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "761fd6a6",
+ "metadata": {},
+ "source": [
+ "We can send out a larger number of requests to the `OnlineMNISTClassifier` deployment to see the autoscaling in action."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7a7a834f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "batch = {\"image\": np.random.rand(10, 1, 28, 28)}\n",
+ "[\n",
+ " mnist_deployment_handle.predict.remote(batch)\n",
+ " for _ in range(100)\n",
+ "]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "91a4e5e9",
+ "metadata": {},
+ "source": [
+ "Looking at the Ray Serve dashboard, we can see that the number of replicas has scaled up to 10 as expected.\n",
+ "\n",
+ "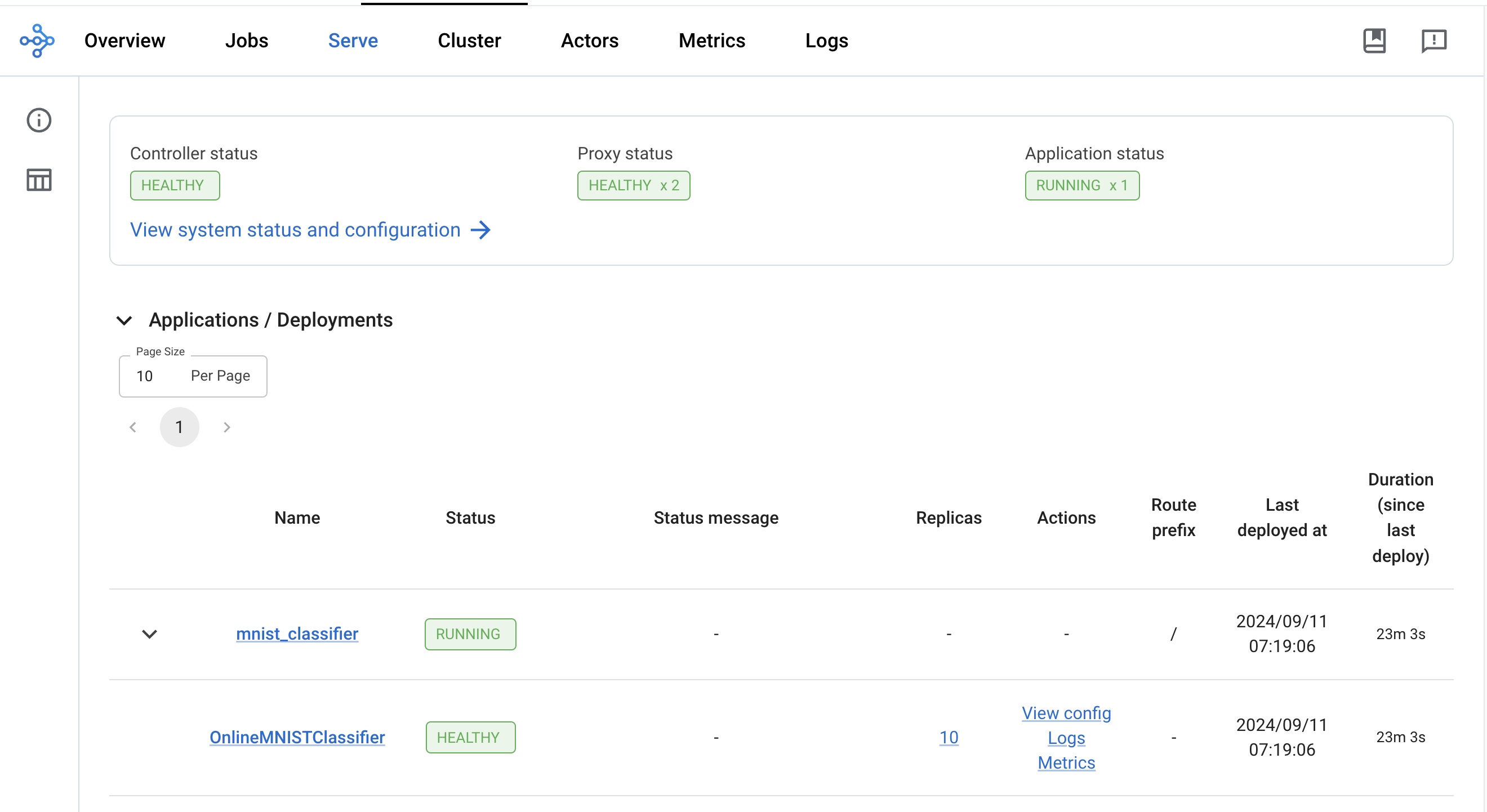 "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c52225df",
+ "metadata": {},
+ "source": [
+ "Let's shutdown the service for now."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0d53e06b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "serve.shutdown()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2e2d1c58",
+ "metadata": {},
+ "source": [
+ "### Composing Deployments\n",
+ "\n",
+ "Ray Serve allows us to compose Deployments together to build more complex applications.\n",
+ "\n",
+ "Lets compose our `OnlineMNISTClassifier` with an `OnlineMNISTPreprocessor` deployment that performs the necessary transformations on the input data.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "67670984",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@serve.deployment\n",
+ "class OnlineMNISTPreprocessor:\n",
+ " def __init__(self):\n",
+ " self.transform = transforms.Compose([\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize((0.5,), (0.5,))\n",
+ " ])\n",
+ " \n",
+ " async def run(self, batch: dict[str, Any]) -> dict[str, Any]:\n",
+ " images = batch[\"image\"]\n",
+ " images = [self.transform(np.array(image, dtype=np.uint8)).cpu().numpy() for image in images]\n",
+ " return {\"image\": images}\n",
+ "\n",
+ "preprocessor_app = OnlineMNISTPreprocessor.bind()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8b0dc24f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "preprocessor_handle = serve.run(preprocessor_app, name='mnist_preprocessor', blocking=False, route_prefix=\"/preprocess\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "92daf899",
+ "metadata": {},
+ "source": [
+ "Let's load an image and pass it to the `ImageTransformDeployment`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "441a8762",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds = ray.data.read_images(\"s3://anyscale-public-materials/ray-ai-libraries/mnist/50_per_index/\", include_paths=True)\n",
+ "image_batch = ds.take_batch(10)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1289797c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# plot the first image using matplotlib\n",
+ "plt.imshow(image_batch[\"image\"][0], cmap=\"gray\")\n",
+ "plt.show()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "94df4e63",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "normalized_batch = await preprocessor_handle.run.remote(image_batch)\n",
+ "\n",
+ "for image in normalized_batch[\"image\"]:\n",
+ " assert image.shape == (1, 28, 28) # channel, height, width\n",
+ " assert image.min() >= -1 and image.max() <= 1 # normalized to [-1, 1]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "da2848fc",
+ "metadata": {},
+ "source": [
+ "We will proceed to shutdown the preprocessor application to prove it will be automatically created by the ingress.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d0ac5957",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "serve.shutdown()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b0e44763",
+ "metadata": {},
+ "source": [
+ "Let's now build an ingress for our application that composes the `ImageTransformDeployment` and `OnlineMNISTClassifier`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "88340028",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@serve.deployment\n",
+ "class ImageServiceIngress:\n",
+ " def __init__(self, preprocessor: OnlineMNISTPreprocessor, model: OnlineMNISTClassifier):\n",
+ " self.preprocessor = preprocessor\n",
+ " self.model = model\n",
+ "\n",
+ " async def __call__(self, request: Request):\n",
+ " batch = json.loads(await request.json())\n",
+ " response = await self.preprocessor.run.remote(batch)\n",
+ " return await self.model.predict.remote(response)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "affcac11",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "image_classifier_ingress = ImageServiceIngress.bind(\n",
+ " preprocessor=OnlineMNISTPreprocessor.bind(),\n",
+ " model=OnlineMNISTClassifier.options(\n",
+ " num_replicas=1,\n",
+ " ray_actor_options={\"num_gpus\": 0.1},\n",
+ " ).bind(local_path=\"/mnt/cluster_storage/model.pt\"),\n",
+ ")\n",
+ "\n",
+ "handle = serve.run(image_classifier_ingress, name='image_classifier', blocking=False)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "aa81a51f",
+ "metadata": {},
+ "source": [
+ "Let's test the application by sending a sample HTTP request to our ingress endpoint.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6d084ee7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "json_request = json.dumps({\"image\": image_batch[\"image\"].tolist()}) \n",
+ "response = requests.post(\"http://localhost:8000/\", json=json_request)\n",
+ "response.json()[\"predicted_label\"]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1fbe8773",
+ "metadata": {},
+ "source": [
+ "### Integrating with FastAPI\n",
+ "\n",
+ "Ray Serve can be integrated with FastAPI to provide:\n",
+ "- HTTP routing\n",
+ "- Pydantic model validation\n",
+ "- OpenAPI documentation\n",
+ "\n",
+ "To integrate a Deployment with FastAPI, we can use the `@serve.ingress` decorator to designate a FastAPI app as the entrypoint for HTTP requests to our Serve application."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5d163431",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "app = FastAPI()\n",
+ "\n",
+ "@serve.deployment\n",
+ "@serve.ingress(app)\n",
+ "class ImageServiceIngress:\n",
+ " def __init__(self, preprocessor: OnlineMNISTPreprocessor, model: OnlineMNISTClassifier):\n",
+ " self.preprocessor = preprocessor\n",
+ " self.model = model\n",
+ " \n",
+ " @app.post(\"/predict\")\n",
+ " async def predict(self, request: Request):\n",
+ " batch = json.loads(await request.json())\n",
+ " response = await self.preprocessor.run.remote(batch)\n",
+ " out = await self.model.predict.remote(response)\n",
+ " return {\"predicted_label\": out[\"predicted_label\"].tolist()}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a3a31b87",
+ "metadata": {},
+ "source": [
+ "We now can build the application and run it."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0371807e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "image_classifier_ingress = ImageServiceIngress.bind(\n",
+ " preprocessor=OnlineMNISTPreprocessor.bind(),\n",
+ " model=OnlineMNISTClassifier.options(\n",
+ " num_replicas=1,\n",
+ " ray_actor_options={\"num_gpus\": 0.1},\n",
+ " ).bind(local_path=\"/mnt/cluster_storage/model.pt\"),\n",
+ ")\n",
+ "\n",
+ "handle = serve.run(image_classifier_ingress, name='image_classifier', blocking=False)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "012894c6",
+ "metadata": {},
+ "source": [
+ "After running the application, we can get test it as an HTTP endpoint programmatically."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2e217336",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "json_request = json.dumps({\"image\": image_batch[\"image\"].tolist()}) \n",
+ "response = requests.post(\"http://localhost:8000/predict\", json=json_request)\n",
+ "response.json()[\"predicted_label\"]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "287ff14a",
+ "metadata": {},
+ "source": [
+ "We can also visit the auto-generated FastAPI docs at http://localhost:8000/docs to get an interactive UI to test our endpoint."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5e2af689",
+ "metadata": {},
+ "source": [
+ "## 4. Ray Serve in Production\n",
+ "\n",
+ "1. Klaviyo built their model serving platform with Ray Serve. See [this article from Klaviyo Engineering](https://klaviyo.tech/how-klaviyo-built-a-robust-model-serving-platform-with-ray-serve-c02ec65788b3)\n",
+ "2. Samsara uses Ray Serve to bridge the gap of development to deployment of their models. See [this article from Samsara Engineering](https://www.samsara.com/blog/building-a-modern-machine-learning-platform-with-ray)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d59f4a09",
+ "metadata": {},
+ "source": [
+ "## Clean up \n",
+ "\n",
+ "Let's shutdown the application and clean up the resources we created."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e0e8131d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "serve.shutdown()\n",
+ "!rm -rf /mnt/cluster_storage/model.pt"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/templates/ray-summit-ai-libraries/Bonus/3b_Tune_Train.ipynb b/templates/ray-summit-ai-libraries/Bonus/3b_Tune_Train.ipynb
new file mode 100644
index 000000000..73c504d8c
--- /dev/null
+++ b/templates/ray-summit-ai-libraries/Bonus/3b_Tune_Train.ipynb
@@ -0,0 +1,206 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Bonus: Hyperparameter tuning of distributed training with Ray Tune and Ray Train\n",
+ "\n",
+ "This is a bonus notebook that shows how to perform hyperparameter tuning of distributed training with Ray Tune and Ray Train.\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c52225df",
+ "metadata": {},
+ "source": [
+ "Let's shutdown the service for now."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0d53e06b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "serve.shutdown()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2e2d1c58",
+ "metadata": {},
+ "source": [
+ "### Composing Deployments\n",
+ "\n",
+ "Ray Serve allows us to compose Deployments together to build more complex applications.\n",
+ "\n",
+ "Lets compose our `OnlineMNISTClassifier` with an `OnlineMNISTPreprocessor` deployment that performs the necessary transformations on the input data.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "67670984",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@serve.deployment\n",
+ "class OnlineMNISTPreprocessor:\n",
+ " def __init__(self):\n",
+ " self.transform = transforms.Compose([\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize((0.5,), (0.5,))\n",
+ " ])\n",
+ " \n",
+ " async def run(self, batch: dict[str, Any]) -> dict[str, Any]:\n",
+ " images = batch[\"image\"]\n",
+ " images = [self.transform(np.array(image, dtype=np.uint8)).cpu().numpy() for image in images]\n",
+ " return {\"image\": images}\n",
+ "\n",
+ "preprocessor_app = OnlineMNISTPreprocessor.bind()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8b0dc24f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "preprocessor_handle = serve.run(preprocessor_app, name='mnist_preprocessor', blocking=False, route_prefix=\"/preprocess\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "92daf899",
+ "metadata": {},
+ "source": [
+ "Let's load an image and pass it to the `ImageTransformDeployment`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "441a8762",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds = ray.data.read_images(\"s3://anyscale-public-materials/ray-ai-libraries/mnist/50_per_index/\", include_paths=True)\n",
+ "image_batch = ds.take_batch(10)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1289797c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# plot the first image using matplotlib\n",
+ "plt.imshow(image_batch[\"image\"][0], cmap=\"gray\")\n",
+ "plt.show()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "94df4e63",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "normalized_batch = await preprocessor_handle.run.remote(image_batch)\n",
+ "\n",
+ "for image in normalized_batch[\"image\"]:\n",
+ " assert image.shape == (1, 28, 28) # channel, height, width\n",
+ " assert image.min() >= -1 and image.max() <= 1 # normalized to [-1, 1]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "da2848fc",
+ "metadata": {},
+ "source": [
+ "We will proceed to shutdown the preprocessor application to prove it will be automatically created by the ingress.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d0ac5957",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "serve.shutdown()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b0e44763",
+ "metadata": {},
+ "source": [
+ "Let's now build an ingress for our application that composes the `ImageTransformDeployment` and `OnlineMNISTClassifier`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "88340028",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@serve.deployment\n",
+ "class ImageServiceIngress:\n",
+ " def __init__(self, preprocessor: OnlineMNISTPreprocessor, model: OnlineMNISTClassifier):\n",
+ " self.preprocessor = preprocessor\n",
+ " self.model = model\n",
+ "\n",
+ " async def __call__(self, request: Request):\n",
+ " batch = json.loads(await request.json())\n",
+ " response = await self.preprocessor.run.remote(batch)\n",
+ " return await self.model.predict.remote(response)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "affcac11",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "image_classifier_ingress = ImageServiceIngress.bind(\n",
+ " preprocessor=OnlineMNISTPreprocessor.bind(),\n",
+ " model=OnlineMNISTClassifier.options(\n",
+ " num_replicas=1,\n",
+ " ray_actor_options={\"num_gpus\": 0.1},\n",
+ " ).bind(local_path=\"/mnt/cluster_storage/model.pt\"),\n",
+ ")\n",
+ "\n",
+ "handle = serve.run(image_classifier_ingress, name='image_classifier', blocking=False)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "aa81a51f",
+ "metadata": {},
+ "source": [
+ "Let's test the application by sending a sample HTTP request to our ingress endpoint.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6d084ee7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "json_request = json.dumps({\"image\": image_batch[\"image\"].tolist()}) \n",
+ "response = requests.post(\"http://localhost:8000/\", json=json_request)\n",
+ "response.json()[\"predicted_label\"]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1fbe8773",
+ "metadata": {},
+ "source": [
+ "### Integrating with FastAPI\n",
+ "\n",
+ "Ray Serve can be integrated with FastAPI to provide:\n",
+ "- HTTP routing\n",
+ "- Pydantic model validation\n",
+ "- OpenAPI documentation\n",
+ "\n",
+ "To integrate a Deployment with FastAPI, we can use the `@serve.ingress` decorator to designate a FastAPI app as the entrypoint for HTTP requests to our Serve application."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5d163431",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "app = FastAPI()\n",
+ "\n",
+ "@serve.deployment\n",
+ "@serve.ingress(app)\n",
+ "class ImageServiceIngress:\n",
+ " def __init__(self, preprocessor: OnlineMNISTPreprocessor, model: OnlineMNISTClassifier):\n",
+ " self.preprocessor = preprocessor\n",
+ " self.model = model\n",
+ " \n",
+ " @app.post(\"/predict\")\n",
+ " async def predict(self, request: Request):\n",
+ " batch = json.loads(await request.json())\n",
+ " response = await self.preprocessor.run.remote(batch)\n",
+ " out = await self.model.predict.remote(response)\n",
+ " return {\"predicted_label\": out[\"predicted_label\"].tolist()}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a3a31b87",
+ "metadata": {},
+ "source": [
+ "We now can build the application and run it."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0371807e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "image_classifier_ingress = ImageServiceIngress.bind(\n",
+ " preprocessor=OnlineMNISTPreprocessor.bind(),\n",
+ " model=OnlineMNISTClassifier.options(\n",
+ " num_replicas=1,\n",
+ " ray_actor_options={\"num_gpus\": 0.1},\n",
+ " ).bind(local_path=\"/mnt/cluster_storage/model.pt\"),\n",
+ ")\n",
+ "\n",
+ "handle = serve.run(image_classifier_ingress, name='image_classifier', blocking=False)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "012894c6",
+ "metadata": {},
+ "source": [
+ "After running the application, we can get test it as an HTTP endpoint programmatically."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2e217336",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "json_request = json.dumps({\"image\": image_batch[\"image\"].tolist()}) \n",
+ "response = requests.post(\"http://localhost:8000/predict\", json=json_request)\n",
+ "response.json()[\"predicted_label\"]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "287ff14a",
+ "metadata": {},
+ "source": [
+ "We can also visit the auto-generated FastAPI docs at http://localhost:8000/docs to get an interactive UI to test our endpoint."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5e2af689",
+ "metadata": {},
+ "source": [
+ "## 4. Ray Serve in Production\n",
+ "\n",
+ "1. Klaviyo built their model serving platform with Ray Serve. See [this article from Klaviyo Engineering](https://klaviyo.tech/how-klaviyo-built-a-robust-model-serving-platform-with-ray-serve-c02ec65788b3)\n",
+ "2. Samsara uses Ray Serve to bridge the gap of development to deployment of their models. See [this article from Samsara Engineering](https://www.samsara.com/blog/building-a-modern-machine-learning-platform-with-ray)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d59f4a09",
+ "metadata": {},
+ "source": [
+ "## Clean up \n",
+ "\n",
+ "Let's shutdown the application and clean up the resources we created."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e0e8131d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "serve.shutdown()\n",
+ "!rm -rf /mnt/cluster_storage/model.pt"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/templates/ray-summit-ai-libraries/Bonus/3b_Tune_Train.ipynb b/templates/ray-summit-ai-libraries/Bonus/3b_Tune_Train.ipynb
new file mode 100644
index 000000000..73c504d8c
--- /dev/null
+++ b/templates/ray-summit-ai-libraries/Bonus/3b_Tune_Train.ipynb
@@ -0,0 +1,206 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Bonus: Hyperparameter tuning of distributed training with Ray Tune and Ray Train\n",
+ "\n",
+ "This is a bonus notebook that shows how to perform hyperparameter tuning of distributed training with Ray Tune and Ray Train.\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Imports"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import tempfile\n",
+ "import os\n",
+ "from typing import Any\n",
+ "\n",
+ "import torch\n",
+ "from torchvision.datasets import MNIST\n",
+ "from torchvision.transforms import Compose, ToTensor, Normalize\n",
+ "from torchvision.models import resnet18\n",
+ "from torch.utils.data import DataLoader\n",
+ "from torch.optim import Adam\n",
+ "from torch.nn import CrossEntropyLoss\n",
+ "\n",
+ "import ray\n",
+ "from ray import tune, train\n",
+ "from ray.train.torch import TorchTrainer"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Here, we will use the example of training a ResNet18 model on the MNIST dataset."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def train_loop_ray_train(config: dict): # pass in hyperparameters in config\n",
+ " criterion = CrossEntropyLoss()\n",
+ "\n",
+ " model = resnet18()\n",
+ " model.conv1 = torch.nn.Conv2d(\n",
+ " 1, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False\n",
+ " )\n",
+ " model = train.torch.prepare_model(model) # Wrap the model in DistributedDataParallel\n",
+ "\n",
+ " global_batch_size = config[\"global_batch_size\"]\n",
+ " batch_size = global_batch_size // ray.train.get_context().get_world_size()\n",
+ " optimizer = Adam(model.parameters(), lr=config[\"lr\"])\n",
+ " transform = Compose([ToTensor(), Normalize((0.5,), (0.5,))])\n",
+ " train_data = MNIST(root=\"./data\", train=True, download=True, transform=transform)\n",
+ " data_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True, drop_last=True)\n",
+ " data_loader = train.torch.prepare_data_loader(data_loader) # Wrap the data loader in a DistributedSampler\n",
+ "\n",
+ " for epoch in range(config[\"num_epochs\"]):\n",
+ " # Ensure data is on the correct device\n",
+ " data_loader.sampler.set_epoch(epoch)\n",
+ "\n",
+ " for (\n",
+ " images,\n",
+ " labels,\n",
+ " ) in data_loader: # images, labels are now sharded across the workers\n",
+ " outputs = model(images)\n",
+ " loss = criterion(outputs, labels)\n",
+ " optimizer.zero_grad()\n",
+ " loss.backward() # Gradients are accumulated across the workers\n",
+ " optimizer.step()\n",
+ "\n",
+ " with tempfile.TemporaryDirectory() as temp_checkpoint_dir:\n",
+ " torch.save(\n",
+ " model.module.state_dict(), os.path.join(temp_checkpoint_dir, \"model.pt\")\n",
+ " )\n",
+ " # Report the loss to Ray Tune\n",
+ " ray.train.report(\n",
+ " {\"loss\": loss.item()},\n",
+ " checkpoint=ray.train.Checkpoint.from_directory(temp_checkpoint_dir),\n",
+ " )"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We now pass the training loop into the `train.torch.TorchTrainer` to perform distributed training."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "trainer = TorchTrainer(\n",
+ " train_loop_ray_train,\n",
+ " train_loop_config={\"num_epochs\": 2, \"global_batch_size\": 128},\n",
+ " run_config=train.RunConfig(\n",
+ " storage_path=\"/mnt/cluster_storage/dist_train_tune_example/\",\n",
+ " name=\"tune_example\",\n",
+ " ),\n",
+ " scaling_config=train.ScalingConfig(\n",
+ " num_workers=2,\n",
+ " use_gpu=True,\n",
+ " ),\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Turns out a Ray Train trainer is itself a Ray Tune trainable, so we can pass it directly into the `tune.Tuner` as we have done before."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "tuner = tune.Tuner(\n",
+ " trainer,\n",
+ " param_space={\n",
+ " \"train_loop_config\": {\n",
+ " \"num_epochs\": 1,\n",
+ " \"global_batch_size\": 128,\n",
+ " \"lr\": tune.loguniform(1e-4, 1e-1),\n",
+ " }\n",
+ " },\n",
+ " tune_config=tune.TuneConfig(\n",
+ " mode=\"min\",\n",
+ " metric=\"loss\",\n",
+ " num_samples=2,\n",
+ " ),\n",
+ ")\n",
+ "\n",
+ "results = tuner.fit()\n",
+ "\n",
+ "best_result = results.get_best_result()\n",
+ "best_result.config"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Clean up"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!rm -rf /mnt/cluster_storage/dist_train_tune_example/"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "base",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 2
+}
diff --git a/templates/ray-summit-ai-libraries/Bonus/6_Intro_Core.ipynb b/templates/ray-summit-ai-libraries/Bonus/6_Intro_Core.ipynb
new file mode 100644
index 000000000..ab3008a01
--- /dev/null
+++ b/templates/ray-summit-ai-libraries/Bonus/6_Intro_Core.ipynb
@@ -0,0 +1,544 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "1fd443a5-c9d3-4b6f-ad72-59c1eba1d112",
+ "metadata": {},
+ "source": [
+ "# Intro to Ray Core\n",
+ "\n",
+ "This notebook introduces Ray Core, the core building block of Ray.\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Imports"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import tempfile\n",
+ "import os\n",
+ "from typing import Any\n",
+ "\n",
+ "import torch\n",
+ "from torchvision.datasets import MNIST\n",
+ "from torchvision.transforms import Compose, ToTensor, Normalize\n",
+ "from torchvision.models import resnet18\n",
+ "from torch.utils.data import DataLoader\n",
+ "from torch.optim import Adam\n",
+ "from torch.nn import CrossEntropyLoss\n",
+ "\n",
+ "import ray\n",
+ "from ray import tune, train\n",
+ "from ray.train.torch import TorchTrainer"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Here, we will use the example of training a ResNet18 model on the MNIST dataset."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def train_loop_ray_train(config: dict): # pass in hyperparameters in config\n",
+ " criterion = CrossEntropyLoss()\n",
+ "\n",
+ " model = resnet18()\n",
+ " model.conv1 = torch.nn.Conv2d(\n",
+ " 1, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False\n",
+ " )\n",
+ " model = train.torch.prepare_model(model) # Wrap the model in DistributedDataParallel\n",
+ "\n",
+ " global_batch_size = config[\"global_batch_size\"]\n",
+ " batch_size = global_batch_size // ray.train.get_context().get_world_size()\n",
+ " optimizer = Adam(model.parameters(), lr=config[\"lr\"])\n",
+ " transform = Compose([ToTensor(), Normalize((0.5,), (0.5,))])\n",
+ " train_data = MNIST(root=\"./data\", train=True, download=True, transform=transform)\n",
+ " data_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True, drop_last=True)\n",
+ " data_loader = train.torch.prepare_data_loader(data_loader) # Wrap the data loader in a DistributedSampler\n",
+ "\n",
+ " for epoch in range(config[\"num_epochs\"]):\n",
+ " # Ensure data is on the correct device\n",
+ " data_loader.sampler.set_epoch(epoch)\n",
+ "\n",
+ " for (\n",
+ " images,\n",
+ " labels,\n",
+ " ) in data_loader: # images, labels are now sharded across the workers\n",
+ " outputs = model(images)\n",
+ " loss = criterion(outputs, labels)\n",
+ " optimizer.zero_grad()\n",
+ " loss.backward() # Gradients are accumulated across the workers\n",
+ " optimizer.step()\n",
+ "\n",
+ " with tempfile.TemporaryDirectory() as temp_checkpoint_dir:\n",
+ " torch.save(\n",
+ " model.module.state_dict(), os.path.join(temp_checkpoint_dir, \"model.pt\")\n",
+ " )\n",
+ " # Report the loss to Ray Tune\n",
+ " ray.train.report(\n",
+ " {\"loss\": loss.item()},\n",
+ " checkpoint=ray.train.Checkpoint.from_directory(temp_checkpoint_dir),\n",
+ " )"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We now pass the training loop into the `train.torch.TorchTrainer` to perform distributed training."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "trainer = TorchTrainer(\n",
+ " train_loop_ray_train,\n",
+ " train_loop_config={\"num_epochs\": 2, \"global_batch_size\": 128},\n",
+ " run_config=train.RunConfig(\n",
+ " storage_path=\"/mnt/cluster_storage/dist_train_tune_example/\",\n",
+ " name=\"tune_example\",\n",
+ " ),\n",
+ " scaling_config=train.ScalingConfig(\n",
+ " num_workers=2,\n",
+ " use_gpu=True,\n",
+ " ),\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Turns out a Ray Train trainer is itself a Ray Tune trainable, so we can pass it directly into the `tune.Tuner` as we have done before."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "tuner = tune.Tuner(\n",
+ " trainer,\n",
+ " param_space={\n",
+ " \"train_loop_config\": {\n",
+ " \"num_epochs\": 1,\n",
+ " \"global_batch_size\": 128,\n",
+ " \"lr\": tune.loguniform(1e-4, 1e-1),\n",
+ " }\n",
+ " },\n",
+ " tune_config=tune.TuneConfig(\n",
+ " mode=\"min\",\n",
+ " metric=\"loss\",\n",
+ " num_samples=2,\n",
+ " ),\n",
+ ")\n",
+ "\n",
+ "results = tuner.fit()\n",
+ "\n",
+ "best_result = results.get_best_result()\n",
+ "best_result.config"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Clean up"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!rm -rf /mnt/cluster_storage/dist_train_tune_example/"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "base",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 2
+}
diff --git a/templates/ray-summit-ai-libraries/Bonus/6_Intro_Core.ipynb b/templates/ray-summit-ai-libraries/Bonus/6_Intro_Core.ipynb
new file mode 100644
index 000000000..ab3008a01
--- /dev/null
+++ b/templates/ray-summit-ai-libraries/Bonus/6_Intro_Core.ipynb
@@ -0,0 +1,544 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "1fd443a5-c9d3-4b6f-ad72-59c1eba1d112",
+ "metadata": {},
+ "source": [
+ "# Intro to Ray Core\n",
+ "\n",
+ "This notebook introduces Ray Core, the core building block of Ray.\n",
+ "\n",
+ "\n",
+ "\n",
+ " Here is the roadmap for this notebook \n",
+ "\n",
+ "
\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d08cc42c",
+ "metadata": {},
+ "source": [
+ "## Imports"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "98399ea9-933a-452f-be3f-bc1535006443",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "import ray"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9ff9ad39-11cb-495e-964f-a05a95159bea",
+ "metadata": {},
+ "source": [
+ "## Ray Core overview\n",
+ "\n",
+ "Ray Core is about:\n",
+ "* distributing computation across many cores, nodes, or devices (e.g., accelerators)\n",
+ "* scheduling *arbitrary task graphs*\n",
+ " * any code you can write, you can distribute, scale, and accelerate with Ray Core\n",
+ "* manage the overhead\n",
+ " * at scale, distributed computation introduces growing \"frictions\" -- data movement, scheduling costs, etc. -- which make the problem harder\n",
+ " * Ray Core addresses these issues as first-order concerns in its design (e.g., via a distributed scheduler)\n",
+ " \n",
+ "(And, of course, for common technical use cases, libraries and other components provide simple dev ex and are built on top of Ray Core)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8c356de6",
+ "metadata": {},
+ "source": [
+ "## `@ray.remote` and `ray.get`\n",
+ "\n",
+ "Here is a diagram which shows the relationship between Python code and Ray tasks.\n",
+ "\n",
+ "- \n",
+ "
- Part 1: Ray Core overview \n", + "
- Part 2: @ray.remote and ray.get \n", + "
- Part 3: Tasks can launch other tasks \n", + "
- Part 4: Ray Actors \n", + "
 "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "bb8b00c1-d320-4b62-a35b-08bea2e848e3",
+ "metadata": {},
+ "source": [
+ "Define a Python function and decorate it so that Ray can schedule it"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "bc20546b-510d-4885-82fa-5d12503d52f4",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "@ray.remote(num_cpus=2)\n",
+ "def f(a, b):\n",
+ " return a + b"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2dfd3ad7-0d0e-4313-82d7-4d36f2e9537b",
+ "metadata": {},
+ "source": [
+ "Tell Ray to schedule the function"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c7f0c8a3-f456-4594-a994-0e5a528c3b78",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "f.remote(1, 2)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a8f99486-6a85-4331-bed6-0af871974977",
+ "metadata": {},
+ "source": [
+ "`ObjectRef` is a handle to a task result. We get an ObjectRef immediately because we don't know\n",
+ "* when the task will run\n",
+ "* whether it will succeed\n",
+ "* whether we really need or want the result locally\n",
+ " * consider a very large result which we may need for other work but which we don't need to inspect"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3c939071-2454-4042-8136-75ffbbf6cce0",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ref = f.remote(1, 2)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7928ca98-dc51-4ecf-b757-92996dd0c69a",
+ "metadata": {},
+ "source": [
+ "If we want to wait (block) and retrieve the corresponding object, we can use `ray.get`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a564c830-d30d-4d4c-adb5-ee12adee605b",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ray.get(ref)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4da412f5-133a-441b-8734-b96f56389f05",
+ "metadata": {},
+ "source": [
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "bb8b00c1-d320-4b62-a35b-08bea2e848e3",
+ "metadata": {},
+ "source": [
+ "Define a Python function and decorate it so that Ray can schedule it"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "bc20546b-510d-4885-82fa-5d12503d52f4",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "@ray.remote(num_cpus=2)\n",
+ "def f(a, b):\n",
+ " return a + b"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2dfd3ad7-0d0e-4313-82d7-4d36f2e9537b",
+ "metadata": {},
+ "source": [
+ "Tell Ray to schedule the function"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c7f0c8a3-f456-4594-a994-0e5a528c3b78",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "f.remote(1, 2)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a8f99486-6a85-4331-bed6-0af871974977",
+ "metadata": {},
+ "source": [
+ "`ObjectRef` is a handle to a task result. We get an ObjectRef immediately because we don't know\n",
+ "* when the task will run\n",
+ "* whether it will succeed\n",
+ "* whether we really need or want the result locally\n",
+ " * consider a very large result which we may need for other work but which we don't need to inspect"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3c939071-2454-4042-8136-75ffbbf6cce0",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ref = f.remote(1, 2)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7928ca98-dc51-4ecf-b757-92996dd0c69a",
+ "metadata": {},
+ "source": [
+ "If we want to wait (block) and retrieve the corresponding object, we can use `ray.get`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a564c830-d30d-4d4c-adb5-ee12adee605b",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ray.get(ref)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4da412f5-133a-441b-8734-b96f56389f05",
+ "metadata": {},
+ "source": [
+ "\n",
+ " \n",
+ "__Activity: define and invoke a Ray task__\n",
+ "\n",
+ "Define a remote function `sqrt_add` that accepts two arguments:\n",
+ "- computes the square-root of the first\n",
+ "- adds the second\n",
+ "- returns the result\n",
+ "\n",
+ "Invoke it as a remote task with 2 different sets of parameters and collect the results\n",
+ "\n",
+ "```python\n",
+ "# Hint: define the below as a remote function\n",
+ "def sqrt_add(a, b):\n",
+ " ... \n",
+ "\n",
+ "# Hint: invoke it as a remote task and collect the results\n",
+ "```\n",
+ "\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ace32382",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Write your solution here"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "34fe7b54",
+ "metadata": {},
+ "source": [
+ "# Solution\n",
+ "\n",
+ "\n",
+ "
\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0f9fab1d-0f41-4175-a6cc-0161454d7718",
+ "metadata": {},
+ "source": [
+ "## Tasks can launch other tasks"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d131321a-7ac9-4a1e-8332-6c2808cde39b",
+ "metadata": {},
+ "source": [
+ "In that example, we organized or arranged the flow of tasks from our original process -- the Python kernel behind this notebook.\n",
+ "\n",
+ "Ray __does not__ require that all of your tasks and their dependencies by arranged from one \"driver\" process.\n",
+ "\n",
+ "Consider:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "39da2976-fccb-41bd-9ccc-2c2e2ff3106a",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "def square(x):\n",
+ " return x * x\n",
+ "\n",
+ "@ray.remote\n",
+ "def sum_of_squares(arr):\n",
+ " return sum(ray.get([square.remote(val) for val in arr]))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f415fe45-c193-4fc0-8a2e-6bc8354d0145",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ray.get(sum_of_squares.remote([3,4,5]))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2840697c-f5d9-437b-8e67-72cfa69dbdb4",
+ "metadata": {},
+ "source": [
+ "In that example, \n",
+ "* our (local) process asked Ray to schedule one task -- a call to `sum_of_squares` -- which that started running somewhere in our cluster;\n",
+ "* within that task, additional code requested multiple additional tasks to be scheduled -- the call to `square` for each item in the list -- which were then scheduled in other locations;\n",
+ "* and when those latter tasks were complete, the our original task computed the sum and completed.\n",
+ "\n",
+ "This ability for tasks to schedule other tasks using uniform semantics makes Ray particularly powerful and flexible."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0d03e83b-bc22-424d-9501-f8aacbca4c60",
+ "metadata": {},
+ "source": [
+ "## Ray Actors\n",
+ "\n",
+ "Actors are Python class instances which can run for a long time in the cluster, which can maintain state, and which can send messages to/from other code.\n",
+ "\n",
+ "Let's look at an example of an actor which maintains a running balance."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0500f797-7c77-4e68-a3d0-32c00544ee19",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "class Accounting:\n",
+ " def __init__(self):\n",
+ " self.total = 0\n",
+ " \n",
+ " def add(self, amount):\n",
+ " self.total += amount\n",
+ " \n",
+ " def remove(self, amount):\n",
+ " self.total -= amount\n",
+ " \n",
+ " def total(self):\n",
+ " return self.total"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a58c3e32",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "
\n",
+ "\n",
+ "Click to see solution
\n", + "\n", + "```python\n", + "import math\n", + "\n", + "@ray.remote\n", + "def sqrt_add(a, b):\n", + " return math.sqrt(a) + b\n", + "\n", + "ray.get(sqrt_add.remote(2, 3)), ray.get(sqrt_add.remote(5, 4))\n", + "```\n", + "\n", + "\n",
+ "\n",
+ "Note: The most common use case for actors is with state that is not mutated but is large enough that we may want to load it only once and ensure we can route calls to it over time, such as a large AI model.\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9ad7a2da-0411-4e77-a371-3583a21c949e",
+ "metadata": {},
+ "source": [
+ "Define an actor with the `@ray.remote` decorator and then use `\n",
+ "\n",
+ "__Activity: linear model inference__\n",
+ "\n",
+ "* Create an actor which applies a model to convert Celsius temperatures to Fahrenheit\n",
+ "* The constructor should take model weights (w1 and w0) and store them as instance state\n",
+ "* A convert method should take a scalar, multiply it by w1 then add w0 (weights retrieved from instance state) and then return the result\n",
+ "\n",
+ "```python\n",
+ "\n",
+ "# Hint: define the below as a remote actor\n",
+ "class LinearModel:\n",
+ " def __init__(self, w0, w1):\n",
+ " # Hint: store the weights\n",
+ "\n",
+ " def convert(self, celsius):\n",
+ " # Hint: convert the celsius temperature to Fahrenheit\n",
+ "\n",
+ "# Hint: create an instance of the LinearModel actor\n",
+ "\n",
+ "# Hint: convert 100 Celsius to Fahrenheit\n",
+ "```\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b425dd5a-a48f-4ef2-bbcf-6be72cd5ce24",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Write your solution here"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f0a91503",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "
\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "49a05d9b",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/templates/ray-summit-ai-libraries/README.md b/templates/ray-summit-ai-libraries/README.md
new file mode 100644
index 000000000..715e59b3a
--- /dev/null
+++ b/templates/ray-summit-ai-libraries/README.md
@@ -0,0 +1,18 @@
+# Ray AI Libraries with PyTorch
+
+## Overview
+Ray AI Libraries provide a high-level, easy-to-use set of APIs for the full AI/ML lifecycle, designed with MLEs and SWEs in mind. Consume all sorts of data, train models, tune them, serve them, and use them for batch inference or semantic featurization (like embeddings) -- all with minimal code, using patterns you already know. If you'd like to simplify a large-scale workflow, this session is for you.
+
+In this workshop, we'll introduce patterns and APIs for using the Ray AI Libraries, including Ray Data, Ray Train, and Ray Serve. We'll use running code examples that demonstrate end-to-end workflows with Ray and show examples featuring both tabular data modeling (e.g., XGBoost) and deep learning models (PyTorch).
+
+By the end of the class, you'll know when and how to replace local, small-scale, or heterogeneous data pipelines with the unified Ray AI Libraries. You'll have working notebooks to use later. And you'll gain experience using Ray to deliver the fastest performance and the largest scales required by today's projects.
+
+## Prerequisites
+This is beginner friendly training, you will learn about Ray fundamentals. However, you are expected to have:
+- Familiarity with basic ML concepts and workflows.
+- Intermediate-level experience with Python.
+
+## Ray Libraries
+- Ray Data
+- Ray Train
+- Ray Serve
diff --git a/templates/ray-summit-core-masterclass/README.md b/templates/ray-summit-core-masterclass/README.md
new file mode 100644
index 000000000..ed003f1fb
--- /dev/null
+++ b/templates/ray-summit-core-masterclass/README.md
@@ -0,0 +1,14 @@
+# Ray Core Masterclass: Architectures, Best Practices, Internals
+
+Ray Core allows developers to leverage a small number of core primitives for building and scaling distributed AI applications.
+
+This training provides you with an extensive and practical understanding of Ray Core concepts. You will review Ray's architecture, API components (tasks, actors, object store), core services, and observability tooling. You will learn about performance and scalability optimizations, as well as best practices validated by industry experts.
+
+By the end of this training, you will have a comprehensive understanding of Ray Core, and you'll be able to apply this knowledge to tackle challenging scaling problems and deliver robust solutions that meet your organization's needs.
+
+## Prerequisites:
+- Some experience with Ray Core or distributed systems.
+- Intermediate-level experience with Python.
+
+# Ray Libraries:
+- Ray Core
diff --git a/templates/ray-summit-core-masterclass/Ray_Core_1_Remote_Functions.ipynb b/templates/ray-summit-core-masterclass/Ray_Core_1_Remote_Functions.ipynb
new file mode 100644
index 000000000..b9730d36b
--- /dev/null
+++ b/templates/ray-summit-core-masterclass/Ray_Core_1_Remote_Functions.ipynb
@@ -0,0 +1,865 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "a14cab54",
+ "metadata": {},
+ "source": [
+ "# A Guided Tour of Ray Core: Remote Tasks\n",
+ "\n",
+ "## Introduction\n",
+ "\n",
+ "Ray enables arbitrary Python functions to be executed asynchronously on separate Python workers. These asynchronous Ray functions are called **tasks**. You can specify task's resource requirements in terms of CPUs, GPUs, and custom resources. These resource requests are used by the cluster scheduler to distribute tasks across the cluster for parallelized execution. \n",
+ "\n",
+ "Transforming Python code into Ray Tasks, Actors, and Immutable Ray objects:\n",
+ "\n",
+ "\n",
+ "
\n",
+ "Click to see solution
\n", + "\n", + "```python\n", + "@ray.remote\n", + "class LinearModel:\n", + " def __init__(self, w0, w1):\n", + " self.w0 = w0\n", + " self.w1 = w1\n", + "\n", + " def convert(self, celsius):\n", + " return self.w1 * celsius + self.w0\n", + "\n", + "model = LinearModel.remote(w1=9/5, w0=32)\n", + "ray.get(model.convert.remote(100))\n", + "```\n", + "\n", + " \n",
+ "\n",
+ "
\n",
+ "\n",
+ "\n", + "Transforming Python function into Ray Tasks:\n", + "
\n",
+ "\n",
+ "## Learning objectives\n",
+ "In this this tutorial, you'll learn about:\n",
+ " * Remote Task Parallel Pattern\n",
+ " * Stateless remote functions as distributed tasks\n",
+ " * Serial vs Parallel execution \n",
+ " * Understand the concept of a Ray task \n",
+ " * Easy API to convert an existing Python function into a Ray remote task\n",
+ " * Walk through examples comparing serial vs. distributed Python functions and Ray tasks respectively"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "bee29917",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "import time\n",
+ "import logging\n",
+ "import math\n",
+ "import random\n",
+ "\n",
+ "from pathlib import Path\n",
+ "from typing import Tuple, List\n",
+ "\n",
+ "import numpy as np\n",
+ "import pandas as pd\n",
+ "import pyarrow.parquet as pq\n",
+ "import tqdm\n",
+ "import ray\n",
+ "import tasks_helper_utils as t_utils"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "74b98b39",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "## 1. Tasks Parallel Pattern\n",
+ "\n",
+ "Ray converts decorated functions with `@ray.remote` into stateless tasks, scheduled anywhere on a Ray node's worker in the cluster. \n",
+ "\n",
+ "Where they will be executed on the cluster (and on what node by which worker process), you don't have to worry about its details. All that is taken care for you. Nor do \n",
+ "you have to reason about it — all that burden is Ray's job. You simply take your existing Python functions and covert them into \n",
+ "distributed stateless *Ray Tasks*: **as simple as that!**"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "893ec22c",
+ "metadata": {},
+ "source": [
+ "### Serial vs Parallelism Execution\n",
+ "\n",
+ "Serial tasks as regular Python functions are executed in a sequential manner, as shown\n",
+ "in the diagram below. If I launch ten tasks, they will run on a single worker, one after the other.\n",
+ " \n",
+ "| |\n",
+ "|:--|\n",
+ "|Timeline of sequential tasks, one after the other.|\n",
+ "\n",
+ "Compared to serial execution, a Ray task executes in parallel, scheduled on different workers. The Raylet will schedule these task based on [scheduling policies.](https://docs.ray.io/en/latest/ray-core/scheduling/index.html#ray-scheduling-strategies)\n",
+ "\n",
+ "|
|\n",
+ "|:--|\n",
+ "|Timeline of sequential tasks, one after the other.|\n",
+ "\n",
+ "Compared to serial execution, a Ray task executes in parallel, scheduled on different workers. The Raylet will schedule these task based on [scheduling policies.](https://docs.ray.io/en/latest/ray-core/scheduling/index.html#ray-scheduling-strategies)\n",
+ "\n",
+ "| |\n",
+ "|:--|\n",
+ "|Sample timeline with ten tasks running across 4 worker nodes in parallel.|\n",
+ "\n",
+ "Let's look at some tasks running serially and then in parallel. For illustration, we'll use a the following tasks:\n",
+ " * Generating fibonacci numbers serially and distributed\n",
+ " * Computing value of pi using the monte carlo method\n",
+ " * Transforming and processing large high-resolution images"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "93a44dfe",
+ "metadata": {},
+ "source": [
+ "But first, some basic concepts: There are a few key differences between an original Python function and the decorated one:\n",
+ "\n",
+ "**Invocation**: The regular version is called with `func_name(args)`, whereas the remote Ray Task version is called with `func_name.remote(args)`. Keep this pattern in mind for all Ray remote execution methods.\n",
+ "\n",
+ "**Mode of execution and return values**: A Python `func_name(args)` executes synchronously and returns the result of the function, whereas a Ray task `func_name.remote(args)` immediately returns an `ObjectRef` (a future) and then executes the task in the background on a remote worker process. \n",
+ "\n",
+ "The result of the future is obtained by calling `ray.get(ObjectRef)` on the `ObjectRef`. This is a blocking function."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8b04aec4",
+ "metadata": {},
+ "source": [
+ "Let's launch a Ray cluster on our local machine."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4aad47d9",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "if ray.is_initialized:\n",
+ " ray.shutdown()\n",
+ "ray.init(logging_level=logging.ERROR)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "27eeba1a",
+ "metadata": {},
+ "source": [
+ "### Example 1: Generating Fibonnaci series\n",
+ "\n",
+ "Let's define two functions: one runs serially, the other runs on a Ray cluster (local or remote). This example is borrowed and refactored from our \n",
+ "blog: [Writing your First Distributed Python Application with Ray](https://www.anyscale.com/blog/writing-your-first-distributed-python-application-with-ray). \n",
+ "(This is an excellent tutorial to get started with the concept of why and when to use Ray tasks and Ray Actors. Highly recommended read!)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "53bb49fa-00c0-4994-bd74-2d1093ff5d3b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "SEQUENCE_SIZE = 100000"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "49994253",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Function for local execution \n",
+ "def generate_fibonacci(sequence_size):\n",
+ " fibonacci = []\n",
+ " for i in range(0, sequence_size):\n",
+ " if i < 2:\n",
+ " fibonacci.append(i)\n",
+ " continue\n",
+ " fibonacci.append(fibonacci[i-1]+fibonacci[i-2])\n",
+ " return len(fibonacci)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "92777c6f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Function for remote Ray task with just a wrapper\n",
+ "@ray.remote\n",
+ "def generate_fibonacci_distributed(sequence_size):\n",
+ " return generate_fibonacci(sequence_size)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0b8b6ff1",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Get the number of cores \n",
+ "os.cpu_count()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "675f4fb2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Normal Python in a single process \n",
+ "def run_local(sequence_size):\n",
+ " results = [generate_fibonacci(sequence_size) for _ in range(os.cpu_count())]\n",
+ " return results"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "45a917b1-7af2-4729-8b93-39883fc5054e",
+ "metadata": {},
+ "source": [
+ "### Run in serial mode"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "199e8e69",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%time\n",
+ "run_local(SEQUENCE_SIZE)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3fc510e9",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Distributed on a Ray cluster\n",
+ "def run_remote(sequence_size):\n",
+ " results = ray.get([generate_fibonacci_distributed.remote(sequence_size) for _ in range(os.cpu_count())])\n",
+ " return results"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8fda02ce-cafd-4183-b36c-6aa28234cdf4",
+ "metadata": {},
+ "source": [
+ "### Run as distributed Ray tasks"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b4ebb951",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%time\n",
+ "run_remote(SEQUENCE_SIZE)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7bcecd59-8b2c-4983-acc1-9572ba04590e",
+ "metadata": {},
+ "source": [
+ "### Recap\n",
+ "As you can see that running as Ray Tasks, we see a significant performance improvment\n",
+ "📈 by simply adding a Python decorator `ray.remote(...)`.\n",
+ "\n",
+ "To see how different values of computing Fibonnacci number affects the serial vs. performance execution times, try the exercise below."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9ea4b7d2-2ceb-4a87-9a7b-3945f15f7d0a",
+ "metadata": {},
+ "source": [
+ "### Example 2: Monte Carlo simulation of estimating π\n",
+ "\n",
+ "Let's estimate the value of π using a [Monte Carlo](https://en.wikipedia.org/wiki/Monte_Carlo_method) method. We randomly sample points within a 2x2 square. We can use the proportion of the points that are contained within the unit circle centered at the origin to estimate the ratio of the area of the circle to the area of the square. \n",
+ "\n",
+ "Given we know that the true ratio to be π/4, we can multiply our estimated ratio by 4 to approximate the value of π. The more points that we sample to calculate this approximation, the closer we get to true value of π to required decimal points.\n",
+ "\n",
+ "|
|\n",
+ "|:--|\n",
+ "|Sample timeline with ten tasks running across 4 worker nodes in parallel.|\n",
+ "\n",
+ "Let's look at some tasks running serially and then in parallel. For illustration, we'll use a the following tasks:\n",
+ " * Generating fibonacci numbers serially and distributed\n",
+ " * Computing value of pi using the monte carlo method\n",
+ " * Transforming and processing large high-resolution images"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "93a44dfe",
+ "metadata": {},
+ "source": [
+ "But first, some basic concepts: There are a few key differences between an original Python function and the decorated one:\n",
+ "\n",
+ "**Invocation**: The regular version is called with `func_name(args)`, whereas the remote Ray Task version is called with `func_name.remote(args)`. Keep this pattern in mind for all Ray remote execution methods.\n",
+ "\n",
+ "**Mode of execution and return values**: A Python `func_name(args)` executes synchronously and returns the result of the function, whereas a Ray task `func_name.remote(args)` immediately returns an `ObjectRef` (a future) and then executes the task in the background on a remote worker process. \n",
+ "\n",
+ "The result of the future is obtained by calling `ray.get(ObjectRef)` on the `ObjectRef`. This is a blocking function."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8b04aec4",
+ "metadata": {},
+ "source": [
+ "Let's launch a Ray cluster on our local machine."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4aad47d9",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "if ray.is_initialized:\n",
+ " ray.shutdown()\n",
+ "ray.init(logging_level=logging.ERROR)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "27eeba1a",
+ "metadata": {},
+ "source": [
+ "### Example 1: Generating Fibonnaci series\n",
+ "\n",
+ "Let's define two functions: one runs serially, the other runs on a Ray cluster (local or remote). This example is borrowed and refactored from our \n",
+ "blog: [Writing your First Distributed Python Application with Ray](https://www.anyscale.com/blog/writing-your-first-distributed-python-application-with-ray). \n",
+ "(This is an excellent tutorial to get started with the concept of why and when to use Ray tasks and Ray Actors. Highly recommended read!)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "53bb49fa-00c0-4994-bd74-2d1093ff5d3b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "SEQUENCE_SIZE = 100000"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "49994253",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Function for local execution \n",
+ "def generate_fibonacci(sequence_size):\n",
+ " fibonacci = []\n",
+ " for i in range(0, sequence_size):\n",
+ " if i < 2:\n",
+ " fibonacci.append(i)\n",
+ " continue\n",
+ " fibonacci.append(fibonacci[i-1]+fibonacci[i-2])\n",
+ " return len(fibonacci)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "92777c6f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Function for remote Ray task with just a wrapper\n",
+ "@ray.remote\n",
+ "def generate_fibonacci_distributed(sequence_size):\n",
+ " return generate_fibonacci(sequence_size)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0b8b6ff1",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Get the number of cores \n",
+ "os.cpu_count()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "675f4fb2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Normal Python in a single process \n",
+ "def run_local(sequence_size):\n",
+ " results = [generate_fibonacci(sequence_size) for _ in range(os.cpu_count())]\n",
+ " return results"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "45a917b1-7af2-4729-8b93-39883fc5054e",
+ "metadata": {},
+ "source": [
+ "### Run in serial mode"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "199e8e69",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%time\n",
+ "run_local(SEQUENCE_SIZE)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3fc510e9",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Distributed on a Ray cluster\n",
+ "def run_remote(sequence_size):\n",
+ " results = ray.get([generate_fibonacci_distributed.remote(sequence_size) for _ in range(os.cpu_count())])\n",
+ " return results"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8fda02ce-cafd-4183-b36c-6aa28234cdf4",
+ "metadata": {},
+ "source": [
+ "### Run as distributed Ray tasks"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b4ebb951",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%time\n",
+ "run_remote(SEQUENCE_SIZE)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7bcecd59-8b2c-4983-acc1-9572ba04590e",
+ "metadata": {},
+ "source": [
+ "### Recap\n",
+ "As you can see that running as Ray Tasks, we see a significant performance improvment\n",
+ "📈 by simply adding a Python decorator `ray.remote(...)`.\n",
+ "\n",
+ "To see how different values of computing Fibonnacci number affects the serial vs. performance execution times, try the exercise below."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9ea4b7d2-2ceb-4a87-9a7b-3945f15f7d0a",
+ "metadata": {},
+ "source": [
+ "### Example 2: Monte Carlo simulation of estimating π\n",
+ "\n",
+ "Let's estimate the value of π using a [Monte Carlo](https://en.wikipedia.org/wiki/Monte_Carlo_method) method. We randomly sample points within a 2x2 square. We can use the proportion of the points that are contained within the unit circle centered at the origin to estimate the ratio of the area of the circle to the area of the square. \n",
+ "\n",
+ "Given we know that the true ratio to be π/4, we can multiply our estimated ratio by 4 to approximate the value of π. The more points that we sample to calculate this approximation, the closer we get to true value of π to required decimal points.\n",
+ "\n",
+ "| |\n",
+ "|:--|\n",
+ "|Estimating the value of π by sampling random points that fall into the circle.|"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "373b1b0b-7ecd-4642-96e3-bcd8724172a5",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Change this to match your cluster scale.\n",
+ "NUM_SAMPLING_TASKS = os.cpu_count()\n",
+ "NUM_SAMPLES_PER_TASK = 10_000_000\n",
+ "TOTAL_NUM_SAMPLES = NUM_SAMPLING_TASKS * NUM_SAMPLES_PER_TASK"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ba80a46c-af65-4a0c-8078-371ef9e17c72",
+ "metadata": {},
+ "source": [
+ "Define a regular function that computes the number of samples\n",
+ "in the circle. This is done by randomly sampling `num_samples` for\n",
+ "x, y between a uniform value of (-1, 1). Using the [math.hypot](https://docs.python.org/3/library/math.html#math.hypot) function, we\n",
+ "compute if it falls within the circle."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c9846144-36cd-43d6-a465-1bfd686398bf",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def sampling_task(num_samples: int, task_id: int, verbose=True) -> int:\n",
+ " num_inside = 0\n",
+ " for i in range(num_samples):\n",
+ " x, y = random.uniform(-1, 1), random.uniform(-1, 1)\n",
+ " # check if the point is inside the circle\n",
+ " if math.hypot(x, y) <= 1:\n",
+ " num_inside += 1\n",
+ " if verbose:\n",
+ " print(f\"Task id: {task_id} | Samples in the circle: {num_inside}\")\n",
+ " return num_inside"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "85c5b9d5-2aa7-4abe-aea5-15aa748cd055",
+ "metadata": {},
+ "source": [
+ "Define a function to run this serially, by launcing `NUM_SAMPLING_TASKS` serial tasks in a comprehension list."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8ca8fe02-a7a4-4522-a2dd-cc57c471bce6",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def run_serial(sample_size) -> List[int]:\n",
+ " results = [sampling_task(sample_size, i+1) for i in range(NUM_SAMPLING_TASKS)]\n",
+ " return results"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9d195094-5c50-40ce-8640-38749acb7d18",
+ "metadata": {},
+ "source": [
+ "Define a function to run this as a remote Ray task, which invokes our sampling function, but since it's decorated\n",
+ "with `@ray.remote`, the task will run on a worker process, tied to a core, on the Ray cluster."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "964a3647-318d-4395-bedc-fa1d825cda4c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "def sample_task_distribute(sample_size, i) -> object:\n",
+ " return sampling_task(sample_size, i)\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b0369350-0b0a-4486-9710-db89dccddf31",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def run_disributed(sample_size) -> List[int]:\n",
+ " # Launch Ray remote tasks in a comprehension list, each returns immediately with a future ObjectRef \n",
+ " # Use ray.get to fetch the computed value; this will block until the ObjectRef is resolved or its value is materialized.\n",
+ " results = ray.get([\n",
+ " sample_task_distribute.remote(sample_size, i+1) for i in range(NUM_SAMPLING_TASKS)\n",
+ " ])\n",
+ " return results"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2b0c52ce-348f-4239-a9e3-e9802e56e6ad",
+ "metadata": {},
+ "source": [
+ "Define a function to calculate the value of π by getting all number of samples inside the circle from the sampling tasks and calculate π."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b94e50ae-0a0f-4c9e-9d8c-9220b04560d4",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def calculate_pi(results: List[int]) -> float:\n",
+ " total_num_inside = sum(results)\n",
+ " pi = (total_num_inside * 4) / TOTAL_NUM_SAMPLES\n",
+ " return pi"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "aa9969a3-8f3d-4fae-9dc4-c4c2340316ab",
+ "metadata": {},
+ "source": [
+ "### Run calculating π serially"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1fe8858c-d292-468d-a78a-5aa9e8749721",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(f\"Running {NUM_SAMPLING_TASKS} tasks serially....\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9fdfd4fb-c4e1-474a-9304-c927eab90471",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%time\n",
+ "results = run_serial(NUM_SAMPLES_PER_TASK)\n",
+ "pi = calculate_pi(results)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c37f6540-982e-430e-a97d-8c3a67e2074d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(f\"Estimated value of π is: {pi:5f}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "31c021f9-1f67-483b-91e6-5d0afbf5319a",
+ "metadata": {},
+ "source": [
+ "### Run calculating π with Ray distributed tasks"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c199b3ce-cfa2-4395-807c-7e67726b12ac",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%time\n",
+ "results = run_disributed(NUM_SAMPLES_PER_TASK)\n",
+ "pi = calculate_pi(results)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a6714a1a-5794-43bb-916b-7881ac02d27d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(f\"Estimated value of π is: {pi:5f}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ed990f02-1fa6-4541-a0ed-27e5e4073027",
+ "metadata": {},
+ "source": [
+ "### Recap\n",
+ "With Ray, we see an a speed up 🚅. But what if we decrease the number of samples? Do we get an accurate represenation of π? Try it for yourself. "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "07bf14f0-f92e-4499-a9c8-d0be99dc7266",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "### Example 3: How to use Ray distributed tasks for image transformation and computation\n",
+ "For this example, we will simulate a compute-intensive task by transforming and computing some operations on large high-resolution images. These tasks are not uncommon in image classification in a DNN for training and transposing\n",
+ "images. \n",
+ "\n",
+ "PyTorch `torchvision.transforms` API provides many transformation APIs. We will use a couple here, along with some `numpy` and `torch.tensor` operations. Our tasks will perform the following compute-intensive transformations:\n",
+ "\n",
+ " 1. Use PIL APIs to [blur the image](https://pillow.readthedocs.io/en/stable/reference/ImageFilter.html) with a filter intensity\n",
+ " 2. Use Torchvision random [trivial wide augmentation](https://pytorch.org/vision/stable/generated/torchvision.transforms.TrivialAugmentWide.html#torchvision.transforms.TrivialAugmentWide)\n",
+ " 3. Convert images into numpy array and tensors and do numpy and torch tensor operations such as [transpose](https://pytorch.org/docs/stable/generated/torch.transpose.html), element-wise [multiplication](https://pytorch.org/docs/stable/generated/torch.mul.html) with a random integers\n",
+ " 4. Do more exponential [tensor power](https://pytorch.org/docs/stable/generated/torch.pow.html) and [multiplication with tensors](https://pytorch.org/docs/stable/generated/torch.mul.html)\n",
+ "\n",
+ "The goal is to compare execution times running these task serially vs. distributed as a Ray Task.\n",
+ "\n",
+ "|
|\n",
+ "|:--|\n",
+ "|Estimating the value of π by sampling random points that fall into the circle.|"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "373b1b0b-7ecd-4642-96e3-bcd8724172a5",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Change this to match your cluster scale.\n",
+ "NUM_SAMPLING_TASKS = os.cpu_count()\n",
+ "NUM_SAMPLES_PER_TASK = 10_000_000\n",
+ "TOTAL_NUM_SAMPLES = NUM_SAMPLING_TASKS * NUM_SAMPLES_PER_TASK"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ba80a46c-af65-4a0c-8078-371ef9e17c72",
+ "metadata": {},
+ "source": [
+ "Define a regular function that computes the number of samples\n",
+ "in the circle. This is done by randomly sampling `num_samples` for\n",
+ "x, y between a uniform value of (-1, 1). Using the [math.hypot](https://docs.python.org/3/library/math.html#math.hypot) function, we\n",
+ "compute if it falls within the circle."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c9846144-36cd-43d6-a465-1bfd686398bf",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def sampling_task(num_samples: int, task_id: int, verbose=True) -> int:\n",
+ " num_inside = 0\n",
+ " for i in range(num_samples):\n",
+ " x, y = random.uniform(-1, 1), random.uniform(-1, 1)\n",
+ " # check if the point is inside the circle\n",
+ " if math.hypot(x, y) <= 1:\n",
+ " num_inside += 1\n",
+ " if verbose:\n",
+ " print(f\"Task id: {task_id} | Samples in the circle: {num_inside}\")\n",
+ " return num_inside"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "85c5b9d5-2aa7-4abe-aea5-15aa748cd055",
+ "metadata": {},
+ "source": [
+ "Define a function to run this serially, by launcing `NUM_SAMPLING_TASKS` serial tasks in a comprehension list."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8ca8fe02-a7a4-4522-a2dd-cc57c471bce6",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def run_serial(sample_size) -> List[int]:\n",
+ " results = [sampling_task(sample_size, i+1) for i in range(NUM_SAMPLING_TASKS)]\n",
+ " return results"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9d195094-5c50-40ce-8640-38749acb7d18",
+ "metadata": {},
+ "source": [
+ "Define a function to run this as a remote Ray task, which invokes our sampling function, but since it's decorated\n",
+ "with `@ray.remote`, the task will run on a worker process, tied to a core, on the Ray cluster."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "964a3647-318d-4395-bedc-fa1d825cda4c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "def sample_task_distribute(sample_size, i) -> object:\n",
+ " return sampling_task(sample_size, i)\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b0369350-0b0a-4486-9710-db89dccddf31",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def run_disributed(sample_size) -> List[int]:\n",
+ " # Launch Ray remote tasks in a comprehension list, each returns immediately with a future ObjectRef \n",
+ " # Use ray.get to fetch the computed value; this will block until the ObjectRef is resolved or its value is materialized.\n",
+ " results = ray.get([\n",
+ " sample_task_distribute.remote(sample_size, i+1) for i in range(NUM_SAMPLING_TASKS)\n",
+ " ])\n",
+ " return results"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2b0c52ce-348f-4239-a9e3-e9802e56e6ad",
+ "metadata": {},
+ "source": [
+ "Define a function to calculate the value of π by getting all number of samples inside the circle from the sampling tasks and calculate π."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b94e50ae-0a0f-4c9e-9d8c-9220b04560d4",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def calculate_pi(results: List[int]) -> float:\n",
+ " total_num_inside = sum(results)\n",
+ " pi = (total_num_inside * 4) / TOTAL_NUM_SAMPLES\n",
+ " return pi"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "aa9969a3-8f3d-4fae-9dc4-c4c2340316ab",
+ "metadata": {},
+ "source": [
+ "### Run calculating π serially"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1fe8858c-d292-468d-a78a-5aa9e8749721",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(f\"Running {NUM_SAMPLING_TASKS} tasks serially....\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9fdfd4fb-c4e1-474a-9304-c927eab90471",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%time\n",
+ "results = run_serial(NUM_SAMPLES_PER_TASK)\n",
+ "pi = calculate_pi(results)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c37f6540-982e-430e-a97d-8c3a67e2074d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(f\"Estimated value of π is: {pi:5f}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "31c021f9-1f67-483b-91e6-5d0afbf5319a",
+ "metadata": {},
+ "source": [
+ "### Run calculating π with Ray distributed tasks"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c199b3ce-cfa2-4395-807c-7e67726b12ac",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%time\n",
+ "results = run_disributed(NUM_SAMPLES_PER_TASK)\n",
+ "pi = calculate_pi(results)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a6714a1a-5794-43bb-916b-7881ac02d27d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(f\"Estimated value of π is: {pi:5f}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ed990f02-1fa6-4541-a0ed-27e5e4073027",
+ "metadata": {},
+ "source": [
+ "### Recap\n",
+ "With Ray, we see an a speed up 🚅. But what if we decrease the number of samples? Do we get an accurate represenation of π? Try it for yourself. "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "07bf14f0-f92e-4499-a9c8-d0be99dc7266",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "### Example 3: How to use Ray distributed tasks for image transformation and computation\n",
+ "For this example, we will simulate a compute-intensive task by transforming and computing some operations on large high-resolution images. These tasks are not uncommon in image classification in a DNN for training and transposing\n",
+ "images. \n",
+ "\n",
+ "PyTorch `torchvision.transforms` API provides many transformation APIs. We will use a couple here, along with some `numpy` and `torch.tensor` operations. Our tasks will perform the following compute-intensive transformations:\n",
+ "\n",
+ " 1. Use PIL APIs to [blur the image](https://pillow.readthedocs.io/en/stable/reference/ImageFilter.html) with a filter intensity\n",
+ " 2. Use Torchvision random [trivial wide augmentation](https://pytorch.org/vision/stable/generated/torchvision.transforms.TrivialAugmentWide.html#torchvision.transforms.TrivialAugmentWide)\n",
+ " 3. Convert images into numpy array and tensors and do numpy and torch tensor operations such as [transpose](https://pytorch.org/docs/stable/generated/torch.transpose.html), element-wise [multiplication](https://pytorch.org/docs/stable/generated/torch.mul.html) with a random integers\n",
+ " 4. Do more exponential [tensor power](https://pytorch.org/docs/stable/generated/torch.pow.html) and [multiplication with tensors](https://pytorch.org/docs/stable/generated/torch.mul.html)\n",
+ "\n",
+ "The goal is to compare execution times running these task serially vs. distributed as a Ray Task.\n",
+ "\n",
+ "| |\n",
+ "|:--|\n",
+ "|Diagram of workers in worker nodes using `ray.put()` to store values and using `ray.get()` to retrieve them from each node's object store.|"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "72a0f0c5-a5b7-45ce-8d37-371e05dd48cd",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Place all images into the object store. Since Ray tasks may be disributed \n",
+ "# across machines, the DATA_DIR may not be present on a worker. However,\n",
+ "# placing them into the Ray distributed objector provides access to any \n",
+ "# remote task scheduled on Ray worker\n",
+ " \n",
+ "images_list_refs = [t_utils.insert_into_object_store(image) for \n",
+ " image in image_list]\n",
+ "images_list_refs[:2]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "93659bf2-ab75-4a97-94e2-bf16e0420d87",
+ "metadata": {},
+ "source": [
+ "### Run serially: each image transformation with a Python function\n",
+ "\n",
+ "We will iterate through the images with batches of 10 (this can be changed 20 or 25, etc) and process them. To simulate a computer-intensive operation on images, we are doing the tensor transformation and computations described above."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "37c09e04-fa04-4c45-b9db-302a0dde3922",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "for idx in BATCHES:\n",
+ " # Use the index to get N number of URLs to images\n",
+ " image_batch_list_refs = images_list_refs[:idx]\n",
+ " print(f\"\\nRunning {len(image_batch_list_refs)} tasks serially....\")\n",
+ " \n",
+ " # Run each one serially\n",
+ " start = time.perf_counter()\n",
+ " serial_results = run_serially(image_batch_list_refs)\n",
+ " end = time.perf_counter()\n",
+ " elapsed = end - start\n",
+ " \n",
+ " # Keep track of batches, execution times as a Tuple\n",
+ " SERIAL_BATCH_TIMES.append((idx, round(elapsed, 2)))\n",
+ " print(f\"Serial transformations/computations of {len(image_batch_list_refs)} images: {elapsed:.2f} sec\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a0a9e510-0152-41ae-a2b4-b08e00a5bcac",
+ "metadata": {},
+ "source": [
+ "### Run distributed: each image transformation with a Ray task\n",
+ "\n",
+ "Let's create a Ray task for an image within each batch and process them. Since our images are large and exsist in the [Ray Distributed object store](https://docs.ray.io/en/latest/ray-core/key-concepts.html#objects), our Ray tasks scheduled on any workder node will have access to them.\n",
+ "\n",
+ "(We will cover Ray shared object store in the next tutorial, so bear with me for now).\n",
+ "\n",
+ "||\n",
+ "|:--|\n",
+ "|Diagram of workers in worker nodes using `ray.put()` to store values and using `ray.get()` to retrieve them from each node's object store.|"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1cb12234-e7a1-4172-b896-c7268dd2ef73",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Iterate over batches, launching Ray task for each image within the processing\n",
+ "# batch\n",
+ "for idx in BATCHES:\n",
+ " image_batch_list_refs = images_list_refs[:idx]\n",
+ " print(f\"\\nRunning {len(image_batch_list_refs)} tasks distributed....\")\n",
+ " \n",
+ " # Run each one serially\n",
+ " start = time.perf_counter()\n",
+ " distributed_results = run_distributed(image_batch_list_refs)\n",
+ " end = time.perf_counter()\n",
+ " elapsed = end - start\n",
+ " \n",
+ " # Keep track of batchs, execution times as a Tuple\n",
+ " DISTRIBUTED_BATCH_TIMES.append((idx, round(elapsed, 2)))\n",
+ " print(f\"Distributed transformations/computations of {len(image_batch_list_refs)} images: {elapsed:.2f} sec\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2e0b1e0a-64e6-4e82-906e-5a2fe7649cdb",
+ "metadata": {},
+ "source": [
+ "### Compare and plot the serial vs. distributed computational times"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e7e74c33-c85f-4916-99f8-9de21aebf7f8",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Print times for each and plot them for comparison\n",
+ "print(f\"Serial times & batches : {SERIAL_BATCH_TIMES}\")\n",
+ "print(f\"Distributed times & batches: {DISTRIBUTED_BATCH_TIMES}\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "17db3ef2-c1d1-4341-8a12-04b229dae6f0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "t_utils.plot_times(BATCHES, SERIAL_BATCH_TIMES, DISTRIBUTED_BATCH_TIMES)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a31bb3a5-57c8-4396-a75c-896c274e1127",
+ "metadata": {},
+ "source": [
+ "### Recap\n",
+ "\n",
+ "We can clearly observe that the overall execution times by Ray tasks is faster 🚅 than serial. Converting an existing serial compute-intensive Python function is as simple as adding the `ray.remote(...)` operator to your Python function. And Ray will handle all the hard bits: scheduling, execution, scaling, memory management, etc.\n",
+ "\n",
+ "As you can see the benefits are tangible in execution times with Ray tasks."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0658478a",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "
|\n",
+ "|:--|\n",
+ "|Diagram of workers in worker nodes using `ray.put()` to store values and using `ray.get()` to retrieve them from each node's object store.|"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "72a0f0c5-a5b7-45ce-8d37-371e05dd48cd",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Place all images into the object store. Since Ray tasks may be disributed \n",
+ "# across machines, the DATA_DIR may not be present on a worker. However,\n",
+ "# placing them into the Ray distributed objector provides access to any \n",
+ "# remote task scheduled on Ray worker\n",
+ " \n",
+ "images_list_refs = [t_utils.insert_into_object_store(image) for \n",
+ " image in image_list]\n",
+ "images_list_refs[:2]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "93659bf2-ab75-4a97-94e2-bf16e0420d87",
+ "metadata": {},
+ "source": [
+ "### Run serially: each image transformation with a Python function\n",
+ "\n",
+ "We will iterate through the images with batches of 10 (this can be changed 20 or 25, etc) and process them. To simulate a computer-intensive operation on images, we are doing the tensor transformation and computations described above."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "37c09e04-fa04-4c45-b9db-302a0dde3922",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "for idx in BATCHES:\n",
+ " # Use the index to get N number of URLs to images\n",
+ " image_batch_list_refs = images_list_refs[:idx]\n",
+ " print(f\"\\nRunning {len(image_batch_list_refs)} tasks serially....\")\n",
+ " \n",
+ " # Run each one serially\n",
+ " start = time.perf_counter()\n",
+ " serial_results = run_serially(image_batch_list_refs)\n",
+ " end = time.perf_counter()\n",
+ " elapsed = end - start\n",
+ " \n",
+ " # Keep track of batches, execution times as a Tuple\n",
+ " SERIAL_BATCH_TIMES.append((idx, round(elapsed, 2)))\n",
+ " print(f\"Serial transformations/computations of {len(image_batch_list_refs)} images: {elapsed:.2f} sec\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a0a9e510-0152-41ae-a2b4-b08e00a5bcac",
+ "metadata": {},
+ "source": [
+ "### Run distributed: each image transformation with a Ray task\n",
+ "\n",
+ "Let's create a Ray task for an image within each batch and process them. Since our images are large and exsist in the [Ray Distributed object store](https://docs.ray.io/en/latest/ray-core/key-concepts.html#objects), our Ray tasks scheduled on any workder node will have access to them.\n",
+ "\n",
+ "(We will cover Ray shared object store in the next tutorial, so bear with me for now).\n",
+ "\n",
+ "||\n",
+ "|:--|\n",
+ "|Diagram of workers in worker nodes using `ray.put()` to store values and using `ray.get()` to retrieve them from each node's object store.|"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1cb12234-e7a1-4172-b896-c7268dd2ef73",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Iterate over batches, launching Ray task for each image within the processing\n",
+ "# batch\n",
+ "for idx in BATCHES:\n",
+ " image_batch_list_refs = images_list_refs[:idx]\n",
+ " print(f\"\\nRunning {len(image_batch_list_refs)} tasks distributed....\")\n",
+ " \n",
+ " # Run each one serially\n",
+ " start = time.perf_counter()\n",
+ " distributed_results = run_distributed(image_batch_list_refs)\n",
+ " end = time.perf_counter()\n",
+ " elapsed = end - start\n",
+ " \n",
+ " # Keep track of batchs, execution times as a Tuple\n",
+ " DISTRIBUTED_BATCH_TIMES.append((idx, round(elapsed, 2)))\n",
+ " print(f\"Distributed transformations/computations of {len(image_batch_list_refs)} images: {elapsed:.2f} sec\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2e0b1e0a-64e6-4e82-906e-5a2fe7649cdb",
+ "metadata": {},
+ "source": [
+ "### Compare and plot the serial vs. distributed computational times"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e7e74c33-c85f-4916-99f8-9de21aebf7f8",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Print times for each and plot them for comparison\n",
+ "print(f\"Serial times & batches : {SERIAL_BATCH_TIMES}\")\n",
+ "print(f\"Distributed times & batches: {DISTRIBUTED_BATCH_TIMES}\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "17db3ef2-c1d1-4341-8a12-04b229dae6f0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "t_utils.plot_times(BATCHES, SERIAL_BATCH_TIMES, DISTRIBUTED_BATCH_TIMES)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a31bb3a5-57c8-4396-a75c-896c274e1127",
+ "metadata": {},
+ "source": [
+ "### Recap\n",
+ "\n",
+ "We can clearly observe that the overall execution times by Ray tasks is faster 🚅 than serial. Converting an existing serial compute-intensive Python function is as simple as adding the `ray.remote(...)` operator to your Python function. And Ray will handle all the hard bits: scheduling, execution, scaling, memory management, etc.\n",
+ "\n",
+ "As you can see the benefits are tangible in execution times with Ray tasks."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0658478a",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "\n",
+ " \n",
+ "__Lab exercise 1__\n",
+ " \n",
+ "Start with this compute intensive Python function evaluated several times in a list comprehension\n",
+ " \n",
+ "```python\n",
+ "import numpy as np\n",
+ "from typing import List\n",
+ "\n",
+ "def my_method(num: int, dims=10) -> List[np.array]:\n",
+ " dot_products = []\n",
+ " for _ in range(num):\n",
+ " # Create a dims x dims matrix\n",
+ " x = np.random.rand(dims, dims)\n",
+ " y = np.random.rand(dims, dims)\n",
+ " # Create a dot product of itself\n",
+ " dot_products.append(np.dot(x, y))\n",
+ " return dot_products\n",
+ "\n",
+ "[my_method(i, 5_000) for i in range(5)]\n",
+ "```\n",
+ "
\n", + " \n", + "* Convert the function into a Ray task\n", + "* Run the invocations of the function in your Ray cluster and collect and print the results\n", + "\n", + "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "bc6626f9-2887-46ca-8c2c-db7a0173fb66",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ray.shutdown()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0d4fa0e7",
+ "metadata": {},
+ "source": [
+ "### Homework\n",
+ "1. For the Example 3, try different batch sizes, and compare the running times. For example, BATCHES = [10, 20, 30, 40, 50, 60, 70, 80, 90, 100]\n",
+ "2. Read this blog: [Parallelizing Python Code](https://www.anyscale.com/blog/parallelizing-python-code), and try some examples."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4d8d5d0c-89d9-40cc-9fb3-85e3ddc59f3c",
+ "metadata": {},
+ "source": [
+ "### Next Step\n",
+ "\n",
+ "Let's move on to the distributed [remote objects lesson](Ray_Core_2_Remote_Objects.ipynb)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "08f363a1",
+ "metadata": {},
+ "source": [
+ "### References\n",
+ "\n",
+ "1. [Modern Parallel and Distributed Python: A Quick Tutorial on Ray](https://towardsdatascience.com/modern-parallel-and-distributed-python-a-quick-tutorial-on-ray-99f8d70369b8) by Robert Nishihara, co-creator of Ray and co-founder Anyscale\n",
+ "2. [Ray Core Introduction](https://www.anyscale.com/events/2022/02/03/introduction-to-ray-core-and-its-ecosystem) by Jules S. Damji"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/templates/ray-summit-core-masterclass/Ray_Core_2_Remote_Objects.ipynb b/templates/ray-summit-core-masterclass/Ray_Core_2_Remote_Objects.ipynb
new file mode 100644
index 000000000..0d94fd3ab
--- /dev/null
+++ b/templates/ray-summit-core-masterclass/Ray_Core_2_Remote_Objects.ipynb
@@ -0,0 +1,706 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# A Guided Tour of Ray Core: Remote Objects\n",
+ "\n",
+ "## Overview\n",
+ "\n",
+ "In Ray, tasks and actors create and compute on objects. We refer to these objects as remote objects because they can be stored anywhere in a Ray cluster, and we use object refs to refer to them. Remote objects are cached in Ray’s distributed shared-memory object store, and there is one object store per node in the cluster. In the cluster setting, a remote object can live on one or many nodes, independent of who holds the object ref(s). Collectively, these individual object store makes a shared object store across the the Ray Cluster, as shown in the diagram below.\n",
+ "\n",
+ "[Remote Objects](https://docs.ray.io/en/latest/walkthrough.html#objects-in-ray)\n",
+ "reside in a distributed [shared-memory object store](https://en.wikipedia.org/wiki/Shared_memory).\n",
+ "\n",
+ "Ray architecture with Ray nodes, each with its own object store. Collectively, it's a shared object store across the cluster\n",
+ "\n", + " \n", + "* Convert the function into a Ray task\n", + "* Run the invocations of the function in your Ray cluster and collect and print the results\n", + "\n", + "
 \n",
+ "\n",
+ "Objects are immutable and can be accessed from anywhere on the cluster, as they are stored in the cluster shared memory. An object ref is essentially a pointer or a unique ID that can be used to refer to a remote object without seeing its value. If you’re familiar with futures in Python, Java or Scala, Ray object refs are conceptually similar.\n",
+ "\n",
+ "In general, small objects are stored in their owner’s **in-process store** (**<=100KB**), while large objects are stored in the **distributed object store**. This decision is meant to reduce the memory footprint and resolution time for each object. Note that in the latter case, a placeholder object is stored in the in-process store to indicate the object has been promoted to shared memory.\n",
+ "\n",
+ "In the case if there is no space in the shared-memory, objects are spilled over to disk. But the main point here is that\n",
+ "shared-memory allows _zero-copy_ access to processes on the same worker node.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "Objects are immutable and can be accessed from anywhere on the cluster, as they are stored in the cluster shared memory. An object ref is essentially a pointer or a unique ID that can be used to refer to a remote object without seeing its value. If you’re familiar with futures in Python, Java or Scala, Ray object refs are conceptually similar.\n",
+ "\n",
+ "In general, small objects are stored in their owner’s **in-process store** (**<=100KB**), while large objects are stored in the **distributed object store**. This decision is meant to reduce the memory footprint and resolution time for each object. Note that in the latter case, a placeholder object is stored in the in-process store to indicate the object has been promoted to shared memory.\n",
+ "\n",
+ "In the case if there is no space in the shared-memory, objects are spilled over to disk. But the main point here is that\n",
+ "shared-memory allows _zero-copy_ access to processes on the same worker node.\n",
+ "\n",
+ " \n",
+ "\n",
+ "## Learning objectives\n",
+ "\n",
+ "In this tutorial, you learn about:\n",
+ "\n",
+ "* Ray Futures as one of the patterns\n",
+ "* Ray's distributed Plasma object store\n",
+ "* How obejcts are stored and fetched from the distributed shared object store\n",
+ " * Use `ray.get` and `ray.put` examples\n",
+ "* How to use Ray tasks and object store to do inference batching at scale"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Object references as futures pattern"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "First, let's start Ray…"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "import random\n",
+ "\n",
+ "from typing import Tuple\n",
+ "\n",
+ "import numpy as np\n",
+ "import pandas as pd\n",
+ "import pyarrow.parquet as pq\n",
+ "import torch\n",
+ "import ray"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "if ray.is_initialized:\n",
+ " ray.shutdown()\n",
+ "ray.init(logging_level=logging.ERROR)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Example 1: Remote Objects"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "To start, we'll create some python objects and put them in shared memory using the [Ray Core APIs](https://docs.ray.io/en/latest/ray-core/package-ref.html)\n",
+ "\n",
+ "* `ray.put()` - put an object in the in-memory object store and return its `RefObjectID`. Use this `RefObjectID` to pass object to any remote task or an Actor method call\n",
+ "* `ray.get()` - get the values from a remote object or a list of remote objects from the object store\n",
+ "\n",
+ "||\n",
+ "|:--|\n",
+ "|Diagram of workers in worker nodes using `ray.put()` to place values and using `ray.get()` to retrieve them from each node's object store. If the workder node's does not have the value of the ObjectRefID, it'll fetched or copied from the worker's node that created it.|\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Create a function to return an random tensor shape. We will use this\n",
+ "tensor to store in our object store and retrieve it later for processing."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def create_rand_tensor(size: Tuple[int, int]) -> torch.tensor:\n",
+ " return torch.randn(size=(size), dtype=torch.float)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "def transform_rand_tensor(tensor: torch.tensor) -> torch.tensor:\n",
+ " return torch.mul(tensor, random.randint(2, 10))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Create random tensors and store them in object store\n",
+ "1. create a random tensor\n",
+ "2. put it in the object store\n",
+ "3. the final list returned from the comprehension is list of `ObjectRefIDs`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "torch.manual_seed(42)\n",
+ "#\n",
+ "# Create a tensor of shape (X, 50)\n",
+ "#\n",
+ "tensor_list_obj_ref = [ray.put(create_rand_tensor(((i+1)*25, 50))) for i in range(0, 100)]\n",
+ "tensor_list_obj_ref[:2], len(tensor_list_obj_ref)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "You can view the object store in the [Ray Dashboard](https://docs.ray.io/en/latest/ray-core/ray-dashboard.html)\n",
+ "**Note**: Use the link above for the actual dashboard"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Fetch the random tensors from the object store"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Retrieve the value of this object reference. \n",
+ "\n",
+ "Small objects are resolved by copying them directly from the _owner’s_ **in-process store**. For example, if the owner calls `ray.get`, the system looks up and deserializes the value from the local **in-process store**. For larger objects greater than 100KB, they will be stored in the distributed object store."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Since we got back a list of ObjectRefIDs, index into the first value of the tensor from \n",
+ "# the list of ObectRefIDs\n",
+ "val = ray.get(tensor_list_obj_ref[0])\n",
+ "val.size(), val"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Alternatively, you can fetch all the values of multiple object references."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "results = ray.get(tensor_list_obj_ref)\n",
+ "results[:1], results[:1][0].size()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Transform tensors stored in the object store"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's transform our tensors stored in the object store, put the transformed tensors in the object store (the ray remote task will implicity store it as a returned value), and then fetch the values."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Transform each tensor in the object store with a remote task in our Python comprehension list"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "transformed_object_list = [transform_rand_tensor.remote(t_obj_ref) for t_obj_ref in tensor_list_obj_ref]\n",
+ "transformed_object_list[:2]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Fetch all the transformed tensors"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "transformed_tensor_values = ray.get(transformed_object_list)\n",
+ "transformed_tensor_values[:2]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Recap\n",
+ "Ray's object store is a shared memory store spanning a Ray cluster. Workers on each Ray node have their own object store, and they can use simple Ray APIs,`ray.put()` and `ray.get()`, to insert values and fetch values of Ray objects created by Ray tasks or Actor methods. Collectively, these individual object stores per node comprise a shared and distributed object store. \n",
+ "\n",
+ "In the above exercise, we created random tensors, inserted them into our object store, transformed them, by iterating over each `ObjectRefID`, sending this `ObjectRefID` to a Ray task, and then fetching the transformed tensor returned by each Ray remote task. "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Passing Objects by Reference\n",
+ "\n",
+ "Ray object references can be freely passed around a Ray application. This means that they can be passed as arguments to tasks, actor methods, and even stored in other objects. Objects are tracked via distributed reference counting, and their data is automatically freed once all references to the object are deleted."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Define a Task\n",
+ "@ray.remote\n",
+ "def echo(x):\n",
+ " print(f\"current value of argument x: {x}\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Define some variables\n",
+ "x = list(range(10))\n",
+ "obj_ref_x = ray.put(x)\n",
+ "y = 25"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Pass-by-value\n",
+ "\n",
+ "Send the object to a task as a top-level argument.\n",
+ "The object will be *de-referenced* automatically, so the task only sees its value."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# send y as value argument\n",
+ "echo.remote(y)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# send a an object reference\n",
+ "# note that the echo function deferences it\n",
+ "echo.remote(obj_ref_x)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Pass-by-reference\n",
+ "\n",
+ "When a parameter is passed inside a Python list or as any other data structure,\n",
+ "the *object ref is preserved*, meaning it's not *de-referenced*. The object data is not transferred to the worker when it is passed by reference, until `ray.get()` is called on the reference.\n",
+ "\n",
+ "You can pass by reference in two ways:\n",
+ " 1. as a dictionary `.remote({\"obj\": obj_ref_x})`\n",
+ " 2. as list of objRefs `.remote([obj_ref_x])`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "x = list(range(20))\n",
+ "obj_ref_x = ray.put(x)\n",
+ "# Echo will not automaticall de-reference it\n",
+ "echo.remote({\"obj\": obj_ref_x})"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "echo.remote([obj_ref_x])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## What about long running tasks?\n",
+ "\n",
+ "Sometimes, you may have tasks that are long running, past their expected times due to some problem, maybe blocked on accessing a variable in the object store. How do you exit or terminate it? Use a timeout!\n",
+ "\n",
+ "Now let's set a timeout to return early from an attempted access of a remote object that is blocking for too long..."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import time\n",
+ "\n",
+ "@ray.remote\n",
+ "def long_running_function ():\n",
+ " time.sleep(10)\n",
+ " return 42"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "You can control how long you want to wait for the task to finish"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%time\n",
+ "\n",
+ "from ray.exceptions import GetTimeoutError\n",
+ "\n",
+ "obj_ref = long_running_function.remote()\n",
+ "\n",
+ "try:\n",
+ " ray.get(obj_ref, timeout=6)\n",
+ "except GetTimeoutError:\n",
+ " print(\"`get` timed out\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Example 2: How to use Tasks and object store for distributed batch inference \n",
+ "\n",
+ "Batch inference is a common distributed application workload in machine learning. It's a process of using a trained model to generate predictions for a collection of observations. \n",
+ "Primarily, it has the following elements:\n",
+ "\n",
+ "**Input dataset**: This is a large collection of observations to generate predictions for. The data is usually stored in an external storage system like S3, HDFS or database, across\n",
+ "many files.\n",
+ "\n",
+ "**ML model**: This is a trained ML model that is usually also stored in an external storage system or in a model store.\n",
+ "\n",
+ "**Predictions**: These are the outputs when applying the ML model on observations. Normally, predictions are usually written back to the storage system.\n",
+ "\n",
+ "For purpose of this exercise, we make the following provisions:\n",
+ " * create a dummy model that returns some fake prediction\n",
+ " * use real-world NYC taxi data to provide large data set for batch inference\n",
+ " * return the predictions instead of writing it back to the disk\n",
+ "\n",
+ "As an example of scaling pattern called **Different Data Same Function** (DDSF), also known as **Distributed Data Parallel** (DDP), our function in this diagram is the \n",
+ "pretrained **model**, and the data is split and disributed as **shards**.\n",
+ "\n",
+ "|
\n",
+ "\n",
+ "## Learning objectives\n",
+ "\n",
+ "In this tutorial, you learn about:\n",
+ "\n",
+ "* Ray Futures as one of the patterns\n",
+ "* Ray's distributed Plasma object store\n",
+ "* How obejcts are stored and fetched from the distributed shared object store\n",
+ " * Use `ray.get` and `ray.put` examples\n",
+ "* How to use Ray tasks and object store to do inference batching at scale"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Object references as futures pattern"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "First, let's start Ray…"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "import random\n",
+ "\n",
+ "from typing import Tuple\n",
+ "\n",
+ "import numpy as np\n",
+ "import pandas as pd\n",
+ "import pyarrow.parquet as pq\n",
+ "import torch\n",
+ "import ray"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "if ray.is_initialized:\n",
+ " ray.shutdown()\n",
+ "ray.init(logging_level=logging.ERROR)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Example 1: Remote Objects"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "To start, we'll create some python objects and put them in shared memory using the [Ray Core APIs](https://docs.ray.io/en/latest/ray-core/package-ref.html)\n",
+ "\n",
+ "* `ray.put()` - put an object in the in-memory object store and return its `RefObjectID`. Use this `RefObjectID` to pass object to any remote task or an Actor method call\n",
+ "* `ray.get()` - get the values from a remote object or a list of remote objects from the object store\n",
+ "\n",
+ "||\n",
+ "|:--|\n",
+ "|Diagram of workers in worker nodes using `ray.put()` to place values and using `ray.get()` to retrieve them from each node's object store. If the workder node's does not have the value of the ObjectRefID, it'll fetched or copied from the worker's node that created it.|\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Create a function to return an random tensor shape. We will use this\n",
+ "tensor to store in our object store and retrieve it later for processing."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def create_rand_tensor(size: Tuple[int, int]) -> torch.tensor:\n",
+ " return torch.randn(size=(size), dtype=torch.float)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "def transform_rand_tensor(tensor: torch.tensor) -> torch.tensor:\n",
+ " return torch.mul(tensor, random.randint(2, 10))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Create random tensors and store them in object store\n",
+ "1. create a random tensor\n",
+ "2. put it in the object store\n",
+ "3. the final list returned from the comprehension is list of `ObjectRefIDs`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "torch.manual_seed(42)\n",
+ "#\n",
+ "# Create a tensor of shape (X, 50)\n",
+ "#\n",
+ "tensor_list_obj_ref = [ray.put(create_rand_tensor(((i+1)*25, 50))) for i in range(0, 100)]\n",
+ "tensor_list_obj_ref[:2], len(tensor_list_obj_ref)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "You can view the object store in the [Ray Dashboard](https://docs.ray.io/en/latest/ray-core/ray-dashboard.html)\n",
+ "**Note**: Use the link above for the actual dashboard"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Fetch the random tensors from the object store"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Retrieve the value of this object reference. \n",
+ "\n",
+ "Small objects are resolved by copying them directly from the _owner’s_ **in-process store**. For example, if the owner calls `ray.get`, the system looks up and deserializes the value from the local **in-process store**. For larger objects greater than 100KB, they will be stored in the distributed object store."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Since we got back a list of ObjectRefIDs, index into the first value of the tensor from \n",
+ "# the list of ObectRefIDs\n",
+ "val = ray.get(tensor_list_obj_ref[0])\n",
+ "val.size(), val"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Alternatively, you can fetch all the values of multiple object references."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "results = ray.get(tensor_list_obj_ref)\n",
+ "results[:1], results[:1][0].size()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Transform tensors stored in the object store"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's transform our tensors stored in the object store, put the transformed tensors in the object store (the ray remote task will implicity store it as a returned value), and then fetch the values."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Transform each tensor in the object store with a remote task in our Python comprehension list"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "transformed_object_list = [transform_rand_tensor.remote(t_obj_ref) for t_obj_ref in tensor_list_obj_ref]\n",
+ "transformed_object_list[:2]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Fetch all the transformed tensors"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "transformed_tensor_values = ray.get(transformed_object_list)\n",
+ "transformed_tensor_values[:2]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Recap\n",
+ "Ray's object store is a shared memory store spanning a Ray cluster. Workers on each Ray node have their own object store, and they can use simple Ray APIs,`ray.put()` and `ray.get()`, to insert values and fetch values of Ray objects created by Ray tasks or Actor methods. Collectively, these individual object stores per node comprise a shared and distributed object store. \n",
+ "\n",
+ "In the above exercise, we created random tensors, inserted them into our object store, transformed them, by iterating over each `ObjectRefID`, sending this `ObjectRefID` to a Ray task, and then fetching the transformed tensor returned by each Ray remote task. "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Passing Objects by Reference\n",
+ "\n",
+ "Ray object references can be freely passed around a Ray application. This means that they can be passed as arguments to tasks, actor methods, and even stored in other objects. Objects are tracked via distributed reference counting, and their data is automatically freed once all references to the object are deleted."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Define a Task\n",
+ "@ray.remote\n",
+ "def echo(x):\n",
+ " print(f\"current value of argument x: {x}\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Define some variables\n",
+ "x = list(range(10))\n",
+ "obj_ref_x = ray.put(x)\n",
+ "y = 25"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Pass-by-value\n",
+ "\n",
+ "Send the object to a task as a top-level argument.\n",
+ "The object will be *de-referenced* automatically, so the task only sees its value."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# send y as value argument\n",
+ "echo.remote(y)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# send a an object reference\n",
+ "# note that the echo function deferences it\n",
+ "echo.remote(obj_ref_x)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Pass-by-reference\n",
+ "\n",
+ "When a parameter is passed inside a Python list or as any other data structure,\n",
+ "the *object ref is preserved*, meaning it's not *de-referenced*. The object data is not transferred to the worker when it is passed by reference, until `ray.get()` is called on the reference.\n",
+ "\n",
+ "You can pass by reference in two ways:\n",
+ " 1. as a dictionary `.remote({\"obj\": obj_ref_x})`\n",
+ " 2. as list of objRefs `.remote([obj_ref_x])`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "x = list(range(20))\n",
+ "obj_ref_x = ray.put(x)\n",
+ "# Echo will not automaticall de-reference it\n",
+ "echo.remote({\"obj\": obj_ref_x})"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "echo.remote([obj_ref_x])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## What about long running tasks?\n",
+ "\n",
+ "Sometimes, you may have tasks that are long running, past their expected times due to some problem, maybe blocked on accessing a variable in the object store. How do you exit or terminate it? Use a timeout!\n",
+ "\n",
+ "Now let's set a timeout to return early from an attempted access of a remote object that is blocking for too long..."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import time\n",
+ "\n",
+ "@ray.remote\n",
+ "def long_running_function ():\n",
+ " time.sleep(10)\n",
+ " return 42"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "You can control how long you want to wait for the task to finish"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%time\n",
+ "\n",
+ "from ray.exceptions import GetTimeoutError\n",
+ "\n",
+ "obj_ref = long_running_function.remote()\n",
+ "\n",
+ "try:\n",
+ " ray.get(obj_ref, timeout=6)\n",
+ "except GetTimeoutError:\n",
+ " print(\"`get` timed out\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Example 2: How to use Tasks and object store for distributed batch inference \n",
+ "\n",
+ "Batch inference is a common distributed application workload in machine learning. It's a process of using a trained model to generate predictions for a collection of observations. \n",
+ "Primarily, it has the following elements:\n",
+ "\n",
+ "**Input dataset**: This is a large collection of observations to generate predictions for. The data is usually stored in an external storage system like S3, HDFS or database, across\n",
+ "many files.\n",
+ "\n",
+ "**ML model**: This is a trained ML model that is usually also stored in an external storage system or in a model store.\n",
+ "\n",
+ "**Predictions**: These are the outputs when applying the ML model on observations. Normally, predictions are usually written back to the storage system.\n",
+ "\n",
+ "For purpose of this exercise, we make the following provisions:\n",
+ " * create a dummy model that returns some fake prediction\n",
+ " * use real-world NYC taxi data to provide large data set for batch inference\n",
+ " * return the predictions instead of writing it back to the disk\n",
+ "\n",
+ "As an example of scaling pattern called **Different Data Same Function** (DDSF), also known as **Distributed Data Parallel** (DDP), our function in this diagram is the \n",
+ "pretrained **model**, and the data is split and disributed as **shards**.\n",
+ "\n",
+ "| |\n",
+ "|:--|\n",
+ "|Distributed batch inference: Different Data Same Function (DDSF).|"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Define a Python closure to load our pretrained model. This model is just a fake model that predicts whether a \n",
+ "tip is warranted contigent on the number of fares (2 or more) on collective rides.\n",
+ "\n",
+ "**Note**: This prediction is fake. The real model will invoke model's `model.predict(input_data)`. Yet\n",
+ "it suffices for this example."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def load_trained_model():\n",
+ " # A fake model that predicts whether tips were given based on number of passengers in the taxi cab.\n",
+ " def model(batch: pd.DataFrame) -> pd.DataFrame:\n",
+ " \n",
+ " # Some model weights and payload so Ray copies the model in the \n",
+ " # shared plasma store for tasks scheduled across nodes.\n",
+ " model.payload = np.arange(10, 100_000, dtype=float)\n",
+ " \n",
+ " # Try with a larger model on a larger machine\n",
+ " #model.payload = np.arange(100, 100_000_000, dtype=float)\n",
+ " model.cls = \"regression\"\n",
+ " \n",
+ " # give a tip if 2 or more passengers\n",
+ " predict = batch[\"passenger_count\"] >= 2 \n",
+ " return pd.DataFrame({\"score\": predict})\n",
+ " \n",
+ " return model "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's define a Ray task that will handle each shard of the NYC taxt data"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "def make_model_batch_predictions(model, shard_path, verbose=False):\n",
+ " if verbose:\n",
+ " print(f\"Batch inference for shard file: {shard_path}\")\n",
+ " df = pq.read_table(shard_path).to_pandas()\n",
+ " result = model(df)\n",
+ "\n",
+ " # Return our prediction data frame\n",
+ " return result"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Get the 12 files consisting of NYC data per month"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# 12 files, one for each remote task.\n",
+ "input_files = [\n",
+ " f\"s3://anonymous@air-example-data/ursa-labs-taxi-data/downsampled_2009_full_year_data.parquet\"\n",
+ " f\"/fe41422b01c04169af2a65a83b753e0f_{i:06d}.parquet\" for i in range(12)]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Insert model into the object store\n",
+ "\n",
+ "`ray.put()` the model just once to local object store, and then pass the reference to the remote tasks.\n",
+ "\n",
+ "It would be highly inefficient if you are passing the model itself like `make_model_prediction.remote(model, file)`,\n",
+ "which in order to pass the model to remote node will implicitly do a `ray.put(model)` for each task, potentially overwhelming\n",
+ "the local object store and causing out-of-memory.\n",
+ "\n",
+ "Instead, we will just pass a reference, and the node where the task is scheduled deference it.\n",
+ "\n",
+ "This is [Ray core API](https://docs.ray.io/en/latest/ray-core/package-ref.html) for putting objects into the Ray Plasma store. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Get the model \n",
+ "model = load_trained_model()\n",
+ "\n",
+ "# Put the model object into the shared object store.\n",
+ "model_ref = ray.put(model)\n",
+ "model_ref"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# List for holding all object references returned from the model's predictions\n",
+ "result_refs = []\n",
+ "\n",
+ "# Launch all prediction tasks. For each file create a Ray remote task to do a batch inference\n",
+ "for file in input_files:\n",
+ " \n",
+ " # Launch a prediction task by passing model reference and shard file to it.\n",
+ " result_refs.append(make_model_batch_predictions.remote(model_ref, file))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Fetch the results"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "results = ray.get(result_refs)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Let's check predictions and output size.\n",
+ "for r in results:\n",
+ " print(f\"Predictions dataframe size: {len(r)} | Total score for tips: {r['score'].sum()}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "
|\n",
+ "|:--|\n",
+ "|Distributed batch inference: Different Data Same Function (DDSF).|"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Define a Python closure to load our pretrained model. This model is just a fake model that predicts whether a \n",
+ "tip is warranted contigent on the number of fares (2 or more) on collective rides.\n",
+ "\n",
+ "**Note**: This prediction is fake. The real model will invoke model's `model.predict(input_data)`. Yet\n",
+ "it suffices for this example."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def load_trained_model():\n",
+ " # A fake model that predicts whether tips were given based on number of passengers in the taxi cab.\n",
+ " def model(batch: pd.DataFrame) -> pd.DataFrame:\n",
+ " \n",
+ " # Some model weights and payload so Ray copies the model in the \n",
+ " # shared plasma store for tasks scheduled across nodes.\n",
+ " model.payload = np.arange(10, 100_000, dtype=float)\n",
+ " \n",
+ " # Try with a larger model on a larger machine\n",
+ " #model.payload = np.arange(100, 100_000_000, dtype=float)\n",
+ " model.cls = \"regression\"\n",
+ " \n",
+ " # give a tip if 2 or more passengers\n",
+ " predict = batch[\"passenger_count\"] >= 2 \n",
+ " return pd.DataFrame({\"score\": predict})\n",
+ " \n",
+ " return model "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's define a Ray task that will handle each shard of the NYC taxt data"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "def make_model_batch_predictions(model, shard_path, verbose=False):\n",
+ " if verbose:\n",
+ " print(f\"Batch inference for shard file: {shard_path}\")\n",
+ " df = pq.read_table(shard_path).to_pandas()\n",
+ " result = model(df)\n",
+ "\n",
+ " # Return our prediction data frame\n",
+ " return result"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Get the 12 files consisting of NYC data per month"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# 12 files, one for each remote task.\n",
+ "input_files = [\n",
+ " f\"s3://anonymous@air-example-data/ursa-labs-taxi-data/downsampled_2009_full_year_data.parquet\"\n",
+ " f\"/fe41422b01c04169af2a65a83b753e0f_{i:06d}.parquet\" for i in range(12)]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Insert model into the object store\n",
+ "\n",
+ "`ray.put()` the model just once to local object store, and then pass the reference to the remote tasks.\n",
+ "\n",
+ "It would be highly inefficient if you are passing the model itself like `make_model_prediction.remote(model, file)`,\n",
+ "which in order to pass the model to remote node will implicitly do a `ray.put(model)` for each task, potentially overwhelming\n",
+ "the local object store and causing out-of-memory.\n",
+ "\n",
+ "Instead, we will just pass a reference, and the node where the task is scheduled deference it.\n",
+ "\n",
+ "This is [Ray core API](https://docs.ray.io/en/latest/ray-core/package-ref.html) for putting objects into the Ray Plasma store. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Get the model \n",
+ "model = load_trained_model()\n",
+ "\n",
+ "# Put the model object into the shared object store.\n",
+ "model_ref = ray.put(model)\n",
+ "model_ref"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# List for holding all object references returned from the model's predictions\n",
+ "result_refs = []\n",
+ "\n",
+ "# Launch all prediction tasks. For each file create a Ray remote task to do a batch inference\n",
+ "for file in input_files:\n",
+ " \n",
+ " # Launch a prediction task by passing model reference and shard file to it.\n",
+ " result_refs.append(make_model_batch_predictions.remote(model_ref, file))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Fetch the results"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "results = ray.get(result_refs)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Let's check predictions and output size.\n",
+ "for r in results:\n",
+ " print(f\"Predictions dataframe size: {len(r)} | Total score for tips: {r['score'].sum()}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "\n",
+ " \n",
+ "__Lab exercise 2__\n",
+ "\n",
+ "\n",
+ "Start with this Python function\n",
+ " \n",
+ "```python\n",
+ "def my_function (num_list):\n",
+ " return sum(num_list)\n",
+ "```\n",
+ "
\n", + " \n", + "* Convert the function into a Ray task\n", + "* Put each of the numbers 0 through 9 into the Ray Object Store and hang on to the corresponding Object Refs\n", + "* Get all of the references objects into a local list using `ray.get( list_of_refs )`\n", + "* Run the function in your Ray cluster passing the local list as a parameter\n", + "\n", + "This runs ... but isn't ideal. What might be a better way to write this code? Why?\n", + "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ray.shutdown()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Recap\n",
+ "\n",
+ "We covered how to \n",
+ " * use Ray `tasks`, `ray.get()` and `ray.put`, \n",
+ " * understand distributed remote object store\n",
+ " * how you to access objects from object store for transformation\n",
+ "\n",
+ "Let's move on to the [Ray Actors lesson](ex_03_remote_classes.ipynb)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Homework\n",
+ "\n",
+ "1. Read references to get advanced deep dives and more about Ray objects\n",
+ "2. [Serialization](https://docs.ray.io/en/latest/ray-core/objects/serialization.html)\n",
+ "3. [Memory Management](https://docs.ray.io/en/latest/ray-core/objects/memory-management.html)\n",
+ "4. [Object Spilling](https://docs.ray.io/en/latest/ray-core/objects/object-spilling.html)\n",
+ "5. [Fault Tolerance](https://docs.ray.io/en/latest/ray-core/objects/fault-tolerance.html)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### References\n",
+ "\n",
+ " * [Ray Architecture Reference](https://docs.google.com/document/d/1tBw9A4j62ruI5omIJbMxly-la5w4q_TjyJgJL_jN2fI/preview)\n",
+ " * [Ray Internals: A peek at ray,get](https://www.youtube.com/watch?v=a1kNnQu6vGw)\n",
+ " * [Ray Internals: Object management with Ownership Model](https://www.youtube.com/watch?v=1oSBxTayfJc)\n",
+ " * [Deep Dive into Ray scheduling Policies](https://www.youtube.com/watch?v=EJUYKXWGzfI)\n",
+ " * [Redis in Ray: Past and future](https://www.anyscale.com/blog/redis-in-ray-past-and-future)\n",
+ " * [StackOverFlow: How Ray Shares Data](https://stackoverflow.com/questions/58082023/how-exactly-does-ray-share-data-to-workers/71500979#71500979)\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 4
+}
diff --git a/templates/ray-summit-core-masterclass/Ray_Core_3_Remote_Classes_part_1.ipynb b/templates/ray-summit-core-masterclass/Ray_Core_3_Remote_Classes_part_1.ipynb
new file mode 100644
index 000000000..bf71053ce
--- /dev/null
+++ b/templates/ray-summit-core-masterclass/Ray_Core_3_Remote_Classes_part_1.ipynb
@@ -0,0 +1,585 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# A Guided Tour of Ray Core: Remote Stateful Classes\n",
+ "\n",
+ "## Overview\n",
+ "\n",
+ "Actors extend the [Ray API](https://docs.ray.io/en/latest/ray-core/package-ref.html) from functions (tasks) to classes. An actor is essentially a stateful worker (or a service). When a new actor is instantiated, a new worker is created or an exsisting worker is used. The methods of the actor are scheduled on that specific worker and can access and mutate the state of that worker. Like tasks, actors support CPU, GPU, and custom resource requirements.\n",
+ "\n",
+ "## Learning objectives\n",
+ "\n",
+ "In this this tutorial, we'll discuss Ray Actors and learn about:\n",
+ "\n",
+ " * How Ray Actors work\n",
+ " * How to write a stateful Ray Actor\n",
+ " * How Ray Actors can be written as a stateful distributed service"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "[Remote Classes](https://docs.ray.io/en/latest/walkthrough.html#remote-classes-actors) (just as remote tasks) use a `@ray.remote` decorator on a Python class. \n",
+ "\n",
+ "Ray Actor pattern is powerful. They allow you to take a Python class and instantiate it as a stateful microservice that can be queried from other actors and tasks and even other Python applications. Actors can be passed as arguments to other tasks and actors. \n",
+ "\n",
+ "\n", + " \n", + "* Convert the function into a Ray task\n", + "* Put each of the numbers 0 through 9 into the Ray Object Store and hang on to the corresponding Object Refs\n", + "* Get all of the references objects into a local list using `ray.get( list_of_refs )`\n", + "* Run the function in your Ray cluster passing the local list as a parameter\n", + "\n", + "This runs ... but isn't ideal. What might be a better way to write this code? Why?\n", + "
 \n",
+ "\n",
+ "When you instantiate a remote Actor, a separate worker process is attached to a worker process and becomes an Actor process on that worker node—all for the purpose of running methods called on the actor. Other Ray tasks and actors can invoke its methods on that process, mutating its internal state if desried. Actors can also be terminated manually if needed. \n",
+ "\n",
+ "
\n",
+ "\n",
+ "When you instantiate a remote Actor, a separate worker process is attached to a worker process and becomes an Actor process on that worker node—all for the purpose of running methods called on the actor. Other Ray tasks and actors can invoke its methods on that process, mutating its internal state if desried. Actors can also be terminated manually if needed. \n",
+ "\n",
+ " \n",
+ "\n",
+ "So let's look at some examples of Python classes converted into Ray Actors."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "import time\n",
+ "import os\n",
+ "import math\n",
+ "import random\n",
+ "import tqdm\n",
+ "\n",
+ "from typing import Dict, Tuple, List\n",
+ "from random import randint\n",
+ "\n",
+ "import numpy as np\n",
+ "\n",
+ "import ray"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "First, let's start Ray…"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "if ray.is_initialized:\n",
+ " ray.shutdown()\n",
+ "ray.init(logging_level=logging.ERROR)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Remote class as a stateful actor"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Example 1: Method tracking for Actors\n",
+ "**Problem**: We want to keep track of who invoked a particular method in different Actors. This could be a use case for telemetry data we want to track about what Actors are being used and its respective methods invoked. Or what Actor service's methods are most frequently accessed or used.\n",
+ "\n",
+ "|
\n",
+ "\n",
+ "So let's look at some examples of Python classes converted into Ray Actors."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "import time\n",
+ "import os\n",
+ "import math\n",
+ "import random\n",
+ "import tqdm\n",
+ "\n",
+ "from typing import Dict, Tuple, List\n",
+ "from random import randint\n",
+ "\n",
+ "import numpy as np\n",
+ "\n",
+ "import ray"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "First, let's start Ray…"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "if ray.is_initialized:\n",
+ " ray.shutdown()\n",
+ "ray.init(logging_level=logging.ERROR)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Remote class as a stateful actor"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Example 1: Method tracking for Actors\n",
+ "**Problem**: We want to keep track of who invoked a particular method in different Actors. This could be a use case for telemetry data we want to track about what Actors are being used and its respective methods invoked. Or what Actor service's methods are most frequently accessed or used.\n",
+ "\n",
+ "| |\n",
+ "|:--|\n",
+ "|Driver code calling different Actor methods.|"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's use this actor to track method invocation of a Ray actor's methods. Each Ray actor instance will track how many times its methods were invoked. \n",
+ "\n",
+ "Define a base class `ActorCls`, and define two sublcasses `ActorClsOne` and `ActorClsTwo`."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Our base class `ActorCls`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class ActorCls:\n",
+ " def __init__(self, name: str):\n",
+ " self.name = name\n",
+ " self.method_calls = {\"method\": 0}\n",
+ "\n",
+ " def method(self, **args) -> None:\n",
+ " # Overwrite this method in the subclass\n",
+ " pass\n",
+ "\n",
+ " def get_all_method_calls(self) -> Tuple[str, Dict[str, int]]:\n",
+ " return self.get_name(), self.method_calls\n",
+ " \n",
+ " def get_name(self) -> str:\n",
+ " return self.name"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Our first super class `ActorClsOne`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "class ActorClsOne(ActorCls):\n",
+ " \n",
+ " def __init__(self, name: str):\n",
+ " super().__init__(name)\n",
+ " \n",
+ " def method(self, **args) -> None:\n",
+ " # do something with kwargs here\n",
+ " time.sleep(args[\"timeout\"])\n",
+ " \n",
+ " # update the respective counter\n",
+ " self.method_calls[\"method\"] += 1"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Our second super class `ActorClsTwo`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "class ActorClsTwo(ActorCls):\n",
+ " \n",
+ " def __init__(self, name: str):\n",
+ " super().__init__(name)\n",
+ " \n",
+ " def method(self, **args) -> None:\n",
+ " # do something with kwargs here\n",
+ " time.sleep(args[\"timeout\"])\n",
+ " \n",
+ " # update the respective counter\n",
+ " self.method_calls[\"method\"] += 1"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Make random calls to Actors \n",
+ "\n",
+ "This is our driver using the two Actors we defined. It randomly calls each Actor\n",
+ "and its respective method.\n",
+ "\n",
+ "An actor instance is created with `class_name.remote(args)`. For example `actor_instance = class_name.remote(args)`. The `args` are arguments\n",
+ "to the actor class construtor.\n",
+ "\n",
+ "To invoke an actor's method, you simple use `actor_instance.method_name.remote(args)`.\n",
+ "\n",
+ "For our case, let's create each instance."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "actor_one = ActorClsOne.remote(\"ActorClsOne\")\n",
+ "actor_two = ActorClsTwo.remote(\"ActorClsTwo\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# A list of Actor classes\n",
+ "CALLERS_NAMES = [\"ActorClsOne\", \"ActorClsTwo\"]\n",
+ "\n",
+ "# A dictionary of Actor instances\n",
+ "CALLERS_CLS_DICT = {\"ActorClsOne\": actor_one, \n",
+ " \"ActorClsTwo\": actor_two}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Iterate over number of classes, and call randomly each super class Actor's method while keeping track locally here for verification."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "count_dict = {\"ActorClsOne\": 0, \"ActorClsTwo\": 0}\n",
+ "for _ in range(len(CALLERS_NAMES)): \n",
+ " for _ in range(15):\n",
+ " name = random.choice(CALLERS_NAMES)\n",
+ " count_dict[name] += 1 \n",
+ " CALLERS_CLS_DICT[name].method.remote(timeout=1, store=\"mongo_db\") if name == \"ActorClsOne\" else CALLERS_CLS_DICT[name].method.remote(timeout=1.5, store=\"delta\")\n",
+ " \n",
+ " print(f\"State of counts in this execution: {count_dict}\")\n",
+ " time.sleep(0.5)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Fetch the count of all the methods called in each Actor called so far. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(ray.get([CALLERS_CLS_DICT[name].get_all_method_calls.remote() for name in CALLERS_NAMES]))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "**Note** that we did not have to reason about where and how the actors are scheduled.\n",
+ "\n",
+ "We did not worry about the socket connection or IP addresses where these actors reside. All that's abstracted away from us. All that's handled by Ray.\n",
+ "\n",
+ "All we did is write Python code, using Ray core APIs, convert our classes into distributed stateful services!"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Look at the Ray Dashboard\n",
+ "\n",
+ "You should see Actors running as process on the workers nodes. Also, click on the `Actors` to view more metrics and data on individual Ray Actors"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Recap\n",
+ "In the above example, we saw how you can use Actors to keep track of how many times its methods were invoked. This could be a useful example for telemetry data if you're interested to obtain the use of Actors deployed as services."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Example 2: Use Actor to keep track of progress \n",
+ "\n",
+ "**Problem**: In our [first tutorial](ex_01_remote_funcs.ipynb), we explored how to approximate the value of π using only tasks. In this example, we extend it by definining a Ray actor that can be called by our Ray sampling tasks to update progress. The sampling Rays tasks send a message (via method call) to the Ray actor to update progress. \n",
+ "\n",
+ "||\n",
+ "|:--|\n",
+ "|Estimating the value of π by sampling random points that fall into the circle.|"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Defining our progress Actor\n",
+ "Let's define a Ray actor that does the following:\n",
+ " * keeps track of each task id and its completed tasks\n",
+ " * can be called (or sent a message to) by sampling tasks to update progress"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "class ProgressPIActor:\n",
+ " def __init__(self, total_num_samples: int):\n",
+ " # total number of all the samples for all the tasks\n",
+ " self.total_num_samples = total_num_samples\n",
+ " # Dict to keep track of each task id\n",
+ " self.num_samples_completed_per_task = {}\n",
+ "\n",
+ " def report_progress(self, task_id: int, num_samples_completed: int) -> None:\n",
+ " # Update sample completed for a task id\n",
+ " self.num_samples_completed_per_task[task_id] = num_samples_completed\n",
+ "\n",
+ " def get_progress(self) -> float:\n",
+ " # Ratio of tasks completed so far and total number of all the samples == num_of_tasks * num_samples \n",
+ " return (\n",
+ " sum(self.num_samples_completed_per_task.values()) / self.total_num_samples\n",
+ " )"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Defining the Sampling Task\n",
+ "\n",
+ "As before in our task tutorial, we define a Ray task that does the sampling up to `num_samples` and returns the number of samples that are inside the circle. The\n",
+ "`frequency_report` is the value at which point we want to update the current `task_id`s progress in our progress actor. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "def sampling_task(num_samples: int, task_id: int, \n",
+ " progress_actor: ray.actor.ActorHandle,\n",
+ " frequency_report: int = 1_000_000) -> int:\n",
+ " num_inside = 0\n",
+ " for i in range(num_samples):\n",
+ " # x, y coordinates that bounded by the circle's radius\n",
+ " x, y = random.uniform(-1, 1), random.uniform(-1, 1)\n",
+ " if math.hypot(x, y) <= 1:\n",
+ " num_inside += 1\n",
+ "\n",
+ " # Report progress every requency_report of samples.\n",
+ " if (i + 1) % frequency_report == 0:\n",
+ " # Send a message or call the actor method.\n",
+ " # This is asynchronous.\n",
+ " progress_actor.report_progress.remote(task_id, i + 1)\n",
+ "\n",
+ " # Report the final progress.\n",
+ " progress_actor.report_progress.remote(task_id, num_samples)\n",
+ " \n",
+ " # Return the total number of samples inside our circle\n",
+ " return num_inside"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Defining some tunable parameters \n",
+ "\n",
+ "These values can be changed for experimentation.\n",
+ " * `NUM_SAMPLING_TASKS` - you can scale this depending on CPUs on your cluster. \n",
+ " * `NUM_SAMPLES_PER_TASK` - you can increase or decrease the number of samples per task to experiment how it affects the accuracy of π\n",
+ " * `SAMPLE_REPORT_FREQUENCY` - report progress after this number has reached in the sampling Ray task"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Change this for experimentation to match your cluster scale.\n",
+ "NUM_SAMPLING_TASKS = os.cpu_count()\n",
+ "NUM_SAMPLES_PER_TASK = 10_000_000\n",
+ "TOTAL_NUM_SAMPLES = NUM_SAMPLING_TASKS * NUM_SAMPLES_PER_TASK\n",
+ "SAMPLE_REPORT_FREQUENCY = 1_000_000\n",
+ "\n",
+ "# Create the progress actor.\n",
+ "progress_actor = ProgressPIActor.remote(TOTAL_NUM_SAMPLES)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Executing Sampling Tasks in parallel\n",
+ "\n",
+ "Using comprehension list, we launch `NUM_SAMPLING_TASKS` as Ray remote tasks, each\n",
+ "sampling with `NUM_SAMPLES_PER_TASK` data points. \n",
+ "\n",
+ "**Note**: We send our progress report actor as a parameter to each Ray task "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Create and execute all sampling tasks in parallel.\n",
+ "# It returns a list of ObjectRefIDs returned by each task.\n",
+ "# The ObjectRefID contains the value of points inside the circle\n",
+ "#\n",
+ "time.sleep(1)\n",
+ "results = [\n",
+ " sampling_task.remote(NUM_SAMPLES_PER_TASK, i, progress_actor, frequency_report=SAMPLE_REPORT_FREQUENCY )\n",
+ " for i in range(NUM_SAMPLING_TASKS)\n",
+ "]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Calling the Progress Actor\n",
+ "\n",
+ "While the task are executing asynchronously, let's check how they are progressing using our Ray Actor."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Query progress periodically.\n",
+ "while True:\n",
+ " progress = ray.get(progress_actor.get_progress.remote())\n",
+ " print(f\"Progress: {int(progress * 100)}%\")\n",
+ "\n",
+ " if progress == 1:\n",
+ " break\n",
+ "\n",
+ " time.sleep(1)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Calculating π\n",
+ "As before the value of π is the ratio of total_num_inside * 4 / total samples. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Get all the sampling tasks results.\n",
+ "total_num_inside = sum(ray.get(results))\n",
+ "pi = (total_num_inside * 4) / TOTAL_NUM_SAMPLES\n",
+ "print(f\"Estimated value of π is: {pi}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Recap\n",
+ "Ray Actors are stateful and their methods can be invoked to pass messages or to alter the internal state of the class. Actors are scheduled on a dedicated Ray node's worker process. As such, all actor's method are executed on that particular worker process.\n",
+ "\n",
+ "In the above two examples, we saw how you can use Actors to keep track how many times its methods were invoked. This could be a useful example for telemetry data if you're interested to obtain the use of Actors deployed as services.\n",
+ "\n",
+ "We also demonstrated how you can use Actors to keep progress of certain Ray tasks; in our case, we tracked progress of Ray tasks approximating the value of π."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "
|\n",
+ "|:--|\n",
+ "|Driver code calling different Actor methods.|"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's use this actor to track method invocation of a Ray actor's methods. Each Ray actor instance will track how many times its methods were invoked. \n",
+ "\n",
+ "Define a base class `ActorCls`, and define two sublcasses `ActorClsOne` and `ActorClsTwo`."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Our base class `ActorCls`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class ActorCls:\n",
+ " def __init__(self, name: str):\n",
+ " self.name = name\n",
+ " self.method_calls = {\"method\": 0}\n",
+ "\n",
+ " def method(self, **args) -> None:\n",
+ " # Overwrite this method in the subclass\n",
+ " pass\n",
+ "\n",
+ " def get_all_method_calls(self) -> Tuple[str, Dict[str, int]]:\n",
+ " return self.get_name(), self.method_calls\n",
+ " \n",
+ " def get_name(self) -> str:\n",
+ " return self.name"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Our first super class `ActorClsOne`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "class ActorClsOne(ActorCls):\n",
+ " \n",
+ " def __init__(self, name: str):\n",
+ " super().__init__(name)\n",
+ " \n",
+ " def method(self, **args) -> None:\n",
+ " # do something with kwargs here\n",
+ " time.sleep(args[\"timeout\"])\n",
+ " \n",
+ " # update the respective counter\n",
+ " self.method_calls[\"method\"] += 1"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Our second super class `ActorClsTwo`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "class ActorClsTwo(ActorCls):\n",
+ " \n",
+ " def __init__(self, name: str):\n",
+ " super().__init__(name)\n",
+ " \n",
+ " def method(self, **args) -> None:\n",
+ " # do something with kwargs here\n",
+ " time.sleep(args[\"timeout\"])\n",
+ " \n",
+ " # update the respective counter\n",
+ " self.method_calls[\"method\"] += 1"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Make random calls to Actors \n",
+ "\n",
+ "This is our driver using the two Actors we defined. It randomly calls each Actor\n",
+ "and its respective method.\n",
+ "\n",
+ "An actor instance is created with `class_name.remote(args)`. For example `actor_instance = class_name.remote(args)`. The `args` are arguments\n",
+ "to the actor class construtor.\n",
+ "\n",
+ "To invoke an actor's method, you simple use `actor_instance.method_name.remote(args)`.\n",
+ "\n",
+ "For our case, let's create each instance."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "actor_one = ActorClsOne.remote(\"ActorClsOne\")\n",
+ "actor_two = ActorClsTwo.remote(\"ActorClsTwo\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# A list of Actor classes\n",
+ "CALLERS_NAMES = [\"ActorClsOne\", \"ActorClsTwo\"]\n",
+ "\n",
+ "# A dictionary of Actor instances\n",
+ "CALLERS_CLS_DICT = {\"ActorClsOne\": actor_one, \n",
+ " \"ActorClsTwo\": actor_two}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Iterate over number of classes, and call randomly each super class Actor's method while keeping track locally here for verification."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "count_dict = {\"ActorClsOne\": 0, \"ActorClsTwo\": 0}\n",
+ "for _ in range(len(CALLERS_NAMES)): \n",
+ " for _ in range(15):\n",
+ " name = random.choice(CALLERS_NAMES)\n",
+ " count_dict[name] += 1 \n",
+ " CALLERS_CLS_DICT[name].method.remote(timeout=1, store=\"mongo_db\") if name == \"ActorClsOne\" else CALLERS_CLS_DICT[name].method.remote(timeout=1.5, store=\"delta\")\n",
+ " \n",
+ " print(f\"State of counts in this execution: {count_dict}\")\n",
+ " time.sleep(0.5)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Fetch the count of all the methods called in each Actor called so far. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(ray.get([CALLERS_CLS_DICT[name].get_all_method_calls.remote() for name in CALLERS_NAMES]))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "**Note** that we did not have to reason about where and how the actors are scheduled.\n",
+ "\n",
+ "We did not worry about the socket connection or IP addresses where these actors reside. All that's abstracted away from us. All that's handled by Ray.\n",
+ "\n",
+ "All we did is write Python code, using Ray core APIs, convert our classes into distributed stateful services!"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Look at the Ray Dashboard\n",
+ "\n",
+ "You should see Actors running as process on the workers nodes. Also, click on the `Actors` to view more metrics and data on individual Ray Actors"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Recap\n",
+ "In the above example, we saw how you can use Actors to keep track of how many times its methods were invoked. This could be a useful example for telemetry data if you're interested to obtain the use of Actors deployed as services."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Example 2: Use Actor to keep track of progress \n",
+ "\n",
+ "**Problem**: In our [first tutorial](ex_01_remote_funcs.ipynb), we explored how to approximate the value of π using only tasks. In this example, we extend it by definining a Ray actor that can be called by our Ray sampling tasks to update progress. The sampling Rays tasks send a message (via method call) to the Ray actor to update progress. \n",
+ "\n",
+ "||\n",
+ "|:--|\n",
+ "|Estimating the value of π by sampling random points that fall into the circle.|"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Defining our progress Actor\n",
+ "Let's define a Ray actor that does the following:\n",
+ " * keeps track of each task id and its completed tasks\n",
+ " * can be called (or sent a message to) by sampling tasks to update progress"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "class ProgressPIActor:\n",
+ " def __init__(self, total_num_samples: int):\n",
+ " # total number of all the samples for all the tasks\n",
+ " self.total_num_samples = total_num_samples\n",
+ " # Dict to keep track of each task id\n",
+ " self.num_samples_completed_per_task = {}\n",
+ "\n",
+ " def report_progress(self, task_id: int, num_samples_completed: int) -> None:\n",
+ " # Update sample completed for a task id\n",
+ " self.num_samples_completed_per_task[task_id] = num_samples_completed\n",
+ "\n",
+ " def get_progress(self) -> float:\n",
+ " # Ratio of tasks completed so far and total number of all the samples == num_of_tasks * num_samples \n",
+ " return (\n",
+ " sum(self.num_samples_completed_per_task.values()) / self.total_num_samples\n",
+ " )"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Defining the Sampling Task\n",
+ "\n",
+ "As before in our task tutorial, we define a Ray task that does the sampling up to `num_samples` and returns the number of samples that are inside the circle. The\n",
+ "`frequency_report` is the value at which point we want to update the current `task_id`s progress in our progress actor. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "def sampling_task(num_samples: int, task_id: int, \n",
+ " progress_actor: ray.actor.ActorHandle,\n",
+ " frequency_report: int = 1_000_000) -> int:\n",
+ " num_inside = 0\n",
+ " for i in range(num_samples):\n",
+ " # x, y coordinates that bounded by the circle's radius\n",
+ " x, y = random.uniform(-1, 1), random.uniform(-1, 1)\n",
+ " if math.hypot(x, y) <= 1:\n",
+ " num_inside += 1\n",
+ "\n",
+ " # Report progress every requency_report of samples.\n",
+ " if (i + 1) % frequency_report == 0:\n",
+ " # Send a message or call the actor method.\n",
+ " # This is asynchronous.\n",
+ " progress_actor.report_progress.remote(task_id, i + 1)\n",
+ "\n",
+ " # Report the final progress.\n",
+ " progress_actor.report_progress.remote(task_id, num_samples)\n",
+ " \n",
+ " # Return the total number of samples inside our circle\n",
+ " return num_inside"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Defining some tunable parameters \n",
+ "\n",
+ "These values can be changed for experimentation.\n",
+ " * `NUM_SAMPLING_TASKS` - you can scale this depending on CPUs on your cluster. \n",
+ " * `NUM_SAMPLES_PER_TASK` - you can increase or decrease the number of samples per task to experiment how it affects the accuracy of π\n",
+ " * `SAMPLE_REPORT_FREQUENCY` - report progress after this number has reached in the sampling Ray task"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Change this for experimentation to match your cluster scale.\n",
+ "NUM_SAMPLING_TASKS = os.cpu_count()\n",
+ "NUM_SAMPLES_PER_TASK = 10_000_000\n",
+ "TOTAL_NUM_SAMPLES = NUM_SAMPLING_TASKS * NUM_SAMPLES_PER_TASK\n",
+ "SAMPLE_REPORT_FREQUENCY = 1_000_000\n",
+ "\n",
+ "# Create the progress actor.\n",
+ "progress_actor = ProgressPIActor.remote(TOTAL_NUM_SAMPLES)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Executing Sampling Tasks in parallel\n",
+ "\n",
+ "Using comprehension list, we launch `NUM_SAMPLING_TASKS` as Ray remote tasks, each\n",
+ "sampling with `NUM_SAMPLES_PER_TASK` data points. \n",
+ "\n",
+ "**Note**: We send our progress report actor as a parameter to each Ray task "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Create and execute all sampling tasks in parallel.\n",
+ "# It returns a list of ObjectRefIDs returned by each task.\n",
+ "# The ObjectRefID contains the value of points inside the circle\n",
+ "#\n",
+ "time.sleep(1)\n",
+ "results = [\n",
+ " sampling_task.remote(NUM_SAMPLES_PER_TASK, i, progress_actor, frequency_report=SAMPLE_REPORT_FREQUENCY )\n",
+ " for i in range(NUM_SAMPLING_TASKS)\n",
+ "]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Calling the Progress Actor\n",
+ "\n",
+ "While the task are executing asynchronously, let's check how they are progressing using our Ray Actor."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Query progress periodically.\n",
+ "while True:\n",
+ " progress = ray.get(progress_actor.get_progress.remote())\n",
+ " print(f\"Progress: {int(progress * 100)}%\")\n",
+ "\n",
+ " if progress == 1:\n",
+ " break\n",
+ "\n",
+ " time.sleep(1)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Calculating π\n",
+ "As before the value of π is the ratio of total_num_inside * 4 / total samples. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Get all the sampling tasks results.\n",
+ "total_num_inside = sum(ray.get(results))\n",
+ "pi = (total_num_inside * 4) / TOTAL_NUM_SAMPLES\n",
+ "print(f\"Estimated value of π is: {pi}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Recap\n",
+ "Ray Actors are stateful and their methods can be invoked to pass messages or to alter the internal state of the class. Actors are scheduled on a dedicated Ray node's worker process. As such, all actor's method are executed on that particular worker process.\n",
+ "\n",
+ "In the above two examples, we saw how you can use Actors to keep track how many times its methods were invoked. This could be a useful example for telemetry data if you're interested to obtain the use of Actors deployed as services.\n",
+ "\n",
+ "We also demonstrated how you can use Actors to keep progress of certain Ray tasks; in our case, we tracked progress of Ray tasks approximating the value of π."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "\n",
+ " \n",
+ "__Lab exercise 3__\n",
+ "\n",
+ "* Start with the code above from \"Making Random Calls to Actors\"\n",
+ "* Add another class, call it `ActorClsThree` and modify the code to keep track of its method. For simplicty, keep track of only a single method. \n",
+ "* Run and look at the results\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Finally, shutdown Ray"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ray.shutdown()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Next Step\n",
+ "\n",
+ "We covered how to use Ray Actors and write a distributed service. Next, let's explore\n",
+ "how Actors can be used to write more complext distributed applications using Ray Actor Tree pattern.\n",
+ "\n",
+ "Let's move on to the [Ray Actor Revised](ex_04_remote_classes_revisited.ipynb)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Homework\n",
+ "\n",
+ "Read these references"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ " * [Writing your First Distributed Python Application with Ray](https://www.anyscale.com/blog/writing-your-first-distributed-python-application-with-ray)\n",
+ " * [Using and Programming with Actors](https://docs.ray.io/en/latest/actors.html)\n",
+ " * [Ray Asynchronous and Threaded Actors: A way to achieve concurrency](https://medium.com/@2twitme/ray-asynchronous-and-threaded-actors-a-way-to-achieve-concurrency-ad9f86145f72)"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 4
+}
diff --git a/templates/ray-summit-core-masterclass/Ray_Core_4_Remote_Classes_part_2.ipynb b/templates/ray-summit-core-masterclass/Ray_Core_4_Remote_Classes_part_2.ipynb
new file mode 100644
index 000000000..2180327a0
--- /dev/null
+++ b/templates/ray-summit-core-masterclass/Ray_Core_4_Remote_Classes_part_2.ipynb
@@ -0,0 +1,559 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Ray Core: Remote Classes as Actors, part 2: Tree of Actors\n",
+ "\n",
+ "## Overview\n",
+ "\n",
+ "Ray has a myriad of design patterns for tasks and actors: https://docs.ray.io/en/latest/ray-core/patterns/index.html\n",
+ "\n",
+ "The patterns suggest best practices to you to write distributed applications. By contrast, the anti-patterns are advice and admonitions for you to avoid pitfalls while using Ray. \n",
+ "\n",
+ "In this tutorial we'll explore one of the design pattern, commonly used in Ray libraries to scale workloads.\n",
+ "\n",
+ "### Tree of Actors Pattern\n",
+ "\n",
+ "This pattern is primarily used in Ray libraries [Ray Tune](https://docs.ray.io/en/latest/tune/index.html), [Ray Train](https://docs.ray.io/en/latest/train/train.html), and [RLlib](https://docs.ray.io/en/latest/rllib/index.html) to train models in a parallel or conduct distributed HPO.\n",
+ "\n",
+ "In a tree of actors pattern, a collection of workers as Ray actors (or in some cases Ray tasks too), are managed by a supervisor actor. For example, you want to train multiple models, each of a different ML algorithm, at the same time, while being able to inspect its state during its training. As methology to examine simple baseline models rapidly, this pattern helps machine learning engineers to quickly build a set of baseline models for comparison.\n",
+ "\n",
+ "| |\n",
+ "|:--|\n",
+ "| Common tree actor pattern with a supervisor launching a supervisor actor|\n",
+ "\n",
+ "This pattern facilitates **Same Data Different Function/Model (SDDF)** scaling pattern. Popular in [AutoML](https://en.wikipedia.org/wiki/Automated_machine_learning) scenarios, where you may want to train different models, with their respective algorithms, at the same time using the same dataset.\n",
+ "\n",
+ "|
|\n",
+ "|:--|\n",
+ "| Common tree actor pattern with a supervisor launching a supervisor actor|\n",
+ "\n",
+ "This pattern facilitates **Same Data Different Function/Model (SDDF)** scaling pattern. Popular in [AutoML](https://en.wikipedia.org/wiki/Automated_machine_learning) scenarios, where you may want to train different models, with their respective algorithms, at the same time using the same dataset.\n",
+ "\n",
+ "| |\n",
+ "|:--|\n",
+ "| Same data different function/model is a common scaling pattern|\n",
+ "\n",
+ "## Learning objectives\n",
+ "\n",
+ "In this this tutorial, we revisit Ray Actors, diving deeper its use for scaling patterns, and learn more about:\n",
+ " * Common Ray Actors patterns used in Ray native libraries for writing distributed Actors\n",
+ " * Tree of Actors \n",
+ " * Same Data Different Functions (SDDF)\n",
+ " * How to use Actors and ActorPool for Batch Inference\n",
+ "\n",
+ "Let's implement a simple example to illustrate this pattern."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Some preliminary imports"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "import time\n",
+ "import ray\n",
+ "import random\n",
+ "from random import randint\n",
+ "import numpy as np\n",
+ "import pandas as pd\n",
+ "import pyarrow.parquet as pq\n",
+ "from pprint import pprint\n",
+ "\n",
+ "import ray\n",
+ "from ray.util.actor_pool import ActorPool"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "First, let's start Ray…"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "if ray.is_initialized:\n",
+ " ray.shutdown()\n",
+ "ray.init(logging_level=logging.ERROR)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Example 1: Supervisor and worker actor pattern\n",
+ "\n",
+ "**Problem**: We want to train multiple small models, say of type linear regression, each with their respective machine learning algorithm, on the same dataset, to create a set of baseline models for comparison. In our case, we use the scikit-learn [California house price](https://scikit-learn.org/stable/modules/generated/sklearn.datasets.fetch_california_housing.html) dataset and use models of type linear regression. We'll train different linear regression models: Decision tree, random forest, and xgboost regressor. Each model is trained and evaluated based on [mean square error](https://en.wikipedia.org/wiki/Mean_squared_error)(MSE).\n",
+ "\n",
+ "To see this pattern used in production at scale, read [Training One Million Machine Learning Models in Record Time with Ray](https://www.anyscale.com/blog/training-one-million-machine-learning-models-in-record-time-with-ray).\n",
+ "Another blog that employs this pattern is training many models per a particular feature, such as a zip code or a product SKU. [Many Models Batch Training at Scale with Ray Core](https://www.anyscale.com/blog/many-models-batch-training-at-scale-with-ray-core)\n",
+ "\n",
+ "|
|\n",
+ "|:--|\n",
+ "| Same data different function/model is a common scaling pattern|\n",
+ "\n",
+ "## Learning objectives\n",
+ "\n",
+ "In this this tutorial, we revisit Ray Actors, diving deeper its use for scaling patterns, and learn more about:\n",
+ " * Common Ray Actors patterns used in Ray native libraries for writing distributed Actors\n",
+ " * Tree of Actors \n",
+ " * Same Data Different Functions (SDDF)\n",
+ " * How to use Actors and ActorPool for Batch Inference\n",
+ "\n",
+ "Let's implement a simple example to illustrate this pattern."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Some preliminary imports"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "import time\n",
+ "import ray\n",
+ "import random\n",
+ "from random import randint\n",
+ "import numpy as np\n",
+ "import pandas as pd\n",
+ "import pyarrow.parquet as pq\n",
+ "from pprint import pprint\n",
+ "\n",
+ "import ray\n",
+ "from ray.util.actor_pool import ActorPool"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "First, let's start Ray…"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "if ray.is_initialized:\n",
+ " ray.shutdown()\n",
+ "ray.init(logging_level=logging.ERROR)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Example 1: Supervisor and worker actor pattern\n",
+ "\n",
+ "**Problem**: We want to train multiple small models, say of type linear regression, each with their respective machine learning algorithm, on the same dataset, to create a set of baseline models for comparison. In our case, we use the scikit-learn [California house price](https://scikit-learn.org/stable/modules/generated/sklearn.datasets.fetch_california_housing.html) dataset and use models of type linear regression. We'll train different linear regression models: Decision tree, random forest, and xgboost regressor. Each model is trained and evaluated based on [mean square error](https://en.wikipedia.org/wiki/Mean_squared_error)(MSE).\n",
+ "\n",
+ "To see this pattern used in production at scale, read [Training One Million Machine Learning Models in Record Time with Ray](https://www.anyscale.com/blog/training-one-million-machine-learning-models-in-record-time-with-ray).\n",
+ "Another blog that employs this pattern is training many models per a particular feature, such as a zip code or a product SKU. [Many Models Batch Training at Scale with Ray Core](https://www.anyscale.com/blog/many-models-batch-training-at-scale-with-ray-core)\n",
+ "\n",
+ "| |\n",
+ "|:--|\n",
+ "|`n_samples = 20640`, target is numeric and corresponds to the average house value in units of 100k.|"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Generic model factory utility \n",
+ "\n",
+ "This factory generates three different algorithms for linear regression–random forest, decsion tree, and xgboost–and trains on the same Scikit learn dataset [California housing price](https://scikit-learn.org/stable/modules/generated/sklearn.datasets.fetch_california_housing.html)\n",
+ "Each training model returns its MSE score, along with time to train and relevant parameters. \n",
+ "\n",
+ "Each model can be in a particular state during training. The final state is `DONE`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from model_helper_utils import RFRActor\n",
+ "from model_helper_utils import DTActor\n",
+ "from model_helper_utils import XGBoostActor\n",
+ "from model_helper_utils import RANDOM_FOREST_CONFIGS, DECISION_TREE_CONFIGS, XGBOOST_CONFIGS\n",
+ "\n",
+ "class ModelFactory:\n",
+ " \"\"\"\n",
+ " Mode factory to create different ML models\n",
+ " \"\"\"\n",
+ " MODEL_TYPES = [\"random_forest\", \"decision_tree\", \"xgboost\"]\n",
+ " \n",
+ " @staticmethod\n",
+ " def create_model(model_name: str) -> ray.actor.ActorHandle:\n",
+ " if model_name not in ModelFactory.MODEL_TYPES:\n",
+ " raise Exception(f\"{model_name} not supported\")\n",
+ " if model_name == \"random_forest\":\n",
+ " configs = RANDOM_FOREST_CONFIGS\n",
+ " return RFRActor.remote(configs)\n",
+ " elif model_name == \"decision_tree\":\n",
+ " configs = DECISION_TREE_CONFIGS\n",
+ " return DTActor.remote(configs)\n",
+ " else: \n",
+ " configs = XGBOOST_CONFIGS\n",
+ " return XGBoostActor.remote(configs)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "### Create an Actor instance as a supervisor\n",
+ "The supervisor creates three worker actors, each with its own respective training model ML algorithm and its training function."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "class Supervisor:\n",
+ " def __init__(self):\n",
+ " # Create three Actor Workers, each by its unique model type and \n",
+ " # their respective training function\n",
+ " self.worker_models = [ModelFactory.create_model(name) for name in ModelFactory.MODEL_TYPES]\n",
+ "\n",
+ " def work(self):\n",
+ " # do the train work for each Actor model\n",
+ " results = [worker_model.train_and_evaluate_model.remote() for worker_model in self.worker_models]\n",
+ " \n",
+ " # Return the final results\n",
+ " return ray.get(results)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Launch Supervisor's workers\n",
+ " * create the Supervisor actor\n",
+ " * launch its workers\n",
+ " * fetch the final results"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "supervisor = Supervisor.remote()\n",
+ "results = supervisor.work.remote()\n",
+ "values = ray.get(results)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let for the workers to finish by returning their `DONE` state"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "states = []\n",
+ "# Wait for all models to finish\n",
+ "while True:\n",
+ " for value in values:\n",
+ " states.append(value[\"state\"])\n",
+ " result = all('DONE' == e for e in states)\n",
+ " if result:\n",
+ " break"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from operator import itemgetter\n",
+ "sorted_by_mse = sorted(values, key=itemgetter('mse'))\n",
+ "print(f\"\\nResults from three training models sorted by MSE ascending order:\")\n",
+ "pprint(sorted_by_mse)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Look at the Ray Dashboard\n",
+ "\n",
+ "You should see Actors running as process on the workers nodes\n",
+ " * Supervisor\n",
+ " * Eeach model actor: RFRActor, DTActor, XGBoostActor\n",
+ " \n",
+ "Also, click on the `Actors` to view more metrics and data on individual Ray Actors"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Recap\n",
+ "To sum up, we went through implementing a tree actor design pattern, in which a Supervisor\n",
+ "launched worker models. Each model, in our case, is a separate linear regression model training on the same data. This tree actor pattern facilitates the **Same Data Different Functions (SDDF)** scaling pattern, a common machine learning workload.\n",
+ "\n",
+ "For modularity, we used `model_helper_utils`, where all the model-related utility code is implemented. From all three linear regression models trained in parallel, with the same dataset, XGBoost seems to have faired well with the best MSE result. This gaves us an initial baseline of set of models to further experiment with different [hyperparameter optimization](https://en.wikipedia.org/wiki/Hyperparameter_optimization). For that I would turn to [Ray Train](https://docs.ray.io/en/latest/train/train.html) and [Ray Tune](https://docs.ray.io/en/latest/tune/index.html), whhich are part of [Ray AIR](https://docs.ray.io/en/latest/ray-air/getting-started.html)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Homework Exercise (Optional):\n",
+ "\n",
+ "Add another linear regression model and train four models. \n",
+ "\n",
+ "**HINTS**:\n",
+ " * modify `model_helper_utils` to create a new super class of `ActorCls`\n",
+ " * add new model configs for the new model\n",
+ " * modify the `ModelFactory` class instantiate this new model\n",
+ " * update the `Supervisor` to include the new model in its training\n",
+ " \n",
+ " You can use one of the linear models from this [array of linear models](https://www.kaggle.com/code/faressayah/practical-introduction-to-10-regression-algorithm).\n",
+ " \n",
+ "Have fun 😜!"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Example 2: Actor-based batch inference\n",
+ "\n",
+ "In our first tutorial on [Ray Tasks](./ex_01_remote_funcs.ipynb) we covered a use case to parallelize batch inference. In short, we\n",
+ "used the **Different Data Same Function(DDSF)** pattern. Here we will use the same pattern but with Ray Actors and [ActorPool](https://docs.ray.io/en/latest/ray-core/actors/actor-utils.html?highlight=ActorPool), which are state-based and preferred method to do batch inference. Primarily, the elements remain the same except for few modifications.\n",
+ "\n",
+ "**Input dataset**: This is a large collection of observations to generate predictions for. The data is usually stored in an external storage system like S3, HDFS or database, across\n",
+ "many, files.\n",
+ "\n",
+ "**ML model**: This is a trained ML model that is usually also stored in an external storage system or in a model store.\n",
+ "\n",
+ "**Predictions**: These are the outputs when applying the ML model on observations. Normally, predictions are usually written back to the storage system. Unlike tasks\n",
+ "doing the predictions, we employ a pool of Actors.\n",
+ "\n",
+ "For purpose of this tutorial, we make the following provisions:\n",
+ " * create a dummy model that returns some fake prediction\n",
+ " * use real-world NYC taxi data to provide large data set for batch inference\n",
+ " * create a pool of actors and submit each shard to the pool.\n",
+ " * return the predictions instead of writing it back to the disk\n",
+ "\n",
+ "As an example of scaling pattern called **Different Data Same Function (DDSF)**, also known as **Distributed Data Parallel** (DDP) paradigm, our function in this digaram is the \n",
+ "pretrained **model** and the data is split and disributed as **shards**.\n",
+ "\n",
+ "||\n",
+ "|:--|\n",
+ "|Different data same function is another scaling pattern|"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "NUM_ACTORS = 6 # You can always increase the number of actors to scale\n",
+ "NUM_SHARD_FILES = 12 # number of shard files you want each each actor to work on"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Our load model closure remains the same\n",
+ "def load_trained_model():\n",
+ " # A fake model that predicts whether tips were given based on number of passengers in the taxi cab.\n",
+ " def model(batch: pd.DataFrame) -> pd.DataFrame:\n",
+ " # Some model payload so Ray copies the model in the shared plasma store to tasks scheduled across nodes.\n",
+ " model.payload = np.arange(10, 10_000, dtype=float)\n",
+ " #model.payload = np.arange(100, 100_000_000, dtype=float)\n",
+ " model.cls = \"regression\"\n",
+ " \n",
+ " # give a tip if 2 or more passengers\n",
+ " predict = batch[\"passenger_count\"] >= 2 \n",
+ " return pd.DataFrame({\"score\": predict})\n",
+ " \n",
+ " return model "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Create a Ray Actor that stores a model reference and does the prediction"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "class NYCBatchPredictor:\n",
+ " def __init__(self, model):\n",
+ " self.model = model\n",
+ "\n",
+ " def predict(self, shard_path):\n",
+ " # read each shard and convert to pandas\n",
+ " df = pq.read_table(shard_path).to_pandas()\n",
+ " \n",
+ " # do the inference with our model and return the result\n",
+ " result = self.model(df)\n",
+ " return result"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "1. Get our trained model instance\n",
+ "2. Store it into the plasma object store"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "model = load_trained_model()\n",
+ "model_ref = ray.put(model)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Fetch our NYC taxi shard files"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Iterate thorough our NYC files ~ 2GB\n",
+ "input_shard_files = [\n",
+ " f\"s3://anonymous@air-example-data/ursa-labs-taxi-data/downsampled_2009_full_year_data.parquet\"\n",
+ " f\"/fe41422b01c04169af2a65a83b753e0f_{i:06d}.parquet\"\n",
+ " for i in range(NUM_SHARD_FILES) ]"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "input_shard_files"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "1. Create five Actor instances, each initialized with the same model reference\n",
+ "2. Create a pool of five actors\n",
+ "\n",
+ "We use the Ray actor pool utility [ActorPool](https://docs.ray.io/en/latest/ray-core/actors/actor-utils.html?highlight=ActorPool#actor-pool).\n",
+ "\n",
+ "[Actool Pool API](https://docs.ray.io/en/latest/ray-core/package-ref.html?highlight=ActorPool#ray-util-actorpool) reference package."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "actors = [NYCBatchPredictor.remote(model_ref) for _ in range(NUM_ACTORS)]\n",
+ "actors_pool = ActorPool(actors)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Submit each shard to the pool of actors for batch reference\n",
+ "# The API syntax is not dissimilar to Python or Ray Multiprocessor pool APIs\n",
+ "\n",
+ "for shard_path in input_shard_files:\n",
+ " # Submit file shard for prediction to the pool\n",
+ " actors_pool.submit(lambda actor, shard: actor.predict.remote(shard), shard_path)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Iterate over finised actor's predictions\n",
+ "while actors_pool.has_next():\n",
+ " r = actors_pool.get_next()\n",
+ " print(f\"Predictions dataframe size: {len(r)} | Total score for tips: {r['score'].sum()}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Recap\n",
+ "\n",
+ "What we have demonstrated above is an Actor tree design pattern, commonly used in Ray for writing distributed applications. In particular, Ray's native libraries such as Train, Tune, Serve, and RLib and [Ray AIR's](https://docs.ray.io/en/latest/ray-air/getting-started.html) components use it for distributed training and tuning trials. \n",
+ "\n",
+ "Additionally, we implemented a DDSF scaling design pattern using an Actor-based predictor model function, using an `ActorPool` utility class instead of task. \n",
+ "\n",
+ "Task-based batch inferene has an overhead cost that can be significant if the model size is large, since it has to fetch the model from the driver's plasma store. We can optimize it by using Ray actors, \n",
+ "which will fetch the model just once and reuse it for all predictions assigned to the same actor in the pool."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "
|\n",
+ "|:--|\n",
+ "|`n_samples = 20640`, target is numeric and corresponds to the average house value in units of 100k.|"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Generic model factory utility \n",
+ "\n",
+ "This factory generates three different algorithms for linear regression–random forest, decsion tree, and xgboost–and trains on the same Scikit learn dataset [California housing price](https://scikit-learn.org/stable/modules/generated/sklearn.datasets.fetch_california_housing.html)\n",
+ "Each training model returns its MSE score, along with time to train and relevant parameters. \n",
+ "\n",
+ "Each model can be in a particular state during training. The final state is `DONE`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from model_helper_utils import RFRActor\n",
+ "from model_helper_utils import DTActor\n",
+ "from model_helper_utils import XGBoostActor\n",
+ "from model_helper_utils import RANDOM_FOREST_CONFIGS, DECISION_TREE_CONFIGS, XGBOOST_CONFIGS\n",
+ "\n",
+ "class ModelFactory:\n",
+ " \"\"\"\n",
+ " Mode factory to create different ML models\n",
+ " \"\"\"\n",
+ " MODEL_TYPES = [\"random_forest\", \"decision_tree\", \"xgboost\"]\n",
+ " \n",
+ " @staticmethod\n",
+ " def create_model(model_name: str) -> ray.actor.ActorHandle:\n",
+ " if model_name not in ModelFactory.MODEL_TYPES:\n",
+ " raise Exception(f\"{model_name} not supported\")\n",
+ " if model_name == \"random_forest\":\n",
+ " configs = RANDOM_FOREST_CONFIGS\n",
+ " return RFRActor.remote(configs)\n",
+ " elif model_name == \"decision_tree\":\n",
+ " configs = DECISION_TREE_CONFIGS\n",
+ " return DTActor.remote(configs)\n",
+ " else: \n",
+ " configs = XGBOOST_CONFIGS\n",
+ " return XGBoostActor.remote(configs)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "### Create an Actor instance as a supervisor\n",
+ "The supervisor creates three worker actors, each with its own respective training model ML algorithm and its training function."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "class Supervisor:\n",
+ " def __init__(self):\n",
+ " # Create three Actor Workers, each by its unique model type and \n",
+ " # their respective training function\n",
+ " self.worker_models = [ModelFactory.create_model(name) for name in ModelFactory.MODEL_TYPES]\n",
+ "\n",
+ " def work(self):\n",
+ " # do the train work for each Actor model\n",
+ " results = [worker_model.train_and_evaluate_model.remote() for worker_model in self.worker_models]\n",
+ " \n",
+ " # Return the final results\n",
+ " return ray.get(results)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Launch Supervisor's workers\n",
+ " * create the Supervisor actor\n",
+ " * launch its workers\n",
+ " * fetch the final results"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "supervisor = Supervisor.remote()\n",
+ "results = supervisor.work.remote()\n",
+ "values = ray.get(results)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let for the workers to finish by returning their `DONE` state"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "states = []\n",
+ "# Wait for all models to finish\n",
+ "while True:\n",
+ " for value in values:\n",
+ " states.append(value[\"state\"])\n",
+ " result = all('DONE' == e for e in states)\n",
+ " if result:\n",
+ " break"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from operator import itemgetter\n",
+ "sorted_by_mse = sorted(values, key=itemgetter('mse'))\n",
+ "print(f\"\\nResults from three training models sorted by MSE ascending order:\")\n",
+ "pprint(sorted_by_mse)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Look at the Ray Dashboard\n",
+ "\n",
+ "You should see Actors running as process on the workers nodes\n",
+ " * Supervisor\n",
+ " * Eeach model actor: RFRActor, DTActor, XGBoostActor\n",
+ " \n",
+ "Also, click on the `Actors` to view more metrics and data on individual Ray Actors"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Recap\n",
+ "To sum up, we went through implementing a tree actor design pattern, in which a Supervisor\n",
+ "launched worker models. Each model, in our case, is a separate linear regression model training on the same data. This tree actor pattern facilitates the **Same Data Different Functions (SDDF)** scaling pattern, a common machine learning workload.\n",
+ "\n",
+ "For modularity, we used `model_helper_utils`, where all the model-related utility code is implemented. From all three linear regression models trained in parallel, with the same dataset, XGBoost seems to have faired well with the best MSE result. This gaves us an initial baseline of set of models to further experiment with different [hyperparameter optimization](https://en.wikipedia.org/wiki/Hyperparameter_optimization). For that I would turn to [Ray Train](https://docs.ray.io/en/latest/train/train.html) and [Ray Tune](https://docs.ray.io/en/latest/tune/index.html), whhich are part of [Ray AIR](https://docs.ray.io/en/latest/ray-air/getting-started.html)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Homework Exercise (Optional):\n",
+ "\n",
+ "Add another linear regression model and train four models. \n",
+ "\n",
+ "**HINTS**:\n",
+ " * modify `model_helper_utils` to create a new super class of `ActorCls`\n",
+ " * add new model configs for the new model\n",
+ " * modify the `ModelFactory` class instantiate this new model\n",
+ " * update the `Supervisor` to include the new model in its training\n",
+ " \n",
+ " You can use one of the linear models from this [array of linear models](https://www.kaggle.com/code/faressayah/practical-introduction-to-10-regression-algorithm).\n",
+ " \n",
+ "Have fun 😜!"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Example 2: Actor-based batch inference\n",
+ "\n",
+ "In our first tutorial on [Ray Tasks](./ex_01_remote_funcs.ipynb) we covered a use case to parallelize batch inference. In short, we\n",
+ "used the **Different Data Same Function(DDSF)** pattern. Here we will use the same pattern but with Ray Actors and [ActorPool](https://docs.ray.io/en/latest/ray-core/actors/actor-utils.html?highlight=ActorPool), which are state-based and preferred method to do batch inference. Primarily, the elements remain the same except for few modifications.\n",
+ "\n",
+ "**Input dataset**: This is a large collection of observations to generate predictions for. The data is usually stored in an external storage system like S3, HDFS or database, across\n",
+ "many, files.\n",
+ "\n",
+ "**ML model**: This is a trained ML model that is usually also stored in an external storage system or in a model store.\n",
+ "\n",
+ "**Predictions**: These are the outputs when applying the ML model on observations. Normally, predictions are usually written back to the storage system. Unlike tasks\n",
+ "doing the predictions, we employ a pool of Actors.\n",
+ "\n",
+ "For purpose of this tutorial, we make the following provisions:\n",
+ " * create a dummy model that returns some fake prediction\n",
+ " * use real-world NYC taxi data to provide large data set for batch inference\n",
+ " * create a pool of actors and submit each shard to the pool.\n",
+ " * return the predictions instead of writing it back to the disk\n",
+ "\n",
+ "As an example of scaling pattern called **Different Data Same Function (DDSF)**, also known as **Distributed Data Parallel** (DDP) paradigm, our function in this digaram is the \n",
+ "pretrained **model** and the data is split and disributed as **shards**.\n",
+ "\n",
+ "||\n",
+ "|:--|\n",
+ "|Different data same function is another scaling pattern|"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "NUM_ACTORS = 6 # You can always increase the number of actors to scale\n",
+ "NUM_SHARD_FILES = 12 # number of shard files you want each each actor to work on"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Our load model closure remains the same\n",
+ "def load_trained_model():\n",
+ " # A fake model that predicts whether tips were given based on number of passengers in the taxi cab.\n",
+ " def model(batch: pd.DataFrame) -> pd.DataFrame:\n",
+ " # Some model payload so Ray copies the model in the shared plasma store to tasks scheduled across nodes.\n",
+ " model.payload = np.arange(10, 10_000, dtype=float)\n",
+ " #model.payload = np.arange(100, 100_000_000, dtype=float)\n",
+ " model.cls = \"regression\"\n",
+ " \n",
+ " # give a tip if 2 or more passengers\n",
+ " predict = batch[\"passenger_count\"] >= 2 \n",
+ " return pd.DataFrame({\"score\": predict})\n",
+ " \n",
+ " return model "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Create a Ray Actor that stores a model reference and does the prediction"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "class NYCBatchPredictor:\n",
+ " def __init__(self, model):\n",
+ " self.model = model\n",
+ "\n",
+ " def predict(self, shard_path):\n",
+ " # read each shard and convert to pandas\n",
+ " df = pq.read_table(shard_path).to_pandas()\n",
+ " \n",
+ " # do the inference with our model and return the result\n",
+ " result = self.model(df)\n",
+ " return result"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "1. Get our trained model instance\n",
+ "2. Store it into the plasma object store"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "model = load_trained_model()\n",
+ "model_ref = ray.put(model)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Fetch our NYC taxi shard files"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Iterate thorough our NYC files ~ 2GB\n",
+ "input_shard_files = [\n",
+ " f\"s3://anonymous@air-example-data/ursa-labs-taxi-data/downsampled_2009_full_year_data.parquet\"\n",
+ " f\"/fe41422b01c04169af2a65a83b753e0f_{i:06d}.parquet\"\n",
+ " for i in range(NUM_SHARD_FILES) ]"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "input_shard_files"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "1. Create five Actor instances, each initialized with the same model reference\n",
+ "2. Create a pool of five actors\n",
+ "\n",
+ "We use the Ray actor pool utility [ActorPool](https://docs.ray.io/en/latest/ray-core/actors/actor-utils.html?highlight=ActorPool#actor-pool).\n",
+ "\n",
+ "[Actool Pool API](https://docs.ray.io/en/latest/ray-core/package-ref.html?highlight=ActorPool#ray-util-actorpool) reference package."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "actors = [NYCBatchPredictor.remote(model_ref) for _ in range(NUM_ACTORS)]\n",
+ "actors_pool = ActorPool(actors)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Submit each shard to the pool of actors for batch reference\n",
+ "# The API syntax is not dissimilar to Python or Ray Multiprocessor pool APIs\n",
+ "\n",
+ "for shard_path in input_shard_files:\n",
+ " # Submit file shard for prediction to the pool\n",
+ " actors_pool.submit(lambda actor, shard: actor.predict.remote(shard), shard_path)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Iterate over finised actor's predictions\n",
+ "while actors_pool.has_next():\n",
+ " r = actors_pool.get_next()\n",
+ " print(f\"Predictions dataframe size: {len(r)} | Total score for tips: {r['score'].sum()}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Recap\n",
+ "\n",
+ "What we have demonstrated above is an Actor tree design pattern, commonly used in Ray for writing distributed applications. In particular, Ray's native libraries such as Train, Tune, Serve, and RLib and [Ray AIR's](https://docs.ray.io/en/latest/ray-air/getting-started.html) components use it for distributed training and tuning trials. \n",
+ "\n",
+ "Additionally, we implemented a DDSF scaling design pattern using an Actor-based predictor model function, using an `ActorPool` utility class instead of task. \n",
+ "\n",
+ "Task-based batch inferene has an overhead cost that can be significant if the model size is large, since it has to fetch the model from the driver's plasma store. We can optimize it by using Ray actors, \n",
+ "which will fetch the model just once and reuse it for all predictions assigned to the same actor in the pool."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "\n",
+ " \n",
+ "__Lab exercise 4__\n",
+ "\n",
+ "* Create an actor that can receive log messages via a `log` method and return all logs via a `get_logs` method\n",
+ "* Create a `run_experiment` task which simulates an experiment by doing the following 9 times:\n",
+ " * sleep for one second\n",
+ " * log a message with the current iteration number to the log actor\n",
+ "* Start 3 simulated experiments in the Ray cluster by running the `run_experiment` task 3 times\n",
+ "* While those experiments are running (in the Ray cluster, remotely), look at the evolving logs as follows:\n",
+ " * iterate 3 times\n",
+ " * each time, sleep for 2 seconds\n",
+ " * retrieve all of the logs from the logging actor\n",
+ " * print those logs out\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ray.shutdown()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Homework\n",
+ "\n",
+ "1. Read references below."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## References"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ " * [Writing your First Distributed Python Application with Ray](https://www.anyscale.com/blog/writing-your-first-distributed-python-application-with-ray)\n",
+ " * [Using and Programming with Actors](https://docs.ray.io/en/latest/actors.html)\n",
+ " * [Ray Asynchronous and Threaded Actors: A way to achieve concurrency](https://medium.com/@2twitme/ray-asynchronous-and-threaded-actors-a-way-to-achieve-concurrency-ad9f86145f72)\n",
+ " * [Training One Million Machine Learning Models in Record Time with Ray](https://www.anyscale.com/blog/training-one-million-machine-learning-models-in-record-time-with-ray)\n",
+ " * [Many Models Batch Training at Scale with Ray Core](https://www.anyscale.com/blog/many-models-batch-training-at-scale-with-ray-core)"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 4
+}
diff --git a/templates/ray-summit-core-masterclass/Ray_Core_5_Best_Practices.ipynb b/templates/ray-summit-core-masterclass/Ray_Core_5_Best_Practices.ipynb
new file mode 100644
index 000000000..80b997f9d
--- /dev/null
+++ b/templates/ray-summit-core-masterclass/Ray_Core_5_Best_Practices.ipynb
@@ -0,0 +1,785 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "82199b11-1e0a-428e-b319-9b28ea0b5abe",
+ "metadata": {},
+ "source": [
+ "# Ray Core: Design Patterns, Anti-patterns and Best Practices\n",
+ "\n",
+ "Ray has a myriad of design patterns for tasks and actors: https://docs.ray.io/en/latest/ray-core/patterns/index.html\n",
+ "\n",
+ "These patterns allows you to write distributed applications. In this tutorial we'll explore one of the design pattern, commonly used in Ray libraries to scale workloads.\n",
+ "\n",
+ "The patterns suggest best practices to you to write distributed applications. By contrast, the anti-patterns are advice and admonitions for you to avoid pitfalls while using Ray. \n",
+ "\n",
+ "In this tutorial we'll explore a few of these design patterns, anti-patterns, tricks and trips first time Ray users."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e69ca38a-c2a3-4c46-9c1d-f2d49755631c",
+ "metadata": {},
+ "source": [
+ "## Learning objectives\n",
+ "\n",
+ "In this this tutorial, you'll learn about:\n",
+ " * Some design patterns and anti-patterns\n",
+ " * Tricks and Tips to avoid when using Ray APIs"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "12ae822a-5dde-433e-a0d6-858a974f3084",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "import math\n",
+ "import random\n",
+ "import time\n",
+ "from typing import List, Tuple\n",
+ "\n",
+ "import numpy as np\n",
+ "import ray"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "21394dd7-2595-4345-bcac-fc7d2fbff101",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "if ray.is_initialized:\n",
+ " ray.shutdown()\n",
+ "ray.init(logging_level=logging.ERROR)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7cecb225-55f7-4819-af07-9f45313a34f1",
+ "metadata": {},
+ "source": [
+ "### Fetching Cluster Information\n",
+ "\n",
+ "Many methods return information:\n",
+ "\n",
+ "| Method | Brief Description |\n",
+ "| :----- | :---------------- |\n",
+ "| [`ray.get_gpu_ids()`](https://ray.readthedocs.io/en/latest/package-ref.html#ray.get_gpu_ids) | GPUs |\n",
+ "| [`ray.nodes()`](https://ray.readthedocs.io/en/latest/package-ref.html#ray.nodes) | Cluster nodes |\n",
+ "| [`ray.cluster_resources()`](https://ray.readthedocs.io/en/latest/package-ref.html#ray.cluster_resources) | All the available resources, used or not |\n",
+ "| [`ray.available_resources()`](https://ray.readthedocs.io/en/latest/package-ref.html#ray.available_resources) | Resources not in use |\n",
+ "\n",
+ "You can see the full list of methods in the [Ray Core](https://docs.ray.io/en/latest/ray-core/api/core.html#core-api) API documention."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b0afc77e-b195-4734-a8ac-d8c1dd8af115",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ray.get_gpu_ids()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0b8a63c8-8290-4da6-91f3-348c8a7b99cc",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ray.cluster_resources()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4d12b1b2-aec6-4894-ae65-fe85a05a31ec",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ray.available_resources()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "556533ac-b3c5-4af3-a0a0-9939a93bb94b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ray.nodes()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9eb8b34a-9fe7-4a13-ad10-b06ce38d6479",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ray.nodes()[0]['Resources']['CPU']"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fb4eec5a-fdbd-4ecf-a8fb-90e6afde6208",
+ "metadata": {},
+ "source": [
+ "## Tips and Tricks and Patterns and Anti-patterns for first-time users\n",
+ "Because Ray's core APIs are simple and flexible, first time users can trip upon certain API calls in Ray's usage patterns. This short tips & tricks will insure you against unexpected results. Below we briefly explore a handful of API calls and their best practices."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2d0d02f8-5f28-47de-b41c-debbcdc334c9",
+ "metadata": {},
+ "source": [
+ "### Use @ray.remote and @ray.method to return multiple arguments\n",
+ "Often, you may wish to return more than a single argument from a Ray Task, or \n",
+ "return more than a single value from an Ray Actor's method. \n",
+ "\n",
+ "Let's look at some examples how you do it."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "fd353e95-387a-4ab2-95ed-8a253a0c153a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@ray.remote(num_returns=3)\n",
+ "def tuple3(id: str, lst: List[float]) -> Tuple[str, int, float]:\n",
+ " one = id.capitalize()\n",
+ " two = random.randint(5, 10)\n",
+ " three = sum(lst)\n",
+ " return (one, two, three)\n",
+ "\n",
+ "# Return three object references with three distinct values in each \n",
+ "x_ref, y_ref, z_ref = tuple3.remote(\"ray rocks!\", [2.2, 4.4, 6.6])\n",
+ "\n",
+ "# Fetch the list of references\n",
+ "x, y, z = ray.get([x_ref, y_ref, z_ref])\n",
+ "print(f'{x}, {y}, {z:.2f}')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7fd79f4e-cd78-4888-9cc2-bfe34e3e73bb",
+ "metadata": {},
+ "source": [
+ "A slight variation of the above example is pack all values in a single return, and then unpack them."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "23334d0e-9850-46ad-9d05-1fc0e130a7d7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@ray.remote(num_returns=1)\n",
+ "def tuple3_packed(id: str, lst: List[float]) -> Tuple[str, int, float]:\n",
+ " one = id.capitalize()\n",
+ " two = random.randint(5, 10)\n",
+ " three = sum(lst)\n",
+ " return (one, two, three)\n",
+ "\n",
+ "# Returns one object references with three values in it\n",
+ "xyz_ref = tuple3_packed.remote(\"ray rocks!\", [2.2, 4.4, 6.6])\n",
+ "\n",
+ "# Fetch from a single object ref and unpack into three values\n",
+ "x, y, z = ray.get(xyz_ref)\n",
+ "print(f'({x}, {y}, {z:.2f})')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "77043af0-ec9c-491c-a455-3d550efe8fb0",
+ "metadata": {},
+ "source": [
+ "Let's do the same for an Ray actor method, except here\n",
+ "we are using a decorator `@ray.method(num_returns=3)` to decorate\n",
+ "a Ray actor's method."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "be970c8f-63f8-48c1-8b41-b25ef815adab",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "class TupleActor:\n",
+ " @ray.method(num_returns=3)\n",
+ " def tuple3(self, id: str, lst: List[float]) -> Tuple[str, int, float]:\n",
+ " one = id.capitalize()\n",
+ " two = random.randint(5, 10)\n",
+ " three = sum(lst)\n",
+ " return (one, two, three)\n",
+ " \n",
+ "# Create an instance of an actor\n",
+ "actor = TupleActor.remote()\n",
+ "x_ref, y_ref, z_ref = actor.tuple3.remote(\"ray rocks!\", [2.2, 4.4, 5.5])\n",
+ "x, y, z = ray.get([x_ref, y_ref, z_ref])\n",
+ "print(f'({x}, {y}, {z:.2f})') "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4a56c554-425e-44ee-a6a4-1a754331025f",
+ "metadata": {},
+ "source": [
+ "### Anti-pattern: Calling ray.get in a loop harms parallelism\n",
+ "\n",
+ "With Ray, all invocations of `.remote()` calls are asynchronous, meaning the operation returns immediately with a promise/future object Reference ID. This is key to achieving massive parallelism, for it allows a devloper to launch many remote tasks, each returning a remote future object ID. Whenever needed, this object ID is fetched with `ray.get.` Because `ray.get` is a blocking call, where and how often you use can affect the performance of your Ray application.\n",
+ "\n",
+ "**TLDR**: Avoid calling `ray.get()` in a loop since it’s a blocking call; use `ray.get()` only for the final result.\n",
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "cb62c5e3-8834-4574-be25-eea7cd17b58f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "def do_some_work(x):\n",
+ " # Assume doing some computation\n",
+ " time.sleep(0.5)\n",
+ " return math.exp(x)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "10c0c73c-acc8-45eb-9a36-a21880a7bb1f",
+ "metadata": {},
+ "source": [
+ "#### Bad usage\n",
+ "We use `ray.get` inside a list comprehension loop, hence it blocks on each call of `.remote()`, delaying until the task is finished and the value\n",
+ "is materialized and fetched from the Ray object store."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0b09cd56-70ca-478d-9ac0-f7cca535db99",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%time\n",
+ "results = [ray.get(do_some_work.remote(x)) for x in range(25)]\n",
+ "results[:5]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d5a6e94d-2b44-4a33-85fa-a717f4087976",
+ "metadata": {},
+ "source": [
+ "#### Good usage\n",
+ "We delay `ray.get` after all the tasks have been invoked and their references have been returned. That is, we don't block on each call but instead do outside the comprehension loop.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5bc26807-64a5-40fa-982e-96d9e7aaf08f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%time\n",
+ "results = ray.get([do_some_work.remote(x) for x in range(25)])\n",
+ "results[:5]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e94a62d0-b9a7-4e52-b334-57f75e84f823",
+ "metadata": {},
+ "source": [
+ "### Anti-pattern: Over-parallelizing with too fine-grained tasks harms speedup\n",
+ "\n",
+ "Ray APIs are general and simple to use. As a result, new comers' natural instinct is to parallelize all tasks, including tiny ones, which can incur an overhead over time. In short, if the Ray remote tasks are tiny or miniscule in compute, they may take longer to execute than their serial Python equivalents.\n",
+ "\n",
+ "**TLDR**: Where possible strive to batch tiny smaller Ray tasks into chuncks to reap the benefits of distributing them."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5c637e9d-077f-4e3d-961b-e2de1b04a852",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Using regular Python task that returns double of the number\n",
+ "def tiny_task(x):\n",
+ " time.sleep(0.00001)\n",
+ " return 2 * x"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0b51e94b-3cc6-4936-9fa3-e66ab75f4142",
+ "metadata": {},
+ "source": [
+ "Run this as a regular sequential Python task."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7448351a-cbf5-4f20-ad45-c75e94814469",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "start_time = time.time()\n",
+ "results = [tiny_task(x) for x in range(100000)]\n",
+ "end_time = time.time()\n",
+ "print(f\"Ordinary funciton call takes {end_time - start_time:.2f} seconds\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "846e2594-cb9a-40ff-a797-8217f899f1cc",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "results[:5], len(results)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2659ea3d-09f8-405e-96db-6faa8fb963b1",
+ "metadata": {},
+ "source": [
+ "Now convert this into Ray remote task"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "53cba8d7-513b-4682-9382-007984b93ed0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "def remote_tiny_task(x):\n",
+ " time.sleep(0.00001)\n",
+ " return 2 * x"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ccdd5b0a-a9b2-41ff-8086-24c426682e45",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "start_time = time.time()\n",
+ "result_ids = [remote_tiny_task.remote(x) for x in range(100000)]\n",
+ "results = ray.get(result_ids)\n",
+ "end_time = time.time()\n",
+ "print(f\"Parallelizing Ray tasks takes {end_time - start_time:.2f} seconds\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "66e28ba8-cfc7-459b-bad4-a8995e7f702e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "results[:5], len(results)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c91612f6-e5d1-48c2-9916-e948b9256e19",
+ "metadata": {},
+ "source": [
+ "Surprisingly, Ray didn’t improve the execution time. In fact, Ray program is actually much slower in execution time than the sequential program! \n",
+ "\n",
+ "_What's going on?_ \n",
+ "\n",
+ "Well, the issue here is that every task invocation has a non-trivial overhead (e.g., scheduling, inter-process communication, updating the system state), and this overhead dominates the actual time it takes to execute the task.\n",
+ "\n",
+ "_What can we do to remedy it?_\n",
+ "\n",
+ "One way to mitigate is to make the remote tasks \"larger\" in order to amortize invocation overhead. This is achieved by aggregating tasks into bigger chunks of 1000.\n",
+ "\n",
+ "**Better approach**: Use batching or chunking\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6f9d88df-42e3-4cef-af52-a0d5af798767",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "def mega_work(start, end):\n",
+ " return [tiny_task(x) for x in range(start, end)]"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "55a84420-ce3c-4915-8ce3-ca74442f0006",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "result_ids = []\n",
+ "start_time = time.time()\n",
+ "\n",
+ "[result_ids.append(mega_work.remote(x*1000, (x+1)*1000)) for x in range(100)]\n",
+ "# fetch the finihsed results\n",
+ "results = ray.get(result_ids)\n",
+ "end_time = time.time()\n",
+ "\n",
+ "print(f\"Parallelizing Ray tasks as batches takes {end_time - start_time:.2f} seconds\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "77f66e0d-028b-444e-975e-06ff86be4b2e",
+ "metadata": {},
+ "source": [
+ "A huge difference in execution time!\n",
+ "\n",
+ "Breaking or restructuring many small tasks into batches or chunks of large Ray remote tasks, as demonstrated above, achieves significant performance gain."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d973062d-2d9b-44ea-bd68-ce849b387d01",
+ "metadata": {},
+ "source": [
+ "### Pattern: Using ray.wait to limit the number of pending tasks\n",
+ "\n",
+ "| Name | Argument Type | Description |\n",
+ "| :--- | :--- | :---------- |\n",
+ "| `ray.get()` | `ObjectRef` or `List[ObjectRefs]` | Return a value in the object ref or list of values from the object IDs. This is a synchronous (i.e., blocking) operation. |\n",
+ "| `ray.wait()` | `List[ObjectRefs]` | From a list of object IDs, returns (1) the list of IDs of the objects that are ready, and (2) the list of IDs of the objects that are not ready yet. By default, it returns one ready object ID at a time. However, by specifying `num_returns=
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "cb62c5e3-8834-4574-be25-eea7cd17b58f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "def do_some_work(x):\n",
+ " # Assume doing some computation\n",
+ " time.sleep(0.5)\n",
+ " return math.exp(x)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "10c0c73c-acc8-45eb-9a36-a21880a7bb1f",
+ "metadata": {},
+ "source": [
+ "#### Bad usage\n",
+ "We use `ray.get` inside a list comprehension loop, hence it blocks on each call of `.remote()`, delaying until the task is finished and the value\n",
+ "is materialized and fetched from the Ray object store."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0b09cd56-70ca-478d-9ac0-f7cca535db99",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%time\n",
+ "results = [ray.get(do_some_work.remote(x)) for x in range(25)]\n",
+ "results[:5]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d5a6e94d-2b44-4a33-85fa-a717f4087976",
+ "metadata": {},
+ "source": [
+ "#### Good usage\n",
+ "We delay `ray.get` after all the tasks have been invoked and their references have been returned. That is, we don't block on each call but instead do outside the comprehension loop.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5bc26807-64a5-40fa-982e-96d9e7aaf08f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%time\n",
+ "results = ray.get([do_some_work.remote(x) for x in range(25)])\n",
+ "results[:5]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e94a62d0-b9a7-4e52-b334-57f75e84f823",
+ "metadata": {},
+ "source": [
+ "### Anti-pattern: Over-parallelizing with too fine-grained tasks harms speedup\n",
+ "\n",
+ "Ray APIs are general and simple to use. As a result, new comers' natural instinct is to parallelize all tasks, including tiny ones, which can incur an overhead over time. In short, if the Ray remote tasks are tiny or miniscule in compute, they may take longer to execute than their serial Python equivalents.\n",
+ "\n",
+ "**TLDR**: Where possible strive to batch tiny smaller Ray tasks into chuncks to reap the benefits of distributing them."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5c637e9d-077f-4e3d-961b-e2de1b04a852",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Using regular Python task that returns double of the number\n",
+ "def tiny_task(x):\n",
+ " time.sleep(0.00001)\n",
+ " return 2 * x"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0b51e94b-3cc6-4936-9fa3-e66ab75f4142",
+ "metadata": {},
+ "source": [
+ "Run this as a regular sequential Python task."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7448351a-cbf5-4f20-ad45-c75e94814469",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "start_time = time.time()\n",
+ "results = [tiny_task(x) for x in range(100000)]\n",
+ "end_time = time.time()\n",
+ "print(f\"Ordinary funciton call takes {end_time - start_time:.2f} seconds\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "846e2594-cb9a-40ff-a797-8217f899f1cc",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "results[:5], len(results)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2659ea3d-09f8-405e-96db-6faa8fb963b1",
+ "metadata": {},
+ "source": [
+ "Now convert this into Ray remote task"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "53cba8d7-513b-4682-9382-007984b93ed0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "def remote_tiny_task(x):\n",
+ " time.sleep(0.00001)\n",
+ " return 2 * x"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ccdd5b0a-a9b2-41ff-8086-24c426682e45",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "start_time = time.time()\n",
+ "result_ids = [remote_tiny_task.remote(x) for x in range(100000)]\n",
+ "results = ray.get(result_ids)\n",
+ "end_time = time.time()\n",
+ "print(f\"Parallelizing Ray tasks takes {end_time - start_time:.2f} seconds\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "66e28ba8-cfc7-459b-bad4-a8995e7f702e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "results[:5], len(results)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c91612f6-e5d1-48c2-9916-e948b9256e19",
+ "metadata": {},
+ "source": [
+ "Surprisingly, Ray didn’t improve the execution time. In fact, Ray program is actually much slower in execution time than the sequential program! \n",
+ "\n",
+ "_What's going on?_ \n",
+ "\n",
+ "Well, the issue here is that every task invocation has a non-trivial overhead (e.g., scheduling, inter-process communication, updating the system state), and this overhead dominates the actual time it takes to execute the task.\n",
+ "\n",
+ "_What can we do to remedy it?_\n",
+ "\n",
+ "One way to mitigate is to make the remote tasks \"larger\" in order to amortize invocation overhead. This is achieved by aggregating tasks into bigger chunks of 1000.\n",
+ "\n",
+ "**Better approach**: Use batching or chunking\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6f9d88df-42e3-4cef-af52-a0d5af798767",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "def mega_work(start, end):\n",
+ " return [tiny_task(x) for x in range(start, end)]"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "55a84420-ce3c-4915-8ce3-ca74442f0006",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "result_ids = []\n",
+ "start_time = time.time()\n",
+ "\n",
+ "[result_ids.append(mega_work.remote(x*1000, (x+1)*1000)) for x in range(100)]\n",
+ "# fetch the finihsed results\n",
+ "results = ray.get(result_ids)\n",
+ "end_time = time.time()\n",
+ "\n",
+ "print(f\"Parallelizing Ray tasks as batches takes {end_time - start_time:.2f} seconds\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "77f66e0d-028b-444e-975e-06ff86be4b2e",
+ "metadata": {},
+ "source": [
+ "A huge difference in execution time!\n",
+ "\n",
+ "Breaking or restructuring many small tasks into batches or chunks of large Ray remote tasks, as demonstrated above, achieves significant performance gain."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d973062d-2d9b-44ea-bd68-ce849b387d01",
+ "metadata": {},
+ "source": [
+ "### Pattern: Using ray.wait to limit the number of pending tasks\n",
+ "\n",
+ "| Name | Argument Type | Description |\n",
+ "| :--- | :--- | :---------- |\n",
+ "| `ray.get()` | `ObjectRef` or `List[ObjectRefs]` | Return a value in the object ref or list of values from the object IDs. This is a synchronous (i.e., blocking) operation. |\n",
+ "| `ray.wait()` | `List[ObjectRefs]` | From a list of object IDs, returns (1) the list of IDs of the objects that are ready, and (2) the list of IDs of the objects that are not ready yet. By default, it returns one ready object ID at a time. However, by specifying `num_returns= |\n",
+ "|:--|\n",
+ "|Execution timeline in both cases: when using `ray.get()` to wait for all results to become available before processing them, and using `ray.wait()` to start processing the results as soon as they become available.|\n",
+ "\n",
+ "\n",
+ "If we use `ray.get()` on the results of multiple tasks we will have to wait until the last one of these tasks finishes. This can be an issue if tasks take widely different amounts of time.\n",
+ "\n",
+ "To illustrate this issue, consider the following example where we run four `transform_images()` tasks in parallel, with each task taking a time uniformly distributed between 0 and 4 seconds. Next, assume the results of these tasks are processed by `classify_images()`, which takes 1 sec per result. The expected running time is then (1) the time it takes to execute the slowest of the `transform_images()` tasks, plus (2) 4 seconds which is the time it takes to execute `classify_images()`.\n",
+ "\n",
+ "Let's look at a simple example."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e89e9961-b804-4b83-a06e-355a8bf699f0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from PIL import Image, ImageFilter"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7434b9a0-480a-473e-9bb7-573713887634",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "random.seed(42)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "591854db-ef49-47f2-ac6c-7e27ed229187",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import time\n",
+ "import random\n",
+ "import ray\n",
+ "\n",
+ "@ray.remote\n",
+ "def transform_images(x):\n",
+ " imarray = np.random.rand(x, x , 3) * 255\n",
+ " img = Image.fromarray(imarray.astype('uint8')).convert('RGBA')\n",
+ " \n",
+ " # Make the image blur with specified intensify\n",
+ " img = img.filter(ImageFilter.GaussianBlur(radius=20))\n",
+ " \n",
+ " time.sleep(random.uniform(0, 4)) # Replace this with extra work you need to do.\n",
+ " return img\n",
+ "\n",
+ "def predict(image):\n",
+ " size = image.size[0]\n",
+ " if size == 16 or size == 32:\n",
+ " return 0\n",
+ " elif size == 64 or size == 128:\n",
+ " return 1\n",
+ " elif size == 256:\n",
+ " return 2\n",
+ " else:\n",
+ " return 3\n",
+ "\n",
+ "def classify_images(images):\n",
+ " preds = []\n",
+ " for image in images:\n",
+ " pred = predict(image)\n",
+ " time.sleep(1)\n",
+ " preds.append(pred)\n",
+ " return preds\n",
+ "\n",
+ "def classify_images_inc(images):\n",
+ " preds = [predict(img) for img in images]\n",
+ " time.sleep(1)\n",
+ " return preds\n",
+ "\n",
+ "SIZES = [16, 32, 64, 128, 256, 512]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "296293e7-ddac-4f65-9236-4864c7152af3",
+ "metadata": {},
+ "source": [
+ "#### Not using ray.wait and no pipelining"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "50ee0fce-9dc5-4cfa-94ba-4141831fe2d5",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "start = time.time()\n",
+ "# Transform the images first and then get the images\n",
+ "images = ray.get([transform_images.remote(image) for image in SIZES])\n",
+ "\n",
+ "# After all images are transformed, classify them\n",
+ "predictions = classify_images(images)\n",
+ "print(f\"Duration without pipelining: {round(time.time() - start, 2)} seconds; predictions: {predictions}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0620caab-4184-4a2e-8ca2-e1c9cd72e7bc",
+ "metadata": {},
+ "source": [
+ "#### Using ray.wait and pipelining"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4542c25a-df3b-419c-b7d2-c225391dc23c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "start = time.time()\n",
+ "result_images_refs = [transform_images.remote(image) for image in SIZES] \n",
+ "predictions = []\n",
+ "\n",
+ "# Loop until all tasks are finished\n",
+ "while len(result_images_refs):\n",
+ " done_image_refs, result_images_refs = ray.wait(result_images_refs, num_returns=1)\n",
+ " preds = classify_images_inc(ray.get(done_image_refs))\n",
+ " predictions.extend(preds)\n",
+ "print(f\"Duration with pipelining: {round(time.time() - start, 2)} seconds; predictions: {predictions}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "06c2203b-70e7-4c83-92bb-d192c29a05d0",
+ "metadata": {},
+ "source": [
+ "**Notice**: You get some incremental difference. However, for compute intensive and many tasks, and over time, this difference will be in order of magnitude.\n",
+ "\n",
+ "For large number of tasks in flight, use `ray.get()` and `ray.wait()` to implement pipeline execution of processing completed tasks.\n",
+ "\n",
+ "**TLDR**: Use pipeline execution to process results returned from the finished Ray tasks using `ray.get()` and `ray.wait()`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7ec0dc75-21d9-4f10-ad2e-d4b14da8aa27",
+ "metadata": {},
+ "source": [
+ "#### Exercise for Pipelining:\n",
+ " * Extend or add more images of sizes: 1024, 2048, ...\n",
+ " * Increase the number of returns to 2, 3, or 4 from the `ray.wait`()`\n",
+ " * Process the images\n",
+ " \n",
+ " Is there a difference in processing time between serial and pipelining?"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d6fd8952-519c-4e71-8281-7eaca52a092c",
+ "metadata": {},
+ "source": [
+ "### Anti-pattern: Passing the same large argument by value repeatedly harms performance\n",
+ "\n",
+ "When passing a large argument (>100KB) by value to a task, Ray will implicitly store the argument in the object store and the worker process will fetch the argument to the local object store from the caller’s object store before running the task. If we pass the same large argument to multiple tasks, Ray will end up storing multiple copies of the argument in the object store since Ray doesn’t do deduplication.\n",
+ "\n",
+ "Instead of passing the large argument by value to multiple tasks, we should use `ray.put()` to store the argument to the object store once and get an ObjectRef, then pass the argument reference to tasks. This way, we make sure all tasks use the same copy of the argument, which is faster and uses less object store memory.\n",
+ "\n",
+ "**TLDR**: Avoid passing the same large argument by value to multiple tasks, use ray.put() and pass by reference instead."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c9fb9d2a-032e-44f5-a0f0-a82755ac5f68",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "def do_work(a):\n",
+ " # do some work with the large object a\n",
+ " return np.sum(a)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "17ce457d-7b8d-4467-a661-1e1d52862c5d",
+ "metadata": {},
+ "source": [
+ "Bad Usage"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f744cbad-f58c-4206-9f0a-b63185b74aa8",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "random.seed(42)\n",
+ "\n",
+ "start = time.time()\n",
+ "a = np.random.rand(5000, 5000)\n",
+ "\n",
+ "# Sending the big array to each remote task, which will\n",
+ "# its copy of the same data into its object store\n",
+ "result_ids = [do_work.remote(a) for x in range(10)]\n",
+ "\n",
+ "results = math.fsum(ray.get(result_ids))\n",
+ "print(f\" results = {results:.2f} and duration = {time.time() - start:.3f} sec\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e3cefdff-bb83-4803-8c6d-7f2c7e5c5e9d",
+ "metadata": {},
+ "source": [
+ "**Better approach**: Put the value in the object store and only send the reference"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "eab448fa-8da4-4434-8b75-bd80b5db68e7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "start = time.time()\n",
+ "# Adding the big array into the object store\n",
+ "a_id_ref = ray.put(a)\n",
+ "\n",
+ "# Now send the objectID ref\n",
+ "result_ids = [do_work.remote(a_id_ref) for x in range(10)]\n",
+ "results = math.fsum(ray.get(result_ids))\n",
+ "print(f\" results = {results:.2f} and duration = {time.time() - start:.3f} sec\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e15dc011-fc45-4e08-8464-646b2e8dbea4",
+ "metadata": {},
+ "source": [
+ "### Recap\n",
+ "In this short tutorial, we got a short glimpse at design pattern, anti-pattern, and tricks and tips. By no means it is comprehensive, but we touched upon some methods we have seen in the previous lessons. With those methods, we explored additional arguments to the `.remote()` call such as number of return statements.\n",
+ "\n",
+ "More importantly, we walked through some tips and tricks that many developers new to Ray can easily stumble upon. Although the examples were short and simple, the lessons behind the cautionary tales are important part of the learning process."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fbba4f2d-ed4a-42f7-b59d-ac7c5f2bca43",
+ "metadata": {},
+ "source": [
+ "### Homework \n",
+ "\n",
+ "There is a advanced and comprehensive list of all [Ray design patterns and anti-design patterns](https://docs.ray.io/en/latest/ray-core/patterns/index.html#design-patterns-anti-patternsray.shutdown()) you can explore at after the class at home.\n",
+ "\n",
+ "### Additional Resource on Best Practices\n",
+ " * [User Guides for Ray Clusters](https://docs.ray.io/en/latest/cluster/vms/user-guides/index.html)\n",
+ " * [Best practices for deploying large clusters](https://docs.ray.io/en/latest/cluster/vms/user-guides/large-cluster-best-practices.html)\n",
+ " * [Launching an On-Premise Cluster](https://docs.ray.io/en/latest/cluster/vms/user-guides/launching-clusters/on-premises.html)\n",
+ " * [Configuring Autoscaling](https://docs.ray.io/en/latest/cluster/vms/user-guides/configuring-autoscaling.html)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "17090bb2-6f50-4929-9f29-2f96013cc978",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ray.shutdown()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6a21ed41-16ad-4d6e-8554-937aa57e7267",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/templates/ray-summit-core-masterclass/Ray_Core_6_ADAG_experimental.ipynb b/templates/ray-summit-core-masterclass/Ray_Core_6_ADAG_experimental.ipynb
new file mode 100644
index 000000000..65ff56e29
--- /dev/null
+++ b/templates/ray-summit-core-masterclass/Ray_Core_6_ADAG_experimental.ipynb
@@ -0,0 +1,397 @@
+{
+ "cells": [
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Ray aDAG Developer Guide - Hands-on Walkthrough\n",
+ "\n",
+ "## 1. Introduction to Ray aDAGs\n",
+ "# Note: Transition to slides to explain \"What is Ray aDAG?\" and \"Why Use aDAGs?\"\n",
+ "# (Discuss performance benefits and specific use cases like LLM inference.)\n",
+ "\n",
+ "# Also note that this requires both torch and ray installed (obviously) but both are prepped already as part of the image \n",
+ "# for Ray Summit Training 2024"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "bc02b887",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Step 2: Define and Create Actors with Ray Core\n",
+ "import ray\n",
+ "\n",
+ "@ray.remote\n",
+ "class EchoActor:\n",
+ " def echo(self, msg):\n",
+ " return msg\n",
+ "\n",
+ "# Create two actors\n",
+ "a = EchoActor.remote()\n",
+ "b = EchoActor.remote()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "27097255",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Send a message and get a response\n",
+ "msg_ref = a.echo.remote(\"hello\")\n",
+ "msg_ref = b.echo.remote(msg_ref)\n",
+ "print(ray.get(msg_ref)) # Expected output: \"hello\""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5aa7187c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "## 3. Using Ray aDAGs for Performance Optimization\n",
+ "# Note: Transition to slides to explain \"How Ray Core traditionally executes tasks\" \n",
+ "# and \"Challenges with dynamic control flow\" (discuss overheads with serialization and object store).\n",
+ "\n",
+ "# Step 3: Define and Execute with Ray DAG API (Classic Ray Core)\n",
+ "import ray.dag\n",
+ "import time"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c58f8f70",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Define a lazy DAG\n",
+ "with ray.dag.InputNode() as inp:\n",
+ " intermediate_inp = a.echo.bind(inp)\n",
+ " dag = b.echo.bind(intermediate_inp)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "85954667",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Execute the DAG with inputs\n",
+ "print(ray.get(dag.execute(\"hello\")))\n",
+ "print(ray.get(dag.execute(\"world\")))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "af998905",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Time the execution\n",
+ "for _ in range(5):\n",
+ " start = time.perf_counter()\n",
+ " ray.get(dag.execute(\"hello\"))\n",
+ " print(\"Took\", time.perf_counter() - start)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c75fecdd",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "## 4. Optimizing with Ray aDAGs\n",
+ "\n",
+ "# Step 4: Compile and Execute with aDAG Backend and time and compare the difference in exec speed\n",
+ "adag = dag.experimental_compile()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "60f46cb6",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Execute the aDAG and measure the time\n",
+ "for _ in range(5):\n",
+ " start = time.perf_counter()\n",
+ " ray.get(adag.execute(\"hello\"))\n",
+ " print(\"Took\", time.perf_counter() - start)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4658867e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Tear down the DAG\n",
+ "adag.teardown()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3ee49cb2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "## 5. [BONUS #1] Multi-Actor Execution in Ray aDAG\n",
+ "\n",
+ "# Step 5: Executing Across Multiple Actors with Ray aDAG\n",
+ "# Create multiple actors\n",
+ "N = 3\n",
+ "actors = [EchoActor.remote() for _ in range(N)]\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a1b0cc48",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "\n",
+ "# Define the DAG with multiple outputs\n",
+ "with ray.dag.InputNode() as inp:\n",
+ " outputs = [actor.echo.bind(inp) for actor in actors]\n",
+ " dag = ray.dag.MultiOutputNode(outputs)\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "af593a22",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "\n",
+ "# Compile and execute the DAG\n",
+ "adag = dag.experimental_compile()\n",
+ "print(ray.get(adag.execute(\"hello\"))) # Expected: [\"hello\", \"hello\", \"hello\"]\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2638f3aa",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "\n",
+ "# Tear down the DAG\n",
+ "adag.teardown()\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a47fa55c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "## 6. [BONUS #2] GPU-GPU Communication with aDAGs\n",
+ "\n",
+ "# Note: Transition to slides to discuss \"GPU-GPU communication and NCCL\".\n",
+ "\n",
+ "# Step 6: GPU to GPU Data Transfer Example\n",
+ "import torch\n",
+ "from ray.experimental.channel.torch_tensor_type import TorchTensorType\n",
+ "\n",
+ "@ray.remote(num_gpus=1)\n",
+ "class GPUSender:\n",
+ " def send(self, shape):\n",
+ " return torch.zeros(shape, device=\"cuda\")\n",
+ "@ray.remote(num_gpus=1)\n",
+ "class GPUReceiver:\n",
+ " def recv(self, tensor: torch.Tensor):\n",
+ " assert tensor.device.type == \"cuda\"\n",
+ " return tensor.shape\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0898fec3",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Create the sender and receiver actors\n",
+ "sender = GPUSender.remote()\n",
+ "receiver = GPUReceiver.remote()\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "10a1cb3b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Define and compile a DAG for GPU-GPU communication\n",
+ "with ray.dag.InputNode() as inp:\n",
+ " dag = sender.send.bind(inp)\n",
+ " dag = dag.with_type_hint(TorchTensorType())\n",
+ " dag = receiver.recv.bind(dag)\n",
+ "adag = dag.experimental_compile()\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "83d03b54",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Execute the DAG and check the results\n",
+ "assert ray.get(adag.execute((10, ))) == (10, )\n",
+ "adag.teardown()\n",
+ "\n",
+ "## 7. Conclusion and Summary\n",
+ "# Note: Transition to slides for summarizing key takeaways and discussing \n",
+ "# limitations of aDAGs (e.g., actor constraints, NCCL)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2e1a177a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Send a message and get a response\n",
+ "msg_ref = a.echo.remote(\"hello\")\n",
+ "msg_ref = b.echo.remote(msg_ref)\n",
+ "print(ray.get(msg_ref)) # Expected output: \"hello\"\n",
+ "## 3. Using Ray aDAGs for Performance Optimization\n",
+ "\n",
+ "# Note: Transition to slides to explain \"How Ray Core traditionally executes tasks\" \n",
+ "# and \"Challenges with dynamic control flow\" (discuss overheads with serialization and object store).\n",
+ "# Step 3: Define and Execute with Ray DAG API (Classic Ray Core)\n",
+ "import ray.dag\n",
+ "import time\n",
+ "\n",
+ "# Define a lazy DAG\n",
+ "with ray.dag.InputNode() as inp:\n",
+ " intermediate_inp = a.echo.bind(inp)\n",
+ " dag = b.echo.bind(intermediate_inp)\n",
+ "# Execute the DAG with inputs\n",
+ "print(ray.get(dag.execute(\"hello\")))\n",
+ "print(ray.get(dag.execute(\"world\")))\n",
+ "# Time the execution\n",
+ "for _ in range(5):\n",
+ " start = time.perf_counter()\n",
+ " ray.get(dag.execute(\"hello\"))\n",
+ " print(\"Took\", time.perf_counter() - start)\n",
+ "## 4. Optimizing with Ray aDAGs\n",
+ "\n",
+ "# Step 4: Compile and Execute with aDAG Backend\n",
+ "# Compile the DAG for aDAG backend\n",
+ "\n",
+ "adag = dag.experimental_compile()\n",
+ "# Execute the aDAG and measure the time\n",
+ "for _ in range(5):\n",
+ " start = time.perf_counter()\n",
+ " ray.get(adag.execute(\"hello\"))\n",
+ " print(\"Took\", time.perf_counter() - start)\n",
+ "# Tear down the DAG\n",
+ "adag.teardown()\n",
+ "\n",
+ "## 5. [BONUS #1] Multi-Actor Execution in Ray aDAG\n",
+ "\n",
+ "# Step 5: Executing Across Multiple Actors with Ray aDAG\n",
+ "# Create multiple actors\n",
+ "N = 3\n",
+ "actors = [EchoActor.remote() for _ in range(N)]\n",
+ "# Define the DAG with multiple outputs\n",
+ "with ray.dag.InputNode() as inp:\n",
+ " outputs = [actor.echo.bind(inp) for actor in actors]\n",
+ " dag = ray.dag.MultiOutputNode(outputs)\n",
+ "# Compile and execute the DAG\n",
+ "adag = dag.experimental_compile()\n",
+ "print(ray.get(adag.execute(\"hello\"))) # Expected: [\"hello\", \"hello\", \"hello\"]\n",
+ "# Tear down the DAG\n",
+ "adag.teardown()\n",
+ "\n",
+ "## 6. [BONUS #2] GPU-GPU Communication with aDAGs\n",
+ "\n",
+ "# Note: Transition to slides to discuss \"GPU-GPU communication and NCCL\".\n",
+ "\n",
+ "# Step 6: GPU to GPU Data Transfer Example\n",
+ "import torch\n",
+ "from ray.experimental.channel.torch_tensor_type import TorchTensorType\n",
+ "\n",
+ "@ray.remote(num_gpus=1)\n",
+ "class GPUSender:\n",
+ " def send(self, shape):\n",
+ " return torch.zeros(shape, device=\"cuda\")\n",
+ "@ray.remote(num_gpus=1)\n",
+ "class GPUReceiver:\n",
+ " def recv(self, tensor: torch.Tensor):\n",
+ " assert tensor.device.type == \"cuda\"\n",
+ " return tensor.shape\n",
+ "# Create the sender and receiver actors\n",
+ "sender = GPUSender.remote()\n",
+ "receiver = GPUReceiver.remote()\n",
+ "# Define and compile a DAG for GPU-GPU communication\n",
+ "with ray.dag.InputNode() as inp:\n",
+ " dag = sender.send.bind(inp)\n",
+ " dag = dag.with_type_hint(TorchTensorType())\n",
+ " dag = receiver.recv.bind(dag)\n",
+ "adag = dag.experimental_compile()\n",
+ "# Execute the DAG and check the results\n",
+ "assert ray.get(adag.execute((10, ))) == (10, )\n",
+ "adag.teardown()\n",
+ "\n",
+ "#"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2318fda6",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# 7. Conclusion and Summary\n",
+ "# Note: Transition to slides for summarizing key takeaways and discussing \n",
+ "# limitations of aDAGs (e.g., actor constraints, NCCL)."
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.12.2"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/templates/ray-summit-core-masterclass/bonus/1_core_examples.ipynb b/templates/ray-summit-core-masterclass/bonus/1_core_examples.ipynb
new file mode 100644
index 000000000..2359777e2
--- /dev/null
+++ b/templates/ray-summit-core-masterclass/bonus/1_core_examples.ipynb
@@ -0,0 +1,1135 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "1fd443a5-c9d3-4b6f-ad72-59c1eba1d112",
+ "metadata": {},
+ "source": [
+ "# A Quick Tour of Ray Core"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "98399ea9-933a-452f-be3f-bc1535006443",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "import ray"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9ff9ad39-11cb-495e-964f-a05a95159bea",
+ "metadata": {},
+ "source": [
+ "## Ray Core is about...\n",
+ "* distributing computation across many cores, nodes, or devices (e.g., accelerators)\n",
+ "* scheduling *arbitrary task graphs*\n",
+ " * any code you can write, you can distribute, scale, and accelerate with Ray Core\n",
+ "* manage the overhead\n",
+ " * at scale, distributed computation introduces growing \"frictions\" -- data movement, scheduling costs, etc. -- which make the problem harder\n",
+ " * Ray Core addresses these issues as first-order concerns in its design (e.g., via a distributed scheduler)\n",
+ " \n",
+ "(And, of course, for common technical use cases, libraries and other components provide simple dev ex and are built on top of Ray Core)\n",
+ "\n",
+ "## `@ray.remote` and `ray.get`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "bb8b00c1-d320-4b62-a35b-08bea2e848e3",
+ "metadata": {},
+ "source": [
+ "Define a Python function and decorate it so that Ray can schedule it"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "bc20546b-510d-4885-82fa-5d12503d52f4",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "def square(a):\n",
+ " return a*a"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2dfd3ad7-0d0e-4313-82d7-4d36f2e9537b",
+ "metadata": {},
+ "source": [
+ "Tell Ray to schedule the function"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c7f0c8a3-f456-4594-a994-0e5a528c3b78",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "square.remote(3)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a8f99486-6a85-4331-bed6-0af871974977",
+ "metadata": {},
+ "source": [
+ "`ObjectRef` is a handle to a task result. We get an ObjectRef immediately because we don't know\n",
+ "* when the task will run\n",
+ "* whether it will succeed\n",
+ "* whether we really need or want the result locally\n",
+ " * consider a very large result which we may need for other work but which we don't need to inspect"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3c939071-2454-4042-8136-75ffbbf6cce0",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ref = square.remote(3)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7928ca98-dc51-4ecf-b757-92996dd0c69a",
+ "metadata": {},
+ "source": [
+ "If we want to wait (block) and retrieve the corresponding object, we can use `ray.get`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a564c830-d30d-4d4c-adb5-ee12adee605b",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ray.get(ref)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4da412f5-133a-441b-8734-b96f56389f05",
+ "metadata": {},
+ "source": [
+ "
|\n",
+ "|:--|\n",
+ "|Execution timeline in both cases: when using `ray.get()` to wait for all results to become available before processing them, and using `ray.wait()` to start processing the results as soon as they become available.|\n",
+ "\n",
+ "\n",
+ "If we use `ray.get()` on the results of multiple tasks we will have to wait until the last one of these tasks finishes. This can be an issue if tasks take widely different amounts of time.\n",
+ "\n",
+ "To illustrate this issue, consider the following example where we run four `transform_images()` tasks in parallel, with each task taking a time uniformly distributed between 0 and 4 seconds. Next, assume the results of these tasks are processed by `classify_images()`, which takes 1 sec per result. The expected running time is then (1) the time it takes to execute the slowest of the `transform_images()` tasks, plus (2) 4 seconds which is the time it takes to execute `classify_images()`.\n",
+ "\n",
+ "Let's look at a simple example."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e89e9961-b804-4b83-a06e-355a8bf699f0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from PIL import Image, ImageFilter"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7434b9a0-480a-473e-9bb7-573713887634",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "random.seed(42)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "591854db-ef49-47f2-ac6c-7e27ed229187",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import time\n",
+ "import random\n",
+ "import ray\n",
+ "\n",
+ "@ray.remote\n",
+ "def transform_images(x):\n",
+ " imarray = np.random.rand(x, x , 3) * 255\n",
+ " img = Image.fromarray(imarray.astype('uint8')).convert('RGBA')\n",
+ " \n",
+ " # Make the image blur with specified intensify\n",
+ " img = img.filter(ImageFilter.GaussianBlur(radius=20))\n",
+ " \n",
+ " time.sleep(random.uniform(0, 4)) # Replace this with extra work you need to do.\n",
+ " return img\n",
+ "\n",
+ "def predict(image):\n",
+ " size = image.size[0]\n",
+ " if size == 16 or size == 32:\n",
+ " return 0\n",
+ " elif size == 64 or size == 128:\n",
+ " return 1\n",
+ " elif size == 256:\n",
+ " return 2\n",
+ " else:\n",
+ " return 3\n",
+ "\n",
+ "def classify_images(images):\n",
+ " preds = []\n",
+ " for image in images:\n",
+ " pred = predict(image)\n",
+ " time.sleep(1)\n",
+ " preds.append(pred)\n",
+ " return preds\n",
+ "\n",
+ "def classify_images_inc(images):\n",
+ " preds = [predict(img) for img in images]\n",
+ " time.sleep(1)\n",
+ " return preds\n",
+ "\n",
+ "SIZES = [16, 32, 64, 128, 256, 512]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "296293e7-ddac-4f65-9236-4864c7152af3",
+ "metadata": {},
+ "source": [
+ "#### Not using ray.wait and no pipelining"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "50ee0fce-9dc5-4cfa-94ba-4141831fe2d5",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "start = time.time()\n",
+ "# Transform the images first and then get the images\n",
+ "images = ray.get([transform_images.remote(image) for image in SIZES])\n",
+ "\n",
+ "# After all images are transformed, classify them\n",
+ "predictions = classify_images(images)\n",
+ "print(f\"Duration without pipelining: {round(time.time() - start, 2)} seconds; predictions: {predictions}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0620caab-4184-4a2e-8ca2-e1c9cd72e7bc",
+ "metadata": {},
+ "source": [
+ "#### Using ray.wait and pipelining"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4542c25a-df3b-419c-b7d2-c225391dc23c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "start = time.time()\n",
+ "result_images_refs = [transform_images.remote(image) for image in SIZES] \n",
+ "predictions = []\n",
+ "\n",
+ "# Loop until all tasks are finished\n",
+ "while len(result_images_refs):\n",
+ " done_image_refs, result_images_refs = ray.wait(result_images_refs, num_returns=1)\n",
+ " preds = classify_images_inc(ray.get(done_image_refs))\n",
+ " predictions.extend(preds)\n",
+ "print(f\"Duration with pipelining: {round(time.time() - start, 2)} seconds; predictions: {predictions}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "06c2203b-70e7-4c83-92bb-d192c29a05d0",
+ "metadata": {},
+ "source": [
+ "**Notice**: You get some incremental difference. However, for compute intensive and many tasks, and over time, this difference will be in order of magnitude.\n",
+ "\n",
+ "For large number of tasks in flight, use `ray.get()` and `ray.wait()` to implement pipeline execution of processing completed tasks.\n",
+ "\n",
+ "**TLDR**: Use pipeline execution to process results returned from the finished Ray tasks using `ray.get()` and `ray.wait()`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7ec0dc75-21d9-4f10-ad2e-d4b14da8aa27",
+ "metadata": {},
+ "source": [
+ "#### Exercise for Pipelining:\n",
+ " * Extend or add more images of sizes: 1024, 2048, ...\n",
+ " * Increase the number of returns to 2, 3, or 4 from the `ray.wait`()`\n",
+ " * Process the images\n",
+ " \n",
+ " Is there a difference in processing time between serial and pipelining?"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d6fd8952-519c-4e71-8281-7eaca52a092c",
+ "metadata": {},
+ "source": [
+ "### Anti-pattern: Passing the same large argument by value repeatedly harms performance\n",
+ "\n",
+ "When passing a large argument (>100KB) by value to a task, Ray will implicitly store the argument in the object store and the worker process will fetch the argument to the local object store from the caller’s object store before running the task. If we pass the same large argument to multiple tasks, Ray will end up storing multiple copies of the argument in the object store since Ray doesn’t do deduplication.\n",
+ "\n",
+ "Instead of passing the large argument by value to multiple tasks, we should use `ray.put()` to store the argument to the object store once and get an ObjectRef, then pass the argument reference to tasks. This way, we make sure all tasks use the same copy of the argument, which is faster and uses less object store memory.\n",
+ "\n",
+ "**TLDR**: Avoid passing the same large argument by value to multiple tasks, use ray.put() and pass by reference instead."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c9fb9d2a-032e-44f5-a0f0-a82755ac5f68",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "def do_work(a):\n",
+ " # do some work with the large object a\n",
+ " return np.sum(a)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "17ce457d-7b8d-4467-a661-1e1d52862c5d",
+ "metadata": {},
+ "source": [
+ "Bad Usage"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f744cbad-f58c-4206-9f0a-b63185b74aa8",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "random.seed(42)\n",
+ "\n",
+ "start = time.time()\n",
+ "a = np.random.rand(5000, 5000)\n",
+ "\n",
+ "# Sending the big array to each remote task, which will\n",
+ "# its copy of the same data into its object store\n",
+ "result_ids = [do_work.remote(a) for x in range(10)]\n",
+ "\n",
+ "results = math.fsum(ray.get(result_ids))\n",
+ "print(f\" results = {results:.2f} and duration = {time.time() - start:.3f} sec\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e3cefdff-bb83-4803-8c6d-7f2c7e5c5e9d",
+ "metadata": {},
+ "source": [
+ "**Better approach**: Put the value in the object store and only send the reference"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "eab448fa-8da4-4434-8b75-bd80b5db68e7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "start = time.time()\n",
+ "# Adding the big array into the object store\n",
+ "a_id_ref = ray.put(a)\n",
+ "\n",
+ "# Now send the objectID ref\n",
+ "result_ids = [do_work.remote(a_id_ref) for x in range(10)]\n",
+ "results = math.fsum(ray.get(result_ids))\n",
+ "print(f\" results = {results:.2f} and duration = {time.time() - start:.3f} sec\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e15dc011-fc45-4e08-8464-646b2e8dbea4",
+ "metadata": {},
+ "source": [
+ "### Recap\n",
+ "In this short tutorial, we got a short glimpse at design pattern, anti-pattern, and tricks and tips. By no means it is comprehensive, but we touched upon some methods we have seen in the previous lessons. With those methods, we explored additional arguments to the `.remote()` call such as number of return statements.\n",
+ "\n",
+ "More importantly, we walked through some tips and tricks that many developers new to Ray can easily stumble upon. Although the examples were short and simple, the lessons behind the cautionary tales are important part of the learning process."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fbba4f2d-ed4a-42f7-b59d-ac7c5f2bca43",
+ "metadata": {},
+ "source": [
+ "### Homework \n",
+ "\n",
+ "There is a advanced and comprehensive list of all [Ray design patterns and anti-design patterns](https://docs.ray.io/en/latest/ray-core/patterns/index.html#design-patterns-anti-patternsray.shutdown()) you can explore at after the class at home.\n",
+ "\n",
+ "### Additional Resource on Best Practices\n",
+ " * [User Guides for Ray Clusters](https://docs.ray.io/en/latest/cluster/vms/user-guides/index.html)\n",
+ " * [Best practices for deploying large clusters](https://docs.ray.io/en/latest/cluster/vms/user-guides/large-cluster-best-practices.html)\n",
+ " * [Launching an On-Premise Cluster](https://docs.ray.io/en/latest/cluster/vms/user-guides/launching-clusters/on-premises.html)\n",
+ " * [Configuring Autoscaling](https://docs.ray.io/en/latest/cluster/vms/user-guides/configuring-autoscaling.html)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "17090bb2-6f50-4929-9f29-2f96013cc978",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ray.shutdown()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6a21ed41-16ad-4d6e-8554-937aa57e7267",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/templates/ray-summit-core-masterclass/Ray_Core_6_ADAG_experimental.ipynb b/templates/ray-summit-core-masterclass/Ray_Core_6_ADAG_experimental.ipynb
new file mode 100644
index 000000000..65ff56e29
--- /dev/null
+++ b/templates/ray-summit-core-masterclass/Ray_Core_6_ADAG_experimental.ipynb
@@ -0,0 +1,397 @@
+{
+ "cells": [
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Ray aDAG Developer Guide - Hands-on Walkthrough\n",
+ "\n",
+ "## 1. Introduction to Ray aDAGs\n",
+ "# Note: Transition to slides to explain \"What is Ray aDAG?\" and \"Why Use aDAGs?\"\n",
+ "# (Discuss performance benefits and specific use cases like LLM inference.)\n",
+ "\n",
+ "# Also note that this requires both torch and ray installed (obviously) but both are prepped already as part of the image \n",
+ "# for Ray Summit Training 2024"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "bc02b887",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Step 2: Define and Create Actors with Ray Core\n",
+ "import ray\n",
+ "\n",
+ "@ray.remote\n",
+ "class EchoActor:\n",
+ " def echo(self, msg):\n",
+ " return msg\n",
+ "\n",
+ "# Create two actors\n",
+ "a = EchoActor.remote()\n",
+ "b = EchoActor.remote()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "27097255",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Send a message and get a response\n",
+ "msg_ref = a.echo.remote(\"hello\")\n",
+ "msg_ref = b.echo.remote(msg_ref)\n",
+ "print(ray.get(msg_ref)) # Expected output: \"hello\""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5aa7187c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "## 3. Using Ray aDAGs for Performance Optimization\n",
+ "# Note: Transition to slides to explain \"How Ray Core traditionally executes tasks\" \n",
+ "# and \"Challenges with dynamic control flow\" (discuss overheads with serialization and object store).\n",
+ "\n",
+ "# Step 3: Define and Execute with Ray DAG API (Classic Ray Core)\n",
+ "import ray.dag\n",
+ "import time"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c58f8f70",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Define a lazy DAG\n",
+ "with ray.dag.InputNode() as inp:\n",
+ " intermediate_inp = a.echo.bind(inp)\n",
+ " dag = b.echo.bind(intermediate_inp)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "85954667",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Execute the DAG with inputs\n",
+ "print(ray.get(dag.execute(\"hello\")))\n",
+ "print(ray.get(dag.execute(\"world\")))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "af998905",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Time the execution\n",
+ "for _ in range(5):\n",
+ " start = time.perf_counter()\n",
+ " ray.get(dag.execute(\"hello\"))\n",
+ " print(\"Took\", time.perf_counter() - start)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c75fecdd",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "## 4. Optimizing with Ray aDAGs\n",
+ "\n",
+ "# Step 4: Compile and Execute with aDAG Backend and time and compare the difference in exec speed\n",
+ "adag = dag.experimental_compile()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "60f46cb6",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Execute the aDAG and measure the time\n",
+ "for _ in range(5):\n",
+ " start = time.perf_counter()\n",
+ " ray.get(adag.execute(\"hello\"))\n",
+ " print(\"Took\", time.perf_counter() - start)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4658867e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Tear down the DAG\n",
+ "adag.teardown()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3ee49cb2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "## 5. [BONUS #1] Multi-Actor Execution in Ray aDAG\n",
+ "\n",
+ "# Step 5: Executing Across Multiple Actors with Ray aDAG\n",
+ "# Create multiple actors\n",
+ "N = 3\n",
+ "actors = [EchoActor.remote() for _ in range(N)]\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a1b0cc48",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "\n",
+ "# Define the DAG with multiple outputs\n",
+ "with ray.dag.InputNode() as inp:\n",
+ " outputs = [actor.echo.bind(inp) for actor in actors]\n",
+ " dag = ray.dag.MultiOutputNode(outputs)\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "af593a22",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "\n",
+ "# Compile and execute the DAG\n",
+ "adag = dag.experimental_compile()\n",
+ "print(ray.get(adag.execute(\"hello\"))) # Expected: [\"hello\", \"hello\", \"hello\"]\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2638f3aa",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "\n",
+ "# Tear down the DAG\n",
+ "adag.teardown()\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a47fa55c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "## 6. [BONUS #2] GPU-GPU Communication with aDAGs\n",
+ "\n",
+ "# Note: Transition to slides to discuss \"GPU-GPU communication and NCCL\".\n",
+ "\n",
+ "# Step 6: GPU to GPU Data Transfer Example\n",
+ "import torch\n",
+ "from ray.experimental.channel.torch_tensor_type import TorchTensorType\n",
+ "\n",
+ "@ray.remote(num_gpus=1)\n",
+ "class GPUSender:\n",
+ " def send(self, shape):\n",
+ " return torch.zeros(shape, device=\"cuda\")\n",
+ "@ray.remote(num_gpus=1)\n",
+ "class GPUReceiver:\n",
+ " def recv(self, tensor: torch.Tensor):\n",
+ " assert tensor.device.type == \"cuda\"\n",
+ " return tensor.shape\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0898fec3",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Create the sender and receiver actors\n",
+ "sender = GPUSender.remote()\n",
+ "receiver = GPUReceiver.remote()\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "10a1cb3b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Define and compile a DAG for GPU-GPU communication\n",
+ "with ray.dag.InputNode() as inp:\n",
+ " dag = sender.send.bind(inp)\n",
+ " dag = dag.with_type_hint(TorchTensorType())\n",
+ " dag = receiver.recv.bind(dag)\n",
+ "adag = dag.experimental_compile()\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "83d03b54",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Execute the DAG and check the results\n",
+ "assert ray.get(adag.execute((10, ))) == (10, )\n",
+ "adag.teardown()\n",
+ "\n",
+ "## 7. Conclusion and Summary\n",
+ "# Note: Transition to slides for summarizing key takeaways and discussing \n",
+ "# limitations of aDAGs (e.g., actor constraints, NCCL)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2e1a177a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Send a message and get a response\n",
+ "msg_ref = a.echo.remote(\"hello\")\n",
+ "msg_ref = b.echo.remote(msg_ref)\n",
+ "print(ray.get(msg_ref)) # Expected output: \"hello\"\n",
+ "## 3. Using Ray aDAGs for Performance Optimization\n",
+ "\n",
+ "# Note: Transition to slides to explain \"How Ray Core traditionally executes tasks\" \n",
+ "# and \"Challenges with dynamic control flow\" (discuss overheads with serialization and object store).\n",
+ "# Step 3: Define and Execute with Ray DAG API (Classic Ray Core)\n",
+ "import ray.dag\n",
+ "import time\n",
+ "\n",
+ "# Define a lazy DAG\n",
+ "with ray.dag.InputNode() as inp:\n",
+ " intermediate_inp = a.echo.bind(inp)\n",
+ " dag = b.echo.bind(intermediate_inp)\n",
+ "# Execute the DAG with inputs\n",
+ "print(ray.get(dag.execute(\"hello\")))\n",
+ "print(ray.get(dag.execute(\"world\")))\n",
+ "# Time the execution\n",
+ "for _ in range(5):\n",
+ " start = time.perf_counter()\n",
+ " ray.get(dag.execute(\"hello\"))\n",
+ " print(\"Took\", time.perf_counter() - start)\n",
+ "## 4. Optimizing with Ray aDAGs\n",
+ "\n",
+ "# Step 4: Compile and Execute with aDAG Backend\n",
+ "# Compile the DAG for aDAG backend\n",
+ "\n",
+ "adag = dag.experimental_compile()\n",
+ "# Execute the aDAG and measure the time\n",
+ "for _ in range(5):\n",
+ " start = time.perf_counter()\n",
+ " ray.get(adag.execute(\"hello\"))\n",
+ " print(\"Took\", time.perf_counter() - start)\n",
+ "# Tear down the DAG\n",
+ "adag.teardown()\n",
+ "\n",
+ "## 5. [BONUS #1] Multi-Actor Execution in Ray aDAG\n",
+ "\n",
+ "# Step 5: Executing Across Multiple Actors with Ray aDAG\n",
+ "# Create multiple actors\n",
+ "N = 3\n",
+ "actors = [EchoActor.remote() for _ in range(N)]\n",
+ "# Define the DAG with multiple outputs\n",
+ "with ray.dag.InputNode() as inp:\n",
+ " outputs = [actor.echo.bind(inp) for actor in actors]\n",
+ " dag = ray.dag.MultiOutputNode(outputs)\n",
+ "# Compile and execute the DAG\n",
+ "adag = dag.experimental_compile()\n",
+ "print(ray.get(adag.execute(\"hello\"))) # Expected: [\"hello\", \"hello\", \"hello\"]\n",
+ "# Tear down the DAG\n",
+ "adag.teardown()\n",
+ "\n",
+ "## 6. [BONUS #2] GPU-GPU Communication with aDAGs\n",
+ "\n",
+ "# Note: Transition to slides to discuss \"GPU-GPU communication and NCCL\".\n",
+ "\n",
+ "# Step 6: GPU to GPU Data Transfer Example\n",
+ "import torch\n",
+ "from ray.experimental.channel.torch_tensor_type import TorchTensorType\n",
+ "\n",
+ "@ray.remote(num_gpus=1)\n",
+ "class GPUSender:\n",
+ " def send(self, shape):\n",
+ " return torch.zeros(shape, device=\"cuda\")\n",
+ "@ray.remote(num_gpus=1)\n",
+ "class GPUReceiver:\n",
+ " def recv(self, tensor: torch.Tensor):\n",
+ " assert tensor.device.type == \"cuda\"\n",
+ " return tensor.shape\n",
+ "# Create the sender and receiver actors\n",
+ "sender = GPUSender.remote()\n",
+ "receiver = GPUReceiver.remote()\n",
+ "# Define and compile a DAG for GPU-GPU communication\n",
+ "with ray.dag.InputNode() as inp:\n",
+ " dag = sender.send.bind(inp)\n",
+ " dag = dag.with_type_hint(TorchTensorType())\n",
+ " dag = receiver.recv.bind(dag)\n",
+ "adag = dag.experimental_compile()\n",
+ "# Execute the DAG and check the results\n",
+ "assert ray.get(adag.execute((10, ))) == (10, )\n",
+ "adag.teardown()\n",
+ "\n",
+ "#"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2318fda6",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# 7. Conclusion and Summary\n",
+ "# Note: Transition to slides for summarizing key takeaways and discussing \n",
+ "# limitations of aDAGs (e.g., actor constraints, NCCL)."
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.12.2"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/templates/ray-summit-core-masterclass/bonus/1_core_examples.ipynb b/templates/ray-summit-core-masterclass/bonus/1_core_examples.ipynb
new file mode 100644
index 000000000..2359777e2
--- /dev/null
+++ b/templates/ray-summit-core-masterclass/bonus/1_core_examples.ipynb
@@ -0,0 +1,1135 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "1fd443a5-c9d3-4b6f-ad72-59c1eba1d112",
+ "metadata": {},
+ "source": [
+ "# A Quick Tour of Ray Core"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "98399ea9-933a-452f-be3f-bc1535006443",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "import ray"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9ff9ad39-11cb-495e-964f-a05a95159bea",
+ "metadata": {},
+ "source": [
+ "## Ray Core is about...\n",
+ "* distributing computation across many cores, nodes, or devices (e.g., accelerators)\n",
+ "* scheduling *arbitrary task graphs*\n",
+ " * any code you can write, you can distribute, scale, and accelerate with Ray Core\n",
+ "* manage the overhead\n",
+ " * at scale, distributed computation introduces growing \"frictions\" -- data movement, scheduling costs, etc. -- which make the problem harder\n",
+ " * Ray Core addresses these issues as first-order concerns in its design (e.g., via a distributed scheduler)\n",
+ " \n",
+ "(And, of course, for common technical use cases, libraries and other components provide simple dev ex and are built on top of Ray Core)\n",
+ "\n",
+ "## `@ray.remote` and `ray.get`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "bb8b00c1-d320-4b62-a35b-08bea2e848e3",
+ "metadata": {},
+ "source": [
+ "Define a Python function and decorate it so that Ray can schedule it"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "bc20546b-510d-4885-82fa-5d12503d52f4",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "def square(a):\n",
+ " return a*a"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2dfd3ad7-0d0e-4313-82d7-4d36f2e9537b",
+ "metadata": {},
+ "source": [
+ "Tell Ray to schedule the function"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c7f0c8a3-f456-4594-a994-0e5a528c3b78",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "square.remote(3)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a8f99486-6a85-4331-bed6-0af871974977",
+ "metadata": {},
+ "source": [
+ "`ObjectRef` is a handle to a task result. We get an ObjectRef immediately because we don't know\n",
+ "* when the task will run\n",
+ "* whether it will succeed\n",
+ "* whether we really need or want the result locally\n",
+ " * consider a very large result which we may need for other work but which we don't need to inspect"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3c939071-2454-4042-8136-75ffbbf6cce0",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ref = square.remote(3)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7928ca98-dc51-4ecf-b757-92996dd0c69a",
+ "metadata": {},
+ "source": [
+ "If we want to wait (block) and retrieve the corresponding object, we can use `ray.get`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a564c830-d30d-4d4c-adb5-ee12adee605b",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ray.get(ref)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4da412f5-133a-441b-8734-b96f56389f05",
+ "metadata": {},
+ "source": [
+ "\n",
+ " \n",
+ "__Activity: define and invoke a Ray task__\n",
+ "\n",
+ "* Define a function that takes a two params, takes the square-root of the first, then adds the second and returns the result\n",
+ "* Invoke it with 2 different sets of parameters and collect the results\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "effbdd51-ec87-4f2e-9d5f-79480c92a14c",
+ "metadata": {},
+ "source": [
+ "### Scheduling multiple tasks"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "327830ae-da4e-4de9-96e3-0cc55df827f9",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "def spin():\n",
+ " total = 0\n",
+ " for i in range(1000):\n",
+ " for j in range(1000):\n",
+ " total += i*j\n",
+ " return total"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3d40508d-73b3-4ea9-8b9c-38408d7a0c55",
+ "metadata": {},
+ "source": [
+ "If we want to run this task many times, we want to\n",
+ "* invoke `.remote` for all invocations\n",
+ "* *if we wish to `get` a result, invoke get on all of the ObjectRefs*"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4387a9d0-7633-4fb2-81e3-8cf81c5a12fe",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "%%time\n",
+ "\n",
+ "out = ray.get([spin.remote() for _ in range(48)])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c03e4922-d10a-44af-904c-f8a4a93eddef",
+ "metadata": {},
+ "source": [
+ "__Don't__ call `remote` to schedule each task, then block with a `get` on its result prior to scheduling the next task because then Ray can't run your work in parallel\n",
+ "\n",
+ "i.e., don't do this:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "bf3c66bb-5de2-4301-bdce-17c0edb2cd75",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "%%time\n",
+ "\n",
+ "out = [ray.get(spin.remote()) for _ in range(48)]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "10ae0d0e-0e9e-4697-863d-f8aabcff54d4",
+ "metadata": {},
+ "source": [
+ "### Task graphs\n",
+ "\n",
+ "The above example is a common scenario, but it is also the easiest (least complex) scheduling scenario. Each task is independent of the others -- this is called \"embarrassingly parallel\"\n",
+ "\n",
+ "Many real-world algorithms are not embarrassingly parallel: some tasks depend on results from one or more other tasks. Scheduling this graphs is more challenging.\n",
+ "\n",
+ "Ray Core is designed to make this straightforward"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f9fa826a-3be0-4094-8f4d-52bd8e9c9475",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "def add(a, b):\n",
+ " return a+b"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1df7dbfb-f287-4cf4-b7db-5566c90937c4",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "arg1 = square.remote(7)\n",
+ "\n",
+ "arg1"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b9cc0d91-33ec-4ded-a558-611cdf74e633",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "arg2 = square.remote(11)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "aabc0016-c1c3-4f4c-83cc-3fbbe9fbe9f5",
+ "metadata": {},
+ "source": [
+ "We want to schedule `add` which depends on two prior invocations of `square`\n",
+ "\n",
+ "We can pass the resulting ObjectRefs -- this means \n",
+ "* we don't have to wait for the dependencies to complete before we can set up `add` for scheduling\n",
+ "* we don't need to have the concrete parameters (Python objects) for the call to `add.remote`\n",
+ "* Ray will automatically resolve the ObjectRefs -- our `add` implementation will never know that we passed ObjectRefs, not, e.g., numbers"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "bbc22b7e-2b95-4e33-aae4-3f54ad9675e3",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "out = add.remote(arg1, arg2)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b7b1316f-e72d-4f62-872d-49dfd0491d2c",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ray.get(out)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "69945376-d63b-4834-b677-ad831d008a38",
+ "metadata": {},
+ "source": [
+ "If we happen to have concrete Python objects to pass -- instead of ObjectRefs -- we can use those. We can use any combination of objects and refs."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "41d6c412-0dad-44d1-b789-b6f6104caceb",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "out2 = add.remote(arg1, 15)\n",
+ "\n",
+ "ray.get(out2)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "996e52ca-737b-4050-8a75-66666de9c93e",
+ "metadata": {},
+ "source": [
+ "We can create more complex graphs by\n",
+ "- writing our code in the usual way\n",
+ "- decorating our functions with `@ray.remote`\n",
+ "- using `.remote` when we need to call a function\n",
+ "- using the resulting ObjectRefs and/or concrete values as parameters"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f027965c-d460-4bea-93c7-5806544742f1",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "def mult(a,b):\n",
+ " return a*b"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ef80603c-04a5-4a3d-8ec4-ef7ac55ae48b",
+ "metadata": {},
+ "source": [
+ "Here, we call\n",
+ "* Mult on the result of\n",
+ " * Square of 2 and\n",
+ " * the sum we get from calling Add on\n",
+ " * Square of 4 and\n",
+ " * Square of 5"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "55a98cc7-1611-42f1-b766-275fbf6177da",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "out3 = mult.remote(square.remote(2), add.remote(square.remote(4), square.remote(5)))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "abb7af59-5a80-4020-9c18-298a2f0163f0",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ray.get(out3)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "54dd226f-40f2-4ea7-8190-ea69632d0ae4",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "__Activity: task graph refactor__\n",
+ "\n",
+ "* Refactor the logic from your earlier Ray task (square-root and add) into two separate functions\n",
+ "* Invoke the square-root-and-add logic with without ever locally retrieving the result of the square-root calculation\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0f9fab1d-0f41-4175-a6cc-0161454d7718",
+ "metadata": {},
+ "source": [
+ "### Tasks can launch other tasks"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d131321a-7ac9-4a1e-8332-6c2808cde39b",
+ "metadata": {},
+ "source": [
+ "In that example, we organized or arranged the flow of tasks from our original process -- the Python kernel behind this notebook.\n",
+ "\n",
+ "Ray __does not__ require that all of your tasks and their dependencies by arranged from one \"driver\" process.\n",
+ "\n",
+ "Consider:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "39da2976-fccb-41bd-9ccc-2c2e2ff3106a",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "def sum_of_squares(arr):\n",
+ " return sum(ray.get([square.remote(val) for val in arr]))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f415fe45-c193-4fc0-8a2e-6bc8354d0145",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ray.get(sum_of_squares.remote([3,4,5]))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2840697c-f5d9-437b-8e67-72cfa69dbdb4",
+ "metadata": {},
+ "source": [
+ "In that example, \n",
+ "* our (local) process asked Ray to schedule one task -- a call to `sum_of_squares` -- which that started running somewhere in our cluster;\n",
+ "* within that task, additional code requested multiple additional tasks to be scheduled -- the call to `square` for each item in the list -- which were then scheduled in other locations;\n",
+ "* and when those latter tasks were complete, the our original task computed the sum and completed.\n",
+ "\n",
+ "This ability for tasks to schedule other tasks using uniform semantics makes Ray particularly powerful and flexible."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0d03e83b-bc22-424d-9501-f8aacbca4c60",
+ "metadata": {},
+ "source": [
+ "## Ray Actors\n",
+ "\n",
+ "Actors are Python class instances which can run for a long time in the cluster, which can maintain state, and which can send messages to/from other code.\n",
+ "\n",
+ "In these examples, we'll show the full power of Ray actors where they can mutate state -- but it is worth noting that a common use of actors is with state that is not mutated but is large enough that we may want to create or load it only once and ensure we can route calls to it over time, such as a large AI model"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0500f797-7c77-4e68-a3d0-32c00544ee19",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "class Accounting:\n",
+ " def __init__(self):\n",
+ " self.total = 0\n",
+ " \n",
+ " def add(self, amount):\n",
+ " self.total += amount\n",
+ " \n",
+ " def remove(self, amount):\n",
+ " self.total -= amount\n",
+ " \n",
+ " def total(self):\n",
+ " return self.total"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9ad7a2da-0411-4e77-a371-3583a21c949e",
+ "metadata": {},
+ "source": [
+ "Define an actor with the `@ray.remote` decorator and then use `\n",
+ "\n",
+ "__Activity: linear model inference__\n",
+ "\n",
+ "* Create an actor which applies a model to convert Celsius temperatures to Fahrenheit\n",
+ "* The constructor should take model weights (w1 and w0) and store them as instance state\n",
+ "* A convert method should take a scalar, multiply it by w1 then add w0 (weights retrieved from instance state) and then return the result\n",
+ "\n",
+ "Bonus activity:\n",
+ "* Instead of passing weights as constructor params, pass a filepath to the constructor. In the constructor, retrieve the weights from the path.\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e07a0efb-9fb4-46d6-84a1-c6dca88819e4",
+ "metadata": {},
+ "source": [
+ "And an actor can itself run remote tasks"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7d913914-f638-41dd-a07a-df1656761f12",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "class EnhancedAccounting:\n",
+ " def __init__(self):\n",
+ " self.total = 0\n",
+ " \n",
+ " def add(self, amount):\n",
+ " self.total += amount\n",
+ " \n",
+ " def remove(self, amount):\n",
+ " self.total -= amount\n",
+ " \n",
+ " def total(self):\n",
+ " return self.total\n",
+ " \n",
+ " def add_a_bunch(self, amount):\n",
+ " bigger_amount = square.remote(amount)\n",
+ " self.total += ray.get(bigger_amount)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a5e59cf3-b55e-487a-af35-0d3f599a6f81",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "acc = EnhancedAccounting.remote()\n",
+ "acc.add.remote(100)\n",
+ "acc.add_a_bunch.remote(5)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b2296434-0c89-435a-8baa-a61ad5ec25d1",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ray.get(acc.total.remote())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c04efe68-fe02-44ab-86c2-342e487c48dc",
+ "metadata": {},
+ "source": [
+ "An actor can also instantiate and use other actors"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "202f9f2a-009f-4807-9ec0-4e4e3375653d",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "class TaxAccounting:\n",
+ " def __init__(self):\n",
+ " self.total = 0\n",
+ " self.tax_account = Accounting.remote()\n",
+ " \n",
+ " def add(self, amount):\n",
+ " self.total += amount/2\n",
+ " self.tax_account.add.remote(amount/2)\n",
+ " \n",
+ " def remove(self, amount):\n",
+ " self.total -= amount\n",
+ " self.tax_account.remove.remote(amount/2)\n",
+ " \n",
+ " def total(self):\n",
+ " tax_total = ray.get(self.tax_account.total.remote())\n",
+ " return (self.total, tax_total)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f682efde-8b9b-4b5f-812f-4808c6bcf64b",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "acc = TaxAccounting.remote()\n",
+ "acc.add.remote(100)\n",
+ "acc.remove.remote(5)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d2350e1e-33ff-412f-8dd6-4c59805395fb",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ray.get(acc.total.remote())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5a089a83-266a-4863-9ed8-d0ff570b8011",
+ "metadata": {},
+ "source": [
+ "And this works regardless of which process creates the various actors.\n",
+ "\n",
+ "That is, above the `TaxAccounting` actor created an `Accounting` actor as a helper."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c3c8f5de-c913-4c2a-aebd-ec249602f7b7",
+ "metadata": {},
+ "source": [
+ "## `ray.put`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "eb5247c0-f083-4275-b14d-b3515d929615",
+ "metadata": {},
+ "source": [
+ "As we've seen the results of tasks are in the Ray object store and the caller gets an object ref which can be used for many purposed. If the caller needs the actual object -- e.g., to implement from conditional logic based on the value -- it can use `ray.get`\n",
+ "\n",
+ "In some cases, we may have a large object locally which we want to use in many Ray tasks.\n",
+ "\n",
+ "The best practice for this is to put the object into the object store (once) to obtain an object ref which we can then use many times.\n",
+ "\n",
+ "For example:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5fc2ad2c-f464-4ccf-bc65-f76269e503e3",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "def append(base, appendix):\n",
+ " return base + \" - \" + appendix"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "301adc4a-f492-4206-922a-d4566c5a80e2",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ray.get(append.remote(\"foo\", \"bar\"))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e4cdf3f9-c9e5-4a2b-b154-0653d2deb806",
+ "metadata": {},
+ "source": [
+ "Now let's pretend that the `base` doc is some very large document"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "fdeab370-e3f7-4c46-b10d-a4520f179a81",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "long_doc = \"\"\"It was the best of times, it was the worst of times, \n",
+ "it was the age of wisdom, it was the age of foolishness, it was the epoch of belief, it was the epoch of incredulity, \n",
+ "it was the season of Light, it was the season of Darkness, it was the spring of hope, it was the winter of despair, \n",
+ "we had everything before us, we had nothing before us, we were all going direct to Heaven, we were all going direct the other way\n",
+ "--in short, the period was so far like the present period that some of its noisiest authorities insisted on its being received, \n",
+ "for good or for evil, in the superlative degree of comparison only.\"\"\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b47011ea-18cb-4d33-ad7b-970a2ccd1c85",
+ "metadata": {},
+ "source": [
+ "We call `ray.put` to obtain a ref that we can use multiple times"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "eabfe5ef-bb3d-4c63-b524-91560416fe72",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "doc_ref = ray.put(long_doc)\n",
+ "doc_ref"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c73bb14e-16f3-482e-8897-eb603aef68db",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "append.remote(doc_ref, \" (Charles Dickens)\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7b3947e0-ac90-4b0b-a193-493b2aaa2a0f",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "append.remote(doc_ref, \" (Dickens 1859)\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "dc1ae098-de4c-49f8-8f29-370462ad12c1",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ray.get(append.remote(doc_ref, '(A Tale of Two Cities)'))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c397ada1-b3b5-4198-825a-220422fc7744",
+ "metadata": {},
+ "source": [
+ "__Note: if we passed the Python object handle -- or even implicitly used a handle that is in our current scope chain -- the code would succeed, but performance might suffer__\n",
+ "\n",
+ "E.g., this will work, but usually should be avoided when the object is large and/or used many times:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "684e6f98-945a-43ea-8bca-776ffa0eae04",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "append.remote(long_doc, \" (Dickens)\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "33e7d7f4-6ae4-478c-8141-8f17b246d67d",
+ "metadata": {},
+ "source": [
+ "this will also work ... but should also be avoided when the scope-chain object is large and/or used many times:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0bcd320b-94db-4714-a0a8-c8e458c33e19",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "def append_to_doc(appendix):\n",
+ " return long_doc + \" - \" + appendix"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c23e5ddd-747b-4b4b-b4a0-710266309efd",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "append_to_doc.remote('foo')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "92115e9a-dcb9-4760-816f-7497c25fb9b7",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "__Activity: object store and performance experiment__\n",
+ "\n",
+ "* Create a Ray task which uses NumPy to multiply a (square 2-D) array by itself and returns the sum of the resulting array\n",
+ "* Starting with a small array (10x10), see how large the array must be before we can see a difference between\n",
+ " * Using `ray.put` to place the array in the object store first, then supplying a reference to the Ray task\n",
+ " * Passing a handle to the array itself as the parameter to the task\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "83c48fdf-7664-46c7-bb91-5a8b14f0f920",
+ "metadata": {},
+ "source": [
+ "## Tracking the state of tasks\n",
+ "\n",
+ "If we just want to inspect the state of a task that may or may not have successfully completed, we can call `.future()` to convert into a future as defined in `concurrent.futures` (Python 3.6+)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "be424dcc-7919-4fa5-94de-73e7028ec7b5",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "s1 = square.remote(1)\n",
+ "\n",
+ "f = s1.future()\n",
+ "\n",
+ "f.done()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "19277999-63fa-4bdd-a738-e6b17dc4fae5",
+ "metadata": {},
+ "source": [
+ "By now it should be done"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5995cce4-71e0-4031-b0f5-70e85b75c240",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "f.done()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "cc5ee2a9-8315-4e34-a0e2-2f74c7774639",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "f.result()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "fd96d83d-18df-4ed6-8165-65caabf875f2",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "type(f)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "05459d0e-1719-4a3e-bf0a-72042517fbcc",
+ "metadata": {},
+ "source": [
+ "### Access to tasks as they are completed\n",
+ "\n",
+ "We may submit a number of tasks and want to access their results -- perhaps to start additional computations -- as they complete.\n",
+ "\n",
+ "That is, we don't want to wait for all of our initial tasks to finish, but we may need to wait for one or more to be done.\n",
+ "\n",
+ "`ray.wait` blocks until 1 or more of the submitted object refs are complete and then returns a tuple or done and not-done refs"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9f985cbf-6b87-4d02-96e1-a116ab80e7de",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "s2 = square.remote(2)\n",
+ "done, not_done = ray.wait([s1, s2])\n",
+ "\n",
+ "done"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9088c8f7-1100-49a9-911f-cc658e9b5518",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "not_done"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a2a6359c-e6e9-4b68-b56d-3cc3b1ca107f",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "If we need to wait for more than one task to complete, we can specify that with the `num_returns` parameter"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f45ae77a-b96b-46a4-9ffc-53c82d3500e7",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "task_refs = [square.remote(i) for i in range(10)]\n",
+ "\n",
+ "done, not_done = ray.wait(task_refs, num_returns=2)\n",
+ "\n",
+ "done"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "eaa39309-8f08-4e51-ab19-65999964819a",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "len(not_done)"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.10.14"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/templates/ray-summit-core-masterclass/bonus/2_task_lifecycle_deep_dive.ipynb b/templates/ray-summit-core-masterclass/bonus/2_task_lifecycle_deep_dive.ipynb
new file mode 100644
index 000000000..b36cefe65
--- /dev/null
+++ b/templates/ray-summit-core-masterclass/bonus/2_task_lifecycle_deep_dive.ipynb
@@ -0,0 +1,945 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "16b752be-c1a2-428b-be5c-bcd3fbaeaf50",
+ "metadata": {},
+ "source": [
+ "# Deep-dive into a Ray task's lifecycle\n",
+ "\n",
+ "In this notebook, we will provide a deep-dive into a Ray task's lifecycle. \n",
+ "\n",
+ "\n",
+ " \n",
+ "__Roadmap: Deep dive into a Ray task's lifecycle__\n",
+ "\n",
+ "1. High-Level Overview of a Task's Lifecycle\n",
+ "2. The Main Components of a Ray Cluster\n",
+ "3. Task Execution Stages in Detail:\n",
+ " 1. Mapping Execution Stages to Cluster Components\n",
+ " 2. Task Submission in Detail\n",
+ " 4. Autoscaling in Detail\n",
+ " 5. Task Scheduling in Detail\n",
+ " 6. Result Handling in Detail\n",
+ "4. Overview of Scheduling Strategies\n",
+ " 1. How does a raylet classify nodes?\n",
+ " 2. Default Scheduling Strategy\n",
+ " 3. Node Affinity Strategy\n",
+ " 4. SPREAD Scheduling Strategy\n",
+ " 5. Placement Group Scheduling Strategy\n",
+ "
\n",
+ "\n",
+ "Note in most cases, the notebook applies to Java, C++, and Python tasks. However certain remarks mainly focus on peculiarities of python tasks."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "df571bb5-5ef5-4a85-9106-429762fc3248",
+ "metadata": {},
+ "source": [
+ "# High-level overview of a task's lifecycle"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "964a4ab2-0760-4a1b-83de-00c08a27433e",
+ "metadata": {},
+ "source": [
+ "We start by visualizing a task's execution using the following diagram:\n",
+ "\n",
+ " \n",
+ "\n",
+ "In case you skipped it, this same diagram was presented in the high-level overview notebook of Ray tasks.\n",
+ "\n",
+ "We will proceed to add more color to this diagram providing useful details for each step of the process"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9065e725-7bb2-4fe9-8a54-78dc1f52eee5",
+ "metadata": {},
+ "source": [
+ "# The main components of a Ray cluster\n",
+ "\n",
+ "A Ray cluster consists of:\n",
+ "- One or more **worker nodes**, where each worker node consists of the following processes:\n",
+ " - **worker processes** responsible for task submission and execution.\n",
+ " - A **raylet** responsible for resource management and task placement.\n",
+ "- One of the worker nodes is designated a **head node** and is responsible for running \n",
+ " - A **global control service** responsible for keeping track of the **cluster-level state** that is not supposed to change too frequently.\n",
+ " - An **autoscaler** service responsible for allocating and removing worker nodes by integrating with different infrastructure providers (e.g. AWS, GCP, ...) to match the resource requirements of the cluster.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "In case you skipped it, this same diagram was presented in the high-level overview notebook of Ray tasks.\n",
+ "\n",
+ "We will proceed to add more color to this diagram providing useful details for each step of the process"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9065e725-7bb2-4fe9-8a54-78dc1f52eee5",
+ "metadata": {},
+ "source": [
+ "# The main components of a Ray cluster\n",
+ "\n",
+ "A Ray cluster consists of:\n",
+ "- One or more **worker nodes**, where each worker node consists of the following processes:\n",
+ " - **worker processes** responsible for task submission and execution.\n",
+ " - A **raylet** responsible for resource management and task placement.\n",
+ "- One of the worker nodes is designated a **head node** and is responsible for running \n",
+ " - A **global control service** responsible for keeping track of the **cluster-level state** that is not supposed to change too frequently.\n",
+ " - An **autoscaler** service responsible for allocating and removing worker nodes by integrating with different infrastructure providers (e.g. AWS, GCP, ...) to match the resource requirements of the cluster.\n",
+ "\n",
+ " \n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f1837554-89d5-46bb-9343-96d2bc125518",
+ "metadata": {},
+ "source": [
+ "# Task execution stages in detail"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "530ceb15-bd56-4078-9186-3a17adccde04",
+ "metadata": {},
+ "source": [
+ "## Mapping execution stages to cluster components"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "de2bdf5e-5d3b-4dca-a922-51c90fe84e24",
+ "metadata": {},
+ "source": [
+ "Now that we are familiar with the different components on a Ray cluster, here is our same task execution diagram revisited with colors indicating which component is responsible for each step.\n",
+ "\n",
+ "- One **worker process** submits the task\n",
+ "- The cluster **autoscaler** will handle upscaling nodes to meet new resource requirements\n",
+ "- **Raylet(s)** will handle task scheduling/placement on a worker\n",
+ "- **One worker process** executes the task\n",
+ "- The result information is sent back to the **submitter worker** once complete"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "313528c7-5685-4828-a5da-f45efcdbb186",
+ "metadata": {},
+ "source": [
+ "
\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f1837554-89d5-46bb-9343-96d2bc125518",
+ "metadata": {},
+ "source": [
+ "# Task execution stages in detail"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "530ceb15-bd56-4078-9186-3a17adccde04",
+ "metadata": {},
+ "source": [
+ "## Mapping execution stages to cluster components"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "de2bdf5e-5d3b-4dca-a922-51c90fe84e24",
+ "metadata": {},
+ "source": [
+ "Now that we are familiar with the different components on a Ray cluster, here is our same task execution diagram revisited with colors indicating which component is responsible for each step.\n",
+ "\n",
+ "- One **worker process** submits the task\n",
+ "- The cluster **autoscaler** will handle upscaling nodes to meet new resource requirements\n",
+ "- **Raylet(s)** will handle task scheduling/placement on a worker\n",
+ "- **One worker process** executes the task\n",
+ "- The result information is sent back to the **submitter worker** once complete"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "313528c7-5685-4828-a5da-f45efcdbb186",
+ "metadata": {},
+ "source": [
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e771bd14-45ab-4a01-ac9d-a85f246acb12",
+ "metadata": {},
+ "source": [
+ "## Task submission in detail"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8520fc88-a756-43e9-8ad3-ad457d4ea288",
+ "metadata": {},
+ "source": [
+ "### Exporting and loading function code"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8f9e8d8f-54c3-49d8-84f7-b073e06dba5c",
+ "metadata": {},
+ "source": [
+ "Remember a task wraps around a given function. The worker executing a task, is executing its underlying function.\n",
+ "\n",
+ "Here are the steps that Ray follows to export and load a task's function:\n",
+ "\n",
+ "1. The submitter worker will serialize a task's function definition\n",
+ " - In the case of Python, Ray makes use of a variant of pickle (cloudpickle) to serialize the function\n",
+ "2. The submitter worker will export the function definition to the GCS Store\n",
+ "3. The executor worker will load and cache the function definition from the GCS Store\n",
+ "4. The executor worker will deserialize the code and execute the function"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ff498cea-99fc-4619-b295-c5e1ee0fc6e8",
+ "metadata": {},
+ "source": [
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e771bd14-45ab-4a01-ac9d-a85f246acb12",
+ "metadata": {},
+ "source": [
+ "## Task submission in detail"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8520fc88-a756-43e9-8ad3-ad457d4ea288",
+ "metadata": {},
+ "source": [
+ "### Exporting and loading function code"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8f9e8d8f-54c3-49d8-84f7-b073e06dba5c",
+ "metadata": {},
+ "source": [
+ "Remember a task wraps around a given function. The worker executing a task, is executing its underlying function.\n",
+ "\n",
+ "Here are the steps that Ray follows to export and load a task's function:\n",
+ "\n",
+ "1. The submitter worker will serialize a task's function definition\n",
+ " - In the case of Python, Ray makes use of a variant of pickle (cloudpickle) to serialize the function\n",
+ "2. The submitter worker will export the function definition to the GCS Store\n",
+ "3. The executor worker will load and cache the function definition from the GCS Store\n",
+ "4. The executor worker will deserialize the code and execute the function"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ff498cea-99fc-4619-b295-c5e1ee0fc6e8",
+ "metadata": {},
+ "source": [
+ " \n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "00b76c87-2f76-4b49-94ef-b41b45c608e7",
+ "metadata": {},
+ "source": [
+ "### Resolving dependencies and data locality"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "310873ef-d5df-4c8e-95f5-0997bd698384",
+ "metadata": {},
+ "source": [
+ "Here are some key steps in task submission:\n",
+ "\n",
+ "1. A submitter worker will resolve a task's dependency locations before creating and submitting the task.\n",
+ "2. A submitter worker will choose the worker node that has most of the dependency data local to it.\n",
+ "3. A submitter worker will request what Ray calls a \"Worker Lease\" from the raylet on the chosen data-locality-optimal node"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "552d341d-8471-48af-b1b8-a9c68a04d37d",
+ "metadata": {},
+ "source": [
+ "
\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "00b76c87-2f76-4b49-94ef-b41b45c608e7",
+ "metadata": {},
+ "source": [
+ "### Resolving dependencies and data locality"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "310873ef-d5df-4c8e-95f5-0997bd698384",
+ "metadata": {},
+ "source": [
+ "Here are some key steps in task submission:\n",
+ "\n",
+ "1. A submitter worker will resolve a task's dependency locations before creating and submitting the task.\n",
+ "2. A submitter worker will choose the worker node that has most of the dependency data local to it.\n",
+ "3. A submitter worker will request what Ray calls a \"Worker Lease\" from the raylet on the chosen data-locality-optimal node"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "552d341d-8471-48af-b1b8-a9c68a04d37d",
+ "metadata": {},
+ "source": [
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "063e5323-3bd8-4cf9-aa9e-5b2db5520623",
+ "metadata": {},
+ "source": [
+ "let's unpack the above steps"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "bc0de1b1-0887-4d50-b2eb-f07b834eeda7",
+ "metadata": {},
+ "source": [
+ "#### Resolving dependencies in detail\n",
+ "\n",
+ "Given a particular task `task1` that depends on, objects `A` and `B` as inputs\n",
+ "\n",
+ "The submitter worker process will perform these two main steps\n",
+ "\n",
+ "1. Wait for each object to be available via async callbacks\n",
+ " - remember `A` and `B` could very well be the outputs of a different task, hence why we need to wait \n",
+ "2. Proceed with scheduling now that all dependencies are resolved\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "063e5323-3bd8-4cf9-aa9e-5b2db5520623",
+ "metadata": {},
+ "source": [
+ "let's unpack the above steps"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "bc0de1b1-0887-4d50-b2eb-f07b834eeda7",
+ "metadata": {},
+ "source": [
+ "#### Resolving dependencies in detail\n",
+ "\n",
+ "Given a particular task `task1` that depends on, objects `A` and `B` as inputs\n",
+ "\n",
+ "The submitter worker process will perform these two main steps\n",
+ "\n",
+ "1. Wait for each object to be available via async callbacks\n",
+ " - remember `A` and `B` could very well be the outputs of a different task, hence why we need to wait \n",
+ "2. Proceed with scheduling now that all dependencies are resolved\n",
+ "\n",
+ " \n",
+ "\n",
+ "Note: Later in the notebook we will discuss ray's distributed ownership and object store which will clarify how the worker can check if the objects are ready. \n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "59848ed9-8bd9-410e-93ed-262838613072",
+ "metadata": {},
+ "source": [
+ "#### Data locality resolution in detail\n",
+ "\n",
+ "The submitter process will choose the node that has the **most number of object argument bytes** already local.\n",
+ "\n",
+ "The diagram shows the same particular task `task1` we saw before. \n",
+ "\n",
+ "
\n",
+ "\n",
+ "Note: Later in the notebook we will discuss ray's distributed ownership and object store which will clarify how the worker can check if the objects are ready. \n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "59848ed9-8bd9-410e-93ed-262838613072",
+ "metadata": {},
+ "source": [
+ "#### Data locality resolution in detail\n",
+ "\n",
+ "The submitter process will choose the node that has the **most number of object argument bytes** already local.\n",
+ "\n",
+ "The diagram shows the same particular task `task1` we saw before. \n",
+ "\n",
+ " \n",
+ "\n",
+ "Note: Small caveat: \"enforcing data locality\" stage is skipped in case the task's specified scheduling policy is stringent (e.g. a node-affinity policy). Scheduling policies will be discussed in more detail later in the notebook.\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e3ab9247-07f5-4f45-a317-fd226e729a38",
+ "metadata": {},
+ "source": [
+ "## Task scheduling in detail"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fce112e4-a12a-4725-930b-0ab9608922c7",
+ "metadata": {},
+ "source": [
+ "Now that a worker lease request is sent, here are the steps that follow to schedule a task\n",
+ "\n",
+ "- The **raylet on the data-locality-optimal node**:\n",
+ " - Receives the worker lease request \n",
+ " - Receives a view of the entire cluster state from the GCS via a periodic broadcast\n",
+ " - Makes a decision: which node is the best to schedule the task on\n",
+ "- The **raylet on the best node** now:\n",
+ " - Attempts to reserve the resources on the node to satisfy the lease\n",
+ " - Updates the GCS in case it succeeds to reserve the resources via a periodic message\n",
+ " \n",
+ "This is shown in the below diagram, the potential autoscaling step prior to finding a best node is left out to simplify"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "334bdd22-9963-4369-a7a6-0212baca2810",
+ "metadata": {},
+ "source": [
+ "\n",
+ "
\n",
+ "\n",
+ "Note: Small caveat: \"enforcing data locality\" stage is skipped in case the task's specified scheduling policy is stringent (e.g. a node-affinity policy). Scheduling policies will be discussed in more detail later in the notebook.\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e3ab9247-07f5-4f45-a317-fd226e729a38",
+ "metadata": {},
+ "source": [
+ "## Task scheduling in detail"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fce112e4-a12a-4725-930b-0ab9608922c7",
+ "metadata": {},
+ "source": [
+ "Now that a worker lease request is sent, here are the steps that follow to schedule a task\n",
+ "\n",
+ "- The **raylet on the data-locality-optimal node**:\n",
+ " - Receives the worker lease request \n",
+ " - Receives a view of the entire cluster state from the GCS via a periodic broadcast\n",
+ " - Makes a decision: which node is the best to schedule the task on\n",
+ "- The **raylet on the best node** now:\n",
+ " - Attempts to reserve the resources on the node to satisfy the lease\n",
+ " - Updates the GCS in case it succeeds to reserve the resources via a periodic message\n",
+ " \n",
+ "This is shown in the below diagram, the potential autoscaling step prior to finding a best node is left out to simplify"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "334bdd22-9963-4369-a7a6-0212baca2810",
+ "metadata": {},
+ "source": [
+ "\n",
+ " \n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5863d0d3-a7be-4d2d-bc44-5fdec1615639",
+ "metadata": {},
+ "source": [
+ "### Scheduling hotpath: leveraging leases and caches\n",
+ "\n",
+ "- A scheduling request at task submission can reuse a leased worker if it has the same:\n",
+ " - Resource requirements as these must be acquired from the node during task execution.\n",
+ " - Shared-memory task arguments, as these must be made local on the node before task execution.\n",
+ "- This \"hot path\" most commonly occurs for **subsequent task executions**. We visualize it in the diagram below. Note how we skip:\n",
+ " - sending a request to a raylet altogether\n",
+ " - storing and fetching the function code in GCS"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9d1e8c3e-4950-4afb-884c-c36e8657c800",
+ "metadata": {},
+ "source": [
+ "
\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5863d0d3-a7be-4d2d-bc44-5fdec1615639",
+ "metadata": {},
+ "source": [
+ "### Scheduling hotpath: leveraging leases and caches\n",
+ "\n",
+ "- A scheduling request at task submission can reuse a leased worker if it has the same:\n",
+ " - Resource requirements as these must be acquired from the node during task execution.\n",
+ " - Shared-memory task arguments, as these must be made local on the node before task execution.\n",
+ "- This \"hot path\" most commonly occurs for **subsequent task executions**. We visualize it in the diagram below. Note how we skip:\n",
+ " - sending a request to a raylet altogether\n",
+ " - storing and fetching the function code in GCS"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9d1e8c3e-4950-4afb-884c-c36e8657c800",
+ "metadata": {},
+ "source": [
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8e540aed-7af5-4274-9a4a-c1193c308ca9",
+ "metadata": {},
+ "source": [
+ "## Autoscaling in detail\n",
+ "\n",
+ "- **Question**: What happens if a raylet fails to find a \"best node for a task\"? Imagine a task that is requesting GPU resources when all the running worker nodes are CPU only.\n",
+ "- **Answer**: The task gets stuck in a pending state until the autoscaler adds GPU nodes to the cluster.\n",
+ "\n",
+ "More specifically, here is how the autoscaling loop works:\n",
+ "\n",
+ "- The worker process submits tasks which request resources such as GPU.\n",
+ "- The raylet attempts to find the best node for the task.\n",
+ "- The raylet fails to find a node that satisfies the task requirements\n",
+ "- The GCS will periodically pull resource usage and receive resource updates from all the raylets\n",
+ "- The autoscaler will periodically fetch the snapshots from GCS.\n",
+ "- The autoscaler looks at the resources available in the cluster, resources requested, what is pending and calculates the number of nodes to satisfy both running and pending tasks.\n",
+ "- The autoscaler then adds or removes nodes from the cluster via the node provider interface (e.g. AWS interface)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "889ac2c6-5d9c-43ff-b156-0ce783861550",
+ "metadata": {},
+ "source": [
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8e540aed-7af5-4274-9a4a-c1193c308ca9",
+ "metadata": {},
+ "source": [
+ "## Autoscaling in detail\n",
+ "\n",
+ "- **Question**: What happens if a raylet fails to find a \"best node for a task\"? Imagine a task that is requesting GPU resources when all the running worker nodes are CPU only.\n",
+ "- **Answer**: The task gets stuck in a pending state until the autoscaler adds GPU nodes to the cluster.\n",
+ "\n",
+ "More specifically, here is how the autoscaling loop works:\n",
+ "\n",
+ "- The worker process submits tasks which request resources such as GPU.\n",
+ "- The raylet attempts to find the best node for the task.\n",
+ "- The raylet fails to find a node that satisfies the task requirements\n",
+ "- The GCS will periodically pull resource usage and receive resource updates from all the raylets\n",
+ "- The autoscaler will periodically fetch the snapshots from GCS.\n",
+ "- The autoscaler looks at the resources available in the cluster, resources requested, what is pending and calculates the number of nodes to satisfy both running and pending tasks.\n",
+ "- The autoscaler then adds or removes nodes from the cluster via the node provider interface (e.g. AWS interface)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "889ac2c6-5d9c-43ff-b156-0ce783861550",
+ "metadata": {},
+ "source": [
+ " \n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8ab2dccb-3420-482f-8d7a-53dbbe10c074",
+ "metadata": {},
+ "source": [
+ "## Result handling in detail"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "79cb730d-9308-4328-9cc6-b846f89c943e",
+ "metadata": {},
+ "source": [
+ "### Cluster components zoom-in"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "97b73d55-40c2-4af8-b04b-d62ea8012224",
+ "metadata": {},
+ "source": [
+ "Let's revisit our mental model for the Ray cluster and add some more detail to which components control and manage objects in Ray.\n",
+ "\n",
+ "- Each worker process stores:\n",
+ " - **An ownership table** contains system metadata (object sizes, locations and reference counts) for the objects to which the worker has a reference\n",
+ " - **An in-process store** used to store small objects.\n",
+ "- Each raylet runs:\n",
+ " - A **shared-memory object store** responsible for storing, transferring, and spilling large objects. The individual object stores in a cluster comprise the _Ray distributed object store_"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6e73764b-947b-4a7e-a0a4-00850d3a189d",
+ "metadata": {},
+ "source": [
+ "
\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8ab2dccb-3420-482f-8d7a-53dbbe10c074",
+ "metadata": {},
+ "source": [
+ "## Result handling in detail"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "79cb730d-9308-4328-9cc6-b846f89c943e",
+ "metadata": {},
+ "source": [
+ "### Cluster components zoom-in"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "97b73d55-40c2-4af8-b04b-d62ea8012224",
+ "metadata": {},
+ "source": [
+ "Let's revisit our mental model for the Ray cluster and add some more detail to which components control and manage objects in Ray.\n",
+ "\n",
+ "- Each worker process stores:\n",
+ " - **An ownership table** contains system metadata (object sizes, locations and reference counts) for the objects to which the worker has a reference\n",
+ " - **An in-process store** used to store small objects.\n",
+ "- Each raylet runs:\n",
+ " - A **shared-memory object store** responsible for storing, transferring, and spilling large objects. The individual object stores in a cluster comprise the _Ray distributed object store_"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6e73764b-947b-4a7e-a0a4-00850d3a189d",
+ "metadata": {},
+ "source": [
+ " \n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "070dd72b-48d0-4f41-8d87-ab6cc47a8207",
+ "metadata": {},
+ "source": [
+ "### Object handling post execution"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ab1da0a9-572b-460c-9ea6-a1ddda00bcca",
+ "metadata": {},
+ "source": [
+ "Let's take a look at the steps involved in object handling:\n",
+ "\n",
+ "- The submitter worker creates an object reference for the output of the task in its ownership table\n",
+ "- The submitter worker then submits the task for scheduling\n",
+ "- The executor worker will execute the task function\n",
+ "- The executor worker will then prepare the return object\n",
+ " - If the return object is small <100KB:\n",
+ " - Return the values inline directly to the submitter's in-process object store.\n",
+ " - If the return object is large:\n",
+ " - Store the objects in the raylet object store\n",
+ "- The executor updates the submitter's ownership table with the location of the object"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a33201b6-6850-47ff-97da-48dbb9c82313",
+ "metadata": {},
+ "source": [
+ "\n",
+ "
\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "070dd72b-48d0-4f41-8d87-ab6cc47a8207",
+ "metadata": {},
+ "source": [
+ "### Object handling post execution"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ab1da0a9-572b-460c-9ea6-a1ddda00bcca",
+ "metadata": {},
+ "source": [
+ "Let's take a look at the steps involved in object handling:\n",
+ "\n",
+ "- The submitter worker creates an object reference for the output of the task in its ownership table\n",
+ "- The submitter worker then submits the task for scheduling\n",
+ "- The executor worker will execute the task function\n",
+ "- The executor worker will then prepare the return object\n",
+ " - If the return object is small <100KB:\n",
+ " - Return the values inline directly to the submitter's in-process object store.\n",
+ " - If the return object is large:\n",
+ " - Store the objects in the raylet object store\n",
+ "- The executor updates the submitter's ownership table with the location of the object"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a33201b6-6850-47ff-97da-48dbb9c82313",
+ "metadata": {},
+ "source": [
+ "\n",
+ " \n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "06a2ca85-2a78-467c-aa56-f80cf23c40a6",
+ "metadata": {},
+ "source": [
+ "### Distributed ownership work in Ray\n",
+ "\n",
+ "#### How does it work?\n",
+ "The process that submits a task is considered to be the owner of the result of the task"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d65c4990-a466-4044-8f81-edc649a8d3e5",
+ "metadata": {},
+ "source": [
+ "
\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "06a2ca85-2a78-467c-aa56-f80cf23c40a6",
+ "metadata": {},
+ "source": [
+ "### Distributed ownership work in Ray\n",
+ "\n",
+ "#### How does it work?\n",
+ "The process that submits a task is considered to be the owner of the result of the task"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d65c4990-a466-4044-8f81-edc649a8d3e5",
+ "metadata": {},
+ "source": [
+ " \n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "89923e26-9910-43a6-a991-757f07917d0d",
+ "metadata": {},
+ "source": [
+ "#### Upsides to distributed ownership\n",
+ "\n",
+ "- Latency: Faster than communicating all ownership information back to a head node.\n",
+ "- Scalability: There is no central bottleneck when attempting to scale the cluster given every worker maintains its own ownership information."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f48a0ba6-de22-4168-971a-ea0b8f465026",
+ "metadata": {},
+ "source": [
+ "#### Downsides to distributed ownership\n",
+ "\n",
+ "- objects fate-share with their owner\n",
+ " - i.e. even though the object is available on an object store in node 2, if node 1 fails, the owner fails, and the object is no longer reachable"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9f19405b-3a65-4b01-9670-60dbaf33b3c3",
+ "metadata": {},
+ "source": [
+ "
\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "89923e26-9910-43a6-a991-757f07917d0d",
+ "metadata": {},
+ "source": [
+ "#### Upsides to distributed ownership\n",
+ "\n",
+ "- Latency: Faster than communicating all ownership information back to a head node.\n",
+ "- Scalability: There is no central bottleneck when attempting to scale the cluster given every worker maintains its own ownership information."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f48a0ba6-de22-4168-971a-ea0b8f465026",
+ "metadata": {},
+ "source": [
+ "#### Downsides to distributed ownership\n",
+ "\n",
+ "- objects fate-share with their owner\n",
+ " - i.e. even though the object is available on an object store in node 2, if node 1 fails, the owner fails, and the object is no longer reachable"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9f19405b-3a65-4b01-9670-60dbaf33b3c3",
+ "metadata": {},
+ "source": [
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "38a04790-a38f-4e56-aa8a-cdcbbc795dcf",
+ "metadata": {},
+ "source": [
+ "### Distributed object store\n",
+ "\n",
+ "The raylet's object store can be thought of as shared memory across all workers on a node.\n",
+ "\n",
+ "For values that can be zero-copy deserialized, passing the ObjectRef to `ray.get` or as a task argument will return a direct pointer to the shared memory buffer to the worker."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "aa8fc3c1-f86e-4157-86d6-73a93e41acfe",
+ "metadata": {},
+ "source": [
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "38a04790-a38f-4e56-aa8a-cdcbbc795dcf",
+ "metadata": {},
+ "source": [
+ "### Distributed object store\n",
+ "\n",
+ "The raylet's object store can be thought of as shared memory across all workers on a node.\n",
+ "\n",
+ "For values that can be zero-copy deserialized, passing the ObjectRef to `ray.get` or as a task argument will return a direct pointer to the shared memory buffer to the worker."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "aa8fc3c1-f86e-4157-86d6-73a93e41acfe",
+ "metadata": {},
+ "source": [
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "dc916b30-6ab0-47e0-b587-b6db4b43e4dd",
+ "metadata": {},
+ "source": [
+ "#### Downside to a shared object-store\n",
+ "\n",
+ "This also means that \"worker\" processes fate-share with their local raylet process.\n",
+ "\n",
+ "A simple mental model to have is `raylet = node` if a raylet fails, all workloads on node will fail "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "75a11ba7-2e48-49f0-9f8c-f17dbc4d3e79",
+ "metadata": {},
+ "source": [
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "dc916b30-6ab0-47e0-b587-b6db4b43e4dd",
+ "metadata": {},
+ "source": [
+ "#### Downside to a shared object-store\n",
+ "\n",
+ "This also means that \"worker\" processes fate-share with their local raylet process.\n",
+ "\n",
+ "A simple mental model to have is `raylet = node` if a raylet fails, all workloads on node will fail "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "75a11ba7-2e48-49f0-9f8c-f17dbc4d3e79",
+ "metadata": {},
+ "source": [
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5d18be57-14d8-4ac8-bc97-9dd2103f5b83",
+ "metadata": {},
+ "source": [
+ "# Overview of scheduling strategies"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0946813d-9312-4e63-9872-7d9c9e14bc96",
+ "metadata": {},
+ "source": [
+ "Ray provides different scheduling strategies that you can set on your task.\n",
+ "\n",
+ "We will go over:\n",
+ "- How a raylet assess feasibility and availability of nodes\n",
+ "- How every scheduling strategy/policy works and when you should use it"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "38ee7a35-f5d1-428d-a3e1-a66c4407fb98",
+ "metadata": {},
+ "source": [
+ "## Node classification\n",
+ "\n",
+ "Given a resource requirement, a raylet classifies a node as one of the following:\n",
+ "- feasible\n",
+ " - available\n",
+ " - not available\n",
+ "- infeasible node \n",
+ "\n",
+ "Let's understand this by looking at an example task `my_task` that has a resource requirement of 3 CPUs:\n",
+ "\n",
+ "- all nodes with >= 3 CPUs are classified as **feasible**\n",
+ " - all **feasible nodes** that have >= 3 CPUs **idle** are classified as **available**"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "007b8d8d-cb3e-49c9-baf9-55aae5a1b8bd",
+ "metadata": {},
+ "source": [
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5d18be57-14d8-4ac8-bc97-9dd2103f5b83",
+ "metadata": {},
+ "source": [
+ "# Overview of scheduling strategies"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0946813d-9312-4e63-9872-7d9c9e14bc96",
+ "metadata": {},
+ "source": [
+ "Ray provides different scheduling strategies that you can set on your task.\n",
+ "\n",
+ "We will go over:\n",
+ "- How a raylet assess feasibility and availability of nodes\n",
+ "- How every scheduling strategy/policy works and when you should use it"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "38ee7a35-f5d1-428d-a3e1-a66c4407fb98",
+ "metadata": {},
+ "source": [
+ "## Node classification\n",
+ "\n",
+ "Given a resource requirement, a raylet classifies a node as one of the following:\n",
+ "- feasible\n",
+ " - available\n",
+ " - not available\n",
+ "- infeasible node \n",
+ "\n",
+ "Let's understand this by looking at an example task `my_task` that has a resource requirement of 3 CPUs:\n",
+ "\n",
+ "- all nodes with >= 3 CPUs are classified as **feasible**\n",
+ " - all **feasible nodes** that have >= 3 CPUs **idle** are classified as **available**"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "007b8d8d-cb3e-49c9-baf9-55aae5a1b8bd",
+ "metadata": {},
+ "source": [
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9755b82f-b86d-4e47-ac4f-5c9238dca42c",
+ "metadata": {},
+ "source": [
+ "## Default scheduling strategy\n",
+ "\n",
+ "This is the default scheduling policy used by Ray\n",
+ "\n",
+ "### Motivation\n",
+ "\n",
+ "Ray attempts to strike a balance between favoring nodes that already cater for data locality and favoring those that have low resource utilization.\n",
+ "\n",
+ "### How does it work?\n",
+ "It is a hybrid policy that combines the following two heuristics:\n",
+ "- Bin packing heuristic\n",
+ "- Load balancing heuristic\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "aa50e575-7810-4762-92c5-ba307c64f1bb",
+ "metadata": {},
+ "source": [
+ "The diagram below shows the policy in action in a bin-packing heuristic/mode\n",
+ "\n",
+ "Note the **Local Node** shown in the diagram is the node that is local to the raylet that received the worker lease request - which in almost all cases is the raylet that satisfies data locality requirements."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "cbc93fb1-0036-4328-902a-fccb85a4afa8",
+ "metadata": {},
+ "source": [
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9755b82f-b86d-4e47-ac4f-5c9238dca42c",
+ "metadata": {},
+ "source": [
+ "## Default scheduling strategy\n",
+ "\n",
+ "This is the default scheduling policy used by Ray\n",
+ "\n",
+ "### Motivation\n",
+ "\n",
+ "Ray attempts to strike a balance between favoring nodes that already cater for data locality and favoring those that have low resource utilization.\n",
+ "\n",
+ "### How does it work?\n",
+ "It is a hybrid policy that combines the following two heuristics:\n",
+ "- Bin packing heuristic\n",
+ "- Load balancing heuristic\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "aa50e575-7810-4762-92c5-ba307c64f1bb",
+ "metadata": {},
+ "source": [
+ "The diagram below shows the policy in action in a bin-packing heuristic/mode\n",
+ "\n",
+ "Note the **Local Node** shown in the diagram is the node that is local to the raylet that received the worker lease request - which in almost all cases is the raylet that satisfies data locality requirements."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "cbc93fb1-0036-4328-902a-fccb85a4afa8",
+ "metadata": {},
+ "source": [
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "637ed34d-1d44-4b58-bbd0-3641f7c365cd",
+ "metadata": {},
+ "source": [
+ "The diagram below shows the policy in action in a load balancing heuristic. \n",
+ "\n",
+ "This occurs when our preferred local node is heavily being utilized. The strategy will now spread new tasks among other feasible and available nodes.\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "637ed34d-1d44-4b58-bbd0-3641f7c365cd",
+ "metadata": {},
+ "source": [
+ "The diagram below shows the policy in action in a load balancing heuristic. \n",
+ "\n",
+ "This occurs when our preferred local node is heavily being utilized. The strategy will now spread new tasks among other feasible and available nodes.\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ec2d5f03-2742-45e0-9939-e4300c98e748",
+ "metadata": {},
+ "source": [
+ "## SPREAD scheduling strategy\n",
+ "\n",
+ "### How does it work?\n",
+ "It behaves like a best-effort round-robin. It spreads across all the available nodes first and then the feasible nodes.\n",
+ "\n",
+ "### Use-cases\n",
+ "- When you want to load-balance your tasks across nodes. e.g. you are building a web service and want to avoid overloading certain nodes.\n",
+ "\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "91c1a5e4-2aae-462d-b4c3-f71280568ec5",
+ "metadata": {},
+ "source": [
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ec2d5f03-2742-45e0-9939-e4300c98e748",
+ "metadata": {},
+ "source": [
+ "## SPREAD scheduling strategy\n",
+ "\n",
+ "### How does it work?\n",
+ "It behaves like a best-effort round-robin. It spreads across all the available nodes first and then the feasible nodes.\n",
+ "\n",
+ "### Use-cases\n",
+ "- When you want to load-balance your tasks across nodes. e.g. you are building a web service and want to avoid overloading certain nodes.\n",
+ "\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "91c1a5e4-2aae-462d-b4c3-f71280568ec5",
+ "metadata": {},
+ "source": [
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6dfbf117-865f-4b6f-88f6-6c9671ffa172",
+ "metadata": {},
+ "source": [
+ "### Sample code"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1610bdc8-ab5e-4de4-9a03-12f6609a0687",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import ray\n",
+ "\n",
+ "\n",
+ "@ray.remote(scheduling_strategy=\"SPREAD\")\n",
+ "def spread_default_func():\n",
+ " return 2\n",
+ "\n",
+ "\n",
+ "ray.get(spread_default_func.remote())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8fbf3515-9c48-42a3-a61f-83d722dc7aee",
+ "metadata": {},
+ "source": [
+ "## Placement Group Scheduling Strategy\n",
+ "\n",
+ "In cases when we want to treat a set of resources as a single unit, we can use placement groups.\n",
+ "\n",
+ "### How does it work?\n",
+ "\n",
+ "- A **placement group** is formed from a set of **resource bundles**\n",
+ " - A **resource bundle** is a list of resource requirements that fit in a single node\n",
+ "- A **placement group** can specify a **placement strategy** that determines how the **resource bundles** are placed\n",
+ " - The **placement strategy** can be one of the following:\n",
+ " - **PACK**: pack the **resource bundles** into as few nodes as possible\n",
+ " - **SPREAD**: spread the **resource bundles** across as many nodes as possible\n",
+ " - **STRICT_PACK**: pack the **resource bundles** into as few nodes as possible and fail if not possible\n",
+ " - **STRICT_SPREAD**: spread the **resource bundles** across as many nodes as possible and fail if not possible\n",
+ "- **Placement Groups** are **atomic** \n",
+ " - i.e. either all the **resource bundles** are placed or none are placed\n",
+ " - GCS uses a two-phase commit protocol to ensure atomicity\n",
+ "\n",
+ "### Use-cases\n",
+ "\n",
+ "Placement groups are used for **atomic gang scheduling**. Imagine the use case of a distributed training that requires 4 GPU nodes total. Other distributed schedulers might first reserve 3 GPUs and hang waiting for the fourth hogging resources in the meantime. Ray, instead, will either reserve all 4 GPUs or it will fail scheduling.\n",
+ "\n",
+ "- Use SPREAD when you want to load-balance your tasks across nodes. e.g. you are building a web service and want to avoid overloading certain nodes.\n",
+ "- Use PACK when you want to maximize resource utilization. e.g. you are running training and want to cut costs by packing all your resource bundles on a small subset of nodes.\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "bd86af99-9c06-4a9c-b73b-0c9f1d1cbe94",
+ "metadata": {},
+ "source": [
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6dfbf117-865f-4b6f-88f6-6c9671ffa172",
+ "metadata": {},
+ "source": [
+ "### Sample code"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1610bdc8-ab5e-4de4-9a03-12f6609a0687",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import ray\n",
+ "\n",
+ "\n",
+ "@ray.remote(scheduling_strategy=\"SPREAD\")\n",
+ "def spread_default_func():\n",
+ " return 2\n",
+ "\n",
+ "\n",
+ "ray.get(spread_default_func.remote())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8fbf3515-9c48-42a3-a61f-83d722dc7aee",
+ "metadata": {},
+ "source": [
+ "## Placement Group Scheduling Strategy\n",
+ "\n",
+ "In cases when we want to treat a set of resources as a single unit, we can use placement groups.\n",
+ "\n",
+ "### How does it work?\n",
+ "\n",
+ "- A **placement group** is formed from a set of **resource bundles**\n",
+ " - A **resource bundle** is a list of resource requirements that fit in a single node\n",
+ "- A **placement group** can specify a **placement strategy** that determines how the **resource bundles** are placed\n",
+ " - The **placement strategy** can be one of the following:\n",
+ " - **PACK**: pack the **resource bundles** into as few nodes as possible\n",
+ " - **SPREAD**: spread the **resource bundles** across as many nodes as possible\n",
+ " - **STRICT_PACK**: pack the **resource bundles** into as few nodes as possible and fail if not possible\n",
+ " - **STRICT_SPREAD**: spread the **resource bundles** across as many nodes as possible and fail if not possible\n",
+ "- **Placement Groups** are **atomic** \n",
+ " - i.e. either all the **resource bundles** are placed or none are placed\n",
+ " - GCS uses a two-phase commit protocol to ensure atomicity\n",
+ "\n",
+ "### Use-cases\n",
+ "\n",
+ "Placement groups are used for **atomic gang scheduling**. Imagine the use case of a distributed training that requires 4 GPU nodes total. Other distributed schedulers might first reserve 3 GPUs and hang waiting for the fourth hogging resources in the meantime. Ray, instead, will either reserve all 4 GPUs or it will fail scheduling.\n",
+ "\n",
+ "- Use SPREAD when you want to load-balance your tasks across nodes. e.g. you are building a web service and want to avoid overloading certain nodes.\n",
+ "- Use PACK when you want to maximize resource utilization. e.g. you are running training and want to cut costs by packing all your resource bundles on a small subset of nodes.\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "bd86af99-9c06-4a9c-b73b-0c9f1d1cbe94",
+ "metadata": {},
+ "source": [
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9553a1dc-a980-42f6-a542-48974140578a",
+ "metadata": {},
+ "source": [
+ "### Example Code"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7fbf1929-0bcc-4abf-a372-e09eea922907",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import ray\n",
+ "from ray.util.scheduling_strategies import PlacementGroupSchedulingStrategy\n",
+ "from ray.util.placement_group import (\n",
+ " placement_group,\n",
+ " placement_group_table,\n",
+ " remove_placement_group,\n",
+ ")\n",
+ "\n",
+ "# Reserve a placement group of 1 bundle that reserves 0.1 CPU\n",
+ "pg = placement_group([{\"CPU\": 0.1}], strategy=\"PACK\", name=\"my_pg\")\n",
+ "\n",
+ "# Wait until placement group is created.\n",
+ "ray.get(pg.ready(), timeout=10)\n",
+ "\n",
+ "# Inspect placement group states using the table\n",
+ "print(placement_group_table(pg))\n",
+ "\n",
+ "\n",
+ "@ray.remote(\n",
+ " scheduling_strategy=PlacementGroupSchedulingStrategy(\n",
+ " placement_group=pg,\n",
+ " ),\n",
+ " # task requirement needs to be less than placement group capacity\n",
+ " num_cpus=0.1,\n",
+ ")\n",
+ "def placement_group_schedule():\n",
+ " return 2\n",
+ "\n",
+ "\n",
+ "out = ray.get(placement_group_schedule.remote())\n",
+ "print(out)\n",
+ "\n",
+ "# Remove placement group.\n",
+ "remove_placement_group(pg)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f1358afc-669c-4ea7-a873-e5747fbec9a2",
+ "metadata": {},
+ "source": [
+ "## Node affinity strategy\n",
+ "\n",
+ "### How does it work?\n",
+ "It assigns a task to a given node in either a strict or soft manner.\n",
+ "\n",
+ "### Use-cases\n",
+ "- When you want to ensure that your task runs on a specific node\n",
+ "\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b3e958ad-4d1f-4513-be26-524b9d3e7958",
+ "metadata": {},
+ "source": [
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9553a1dc-a980-42f6-a542-48974140578a",
+ "metadata": {},
+ "source": [
+ "### Example Code"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7fbf1929-0bcc-4abf-a372-e09eea922907",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import ray\n",
+ "from ray.util.scheduling_strategies import PlacementGroupSchedulingStrategy\n",
+ "from ray.util.placement_group import (\n",
+ " placement_group,\n",
+ " placement_group_table,\n",
+ " remove_placement_group,\n",
+ ")\n",
+ "\n",
+ "# Reserve a placement group of 1 bundle that reserves 0.1 CPU\n",
+ "pg = placement_group([{\"CPU\": 0.1}], strategy=\"PACK\", name=\"my_pg\")\n",
+ "\n",
+ "# Wait until placement group is created.\n",
+ "ray.get(pg.ready(), timeout=10)\n",
+ "\n",
+ "# Inspect placement group states using the table\n",
+ "print(placement_group_table(pg))\n",
+ "\n",
+ "\n",
+ "@ray.remote(\n",
+ " scheduling_strategy=PlacementGroupSchedulingStrategy(\n",
+ " placement_group=pg,\n",
+ " ),\n",
+ " # task requirement needs to be less than placement group capacity\n",
+ " num_cpus=0.1,\n",
+ ")\n",
+ "def placement_group_schedule():\n",
+ " return 2\n",
+ "\n",
+ "\n",
+ "out = ray.get(placement_group_schedule.remote())\n",
+ "print(out)\n",
+ "\n",
+ "# Remove placement group.\n",
+ "remove_placement_group(pg)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f1358afc-669c-4ea7-a873-e5747fbec9a2",
+ "metadata": {},
+ "source": [
+ "## Node affinity strategy\n",
+ "\n",
+ "### How does it work?\n",
+ "It assigns a task to a given node in either a strict or soft manner.\n",
+ "\n",
+ "### Use-cases\n",
+ "- When you want to ensure that your task runs on a specific node\n",
+ "\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b3e958ad-4d1f-4513-be26-524b9d3e7958",
+ "metadata": {},
+ "source": [
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c66136a5-980f-455c-b97a-28e29597a49a",
+ "metadata": {},
+ "source": [
+ "### Sample code"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f2f9ad3f-ce48-4579-a58b-023409575197",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def find_a_node_with(resource, amount):\n",
+ " for node in ray.nodes():\n",
+ " if resource in node['Resources'] and node['Resources'][resource] >= amount:\n",
+ " return node\n",
+ " return None"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c2c03228-23bf-464e-a895-ce752a03401b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "node = find_a_node_with('CPU', 1)\n",
+ "\n",
+ "node"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "61371ae5-ffa8-48a0-b4e0-be5378c7874a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import ray\n",
+ "from ray.util.scheduling_strategies import NodeAffinitySchedulingStrategy\n",
+ "\n",
+ "# pin this task to only run on the current node id\n",
+ "run_on_same_node = NodeAffinitySchedulingStrategy(\n",
+ " node_id=node['NodeID'], \n",
+ " soft=False,\n",
+ ")\n",
+ "\n",
+ "@ray.remote(\n",
+ " scheduling_strategy=run_on_same_node\n",
+ ")\n",
+ "def node_affinity_schedule():\n",
+ " return 2\n",
+ "\n",
+ "\n",
+ "ray.get(node_affinity_schedule.remote())"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "55ff64bc-f5c5-4278-b193-1311ad612f84",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/templates/ray-summit-core-masterclass/data/file_1.txt b/templates/ray-summit-core-masterclass/data/file_1.txt
new file mode 100644
index 000000000..4013ed536
--- /dev/null
+++ b/templates/ray-summit-core-masterclass/data/file_1.txt
@@ -0,0 +1,10 @@
+ 0, 48, 72, 75, 54, 89, 84, 68, 9, 38
+ 3, 40, 73, 58, 10, 35, 96, 6, 65, 33
+ 55, 67, 12, 97, 52, 73, 7, 76, 39, 50
+ 59, 34, 20, 40, 92, 55, 11, 39, 93, 38
+ 89, 89, 37, 52, 48, 86, 49, 3, 19, 50
+ 84, 37, 68, 11, 20, 36, 46, 61, 52, 77
+ 70, 90, 56, 55, 49, 76, 94, 28, 32, 23
+ 5, 44, 92, 15, 53, 63, 87, 75, 61, 25
+ 51, 58, 29, 30, 93, 94, 52, 72, 80, 27
+ 1, 28, 82, 35, 89, 36, 10, 84, 85, 65
diff --git a/templates/ray-summit-core-masterclass/data/file_2.txt b/templates/ray-summit-core-masterclass/data/file_2.txt
new file mode 100644
index 000000000..99b0feff6
--- /dev/null
+++ b/templates/ray-summit-core-masterclass/data/file_2.txt
@@ -0,0 +1,10 @@
+101, 31, 83,124, 41, 73, 0,121, 14, 98
+137, 3, 77, 38,117, 79,104, 96, 62,117
+ 99, 92,139, 29, 59, 30,116, 30, 74, 12
+130,105,145,124, 39, 50, 66, 9,126, 24
+ 32, 33, 34, 90, 43,140,136,149,140, 22
+ 14, 8,138,101,136, 60, 41,110, 92,105
+ 44, 76,104, 6,121,135, 41,132,131, 26
+ 1, 1,112, 45,146, 29, 44,104, 75,122
+132, 63, 70,109, 49, 75, 33, 36, 38,105
+131, 71, 51, 79,109,146, 71, 27, 65,126
diff --git a/templates/ray-summit-core-masterclass/model_helper_utils.py b/templates/ray-summit-core-masterclass/model_helper_utils.py
new file mode 100644
index 000000000..0896e8106
--- /dev/null
+++ b/templates/ray-summit-core-masterclass/model_helper_utils.py
@@ -0,0 +1,198 @@
+import time
+from typing import Dict, Any
+
+import ray
+import xgboost as xgb
+from sklearn.datasets import fetch_california_housing
+from sklearn.ensemble import RandomForestRegressor
+from sklearn.metrics import mean_squared_error
+from sklearn.model_selection import train_test_split
+from sklearn.tree import DecisionTreeRegressor
+
+# states to inspect
+STATES = ["INITIALIZED", "RUNNING", "DONE"]
+
+DECISION_TREE_CONFIGS = {"max_depth": 10, "name": "decision_tree"}
+
+RANDOM_FOREST_CONFIGS = {"n_estimators": 25, "name": "random_forest"}
+
+XGBOOST_CONFIGS = {
+ "max_depth": 10,
+ "n_estimators": 25,
+ "lr": 0.1,
+ "eta": 0.3,
+ "colsample_bytree": 1,
+ "name": "xgboost",
+}
+
+# dataset
+X_data, y_data = fetch_california_housing(return_X_y=True, as_frame=True)
+
+
+class ActorCls:
+ """
+ Base class for our Ray Actor workers models
+ """
+
+ def __init__(self, configs: Dict[Any, Any]) -> None:
+ self.configs = configs
+ self.name = configs["name"]
+ self.state = STATES[0]
+ self.X_train, self.X_test, self.y_train, self.y_test = train_test_split(
+ X_data, y_data, test_size=0.2, random_state=4
+ )
+
+ self.model = None
+
+ def get_name(self) -> str:
+ return self.name
+
+ def get_state(self) -> str:
+ return self.state
+
+ def train_and_evaluate_model(self) -> Dict[Any, Any]:
+ """
+ Overwrite this function in super class
+ """
+ pass
+
+
+@ray.remote
+class RFRActor(ActorCls):
+ """
+ An actor model to train and score the calfornia house data using Random Forest Regressor
+ """
+
+ def __init__(self, configs):
+ super().__init__(configs)
+ self.estimators = configs["n_estimators"]
+
+ def train_and_evaluate_model(self) -> Dict[Any, Any]:
+ """
+ Train the model and evaluate and report MSE
+ """
+
+ self.model = RandomForestRegressor(
+ n_estimators=self.estimators, random_state=42
+ )
+
+ print(
+ f"Start training model {self.name} with estimators: {self.estimators} ..."
+ )
+
+ start_time = time.time()
+ self.model.fit(self.X_train, self.y_train)
+ self.state = STATES[1]
+ y_pred = self.model.predict(self.X_test)
+ score = mean_squared_error(self.y_test, y_pred)
+ self.state = STATES[2]
+
+ end_time = time.time()
+ print(
+ f"End training model {self.name} with estimators: {self.estimators} took: {end_time - start_time:.2f} seconds"
+ )
+
+ return {
+ "state": self.get_state(),
+ "name": self.get_name(),
+ "estimators": self.estimators,
+ "mse": round(score, 4),
+ "time": round(end_time - start_time, 2),
+ }
+
+
+@ray.remote
+class DTActor(ActorCls):
+ """
+ An actor model to train and score the calfornia house data using Decision Tree Regressor
+ """
+
+ def __init__(self, configs):
+ super().__init__(configs)
+ self.max_depth = configs["max_depth"]
+
+ def train_and_evaluate_model(self) -> Dict[Any, Any]:
+ """
+ Train the model and evaluate and report MSE
+ """
+
+ self.model = DecisionTreeRegressor(max_depth=self.max_depth, random_state=42)
+
+ print(
+ f"Start training model {self.name} with max depth: { self.max_depth } ..."
+ )
+
+ start_time = time.time()
+ self.model.fit(self.X_train, self.y_train)
+ self.state = STATES[1]
+ y_pred = self.model.predict(self.X_test)
+ score = mean_squared_error(self.y_test, y_pred)
+ self.state = STATES[2]
+
+ end_time = time.time()
+ print(
+ f"End training model {self.name} with max_depth tree: {self.max_depth} took: {end_time - start_time:.2f} seconds"
+ )
+
+ return {
+ "state": self.get_state(),
+ "name": self.get_name(),
+ "max_depth": self.max_depth,
+ "mse": round(score, 4),
+ "time": round(end_time - start_time, 2),
+ }
+
+
+@ray.remote
+class XGBoostActor(ActorCls):
+ """
+ An actor model to train and score the calfornia house data using XGBoost Regressor
+ """
+
+ def __init__(self, configs):
+ super().__init__(configs)
+
+ self.max_depth = configs["max_depth"]
+ self.estimators = configs["n_estimators"]
+ self.colsample = configs["colsample_bytree"]
+ self.eta = configs["eta"]
+ self.lr = configs["lr"]
+
+ def train_and_evaluate_model(self) -> Dict[Any, Any]:
+ """
+ Train the model and evaluate and report MSE
+ """
+
+ self.model = xgb.XGBRegressor(
+ objective="reg:squarederror",
+ colsample_bytree=self.colsample,
+ eta=self.eta,
+ learning_rate=self.lr,
+ max_depth=self.max_depth,
+ n_estimators=self.estimators,
+ random_state=42,
+ )
+
+ print(
+ f"Start training model {self.name} with estimators: {self.estimators} and max depth: { self.max_depth } ..."
+ )
+ start_time = time.time()
+ self.model.fit(self.X_train, self.y_train)
+ self.state = STATES[1]
+ y_pred = self.model.predict(self.X_test)
+ score = mean_squared_error(self.y_test, y_pred)
+ self.state = STATES[2]
+
+ end_time = time.time()
+ print(
+ f"End training model {self.name} with estimators: {self.estimators} and max depth: { self.max_depth } and took: {end_time - start_time:.2f}"
+ )
+
+ return {
+ "state": self.get_state(),
+ "name": self.get_name(),
+ "max_depth": self.max_depth,
+ "mse": round(score, 4),
+ "estimators": self.estimators,
+ "time": round(end_time - start_time, 2),
+ }
diff --git a/templates/ray-summit-core-masterclass/solutions/ex_01_solution.ipynb b/templates/ray-summit-core-masterclass/solutions/ex_01_solution.ipynb
new file mode 100644
index 000000000..4ad8fa90a
--- /dev/null
+++ b/templates/ray-summit-core-masterclass/solutions/ex_01_solution.ipynb
@@ -0,0 +1,92 @@
+{
+ "cells": [
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "db1a7d02-4378-4184-bd08-d29c7ae8d8ab",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import math\n",
+ "import numpy as np\n",
+ "import logging\n",
+ "from pprint import pprint\n",
+ "from typing import List\n",
+ "import ray"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b4ef2d84-4903-429e-96c8-a24210ceec34",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "def remote_method(num: int, dims=10) -> List[np.array]:\n",
+ " dot_products = []\n",
+ " for _ in range(num):\n",
+ " # Create a dims x dims matrix\n",
+ " x = np.random.rand(dims, dims)\n",
+ " y = np.random.rand(dims, dims)\n",
+ " # Create a dot product of itself\n",
+ " dot_products.append(np.dot(x, y))\n",
+ " return dot_products"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "68e43170-0260-4f7b-91df-4433770145a2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "if ray.is_initialized:\n",
+ " ray.shutdown()\n",
+ "ray.init(logging_level=logging.ERROR)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f0677e24-0b30-4831-b348-2ce8147576a8",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "results = [remote_method.remote(i, 5_000) for i in range(5)]\n",
+ "print(ray.get(results))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8482dfac-4043-410c-a75d-1588cfd893c7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ray.shutdown()"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.8.13"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/templates/ray-summit-core-masterclass/solutions/ex_02_solution.ipynb b/templates/ray-summit-core-masterclass/solutions/ex_02_solution.ipynb
new file mode 100644
index 000000000..a4e0f112b
--- /dev/null
+++ b/templates/ray-summit-core-masterclass/solutions/ex_02_solution.ipynb
@@ -0,0 +1,141 @@
+{
+ "cells": [
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1be69dae-83d9-43d1-81e7-41c26b683ce3",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "import ray\n",
+ "\n",
+ "if ray.is_initialized:\n",
+ " ray.shutdown()\n",
+ "ray.init(logging_level=logging.ERROR)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8110da95-01b2-4b73-ba13-f7cfea166329",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "def my_function (num_list):\n",
+ " return sum(num_list)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7bf709bd-217c-4553-80c1-042c7dddb34f",
+ "metadata": {},
+ "source": [
+ "### Exercise 2 Solution"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7618f6df-f2b6-4286-9dae-fe24497caae0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "obj_refs = [ray.put(i) for i in range(10)]\n",
+ "obj_refs"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6835d594-e51d-4da8-a53c-01d7d6c39e44",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "values = ray.get(obj_refs)\n",
+ "values"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4a48c181-a6c8-41fe-bf71-78ceaaff2fef",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sum_obj_ref = my_function.remote(values)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3ec83055-db03-4651-959b-26d116905ea5",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ray.get(sum_obj_ref)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "600bc0a1-72e9-4308-98cd-8274f3992bbd",
+ "metadata": {},
+ "source": [
+ "### Better code"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "64145de4-9120-4427-9848-20a77cec576e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "def my_ray_sum(ref_list):\n",
+ " objects = ray.get(ref_list)\n",
+ " return sum(objects)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "67d908a2-3b28-4df8-89ac-947d84e8f9b9",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ray.get(my_ray_sum.remote(obj_refs))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c4f9a713-93c1-4b54-bb60-60ddccf1d76f",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/templates/ray-summit-core-masterclass/solutions/ex_03_solution.ipynb b/templates/ray-summit-core-masterclass/solutions/ex_03_solution.ipynb
new file mode 100644
index 000000000..ac627889c
--- /dev/null
+++ b/templates/ray-summit-core-masterclass/solutions/ex_03_solution.ipynb
@@ -0,0 +1,208 @@
+{
+ "cells": [
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b456a148-3f34-468f-a889-3f319489444b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "import time\n",
+ "import os\n",
+ "import math\n",
+ "import ray\n",
+ "import random\n",
+ "import tqdm\n",
+ "from typing import Dict, Tuple, List\n",
+ "from random import randint\n",
+ "import numpy as np"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "834f3f49-5ce3-4942-a8d2-7aa490fdb73b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "if ray.is_initialized:\n",
+ " ray.shutdown()\n",
+ "ray.init(logging_level=logging.ERROR)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1098ee33-9bec-4345-ba87-4a1ed9b87437",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class ActorCls:\n",
+ " def __init__(self, name: str):\n",
+ " self.name = name\n",
+ " self.method_calls = {\"method\": 0}\n",
+ "\n",
+ " def method(self, **args) -> None:\n",
+ " # Overwrite this method in the subclass\n",
+ " pass\n",
+ "\n",
+ " def get_all_method_calls(self) -> Tuple[str, Dict[str, int]]:\n",
+ " return self.get_name(), self.method_calls\n",
+ " \n",
+ " def get_name(self) -> str:\n",
+ " return self.name"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5ce35e3d-566e-493a-99c1-560eb1ca0788",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "class ActorClsOne(ActorCls):\n",
+ " \n",
+ " def __init__(self, name: str):\n",
+ " super().__init__(name)\n",
+ " \n",
+ " def method(self, **args) -> None:\n",
+ " # do something with kwargs here\n",
+ " time.sleep(args[\"timeout\"])\n",
+ " \n",
+ " # update the respective counter\n",
+ " self.method_calls[\"method\"] += 1"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "93940068-fde2-48da-9621-c7bb769cf300",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "class ActorClsTwo(ActorCls):\n",
+ " \n",
+ " def __init__(self, name: str):\n",
+ " super().__init__(name)\n",
+ " \n",
+ " def method(self, **args) -> None:\n",
+ " # do something with kwargs here\n",
+ " time.sleep(args[\"timeout\"])\n",
+ " \n",
+ " # update the respective counter\n",
+ " self.method_calls[\"method\"] += 1"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "42b7346a-e3e0-4074-a426-8753b1df687e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "class ActorClsThree(ActorCls):\n",
+ " \n",
+ " def __init__(self, name: str):\n",
+ " super().__init__(name)\n",
+ " \n",
+ " def method(self, **args) -> None:\n",
+ " # do something with kwargs here\n",
+ " time.sleep(args[\"timeout\"])\n",
+ " \n",
+ " # update the respective counter\n",
+ " self.method_calls[\"method\"] += 1"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8aa5fc45-b15b-4c2d-aec1-9c051d37c423",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "actor_one = ActorClsOne.remote(\"ActorClsOne\")\n",
+ "actor_two = ActorClsTwo.remote(\"ActorClsTwo\")\n",
+ "actor_three = ActorClsTwo.remote(\"ActorClsThree\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c30cb397-2f64-491c-9a34-60f3687e9b5d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# A list of Actor classes\n",
+ "CALLERS_NAMES = [\"ActorClsOne\", \"ActorClsTwo\", \"ActorClsThree\"]\n",
+ "\n",
+ "# A dictionary of Actor instances\n",
+ "CALLERS_CLS_DICT = {\"ActorClsOne\": actor_one, \n",
+ " \"ActorClsTwo\": actor_two,\n",
+ " \"ActorClsThree\": actor_three}"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "22a4f44a-77b2-4459-a863-84b986eb5a1b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "count_dict = {\"ActorClsOne\": 0, \"ActorClsTwo\": 0, \"ActorClsThree\": 0}\n",
+ "for _ in range(len(CALLERS_NAMES)): \n",
+ " for _ in range(15):\n",
+ " name = random.choice(CALLERS_NAMES)\n",
+ " count_dict[name] += 1 \n",
+ " CALLERS_CLS_DICT[name].method.remote(timeout=1, store=\"mongo_db\") if name == \"ActorClsOne\" else CALLERS_CLS_DICT[name].method.remote(timeout=1.5, store=\"delta\")\n",
+ " \n",
+ " print(f\"State of counts in this execution: {count_dict}\")\n",
+ " time.sleep(0.5)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a2897704-2400-4731-b6e9-44164aa46db8",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(ray.get([CALLERS_CLS_DICT[name].get_all_method_calls.remote() for name in CALLERS_NAMES]))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8a2d525b-da65-41b2-bf32-f950926bbd31",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ray.shutdown()"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.8.13"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/templates/ray-summit-core-masterclass/solutions/ex_04_solution.ipynb b/templates/ray-summit-core-masterclass/solutions/ex_04_solution.ipynb
new file mode 100644
index 000000000..3baa03141
--- /dev/null
+++ b/templates/ray-summit-core-masterclass/solutions/ex_04_solution.ipynb
@@ -0,0 +1,149 @@
+{
+ "cells": [
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e425ccaf-273b-4126-8b2b-147dbbd8aa8a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "import time\n",
+ "import ray\n",
+ "import random\n",
+ "from random import randint\n",
+ "import numpy as np"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2f61c376-5c2f-4f26-bd57-1b50624dadbd",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from collections import defaultdict\n",
+ "@ray.remote\n",
+ "class LoggingActor(object):\n",
+ " def __init__(self):\n",
+ " # create a container of dictionaries.\n",
+ " self.logs = defaultdict(list)\n",
+ " \n",
+ " # log the message for a particular experiment in its \n",
+ " # respective dictionary\n",
+ " def log(self, index, message):\n",
+ " self.logs[index].append(message)\n",
+ " \n",
+ " # fetch all logs as collection\n",
+ " def get_logs(self):\n",
+ " return dict(self.logs)\n",
+ " \n",
+ "@ray.remote\n",
+ "def run_experiment(experiment_index, logging_actor):\n",
+ " for i in range(9):\n",
+ " # pretend this is an experiment that produces a nine results for \n",
+ " # experiment result; in our case it's just a simple message \n",
+ " # Push a logging message to the actor.\n",
+ " time.sleep(1)\n",
+ " exp_key = f\"experiment-{experiment_index}\"\n",
+ " logging_actor.log.remote(exp_key, 'On iteration {}'.format(i)) "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "566abe08-0af6-42e7-ba57-532166f4d0ce",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "if ray.is_initialized:\n",
+ " ray.shutdown()\n",
+ "ray.init(logging_level=logging.ERROR)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "272895a1-4fb1-4235-9ddd-65e76930554e",
+ "metadata": {},
+ "source": [
+ "Run three experiments."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "cd2a3f51-92a1-4ff9-8d22-56b47ebf69da",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "logging_actor = LoggingActor.remote()\n",
+ "experiment_ids = []\n",
+ "# Run three different experiments\n",
+ "for i in range(3):\n",
+ " experiment_ids.append(run_experiment.remote(i, logging_actor))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "50212dd0-bd49-48f0-b5b2-27cb0baa3d52",
+ "metadata": {},
+ "source": [
+ "### Fetch the results \n",
+ "\n",
+ "For each experement, we will have 9 iteration results"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3ed4fc03-339f-4866-a3ef-dfd12051d078",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "for i in range(3):\n",
+ " time.sleep(2)\n",
+ " logs = logging_actor.get_logs.remote()\n",
+ " print(ray.get(logs))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "13c39791-63e1-4563-9d7c-e9aab7700d34",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ray.shutdown()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ac83c842-227b-4f8d-a974-14747748d5ad",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/templates/ray-summit-core-masterclass/tasks_helper_utils.py b/templates/ray-summit-core-masterclass/tasks_helper_utils.py
new file mode 100644
index 000000000..cc16c4abb
--- /dev/null
+++ b/templates/ray-summit-core-masterclass/tasks_helper_utils.py
@@ -0,0 +1,226 @@
+import os
+import random
+from typing import List, Tuple
+
+import matplotlib.pyplot as plt
+import numpy as np
+import pandas as pd
+import requests
+import torch
+from PIL import Image, ImageFilter
+from torchvision import transforms as T
+import ray
+
+#
+# borrowed URLs ideas and heavily modified from https://analyticsindiamag.com/how-to-run-python-code-concurrently-using-multithreading/
+#
+
+URLS = [
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/305821.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/509922.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/325812.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/1252814.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/1420709.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/963486.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/1557183.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/3023211.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/1031641.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/439227.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/696644.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/911254.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/1001990.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/3518623.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/916044.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/2253879.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/3316918.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/942317.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/1090638.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/1279813.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/434645.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/1571460.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/1080696.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/271816.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/421927.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/302428.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/443383.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/3685175.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/2885578.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/3530116.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/9668911.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/14704971.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/13865510.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/6607387.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/13716813.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/14690500.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/14690501.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/14615366.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/14344696.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/14661919.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/5977791.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/5211747.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/5995657.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/8574183.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/14690503.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/2100941.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/112460.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/116675.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/3586966.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/313782.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/370717.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/1323550.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/11374974.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/408951.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/3889870.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/1774389.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/3889854.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/2196578.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/2885320.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/7189303.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/9697598.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/6431298.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/7131157.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/4840134.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/5359974.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/3889854.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/1753272.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/2328863.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/6102161.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/6101986.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/3334492.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/5708915.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/5708913.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/6102436.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/6102144.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/6102003.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/6194087.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/5847900.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/1671479.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/3335507.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/6102522.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/6211095.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/720347.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/3516015.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/3325717.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/849835.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/302743.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/167699.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/259620.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/300857.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/789380.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/735987.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/572897.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/300857.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/760971.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/789382.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/1004665.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/facilities.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/3984080835_71b0426844_b.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/33041.jpg"
+]
+
+THUMB_SIZE = (64, 64)
+
+
+def extract_times(lst: Tuple[int, float]) -> List[float]:
+ """
+ Given a list of Tuples[batch_size, execution_time] extract the latter
+ """
+ times = [t[1] for t in lst]
+ return times
+
+
+def plot_times(batches: List[int], s_lst: List[float], d_lst: List[float]) -> None:
+ """
+ Plot the execution times for serail vs distributed for each respective batch size of images
+ """
+ s_times = extract_times(s_lst)
+ d_times = extract_times(d_lst)
+ data = {"batches": batches, "serial": s_times, "distributed": d_times}
+
+ df = pd.DataFrame(data)
+ df.plot(x="batches", y=["serial", "distributed"], kind="bar")
+ plt.ylabel("Times in sec", fontsize=12)
+ plt.xlabel("Number of Batches of Images", fontsize=12)
+ plt.grid(False)
+ plt.show()
+
+
+def display_random_images(image_list: List[str], n: int = 3) -> None:
+ """
+ Display a grid of images, default 3 of images we want to process
+ """
+ random_samples_idx = random.sample(range(len(image_list)), k=n)
+ plt.figure(figsize=(16, 8))
+ for i, targ_sample in enumerate(random_samples_idx):
+ plt.subplot(1, n, i + 1)
+ img = Image.open(image_list[targ_sample])
+ img_as_array = np.asarray(img)
+ plt.imshow(img_as_array)
+ title = f"\nshape: {img.size}"
+ plt.axis("off")
+ plt.title(title)
+ plt.show()
+
+
+def download_images(url: str, data_dir: str) -> None:
+ """
+ Given a URL and the image data directory, fetch the URL and save it in the data directory
+ """
+ img_data = requests.get(url).content
+ img_name = url.split("/")[5]
+ img_name = f"{data_dir}/{img_name}"
+ with open(img_name, "wb+") as f:
+ f.write(img_data)
+
+def insert_into_object_store(img_name:str):
+ """
+ Insert the image into the object store and return its object reference
+ """
+ import ray
+
+ img = Image.open(img_name)
+ img_ref = ray.put(img)
+ return img_ref
+
+
+def transform_image(img_ref:object, fetch_image=True, verbose=False):
+ """
+ This is a deliberate compute intensive image transfromation and tensor operation
+ to simulate a compute intensive image processing
+ """
+ import ray
+
+ # Only fetch the image from the object store if called serially.
+ if fetch_image:
+ img = ray.get(img_ref)
+ else:
+ img = img_ref
+ before_shape = img.size
+
+ # Make the image blur with specified intensify
+ # Use torchvision transformation to augment the image
+ img = img.filter(ImageFilter.GaussianBlur(radius=20))
+ augmentor = T.TrivialAugmentWide(num_magnitude_bins=31)
+ img = augmentor(img)
+
+ # Convert image to tensor and transpose
+ tensor = torch.tensor(np.asarray(img))
+ t_tensor = torch.transpose(tensor, 0, 1)
+
+ # compute intensive operations on tensors
+ random.seed(42)
+ for _ in range(3):
+ tensor.pow(3).sum()
+ t_tensor.pow(3).sum()
+ torch.mul(tensor, random.randint(2, 10))
+ torch.mul(t_tensor, random.randint(2, 10))
+ torch.mul(tensor, tensor)
+ torch.mul(t_tensor, t_tensor)
+
+ # Resize to a thumbnail
+ img.thumbnail(THUMB_SIZE)
+ after_shape = img.size
+ if verbose:
+ print(f"augmented: shape:{img.size}| image tensor shape:{tensor.size()} transpose shape:{t_tensor.size()}")
+
+ return before_shape, after_shape
diff --git a/templates/ray-summit-end-to-end-llms/01_Finetuning_LLMs.ipynb b/templates/ray-summit-end-to-end-llms/01_Finetuning_LLMs.ipynb
new file mode 100644
index 000000000..7c9a3b945
--- /dev/null
+++ b/templates/ray-summit-end-to-end-llms/01_Finetuning_LLMs.ipynb
@@ -0,0 +1,417 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Finetuning LLMs\n",
+ "\n",
+ "In this notebook we will be making use of Anyscale's LLMForge to finetune our first LLM model. \n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c66136a5-980f-455c-b97a-28e29597a49a",
+ "metadata": {},
+ "source": [
+ "### Sample code"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f2f9ad3f-ce48-4579-a58b-023409575197",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def find_a_node_with(resource, amount):\n",
+ " for node in ray.nodes():\n",
+ " if resource in node['Resources'] and node['Resources'][resource] >= amount:\n",
+ " return node\n",
+ " return None"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c2c03228-23bf-464e-a895-ce752a03401b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "node = find_a_node_with('CPU', 1)\n",
+ "\n",
+ "node"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "61371ae5-ffa8-48a0-b4e0-be5378c7874a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import ray\n",
+ "from ray.util.scheduling_strategies import NodeAffinitySchedulingStrategy\n",
+ "\n",
+ "# pin this task to only run on the current node id\n",
+ "run_on_same_node = NodeAffinitySchedulingStrategy(\n",
+ " node_id=node['NodeID'], \n",
+ " soft=False,\n",
+ ")\n",
+ "\n",
+ "@ray.remote(\n",
+ " scheduling_strategy=run_on_same_node\n",
+ ")\n",
+ "def node_affinity_schedule():\n",
+ " return 2\n",
+ "\n",
+ "\n",
+ "ray.get(node_affinity_schedule.remote())"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "55ff64bc-f5c5-4278-b193-1311ad612f84",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/templates/ray-summit-core-masterclass/data/file_1.txt b/templates/ray-summit-core-masterclass/data/file_1.txt
new file mode 100644
index 000000000..4013ed536
--- /dev/null
+++ b/templates/ray-summit-core-masterclass/data/file_1.txt
@@ -0,0 +1,10 @@
+ 0, 48, 72, 75, 54, 89, 84, 68, 9, 38
+ 3, 40, 73, 58, 10, 35, 96, 6, 65, 33
+ 55, 67, 12, 97, 52, 73, 7, 76, 39, 50
+ 59, 34, 20, 40, 92, 55, 11, 39, 93, 38
+ 89, 89, 37, 52, 48, 86, 49, 3, 19, 50
+ 84, 37, 68, 11, 20, 36, 46, 61, 52, 77
+ 70, 90, 56, 55, 49, 76, 94, 28, 32, 23
+ 5, 44, 92, 15, 53, 63, 87, 75, 61, 25
+ 51, 58, 29, 30, 93, 94, 52, 72, 80, 27
+ 1, 28, 82, 35, 89, 36, 10, 84, 85, 65
diff --git a/templates/ray-summit-core-masterclass/data/file_2.txt b/templates/ray-summit-core-masterclass/data/file_2.txt
new file mode 100644
index 000000000..99b0feff6
--- /dev/null
+++ b/templates/ray-summit-core-masterclass/data/file_2.txt
@@ -0,0 +1,10 @@
+101, 31, 83,124, 41, 73, 0,121, 14, 98
+137, 3, 77, 38,117, 79,104, 96, 62,117
+ 99, 92,139, 29, 59, 30,116, 30, 74, 12
+130,105,145,124, 39, 50, 66, 9,126, 24
+ 32, 33, 34, 90, 43,140,136,149,140, 22
+ 14, 8,138,101,136, 60, 41,110, 92,105
+ 44, 76,104, 6,121,135, 41,132,131, 26
+ 1, 1,112, 45,146, 29, 44,104, 75,122
+132, 63, 70,109, 49, 75, 33, 36, 38,105
+131, 71, 51, 79,109,146, 71, 27, 65,126
diff --git a/templates/ray-summit-core-masterclass/model_helper_utils.py b/templates/ray-summit-core-masterclass/model_helper_utils.py
new file mode 100644
index 000000000..0896e8106
--- /dev/null
+++ b/templates/ray-summit-core-masterclass/model_helper_utils.py
@@ -0,0 +1,198 @@
+import time
+from typing import Dict, Any
+
+import ray
+import xgboost as xgb
+from sklearn.datasets import fetch_california_housing
+from sklearn.ensemble import RandomForestRegressor
+from sklearn.metrics import mean_squared_error
+from sklearn.model_selection import train_test_split
+from sklearn.tree import DecisionTreeRegressor
+
+# states to inspect
+STATES = ["INITIALIZED", "RUNNING", "DONE"]
+
+DECISION_TREE_CONFIGS = {"max_depth": 10, "name": "decision_tree"}
+
+RANDOM_FOREST_CONFIGS = {"n_estimators": 25, "name": "random_forest"}
+
+XGBOOST_CONFIGS = {
+ "max_depth": 10,
+ "n_estimators": 25,
+ "lr": 0.1,
+ "eta": 0.3,
+ "colsample_bytree": 1,
+ "name": "xgboost",
+}
+
+# dataset
+X_data, y_data = fetch_california_housing(return_X_y=True, as_frame=True)
+
+
+class ActorCls:
+ """
+ Base class for our Ray Actor workers models
+ """
+
+ def __init__(self, configs: Dict[Any, Any]) -> None:
+ self.configs = configs
+ self.name = configs["name"]
+ self.state = STATES[0]
+ self.X_train, self.X_test, self.y_train, self.y_test = train_test_split(
+ X_data, y_data, test_size=0.2, random_state=4
+ )
+
+ self.model = None
+
+ def get_name(self) -> str:
+ return self.name
+
+ def get_state(self) -> str:
+ return self.state
+
+ def train_and_evaluate_model(self) -> Dict[Any, Any]:
+ """
+ Overwrite this function in super class
+ """
+ pass
+
+
+@ray.remote
+class RFRActor(ActorCls):
+ """
+ An actor model to train and score the calfornia house data using Random Forest Regressor
+ """
+
+ def __init__(self, configs):
+ super().__init__(configs)
+ self.estimators = configs["n_estimators"]
+
+ def train_and_evaluate_model(self) -> Dict[Any, Any]:
+ """
+ Train the model and evaluate and report MSE
+ """
+
+ self.model = RandomForestRegressor(
+ n_estimators=self.estimators, random_state=42
+ )
+
+ print(
+ f"Start training model {self.name} with estimators: {self.estimators} ..."
+ )
+
+ start_time = time.time()
+ self.model.fit(self.X_train, self.y_train)
+ self.state = STATES[1]
+ y_pred = self.model.predict(self.X_test)
+ score = mean_squared_error(self.y_test, y_pred)
+ self.state = STATES[2]
+
+ end_time = time.time()
+ print(
+ f"End training model {self.name} with estimators: {self.estimators} took: {end_time - start_time:.2f} seconds"
+ )
+
+ return {
+ "state": self.get_state(),
+ "name": self.get_name(),
+ "estimators": self.estimators,
+ "mse": round(score, 4),
+ "time": round(end_time - start_time, 2),
+ }
+
+
+@ray.remote
+class DTActor(ActorCls):
+ """
+ An actor model to train and score the calfornia house data using Decision Tree Regressor
+ """
+
+ def __init__(self, configs):
+ super().__init__(configs)
+ self.max_depth = configs["max_depth"]
+
+ def train_and_evaluate_model(self) -> Dict[Any, Any]:
+ """
+ Train the model and evaluate and report MSE
+ """
+
+ self.model = DecisionTreeRegressor(max_depth=self.max_depth, random_state=42)
+
+ print(
+ f"Start training model {self.name} with max depth: { self.max_depth } ..."
+ )
+
+ start_time = time.time()
+ self.model.fit(self.X_train, self.y_train)
+ self.state = STATES[1]
+ y_pred = self.model.predict(self.X_test)
+ score = mean_squared_error(self.y_test, y_pred)
+ self.state = STATES[2]
+
+ end_time = time.time()
+ print(
+ f"End training model {self.name} with max_depth tree: {self.max_depth} took: {end_time - start_time:.2f} seconds"
+ )
+
+ return {
+ "state": self.get_state(),
+ "name": self.get_name(),
+ "max_depth": self.max_depth,
+ "mse": round(score, 4),
+ "time": round(end_time - start_time, 2),
+ }
+
+
+@ray.remote
+class XGBoostActor(ActorCls):
+ """
+ An actor model to train and score the calfornia house data using XGBoost Regressor
+ """
+
+ def __init__(self, configs):
+ super().__init__(configs)
+
+ self.max_depth = configs["max_depth"]
+ self.estimators = configs["n_estimators"]
+ self.colsample = configs["colsample_bytree"]
+ self.eta = configs["eta"]
+ self.lr = configs["lr"]
+
+ def train_and_evaluate_model(self) -> Dict[Any, Any]:
+ """
+ Train the model and evaluate and report MSE
+ """
+
+ self.model = xgb.XGBRegressor(
+ objective="reg:squarederror",
+ colsample_bytree=self.colsample,
+ eta=self.eta,
+ learning_rate=self.lr,
+ max_depth=self.max_depth,
+ n_estimators=self.estimators,
+ random_state=42,
+ )
+
+ print(
+ f"Start training model {self.name} with estimators: {self.estimators} and max depth: { self.max_depth } ..."
+ )
+ start_time = time.time()
+ self.model.fit(self.X_train, self.y_train)
+ self.state = STATES[1]
+ y_pred = self.model.predict(self.X_test)
+ score = mean_squared_error(self.y_test, y_pred)
+ self.state = STATES[2]
+
+ end_time = time.time()
+ print(
+ f"End training model {self.name} with estimators: {self.estimators} and max depth: { self.max_depth } and took: {end_time - start_time:.2f}"
+ )
+
+ return {
+ "state": self.get_state(),
+ "name": self.get_name(),
+ "max_depth": self.max_depth,
+ "mse": round(score, 4),
+ "estimators": self.estimators,
+ "time": round(end_time - start_time, 2),
+ }
diff --git a/templates/ray-summit-core-masterclass/solutions/ex_01_solution.ipynb b/templates/ray-summit-core-masterclass/solutions/ex_01_solution.ipynb
new file mode 100644
index 000000000..4ad8fa90a
--- /dev/null
+++ b/templates/ray-summit-core-masterclass/solutions/ex_01_solution.ipynb
@@ -0,0 +1,92 @@
+{
+ "cells": [
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "db1a7d02-4378-4184-bd08-d29c7ae8d8ab",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import math\n",
+ "import numpy as np\n",
+ "import logging\n",
+ "from pprint import pprint\n",
+ "from typing import List\n",
+ "import ray"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b4ef2d84-4903-429e-96c8-a24210ceec34",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "def remote_method(num: int, dims=10) -> List[np.array]:\n",
+ " dot_products = []\n",
+ " for _ in range(num):\n",
+ " # Create a dims x dims matrix\n",
+ " x = np.random.rand(dims, dims)\n",
+ " y = np.random.rand(dims, dims)\n",
+ " # Create a dot product of itself\n",
+ " dot_products.append(np.dot(x, y))\n",
+ " return dot_products"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "68e43170-0260-4f7b-91df-4433770145a2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "if ray.is_initialized:\n",
+ " ray.shutdown()\n",
+ "ray.init(logging_level=logging.ERROR)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f0677e24-0b30-4831-b348-2ce8147576a8",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "results = [remote_method.remote(i, 5_000) for i in range(5)]\n",
+ "print(ray.get(results))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8482dfac-4043-410c-a75d-1588cfd893c7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ray.shutdown()"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.8.13"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/templates/ray-summit-core-masterclass/solutions/ex_02_solution.ipynb b/templates/ray-summit-core-masterclass/solutions/ex_02_solution.ipynb
new file mode 100644
index 000000000..a4e0f112b
--- /dev/null
+++ b/templates/ray-summit-core-masterclass/solutions/ex_02_solution.ipynb
@@ -0,0 +1,141 @@
+{
+ "cells": [
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1be69dae-83d9-43d1-81e7-41c26b683ce3",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "import ray\n",
+ "\n",
+ "if ray.is_initialized:\n",
+ " ray.shutdown()\n",
+ "ray.init(logging_level=logging.ERROR)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8110da95-01b2-4b73-ba13-f7cfea166329",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "def my_function (num_list):\n",
+ " return sum(num_list)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7bf709bd-217c-4553-80c1-042c7dddb34f",
+ "metadata": {},
+ "source": [
+ "### Exercise 2 Solution"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7618f6df-f2b6-4286-9dae-fe24497caae0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "obj_refs = [ray.put(i) for i in range(10)]\n",
+ "obj_refs"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6835d594-e51d-4da8-a53c-01d7d6c39e44",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "values = ray.get(obj_refs)\n",
+ "values"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4a48c181-a6c8-41fe-bf71-78ceaaff2fef",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sum_obj_ref = my_function.remote(values)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3ec83055-db03-4651-959b-26d116905ea5",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ray.get(sum_obj_ref)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "600bc0a1-72e9-4308-98cd-8274f3992bbd",
+ "metadata": {},
+ "source": [
+ "### Better code"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "64145de4-9120-4427-9848-20a77cec576e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "def my_ray_sum(ref_list):\n",
+ " objects = ray.get(ref_list)\n",
+ " return sum(objects)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "67d908a2-3b28-4df8-89ac-947d84e8f9b9",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ray.get(my_ray_sum.remote(obj_refs))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c4f9a713-93c1-4b54-bb60-60ddccf1d76f",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/templates/ray-summit-core-masterclass/solutions/ex_03_solution.ipynb b/templates/ray-summit-core-masterclass/solutions/ex_03_solution.ipynb
new file mode 100644
index 000000000..ac627889c
--- /dev/null
+++ b/templates/ray-summit-core-masterclass/solutions/ex_03_solution.ipynb
@@ -0,0 +1,208 @@
+{
+ "cells": [
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b456a148-3f34-468f-a889-3f319489444b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "import time\n",
+ "import os\n",
+ "import math\n",
+ "import ray\n",
+ "import random\n",
+ "import tqdm\n",
+ "from typing import Dict, Tuple, List\n",
+ "from random import randint\n",
+ "import numpy as np"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "834f3f49-5ce3-4942-a8d2-7aa490fdb73b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "if ray.is_initialized:\n",
+ " ray.shutdown()\n",
+ "ray.init(logging_level=logging.ERROR)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1098ee33-9bec-4345-ba87-4a1ed9b87437",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class ActorCls:\n",
+ " def __init__(self, name: str):\n",
+ " self.name = name\n",
+ " self.method_calls = {\"method\": 0}\n",
+ "\n",
+ " def method(self, **args) -> None:\n",
+ " # Overwrite this method in the subclass\n",
+ " pass\n",
+ "\n",
+ " def get_all_method_calls(self) -> Tuple[str, Dict[str, int]]:\n",
+ " return self.get_name(), self.method_calls\n",
+ " \n",
+ " def get_name(self) -> str:\n",
+ " return self.name"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5ce35e3d-566e-493a-99c1-560eb1ca0788",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "class ActorClsOne(ActorCls):\n",
+ " \n",
+ " def __init__(self, name: str):\n",
+ " super().__init__(name)\n",
+ " \n",
+ " def method(self, **args) -> None:\n",
+ " # do something with kwargs here\n",
+ " time.sleep(args[\"timeout\"])\n",
+ " \n",
+ " # update the respective counter\n",
+ " self.method_calls[\"method\"] += 1"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "93940068-fde2-48da-9621-c7bb769cf300",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "class ActorClsTwo(ActorCls):\n",
+ " \n",
+ " def __init__(self, name: str):\n",
+ " super().__init__(name)\n",
+ " \n",
+ " def method(self, **args) -> None:\n",
+ " # do something with kwargs here\n",
+ " time.sleep(args[\"timeout\"])\n",
+ " \n",
+ " # update the respective counter\n",
+ " self.method_calls[\"method\"] += 1"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "42b7346a-e3e0-4074-a426-8753b1df687e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@ray.remote\n",
+ "class ActorClsThree(ActorCls):\n",
+ " \n",
+ " def __init__(self, name: str):\n",
+ " super().__init__(name)\n",
+ " \n",
+ " def method(self, **args) -> None:\n",
+ " # do something with kwargs here\n",
+ " time.sleep(args[\"timeout\"])\n",
+ " \n",
+ " # update the respective counter\n",
+ " self.method_calls[\"method\"] += 1"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8aa5fc45-b15b-4c2d-aec1-9c051d37c423",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "actor_one = ActorClsOne.remote(\"ActorClsOne\")\n",
+ "actor_two = ActorClsTwo.remote(\"ActorClsTwo\")\n",
+ "actor_three = ActorClsTwo.remote(\"ActorClsThree\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c30cb397-2f64-491c-9a34-60f3687e9b5d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# A list of Actor classes\n",
+ "CALLERS_NAMES = [\"ActorClsOne\", \"ActorClsTwo\", \"ActorClsThree\"]\n",
+ "\n",
+ "# A dictionary of Actor instances\n",
+ "CALLERS_CLS_DICT = {\"ActorClsOne\": actor_one, \n",
+ " \"ActorClsTwo\": actor_two,\n",
+ " \"ActorClsThree\": actor_three}"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "22a4f44a-77b2-4459-a863-84b986eb5a1b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "count_dict = {\"ActorClsOne\": 0, \"ActorClsTwo\": 0, \"ActorClsThree\": 0}\n",
+ "for _ in range(len(CALLERS_NAMES)): \n",
+ " for _ in range(15):\n",
+ " name = random.choice(CALLERS_NAMES)\n",
+ " count_dict[name] += 1 \n",
+ " CALLERS_CLS_DICT[name].method.remote(timeout=1, store=\"mongo_db\") if name == \"ActorClsOne\" else CALLERS_CLS_DICT[name].method.remote(timeout=1.5, store=\"delta\")\n",
+ " \n",
+ " print(f\"State of counts in this execution: {count_dict}\")\n",
+ " time.sleep(0.5)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a2897704-2400-4731-b6e9-44164aa46db8",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(ray.get([CALLERS_CLS_DICT[name].get_all_method_calls.remote() for name in CALLERS_NAMES]))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8a2d525b-da65-41b2-bf32-f950926bbd31",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ray.shutdown()"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.8.13"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/templates/ray-summit-core-masterclass/solutions/ex_04_solution.ipynb b/templates/ray-summit-core-masterclass/solutions/ex_04_solution.ipynb
new file mode 100644
index 000000000..3baa03141
--- /dev/null
+++ b/templates/ray-summit-core-masterclass/solutions/ex_04_solution.ipynb
@@ -0,0 +1,149 @@
+{
+ "cells": [
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e425ccaf-273b-4126-8b2b-147dbbd8aa8a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "import time\n",
+ "import ray\n",
+ "import random\n",
+ "from random import randint\n",
+ "import numpy as np"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2f61c376-5c2f-4f26-bd57-1b50624dadbd",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from collections import defaultdict\n",
+ "@ray.remote\n",
+ "class LoggingActor(object):\n",
+ " def __init__(self):\n",
+ " # create a container of dictionaries.\n",
+ " self.logs = defaultdict(list)\n",
+ " \n",
+ " # log the message for a particular experiment in its \n",
+ " # respective dictionary\n",
+ " def log(self, index, message):\n",
+ " self.logs[index].append(message)\n",
+ " \n",
+ " # fetch all logs as collection\n",
+ " def get_logs(self):\n",
+ " return dict(self.logs)\n",
+ " \n",
+ "@ray.remote\n",
+ "def run_experiment(experiment_index, logging_actor):\n",
+ " for i in range(9):\n",
+ " # pretend this is an experiment that produces a nine results for \n",
+ " # experiment result; in our case it's just a simple message \n",
+ " # Push a logging message to the actor.\n",
+ " time.sleep(1)\n",
+ " exp_key = f\"experiment-{experiment_index}\"\n",
+ " logging_actor.log.remote(exp_key, 'On iteration {}'.format(i)) "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "566abe08-0af6-42e7-ba57-532166f4d0ce",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "if ray.is_initialized:\n",
+ " ray.shutdown()\n",
+ "ray.init(logging_level=logging.ERROR)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "272895a1-4fb1-4235-9ddd-65e76930554e",
+ "metadata": {},
+ "source": [
+ "Run three experiments."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "cd2a3f51-92a1-4ff9-8d22-56b47ebf69da",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "logging_actor = LoggingActor.remote()\n",
+ "experiment_ids = []\n",
+ "# Run three different experiments\n",
+ "for i in range(3):\n",
+ " experiment_ids.append(run_experiment.remote(i, logging_actor))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "50212dd0-bd49-48f0-b5b2-27cb0baa3d52",
+ "metadata": {},
+ "source": [
+ "### Fetch the results \n",
+ "\n",
+ "For each experement, we will have 9 iteration results"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3ed4fc03-339f-4866-a3ef-dfd12051d078",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "for i in range(3):\n",
+ " time.sleep(2)\n",
+ " logs = logging_actor.get_logs.remote()\n",
+ " print(ray.get(logs))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "13c39791-63e1-4563-9d7c-e9aab7700d34",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ray.shutdown()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ac83c842-227b-4f8d-a974-14747748d5ad",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/templates/ray-summit-core-masterclass/tasks_helper_utils.py b/templates/ray-summit-core-masterclass/tasks_helper_utils.py
new file mode 100644
index 000000000..cc16c4abb
--- /dev/null
+++ b/templates/ray-summit-core-masterclass/tasks_helper_utils.py
@@ -0,0 +1,226 @@
+import os
+import random
+from typing import List, Tuple
+
+import matplotlib.pyplot as plt
+import numpy as np
+import pandas as pd
+import requests
+import torch
+from PIL import Image, ImageFilter
+from torchvision import transforms as T
+import ray
+
+#
+# borrowed URLs ideas and heavily modified from https://analyticsindiamag.com/how-to-run-python-code-concurrently-using-multithreading/
+#
+
+URLS = [
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/305821.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/509922.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/325812.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/1252814.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/1420709.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/963486.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/1557183.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/3023211.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/1031641.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/439227.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/696644.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/911254.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/1001990.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/3518623.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/916044.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/2253879.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/3316918.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/942317.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/1090638.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/1279813.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/434645.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/1571460.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/1080696.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/271816.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/421927.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/302428.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/443383.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/3685175.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/2885578.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/3530116.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/9668911.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/14704971.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/13865510.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/6607387.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/13716813.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/14690500.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/14690501.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/14615366.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/14344696.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/14661919.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/5977791.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/5211747.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/5995657.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/8574183.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/14690503.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/2100941.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/112460.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/116675.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/3586966.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/313782.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/370717.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/1323550.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/11374974.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/408951.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/3889870.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/1774389.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/3889854.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/2196578.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/2885320.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/7189303.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/9697598.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/6431298.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/7131157.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/4840134.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/5359974.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/3889854.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/1753272.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/2328863.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/6102161.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/6101986.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/3334492.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/5708915.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/5708913.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/6102436.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/6102144.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/6102003.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/6194087.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/5847900.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/1671479.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/3335507.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/6102522.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/6211095.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/720347.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/3516015.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/3325717.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/849835.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/302743.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/167699.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/259620.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/300857.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/789380.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/735987.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/572897.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/300857.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/760971.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/789382.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/1004665.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/facilities.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/3984080835_71b0426844_b.jpg",
+ "https://anyscale-public-materials.s3.us-west-2.amazonaws.com/ray-summit/ray-core/33041.jpg"
+]
+
+THUMB_SIZE = (64, 64)
+
+
+def extract_times(lst: Tuple[int, float]) -> List[float]:
+ """
+ Given a list of Tuples[batch_size, execution_time] extract the latter
+ """
+ times = [t[1] for t in lst]
+ return times
+
+
+def plot_times(batches: List[int], s_lst: List[float], d_lst: List[float]) -> None:
+ """
+ Plot the execution times for serail vs distributed for each respective batch size of images
+ """
+ s_times = extract_times(s_lst)
+ d_times = extract_times(d_lst)
+ data = {"batches": batches, "serial": s_times, "distributed": d_times}
+
+ df = pd.DataFrame(data)
+ df.plot(x="batches", y=["serial", "distributed"], kind="bar")
+ plt.ylabel("Times in sec", fontsize=12)
+ plt.xlabel("Number of Batches of Images", fontsize=12)
+ plt.grid(False)
+ plt.show()
+
+
+def display_random_images(image_list: List[str], n: int = 3) -> None:
+ """
+ Display a grid of images, default 3 of images we want to process
+ """
+ random_samples_idx = random.sample(range(len(image_list)), k=n)
+ plt.figure(figsize=(16, 8))
+ for i, targ_sample in enumerate(random_samples_idx):
+ plt.subplot(1, n, i + 1)
+ img = Image.open(image_list[targ_sample])
+ img_as_array = np.asarray(img)
+ plt.imshow(img_as_array)
+ title = f"\nshape: {img.size}"
+ plt.axis("off")
+ plt.title(title)
+ plt.show()
+
+
+def download_images(url: str, data_dir: str) -> None:
+ """
+ Given a URL and the image data directory, fetch the URL and save it in the data directory
+ """
+ img_data = requests.get(url).content
+ img_name = url.split("/")[5]
+ img_name = f"{data_dir}/{img_name}"
+ with open(img_name, "wb+") as f:
+ f.write(img_data)
+
+def insert_into_object_store(img_name:str):
+ """
+ Insert the image into the object store and return its object reference
+ """
+ import ray
+
+ img = Image.open(img_name)
+ img_ref = ray.put(img)
+ return img_ref
+
+
+def transform_image(img_ref:object, fetch_image=True, verbose=False):
+ """
+ This is a deliberate compute intensive image transfromation and tensor operation
+ to simulate a compute intensive image processing
+ """
+ import ray
+
+ # Only fetch the image from the object store if called serially.
+ if fetch_image:
+ img = ray.get(img_ref)
+ else:
+ img = img_ref
+ before_shape = img.size
+
+ # Make the image blur with specified intensify
+ # Use torchvision transformation to augment the image
+ img = img.filter(ImageFilter.GaussianBlur(radius=20))
+ augmentor = T.TrivialAugmentWide(num_magnitude_bins=31)
+ img = augmentor(img)
+
+ # Convert image to tensor and transpose
+ tensor = torch.tensor(np.asarray(img))
+ t_tensor = torch.transpose(tensor, 0, 1)
+
+ # compute intensive operations on tensors
+ random.seed(42)
+ for _ in range(3):
+ tensor.pow(3).sum()
+ t_tensor.pow(3).sum()
+ torch.mul(tensor, random.randint(2, 10))
+ torch.mul(t_tensor, random.randint(2, 10))
+ torch.mul(tensor, tensor)
+ torch.mul(t_tensor, t_tensor)
+
+ # Resize to a thumbnail
+ img.thumbnail(THUMB_SIZE)
+ after_shape = img.size
+ if verbose:
+ print(f"augmented: shape:{img.size}| image tensor shape:{tensor.size()} transpose shape:{t_tensor.size()}")
+
+ return before_shape, after_shape
diff --git a/templates/ray-summit-end-to-end-llms/01_Finetuning_LLMs.ipynb b/templates/ray-summit-end-to-end-llms/01_Finetuning_LLMs.ipynb
new file mode 100644
index 000000000..7c9a3b945
--- /dev/null
+++ b/templates/ray-summit-end-to-end-llms/01_Finetuning_LLMs.ipynb
@@ -0,0 +1,417 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Finetuning LLMs\n",
+ "\n",
+ "In this notebook we will be making use of Anyscale's LLMForge to finetune our first LLM model. \n",
+ "\n",
+ "\n",
+ " Here is the roadmap for this notebook:\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Imports"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import anyscale"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 0. Why finetune LLMs?\n",
+ "\n",
+ "The main usecase for finetuning LLMs is to adapt a pre-trained model to a specific task or dataset.\n",
+ "\n",
+ "- **Task-Specific Performance**: Fine-tuning hones an LLM's capabilities for a particular task, leading to superior performance.\n",
+ "- **Resource Efficiency**: We can use smaller LLMs that require less computational resources to achieve better performance than larger general-purpose models.\n",
+ "- **Privacy and Security**: We can self-host finetuned models to ensure that our data is not shared with third parties.\n",
+ "\n",
+ "In this guide, we will be finetuning an LLM model on a custom video gaming dataset. \n",
+ "\n",
+ "The task is a functional representation task where we want to extract structured data from user input on video games."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "vscode": {
+ "languageId": "plaintext"
+ }
+ },
+ "source": [
+ "## 1. Introduction to LLMForge\n",
+ "\n",
+ "\n",
+ "Anyscale's [LLMForge](https://docs.anyscale.com/llms/finetuning/intro/#what-is-llmforge) provides an easy to use library for fine-tuning LLMs.\n",
+ "\n",
+ "\n",
+ "Here is a diagram that shows a *typical workflow* when working with LLMForge:\n",
+ "\n",
+ "\n",
+ "- \n",
+ "
- Part 0: Why finetune LLMs? \n", + "
- Part 1: Introduction to LLMForge \n", + "
- Part 2: Submitting an LLM Finetuning Job \n", + "
- Part 3: Tracking the Progress of the Job \n", + "
- Part 4: Tailoring LLMForge to Your Needs \n", + "
 "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "vscode": {
+ "languageId": "plaintext"
+ }
+ },
+ "source": [
+ "### Preparing an LLMForge configuration file\n",
+ "\n",
+ "We have already prepared a configuration file for you under `configs/training/lora/mistral-7b.yaml`\n",
+ "\n",
+ "Here are the file contents:\n",
+ "\n",
+ "```yaml\n",
+ "# Change this to the model you want to fine-tune\n",
+ "model_id: mistralai/Mistral-7B-Instruct-v0.1\n",
+ "\n",
+ "# Change this to the path to your training data\n",
+ "train_path: s3://anyscale-public-materials/llm-finetuning/viggo_inverted/train/subset-500.jsonl\n",
+ "\n",
+ "# Change this to the path to your validation data. This is optional\n",
+ "valid_path: s3://anyscale-public-materials/llm-finetuning/viggo_inverted/valid/data.jsonl\n",
+ "\n",
+ "# Change this to the context length you want to use. Examples with longer\n",
+ "# context length will be truncated.\n",
+ "context_length: 512\n",
+ "\n",
+ "# Change this to total number of GPUs that you want to use\n",
+ "num_devices: 2\n",
+ "\n",
+ "# Change this to the number of epochs that you want to train for\n",
+ "num_epochs: 3\n",
+ "\n",
+ "# Change this to the batch size that you want to use\n",
+ "train_batch_size_per_device: 16\n",
+ "eval_batch_size_per_device: 16\n",
+ "\n",
+ "# Change this to the learning rate that you want to use\n",
+ "learning_rate: 1e-4\n",
+ "\n",
+ "# This will pad batches to the longest sequence. Use \"max_length\" when profiling to profile the worst case.\n",
+ "padding: \"longest\"\n",
+ "\n",
+ "# By default, we will keep the best checkpoint. You can change this to keep more checkpoints.\n",
+ "num_checkpoints_to_keep: 1\n",
+ "\n",
+ "# Deepspeed configuration, you can provide your own deepspeed setup\n",
+ "deepspeed:\n",
+ " config_path: configs/deepspeed/zero_3_offload_optim+param.json\n",
+ "\n",
+ "# Lora configuration\n",
+ "lora_config:\n",
+ " r: 8\n",
+ " lora_alpha: 16\n",
+ " lora_dropout: 0.05\n",
+ " target_modules:\n",
+ " - q_proj\n",
+ " - v_proj\n",
+ " - k_proj\n",
+ " - o_proj\n",
+ " - gate_proj\n",
+ " - up_proj\n",
+ " - down_proj\n",
+ " - embed_tokens\n",
+ " - lm_head\n",
+ " task_type: \"CAUSAL_LM\"\n",
+ " bias: \"none\"\n",
+ " modules_to_save: []\n",
+ "\n",
+ "````"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "vscode": {
+ "languageId": "plaintext"
+ }
+ },
+ "source": [
+ "\n",
+ "Anyscale's LLMForge's finetune config can be split into the following:\n",
+ "\n",
+ "- **Model Configuration:**\n",
+ " - `model_id`: The Hugging Face model name.\n",
+ " \n",
+ "- **Data Configuration:**\n",
+ " - `train_path`: The path to the training data.\n",
+ " - `valid_path`: The path to the validation data.\n",
+ " - `context_length`: The maximum number of tokens in the input.\n",
+ " \n",
+ "- **Training Configuration:**\n",
+ " - `learning_rate`: The learning rate for the optimizer.\n",
+ " - `num_epochs`: The number of epochs to train for.\n",
+ " - `train_batch_size_per_device`: The batch size per device for training.\n",
+ " - `eval_batch_size_per_device`: The evaluation batch size per device.\n",
+ " - `num_devices`: The number of devices to train on.\n",
+ " \n",
+ "- **Output Configuration:**\n",
+ " - `num_checkpoints_to_keep`: The number of checkpoints to retain.\n",
+ " - `output_dir`: The output directory for the model outputs.\n",
+ "\n",
+ "- **Advanced Training Configuration:**\n",
+ " - **LoRA Configuration:**\n",
+ " - `lora_config`: The LoRA configuration. Key parameters include:\n",
+ " - `r`: The rank of the LoRA matrix.\n",
+ " - `target_modules`: The modules to which LoRA will be applied.\n",
+ " - `lora_alpha`: The LoRA alpha parameter (a scaling factor).\n",
+ " - **DeepSpeed Configuration:**\n",
+ " - `deepspeed`: Settings for distributed training strategies such as DeepSpeed ZeRO (Zero Redundancy Optimizer).\n",
+ " - This may include specifying the ZeRO stage (to control what objects are sharded/split across GPUs).\n",
+ " - Optionally, enable CPU offloading for parameter and optimizer states.\n",
+ " \n",
+ "\n",
+ "Default configurations for all popular models are available in the `llm-forge` library, which serve as a good starting point for most tasks.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "vscode": {
+ "languageId": "plaintext"
+ }
+ },
+ "source": [
+ "## 2. Submitting an LLM Finetuning Job\n",
+ "\n",
+ "To run the finetuning, we will be using the Anyscale Job SDK.\n",
+ "\n",
+ "We start by defining a JobConfig object with the following content:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "job_config = anyscale.job.JobConfig(\n",
+ " # The command to run the finetuning process\n",
+ " entrypoint=\"llmforge anyscale finetune configs/training/lora/mistral-7b.yaml\",\n",
+ " # The image to use for the job\n",
+ " image_uri=\"localhost:5555/anyscale/llm-forge:0.5.4\",\n",
+ " # Retry the job up to 1 times\n",
+ " max_retries=1\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can then run the following command to submit the job:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "job_id = anyscale.job.submit(config=job_config)\n",
+ "job_id"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "vscode": {
+ "languageId": "plaintext"
+ }
+ },
+ "source": [
+ "### Preparing an LLMForge configuration file\n",
+ "\n",
+ "We have already prepared a configuration file for you under `configs/training/lora/mistral-7b.yaml`\n",
+ "\n",
+ "Here are the file contents:\n",
+ "\n",
+ "```yaml\n",
+ "# Change this to the model you want to fine-tune\n",
+ "model_id: mistralai/Mistral-7B-Instruct-v0.1\n",
+ "\n",
+ "# Change this to the path to your training data\n",
+ "train_path: s3://anyscale-public-materials/llm-finetuning/viggo_inverted/train/subset-500.jsonl\n",
+ "\n",
+ "# Change this to the path to your validation data. This is optional\n",
+ "valid_path: s3://anyscale-public-materials/llm-finetuning/viggo_inverted/valid/data.jsonl\n",
+ "\n",
+ "# Change this to the context length you want to use. Examples with longer\n",
+ "# context length will be truncated.\n",
+ "context_length: 512\n",
+ "\n",
+ "# Change this to total number of GPUs that you want to use\n",
+ "num_devices: 2\n",
+ "\n",
+ "# Change this to the number of epochs that you want to train for\n",
+ "num_epochs: 3\n",
+ "\n",
+ "# Change this to the batch size that you want to use\n",
+ "train_batch_size_per_device: 16\n",
+ "eval_batch_size_per_device: 16\n",
+ "\n",
+ "# Change this to the learning rate that you want to use\n",
+ "learning_rate: 1e-4\n",
+ "\n",
+ "# This will pad batches to the longest sequence. Use \"max_length\" when profiling to profile the worst case.\n",
+ "padding: \"longest\"\n",
+ "\n",
+ "# By default, we will keep the best checkpoint. You can change this to keep more checkpoints.\n",
+ "num_checkpoints_to_keep: 1\n",
+ "\n",
+ "# Deepspeed configuration, you can provide your own deepspeed setup\n",
+ "deepspeed:\n",
+ " config_path: configs/deepspeed/zero_3_offload_optim+param.json\n",
+ "\n",
+ "# Lora configuration\n",
+ "lora_config:\n",
+ " r: 8\n",
+ " lora_alpha: 16\n",
+ " lora_dropout: 0.05\n",
+ " target_modules:\n",
+ " - q_proj\n",
+ " - v_proj\n",
+ " - k_proj\n",
+ " - o_proj\n",
+ " - gate_proj\n",
+ " - up_proj\n",
+ " - down_proj\n",
+ " - embed_tokens\n",
+ " - lm_head\n",
+ " task_type: \"CAUSAL_LM\"\n",
+ " bias: \"none\"\n",
+ " modules_to_save: []\n",
+ "\n",
+ "````"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "vscode": {
+ "languageId": "plaintext"
+ }
+ },
+ "source": [
+ "\n",
+ "Anyscale's LLMForge's finetune config can be split into the following:\n",
+ "\n",
+ "- **Model Configuration:**\n",
+ " - `model_id`: The Hugging Face model name.\n",
+ " \n",
+ "- **Data Configuration:**\n",
+ " - `train_path`: The path to the training data.\n",
+ " - `valid_path`: The path to the validation data.\n",
+ " - `context_length`: The maximum number of tokens in the input.\n",
+ " \n",
+ "- **Training Configuration:**\n",
+ " - `learning_rate`: The learning rate for the optimizer.\n",
+ " - `num_epochs`: The number of epochs to train for.\n",
+ " - `train_batch_size_per_device`: The batch size per device for training.\n",
+ " - `eval_batch_size_per_device`: The evaluation batch size per device.\n",
+ " - `num_devices`: The number of devices to train on.\n",
+ " \n",
+ "- **Output Configuration:**\n",
+ " - `num_checkpoints_to_keep`: The number of checkpoints to retain.\n",
+ " - `output_dir`: The output directory for the model outputs.\n",
+ "\n",
+ "- **Advanced Training Configuration:**\n",
+ " - **LoRA Configuration:**\n",
+ " - `lora_config`: The LoRA configuration. Key parameters include:\n",
+ " - `r`: The rank of the LoRA matrix.\n",
+ " - `target_modules`: The modules to which LoRA will be applied.\n",
+ " - `lora_alpha`: The LoRA alpha parameter (a scaling factor).\n",
+ " - **DeepSpeed Configuration:**\n",
+ " - `deepspeed`: Settings for distributed training strategies such as DeepSpeed ZeRO (Zero Redundancy Optimizer).\n",
+ " - This may include specifying the ZeRO stage (to control what objects are sharded/split across GPUs).\n",
+ " - Optionally, enable CPU offloading for parameter and optimizer states.\n",
+ " \n",
+ "\n",
+ "Default configurations for all popular models are available in the `llm-forge` library, which serve as a good starting point for most tasks.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "vscode": {
+ "languageId": "plaintext"
+ }
+ },
+ "source": [
+ "## 2. Submitting an LLM Finetuning Job\n",
+ "\n",
+ "To run the finetuning, we will be using the Anyscale Job SDK.\n",
+ "\n",
+ "We start by defining a JobConfig object with the following content:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "job_config = anyscale.job.JobConfig(\n",
+ " # The command to run the finetuning process\n",
+ " entrypoint=\"llmforge anyscale finetune configs/training/lora/mistral-7b.yaml\",\n",
+ " # The image to use for the job\n",
+ " image_uri=\"localhost:5555/anyscale/llm-forge:0.5.4\",\n",
+ " # Retry the job up to 1 times\n",
+ " max_retries=1\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can then run the following command to submit the job:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "job_id = anyscale.job.submit(config=job_config)\n",
+ "job_id"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "Note: by default the job will make use of the same compute configuration as the current workspace that is submitting the job unless specified otherwise.\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "vscode": {
+ "languageId": "plaintext"
+ }
+ },
+ "source": [
+ "## 3. Tracking the Progress of the Job\n",
+ "\n",
+ "Once the job is submitted, we can make use of the observability features of the Anyscale platform to track the progress of the job at the following location: https://console.anyscale.com/jobs/{job_id}\n",
+ "\n",
+ "More specifically, we can inspect the following:\n",
+ "- Logs to view which stage of the finetuning process the job is currently at.\n",
+ "- Hardware utilization metrics to ensure that the job is making full use of the resources allocated to it.\n",
+ "- Training metrics to see how the model is performing on the validation set."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "If you would like to follow the job logs in real-time, you can run the following command:\n",
+ "\n",
+ "```bash\n",
+ "!anyscale job logs --id {job_id} -f\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "vscode": {
+ "languageId": "plaintext"
+ }
+ },
+ "source": [
+ "If you head to the Job's dashboard, you can see the hardware utilization metrics showcasing the GPU utilization and the memory usage:\n",
+ "\n",
+ " \n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Under the job's log tab, you can see a snippet of the logs showcasing the training metrics:\n",
+ "\n",
+ "```\n",
+ "2024-09-04, 17:36:21.824\tdriver\t╭───────────────────────────────────────────────╮\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ Training result │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t├───────────────────────────────────────────────┤\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ checkpoint_dir_name │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ time_this_iter_s 9.07254 │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ time_total_s 414.102 │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ training_iteration 29 │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ avg_bwd_time_per_epoch │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ avg_fwd_time_per_epoch │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ avg_train_loss_epoch │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ bwd_time 5.13469 │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ epoch 1 │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ eval_loss │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ eval_time_per_epoch │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ fwd_time 3.94241 │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ learning_rate 5e-05 │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ num_iterations 13 │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ perplexity │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ step 12 │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ total_trained_steps 29 │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ total_update_time 268.125 │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ train_loss_batch 0.28994 │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ train_time_per_epoch │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ train_time_per_step 9.07861 │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ trained_tokens 280128 │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ trained_tokens_this_iter 10752 │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ trained_tokens_throughput 1044.76 │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ trained_tokens_throughput_this_iter 1184.51 │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t╰───────────────────────────────────────────────╯\n",
+ "2024-09-04, 17:36:21.824\tdriver\t(RayTrainWorker pid=2484, ip=10.0.32.0) [epoch 1 step 12] loss: 0.28619903326034546 step-time: 9.077147483825684\n",
+ "```\n",
+ "\n",
+ "\n",
+ "Note, you can also run tools like tensorboard to visualize the training metrics."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 4. Tailoring LLMForge to Your Needs\n",
+ "\n",
+ "### 1. Start with a default configuration\n",
+ "\n",
+ "Use the Anyscale [finetuning LLMs template](https://console.anyscale.com/v2/template-preview/finetuning_llms_v2) which contains a default configuration for the most common models.\n",
+ "\n",
+ "### 2. Customize to point to your data\n",
+ "\n",
+ "Use the `train_path` and `valid_path` to point to your data. Update the `context_length` to fit your expected sequence length.\n",
+ "\n",
+ "### 3. Run the job and monitor for performance bottlenecks\n",
+ "\n",
+ "Here are some common performance bottlenecks:\n",
+ "\n",
+ "#### Minimize GPU communication overhead\n",
+ "If you can secure a large instance and perform the finetuning on a single node, then this will be advisable to reduce the communication overhead during distributed training. You can specify a larger node instances by setting a custom compute configuration in the `job.yaml` file.\n",
+ "\n",
+ "#### Maximize GPU memory utilization\n",
+ "\n",
+ "The following parameters affect your GPU memory utilization\n",
+ "\n",
+ "1. The batch size per device\n",
+ "2. The chosen context length\n",
+ "3. The padding type\n",
+ "\n",
+ "In addition, other configurations like deepspeed will also have an effect on your memory.\n",
+ "\n",
+ "You will want to tune these parameters to maximize your hardware utilization.\n",
+ "\n",
+ "
\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Under the job's log tab, you can see a snippet of the logs showcasing the training metrics:\n",
+ "\n",
+ "```\n",
+ "2024-09-04, 17:36:21.824\tdriver\t╭───────────────────────────────────────────────╮\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ Training result │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t├───────────────────────────────────────────────┤\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ checkpoint_dir_name │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ time_this_iter_s 9.07254 │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ time_total_s 414.102 │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ training_iteration 29 │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ avg_bwd_time_per_epoch │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ avg_fwd_time_per_epoch │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ avg_train_loss_epoch │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ bwd_time 5.13469 │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ epoch 1 │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ eval_loss │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ eval_time_per_epoch │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ fwd_time 3.94241 │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ learning_rate 5e-05 │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ num_iterations 13 │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ perplexity │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ step 12 │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ total_trained_steps 29 │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ total_update_time 268.125 │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ train_loss_batch 0.28994 │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ train_time_per_epoch │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ train_time_per_step 9.07861 │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ trained_tokens 280128 │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ trained_tokens_this_iter 10752 │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ trained_tokens_throughput 1044.76 │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t│ trained_tokens_throughput_this_iter 1184.51 │\n",
+ "2024-09-04, 17:36:21.824\tdriver\t╰───────────────────────────────────────────────╯\n",
+ "2024-09-04, 17:36:21.824\tdriver\t(RayTrainWorker pid=2484, ip=10.0.32.0) [epoch 1 step 12] loss: 0.28619903326034546 step-time: 9.077147483825684\n",
+ "```\n",
+ "\n",
+ "\n",
+ "Note, you can also run tools like tensorboard to visualize the training metrics."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 4. Tailoring LLMForge to Your Needs\n",
+ "\n",
+ "### 1. Start with a default configuration\n",
+ "\n",
+ "Use the Anyscale [finetuning LLMs template](https://console.anyscale.com/v2/template-preview/finetuning_llms_v2) which contains a default configuration for the most common models.\n",
+ "\n",
+ "### 2. Customize to point to your data\n",
+ "\n",
+ "Use the `train_path` and `valid_path` to point to your data. Update the `context_length` to fit your expected sequence length.\n",
+ "\n",
+ "### 3. Run the job and monitor for performance bottlenecks\n",
+ "\n",
+ "Here are some common performance bottlenecks:\n",
+ "\n",
+ "#### Minimize GPU communication overhead\n",
+ "If you can secure a large instance and perform the finetuning on a single node, then this will be advisable to reduce the communication overhead during distributed training. You can specify a larger node instances by setting a custom compute configuration in the `job.yaml` file.\n",
+ "\n",
+ "#### Maximize GPU memory utilization\n",
+ "\n",
+ "The following parameters affect your GPU memory utilization\n",
+ "\n",
+ "1. The batch size per device\n",
+ "2. The chosen context length\n",
+ "3. The padding type\n",
+ "\n",
+ "In addition, other configurations like deepspeed will also have an effect on your memory.\n",
+ "\n",
+ "You will want to tune these parameters to maximize your hardware utilization.\n",
+ "\n",
+ "\n",
+ "\n",
+ " Note: For an advanced tuning guide check out [this guide here](https://docs.anyscale.com/canary/llms/finetuning/guides/optimize_cost/)\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "vscode": {
+ "languageId": "plaintext"
+ }
+ },
+ "source": [
+ "## Next Steps\n",
+ "\n",
+ "We jumped directly into finetuning an LLM but in the next notebooks we will cover the following topics:\n",
+ "\n",
+ "1. How did we prepare the data for finetuning?\n",
+ "2. How should we evaluate the model?\n",
+ "3. How do we deploy the model?\n"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "base",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.9.19"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 2
+}
diff --git a/templates/ray-summit-end-to-end-llms/02_Preparing_Data.ipynb b/templates/ray-summit-end-to-end-llms/02_Preparing_Data.ipynb
new file mode 100644
index 000000000..174299f0e
--- /dev/null
+++ b/templates/ray-summit-end-to-end-llms/02_Preparing_Data.ipynb
@@ -0,0 +1,698 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Preparing Data for Fine-Tuning a Large Language Model\n",
+ "\n",
+ "It is critical to prepare quality data in the correct format to fine-tune a large language model.\n",
+ "\n",
+ "\n",
+ "\n",
+ " Here is the roadmap for this notebook:\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "vscode": {
+ "languageId": "plaintext"
+ }
+ },
+ "source": [
+ "## Imports"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "import uuid\n",
+ "from typing import Any\n",
+ "\n",
+ "import anyscale\n",
+ "import pandas as pd\n",
+ "import ray\n",
+ "from datasets import load_dataset"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ctx = ray.data.DataContext.get_current()\n",
+ "ctx.enable_operator_progress_bars = False"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "vscode": {
+ "languageId": "plaintext"
+ }
+ },
+ "source": [
+ "## 1. Preparing a sample dataset\n",
+ "\n",
+ "Let's start by preparing a small dataset for fine-tuning a large language model. "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "vscode": {
+ "languageId": "plaintext"
+ }
+ },
+ "source": [
+ "### Dataset\n",
+ "\n",
+ "We'll be using the [ViGGO dataset](https://huggingface.co/datasets/GEM/viggo) dataset, where the input (`meaning_representation`) is a structured collection of the overall intent (ex. `inform`) and entities (ex. `release_year`) and the output (`target`) is an unstructured sentence that incorporates all the structured input information. \n",
+ "\n",
+ "But for our task, we'll **reverse** this dataset where the input will be the unstructured sentence and the output will be the structured information.\n",
+ "\n",
+ "```python\n",
+ "# Input (unstructured sentence):\n",
+ "\"Dirt: Showdown from 2012 is a sport racing game for the PlayStation, Xbox, PC rated E 10+ (for Everyone 10 and Older). It's not available on Steam, Linux, or Mac.\"\n",
+ "\n",
+ "# Output (function + attributes): \n",
+ "\"inform(name[Dirt: Showdown], release_year[2012], esrb[E 10+ (for Everyone 10 and Older)], genres[driving/racing, sport], platforms[PlayStation, Xbox, PC], available_on_steam[no], has_linux_release[no], has_mac_release[no])\"\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "vscode": {
+ "languageId": "plaintext"
+ }
+ },
+ "source": [
+ "### Schema\n",
+ "\n",
+ "The preprocessing we'll do involves formatting our dataset into the schema required for fine-tuning (`system`, `user`, `assistant`) conversations.\n",
+ "\n",
+ "- `system`: description of the behavior or personality of the model. As a best practice, this should be the same for all examples in the fine-tuning dataset, and should remain the same system prompt when moved to production.\n",
+ "- `user`: user message, or \"prompt,\" that provides a request for the model to respond to.\n",
+ "- `assistant`: stores previous responses but can also contain examples of intended responses for the LLM to return.\n",
+ "\n",
+ "```python\n",
+ "conversations = [\n",
+ " {\"messages\": [\n",
+ " {'role': 'system', 'content': system_content},\n",
+ " {'role': 'user', 'content': item['target']},\n",
+ " {'role': 'assistant', 'content': item['meaning_representation']}\n",
+ " ]},\n",
+ " {\"messages\": [...]},\n",
+ " ...\n",
+ "]\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "vscode": {
+ "languageId": "plaintext"
+ }
+ },
+ "source": [
+ "### Loading a sample dataset\n",
+ "\n",
+ "We will make use of the `datasets` library to load the ViGGO dataset and prepare a sample dataset for fine-tuning."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "dataset = load_dataset(\"GEM/viggo\", trust_remote_code=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's inspect the data splits available in the dataset:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Data splits\n",
+ "train_set = dataset['train']\n",
+ "val_set = dataset['validation']\n",
+ "test_set = dataset['test']\n",
+ "print (f\"train: {len(train_set)}\")\n",
+ "print (f\"val: {len(val_set)}\")\n",
+ "print (f\"test: {len(test_set)}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Here is a single row of the dataset"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "for row in test_set:\n",
+ " break\n",
+ "row"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Here is a function that will transform the row into a format that can be used by the model."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def to_schema(row: dict[str, Any], system_content: str) -> dict[str, Any]:\n",
+ " messages = [\n",
+ " {\"role\": \"system\", \"content\": system_content},\n",
+ " {\"role\": \"user\", \"content\": row[\"target\"]},\n",
+ " {\"role\": \"assistant\", \"content\": row[\"meaning_representation\"]},\n",
+ " ]\n",
+ " return {\"messages\": messages}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We will use the following system prompt:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# System content\n",
+ "system_content = (\n",
+ " \"Given a target sentence construct the underlying meaning representation of the input \"\n",
+ " \"sentence as a single function with attributes and attribute values. This function \"\n",
+ " \"should describe the target string accurately and the function must be one of the \"\n",
+ " \"following ['inform', 'request', 'give_opinion', 'confirm', 'verify_attribute', \"\n",
+ " \"'suggest', 'request_explanation', 'recommend', 'request_attribute']. The attributes \"\n",
+ " \"must be one of the following: ['name', 'exp_release_date', 'release_year', 'developer', \"\n",
+ " \"'esrb', 'rating', 'genres', 'player_perspective', 'has_multiplayer', 'platforms', \"\n",
+ " \"'available_on_steam', 'has_linux_release', 'has_mac_release', 'specifier']\")\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can now convert the data to the schema format."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "converted_data = []\n",
+ "\n",
+ "for row in train_set:\n",
+ " row[\"schema\"] = to_schema(row, system_content)\n",
+ " converted_data.append(row[\"schema\"])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Here is how the schema looks like for a single row"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "row[\"schema\"]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can then make use of pandas to first view our dataset"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "converted_df = pd.DataFrame(converted_data)\n",
+ "converted_df.head()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "we then store our training dataset which is now ready for finetuning via LLMForge"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "converted_df.to_json(\"train.jsonl\", orient=\"records\", lines=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 2. Introduction to Ray Data\n",
+ "\n",
+ "\n",
+ "Ray Data is a scalable data processing library for ML workloads, particularly suited for the following workloads:\n",
+ "\n",
+ "\n",
+ "\n",
+ "Ray Data is particularly useful for streaming data on a heterogenous cluster:\n",
+ "\n",
+ "- \n",
+ "
- Part 1: Preparing a sample dataset. \n", + "
- Part 2: Introduction to Ray Data. \n", + "
- Part 3: Migrating to a scalable pipeline. \n", + "
- Part 4: Using the Anyscale Datasets registry. \n", + "
 \n",
+ "\n",
+ "Your production pipeline for preparing data for fine-tuning a large language model could require:\n",
+ "1. Loading mutli-modal datasets\n",
+ "2. Inferencing against guardrail models to remove low-quality and PII data.\n",
+ "3. Preprocessing data to the schema required for fine-tuning.\n",
+ "\n",
+ "You will want to make the most efficient use of your cluster to process this data. Ray Data can help you do this."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Ray Data's API\n",
+ "\n",
+ "Here are the steps to make use of Ray Data:\n",
+ "1. Create a Ray Dataset usually by pointing to a data source.\n",
+ "2. Apply transformations to the Ray Dataset.\n",
+ "3. Write out the results to a data source.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Loading Data\n",
+ "\n",
+ "Ray Data has a number of [IO connectors](https://docs.ray.io/en/latest/data/api/input_output.html) to most commonly used formats.\n",
+ "\n",
+ "For purposes of this introduction, we will use the `from_huggingface` function to read the dataset we prepared in the previous section but this time we enable streaming."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "train_streaming_ds = load_dataset(\n",
+ " path=\"GEM/viggo\",\n",
+ " name=\"default\",\n",
+ " streaming=True, # Enable streaming\n",
+ " split=\"train\",\n",
+ ")\n",
+ "\n",
+ "train_ds = ray.data.from_huggingface(train_streaming_ds)\n",
+ "train_ds"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "
\n",
+ "\n",
+ "Your production pipeline for preparing data for fine-tuning a large language model could require:\n",
+ "1. Loading mutli-modal datasets\n",
+ "2. Inferencing against guardrail models to remove low-quality and PII data.\n",
+ "3. Preprocessing data to the schema required for fine-tuning.\n",
+ "\n",
+ "You will want to make the most efficient use of your cluster to process this data. Ray Data can help you do this."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Ray Data's API\n",
+ "\n",
+ "Here are the steps to make use of Ray Data:\n",
+ "1. Create a Ray Dataset usually by pointing to a data source.\n",
+ "2. Apply transformations to the Ray Dataset.\n",
+ "3. Write out the results to a data source.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Loading Data\n",
+ "\n",
+ "Ray Data has a number of [IO connectors](https://docs.ray.io/en/latest/data/api/input_output.html) to most commonly used formats.\n",
+ "\n",
+ "For purposes of this introduction, we will use the `from_huggingface` function to read the dataset we prepared in the previous section but this time we enable streaming."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "train_streaming_ds = load_dataset(\n",
+ " path=\"GEM/viggo\",\n",
+ " name=\"default\",\n",
+ " streaming=True, # Enable streaming\n",
+ " split=\"train\",\n",
+ ")\n",
+ "\n",
+ "train_ds = ray.data.from_huggingface(train_streaming_ds)\n",
+ "train_ds"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "Note that we can also stream data directly from huggingface or from any other source (e.g. parquet on S3)\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Transforming Data\n",
+ "\n",
+ "Datasets can be transformed by applying a row-wise `map` operation. We do this by providing a user-defined function that takes a row as input and returns a row as output."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def to_schema_map(row: dict[str, Any]) -> dict[str, Any]:\n",
+ " return to_schema(row, system_content=system_content)\n",
+ "\n",
+ "train_ds_with_schema = train_ds.map(to_schema_map)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Lazy execution\n",
+ "\n",
+ "By default, `map` is lazy, meaning that it will not actually execute the function until you consume it. This allows for optimizations like pipelining and fusing of operations.\n",
+ "\n",
+ "To inspect a few rows of the dataset, you can use the `take` method:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "train_ds_with_schema.take(2)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Writing Data\n",
+ "\n",
+ "We can then write out the data to disk using the avialable IO connector methods."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "uuid_ = str(uuid.uuid4())\n",
+ "storage_path = f\"/mnt/cluster_storage/ray_summit/e2e_llms/{uuid_}\"\n",
+ "storage_path\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We make use of the `write_json` method to write the dataset to the storage path in a distributed manner."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "train_ds_with_schema.write_json(f\"{storage_path}/train\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's inspect the generated files:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!ls {storage_path}/train/ --human-readable"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Recap of our Ray Data pipeline\n",
+ "\n",
+ "Here is our Ray data pipeline condensed into the following chained operations:\n",
+ "\n",
+ "```python\n",
+ "(\n",
+ " ray.data.from_huggingface(train_streaming_ds)\n",
+ " .map(to_schema_map)\n",
+ " .write_json(f\"{storage_path}/train\")\n",
+ ")\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "### Lab activity: Apply more elaborate preprocessing\n",
+ "\n",
+ "Assume you have a function that you would like to apply to remove all `give_opinion` messages to avoid finetuning on sensitive user opinions.\n",
+ "\n",
+ "In a production setting, think of this as applying a Guardrail model that you use to detect and filter out poor quality data or PII data.\n",
+ "\n",
+ "i.e. given this code:\n",
+ "\n",
+ "```python\n",
+ "def is_give_opinion(conversation):\n",
+ " sys, user, assistant = conversation\n",
+ " return \"give_opinion\" in assistant[\"content\"]\n",
+ "\n",
+ "\n",
+ "def filter_opinions(row) -> bool:\n",
+ " # Hint: call is_give_opinion on the row\n",
+ " ...\n",
+ "\n",
+ "(\n",
+ " ray.data.from_huggingface(train_streaming_ds)\n",
+ " .map(to_schema_map)\n",
+ " .filter(filter_opinions)\n",
+ " .write_json(f\"{storage_path}/train_without_opinion\")\n",
+ ")\n",
+ "```\n",
+ "\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Write your solution here\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Using Anyscale Datasets\n",
+ "\n",
+ "Anyscale Datasets is a managed dataset registry and discovery service that allows you to:\n",
+ "\n",
+ "- Centralize dataset storage\n",
+ "- Version datasets\n",
+ "- Track dataset usage\n",
+ "- Manage dataset access\n",
+ "\n",
+ "Let's upload our training data to the Anyscale Datasets registry."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "anyscale_dataset = anyscale.llm.dataset.upload(\n",
+ " \"train.jsonl\",\n",
+ " name=\"viggo_train\",\n",
+ " description=(\n",
+ " \"VIGGO dataset for E2E LLM template: train split\"\n",
+ " ),\n",
+ " )\n",
+ "\n",
+ "anyscale_dataset"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "The dataset is now saved to the Anyscale Datasets registry.\n",
+ "\n",
+ "To load the Anyscale Dataset back into a Ray Dataset, you can do:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "anyscale_dataset = anyscale.llm.dataset.get(\"viggo_train\")\n",
+ "train_ds_with_schema = ray.data.read_json(anyscale_dataset.storage_uri)\n",
+ "train_ds_with_schema"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "You may also want to download the contents of the Dataset file directly, in this case, a `.jsonl` file."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "dataset_contents: bytes = anyscale.llm.dataset.download(\"viggo_train\")\n",
+ "lines = dataset_contents.decode().splitlines()\n",
+ "print(\"# of rows:\", len(lines))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Or version the Dataset:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "anyscale_dataset = anyscale.llm.dataset.get(\"viggo_train\")\n",
+ "latest_version = anyscale_dataset.version\n",
+ "anyscale_dataset = anyscale.llm.dataset.upload(\n",
+ " \"train.jsonl\",\n",
+ " name=\"viggo_train\",\n",
+ " description=(\n",
+ " f\"VIGGO dataset for E2E LLM template: train split, version {latest_version + 1}\"\n",
+ " ),\n",
+ ")\n",
+ "\n",
+ "print(\"Latest version:\", anyscale.llm.dataset.get(\"viggo_train\"))\n",
+ "print(\"Second latest version:\", anyscale.llm.dataset.get(\"viggo_train\", version=-1))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Finally, you can use the Anyscale dataset in your LLMForge fine-tuning jobs."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "base",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.9.19"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 2
+}
diff --git a/templates/ray-summit-end-to-end-llms/03_Evaluating_LLMs.ipynb b/templates/ray-summit-end-to-end-llms/03_Evaluating_LLMs.ipynb
new file mode 100644
index 000000000..16aa47f2f
--- /dev/null
+++ b/templates/ray-summit-end-to-end-llms/03_Evaluating_LLMs.ipynb
@@ -0,0 +1,1242 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Evaluation\n",
+ "\n",
+ "Now we'll evaluate our fine-tuned LLM to see how well it performs on our task. Here is the roadmap for our notebook:\n",
+ "\n",
+ "\n",
+ "
\n",
+ "\n",
+ "Click here to view the solution
\n", + "\n", + "```python\n", + "def is_give_opinion(conversation):\n", + " sys, user, assistant = conversation\n", + " return \"give_opinion\" in assistant[\"content\"]\n", + "\n", + "\n", + "def filter_opinions(row) -> bool:\n", + " return not is_give_opinion(row[\"messages\"])\n", + "\n", + "(\n", + " ray.data.from_huggingface(train_streaming_ds)\n", + " .map(to_schema_map)\n", + " .filter(filter_opinions)\n", + " .write_json(f\"{storage_path}/train_without_opinion\")\n", + ")\n", + "```\n", + "\n", + "\n", + "\n",
+ " Here is the roadmap for this notebook:\n",
+ "\n",
+ "
\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Imports"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "from typing import Any, Optional\n",
+ "\n",
+ "import anyscale\n",
+ "import numpy as np\n",
+ "import pandas as pd\n",
+ "import ray\n",
+ "import re\n",
+ "\n",
+ "from rich import print as rprint\n",
+ "from transformers import AutoTokenizer\n",
+ "from vllm.lora.request import LoRARequest\n",
+ "from vllm import LLM, SamplingParams"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ctx = ray.data.DataContext.get_current()\n",
+ "ctx.enable_operator_progress_bars = False\n",
+ "ctx.enable_progress_bars = False"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "vscode": {
+ "languageId": "plaintext"
+ }
+ },
+ "source": [
+ "## 0. Overview of LLM Evaluation\n",
+ "\n",
+ "Here are the main steps for evaluating a language model:\n",
+ "\n",
+ "1. Prepare Evaluation Data:\n",
+ " 1. Get data representative of the task you want to evaluate the model on.\n",
+ " 2. Prepare it in the proper format for the model.\n",
+ "2. Generate responses using your LLM\n",
+ " 1. Run batch inference on the evaluation data.\n",
+ "3. Produce evaluation metrics\n",
+ " 1. Choose a metric based on the model's output.\n",
+ " 2. Compare the model's performance to a baseline model to see if it's better.\n",
+ "\n",
+ "Here is a diagram of the evaluation process:\n",
+ "\n",
+ "- \n",
+ "
- Part1: Overview of LLM Evaluation \n", + "
- Part2: Loading Test Data \n", + "
- Part3: Forming our Inputs and Outputs \n", + "
- Part4: Running Model Inference \n", + "
- Part5: Generating Evaluation Metrics \n", + "
- Part6: Comparing with a Baseline Model \n", + "
 \n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 1. Load model artifacts\n",
+ "\n",
+ "Now that our finetuning is complete, we can load the model artifacts from cloud storage to a local [cluster storage](https://docs.anyscale.com/workspaces/storage/#cluster-storage) to use for other workloads.\n",
+ "\n",
+ "To retrieve information about your fine-tuned model, Anyscale provides a convenient model registry SDK."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ " 🔄 REPLACE : Use the job ID of your fine-tuning run"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "model_info = anyscale.llm.model.get(job_id=\"prodjob_123\") # REPLACE with the job ID for your fine-tuning run\n",
+ "rprint(model_info)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's extract the model ID from the model info."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "model_id = model_info.id"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We will download the artifacts from the cloud storage bucket to our local cluster storage"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "s3_storage_uri = (\n",
+ " f\"{os.environ['ANYSCALE_ARTIFACT_STORAGE']}\"\n",
+ " f\"/lora_fine_tuning/{model_id}\"\n",
+ ")\n",
+ "# s3_storage_uri = model_info.storage_uri \n",
+ "s3_path_wo_bucket = '/'.join(s3_storage_uri.split('/')[3:])\n",
+ "\n",
+ "local_artifacts_dir = \"/mnt/cluster_storage\"\n",
+ "local_artifacts_path = os.path.join(local_artifacts_dir, s3_path_wo_bucket)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!aws s3 sync {s3_storage_uri} {local_artifacts_path}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "
\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 1. Load model artifacts\n",
+ "\n",
+ "Now that our finetuning is complete, we can load the model artifacts from cloud storage to a local [cluster storage](https://docs.anyscale.com/workspaces/storage/#cluster-storage) to use for other workloads.\n",
+ "\n",
+ "To retrieve information about your fine-tuned model, Anyscale provides a convenient model registry SDK."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ " 🔄 REPLACE : Use the job ID of your fine-tuning run"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "model_info = anyscale.llm.model.get(job_id=\"prodjob_123\") # REPLACE with the job ID for your fine-tuning run\n",
+ "rprint(model_info)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's extract the model ID from the model info."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "model_id = model_info.id"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We will download the artifacts from the cloud storage bucket to our local cluster storage"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "s3_storage_uri = (\n",
+ " f\"{os.environ['ANYSCALE_ARTIFACT_STORAGE']}\"\n",
+ " f\"/lora_fine_tuning/{model_id}\"\n",
+ ")\n",
+ "# s3_storage_uri = model_info.storage_uri \n",
+ "s3_path_wo_bucket = '/'.join(s3_storage_uri.split('/')[3:])\n",
+ "\n",
+ "local_artifacts_dir = \"/mnt/cluster_storage\"\n",
+ "local_artifacts_path = os.path.join(local_artifacts_dir, s3_path_wo_bucket)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!aws s3 sync {s3_storage_uri} {local_artifacts_path}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "Backup: In case you don't have access to a successful finetuning job, you can download the artifacts by running this code in a python cell.\n",
+ "\n",
+ "```python\n",
+ "model_id = \"mistralai/Mistral-7B-Instruct-v0.1:aitra:qzoyg\"\n",
+ "local_artifacts_path = f\"/mnt/cluster_storage/llm-finetuning/lora_fine_tuning/{model_id}\"\n",
+ "!aws s3 sync s3://anyscale-public-materials/llm-finetuning/lora_fine_tuning/{model_id} {local_artifacts_path}\n",
+ "```\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "vscode": {
+ "languageId": "plaintext"
+ }
+ },
+ "source": [
+ "## 2. Reading the test data\n",
+ "\n",
+ "Let's start by reading the test data to evaluate our fine-tuned LLM. This test data has undergone the same preparation process as the training data - i.e. it is in the correct schema format."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "test_ds = (\n",
+ " ray.data.read_json(\n",
+ " \"s3://anyscale-public-materials/llm-finetuning/viggo_inverted/test/data.jsonl\"\n",
+ " )\n",
+ ")\n",
+ "test_ds"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "test_ds = test_ds.limit(100) # We limit to 100 for the sake of time but still sufficient size."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "NOTE: It is important to split the dataset into a train, validation, and test set. The test set should be used only for evaluation purposes. The model should not be trained or tuned on the test set.\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "vscode": {
+ "languageId": "plaintext"
+ }
+ },
+ "source": [
+ "## 3. Forming our Inputs and Outputs\n",
+ "\n",
+ "Let's split the test data into inputs and outputs. Our inputs are the \"system\" and \"user\" prompts, and the outputs are the responses generated by the \"assistant\".\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def split_inputs_outputs(row):\n",
+ " row[\"input_messages\"] = [\n",
+ " message for message in row[\"messages\"] if message[\"role\"] != \"assistant\"\n",
+ " ]\n",
+ " row[\"output_messages\"] = [\n",
+ " message for message in row[\"messages\"] if message[\"role\"] == \"assistant\"\n",
+ " ]\n",
+ " del row[\"messages\"]\n",
+ " return row\n",
+ "\n",
+ "test_ds_inputs_outputs = test_ds.map(split_inputs_outputs)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's inspect a sample batch"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sample_batch = test_ds_inputs_outputs.take_batch(1)\n",
+ "sample_batch"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We choose to fetch the LLM model files from an s3 bucket instead of huggingface. This is much more likely what you might do in a production environment."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "base_model = \"/mnt/cluster_storage/mistralai--Mistral-7B-Instruct-v0.1/\""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!aws s3 sync \"s3://anyscale-public-materials/llm/mistralai--Mistral-7B-Instruct-v0.1/\" {base_model} --region us-west-2"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We'll load the appropriate tokenizer to apply to our input data."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "tokenizer = AutoTokenizer.from_pretrained(base_model)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "A tokenizer encodes the input text into a list of token ids that the model can understand."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "tokenizer.encode(\"Hello there\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "The token ids are simply the indices of the tokens in the model's vocabulary."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "tokenizer.tokenize(\"Hello there\", add_special_tokens=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "In addition to tokenizing, we will need to convert the prompt into the template format that the model expects."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "tokenizer.apply_chat_template(\n",
+ " conversation=sample_batch[\"input_messages\"][0],\n",
+ " add_generation_prompt=True,\n",
+ " tokenize=False,\n",
+ " return_tensors=\"np\",\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "To apply the prompt template and tokenize the input data, we'll use the following stateful transformation:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class MistralTokenizer:\n",
+ " def __init__(self):\n",
+ " self.tokenizer = AutoTokenizer.from_pretrained(base_model)\n",
+ "\n",
+ " def __call__(self, row: dict[str, Any]) -> dict[str, Any]:\n",
+ " row[\"input_tokens\"] = self.tokenizer.apply_chat_template(\n",
+ " conversation=row[\"input_messages\"],\n",
+ " add_generation_prompt=True,\n",
+ " tokenize=True,\n",
+ " return_tensors=\"np\",\n",
+ " ).squeeze()\n",
+ " return row\n",
+ "\n",
+ "\n",
+ "test_ds_inputs_tokenized = test_ds_inputs_outputs.map(\n",
+ " MistralTokenizer,\n",
+ " concurrency=2,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sample_tokenized_batch = test_ds_inputs_tokenized.take_batch(1)\n",
+ "sample_tokenized_batch[\"input_tokens\"][0].shape"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can then proceed to materialize the dataset."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "test_ds_inputs_tokenized = test_ds_inputs_tokenized.materialize()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Materializing the dataset could be useful if we want to compute metrics on the tokens like the maximum input token length for instance."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def compute_token_length(row: dict) -> dict:\n",
+ " row[\"token_length\"] = len(row[\"input_tokens\"])\n",
+ " return row\n",
+ "\n",
+ "max_input_length = test_ds_inputs_tokenized.map(compute_token_length).max(on=\"token_length\")\n",
+ "max_input_length"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "vscode": {
+ "languageId": "plaintext"
+ }
+ },
+ "source": [
+ "## 5. Running Model Inference\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "vscode": {
+ "languageId": "plaintext"
+ }
+ },
+ "source": [
+ "#### Quick Intro to vLLM\n",
+ "\n",
+ "vLLM is a library for high throughput generation of LLM models by leveraging various performance optimizations, primarily: \n",
+ "\n",
+ "* Efficient management of attention key and value memory with PagedAttention \n",
+ "* Fast model execution with CUDA/HIP graph\n",
+ "* Quantization: GPTQ, AWQ, SqueezeLLM, FP8 KV Cache\n",
+ "* Optimized CUDA kernels\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "vLLM makes available an `LLM` class which can be called along with sampling parameters to generate outputs.\n",
+ "\n",
+ "Here is how we can build a stateful transformation to perform batch inference on our test data:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class LLMPredictor:\n",
+ " def __init__(\n",
+ " self, hf_model: str, sampling_params: SamplingParams, lora_path: str = None\n",
+ " ):\n",
+ " # 1. Load the LLM\n",
+ " self.llm = LLM(\n",
+ " model=hf_model,\n",
+ " enable_lora=bool(lora_path),\n",
+ " gpu_memory_utilization=0.95,\n",
+ " kv_cache_dtype=\"fp8\",\n",
+ " )\n",
+ "\n",
+ " self.sampling_params = sampling_params\n",
+ " # 2. Prepare a LoRA request if a LoRA path is provided\n",
+ " self.lora_request = (\n",
+ " LoRARequest(\n",
+ " lora_name=\"lora_adapter\", lora_int_id=1, lora_local_path=lora_path\n",
+ " )\n",
+ " if lora_path\n",
+ " else None\n",
+ " )\n",
+ "\n",
+ " def __call__(self, batch: dict[str, np.ndarray]) -> dict[str, np.ndarray]:\n",
+ " # 3. Generate outputs\n",
+ " responses = self.llm.generate(\n",
+ " prompt_token_ids=[ids.squeeze().tolist() for ids in batch[\"input_tokens\"]],\n",
+ " sampling_params=self.sampling_params,\n",
+ " lora_request=self.lora_request,\n",
+ " )\n",
+ "\n",
+ " return {\n",
+ " \"prompt\": [\n",
+ " \" \".join(message[\"content\"] for message in messages)\n",
+ " for messages in batch[\"input_messages\"]\n",
+ " ],\n",
+ " \"expected_output\": [\n",
+ " message[\"content\"]\n",
+ " for messages in batch[\"output_messages\"]\n",
+ " for message in messages\n",
+ " ],\n",
+ " \"generated_text\": [resp.outputs[0].text for resp in responses],\n",
+ " }\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We then apply the transformation like so:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sampling_params = SamplingParams(temperature=0, max_tokens=1024, detokenize=True)\n",
+ "\n",
+ "test_ds_responses = test_ds_inputs_tokenized.map_batches(\n",
+ " LLMPredictor,\n",
+ " fn_constructor_kwargs={\n",
+ " \"hf_model\": base_model,\n",
+ " \"sampling_params\": sampling_params,\n",
+ " \"lora_path\": local_artifacts_path,\n",
+ " },\n",
+ " concurrency=1, # number of LLM instances\n",
+ " num_gpus=1, # GPUs per LLM instance\n",
+ " batch_size=40,\n",
+ ")\n",
+ "\n",
+ "test_ds_responses = test_ds_responses.materialize()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "Note: Running inference can take a long time depending on the size of the dataset and the model. Additional time may be required for the model to automatically scale up to handle the workload.\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sample_response = test_ds_responses.take_batch(2)\n",
+ "sample_response"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "### Activity: Find the optimal batch size\n",
+ "\n",
+ "To run batch inference efficiently, we should always look to maximize our hardware utilization. \n",
+ "\n",
+ "To that end, you need to find the batch size that will maximize our GPU memory usage. \n",
+ "\n",
+ "Hint: make use of the metrics tab to look at the hardware utilization and iteratively find your batch size.\n",
+ "\n",
+ "\n",
+ "```python\n",
+ "test_ds_inputs_tokenized.map_batches(\n",
+ " LLMPredictor,\n",
+ " fn_constructor_kwargs={\n",
+ " \"hf_model\": base_model,\n",
+ " \"sampling_params\": sampling_params,\n",
+ " \"lora_path\": local_artifacts_path,\n",
+ " },\n",
+ " concurrency=1, \n",
+ " num_gpus=1, \n",
+ " batch_size=40, # Hint: find the optimal batch size.\n",
+ ").materialize()\n",
+ "```\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Write your solution here\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "vscode": {
+ "languageId": "plaintext"
+ }
+ },
+ "source": [
+ "## 6. Generating Evaluation Metrics\n",
+ "\n",
+ "Depending on your task, you will want to choose the proper evaluation metric. \n",
+ "\n",
+ "In our functional representation task, the output is constrained into a limited set of categories and therefore standard classification evaluation metrics are a good choice.\n",
+ "\n",
+ "In more open-ended response generation tasks, you might want to consider making use of an LLM as a judge to generate a scoring metric."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Post-processing the responses\n",
+ "\n",
+ "We will evaluate the accuracy at two levels:\n",
+ "- accuracy of predicting the correct function type\n",
+ "- accuracy of predicting the correct attribute types (a much more difficult task)\n",
+ "\n",
+ "Lets post process the outputs to extract the ground-truth vs model predicted function types and attriute types"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def extract_function_type(response: str) -> Optional[str]:\n",
+ " \"\"\"Extract the function type from the response.\"\"\"\n",
+ " if response is None:\n",
+ " return None\n",
+ "\n",
+ " # pattern to match is \"{function_type}({attributes})\"\n",
+ " expected_pattern = re.compile(r\"^(?P\n",
+ "\n",
+ "
\n",
+ "\n",
+ "Click here to see the solution
\n", + "\n", + "```python\n", + "test_ds_inputs_tokenized.map_batches(\n", + " LLMPredictor,\n", + " fn_constructor_kwargs={\n", + " \"hf_model\": base_model,\n", + " \"sampling_params\": sampling_params,\n", + " \"lora_path\": local_artifacts_path,\n", + " },\n", + " concurrency=1, \n", + " num_gpus=1, \n", + " batch_size=70,\n", + ").materialize()\n", + "```\n", + "\n", + "\n",
+ "\n",
+ "### Activity: Change the attribute types accuracy metric\n",
+ "\n",
+ "Our current metric for attribute types is not very strict. \n",
+ "\n",
+ "Can you make it stricter by setting `attr_types_match` to `True` only when the model's predicted attribute types and the ground truth attribute types are exactly the same in the order they appear?\n",
+ "\n",
+ "\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Write your solution here"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 4. Querying our LLM application\n",
+ "\n",
+ "Let's first build a client to query our LLM"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def build_client(base_url: str, api_key: str) -> openai.OpenAI:\n",
+ " return openai.OpenAI(\n",
+ " base_url=base_url.rstrip(\"/\") + \"/v1\",\n",
+ " api_key=api_key,\n",
+ " )"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "client = build_client(\"http://localhost:8000\", \"NOT A REAL KEY\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Next, we build a query function to send requests to our LLM application."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def query(\n",
+ " client: openai.OpenAI,\n",
+ " llm_model: str,\n",
+ " system_message: dict[str, str],\n",
+ " user_message: dict[str, str],\n",
+ " temperature: float = 0,\n",
+ " timeout: float = 3 * 60,\n",
+ ") -> Optional[str]:\n",
+ " model_response = client.chat.completions.create(\n",
+ " model=llm_model,\n",
+ " messages=[system_message, user_message],\n",
+ " temperature=temperature,\n",
+ " timeout=timeout,\n",
+ " )\n",
+ " model_output = model_response.choices[0].message.content\n",
+ " return model_output"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ " 🔄 REPLACE : Use the job ID of your fine-tuning run"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "model_info = anyscale.llm.model.get(job_id=\"prodjob_123\") # REPLACE with the job ID for your fine-tuning run"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's extract the base model ID and the model ID from the model info."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "base_model = model_info.base_model_id\n",
+ "finetuned_model_id = model_info.id\n",
+ "finetuned_model_id"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 4. Querying our LLM application\n",
+ "\n",
+ "Let's first build a client to query our LLM"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def build_client(base_url: str, api_key: str) -> openai.OpenAI:\n",
+ " return openai.OpenAI(\n",
+ " base_url=base_url.rstrip(\"/\") + \"/v1\",\n",
+ " api_key=api_key,\n",
+ " )"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "client = build_client(\"http://localhost:8000\", \"NOT A REAL KEY\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Next, we build a query function to send requests to our LLM application."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def query(\n",
+ " client: openai.OpenAI,\n",
+ " llm_model: str,\n",
+ " system_message: dict[str, str],\n",
+ " user_message: dict[str, str],\n",
+ " temperature: float = 0,\n",
+ " timeout: float = 3 * 60,\n",
+ ") -> Optional[str]:\n",
+ " model_response = client.chat.completions.create(\n",
+ " model=llm_model,\n",
+ " messages=[system_message, user_message],\n",
+ " temperature=temperature,\n",
+ " timeout=timeout,\n",
+ " )\n",
+ " model_output = model_response.choices[0].message.content\n",
+ " return model_output"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ " 🔄 REPLACE : Use the job ID of your fine-tuning run"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "model_info = anyscale.llm.model.get(job_id=\"prodjob_123\") # REPLACE with the job ID for your fine-tuning run"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's extract the base model ID and the model ID from the model info."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "base_model = model_info.base_model_id\n",
+ "finetuned_model_id = model_info.id\n",
+ "finetuned_model_id"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ ".serve.anyscale.com/\", \"\")\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "base",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.9.19"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 2
+}
diff --git a/templates/ray-summit-end-to-end-llms/README.md b/templates/ray-summit-end-to-end-llms/README.md
new file mode 100644
index 000000000..169ac7508
--- /dev/null
+++ b/templates/ray-summit-end-to-end-llms/README.md
@@ -0,0 +1,16 @@
+# End-to-end LLM workflows at scale - MLOps best practices meets Large Language Models
+
+In the era of AI, fine-tuning large language models (LLMs) for specific tasks has become essential for delivering high-quality, tailored solutions. This workshop will guide you through the process of building end-to-end workflows for LLMs at scale, focusing on MLOps best practices and leveraging Anyscale's LLMForge for fine-tuning.
+
+You'll start by fine-tuning a large language model for a specific functional representation task, using Ray Data for batch evaluation of the fine-tuned model. You'll also learn to deploy the model using Ray Serve, ensuring efficient and scalable deployment. The workshop will conclude with a deep dive into adopting MLOps best practices, including automated retraining and evaluation to maintain and improve model performance.
+
+By the end of this session, you'll have a comprehensive understanding of how to manage the full lifecycle of LLM workflows, from fine-tuning and evaluation to deployment and continuous improvement. You'll gain practical skills to implement scalable, efficient, and automated workflows for large language models, ensuring they remain accurate and effective over time.
+
+## Prerequisites:
+- Familiarity with MLOps and LLM use cases.
+- Intermediate-level experience with Python.
+
+## Ray Libraries:
+- Ray Data
+- Ray Train
+- Ray Serve
\ No newline at end of file
diff --git a/templates/ray-summit-end-to-end-llms/bonus/MLOps_and_LLMs.ipynb b/templates/ray-summit-end-to-end-llms/bonus/MLOps_and_LLMs.ipynb
new file mode 100644
index 000000000..8e5b1b902
--- /dev/null
+++ b/templates/ray-summit-end-to-end-llms/bonus/MLOps_and_LLMs.ipynb
@@ -0,0 +1,102 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# MLOPs and LLMs\n",
+ "\n",
+ "Creating an LLM application is not a one-time task. It's extremely important that we continue to iterate and keep our model up to date. \n",
+ "\n",
+ "This MLOps best practice of continuous monitoring and improvement in production should also be applied to LLMs. It involves regular fine-tuning and re-evaluation of the model to ensure optimal performance.\n",
+ "\n",
+ "What you will end up with is a data flywheel, where you are continuously iterating on your data and model.\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "vscode": {
+ "languageId": "plaintext"
+ }
+ },
+ "source": [
+ "This flywheel can be split into two main phases:\n",
+ "\n",
+ "1. Continuous Iteration on the data\n",
+ "2. Continuous Iteration on the model\n",
+ "\n",
+ "Here is a visual representation of the data flywheel:\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "vscode": {
+ "languageId": "plaintext"
+ }
+ },
+ "source": [
+ "This flywheel can be split into two main phases:\n",
+ "\n",
+ "1. Continuous Iteration on the data\n",
+ "2. Continuous Iteration on the model\n",
+ "\n",
+ "Here is a visual representation of the data flywheel:\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "#### 1. Continuous Iteration on the data\n",
+ "\n",
+ "This phase involves:\n",
+ "- collection of new data\n",
+ "- incorporation of user feedback\n",
+ "- evaluation of data quality\n",
+ "- cleaning of data\n",
+ "- augmentation of data\n",
+ "- curation of data\n",
+ "\n",
+ "#### 2. Continuous Iteration on the model\n",
+ "\n",
+ "This involves continuous:\n",
+ "- evaluation of model performance\n",
+ "- analysis of model outputs\n",
+ "- fine-tuning of the model\n",
+ "\n",
+ "##### Champion-challenger evaluation framework\n",
+ "One pattern that emerges is the use of a champion-challenger evaluation framework.\n",
+ "\n",
+ "This is a framework for evaluating and selecting between different versions of a model. \n",
+ "\n",
+ "It involves:\n",
+ "- selecting a champion model\n",
+ "- fine-tuning a challenger model\n",
+ "- evaluating the performance of the champion and challenger\n",
+ "- selecting the best performing model\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Automated Retraining of LLMs\n",
+ "\n",
+ "With the use of orchestration tools like Airflow, we can choose to automate this process integrating with Ray and Anyscale.\n",
+ "\n",
+ "Here is a diagram showing the process:\n",
+ "\n",
+ "
\n",
+ "\n",
+ "\n",
+ "#### 1. Continuous Iteration on the data\n",
+ "\n",
+ "This phase involves:\n",
+ "- collection of new data\n",
+ "- incorporation of user feedback\n",
+ "- evaluation of data quality\n",
+ "- cleaning of data\n",
+ "- augmentation of data\n",
+ "- curation of data\n",
+ "\n",
+ "#### 2. Continuous Iteration on the model\n",
+ "\n",
+ "This involves continuous:\n",
+ "- evaluation of model performance\n",
+ "- analysis of model outputs\n",
+ "- fine-tuning of the model\n",
+ "\n",
+ "##### Champion-challenger evaluation framework\n",
+ "One pattern that emerges is the use of a champion-challenger evaluation framework.\n",
+ "\n",
+ "This is a framework for evaluating and selecting between different versions of a model. \n",
+ "\n",
+ "It involves:\n",
+ "- selecting a champion model\n",
+ "- fine-tuning a challenger model\n",
+ "- evaluating the performance of the champion and challenger\n",
+ "- selecting the best performing model\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Automated Retraining of LLMs\n",
+ "\n",
+ "With the use of orchestration tools like Airflow, we can choose to automate this process integrating with Ray and Anyscale.\n",
+ "\n",
+ "Here is a diagram showing the process:\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "base",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.9.19"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 2
+}
diff --git a/templates/ray-summit-end-to-end-llms/configs/deepspeed/zero_3_offload_optim+param.json b/templates/ray-summit-end-to-end-llms/configs/deepspeed/zero_3_offload_optim+param.json
new file mode 100644
index 000000000..c89d62f2c
--- /dev/null
+++ b/templates/ray-summit-end-to-end-llms/configs/deepspeed/zero_3_offload_optim+param.json
@@ -0,0 +1,35 @@
+{
+ "fp16": {
+ "enabled": "auto"
+ },
+ "bf16": {
+ "enabled": true
+ },
+ "zero_optimization": {
+ "stage": 3,
+ "offload_optimizer": {
+ "device": "cpu",
+ "pin_memory": true
+ },
+ "offload_param": {
+ "device": "cpu",
+ "pin_memory": true
+ },
+ "overlap_comm": true,
+ "contiguous_gradients": true,
+ "sub_group_size": 1e9,
+ "reduce_bucket_size": 5e8,
+ "stage3_prefetch_bucket_size": 5e8,
+ "stage3_param_persistence_threshold": 1e6,
+ "stage3_max_live_parameters": 1e9,
+ "stage3_max_reuse_distance": 1e9,
+ "stage3_gather_16bit_weights_on_model_save": true,
+ "round_robin_gradients": true
+ },
+ "gradient_accumulation_steps": "auto",
+ "gradient_clipping": "auto",
+ "steps_per_print": 10,
+ "train_batch_size": "auto",
+ "train_micro_batch_size_per_gpu": "auto",
+ "wall_clock_breakdown": false
+ }
diff --git a/templates/ray-summit-end-to-end-llms/configs/training/lora/mistral-7b.yaml b/templates/ray-summit-end-to-end-llms/configs/training/lora/mistral-7b.yaml
new file mode 100644
index 000000000..4129259aa
--- /dev/null
+++ b/templates/ray-summit-end-to-end-llms/configs/training/lora/mistral-7b.yaml
@@ -0,0 +1,54 @@
+# Change this to the model you want to fine-tune
+model_id: mistralai/Mistral-7B-Instruct-v0.1
+
+# Change this to the path to your training data
+train_path: s3://anyscale-public-materials/llm-finetuning/viggo_inverted/train/subset-500.jsonl
+
+# Change this to the path to your validation data. This is optional
+valid_path: s3://anyscale-public-materials/llm-finetuning/viggo_inverted/valid/data.jsonl
+
+# Change this to the context length you want to use. Examples with longer
+# context length will be truncated.
+context_length: 512
+
+# Change this to total number of GPUs that you want to use
+num_devices: 2
+
+# Change this to the number of epochs that you want to train for
+num_epochs: 3
+
+# Change this to the batch size that you want to use
+train_batch_size_per_device: 16
+eval_batch_size_per_device: 16
+
+# Change this to the learning rate that you want to use
+learning_rate: 1e-4
+
+# This will pad batches to the longest sequence. Use "max_length" when profiling to profile the worst case.
+padding: "longest"
+
+# By default, we will keep the best checkpoint. You can change this to keep more checkpoints.
+num_checkpoints_to_keep: 1
+
+# Deepspeed configuration, you can provide your own deepspeed setup
+deepspeed:
+ config_path: configs/deepspeed/zero_3_offload_optim+param.json
+
+# Lora configuration
+lora_config:
+ r: 8
+ lora_alpha: 16
+ lora_dropout: 0.05
+ target_modules:
+ - q_proj
+ - v_proj
+ - k_proj
+ - o_proj
+ - gate_proj
+ - up_proj
+ - down_proj
+ - embed_tokens
+ - lm_head
+ task_type: "CAUSAL_LM"
+ bias: "none"
+ modules_to_save: []
diff --git a/templates/ray-summit-multi-modal-search/README.md b/templates/ray-summit-multi-modal-search/README.md
new file mode 100644
index 000000000..dd8d728ec
--- /dev/null
+++ b/templates/ray-summit-multi-modal-search/README.md
@@ -0,0 +1,16 @@
+# Reinventing Multi-Modal Search with LLMs and Large Scale Data Processing
+
+Traditional search systems often struggle with handling unstructured data, especially non-text data like images. In this workshop, you'll learn how to enhance legacy search systems using generative and embedding models for richer data representation.
+
+You will build a scalable multi-modal data indexing pipeline and a hybrid search backend using Anyscale and MongoDB. The training will cover practical applications of Ray Data for scalable batch inference, Ray Serve for deploying and scaling the search application, vLLM for integrating large language models and MongoDB Atlas for both lexical and vector search.
+
+By the end of this session, you'll have the skills to implement advanced AI tooling for creating a scalable and efficient search system capable of handling diverse data types in enterprise applications.
+
+## Prerequisites:
+- Familiarity with large scale data processing.
+- Prior experience with Ray Data or Ray Serve is not required, but participants with some experience in these frameworks will have an advantage in understanding the more advanced topics that will be covered in the training.
+- Intermediate-level experience with Python.
+
+## Ray Libraries:
+- Ray Data
+- Ray Serve
\ No newline at end of file
diff --git a/templates/ray-summit-multi-modal-search/no-color-application/app.yaml b/templates/ray-summit-multi-modal-search/no-color-application/app.yaml
new file mode 100644
index 000000000..2e8d5a984
--- /dev/null
+++ b/templates/ray-summit-multi-modal-search/no-color-application/app.yaml
@@ -0,0 +1,10 @@
+name: mongo-search-front-middle
+applications:
+ - name: frontend
+ route_prefix: /
+ import_path: frontend:app
+ - name: backend
+ route_prefix: /backend
+ import_path: backend:app
+query_auth_token_enabled: false
+requirements: requirements.txt
diff --git a/templates/ray-summit-multi-modal-search/no-color-application/backend.py b/templates/ray-summit-multi-modal-search/no-color-application/backend.py
new file mode 100644
index 000000000..4eccf827c
--- /dev/null
+++ b/templates/ray-summit-multi-modal-search/no-color-application/backend.py
@@ -0,0 +1,499 @@
+import asyncio
+from typing import Optional
+from motor.motor_asyncio import AsyncIOMotorClient
+import os
+import logging
+from ray.serve import deployment, ingress
+from ray.serve.handle import DeploymentHandle
+from fastapi import FastAPI
+from sentence_transformers import SentenceTransformer
+
+def vector_search(
+ vector_search_index_name: str,
+ vector_search_path: str,
+ embedding: list[float],
+ n: int,
+ min_price: int,
+ max_price: int,
+ min_rating: float,
+ categories: list[str],
+ colors: list[str],
+ seasons: list[str],
+ cosine_score_threshold: float = 0.92,
+) -> list[dict]:
+ return [
+ {
+ "$vectorSearch": {
+ "index": vector_search_index_name,
+ "path": vector_search_path,
+ "queryVector": embedding.tolist(),
+ "numCandidates": 100,
+ "limit": n,
+ "filter": {
+ "price": {"$gte": min_price, "$lte": max_price},
+ "rating": {"$gte": min_rating},
+ "category": {"$in": categories},
+# "color": {"$in": colors},
+ "season": {"$in": seasons},
+ },
+ }
+ },
+ {
+ "$project": {
+ "_id": 1,
+ "img": 1,
+ "name": 1,
+ "score": {"$meta": "vectorSearchScore"},
+ }
+ },
+ {"$match": {"score": {"$gte": cosine_score_threshold}}},
+ ]
+
+
+def lexical_search(text_search: str, text_search_index_name: str) -> list[dict]:
+ return [
+ {
+ "$search": {
+ "index": text_search_index_name,
+ "text": {
+ "query": text_search,
+ "path": "name",
+ },
+ }
+ }
+ ]
+
+
+def match_on_metadata(
+ min_price: int,
+ max_price: int,
+ min_rating: float,
+ n: int,
+ categories: list[str] | None = None,
+ colors: list[str] | None = None,
+ seasons: list[str] | None = None,
+) -> list[dict]:
+ match_spec = {
+ "price": {
+ "$gte": min_price,
+ "$lte": max_price,
+ },
+ "rating": {"$gte": min_rating},
+ }
+ if categories:
+ match_spec["category"] = {"$in": categories}
+# if colors:
+# match_spec["color"] = {"$in": colors}
+ if seasons:
+ match_spec["season"] = {"$in": seasons}
+
+ return [
+ {
+ "$match": match_spec,
+ },
+ {"$limit": n},
+ ]
+
+
+def convert_rank_to_score(score_name: str, score_penalty: float) -> list[dict]:
+ return [
+ {
+ "$group": {
+ "_id": None,
+ "docs": {
+ "$push": "$$ROOT",
+ },
+ }
+ },
+ {
+ "$unwind": {
+ "path": "$docs",
+ "includeArrayIndex": "rank",
+ }
+ },
+ {
+ "$addFields": {
+ score_name: {
+ "$divide": [
+ 1.0,
+ {"$add": ["$rank", score_penalty, 1]},
+ ]
+ }
+ }
+ },
+ {
+ "$project": {
+ score_name: 1,
+ "_id": "$docs._id",
+ "name": "$docs.name",
+ "img": "$docs.img",
+ }
+ },
+ ]
+
+
+def rerank_by_combined_score(
+ vs_score_name: str, fts_score_name: str, n: int
+) -> list[dict]:
+ return [
+ {
+ "$group": {
+ "_id": "$name",
+ "img": {"$first": "$img"},
+ vs_score_name: {"$max": f"${vs_score_name}"},
+ fts_score_name: {"$max": f"${fts_score_name}"},
+ }
+ },
+ {
+ "$project": {
+ "_id": 1,
+ "img": 1,
+ vs_score_name: {"$ifNull": [f"${vs_score_name}", 0]},
+ fts_score_name: {"$ifNull": [f"${fts_score_name}", 0]},
+ }
+ },
+ {
+ "$project": {
+ "name": "$_id",
+ "img": 1,
+ vs_score_name: 1,
+ fts_score_name: 1,
+ "score": {"$add": [f"${fts_score_name}", f"${vs_score_name}"]},
+ }
+ },
+ {"$sort": {"score": -1}},
+ {"$limit": n},
+ ]
+
+
+def hybrid_search(
+ collection_name: str,
+ text_search: str,
+ text_search_index_name: str,
+ vector_search_index_name: str,
+ vector_search_path: str,
+ embedding: list[float],
+ n: int,
+ min_price: int,
+ max_price: int,
+ min_rating: float,
+ categories: list[str],
+ colors: list[str],
+ seasons: list[str],
+ vector_penalty: int,
+ full_text_penalty: int,
+ cosine_score_threshold: float = 0.92,
+) -> list[dict]:
+ # 1. Perform vector search
+ vector_search_stages = vector_search(
+ vector_search_index_name=vector_search_index_name,
+ vector_search_path=vector_search_path,
+ embedding=embedding,
+ n=n,
+ min_price=min_price,
+ max_price=max_price,
+ min_rating=min_rating,
+ categories=categories,
+ colors=colors,
+ seasons=seasons,
+ cosine_score_threshold=cosine_score_threshold,
+ )
+ convert_vector_rank_to_score_stages = convert_rank_to_score(
+ score_name="vs_score", score_penalty=vector_penalty
+ )
+
+ # 2. Perform lexical search
+ lexical_search_stages = lexical_search(text_search=text_search, text_search_index_name=text_search_index_name)
+ post_filter_stages = match_on_metadata(
+ min_price=min_price,
+ max_price=max_price,
+ min_rating=min_rating,
+ categories=categories,
+ colors=colors,
+ seasons=seasons,
+ n=n,
+ )
+ convert_text_rank_to_score_stages = convert_rank_to_score(
+ score_name="fts_score", score_penalty=full_text_penalty
+ )
+
+ # 3. Rerank by combined score
+ rerank_stages = rerank_by_combined_score(
+ vs_score_name="vs_score", fts_score_name="fts_score", n=n
+ )
+
+ # 4. Put it all together
+ return [
+ *vector_search_stages,
+ *convert_vector_rank_to_score_stages,
+ {
+ "$unionWith": {
+ "coll": collection_name,
+ "pipeline": [
+ *lexical_search_stages,
+ *post_filter_stages,
+ *convert_text_rank_to_score_stages,
+ ],
+ }
+ },
+ *rerank_stages,
+ ]
+
+
+@deployment
+class EmbeddingModel:
+ def __init__(self, model: str = "thenlper/gte-large") -> None:
+ self.model = SentenceTransformer(model)
+
+ async def compute_embedding(self, text: str) -> list[float]:
+ loop = asyncio.get_event_loop()
+ return await loop.run_in_executor(None, lambda: self.model.encode(text))
+
+
+@deployment
+class QueryLegacySearch:
+ def __init__(
+ self,
+ database_name: str = "myntra",
+ collection_name: str = "myntra-items-offline",
+ ) -> None:
+ self.client = AsyncIOMotorClient(os.environ["DB_CONNECTION_STRING"])
+ self.database_name = database_name
+ self.collection_name = collection_name
+
+ async def run(
+ self,
+ text_search: Optional[str],
+ min_price: int,
+ max_price: int,
+ min_rating: float,
+ n: int = 20,
+ text_search_index_name: str = "lexical_text_search_index",
+ ) -> list[tuple[str, str]]:
+ logger = logging.getLogger("ray.serve")
+ logger.setLevel(logging.DEBUG)
+
+ db = self.client[self.database_name]
+ collection = db[self.collection_name]
+
+ pipeline = []
+ if text_search.strip():
+ pipeline.extend(
+ lexical_search(
+ text_search=text_search,
+ text_search_index_name=text_search_index_name,
+ )
+ )
+
+ pipeline.extend(
+ match_on_metadata(
+ min_price=min_price,
+ max_price=max_price,
+ min_rating=min_rating,
+ n=n,
+ )
+ )
+
+ logger.debug(f"Running pipeline: {pipeline}")
+
+ records = collection.aggregate(pipeline)
+ results = [
+ (record["img"].split(";")[-1].strip(), record["name"])
+ async for record in records
+ ]
+
+ n_results = len(results)
+ logger.debug(f"Found {n_results=} results")
+
+ return results
+
+
+@deployment
+class QueryAIEnabledSearch:
+ def __init__(
+ self,
+ embedding_model: DeploymentHandle,
+ database_name: str = "myntra",
+ collection_name: str = "myntra-items-offline",
+ ) -> None:
+ self.client = AsyncIOMotorClient(os.environ["DB_CONNECTION_STRING"])
+ self.embedding_model = embedding_model
+ self.database_name = database_name
+ self.collection_name = collection_name
+
+ async def run(
+ self,
+ text_search: str,
+ min_price: int,
+ max_price: int,
+ min_rating: float,
+ categories: list[str],
+ colors: list[str],
+ seasons: list[str],
+ n: int,
+ search_type: set[str],
+ vector_search_index_name: str = "vector_search_index",
+ vector_search_path: str = "description_embedding",
+ text_search_index_name: str = "lexical_text_search_index",
+ vector_penalty: int = 1,
+ full_text_penalty: int = 10,
+ ):
+ logger = logging.getLogger("ray.serve")
+ logger.setLevel(logging.DEBUG)
+
+ db = self.client[self.database_name]
+ collection = db[self.collection_name]
+
+ pipeline = []
+ if text_search.strip():
+
+ if "vector" in search_type:
+ logger.debug(f"Computing embedding for {text_search=}")
+ embedding = await self.embedding_model.compute_embedding.remote(
+ text_search
+ )
+
+ is_hybrid = search_type == {"vector", "lexical"}
+ if is_hybrid:
+ pipeline.extend(
+ hybrid_search(
+ self.collection_name,
+ text_search,
+ text_search_index_name,
+ vector_search_index_name,
+ vector_search_path,
+ embedding,
+ n,
+ min_price,
+ max_price,
+ min_rating,
+ categories,
+ colors,
+ seasons,
+ vector_penalty,
+ full_text_penalty,
+ )
+ )
+ elif search_type == {"vector"}:
+ pipeline.extend(
+ vector_search(
+ vector_search_index_name,
+ vector_search_path,
+ embedding,
+ n,
+ min_price,
+ max_price,
+ min_rating,
+ categories,
+ colors,
+ seasons,
+ )
+ )
+ elif search_type == {"lexical"}:
+ pipeline.extend(
+ lexical_search(
+ text_search=text_search,
+ text_search_index_name=text_search_index_name,
+ )
+ )
+ pipeline.extend(
+ match_on_metadata(
+ min_price=min_price,
+ max_price=max_price,
+ min_rating=min_rating,
+ n=n,
+ categories=categories,
+ colors=colors,
+ seasons=seasons,
+ )
+ )
+ else:
+ pipeline = match_on_metadata(
+ min_price=min_price,
+ max_price=max_price,
+ min_rating=min_rating,
+ n=n,
+ categories=categories,
+ colors=colors,
+ seasons=seasons,
+ )
+
+ records = collection.aggregate(pipeline)
+ logger.debug(f"Running pipeline: {pipeline}")
+ records = [record async for record in records]
+ results = [
+ (record["img"].split(";")[-1].strip(), record["name"]) for record in records
+ ]
+ num_results = len(results)
+
+ logger.debug(f"Found {num_results=} results")
+ return results
+
+
+fastapi = FastAPI()
+
+
+@deployment
+@ingress(fastapi)
+class QueryApplication:
+
+ def __init__(
+ self,
+ query_legacy: QueryLegacySearch,
+ query_ai_enabled: QueryAIEnabledSearch,
+ ):
+ self.query_legacy = query_legacy
+ self.query_ai_enabled = query_ai_enabled
+
+ @fastapi.get("/legacy")
+ async def query_legacy_search(
+ self,
+ text_search: str,
+ min_price: int,
+ max_price: int,
+ min_rating: float,
+ num_results: int,
+ ):
+ return await self.query_legacy.run.remote(
+ text_search=text_search,
+ min_price=min_price,
+ max_price=max_price,
+ min_rating=min_rating,
+ n=num_results,
+ )
+
+ @fastapi.get("/ai_enabled")
+ async def query_ai_enabled_search(
+ self,
+ text_search: str,
+ min_price: int,
+ max_price: int,
+ min_rating: float,
+ categories: list[str],
+ colors: list[str],
+ seasons: list[str],
+ num_results: int,
+ embedding_column: str,
+ search_type: list[str],
+ ):
+ logger = logging.getLogger("ray.serve")
+ logger.setLevel(logging.DEBUG)
+ logger.debug(f"Running query_ai_enabled_search with {locals()=}")
+ return await self.query_ai_enabled.run.remote(
+ text_search=text_search,
+ min_price=min_price,
+ max_price=max_price,
+ min_rating=min_rating,
+ categories=categories,
+ colors=colors,
+ seasons=seasons,
+ n=num_results,
+ vector_search_path=f"{embedding_column.lower()}_embedding",
+ search_type={type_.lower() for type_ in search_type},
+ )
+
+
+query_legacy = QueryLegacySearch.bind()
+embedding_model = EmbeddingModel.bind()
+query_ai_enabled = QueryAIEnabledSearch.bind(embedding_model)
+app = QueryApplication.bind(query_legacy, query_ai_enabled)
diff --git a/templates/ray-summit-multi-modal-search/no-color-application/command.txt b/templates/ray-summit-multi-modal-search/no-color-application/command.txt
new file mode 100644
index 000000000..b40a8d0b6
--- /dev/null
+++ b/templates/ray-summit-multi-modal-search/no-color-application/command.txt
@@ -0,0 +1 @@
+anyscale service deploy -f app.yaml
diff --git a/templates/ray-summit-multi-modal-search/no-color-application/frontend.py b/templates/ray-summit-multi-modal-search/no-color-application/frontend.py
new file mode 100644
index 000000000..836d3833a
--- /dev/null
+++ b/templates/ray-summit-multi-modal-search/no-color-application/frontend.py
@@ -0,0 +1,235 @@
+from typing import Optional
+import gradio as gr
+from ray.serve.gradio_integrations import GradioServer
+import requests
+
+ANYSCALE_BACKEND_SERVICE_URL = "http://localhost:8000/backend"
+
+
+def filter_products_legacy(
+ text_query: Optional[str],
+ min_price: int,
+ max_price: int,
+ min_rating: float,
+ num_results: int,
+) -> list[tuple[str, str]]:
+ response = requests.get(
+ f"{ANYSCALE_BACKEND_SERVICE_URL}/legacy",
+ params={
+ "text_search": text_query or "",
+ "min_price": min_price,
+ "max_price": max_price,
+ "min_rating": min_rating,
+ "num_results": num_results,
+ },
+ )
+ return response.json()
+
+
+def filter_products_with_ai(
+ text_search: Optional[str],
+ min_price: int,
+ max_price: int,
+ min_rating: float,
+ categories: list[str],
+ colors: list[str],
+ seasons: list[str],
+ num_results: int,
+ search_type: list[str],
+ embedding_column: str,
+):
+ params = {
+ "text_search": text_search or "",
+ "min_price": min_price,
+ "max_price": max_price,
+ "min_rating": min_rating,
+ "num_results": num_results,
+ "embedding_column": embedding_column,
+ }
+ body = {
+ "categories": categories,
+ "colors": colors,
+ "seasons": seasons,
+ "search_type": search_type,
+ }
+
+ response = requests.get(
+ f"{ANYSCALE_BACKEND_SERVICE_URL}/ai_enabled",
+ params=params,
+ json=body,
+ )
+ results = response.json()
+
+ return results
+
+
+def build_interface():
+ price_min = 0
+ price_max = 100_000
+
+ # Get rating range
+ rating_min = 0
+ rating_max = 5
+
+ # Gradio Interface
+ with gr.Blocks(
+ # theme="shivi/calm_foam",
+ title="Multi-modal search",
+ ) as iface:
+ with gr.Tab(label="Legacy Search"):
+ with gr.Row():
+ with gr.Column(scale=1):
+ keywords_component = gr.Textbox(label="Keywords")
+ min_price_component = gr.Slider(
+ price_min, price_max, label="Min Price", value=price_min
+ )
+ max_price_component = gr.Slider(
+ price_min, price_max, label="Max Price", value=price_max
+ )
+ min_rating_component = gr.Slider(
+ rating_min, rating_max, step=0.25, label="Min Rating"
+ )
+ max_num_results_component = gr.Slider(
+ 1, 100, step=1, label="Max Results", value=20
+ )
+ filter_button_component = gr.Button("Filter")
+ with gr.Column(scale=3):
+ gallery = gr.Gallery(
+ label="Filtered Products",
+ columns=3,
+ height=800,
+ )
+ inputs = [
+ keywords_component,
+ min_price_component,
+ max_price_component,
+ min_rating_component,
+ max_num_results_component,
+ ]
+ filter_button_component.click(
+ filter_products_legacy, inputs=inputs, outputs=gallery
+ )
+ iface.load(
+ filter_products_legacy,
+ inputs=inputs,
+ outputs=gallery,
+ )
+
+ with gr.Tab(label="AI enabled search"):
+ with gr.Row():
+ with gr.Column(scale=1):
+ text_component = gr.Textbox(label="Text Search")
+ min_price_component = gr.Slider(
+ price_min, price_max, label="Min Price", value=price_min
+ )
+ max_price_component = gr.Slider(
+ price_min, price_max, label="Max Price", value=price_max
+ )
+
+ min_rating_component = gr.Slider(
+ rating_min, rating_max, step=0.25, label="Min Rating"
+ )
+ category_component = gr.CheckboxGroup(
+ ["Tops", "Bottoms", "Dresses", "Footwear", "Accessories"],
+ label="Category",
+ value=[
+ "Tops",
+ "Bottoms",
+ "Dresses",
+ "Footwear",
+ "Accessories",
+ ],
+ )
+ season_component = gr.CheckboxGroup(
+ ["Summer", "Winter", "Spring", "Fall"],
+ label="Season",
+ value=[
+ "Summer",
+ "Winter",
+ "Spring",
+ "Fall",
+ ],
+ )
+ color_component = gr.CheckboxGroup(
+ [
+ "Red",
+ "Blue",
+ "Green",
+ "Yellow",
+ "Black",
+ "White",
+ "Pink",
+ "Purple",
+ "Orange",
+ "Brown",
+ "Grey",
+ ],
+ label="Color",
+ value=[
+ "Red",
+ "Blue",
+ "Green",
+ "Yellow",
+ "Black",
+ "White",
+ "Pink",
+ "Purple",
+ "Orange",
+ "Brown",
+ "Grey",
+ ],
+ )
+ max_num_results_component = gr.Slider(
+ 1, 100, step=1, label="Max Results", value=20
+ )
+
+ # add an engine advanced options
+ with gr.Accordion(label="Advanced Engine Options"):
+ # checkbox for type of search - lexical and/or vector
+ search_type_component = gr.CheckboxGroup(
+ ["Lexical", "Vector"],
+ label="Search Type",
+ value=["Lexical", "Vector"],
+ )
+ # dropdwon for embedding column - name or description
+ embedding_column_component = gr.Dropdown(
+ ["name", "description"],
+ label="Embedding Column",
+ value="description",
+ )
+
+ filter_button_component = gr.Button("Filter")
+ with gr.Column(scale=3):
+ gallery = gr.Gallery(
+ label="Filtered Products",
+ columns=3,
+ height=800,
+ )
+ inputs = [
+ text_component,
+ min_price_component,
+ max_price_component,
+ min_rating_component,
+ category_component,
+ color_component,
+ season_component,
+ max_num_results_component,
+ search_type_component,
+ embedding_column_component,
+ ]
+
+ filter_button_component.click(
+ filter_products_with_ai,
+ inputs=inputs,
+ outputs=gallery,
+ )
+ iface.load(
+ filter_products_with_ai,
+ inputs=inputs,
+ outputs=gallery,
+ )
+
+ return iface
+
+
+app = GradioServer.options(ray_actor_options={"num_cpus": 1}).bind(build_interface)
diff --git a/templates/ray-summit-multi-modal-search/no-color-application/requirements.txt b/templates/ray-summit-multi-modal-search/no-color-application/requirements.txt
new file mode 100644
index 000000000..08eacd285
--- /dev/null
+++ b/templates/ray-summit-multi-modal-search/no-color-application/requirements.txt
@@ -0,0 +1,6 @@
+# base image: anyscale/ray:2.24.0-py311
+# frontend
+gradio==3.50.2
+# backend
+motor==3.5.0
+sentence-transformers==3.0.1
diff --git a/templates/ray-summit-multi-modal-search/pipeline_tutorial/1_setup_tools.ipynb b/templates/ray-summit-multi-modal-search/pipeline_tutorial/1_setup_tools.ipynb
new file mode 100644
index 000000000..d17808132
--- /dev/null
+++ b/templates/ray-summit-multi-modal-search/pipeline_tutorial/1_setup_tools.ipynb
@@ -0,0 +1,336 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "52f6531b-32d1-436c-b4f4-9b62ffdcf5c5",
+ "metadata": {},
+ "source": [
+ "# Reinventing Multi-Modal Search with Anyscale and MongoDB\n",
+ "\n",
+ "What we are learning about and building today: https://www.anyscale.com/blog/reinventing-multi-modal-search-with-anyscale-and-mongodb\n",
+ "\n",
+ "The following instructions will help you get set up your environment\n",
+ "\n",
+ "## Register for Anyscale if needed\n",
+ "\n",
+ "If you're attending this class at Ray Summit 2024, then you already have an Anyscale account -- we'll use that one!\n",
+ "\n",
+ "If you're trying out this application later or on your own,\n",
+ "* You can register for Anyscale [here](https://console.anyscale.com/register/ha?utm_source=github&utm_medium=github&utm_content=multi-modal-search-anyscale-mongodb).\n",
+ "\n",
+ "## Login to Anyscale\n",
+ "\n",
+ "Once you have an account, [login](https://console.anyscale.com/v2?utm_source=github&utm_medium=github&utm_content=multi-modal-search-anyscale-mongodb) here.\n",
+ "\n",
+ "## Get set up with MongoDB\n",
+ "\n",
+ "Check out the Mongo Developer Intro Lab at https://mongodb-developer.github.io/intro-lab/\n",
+ "\n",
+ "That tutorial -- presented live at Ray Summit 2024 -- covers the following key steps:\n",
+ "* Get you set up with a free MongoDB Atlas account \n",
+ "* Create a free MongoDB cluster\n",
+ "* Configure securityy to allow public access to your cluster (for demo/class purposes only)\n",
+ "* Create your database user and save the password\n",
+ "* Get the connection string for your MongoDB cluster\n",
+ "\n",
+ "## Register or login to Hugging Face\n",
+ "\n",
+ "If you don't have a Hugging Face account, you can register [here](https://huggingface.co/join). \n",
+ "\n",
+ "If you already have an account, [login](https://huggingface.co/login) here.\n",
+ "\n",
+ "Visit the [tokens](https://huggingface.co/settings/tokens) page to generate a new API token.\n",
+ "\n",
+ "Visit the following model pages and request access to these models:\n",
+ "- [llava-hf/llava-v1.6-mistral-7b-hf](https://huggingface.co/llava-hf/llava-v1.6-mistral-7b-hf)\n",
+ "- [mistralai/Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1)\n",
+ "\n",
+ "Once you have access to these models, you can proceed with the next steps.\n",
+ "\n",
+ "## Launch a workspace in Anyscale for this project\n",
+ "\n",
+ "At Ray Summit 2024, you're probably already running the right workspace. If you're doing this tutorial on your own, choose the Anyscale Ray Summit 2024 template\n",
+ "\n",
+ "## Configure environment variables in your Anyscale Workspace\n",
+ "\n",
+ "Under the __Dependencies__ tab in the workspace view, set the MongoDB connection string `DB_CONNECTION_STRING` and huggingface access token `HF_TOKEN` as environment variables.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "\n"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "base",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.9.19"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 2
+}
diff --git a/templates/ray-summit-end-to-end-llms/configs/deepspeed/zero_3_offload_optim+param.json b/templates/ray-summit-end-to-end-llms/configs/deepspeed/zero_3_offload_optim+param.json
new file mode 100644
index 000000000..c89d62f2c
--- /dev/null
+++ b/templates/ray-summit-end-to-end-llms/configs/deepspeed/zero_3_offload_optim+param.json
@@ -0,0 +1,35 @@
+{
+ "fp16": {
+ "enabled": "auto"
+ },
+ "bf16": {
+ "enabled": true
+ },
+ "zero_optimization": {
+ "stage": 3,
+ "offload_optimizer": {
+ "device": "cpu",
+ "pin_memory": true
+ },
+ "offload_param": {
+ "device": "cpu",
+ "pin_memory": true
+ },
+ "overlap_comm": true,
+ "contiguous_gradients": true,
+ "sub_group_size": 1e9,
+ "reduce_bucket_size": 5e8,
+ "stage3_prefetch_bucket_size": 5e8,
+ "stage3_param_persistence_threshold": 1e6,
+ "stage3_max_live_parameters": 1e9,
+ "stage3_max_reuse_distance": 1e9,
+ "stage3_gather_16bit_weights_on_model_save": true,
+ "round_robin_gradients": true
+ },
+ "gradient_accumulation_steps": "auto",
+ "gradient_clipping": "auto",
+ "steps_per_print": 10,
+ "train_batch_size": "auto",
+ "train_micro_batch_size_per_gpu": "auto",
+ "wall_clock_breakdown": false
+ }
diff --git a/templates/ray-summit-end-to-end-llms/configs/training/lora/mistral-7b.yaml b/templates/ray-summit-end-to-end-llms/configs/training/lora/mistral-7b.yaml
new file mode 100644
index 000000000..4129259aa
--- /dev/null
+++ b/templates/ray-summit-end-to-end-llms/configs/training/lora/mistral-7b.yaml
@@ -0,0 +1,54 @@
+# Change this to the model you want to fine-tune
+model_id: mistralai/Mistral-7B-Instruct-v0.1
+
+# Change this to the path to your training data
+train_path: s3://anyscale-public-materials/llm-finetuning/viggo_inverted/train/subset-500.jsonl
+
+# Change this to the path to your validation data. This is optional
+valid_path: s3://anyscale-public-materials/llm-finetuning/viggo_inverted/valid/data.jsonl
+
+# Change this to the context length you want to use. Examples with longer
+# context length will be truncated.
+context_length: 512
+
+# Change this to total number of GPUs that you want to use
+num_devices: 2
+
+# Change this to the number of epochs that you want to train for
+num_epochs: 3
+
+# Change this to the batch size that you want to use
+train_batch_size_per_device: 16
+eval_batch_size_per_device: 16
+
+# Change this to the learning rate that you want to use
+learning_rate: 1e-4
+
+# This will pad batches to the longest sequence. Use "max_length" when profiling to profile the worst case.
+padding: "longest"
+
+# By default, we will keep the best checkpoint. You can change this to keep more checkpoints.
+num_checkpoints_to_keep: 1
+
+# Deepspeed configuration, you can provide your own deepspeed setup
+deepspeed:
+ config_path: configs/deepspeed/zero_3_offload_optim+param.json
+
+# Lora configuration
+lora_config:
+ r: 8
+ lora_alpha: 16
+ lora_dropout: 0.05
+ target_modules:
+ - q_proj
+ - v_proj
+ - k_proj
+ - o_proj
+ - gate_proj
+ - up_proj
+ - down_proj
+ - embed_tokens
+ - lm_head
+ task_type: "CAUSAL_LM"
+ bias: "none"
+ modules_to_save: []
diff --git a/templates/ray-summit-multi-modal-search/README.md b/templates/ray-summit-multi-modal-search/README.md
new file mode 100644
index 000000000..dd8d728ec
--- /dev/null
+++ b/templates/ray-summit-multi-modal-search/README.md
@@ -0,0 +1,16 @@
+# Reinventing Multi-Modal Search with LLMs and Large Scale Data Processing
+
+Traditional search systems often struggle with handling unstructured data, especially non-text data like images. In this workshop, you'll learn how to enhance legacy search systems using generative and embedding models for richer data representation.
+
+You will build a scalable multi-modal data indexing pipeline and a hybrid search backend using Anyscale and MongoDB. The training will cover practical applications of Ray Data for scalable batch inference, Ray Serve for deploying and scaling the search application, vLLM for integrating large language models and MongoDB Atlas for both lexical and vector search.
+
+By the end of this session, you'll have the skills to implement advanced AI tooling for creating a scalable and efficient search system capable of handling diverse data types in enterprise applications.
+
+## Prerequisites:
+- Familiarity with large scale data processing.
+- Prior experience with Ray Data or Ray Serve is not required, but participants with some experience in these frameworks will have an advantage in understanding the more advanced topics that will be covered in the training.
+- Intermediate-level experience with Python.
+
+## Ray Libraries:
+- Ray Data
+- Ray Serve
\ No newline at end of file
diff --git a/templates/ray-summit-multi-modal-search/no-color-application/app.yaml b/templates/ray-summit-multi-modal-search/no-color-application/app.yaml
new file mode 100644
index 000000000..2e8d5a984
--- /dev/null
+++ b/templates/ray-summit-multi-modal-search/no-color-application/app.yaml
@@ -0,0 +1,10 @@
+name: mongo-search-front-middle
+applications:
+ - name: frontend
+ route_prefix: /
+ import_path: frontend:app
+ - name: backend
+ route_prefix: /backend
+ import_path: backend:app
+query_auth_token_enabled: false
+requirements: requirements.txt
diff --git a/templates/ray-summit-multi-modal-search/no-color-application/backend.py b/templates/ray-summit-multi-modal-search/no-color-application/backend.py
new file mode 100644
index 000000000..4eccf827c
--- /dev/null
+++ b/templates/ray-summit-multi-modal-search/no-color-application/backend.py
@@ -0,0 +1,499 @@
+import asyncio
+from typing import Optional
+from motor.motor_asyncio import AsyncIOMotorClient
+import os
+import logging
+from ray.serve import deployment, ingress
+from ray.serve.handle import DeploymentHandle
+from fastapi import FastAPI
+from sentence_transformers import SentenceTransformer
+
+def vector_search(
+ vector_search_index_name: str,
+ vector_search_path: str,
+ embedding: list[float],
+ n: int,
+ min_price: int,
+ max_price: int,
+ min_rating: float,
+ categories: list[str],
+ colors: list[str],
+ seasons: list[str],
+ cosine_score_threshold: float = 0.92,
+) -> list[dict]:
+ return [
+ {
+ "$vectorSearch": {
+ "index": vector_search_index_name,
+ "path": vector_search_path,
+ "queryVector": embedding.tolist(),
+ "numCandidates": 100,
+ "limit": n,
+ "filter": {
+ "price": {"$gte": min_price, "$lte": max_price},
+ "rating": {"$gte": min_rating},
+ "category": {"$in": categories},
+# "color": {"$in": colors},
+ "season": {"$in": seasons},
+ },
+ }
+ },
+ {
+ "$project": {
+ "_id": 1,
+ "img": 1,
+ "name": 1,
+ "score": {"$meta": "vectorSearchScore"},
+ }
+ },
+ {"$match": {"score": {"$gte": cosine_score_threshold}}},
+ ]
+
+
+def lexical_search(text_search: str, text_search_index_name: str) -> list[dict]:
+ return [
+ {
+ "$search": {
+ "index": text_search_index_name,
+ "text": {
+ "query": text_search,
+ "path": "name",
+ },
+ }
+ }
+ ]
+
+
+def match_on_metadata(
+ min_price: int,
+ max_price: int,
+ min_rating: float,
+ n: int,
+ categories: list[str] | None = None,
+ colors: list[str] | None = None,
+ seasons: list[str] | None = None,
+) -> list[dict]:
+ match_spec = {
+ "price": {
+ "$gte": min_price,
+ "$lte": max_price,
+ },
+ "rating": {"$gte": min_rating},
+ }
+ if categories:
+ match_spec["category"] = {"$in": categories}
+# if colors:
+# match_spec["color"] = {"$in": colors}
+ if seasons:
+ match_spec["season"] = {"$in": seasons}
+
+ return [
+ {
+ "$match": match_spec,
+ },
+ {"$limit": n},
+ ]
+
+
+def convert_rank_to_score(score_name: str, score_penalty: float) -> list[dict]:
+ return [
+ {
+ "$group": {
+ "_id": None,
+ "docs": {
+ "$push": "$$ROOT",
+ },
+ }
+ },
+ {
+ "$unwind": {
+ "path": "$docs",
+ "includeArrayIndex": "rank",
+ }
+ },
+ {
+ "$addFields": {
+ score_name: {
+ "$divide": [
+ 1.0,
+ {"$add": ["$rank", score_penalty, 1]},
+ ]
+ }
+ }
+ },
+ {
+ "$project": {
+ score_name: 1,
+ "_id": "$docs._id",
+ "name": "$docs.name",
+ "img": "$docs.img",
+ }
+ },
+ ]
+
+
+def rerank_by_combined_score(
+ vs_score_name: str, fts_score_name: str, n: int
+) -> list[dict]:
+ return [
+ {
+ "$group": {
+ "_id": "$name",
+ "img": {"$first": "$img"},
+ vs_score_name: {"$max": f"${vs_score_name}"},
+ fts_score_name: {"$max": f"${fts_score_name}"},
+ }
+ },
+ {
+ "$project": {
+ "_id": 1,
+ "img": 1,
+ vs_score_name: {"$ifNull": [f"${vs_score_name}", 0]},
+ fts_score_name: {"$ifNull": [f"${fts_score_name}", 0]},
+ }
+ },
+ {
+ "$project": {
+ "name": "$_id",
+ "img": 1,
+ vs_score_name: 1,
+ fts_score_name: 1,
+ "score": {"$add": [f"${fts_score_name}", f"${vs_score_name}"]},
+ }
+ },
+ {"$sort": {"score": -1}},
+ {"$limit": n},
+ ]
+
+
+def hybrid_search(
+ collection_name: str,
+ text_search: str,
+ text_search_index_name: str,
+ vector_search_index_name: str,
+ vector_search_path: str,
+ embedding: list[float],
+ n: int,
+ min_price: int,
+ max_price: int,
+ min_rating: float,
+ categories: list[str],
+ colors: list[str],
+ seasons: list[str],
+ vector_penalty: int,
+ full_text_penalty: int,
+ cosine_score_threshold: float = 0.92,
+) -> list[dict]:
+ # 1. Perform vector search
+ vector_search_stages = vector_search(
+ vector_search_index_name=vector_search_index_name,
+ vector_search_path=vector_search_path,
+ embedding=embedding,
+ n=n,
+ min_price=min_price,
+ max_price=max_price,
+ min_rating=min_rating,
+ categories=categories,
+ colors=colors,
+ seasons=seasons,
+ cosine_score_threshold=cosine_score_threshold,
+ )
+ convert_vector_rank_to_score_stages = convert_rank_to_score(
+ score_name="vs_score", score_penalty=vector_penalty
+ )
+
+ # 2. Perform lexical search
+ lexical_search_stages = lexical_search(text_search=text_search, text_search_index_name=text_search_index_name)
+ post_filter_stages = match_on_metadata(
+ min_price=min_price,
+ max_price=max_price,
+ min_rating=min_rating,
+ categories=categories,
+ colors=colors,
+ seasons=seasons,
+ n=n,
+ )
+ convert_text_rank_to_score_stages = convert_rank_to_score(
+ score_name="fts_score", score_penalty=full_text_penalty
+ )
+
+ # 3. Rerank by combined score
+ rerank_stages = rerank_by_combined_score(
+ vs_score_name="vs_score", fts_score_name="fts_score", n=n
+ )
+
+ # 4. Put it all together
+ return [
+ *vector_search_stages,
+ *convert_vector_rank_to_score_stages,
+ {
+ "$unionWith": {
+ "coll": collection_name,
+ "pipeline": [
+ *lexical_search_stages,
+ *post_filter_stages,
+ *convert_text_rank_to_score_stages,
+ ],
+ }
+ },
+ *rerank_stages,
+ ]
+
+
+@deployment
+class EmbeddingModel:
+ def __init__(self, model: str = "thenlper/gte-large") -> None:
+ self.model = SentenceTransformer(model)
+
+ async def compute_embedding(self, text: str) -> list[float]:
+ loop = asyncio.get_event_loop()
+ return await loop.run_in_executor(None, lambda: self.model.encode(text))
+
+
+@deployment
+class QueryLegacySearch:
+ def __init__(
+ self,
+ database_name: str = "myntra",
+ collection_name: str = "myntra-items-offline",
+ ) -> None:
+ self.client = AsyncIOMotorClient(os.environ["DB_CONNECTION_STRING"])
+ self.database_name = database_name
+ self.collection_name = collection_name
+
+ async def run(
+ self,
+ text_search: Optional[str],
+ min_price: int,
+ max_price: int,
+ min_rating: float,
+ n: int = 20,
+ text_search_index_name: str = "lexical_text_search_index",
+ ) -> list[tuple[str, str]]:
+ logger = logging.getLogger("ray.serve")
+ logger.setLevel(logging.DEBUG)
+
+ db = self.client[self.database_name]
+ collection = db[self.collection_name]
+
+ pipeline = []
+ if text_search.strip():
+ pipeline.extend(
+ lexical_search(
+ text_search=text_search,
+ text_search_index_name=text_search_index_name,
+ )
+ )
+
+ pipeline.extend(
+ match_on_metadata(
+ min_price=min_price,
+ max_price=max_price,
+ min_rating=min_rating,
+ n=n,
+ )
+ )
+
+ logger.debug(f"Running pipeline: {pipeline}")
+
+ records = collection.aggregate(pipeline)
+ results = [
+ (record["img"].split(";")[-1].strip(), record["name"])
+ async for record in records
+ ]
+
+ n_results = len(results)
+ logger.debug(f"Found {n_results=} results")
+
+ return results
+
+
+@deployment
+class QueryAIEnabledSearch:
+ def __init__(
+ self,
+ embedding_model: DeploymentHandle,
+ database_name: str = "myntra",
+ collection_name: str = "myntra-items-offline",
+ ) -> None:
+ self.client = AsyncIOMotorClient(os.environ["DB_CONNECTION_STRING"])
+ self.embedding_model = embedding_model
+ self.database_name = database_name
+ self.collection_name = collection_name
+
+ async def run(
+ self,
+ text_search: str,
+ min_price: int,
+ max_price: int,
+ min_rating: float,
+ categories: list[str],
+ colors: list[str],
+ seasons: list[str],
+ n: int,
+ search_type: set[str],
+ vector_search_index_name: str = "vector_search_index",
+ vector_search_path: str = "description_embedding",
+ text_search_index_name: str = "lexical_text_search_index",
+ vector_penalty: int = 1,
+ full_text_penalty: int = 10,
+ ):
+ logger = logging.getLogger("ray.serve")
+ logger.setLevel(logging.DEBUG)
+
+ db = self.client[self.database_name]
+ collection = db[self.collection_name]
+
+ pipeline = []
+ if text_search.strip():
+
+ if "vector" in search_type:
+ logger.debug(f"Computing embedding for {text_search=}")
+ embedding = await self.embedding_model.compute_embedding.remote(
+ text_search
+ )
+
+ is_hybrid = search_type == {"vector", "lexical"}
+ if is_hybrid:
+ pipeline.extend(
+ hybrid_search(
+ self.collection_name,
+ text_search,
+ text_search_index_name,
+ vector_search_index_name,
+ vector_search_path,
+ embedding,
+ n,
+ min_price,
+ max_price,
+ min_rating,
+ categories,
+ colors,
+ seasons,
+ vector_penalty,
+ full_text_penalty,
+ )
+ )
+ elif search_type == {"vector"}:
+ pipeline.extend(
+ vector_search(
+ vector_search_index_name,
+ vector_search_path,
+ embedding,
+ n,
+ min_price,
+ max_price,
+ min_rating,
+ categories,
+ colors,
+ seasons,
+ )
+ )
+ elif search_type == {"lexical"}:
+ pipeline.extend(
+ lexical_search(
+ text_search=text_search,
+ text_search_index_name=text_search_index_name,
+ )
+ )
+ pipeline.extend(
+ match_on_metadata(
+ min_price=min_price,
+ max_price=max_price,
+ min_rating=min_rating,
+ n=n,
+ categories=categories,
+ colors=colors,
+ seasons=seasons,
+ )
+ )
+ else:
+ pipeline = match_on_metadata(
+ min_price=min_price,
+ max_price=max_price,
+ min_rating=min_rating,
+ n=n,
+ categories=categories,
+ colors=colors,
+ seasons=seasons,
+ )
+
+ records = collection.aggregate(pipeline)
+ logger.debug(f"Running pipeline: {pipeline}")
+ records = [record async for record in records]
+ results = [
+ (record["img"].split(";")[-1].strip(), record["name"]) for record in records
+ ]
+ num_results = len(results)
+
+ logger.debug(f"Found {num_results=} results")
+ return results
+
+
+fastapi = FastAPI()
+
+
+@deployment
+@ingress(fastapi)
+class QueryApplication:
+
+ def __init__(
+ self,
+ query_legacy: QueryLegacySearch,
+ query_ai_enabled: QueryAIEnabledSearch,
+ ):
+ self.query_legacy = query_legacy
+ self.query_ai_enabled = query_ai_enabled
+
+ @fastapi.get("/legacy")
+ async def query_legacy_search(
+ self,
+ text_search: str,
+ min_price: int,
+ max_price: int,
+ min_rating: float,
+ num_results: int,
+ ):
+ return await self.query_legacy.run.remote(
+ text_search=text_search,
+ min_price=min_price,
+ max_price=max_price,
+ min_rating=min_rating,
+ n=num_results,
+ )
+
+ @fastapi.get("/ai_enabled")
+ async def query_ai_enabled_search(
+ self,
+ text_search: str,
+ min_price: int,
+ max_price: int,
+ min_rating: float,
+ categories: list[str],
+ colors: list[str],
+ seasons: list[str],
+ num_results: int,
+ embedding_column: str,
+ search_type: list[str],
+ ):
+ logger = logging.getLogger("ray.serve")
+ logger.setLevel(logging.DEBUG)
+ logger.debug(f"Running query_ai_enabled_search with {locals()=}")
+ return await self.query_ai_enabled.run.remote(
+ text_search=text_search,
+ min_price=min_price,
+ max_price=max_price,
+ min_rating=min_rating,
+ categories=categories,
+ colors=colors,
+ seasons=seasons,
+ n=num_results,
+ vector_search_path=f"{embedding_column.lower()}_embedding",
+ search_type={type_.lower() for type_ in search_type},
+ )
+
+
+query_legacy = QueryLegacySearch.bind()
+embedding_model = EmbeddingModel.bind()
+query_ai_enabled = QueryAIEnabledSearch.bind(embedding_model)
+app = QueryApplication.bind(query_legacy, query_ai_enabled)
diff --git a/templates/ray-summit-multi-modal-search/no-color-application/command.txt b/templates/ray-summit-multi-modal-search/no-color-application/command.txt
new file mode 100644
index 000000000..b40a8d0b6
--- /dev/null
+++ b/templates/ray-summit-multi-modal-search/no-color-application/command.txt
@@ -0,0 +1 @@
+anyscale service deploy -f app.yaml
diff --git a/templates/ray-summit-multi-modal-search/no-color-application/frontend.py b/templates/ray-summit-multi-modal-search/no-color-application/frontend.py
new file mode 100644
index 000000000..836d3833a
--- /dev/null
+++ b/templates/ray-summit-multi-modal-search/no-color-application/frontend.py
@@ -0,0 +1,235 @@
+from typing import Optional
+import gradio as gr
+from ray.serve.gradio_integrations import GradioServer
+import requests
+
+ANYSCALE_BACKEND_SERVICE_URL = "http://localhost:8000/backend"
+
+
+def filter_products_legacy(
+ text_query: Optional[str],
+ min_price: int,
+ max_price: int,
+ min_rating: float,
+ num_results: int,
+) -> list[tuple[str, str]]:
+ response = requests.get(
+ f"{ANYSCALE_BACKEND_SERVICE_URL}/legacy",
+ params={
+ "text_search": text_query or "",
+ "min_price": min_price,
+ "max_price": max_price,
+ "min_rating": min_rating,
+ "num_results": num_results,
+ },
+ )
+ return response.json()
+
+
+def filter_products_with_ai(
+ text_search: Optional[str],
+ min_price: int,
+ max_price: int,
+ min_rating: float,
+ categories: list[str],
+ colors: list[str],
+ seasons: list[str],
+ num_results: int,
+ search_type: list[str],
+ embedding_column: str,
+):
+ params = {
+ "text_search": text_search or "",
+ "min_price": min_price,
+ "max_price": max_price,
+ "min_rating": min_rating,
+ "num_results": num_results,
+ "embedding_column": embedding_column,
+ }
+ body = {
+ "categories": categories,
+ "colors": colors,
+ "seasons": seasons,
+ "search_type": search_type,
+ }
+
+ response = requests.get(
+ f"{ANYSCALE_BACKEND_SERVICE_URL}/ai_enabled",
+ params=params,
+ json=body,
+ )
+ results = response.json()
+
+ return results
+
+
+def build_interface():
+ price_min = 0
+ price_max = 100_000
+
+ # Get rating range
+ rating_min = 0
+ rating_max = 5
+
+ # Gradio Interface
+ with gr.Blocks(
+ # theme="shivi/calm_foam",
+ title="Multi-modal search",
+ ) as iface:
+ with gr.Tab(label="Legacy Search"):
+ with gr.Row():
+ with gr.Column(scale=1):
+ keywords_component = gr.Textbox(label="Keywords")
+ min_price_component = gr.Slider(
+ price_min, price_max, label="Min Price", value=price_min
+ )
+ max_price_component = gr.Slider(
+ price_min, price_max, label="Max Price", value=price_max
+ )
+ min_rating_component = gr.Slider(
+ rating_min, rating_max, step=0.25, label="Min Rating"
+ )
+ max_num_results_component = gr.Slider(
+ 1, 100, step=1, label="Max Results", value=20
+ )
+ filter_button_component = gr.Button("Filter")
+ with gr.Column(scale=3):
+ gallery = gr.Gallery(
+ label="Filtered Products",
+ columns=3,
+ height=800,
+ )
+ inputs = [
+ keywords_component,
+ min_price_component,
+ max_price_component,
+ min_rating_component,
+ max_num_results_component,
+ ]
+ filter_button_component.click(
+ filter_products_legacy, inputs=inputs, outputs=gallery
+ )
+ iface.load(
+ filter_products_legacy,
+ inputs=inputs,
+ outputs=gallery,
+ )
+
+ with gr.Tab(label="AI enabled search"):
+ with gr.Row():
+ with gr.Column(scale=1):
+ text_component = gr.Textbox(label="Text Search")
+ min_price_component = gr.Slider(
+ price_min, price_max, label="Min Price", value=price_min
+ )
+ max_price_component = gr.Slider(
+ price_min, price_max, label="Max Price", value=price_max
+ )
+
+ min_rating_component = gr.Slider(
+ rating_min, rating_max, step=0.25, label="Min Rating"
+ )
+ category_component = gr.CheckboxGroup(
+ ["Tops", "Bottoms", "Dresses", "Footwear", "Accessories"],
+ label="Category",
+ value=[
+ "Tops",
+ "Bottoms",
+ "Dresses",
+ "Footwear",
+ "Accessories",
+ ],
+ )
+ season_component = gr.CheckboxGroup(
+ ["Summer", "Winter", "Spring", "Fall"],
+ label="Season",
+ value=[
+ "Summer",
+ "Winter",
+ "Spring",
+ "Fall",
+ ],
+ )
+ color_component = gr.CheckboxGroup(
+ [
+ "Red",
+ "Blue",
+ "Green",
+ "Yellow",
+ "Black",
+ "White",
+ "Pink",
+ "Purple",
+ "Orange",
+ "Brown",
+ "Grey",
+ ],
+ label="Color",
+ value=[
+ "Red",
+ "Blue",
+ "Green",
+ "Yellow",
+ "Black",
+ "White",
+ "Pink",
+ "Purple",
+ "Orange",
+ "Brown",
+ "Grey",
+ ],
+ )
+ max_num_results_component = gr.Slider(
+ 1, 100, step=1, label="Max Results", value=20
+ )
+
+ # add an engine advanced options
+ with gr.Accordion(label="Advanced Engine Options"):
+ # checkbox for type of search - lexical and/or vector
+ search_type_component = gr.CheckboxGroup(
+ ["Lexical", "Vector"],
+ label="Search Type",
+ value=["Lexical", "Vector"],
+ )
+ # dropdwon for embedding column - name or description
+ embedding_column_component = gr.Dropdown(
+ ["name", "description"],
+ label="Embedding Column",
+ value="description",
+ )
+
+ filter_button_component = gr.Button("Filter")
+ with gr.Column(scale=3):
+ gallery = gr.Gallery(
+ label="Filtered Products",
+ columns=3,
+ height=800,
+ )
+ inputs = [
+ text_component,
+ min_price_component,
+ max_price_component,
+ min_rating_component,
+ category_component,
+ color_component,
+ season_component,
+ max_num_results_component,
+ search_type_component,
+ embedding_column_component,
+ ]
+
+ filter_button_component.click(
+ filter_products_with_ai,
+ inputs=inputs,
+ outputs=gallery,
+ )
+ iface.load(
+ filter_products_with_ai,
+ inputs=inputs,
+ outputs=gallery,
+ )
+
+ return iface
+
+
+app = GradioServer.options(ray_actor_options={"num_cpus": 1}).bind(build_interface)
diff --git a/templates/ray-summit-multi-modal-search/no-color-application/requirements.txt b/templates/ray-summit-multi-modal-search/no-color-application/requirements.txt
new file mode 100644
index 000000000..08eacd285
--- /dev/null
+++ b/templates/ray-summit-multi-modal-search/no-color-application/requirements.txt
@@ -0,0 +1,6 @@
+# base image: anyscale/ray:2.24.0-py311
+# frontend
+gradio==3.50.2
+# backend
+motor==3.5.0
+sentence-transformers==3.0.1
diff --git a/templates/ray-summit-multi-modal-search/pipeline_tutorial/1_setup_tools.ipynb b/templates/ray-summit-multi-modal-search/pipeline_tutorial/1_setup_tools.ipynb
new file mode 100644
index 000000000..d17808132
--- /dev/null
+++ b/templates/ray-summit-multi-modal-search/pipeline_tutorial/1_setup_tools.ipynb
@@ -0,0 +1,336 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "52f6531b-32d1-436c-b4f4-9b62ffdcf5c5",
+ "metadata": {},
+ "source": [
+ "# Reinventing Multi-Modal Search with Anyscale and MongoDB\n",
+ "\n",
+ "What we are learning about and building today: https://www.anyscale.com/blog/reinventing-multi-modal-search-with-anyscale-and-mongodb\n",
+ "\n",
+ "The following instructions will help you get set up your environment\n",
+ "\n",
+ "## Register for Anyscale if needed\n",
+ "\n",
+ "If you're attending this class at Ray Summit 2024, then you already have an Anyscale account -- we'll use that one!\n",
+ "\n",
+ "If you're trying out this application later or on your own,\n",
+ "* You can register for Anyscale [here](https://console.anyscale.com/register/ha?utm_source=github&utm_medium=github&utm_content=multi-modal-search-anyscale-mongodb).\n",
+ "\n",
+ "## Login to Anyscale\n",
+ "\n",
+ "Once you have an account, [login](https://console.anyscale.com/v2?utm_source=github&utm_medium=github&utm_content=multi-modal-search-anyscale-mongodb) here.\n",
+ "\n",
+ "## Get set up with MongoDB\n",
+ "\n",
+ "Check out the Mongo Developer Intro Lab at https://mongodb-developer.github.io/intro-lab/\n",
+ "\n",
+ "That tutorial -- presented live at Ray Summit 2024 -- covers the following key steps:\n",
+ "* Get you set up with a free MongoDB Atlas account \n",
+ "* Create a free MongoDB cluster\n",
+ "* Configure securityy to allow public access to your cluster (for demo/class purposes only)\n",
+ "* Create your database user and save the password\n",
+ "* Get the connection string for your MongoDB cluster\n",
+ "\n",
+ "## Register or login to Hugging Face\n",
+ "\n",
+ "If you don't have a Hugging Face account, you can register [here](https://huggingface.co/join). \n",
+ "\n",
+ "If you already have an account, [login](https://huggingface.co/login) here.\n",
+ "\n",
+ "Visit the [tokens](https://huggingface.co/settings/tokens) page to generate a new API token.\n",
+ "\n",
+ "Visit the following model pages and request access to these models:\n",
+ "- [llava-hf/llava-v1.6-mistral-7b-hf](https://huggingface.co/llava-hf/llava-v1.6-mistral-7b-hf)\n",
+ "- [mistralai/Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1)\n",
+ "\n",
+ "Once you have access to these models, you can proceed with the next steps.\n",
+ "\n",
+ "## Launch a workspace in Anyscale for this project\n",
+ "\n",
+ "At Ray Summit 2024, you're probably already running the right workspace. If you're doing this tutorial on your own, choose the Anyscale Ray Summit 2024 template\n",
+ "\n",
+ "## Configure environment variables in your Anyscale Workspace\n",
+ "\n",
+ "Under the __Dependencies__ tab in the workspace view, set the MongoDB connection string `DB_CONNECTION_STRING` and huggingface access token `HF_TOKEN` as environment variables.\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7503a017-f50b-485d-8bef-53d3bb6c8a44",
+ "metadata": {},
+ "source": [
+ "---"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3986fc0a-86f6-4b6e-aed0-cee807243c9f",
+ "metadata": {},
+ "source": [
+ "## Test database connection"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8f9aab15-a2d0-4467-b177-3e8a57052cc6",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import pymongo\n",
+ "from pymongo import MongoClient, ASCENDING, DESCENDING\n",
+ "import os\n",
+ "from pymongo.operations import IndexModel, SearchIndexModel"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1772c405-0e28-4760-9374-00a1194ddf37",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "db_name: str = \"myntra\"\n",
+ "collection_name: str = \"myntra-items-offline\""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c01d4912-d0d1-455a-b0ee-9d307de720ab",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "client = MongoClient(os.environ[\"DB_CONNECTION_STRING\"])\n",
+ "db = client[db_name]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "91e2cadd-12cc-498b-8aba-bd60f6d12cf3",
+ "metadata": {},
+ "source": [
+ "*If the `DB_CONNECTION_STRING` env var is not found, you may need to terminate and then restart the workspace.*"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "cb470e0b-f790-42ec-9198-da6300d87022",
+ "metadata": {},
+ "source": [
+ "### Setup collection\n",
+ "\n",
+ "Run this code one time after you've created your database, to set up the collection and indexes"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b87069bc",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "db.drop_collection(collection_name)\n",
+ "\n",
+ "my_collection = db[collection_name]\n",
+ "\n",
+ "my_collection.create_indexes(\n",
+ " [\n",
+ " IndexModel([(\"rating\", DESCENDING)]),\n",
+ " IndexModel([(\"category\", ASCENDING)]),\n",
+ " IndexModel([(\"season\", ASCENDING)]),\n",
+ " IndexModel([(\"color\", ASCENDING)]),\n",
+ " ]\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "35d1bc92-9d22-4f85-aef0-e6be8f1b38b0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fts_model = SearchIndexModel(\n",
+ " definition={\n",
+ " \"mappings\": {\n",
+ " \"dynamic\": False,\n",
+ " \"fields\": {\n",
+ " \"name\": {\"type\": \"string\", \"analyzer\": \"lucene.standard\",}\n",
+ " }\n",
+ " }\n",
+ " },\n",
+ " name=\"lexical_text_search_index\",\n",
+ " type=\"search\"\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "df23997f-c7cc-4cec-8f16-11014ad8b733",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "vs_model = SearchIndexModel(\n",
+ " definition={\n",
+ " \"fields\": [\n",
+ " {\n",
+ " \"numDimensions\": 1024,\n",
+ " \"similarity\": \"cosine\",\n",
+ " \"type\": \"vector\",\n",
+ " \"path\": \"description_embedding\",\n",
+ " },\n",
+ " {\n",
+ " \"numDimensions\": 1024,\n",
+ " \"similarity\": \"cosine\",\n",
+ " \"type\": \"vector\",\n",
+ " \"path\": \"name_embedding\",\n",
+ " }, \n",
+ " {\n",
+ " \"type\": \"filter\",\n",
+ " \"path\": \"category\",\n",
+ " },\n",
+ " {\n",
+ " \"type\": \"filter\",\n",
+ " \"path\": \"season\",\n",
+ " },\n",
+ " {\n",
+ " \"type\": \"filter\",\n",
+ " \"path\": \"color\",\n",
+ " },\n",
+ " {\n",
+ " \"type\": \"filter\",\n",
+ " \"path\": \"rating\",\n",
+ " },\n",
+ " {\n",
+ " \"type\": \"filter\",\n",
+ " \"path\": \"price\",\n",
+ " },\n",
+ " ],\n",
+ " },\n",
+ " name=\"vector_search_index\",\n",
+ " type=\"vectorSearch\"\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "170f4bd6-e70c-4d5b-b872-0a5123082206",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "my_collection.create_search_indexes(models=[fts_model, vs_model])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4d47c025-c220-4ac8-904f-6a1224a36f11",
+ "metadata": {},
+ "source": [
+ "### Count docs"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5814f906-2d18-4c13-a135-d0f2bd85c7b3",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "my_collection.count_documents({})"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "74063927-75e7-459e-931d-729500d5661c",
+ "metadata": {},
+ "source": [
+ "# Architecture\n",
+ "\n",
+ "We split our system into an offline data indexing stage and an online search stage.\n",
+ "\n",
+ "The offline data indexing stage performs the processing, embedding, and upserting text and images into a MongoDB database that supports vector search across multiple fields and dimensions. This stage is built by running multi-modal data pipelines at scale using Anyscale for AI compute platform.\n",
+ "\n",
+ "The online search stage performs the necessary search operations by combining legacy text matching with advanced semantic search capabilities offered by MongoDB. This stage is built by running a multi-modal search backend on Anyscale.\n",
+ "\n",
+ "## Multi-Modal Data Pipelines at Scale\n",
+ "\n",
+ "### Overview\n",
+ "The data pipelines show how to perform offline batch inference and embeddings generation at scale. The pipelines are designed to handle both text and image data by running multi-modal large language model instances. \n",
+ "\n",
+ "### Technology Stack\n",
+ "\n",
+ "- `ray[data]`\n",
+ "- `vLLM`\n",
+ "- `pymongo`\n",
+ "- `sentence-transformers`\n",
+ "\n",
+ "## Multi-Modal Search at Scale\n",
+ "\n",
+ "### Overview\n",
+ "The search backend combines legacy lexical text matching with advanced semantic search capabilities, offering a robust hybrid search solution. \n",
+ "\n",
+ "### Technology Stack\n",
+ "- `ray[serve]`\n",
+ "- `gradio`\n",
+ "- `motor`\n",
+ "- `sentence-transformers`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9968d7a4-1a46-451d-9b8f-8bf62a1005b9",
+ "metadata": {},
+ "source": [
+ "### Empty collection\n",
+ "\n",
+ "As you're working, you may have experiment, errors, or changes which alter the MongoDB collection. To drop all records in the collection, use the following line."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "990ab0bb-299c-4109-9e64-c89f3731c5fe",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "my_collection.delete_many({})"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "714fefa5-2189-4726-a25f-e4952f816861",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/templates/ray-summit-multi-modal-search/pipeline_tutorial/2_intro_data.ipynb b/templates/ray-summit-multi-modal-search/pipeline_tutorial/2_intro_data.ipynb
new file mode 100644
index 000000000..8990125c4
--- /dev/null
+++ b/templates/ray-summit-multi-modal-search/pipeline_tutorial/2_intro_data.ipynb
@@ -0,0 +1,523 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Intro to Ray Data"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Ray Datasets: Distributed Data Preprocessing\n",
+ "\n",
+ "Ray Datasets are the standard way to load and exchange data in Ray libraries and applications. They provide basic distributed data transformations such as maps ([`map_batches`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.map_batches.html#ray.data.Dataset.map_batches \"ray.data.Dataset.map_batches\")), global and grouped aggregations ([`GroupedDataset`](https://docs.ray.io/en/latest/data/api/doc/ray.data.grouped_dataset.GroupedDataset.html#ray.data.grouped_dataset.GroupedDataset \"ray.data.grouped_dataset.GroupedDataset\")), and shuffling operations ([`random_shuffle`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.random_shuffle.html#ray.data.Dataset.random_shuffle \"ray.data.Dataset.random_shuffle\"), [`sort`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.sort.html#ray.data.Dataset.sort \"ray.data.Dataset.sort\"), [`repartition`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.repartition.html#ray.data.Dataset.repartition \"ray.data.Dataset.repartition\")), and are compatible with a variety of file formats, data sources, and distributed frameworks.\n",
+ "\n",
+ "Here's an overview of the integrations with other processing frameworks, file formats, and supported operations, as well as a glimpse at the Ray Datasets API.\n",
+ "\n",
+ "Check the [Input/Output reference](https://docs.ray.io/en/latest/data/api/input_output.html#input-output) to see if your favorite format is already supported.\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7503a017-f50b-485d-8bef-53d3bb6c8a44",
+ "metadata": {},
+ "source": [
+ "---"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3986fc0a-86f6-4b6e-aed0-cee807243c9f",
+ "metadata": {},
+ "source": [
+ "## Test database connection"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8f9aab15-a2d0-4467-b177-3e8a57052cc6",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import pymongo\n",
+ "from pymongo import MongoClient, ASCENDING, DESCENDING\n",
+ "import os\n",
+ "from pymongo.operations import IndexModel, SearchIndexModel"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1772c405-0e28-4760-9374-00a1194ddf37",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "db_name: str = \"myntra\"\n",
+ "collection_name: str = \"myntra-items-offline\""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c01d4912-d0d1-455a-b0ee-9d307de720ab",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "client = MongoClient(os.environ[\"DB_CONNECTION_STRING\"])\n",
+ "db = client[db_name]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "91e2cadd-12cc-498b-8aba-bd60f6d12cf3",
+ "metadata": {},
+ "source": [
+ "*If the `DB_CONNECTION_STRING` env var is not found, you may need to terminate and then restart the workspace.*"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "cb470e0b-f790-42ec-9198-da6300d87022",
+ "metadata": {},
+ "source": [
+ "### Setup collection\n",
+ "\n",
+ "Run this code one time after you've created your database, to set up the collection and indexes"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b87069bc",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "db.drop_collection(collection_name)\n",
+ "\n",
+ "my_collection = db[collection_name]\n",
+ "\n",
+ "my_collection.create_indexes(\n",
+ " [\n",
+ " IndexModel([(\"rating\", DESCENDING)]),\n",
+ " IndexModel([(\"category\", ASCENDING)]),\n",
+ " IndexModel([(\"season\", ASCENDING)]),\n",
+ " IndexModel([(\"color\", ASCENDING)]),\n",
+ " ]\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "35d1bc92-9d22-4f85-aef0-e6be8f1b38b0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fts_model = SearchIndexModel(\n",
+ " definition={\n",
+ " \"mappings\": {\n",
+ " \"dynamic\": False,\n",
+ " \"fields\": {\n",
+ " \"name\": {\"type\": \"string\", \"analyzer\": \"lucene.standard\",}\n",
+ " }\n",
+ " }\n",
+ " },\n",
+ " name=\"lexical_text_search_index\",\n",
+ " type=\"search\"\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "df23997f-c7cc-4cec-8f16-11014ad8b733",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "vs_model = SearchIndexModel(\n",
+ " definition={\n",
+ " \"fields\": [\n",
+ " {\n",
+ " \"numDimensions\": 1024,\n",
+ " \"similarity\": \"cosine\",\n",
+ " \"type\": \"vector\",\n",
+ " \"path\": \"description_embedding\",\n",
+ " },\n",
+ " {\n",
+ " \"numDimensions\": 1024,\n",
+ " \"similarity\": \"cosine\",\n",
+ " \"type\": \"vector\",\n",
+ " \"path\": \"name_embedding\",\n",
+ " }, \n",
+ " {\n",
+ " \"type\": \"filter\",\n",
+ " \"path\": \"category\",\n",
+ " },\n",
+ " {\n",
+ " \"type\": \"filter\",\n",
+ " \"path\": \"season\",\n",
+ " },\n",
+ " {\n",
+ " \"type\": \"filter\",\n",
+ " \"path\": \"color\",\n",
+ " },\n",
+ " {\n",
+ " \"type\": \"filter\",\n",
+ " \"path\": \"rating\",\n",
+ " },\n",
+ " {\n",
+ " \"type\": \"filter\",\n",
+ " \"path\": \"price\",\n",
+ " },\n",
+ " ],\n",
+ " },\n",
+ " name=\"vector_search_index\",\n",
+ " type=\"vectorSearch\"\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "170f4bd6-e70c-4d5b-b872-0a5123082206",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "my_collection.create_search_indexes(models=[fts_model, vs_model])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4d47c025-c220-4ac8-904f-6a1224a36f11",
+ "metadata": {},
+ "source": [
+ "### Count docs"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5814f906-2d18-4c13-a135-d0f2bd85c7b3",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "my_collection.count_documents({})"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "74063927-75e7-459e-931d-729500d5661c",
+ "metadata": {},
+ "source": [
+ "# Architecture\n",
+ "\n",
+ "We split our system into an offline data indexing stage and an online search stage.\n",
+ "\n",
+ "The offline data indexing stage performs the processing, embedding, and upserting text and images into a MongoDB database that supports vector search across multiple fields and dimensions. This stage is built by running multi-modal data pipelines at scale using Anyscale for AI compute platform.\n",
+ "\n",
+ "The online search stage performs the necessary search operations by combining legacy text matching with advanced semantic search capabilities offered by MongoDB. This stage is built by running a multi-modal search backend on Anyscale.\n",
+ "\n",
+ "## Multi-Modal Data Pipelines at Scale\n",
+ "\n",
+ "### Overview\n",
+ "The data pipelines show how to perform offline batch inference and embeddings generation at scale. The pipelines are designed to handle both text and image data by running multi-modal large language model instances. \n",
+ "\n",
+ "### Technology Stack\n",
+ "\n",
+ "- `ray[data]`\n",
+ "- `vLLM`\n",
+ "- `pymongo`\n",
+ "- `sentence-transformers`\n",
+ "\n",
+ "## Multi-Modal Search at Scale\n",
+ "\n",
+ "### Overview\n",
+ "The search backend combines legacy lexical text matching with advanced semantic search capabilities, offering a robust hybrid search solution. \n",
+ "\n",
+ "### Technology Stack\n",
+ "- `ray[serve]`\n",
+ "- `gradio`\n",
+ "- `motor`\n",
+ "- `sentence-transformers`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9968d7a4-1a46-451d-9b8f-8bf62a1005b9",
+ "metadata": {},
+ "source": [
+ "### Empty collection\n",
+ "\n",
+ "As you're working, you may have experiment, errors, or changes which alter the MongoDB collection. To drop all records in the collection, use the following line."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "990ab0bb-299c-4109-9e64-c89f3731c5fe",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "my_collection.delete_many({})"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "714fefa5-2189-4726-a25f-e4952f816861",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/templates/ray-summit-multi-modal-search/pipeline_tutorial/2_intro_data.ipynb b/templates/ray-summit-multi-modal-search/pipeline_tutorial/2_intro_data.ipynb
new file mode 100644
index 000000000..8990125c4
--- /dev/null
+++ b/templates/ray-summit-multi-modal-search/pipeline_tutorial/2_intro_data.ipynb
@@ -0,0 +1,523 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Intro to Ray Data"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Ray Datasets: Distributed Data Preprocessing\n",
+ "\n",
+ "Ray Datasets are the standard way to load and exchange data in Ray libraries and applications. They provide basic distributed data transformations such as maps ([`map_batches`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.map_batches.html#ray.data.Dataset.map_batches \"ray.data.Dataset.map_batches\")), global and grouped aggregations ([`GroupedDataset`](https://docs.ray.io/en/latest/data/api/doc/ray.data.grouped_dataset.GroupedDataset.html#ray.data.grouped_dataset.GroupedDataset \"ray.data.grouped_dataset.GroupedDataset\")), and shuffling operations ([`random_shuffle`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.random_shuffle.html#ray.data.Dataset.random_shuffle \"ray.data.Dataset.random_shuffle\"), [`sort`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.sort.html#ray.data.Dataset.sort \"ray.data.Dataset.sort\"), [`repartition`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.repartition.html#ray.data.Dataset.repartition \"ray.data.Dataset.repartition\")), and are compatible with a variety of file formats, data sources, and distributed frameworks.\n",
+ "\n",
+ "Here's an overview of the integrations with other processing frameworks, file formats, and supported operations, as well as a glimpse at the Ray Datasets API.\n",
+ "\n",
+ "Check the [Input/Output reference](https://docs.ray.io/en/latest/data/api/input_output.html#input-output) to see if your favorite format is already supported.\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Data Loading and Preprocessing for ML Training\n",
+ "-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------\n",
+ "\n",
+ "Use Ray Datasets to load and preprocess data for distributed [ML training pipelines](https://docs.ray.io/en/latest/train/train.html#train-docs). Compared to other loading solutions, Datasets are more flexible (e.g., can express higher-quality per-epoch global shuffles) and provides [higher overall performance](https://www.anyscale.com/blog/why-third-generation-ml-platforms-are-more-performant).\n",
+ "\n",
+ "Use Datasets as a last-mile bridge from storage or ETL pipeline outputs to distributed applications and libraries in Ray. Don't use it as a replacement for more general data processing systems.\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Data Loading and Preprocessing for ML Training\n",
+ "-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------\n",
+ "\n",
+ "Use Ray Datasets to load and preprocess data for distributed [ML training pipelines](https://docs.ray.io/en/latest/train/train.html#train-docs). Compared to other loading solutions, Datasets are more flexible (e.g., can express higher-quality per-epoch global shuffles) and provides [higher overall performance](https://www.anyscale.com/blog/why-third-generation-ml-platforms-are-more-performant).\n",
+ "\n",
+ "Use Datasets as a last-mile bridge from storage or ETL pipeline outputs to distributed applications and libraries in Ray. Don't use it as a replacement for more general data processing systems.\n",
+ "\n",
+ " \n",
+ "\n",
+ "To learn more about the features Datasets supports, read the [Datasets User Guide](https://docs.ray.io/en/latest/data/user-guide.html#data-user-guide).\n",
+ "\n",
+ "### Datasets for Parallel Compute\n",
+ "-------------------------------------------------------------------------------------------------------------------------------------------\n",
+ "\n",
+ "Datasets also simplify general purpose parallel GPU and CPU compute in Ray; for instance, for [GPU batch inference](https://docs.ray.io/en/latest/ray-overview/use-cases.html#ref-use-cases-batch-infer). They provide a higher-level API for Ray tasks and actors for such embarrassingly parallel compute, internally handling operations like batching, pipelining, and memory management.\n",
+ "\n",
+ "\n",
+ "\n",
+ "As part of the Ray ecosystem, Ray Datasets can leverage the full functionality of Ray's distributed scheduler, e.g., using actors for optimizing setup time and GPU scheduling."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Datasets\n",
+ "------------------------------------------------------------------------------------------------------\n",
+ "\n",
+ "A Dataset consists of a list of Ray object references to *blocks*. Having multiple blocks in a dataset allows for parallel transformation and ingest.\n",
+ "\n",
+ "The following figure visualizes a tabular dataset with three blocks, each block holding 1000 rows each:\n",
+ "\n",
+ "\n",
+ "\n",
+ "Since a Dataset is just a list of Ray object references, it can be freely passed between Ray tasks, actors, and libraries like any other object reference. This flexibility is a unique characteristic of Ray Datasets."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Reading Data[](https://docs.ray.io/en/latest/data/key-concepts.html#reading-data \"Permalink to this headline\")\n",
+ "\n",
+ "Datasets uses Ray tasks to read data from remote storage. When reading from a file-based datasource (e.g., S3, GCS), it creates a number of read tasks proportional to the number of CPUs in the cluster. Each read task reads its assigned files and produces an output block:\n",
+ "\n",
+ "
\n",
+ "\n",
+ "To learn more about the features Datasets supports, read the [Datasets User Guide](https://docs.ray.io/en/latest/data/user-guide.html#data-user-guide).\n",
+ "\n",
+ "### Datasets for Parallel Compute\n",
+ "-------------------------------------------------------------------------------------------------------------------------------------------\n",
+ "\n",
+ "Datasets also simplify general purpose parallel GPU and CPU compute in Ray; for instance, for [GPU batch inference](https://docs.ray.io/en/latest/ray-overview/use-cases.html#ref-use-cases-batch-infer). They provide a higher-level API for Ray tasks and actors for such embarrassingly parallel compute, internally handling operations like batching, pipelining, and memory management.\n",
+ "\n",
+ "\n",
+ "\n",
+ "As part of the Ray ecosystem, Ray Datasets can leverage the full functionality of Ray's distributed scheduler, e.g., using actors for optimizing setup time and GPU scheduling."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Datasets\n",
+ "------------------------------------------------------------------------------------------------------\n",
+ "\n",
+ "A Dataset consists of a list of Ray object references to *blocks*. Having multiple blocks in a dataset allows for parallel transformation and ingest.\n",
+ "\n",
+ "The following figure visualizes a tabular dataset with three blocks, each block holding 1000 rows each:\n",
+ "\n",
+ "\n",
+ "\n",
+ "Since a Dataset is just a list of Ray object references, it can be freely passed between Ray tasks, actors, and libraries like any other object reference. This flexibility is a unique characteristic of Ray Datasets."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Reading Data[](https://docs.ray.io/en/latest/data/key-concepts.html#reading-data \"Permalink to this headline\")\n",
+ "\n",
+ "Datasets uses Ray tasks to read data from remote storage. When reading from a file-based datasource (e.g., S3, GCS), it creates a number of read tasks proportional to the number of CPUs in the cluster. Each read task reads its assigned files and produces an output block:\n",
+ "\n",
+ " \n",
+ "\n",
+ "### Transforming Data[](https://docs.ray.io/en/latest/data/key-concepts.html#transforming-data \"Permalink to this headline\")\n",
+ "\n",
+ "Datasets can use either Ray tasks or Ray actors to transform datasets. Using actors allows for expensive state initialization (e.g., for GPU-based tasks) to be cached.\n",
+ "\n",
+ "### Shuffling Data[](https://docs.ray.io/en/latest/data/key-concepts.html#shuffling-data \"Permalink to this headline\")\n",
+ "\n",
+ "Certain operations like *sort* or *groupby* require data blocks to be partitioned by value, or *shuffled*. Datasets uses tasks to implement distributed shuffles in a map-reduce style, using map tasks to partition blocks by value, and then reduce tasks to merge co-partitioned blocks together.\n",
+ "\n",
+ "You can also change just the number of blocks of a Dataset using [`repartition()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.repartition.html#ray.data.Dataset.repartition \"ray.data.Dataset.repartition\"). Repartition has two modes:\n",
+ "\n",
+ "1. `shuffle=False` - performs the minimal data movement needed to equalize block sizes\n",
+ "\n",
+ "2. `shuffle=True` - performs a full distributed shuffle\n",
+ "\n",
+ "
\n",
+ "\n",
+ "### Transforming Data[](https://docs.ray.io/en/latest/data/key-concepts.html#transforming-data \"Permalink to this headline\")\n",
+ "\n",
+ "Datasets can use either Ray tasks or Ray actors to transform datasets. Using actors allows for expensive state initialization (e.g., for GPU-based tasks) to be cached.\n",
+ "\n",
+ "### Shuffling Data[](https://docs.ray.io/en/latest/data/key-concepts.html#shuffling-data \"Permalink to this headline\")\n",
+ "\n",
+ "Certain operations like *sort* or *groupby* require data blocks to be partitioned by value, or *shuffled*. Datasets uses tasks to implement distributed shuffles in a map-reduce style, using map tasks to partition blocks by value, and then reduce tasks to merge co-partitioned blocks together.\n",
+ "\n",
+ "You can also change just the number of blocks of a Dataset using [`repartition()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.repartition.html#ray.data.Dataset.repartition \"ray.data.Dataset.repartition\"). Repartition has two modes:\n",
+ "\n",
+ "1. `shuffle=False` - performs the minimal data movement needed to equalize block sizes\n",
+ "\n",
+ "2. `shuffle=True` - performs a full distributed shuffle\n",
+ "\n",
+ " \n",
+ "\n",
+ "Datasets shuffle can scale to processing hundreds of terabytes of data. See the [Performance Tips Guide](https://docs.ray.io/en/latest/data/performance-tips.html#shuffle-performance-tips) for an in-depth guide on shuffle performance."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Execution mode\n",
+ "\n",
+ "Most transformations are lazy. They don't execute until you consume a dataset or call [`Dataset.materialize()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.materialize.html#ray.data.Dataset.materialize \"ray.data.Dataset.materialize\").\n",
+ "\n",
+ "The transformations are executed in a streaming way, incrementally on the data and with operators processed in parallel. For an in-depth guide on Datasets execution, read https://docs.ray.io/en/releases-2.35.0/data/data-internals.html\n",
+ "\n",
+ "### Fault tolerance\n",
+ "\n",
+ "Datasets performs *lineage reconstruction* to recover data. If an application error or system failure occurs, Datasets recreates lost blocks by re-executing tasks.\n",
+ "\n",
+ "Fault tolerance isn't supported in two cases:\n",
+ "\n",
+ "- If the original worker process that created the Dataset dies. This is because the creator stores the metadata for the [objects](https://docs.ray.io/en/releases-2.35.0/ray-core/fault_tolerance/objects.html) that comprise the Dataset.\n",
+ "\n",
+ "- If you a Ray actor is provided for transformations (e.g., map_batches). This is because Datasets relies on [task-based fault tolerance](https://docs.ray.io/en/releases-2.35.0/ray-core/fault_tolerance/tasks.html).\n",
+ " - __Note__ however: for many common AI inference or data preprocessing tasks using actors, the actor state is recoverable from elsewhere (e.g., a model store, huggingface hub, etc.) so this limitation has minimal impact"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Example operations: Transforming Datasets\n",
+ "\n",
+ "Datasets transformations take in datasets and produce new datasets. For example, *map* is a transformation that applies a user-defined function on each dataset record and returns a new dataset as the result. Datasets transformations can be composed to express a chain of computations.\n",
+ "\n",
+ "There are two main types of transformations:\n",
+ "\n",
+ "- One-to-one: each input block will contribute to only one output block, such as [`ds.map_batches()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.map_batches.html#ray.data.Dataset.map_batches \"ray.data.Dataset.map_batches\").\n",
+ "\n",
+ "- All-to-all: input blocks can contribute to multiple output blocks, such as [`ds.random_shuffle()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.random_shuffle.html#ray.data.Dataset.random_shuffle \"ray.data.Dataset.random_shuffle\").\n",
+ "\n",
+ "Here is a table listing some common transformations supported by Ray Datasets."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Common Ray Datasets transformations.[](https://docs.ray.io/en/latest/data/transforming-datasets.html#id2 \"Permalink to this table\")\n",
+ "\n",
+ "| Transformation | Type | Description |\n",
+ "| --- | --- | --- |\n",
+ "|[`ds.map_batches()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.map_batches.html#ray.data.Dataset.map_batches \"ray.data.Dataset.map_batches\")|One-to-one|Apply a given function to batches of records of this dataset.|\n",
+ "|[`ds.add_column()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.add_column.html#ray.data.Dataset.add_column \"ray.data.Dataset.add_column\")|One-to-one|Apply a given function to batches of records to create a new column.|\n",
+ "|[`ds.drop_columns()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.add_column.html#ray.data.Dataset.add_column \"ray.data.Dataset.add_column\")|One-to-one|Drop the given columns from the dataset.|\n",
+ "|[`ds.split()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.split.html#ray.data.Dataset.split \"ray.data.Dataset.split\")|One-to-one|Split the dataset into N disjoint pieces.|\n",
+ "|[`ds.repartition(shuffle=False)`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.repartition.html#ray.data.Dataset.repartition \"ray.data.Dataset.repartition\")|One-to-one|Repartition the dataset into N blocks, without shuffling the data.|\n",
+ "|[`ds.repartition(shuffle=True)`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.repartition.html#ray.data.Dataset.repartition \"ray.data.Dataset.repartition\")|All-to-all|Repartition the dataset into N blocks, shuffling the data during repartition.|\n",
+ "|[`ds.random_shuffle()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.random_shuffle.html#ray.data.Dataset.random_shuffle \"ray.data.Dataset.random_shuffle\")|All-to-all|Randomly shuffle the elements of this dataset.|\n",
+ "|[`ds.sort()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.sort.html#ray.data.Dataset.sort \"ray.data.Dataset.sort\")|All-to-all|Sort the dataset by a sortkey.|\n",
+ "|[`ds.groupby()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.groupby.html#ray.data.Dataset.groupby \"ray.data.Dataset.groupby\")|All-to-all|Group the dataset by a groupkey.|"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "> __Tip__\n",
+ ">\n",
+ "> Datasets also provides the convenience transformation methods [`ds.map()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.map.html#ray.data.Dataset.map \"ray.data.Dataset.map\"), [`ds.flat_map()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.flat_map.html#ray.data.Dataset.flat_map \"ray.data.Dataset.flat_map\"), and [`ds.filter()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.filter.html#ray.data.Dataset.filter \"ray.data.Dataset.filter\"), which are not vectorized (slower than [`ds.map_batches()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.map_batches.html#ray.data.Dataset.map_batches \"ray.data.Dataset.map_batches\")), but may be useful for development.\n",
+ "\n",
+ "The following is an example to make use of those transformation APIs for processing the Iris dataset."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "import ray\n",
+ "\n",
+ "ds = ray.data.read_csv(\"s3://anyscale-materials/data/iris.csv\")\n",
+ "\n",
+ "ds"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ds.show(3)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ds.write_parquet('/mnt/cluster_storage/parquet_iris')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "! ls -l /mnt/cluster_storage/parquet_iris/"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ds = ds.repartition(5)\n",
+ "\n",
+ "ds"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ds.take_batch(5)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "def transform_batch(batch):\n",
+ " \n",
+ " areas = []\n",
+ " for ix in range(len(batch['Id'])):\n",
+ " areas.append(batch[\"PetalLengthCm\"][ix] * batch[\"PetalWidthCm\"][ix]) \n",
+ " batch['approximate_petal_area'] = areas\n",
+ " return batch\n",
+ "\n",
+ "ds.map_batches(transform_batch).show(5)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ds.map_batches(transform_batch).take_batch()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "def transform_batch_vectorized(batch): \n",
+ " batch['approximate_petal_area'] = batch[\"PetalLengthCm\"][ix] * batch[\"PetalWidthCm\"][ix]\n",
+ " return batch\n",
+ "\n",
+ "ds.map_batches(transform_batch).show(5)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# Group by the variety.\n",
+ "ds.groupby(\"Species\").count().show()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Force computation and local caching if desired with `materialize`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ds.materialize()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Transforming data with actors\n",
+ "\n",
+ "When using the actor compute strategy, per-row and per-batch UDFs can also be *callable classes*, i.e. classes that implement the `__call__` magic method. The constructor of the class can be used for stateful setup, and will be only invoked once per worker actor.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "Datasets shuffle can scale to processing hundreds of terabytes of data. See the [Performance Tips Guide](https://docs.ray.io/en/latest/data/performance-tips.html#shuffle-performance-tips) for an in-depth guide on shuffle performance."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Execution mode\n",
+ "\n",
+ "Most transformations are lazy. They don't execute until you consume a dataset or call [`Dataset.materialize()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.materialize.html#ray.data.Dataset.materialize \"ray.data.Dataset.materialize\").\n",
+ "\n",
+ "The transformations are executed in a streaming way, incrementally on the data and with operators processed in parallel. For an in-depth guide on Datasets execution, read https://docs.ray.io/en/releases-2.35.0/data/data-internals.html\n",
+ "\n",
+ "### Fault tolerance\n",
+ "\n",
+ "Datasets performs *lineage reconstruction* to recover data. If an application error or system failure occurs, Datasets recreates lost blocks by re-executing tasks.\n",
+ "\n",
+ "Fault tolerance isn't supported in two cases:\n",
+ "\n",
+ "- If the original worker process that created the Dataset dies. This is because the creator stores the metadata for the [objects](https://docs.ray.io/en/releases-2.35.0/ray-core/fault_tolerance/objects.html) that comprise the Dataset.\n",
+ "\n",
+ "- If you a Ray actor is provided for transformations (e.g., map_batches). This is because Datasets relies on [task-based fault tolerance](https://docs.ray.io/en/releases-2.35.0/ray-core/fault_tolerance/tasks.html).\n",
+ " - __Note__ however: for many common AI inference or data preprocessing tasks using actors, the actor state is recoverable from elsewhere (e.g., a model store, huggingface hub, etc.) so this limitation has minimal impact"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Example operations: Transforming Datasets\n",
+ "\n",
+ "Datasets transformations take in datasets and produce new datasets. For example, *map* is a transformation that applies a user-defined function on each dataset record and returns a new dataset as the result. Datasets transformations can be composed to express a chain of computations.\n",
+ "\n",
+ "There are two main types of transformations:\n",
+ "\n",
+ "- One-to-one: each input block will contribute to only one output block, such as [`ds.map_batches()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.map_batches.html#ray.data.Dataset.map_batches \"ray.data.Dataset.map_batches\").\n",
+ "\n",
+ "- All-to-all: input blocks can contribute to multiple output blocks, such as [`ds.random_shuffle()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.random_shuffle.html#ray.data.Dataset.random_shuffle \"ray.data.Dataset.random_shuffle\").\n",
+ "\n",
+ "Here is a table listing some common transformations supported by Ray Datasets."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Common Ray Datasets transformations.[](https://docs.ray.io/en/latest/data/transforming-datasets.html#id2 \"Permalink to this table\")\n",
+ "\n",
+ "| Transformation | Type | Description |\n",
+ "| --- | --- | --- |\n",
+ "|[`ds.map_batches()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.map_batches.html#ray.data.Dataset.map_batches \"ray.data.Dataset.map_batches\")|One-to-one|Apply a given function to batches of records of this dataset.|\n",
+ "|[`ds.add_column()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.add_column.html#ray.data.Dataset.add_column \"ray.data.Dataset.add_column\")|One-to-one|Apply a given function to batches of records to create a new column.|\n",
+ "|[`ds.drop_columns()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.add_column.html#ray.data.Dataset.add_column \"ray.data.Dataset.add_column\")|One-to-one|Drop the given columns from the dataset.|\n",
+ "|[`ds.split()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.split.html#ray.data.Dataset.split \"ray.data.Dataset.split\")|One-to-one|Split the dataset into N disjoint pieces.|\n",
+ "|[`ds.repartition(shuffle=False)`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.repartition.html#ray.data.Dataset.repartition \"ray.data.Dataset.repartition\")|One-to-one|Repartition the dataset into N blocks, without shuffling the data.|\n",
+ "|[`ds.repartition(shuffle=True)`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.repartition.html#ray.data.Dataset.repartition \"ray.data.Dataset.repartition\")|All-to-all|Repartition the dataset into N blocks, shuffling the data during repartition.|\n",
+ "|[`ds.random_shuffle()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.random_shuffle.html#ray.data.Dataset.random_shuffle \"ray.data.Dataset.random_shuffle\")|All-to-all|Randomly shuffle the elements of this dataset.|\n",
+ "|[`ds.sort()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.sort.html#ray.data.Dataset.sort \"ray.data.Dataset.sort\")|All-to-all|Sort the dataset by a sortkey.|\n",
+ "|[`ds.groupby()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.groupby.html#ray.data.Dataset.groupby \"ray.data.Dataset.groupby\")|All-to-all|Group the dataset by a groupkey.|"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "> __Tip__\n",
+ ">\n",
+ "> Datasets also provides the convenience transformation methods [`ds.map()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.map.html#ray.data.Dataset.map \"ray.data.Dataset.map\"), [`ds.flat_map()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.flat_map.html#ray.data.Dataset.flat_map \"ray.data.Dataset.flat_map\"), and [`ds.filter()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.filter.html#ray.data.Dataset.filter \"ray.data.Dataset.filter\"), which are not vectorized (slower than [`ds.map_batches()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.map_batches.html#ray.data.Dataset.map_batches \"ray.data.Dataset.map_batches\")), but may be useful for development.\n",
+ "\n",
+ "The following is an example to make use of those transformation APIs for processing the Iris dataset."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "import ray\n",
+ "\n",
+ "ds = ray.data.read_csv(\"s3://anyscale-materials/data/iris.csv\")\n",
+ "\n",
+ "ds"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ds.show(3)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ds.write_parquet('/mnt/cluster_storage/parquet_iris')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "! ls -l /mnt/cluster_storage/parquet_iris/"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ds = ds.repartition(5)\n",
+ "\n",
+ "ds"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ds.take_batch(5)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "def transform_batch(batch):\n",
+ " \n",
+ " areas = []\n",
+ " for ix in range(len(batch['Id'])):\n",
+ " areas.append(batch[\"PetalLengthCm\"][ix] * batch[\"PetalWidthCm\"][ix]) \n",
+ " batch['approximate_petal_area'] = areas\n",
+ " return batch\n",
+ "\n",
+ "ds.map_batches(transform_batch).show(5)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ds.map_batches(transform_batch).take_batch()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "def transform_batch_vectorized(batch): \n",
+ " batch['approximate_petal_area'] = batch[\"PetalLengthCm\"][ix] * batch[\"PetalWidthCm\"][ix]\n",
+ " return batch\n",
+ "\n",
+ "ds.map_batches(transform_batch).show(5)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# Group by the variety.\n",
+ "ds.groupby(\"Species\").count().show()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Force computation and local caching if desired with `materialize`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ds.materialize()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Transforming data with actors\n",
+ "\n",
+ "When using the actor compute strategy, per-row and per-batch UDFs can also be *callable classes*, i.e. classes that implement the `__call__` magic method. The constructor of the class can be used for stateful setup, and will be only invoked once per worker actor.\n",
+ "\n",
+ "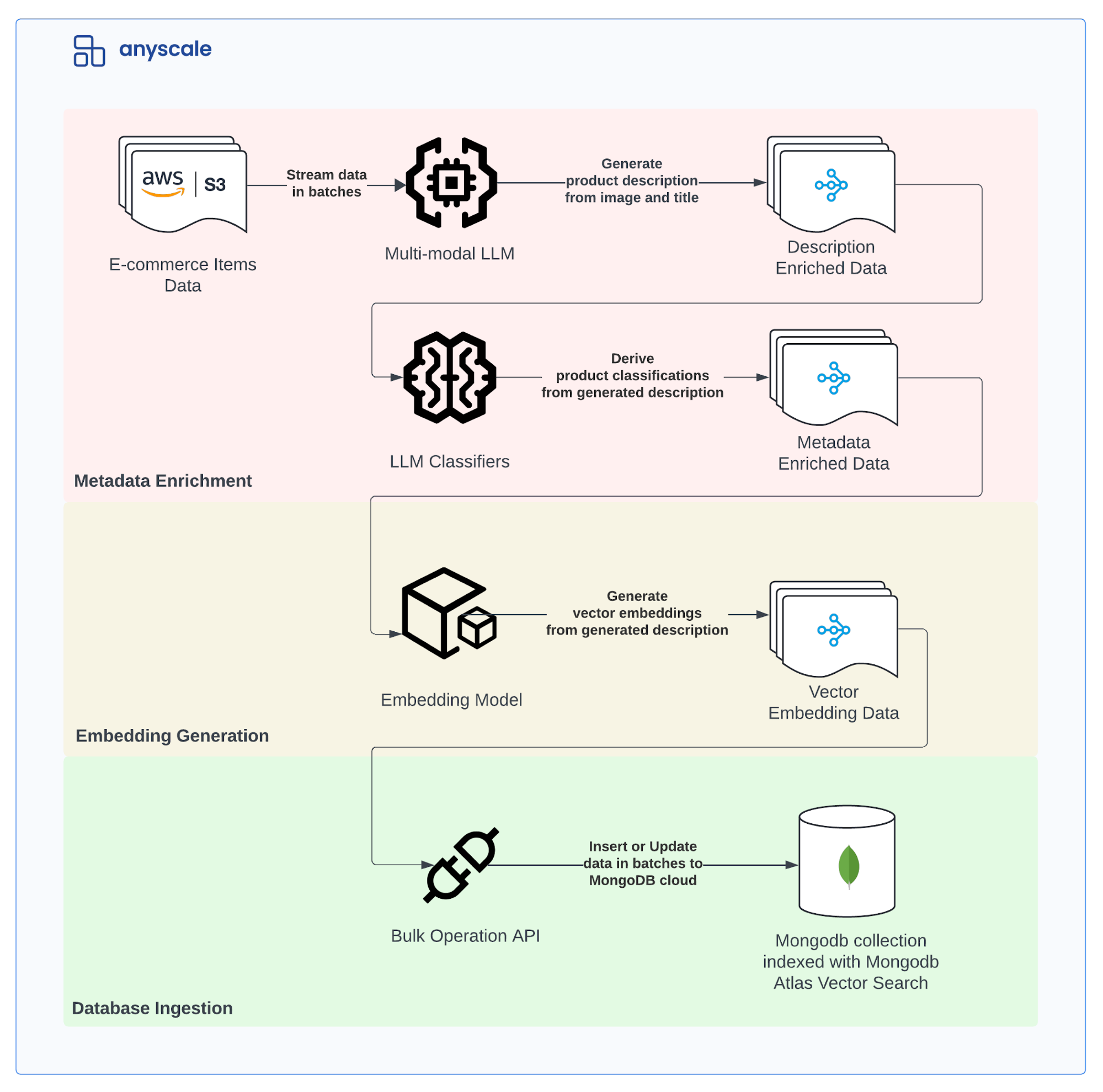 \n",
+ "\n",
+ "__Let's look at the scaling opportunites__\n",
+ "\n",
+ "
\n",
+ "\n",
+ "__Let's look at the scaling opportunites__\n",
+ "\n",
+ "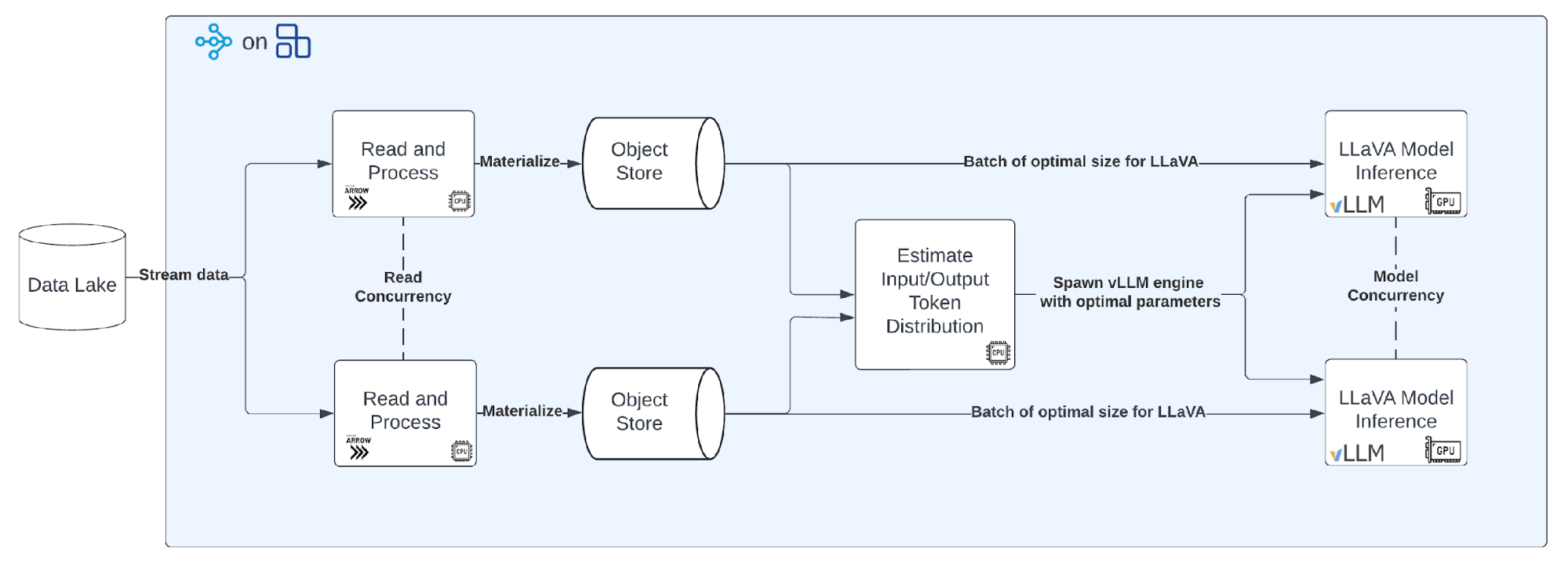 \n",
+ "\n",
+ "
\n",
+ "\n",
+ "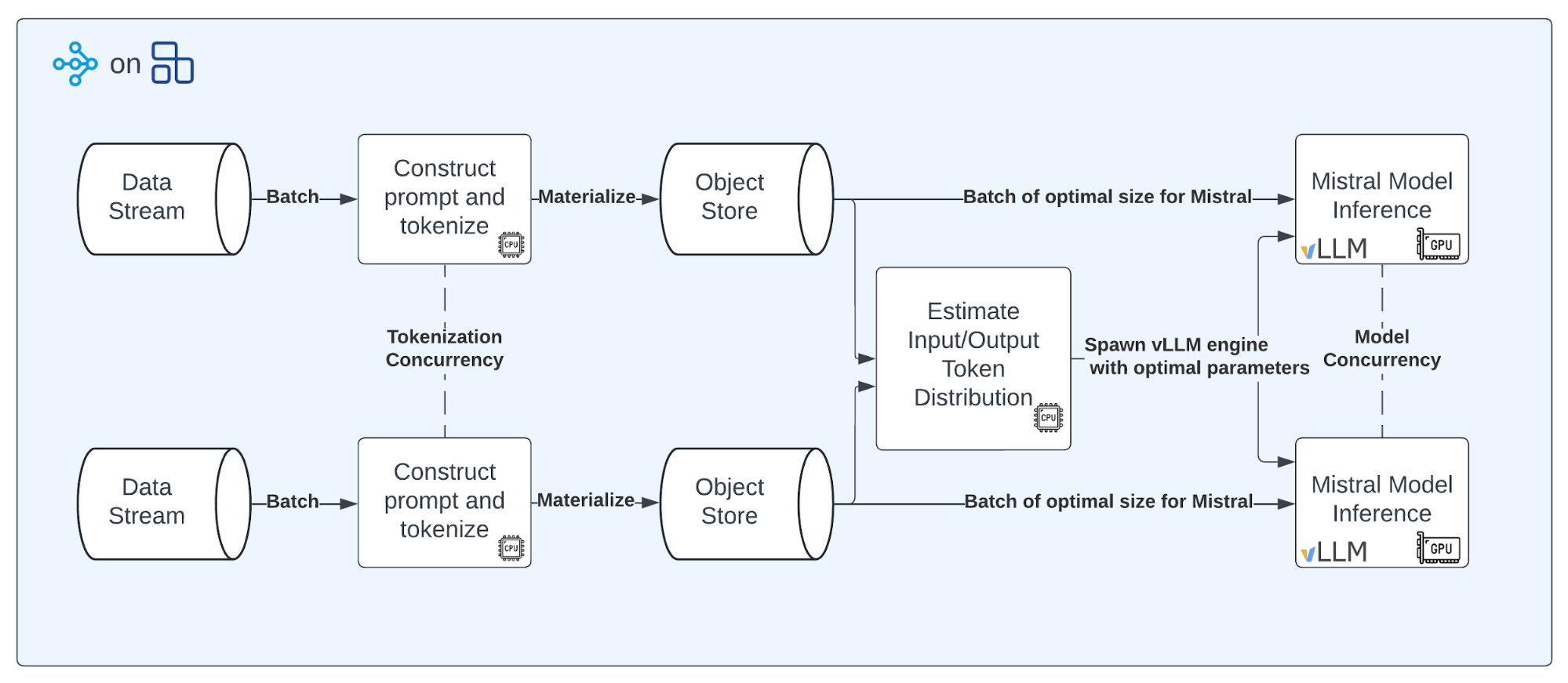 \n",
+ "\n",
+ "For this tutorial, we'll use a small number of records and a small scaling configuration"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "055ee1a1-2e25-4121-962f-fc758ff7b02b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nsamples=200"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0f2dc142-3529-4dd1-981a-61471a2f9531",
+ "metadata": {},
+ "source": [
+ "The workers below will corresponds to processes, each assigned a CPU and optionally a GPU. Ray allows more flexibility but we'll keep this pipeline as simples as possible."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1cc8bd87-b22e-48f3-8c09-2065ae4a4fa8",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "num_image_download_workers=2\n",
+ "\n",
+ "num_llava_tokenizer_workers=2\n",
+ "\n",
+ "num_llava_model_workers=1\n",
+ "# llava_model_accelerator_type=NVIDIA_TESLA_A10G\n",
+ "llava_model_batch_size=80\n",
+ "\n",
+ "num_mistral_tokenizer_workers_per_classifier=2\n",
+ "\n",
+ "num_mistral_model_workers_per_classifier=1\n",
+ "mistral_model_batch_size=80\n",
+ "# mistral_model_accelerator_type=NVIDIA_TESLA_A10G\n",
+ "\n",
+ "num_mistral_detokenizer_workers_per_classifier=2\n",
+ "\n",
+ "num_embedder_workers=1\n",
+ "embedding_model_batch_size=80\n",
+ "# embedding_model_accelerator_type=NVIDIA_TESLA_A10G\n",
+ "\n",
+ "db_update_batch_size=80\n",
+ "\n",
+ "num_db_workers=2"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "94205417-4883-4bce-8c64-6ec535e2ea3b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "db_name: str = \"myntra\"\n",
+ "collection_name: str = \"myntra-items-offline\"\n",
+ "cluster_size: str = \"m0\"\n",
+ "scaling_config_path: str = \"\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "64303167",
+ "metadata": {},
+ "source": [
+ "### Read raw data\n",
+ "\n",
+ "The data comes from a subset of the Myntra retail products dataset: https://www.kaggle.com/datasets/ronakbokaria/myntra-products-dataset"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2cf89b33-d854-4f1c-9423-d98be0a1a762",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "path = 's3://anyscale-public-materials/mongodb-demo/raw/myntra_subset_deduped_10000.csv'"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "478ad343-f631-4cc1-8c35-5010a2a300ac",
+ "metadata": {},
+ "source": [
+ "The Ray Data `read` methods use PyArrow in most cases for the physical reads -- the schema here is provided as PyArrow types.\n",
+ "\n",
+ "> Learn more about the Apache Arrow project https://arrow.apache.org/docs/python/index.html"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b6e15f99-f28d-41f7-9aeb-c7f5fe0597c7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def read_data(path: str, nsamples: int) -> ray.data.Dataset:\n",
+ " ds = ray.data.read_csv(\n",
+ " path,\n",
+ " parse_options=csv.ParseOptions(newlines_in_values=True),\n",
+ " convert_options=csv.ConvertOptions(\n",
+ " column_types={\n",
+ " \"id\": pa.int64(),\n",
+ " \"name\": pa.string(),\n",
+ " \"img\": pa.string(),\n",
+ " \"asin\": pa.string(),\n",
+ " \"price\": pa.float64(),\n",
+ " \"mrp\": pa.float64(),\n",
+ " \"rating\": pa.float64(),\n",
+ " \"ratingTotal\": pa.int64(),\n",
+ " \"discount\": pa.int64(),\n",
+ " \"seller\": pa.string(),\n",
+ " \"purl\": pa.string(),\n",
+ " }\n",
+ " ),\n",
+ " override_num_blocks=nsamples,\n",
+ " )\n",
+ " return ds.limit(nsamples)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4e814ee7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds = read_data(path, nsamples)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "894bc732-5314-4dda-aed4-2c8f164fad80",
+ "metadata": {},
+ "source": [
+ "### Preprocess data\n",
+ "\n",
+ "The following operations will be transforms applied to our data. \n",
+ "\n",
+ "We'll define them first...\n",
+ "* functions for stateless operations\n",
+ "* classes for operations which reuse state\n",
+ "\n",
+ "... and then plug them into our pipeline with Ray's `map_batches` API"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "377a5339",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def download_image(url: str) -> bytes:\n",
+ " try:\n",
+ " response = requests.get(url)\n",
+ " response.raise_for_status()\n",
+ " return response.content\n",
+ " except Exception:\n",
+ " return b\"\"\n",
+ "\n",
+ "def download_images(batch: dict[str, np.ndarray]) -> dict[str, np.ndarray]:\n",
+ " with ThreadPoolExecutor() as executor:\n",
+ " batch[\"url\"] = batch[\"img\"]\n",
+ " batch[\"img\"] = list(executor.map(download_image, batch[\"url\"])) # type: ignore\n",
+ " return batch\n",
+ "\n",
+ "class LargestCenterSquare:\n",
+ " \"\"\"Largest center square crop for images.\"\"\"\n",
+ "\n",
+ " def __init__(self, size: int) -> None:\n",
+ " self.size = size\n",
+ "\n",
+ " def __call__(self, row: dict[str, Any]) -> dict[str, Any]:\n",
+ " \"\"\"Crop the largest center square from an image.\"\"\"\n",
+ " img = Image.open(io.BytesIO(row[\"img\"]))\n",
+ "\n",
+ " # First, resize the image such that the smallest side is self.size while preserving aspect ratio.\n",
+ " img = torchvision.transforms.functional.resize(\n",
+ " img=img,\n",
+ " size=self.size,\n",
+ " )\n",
+ "\n",
+ " # Then take a center crop to a square.\n",
+ " w, h = img.size\n",
+ " c_top = (h - self.size) // 2\n",
+ " c_left = (w - self.size) // 2\n",
+ " row[\"img\"] = torchvision.transforms.functional.crop(\n",
+ " img=img,\n",
+ " top=c_top,\n",
+ " left=c_left,\n",
+ " height=self.size,\n",
+ " width=self.size,\n",
+ " )\n",
+ "\n",
+ " return row\n",
+ "\n",
+ "DESCRIPTION_PROMPT_TEMPLATE = \"
\n",
+ "\n",
+ "For this tutorial, we'll use a small number of records and a small scaling configuration"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "055ee1a1-2e25-4121-962f-fc758ff7b02b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nsamples=200"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0f2dc142-3529-4dd1-981a-61471a2f9531",
+ "metadata": {},
+ "source": [
+ "The workers below will corresponds to processes, each assigned a CPU and optionally a GPU. Ray allows more flexibility but we'll keep this pipeline as simples as possible."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1cc8bd87-b22e-48f3-8c09-2065ae4a4fa8",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "num_image_download_workers=2\n",
+ "\n",
+ "num_llava_tokenizer_workers=2\n",
+ "\n",
+ "num_llava_model_workers=1\n",
+ "# llava_model_accelerator_type=NVIDIA_TESLA_A10G\n",
+ "llava_model_batch_size=80\n",
+ "\n",
+ "num_mistral_tokenizer_workers_per_classifier=2\n",
+ "\n",
+ "num_mistral_model_workers_per_classifier=1\n",
+ "mistral_model_batch_size=80\n",
+ "# mistral_model_accelerator_type=NVIDIA_TESLA_A10G\n",
+ "\n",
+ "num_mistral_detokenizer_workers_per_classifier=2\n",
+ "\n",
+ "num_embedder_workers=1\n",
+ "embedding_model_batch_size=80\n",
+ "# embedding_model_accelerator_type=NVIDIA_TESLA_A10G\n",
+ "\n",
+ "db_update_batch_size=80\n",
+ "\n",
+ "num_db_workers=2"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "94205417-4883-4bce-8c64-6ec535e2ea3b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "db_name: str = \"myntra\"\n",
+ "collection_name: str = \"myntra-items-offline\"\n",
+ "cluster_size: str = \"m0\"\n",
+ "scaling_config_path: str = \"\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "64303167",
+ "metadata": {},
+ "source": [
+ "### Read raw data\n",
+ "\n",
+ "The data comes from a subset of the Myntra retail products dataset: https://www.kaggle.com/datasets/ronakbokaria/myntra-products-dataset"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2cf89b33-d854-4f1c-9423-d98be0a1a762",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "path = 's3://anyscale-public-materials/mongodb-demo/raw/myntra_subset_deduped_10000.csv'"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "478ad343-f631-4cc1-8c35-5010a2a300ac",
+ "metadata": {},
+ "source": [
+ "The Ray Data `read` methods use PyArrow in most cases for the physical reads -- the schema here is provided as PyArrow types.\n",
+ "\n",
+ "> Learn more about the Apache Arrow project https://arrow.apache.org/docs/python/index.html"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b6e15f99-f28d-41f7-9aeb-c7f5fe0597c7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def read_data(path: str, nsamples: int) -> ray.data.Dataset:\n",
+ " ds = ray.data.read_csv(\n",
+ " path,\n",
+ " parse_options=csv.ParseOptions(newlines_in_values=True),\n",
+ " convert_options=csv.ConvertOptions(\n",
+ " column_types={\n",
+ " \"id\": pa.int64(),\n",
+ " \"name\": pa.string(),\n",
+ " \"img\": pa.string(),\n",
+ " \"asin\": pa.string(),\n",
+ " \"price\": pa.float64(),\n",
+ " \"mrp\": pa.float64(),\n",
+ " \"rating\": pa.float64(),\n",
+ " \"ratingTotal\": pa.int64(),\n",
+ " \"discount\": pa.int64(),\n",
+ " \"seller\": pa.string(),\n",
+ " \"purl\": pa.string(),\n",
+ " }\n",
+ " ),\n",
+ " override_num_blocks=nsamples,\n",
+ " )\n",
+ " return ds.limit(nsamples)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4e814ee7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds = read_data(path, nsamples)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "894bc732-5314-4dda-aed4-2c8f164fad80",
+ "metadata": {},
+ "source": [
+ "### Preprocess data\n",
+ "\n",
+ "The following operations will be transforms applied to our data. \n",
+ "\n",
+ "We'll define them first...\n",
+ "* functions for stateless operations\n",
+ "* classes for operations which reuse state\n",
+ "\n",
+ "... and then plug them into our pipeline with Ray's `map_batches` API"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "377a5339",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def download_image(url: str) -> bytes:\n",
+ " try:\n",
+ " response = requests.get(url)\n",
+ " response.raise_for_status()\n",
+ " return response.content\n",
+ " except Exception:\n",
+ " return b\"\"\n",
+ "\n",
+ "def download_images(batch: dict[str, np.ndarray]) -> dict[str, np.ndarray]:\n",
+ " with ThreadPoolExecutor() as executor:\n",
+ " batch[\"url\"] = batch[\"img\"]\n",
+ " batch[\"img\"] = list(executor.map(download_image, batch[\"url\"])) # type: ignore\n",
+ " return batch\n",
+ "\n",
+ "class LargestCenterSquare:\n",
+ " \"\"\"Largest center square crop for images.\"\"\"\n",
+ "\n",
+ " def __init__(self, size: int) -> None:\n",
+ " self.size = size\n",
+ "\n",
+ " def __call__(self, row: dict[str, Any]) -> dict[str, Any]:\n",
+ " \"\"\"Crop the largest center square from an image.\"\"\"\n",
+ " img = Image.open(io.BytesIO(row[\"img\"]))\n",
+ "\n",
+ " # First, resize the image such that the smallest side is self.size while preserving aspect ratio.\n",
+ " img = torchvision.transforms.functional.resize(\n",
+ " img=img,\n",
+ " size=self.size,\n",
+ " )\n",
+ "\n",
+ " # Then take a center crop to a square.\n",
+ " w, h = img.size\n",
+ " c_top = (h - self.size) // 2\n",
+ " c_left = (w - self.size) // 2\n",
+ " row[\"img\"] = torchvision.transforms.functional.crop(\n",
+ " img=img,\n",
+ " top=c_top,\n",
+ " left=c_left,\n",
+ " height=self.size,\n",
+ " width=self.size,\n",
+ " )\n",
+ "\n",
+ " return row\n",
+ "\n",
+ "DESCRIPTION_PROMPT_TEMPLATE = \"\" * 1176 + (\n",
+ " \"\\nUSER: Generate an ecommerce product description given the image and this title: {title}.\"\n",
+ " \"Make sure to include information about the color of the product in the description.\"\n",
+ " \"\\nASSISTANT:\"\n",
+ ")\n",
+ "\n",
+ "def gen_description_prompt(row: dict[str, Any]) -> dict[str, Any]:\n",
+ " title = row[\"name\"]\n",
+ " row[\"description_prompt\"] = DESCRIPTION_PROMPT_TEMPLATE.format(title=title)\n",
+ "\n",
+ " return row"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a617430f-bca6-4ef2-9977-01e0971742df",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds = (\n",
+ " ds.map_batches(download_images, num_cpus=4, concurrency=num_image_download_workers)\n",
+ " .filter(lambda x: bool(x[\"img\"]))\n",
+ " .map(LargestCenterSquare(size=336))\n",
+ " .map(gen_description_prompt)\n",
+ " .materialize()\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "47856d84-3d00-4693-aa58-c5884718a58b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds.take_batch(2)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d55ebe3b-0626-4207-936f-9edc2756f7c7",
+ "metadata": {},
+ "source": [
+ "### Estimate input/output token distribution for LLAVA model"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0bf821e6",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class LlaVAMistralTokenizer:\n",
+ " def __init__(self):\n",
+ " self.tokenizer = AutoTokenizer.from_pretrained(\n",
+ " \"llava-hf/llava-v1.6-mistral-7b-hf\",\n",
+ " )\n",
+ "\n",
+ " def __call__(self, batch: dict[str, np.ndarray], input: str, output: str):\n",
+ " batch[output] = self.tokenizer.batch_encode_plus(batch[input].tolist())[\"input_ids\"]\n",
+ " return batch\n",
+ " \n",
+ "def compute_num_tokens(row: dict[str, Any], col: str) -> dict[str, Any]:\n",
+ " row[\"num_tokens\"] = len(row[col])\n",
+ " return row\n",
+ " \n",
+ "max_input_tokens = (\n",
+ " ds.map_batches(\n",
+ " LlaVAMistralTokenizer,\n",
+ " fn_kwargs={\n",
+ " \"input\": \"description_prompt\",\n",
+ " \"output\": \"description_prompt_tokens\",\n",
+ " },\n",
+ " concurrency=num_llava_tokenizer_workers,\n",
+ " num_cpus=1,\n",
+ " )\n",
+ " .select_columns([\"description_prompt_tokens\"])\n",
+ " .map(compute_num_tokens, fn_kwargs={\"col\": \"description_prompt_tokens\"})\n",
+ " .max(on=\"num_tokens\")\n",
+ ")\n",
+ "\n",
+ "max_output_tokens = 256 # maximum size of desired product description\n",
+ "max_model_length = max_input_tokens + max_output_tokens\n",
+ "print(\n",
+ " f\"Description gen: {max_input_tokens=} {max_output_tokens=} {max_model_length=}\"\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d3ad8191-cd7e-4718-934f-7e42a8bddeef",
+ "metadata": {},
+ "source": [
+ "### Generate description using LLAVA model inference"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f61ba8e1",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class LlaVAMistral:\n",
+ " def __init__(\n",
+ " self,\n",
+ " max_model_len: int,\n",
+ " max_num_seqs: int = 400,\n",
+ " max_tokens: int = 1024,\n",
+ " # NOTE: \"fp8\" currently doesn't support FlashAttention-2 backend so while\n",
+ " # we can fit more sequences in memory, performance will be suboptimal\n",
+ " kv_cache_dtype: str = \"fp8\",\n",
+ " ):\n",
+ " self.llm = LLM(\n",
+ " model=\"llava-hf/llava-v1.6-mistral-7b-hf\",\n",
+ " trust_remote_code=True,\n",
+ " enable_lora=False,\n",
+ " max_num_seqs=max_num_seqs,\n",
+ " max_model_len=max_model_len,\n",
+ " gpu_memory_utilization=0.95,\n",
+ " image_input_type=\"pixel_values\",\n",
+ " image_token_id=32000,\n",
+ " image_input_shape=\"1,3,336,336\",\n",
+ " image_feature_size=1176,\n",
+ " kv_cache_dtype=kv_cache_dtype,\n",
+ " preemption_mode=\"swap\",\n",
+ " )\n",
+ " self.sampling_params = SamplingParams(\n",
+ " n=1,\n",
+ " presence_penalty=0,\n",
+ " frequency_penalty=0,\n",
+ " repetition_penalty=1,\n",
+ " length_penalty=1,\n",
+ " top_p=1,\n",
+ " top_k=-1,\n",
+ " temperature=0,\n",
+ " use_beam_search=False,\n",
+ " ignore_eos=False,\n",
+ " max_tokens=max_tokens,\n",
+ " seed=None,\n",
+ " detokenize=True,\n",
+ " )\n",
+ "\n",
+ " def __call__(self, batch: dict[str, np.ndarray], col: str) -> dict[str, np.ndarray]:\n",
+ " prompts = batch[col]\n",
+ " images = batch[\"img\"]\n",
+ " responses = self.llm.generate(\n",
+ " [\n",
+ " {\n",
+ " \"prompt\": prompt,\n",
+ " \"multi_modal_data\": ImagePixelData(image),\n",
+ " }\n",
+ " for prompt, image in zip(prompts, images)\n",
+ " ],\n",
+ " sampling_params=self.sampling_params,\n",
+ " )\n",
+ "\n",
+ " batch[\"description\"] = [resp.outputs[0].text for resp in responses] # type: ignore\n",
+ " return batch"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e6620303-8cf5-49d3-9f03-9c17131dae0a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds = ds.map_batches(\n",
+ " LlaVAMistral,\n",
+ " fn_constructor_kwargs={\n",
+ " \"max_model_len\": max_model_length,\n",
+ " \"max_tokens\": max_output_tokens,\n",
+ " \"max_num_seqs\": 400,\n",
+ " },\n",
+ " fn_kwargs={\"col\": \"description_prompt\"},\n",
+ " batch_size=llava_model_batch_size,\n",
+ " num_gpus=1.0,\n",
+ " concurrency=num_llava_model_workers,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9dc77eaa-e3b8-4252-9540-de13d4f86267",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds = ds.materialize()\n",
+ "\n",
+ "ds.take_batch(2)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "39b943c5-c1a6-42c1-bf68-1bda39dddc9f",
+ "metadata": {},
+ "source": [
+ "### Generate classifier prompts and tokenize them\n",
+ "\n",
+ "In the classification step, we'll reduce the number of classifiers (vs. the full pipeline) to require fewer GPUs"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1a82b384-3730-45da-b41a-28c03b3bef4c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def construct_prompt_classifier(\n",
+ " row: dict[str, Any],\n",
+ " prompt_template: str,\n",
+ " classes: list[str],\n",
+ " col: str,\n",
+ ") -> dict[str, Any]:\n",
+ " classes_str = \", \".join(classes)\n",
+ " title = row[\"name\"]\n",
+ " description = row[\"description\"]\n",
+ " row[f\"{col}_prompt\"] = prompt_template.format(\n",
+ " title=title,\n",
+ " description=description,\n",
+ " classes_str=classes_str,\n",
+ " )\n",
+ " return row\n",
+ " \n",
+ "classifiers: dict[str, Any] = {\n",
+ " \"category\": {\n",
+ " \"classes\": [\"Tops\", \"Bottoms\", \"Dresses\", \"Footwear\", \"Accessories\"],\n",
+ " \"prompt_template\": (\n",
+ " \"Given the title of this product: {title} and \"\n",
+ " \"the description: {description}, what category does it belong to? \"\n",
+ " \"Chose from the following categories: {classes_str}. \"\n",
+ " \"Return the category that best fits the product. Only return the category name and nothing else.\"\n",
+ " ),\n",
+ " \"prompt_constructor\": construct_prompt_classifier,\n",
+ " },\n",
+ " \"season\": {\n",
+ " \"classes\": [\"Summer\", \"Winter\", \"Spring\", \"Fall\"],\n",
+ " \"prompt_template\": (\n",
+ " \"Given the title of this product: {title} and \"\n",
+ " \"the description: {description}, what season does it belong to? \"\n",
+ " \"Chose from the following seasons: {classes_str}. \"\n",
+ " \"Return the season that best fits the product. Only return the season name and nothing else.\"\n",
+ " ),\n",
+ " \"prompt_constructor\": construct_prompt_classifier,\n",
+ " },\n",
+ "# \"color\": {\n",
+ "# \"classes\": [\n",
+ "# \"Red\",\n",
+ "# \"Blue\",\n",
+ "# \"Green\",\n",
+ "# \"Yellow\",\n",
+ "# \"Black\",\n",
+ "# \"White\",\n",
+ "# \"Pink\",\n",
+ "# \"Purple\",\n",
+ "# \"Orange\",\n",
+ "# \"Brown\",\n",
+ "# \"Grey\",\n",
+ "# ],\n",
+ "# \"prompt_template\": (\n",
+ "# \"Given the title of this product: {title} and \"\n",
+ "# \"the description: {description}, what color does it belong to? \"\n",
+ "# \"Chose from the following colors: {classes_str}. \"\n",
+ "# \"Return the color that best fits the product. Only return the color name and nothing else.\"\n",
+ "# ),\n",
+ "# \"prompt_constructor\": construct_prompt_classifier,\n",
+ "# },\n",
+ "}"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "886e5700-c9b6-422a-89ad-c8df6ef88cb6",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class MistralTokenizer:\n",
+ " def __init__(self):\n",
+ " self.tokenizer = AutoTokenizer.from_pretrained(\n",
+ " \"mistralai/Mistral-7B-Instruct-v0.1\",\n",
+ " )\n",
+ "\n",
+ " def __call__(self, batch: dict, input: str, output: str):\n",
+ " batch[output] = self.tokenizer.apply_chat_template(\n",
+ " conversation=[[{\"role\": \"user\", \"content\": input_}] for input_ in batch[input]],\n",
+ " add_generation_prompt=True,\n",
+ " tokenize=True,\n",
+ " return_tensors=\"np\",\n",
+ " )\n",
+ " return batch"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3516685f-0a4d-4213-832e-1e99f13b889a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "for classifier, classifier_spec in classifiers.items():\n",
+ " ds = (\n",
+ " ds.map(\n",
+ " classifier_spec[\"prompt_constructor\"],\n",
+ " fn_kwargs={\n",
+ " \"prompt_template\": classifier_spec[\"prompt_template\"],\n",
+ " \"classes\": classifier_spec[\"classes\"],\n",
+ " \"col\": classifier,\n",
+ " },\n",
+ " )\n",
+ " .map_batches(\n",
+ " MistralTokenizer,\n",
+ " fn_kwargs={\n",
+ " \"input\": f\"{classifier}_prompt\",\n",
+ " \"output\": f\"{classifier}_prompt_tokens\",\n",
+ " },\n",
+ " concurrency=num_mistral_tokenizer_workers_per_classifier,\n",
+ " num_cpus=1,\n",
+ " )\n",
+ " .materialize()\n",
+ " )"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "288048f4-ab7e-481e-926b-302022218871",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds.take_batch(2)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e1194ab8-fb02-4e8a-a891-08d35636b6c6",
+ "metadata": {},
+ "source": [
+ "### Estimate input/output token distribution for Mistral models"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "384192e4",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "for classifier, classifier_spec in classifiers.items():\n",
+ " max_output_tokens = (\n",
+ " ray.data.from_items(\n",
+ " [\n",
+ " {\n",
+ " \"output\": max(classifier_spec[\"classes\"], key=len),\n",
+ " }\n",
+ " ]\n",
+ " )\n",
+ " .map_batches(\n",
+ " MistralTokenizer,\n",
+ " fn_kwargs={\n",
+ " \"input\": \"output\",\n",
+ " \"output\": \"output_tokens\",\n",
+ " },\n",
+ " concurrency=1,\n",
+ " num_cpus=1,\n",
+ " )\n",
+ " .map(\n",
+ " compute_num_tokens,\n",
+ " fn_kwargs={\"col\": \"output_tokens\"},\n",
+ " )\n",
+ " .max(on=\"num_tokens\")\n",
+ " )\n",
+ " # allow for 40 tokens of buffer to account for non-exact outputs e.g \"the color is Red\" instead of just \"Red\"\n",
+ " buffer_size = 40\n",
+ " classifier_spec[\"max_output_tokens\"] = max_output_tokens + buffer_size\n",
+ "\n",
+ " max_input_tokens = (\n",
+ " ds.select_columns([f\"{classifier}_prompt_tokens\"])\n",
+ " .map(compute_num_tokens, fn_kwargs={\"col\": f\"{classifier}_prompt_tokens\"})\n",
+ " .max(on=\"num_tokens\")\n",
+ " )\n",
+ " max_output_tokens = classifier_spec[\"max_output_tokens\"]\n",
+ " print(f\"{classifier=} {max_input_tokens=} {max_output_tokens=}\")\n",
+ " max_model_length = max_input_tokens + max_output_tokens\n",
+ " classifier_spec[\"max_model_length\"] = max_model_length"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "12b51961-b4be-41d9-9875-569cd183f86a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class MistralvLLM:\n",
+ " def __init__(\n",
+ " self,\n",
+ " max_model_len: int = 4096,\n",
+ " max_tokens: int = 2048,\n",
+ " max_num_seqs: int = 256,\n",
+ " # NOTE: \"fp8\" currently doesn't support FlashAttention-2 backend so while\n",
+ " # we can fit more sequences in memory, performance will be suboptimal\n",
+ " kv_cache_dtype: str = \"fp8\",\n",
+ " ):\n",
+ " self.llm = LLM(\n",
+ " model=\"mistralai/Mistral-7B-Instruct-v0.1\",\n",
+ " trust_remote_code=True,\n",
+ " enable_lora=False,\n",
+ " max_num_seqs=max_num_seqs,\n",
+ " max_model_len=max_model_len,\n",
+ " gpu_memory_utilization=0.90,\n",
+ " skip_tokenizer_init=True,\n",
+ " kv_cache_dtype=kv_cache_dtype,\n",
+ " preemption_mode=\"swap\",\n",
+ " )\n",
+ " self.sampling_params = SamplingParams(\n",
+ " n=1,\n",
+ " presence_penalty=0,\n",
+ " frequency_penalty=0,\n",
+ " repetition_penalty=1,\n",
+ " length_penalty=1,\n",
+ " top_p=1,\n",
+ " top_k=-1,\n",
+ " temperature=0,\n",
+ " use_beam_search=False,\n",
+ " ignore_eos=False,\n",
+ " max_tokens=max_tokens,\n",
+ " seed=None,\n",
+ " detokenize=False,\n",
+ " )\n",
+ "\n",
+ " def __call__(\n",
+ " self, batch: dict[str, np.ndarray], input: str, output: str\n",
+ " ) -> dict[str, np.ndarray]:\n",
+ " responses = self.llm.generate(\n",
+ " prompt_token_ids=[ids.tolist() for ids in batch[input]],\n",
+ " sampling_params=self.sampling_params,\n",
+ " )\n",
+ " batch[output] = [resp.outputs[0].token_ids for resp in responses] # type: ignore\n",
+ " return batch\n",
+ "\n",
+ "\n",
+ "class MistralDeTokenizer:\n",
+ " def __init__(self) -> None:\n",
+ " self.tokenizer = AutoTokenizer.from_pretrained(\n",
+ " \"mistralai/Mistral-7B-Instruct-v0.1\",\n",
+ " )\n",
+ "\n",
+ " def __call__(self, batch: dict[str, np.ndarray], key: str) -> dict[str, np.ndarray]:\n",
+ " batch[key] = self.tokenizer.batch_decode(batch[key], skip_special_tokens=True)\n",
+ " return batch"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "eaafe5df-0b34-48e2-92cb-23b75f933022",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def clean_response(\n",
+ " row: dict[str, Any], response_col: str, classes: list[str]\n",
+ ") -> dict[str, Any]:\n",
+ " response_str = row[response_col]\n",
+ " matches = []\n",
+ " for class_ in classes:\n",
+ " if class_.lower() in response_str.lower():\n",
+ " matches.append(class_)\n",
+ " if len(matches) == 1:\n",
+ " response = matches[0]\n",
+ " else:\n",
+ " response = None\n",
+ " row[response_col] = response\n",
+ " return row"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8fa0e675-24c0-4438-af7e-32f16a9758dd",
+ "metadata": {},
+ "source": [
+ "### Generate classifier responses using Mistral model inference"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "dbcfecd5",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "for classifier, classifier_spec in classifiers.items():\n",
+ " ds = (\n",
+ " ds.map_batches(\n",
+ " MistralvLLM,\n",
+ " fn_kwargs={\n",
+ " \"input\": f\"{classifier}_prompt_tokens\",\n",
+ " \"output\": f\"{classifier}_response\",\n",
+ " },\n",
+ " fn_constructor_kwargs={\n",
+ " \"max_model_len\": classifier_spec[\"max_model_length\"],\n",
+ " \"max_tokens\": classifier_spec[\"max_output_tokens\"],\n",
+ " },\n",
+ " batch_size=mistral_model_batch_size,\n",
+ " num_gpus=1.0,\n",
+ " concurrency=num_mistral_model_workers_per_classifier,\n",
+ " )\n",
+ " .map_batches(\n",
+ " MistralDeTokenizer,\n",
+ " fn_kwargs={\"key\": f\"{classifier}_response\"},\n",
+ " concurrency=num_mistral_detokenizer_workers_per_classifier,\n",
+ " num_cpus=1,\n",
+ " )\n",
+ " .map(\n",
+ " clean_response,\n",
+ " fn_kwargs={\n",
+ " \"classes\": classifier_spec[\"classes\"],\n",
+ " \"response_col\": f\"{classifier}_response\",\n",
+ " },\n",
+ " )\n",
+ " )"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a173b1a6-94d9-4328-813f-6aef29de8b6f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds = ds.materialize()\n",
+ "\n",
+ "ds.take_batch(2)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "37324ffe-ce01-447e-92de-a8d9aac22364",
+ "metadata": {},
+ "source": [
+ "### Generate embeddings using embedding model inference\n",
+ "\n",
+ "To reduce resource requirements, we'll alter this code vs. the full pipeline, to run the embedder model on CPU. It's not quite as fast but performance is acceptable for small data scales."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2098e525",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class EmbedderSentenceTransformer:\n",
+ " def __init__(self, model: str = \"thenlper/gte-large\", device: str = \"cuda\"):\n",
+ " self.model = SentenceTransformer(model) # comment out the use of the device param to keep model on CPU\n",
+ "\n",
+ " def __call__(\n",
+ " self, batch: dict[str, np.ndarray], cols: list[str]\n",
+ " ) -> dict[str, np.ndarray]:\n",
+ " for col in cols:\n",
+ " batch[f\"{col}_embedding\"] = self.model.encode( # type: ignore\n",
+ " batch[col].tolist(), batch_size=len(batch[col])\n",
+ " )\n",
+ " return batch\n",
+ " \n",
+ "ds = ds.map_batches(\n",
+ " EmbedderSentenceTransformer,\n",
+ " fn_kwargs={\"cols\": [\"name\", \"description\"]},\n",
+ " batch_size=embedding_model_batch_size,\n",
+ " #num_gpus=1.0,\n",
+ " concurrency=num_embedder_workers,\n",
+ " #accelerator_type=embedding_model_accelerator_type,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "10c11d4f-3ec8-4dab-ab31-af6b1fcb3b6f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds = ds.materialize()\n",
+ "\n",
+ "ds.take_batch(2)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ce937ffd",
+ "metadata": {},
+ "source": [
+ "### Upsert records into MongoDB collection"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ab77777d-ce15-4114-a3ae-ccf197a34dbf",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def update_record(batch: dict[str, np.ndarray]) -> dict[str, np.ndarray]:\n",
+ " batch[\"_id\"] = batch[\"name\"]\n",
+ " return {\n",
+ " \"_id\": batch[\"_id\"],\n",
+ " \"name\": batch[\"name\"],\n",
+ " \"img\": batch[\"url\"],\n",
+ " \"price\": batch[\"price\"],\n",
+ " \"rating\": batch[\"rating\"],\n",
+ " \"description\": batch[\"description\"],\n",
+ " \"category\": batch[\"category_response\"],\n",
+ " \"season\": batch[\"season_response\"],\n",
+ "# \"color\": batch[\"color_response\"],\n",
+ " \"name_embedding\": batch[\"name_embedding\"].tolist(),\n",
+ " \"description_embedding\": batch[\"description_embedding\"].tolist(),\n",
+ " }\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8b2e5a17-6155-40b8-82e6-265c87d5a1b4",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class MongoBulkUpdate:\n",
+ " def __init__(self, db: str, collection: str) -> None:\n",
+ " client = MongoClient(os.environ[\"DB_CONNECTION_STRING\"])\n",
+ " self.collection = client[db][collection]\n",
+ "\n",
+ " def __call__(self, batch_df: pd.DataFrame) -> dict[str, np.ndarray]:\n",
+ " docs = batch_df.to_dict(orient=\"records\")\n",
+ " bulk_ops = [\n",
+ " UpdateOne(filter={\"_id\": doc[\"_id\"]}, update={\"$set\": doc}, upsert=True)\n",
+ " for doc in docs\n",
+ " ]\n",
+ " self.collection.bulk_write(bulk_ops)\n",
+ " return {}"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "16007dc4-785b-42c0-83aa-0658b4870f1c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "(\n",
+ " ds.map_batches(update_record)\n",
+ " .map_batches(\n",
+ " MongoBulkUpdate,\n",
+ " fn_constructor_kwargs={\n",
+ " \"db\": db_name,\n",
+ " \"collection\": collection_name,\n",
+ " },\n",
+ " batch_size=db_update_batch_size,\n",
+ " concurrency=num_db_workers,\n",
+ " num_cpus=0.1,\n",
+ " batch_format=\"pandas\",\n",
+ " )\n",
+ " .materialize()\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "68672d22-b9e0-46bd-926d-a6b0400c3e9e",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/templates/ray-summit-multi-modal-search/pipeline_tutorial/A_simple_query.ipynb b/templates/ray-summit-multi-modal-search/pipeline_tutorial/A_simple_query.ipynb
new file mode 100644
index 000000000..a326236b9
--- /dev/null
+++ b/templates/ray-summit-multi-modal-search/pipeline_tutorial/A_simple_query.ipynb
@@ -0,0 +1,271 @@
+{
+ "cells": [
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ba125a8a-1243-4068-b9d1-fe1011b06048",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import pymongo\n",
+ "from pymongo import MongoClient\n",
+ "import os"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "07148e50-d572-43af-92f6-a412945dc307",
+ "metadata": {},
+ "source": [
+ "# Example minimal queries"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "aa8b399e-3388-4f58-919e-51065569a8cc",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "db_name: str = \"myntra\"\n",
+ "collection_name: str = \"myntra-items-offline\""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5e2efe4e-2b91-4f35-b4ff-0c5a1809c6b4",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "client = MongoClient(os.environ[\"DB_CONNECTION_STRING\"])\n",
+ "collection = client[db_name][collection_name]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d8bec448-736e-4385-b329-ce3af3a64b93",
+ "metadata": {},
+ "source": [
+ "## Combining text query and metadata filtering"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "abc1ab12-ad2d-4fb6-95a5-525e2d2c1e37",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "text_search = 'dress'\n",
+ "text_search_index_name = 'lexical_text_search_index'\n",
+ "min_price=0\n",
+ "max_price=10_000\n",
+ "min_rating=0\n",
+ "n=10"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1e6dbcb2-cfdf-4841-9306-cf5ba315037e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def lexical_search(text_search: str, text_search_index_name: str) -> list[dict]:\n",
+ " return [\n",
+ " {\n",
+ " \"$search\": {\n",
+ " \"index\": text_search_index_name,\n",
+ " \"text\": {\n",
+ " \"query\": text_search,\n",
+ " \"path\": \"name\",\n",
+ " },\n",
+ " }\n",
+ " }\n",
+ " ]\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "09aff549-19e9-4594-b39b-3d2c7afdcb63",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def match_on_metadata(\n",
+ " min_price: int,\n",
+ " max_price: int,\n",
+ " min_rating: float,\n",
+ " n: int,\n",
+ " categories: list[str] | None = None,\n",
+ " colors: list[str] | None = None,\n",
+ " seasons: list[str] | None = None,\n",
+ ") -> list[dict]:\n",
+ " match_spec = {\n",
+ " \"price\": {\n",
+ " \"$gte\": min_price,\n",
+ " \"$lte\": max_price,\n",
+ " },\n",
+ " \"rating\": {\"$gte\": min_rating},\n",
+ " }\n",
+ " if categories:\n",
+ " match_spec[\"category\"] = {\"$in\": categories}\n",
+ " if colors:\n",
+ " match_spec[\"color\"] = {\"$in\": colors}\n",
+ " if seasons:\n",
+ " match_spec[\"season\"] = {\"$in\": seasons}\n",
+ "\n",
+ " return [\n",
+ " {\n",
+ " \"$match\": match_spec,\n",
+ " },\n",
+ " {\"$limit\": n},\n",
+ " ]\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "71938468-986c-4626-9781-52be9396438a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "pipeline = []\n",
+ "if text_search.strip():\n",
+ " pipeline.extend(\n",
+ " lexical_search(\n",
+ " text_search=text_search,\n",
+ " text_search_index_name=text_search_index_name,\n",
+ " )\n",
+ " )\n",
+ "\n",
+ "pipeline.extend(\n",
+ " match_on_metadata(\n",
+ " min_price=min_price,\n",
+ " max_price=max_price,\n",
+ " min_rating=min_rating,\n",
+ " n=n,\n",
+ " )\n",
+ ")\n",
+ "\n",
+ "records = collection.aggregate(pipeline)\n",
+ "results = [\n",
+ " (record[\"img\"].split(\";\")[-1].strip(), record[\"name\"])\n",
+ " # async \n",
+ " for record in records\n",
+ "]\n",
+ "\n",
+ "n_results = len(results)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ac668cfb-b72e-4f2c-8102-93cadaf73849",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "results"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "80f78352-dcce-4877-9288-5c6b5b29644e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "n_results"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "39b3d1ab-a3f1-49f0-a80f-7dbc4e11aa7d",
+ "metadata": {},
+ "source": [
+ "## Example vector search"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f4ac12fe-634b-4728-a92f-34ff05d96722",
+ "metadata": {},
+ "source": [
+ "Embedding for the text \"dress\""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f9281c8a-a802-48a0-ac2f-c00bd47b72f7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "query_vector = [-0.024136465042829514, -0.023728929460048676, -0.03186793625354767, -0.01082341093569994, -0.0150108328089118, 0.016808178275823593, 0.013221118599176407, 0.020104017108678818, 0.04778704419732094, 0.036966968327760696, 0.061754439026117325, -0.00010883400682359934, 0.0340559147298336, -0.03324975073337555, -0.007400914561003447, 0.03463617339730263, -0.036423392593860626, -0.062387656420469284, -0.020940301939845085, 0.030518634244799614, -0.03109283745288849, 0.008197261020541191, -0.10206734389066696, -0.031112831085920334, -0.03018222376704216, 0.05737512186169624, 0.02595696412026882, -0.01188658643513918, 0.034131456166505814, 0.04093340411782265, -0.03607457876205444, -0.0022378929425030947, 0.013730671256780624, -0.04829508811235428, -0.018866294994950294, -0.009474823251366615, 0.023982089012861252, -0.0374121256172657, -0.02453644946217537, -0.047164227813482285, 0.0205993615090847, -0.018402118235826492, 0.03555254265666008, -0.03199446573853493, -0.04303589090704918, -0.013559038750827312, 0.009827944450080395, -0.06439293920993805, 0.01570974476635456, -0.007694865111261606, 0.014262297190725803, -0.02435862272977829, -0.02107273042201996, -0.0026534656062722206, -0.0022659788373857737, 0.004232665523886681, 0.01789276860654354, -0.019983308389782906, -0.033662762492895126, -0.019748598337173462, 0.02828417532145977, -0.006983633618801832, 0.01270337961614132, -0.0661192536354065, 0.03286021202802658, 0.03306064382195473, -0.0036307754926383495, 0.009994429536163807, -0.009047215804457664, -0.01783219538629055, 0.02865288034081459, 0.01264595240354538, -0.0048859575763344765, -0.01729229837656021, -0.0047726440243422985, 0.0006044947658665478, -0.023932592943310738, -0.0010761216981336474, -0.0008062702254392207, 0.011442938819527626, 0.04319433122873306, 0.03948844596743584, 0.002560243709012866, 0.016901226714253426, -0.04001779854297638, -0.04067693650722504, -0.018264926970005035, 0.030025199055671692, 0.002787400037050247, 0.008525812067091465, -0.01818443462252617, 0.05514531955122948, -0.0035623395815491676, -0.015101402066648006, 0.02167498506605625, 0.049612291157245636, -0.03224371373653412, 0.018000302836298943, 0.016536416485905647, 0.019323576241731644, 0.032353684306144714, 0.026254400610923767, -0.0017869853181764483, 0.04761822149157524, -0.04318494349718094, 0.014297629706561565, 0.01058721262961626, -0.025402626022696495, -0.03606828302145004, -0.038587845861911774, 0.016939446330070496, -0.031492382287979126, 0.03160407394170761, 0.0041166129522025585, -0.011724643409252167, 0.04952608421444893, 0.012676567770540714, 0.027847399935126305, -0.020507030189037323, 0.002019185572862625, 0.028075164183974266, 0.021089721471071243, 0.009731605648994446, -0.020754646509885788, 0.019544892013072968, -0.04115282744169235, -0.033457450568675995, 0.0892089381814003, -0.023721512407064438, -0.004559481516480446, 0.008517077192664146, -0.03142441436648369, 0.01797575317323208, 0.033843737095594406, -0.02061385288834572, 0.020094718784093857, -0.031926028430461884, 0.017796428874135017, 0.001020433846861124, -0.07218600064516068, 0.06783035397529602, 0.023565558716654778, -0.018844427540898323, 0.08426930010318756, 0.03665178269147873, 0.04787234961986542, 0.030529847368597984, 0.002824636874720454, -0.038247279822826385, -0.00033479975536465645, -0.015567732974886894, 0.026125576347112656, -0.014239468611776829, 0.03622389957308769, 0.029984503984451294, 0.006184131372720003, -0.0034912247210741043, -0.012457478791475296, 0.002699977718293667, 0.023633498698472977, -0.009476094506680965, 0.004161766730248928, -0.022885851562023163, 0.02100110799074173, 0.002005532383918762, 0.02960014156997204, -0.03621998429298401, -0.007284307852387428, -0.006691812537610531, -0.02920294553041458, 0.009404204785823822, -0.000725898309610784, 0.007698355242609978, 0.0011397459311410785, -0.0035187334287911654, 0.05228735879063606, 0.03257794678211212, -0.0041107297874987125, 0.018327724188566208, 0.02347324602305889, -0.017657630145549774, -0.006876824423670769, -0.037516556680202484, 0.056226834654808044, 0.010437414981424809, -0.010648004710674286, 0.013965846039354801, -0.017816314473748207, -0.04828454181551933, -0.039009157568216324, 0.012892982922494411, 0.021801088005304337, -0.020459666848182678, 0.0238940492272377, 0.04361308366060257, 0.021244050934910774, -0.01140366867184639, 0.021489137783646584, -0.02046596072614193, -0.03192463889718056, -0.02486291714012623, 0.05358368903398514, -0.05018409341573715, 0.011774512939155102, 0.027243604883551598, -0.030060892924666405, 0.035313479602336884, 0.031342506408691406, -0.05820516496896744, 0.014512723311781883, 0.04629703238606453, -0.0004279354470781982, 0.0058724540285766125, -0.008254481479525566, 0.01707361824810505, -0.01144208014011383, -0.034239765256643295, 0.039355892688035965, -0.02448633499443531, -0.0025807558558881283, 0.010931854136288166, 0.0355960913002491, 0.044449009001255035, 0.03646925091743469, -0.026959165930747986, -0.009241391904652119, 0.017054572701454163, 0.06519397348165512, -0.004746947903186083, 0.02028416097164154, -0.010715944692492485, 0.0566108301281929, 0.03146633133292198, 0.03768735006451607, 0.04316890239715576, 0.009603815153241158, 0.031991127878427505, 0.030562693253159523, -0.03921894729137421, 0.051937852054834366, 0.00465276138857007, 0.010889410972595215, 0.02541661448776722, 0.035771600902080536, -0.013572142459452152, 0.040570277720689774, 0.0021343843545764685, -0.009320247918367386, -0.013280742801725864, 0.028611017391085625, 0.023610794916749, 0.042209647595882416, 0.034439101815223694, 0.04351917654275894, -0.02910654991865158, 0.017301995307207108, 0.029629642143845558, 0.07915602624416351, -0.011150387115776539, 0.0030616705771535635, 0.00605747802183032, 0.018452560529112816, -0.01935412734746933, 0.028892822563648224, 0.013913779519498348, 0.02795044332742691, 0.009615649469196796, 0.02493513934314251, -0.0039544543251395226, -0.0473797507584095, -0.047195952385663986, -0.04437507316470146, -0.025916771963238716, -0.029634589329361916, -0.01014145277440548, -0.001198369194753468, 0.02128221094608307, -0.03416239097714424, 0.04883786663413048, 0.0220356322824955, -0.03184516727924347, -0.061647336930036545, -0.02337268553674221, 0.07285881787538528, 0.005595417693257332, 0.026931721717119217, -0.03478135168552399, 0.032939255237579346, -0.004723012447357178, 0.04429890960454941, -0.052908267825841904, -0.02107255533337593, 0.012674191035330296, -0.007246042136102915, 0.05158349871635437, -0.03492041677236557, -0.020263422280550003, 0.00308004068210721, -0.045279331505298615, -0.07180838286876678, -0.00793076679110527, 0.020312152802944183, -0.03555338829755783, 0.017932122573256493, -0.049126580357551575, 0.04453456774353981, 0.0251720380038023, -0.025084728375077248, 0.04691745713353157, 0.02653566189110279, -0.05629954859614372, 0.018988817930221558, 0.02960270084440708, -0.007907168008387089, -0.05775388702750206, 0.05932541936635971, 0.05756717547774315, -0.0017637134296819568, -0.025688422843813896, -0.0035485397092998028, -0.04071512073278427, -0.0222929734736681, 0.020771561190485954, 0.003261130303144455, -0.03628822788596153, 0.029039397835731506, 0.014385415241122246, -0.08968624472618103, 0.020115850493311882, -0.029533090069890022, -0.03988682106137276, -0.05137473717331886, -0.035710833966732025, 0.023409154266119003, 0.03776099532842636, -6.472045060945675e-05, -0.02103831246495247, -0.010178589262068272, 0.003695087041705847, 0.021520432084798813, 0.03831468150019646, -0.02052910439670086, 0.04889426380395889, 0.0462011955678463, -0.013410990126430988, 0.005569192580878735, 0.012486474588513374, -0.023895632475614548, -0.003931901417672634, 0.027597758919000626, -0.001578913303092122, 0.017619002610445023, 0.029947640374302864, 0.0074917022138834, -0.011757146567106247, 0.019682101905345917, -0.042260706424713135, -0.030111977830529213, -0.004962125327438116, -0.007144961040467024, 0.030902069061994553, 0.0147103788331151, 0.00890989601612091, -0.03522372990846634, -0.021479228511452675, -0.05341045558452606, 0.03047531098127365, -0.002037174766883254, 0.031798649579286575, -0.05343581363558769, 0.04313056543469429, -0.0017008042195811868, -0.046101197600364685, 0.05441506952047348, -0.06114301085472107, 0.00013871588453184813, 0.05054549127817154, 0.005809216760098934, 0.024418434128165245, -0.027752192690968513, 0.0051126196049153805, -0.0391683392226696, 0.009865165688097477, 0.03148941695690155, 0.0033974298276007175, 0.009123885072767735, -0.04306021332740784, -0.01097997184842825, -0.029876379296183586, -0.027562560513615608, 0.0022206061985343695, 0.004676004871726036, 0.017239216715097427, -0.017488526180386543, -0.0402672216296196, -0.03384297713637352, 0.028313562273979187, 0.0295184887945652, 0.02074993960559368, 0.03317086398601532, 0.046707283705472946, 0.011596030555665493, 0.014065463095903397, 0.041696708649396896, -0.05310836434364319, 0.04447789490222931, -0.056267354637384415, 0.04015779867768288, 0.022455278784036636, -0.0025771090295165777, -0.011421714909374714, -0.02249634638428688, -0.01714319735765457, 0.024908626452088356, 0.02568625845015049, -0.032582078129053116, -0.04875703528523445, 0.019736746326088905, 0.005784394685178995, 0.03638589009642601, -0.024627715349197388, -0.04112233966588974, 0.016171235591173172, 0.02308547869324684, 0.02366534247994423, -0.030561599880456924, 0.02236560545861721, -0.02389754354953766, 0.039137158542871475, 0.038774315267801285, -0.013904178515076637, -0.02557908371090889, -0.021563535556197166, -0.042091358453035355, -0.04108969867229462, -0.024592064321041107, 0.036652132868766785, 0.0032373329158872366, 0.03800315037369728, -0.0259995236992836, 0.02721782587468624, 0.03596947342157364, 0.0034172344021499157, 0.0027664408553391695, 0.0073640719056129456, 0.011904116719961166, 0.008274887688457966, 0.04355943948030472, -0.018800662830471992, -0.0060120546258986, 0.023152261972427368, -0.06641967594623566, 0.030216369777917862, 0.0011208064388483763, -0.0012782829580828547, 0.0010003423085436225, 0.007205942180007696, 0.034843359142541885, 0.021076340228319168, -0.027115458622574806, 0.022761935368180275, -0.044145576655864716, 0.021388037130236626, -0.0567937009036541, -0.045064687728881836, 0.08522528409957886, -0.02075996808707714, -0.020261425524950027, 0.04359766095876694, 0.04410471022129059, -0.0035222102887928486, -0.009108681231737137, 0.02646227739751339, -0.03554845228791237, 0.01779068075120449, -0.03581691160798073, -0.010217325761914253, -0.027149328961968422, -0.04389818757772446, -0.007348119746893644, -0.02076849900186062, 0.013682805001735687, 0.009809782728552818, -0.03494220972061157, -0.03405246511101723, -0.0776825100183487, -0.030826415866613388, 0.007848965935409069, -0.009186530485749245, 0.024486856535077095, -0.015498635359108448, -0.024391451850533485, -0.015553277917206287, -0.03670336678624153, 0.018786832690238953, -0.016271045431494713, 0.0015455955872312188, -0.02287895977497101, -0.003919864073395729, 0.013413826003670692, 0.006799465976655483, -0.005125628784298897, -0.03806310519576073, -0.009914030320942402, 0.019929643720388412, -0.01597391627728939, -0.03921595960855484, 0.01797918602824211, -0.03757511451840401, -0.033648304641246796, -0.018641909584403038, 0.004708806052803993, 0.018534060567617416, 0.002305879956111312, 0.05184216797351837, 0.022654572501778603, 0.01962568610906601, 0.002412548055872321, -0.016045503318309784, 0.04193412885069847, 0.024484949186444283, -0.044798072427511215, -0.016152026131749153, 0.04343743249773979, 0.007785973139107227, 0.042069535702466965, 0.004373084753751755, -0.022511979565024376, -0.05041269585490227, -0.05011767894029617, -0.012169434688985348, -0.03610678389668465, -0.03506149724125862, -0.06163753569126129, -0.023480314761400223, -0.0038458623457700014, 0.03567172586917877, -0.003540861653164029, 0.017518483102321625, -0.008856534026563168, -0.05403071269392967, -0.0034520470071583986, -0.03720111772418022, -0.016007060185074806, -0.008873220533132553, -0.022026490420103073, -0.023521607741713524, 0.05590851232409477, -0.0004931605071760714, 0.052897050976753235, 0.027192985638976097, 0.006180732045322657, 0.02127205953001976, -0.035947732627391815, -0.03637014701962471, -0.06025996804237366, 0.0048209382221102715, -0.001171763171441853, 0.03144657984375954, 0.011349749751389027, -0.016657594591379166, 0.03373599797487259, -0.04576202854514122, 0.01021086797118187, -0.00757613405585289, -0.01253489963710308, -0.025599095970392227, -0.03161827102303505, 0.0562964491546154, -0.03356998413801193, 0.0165901780128479, -0.028999296948313713, 0.045910391956567764, 0.02929147705435753, 0.015289496630430222, -0.03967085853219032, -0.017411651089787483, -0.02390330284833908, -0.0383971706032753, 0.051908548921346664, -0.0041244071908295155, -0.02972569316625595, -0.05536685511469841, 0.004971896298229694, 0.061480648815631866, -0.019284488633275032, 0.021845996379852295, 0.03989787772297859, -0.014510140754282475, 0.013151167891919613, -0.02872444875538349, 0.03728681057691574, 0.027902944013476372, -0.017096269875764847, -0.008116280660033226, -0.05707154422998428, -0.03023579716682434, 0.013919169083237648, -0.045837294310331345, -0.05870185047388077, -0.04218591749668121, -0.005499355029314756, 0.06527318060398102, -0.009279721416532993, 0.04946454241871834, -0.016467086970806122, -0.027277477085590363, -0.03707776963710785, 0.06605549156665802, 0.016879627481102943, 0.01567702740430832, 0.010297874920070171, 0.014786206185817719, -0.008019065484404564, 0.02376498281955719, -0.017359241843223572, -0.04446140676736832, -0.0621924065053463, 0.07404530793428421, -0.02004597894847393, -0.05796246603131294, 0.0014579270500689745, 0.06070335954427719, -0.062255777418613434, -0.02822248823940754, -0.019852740690112114, -0.009004471823573112, 0.033728569746017456, -0.025793375447392464, 0.019177177920937538, -0.006851433776319027, 0.02970508486032486, 0.030179953202605247, 0.03527805581688881, -0.013606218621134758, 0.0431487150490284, 0.0010086470283567905, 0.04606986045837402, -0.015474792569875717, -0.005252708215266466, 0.025650765746831894, -0.033665720373392105, -0.003077165922150016, -0.019452586770057678, -0.017762647941708565, -0.015435555018484592, -0.0010351247619837523, 0.03982628509402275, 0.001056996756233275, -0.004833381623029709, 0.028836818411946297, -0.03229289874434471, 0.040309421718120575, -0.015145573765039444, 0.027250196784734726, 0.018166130408644676, -0.022787678986787796, -0.05943514406681061, -0.046602729707956314, 0.06222428008913994, 0.030677637085318565, 0.02076210081577301, -0.05279617756605148, -0.016923649236559868, 0.05188162252306938, 0.015383400954306126, -0.01435035653412342, -0.06151856854557991, -0.02672400139272213, -0.048457883298397064, -0.02827247604727745, -0.016949184238910675, -0.024282298982143402, 0.015110498294234276, 0.033530108630657196, 0.012918166816234589, -0.015784982591867447, 0.000676896539516747, -0.00679439352825284, -0.0016669087344780564, -0.011877770535647869, -0.018313201144337654, 0.029236217960715294, -0.031782366335392, -0.05707327276468277, -0.04415097087621689, -0.0068635703064501286, -0.014224007725715637, -0.008972174488008022, -0.040772974491119385, 0.007232875097543001, -0.036272693425416946, 0.01984979957342148, 0.009658361785113811, 0.041073255240917206, -0.006101801060140133, -0.02416880987584591, -0.019898654893040657, 0.012876676395535469, 0.00016556063201278448, 0.027064945548772812, 0.027218354865908623, -0.02053120546042919, 0.00884199794381857, 0.025847477838397026, -0.0183626227080822, -0.016478542238473892, 0.016405297443270683, 0.005429032724350691, -0.011533739045262337, -0.07160912454128265, -0.01083840150386095, -0.015387553721666336, -0.04261346161365509, 0.0324200764298439, -0.030311526730656624, 0.0020904135890305042, 0.011427994817495346, -0.011354411952197552, 0.012781173922121525, 0.05792901664972305, 0.009468398988246918, 0.057423919439315796, 0.012971822172403336, 0.028149956837296486, 0.022505884990096092, -0.009038998745381832, 0.028309572488069534, 0.05068499222397804, 0.02441098913550377, -0.004449956584721804, 0.0013302656589075923, 0.022844398394227028, -0.004337259102612734, 0.03343599662184715, -0.019148841500282288, -0.04196668788790703, -0.054949741810560226, -0.020762955769896507, -0.030894717201590538, 0.030482610687613487, 0.0028240755200386047, -0.014604011550545692, 0.053040388971567154, -0.04296177253127098, -0.02487114630639553, 0.008476530201733112, -0.05107930675148964, -0.028654105961322784, 0.024989651516079903, -0.020352430641651154, 0.020626064389944077, -0.009219222702085972, -0.03225496783852577, 0.0026903680991381407, -0.02461285889148712, -0.005108219105750322, -0.01833292469382286, 0.02293836697936058, -0.04259997978806496, 0.00858478806912899, 0.004541977774351835, -0.022543825209140778, 0.04408576339483261, 0.044215377420186996, -0.03558366373181343, -0.055398426949977875, 0.014820551499724388, -0.017116542905569077, 0.021352438256144524, 0.00898418202996254, -0.003302273340523243, 0.02605890855193138, -0.010787800885736942, 0.0009743990958668292, -0.008440643548965454, 0.01656857505440712, 0.0017043736297637224, 0.019138097763061523, -0.012315122410655022, -0.016400862485170364, -0.03827257826924324, 0.030305011197924614, 0.0038654799573123455, -0.0461978018283844, -0.012136342003941536, 0.0406438410282135, 0.02786164917051792, -0.024076636880636215, 0.018328983336687088, -0.015065009705722332, 0.030084604397416115, -0.03514893725514412, -0.01791638322174549, -0.022419355809688568, 0.017877116799354553, 0.013841292820870876, 0.020112590864300728, 0.01941867545247078, 0.018959594890475273, 0.04393429681658745, 0.02244577556848526, 0.013069085776805878, 0.03352518007159233, 0.05131212994456291, -0.03468658775091171, -0.012824981473386288, -0.019026294350624084, -0.007912250235676765, 0.006991938222199678, -0.007022670470178127, 0.011886459775269032, -0.026636524125933647, 0.0014336026506498456, -0.012980005703866482, -0.0426643043756485, 0.04091828316450119, -0.03653635457158089, 0.004646995570510626, -0.01764812134206295, 0.012330028228461742, 0.005317614413797855, 0.04854132980108261, 0.04241035133600235, 0.0031993642915040255, -2.4022041543503292e-05, 0.012300238013267517, -0.02156667970120907, 0.02942373976111412, 0.02931295521557331, -0.007913554087281227, 0.005917118862271309, 0.00796228926628828, 0.009082053788006306, -0.014223751612007618, -0.015265019610524178, 0.006661089137196541, -0.0328555628657341, 0.0371633805334568, -0.031423136591911316, -0.022577429190278053, 0.05065266042947769, -0.040365174412727356, -0.006416310556232929, -0.024516049772500992, 0.049850840121507645, -0.019526736810803413, -0.005364623386412859, 0.021171536296606064, 0.01772318407893181, -0.03629846125841141, 0.06399472802877426, -0.013322308659553528, 0.0584615059196949, 0.0025386761408299208, 0.057182833552360535, -0.018492452800273895, 0.04985341429710388, 0.017360148951411247, -0.030813002958893776, -0.02299424260854721, -0.0005577250267378986, 0.0032063110265880823, -0.052540719509124756, 0.004513117019087076, -0.023615268990397453, -0.010156054049730301, -0.05734248831868172, -0.0034615786280483007, -0.00840687658637762, 0.042960021644830704, -0.013433185406029224, -0.03933856636285782, -0.00243240874260664, 0.022423943504691124, -0.03300131484866142, -0.007336396258324385, 0.007686299737542868, 0.056139953434467316, -0.006219574250280857, -0.012558910995721817, -0.0162200890481472, -0.03473757579922676, -0.024645088240504265, -0.02992498315870762, 0.08166597038507462, -0.007272781804203987, -0.03045867197215557, -0.039733465760946274, -0.05261974036693573, 0.0060821957886219025, 0.007268948946148157, -0.04023372754454613, -0.030833439901471138, 0.06685485690832138, 0.04595223069190979, -0.0033289585262537003, -0.006033727899193764, -0.03473981097340584, 0.022295743227005005, 0.022339927032589912, 0.06572134792804718, -0.011759467422962189, 0.056051820516586304, 0.04736318811774254, -0.052341241389513016, -0.0013137281639501452, -0.025487635284662247, 0.03562435507774353, -0.010556125082075596, 0.013089721091091633, -0.018666012212634087, 0.03802625834941864, -0.002297690836712718, -0.03506523370742798, 0.032235369086265564, 0.021482843905687332, 0.008531543426215649, -0.042011555284261703, -0.09686960279941559, 0.00405152328312397, -0.07200459390878677, -0.00779748847708106, -0.06629585474729538, 0.024881139397621155, 0.00783358421176672, 0.009105878882110119, -0.007014678791165352, -0.05316596478223801, 0.15715666115283966, 0.026312783360481262, 0.04170495271682739, -0.0024423825088888407, 0.03255728632211685, 0.04389331489801407, -0.0033591107930988073, -0.0044932602904737, 0.00027515762485563755, -0.015456654131412506, 0.02745087631046772, 0.02001403272151947, 0.039437443017959595, -0.015141886658966541, 0.016828017309308052, 0.0350237712264061, -0.026708193123340607, 0.024615582078695297, 0.02645600028336048, -0.02915438823401928, -0.07947345077991486, 0.019846046343445778, 0.016488824039697647, 0.025612076744437218, 0.0023415074683725834, -0.002516100648790598, -0.00579975126311183, -0.05305306240916252, -0.008046052418649197, -0.015546994283795357, 0.03372327983379364, -0.041342880576848984, 0.02370927855372429, -0.005892025772482157, -0.044583678245544434, 0.05119594559073448, 0.023535238578915596, -0.014886204153299332, 0.0010607045842334628, 0.014597799628973007, -0.04223111271858215, -0.010579951107501984, 0.026145394891500473, -0.04237351194024086, -0.002020868007093668, 0.02380148135125637, -0.04308566078543663, 0.006028672680258751, 0.000558320025447756, -0.035066910088062286, 0.06088153272867203, -0.05992026627063751, 0.019113434478640556, -0.01665104739367962, -0.04205554723739624, 0.02525733783841133, 0.017619462683796883, -0.019967960193753242, -0.018884116783738136, 0.02735177055001259, 0.022821063175797462, 0.00044950968003831804, -0.017049498856067657, -0.02620229497551918, -0.011528629809617996, -0.0010521435178816319, 0.014900805428624153, -0.006195124238729477, 0.01612023264169693, -0.03386173024773598, -0.010201094672083855, -0.017007552087306976, 0.004599532578140497, -0.003167906543239951, 0.04364302009344101, 0.0144586730748415, -0.014103000983595848, 0.052093490958213806, 0.00992075726389885, -0.04009290412068367, -0.00022297556279227138, -0.04304269701242447, -0.006559044122695923, 0.004573266953229904, 0.03959871083498001, 0.03816087916493416, -0.04470319300889969, -0.041086699813604355, -0.01534073706716299, 0.06998822838068008, 0.037421099841594696, 0.06769272685050964, -0.010106327943503857, 0.00033660681219771504, -0.017923248931765556]"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c715e4c6-b7e1-4094-9e5e-e6b54f4b2fc3",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "results = collection.aggregate([\n",
+ " {\n",
+ " \"$vectorSearch\": {\n",
+ " \"index\": \"vector_search_index\",\n",
+ " \"path\": \"description_embedding\",\n",
+ " \"queryVector\": query_vector,\n",
+ " \"numCandidates\": 100,\n",
+ " \"limit\": 10\n",
+ " }\n",
+ " }\n",
+ "])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "93ff100f-ad25-4256-85ac-4bc7719bdf49",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "for i in results:\n",
+ " del i['description_embedding']\n",
+ " del i['name_embedding']\n",
+ " print(i)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8af67bfd-b095-49c5-943a-777e9daae6f2",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/templates/ray-summit-multi-modal-search/pipeline_tutorial/B_process_1000_data.ipynb b/templates/ray-summit-multi-modal-search/pipeline_tutorial/B_process_1000_data.ipynb
new file mode 100644
index 000000000..1e7996bfe
--- /dev/null
+++ b/templates/ray-summit-multi-modal-search/pipeline_tutorial/B_process_1000_data.ipynb
@@ -0,0 +1,791 @@
+{
+ "cells": [
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "54b72fa4-6e0a-4057-861c-4c61593c1007",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import io\n",
+ "import os\n",
+ "from concurrent.futures import ThreadPoolExecutor\n",
+ "from typing import Any, Literal, Type\n",
+ "import numpy as np\n",
+ "import requests\n",
+ "import ray\n",
+ "import torchvision\n",
+ "from enum import Enum\n",
+ "import typer\n",
+ "import pandas as pd\n",
+ "import pyarrow as pa\n",
+ "from pyarrow import csv\n",
+ "from pydantic import BaseModel\n",
+ "from ray.util.accelerators import NVIDIA_TESLA_A10G\n",
+ "from sentence_transformers import SentenceTransformer\n",
+ "from transformers import AutoTokenizer\n",
+ "from vllm.multimodal.image import ImagePixelData\n",
+ "from vllm import LLM, SamplingParams\n",
+ "from PIL import Image\n",
+ "from pymongo import MongoClient, UpdateOne"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9087e741-3ab2-436d-b5d3-412dd8592b1a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "! date"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "055ee1a1-2e25-4121-962f-fc758ff7b02b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nsamples=1_000"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1cc8bd87-b22e-48f3-8c09-2065ae4a4fa8",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "num_image_download_workers=3\n",
+ "num_llava_tokenizer_workers=2\n",
+ "num_llava_model_workers=1\n",
+ "llava_model_accelerator_type=NVIDIA_TESLA_A10G\n",
+ "llava_model_batch_size=80\n",
+ "num_mistral_tokenizer_workers_per_classifier=2\n",
+ "num_mistral_model_workers_per_classifier=1\n",
+ "num_mistral_detokenizer_workers_per_classifier=2\n",
+ "mistral_model_batch_size=80\n",
+ "mistral_model_accelerator_type=NVIDIA_TESLA_A10G\n",
+ "num_embedder_workers=1\n",
+ "embedding_model_batch_size=80\n",
+ "embedding_model_accelerator_type=NVIDIA_TESLA_A10G\n",
+ "db_update_batch_size=80\n",
+ "num_db_workers=10"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "94205417-4883-4bce-8c64-6ec535e2ea3b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "db_name: str = \"myntra\"\n",
+ "collection_name: str = \"myntra-items-offline\"\n",
+ "cluster_size: str = \"m0\"\n",
+ "scaling_config_path: str = \"\""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2cf89b33-d854-4f1c-9423-d98be0a1a762",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "path = 's3://anyscale-public-materials/mongodb-demo/raw/myntra_subset_deduped_10000.csv'"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b6e15f99-f28d-41f7-9aeb-c7f5fe0597c7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def read_data(path: str, nsamples: int) -> ray.data.Dataset:\n",
+ " ds = ray.data.read_csv(\n",
+ " path,\n",
+ " parse_options=csv.ParseOptions(newlines_in_values=True),\n",
+ " convert_options=csv.ConvertOptions(\n",
+ " column_types={\n",
+ " \"id\": pa.int64(),\n",
+ " \"name\": pa.string(),\n",
+ " \"img\": pa.string(),\n",
+ " \"asin\": pa.string(),\n",
+ " \"price\": pa.float64(),\n",
+ " \"mrp\": pa.float64(),\n",
+ " \"rating\": pa.float64(),\n",
+ " \"ratingTotal\": pa.int64(),\n",
+ " \"discount\": pa.int64(),\n",
+ " \"seller\": pa.string(),\n",
+ " \"purl\": pa.string(),\n",
+ " }\n",
+ " ),\n",
+ " override_num_blocks=nsamples,\n",
+ " )\n",
+ " return ds.limit(nsamples)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "894bc732-5314-4dda-aed4-2c8f164fad80",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# 1. Read and preprocess data\n",
+ "\n",
+ "def download_image(url: str) -> bytes:\n",
+ " try:\n",
+ " response = requests.get(url)\n",
+ " response.raise_for_status()\n",
+ " return response.content\n",
+ " except Exception:\n",
+ " return b\"\"\n",
+ "\n",
+ "def download_images(batch: dict[str, np.ndarray]) -> dict[str, np.ndarray]:\n",
+ " with ThreadPoolExecutor() as executor:\n",
+ " batch[\"url\"] = batch[\"img\"]\n",
+ " batch[\"img\"] = list(executor.map(download_image, batch[\"url\"])) # type: ignore\n",
+ " return batch\n",
+ "\n",
+ "class LargestCenterSquare:\n",
+ " \"\"\"Largest center square crop for images.\"\"\"\n",
+ "\n",
+ " def __init__(self, size: int) -> None:\n",
+ " self.size = size\n",
+ "\n",
+ " def __call__(self, row: dict[str, Any]) -> dict[str, Any]:\n",
+ " \"\"\"Crop the largest center square from an image.\"\"\"\n",
+ " img = Image.open(io.BytesIO(row[\"img\"]))\n",
+ "\n",
+ " # First, resize the image such that the smallest side is self.size while preserving aspect ratio.\n",
+ " img = torchvision.transforms.functional.resize(\n",
+ " img=img,\n",
+ " size=self.size,\n",
+ " )\n",
+ "\n",
+ " # Then take a center crop to a square.\n",
+ " w, h = img.size\n",
+ " c_top = (h - self.size) // 2\n",
+ " c_left = (w - self.size) // 2\n",
+ " row[\"img\"] = torchvision.transforms.functional.crop(\n",
+ " img=img,\n",
+ " top=c_top,\n",
+ " left=c_left,\n",
+ " height=self.size,\n",
+ " width=self.size,\n",
+ " )\n",
+ "\n",
+ " return row\n",
+ "\n",
+ "DESCRIPTION_PROMPT_TEMPLATE = \"\" * 1176 + (\n",
+ " \"\\nUSER: Generate an ecommerce product description given the image and this title: {title}.\"\n",
+ " \"Make sure to include information about the color of the product in the description.\"\n",
+ " \"\\nASSISTANT:\"\n",
+ ")\n",
+ "\n",
+ "def gen_description_prompt(row: dict[str, Any]) -> dict[str, Any]:\n",
+ " title = row[\"name\"]\n",
+ " row[\"description_prompt\"] = DESCRIPTION_PROMPT_TEMPLATE.format(title=title)\n",
+ "\n",
+ " return row"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a617430f-bca6-4ef2-9977-01e0971742df",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds = read_data(path, nsamples)\n",
+ "\n",
+ "ds = (\n",
+ " ds.map_batches(download_images, num_cpus=4, concurrency=num_image_download_workers)\n",
+ " .filter(lambda x: bool(x[\"img\"]))\n",
+ " .map(LargestCenterSquare(size=336))\n",
+ " .map(gen_description_prompt)\n",
+ " .materialize()\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d55ebe3b-0626-4207-936f-9edc2756f7c7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# 2. Estimate input/output token distribution for LLAVA model\n",
+ "\n",
+ "class LlaVAMistralTokenizer:\n",
+ " def __init__(self):\n",
+ " self.tokenizer = AutoTokenizer.from_pretrained(\n",
+ " \"llava-hf/llava-v1.6-mistral-7b-hf\",\n",
+ " )\n",
+ "\n",
+ " def __call__(self, batch: dict[str, np.ndarray], input: str, output: str):\n",
+ " batch[output] = self.tokenizer.batch_encode_plus(batch[input].tolist())[\"input_ids\"]\n",
+ " return batch\n",
+ " \n",
+ "def compute_num_tokens(row: dict[str, Any], col: str) -> dict[str, Any]:\n",
+ " row[\"num_tokens\"] = len(row[col])\n",
+ " return row\n",
+ " \n",
+ "max_input_tokens = (\n",
+ " ds.map_batches(\n",
+ " LlaVAMistralTokenizer,\n",
+ " fn_kwargs={\n",
+ " \"input\": \"description_prompt\",\n",
+ " \"output\": \"description_prompt_tokens\",\n",
+ " },\n",
+ " concurrency=num_llava_tokenizer_workers,\n",
+ " num_cpus=1,\n",
+ " )\n",
+ " .select_columns([\"description_prompt_tokens\"])\n",
+ " .map(compute_num_tokens, fn_kwargs={\"col\": \"description_prompt_tokens\"})\n",
+ " .max(on=\"num_tokens\")\n",
+ ")\n",
+ "\n",
+ "max_output_tokens = 256 # maximum size of desired product description\n",
+ "max_model_length = max_input_tokens + max_output_tokens\n",
+ "print(\n",
+ " f\"Description gen: {max_input_tokens=} {max_output_tokens=} {max_model_length=}\"\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d3ad8191-cd7e-4718-934f-7e42a8bddeef",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# 3. Generate description using LLAVA model inference\n",
+ "\n",
+ "class LlaVAMistral:\n",
+ " def __init__(\n",
+ " self,\n",
+ " max_model_len: int,\n",
+ " max_num_seqs: int = 400,\n",
+ " max_tokens: int = 1024,\n",
+ " # NOTE: \"fp8\" currently doesn't support FlashAttention-2 backend so while\n",
+ " # we can fit more sequences in memory, performance will be suboptimal\n",
+ " kv_cache_dtype: str = \"fp8\",\n",
+ " ):\n",
+ " self.llm = LLM(\n",
+ " model=\"llava-hf/llava-v1.6-mistral-7b-hf\",\n",
+ " trust_remote_code=True,\n",
+ " enable_lora=False,\n",
+ " max_num_seqs=max_num_seqs,\n",
+ " max_model_len=max_model_len,\n",
+ " gpu_memory_utilization=0.95,\n",
+ " image_input_type=\"pixel_values\",\n",
+ " image_token_id=32000,\n",
+ " image_input_shape=\"1,3,336,336\",\n",
+ " image_feature_size=1176,\n",
+ " kv_cache_dtype=kv_cache_dtype,\n",
+ " preemption_mode=\"swap\",\n",
+ " )\n",
+ " self.sampling_params = SamplingParams(\n",
+ " n=1,\n",
+ " presence_penalty=0,\n",
+ " frequency_penalty=0,\n",
+ " repetition_penalty=1,\n",
+ " length_penalty=1,\n",
+ " top_p=1,\n",
+ " top_k=-1,\n",
+ " temperature=0,\n",
+ " use_beam_search=False,\n",
+ " ignore_eos=False,\n",
+ " max_tokens=max_tokens,\n",
+ " seed=None,\n",
+ " detokenize=True,\n",
+ " )\n",
+ "\n",
+ " def __call__(self, batch: dict[str, np.ndarray], col: str) -> dict[str, np.ndarray]:\n",
+ " prompts = batch[col]\n",
+ " images = batch[\"img\"]\n",
+ " responses = self.llm.generate(\n",
+ " [\n",
+ " {\n",
+ " \"prompt\": prompt,\n",
+ " \"multi_modal_data\": ImagePixelData(image),\n",
+ " }\n",
+ " for prompt, image in zip(prompts, images)\n",
+ " ],\n",
+ " sampling_params=self.sampling_params,\n",
+ " )\n",
+ "\n",
+ " batch[\"description\"] = [resp.outputs[0].text for resp in responses] # type: ignore\n",
+ " return batch"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e6620303-8cf5-49d3-9f03-9c17131dae0a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds = ds.map_batches(\n",
+ " LlaVAMistral,\n",
+ " fn_constructor_kwargs={\n",
+ " \"max_model_len\": max_model_length,\n",
+ " \"max_tokens\": max_output_tokens,\n",
+ " \"max_num_seqs\": 400,\n",
+ " },\n",
+ " fn_kwargs={\"col\": \"description_prompt\"},\n",
+ " batch_size=llava_model_batch_size,\n",
+ " num_gpus=1.0,\n",
+ " concurrency=num_llava_model_workers,\n",
+ " accelerator_type=llava_model_accelerator_type,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "cb7447b3-bb11-44fd-b3a1-cc6fa80a46d2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def construct_prompt_classifier(\n",
+ " row: dict[str, Any],\n",
+ " prompt_template: str,\n",
+ " classes: list[str],\n",
+ " col: str,\n",
+ ") -> dict[str, Any]:\n",
+ " classes_str = \", \".join(classes)\n",
+ " title = row[\"name\"]\n",
+ " description = row[\"description\"]\n",
+ " row[f\"{col}_prompt\"] = prompt_template.format(\n",
+ " title=title,\n",
+ " description=description,\n",
+ " classes_str=classes_str,\n",
+ " )\n",
+ " return row\n",
+ " \n",
+ "classifiers: dict[str, Any] = {\n",
+ " \"category\": {\n",
+ " \"classes\": [\"Tops\", \"Bottoms\", \"Dresses\", \"Footwear\", \"Accessories\"],\n",
+ " \"prompt_template\": (\n",
+ " \"Given the title of this product: {title} and \"\n",
+ " \"the description: {description}, what category does it belong to? \"\n",
+ " \"Chose from the following categories: {classes_str}. \"\n",
+ " \"Return the category that best fits the product. Only return the category name and nothing else.\"\n",
+ " ),\n",
+ " \"prompt_constructor\": construct_prompt_classifier,\n",
+ " },\n",
+ " \"season\": {\n",
+ " \"classes\": [\"Summer\", \"Winter\", \"Spring\", \"Fall\"],\n",
+ " \"prompt_template\": (\n",
+ " \"Given the title of this product: {title} and \"\n",
+ " \"the description: {description}, what season does it belong to? \"\n",
+ " \"Chose from the following seasons: {classes_str}. \"\n",
+ " \"Return the season that best fits the product. Only return the season name and nothing else.\"\n",
+ " ),\n",
+ " \"prompt_constructor\": construct_prompt_classifier,\n",
+ " },\n",
+ " \"color\": {\n",
+ " \"classes\": [\n",
+ " \"Red\",\n",
+ " \"Blue\",\n",
+ " \"Green\",\n",
+ " \"Yellow\",\n",
+ " \"Black\",\n",
+ " \"White\",\n",
+ " \"Pink\",\n",
+ " \"Purple\",\n",
+ " \"Orange\",\n",
+ " \"Brown\",\n",
+ " \"Grey\",\n",
+ " ],\n",
+ " \"prompt_template\": (\n",
+ " \"Given the title of this product: {title} and \"\n",
+ " \"the description: {description}, what color does it belong to? \"\n",
+ " \"Chose from the following colors: {classes_str}. \"\n",
+ " \"Return the color that best fits the product. Only return the color name and nothing else.\"\n",
+ " ),\n",
+ " \"prompt_constructor\": construct_prompt_classifier,\n",
+ " },\n",
+ "}"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ff7d56b3-5ef5-4bd7-b7a0-c1618fba8957",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class MistralTokenizer:\n",
+ " def __init__(self):\n",
+ " self.tokenizer = AutoTokenizer.from_pretrained(\n",
+ " \"mistralai/Mistral-7B-Instruct-v0.1\",\n",
+ " )\n",
+ "\n",
+ " def __call__(self, batch: dict, input: str, output: str):\n",
+ " batch[output] = self.tokenizer.apply_chat_template(\n",
+ " conversation=[[{\"role\": \"user\", \"content\": input_}] for input_ in batch[input]],\n",
+ " add_generation_prompt=True,\n",
+ " tokenize=True,\n",
+ " return_tensors=\"np\",\n",
+ " )\n",
+ " return batch"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "244945a9-e4d4-455b-86f8-836c3c8ff0d0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# 4. Generate classifier prompts and tokenize them\n",
+ "for classifier, classifier_spec in classifiers.items():\n",
+ " ds = (\n",
+ " ds.map(\n",
+ " classifier_spec[\"prompt_constructor\"],\n",
+ " fn_kwargs={\n",
+ " \"prompt_template\": classifier_spec[\"prompt_template\"],\n",
+ " \"classes\": classifier_spec[\"classes\"],\n",
+ " \"col\": classifier,\n",
+ " },\n",
+ " )\n",
+ " .map_batches(\n",
+ " MistralTokenizer,\n",
+ " fn_kwargs={\n",
+ " \"input\": f\"{classifier}_prompt\",\n",
+ " \"output\": f\"{classifier}_prompt_tokens\",\n",
+ " },\n",
+ " concurrency=num_mistral_tokenizer_workers_per_classifier,\n",
+ " num_cpus=1,\n",
+ " )\n",
+ " .materialize()\n",
+ " )"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "756f2c3d-9e23-4d7c-adee-4e5190a00567",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# 5. Estimate input/output token distribution for Mistral models\n",
+ "for classifier, classifier_spec in classifiers.items():\n",
+ " max_output_tokens = (\n",
+ " ray.data.from_items(\n",
+ " [\n",
+ " {\n",
+ " \"output\": max(classifier_spec[\"classes\"], key=len),\n",
+ " }\n",
+ " ]\n",
+ " )\n",
+ " .map_batches(\n",
+ " MistralTokenizer,\n",
+ " fn_kwargs={\n",
+ " \"input\": \"output\",\n",
+ " \"output\": \"output_tokens\",\n",
+ " },\n",
+ " concurrency=1,\n",
+ " num_cpus=1,\n",
+ " )\n",
+ " .map(\n",
+ " compute_num_tokens,\n",
+ " fn_kwargs={\"col\": \"output_tokens\"},\n",
+ " )\n",
+ " .max(on=\"num_tokens\")\n",
+ " )\n",
+ " # allow for 40 tokens of buffer to account for non-exact outputs e.g \"the color is Red\" instead of just \"Red\"\n",
+ " buffer_size = 40\n",
+ " classifier_spec[\"max_output_tokens\"] = max_output_tokens + buffer_size\n",
+ "\n",
+ " max_input_tokens = (\n",
+ " ds.select_columns([f\"{classifier}_prompt_tokens\"])\n",
+ " .map(compute_num_tokens, fn_kwargs={\"col\": f\"{classifier}_prompt_tokens\"})\n",
+ " .max(on=\"num_tokens\")\n",
+ " )\n",
+ " max_output_tokens = classifier_spec[\"max_output_tokens\"]\n",
+ " print(f\"{classifier=} {max_input_tokens=} {max_output_tokens=}\")\n",
+ " max_model_length = max_input_tokens + max_output_tokens\n",
+ " classifier_spec[\"max_model_length\"] = max_model_length"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6a14469d-84f4-44bf-b651-9fc76bceb1ff",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class MistralvLLM:\n",
+ " def __init__(\n",
+ " self,\n",
+ " max_model_len: int = 4096,\n",
+ " max_tokens: int = 2048,\n",
+ " max_num_seqs: int = 256,\n",
+ " # NOTE: \"fp8\" currently doesn't support FlashAttention-2 backend so while\n",
+ " # we can fit more sequences in memory, performance will be suboptimal\n",
+ " kv_cache_dtype: str = \"fp8\",\n",
+ " ):\n",
+ " self.llm = LLM(\n",
+ " model=\"mistralai/Mistral-7B-Instruct-v0.1\",\n",
+ " trust_remote_code=True,\n",
+ " enable_lora=False,\n",
+ " max_num_seqs=max_num_seqs,\n",
+ " max_model_len=max_model_len,\n",
+ " gpu_memory_utilization=0.90,\n",
+ " skip_tokenizer_init=True,\n",
+ " kv_cache_dtype=kv_cache_dtype,\n",
+ " preemption_mode=\"swap\",\n",
+ " )\n",
+ " self.sampling_params = SamplingParams(\n",
+ " n=1,\n",
+ " presence_penalty=0,\n",
+ " frequency_penalty=0,\n",
+ " repetition_penalty=1,\n",
+ " length_penalty=1,\n",
+ " top_p=1,\n",
+ " top_k=-1,\n",
+ " temperature=0,\n",
+ " use_beam_search=False,\n",
+ " ignore_eos=False,\n",
+ " max_tokens=max_tokens,\n",
+ " seed=None,\n",
+ " detokenize=False,\n",
+ " )\n",
+ "\n",
+ " def __call__(\n",
+ " self, batch: dict[str, np.ndarray], input: str, output: str\n",
+ " ) -> dict[str, np.ndarray]:\n",
+ " responses = self.llm.generate(\n",
+ " prompt_token_ids=[ids.tolist() for ids in batch[input]],\n",
+ " sampling_params=self.sampling_params,\n",
+ " )\n",
+ " batch[output] = [resp.outputs[0].token_ids for resp in responses] # type: ignore\n",
+ " return batch\n",
+ "\n",
+ "\n",
+ "class MistralDeTokenizer:\n",
+ " def __init__(self) -> None:\n",
+ " self.tokenizer = AutoTokenizer.from_pretrained(\n",
+ " \"mistralai/Mistral-7B-Instruct-v0.1\",\n",
+ " )\n",
+ "\n",
+ " def __call__(self, batch: dict[str, np.ndarray], key: str) -> dict[str, np.ndarray]:\n",
+ " batch[key] = self.tokenizer.batch_decode(batch[key], skip_special_tokens=True)\n",
+ " return batch"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2482e476-7377-4574-8ad1-c137d2ab6ccb",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def clean_response(\n",
+ " row: dict[str, Any], response_col: str, classes: list[str]\n",
+ ") -> dict[str, Any]:\n",
+ " response_str = row[response_col]\n",
+ " matches = []\n",
+ " for class_ in classes:\n",
+ " if class_.lower() in response_str.lower():\n",
+ " matches.append(class_)\n",
+ " if len(matches) == 1:\n",
+ " response = matches[0]\n",
+ " else:\n",
+ " response = None\n",
+ " row[response_col] = response\n",
+ " return row"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "99683256-2ceb-4c50-9467-bc3d46676f67",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# 6. Generate classifier responses using Mistral model inference\n",
+ "for classifier, classifier_spec in classifiers.items():\n",
+ " ds = (\n",
+ " ds.map_batches(\n",
+ " MistralvLLM,\n",
+ " fn_kwargs={\n",
+ " \"input\": f\"{classifier}_prompt_tokens\",\n",
+ " \"output\": f\"{classifier}_response\",\n",
+ " },\n",
+ " fn_constructor_kwargs={\n",
+ " \"max_model_len\": classifier_spec[\"max_model_length\"],\n",
+ " \"max_tokens\": classifier_spec[\"max_output_tokens\"],\n",
+ " },\n",
+ " batch_size=mistral_model_batch_size,\n",
+ " num_gpus=1.0,\n",
+ " concurrency=num_mistral_model_workers_per_classifier,\n",
+ " accelerator_type=mistral_model_accelerator_type,\n",
+ " )\n",
+ " .map_batches(\n",
+ " MistralDeTokenizer,\n",
+ " fn_kwargs={\"key\": f\"{classifier}_response\"},\n",
+ " concurrency=num_mistral_detokenizer_workers_per_classifier,\n",
+ " num_cpus=1,\n",
+ " )\n",
+ " .map(\n",
+ " clean_response,\n",
+ " fn_kwargs={\n",
+ " \"classes\": classifier_spec[\"classes\"],\n",
+ " \"response_col\": f\"{classifier}_response\",\n",
+ " },\n",
+ " )\n",
+ " )"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "37324ffe-ce01-447e-92de-a8d9aac22364",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# 7. Generate embeddings using embedding model inference\n",
+ "\n",
+ "class EmbedderSentenceTransformer:\n",
+ " def __init__(self, model: str = \"thenlper/gte-large\", device: str = \"cuda\"):\n",
+ " self.model = SentenceTransformer(model, device=device)\n",
+ "\n",
+ " def __call__(\n",
+ " self, batch: dict[str, np.ndarray], cols: list[str]\n",
+ " ) -> dict[str, np.ndarray]:\n",
+ " for col in cols:\n",
+ " batch[f\"{col}_embedding\"] = self.model.encode( # type: ignore\n",
+ " batch[col].tolist(), batch_size=len(batch[col])\n",
+ " )\n",
+ " return batch\n",
+ " \n",
+ "ds = ds.map_batches(\n",
+ " EmbedderSentenceTransformer,\n",
+ " fn_kwargs={\"cols\": [\"name\", \"description\"]},\n",
+ " batch_size=embedding_model_batch_size,\n",
+ " num_gpus=1.0,\n",
+ " concurrency=num_embedder_workers,\n",
+ " accelerator_type=embedding_model_accelerator_type,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "20d5c7a9",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def update_record(batch: dict[str, np.ndarray]) -> dict[str, np.ndarray]:\n",
+ " batch[\"_id\"] = batch[\"name\"]\n",
+ " return {\n",
+ " \"_id\": batch[\"_id\"],\n",
+ " \"name\": batch[\"name\"],\n",
+ " \"img\": batch[\"url\"],\n",
+ " \"price\": batch[\"price\"],\n",
+ " \"rating\": batch[\"rating\"],\n",
+ " \"description\": batch[\"description\"],\n",
+ " \"category\": batch[\"category_response\"],\n",
+ " \"season\": batch[\"season_response\"],\n",
+ " \"color\": batch[\"color_response\"],\n",
+ " \"name_embedding\": batch[\"name_embedding\"].tolist(),\n",
+ " \"description_embedding\": batch[\"description_embedding\"].tolist(),\n",
+ " }\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8db26b0c-2547-4109-baf1-efc80d1e79dc",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class MongoBulkUpdate:\n",
+ " def __init__(self, db: str, collection: str) -> None:\n",
+ " client = MongoClient(os.environ[\"DB_CONNECTION_STRING\"])\n",
+ " self.collection = client[db][collection]\n",
+ "\n",
+ " def __call__(self, batch_df: pd.DataFrame) -> dict[str, np.ndarray]:\n",
+ " docs = batch_df.to_dict(orient=\"records\")\n",
+ " bulk_ops = [\n",
+ " UpdateOne(filter={\"_id\": doc[\"_id\"]}, update={\"$set\": doc}, upsert=True)\n",
+ " for doc in docs\n",
+ " ]\n",
+ " self.collection.bulk_write(bulk_ops)\n",
+ " return {}"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "16007dc4-785b-42c0-83aa-0658b4870f1c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "(\n",
+ " ds.map_batches(update_record)\n",
+ " .map_batches(\n",
+ " MongoBulkUpdate,\n",
+ " fn_constructor_kwargs={\n",
+ " \"db\": db_name,\n",
+ " \"collection\": collection_name,\n",
+ " },\n",
+ " batch_size=db_update_batch_size,\n",
+ " concurrency=num_db_workers,\n",
+ " num_cpus=0.1,\n",
+ " batch_format=\"pandas\",\n",
+ " )\n",
+ " .materialize()\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d74de3db-6bb9-48dd-b061-5ddffd90a981",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "! date"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a8c7087d-fc99-45b5-95ee-17d7a568024e",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/templates/ray-summit-rag/01_Intro_to_RAG.ipynb b/templates/ray-summit-rag/01_Intro_to_RAG.ipynb
new file mode 100644
index 000000000..f7a1f1a76
--- /dev/null
+++ b/templates/ray-summit-rag/01_Intro_to_RAG.ipynb
@@ -0,0 +1,515 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Intro to RAG\n",
+ "\n",
+ " \n",
+ "\n",
+ "We prompt an LLM and get back a response."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def prompt_llm(user_prompt, model=\"mistralai/Mistral-7B-Instruct-v0.1\", temperature=0, **kwargs):\n",
+ " # Initialize a client to perform API requests\n",
+ " client = openai.OpenAI(\n",
+ " base_url=ANYSCALE_SERVICE_BASE_URL,\n",
+ " api_key=ANYSCALE_API_KEY,\n",
+ " )\n",
+ " \n",
+ " # Call the chat completions endpoint\n",
+ " chat_completion = client.chat.completions.create(\n",
+ " model=model,\n",
+ " messages=[\n",
+ " # Prime the system with a system message - a common best practice\n",
+ " {\"role\": \"system\", \"content\": \"You are a helpful assistant.\"},\n",
+ " # Send the user message with the proper \"user\" role and \"content\"\n",
+ " {\"role\": \"user\", \"content\": user_prompt},\n",
+ " ],\n",
+ " temperature=temperature,\n",
+ " **kwargs,\n",
+ " )\n",
+ "\n",
+ " return chat_completion"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "As an example, we will prompt an LLM about the capital of France."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "prompt = \"What is the capital of France?\"\n",
+ "response = prompt_llm(prompt)\n",
+ "print(response.choices[0].message.content)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's consider the case of prompting the LLM about **internal** company documents. \n",
+ "\n",
+ "Think of technical company documents and company policies that are not available on the internet.\n",
+ "\n",
+ "Given the LLM has not been trained on these documents, it will not be able to provide a good response."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "prompt = \"Can I rent the company car on weekends?\"\n",
+ "response = prompt_llm(prompt)\n",
+ "print(response.choices[0].message.content)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "vscode": {
+ "languageId": "plaintext"
+ }
+ },
+ "source": [
+ "## In-context learning and LLMs\n",
+ "\n",
+ "It turns out LLMs excel at in-context learning, meaning they can utilize additional context provided with a user prompt to generate a response that is grounded in the provided context. \n",
+ "\n",
+ "Here a diagram of the system with in-context learning:\n",
+ "\n",
+ "
\n",
+ "\n",
+ "We prompt an LLM and get back a response."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def prompt_llm(user_prompt, model=\"mistralai/Mistral-7B-Instruct-v0.1\", temperature=0, **kwargs):\n",
+ " # Initialize a client to perform API requests\n",
+ " client = openai.OpenAI(\n",
+ " base_url=ANYSCALE_SERVICE_BASE_URL,\n",
+ " api_key=ANYSCALE_API_KEY,\n",
+ " )\n",
+ " \n",
+ " # Call the chat completions endpoint\n",
+ " chat_completion = client.chat.completions.create(\n",
+ " model=model,\n",
+ " messages=[\n",
+ " # Prime the system with a system message - a common best practice\n",
+ " {\"role\": \"system\", \"content\": \"You are a helpful assistant.\"},\n",
+ " # Send the user message with the proper \"user\" role and \"content\"\n",
+ " {\"role\": \"user\", \"content\": user_prompt},\n",
+ " ],\n",
+ " temperature=temperature,\n",
+ " **kwargs,\n",
+ " )\n",
+ "\n",
+ " return chat_completion"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "As an example, we will prompt an LLM about the capital of France."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "prompt = \"What is the capital of France?\"\n",
+ "response = prompt_llm(prompt)\n",
+ "print(response.choices[0].message.content)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's consider the case of prompting the LLM about **internal** company documents. \n",
+ "\n",
+ "Think of technical company documents and company policies that are not available on the internet.\n",
+ "\n",
+ "Given the LLM has not been trained on these documents, it will not be able to provide a good response."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "prompt = \"Can I rent the company car on weekends?\"\n",
+ "response = prompt_llm(prompt)\n",
+ "print(response.choices[0].message.content)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "vscode": {
+ "languageId": "plaintext"
+ }
+ },
+ "source": [
+ "## In-context learning and LLMs\n",
+ "\n",
+ "It turns out LLMs excel at in-context learning, meaning they can utilize additional context provided with a user prompt to generate a response that is grounded in the provided context. \n",
+ "\n",
+ "Here a diagram of the system with in-context learning:\n",
+ "\n",
+ " \n",
+ "\n",
+ "For a formal understanding, refer to the paper titled [In-Context Retrieval-Augmented Language Models](https://arxiv.org/pdf/2302.00083.pdf), which performs experiments to validate in-context learning.\n",
+ "\n",
+ "\n",
+ "Let's consider the case of prompting the LLM about internal company policies. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "context = \"\"\"\n",
+ "Here are the company policies that you need to know about:\n",
+ "\n",
+ "1. You are not allowed to use the company's computers between 9am and 5pm. \n",
+ "2. You are not allowed to use the company car on weekends.\n",
+ "\"\"\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "This time, we provide the LLM with the company's policies as context."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "query = \"Am I allowed to use the company car on weekends?\"\n",
+ "\n",
+ "prompt = f\"\"\"\n",
+ "Given the following context:\n",
+ "{context}\n",
+ "\n",
+ "What is the answer to the following question:\n",
+ "{query}\n",
+ "\"\"\"\n",
+ "\n",
+ "response = prompt_llm(prompt)\n",
+ "print(response.choices[0].message.content)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We get back the correct answer to the question, which is \"You are not allowed to use the company car on weekends.\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "vscode": {
+ "languageId": "plaintext"
+ }
+ },
+ "source": [
+ "## Retrieval and semantic search\n",
+ "\n",
+ "In a real-world scenario, we can't provide the LLM with the entire company's data as context. It would be inefficient to do so from both a cost and performance perspective.\n",
+ "\n",
+ "So we will need a retrieval system to find the most relevant context.\n",
+ "\n",
+ "One effective retrieval system is semantic search, which uses embeddings to find the most relevant context."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "vscode": {
+ "languageId": "plaintext"
+ }
+ },
+ "source": [
+ "### What is semantic search ?\n",
+ "\n",
+ "Semantic search enables us to find documents that share a similar meaning with our queries.\n",
+ "\n",
+ "To capture the \"meaning\" of a query, we use specialized encoders known as \"embedding models.\"\n",
+ "\n",
+ "Embedding models encode text into a high-dimensional vector, playing a crucial role in converting language into a mathematical format for efficient comparison and retrieval.\n",
+ "\n",
+ "\n",
+ "### How do embedding models work?\n",
+ "\n",
+ "Embedding models are trained on a large corpus of text data to learn the relationships between words and phrases.\n",
+ "\n",
+ "The model represents each word or phrase as a high-dimensional vector, where similar words are closer together in the vector space.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "For a formal understanding, refer to the paper titled [In-Context Retrieval-Augmented Language Models](https://arxiv.org/pdf/2302.00083.pdf), which performs experiments to validate in-context learning.\n",
+ "\n",
+ "\n",
+ "Let's consider the case of prompting the LLM about internal company policies. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "context = \"\"\"\n",
+ "Here are the company policies that you need to know about:\n",
+ "\n",
+ "1. You are not allowed to use the company's computers between 9am and 5pm. \n",
+ "2. You are not allowed to use the company car on weekends.\n",
+ "\"\"\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "This time, we provide the LLM with the company's policies as context."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "query = \"Am I allowed to use the company car on weekends?\"\n",
+ "\n",
+ "prompt = f\"\"\"\n",
+ "Given the following context:\n",
+ "{context}\n",
+ "\n",
+ "What is the answer to the following question:\n",
+ "{query}\n",
+ "\"\"\"\n",
+ "\n",
+ "response = prompt_llm(prompt)\n",
+ "print(response.choices[0].message.content)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We get back the correct answer to the question, which is \"You are not allowed to use the company car on weekends.\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "vscode": {
+ "languageId": "plaintext"
+ }
+ },
+ "source": [
+ "## Retrieval and semantic search\n",
+ "\n",
+ "In a real-world scenario, we can't provide the LLM with the entire company's data as context. It would be inefficient to do so from both a cost and performance perspective.\n",
+ "\n",
+ "So we will need a retrieval system to find the most relevant context.\n",
+ "\n",
+ "One effective retrieval system is semantic search, which uses embeddings to find the most relevant context."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "vscode": {
+ "languageId": "plaintext"
+ }
+ },
+ "source": [
+ "### What is semantic search ?\n",
+ "\n",
+ "Semantic search enables us to find documents that share a similar meaning with our queries.\n",
+ "\n",
+ "To capture the \"meaning\" of a query, we use specialized encoders known as \"embedding models.\"\n",
+ "\n",
+ "Embedding models encode text into a high-dimensional vector, playing a crucial role in converting language into a mathematical format for efficient comparison and retrieval.\n",
+ "\n",
+ "\n",
+ "### How do embedding models work?\n",
+ "\n",
+ "Embedding models are trained on a large corpus of text data to learn the relationships between words and phrases.\n",
+ "\n",
+ "The model represents each word or phrase as a high-dimensional vector, where similar words are closer together in the vector space.\n",
+ "\n",
+ " \n",
+ "\n",
+ "The diagram shows word embedding vectors in a 2D space. Semantically similar words end up close to each other in the reduced vector space. \n",
+ "\n",
+ "Note for semantic search, we use sequence embeddings with a much higher dimensionality offering much richer representations."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Generating embeddings\n",
+ "\n",
+ "Here is how to generate embeddings using the `sentence-transformers` library."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "embedding_model = SentenceTransformer(\"BAAI/bge-small-en-v1.5\")\n",
+ "\n",
+ "prompt = \"Am I allowed to use the company car on weekends?\"\n",
+ "\n",
+ "document_1 = \"You are not allowed to use the company's computers between 9am and 5pm.\"\n",
+ "document_2 = \"You are not allowed to use the company car on weekends.\"\n",
+ "\n",
+ "prompt_embedding_vector = embedding_model.encode(prompt)\n",
+ "document_1_embedding_vector = embedding_model.encode(document_1)\n",
+ "document_2_embedding_vector = embedding_model.encode(document_2)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Now, we can find the similarity between the prompt and document vectors by computing the cosine similarity."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "similarities = cosine_similarity([prompt_embedding_vector], [document_1_embedding_vector, document_2_embedding_vector]).flatten()\n",
+ "similarity_between_prompt_and_document_1, similarity_between_prompt_and_document_2 = similarities\n",
+ "print(f\"{similarity_between_prompt_and_document_1=}\")\n",
+ "print(f\"{similarity_between_prompt_and_document_2=}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "
\n",
+ "\n",
+ "The diagram shows word embedding vectors in a 2D space. Semantically similar words end up close to each other in the reduced vector space. \n",
+ "\n",
+ "Note for semantic search, we use sequence embeddings with a much higher dimensionality offering much richer representations."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Generating embeddings\n",
+ "\n",
+ "Here is how to generate embeddings using the `sentence-transformers` library."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "embedding_model = SentenceTransformer(\"BAAI/bge-small-en-v1.5\")\n",
+ "\n",
+ "prompt = \"Am I allowed to use the company car on weekends?\"\n",
+ "\n",
+ "document_1 = \"You are not allowed to use the company's computers between 9am and 5pm.\"\n",
+ "document_2 = \"You are not allowed to use the company car on weekends.\"\n",
+ "\n",
+ "prompt_embedding_vector = embedding_model.encode(prompt)\n",
+ "document_1_embedding_vector = embedding_model.encode(document_1)\n",
+ "document_2_embedding_vector = embedding_model.encode(document_2)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Now, we can find the similarity between the prompt and document vectors by computing the cosine similarity."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "similarities = cosine_similarity([prompt_embedding_vector], [document_1_embedding_vector, document_2_embedding_vector]).flatten()\n",
+ "similarity_between_prompt_and_document_1, similarity_between_prompt_and_document_2 = similarities\n",
+ "print(f\"{similarity_between_prompt_and_document_1=}\")\n",
+ "print(f\"{similarity_between_prompt_and_document_2=}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ " \n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Why RAG ?\n",
+ "\n",
+ "RAG systems enhance LLMs by:\n",
+ "\n",
+ "- Reducing hallucinations with relevant context.\n",
+ "- Providing clear information attribution.\n",
+ "- Enabling access control to information."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### How can we build a basic RAG system ?\n",
+ "\n",
+ "A common approach for building a basic RAG systems is by:\n",
+ "\n",
+ "1. Encoding our documents, commonly referred to as generating embeddings of our documents.\n",
+ "2. Storing the generated embeddings in a vector store.\n",
+ "3. Encoding our user query.\n",
+ "4. Retrieving relevant documents from our vector store given the encoded user query.\n",
+ "5. Augmenting the user prompt with the retrieved context.\n",
+ "\n",
+ "
\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Why RAG ?\n",
+ "\n",
+ "RAG systems enhance LLMs by:\n",
+ "\n",
+ "- Reducing hallucinations with relevant context.\n",
+ "- Providing clear information attribution.\n",
+ "- Enabling access control to information."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### How can we build a basic RAG system ?\n",
+ "\n",
+ "A common approach for building a basic RAG systems is by:\n",
+ "\n",
+ "1. Encoding our documents, commonly referred to as generating embeddings of our documents.\n",
+ "2. Storing the generated embeddings in a vector store.\n",
+ "3. Encoding our user query.\n",
+ "4. Retrieving relevant documents from our vector store given the encoded user query.\n",
+ "5. Augmenting the user prompt with the retrieved context.\n",
+ "\n",
+ " \n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Key Stages:\n",
+ "\n",
+ "- **Stage 1: Indexing**\n",
+ " 1. Loading the documents from a source like a website, API, or database.\n",
+ " 2. Processing the documents into \"embeddable\" document chunks.\n",
+ " 3. Encoding the documents chunks into embedding vectors.\n",
+ " 4. Storing the document embedding vectors in a vector store.\n",
+ "- **Stage 2: Retrieval**\n",
+ " 1. Encoding the user query.\n",
+ " 2. Retrieving the most similar documents from the vector store given the encoded user query.\n",
+ "- **Stage 3: Generation**\n",
+ " 1. Augmenting the prompt with the provided context.\n",
+ " 2. Generating a response from the augmented prompt.\n",
+ "\n",
+ "Stage 1 is setup; Stages 2 and 3 are operational.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Next steps: Building a RAG-based QA engine for the Ray documentation\n",
+ "\n",
+ "We will start to build a RAG-based QA engine for the Ray documentation. This will be an attempt to recreate the \"Ask AI\" bot on the Ray [documentation website](https://docs.ray.io/en/latest/)."
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.10.11"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 4
+}
diff --git a/templates/ray-summit-rag/02_Index_Data.ipynb b/templates/ray-summit-rag/02_Index_Data.ipynb
new file mode 100644
index 000000000..ea776d870
--- /dev/null
+++ b/templates/ray-summit-rag/02_Index_Data.ipynb
@@ -0,0 +1,1804 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "84acd29e",
+ "metadata": {},
+ "source": [
+ "# Indexing Data for RAG using Ray Data\n",
+ "\n",
+ "The first stage of RAG is to index the data. This can be done by creating embeddings for the data and storing them in a vector store. \n",
+ "\n",
+ "This notebook will walk you through the process of creating an embedding pipeline and then scaling it with Ray Data.\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "da494e7d",
+ "metadata": {},
+ "source": [
+ "## Embeddings pipeline overview\n",
+ "\n",
+ "What are the steps involved in generating embeddings? In the most common case for text data, the steps are as follows:\n",
+ "\n",
+ "1. Load documents\n",
+ "2. Process documents into chunks\n",
+ " 1. Process documents into chunks\n",
+ " 2. Optionally persist chunks\n",
+ "3. Generate embeddings from chunks\n",
+ " 1. Generate embeddings from chunks\n",
+ " 2. Optionally persist embeddings\n",
+ "4. Upsert embeddings into a database"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "68c493e7",
+ "metadata": {},
+ "source": [
+ "## Simple pipeline for a real use-case"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "46bf7061",
+ "metadata": {},
+ "source": [
+ "Let's now assume we want to \"embed the Ray documentation website\". \n",
+ "\n",
+ "We will circle back and start with a small sample dataset taken from the ray documentation. \n",
+ "\n",
+ "To visualize our pipeline, see the diagram below:\n",
+ "\n",
+ "
\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Key Stages:\n",
+ "\n",
+ "- **Stage 1: Indexing**\n",
+ " 1. Loading the documents from a source like a website, API, or database.\n",
+ " 2. Processing the documents into \"embeddable\" document chunks.\n",
+ " 3. Encoding the documents chunks into embedding vectors.\n",
+ " 4. Storing the document embedding vectors in a vector store.\n",
+ "- **Stage 2: Retrieval**\n",
+ " 1. Encoding the user query.\n",
+ " 2. Retrieving the most similar documents from the vector store given the encoded user query.\n",
+ "- **Stage 3: Generation**\n",
+ " 1. Augmenting the prompt with the provided context.\n",
+ " 2. Generating a response from the augmented prompt.\n",
+ "\n",
+ "Stage 1 is setup; Stages 2 and 3 are operational.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Next steps: Building a RAG-based QA engine for the Ray documentation\n",
+ "\n",
+ "We will start to build a RAG-based QA engine for the Ray documentation. This will be an attempt to recreate the \"Ask AI\" bot on the Ray [documentation website](https://docs.ray.io/en/latest/)."
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.10.11"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 4
+}
diff --git a/templates/ray-summit-rag/02_Index_Data.ipynb b/templates/ray-summit-rag/02_Index_Data.ipynb
new file mode 100644
index 000000000..ea776d870
--- /dev/null
+++ b/templates/ray-summit-rag/02_Index_Data.ipynb
@@ -0,0 +1,1804 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "84acd29e",
+ "metadata": {},
+ "source": [
+ "# Indexing Data for RAG using Ray Data\n",
+ "\n",
+ "The first stage of RAG is to index the data. This can be done by creating embeddings for the data and storing them in a vector store. \n",
+ "\n",
+ "This notebook will walk you through the process of creating an embedding pipeline and then scaling it with Ray Data.\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "da494e7d",
+ "metadata": {},
+ "source": [
+ "## Embeddings pipeline overview\n",
+ "\n",
+ "What are the steps involved in generating embeddings? In the most common case for text data, the steps are as follows:\n",
+ "\n",
+ "1. Load documents\n",
+ "2. Process documents into chunks\n",
+ " 1. Process documents into chunks\n",
+ " 2. Optionally persist chunks\n",
+ "3. Generate embeddings from chunks\n",
+ " 1. Generate embeddings from chunks\n",
+ " 2. Optionally persist embeddings\n",
+ "4. Upsert embeddings into a database"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "68c493e7",
+ "metadata": {},
+ "source": [
+ "## Simple pipeline for a real use-case"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "46bf7061",
+ "metadata": {},
+ "source": [
+ "Let's now assume we want to \"embed the Ray documentation website\". \n",
+ "\n",
+ "We will circle back and start with a small sample dataset taken from the ray documentation. \n",
+ "\n",
+ "To visualize our pipeline, see the diagram below:\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2c035b5b",
+ "metadata": {},
+ "source": [
+ "### 1. Load documents\n",
+ "\n",
+ "First step, we load the data using `pandas`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7680f3d7",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "df = pd.read_json(DATA_DIR / \"small_sample\" / \"sample-input.jsonl\", lines=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "cef6158e-febf-48ae-aa1d-2ddb1d3a99bd",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "We have a dataset of 4 documents fetched from online content and stored as objects in a json file.\n",
+ "\n",
+ "Here are some of the notable columns:\n",
+ "- `text` column which contains the text of the document that we want to embed.\n",
+ "- `section_url` column which contains the section under which the document is found.\n",
+ "- `page_url` column which contains the page under which the document is found."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f189a745-6c07-432c-8a45-0e8f551e6a36",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "df"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "291194b7",
+ "metadata": {},
+ "source": [
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "aa786d3c",
+ "metadata": {},
+ "source": [
+ "### 2. Process documents into chunks\n",
+ "\n",
+ "Given a `ray.data.Dataset`, we can apply transformations to it. There are two types of transformations:\n",
+ "1. **row-wise transformations**\n",
+ " - `map`: a 1-to-1 function that is applied to each row in the dataset.\n",
+ " - `filter`: a 1-to-1 function that is applied to each row in the dataset and filters out rows that don’t satisfy the condition.\n",
+ " - `flat_map`: a 1-to-many function that is applied to each row in the dataset and then flattens the results into a single dataset.\n",
+ "2. **batch-wise transformations**\n",
+ " - `map_batches`: a 1-to-n function that is applied to each batch in the dataset.\n",
+ "\n",
+ "\n",
+ "We chose to make use of `flat_map` to generate a list of chunk rows. `flat_map` will create `FlatMap` tasks which will be scheduled in parallel to process as many rows as possible at once."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f52bb9ee",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "def chunk_row(row):\n",
+ " chunk_size = 128\n",
+ " words_to_tokens = 1.2\n",
+ " num_tokens = int(chunk_size // words_to_tokens)\n",
+ "\n",
+ " def get_num_words(text):\n",
+ " return len(text.split())\n",
+ "\n",
+ " splitter = RecursiveCharacterTextSplitter(\n",
+ " chunk_size=num_tokens,\n",
+ " keep_separator=True, \n",
+ " length_function=get_num_words, \n",
+ " chunk_overlap=0,\n",
+ " )\n",
+ "\n",
+ " chunks = []\n",
+ " for chunk in splitter.split_text(row[\"text\"]):\n",
+ " chunks.append(\n",
+ " {\n",
+ " \"text\": chunk,\n",
+ " \"section_url\": row[\"section_url\"],\n",
+ " \"page_url\": row[\"page_url\"],\n",
+ " }\n",
+ " )\n",
+ " return chunks\n",
+ "\n",
+ "ds_sample_input_chunked = ds_sample_input.flat_map(chunk_row)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "54c5ee9b",
+ "metadata": {},
+ "source": [
+ "To verify our `flat_map` is working, we can consume a limited number of rows from the dataset.\n",
+ "\n",
+ "To do so, we an either call\n",
+ "- `take` to specify a limited number of rows from the dataset.\n",
+ "- `take_batch` to specify a limited number of batches from the dataset.\n",
+ "\n",
+ "Here we call `take(2)` to return 2 rows."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "89bf2c18",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ds_sample_input_chunked.take(2)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ae6c2abb",
+ "metadata": {},
+ "source": [
+ "### 3. Generate embeddings from chunks\n",
+ "\n",
+ "For our third step, we apply the embeddings using `map_batches`, which will be implemented using `MapBatches` tasks scheduled in parallel."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e85a86f0",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "def embed_batch(batch):\n",
+ " assert isinstance(batch, dict)\n",
+ " for key in batch.keys():\n",
+ " assert key in [\"text\", \"section_url\", \"page_url\"]\n",
+ " for val in batch.values():\n",
+ " assert isinstance(val, np.ndarray), type(val)\n",
+ "\n",
+ " model = SentenceTransformer('thenlper/gte-large')\n",
+ " text = batch[\"text\"].tolist()\n",
+ " embeddings = model.encode(text, batch_size=len(text))\n",
+ " batch[\"embeddings\"] = embeddings.tolist()\n",
+ " return batch\n",
+ "\n",
+ "ds_sample_input_embedded = ds_sample_input_chunked.map_batches(embed_batch)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "52a97e92",
+ "metadata": {},
+ "source": [
+ "#### Save embeddings to disk\n",
+ "\n",
+ "For our fourth step, we write our dataset to parquet using `write_parquet`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3e8c08db",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "%%time\n",
+ "\n",
+ "output_path = DATA_DIR / \"small_sample\" / \"sample-output\"\n",
+ "if output_path.exists():\n",
+ " shutil.rmtree(output_path)\n",
+ "\n",
+ "ds_sample_input_embedded.write_parquet(output_path)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "18d6ccf4",
+ "metadata": {},
+ "source": [
+ "We inspect the created parquet output directory. Every write task will create a separate file in the output directory."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a389e8f8-e2c1-484c-9df4-c2e383b34fc9",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "!ls -llah {output_path} "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d2ef4b25",
+ "metadata": {},
+ "source": [
+ "We can read the parquet file back into a pandas dataframe."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "16a305d0-81e0-4c93-9770-9ed0a8b65e6b",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "df = ray.data.read_parquet(DATA_DIR / \"small_sample\" / \"sample-output\").to_pandas()\n",
+ "df"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "df7f7b49-4a0c-4160-bc35-341894ad4149",
+ "metadata": {},
+ "source": [
+ "### 4. Upsert embeddings to vector store\n",
+ "\n",
+ "The final step is to upsert the embeddings into a database. We will skip this step for now."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "efabf980",
+ "metadata": {},
+ "source": [
+ "**Recap**\n",
+ "\n",
+ "Here is our entire pipeline:\n",
+ "\n",
+ "```python\n",
+ "(\n",
+ " ray.data.read_json(DATA_DIR / \"small_sample\" / \"sample-input.jsonl\")\n",
+ " .flat_map(chunk_row)\n",
+ " .map_batches(embed_batch)\n",
+ " .write_parquet(DATA_DIR / \"small_sample\" / \"sample-output\")\n",
+ ")\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "380e0822",
+ "metadata": {},
+ "source": [
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2c035b5b",
+ "metadata": {},
+ "source": [
+ "### 1. Load documents\n",
+ "\n",
+ "First step, we load the data using `pandas`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7680f3d7",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "df = pd.read_json(DATA_DIR / \"small_sample\" / \"sample-input.jsonl\", lines=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "cef6158e-febf-48ae-aa1d-2ddb1d3a99bd",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "We have a dataset of 4 documents fetched from online content and stored as objects in a json file.\n",
+ "\n",
+ "Here are some of the notable columns:\n",
+ "- `text` column which contains the text of the document that we want to embed.\n",
+ "- `section_url` column which contains the section under which the document is found.\n",
+ "- `page_url` column which contains the page under which the document is found."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f189a745-6c07-432c-8a45-0e8f551e6a36",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "df"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "291194b7",
+ "metadata": {},
+ "source": [
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "aa786d3c",
+ "metadata": {},
+ "source": [
+ "### 2. Process documents into chunks\n",
+ "\n",
+ "Given a `ray.data.Dataset`, we can apply transformations to it. There are two types of transformations:\n",
+ "1. **row-wise transformations**\n",
+ " - `map`: a 1-to-1 function that is applied to each row in the dataset.\n",
+ " - `filter`: a 1-to-1 function that is applied to each row in the dataset and filters out rows that don’t satisfy the condition.\n",
+ " - `flat_map`: a 1-to-many function that is applied to each row in the dataset and then flattens the results into a single dataset.\n",
+ "2. **batch-wise transformations**\n",
+ " - `map_batches`: a 1-to-n function that is applied to each batch in the dataset.\n",
+ "\n",
+ "\n",
+ "We chose to make use of `flat_map` to generate a list of chunk rows. `flat_map` will create `FlatMap` tasks which will be scheduled in parallel to process as many rows as possible at once."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f52bb9ee",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "def chunk_row(row):\n",
+ " chunk_size = 128\n",
+ " words_to_tokens = 1.2\n",
+ " num_tokens = int(chunk_size // words_to_tokens)\n",
+ "\n",
+ " def get_num_words(text):\n",
+ " return len(text.split())\n",
+ "\n",
+ " splitter = RecursiveCharacterTextSplitter(\n",
+ " chunk_size=num_tokens,\n",
+ " keep_separator=True, \n",
+ " length_function=get_num_words, \n",
+ " chunk_overlap=0,\n",
+ " )\n",
+ "\n",
+ " chunks = []\n",
+ " for chunk in splitter.split_text(row[\"text\"]):\n",
+ " chunks.append(\n",
+ " {\n",
+ " \"text\": chunk,\n",
+ " \"section_url\": row[\"section_url\"],\n",
+ " \"page_url\": row[\"page_url\"],\n",
+ " }\n",
+ " )\n",
+ " return chunks\n",
+ "\n",
+ "ds_sample_input_chunked = ds_sample_input.flat_map(chunk_row)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "54c5ee9b",
+ "metadata": {},
+ "source": [
+ "To verify our `flat_map` is working, we can consume a limited number of rows from the dataset.\n",
+ "\n",
+ "To do so, we an either call\n",
+ "- `take` to specify a limited number of rows from the dataset.\n",
+ "- `take_batch` to specify a limited number of batches from the dataset.\n",
+ "\n",
+ "Here we call `take(2)` to return 2 rows."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "89bf2c18",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ds_sample_input_chunked.take(2)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ae6c2abb",
+ "metadata": {},
+ "source": [
+ "### 3. Generate embeddings from chunks\n",
+ "\n",
+ "For our third step, we apply the embeddings using `map_batches`, which will be implemented using `MapBatches` tasks scheduled in parallel."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e85a86f0",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "def embed_batch(batch):\n",
+ " assert isinstance(batch, dict)\n",
+ " for key in batch.keys():\n",
+ " assert key in [\"text\", \"section_url\", \"page_url\"]\n",
+ " for val in batch.values():\n",
+ " assert isinstance(val, np.ndarray), type(val)\n",
+ "\n",
+ " model = SentenceTransformer('thenlper/gte-large')\n",
+ " text = batch[\"text\"].tolist()\n",
+ " embeddings = model.encode(text, batch_size=len(text))\n",
+ " batch[\"embeddings\"] = embeddings.tolist()\n",
+ " return batch\n",
+ "\n",
+ "ds_sample_input_embedded = ds_sample_input_chunked.map_batches(embed_batch)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "52a97e92",
+ "metadata": {},
+ "source": [
+ "#### Save embeddings to disk\n",
+ "\n",
+ "For our fourth step, we write our dataset to parquet using `write_parquet`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3e8c08db",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "%%time\n",
+ "\n",
+ "output_path = DATA_DIR / \"small_sample\" / \"sample-output\"\n",
+ "if output_path.exists():\n",
+ " shutil.rmtree(output_path)\n",
+ "\n",
+ "ds_sample_input_embedded.write_parquet(output_path)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "18d6ccf4",
+ "metadata": {},
+ "source": [
+ "We inspect the created parquet output directory. Every write task will create a separate file in the output directory."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a389e8f8-e2c1-484c-9df4-c2e383b34fc9",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "!ls -llah {output_path} "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d2ef4b25",
+ "metadata": {},
+ "source": [
+ "We can read the parquet file back into a pandas dataframe."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "16a305d0-81e0-4c93-9770-9ed0a8b65e6b",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "df = ray.data.read_parquet(DATA_DIR / \"small_sample\" / \"sample-output\").to_pandas()\n",
+ "df"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "df7f7b49-4a0c-4160-bc35-341894ad4149",
+ "metadata": {},
+ "source": [
+ "### 4. Upsert embeddings to vector store\n",
+ "\n",
+ "The final step is to upsert the embeddings into a database. We will skip this step for now."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "efabf980",
+ "metadata": {},
+ "source": [
+ "**Recap**\n",
+ "\n",
+ "Here is our entire pipeline:\n",
+ "\n",
+ "```python\n",
+ "(\n",
+ " ray.data.read_json(DATA_DIR / \"small_sample\" / \"sample-input.jsonl\")\n",
+ " .flat_map(chunk_row)\n",
+ " .map_batches(embed_batch)\n",
+ " .write_parquet(DATA_DIR / \"small_sample\" / \"sample-output\")\n",
+ ")\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "380e0822",
+ "metadata": {},
+ "source": [
+ " \n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0b675c09",
+ "metadata": {},
+ "source": [
+ "### Phase 1: Preparing input files\n",
+ "\n",
+ "First, we need to prepare our documents by performing the following steps\n",
+ "1. Fetch all the Ray documentation from the web.\n",
+ "2. Parse the web pages to extract the text."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "667c2c2f",
+ "metadata": {},
+ "source": [
+ "#### 1. Fetch all the Ray documentation from the web.\n",
+ "\n",
+ "We have already fetched the Ray documentation and stored it on S3."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6c88dbbe",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "raw_web_pages_dir = CloudPath(\n",
+ " \"s3://anyscale-public-materials/ray-documentation-html-files/unzipped/\"\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "14628649",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "raw_web_pages_dir.exists(), raw_web_pages_dir.is_dir()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "dfc2b87f",
+ "metadata": {},
+ "source": [
+ "#### 2. Parse the web pages to extract the text.\n",
+ "\n",
+ "We first read all HTML files in the raw web pages directory into a `ray.data.Dataset`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "cebe9021",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ds_web_page_paths = ray.data.from_items(\n",
+ " [{\"path\": path} for path in raw_web_pages_dir.glob(\"**/*.html\")]\n",
+ ")\n",
+ "ds_web_page_paths"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d448ad80",
+ "metadata": {},
+ "source": [
+ "Note that this only includes the latest version of the ray documentation. This size would be drastically multiplied if we included all versions of the documentation."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2f788923",
+ "metadata": {},
+ "source": [
+ "##### Utilize inherent structure to improve the documents \n",
+ "\n",
+ "Documentation [webpages](https://docs.ray.io/en/latest/rllib/rllib-env.html) are naturally split into sections. We can use this to our advantage by returning our documents as sections. This will facilitate producing semantically coherent chunks. \n",
+ "\n",
+ "
\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0b675c09",
+ "metadata": {},
+ "source": [
+ "### Phase 1: Preparing input files\n",
+ "\n",
+ "First, we need to prepare our documents by performing the following steps\n",
+ "1. Fetch all the Ray documentation from the web.\n",
+ "2. Parse the web pages to extract the text."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "667c2c2f",
+ "metadata": {},
+ "source": [
+ "#### 1. Fetch all the Ray documentation from the web.\n",
+ "\n",
+ "We have already fetched the Ray documentation and stored it on S3."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6c88dbbe",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "raw_web_pages_dir = CloudPath(\n",
+ " \"s3://anyscale-public-materials/ray-documentation-html-files/unzipped/\"\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "14628649",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "raw_web_pages_dir.exists(), raw_web_pages_dir.is_dir()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "dfc2b87f",
+ "metadata": {},
+ "source": [
+ "#### 2. Parse the web pages to extract the text.\n",
+ "\n",
+ "We first read all HTML files in the raw web pages directory into a `ray.data.Dataset`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "cebe9021",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ds_web_page_paths = ray.data.from_items(\n",
+ " [{\"path\": path} for path in raw_web_pages_dir.glob(\"**/*.html\")]\n",
+ ")\n",
+ "ds_web_page_paths"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d448ad80",
+ "metadata": {},
+ "source": [
+ "Note that this only includes the latest version of the ray documentation. This size would be drastically multiplied if we included all versions of the documentation."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2f788923",
+ "metadata": {},
+ "source": [
+ "##### Utilize inherent structure to improve the documents \n",
+ "\n",
+ "Documentation [webpages](https://docs.ray.io/en/latest/rllib/rllib-env.html) are naturally split into sections. We can use this to our advantage by returning our documents as sections. This will facilitate producing semantically coherent chunks. \n",
+ "\n",
+ " \n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "25b5a4dc",
+ "metadata": {},
+ "source": [
+ "We are producing multiple documents from each HTML file. We will use the `flat_map` method to produce multiple documents from each HTML file."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "44037192",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "def path_to_uri(\n",
+ " path: CloudPath, scheme: str = \"https://\", domain: str = \"docs.ray.io\"\n",
+ ") -> str:\n",
+ " return scheme + domain + str(path).split(domain)[-1]\n",
+ "\n",
+ "def extract_sections_from_html(record: dict) -> list[dict]:\n",
+ " documents = []\n",
+ " # 1. Request the page and parse it using BeautifulSoup\n",
+ " with record[\"path\"].open(\"r\", encoding=\"utf-8\", force_overwrite_from_cloud=True) as html_file:\n",
+ " soup = BeautifulSoup(html_file, \"html.parser\")\n",
+ "\n",
+ " page_url = path_to_uri(record[\"path\"])\n",
+ "\n",
+ " # 2. Find all sections\n",
+ " sections = soup.find_all(\"section\")\n",
+ " for section in sections:\n",
+ " # 3. Extract text from the section but not from the subsections\n",
+ " section_text = \"\\n\".join(\n",
+ " [child.text for child in section.children if child.name != \"section\"]\n",
+ " )\n",
+ " # 4. Construct the section url\n",
+ " section_url = page_url + \"#\" + section[\"id\"]\n",
+ " # 5. Create a document object with the text, source page, source section uri\n",
+ " documents.append(\n",
+ " {\n",
+ " \"text\": section_text,\n",
+ " \"section_url\": section_url,\n",
+ " \"page_url\": page_url,\n",
+ " }\n",
+ " )\n",
+ " return documents\n",
+ "\n",
+ "\n",
+ "ds_sections = ds_web_page_paths.flat_map(extract_sections_from_html)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8f853bd4",
+ "metadata": {},
+ "source": [
+ "Finally we store the produced dataset in parquet format."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a6fff8e1",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "%%time\n",
+ "if (DATA_DIR / \"full_scale\" / \"02_sections\").exists():\n",
+ " shutil.rmtree(DATA_DIR / \"full_scale\" / \"02_sections\")\n",
+ "ds_sections.write_parquet(DATA_DIR / \"full_scale\" / \"02_sections\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9b27d396",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "!ls -llh {DATA_DIR / \"full_scale\" / \"02_sections\"}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "aeda8999-9b56-4347-b3bd-6f740ece7b54",
+ "metadata": {},
+ "source": [
+ "Let's count how many documents we will have after processing the sections."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "45d20170-970e-4c41-a830-19b28a36ed08",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ray.data.read_parquet(DATA_DIR / \"full_scale\" / \"02_sections\").count()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a8c55a29",
+ "metadata": {},
+ "source": [
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "59e3516c",
+ "metadata": {},
+ "source": [
+ "## 1. Building Retriever components\n",
+ "Retrieval is implemented in the following steps:\n",
+ "\n",
+ "1. Encode the user query\n",
+ "2. Search the vector store\n",
+ "3. Compose a context from the retrieved documents"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d3ac27aa",
+ "metadata": {},
+ "source": [
+ "### 1. Encode the user query\n",
+ "To encode the query, we will use the same embedding model that we used to encode the documents. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "aa4db779",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class QueryEncoder:\n",
+ " def __init__(self):\n",
+ " self.embedding_model_name = EMBEDDING_MODEL_NAME\n",
+ " self.model = SentenceTransformer(self.embedding_model_name)\n",
+ "\n",
+ " def encode(self, query: str) -> list[float]:\n",
+ " return self.model.encode(query).tolist()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "62ce0b02",
+ "metadata": {},
+ "source": [
+ "We try out our QueryEncoder by encoding a sample query relevant to our domain."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "eb4c7627",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "query_encoder = QueryEncoder()\n",
+ "query = \"How can I deploy Ray Serve to Kubernetes?\"\n",
+ "embeddings_vector = query_encoder.encode(query)\n",
+ "\n",
+ "type(embeddings_vector), len(embeddings_vector)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ca5b790f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "embeddings_vector[:5]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "73087086",
+ "metadata": {},
+ "source": [
+ "### 2. Search the vector store\n",
+ "Next, we will search the vector store to retrieve the closest documents to the query.\n",
+ "\n",
+ "We implement a `VectorStore` abstraction that reiles on the chroma client to search the vector store."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "56e07e22",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class VectorStore:\n",
+ " def __init__(self):\n",
+ " chroma_client = chromadb.PersistentClient(\n",
+ " path=\"/mnt/cluster_storage/vector_store\"\n",
+ " )\n",
+ " self._collection = chroma_client.get_collection(CHROMA_COLLECTION_NAME)\n",
+ "\n",
+ " def query(self, query_embedding: list[float], top_k: int) -> dict:\n",
+ " \"\"\"Retrieve the most similar chunks to the given query embedding.\"\"\"\n",
+ " if top_k == 0:\n",
+ " return {\"documents\": [], \"usage\": {}}\n",
+ "\n",
+ " response = self._collection.query(\n",
+ " query_embeddings=[query_embedding],\n",
+ " n_results=top_k,\n",
+ " )\n",
+ "\n",
+ " return {\n",
+ " \"documents\": [\n",
+ " {\n",
+ " \"text\": text,\n",
+ " \"section_url\": metadata[\"section_url\"],\n",
+ " }\n",
+ " for text, metadata in zip(\n",
+ " response[\"documents\"][0], response[\"metadatas\"][0]\n",
+ " )\n",
+ " ],\n",
+ " }"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2141b44c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "vector_store = VectorStore()\n",
+ "vector_store_response = vector_store.query(\n",
+ " query_embedding=embeddings_vector,\n",
+ " top_k=3,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "32ae23d4",
+ "metadata": {},
+ "source": [
+ "We can inspect the retrieved document URLs given our query"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "33e0e6be",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "for doc in vector_store_response[\"documents\"]:\n",
+ " print(doc[\"section_url\"])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b50af105",
+ "metadata": {},
+ "source": [
+ "### 3. Compose a context from the retrieved documents\n",
+ "\n",
+ "We put together a `Retriever` that encapsulates the entire retrieval process so far.\n",
+ "\n",
+ "It also composes the context from the retrieved documents by simply concatenating the retrieved chunks."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2e0a5a9c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class Retriever:\n",
+ " def __init__(self, query_encoder, vector_store):\n",
+ " self.query_encoder = query_encoder\n",
+ " self.vector_store = vector_store\n",
+ "\n",
+ " def _compose_context(self, contexts: list[str]) -> str:\n",
+ " sep = 100 * \"-\"\n",
+ " return \"\\n\\n\".join([f\"{sep}\\n{context}\" for context in contexts])\n",
+ "\n",
+ " def retrieve(self, query: str, top_k: int) -> dict:\n",
+ " \"\"\"Retrieve the context and sources for the given query.\"\"\"\n",
+ " encoded_query = self.query_encoder.encode(query)\n",
+ " vector_store_response = self.vector_store.query(\n",
+ " query_embedding=encoded_query,\n",
+ " top_k=top_k,\n",
+ " )\n",
+ " contexts = [chunk[\"text\"] for chunk in vector_store_response[\"documents\"]]\n",
+ " sources = [chunk[\"section_url\"] for chunk in vector_store_response[\"documents\"]]\n",
+ " return {\n",
+ " \"contexts\": contexts,\n",
+ " \"composed_context\": self._compose_context(contexts),\n",
+ " \"sources\": sources,\n",
+ " }"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e6a32543",
+ "metadata": {},
+ "source": [
+ "We run the retriever to check it is working as expected\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c3b5997c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "retriever = Retriever(query_encoder=query_encoder, vector_store=vector_store)\n",
+ "retrieval_response = retriever.retrieve(\n",
+ " query=query,\n",
+ " top_k=3,\n",
+ ")\n",
+ "retrieval_response"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e350b905",
+ "metadata": {},
+ "source": [
+ "We inspect the retrieved context"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b3438a51",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(retrieval_response[\"composed_context\"])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6687d2a7",
+ "metadata": {},
+ "source": [
+ "## 2. Building Response Generation\n",
+ "\n",
+ "We will generate a response using an LLM server offering an openai-compatible API.\n",
+ "\n",
+ "To do so we implement a simple LLM client class that encapsulates the generation process."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8969eb0b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class LLMClient:\n",
+ " def __init__(self):\n",
+ " # Initialize a client to perform API requests\n",
+ " self.client = openai.OpenAI(\n",
+ " base_url=ANYSCALE_SERVICE_BASE_URL,\n",
+ " api_key=ANYSCALE_API_KEY,\n",
+ " )\n",
+ "\n",
+ " def generate(self, user_prompt: str, model=\"mistralai/Mistral-7B-Instruct-v0.1\", temperature: float = 0, **kwargs: Any) -> ChatCompletion:\n",
+ " \"\"\"Generate a completion from the given user prompt.\"\"\"\n",
+ " # Call the chat completions endpoint\n",
+ " chat_completion = self.client.chat.completions.create(\n",
+ " model=model,\n",
+ " messages=[\n",
+ " # Prime the system with a system message - a common best practice\n",
+ " {\"role\": \"system\", \"content\": \"You are a helpful assistant.\"},\n",
+ " # Send the user message with the proper \"user\" role and \"content\"\n",
+ " {\"role\": \"user\", \"content\": user_prompt},\n",
+ " ],\n",
+ " temperature=temperature,\n",
+ " **kwargs,\n",
+ " )\n",
+ "\n",
+ " return chat_completion"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "470e493a",
+ "metadata": {},
+ "source": [
+ "Note we are currently making use of an already deployed open-source LLM running on Anyscale.\n",
+ "\n",
+ "In case you want to deploy your own LLM, you can follow the instructions in the [Anyscale documentation](https://docs.anyscale.com/)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "29ca2e50",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "llm_client = LLMClient()\n",
+ "response = llm_client.generate(\"What is the capital of France?\")\n",
+ "print(response.choices[0].message.content)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3f1b49c6",
+ "metadata": {},
+ "source": [
+ "## 3. Putting it all together into a QA Engine\n",
+ "Given a user query we will want our RAG based QA engine to perform the following steps:\n",
+ "\n",
+ "1. Retrieve the closest documents to the query\n",
+ "2. Augment the query with the context\n",
+ "3. Generate a response to the augmented query"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "10197527",
+ "metadata": {},
+ "source": [
+ "We decide on a simple prompt template to augment the user's query with the retrieved context. The template is as follows:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "668f5d82",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "prompt_template_rag = \"\"\"\n",
+ "Given the following context:\n",
+ "{composed_context}\n",
+ "\n",
+ "Answer the following question:\n",
+ "{query}\n",
+ "\n",
+ "If you cannot provide an answer based on the context, please say \"I don't know.\"\n",
+ "Do not use the term \"context\" in your response.\"\"\"\n",
+ "\n",
+ "\n",
+ "def augment_prompt(query: str, composed_context: str) -> str:\n",
+ " \"\"\"Augment the prompt with the given query and contexts.\"\"\"\n",
+ " return prompt_template_rag.format(composed_context=composed_context, query=query)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "100fabee",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "augmented_prompt = augment_prompt(\n",
+ " query=query,\n",
+ " composed_context=retrieval_response[\"composed_context\"],\n",
+ ")\n",
+ "print(augmented_prompt)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a380ede7",
+ "metadata": {},
+ "source": [
+ "
\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "25b5a4dc",
+ "metadata": {},
+ "source": [
+ "We are producing multiple documents from each HTML file. We will use the `flat_map` method to produce multiple documents from each HTML file."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "44037192",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "def path_to_uri(\n",
+ " path: CloudPath, scheme: str = \"https://\", domain: str = \"docs.ray.io\"\n",
+ ") -> str:\n",
+ " return scheme + domain + str(path).split(domain)[-1]\n",
+ "\n",
+ "def extract_sections_from_html(record: dict) -> list[dict]:\n",
+ " documents = []\n",
+ " # 1. Request the page and parse it using BeautifulSoup\n",
+ " with record[\"path\"].open(\"r\", encoding=\"utf-8\", force_overwrite_from_cloud=True) as html_file:\n",
+ " soup = BeautifulSoup(html_file, \"html.parser\")\n",
+ "\n",
+ " page_url = path_to_uri(record[\"path\"])\n",
+ "\n",
+ " # 2. Find all sections\n",
+ " sections = soup.find_all(\"section\")\n",
+ " for section in sections:\n",
+ " # 3. Extract text from the section but not from the subsections\n",
+ " section_text = \"\\n\".join(\n",
+ " [child.text for child in section.children if child.name != \"section\"]\n",
+ " )\n",
+ " # 4. Construct the section url\n",
+ " section_url = page_url + \"#\" + section[\"id\"]\n",
+ " # 5. Create a document object with the text, source page, source section uri\n",
+ " documents.append(\n",
+ " {\n",
+ " \"text\": section_text,\n",
+ " \"section_url\": section_url,\n",
+ " \"page_url\": page_url,\n",
+ " }\n",
+ " )\n",
+ " return documents\n",
+ "\n",
+ "\n",
+ "ds_sections = ds_web_page_paths.flat_map(extract_sections_from_html)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8f853bd4",
+ "metadata": {},
+ "source": [
+ "Finally we store the produced dataset in parquet format."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a6fff8e1",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "%%time\n",
+ "if (DATA_DIR / \"full_scale\" / \"02_sections\").exists():\n",
+ " shutil.rmtree(DATA_DIR / \"full_scale\" / \"02_sections\")\n",
+ "ds_sections.write_parquet(DATA_DIR / \"full_scale\" / \"02_sections\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9b27d396",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "!ls -llh {DATA_DIR / \"full_scale\" / \"02_sections\"}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "aeda8999-9b56-4347-b3bd-6f740ece7b54",
+ "metadata": {},
+ "source": [
+ "Let's count how many documents we will have after processing the sections."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "45d20170-970e-4c41-a830-19b28a36ed08",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ray.data.read_parquet(DATA_DIR / \"full_scale\" / \"02_sections\").count()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a8c55a29",
+ "metadata": {},
+ "source": [
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "59e3516c",
+ "metadata": {},
+ "source": [
+ "## 1. Building Retriever components\n",
+ "Retrieval is implemented in the following steps:\n",
+ "\n",
+ "1. Encode the user query\n",
+ "2. Search the vector store\n",
+ "3. Compose a context from the retrieved documents"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d3ac27aa",
+ "metadata": {},
+ "source": [
+ "### 1. Encode the user query\n",
+ "To encode the query, we will use the same embedding model that we used to encode the documents. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "aa4db779",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class QueryEncoder:\n",
+ " def __init__(self):\n",
+ " self.embedding_model_name = EMBEDDING_MODEL_NAME\n",
+ " self.model = SentenceTransformer(self.embedding_model_name)\n",
+ "\n",
+ " def encode(self, query: str) -> list[float]:\n",
+ " return self.model.encode(query).tolist()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "62ce0b02",
+ "metadata": {},
+ "source": [
+ "We try out our QueryEncoder by encoding a sample query relevant to our domain."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "eb4c7627",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "query_encoder = QueryEncoder()\n",
+ "query = \"How can I deploy Ray Serve to Kubernetes?\"\n",
+ "embeddings_vector = query_encoder.encode(query)\n",
+ "\n",
+ "type(embeddings_vector), len(embeddings_vector)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ca5b790f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "embeddings_vector[:5]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "73087086",
+ "metadata": {},
+ "source": [
+ "### 2. Search the vector store\n",
+ "Next, we will search the vector store to retrieve the closest documents to the query.\n",
+ "\n",
+ "We implement a `VectorStore` abstraction that reiles on the chroma client to search the vector store."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "56e07e22",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class VectorStore:\n",
+ " def __init__(self):\n",
+ " chroma_client = chromadb.PersistentClient(\n",
+ " path=\"/mnt/cluster_storage/vector_store\"\n",
+ " )\n",
+ " self._collection = chroma_client.get_collection(CHROMA_COLLECTION_NAME)\n",
+ "\n",
+ " def query(self, query_embedding: list[float], top_k: int) -> dict:\n",
+ " \"\"\"Retrieve the most similar chunks to the given query embedding.\"\"\"\n",
+ " if top_k == 0:\n",
+ " return {\"documents\": [], \"usage\": {}}\n",
+ "\n",
+ " response = self._collection.query(\n",
+ " query_embeddings=[query_embedding],\n",
+ " n_results=top_k,\n",
+ " )\n",
+ "\n",
+ " return {\n",
+ " \"documents\": [\n",
+ " {\n",
+ " \"text\": text,\n",
+ " \"section_url\": metadata[\"section_url\"],\n",
+ " }\n",
+ " for text, metadata in zip(\n",
+ " response[\"documents\"][0], response[\"metadatas\"][0]\n",
+ " )\n",
+ " ],\n",
+ " }"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2141b44c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "vector_store = VectorStore()\n",
+ "vector_store_response = vector_store.query(\n",
+ " query_embedding=embeddings_vector,\n",
+ " top_k=3,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "32ae23d4",
+ "metadata": {},
+ "source": [
+ "We can inspect the retrieved document URLs given our query"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "33e0e6be",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "for doc in vector_store_response[\"documents\"]:\n",
+ " print(doc[\"section_url\"])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b50af105",
+ "metadata": {},
+ "source": [
+ "### 3. Compose a context from the retrieved documents\n",
+ "\n",
+ "We put together a `Retriever` that encapsulates the entire retrieval process so far.\n",
+ "\n",
+ "It also composes the context from the retrieved documents by simply concatenating the retrieved chunks."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2e0a5a9c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class Retriever:\n",
+ " def __init__(self, query_encoder, vector_store):\n",
+ " self.query_encoder = query_encoder\n",
+ " self.vector_store = vector_store\n",
+ "\n",
+ " def _compose_context(self, contexts: list[str]) -> str:\n",
+ " sep = 100 * \"-\"\n",
+ " return \"\\n\\n\".join([f\"{sep}\\n{context}\" for context in contexts])\n",
+ "\n",
+ " def retrieve(self, query: str, top_k: int) -> dict:\n",
+ " \"\"\"Retrieve the context and sources for the given query.\"\"\"\n",
+ " encoded_query = self.query_encoder.encode(query)\n",
+ " vector_store_response = self.vector_store.query(\n",
+ " query_embedding=encoded_query,\n",
+ " top_k=top_k,\n",
+ " )\n",
+ " contexts = [chunk[\"text\"] for chunk in vector_store_response[\"documents\"]]\n",
+ " sources = [chunk[\"section_url\"] for chunk in vector_store_response[\"documents\"]]\n",
+ " return {\n",
+ " \"contexts\": contexts,\n",
+ " \"composed_context\": self._compose_context(contexts),\n",
+ " \"sources\": sources,\n",
+ " }"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e6a32543",
+ "metadata": {},
+ "source": [
+ "We run the retriever to check it is working as expected\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c3b5997c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "retriever = Retriever(query_encoder=query_encoder, vector_store=vector_store)\n",
+ "retrieval_response = retriever.retrieve(\n",
+ " query=query,\n",
+ " top_k=3,\n",
+ ")\n",
+ "retrieval_response"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e350b905",
+ "metadata": {},
+ "source": [
+ "We inspect the retrieved context"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b3438a51",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(retrieval_response[\"composed_context\"])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6687d2a7",
+ "metadata": {},
+ "source": [
+ "## 2. Building Response Generation\n",
+ "\n",
+ "We will generate a response using an LLM server offering an openai-compatible API.\n",
+ "\n",
+ "To do so we implement a simple LLM client class that encapsulates the generation process."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8969eb0b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class LLMClient:\n",
+ " def __init__(self):\n",
+ " # Initialize a client to perform API requests\n",
+ " self.client = openai.OpenAI(\n",
+ " base_url=ANYSCALE_SERVICE_BASE_URL,\n",
+ " api_key=ANYSCALE_API_KEY,\n",
+ " )\n",
+ "\n",
+ " def generate(self, user_prompt: str, model=\"mistralai/Mistral-7B-Instruct-v0.1\", temperature: float = 0, **kwargs: Any) -> ChatCompletion:\n",
+ " \"\"\"Generate a completion from the given user prompt.\"\"\"\n",
+ " # Call the chat completions endpoint\n",
+ " chat_completion = self.client.chat.completions.create(\n",
+ " model=model,\n",
+ " messages=[\n",
+ " # Prime the system with a system message - a common best practice\n",
+ " {\"role\": \"system\", \"content\": \"You are a helpful assistant.\"},\n",
+ " # Send the user message with the proper \"user\" role and \"content\"\n",
+ " {\"role\": \"user\", \"content\": user_prompt},\n",
+ " ],\n",
+ " temperature=temperature,\n",
+ " **kwargs,\n",
+ " )\n",
+ "\n",
+ " return chat_completion"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "470e493a",
+ "metadata": {},
+ "source": [
+ "Note we are currently making use of an already deployed open-source LLM running on Anyscale.\n",
+ "\n",
+ "In case you want to deploy your own LLM, you can follow the instructions in the [Anyscale documentation](https://docs.anyscale.com/)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "29ca2e50",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "llm_client = LLMClient()\n",
+ "response = llm_client.generate(\"What is the capital of France?\")\n",
+ "print(response.choices[0].message.content)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3f1b49c6",
+ "metadata": {},
+ "source": [
+ "## 3. Putting it all together into a QA Engine\n",
+ "Given a user query we will want our RAG based QA engine to perform the following steps:\n",
+ "\n",
+ "1. Retrieve the closest documents to the query\n",
+ "2. Augment the query with the context\n",
+ "3. Generate a response to the augmented query"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "10197527",
+ "metadata": {},
+ "source": [
+ "We decide on a simple prompt template to augment the user's query with the retrieved context. The template is as follows:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "668f5d82",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "prompt_template_rag = \"\"\"\n",
+ "Given the following context:\n",
+ "{composed_context}\n",
+ "\n",
+ "Answer the following question:\n",
+ "{query}\n",
+ "\n",
+ "If you cannot provide an answer based on the context, please say \"I don't know.\"\n",
+ "Do not use the term \"context\" in your response.\"\"\"\n",
+ "\n",
+ "\n",
+ "def augment_prompt(query: str, composed_context: str) -> str:\n",
+ " \"\"\"Augment the prompt with the given query and contexts.\"\"\"\n",
+ " return prompt_template_rag.format(composed_context=composed_context, query=query)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "100fabee",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "augmented_prompt = augment_prompt(\n",
+ " query=query,\n",
+ " composed_context=retrieval_response[\"composed_context\"],\n",
+ ")\n",
+ "print(augmented_prompt)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a380ede7",
+ "metadata": {},
+ "source": [
+ " \n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "The `autoscaling_config` parameter specifies the minimum and maximum number of replicas that can be created. \n",
+ "\n",
+ "The `ray_actor_options` parameter specifies the resources allocated to each replica. In this case, we allocate 1/10th (0.1) of a GPU to each replica."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f8b846b0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@serve.deployment(\n",
+ " ray_actor_options={\"num_gpus\": 0.1},\n",
+ " autoscaling_config={\"min_replicas\": 1, \"max_replicas\": 2},\n",
+ ")\n",
+ "class QueryEncoder:\n",
+ " def __init__(self):\n",
+ " self.embedding_model_name = EMBEDDING_MODEL_NAME\n",
+ " self.model = SentenceTransformer(self.embedding_model_name, device=\"cuda\")\n",
+ "\n",
+ " def encode(self, query: str) -> list[float]:\n",
+ " return self.model.encode(query).tolist()\n",
+ "\n",
+ "\n",
+ "query_encoder = QueryEncoder.bind()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9ae07650",
+ "metadata": {},
+ "source": [
+ "To send a gRPC request to the deployment, we need to:\n",
+ "1. start running the deployment and fetch back its handle using `serve.run`\n",
+ "2. send a request to the deployment using the handle using `.remote()`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "eb6db68e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "query_encoder_handle = serve.run(query_encoder, route_prefix=\"/query-encoder\")\n",
+ "query = \"How can I deploy Ray Serve to Kubernetes?\"\n",
+ "embeddings_vector = await query_encoder_handle.encode.remote(query)\n",
+ "\n",
+ "type(embeddings_vector), len(embeddings_vector)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a9a3528c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "embeddings_vector[:5]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "67ce46aa",
+ "metadata": {},
+ "source": [
+ "### 2. Search the vector store\n",
+ "\n",
+ "Next we would wrap the vector store with a `serve.deployment`. \n",
+ "\n",
+ "Note, we resort to a hack to ensure the vector store is running on the head node. This is because we are running a local chromadb in development mode which does not allow for concurrent access across nodes."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e314b9d7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@serve.deployment(\n",
+ " ray_actor_options={\"num_cpus\": 0, \"resources\": {\"is_head_node\": 1}},\n",
+ ")\n",
+ "class VectorStore:\n",
+ " def __init__(self):\n",
+ " chroma_client = chromadb.PersistentClient(\n",
+ " path=\"/mnt/cluster_storage/vector_store\"\n",
+ " )\n",
+ " self._collection = chroma_client.get_collection(CHROMA_COLLECTION_NAME)\n",
+ "\n",
+ " async def query(self, query_embedding: list[float], top_k: int) -> dict:\n",
+ " \"\"\"Retrieve the most similar chunks to the given query embedding.\"\"\"\n",
+ " if top_k == 0:\n",
+ " return {\"documents\": [], \"usage\": {}}\n",
+ "\n",
+ " response = self._collection.query(\n",
+ " query_embeddings=[query_embedding],\n",
+ " n_results=top_k,\n",
+ " )\n",
+ "\n",
+ " return {\n",
+ " \"documents\": [\n",
+ " {\n",
+ " \"text\": text,\n",
+ " \"section_url\": metadata[\"section_url\"],\n",
+ " }\n",
+ " for text, metadata in zip(\n",
+ " response[\"documents\"][0], response[\"metadatas\"][0]\n",
+ " )\n",
+ " ],\n",
+ " }\n",
+ "\n",
+ "vector_store = VectorStore.bind()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f1b7ebeb",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "vector_store_handle = serve.run(vector_store, route_prefix=\"/vector-store\")\n",
+ "vector_store_response = await vector_store_handle.query.remote(\n",
+ " query_embedding=embeddings_vector,\n",
+ " top_k=3,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9381166d",
+ "metadata": {},
+ "source": [
+ "We can inspect the retrieved document URLs given our query"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d91c7f69",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "for doc in vector_store_response[\"documents\"]:\n",
+ " print(doc[\"section_url\"])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d5310c44",
+ "metadata": {},
+ "source": [
+ "### 3. Compose a context from the retrieved documents\n",
+ "\n",
+ "We put together a `Retriever` that encapsulates the entire retrieval process so far.\n",
+ "\n",
+ "It also composes the context from the retrieved documents by simply concatenating the retrieved chunks."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "842765a1",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@serve.deployment(\n",
+ " ray_actor_options={\"num_cpus\": 0.1},\n",
+ ")\n",
+ "class Retriever:\n",
+ " def __init__(self, query_encoder, vector_store):\n",
+ " self.query_encoder = query_encoder\n",
+ " self.vector_store = vector_store\n",
+ "\n",
+ " def _compose_context(self, contexts: list[str]) -> str:\n",
+ " sep = 100 * \"-\"\n",
+ " return \"\\n\\n\".join([f\"{sep}\\n{context}\" for context in contexts])\n",
+ "\n",
+ " async def retrieve(self, query: str, top_k: int) -> dict:\n",
+ " \"\"\"Retrieve the context and sources for the given query.\"\"\"\n",
+ " encoded_query = await self.query_encoder.encode.remote(query)\n",
+ " vector_store_response = await self.vector_store.query.remote(\n",
+ " query_embedding=encoded_query,\n",
+ " top_k=top_k,\n",
+ " )\n",
+ " contexts = [chunk[\"text\"] for chunk in vector_store_response[\"documents\"]]\n",
+ " sources = [chunk[\"section_url\"] for chunk in vector_store_response[\"documents\"]]\n",
+ " return {\n",
+ " \"contexts\": contexts,\n",
+ " \"composed_context\": self._compose_context(contexts),\n",
+ " \"sources\": sources,\n",
+ " }\n",
+ "\n",
+ "\n",
+ "retriever = Retriever.bind(query_encoder=query_encoder, vector_store=vector_store)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f916b83c",
+ "metadata": {},
+ "source": [
+ "We run the retriever to check it is working as expected"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a4496e4b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "retriever_handle = serve.run(retriever, route_prefix=\"/retriever\")\n",
+ "retrieval_response = await retriever_handle.retrieve.remote(\n",
+ " query=query,\n",
+ " top_k=3,\n",
+ ")\n",
+ "retrieval_response"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ed7c0228",
+ "metadata": {},
+ "source": [
+ "We inspect the retrieved context"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8664a00a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(retrieval_response[\"composed_context\"])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f28bd2bf",
+ "metadata": {},
+ "source": [
+ "## 2. Building Response Generation\n",
+ "\n",
+ "Next we will wrap the LLM client as its own deployment. Here we showcase that we can also make use of fractional CPUs for this client deployment. \n",
+ "\n",
+ "Note: Separating the client as its own deployment is optional and could have been included in the QA engine deployment."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0c7dfe52",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@serve.deployment(\n",
+ " ray_actor_options={\"num_cpus\": 0.1},\n",
+ ")\n",
+ "class LLMClient:\n",
+ " def __init__(self):\n",
+ " # Initialize a client to perform API requests\n",
+ " self.client = openai.OpenAI(\n",
+ " base_url=ANYSCALE_SERVICE_BASE_URL,\n",
+ " api_key=ANYSCALE_API_KEY,\n",
+ " )\n",
+ "\n",
+ " def generate(\n",
+ " self,\n",
+ " user_prompt: str,\n",
+ " model=\"mistralai/Mistral-7B-Instruct-v0.1\",\n",
+ " temperature: float = 0,\n",
+ " **kwargs: Any,\n",
+ " ) -> ChatCompletion:\n",
+ " \"\"\"Generate a completion from the given user prompt.\"\"\"\n",
+ " # Call the chat completions endpoint\n",
+ " chat_completion = self.client.chat.completions.create(\n",
+ " model=model,\n",
+ " messages=[\n",
+ " # Prime the system with a system message - a common best practice\n",
+ " {\"role\": \"system\", \"content\": \"You are a helpful assistant.\"},\n",
+ " # Send the user message with the proper \"user\" role and \"content\"\n",
+ " {\"role\": \"user\", \"content\": user_prompt},\n",
+ " ],\n",
+ " temperature=temperature,\n",
+ " **kwargs,\n",
+ " )\n",
+ "\n",
+ " return chat_completion\n",
+ "\n",
+ "\n",
+ "llm_client = LLMClient.bind()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "36142cb0",
+ "metadata": {},
+ "source": [
+ "Note we are currently making use of an already deployed open-source LLM running on Anyscale.\n",
+ "\n",
+ "In case you want to deploy your own LLM, you can follow this [ready-built Anyscale Deploy LLMs template](https://console.anyscale.com/v2/template-preview/endpoints_v2)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b22be87b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "llm_client_handle = serve.run(llm_client, route_prefix=\"/llm\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "adde280d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "llm_response = await llm_client_handle.generate.remote( \n",
+ " user_prompt=\"What is the capital of France?\",\n",
+ ")\n",
+ "llm_response.choices[0].message.content"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fcab6183",
+ "metadata": {},
+ "source": [
+ "### Putting it all together\n",
+ "Given a user query we will want our RAG based QA engine to perform the following steps:\n",
+ "\n",
+ "1. Retrieve the closest documents to the query\n",
+ "2. Augment the query with the context\n",
+ "3. Generate a response to the augmented query"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "34304b2f",
+ "metadata": {},
+ "source": [
+ "We decide on a simple prompt template to augment the user's query with the retrieved context. The template is as follows:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "95d24422",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "prompt_template_rag = \"\"\"\n",
+ "Given the following context:\n",
+ "{composed_context}\n",
+ "\n",
+ "Answer the following question:\n",
+ "{query}\n",
+ "\n",
+ "If you cannot provide an answer based on the context, please say \"I don't know.\"\n",
+ "Do not use the term \"context\" in your response.\"\"\"\n",
+ "\n",
+ "\n",
+ "def augment_prompt(query: str, composed_context: str) -> str:\n",
+ " \"\"\"Augment the prompt with the given query and contexts.\"\"\"\n",
+ " return prompt_template_rag.format(composed_context=composed_context, query=query)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b2e67b56",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "augmented_prompt = augment_prompt(\n",
+ " \"How can I deploy Ray Serve to Kubernetes?\",\n",
+ " retrieval_response[\"composed_context\"],\n",
+ ")\n",
+ "print(augmented_prompt)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "78e56f6a",
+ "metadata": {},
+ "source": [
+ "
\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "The `autoscaling_config` parameter specifies the minimum and maximum number of replicas that can be created. \n",
+ "\n",
+ "The `ray_actor_options` parameter specifies the resources allocated to each replica. In this case, we allocate 1/10th (0.1) of a GPU to each replica."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f8b846b0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@serve.deployment(\n",
+ " ray_actor_options={\"num_gpus\": 0.1},\n",
+ " autoscaling_config={\"min_replicas\": 1, \"max_replicas\": 2},\n",
+ ")\n",
+ "class QueryEncoder:\n",
+ " def __init__(self):\n",
+ " self.embedding_model_name = EMBEDDING_MODEL_NAME\n",
+ " self.model = SentenceTransformer(self.embedding_model_name, device=\"cuda\")\n",
+ "\n",
+ " def encode(self, query: str) -> list[float]:\n",
+ " return self.model.encode(query).tolist()\n",
+ "\n",
+ "\n",
+ "query_encoder = QueryEncoder.bind()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9ae07650",
+ "metadata": {},
+ "source": [
+ "To send a gRPC request to the deployment, we need to:\n",
+ "1. start running the deployment and fetch back its handle using `serve.run`\n",
+ "2. send a request to the deployment using the handle using `.remote()`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "eb6db68e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "query_encoder_handle = serve.run(query_encoder, route_prefix=\"/query-encoder\")\n",
+ "query = \"How can I deploy Ray Serve to Kubernetes?\"\n",
+ "embeddings_vector = await query_encoder_handle.encode.remote(query)\n",
+ "\n",
+ "type(embeddings_vector), len(embeddings_vector)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a9a3528c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "embeddings_vector[:5]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "67ce46aa",
+ "metadata": {},
+ "source": [
+ "### 2. Search the vector store\n",
+ "\n",
+ "Next we would wrap the vector store with a `serve.deployment`. \n",
+ "\n",
+ "Note, we resort to a hack to ensure the vector store is running on the head node. This is because we are running a local chromadb in development mode which does not allow for concurrent access across nodes."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e314b9d7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@serve.deployment(\n",
+ " ray_actor_options={\"num_cpus\": 0, \"resources\": {\"is_head_node\": 1}},\n",
+ ")\n",
+ "class VectorStore:\n",
+ " def __init__(self):\n",
+ " chroma_client = chromadb.PersistentClient(\n",
+ " path=\"/mnt/cluster_storage/vector_store\"\n",
+ " )\n",
+ " self._collection = chroma_client.get_collection(CHROMA_COLLECTION_NAME)\n",
+ "\n",
+ " async def query(self, query_embedding: list[float], top_k: int) -> dict:\n",
+ " \"\"\"Retrieve the most similar chunks to the given query embedding.\"\"\"\n",
+ " if top_k == 0:\n",
+ " return {\"documents\": [], \"usage\": {}}\n",
+ "\n",
+ " response = self._collection.query(\n",
+ " query_embeddings=[query_embedding],\n",
+ " n_results=top_k,\n",
+ " )\n",
+ "\n",
+ " return {\n",
+ " \"documents\": [\n",
+ " {\n",
+ " \"text\": text,\n",
+ " \"section_url\": metadata[\"section_url\"],\n",
+ " }\n",
+ " for text, metadata in zip(\n",
+ " response[\"documents\"][0], response[\"metadatas\"][0]\n",
+ " )\n",
+ " ],\n",
+ " }\n",
+ "\n",
+ "vector_store = VectorStore.bind()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f1b7ebeb",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "vector_store_handle = serve.run(vector_store, route_prefix=\"/vector-store\")\n",
+ "vector_store_response = await vector_store_handle.query.remote(\n",
+ " query_embedding=embeddings_vector,\n",
+ " top_k=3,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9381166d",
+ "metadata": {},
+ "source": [
+ "We can inspect the retrieved document URLs given our query"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d91c7f69",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "for doc in vector_store_response[\"documents\"]:\n",
+ " print(doc[\"section_url\"])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d5310c44",
+ "metadata": {},
+ "source": [
+ "### 3. Compose a context from the retrieved documents\n",
+ "\n",
+ "We put together a `Retriever` that encapsulates the entire retrieval process so far.\n",
+ "\n",
+ "It also composes the context from the retrieved documents by simply concatenating the retrieved chunks."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "842765a1",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@serve.deployment(\n",
+ " ray_actor_options={\"num_cpus\": 0.1},\n",
+ ")\n",
+ "class Retriever:\n",
+ " def __init__(self, query_encoder, vector_store):\n",
+ " self.query_encoder = query_encoder\n",
+ " self.vector_store = vector_store\n",
+ "\n",
+ " def _compose_context(self, contexts: list[str]) -> str:\n",
+ " sep = 100 * \"-\"\n",
+ " return \"\\n\\n\".join([f\"{sep}\\n{context}\" for context in contexts])\n",
+ "\n",
+ " async def retrieve(self, query: str, top_k: int) -> dict:\n",
+ " \"\"\"Retrieve the context and sources for the given query.\"\"\"\n",
+ " encoded_query = await self.query_encoder.encode.remote(query)\n",
+ " vector_store_response = await self.vector_store.query.remote(\n",
+ " query_embedding=encoded_query,\n",
+ " top_k=top_k,\n",
+ " )\n",
+ " contexts = [chunk[\"text\"] for chunk in vector_store_response[\"documents\"]]\n",
+ " sources = [chunk[\"section_url\"] for chunk in vector_store_response[\"documents\"]]\n",
+ " return {\n",
+ " \"contexts\": contexts,\n",
+ " \"composed_context\": self._compose_context(contexts),\n",
+ " \"sources\": sources,\n",
+ " }\n",
+ "\n",
+ "\n",
+ "retriever = Retriever.bind(query_encoder=query_encoder, vector_store=vector_store)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f916b83c",
+ "metadata": {},
+ "source": [
+ "We run the retriever to check it is working as expected"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a4496e4b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "retriever_handle = serve.run(retriever, route_prefix=\"/retriever\")\n",
+ "retrieval_response = await retriever_handle.retrieve.remote(\n",
+ " query=query,\n",
+ " top_k=3,\n",
+ ")\n",
+ "retrieval_response"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ed7c0228",
+ "metadata": {},
+ "source": [
+ "We inspect the retrieved context"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8664a00a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(retrieval_response[\"composed_context\"])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f28bd2bf",
+ "metadata": {},
+ "source": [
+ "## 2. Building Response Generation\n",
+ "\n",
+ "Next we will wrap the LLM client as its own deployment. Here we showcase that we can also make use of fractional CPUs for this client deployment. \n",
+ "\n",
+ "Note: Separating the client as its own deployment is optional and could have been included in the QA engine deployment."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0c7dfe52",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@serve.deployment(\n",
+ " ray_actor_options={\"num_cpus\": 0.1},\n",
+ ")\n",
+ "class LLMClient:\n",
+ " def __init__(self):\n",
+ " # Initialize a client to perform API requests\n",
+ " self.client = openai.OpenAI(\n",
+ " base_url=ANYSCALE_SERVICE_BASE_URL,\n",
+ " api_key=ANYSCALE_API_KEY,\n",
+ " )\n",
+ "\n",
+ " def generate(\n",
+ " self,\n",
+ " user_prompt: str,\n",
+ " model=\"mistralai/Mistral-7B-Instruct-v0.1\",\n",
+ " temperature: float = 0,\n",
+ " **kwargs: Any,\n",
+ " ) -> ChatCompletion:\n",
+ " \"\"\"Generate a completion from the given user prompt.\"\"\"\n",
+ " # Call the chat completions endpoint\n",
+ " chat_completion = self.client.chat.completions.create(\n",
+ " model=model,\n",
+ " messages=[\n",
+ " # Prime the system with a system message - a common best practice\n",
+ " {\"role\": \"system\", \"content\": \"You are a helpful assistant.\"},\n",
+ " # Send the user message with the proper \"user\" role and \"content\"\n",
+ " {\"role\": \"user\", \"content\": user_prompt},\n",
+ " ],\n",
+ " temperature=temperature,\n",
+ " **kwargs,\n",
+ " )\n",
+ "\n",
+ " return chat_completion\n",
+ "\n",
+ "\n",
+ "llm_client = LLMClient.bind()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "36142cb0",
+ "metadata": {},
+ "source": [
+ "Note we are currently making use of an already deployed open-source LLM running on Anyscale.\n",
+ "\n",
+ "In case you want to deploy your own LLM, you can follow this [ready-built Anyscale Deploy LLMs template](https://console.anyscale.com/v2/template-preview/endpoints_v2)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b22be87b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "llm_client_handle = serve.run(llm_client, route_prefix=\"/llm\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "adde280d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "llm_response = await llm_client_handle.generate.remote( \n",
+ " user_prompt=\"What is the capital of France?\",\n",
+ ")\n",
+ "llm_response.choices[0].message.content"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fcab6183",
+ "metadata": {},
+ "source": [
+ "### Putting it all together\n",
+ "Given a user query we will want our RAG based QA engine to perform the following steps:\n",
+ "\n",
+ "1. Retrieve the closest documents to the query\n",
+ "2. Augment the query with the context\n",
+ "3. Generate a response to the augmented query"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "34304b2f",
+ "metadata": {},
+ "source": [
+ "We decide on a simple prompt template to augment the user's query with the retrieved context. The template is as follows:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "95d24422",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "prompt_template_rag = \"\"\"\n",
+ "Given the following context:\n",
+ "{composed_context}\n",
+ "\n",
+ "Answer the following question:\n",
+ "{query}\n",
+ "\n",
+ "If you cannot provide an answer based on the context, please say \"I don't know.\"\n",
+ "Do not use the term \"context\" in your response.\"\"\"\n",
+ "\n",
+ "\n",
+ "def augment_prompt(query: str, composed_context: str) -> str:\n",
+ " \"\"\"Augment the prompt with the given query and contexts.\"\"\"\n",
+ " return prompt_template_rag.format(composed_context=composed_context, query=query)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b2e67b56",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "augmented_prompt = augment_prompt(\n",
+ " \"How can I deploy Ray Serve to Kubernetes?\",\n",
+ " retrieval_response[\"composed_context\"],\n",
+ ")\n",
+ "print(augmented_prompt)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "78e56f6a",
+ "metadata": {},
+ "source": [
+ "\n self.observation_space = \n def reset(self, seed, options):\n return , \n def step(self, action):\n return , , , , \n\nray.init()\nalgo = ppo.PPO(env=MyEnv, config={\n \"env_config\": {}, # config to pass to env class\n})\n\nwhile True:\n print(algo.train())\n\n\n\n\nYou can also register a custom env creator function with a string name. This function must take a single env_config (dict) parameter and return an env instance:\n\n\nfrom ray.tune.registry import register_env\n\ndef env_creator(env_config):\n return MyEnv(...) # return an env instance\n\nregister_env(\"my_env\", env_creator)\nalgo = ppo.PPO(env=\"my_env\")\n\n\n\n\nFor a full runnable code example using the custom environment API, see custom_env.py.\n\n\n\nWarning\nThe gymnasium registry is not compatible with Ray. Instead, always use the registration flows documented above to ensure Ray workers can access the environment.\n\n\n\nIn the above example, note that the env_creator function takes in an env_config object.\nThis is a dict containing options passed in through your algorithm.\nYou can also access env_config.worker_index and env_config.vector_index to get the worker id and env id within the worker (if num_envs_per_worker > 0).\nThis can be useful if you want to train over an ensemble of different environments, for example:\n\n\nclass MultiEnv(gym.Env):\n def __init__(self, env_config):\n # pick actual env based on worker and env indexes\n self.env = gym.make(\n choose_env_for(env_config.worker_index, env_config.vector_index))\n self.action_space = self.env.action_space\n self.observation_space = self.env.observation_space\n def reset(self, seed, options):\n return self.env.reset(seed, options)\n def step(self, action):\n return self.env.step(action)\n\nregister_env(\"multienv\", lambda config: MultiEnv(config))\n\n\n\n\n\nTip\nWhen using logging in an environment, the logging configuration needs to be done inside the environment, which runs inside Ray workers. Any configurations outside the environment, e.g., before starting Ray will be ignored.\n\n\n","section_url":"https:\/\/docs.ray.io\/en\/master\/rllib-env.html#configuring-environments","page_url":"https:\/\/docs.ray.io\/en\/master\/rllib-env.html"}
+{"text":"\n\nGymnasium#\n\n\nRLlib uses Gymnasium as its environment interface for single-agent training. For more information on how to implement a custom Gymnasium environment, see the gymnasium.Env class definition. You may find the SimpleCorridor example useful as a reference.\n\n\n\n\n\n","section_url":"https:\/\/docs.ray.io\/en\/master\/rllib-env.html#gymnasium","page_url":"https:\/\/docs.ray.io\/en\/master\/rllib-env.html"}
+{"text":"\n\nPerformance#\n\n\n\nTip\nAlso check out the scaling guide for RLlib training.\n\n\n\nThere are two ways to scale experience collection with Gym environments:\n\n\n\n\nVectorization within a single process: Though many envs can achieve high frame rates per core, their throughput is limited in practice by policy evaluation between steps. For example, even small TensorFlow models incur a couple milliseconds of latency to evaluate. This can be worked around by creating multiple envs per process and batching policy evaluations across these envs.\n\n\nYou can configure {\"num_envs_per_worker\": M} to have RLlib create M concurrent environments per worker. RLlib auto-vectorizes Gym environments via VectorEnv.wrap().\n\n\nDistribute across multiple processes: You can also have RLlib create multiple processes (Ray actors) for experience collection. In most algorithms this can be controlled by setting the {\"num_workers\": N} config.\n\n\n\n\n\n\n\nYou can also combine vectorization and distributed execution, as shown in the above figure. Here we plot just the throughput of RLlib policy evaluation from 1 to 128 CPUs. PongNoFrameskip-v4 on GPU scales from 2.4k to \u223c200k actions\/s, and Pendulum-v1 on CPU from 15k to 1.5M actions\/s. One machine was used for 1-16 workers, and a Ray cluster of four machines for 32-128 workers. Each worker was configured with num_envs_per_worker=64.\n\n","section_url":"https:\/\/docs.ray.io\/en\/master\/rllib-env.html#performance","page_url":"https:\/\/docs.ray.io\/en\/master\/rllib-env.html"}
+{"text":"\n\nExpensive Environments#\n\n\nSome environments may be very resource-intensive to create. RLlib will create num_workers + 1 copies of the environment since one copy is needed for the driver process. To avoid paying the extra overhead of the driver copy, which is needed to access the env\u2019s action and observation spaces, you can defer environment initialization until reset() is called.\n\n","section_url":"https:\/\/docs.ray.io\/en\/master\/rllib-env.html#expensive-environments","page_url":"https:\/\/docs.ray.io\/en\/master\/rllib-env.html"}
diff --git a/templates/ray-summit-stable-diffusion/01_Intro.ipynb b/templates/ray-summit-stable-diffusion/01_Intro.ipynb
new file mode 100644
index 000000000..551253ab9
--- /dev/null
+++ b/templates/ray-summit-stable-diffusion/01_Intro.ipynb
@@ -0,0 +1,826 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Intro to Stable Diffusion and Ray"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's start with a gentle introduction to using Stable Diffusion and Ray\n",
+ "\n",
+ "\n",
+ "\n",
+ "Your production pipeline for generating images from text could require:\n",
+ "1. Loading a large number of text prompts\n",
+ "2. Generating images using large scale diffusion models\n",
+ "3. Inferencing against guardrail models to remove low-quality and NSFW images\n",
+ "\n",
+ "You will want to make the most efficient use of your cluster to process this data. Ray Data can help you do this."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Ray Data's API\n",
+ "\n",
+ "Here are the steps to make use of Ray Data:\n",
+ "1. Create a Ray Dataset usually by pointing to a data source.\n",
+ "2. Apply transformations to the Ray Dataset.\n",
+ "3. Write out the results to a data source.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Loading Data\n",
+ "\n",
+ "Ray Data has a number of [IO connectors](https://docs.ray.io/en/latest/data/api/input_output.html) to most commonly used formats.\n",
+ "\n",
+ "For purposes of this introduction, we will use the `from_items` function to create a dataset from a list of items."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds_items = ray.data.from_items(items)\n",
+ "ds_items"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Transforming Data\n",
+ "\n",
+ "Datasets can be transformed by applying a row-wise `map` operation. We do this by providing a user-defined function that takes a row as input and returns a row as output."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def artify_row(row: dict[str, Any]) -> dict[str, Any]:\n",
+ " row[\"art\"] = text2art(row[\"item\"])\n",
+ " return row\n",
+ "\n",
+ "ds_items_artified = ds_items.map(artify_row)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Lazy execution\n",
+ "\n",
+ "By default, `map` is lazy, meaning that it will not actually execute the function until you consume it. This allows for optimizations like pipelining and fusing of operations.\n",
+ "\n",
+ "To inspect a few rows of the dataset, you can use the `take` method:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sample = ds_items_artified.take(2)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's inspect the sample:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(sample[0][\"item\"])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(sample[0][\"art\"])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Writing Data\n",
+ "\n",
+ "We can then write out the data to disk using the avialable [IO connector methods](https://docs.ray.io/en/latest/data/api/input_output.html).\n",
+ "\n",
+ "Here we will write the data to a JSON file to a shared storage location."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds_items_artified.write_json(\"/mnt/cluster_storage/ascii_art\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can now inspect the written files:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!ls /mnt/cluster_storage/ascii_art"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Recap of our Ray Data pipeline\n",
+ "\n",
+ "Here is our Ray data pipeline condensed into the following chained operations:\n",
+ "\n",
+ "```python\n",
+ "(\n",
+ " ray.data.from_items(items)\n",
+ " .map(artify_row)\n",
+ " .write_json(\"/mnt/cluster_storage/ascii_art\")\n",
+ ")\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Batch Inference with Stable Diffusion\n",
+ "\n",
+ "Now that we have a simple data pipeline, let's use Stable Diffusion to generate actual images from text.\n",
+ "\n",
+ "This will follow a very similar pattern. Let's say we are starting out with the following prompts:\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "prompts = [\n",
+ " \"An astronaut on a horse\",\n",
+ " \"A cat with a jetpack\",\n",
+ "] * 12"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We create a Ray Dataset from the prompts"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds_prompts = ray.data.from_items(prompts)\n",
+ "ds_prompts"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We now apply want to apply a DiffusionPipeline to the dataset. \n",
+ "\n",
+ "We first define a function that creates and applies the pipeline to a single row."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def apply_stable_diffusion(row: dict[str, Any]) -> dict[str, Any]:\n",
+ " # Create the stable diffusion pipeline\n",
+ " pipe = DiffusionPipeline.from_pretrained(\n",
+ " pretrained_model_name_or_path=\"stabilityai/stable-diffusion-2\",\n",
+ " torch_dtype=torch.float16,\n",
+ " use_safetensors=True,\n",
+ " variant=\"fp16\",\n",
+ " ).to(\"cuda\")\n",
+ " prompt = row[\"item\"]\n",
+ " # Apply the pipeline to the prompt\n",
+ " output = pipe(prompt, height=512, width=512)\n",
+ " # Extract the image from the output and construct the row\n",
+ " return {\"item\": prompt, \"image\": output.images[0]}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can now apply the function to each row in the dataset using the `map` method."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds_images_generated_mapping_by_row = ds_prompts.map(\n",
+ " apply_stable_diffusion,\n",
+ " num_gpus=1, # specify the number of GPUs per task\n",
+ ") "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Instead of parallelizing the inference per row, we can parallelize the inference per batch.\n",
+ "\n",
+ "Mapping over batches instead of rows is useful when we can benefit from vectorized operations on the batch level. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def apply_stable_diffusion_batch(batch: dict[str, np.ndarray]) -> dict[str, np.ndarray]:\n",
+ " pipe = DiffusionPipeline.from_pretrained(\n",
+ " pretrained_model_name_or_path=\"stabilityai/stable-diffusion-2\",\n",
+ " torch_dtype=torch.float16,\n",
+ " use_safetensors=True,\n",
+ " variant=\"fp16\",\n",
+ " ).to(\"cuda\")\n",
+ " # Extract the prompts from the batch\n",
+ " prompts = batch[\"item\"].tolist()\n",
+ " # Apply the pipeline to the prompts\n",
+ " outputs = pipe(prompts, height=512, width=512)\n",
+ " # Extract the images from the outputs and construct the batch\n",
+ " return {\"item\": prompts, \"image\": outputs.images}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We now apply the function to each batch in the dataset using the `map_batches` method."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds_images_generated_mapping_by_batch = ds_prompts.map_batches(\n",
+ " apply_stable_diffusion_batch,\n",
+ " batch_size=24, # specify the batch size per task to maximize GPU utilization\n",
+ " num_gpus=1, \n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "The current implementation requires us to load the pipeline for each batch we process.\n",
+ "\n",
+ "We can avoid reloading the pipeline for each batch by creating a stateful transformation, implemented as a callable class where:\n",
+ "- `__init__`: initializes worker processes that will load the pipeline once and reuse it for transforming each batch.\n",
+ "- `__call__`: applies the pipeline to the batch and returns the transformed batch."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class StableDiffusion:\n",
+ " def __init__(self, model_id: str = \"stabilityai/stable-diffusion-2\") -> None:\n",
+ " self.pipe = DiffusionPipeline.from_pretrained(\n",
+ " model_id, torch_dtype=torch.float16, use_safetensors=True, variant=\"fp16\"\n",
+ " ).to(\"cuda\")\n",
+ "\n",
+ " def __call__(\n",
+ " self, batch: dict[str, np.ndarray], img_size: int = 512\n",
+ " ) -> dict[str, np.ndarray]:\n",
+ " prompts = batch[\"item\"].tolist()\n",
+ " batch[\"image\"] = self.pipe(prompts, height=img_size, width=img_size).images\n",
+ " return batch"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can now apply the class to each batch in the dataset using the same `map_batches` method."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds_images_generated_by_stateful_transform = ds_prompts.map_batches(\n",
+ " StableDiffusion,\n",
+ " batch_size=24,\n",
+ " num_gpus=1, \n",
+ " concurrency=1, # number of workers to launch\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "  \n",
+ "
\n",
+ " Image taken from Everything you need to know about stable diffusion\n",
+ " \n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Clean up"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!rm -rf /mnt/cluster_storage/ascii_art\n",
+ "!rm -rf {artifact_path}\n",
+ "!rm ascii_art.json"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "base",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 2
+}
diff --git a/templates/ray-summit-stable-diffusion/02_Primer.ipynb b/templates/ray-summit-stable-diffusion/02_Primer.ipynb
new file mode 100644
index 000000000..de95d2bd4
--- /dev/null
+++ b/templates/ray-summit-stable-diffusion/02_Primer.ipynb
@@ -0,0 +1,122 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Primer on Stable Diffusion V2\n",
+ "\n",
+ "Let's explore the stages involved in the Stable Diffusion V2 pre-training pipeline.\n",
+ "\n",
+ "\n",
+ "  \n",
+ "
\n",
+ " Image taken from Reducing the Cost of Pre-training Stable Diffusion by 3.7x with Anyscale\n",
+ " \n",
+ " \n",
+ "\n",
+ "As shown in the diagram, the pre-training of the Stable Diffusion V2 model consists of the following steps:\n",
+ "\n",
+ "1. A pre-trained VAE and a text encoder(OpenCLIP-ViT/H) encodes the input images and text prompts. \n",
+ "2. A trainable U-Net model learns the diffusion process with the image latents and text embeddings. \n",
+ "3. The loss is calculated based on the input noise and the noise predicted by the U-Net.\n",
+ "\n",
+ "Here's a visual representation of the full forward diffusion process as presented in the paper titled Denoising Diffusion Probabilistic Models.\n",
+ "\n",
+ " \n",
+ "\n",
+ "The U-Net model improves at predicting and removing noise from images using text descriptions. This iterative process, involving noise prediction and subtraction, ultimately yields an image matching the text input.\n",
+ "\n",
+ "Below is the reverse diffusion process visualized, which generates the final image:\n",
+ "\n",
+ "
\n",
+ "\n",
+ "The U-Net model improves at predicting and removing noise from images using text descriptions. This iterative process, involving noise prediction and subtraction, ultimately yields an image matching the text input.\n",
+ "\n",
+ "Below is the reverse diffusion process visualized, which generates the final image:\n",
+ "\n",
+ " \n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 2. Data pre-processing in more detail\n",
+ "\n",
+ "### Encoding the input images and text prompts\n",
+ "\n",
+ "Below is a diagram showing the how the VAE encodes/decodes the input images.\n",
+ "\n",
+ "
\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 2. Data pre-processing in more detail\n",
+ "\n",
+ "### Encoding the input images and text prompts\n",
+ "\n",
+ "Below is a diagram showing the how the VAE encodes/decodes the input images.\n",
+ "\n",
+ "\n",
+ "  \n",
+ "
\n",
+ " Image taken from Processing 2 Billion Images for Stable Diffusion Model Training\n",
+ " \n",
+ "\n",
+ "Basically a VAE model will:\n",
+ "- Encode the input image into a latent space think of it as a compressed representation of the input image.\n",
+ "- Decode the latent space back to the original image.\n",
+ "\n",
+ "\n",
+ "Below is a diagram showing the how the text encoder encodes the input text prompts.\n",
+ "\n",
+ "\n",
+ "  \n",
+ "
\n",
+ " Image taken from Processing 2 Billion Images for Stable Diffusion Model Training\n",
+ " \n",
+ " \n",
+ "\n",
+ "Basically a text encoder model will:\n",
+ "- Tokenize the input text prompt given a particular vocabulary and convert it to a sequence of tokens.\n",
+ "- Encode the sequence of tokens into a latent space think of it as a compressed vector representation of the input text prompt."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "vscode": {
+ "languageId": "plaintext"
+ }
+ },
+ "source": [
+ "## 3. Compute requirements for pre-processing and training\n",
+ "\n",
+ "Running the encoders on the same GPU as the U-Net model is not efficient. \n",
+ "\n",
+ "The encoders are smaller models and won't be able to use the large VRAM on the A100 GPUs if the same batch size needs to be used across all the models.\n",
+ "\n",
+ "Instead, we would like a heterogeneous cluster of machines where we use A10G GPUs for the encoders and larger A100 GPUs for the U-Net model.\n",
+ "\n",
+ " \n",
+ "\n"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "base",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "name": "python",
+ "version": "3.11.9"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 2
+}
diff --git a/templates/ray-summit-stable-diffusion/03_Preprocessing.ipynb b/templates/ray-summit-stable-diffusion/03_Preprocessing.ipynb
new file mode 100644
index 000000000..5897634a6
--- /dev/null
+++ b/templates/ray-summit-stable-diffusion/03_Preprocessing.ipynb
@@ -0,0 +1,812 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "beda561e",
+ "metadata": {},
+ "source": [
+ "# Pre-processing for Stable Diffusion V2\n",
+ "\n",
+ "Let's build a scalable preprocessing pipeline for the Stable Diffusion V2 model.\n",
+ "\n",
+ "
\n",
+ "\n"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "base",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "name": "python",
+ "version": "3.11.9"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 2
+}
diff --git a/templates/ray-summit-stable-diffusion/03_Preprocessing.ipynb b/templates/ray-summit-stable-diffusion/03_Preprocessing.ipynb
new file mode 100644
index 000000000..5897634a6
--- /dev/null
+++ b/templates/ray-summit-stable-diffusion/03_Preprocessing.ipynb
@@ -0,0 +1,812 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "beda561e",
+ "metadata": {},
+ "source": [
+ "# Pre-processing for Stable Diffusion V2\n",
+ "\n",
+ "Let's build a scalable preprocessing pipeline for the Stable Diffusion V2 model.\n",
+ "\n",
+ " \n",
+ "\n",
+ "Ray Data loads the data from a remote storage system, then streams the data through two processing main stages:\n",
+ "1. **Transformation**\n",
+ " 1. Cropping and normalizing images.\n",
+ " 2. Tokenizing the text captions using a CLIP tokenizer.\n",
+ "2. **Encoding**\n",
+ " 1. Compressing images into a latent space using a VAE encoder.\n",
+ " 2. Generating text embeddings using a CLIP model.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2a2e8517-65f9-4c41-9144-57df326f6c02",
+ "metadata": {},
+ "source": [
+ "### 1. Reading in the data\n",
+ "\n",
+ "We're going to preprocess part of the LAION-art-8M dataset. To save time, we have provided a sample of the dataset on S3.\n",
+ "\n",
+ "We'll read this sample data and create a Ray dataset from it."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "fb3c85d9-1e00-492d-b119-fca467a42f8c",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "schema = pa.schema(\n",
+ " [\n",
+ " pa.field(\"caption\", getattr(pa, \"string\")()),\n",
+ " pa.field(\"height\", getattr(pa, \"float64\")()),\n",
+ " pa.field(\"width\", getattr(pa, \"float64\")()),\n",
+ " pa.field(\"jpg\", getattr(pa, \"binary\")()),\n",
+ " ]\n",
+ ")\n",
+ "\n",
+ "ds = ray.data.read_parquet(\n",
+ " \"s3://anyscale-public-materials/ray-summit/stable-diffusion/data/raw/\",\n",
+ " schema=schema,\n",
+ ")\n",
+ "\n",
+ "ds"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5fa9aad4-f273-4e8c-9fcf-8346fbff09a8",
+ "metadata": {},
+ "source": [
+ "We know that when we run that step, we're not actually processing the whole dataset -- that's the whole idea behind lazy execution of the data pipeline.\n",
+ "\n",
+ "But Ray does sample the data to determine metadata like the number of files and data schema."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "101b2899-13ae-4063-8dab-fb9e47b51e5c",
+ "metadata": {},
+ "source": [
+ "### 2. Transforming images and captions\n",
+ "\n",
+ "#### 2.1 Cropping and normalizing images\n",
+ "We start by preprocessing the images: \n",
+ "\n",
+ "We need to perform these two operations on the images:\n",
+ "1. Crop the images to a square aspect ratio.\n",
+ "2. Normalize the pixel values to the distribution expected by the VAE encoder.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3d2c77f4",
+ "metadata": {},
+ "source": [
+ "#### Step 1. Cropping the image"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d5d56d06-0546-4e40-9107-bb683e43fe95",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "class LargestCenterSquare:\n",
+ " \"\"\"Largest center square crop for images.\"\"\"\n",
+ "\n",
+ " def __init__(self, size: int) -> None:\n",
+ " self.size = size\n",
+ "\n",
+ " def __call__(self, img: Image.Image) -> Image.Image:\n",
+ " \"\"\"Crop the largest center square from an image.\"\"\"\n",
+ " # First, resize the image such that the smallest\n",
+ " # side is self.size while preserving aspect ratio.\n",
+ " img = torchvision.transforms.functional.resize(\n",
+ " img=img,\n",
+ " size=self.size,\n",
+ " )\n",
+ "\n",
+ " # Then take a center crop to a square.\n",
+ " w, h = img.size\n",
+ " c_top = (h - self.size) // 2\n",
+ " c_left = (w - self.size) // 2\n",
+ " img = torchvision.transforms.functional.crop(\n",
+ " img=img,\n",
+ " top=c_top,\n",
+ " left=c_left,\n",
+ " height=self.size,\n",
+ " width=self.size,\n",
+ " )\n",
+ " return img"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "55618e3f-f60f-456d-ab0c-edabca9c87b1",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "resolution = 512\n",
+ "crop = LargestCenterSquare(resolution)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "32f1eabd",
+ "metadata": {},
+ "source": [
+ "Let's take a simple example to understand visualize how the crop function works."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "920fec45",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds_example = ds.filter(lambda row: row[\"caption\"] == 'strawberry-lemonmousse-cake-3')\n",
+ "example_image = ds_example.take(1)[0]\n",
+ "image = Image.open(io.BytesIO(example_image[\"jpg\"]))\n",
+ "image"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "18cf17c5",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "crop(image)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "66cee5af",
+ "metadata": {},
+ "source": [
+ "#### Step 2. Normalizing the image\n",
+ "\n",
+ "We need to normalize the pixel values to the distribution expected by the VAE encoder. \n",
+ "\n",
+ "The VAE encoder expects pixel values in the range [-1, 1]\n",
+ "\n",
+ "Our images are in the range [0, 1] with an approximate mean of 0.5 in the center. \n",
+ "\n",
+ "To normalize the images, we'll subtract 0.5 from each pixel value and divide by 0.5"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "98f54b3f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "normalize = torchvision.transforms.Compose(\n",
+ " [\n",
+ " torchvision.transforms.ToTensor(),\n",
+ " torchvision.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),\n",
+ " ]\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2d34b6a7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "normalized = normalize(crop(image))\n",
+ "\n",
+ "normalized.min(), normalized.max()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0961204b",
+ "metadata": {},
+ "source": [
+ "#### Putting it together into a single transform function"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "86cef17d",
+ "metadata": {},
+ "source": [
+ "We build a `transform_images` below to crop and normalize the images."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a27d0a0d-260e-4782-bd7d-848228147cff",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def convert_tensor_to_array(tensor: torch.Tensor, dtype=np.float32) -> np.ndarray:\n",
+ " \"\"\"Convert a torch tensor to a numpy array.\"\"\"\n",
+ " array = tensor.detach().cpu().numpy()\n",
+ " return array.astype(dtype)\n",
+ "\n",
+ "\n",
+ "def transform_images(row: dict[str, Any]) -> np.ndarray:\n",
+ " \"\"\"Transform image to a square-sized normalized tensor.\"\"\"\n",
+ " try:\n",
+ " image = Image.open(io.BytesIO(row[\"jpg\"]))\n",
+ " except Exception as e:\n",
+ " logging.error(f\"Error opening image: {e}\")\n",
+ " return []\n",
+ "\n",
+ " if image.mode != \"RGB\":\n",
+ " image = image.convert(\"RGB\")\n",
+ "\n",
+ " image = crop(image)\n",
+ " normalized_image_tensor = normalize(image)\n",
+ "\n",
+ " row[f\"image_{resolution}\"] = convert_tensor_to_array(normalized_image_tensor)\n",
+ " return [row]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "780d98a8",
+ "metadata": {},
+ "source": [
+ "
\n",
+ "\n",
+ "Ray Data loads the data from a remote storage system, then streams the data through two processing main stages:\n",
+ "1. **Transformation**\n",
+ " 1. Cropping and normalizing images.\n",
+ " 2. Tokenizing the text captions using a CLIP tokenizer.\n",
+ "2. **Encoding**\n",
+ " 1. Compressing images into a latent space using a VAE encoder.\n",
+ " 2. Generating text embeddings using a CLIP model.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2a2e8517-65f9-4c41-9144-57df326f6c02",
+ "metadata": {},
+ "source": [
+ "### 1. Reading in the data\n",
+ "\n",
+ "We're going to preprocess part of the LAION-art-8M dataset. To save time, we have provided a sample of the dataset on S3.\n",
+ "\n",
+ "We'll read this sample data and create a Ray dataset from it."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "fb3c85d9-1e00-492d-b119-fca467a42f8c",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "schema = pa.schema(\n",
+ " [\n",
+ " pa.field(\"caption\", getattr(pa, \"string\")()),\n",
+ " pa.field(\"height\", getattr(pa, \"float64\")()),\n",
+ " pa.field(\"width\", getattr(pa, \"float64\")()),\n",
+ " pa.field(\"jpg\", getattr(pa, \"binary\")()),\n",
+ " ]\n",
+ ")\n",
+ "\n",
+ "ds = ray.data.read_parquet(\n",
+ " \"s3://anyscale-public-materials/ray-summit/stable-diffusion/data/raw/\",\n",
+ " schema=schema,\n",
+ ")\n",
+ "\n",
+ "ds"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5fa9aad4-f273-4e8c-9fcf-8346fbff09a8",
+ "metadata": {},
+ "source": [
+ "We know that when we run that step, we're not actually processing the whole dataset -- that's the whole idea behind lazy execution of the data pipeline.\n",
+ "\n",
+ "But Ray does sample the data to determine metadata like the number of files and data schema."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "101b2899-13ae-4063-8dab-fb9e47b51e5c",
+ "metadata": {},
+ "source": [
+ "### 2. Transforming images and captions\n",
+ "\n",
+ "#### 2.1 Cropping and normalizing images\n",
+ "We start by preprocessing the images: \n",
+ "\n",
+ "We need to perform these two operations on the images:\n",
+ "1. Crop the images to a square aspect ratio.\n",
+ "2. Normalize the pixel values to the distribution expected by the VAE encoder.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3d2c77f4",
+ "metadata": {},
+ "source": [
+ "#### Step 1. Cropping the image"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d5d56d06-0546-4e40-9107-bb683e43fe95",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "class LargestCenterSquare:\n",
+ " \"\"\"Largest center square crop for images.\"\"\"\n",
+ "\n",
+ " def __init__(self, size: int) -> None:\n",
+ " self.size = size\n",
+ "\n",
+ " def __call__(self, img: Image.Image) -> Image.Image:\n",
+ " \"\"\"Crop the largest center square from an image.\"\"\"\n",
+ " # First, resize the image such that the smallest\n",
+ " # side is self.size while preserving aspect ratio.\n",
+ " img = torchvision.transforms.functional.resize(\n",
+ " img=img,\n",
+ " size=self.size,\n",
+ " )\n",
+ "\n",
+ " # Then take a center crop to a square.\n",
+ " w, h = img.size\n",
+ " c_top = (h - self.size) // 2\n",
+ " c_left = (w - self.size) // 2\n",
+ " img = torchvision.transforms.functional.crop(\n",
+ " img=img,\n",
+ " top=c_top,\n",
+ " left=c_left,\n",
+ " height=self.size,\n",
+ " width=self.size,\n",
+ " )\n",
+ " return img"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "55618e3f-f60f-456d-ab0c-edabca9c87b1",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "resolution = 512\n",
+ "crop = LargestCenterSquare(resolution)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "32f1eabd",
+ "metadata": {},
+ "source": [
+ "Let's take a simple example to understand visualize how the crop function works."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "920fec45",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds_example = ds.filter(lambda row: row[\"caption\"] == 'strawberry-lemonmousse-cake-3')\n",
+ "example_image = ds_example.take(1)[0]\n",
+ "image = Image.open(io.BytesIO(example_image[\"jpg\"]))\n",
+ "image"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "18cf17c5",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "crop(image)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "66cee5af",
+ "metadata": {},
+ "source": [
+ "#### Step 2. Normalizing the image\n",
+ "\n",
+ "We need to normalize the pixel values to the distribution expected by the VAE encoder. \n",
+ "\n",
+ "The VAE encoder expects pixel values in the range [-1, 1]\n",
+ "\n",
+ "Our images are in the range [0, 1] with an approximate mean of 0.5 in the center. \n",
+ "\n",
+ "To normalize the images, we'll subtract 0.5 from each pixel value and divide by 0.5"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "98f54b3f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "normalize = torchvision.transforms.Compose(\n",
+ " [\n",
+ " torchvision.transforms.ToTensor(),\n",
+ " torchvision.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),\n",
+ " ]\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2d34b6a7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "normalized = normalize(crop(image))\n",
+ "\n",
+ "normalized.min(), normalized.max()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0961204b",
+ "metadata": {},
+ "source": [
+ "#### Putting it together into a single transform function"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "86cef17d",
+ "metadata": {},
+ "source": [
+ "We build a `transform_images` below to crop and normalize the images."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a27d0a0d-260e-4782-bd7d-848228147cff",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def convert_tensor_to_array(tensor: torch.Tensor, dtype=np.float32) -> np.ndarray:\n",
+ " \"\"\"Convert a torch tensor to a numpy array.\"\"\"\n",
+ " array = tensor.detach().cpu().numpy()\n",
+ " return array.astype(dtype)\n",
+ "\n",
+ "\n",
+ "def transform_images(row: dict[str, Any]) -> np.ndarray:\n",
+ " \"\"\"Transform image to a square-sized normalized tensor.\"\"\"\n",
+ " try:\n",
+ " image = Image.open(io.BytesIO(row[\"jpg\"]))\n",
+ " except Exception as e:\n",
+ " logging.error(f\"Error opening image: {e}\")\n",
+ " return []\n",
+ "\n",
+ " if image.mode != \"RGB\":\n",
+ " image = image.convert(\"RGB\")\n",
+ "\n",
+ " image = crop(image)\n",
+ " normalized_image_tensor = normalize(image)\n",
+ "\n",
+ " row[f\"image_{resolution}\"] = convert_tensor_to_array(normalized_image_tensor)\n",
+ " return [row]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "780d98a8",
+ "metadata": {},
+ "source": [
+ " \n",
+ "\n",
+ "The preceding architecture diagram illustrates the training pipeline for Stable Diffusion. \n",
+ "\n",
+ "It is primarily composed of three main stages:\n",
+ "1. **Streaming data from the preprocessing stage**\n",
+ "2. **Training the model**\n",
+ "3. **Storing the model checkpoints**\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ae7c50ba",
+ "metadata": {},
+ "source": [
+ "## 1. Load the preprocessed data into a Ray Dataset\n",
+ "\n",
+ "Let's start by specifying the datasets we want to use. We'll use `parquet` data that was generated using the same preprocessing pipeline."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "40392506-334f-4b05-9bb0-f2815daff428",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "columns = [\"image_latents_256\", \"caption_latents\"]\n",
+ "\n",
+ "train_data_uri = (\n",
+ " \"s3://anyscale-public-materials/ray-summit/stable-diffusion/data/preprocessed/256/\"\n",
+ ")\n",
+ "train_ds = ray.data.read_parquet(train_data_uri, columns=columns, shuffle=\"files\")\n",
+ "train_ds"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e4e9f3a7",
+ "metadata": {},
+ "source": [
+ "
\n",
+ "\n",
+ "The preceding architecture diagram illustrates the training pipeline for Stable Diffusion. \n",
+ "\n",
+ "It is primarily composed of three main stages:\n",
+ "1. **Streaming data from the preprocessing stage**\n",
+ "2. **Training the model**\n",
+ "3. **Storing the model checkpoints**\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ae7c50ba",
+ "metadata": {},
+ "source": [
+ "## 1. Load the preprocessed data into a Ray Dataset\n",
+ "\n",
+ "Let's start by specifying the datasets we want to use. We'll use `parquet` data that was generated using the same preprocessing pipeline."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "40392506-334f-4b05-9bb0-f2815daff428",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "columns = [\"image_latents_256\", \"caption_latents\"]\n",
+ "\n",
+ "train_data_uri = (\n",
+ " \"s3://anyscale-public-materials/ray-summit/stable-diffusion/data/preprocessed/256/\"\n",
+ ")\n",
+ "train_ds = ray.data.read_parquet(train_data_uri, columns=columns, shuffle=\"files\")\n",
+ "train_ds"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e4e9f3a7",
+ "metadata": {},
+ "source": [
+ " \n",
+ "\n",
+ "Note how the model state is initially synchronized across all the GPUs before the training loop begins.\n",
+ "\n",
+ "Then after each backward pass, the gradients are synchronized across all the GPUs. "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6c9f8204",
+ "metadata": {},
+ "source": [
+ "### Ray Train Migration\n",
+ "\n",
+ "Here are the changes we need to make to the training loop to migrate it to Ray Train."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6b42be9f-fad5-4f3f-8a1c-5812c5573eca",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "def train_loop_per_worker(\n",
+ " config: dict, # Update the function signature to comply with Ray Train\n",
+ "): \n",
+ " # Prepare data loaders using Ray\n",
+ " train_ds = ray.train.get_dataset_shard(\"train\")\n",
+ " train_dataloader = train_ds.iter_torch_batches(\n",
+ " batch_size=config[\"batch_size_per_worker\"],\n",
+ " drop_last=True,\n",
+ " prefetch_batches=config[\"prefetch_batches\"],\n",
+ " )\n",
+ "\n",
+ " # Same model initialization as vanilla lightning\n",
+ " torch.set_float32_matmul_precision(\"high\")\n",
+ " model = StableDiffusion(\n",
+ " lr=config[\"lr\"],\n",
+ " resolution=config[\"resolution\"],\n",
+ " weight_decay=config[\"weight_decay\"],\n",
+ " num_warmup_steps=config[\"num_warmup_steps\"],\n",
+ " model_name=config[\"model_name\"],\n",
+ " )\n",
+ "\n",
+ " # Same trainer setup as vanilla lightning except we add Ray Train specific arguments\n",
+ " trainer = pl.Trainer(\n",
+ " max_steps=config[\"max_steps\"],\n",
+ " max_epochs=config[\"max_epochs\"],\n",
+ " accelerator=\"gpu\",\n",
+ " precision=\"bf16-mixed\",\n",
+ " devices=\"auto\", # Set devices to \"auto\" to use all available GPUs\n",
+ " strategy=RayDDPStrategy(), # Use RayDDPStrategy for distributed data parallel training\n",
+ " plugins=[\n",
+ " RayLightningEnvironment()\n",
+ " ], # Use RayLightningEnvironment to run the Lightning Trainer\n",
+ " callbacks=[\n",
+ " RayTrainReportCallback()\n",
+ " ], # Use RayTrainReportCallback to report metrics and checkpoints\n",
+ " enable_checkpointing=False, # Disable lightning checkpointing\n",
+ " )\n",
+ "\n",
+ " # 4. Same as vanilla lightning\n",
+ " trainer.fit(model, train_dataloaders=train_dataloader)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ae5328b5",
+ "metadata": {},
+ "source": [
+ "Here is the same diagram as before but with the Ray Train specific components highlighted.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "Note how the model state is initially synchronized across all the GPUs before the training loop begins.\n",
+ "\n",
+ "Then after each backward pass, the gradients are synchronized across all the GPUs. "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6c9f8204",
+ "metadata": {},
+ "source": [
+ "### Ray Train Migration\n",
+ "\n",
+ "Here are the changes we need to make to the training loop to migrate it to Ray Train."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6b42be9f-fad5-4f3f-8a1c-5812c5573eca",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "def train_loop_per_worker(\n",
+ " config: dict, # Update the function signature to comply with Ray Train\n",
+ "): \n",
+ " # Prepare data loaders using Ray\n",
+ " train_ds = ray.train.get_dataset_shard(\"train\")\n",
+ " train_dataloader = train_ds.iter_torch_batches(\n",
+ " batch_size=config[\"batch_size_per_worker\"],\n",
+ " drop_last=True,\n",
+ " prefetch_batches=config[\"prefetch_batches\"],\n",
+ " )\n",
+ "\n",
+ " # Same model initialization as vanilla lightning\n",
+ " torch.set_float32_matmul_precision(\"high\")\n",
+ " model = StableDiffusion(\n",
+ " lr=config[\"lr\"],\n",
+ " resolution=config[\"resolution\"],\n",
+ " weight_decay=config[\"weight_decay\"],\n",
+ " num_warmup_steps=config[\"num_warmup_steps\"],\n",
+ " model_name=config[\"model_name\"],\n",
+ " )\n",
+ "\n",
+ " # Same trainer setup as vanilla lightning except we add Ray Train specific arguments\n",
+ " trainer = pl.Trainer(\n",
+ " max_steps=config[\"max_steps\"],\n",
+ " max_epochs=config[\"max_epochs\"],\n",
+ " accelerator=\"gpu\",\n",
+ " precision=\"bf16-mixed\",\n",
+ " devices=\"auto\", # Set devices to \"auto\" to use all available GPUs\n",
+ " strategy=RayDDPStrategy(), # Use RayDDPStrategy for distributed data parallel training\n",
+ " plugins=[\n",
+ " RayLightningEnvironment()\n",
+ " ], # Use RayLightningEnvironment to run the Lightning Trainer\n",
+ " callbacks=[\n",
+ " RayTrainReportCallback()\n",
+ " ], # Use RayTrainReportCallback to report metrics and checkpoints\n",
+ " enable_checkpointing=False, # Disable lightning checkpointing\n",
+ " )\n",
+ "\n",
+ " # 4. Same as vanilla lightning\n",
+ " trainer.fit(model, train_dataloaders=train_dataloader)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ae5328b5",
+ "metadata": {},
+ "source": [
+ "Here is the same diagram as before but with the Ray Train specific components highlighted.\n",
+ "\n",
+ " \n",
+ "\n",
+ "We made use of:\n",
+ "- `ray.train.get_dataset_shard(\"train\")` to get the training dataset shard.\n",
+ "- `RayDDPStrategy` to perform distributed data parallel training.\n",
+ "- `RayLightningEnvironment` to run the Lightning Trainer.\n",
+ "- `RayTrainReportCallback` to report metrics and checkpoints."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "242d8ccb-30c2-4491-a381-63ac3330bc2e",
+ "metadata": {},
+ "source": [
+ "## 5. Create and fit a Ray Train TorchTrainer\n",
+ "\n",
+ "Let's first specify the scaling configuration to tell Ray Train to use 2 GPU training workers."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "86459a71",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "scaling_config = ray.train.ScalingConfig(num_workers=2, use_gpu=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "27b32a89",
+ "metadata": {},
+ "source": [
+ "We then specify the run configuration to tell Ray Train where to store the checkpoints and metrics"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f441b156",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "storage_path = \"/mnt/cluster_storage/\"\n",
+ "experiment_name = \"stable-diffusion-pretraining\"\n",
+ "\n",
+ "run_config = ray.train.RunConfig(name=experiment_name, storage_path=storage_path)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7c1d2f69",
+ "metadata": {},
+ "source": [
+ "Now we can create our Ray Train `TorchTrainer`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "052fa684",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "train_loop_config = {\n",
+ " \"batch_size_per_worker\": 8,\n",
+ " \"prefetch_batches\": 2,\n",
+ " \"lr\": 0.0001,\n",
+ " \"num_warmup_steps\": 10_000,\n",
+ " \"weight_decay\": 0.01,\n",
+ " \"max_steps\": 550_000,\n",
+ " \"max_epochs\": 1,\n",
+ " \"resolution\": 256,\n",
+ " \"model_name\": \"stabilityai/stable-diffusion-2-base\",\n",
+ "}\n",
+ "\n",
+ "trainer = TorchTrainer(\n",
+ " train_loop_per_worker,\n",
+ " train_loop_config=train_loop_config,\n",
+ " scaling_config=scaling_config,\n",
+ " run_config=run_config,\n",
+ " datasets=ray_datasets,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1dac0bcd",
+ "metadata": {},
+ "source": [
+ "Here is a high-level architecture of how Ray Train works:\n",
+ "\n",
+ "
\n",
+ "\n",
+ "We made use of:\n",
+ "- `ray.train.get_dataset_shard(\"train\")` to get the training dataset shard.\n",
+ "- `RayDDPStrategy` to perform distributed data parallel training.\n",
+ "- `RayLightningEnvironment` to run the Lightning Trainer.\n",
+ "- `RayTrainReportCallback` to report metrics and checkpoints."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "242d8ccb-30c2-4491-a381-63ac3330bc2e",
+ "metadata": {},
+ "source": [
+ "## 5. Create and fit a Ray Train TorchTrainer\n",
+ "\n",
+ "Let's first specify the scaling configuration to tell Ray Train to use 2 GPU training workers."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "86459a71",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "scaling_config = ray.train.ScalingConfig(num_workers=2, use_gpu=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "27b32a89",
+ "metadata": {},
+ "source": [
+ "We then specify the run configuration to tell Ray Train where to store the checkpoints and metrics"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f441b156",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "storage_path = \"/mnt/cluster_storage/\"\n",
+ "experiment_name = \"stable-diffusion-pretraining\"\n",
+ "\n",
+ "run_config = ray.train.RunConfig(name=experiment_name, storage_path=storage_path)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7c1d2f69",
+ "metadata": {},
+ "source": [
+ "Now we can create our Ray Train `TorchTrainer`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "052fa684",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "train_loop_config = {\n",
+ " \"batch_size_per_worker\": 8,\n",
+ " \"prefetch_batches\": 2,\n",
+ " \"lr\": 0.0001,\n",
+ " \"num_warmup_steps\": 10_000,\n",
+ " \"weight_decay\": 0.01,\n",
+ " \"max_steps\": 550_000,\n",
+ " \"max_epochs\": 1,\n",
+ " \"resolution\": 256,\n",
+ " \"model_name\": \"stabilityai/stable-diffusion-2-base\",\n",
+ "}\n",
+ "\n",
+ "trainer = TorchTrainer(\n",
+ " train_loop_per_worker,\n",
+ " train_loop_config=train_loop_config,\n",
+ " scaling_config=scaling_config,\n",
+ " run_config=run_config,\n",
+ " datasets=ray_datasets,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1dac0bcd",
+ "metadata": {},
+ "source": [
+ "Here is a high-level architecture of how Ray Train works:\n",
+ "\n",
+ " \n",
+ "\n",
+ "Here are some key points:\n",
+ "- The scaling config specifies the number of training workers.\n",
+ "- A trainer actor process is launched that oversees the training workers."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "81045b35",
+ "metadata": {},
+ "source": [
+ "We call `.fit()` to start the training job."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ebc0bc5d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "result = trainer.fit()\n",
+ "result"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "675ad286-7eb5-4692-a999-9d8159814ceb",
+ "metadata": {},
+ "source": [
+ "## 6. Fault Tolerance in Ray Train\n",
+ "\n",
+ "Ray Train provides two main mechanisms to handle failures:\n",
+ "- Automatic retries\n",
+ "- Manual restoration\n",
+ "\n",
+ "Here is a diagram showing these two primary mechanisms:\n",
+ "\n",
+ "
\n",
+ "\n",
+ "Here are some key points:\n",
+ "- The scaling config specifies the number of training workers.\n",
+ "- A trainer actor process is launched that oversees the training workers."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "81045b35",
+ "metadata": {},
+ "source": [
+ "We call `.fit()` to start the training job."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ebc0bc5d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "result = trainer.fit()\n",
+ "result"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "675ad286-7eb5-4692-a999-9d8159814ceb",
+ "metadata": {},
+ "source": [
+ "## 6. Fault Tolerance in Ray Train\n",
+ "\n",
+ "Ray Train provides two main mechanisms to handle failures:\n",
+ "- Automatic retries\n",
+ "- Manual restoration\n",
+ "\n",
+ "Here is a diagram showing these two primary mechanisms:\n",
+ "\n",
+ " \n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4e381954",
+ "metadata": {},
+ "source": [
+ "### Modifying the Training Loop to Enable Checkpoint Loading\n",
+ "\n",
+ "We need to make use of `get_checkpoint()` in the training loop to enable checkpoint loading for fault tolerance.\n",
+ "\n",
+ "Here is how the modified training loop looks like."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "77d432a3",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def train_loop_per_worker_with_checkpoint_loading(config: dict):\n",
+ " # Same data loading as before\n",
+ " train_ds = ray.train.get_dataset_shard(\"train\")\n",
+ " train_dataloader = train_ds.iter_torch_batches(\n",
+ " batch_size=config[\"batch_size_per_worker\"],\n",
+ " drop_last=True,\n",
+ " prefetch_batches=config[\"prefetch_batches\"],\n",
+ " )\n",
+ "\n",
+ " # Same model initialization as before\n",
+ " torch.set_float32_matmul_precision(\"high\")\n",
+ " model = StableDiffusion(\n",
+ " lr=config[\"lr\"],\n",
+ " resolution=config[\"resolution\"],\n",
+ " weight_decay=config[\"weight_decay\"],\n",
+ " num_warmup_steps=config[\"num_warmup_steps\"],\n",
+ " model_name=config[\"model_name\"],\n",
+ " )\n",
+ "\n",
+ " # Same trainer setup as before\n",
+ " trainer = pl.Trainer(\n",
+ " max_steps=config[\"max_steps\"],\n",
+ " max_epochs=config[\"max_epochs\"],\n",
+ " accelerator=\"gpu\",\n",
+ " precision=\"bf16-mixed\",\n",
+ " devices=\"auto\",\n",
+ " strategy=RayDDPStrategy(),\n",
+ " plugins=[RayLightningEnvironment()],\n",
+ " callbacks=[RayTrainReportCallback()],\n",
+ " enable_checkpointing=False,\n",
+ " )\n",
+ "\n",
+ " # Load the latest checkpoint if it exists\n",
+ " checkpoint = ray.train.get_checkpoint()\n",
+ " if checkpoint:\n",
+ " # Continue training from a previous checkpoint\n",
+ " with checkpoint.as_directory() as ckpt_dir:\n",
+ " ckpt_path = os.path.join(ckpt_dir, \"checkpoint.ckpt\")\n",
+ "\n",
+ " # Call .fit with the ckpt_path\n",
+ " # This will restore both the model weights and the trainer states (optimizer, steps, callbacks)\n",
+ " trainer.fit(\n",
+ " model,\n",
+ " train_dataloaders=train_dataloader,\n",
+ " ckpt_path=ckpt_path,\n",
+ " )\n",
+ " \n",
+ " # If no checkpoint is provided, start from scratch\n",
+ " else:\n",
+ " trainer.fit(model, train_dataloaders=train_dataloader)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "878adcd0",
+ "metadata": {},
+ "source": [
+ "### Configuring Automatic Retries\n",
+ "\n",
+ "Now that we have enabled checkpoint loading, we can configure a failure config which sets the maximum number of retries for a training job."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "fd6d3cdb",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "failure_config = ray.train.FailureConfig(max_failures=3)\n",
+ "\n",
+ "trainer = TorchTrainer(\n",
+ " train_loop_per_worker_with_checkpoint_loading,\n",
+ " train_loop_config=train_loop_config,\n",
+ " scaling_config=ray.train.ScalingConfig(num_workers=2, use_gpu=True),\n",
+ " run_config=ray.train.RunConfig(\n",
+ " name=experiment_name,\n",
+ " storage_path=storage_path,\n",
+ " failure_config=failure_config, # Pass the failure config\n",
+ " ),\n",
+ " datasets=ray_datasets,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "164a57d3",
+ "metadata": {},
+ "source": [
+ "Now we can proceed to run the training job as before."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0d6f6bf9",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "trainer.fit()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "84437cfd",
+ "metadata": {},
+ "source": [
+ "### Performing a Manual Restoration\n",
+ "\n",
+ "In case the retries are exhausted, we can perform a manual restoration using the `TorchTrainer.restore` method. \n",
+ "\n",
+ "We can first check that we can still restore from a failed experiment by running the `can_restore` method."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "81176b07",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "can_restore = TorchTrainer.can_restore(path=os.path.join(storage_path, experiment_name))\n",
+ "can_restore"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "326d1b54",
+ "metadata": {},
+ "source": [
+ "This is mainly checking if the `trainer.pkl` file exists so we can re-create the TorchTrainer object."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "febde28d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!ls {storage_path}/{experiment_name}/trainer.pkl"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "552b77f1",
+ "metadata": {},
+ "source": [
+ "Let's restore the trainer using the `restore` method. We will however override the `train_loop_per_worker` function to perform the proper checkpoint loading."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2ca64d0d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "restored_trainer = TorchTrainer.restore(\n",
+ " path=os.path.join(storage_path, experiment_name),\n",
+ " datasets=ray_datasets,\n",
+ " train_loop_per_worker=train_loop_per_worker_with_checkpoint_loading,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1ab08cae",
+ "metadata": {},
+ "source": [
+ "Here is a view of our restored trainer."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d55e3907",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "restored_trainer"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "08c3a730",
+ "metadata": {},
+ "source": [
+ "Running the `fit` method will resume training from the last checkpoint. \n",
+ "\n",
+ "Given we already have completed all epochs, we expect the training to terminate immediately."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0f65deff",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "result = restored_trainer.fit()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5eb2e18c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "result"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "33b73ce0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "result.checkpoint"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "396caa4a",
+ "metadata": {},
+ "source": [
+ "## Clean up \n",
+ "\n",
+ "Let's clean up the storage path to remove the checkpoints and artifacts we created during this notebook."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "373ad2bd",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!rm -rf /mnt/cluster_storage/stable-diffusion-pretraining"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/templates/ray-summit-stable-diffusion/Bonus/04b_Advanced_Pretraining.ipynb b/templates/ray-summit-stable-diffusion/Bonus/04b_Advanced_Pretraining.ipynb
new file mode 100644
index 000000000..400e89d38
--- /dev/null
+++ b/templates/ray-summit-stable-diffusion/Bonus/04b_Advanced_Pretraining.ipynb
@@ -0,0 +1,456 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "7078ab58-6ca4-4255-8050-b7c5fe7eae1c",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "# Distributed Training Optimizations for Stable Diffusion\n",
+ "\n",
+ "This notebook demonstrates certain optimizations that can be applied to the training process to improve performance and reduce costs.\n",
+ "\n",
+ "
\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4e381954",
+ "metadata": {},
+ "source": [
+ "### Modifying the Training Loop to Enable Checkpoint Loading\n",
+ "\n",
+ "We need to make use of `get_checkpoint()` in the training loop to enable checkpoint loading for fault tolerance.\n",
+ "\n",
+ "Here is how the modified training loop looks like."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "77d432a3",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def train_loop_per_worker_with_checkpoint_loading(config: dict):\n",
+ " # Same data loading as before\n",
+ " train_ds = ray.train.get_dataset_shard(\"train\")\n",
+ " train_dataloader = train_ds.iter_torch_batches(\n",
+ " batch_size=config[\"batch_size_per_worker\"],\n",
+ " drop_last=True,\n",
+ " prefetch_batches=config[\"prefetch_batches\"],\n",
+ " )\n",
+ "\n",
+ " # Same model initialization as before\n",
+ " torch.set_float32_matmul_precision(\"high\")\n",
+ " model = StableDiffusion(\n",
+ " lr=config[\"lr\"],\n",
+ " resolution=config[\"resolution\"],\n",
+ " weight_decay=config[\"weight_decay\"],\n",
+ " num_warmup_steps=config[\"num_warmup_steps\"],\n",
+ " model_name=config[\"model_name\"],\n",
+ " )\n",
+ "\n",
+ " # Same trainer setup as before\n",
+ " trainer = pl.Trainer(\n",
+ " max_steps=config[\"max_steps\"],\n",
+ " max_epochs=config[\"max_epochs\"],\n",
+ " accelerator=\"gpu\",\n",
+ " precision=\"bf16-mixed\",\n",
+ " devices=\"auto\",\n",
+ " strategy=RayDDPStrategy(),\n",
+ " plugins=[RayLightningEnvironment()],\n",
+ " callbacks=[RayTrainReportCallback()],\n",
+ " enable_checkpointing=False,\n",
+ " )\n",
+ "\n",
+ " # Load the latest checkpoint if it exists\n",
+ " checkpoint = ray.train.get_checkpoint()\n",
+ " if checkpoint:\n",
+ " # Continue training from a previous checkpoint\n",
+ " with checkpoint.as_directory() as ckpt_dir:\n",
+ " ckpt_path = os.path.join(ckpt_dir, \"checkpoint.ckpt\")\n",
+ "\n",
+ " # Call .fit with the ckpt_path\n",
+ " # This will restore both the model weights and the trainer states (optimizer, steps, callbacks)\n",
+ " trainer.fit(\n",
+ " model,\n",
+ " train_dataloaders=train_dataloader,\n",
+ " ckpt_path=ckpt_path,\n",
+ " )\n",
+ " \n",
+ " # If no checkpoint is provided, start from scratch\n",
+ " else:\n",
+ " trainer.fit(model, train_dataloaders=train_dataloader)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "878adcd0",
+ "metadata": {},
+ "source": [
+ "### Configuring Automatic Retries\n",
+ "\n",
+ "Now that we have enabled checkpoint loading, we can configure a failure config which sets the maximum number of retries for a training job."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "fd6d3cdb",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "failure_config = ray.train.FailureConfig(max_failures=3)\n",
+ "\n",
+ "trainer = TorchTrainer(\n",
+ " train_loop_per_worker_with_checkpoint_loading,\n",
+ " train_loop_config=train_loop_config,\n",
+ " scaling_config=ray.train.ScalingConfig(num_workers=2, use_gpu=True),\n",
+ " run_config=ray.train.RunConfig(\n",
+ " name=experiment_name,\n",
+ " storage_path=storage_path,\n",
+ " failure_config=failure_config, # Pass the failure config\n",
+ " ),\n",
+ " datasets=ray_datasets,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "164a57d3",
+ "metadata": {},
+ "source": [
+ "Now we can proceed to run the training job as before."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0d6f6bf9",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "trainer.fit()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "84437cfd",
+ "metadata": {},
+ "source": [
+ "### Performing a Manual Restoration\n",
+ "\n",
+ "In case the retries are exhausted, we can perform a manual restoration using the `TorchTrainer.restore` method. \n",
+ "\n",
+ "We can first check that we can still restore from a failed experiment by running the `can_restore` method."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "81176b07",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "can_restore = TorchTrainer.can_restore(path=os.path.join(storage_path, experiment_name))\n",
+ "can_restore"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "326d1b54",
+ "metadata": {},
+ "source": [
+ "This is mainly checking if the `trainer.pkl` file exists so we can re-create the TorchTrainer object."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "febde28d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!ls {storage_path}/{experiment_name}/trainer.pkl"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "552b77f1",
+ "metadata": {},
+ "source": [
+ "Let's restore the trainer using the `restore` method. We will however override the `train_loop_per_worker` function to perform the proper checkpoint loading."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2ca64d0d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "restored_trainer = TorchTrainer.restore(\n",
+ " path=os.path.join(storage_path, experiment_name),\n",
+ " datasets=ray_datasets,\n",
+ " train_loop_per_worker=train_loop_per_worker_with_checkpoint_loading,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1ab08cae",
+ "metadata": {},
+ "source": [
+ "Here is a view of our restored trainer."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d55e3907",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "restored_trainer"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "08c3a730",
+ "metadata": {},
+ "source": [
+ "Running the `fit` method will resume training from the last checkpoint. \n",
+ "\n",
+ "Given we already have completed all epochs, we expect the training to terminate immediately."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0f65deff",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "result = restored_trainer.fit()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5eb2e18c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "result"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "33b73ce0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "result.checkpoint"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "396caa4a",
+ "metadata": {},
+ "source": [
+ "## Clean up \n",
+ "\n",
+ "Let's clean up the storage path to remove the checkpoints and artifacts we created during this notebook."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "373ad2bd",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!rm -rf /mnt/cluster_storage/stable-diffusion-pretraining"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/templates/ray-summit-stable-diffusion/Bonus/04b_Advanced_Pretraining.ipynb b/templates/ray-summit-stable-diffusion/Bonus/04b_Advanced_Pretraining.ipynb
new file mode 100644
index 000000000..400e89d38
--- /dev/null
+++ b/templates/ray-summit-stable-diffusion/Bonus/04b_Advanced_Pretraining.ipynb
@@ -0,0 +1,456 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "7078ab58-6ca4-4255-8050-b7c5fe7eae1c",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "# Distributed Training Optimizations for Stable Diffusion\n",
+ "\n",
+ "This notebook demonstrates certain optimizations that can be applied to the training process to improve performance and reduce costs.\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "cfebb6c6",
+ "metadata": {},
+ "source": [
+ "### FSDP configuration:\n",
+ "\n",
+ "#### Sharding strategy:\n",
+ "\n",
+ "There are three different modes of the FSDP sharding strategy:\n",
+ "\n",
+ "1. `NO_SHARD`: Parameters, gradients, and optimizer states are not sharded. Similar to DDP.\n",
+ "2. `SHARD_GRAD_OP`: Gradients and optimizer states are sharded during computation, and additionally, parameters are sharded outside computation. Similar to ZeRO stage-2.\n",
+ "3. `FULL_SHARD`: Parameters, gradients, and optimizer states are sharded. It has minimal GRAM usage among the 3 options. Similar to ZeRO stage-3.\n",
+ "\n",
+ "#### Auto-wrap policy:\n",
+ "\n",
+ "Model layers are often wrapped with FSDP in a layered fashion. This means that only the layers in a single FSDP instance are required to aggregate all parameters to a single device during forwarding or backward calculations.\n",
+ "\n",
+ "Depending on the model architecture, we might need to specify a custom auto-wrap policy.\n",
+ "\n",
+ "For example, we can use the `transformer_auto_wrap_policy` to automatically wrap each Transformer Block into a single FSDP instance.\n",
+ "\n",
+ "#### Overlap communication with computation:\n",
+ "\n",
+ "You can specify to overlap the upcoming all-gather while executing the current forward/backward pass. It can improve throughput but may slightly increase peak memory usage. Set `backward_prefetch` and `forward_prefetch` to overlap communication with computation.\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "bc993de5",
+ "metadata": {},
+ "source": [
+ "Let's update our training loop to use FSDP."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ed963f6f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def train_loop_per_worker_fsdp(config):\n",
+ " train_ds = ray.train.get_dataset_shard(\"train\")\n",
+ " train_dataloader = train_ds.iter_torch_batches(\n",
+ " batch_size=config[\"batch_size_per_worker\"],\n",
+ " drop_last=True,\n",
+ " )\n",
+ "\n",
+ " torch.set_float32_matmul_precision(\"high\")\n",
+ " model = StableDiffusion(\n",
+ " lr=config[\"lr\"],\n",
+ " resolution=config[\"resolution\"],\n",
+ " weight_decay=config[\"weight_decay\"],\n",
+ " num_warmup_steps=config[\"num_warmup_steps\"],\n",
+ " model_name=config[\"model_name\"],\n",
+ " )\n",
+ "\n",
+ " trainer = pl.Trainer(\n",
+ " max_steps=config[\"max_steps\"],\n",
+ " max_epochs=config[\"max_epochs\"],\n",
+ " accelerator=\"gpu\",\n",
+ " devices=\"auto\",\n",
+ " precision=\"bf16-mixed\",\n",
+ " strategy=RayFSDPStrategy( # Use RayFSDPStrategy instead of RayDDPStrategy\n",
+ " sharding_strategy=\"SHARD_GRAD_OP\", # Run FSDP with SHARD_GRAD_OP sharding strategy\n",
+ " backward_prefetch=BackwardPrefetch.BACKWARD_PRE, # Overlap communication with computation in backward pass\n",
+ " ),\n",
+ " plugins=[RayLightningEnvironment()],\n",
+ " callbacks=[RayTrainReportCallback()],\n",
+ " enable_checkpointing=False,\n",
+ " )\n",
+ "\n",
+ " trainer.fit(model, train_dataloaders=train_dataloader)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4c8ecabd",
+ "metadata": {},
+ "source": [
+ "Let's run the training loop with FSDP."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "152c6749",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "storage_path = \"/mnt/cluster_storage/\"\n",
+ "experiment_name = \"stable-diffusion-pretraining-fsdp\"\n",
+ "\n",
+ "train_loop_config = {\n",
+ " \"batch_size_per_worker\": 8,\n",
+ " \"prefetch_batches\": 2,\n",
+ " \"every_n_train_steps\": 10, # Report metrics and checkpoints every 10 steps\n",
+ " \"lr\": 0.0001,\n",
+ " \"num_warmup_steps\": 10_000,\n",
+ " \"weight_decay\": 0.01,\n",
+ " \"max_steps\": 550_000,\n",
+ " \"max_epochs\": 1,\n",
+ " \"resolution\": 256,\n",
+ " \"model_name\": \"stabilityai/stable-diffusion-2-base\",\n",
+ "}\n",
+ "\n",
+ "run_config = ray.train.RunConfig(name=experiment_name, storage_path=storage_path)\n",
+ "\n",
+ "scaling_config = ray.train.ScalingConfig(\n",
+ " num_workers=2,\n",
+ " use_gpu=True,\n",
+ ")\n",
+ "\n",
+ "trainer = TorchTrainer(\n",
+ " train_loop_per_worker_fsdp,\n",
+ " train_loop_config=train_loop_config,\n",
+ " scaling_config=scaling_config,\n",
+ " run_config=run_config,\n",
+ " datasets=ray_datasets,\n",
+ ")\n",
+ "\n",
+ "result = trainer.fit()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9ab5d955",
+ "metadata": {},
+ "source": [
+ "Let's load the model from the checkpoint and inspect it."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c69903e5",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "with result.checkpoint.as_directory() as checkpoint_dir:\n",
+ " ckpt_path = os.path.join(checkpoint_dir, \"checkpoint.ckpt\")\n",
+ " model = StableDiffusion.load_from_checkpoint(ckpt_path, map_location=\"cpu\")\n",
+ " print(model)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3d1c4b82",
+ "metadata": {},
+ "source": [
+ "## 3. Online (end-to-end) preprocessing and training\n",
+ "\n",
+ "Looking ahead at more challenging Stable Diffusion training pipelines, we will need to handle data in a more sophisticated way.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9f79ea61",
+ "metadata": {},
+ "source": [
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "cfebb6c6",
+ "metadata": {},
+ "source": [
+ "### FSDP configuration:\n",
+ "\n",
+ "#### Sharding strategy:\n",
+ "\n",
+ "There are three different modes of the FSDP sharding strategy:\n",
+ "\n",
+ "1. `NO_SHARD`: Parameters, gradients, and optimizer states are not sharded. Similar to DDP.\n",
+ "2. `SHARD_GRAD_OP`: Gradients and optimizer states are sharded during computation, and additionally, parameters are sharded outside computation. Similar to ZeRO stage-2.\n",
+ "3. `FULL_SHARD`: Parameters, gradients, and optimizer states are sharded. It has minimal GRAM usage among the 3 options. Similar to ZeRO stage-3.\n",
+ "\n",
+ "#### Auto-wrap policy:\n",
+ "\n",
+ "Model layers are often wrapped with FSDP in a layered fashion. This means that only the layers in a single FSDP instance are required to aggregate all parameters to a single device during forwarding or backward calculations.\n",
+ "\n",
+ "Depending on the model architecture, we might need to specify a custom auto-wrap policy.\n",
+ "\n",
+ "For example, we can use the `transformer_auto_wrap_policy` to automatically wrap each Transformer Block into a single FSDP instance.\n",
+ "\n",
+ "#### Overlap communication with computation:\n",
+ "\n",
+ "You can specify to overlap the upcoming all-gather while executing the current forward/backward pass. It can improve throughput but may slightly increase peak memory usage. Set `backward_prefetch` and `forward_prefetch` to overlap communication with computation.\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "bc993de5",
+ "metadata": {},
+ "source": [
+ "Let's update our training loop to use FSDP."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ed963f6f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def train_loop_per_worker_fsdp(config):\n",
+ " train_ds = ray.train.get_dataset_shard(\"train\")\n",
+ " train_dataloader = train_ds.iter_torch_batches(\n",
+ " batch_size=config[\"batch_size_per_worker\"],\n",
+ " drop_last=True,\n",
+ " )\n",
+ "\n",
+ " torch.set_float32_matmul_precision(\"high\")\n",
+ " model = StableDiffusion(\n",
+ " lr=config[\"lr\"],\n",
+ " resolution=config[\"resolution\"],\n",
+ " weight_decay=config[\"weight_decay\"],\n",
+ " num_warmup_steps=config[\"num_warmup_steps\"],\n",
+ " model_name=config[\"model_name\"],\n",
+ " )\n",
+ "\n",
+ " trainer = pl.Trainer(\n",
+ " max_steps=config[\"max_steps\"],\n",
+ " max_epochs=config[\"max_epochs\"],\n",
+ " accelerator=\"gpu\",\n",
+ " devices=\"auto\",\n",
+ " precision=\"bf16-mixed\",\n",
+ " strategy=RayFSDPStrategy( # Use RayFSDPStrategy instead of RayDDPStrategy\n",
+ " sharding_strategy=\"SHARD_GRAD_OP\", # Run FSDP with SHARD_GRAD_OP sharding strategy\n",
+ " backward_prefetch=BackwardPrefetch.BACKWARD_PRE, # Overlap communication with computation in backward pass\n",
+ " ),\n",
+ " plugins=[RayLightningEnvironment()],\n",
+ " callbacks=[RayTrainReportCallback()],\n",
+ " enable_checkpointing=False,\n",
+ " )\n",
+ "\n",
+ " trainer.fit(model, train_dataloaders=train_dataloader)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4c8ecabd",
+ "metadata": {},
+ "source": [
+ "Let's run the training loop with FSDP."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "152c6749",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "storage_path = \"/mnt/cluster_storage/\"\n",
+ "experiment_name = \"stable-diffusion-pretraining-fsdp\"\n",
+ "\n",
+ "train_loop_config = {\n",
+ " \"batch_size_per_worker\": 8,\n",
+ " \"prefetch_batches\": 2,\n",
+ " \"every_n_train_steps\": 10, # Report metrics and checkpoints every 10 steps\n",
+ " \"lr\": 0.0001,\n",
+ " \"num_warmup_steps\": 10_000,\n",
+ " \"weight_decay\": 0.01,\n",
+ " \"max_steps\": 550_000,\n",
+ " \"max_epochs\": 1,\n",
+ " \"resolution\": 256,\n",
+ " \"model_name\": \"stabilityai/stable-diffusion-2-base\",\n",
+ "}\n",
+ "\n",
+ "run_config = ray.train.RunConfig(name=experiment_name, storage_path=storage_path)\n",
+ "\n",
+ "scaling_config = ray.train.ScalingConfig(\n",
+ " num_workers=2,\n",
+ " use_gpu=True,\n",
+ ")\n",
+ "\n",
+ "trainer = TorchTrainer(\n",
+ " train_loop_per_worker_fsdp,\n",
+ " train_loop_config=train_loop_config,\n",
+ " scaling_config=scaling_config,\n",
+ " run_config=run_config,\n",
+ " datasets=ray_datasets,\n",
+ ")\n",
+ "\n",
+ "result = trainer.fit()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9ab5d955",
+ "metadata": {},
+ "source": [
+ "Let's load the model from the checkpoint and inspect it."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c69903e5",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "with result.checkpoint.as_directory() as checkpoint_dir:\n",
+ " ckpt_path = os.path.join(checkpoint_dir, \"checkpoint.ckpt\")\n",
+ " model = StableDiffusion.load_from_checkpoint(ckpt_path, map_location=\"cpu\")\n",
+ " print(model)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3d1c4b82",
+ "metadata": {},
+ "source": [
+ "## 3. Online (end-to-end) preprocessing and training\n",
+ "\n",
+ "Looking ahead at more challenging Stable Diffusion training pipelines, we will need to handle data in a more sophisticated way.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9f79ea61",
+ "metadata": {},
+ "source": [
+ "![]() "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "db9d74fd",
+ "metadata": {},
+ "source": [
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "db9d74fd",
+ "metadata": {},
+ "source": [
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0ac4c6e1",
+ "metadata": {},
+ "source": [
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0ac4c6e1",
+ "metadata": {},
+ "source": [
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "df44c586",
+ "metadata": {},
+ "source": [
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "df44c586",
+ "metadata": {},
+ "source": [
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9a89b951",
+ "metadata": {},
+ "source": [
+ "### Resources for online preprocessing and training\n",
+ "\n",
+ "Check out the following resources for more details:\n",
+ "\n",
+ "- [Reducing the Cost of Pre-training Stable Diffusion by 3.7x with Anyscale](https://www.anyscale.com/blog/scalable-and-cost-efficient-stable-diffusion-pre-training-with-ray)\n",
+ "- [Pretraining Stable Diffusion (V2) workspace template](https://console.anyscale.com/v2/template-preview/stable-diffusion-pretraining)\n",
+ "- [Processing 2 Billion Images for Stable Diffusion Model Training - Definitive Guides with Ray Series](https://www.anyscale.com/blog/processing-2-billion-images-for-stable-diffusion-model-training-definitive-guides-with-ray-series)\n",
+ "- [We Pre-Trained Stable Diffusion Models on 2 billion Images and Didn't Break the Bank - Definitive Guides with Ray Series](https://www.anyscale.com/blog/we-pre-trained-stable-diffusion-models-on-2-billion-images-and-didnt-break-the-bank-definitive-guides-with-ray-series)\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ac62329a",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/templates/ray-summit-stable-diffusion/README.md b/templates/ray-summit-stable-diffusion/README.md
new file mode 100644
index 000000000..32f5e6de3
--- /dev/null
+++ b/templates/ray-summit-stable-diffusion/README.md
@@ -0,0 +1,17 @@
+# Scalable Generative AI with Stable Diffusion Models - From Pre-Training to Production
+
+Text-to-image generative AI models, like Stable Diffusion, are transforming the creative industry by generating high-quality images from text descriptions. In this workshop, you'll learn how to build scalable systems for these models by creating an end-to-end pipeline for pre-training a Stable Diffusion model on a billion-scale dataset using Ray Data and Ray Train.
+
+You'll explore how to efficiently stream data preprocessing and conduct distributed training across multiple GPUs. Additionally, you'll gain practical experience in deploying and scaling a Stable Diffusion model using Ray Serve, allowing you to deliver real-time, high-quality generative outputs.
+
+By the end of this session, you'll have a solid understanding of how to implement a complete generative AI pipeline with Ray. You'll leave with the skills to pre-train, deploy, and scale Stable Diffusion models, ready to handle large-scale generative tasks and produce impressive results.
+
+## Prerequisites:
+- Basic familiarity with computer vision tasks, including common challenges with data processing, training, and inference.
+- Intermediate programming skills with Python.
+- Basic understanding of text-to-image use cases.
+
+## Ray Libraries:
+- Ray Data
+- Ray Train
+- Ray Serve
\ No newline at end of file
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9a89b951",
+ "metadata": {},
+ "source": [
+ "### Resources for online preprocessing and training\n",
+ "\n",
+ "Check out the following resources for more details:\n",
+ "\n",
+ "- [Reducing the Cost of Pre-training Stable Diffusion by 3.7x with Anyscale](https://www.anyscale.com/blog/scalable-and-cost-efficient-stable-diffusion-pre-training-with-ray)\n",
+ "- [Pretraining Stable Diffusion (V2) workspace template](https://console.anyscale.com/v2/template-preview/stable-diffusion-pretraining)\n",
+ "- [Processing 2 Billion Images for Stable Diffusion Model Training - Definitive Guides with Ray Series](https://www.anyscale.com/blog/processing-2-billion-images-for-stable-diffusion-model-training-definitive-guides-with-ray-series)\n",
+ "- [We Pre-Trained Stable Diffusion Models on 2 billion Images and Didn't Break the Bank - Definitive Guides with Ray Series](https://www.anyscale.com/blog/we-pre-trained-stable-diffusion-models-on-2-billion-images-and-didnt-break-the-bank-definitive-guides-with-ray-series)\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ac62329a",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/templates/ray-summit-stable-diffusion/README.md b/templates/ray-summit-stable-diffusion/README.md
new file mode 100644
index 000000000..32f5e6de3
--- /dev/null
+++ b/templates/ray-summit-stable-diffusion/README.md
@@ -0,0 +1,17 @@
+# Scalable Generative AI with Stable Diffusion Models - From Pre-Training to Production
+
+Text-to-image generative AI models, like Stable Diffusion, are transforming the creative industry by generating high-quality images from text descriptions. In this workshop, you'll learn how to build scalable systems for these models by creating an end-to-end pipeline for pre-training a Stable Diffusion model on a billion-scale dataset using Ray Data and Ray Train.
+
+You'll explore how to efficiently stream data preprocessing and conduct distributed training across multiple GPUs. Additionally, you'll gain practical experience in deploying and scaling a Stable Diffusion model using Ray Serve, allowing you to deliver real-time, high-quality generative outputs.
+
+By the end of this session, you'll have a solid understanding of how to implement a complete generative AI pipeline with Ray. You'll leave with the skills to pre-train, deploy, and scale Stable Diffusion models, ready to handle large-scale generative tasks and produce impressive results.
+
+## Prerequisites:
+- Basic familiarity with computer vision tasks, including common challenges with data processing, training, and inference.
+- Intermediate programming skills with Python.
+- Basic understanding of text-to-image use cases.
+
+## Ray Libraries:
+- Ray Data
+- Ray Train
+- Ray Serve
\ No newline at end of file
\n",
+ "\n",
+ "
\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "vscode": {
+ "languageId": "plaintext"
+ }
+ },
+ "source": [
+ "## 7. Running Baseline Model Inference\n",
+ "\n",
+ "We will benchmark the performance to the unfinetuned version of the same LLM. \n",
+ "\n",
+ "### Using Few-shot learning for the baseline model\n",
+ "\n",
+ "We will augment the prompt with few-shot examples as a prompt-engineering approach to provide a fair comparison between the finetuned and unfinetuned models given the unfinetuned model fails to perform the task out of the box."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let us read in from our training data up to 20 examples "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "df_few_shot = ray.data.read_json(\"s3://anyscale-public-materials/llm-finetuning/viggo_inverted/train/subset-500.jsonl\").limit(20).to_pandas()\n",
+ "examples = df_few_shot['messages'].tolist()\n",
+ "examples[:2]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's take a sample conversation from our test dataset"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sample_conversations = test_ds.take_batch(2)\n",
+ "sample_conversations[\"messages\"][0]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Here is how we will build our prompt with few shot examples"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def few_shot(messages: list, examples: list) -> list:\n",
+ " \"\"\"Build a prompt for few-shot learning given a user input and examples.\"\"\"\n",
+ " system_message, user_message, assistant_message = messages\n",
+ " user_text = user_message[\"content\"]\n",
+ "\n",
+ " example_preface = (\n",
+ " \"Examples are printed below.\"\n",
+ " if len(examples) > 1\n",
+ " else \"An example is printed below.\"\n",
+ " )\n",
+ " example_preface += (\n",
+ " ' Note: you are to respond with the string after \"Output: \" only.'\n",
+ " )\n",
+ " examples_parsed = \"\\n\\n\".join(\n",
+ " [\n",
+ " f\"{user['content']}\\nOutput: {assistant['content']}\"\n",
+ " for (system, user, assistant) in examples\n",
+ " ]\n",
+ " )\n",
+ " response_preface = \"Now please provide the output for:\"\n",
+ " user_text = f\"{example_preface}\\n\\n{examples_parsed}\\n\\n{response_preface}\\n{user_text}\\nOutput: \"\n",
+ " return [system_message, {\"role\": \"user\", \"content\": user_text}, assistant_message]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Now we apply `few_shot` function with only two examples"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "conversation = sample_conversations[\"messages\"][0]\n",
+ "conversation_with_few_shot = few_shot(conversation, examples[:2])\n",
+ "conversation_with_few_shot"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Here is the updated user prompt"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(conversation_with_few_shot[1][\"content\"])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's map this across our entire dataset"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def apply_few_shot(row: dict[str, Any]) -> dict[str, Any]:\n",
+ " row[\"messages\"] = few_shot(row[\"messages\"], examples)\n",
+ " return row\n",
+ "\n",
+ "test_ds_with_few_shot = test_ds.map(apply_few_shot)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We now proceed to generate responses"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sampling_params = SamplingParams(temperature=0, max_tokens=2048, detokenize=True)\n",
+ "\n",
+ "test_ds_responses_few_shot = (\n",
+ " test_ds_with_few_shot.map(split_inputs_outputs)\n",
+ " .map(\n",
+ " MistralTokenizer,\n",
+ " concurrency=2,\n",
+ " )\n",
+ " .map_batches(\n",
+ " LLMPredictor,\n",
+ " fn_constructor_kwargs={\n",
+ " \"hf_model\": base_model,\n",
+ " \"sampling_params\": sampling_params,\n",
+ " },\n",
+ " concurrency=1, # number of LLM instances\n",
+ " num_gpus=1, # GPUs per LLM instance\n",
+ " batch_size=10,\n",
+ " )\n",
+ " .map(post_process)\n",
+ " .materialize()\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 8. Comparing Evaluation Metrics\n",
+ "\n",
+ "Let's produce the evaluation metrics on our baseline to compare"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fn_type_accuracy_percent_few_shot = test_ds_responses_few_shot.map_batches(check_function_type_accuracy).mean(on=\"fn_type_match\") * 100 \n",
+ "print(f\"The correct function type is predicted at {fn_type_accuracy_percent_few_shot}% accuracy\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "attr_types_accuracy_percent_few_shot = test_ds_responses_few_shot.map_batches(check_attribute_types_accuracy, batch_format=\"pandas\").mean(on=\"attr_types_match\") * 100 \n",
+ "print(f\"The correct attribute types are predicted at {attr_types_accuracy_percent_few_shot}% accuracy\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# clean up - uncomment to delete the artifacts\n",
+ "# !rm -rf /mnt/cluster_storage/llm-finetuning/"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "base",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.9.19"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 2
+}
diff --git a/templates/ray-summit-end-to-end-llms/04_Deploying_LLMs.ipynb b/templates/ray-summit-end-to-end-llms/04_Deploying_LLMs.ipynb
new file mode 100644
index 000000000..7967c2fd2
--- /dev/null
+++ b/templates/ray-summit-end-to-end-llms/04_Deploying_LLMs.ipynb
@@ -0,0 +1,570 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Deploy, configure, and serve LLMs \n",
+ "\n",
+ "This guide benefits from an Anyscale library for serving LLMs on Anyscale called [RayLLM](http://https://docs.anyscale.com/llms/serving/intro).\n",
+ "\n",
+ "Click here to see the solution
\n", + "\n", + "```python\n", + "def check_attribute_types_accuracy(batch: pd.DataFrame) -> pd.DataFrame:\n", + " batch[\"attr_types_match\"] = batch[\"ground_truth_attr_types\"].apply(list) == batch[\"model_attr_types\"].apply(list)\n", + " return batch\n", + "\n", + "attr_types_accuracy_percent = test_ds_responses_processed.map_batches(check_attribute_types_accuracy, batch_format=\"pandas\").mean(on=\"attr_types_match\") * 100 \n", + "print(f\"The correct attribute types are predicted at {attr_types_accuracy_percent}% accuracy\")\n", + "```\n", + "\n", + "\n",
+ " Here is the roadmap for this notebook:\n",
+ "
\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Imports"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "from typing import Optional\n",
+ "\n",
+ "import anyscale\n",
+ "import openai\n",
+ "import ray\n",
+ "from ray import serve"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ctx = ray.data.DataContext.get_current()\n",
+ "ctx.enable_operator_progress_bars = False\n",
+ "ctx.enable_progress_bars = False"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 1. Overview of RayLLM\n",
+ "RayLLM provides a number of features that simplify LLM development, including:\n",
+ "- An extensive suite of pre-configured open source LLMs.\n",
+ "- An OpenAI-compatible REST API.\n",
+ "\n",
+ "As well as operational features to efficiently scale LLM apps:\n",
+ "- Optimizations such as continuous batching, quantization and streaming.\n",
+ "- Production-grade autoscaling support, including scale-to-zero.\n",
+ "- Native multi-GPU & multi-node model deployments.\n",
+ "\n",
+ "To learn more about RayLLM, check out [the docs](http://https://docs.anyscale.com/llms/serving/intro). \n",
+ "\n",
+ "For a full guide on how to deploy LLMs, check out this [workspace template](https://docs.anyscale.com/examples/deploy-llms/)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 2. Generating a RayLLM Configuration\n",
+ "\n",
+ "The first step is to set up a huggingface token in order to access the huggingface model hub. You can get a token by signing up at [huggingface](https://huggingface.co/login). \n",
+ "\n",
+ "You then will need to visit the [mistralai/Mistral-7B-Instruct-v0.1 model page ](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1) and request access to the model.\n",
+ "\n",
+ "Once you have your token, you can proceed to open a terminal window (via Menu > Terminal > New Terminal) and run the `rayllm gen-config` command. \n",
+ "\n",
+ "Below are similar prompts to what you will see:"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "```bash\n",
+ "(base) ray@ip-10-0-4-24:~/default/ray-summit-2024-training/End_to_End_LLMs/bonus$ rayllm gen-config\n",
+ "We have provided the defaults for the following models:\n",
+ "meta-llama/Llama-2-7b-chat-hf\n",
+ "meta-llama/Llama-2-13b-chat-hf\n",
+ "meta-llama/Llama-2-70b-chat-hf\n",
+ "meta-llama/Meta-Llama-3-8B-Instruct\n",
+ "meta-llama/Meta-Llama-3-70B-Instruct\n",
+ "meta-llama/Meta-Llama-3.1-8B-Instruct\n",
+ "meta-llama/Meta-Llama-3.1-70B-Instruct\n",
+ "mistralai/Mistral-7B-Instruct-v0.1\n",
+ "mistralai/Mixtral-8x7B-Instruct-v0.1\n",
+ "mistralai/Mixtral-8x22B-Instruct-v0.1\n",
+ "google/gemma-7b-it\n",
+ "llava-hf/llava-v1.6-mistral-7b-hf\n",
+ "Please enter the model ID you would like to serve, or enter your own custom model ID: mistralai/Mistral-7B-Instruct-v0.1\n",
+ "GPU type [L4/A10/A100_40G/A100_80G/H100]: L4\n",
+ "Tensor parallelism (1): 1\n",
+ "Enable LoRA serving [y/n] (n): y\n",
+ "LoRA weights storage URI. If not provided, the default will be used. \n",
+ "(s3://anyscale-production-data-cld-91sl4yby42b2ivfp1inig5suuy/org_uhhav3lw5hg4risfz57ct1tg9s/cld_91sl4yby42b2ivfp1inig5suuy/artifact_storage/lora_fine_tuning): \n",
+ "Maximum number of LoRA models per replica (16): \n",
+ "Further customize the auto-scaling config [y/n] (n): n\n",
+ "Enable token authentication?\n",
+ "Note: Auth-enabled services require manual addition to playground. [y/n] (n): y\n",
+ "\n",
+ "Your serve configuration file is successfully written to ./serve_20240907010212.yaml\n",
+ "\n",
+ "Do you want to start up the server locally? [y/n] (y): y\n",
+ "Run the serving command in the background: [y/n] (y): y\n",
+ "Running: serve run ./serve_20240907010212.yaml --non-blocking\n",
+ "```\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 3.Running a RayLLM application\n",
+ "\n",
+ "In the final steps of the interactive command we ran above, we can see that we ran the model locally by executing:\n",
+ "\n",
+ "```bash\n",
+ "serve run ./serve_20240907010212.yaml --non-blocking\n",
+ "```\n",
+ "\n",
+ "We can validate that the indeed our application is running by checking the Ray Serve dashboard. \n",
+ "\n",
+ "It should now look like this:\n",
+ "\n",
+ "- \n",
+ "
- Part 1: Overview of RayLLM \n", + "
- Part 2: Generating a RayLLM Configuration \n", + "
- Part 3: Running a RayLLM application \n", + "
- Part 4: Querying our RayLLM application \n", + "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 4. Querying our LLM application\n",
+ "\n",
+ "Let's first build a client to query our LLM"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def build_client(base_url: str, api_key: str) -> openai.OpenAI:\n",
+ " return openai.OpenAI(\n",
+ " base_url=base_url.rstrip(\"/\") + \"/v1\",\n",
+ " api_key=api_key,\n",
+ " )"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "client = build_client(\"http://localhost:8000\", \"NOT A REAL KEY\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Next, we build a query function to send requests to our LLM application."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def query(\n",
+ " client: openai.OpenAI,\n",
+ " llm_model: str,\n",
+ " system_message: dict[str, str],\n",
+ " user_message: dict[str, str],\n",
+ " temperature: float = 0,\n",
+ " timeout: float = 3 * 60,\n",
+ ") -> Optional[str]:\n",
+ " model_response = client.chat.completions.create(\n",
+ " model=llm_model,\n",
+ " messages=[system_message, user_message],\n",
+ " temperature=temperature,\n",
+ " timeout=timeout,\n",
+ " )\n",
+ " model_output = model_response.choices[0].message.content\n",
+ " return model_output"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ " 🔄 REPLACE : Use the job ID of your fine-tuning run"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "model_info = anyscale.llm.model.get(job_id=\"prodjob_123\") # REPLACE with the job ID for your fine-tuning run"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's extract the base model ID and the model ID from the model info."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "base_model = model_info.base_model_id\n",
+ "finetuned_model_id = model_info.id\n",
+ "finetuned_model_id"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "Backup: In case you don't have access to a successful finetuning job, you can copy the artifacts using the following command:\n",
+ "\n",
+ "```python\n",
+ "base_model = \"mistralai/Mistral-7B-Instruct-v0.1\"\n",
+ "finetuned_model_id = \"mistralai/Mistral-7B-Instruct-v0.1:aitra:qzoyg\"\n",
+ "s3_lora_path = (\n",
+ " f\"{os.environ['ANYSCALE_ARTIFACT_STORAGE']}\"\n",
+ " f\"/lora_fine_tuning/{model_id}\"\n",
+ ")\n",
+ "!aws s3 sync s3://anyscale-public-materials/llm-finetuning/lora_fine_tuning/{model_id} {s3_lora_path}\n",
+ "```\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's first test our base model"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "query(\n",
+ " client=client,\n",
+ " llm_model=base_model,\n",
+ " system_message={\"content\": \"you are a helpful assistant\", \"role\": \"system\"},\n",
+ " user_message={\"content\": \"Hello there\", \"role\": \"user\"},\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's now query our finetuned LLM using the generated model id"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "query(\n",
+ " client=client,\n",
+ " llm_model=finetuned_model_id,\n",
+ " system_message={\"content\": \"you are a helpful assistant\", \"role\": \"system\"},\n",
+ " user_message={\"content\": \"Hello there\", \"role\": \"user\"},\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ " 💡 INSIGHT : Ray Serve and Anyscale support [serving multiple LoRA adapters](https://github.com/anyscale/templates/blob/main/templates/endpoints_v2/examples/lora/DeployLora.ipynb) with a common base model in the same request batch which allows you to serve a wide variety of use-cases without increasing hardware spend. In addition, we use Serve multiplexing to reduce the number of swaps for LoRA adapters. There is a slight latency overhead to serving a LoRA model compared to the base model, typically 10-20%.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's test this on our VIGGO dataset by reading in a sample conversation."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "test_sample = (\n",
+ " ray.data.read_json(\n",
+ " \"s3://anyscale-public-materials/llm-finetuning/viggo_inverted/test/data.jsonl\"\n",
+ " )\n",
+ " .to_pandas()[\"messages\"]\n",
+ " .tolist()\n",
+ ")\n",
+ "test_conversation = test_sample[0]\n",
+ "test_conversation"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can check to see the response from our base model"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "response_base_model = query(\n",
+ " client=client,\n",
+ " llm_model=base_model,\n",
+ " system_message=test_conversation[0],\n",
+ " user_message=test_conversation[1]\n",
+ ")\n",
+ "print(response_base_model)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's check if our finetuned model will provide a response with the format that we expect."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "response_finetuned_model = query(\n",
+ " client=client,\n",
+ " llm_model=finetuned_model_id,\n",
+ " system_message=test_conversation[0],\n",
+ " user_message=test_conversation[1]\n",
+ ")\n",
+ "\n",
+ "print(response_finetuned_model)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "As expected, the finetuned model provides a more accurate and relevant response."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "expected_response = test_conversation[-1]\n",
+ "expected_response[\"content\"]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "### Activity: Query the model with few-shot learning\n",
+ "\n",
+ "Confirm that indeed few-shot learning will assist our base model by augmenting the prompt.\n",
+ "\n",
+ "```python\n",
+ "system_message = test_conversation[0]\n",
+ "user_message = test_conversation[1]\n",
+ "\n",
+ "examples = \"\"\"\n",
+ "Here is the target sentence:\n",
+ "Dirt: Showdown from 2012 is a sport racing game for the PlayStation, Xbox, PC rated E 10+ (for Everyone 10 and Older). It's not available on Steam, Linux, or Mac.\n",
+ "Output: inform(name[Dirt: Showdown], release_year[2012], esrb[E 10+ (for Everyone 10 and Older)], genres[driving/racing, sport], platforms[PlayStation, Xbox, PC], available_on_steam[no], has_linux_release[no], has_mac_release[no])\n",
+ "\n",
+ "Here is the target sentence:\n",
+ "Dirt: Showdown is a sport racing game that was released in 2012. The game is available on PlayStation, Xbox, and PC, and it has an ESRB Rating of E 10+ (for Everyone 10 and Older). However, it is not yet available as a Steam, Linux, or Mac release.\n",
+ "Output: inform(name[Dirt: Showdown], release_year[2012], esrb[E 10+ (for Everyone 10 and Older)], genres[driving/racing, sport], platforms[PlayStation, Xbox, PC], available_on_steam[no], has_linux_release[no], has_mac_release[no])\n",
+ "\"\"\"\n",
+ "\n",
+ "user_message = {\n",
+ " \"role\": \"user\",\n",
+ " \"content\": ... # Hint: update the user message content to include the examples\n",
+ "}, \n",
+ "\n",
+ "# Run the query\n",
+ "query(\n",
+ " client=client,\n",
+ " llm_model=base_model,\n",
+ " system_message=system_message,\n",
+ " user_message=user_message\n",
+ ")\n",
+ "```\n",
+ "\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Write your solution here\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "
\n", + "\n", + "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's clean up and shutdown our RayLLM application."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "serve.shutdown()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Bonus: Deploying as an Anyscale Service\n",
+ "\n",
+ "In case you want to productionize your LLM app, you can deploy it as an Anyscale Service. \n",
+ "\n",
+ "To do so, you can use the Anyscale CLI to deploy your application.\n",
+ "\n",
+ "```bash\n",
+ "anyscale service deploy -f ./serve_20240907010212.yaml\n",
+ "```\n",
+ "\n",
+ "You can then query your application using the same `query` function we defined earlier. Except this time, your client now points to the Anyscale endpoint and your API key is the generated authentication token.\n",
+ "\n",
+ "```python\n",
+ "client = build_client(\"https://\n",
+ "\n",
+ "
\n",
+ "Click here to see the solution
\n", + "\n", + "```python\n", + "system_message = test_conversation[0]\n", + "user_message = test_conversation[1]\n", + "\n", + "examples = \"\"\"\n", + "Here is the target sentence:\n", + "Dirt: Showdown from 2012 is a sport racing game for the PlayStation, Xbox, PC rated E 10+ (for Everyone 10 and Older). It's not available on Steam, Linux, or Mac.\n", + "Output: inform(name[Dirt: Showdown], release_year[2012], esrb[E 10+ (for Everyone 10 and Older)], genres[driving/racing, sport], platforms[PlayStation, Xbox, PC], available_on_steam[no], has_linux_release[no], has_mac_release[no])\n", + "\n", + "Here is the target sentence:\n", + "Dirt: Showdown is a sport racing game that was released in 2012. The game is available on PlayStation, Xbox, and PC, and it has an ESRB Rating of E 10+ (for Everyone 10 and Older). However, it is not yet available as a Steam, Linux, or Mac release.\n", + "Output: inform(name[Dirt: Showdown], release_year[2012], esrb[E 10+ (for Everyone 10 and Older)], genres[driving/racing, sport], platforms[PlayStation, Xbox, PC], available_on_steam[no], has_linux_release[no], has_mac_release[no])\n", + "\"\"\"\n", + "\n", + "user_message_with_examples = {\n", + " \"role\": \"user\",\n", + " \"content\": (\n", + "f\"\"\"\n", + "Here are examples of the target output:\n", + "{examples}\n", + "\n", + "Now please provide the output for:\n", + "Here is the target sentence:\n", + "{user_message[\"content\"]}\n", + "Output: \n", + "\"\"\"\n", + ")\n", + "}\n", + "\n", + "\n", + "# Run the query\n", + "query(\n", + " client=client,\n", + " llm_model=base_model,\n", + " system_message=system_message,\n", + " user_message=user_message_with_examples\n", + ")\n", + "```\n", + "\n", + "\n", + "\n", + "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "vscode": {
+ "languageId": "plaintext"
+ }
+ },
+ "source": [
+ "This flywheel can be split into two main phases:\n",
+ "\n",
+ "1. Continuous Iteration on the data\n",
+ "2. Continuous Iteration on the model\n",
+ "\n",
+ "Here is a visual representation of the data flywheel:\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "#### 1. Continuous Iteration on the data\n",
+ "\n",
+ "This phase involves:\n",
+ "- collection of new data\n",
+ "- incorporation of user feedback\n",
+ "- evaluation of data quality\n",
+ "- cleaning of data\n",
+ "- augmentation of data\n",
+ "- curation of data\n",
+ "\n",
+ "#### 2. Continuous Iteration on the model\n",
+ "\n",
+ "This involves continuous:\n",
+ "- evaluation of model performance\n",
+ "- analysis of model outputs\n",
+ "- fine-tuning of the model\n",
+ "\n",
+ "##### Champion-challenger evaluation framework\n",
+ "One pattern that emerges is the use of a champion-challenger evaluation framework.\n",
+ "\n",
+ "This is a framework for evaluating and selecting between different versions of a model. \n",
+ "\n",
+ "It involves:\n",
+ "- selecting a champion model\n",
+ "- fine-tuning a challenger model\n",
+ "- evaluating the performance of the champion and challenger\n",
+ "- selecting the best performing model\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Automated Retraining of LLMs\n",
+ "\n",
+ "With the use of orchestration tools like Airflow, we can choose to automate this process integrating with Ray and Anyscale.\n",
+ "\n",
+ "Here is a diagram showing the process:\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "base",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.9.19"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 2
+}
diff --git a/templates/ray-summit-end-to-end-llms/configs/deepspeed/zero_3_offload_optim+param.json b/templates/ray-summit-end-to-end-llms/configs/deepspeed/zero_3_offload_optim+param.json
new file mode 100644
index 000000000..c89d62f2c
--- /dev/null
+++ b/templates/ray-summit-end-to-end-llms/configs/deepspeed/zero_3_offload_optim+param.json
@@ -0,0 +1,35 @@
+{
+ "fp16": {
+ "enabled": "auto"
+ },
+ "bf16": {
+ "enabled": true
+ },
+ "zero_optimization": {
+ "stage": 3,
+ "offload_optimizer": {
+ "device": "cpu",
+ "pin_memory": true
+ },
+ "offload_param": {
+ "device": "cpu",
+ "pin_memory": true
+ },
+ "overlap_comm": true,
+ "contiguous_gradients": true,
+ "sub_group_size": 1e9,
+ "reduce_bucket_size": 5e8,
+ "stage3_prefetch_bucket_size": 5e8,
+ "stage3_param_persistence_threshold": 1e6,
+ "stage3_max_live_parameters": 1e9,
+ "stage3_max_reuse_distance": 1e9,
+ "stage3_gather_16bit_weights_on_model_save": true,
+ "round_robin_gradients": true
+ },
+ "gradient_accumulation_steps": "auto",
+ "gradient_clipping": "auto",
+ "steps_per_print": 10,
+ "train_batch_size": "auto",
+ "train_micro_batch_size_per_gpu": "auto",
+ "wall_clock_breakdown": false
+ }
diff --git a/templates/ray-summit-end-to-end-llms/configs/training/lora/mistral-7b.yaml b/templates/ray-summit-end-to-end-llms/configs/training/lora/mistral-7b.yaml
new file mode 100644
index 000000000..4129259aa
--- /dev/null
+++ b/templates/ray-summit-end-to-end-llms/configs/training/lora/mistral-7b.yaml
@@ -0,0 +1,54 @@
+# Change this to the model you want to fine-tune
+model_id: mistralai/Mistral-7B-Instruct-v0.1
+
+# Change this to the path to your training data
+train_path: s3://anyscale-public-materials/llm-finetuning/viggo_inverted/train/subset-500.jsonl
+
+# Change this to the path to your validation data. This is optional
+valid_path: s3://anyscale-public-materials/llm-finetuning/viggo_inverted/valid/data.jsonl
+
+# Change this to the context length you want to use. Examples with longer
+# context length will be truncated.
+context_length: 512
+
+# Change this to total number of GPUs that you want to use
+num_devices: 2
+
+# Change this to the number of epochs that you want to train for
+num_epochs: 3
+
+# Change this to the batch size that you want to use
+train_batch_size_per_device: 16
+eval_batch_size_per_device: 16
+
+# Change this to the learning rate that you want to use
+learning_rate: 1e-4
+
+# This will pad batches to the longest sequence. Use "max_length" when profiling to profile the worst case.
+padding: "longest"
+
+# By default, we will keep the best checkpoint. You can change this to keep more checkpoints.
+num_checkpoints_to_keep: 1
+
+# Deepspeed configuration, you can provide your own deepspeed setup
+deepspeed:
+ config_path: configs/deepspeed/zero_3_offload_optim+param.json
+
+# Lora configuration
+lora_config:
+ r: 8
+ lora_alpha: 16
+ lora_dropout: 0.05
+ target_modules:
+ - q_proj
+ - v_proj
+ - k_proj
+ - o_proj
+ - gate_proj
+ - up_proj
+ - down_proj
+ - embed_tokens
+ - lm_head
+ task_type: "CAUSAL_LM"
+ bias: "none"
+ modules_to_save: []
diff --git a/templates/ray-summit-multi-modal-search/README.md b/templates/ray-summit-multi-modal-search/README.md
new file mode 100644
index 000000000..dd8d728ec
--- /dev/null
+++ b/templates/ray-summit-multi-modal-search/README.md
@@ -0,0 +1,16 @@
+# Reinventing Multi-Modal Search with LLMs and Large Scale Data Processing
+
+Traditional search systems often struggle with handling unstructured data, especially non-text data like images. In this workshop, you'll learn how to enhance legacy search systems using generative and embedding models for richer data representation.
+
+You will build a scalable multi-modal data indexing pipeline and a hybrid search backend using Anyscale and MongoDB. The training will cover practical applications of Ray Data for scalable batch inference, Ray Serve for deploying and scaling the search application, vLLM for integrating large language models and MongoDB Atlas for both lexical and vector search.
+
+By the end of this session, you'll have the skills to implement advanced AI tooling for creating a scalable and efficient search system capable of handling diverse data types in enterprise applications.
+
+## Prerequisites:
+- Familiarity with large scale data processing.
+- Prior experience with Ray Data or Ray Serve is not required, but participants with some experience in these frameworks will have an advantage in understanding the more advanced topics that will be covered in the training.
+- Intermediate-level experience with Python.
+
+## Ray Libraries:
+- Ray Data
+- Ray Serve
\ No newline at end of file
diff --git a/templates/ray-summit-multi-modal-search/no-color-application/app.yaml b/templates/ray-summit-multi-modal-search/no-color-application/app.yaml
new file mode 100644
index 000000000..2e8d5a984
--- /dev/null
+++ b/templates/ray-summit-multi-modal-search/no-color-application/app.yaml
@@ -0,0 +1,10 @@
+name: mongo-search-front-middle
+applications:
+ - name: frontend
+ route_prefix: /
+ import_path: frontend:app
+ - name: backend
+ route_prefix: /backend
+ import_path: backend:app
+query_auth_token_enabled: false
+requirements: requirements.txt
diff --git a/templates/ray-summit-multi-modal-search/no-color-application/backend.py b/templates/ray-summit-multi-modal-search/no-color-application/backend.py
new file mode 100644
index 000000000..4eccf827c
--- /dev/null
+++ b/templates/ray-summit-multi-modal-search/no-color-application/backend.py
@@ -0,0 +1,499 @@
+import asyncio
+from typing import Optional
+from motor.motor_asyncio import AsyncIOMotorClient
+import os
+import logging
+from ray.serve import deployment, ingress
+from ray.serve.handle import DeploymentHandle
+from fastapi import FastAPI
+from sentence_transformers import SentenceTransformer
+
+def vector_search(
+ vector_search_index_name: str,
+ vector_search_path: str,
+ embedding: list[float],
+ n: int,
+ min_price: int,
+ max_price: int,
+ min_rating: float,
+ categories: list[str],
+ colors: list[str],
+ seasons: list[str],
+ cosine_score_threshold: float = 0.92,
+) -> list[dict]:
+ return [
+ {
+ "$vectorSearch": {
+ "index": vector_search_index_name,
+ "path": vector_search_path,
+ "queryVector": embedding.tolist(),
+ "numCandidates": 100,
+ "limit": n,
+ "filter": {
+ "price": {"$gte": min_price, "$lte": max_price},
+ "rating": {"$gte": min_rating},
+ "category": {"$in": categories},
+# "color": {"$in": colors},
+ "season": {"$in": seasons},
+ },
+ }
+ },
+ {
+ "$project": {
+ "_id": 1,
+ "img": 1,
+ "name": 1,
+ "score": {"$meta": "vectorSearchScore"},
+ }
+ },
+ {"$match": {"score": {"$gte": cosine_score_threshold}}},
+ ]
+
+
+def lexical_search(text_search: str, text_search_index_name: str) -> list[dict]:
+ return [
+ {
+ "$search": {
+ "index": text_search_index_name,
+ "text": {
+ "query": text_search,
+ "path": "name",
+ },
+ }
+ }
+ ]
+
+
+def match_on_metadata(
+ min_price: int,
+ max_price: int,
+ min_rating: float,
+ n: int,
+ categories: list[str] | None = None,
+ colors: list[str] | None = None,
+ seasons: list[str] | None = None,
+) -> list[dict]:
+ match_spec = {
+ "price": {
+ "$gte": min_price,
+ "$lte": max_price,
+ },
+ "rating": {"$gte": min_rating},
+ }
+ if categories:
+ match_spec["category"] = {"$in": categories}
+# if colors:
+# match_spec["color"] = {"$in": colors}
+ if seasons:
+ match_spec["season"] = {"$in": seasons}
+
+ return [
+ {
+ "$match": match_spec,
+ },
+ {"$limit": n},
+ ]
+
+
+def convert_rank_to_score(score_name: str, score_penalty: float) -> list[dict]:
+ return [
+ {
+ "$group": {
+ "_id": None,
+ "docs": {
+ "$push": "$$ROOT",
+ },
+ }
+ },
+ {
+ "$unwind": {
+ "path": "$docs",
+ "includeArrayIndex": "rank",
+ }
+ },
+ {
+ "$addFields": {
+ score_name: {
+ "$divide": [
+ 1.0,
+ {"$add": ["$rank", score_penalty, 1]},
+ ]
+ }
+ }
+ },
+ {
+ "$project": {
+ score_name: 1,
+ "_id": "$docs._id",
+ "name": "$docs.name",
+ "img": "$docs.img",
+ }
+ },
+ ]
+
+
+def rerank_by_combined_score(
+ vs_score_name: str, fts_score_name: str, n: int
+) -> list[dict]:
+ return [
+ {
+ "$group": {
+ "_id": "$name",
+ "img": {"$first": "$img"},
+ vs_score_name: {"$max": f"${vs_score_name}"},
+ fts_score_name: {"$max": f"${fts_score_name}"},
+ }
+ },
+ {
+ "$project": {
+ "_id": 1,
+ "img": 1,
+ vs_score_name: {"$ifNull": [f"${vs_score_name}", 0]},
+ fts_score_name: {"$ifNull": [f"${fts_score_name}", 0]},
+ }
+ },
+ {
+ "$project": {
+ "name": "$_id",
+ "img": 1,
+ vs_score_name: 1,
+ fts_score_name: 1,
+ "score": {"$add": [f"${fts_score_name}", f"${vs_score_name}"]},
+ }
+ },
+ {"$sort": {"score": -1}},
+ {"$limit": n},
+ ]
+
+
+def hybrid_search(
+ collection_name: str,
+ text_search: str,
+ text_search_index_name: str,
+ vector_search_index_name: str,
+ vector_search_path: str,
+ embedding: list[float],
+ n: int,
+ min_price: int,
+ max_price: int,
+ min_rating: float,
+ categories: list[str],
+ colors: list[str],
+ seasons: list[str],
+ vector_penalty: int,
+ full_text_penalty: int,
+ cosine_score_threshold: float = 0.92,
+) -> list[dict]:
+ # 1. Perform vector search
+ vector_search_stages = vector_search(
+ vector_search_index_name=vector_search_index_name,
+ vector_search_path=vector_search_path,
+ embedding=embedding,
+ n=n,
+ min_price=min_price,
+ max_price=max_price,
+ min_rating=min_rating,
+ categories=categories,
+ colors=colors,
+ seasons=seasons,
+ cosine_score_threshold=cosine_score_threshold,
+ )
+ convert_vector_rank_to_score_stages = convert_rank_to_score(
+ score_name="vs_score", score_penalty=vector_penalty
+ )
+
+ # 2. Perform lexical search
+ lexical_search_stages = lexical_search(text_search=text_search, text_search_index_name=text_search_index_name)
+ post_filter_stages = match_on_metadata(
+ min_price=min_price,
+ max_price=max_price,
+ min_rating=min_rating,
+ categories=categories,
+ colors=colors,
+ seasons=seasons,
+ n=n,
+ )
+ convert_text_rank_to_score_stages = convert_rank_to_score(
+ score_name="fts_score", score_penalty=full_text_penalty
+ )
+
+ # 3. Rerank by combined score
+ rerank_stages = rerank_by_combined_score(
+ vs_score_name="vs_score", fts_score_name="fts_score", n=n
+ )
+
+ # 4. Put it all together
+ return [
+ *vector_search_stages,
+ *convert_vector_rank_to_score_stages,
+ {
+ "$unionWith": {
+ "coll": collection_name,
+ "pipeline": [
+ *lexical_search_stages,
+ *post_filter_stages,
+ *convert_text_rank_to_score_stages,
+ ],
+ }
+ },
+ *rerank_stages,
+ ]
+
+
+@deployment
+class EmbeddingModel:
+ def __init__(self, model: str = "thenlper/gte-large") -> None:
+ self.model = SentenceTransformer(model)
+
+ async def compute_embedding(self, text: str) -> list[float]:
+ loop = asyncio.get_event_loop()
+ return await loop.run_in_executor(None, lambda: self.model.encode(text))
+
+
+@deployment
+class QueryLegacySearch:
+ def __init__(
+ self,
+ database_name: str = "myntra",
+ collection_name: str = "myntra-items-offline",
+ ) -> None:
+ self.client = AsyncIOMotorClient(os.environ["DB_CONNECTION_STRING"])
+ self.database_name = database_name
+ self.collection_name = collection_name
+
+ async def run(
+ self,
+ text_search: Optional[str],
+ min_price: int,
+ max_price: int,
+ min_rating: float,
+ n: int = 20,
+ text_search_index_name: str = "lexical_text_search_index",
+ ) -> list[tuple[str, str]]:
+ logger = logging.getLogger("ray.serve")
+ logger.setLevel(logging.DEBUG)
+
+ db = self.client[self.database_name]
+ collection = db[self.collection_name]
+
+ pipeline = []
+ if text_search.strip():
+ pipeline.extend(
+ lexical_search(
+ text_search=text_search,
+ text_search_index_name=text_search_index_name,
+ )
+ )
+
+ pipeline.extend(
+ match_on_metadata(
+ min_price=min_price,
+ max_price=max_price,
+ min_rating=min_rating,
+ n=n,
+ )
+ )
+
+ logger.debug(f"Running pipeline: {pipeline}")
+
+ records = collection.aggregate(pipeline)
+ results = [
+ (record["img"].split(";")[-1].strip(), record["name"])
+ async for record in records
+ ]
+
+ n_results = len(results)
+ logger.debug(f"Found {n_results=} results")
+
+ return results
+
+
+@deployment
+class QueryAIEnabledSearch:
+ def __init__(
+ self,
+ embedding_model: DeploymentHandle,
+ database_name: str = "myntra",
+ collection_name: str = "myntra-items-offline",
+ ) -> None:
+ self.client = AsyncIOMotorClient(os.environ["DB_CONNECTION_STRING"])
+ self.embedding_model = embedding_model
+ self.database_name = database_name
+ self.collection_name = collection_name
+
+ async def run(
+ self,
+ text_search: str,
+ min_price: int,
+ max_price: int,
+ min_rating: float,
+ categories: list[str],
+ colors: list[str],
+ seasons: list[str],
+ n: int,
+ search_type: set[str],
+ vector_search_index_name: str = "vector_search_index",
+ vector_search_path: str = "description_embedding",
+ text_search_index_name: str = "lexical_text_search_index",
+ vector_penalty: int = 1,
+ full_text_penalty: int = 10,
+ ):
+ logger = logging.getLogger("ray.serve")
+ logger.setLevel(logging.DEBUG)
+
+ db = self.client[self.database_name]
+ collection = db[self.collection_name]
+
+ pipeline = []
+ if text_search.strip():
+
+ if "vector" in search_type:
+ logger.debug(f"Computing embedding for {text_search=}")
+ embedding = await self.embedding_model.compute_embedding.remote(
+ text_search
+ )
+
+ is_hybrid = search_type == {"vector", "lexical"}
+ if is_hybrid:
+ pipeline.extend(
+ hybrid_search(
+ self.collection_name,
+ text_search,
+ text_search_index_name,
+ vector_search_index_name,
+ vector_search_path,
+ embedding,
+ n,
+ min_price,
+ max_price,
+ min_rating,
+ categories,
+ colors,
+ seasons,
+ vector_penalty,
+ full_text_penalty,
+ )
+ )
+ elif search_type == {"vector"}:
+ pipeline.extend(
+ vector_search(
+ vector_search_index_name,
+ vector_search_path,
+ embedding,
+ n,
+ min_price,
+ max_price,
+ min_rating,
+ categories,
+ colors,
+ seasons,
+ )
+ )
+ elif search_type == {"lexical"}:
+ pipeline.extend(
+ lexical_search(
+ text_search=text_search,
+ text_search_index_name=text_search_index_name,
+ )
+ )
+ pipeline.extend(
+ match_on_metadata(
+ min_price=min_price,
+ max_price=max_price,
+ min_rating=min_rating,
+ n=n,
+ categories=categories,
+ colors=colors,
+ seasons=seasons,
+ )
+ )
+ else:
+ pipeline = match_on_metadata(
+ min_price=min_price,
+ max_price=max_price,
+ min_rating=min_rating,
+ n=n,
+ categories=categories,
+ colors=colors,
+ seasons=seasons,
+ )
+
+ records = collection.aggregate(pipeline)
+ logger.debug(f"Running pipeline: {pipeline}")
+ records = [record async for record in records]
+ results = [
+ (record["img"].split(";")[-1].strip(), record["name"]) for record in records
+ ]
+ num_results = len(results)
+
+ logger.debug(f"Found {num_results=} results")
+ return results
+
+
+fastapi = FastAPI()
+
+
+@deployment
+@ingress(fastapi)
+class QueryApplication:
+
+ def __init__(
+ self,
+ query_legacy: QueryLegacySearch,
+ query_ai_enabled: QueryAIEnabledSearch,
+ ):
+ self.query_legacy = query_legacy
+ self.query_ai_enabled = query_ai_enabled
+
+ @fastapi.get("/legacy")
+ async def query_legacy_search(
+ self,
+ text_search: str,
+ min_price: int,
+ max_price: int,
+ min_rating: float,
+ num_results: int,
+ ):
+ return await self.query_legacy.run.remote(
+ text_search=text_search,
+ min_price=min_price,
+ max_price=max_price,
+ min_rating=min_rating,
+ n=num_results,
+ )
+
+ @fastapi.get("/ai_enabled")
+ async def query_ai_enabled_search(
+ self,
+ text_search: str,
+ min_price: int,
+ max_price: int,
+ min_rating: float,
+ categories: list[str],
+ colors: list[str],
+ seasons: list[str],
+ num_results: int,
+ embedding_column: str,
+ search_type: list[str],
+ ):
+ logger = logging.getLogger("ray.serve")
+ logger.setLevel(logging.DEBUG)
+ logger.debug(f"Running query_ai_enabled_search with {locals()=}")
+ return await self.query_ai_enabled.run.remote(
+ text_search=text_search,
+ min_price=min_price,
+ max_price=max_price,
+ min_rating=min_rating,
+ categories=categories,
+ colors=colors,
+ seasons=seasons,
+ n=num_results,
+ vector_search_path=f"{embedding_column.lower()}_embedding",
+ search_type={type_.lower() for type_ in search_type},
+ )
+
+
+query_legacy = QueryLegacySearch.bind()
+embedding_model = EmbeddingModel.bind()
+query_ai_enabled = QueryAIEnabledSearch.bind(embedding_model)
+app = QueryApplication.bind(query_legacy, query_ai_enabled)
diff --git a/templates/ray-summit-multi-modal-search/no-color-application/command.txt b/templates/ray-summit-multi-modal-search/no-color-application/command.txt
new file mode 100644
index 000000000..b40a8d0b6
--- /dev/null
+++ b/templates/ray-summit-multi-modal-search/no-color-application/command.txt
@@ -0,0 +1 @@
+anyscale service deploy -f app.yaml
diff --git a/templates/ray-summit-multi-modal-search/no-color-application/frontend.py b/templates/ray-summit-multi-modal-search/no-color-application/frontend.py
new file mode 100644
index 000000000..836d3833a
--- /dev/null
+++ b/templates/ray-summit-multi-modal-search/no-color-application/frontend.py
@@ -0,0 +1,235 @@
+from typing import Optional
+import gradio as gr
+from ray.serve.gradio_integrations import GradioServer
+import requests
+
+ANYSCALE_BACKEND_SERVICE_URL = "http://localhost:8000/backend"
+
+
+def filter_products_legacy(
+ text_query: Optional[str],
+ min_price: int,
+ max_price: int,
+ min_rating: float,
+ num_results: int,
+) -> list[tuple[str, str]]:
+ response = requests.get(
+ f"{ANYSCALE_BACKEND_SERVICE_URL}/legacy",
+ params={
+ "text_search": text_query or "",
+ "min_price": min_price,
+ "max_price": max_price,
+ "min_rating": min_rating,
+ "num_results": num_results,
+ },
+ )
+ return response.json()
+
+
+def filter_products_with_ai(
+ text_search: Optional[str],
+ min_price: int,
+ max_price: int,
+ min_rating: float,
+ categories: list[str],
+ colors: list[str],
+ seasons: list[str],
+ num_results: int,
+ search_type: list[str],
+ embedding_column: str,
+):
+ params = {
+ "text_search": text_search or "",
+ "min_price": min_price,
+ "max_price": max_price,
+ "min_rating": min_rating,
+ "num_results": num_results,
+ "embedding_column": embedding_column,
+ }
+ body = {
+ "categories": categories,
+ "colors": colors,
+ "seasons": seasons,
+ "search_type": search_type,
+ }
+
+ response = requests.get(
+ f"{ANYSCALE_BACKEND_SERVICE_URL}/ai_enabled",
+ params=params,
+ json=body,
+ )
+ results = response.json()
+
+ return results
+
+
+def build_interface():
+ price_min = 0
+ price_max = 100_000
+
+ # Get rating range
+ rating_min = 0
+ rating_max = 5
+
+ # Gradio Interface
+ with gr.Blocks(
+ # theme="shivi/calm_foam",
+ title="Multi-modal search",
+ ) as iface:
+ with gr.Tab(label="Legacy Search"):
+ with gr.Row():
+ with gr.Column(scale=1):
+ keywords_component = gr.Textbox(label="Keywords")
+ min_price_component = gr.Slider(
+ price_min, price_max, label="Min Price", value=price_min
+ )
+ max_price_component = gr.Slider(
+ price_min, price_max, label="Max Price", value=price_max
+ )
+ min_rating_component = gr.Slider(
+ rating_min, rating_max, step=0.25, label="Min Rating"
+ )
+ max_num_results_component = gr.Slider(
+ 1, 100, step=1, label="Max Results", value=20
+ )
+ filter_button_component = gr.Button("Filter")
+ with gr.Column(scale=3):
+ gallery = gr.Gallery(
+ label="Filtered Products",
+ columns=3,
+ height=800,
+ )
+ inputs = [
+ keywords_component,
+ min_price_component,
+ max_price_component,
+ min_rating_component,
+ max_num_results_component,
+ ]
+ filter_button_component.click(
+ filter_products_legacy, inputs=inputs, outputs=gallery
+ )
+ iface.load(
+ filter_products_legacy,
+ inputs=inputs,
+ outputs=gallery,
+ )
+
+ with gr.Tab(label="AI enabled search"):
+ with gr.Row():
+ with gr.Column(scale=1):
+ text_component = gr.Textbox(label="Text Search")
+ min_price_component = gr.Slider(
+ price_min, price_max, label="Min Price", value=price_min
+ )
+ max_price_component = gr.Slider(
+ price_min, price_max, label="Max Price", value=price_max
+ )
+
+ min_rating_component = gr.Slider(
+ rating_min, rating_max, step=0.25, label="Min Rating"
+ )
+ category_component = gr.CheckboxGroup(
+ ["Tops", "Bottoms", "Dresses", "Footwear", "Accessories"],
+ label="Category",
+ value=[
+ "Tops",
+ "Bottoms",
+ "Dresses",
+ "Footwear",
+ "Accessories",
+ ],
+ )
+ season_component = gr.CheckboxGroup(
+ ["Summer", "Winter", "Spring", "Fall"],
+ label="Season",
+ value=[
+ "Summer",
+ "Winter",
+ "Spring",
+ "Fall",
+ ],
+ )
+ color_component = gr.CheckboxGroup(
+ [
+ "Red",
+ "Blue",
+ "Green",
+ "Yellow",
+ "Black",
+ "White",
+ "Pink",
+ "Purple",
+ "Orange",
+ "Brown",
+ "Grey",
+ ],
+ label="Color",
+ value=[
+ "Red",
+ "Blue",
+ "Green",
+ "Yellow",
+ "Black",
+ "White",
+ "Pink",
+ "Purple",
+ "Orange",
+ "Brown",
+ "Grey",
+ ],
+ )
+ max_num_results_component = gr.Slider(
+ 1, 100, step=1, label="Max Results", value=20
+ )
+
+ # add an engine advanced options
+ with gr.Accordion(label="Advanced Engine Options"):
+ # checkbox for type of search - lexical and/or vector
+ search_type_component = gr.CheckboxGroup(
+ ["Lexical", "Vector"],
+ label="Search Type",
+ value=["Lexical", "Vector"],
+ )
+ # dropdwon for embedding column - name or description
+ embedding_column_component = gr.Dropdown(
+ ["name", "description"],
+ label="Embedding Column",
+ value="description",
+ )
+
+ filter_button_component = gr.Button("Filter")
+ with gr.Column(scale=3):
+ gallery = gr.Gallery(
+ label="Filtered Products",
+ columns=3,
+ height=800,
+ )
+ inputs = [
+ text_component,
+ min_price_component,
+ max_price_component,
+ min_rating_component,
+ category_component,
+ color_component,
+ season_component,
+ max_num_results_component,
+ search_type_component,
+ embedding_column_component,
+ ]
+
+ filter_button_component.click(
+ filter_products_with_ai,
+ inputs=inputs,
+ outputs=gallery,
+ )
+ iface.load(
+ filter_products_with_ai,
+ inputs=inputs,
+ outputs=gallery,
+ )
+
+ return iface
+
+
+app = GradioServer.options(ray_actor_options={"num_cpus": 1}).bind(build_interface)
diff --git a/templates/ray-summit-multi-modal-search/no-color-application/requirements.txt b/templates/ray-summit-multi-modal-search/no-color-application/requirements.txt
new file mode 100644
index 000000000..08eacd285
--- /dev/null
+++ b/templates/ray-summit-multi-modal-search/no-color-application/requirements.txt
@@ -0,0 +1,6 @@
+# base image: anyscale/ray:2.24.0-py311
+# frontend
+gradio==3.50.2
+# backend
+motor==3.5.0
+sentence-transformers==3.0.1
diff --git a/templates/ray-summit-multi-modal-search/pipeline_tutorial/1_setup_tools.ipynb b/templates/ray-summit-multi-modal-search/pipeline_tutorial/1_setup_tools.ipynb
new file mode 100644
index 000000000..d17808132
--- /dev/null
+++ b/templates/ray-summit-multi-modal-search/pipeline_tutorial/1_setup_tools.ipynb
@@ -0,0 +1,336 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "52f6531b-32d1-436c-b4f4-9b62ffdcf5c5",
+ "metadata": {},
+ "source": [
+ "# Reinventing Multi-Modal Search with Anyscale and MongoDB\n",
+ "\n",
+ "What we are learning about and building today: https://www.anyscale.com/blog/reinventing-multi-modal-search-with-anyscale-and-mongodb\n",
+ "\n",
+ "The following instructions will help you get set up your environment\n",
+ "\n",
+ "## Register for Anyscale if needed\n",
+ "\n",
+ "If you're attending this class at Ray Summit 2024, then you already have an Anyscale account -- we'll use that one!\n",
+ "\n",
+ "If you're trying out this application later or on your own,\n",
+ "* You can register for Anyscale [here](https://console.anyscale.com/register/ha?utm_source=github&utm_medium=github&utm_content=multi-modal-search-anyscale-mongodb).\n",
+ "\n",
+ "## Login to Anyscale\n",
+ "\n",
+ "Once you have an account, [login](https://console.anyscale.com/v2?utm_source=github&utm_medium=github&utm_content=multi-modal-search-anyscale-mongodb) here.\n",
+ "\n",
+ "## Get set up with MongoDB\n",
+ "\n",
+ "Check out the Mongo Developer Intro Lab at https://mongodb-developer.github.io/intro-lab/\n",
+ "\n",
+ "That tutorial -- presented live at Ray Summit 2024 -- covers the following key steps:\n",
+ "* Get you set up with a free MongoDB Atlas account \n",
+ "* Create a free MongoDB cluster\n",
+ "* Configure securityy to allow public access to your cluster (for demo/class purposes only)\n",
+ "* Create your database user and save the password\n",
+ "* Get the connection string for your MongoDB cluster\n",
+ "\n",
+ "## Register or login to Hugging Face\n",
+ "\n",
+ "If you don't have a Hugging Face account, you can register [here](https://huggingface.co/join). \n",
+ "\n",
+ "If you already have an account, [login](https://huggingface.co/login) here.\n",
+ "\n",
+ "Visit the [tokens](https://huggingface.co/settings/tokens) page to generate a new API token.\n",
+ "\n",
+ "Visit the following model pages and request access to these models:\n",
+ "- [llava-hf/llava-v1.6-mistral-7b-hf](https://huggingface.co/llava-hf/llava-v1.6-mistral-7b-hf)\n",
+ "- [mistralai/Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1)\n",
+ "\n",
+ "Once you have access to these models, you can proceed with the next steps.\n",
+ "\n",
+ "## Launch a workspace in Anyscale for this project\n",
+ "\n",
+ "At Ray Summit 2024, you're probably already running the right workspace. If you're doing this tutorial on your own, choose the Anyscale Ray Summit 2024 template\n",
+ "\n",
+ "## Configure environment variables in your Anyscale Workspace\n",
+ "\n",
+ "Under the __Dependencies__ tab in the workspace view, set the MongoDB connection string `DB_CONNECTION_STRING` and huggingface access token `HF_TOKEN` as environment variables.\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7503a017-f50b-485d-8bef-53d3bb6c8a44",
+ "metadata": {},
+ "source": [
+ "---"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3986fc0a-86f6-4b6e-aed0-cee807243c9f",
+ "metadata": {},
+ "source": [
+ "## Test database connection"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8f9aab15-a2d0-4467-b177-3e8a57052cc6",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import pymongo\n",
+ "from pymongo import MongoClient, ASCENDING, DESCENDING\n",
+ "import os\n",
+ "from pymongo.operations import IndexModel, SearchIndexModel"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1772c405-0e28-4760-9374-00a1194ddf37",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "db_name: str = \"myntra\"\n",
+ "collection_name: str = \"myntra-items-offline\""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c01d4912-d0d1-455a-b0ee-9d307de720ab",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "client = MongoClient(os.environ[\"DB_CONNECTION_STRING\"])\n",
+ "db = client[db_name]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "91e2cadd-12cc-498b-8aba-bd60f6d12cf3",
+ "metadata": {},
+ "source": [
+ "*If the `DB_CONNECTION_STRING` env var is not found, you may need to terminate and then restart the workspace.*"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "cb470e0b-f790-42ec-9198-da6300d87022",
+ "metadata": {},
+ "source": [
+ "### Setup collection\n",
+ "\n",
+ "Run this code one time after you've created your database, to set up the collection and indexes"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b87069bc",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "db.drop_collection(collection_name)\n",
+ "\n",
+ "my_collection = db[collection_name]\n",
+ "\n",
+ "my_collection.create_indexes(\n",
+ " [\n",
+ " IndexModel([(\"rating\", DESCENDING)]),\n",
+ " IndexModel([(\"category\", ASCENDING)]),\n",
+ " IndexModel([(\"season\", ASCENDING)]),\n",
+ " IndexModel([(\"color\", ASCENDING)]),\n",
+ " ]\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "35d1bc92-9d22-4f85-aef0-e6be8f1b38b0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fts_model = SearchIndexModel(\n",
+ " definition={\n",
+ " \"mappings\": {\n",
+ " \"dynamic\": False,\n",
+ " \"fields\": {\n",
+ " \"name\": {\"type\": \"string\", \"analyzer\": \"lucene.standard\",}\n",
+ " }\n",
+ " }\n",
+ " },\n",
+ " name=\"lexical_text_search_index\",\n",
+ " type=\"search\"\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "df23997f-c7cc-4cec-8f16-11014ad8b733",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "vs_model = SearchIndexModel(\n",
+ " definition={\n",
+ " \"fields\": [\n",
+ " {\n",
+ " \"numDimensions\": 1024,\n",
+ " \"similarity\": \"cosine\",\n",
+ " \"type\": \"vector\",\n",
+ " \"path\": \"description_embedding\",\n",
+ " },\n",
+ " {\n",
+ " \"numDimensions\": 1024,\n",
+ " \"similarity\": \"cosine\",\n",
+ " \"type\": \"vector\",\n",
+ " \"path\": \"name_embedding\",\n",
+ " }, \n",
+ " {\n",
+ " \"type\": \"filter\",\n",
+ " \"path\": \"category\",\n",
+ " },\n",
+ " {\n",
+ " \"type\": \"filter\",\n",
+ " \"path\": \"season\",\n",
+ " },\n",
+ " {\n",
+ " \"type\": \"filter\",\n",
+ " \"path\": \"color\",\n",
+ " },\n",
+ " {\n",
+ " \"type\": \"filter\",\n",
+ " \"path\": \"rating\",\n",
+ " },\n",
+ " {\n",
+ " \"type\": \"filter\",\n",
+ " \"path\": \"price\",\n",
+ " },\n",
+ " ],\n",
+ " },\n",
+ " name=\"vector_search_index\",\n",
+ " type=\"vectorSearch\"\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "170f4bd6-e70c-4d5b-b872-0a5123082206",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "my_collection.create_search_indexes(models=[fts_model, vs_model])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4d47c025-c220-4ac8-904f-6a1224a36f11",
+ "metadata": {},
+ "source": [
+ "### Count docs"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5814f906-2d18-4c13-a135-d0f2bd85c7b3",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "my_collection.count_documents({})"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "74063927-75e7-459e-931d-729500d5661c",
+ "metadata": {},
+ "source": [
+ "# Architecture\n",
+ "\n",
+ "We split our system into an offline data indexing stage and an online search stage.\n",
+ "\n",
+ "The offline data indexing stage performs the processing, embedding, and upserting text and images into a MongoDB database that supports vector search across multiple fields and dimensions. This stage is built by running multi-modal data pipelines at scale using Anyscale for AI compute platform.\n",
+ "\n",
+ "The online search stage performs the necessary search operations by combining legacy text matching with advanced semantic search capabilities offered by MongoDB. This stage is built by running a multi-modal search backend on Anyscale.\n",
+ "\n",
+ "## Multi-Modal Data Pipelines at Scale\n",
+ "\n",
+ "### Overview\n",
+ "The data pipelines show how to perform offline batch inference and embeddings generation at scale. The pipelines are designed to handle both text and image data by running multi-modal large language model instances. \n",
+ "\n",
+ "### Technology Stack\n",
+ "\n",
+ "- `ray[data]`\n",
+ "- `vLLM`\n",
+ "- `pymongo`\n",
+ "- `sentence-transformers`\n",
+ "\n",
+ "## Multi-Modal Search at Scale\n",
+ "\n",
+ "### Overview\n",
+ "The search backend combines legacy lexical text matching with advanced semantic search capabilities, offering a robust hybrid search solution. \n",
+ "\n",
+ "### Technology Stack\n",
+ "- `ray[serve]`\n",
+ "- `gradio`\n",
+ "- `motor`\n",
+ "- `sentence-transformers`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9968d7a4-1a46-451d-9b8f-8bf62a1005b9",
+ "metadata": {},
+ "source": [
+ "### Empty collection\n",
+ "\n",
+ "As you're working, you may have experiment, errors, or changes which alter the MongoDB collection. To drop all records in the collection, use the following line."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "990ab0bb-299c-4109-9e64-c89f3731c5fe",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "my_collection.delete_many({})"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "714fefa5-2189-4726-a25f-e4952f816861",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/templates/ray-summit-multi-modal-search/pipeline_tutorial/2_intro_data.ipynb b/templates/ray-summit-multi-modal-search/pipeline_tutorial/2_intro_data.ipynb
new file mode 100644
index 000000000..8990125c4
--- /dev/null
+++ b/templates/ray-summit-multi-modal-search/pipeline_tutorial/2_intro_data.ipynb
@@ -0,0 +1,523 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Intro to Ray Data"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Ray Datasets: Distributed Data Preprocessing\n",
+ "\n",
+ "Ray Datasets are the standard way to load and exchange data in Ray libraries and applications. They provide basic distributed data transformations such as maps ([`map_batches`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.map_batches.html#ray.data.Dataset.map_batches \"ray.data.Dataset.map_batches\")), global and grouped aggregations ([`GroupedDataset`](https://docs.ray.io/en/latest/data/api/doc/ray.data.grouped_dataset.GroupedDataset.html#ray.data.grouped_dataset.GroupedDataset \"ray.data.grouped_dataset.GroupedDataset\")), and shuffling operations ([`random_shuffle`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.random_shuffle.html#ray.data.Dataset.random_shuffle \"ray.data.Dataset.random_shuffle\"), [`sort`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.sort.html#ray.data.Dataset.sort \"ray.data.Dataset.sort\"), [`repartition`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.repartition.html#ray.data.Dataset.repartition \"ray.data.Dataset.repartition\")), and are compatible with a variety of file formats, data sources, and distributed frameworks.\n",
+ "\n",
+ "Here's an overview of the integrations with other processing frameworks, file formats, and supported operations, as well as a glimpse at the Ray Datasets API.\n",
+ "\n",
+ "Check the [Input/Output reference](https://docs.ray.io/en/latest/data/api/input_output.html#input-output) to see if your favorite format is already supported.\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Data Loading and Preprocessing for ML Training\n",
+ "-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------\n",
+ "\n",
+ "Use Ray Datasets to load and preprocess data for distributed [ML training pipelines](https://docs.ray.io/en/latest/train/train.html#train-docs). Compared to other loading solutions, Datasets are more flexible (e.g., can express higher-quality per-epoch global shuffles) and provides [higher overall performance](https://www.anyscale.com/blog/why-third-generation-ml-platforms-are-more-performant).\n",
+ "\n",
+ "Use Datasets as a last-mile bridge from storage or ETL pipeline outputs to distributed applications and libraries in Ray. Don't use it as a replacement for more general data processing systems.\n",
+ "\n",
+ "\n",
+ "\n",
+ "To learn more about the features Datasets supports, read the [Datasets User Guide](https://docs.ray.io/en/latest/data/user-guide.html#data-user-guide).\n",
+ "\n",
+ "### Datasets for Parallel Compute\n",
+ "-------------------------------------------------------------------------------------------------------------------------------------------\n",
+ "\n",
+ "Datasets also simplify general purpose parallel GPU and CPU compute in Ray; for instance, for [GPU batch inference](https://docs.ray.io/en/latest/ray-overview/use-cases.html#ref-use-cases-batch-infer). They provide a higher-level API for Ray tasks and actors for such embarrassingly parallel compute, internally handling operations like batching, pipelining, and memory management.\n",
+ "\n",
+ "\n",
+ "\n",
+ "As part of the Ray ecosystem, Ray Datasets can leverage the full functionality of Ray's distributed scheduler, e.g., using actors for optimizing setup time and GPU scheduling."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Datasets\n",
+ "------------------------------------------------------------------------------------------------------\n",
+ "\n",
+ "A Dataset consists of a list of Ray object references to *blocks*. Having multiple blocks in a dataset allows for parallel transformation and ingest.\n",
+ "\n",
+ "The following figure visualizes a tabular dataset with three blocks, each block holding 1000 rows each:\n",
+ "\n",
+ "\n",
+ "\n",
+ "Since a Dataset is just a list of Ray object references, it can be freely passed between Ray tasks, actors, and libraries like any other object reference. This flexibility is a unique characteristic of Ray Datasets."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Reading Data[](https://docs.ray.io/en/latest/data/key-concepts.html#reading-data \"Permalink to this headline\")\n",
+ "\n",
+ "Datasets uses Ray tasks to read data from remote storage. When reading from a file-based datasource (e.g., S3, GCS), it creates a number of read tasks proportional to the number of CPUs in the cluster. Each read task reads its assigned files and produces an output block:\n",
+ "\n",
+ "\n",
+ "\n",
+ "### Transforming Data[](https://docs.ray.io/en/latest/data/key-concepts.html#transforming-data \"Permalink to this headline\")\n",
+ "\n",
+ "Datasets can use either Ray tasks or Ray actors to transform datasets. Using actors allows for expensive state initialization (e.g., for GPU-based tasks) to be cached.\n",
+ "\n",
+ "### Shuffling Data[](https://docs.ray.io/en/latest/data/key-concepts.html#shuffling-data \"Permalink to this headline\")\n",
+ "\n",
+ "Certain operations like *sort* or *groupby* require data blocks to be partitioned by value, or *shuffled*. Datasets uses tasks to implement distributed shuffles in a map-reduce style, using map tasks to partition blocks by value, and then reduce tasks to merge co-partitioned blocks together.\n",
+ "\n",
+ "You can also change just the number of blocks of a Dataset using [`repartition()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.repartition.html#ray.data.Dataset.repartition \"ray.data.Dataset.repartition\"). Repartition has two modes:\n",
+ "\n",
+ "1. `shuffle=False` - performs the minimal data movement needed to equalize block sizes\n",
+ "\n",
+ "2. `shuffle=True` - performs a full distributed shuffle\n",
+ "\n",
+ "\n",
+ "\n",
+ "Datasets shuffle can scale to processing hundreds of terabytes of data. See the [Performance Tips Guide](https://docs.ray.io/en/latest/data/performance-tips.html#shuffle-performance-tips) for an in-depth guide on shuffle performance."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Execution mode\n",
+ "\n",
+ "Most transformations are lazy. They don't execute until you consume a dataset or call [`Dataset.materialize()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.materialize.html#ray.data.Dataset.materialize \"ray.data.Dataset.materialize\").\n",
+ "\n",
+ "The transformations are executed in a streaming way, incrementally on the data and with operators processed in parallel. For an in-depth guide on Datasets execution, read https://docs.ray.io/en/releases-2.35.0/data/data-internals.html\n",
+ "\n",
+ "### Fault tolerance\n",
+ "\n",
+ "Datasets performs *lineage reconstruction* to recover data. If an application error or system failure occurs, Datasets recreates lost blocks by re-executing tasks.\n",
+ "\n",
+ "Fault tolerance isn't supported in two cases:\n",
+ "\n",
+ "- If the original worker process that created the Dataset dies. This is because the creator stores the metadata for the [objects](https://docs.ray.io/en/releases-2.35.0/ray-core/fault_tolerance/objects.html) that comprise the Dataset.\n",
+ "\n",
+ "- If you a Ray actor is provided for transformations (e.g., map_batches). This is because Datasets relies on [task-based fault tolerance](https://docs.ray.io/en/releases-2.35.0/ray-core/fault_tolerance/tasks.html).\n",
+ " - __Note__ however: for many common AI inference or data preprocessing tasks using actors, the actor state is recoverable from elsewhere (e.g., a model store, huggingface hub, etc.) so this limitation has minimal impact"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Example operations: Transforming Datasets\n",
+ "\n",
+ "Datasets transformations take in datasets and produce new datasets. For example, *map* is a transformation that applies a user-defined function on each dataset record and returns a new dataset as the result. Datasets transformations can be composed to express a chain of computations.\n",
+ "\n",
+ "There are two main types of transformations:\n",
+ "\n",
+ "- One-to-one: each input block will contribute to only one output block, such as [`ds.map_batches()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.map_batches.html#ray.data.Dataset.map_batches \"ray.data.Dataset.map_batches\").\n",
+ "\n",
+ "- All-to-all: input blocks can contribute to multiple output blocks, such as [`ds.random_shuffle()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.random_shuffle.html#ray.data.Dataset.random_shuffle \"ray.data.Dataset.random_shuffle\").\n",
+ "\n",
+ "Here is a table listing some common transformations supported by Ray Datasets."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Common Ray Datasets transformations.[](https://docs.ray.io/en/latest/data/transforming-datasets.html#id2 \"Permalink to this table\")\n",
+ "\n",
+ "| Transformation | Type | Description |\n",
+ "| --- | --- | --- |\n",
+ "|[`ds.map_batches()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.map_batches.html#ray.data.Dataset.map_batches \"ray.data.Dataset.map_batches\")|One-to-one|Apply a given function to batches of records of this dataset.|\n",
+ "|[`ds.add_column()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.add_column.html#ray.data.Dataset.add_column \"ray.data.Dataset.add_column\")|One-to-one|Apply a given function to batches of records to create a new column.|\n",
+ "|[`ds.drop_columns()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.add_column.html#ray.data.Dataset.add_column \"ray.data.Dataset.add_column\")|One-to-one|Drop the given columns from the dataset.|\n",
+ "|[`ds.split()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.split.html#ray.data.Dataset.split \"ray.data.Dataset.split\")|One-to-one|Split the dataset into N disjoint pieces.|\n",
+ "|[`ds.repartition(shuffle=False)`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.repartition.html#ray.data.Dataset.repartition \"ray.data.Dataset.repartition\")|One-to-one|Repartition the dataset into N blocks, without shuffling the data.|\n",
+ "|[`ds.repartition(shuffle=True)`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.repartition.html#ray.data.Dataset.repartition \"ray.data.Dataset.repartition\")|All-to-all|Repartition the dataset into N blocks, shuffling the data during repartition.|\n",
+ "|[`ds.random_shuffle()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.random_shuffle.html#ray.data.Dataset.random_shuffle \"ray.data.Dataset.random_shuffle\")|All-to-all|Randomly shuffle the elements of this dataset.|\n",
+ "|[`ds.sort()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.sort.html#ray.data.Dataset.sort \"ray.data.Dataset.sort\")|All-to-all|Sort the dataset by a sortkey.|\n",
+ "|[`ds.groupby()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.groupby.html#ray.data.Dataset.groupby \"ray.data.Dataset.groupby\")|All-to-all|Group the dataset by a groupkey.|"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "> __Tip__\n",
+ ">\n",
+ "> Datasets also provides the convenience transformation methods [`ds.map()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.map.html#ray.data.Dataset.map \"ray.data.Dataset.map\"), [`ds.flat_map()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.flat_map.html#ray.data.Dataset.flat_map \"ray.data.Dataset.flat_map\"), and [`ds.filter()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.filter.html#ray.data.Dataset.filter \"ray.data.Dataset.filter\"), which are not vectorized (slower than [`ds.map_batches()`](https://docs.ray.io/en/latest/data/api/doc/ray.data.Dataset.map_batches.html#ray.data.Dataset.map_batches \"ray.data.Dataset.map_batches\")), but may be useful for development.\n",
+ "\n",
+ "The following is an example to make use of those transformation APIs for processing the Iris dataset."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "import ray\n",
+ "\n",
+ "ds = ray.data.read_csv(\"s3://anyscale-materials/data/iris.csv\")\n",
+ "\n",
+ "ds"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ds.show(3)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ds.write_parquet('/mnt/cluster_storage/parquet_iris')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "! ls -l /mnt/cluster_storage/parquet_iris/"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ds = ds.repartition(5)\n",
+ "\n",
+ "ds"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ds.take_batch(5)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "def transform_batch(batch):\n",
+ " \n",
+ " areas = []\n",
+ " for ix in range(len(batch['Id'])):\n",
+ " areas.append(batch[\"PetalLengthCm\"][ix] * batch[\"PetalWidthCm\"][ix]) \n",
+ " batch['approximate_petal_area'] = areas\n",
+ " return batch\n",
+ "\n",
+ "ds.map_batches(transform_batch).show(5)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ds.map_batches(transform_batch).take_batch()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "def transform_batch_vectorized(batch): \n",
+ " batch['approximate_petal_area'] = batch[\"PetalLengthCm\"][ix] * batch[\"PetalWidthCm\"][ix]\n",
+ " return batch\n",
+ "\n",
+ "ds.map_batches(transform_batch).show(5)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# Group by the variety.\n",
+ "ds.groupby(\"Species\").count().show()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Force computation and local caching if desired with `materialize`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ds.materialize()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Transforming data with actors\n",
+ "\n",
+ "When using the actor compute strategy, per-row and per-batch UDFs can also be *callable classes*, i.e. classes that implement the `__call__` magic method. The constructor of the class can be used for stateful setup, and will be only invoked once per worker actor.\n",
+ "\n",
+ "\n",
+ "Note: These transformation APIs take the uninstantiated callable class as an argument, not an instance of the class.\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "class ModelExample:\n",
+ " def __init__(self):\n",
+ " expensive_model_weights = [ 0.3, 1.75 ]\n",
+ " self.complex_model = lambda petal_width: (petal_width + expensive_model_weights[0]) ** expensive_model_weights[1]\n",
+ "\n",
+ " def __call__(self, batch):\n",
+ " batch[\"predictions\"] = self.complex_model(batch[\"PetalWidthCm\"])\n",
+ " return batch\n",
+ "\n",
+ "ds.map_batches(ModelExample, concurrency=2).show(10)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ " \n",
+ "__Lab activity: Stateless transformation__\n",
+ " \n",
+ "1. Create a Ray Dataset from the iris data in `s3://anyscale-materials/data/iris.csv`\n",
+ "1. Create a \"sum of features\" transformation that calculates the sum of the Sepal Length, Sepal Width, Petal Length, and Petal Width features for the records\n",
+ " 1. Design this transformation to take a Ray Dataset *batch* of records\n",
+ " 1. Return the records without the ID column but with an additional column called \"sum\"\n",
+ " 1. Hint: you do not need to use NumPy, but the calculation may be easier/simpler to code using NumPy vectorized operations with the records in the batch\n",
+ "
\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ " \n",
+ "__Lab activity: Stateful transformation__\n",
+ " \n",
+ "1. Create a Ray Dataset from the iris data in `s3://anyscale-materials/data/iris.csv`\n",
+ "1. Create an class that makes predictions on iris records using these steps:\n",
+ " 1. in the class constructor, create an instance of the following \"model\" class:\n",
+ " ```python\n",
+ "\n",
+ " class SillyModel():\n",
+ "\n",
+ " def predict(self, petal_length):\n",
+ " return petal_length + 0.42\n",
+ "\n",
+ "\n",
+ " ```\n",
+ " 1. in the `__call__` method of the actor class\n",
+ " 1. take a batch of records\n",
+ " 1. create predictions for each record in the batch using the model instance\n",
+ " 1. Hint: the code may be simpler using NumPy vectorized operations\n",
+ " 1. add the predictions to the record batch\n",
+ " 1. return the new, augmented batch\n",
+ "1. Use that class to perform batch inference on the dataset using actors\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Batch classification for featurization: toy example"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from transformers import pipeline\n",
+ "import torch\n",
+ "\n",
+ "CHAT_MODEL = 'stabilityai/StableBeluga-7B'"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "items = [\n",
+ " \"This brown sweater features orange and golden leaves\",\n",
+ " \"This Christmas sweater features icicles, skiers, snowmen and reindeer\",\n",
+ " \"This light-green sweater features tulips blooming\",\n",
+ " \"This short-sleeve baseball jersey is designed for warm weather\"\n",
+ "]"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "data = ray.data.from_items(items)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "data.take_batch(2)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def build_prompt(items):\n",
+ " prompts = ['You are a helpful assistant.### User: Based on the following product description, '\n",
+ " +'please choose the season that best matches the product. Choose from SPRING, SUMMER, WINTER, FALL. '\n",
+ " +f'Output just the season. \"{item}\"### Assistant:' for item in items['item']]\n",
+ " items['prompt'] = prompts\n",
+ " return items"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "class Chat:\n",
+ " def __init__(self): \n",
+ " self._model = pipeline(\"text-generation\", model=CHAT_MODEL, device=0, model_kwargs={'torch_dtype':torch.float16, 'cache_dir': '/mnt/local_storage'})\n",
+ " pass\n",
+ " \n",
+ " def get_responses(self, messages):\n",
+ " return self._model(messages, max_length=200)\n",
+ "\n",
+ " def __call__(self, batch):\n",
+ " batch['season'] = self.get_responses(list(batch['prompt']))\n",
+ " return batch"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "data.map_batches(build_prompt).take_all()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "data.map_batches(build_prompt).map_batches(Chat, num_gpus=1, concurrency=2, batch_size=2).take_all()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 4
+}
diff --git a/templates/ray-summit-multi-modal-search/pipeline_tutorial/2a_sol_data.ipynb b/templates/ray-summit-multi-modal-search/pipeline_tutorial/2a_sol_data.ipynb
new file mode 100644
index 000000000..f166cf5d8
--- /dev/null
+++ b/templates/ray-summit-multi-modal-search/pipeline_tutorial/2a_sol_data.ipynb
@@ -0,0 +1,207 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "2bab3ec5-e8e5-449b-abd3-f611b2a7de81",
+ "metadata": {},
+ "source": [
+ "\n",
+ " \n",
+ "__Lab activity: Stateless transformation__\n",
+ " \n",
+ "1. Create a Ray Dataset from the iris data in `s3://anyscale-materials/data/iris.csv`\n",
+ "1. Create a \"sum of features\" transformation that calculates the sum of the Sepal Length, Sepal Width, Petal Length, and Petal Width features for the records\n",
+ " 1. Design this transformation to take a Ray Dataset *batch* of records\n",
+ " 1. Return the records without the ID column but with an additional column called \"sum\"\n",
+ " 1. Hint: you do not need to use NumPy, but the calculation may be easier/simpler to code using NumPy vectorized operations with the records in the batch\n",
+ "
\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "eb23fad0-bdd7-4194-9795-81e8422fbe88",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "import ray"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b26b279b-0396-49de-8ccb-9f449d01dd6f",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ds = ray.data.read_csv('s3://anyscale-materials/data/iris.csv')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "345192a6-042e-4d3d-945d-07b5a17b2ac2",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "def sum_of_features(batch):\n",
+ " sep_len, sep_wid, pet_len, pet_wid = batch['SepalLengthCm'], batch['SepalWidthCm'], batch['PetalLengthCm'], batch['PetalWidthCm']\n",
+ " sums = [ sep_len[i] + sep_wid[i] + pet_len[i] + pet_wid[i] for i in range(len(sep_len)) ]\n",
+ " batch['sum'] = sums\n",
+ " del batch['Id']\n",
+ " return batch"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "80b0e491-ba21-421c-af40-51c124900775",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ds.map_batches(sum_of_features).show()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "61375dad-da12-4b7b-9593-6104ff106097",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "def sum_of_features_vec(batch):\n",
+ " batch['sum'] = batch['SepalLengthCm'] + batch['SepalWidthCm'] + batch['PetalLengthCm'] + batch['PetalWidthCm']\n",
+ " del batch['Id']\n",
+ " return batch\n",
+ "\n",
+ "ds.map_batches(sum_of_features).show()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9afdc681-040f-4402-b07f-cf8aa688c2f8",
+ "metadata": {},
+ "source": [
+ "\n",
+ " \n",
+ "__Lab activity: Stateful transformation__\n",
+ " \n",
+ "1. Create a Ray Dataset from the iris data in `s3://anyscale-materials/data/iris.csv`\n",
+ "1. Create an class that makes predictions on iris records using these steps:\n",
+ " 1. in the class constructor, create an instance of the following \"model\" class:\n",
+ " ```python\n",
+ "\n",
+ " class SillyModel():\n",
+ "\n",
+ " def predict(self, petal_length):\n",
+ " return petal_length + 0.42\n",
+ "\n",
+ "\n",
+ " ```\n",
+ " 1. in the `__call__` method of the actor class\n",
+ " 1. take a batch of records\n",
+ " 1. create predictions for each record in the batch using the model instance\n",
+ " 1. Hint: the code may be simpler using NumPy vectorized operations\n",
+ " 1. add the predictions to the record batch\n",
+ " 1. return the new, augmented batch\n",
+ "1. Use that class to perform batch inference on the dataset using actors\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "af6e0512-2f04-4407-8df8-288a35794d6e",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ds = ray.data.read_csv('s3://anyscale-materials/data/iris.csv')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "47938b25-e13a-4273-8ebc-df747e64b9d4",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "class SillyModel():\n",
+ " def predict(self, petal_length):\n",
+ " return petal_length + 0.42"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6b4c2148-8a5c-40d6-a628-4a6d26772700",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "class MyBatchPredictor():\n",
+ " def __init__(self):\n",
+ " self.model = SillyModel()\n",
+ " \n",
+ " def __call__(self, batch):\n",
+ " batch['predictions'] = self.model.predict(batch['PetalLengthCm'])\n",
+ " return batch"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4739e64e-8c76-4e11-b959-696c1c707f10",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ds.map_batches(MyBatchPredictor, concurrency=3).show()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f87820e5-14c9-4e9f-be57-3274aa751516",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/templates/ray-summit-multi-modal-search/pipeline_tutorial/3_process_data.ipynb b/templates/ray-summit-multi-modal-search/pipeline_tutorial/3_process_data.ipynb
new file mode 100644
index 000000000..480541901
--- /dev/null
+++ b/templates/ray-summit-multi-modal-search/pipeline_tutorial/3_process_data.ipynb
@@ -0,0 +1,955 @@
+{
+ "cells": [
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8253df45-49fb-4034-9aa7-679ada01abd0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import io\n",
+ "import os\n",
+ "from concurrent.futures import ThreadPoolExecutor\n",
+ "from typing import Any, Literal, Type\n",
+ "import numpy as np\n",
+ "import requests\n",
+ "import ray\n",
+ "import torchvision\n",
+ "from enum import Enum\n",
+ "import typer\n",
+ "import pandas as pd\n",
+ "import pyarrow as pa\n",
+ "from pyarrow import csv\n",
+ "from pydantic import BaseModel\n",
+ "from sentence_transformers import SentenceTransformer\n",
+ "from transformers import AutoTokenizer\n",
+ "from vllm.multimodal.image import ImagePixelData\n",
+ "from vllm import LLM, SamplingParams\n",
+ "from PIL import Image\n",
+ "from pymongo import MongoClient, UpdateOne"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e432dd3d-f0cb-4884-8c8e-df3ac81f173c",
+ "metadata": {},
+ "source": [
+ "# Reinventing Multi-Modal Search with Anyscale and MongoDB\n",
+ "\n",
+ "## Data processing pipeline tutorial\n",
+ "\n",
+ "__Let's look at the data flow logic__\n",
+ "\n",
+ "\n",
+ "\n",
+ "__Let's look at the scaling opportunites__\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "For this tutorial, we'll use a small number of records and a small scaling configuration"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "055ee1a1-2e25-4121-962f-fc758ff7b02b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nsamples=200"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0f2dc142-3529-4dd1-981a-61471a2f9531",
+ "metadata": {},
+ "source": [
+ "The workers below will corresponds to processes, each assigned a CPU and optionally a GPU. Ray allows more flexibility but we'll keep this pipeline as simples as possible."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1cc8bd87-b22e-48f3-8c09-2065ae4a4fa8",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "num_image_download_workers=2\n",
+ "\n",
+ "num_llava_tokenizer_workers=2\n",
+ "\n",
+ "num_llava_model_workers=1\n",
+ "# llava_model_accelerator_type=NVIDIA_TESLA_A10G\n",
+ "llava_model_batch_size=80\n",
+ "\n",
+ "num_mistral_tokenizer_workers_per_classifier=2\n",
+ "\n",
+ "num_mistral_model_workers_per_classifier=1\n",
+ "mistral_model_batch_size=80\n",
+ "# mistral_model_accelerator_type=NVIDIA_TESLA_A10G\n",
+ "\n",
+ "num_mistral_detokenizer_workers_per_classifier=2\n",
+ "\n",
+ "num_embedder_workers=1\n",
+ "embedding_model_batch_size=80\n",
+ "# embedding_model_accelerator_type=NVIDIA_TESLA_A10G\n",
+ "\n",
+ "db_update_batch_size=80\n",
+ "\n",
+ "num_db_workers=2"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "94205417-4883-4bce-8c64-6ec535e2ea3b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "db_name: str = \"myntra\"\n",
+ "collection_name: str = \"myntra-items-offline\"\n",
+ "cluster_size: str = \"m0\"\n",
+ "scaling_config_path: str = \"\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "64303167",
+ "metadata": {},
+ "source": [
+ "### Read raw data\n",
+ "\n",
+ "The data comes from a subset of the Myntra retail products dataset: https://www.kaggle.com/datasets/ronakbokaria/myntra-products-dataset"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2cf89b33-d854-4f1c-9423-d98be0a1a762",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "path = 's3://anyscale-public-materials/mongodb-demo/raw/myntra_subset_deduped_10000.csv'"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "478ad343-f631-4cc1-8c35-5010a2a300ac",
+ "metadata": {},
+ "source": [
+ "The Ray Data `read` methods use PyArrow in most cases for the physical reads -- the schema here is provided as PyArrow types.\n",
+ "\n",
+ "> Learn more about the Apache Arrow project https://arrow.apache.org/docs/python/index.html"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b6e15f99-f28d-41f7-9aeb-c7f5fe0597c7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def read_data(path: str, nsamples: int) -> ray.data.Dataset:\n",
+ " ds = ray.data.read_csv(\n",
+ " path,\n",
+ " parse_options=csv.ParseOptions(newlines_in_values=True),\n",
+ " convert_options=csv.ConvertOptions(\n",
+ " column_types={\n",
+ " \"id\": pa.int64(),\n",
+ " \"name\": pa.string(),\n",
+ " \"img\": pa.string(),\n",
+ " \"asin\": pa.string(),\n",
+ " \"price\": pa.float64(),\n",
+ " \"mrp\": pa.float64(),\n",
+ " \"rating\": pa.float64(),\n",
+ " \"ratingTotal\": pa.int64(),\n",
+ " \"discount\": pa.int64(),\n",
+ " \"seller\": pa.string(),\n",
+ " \"purl\": pa.string(),\n",
+ " }\n",
+ " ),\n",
+ " override_num_blocks=nsamples,\n",
+ " )\n",
+ " return ds.limit(nsamples)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4e814ee7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds = read_data(path, nsamples)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "894bc732-5314-4dda-aed4-2c8f164fad80",
+ "metadata": {},
+ "source": [
+ "### Preprocess data\n",
+ "\n",
+ "The following operations will be transforms applied to our data. \n",
+ "\n",
+ "We'll define them first...\n",
+ "* functions for stateless operations\n",
+ "* classes for operations which reuse state\n",
+ "\n",
+ "... and then plug them into our pipeline with Ray's `map_batches` API"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "377a5339",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def download_image(url: str) -> bytes:\n",
+ " try:\n",
+ " response = requests.get(url)\n",
+ " response.raise_for_status()\n",
+ " return response.content\n",
+ " except Exception:\n",
+ " return b\"\"\n",
+ "\n",
+ "def download_images(batch: dict[str, np.ndarray]) -> dict[str, np.ndarray]:\n",
+ " with ThreadPoolExecutor() as executor:\n",
+ " batch[\"url\"] = batch[\"img\"]\n",
+ " batch[\"img\"] = list(executor.map(download_image, batch[\"url\"])) # type: ignore\n",
+ " return batch\n",
+ "\n",
+ "class LargestCenterSquare:\n",
+ " \"\"\"Largest center square crop for images.\"\"\"\n",
+ "\n",
+ " def __init__(self, size: int) -> None:\n",
+ " self.size = size\n",
+ "\n",
+ " def __call__(self, row: dict[str, Any]) -> dict[str, Any]:\n",
+ " \"\"\"Crop the largest center square from an image.\"\"\"\n",
+ " img = Image.open(io.BytesIO(row[\"img\"]))\n",
+ "\n",
+ " # First, resize the image such that the smallest side is self.size while preserving aspect ratio.\n",
+ " img = torchvision.transforms.functional.resize(\n",
+ " img=img,\n",
+ " size=self.size,\n",
+ " )\n",
+ "\n",
+ " # Then take a center crop to a square.\n",
+ " w, h = img.size\n",
+ " c_top = (h - self.size) // 2\n",
+ " c_left = (w - self.size) // 2\n",
+ " row[\"img\"] = torchvision.transforms.functional.crop(\n",
+ " img=img,\n",
+ " top=c_top,\n",
+ " left=c_left,\n",
+ " height=self.size,\n",
+ " width=self.size,\n",
+ " )\n",
+ "\n",
+ " return row\n",
+ "\n",
+ "DESCRIPTION_PROMPT_TEMPLATE = \"\n",
+ " Here is the roadmap for this notebook:\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "vscode": {
+ "languageId": "plaintext"
+ }
+ },
+ "source": [
+ "## Imports"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "import json\n",
+ "\n",
+ "import openai\n",
+ "from sentence_transformers import SentenceTransformer\n",
+ "from sklearn.metrics.pairwise import cosine_similarity"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Pre-requisite setup\n",
+ "\n",
+ "- \n",
+ "
- Part 1: Prompting an LLM without RAG \n", + "
- Part 2: In-context learning and LLMs \n", + "
- Part 3: Retrieval and semantic search \n", + "
- Part 4: RAG: High-level overview \n", + "
Important if you want to run this notebook: \n",
+ "\n",
+ "This RAG notebook requires having a running LLM Anyscale service. To deploy an LLM as an Anyscale service, you can follow the step-by-step instructions in this [Deploy an LLM workspace template](https://console.anyscale.com/v2/template-preview/endpoints_v2). Make sure to choose the `mistralai/Mistral-7B-Instruct-v0.1` model when deploying.\n",
+ "\n",
+ "
\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Constants\n",
+ "\n",
+ " 🔄 REPLACE : Use the url and api key from the Anyscale service you deployed\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ANYSCALE_SERVICE_BASE_URL = \"replace-with-my-anyscale-service-url\"\n",
+ "ANYSCALE_API_KEY = \"replace-with-my-anyscale-api-key\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "vscode": {
+ "languageId": "plaintext"
+ }
+ },
+ "source": [
+ "## What is RAG ?\n",
+ "\n",
+ "Retrieval augmented generation (RAG) combines Large Language models (LLMs) and information retrieval systems to provide a more robust and context-aware response generation system. It was introduced by Lewis et al. in the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "vscode": {
+ "languageId": "plaintext"
+ }
+ },
+ "source": [
+ "## Prompting an LLM without RAG\n",
+ "\n",
+ "Here is our system without RAG. \n",
+ "\n",
+ "\n",
+ "\n",
+ "We prompt an LLM and get back a response."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def prompt_llm(user_prompt, model=\"mistralai/Mistral-7B-Instruct-v0.1\", temperature=0, **kwargs):\n",
+ " # Initialize a client to perform API requests\n",
+ " client = openai.OpenAI(\n",
+ " base_url=ANYSCALE_SERVICE_BASE_URL,\n",
+ " api_key=ANYSCALE_API_KEY,\n",
+ " )\n",
+ " \n",
+ " # Call the chat completions endpoint\n",
+ " chat_completion = client.chat.completions.create(\n",
+ " model=model,\n",
+ " messages=[\n",
+ " # Prime the system with a system message - a common best practice\n",
+ " {\"role\": \"system\", \"content\": \"You are a helpful assistant.\"},\n",
+ " # Send the user message with the proper \"user\" role and \"content\"\n",
+ " {\"role\": \"user\", \"content\": user_prompt},\n",
+ " ],\n",
+ " temperature=temperature,\n",
+ " **kwargs,\n",
+ " )\n",
+ "\n",
+ " return chat_completion"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "As an example, we will prompt an LLM about the capital of France."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "prompt = \"What is the capital of France?\"\n",
+ "response = prompt_llm(prompt)\n",
+ "print(response.choices[0].message.content)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's consider the case of prompting the LLM about **internal** company documents. \n",
+ "\n",
+ "Think of technical company documents and company policies that are not available on the internet.\n",
+ "\n",
+ "Given the LLM has not been trained on these documents, it will not be able to provide a good response."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "prompt = \"Can I rent the company car on weekends?\"\n",
+ "response = prompt_llm(prompt)\n",
+ "print(response.choices[0].message.content)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "vscode": {
+ "languageId": "plaintext"
+ }
+ },
+ "source": [
+ "## In-context learning and LLMs\n",
+ "\n",
+ "It turns out LLMs excel at in-context learning, meaning they can utilize additional context provided with a user prompt to generate a response that is grounded in the provided context. \n",
+ "\n",
+ "Here a diagram of the system with in-context learning:\n",
+ "\n",
+ "\n",
+ "\n",
+ "For a formal understanding, refer to the paper titled [In-Context Retrieval-Augmented Language Models](https://arxiv.org/pdf/2302.00083.pdf), which performs experiments to validate in-context learning.\n",
+ "\n",
+ "\n",
+ "Let's consider the case of prompting the LLM about internal company policies. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "context = \"\"\"\n",
+ "Here are the company policies that you need to know about:\n",
+ "\n",
+ "1. You are not allowed to use the company's computers between 9am and 5pm. \n",
+ "2. You are not allowed to use the company car on weekends.\n",
+ "\"\"\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "This time, we provide the LLM with the company's policies as context."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "query = \"Am I allowed to use the company car on weekends?\"\n",
+ "\n",
+ "prompt = f\"\"\"\n",
+ "Given the following context:\n",
+ "{context}\n",
+ "\n",
+ "What is the answer to the following question:\n",
+ "{query}\n",
+ "\"\"\"\n",
+ "\n",
+ "response = prompt_llm(prompt)\n",
+ "print(response.choices[0].message.content)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We get back the correct answer to the question, which is \"You are not allowed to use the company car on weekends.\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "vscode": {
+ "languageId": "plaintext"
+ }
+ },
+ "source": [
+ "## Retrieval and semantic search\n",
+ "\n",
+ "In a real-world scenario, we can't provide the LLM with the entire company's data as context. It would be inefficient to do so from both a cost and performance perspective.\n",
+ "\n",
+ "So we will need a retrieval system to find the most relevant context.\n",
+ "\n",
+ "One effective retrieval system is semantic search, which uses embeddings to find the most relevant context."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "vscode": {
+ "languageId": "plaintext"
+ }
+ },
+ "source": [
+ "### What is semantic search ?\n",
+ "\n",
+ "Semantic search enables us to find documents that share a similar meaning with our queries.\n",
+ "\n",
+ "To capture the \"meaning\" of a query, we use specialized encoders known as \"embedding models.\"\n",
+ "\n",
+ "Embedding models encode text into a high-dimensional vector, playing a crucial role in converting language into a mathematical format for efficient comparison and retrieval.\n",
+ "\n",
+ "\n",
+ "### How do embedding models work?\n",
+ "\n",
+ "Embedding models are trained on a large corpus of text data to learn the relationships between words and phrases.\n",
+ "\n",
+ "The model represents each word or phrase as a high-dimensional vector, where similar words are closer together in the vector space.\n",
+ "\n",
+ "\n",
+ "\n",
+ "The diagram shows word embedding vectors in a 2D space. Semantically similar words end up close to each other in the reduced vector space. \n",
+ "\n",
+ "Note for semantic search, we use sequence embeddings with a much higher dimensionality offering much richer representations."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Generating embeddings\n",
+ "\n",
+ "Here is how to generate embeddings using the `sentence-transformers` library."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "embedding_model = SentenceTransformer(\"BAAI/bge-small-en-v1.5\")\n",
+ "\n",
+ "prompt = \"Am I allowed to use the company car on weekends?\"\n",
+ "\n",
+ "document_1 = \"You are not allowed to use the company's computers between 9am and 5pm.\"\n",
+ "document_2 = \"You are not allowed to use the company car on weekends.\"\n",
+ "\n",
+ "prompt_embedding_vector = embedding_model.encode(prompt)\n",
+ "document_1_embedding_vector = embedding_model.encode(document_1)\n",
+ "document_2_embedding_vector = embedding_model.encode(document_2)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Now, we can find the similarity between the prompt and document vectors by computing the cosine similarity."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "similarities = cosine_similarity([prompt_embedding_vector], [document_1_embedding_vector, document_2_embedding_vector]).flatten()\n",
+ "similarity_between_prompt_and_document_1, similarity_between_prompt_and_document_2 = similarities\n",
+ "print(f\"{similarity_between_prompt_and_document_1=}\")\n",
+ "print(f\"{similarity_between_prompt_and_document_2=}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "### Activity: Find the most similar document\n",
+ "\n",
+ "Given the following two documents and prompt:\n",
+ "\n",
+ "```python\n",
+ "prompt = \"What is the current king of england's name?\"\n",
+ "\n",
+ "document_1 = \"British monarchy head at present moment: Charles III\"\n",
+ "document_2 = \"The current king of spain's name is Felipe VI\"\n",
+ "\n",
+ "# Hint: Compute the embedding vector for the prompt and the documents.\n",
+ "\n",
+ "# Hint: Use a similarity metric to find the most similar document to the prompt.\n",
+ "\n",
+ "```\n",
+ "\n",
+ "Find the closest document to the prompt using the `BAAI/bge-small-en-v1.5` model. \n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Write your solution here\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ " \n",
+ "\n",
+ "
\n",
+ "Click here to see the solution
\n", + "\n", + "```python\n", + "prompt = \"What is the current king of england's name?\"\n", + "\n", + "document_1 = \"British monarchy head at present moment: Charles III\"\n", + "document_2 = \"The current king of spain's name is Felipe VI\"\n", + "\n", + "# Compute the embedding vector for the prompt and the documents.\n", + "prompt_embedding_vector = embedding_model.encode(prompt)\n", + "document_1_embedding_vector = embedding_model.encode(document_1)\n", + "document_2_embedding_vector = embedding_model.encode(document_2)\n", + "\n", + "# Use a similarity metric to find the most similar document to the prompt.\n", + "similarities = cosine_similarity([prompt_embedding_vector], [document_1_embedding_vector, document_2_embedding_vector]).flatten()\n", + "similarity_between_prompt_and_document_1, similarity_between_prompt_and_document_2 = similarities\n", + "if similarity_between_prompt_and_document_1 > similarity_between_prompt_and_document_2:\n", + " print(\"Document 1 is more similar to the prompt\")\n", + "else:\n", + " print(\"Document 2 is more similar to the prompt\")\n", + "```\n", + "\n", + "\n",
+ "\n",
+ "Note: how even though `document_2` has direct word matches to the provided prompt, such as \"the,\" \"current,\" \"king,\" and \"name,\" its meaning is less similar than `document_1`, which uses different terms like \"British monarchy head.\" This is an example of how semantic search can be more effective than lexical (keyword-based) search.\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "vscode": {
+ "languageId": "plaintext"
+ }
+ },
+ "source": [
+ "## RAG: High-level overview\n",
+ "\n",
+ "With RAG, we now have a retrieval system that finds the most relevant context and provides it to the LLM.\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Why RAG ?\n",
+ "\n",
+ "RAG systems enhance LLMs by:\n",
+ "\n",
+ "- Reducing hallucinations with relevant context.\n",
+ "- Providing clear information attribution.\n",
+ "- Enabling access control to information."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### How can we build a basic RAG system ?\n",
+ "\n",
+ "A common approach for building a basic RAG systems is by:\n",
+ "\n",
+ "1. Encoding our documents, commonly referred to as generating embeddings of our documents.\n",
+ "2. Storing the generated embeddings in a vector store.\n",
+ "3. Encoding our user query.\n",
+ "4. Retrieving relevant documents from our vector store given the encoded user query.\n",
+ "5. Augmenting the user prompt with the retrieved context.\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Key Stages:\n",
+ "\n",
+ "- **Stage 1: Indexing**\n",
+ " 1. Loading the documents from a source like a website, API, or database.\n",
+ " 2. Processing the documents into \"embeddable\" document chunks.\n",
+ " 3. Encoding the documents chunks into embedding vectors.\n",
+ " 4. Storing the document embedding vectors in a vector store.\n",
+ "- **Stage 2: Retrieval**\n",
+ " 1. Encoding the user query.\n",
+ " 2. Retrieving the most similar documents from the vector store given the encoded user query.\n",
+ "- **Stage 3: Generation**\n",
+ " 1. Augmenting the prompt with the provided context.\n",
+ " 2. Generating a response from the augmented prompt.\n",
+ "\n",
+ "Stage 1 is setup; Stages 2 and 3 are operational.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Next steps: Building a RAG-based QA engine for the Ray documentation\n",
+ "\n",
+ "We will start to build a RAG-based QA engine for the Ray documentation. This will be an attempt to recreate the \"Ask AI\" bot on the Ray [documentation website](https://docs.ray.io/en/latest/)."
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.10.11"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 4
+}
diff --git a/templates/ray-summit-rag/02_Index_Data.ipynb b/templates/ray-summit-rag/02_Index_Data.ipynb
new file mode 100644
index 000000000..ea776d870
--- /dev/null
+++ b/templates/ray-summit-rag/02_Index_Data.ipynb
@@ -0,0 +1,1804 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "84acd29e",
+ "metadata": {},
+ "source": [
+ "# Indexing Data for RAG using Ray Data\n",
+ "\n",
+ "The first stage of RAG is to index the data. This can be done by creating embeddings for the data and storing them in a vector store. \n",
+ "\n",
+ "This notebook will walk you through the process of creating an embedding pipeline and then scaling it with Ray Data.\n",
+ "\n",
+ "\n",
+ " Here is the roadmap for this notebook:\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "038051e6",
+ "metadata": {},
+ "source": [
+ "## Setup\n",
+ "\n",
+ "### Imports"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "569c771f-2c84-4016-8dea-0eb9d844d6ab",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "import shutil\n",
+ "from pathlib import Path\n",
+ "\n",
+ "import numpy as np\n",
+ "import pandas as pd\n",
+ "import chromadb\n",
+ "\n",
+ "import joblib\n",
+ "import psutil\n",
+ "import ray\n",
+ "from cloudpathlib import CloudPath\n",
+ "from bs4 import BeautifulSoup\n",
+ "from langchain_text_splitters import RecursiveCharacterTextSplitter\n",
+ "from sentence_transformers import SentenceTransformer"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "942484a5",
+ "metadata": {},
+ "source": [
+ "### Constants"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a8d847d3",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "if os.environ.get(\"ANYSCALE_ARTIFACT_STORAGE\"):\n",
+ " DATA_DIR = Path(\"/mnt/cluster_storage/\")\n",
+ " shutil.copytree(Path(\"./data/\"), DATA_DIR, dirs_exist_ok=True)\n",
+ "else:\n",
+ " DATA_DIR = Path(\"./data/\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "db9936f4",
+ "metadata": {},
+ "source": [
+ "## RAG Overview Recap\n",
+ "\n",
+ "As a recap here are the three main phases of implementing RAG\n",
+ "\n",
+ "- \n",
+ "
- Part 0: RAG overview recap \n", + "
- Part 1: Embeddings pipeline overview \n", + "
- Part 2: Simplest possible embedding pipeline \n", + "
- Part 3: Simple pipeline for a real use-case \n", + "
- Part 4: Migrating the simple pipeline to Ray Data \n", + "
- Part 5: Building a vector store \n", + "
- Part 6: Key takeaways \n", + "
\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "da494e7d",
+ "metadata": {},
+ "source": [
+ "## Embeddings pipeline overview\n",
+ "\n",
+ "What are the steps involved in generating embeddings? In the most common case for text data, the steps are as follows:\n",
+ "\n",
+ "1. Load documents\n",
+ "2. Process documents into chunks\n",
+ " 1. Process documents into chunks\n",
+ " 2. Optionally persist chunks\n",
+ "3. Generate embeddings from chunks\n",
+ " 1. Generate embeddings from chunks\n",
+ " 2. Optionally persist embeddings\n",
+ "4. Upsert embeddings into a database"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "68c493e7",
+ "metadata": {},
+ "source": [
+ "## Simple pipeline for a real use-case"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "46bf7061",
+ "metadata": {},
+ "source": [
+ "Let's now assume we want to \"embed the Ray documentation website\". \n",
+ "\n",
+ "We will circle back and start with a small sample dataset taken from the ray documentation. \n",
+ "\n",
+ "To visualize our pipeline, see the diagram below:\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2c035b5b",
+ "metadata": {},
+ "source": [
+ "### 1. Load documents\n",
+ "\n",
+ "First step, we load the data using `pandas`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7680f3d7",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "df = pd.read_json(DATA_DIR / \"small_sample\" / \"sample-input.jsonl\", lines=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "cef6158e-febf-48ae-aa1d-2ddb1d3a99bd",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "We have a dataset of 4 documents fetched from online content and stored as objects in a json file.\n",
+ "\n",
+ "Here are some of the notable columns:\n",
+ "- `text` column which contains the text of the document that we want to embed.\n",
+ "- `section_url` column which contains the section under which the document is found.\n",
+ "- `page_url` column which contains the page under which the document is found."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f189a745-6c07-432c-8a45-0e8f551e6a36",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "df"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "291194b7",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "**Considerations for scaling the pipeline:**\n",
+ "- Memory: We currently load the entire file into memory. This is not a problem for small files, but can be a problem for large files.\n",
+ "- Latency: Reading the file from disk is slow. We can speed this up by using a faster disk, but we can also speed this up by parallelizing the read.\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6f8b84e3-aca6-4b9d-bbb3-0b16ba5a6c30",
+ "metadata": {},
+ "source": [
+ "### 2. Process documents into chunks\n",
+ "\n",
+ "We will use langchain's `RecursiveCharacterTextSplitter` to split the text into chunks. \n",
+ "\n",
+ "It works by first splitting on paragraphs, then sentences, then words, then characters. It is a recursive algorithm that will stop once the chunk size is satisfied.\n",
+ "\n",
+ "Let's try it out on a sampe document."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d5c0df2d",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "text = \"\"\"\n",
+ "This is the first part. Estimate me like 12 words long.\n",
+ "\n",
+ "This is the second part. Estimate me like 12 words long.\n",
+ "\n",
+ "This is the third part. Estimate me like 12 words long.\n",
+ "\"\"\"\n",
+ "\n",
+ "splitter = RecursiveCharacterTextSplitter(\n",
+ " separators=[\"\\n\\n\", \"\\n\", \" \", \"\"], # The default separators used by the splitter\n",
+ " chunk_size=24,\n",
+ " chunk_overlap=0,\n",
+ " length_function=lambda x: len(x.split(\" \")),\n",
+ ")\n",
+ "splitter.split_text(text)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0810e6d8",
+ "metadata": {},
+ "source": [
+ "If we change the paragraphs, the chunk contents will change"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "77a22363",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "text = \"\"\"\n",
+ "This is the first part. Estimate me like 12 words long.\n",
+ "\n",
+ "This is the second part. Estimate me like 12 words long.\n",
+ "This is the third part. Estimate me like 12 words long.\n",
+ "\"\"\"\n",
+ "\n",
+ "splitter = RecursiveCharacterTextSplitter(\n",
+ " separators=[\"\\n\\n\", \"\\n\", \" \", \"\"], # The default separators used by the splitter\n",
+ " chunk_size=24,\n",
+ " chunk_overlap=0,\n",
+ " length_function=lambda x: len(x.split(\" \")),\n",
+ ")\n",
+ "splitter.split_text(text)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "14de14fc",
+ "metadata": {},
+ "source": [
+ "We now proceed to:\n",
+ "\n",
+ "1. Configure the `RecursiveCharacterTextSplitter`\n",
+ "2. Run it over all the documents in the dataset"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d80d46e9-7fd3-4c51-bf67-61dffbe6c8e3",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "chunk_size = 128 # Chunk size is usually specified in tokens\n",
+ "words_to_tokens = 1.2 # Heuristic for converting tokens to words\n",
+ "chunk_size_in_words = int(chunk_size // words_to_tokens)\n",
+ "\n",
+ "\n",
+ "splitter = RecursiveCharacterTextSplitter(\n",
+ " chunk_size=chunk_size_in_words,\n",
+ " length_function=lambda x: len(x.split()),\n",
+ " chunk_overlap=0,\n",
+ ")\n",
+ "\n",
+ "chunks = []\n",
+ "for idx, row in df.iterrows():\n",
+ " for chunk in splitter.split_text(row[\"text\"]):\n",
+ " chunks.append(\n",
+ " {\n",
+ " \"text\": chunk,\n",
+ " \"section_url\": row[\"section_url\"],\n",
+ " \"page_url\": row[\"page_url\"],\n",
+ " }\n",
+ " )"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "db9ff5d5",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "**Considerations for choosing the chunk size**\n",
+ "\n",
+ " - We want the chunks small enough to:\n",
+ " - Fit into the context window of our chosen embedding model\n",
+ " - Be semantically coherent - i.e. concentrate on ideally a single topic\n",
+ " - We want the chunks large enough to:\n",
+ " - Contain enough information to be semantically meaningful.\n",
+ " - Avoid creating too many embeddings which can be expensive to store and query.\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0c3a2912",
+ "metadata": {},
+ "source": [
+ "Let's inspect the chunks produced for the first document."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9a6c9f9a",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "first_document = df[\"text\"].iloc[0]\n",
+ "print(\"first document is\", len(first_document.split()), \"words\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ce8416b2-5ca1-40ad-9dc0-7505cbc97c91",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "for k, v in chunks[0].items():\n",
+ " if k == \"text\":\n",
+ " print(\"first chunk of first document is\", len(v.split()), \"words\")\n",
+ " else:\n",
+ " print(k, v)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "81caba36",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "for k, v in chunks[1].items():\n",
+ " if k == \"text\":\n",
+ " print(\"second chunk of first document is\", len(v.split()), \"words\")\n",
+ " else:\n",
+ " print(k, v)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4617ebad-f9b8-4cc7-b29d-f69b4ca5036f",
+ "metadata": {},
+ "source": [
+ "### 3. Generate embeddings from chunks\n",
+ "\n",
+ "For our third step, we want to load a good embedding model. \n",
+ "\n",
+ "**Suggested steps to choosing an embedding model:**\n",
+ "1. Visit the [MTEB leaderboard](https://huggingface.co/spaces/mteb/leaderboard) on HuggingFace.\n",
+ "2. Find a model that satisfies the following considerations:\n",
+ " - Does the model perform well overall and in the task you are interested in?\n",
+ " - Is the model closed-source or open-source?\n",
+ " - If it is closed-source:\n",
+ " - What are the costs, security, and privacy implications?\n",
+ " - If it is open-source:\n",
+ " - What are its resource requirements if you want to self-host it?\n",
+ " - Is it readily available as a service by third-party providers like Anyscale, Fireworks, or Togther AI?\n",
+ "\n",
+ "We will use `thenlper/gte-large` model from the [HuggingFace Model Hub](https://huggingface.co/thenlper/gte-large) given it is an open-source model and is available as a service by Anyscale and performs relatively well in the MTEB leaderboard.\n",
+ "\n",
+ "\n",
+ "\n",
+ "Note: be wary of models that overfit to the MTEB leaderboard. It is important to test the model on your own data.\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c301f9a0",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "svmem = psutil.virtual_memory()\n",
+ "\n",
+ "# memory used in GB\n",
+ "memory_used = svmem.total - svmem.available\n",
+ "memory_used_gb_before_model_load = memory_used / (1024**3)\n",
+ "memory_used_gb_before_model_load"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e3112f3d",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "%%time\n",
+ "model = SentenceTransformer('thenlper/gte-large', device='cpu')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b25590d7",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "svmem = psutil.virtual_memory()\n",
+ "memory_used = svmem.total - svmem.available\n",
+ "memory_used_gb_after_model_load = memory_used / (1024**3)\n",
+ "memory_used_gb_after_model_load"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8dd92639",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "model_memory_usage = memory_used_gb_after_model_load - memory_used_gb_before_model_load\n",
+ "model_memory_usage"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2ad64a18",
+ "metadata": {},
+ "source": [
+ "Loading the embedding model took around 1 GB of memory.\n",
+ "\n",
+ "Let's see how slow it is to generate an embedding."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9340e099",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "%%time\n",
+ "\n",
+ "embeddings = model.encode([chunk[\"text\"] for chunk in chunks])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "095f9601-0def-44fc-9852-74ea78abe329",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "len(chunks)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "49537d91",
+ "metadata": {},
+ "source": [
+ "It takes on the order of a few seconds to embed 8 chunks on our CPU. We will most definitely need a GPU to speed things up."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fb35f3d5-eaeb-4338-a00b-d07cd477d034",
+ "metadata": {},
+ "source": [
+ "#### Save embeddings to disk\n",
+ "\n",
+ "As a fourth step, we want to store our generated embeddings as a parquet file."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0153e93c",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "df_output = pd.DataFrame(chunks)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a75eb31f",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "df_output[\"embeddings\"] = embeddings.tolist()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "68e2bca2",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "df_output"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "59aad3a7",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "df_output.to_parquet(DATA_DIR / \"sample-output-pandas.parquet\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "84d5a657-90c6-4af7-91d2-4e0ef75005cb",
+ "metadata": {},
+ "source": [
+ "### 4. Upsert embeddings to vector store\n",
+ "\n",
+ "The final step is to upsert the embeddings into a database. We will skip this step for now."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "824ae888-4217-4240-9749-59997de57a36",
+ "metadata": {},
+ "source": [
+ "## Migrating the simple pipeline to Ray Data"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c2203991",
+ "metadata": {},
+ "source": [
+ "We now want to migrate our implementation to use Ray Data to drastically scale our pipeline for larger datasets.\n",
+ "\n",
+ "### 1. Load documents\n",
+ "\n",
+ "Let's start with a first pass conversion of our data pipeline to use Ray Data. \n",
+ "\n",
+ "Instead of `pandas.read_json`, use `ray.data.read_json` to instantiate a `ray.data.Dataset` that will eventually read our file."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "02879966",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ds_sample_input = ray.data.read_json(DATA_DIR / \"small_sample\" / \"sample-input.jsonl\")\n",
+ "type(ds_sample_input)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a8ee87a5",
+ "metadata": {},
+ "source": [
+ "`ray.data.read_json` returns a `ray.data.Dataset` which is a distributed collection of data. Execution in Ray Data by default is:\n",
+ "- **Lazy**: `Dataset` transformations aren’t executed until you call a consumption operation.\n",
+ "- **Streaming**: `Dataset` transformations are executed in a streaming way, incrementally on the base data, one block at a time.\n",
+ "\n",
+ "Accordingly `ray.data.Dataset` will only fetch back some high-level metadata and schema information about the file, but not the actual data."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b079ec1a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds_sample_input"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d5c30d74",
+ "metadata": {},
+ "source": [
+ "### Under the hood\n",
+ "\n",
+ "Ray Data uses Ray tasks to read files in parallel. Each read task reads one or more files and produces one or more output blocks.\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "aa786d3c",
+ "metadata": {},
+ "source": [
+ "### 2. Process documents into chunks\n",
+ "\n",
+ "Given a `ray.data.Dataset`, we can apply transformations to it. There are two types of transformations:\n",
+ "1. **row-wise transformations**\n",
+ " - `map`: a 1-to-1 function that is applied to each row in the dataset.\n",
+ " - `filter`: a 1-to-1 function that is applied to each row in the dataset and filters out rows that don’t satisfy the condition.\n",
+ " - `flat_map`: a 1-to-many function that is applied to each row in the dataset and then flattens the results into a single dataset.\n",
+ "2. **batch-wise transformations**\n",
+ " - `map_batches`: a 1-to-n function that is applied to each batch in the dataset.\n",
+ "\n",
+ "\n",
+ "We chose to make use of `flat_map` to generate a list of chunk rows. `flat_map` will create `FlatMap` tasks which will be scheduled in parallel to process as many rows as possible at once."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f52bb9ee",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "def chunk_row(row):\n",
+ " chunk_size = 128\n",
+ " words_to_tokens = 1.2\n",
+ " num_tokens = int(chunk_size // words_to_tokens)\n",
+ "\n",
+ " def get_num_words(text):\n",
+ " return len(text.split())\n",
+ "\n",
+ " splitter = RecursiveCharacterTextSplitter(\n",
+ " chunk_size=num_tokens,\n",
+ " keep_separator=True, \n",
+ " length_function=get_num_words, \n",
+ " chunk_overlap=0,\n",
+ " )\n",
+ "\n",
+ " chunks = []\n",
+ " for chunk in splitter.split_text(row[\"text\"]):\n",
+ " chunks.append(\n",
+ " {\n",
+ " \"text\": chunk,\n",
+ " \"section_url\": row[\"section_url\"],\n",
+ " \"page_url\": row[\"page_url\"],\n",
+ " }\n",
+ " )\n",
+ " return chunks\n",
+ "\n",
+ "ds_sample_input_chunked = ds_sample_input.flat_map(chunk_row)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "54c5ee9b",
+ "metadata": {},
+ "source": [
+ "To verify our `flat_map` is working, we can consume a limited number of rows from the dataset.\n",
+ "\n",
+ "To do so, we an either call\n",
+ "- `take` to specify a limited number of rows from the dataset.\n",
+ "- `take_batch` to specify a limited number of batches from the dataset.\n",
+ "\n",
+ "Here we call `take(2)` to return 2 rows."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "89bf2c18",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ds_sample_input_chunked.take(2)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ae6c2abb",
+ "metadata": {},
+ "source": [
+ "### 3. Generate embeddings from chunks\n",
+ "\n",
+ "For our third step, we apply the embeddings using `map_batches`, which will be implemented using `MapBatches` tasks scheduled in parallel."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e85a86f0",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "def embed_batch(batch):\n",
+ " assert isinstance(batch, dict)\n",
+ " for key in batch.keys():\n",
+ " assert key in [\"text\", \"section_url\", \"page_url\"]\n",
+ " for val in batch.values():\n",
+ " assert isinstance(val, np.ndarray), type(val)\n",
+ "\n",
+ " model = SentenceTransformer('thenlper/gte-large')\n",
+ " text = batch[\"text\"].tolist()\n",
+ " embeddings = model.encode(text, batch_size=len(text))\n",
+ " batch[\"embeddings\"] = embeddings.tolist()\n",
+ " return batch\n",
+ "\n",
+ "ds_sample_input_embedded = ds_sample_input_chunked.map_batches(embed_batch)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "52a97e92",
+ "metadata": {},
+ "source": [
+ "#### Save embeddings to disk\n",
+ "\n",
+ "For our fourth step, we write our dataset to parquet using `write_parquet`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3e8c08db",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "%%time\n",
+ "\n",
+ "output_path = DATA_DIR / \"small_sample\" / \"sample-output\"\n",
+ "if output_path.exists():\n",
+ " shutil.rmtree(output_path)\n",
+ "\n",
+ "ds_sample_input_embedded.write_parquet(output_path)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "18d6ccf4",
+ "metadata": {},
+ "source": [
+ "We inspect the created parquet output directory. Every write task will create a separate file in the output directory."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a389e8f8-e2c1-484c-9df4-c2e383b34fc9",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "!ls -llah {output_path} "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d2ef4b25",
+ "metadata": {},
+ "source": [
+ "We can read the parquet file back into a pandas dataframe."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "16a305d0-81e0-4c93-9770-9ed0a8b65e6b",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "df = ray.data.read_parquet(DATA_DIR / \"small_sample\" / \"sample-output\").to_pandas()\n",
+ "df"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "df7f7b49-4a0c-4160-bc35-341894ad4149",
+ "metadata": {},
+ "source": [
+ "### 4. Upsert embeddings to vector store\n",
+ "\n",
+ "The final step is to upsert the embeddings into a database. We will skip this step for now."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "efabf980",
+ "metadata": {},
+ "source": [
+ "**Recap**\n",
+ "\n",
+ "Here is our entire pipeline:\n",
+ "\n",
+ "```python\n",
+ "(\n",
+ " ray.data.read_json(DATA_DIR / \"small_sample\" / \"sample-input.jsonl\")\n",
+ " .flat_map(chunk_row)\n",
+ " .map_batches(embed_batch)\n",
+ " .write_parquet(DATA_DIR / \"small_sample\" / \"sample-output\")\n",
+ ")\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "380e0822",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "### Activity: Implement the pipeline using a different embedding model\n",
+ "\n",
+ "Re-implement the entire data pipeline but this time use a different embedding model `BAAI/bge-large-en-v1.5` which outperforms `thenlper/gte-large` on certain parts of the MTEB leaderboard.\n",
+ "\n",
+ "NOTE: make sure to output the results to a different directory.\n",
+ "\n",
+ "```python\n",
+ "# Hint: Use the code in the recap section as a template but update the embedding transformation.\n",
+ "```\n",
+ "\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "74e64859",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Write your solution here\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5664875b",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4d7880df",
+ "metadata": {},
+ "source": [
+ "## Scaling the pipeline with Ray Data\n",
+ "\n",
+ "Let's explore how to scale our pipeline to a larger dataset using Ray Data.\n",
+ "\n",
+ " \n",
+ "\n",
+ "
\n",
+ "\n",
+ "Click here to see the solution
\n", + "\n", + "```python\n", + "def embed_batch(batch):\n", + " # Load the embedding model\n", + " model = SentenceTransformer(\"BAAI/bge-large-en-v1.5\")\n", + " text = batch[\"text\"].tolist()\n", + " embeddings = model.encode(text, batch_size=len(text))\n", + " batch[\"embeddings\"] = embeddings.tolist()\n", + " return batch\n", + "\n", + "(\n", + " ray.data.read_json(DATA_DIR / \"small_sample\" / \"sample-input.jsonl\")\n", + " .flat_map(chunk_row)\n", + " .map_batches(embed_batch)\n", + " .write_parquet(DATA_DIR / \"small_sample\" / \"sample-output-bge\")\n", + ")\n", + "\n", + "# inspect output\n", + "ray.data.read_parquet(DATA_DIR / \"small_sample\" / \"sample-output-bge\").to_pandas()\n", + "```\n", + "\n", + "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0b675c09",
+ "metadata": {},
+ "source": [
+ "### Phase 1: Preparing input files\n",
+ "\n",
+ "First, we need to prepare our documents by performing the following steps\n",
+ "1. Fetch all the Ray documentation from the web.\n",
+ "2. Parse the web pages to extract the text."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "667c2c2f",
+ "metadata": {},
+ "source": [
+ "#### 1. Fetch all the Ray documentation from the web.\n",
+ "\n",
+ "We have already fetched the Ray documentation and stored it on S3."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6c88dbbe",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "raw_web_pages_dir = CloudPath(\n",
+ " \"s3://anyscale-public-materials/ray-documentation-html-files/unzipped/\"\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "14628649",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "raw_web_pages_dir.exists(), raw_web_pages_dir.is_dir()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "dfc2b87f",
+ "metadata": {},
+ "source": [
+ "#### 2. Parse the web pages to extract the text.\n",
+ "\n",
+ "We first read all HTML files in the raw web pages directory into a `ray.data.Dataset`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "cebe9021",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ds_web_page_paths = ray.data.from_items(\n",
+ " [{\"path\": path} for path in raw_web_pages_dir.glob(\"**/*.html\")]\n",
+ ")\n",
+ "ds_web_page_paths"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d448ad80",
+ "metadata": {},
+ "source": [
+ "Note that this only includes the latest version of the ray documentation. This size would be drastically multiplied if we included all versions of the documentation."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2f788923",
+ "metadata": {},
+ "source": [
+ "##### Utilize inherent structure to improve the documents \n",
+ "\n",
+ "Documentation [webpages](https://docs.ray.io/en/latest/rllib/rllib-env.html) are naturally split into sections. We can use this to our advantage by returning our documents as sections. This will facilitate producing semantically coherent chunks. \n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "25b5a4dc",
+ "metadata": {},
+ "source": [
+ "We are producing multiple documents from each HTML file. We will use the `flat_map` method to produce multiple documents from each HTML file."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "44037192",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "def path_to_uri(\n",
+ " path: CloudPath, scheme: str = \"https://\", domain: str = \"docs.ray.io\"\n",
+ ") -> str:\n",
+ " return scheme + domain + str(path).split(domain)[-1]\n",
+ "\n",
+ "def extract_sections_from_html(record: dict) -> list[dict]:\n",
+ " documents = []\n",
+ " # 1. Request the page and parse it using BeautifulSoup\n",
+ " with record[\"path\"].open(\"r\", encoding=\"utf-8\", force_overwrite_from_cloud=True) as html_file:\n",
+ " soup = BeautifulSoup(html_file, \"html.parser\")\n",
+ "\n",
+ " page_url = path_to_uri(record[\"path\"])\n",
+ "\n",
+ " # 2. Find all sections\n",
+ " sections = soup.find_all(\"section\")\n",
+ " for section in sections:\n",
+ " # 3. Extract text from the section but not from the subsections\n",
+ " section_text = \"\\n\".join(\n",
+ " [child.text for child in section.children if child.name != \"section\"]\n",
+ " )\n",
+ " # 4. Construct the section url\n",
+ " section_url = page_url + \"#\" + section[\"id\"]\n",
+ " # 5. Create a document object with the text, source page, source section uri\n",
+ " documents.append(\n",
+ " {\n",
+ " \"text\": section_text,\n",
+ " \"section_url\": section_url,\n",
+ " \"page_url\": page_url,\n",
+ " }\n",
+ " )\n",
+ " return documents\n",
+ "\n",
+ "\n",
+ "ds_sections = ds_web_page_paths.flat_map(extract_sections_from_html)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8f853bd4",
+ "metadata": {},
+ "source": [
+ "Finally we store the produced dataset in parquet format."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a6fff8e1",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "%%time\n",
+ "if (DATA_DIR / \"full_scale\" / \"02_sections\").exists():\n",
+ " shutil.rmtree(DATA_DIR / \"full_scale\" / \"02_sections\")\n",
+ "ds_sections.write_parquet(DATA_DIR / \"full_scale\" / \"02_sections\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9b27d396",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "!ls -llh {DATA_DIR / \"full_scale\" / \"02_sections\"}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "aeda8999-9b56-4347-b3bd-6f740ece7b54",
+ "metadata": {},
+ "source": [
+ "Let's count how many documents we will have after processing the sections."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "45d20170-970e-4c41-a830-19b28a36ed08",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ray.data.read_parquet(DATA_DIR / \"full_scale\" / \"02_sections\").count()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a8c55a29",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "**Considerations for reading input files into Ray Data:**\n",
+ "\n",
+ "Pruning columns and using filter pushdown can optimize parquet file reads:\n",
+ "- Specify only necessary columns when dealing with column-oriented formats to reduce memory usage.\n",
+ "- Apply filter pushdown in `ray.data.read_parquet` to retrieve only rows that meet certain conditions.\n",
+ "\n",
+ "However, as our dataset's memory footprint is predominantly due to the 'text' column, these optimizations will have a limited impact on reducing memory load.\n",
+ "\n",
+ "
\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c6349758",
+ "metadata": {},
+ "source": [
+ "### Phase 2: Generating Embeddings\n",
+ "\n",
+ "Now that we have our documents, we can proceed to generate embeddings.\n",
+ "\n",
+ "#### 1. Load documents\n",
+ "We begin by reading the documents from the \"02_sections\" directory."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "41cabac4",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ds_sections = ray.data.read_parquet(DATA_DIR / \"full_scale\" / \"02_sections\")\n",
+ "\n",
+ "ds_sections"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "75131c7b",
+ "metadata": {},
+ "source": [
+ "#### Applying chunking as a transformation\n",
+ "\n",
+ "We apply our chunking transformation using `flat_map`, which applies a 1-to-many function to each row in the dataset and then flattens the results into a single dataset."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3ed69ca1",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ds_sections_chunked = ds_sections.flat_map(chunk_row)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f07f2f96",
+ "metadata": {},
+ "source": [
+ "We could have used `map_batches` instead to apply a many-to-many function to each batch of rows in the dataset. However, given our chunking transformation is not vectorized, `map_batches` will not be faster."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "229450f6",
+ "metadata": {},
+ "source": [
+ "Let's run the chunking and count our total number of chunks."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7a8aaa46",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ds_sections_chunked.count()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "94b485be",
+ "metadata": {},
+ "source": [
+ "#### Applying embedding as a transformation\n",
+ "\n",
+ "We want to load the embedding model once and reuse it across multiple transformation tasks.\n",
+ "\n",
+ "To do so, we want to use call `map_batches` with **stateful transform** instead of a *stateless transform*. \n",
+ "\n",
+ "This means we create a pool of processes called actors where the model is already loaded in memory.\n",
+ "\n",
+ "Each actor will run a `MapBatch` process where:\n",
+ " - initial state is handled in `__init__`\n",
+ " - task is invoked using `__call__` method"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "fab910d5",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "num_workers = 2\n",
+ "device = \"cuda\"\n",
+ "\n",
+ "class EmbedBatch:\n",
+ " def __init__(self):\n",
+ " self.model = SentenceTransformer(\"thenlper/gte-large\", device=device)\n",
+ "\n",
+ " def __call__(self, batch):\n",
+ " text = batch[\"text\"].tolist()\n",
+ " embeddings = self.model.encode(text, batch_size=len(text))\n",
+ " batch[\"embeddings\"] = embeddings.tolist()\n",
+ " return batch\n",
+ "\n",
+ "ds_sections_embedded = ds_sections_chunked.map_batches(\n",
+ " EmbedBatch,\n",
+ " # Number of actors to launch.\n",
+ " concurrency=num_workers,\n",
+ " # Size of batch passed to embeddings actor.\n",
+ " batch_size=200,\n",
+ " # 1 GPU for each actor.\n",
+ " num_gpus=1,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "eaadfbcb",
+ "metadata": {},
+ "source": [
+ "#### Writing the embeddings to disk\n",
+ "\n",
+ "Now that we need to write the embeddings to disk, the data pipeline will get executed and will stream the data to the GPU nodes to perform the embedding generation."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "dab59319-0e69-4fd5-8f0e-d556c5c4881e",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "%%time\n",
+ "\n",
+ "if (DATA_DIR / \"full_scale\" / \"03_embeddings\").exists():\n",
+ " shutil.rmtree(DATA_DIR / \"full_scale\" / \"03_embeddings\")\n",
+ "(\n",
+ " ds_sections_embedded.write_parquet(path=DATA_DIR / \"full_scale\" / \"03_embeddings\")\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a0a4cf7c",
+ "metadata": {},
+ "source": [
+ "##### Inspecting the Ray Data dashboard\n",
+ "\n",
+ "If we take a look at the metrics tab of the ray data dashboard, we can check to see:\n",
+ "\n",
+ "- The GPU utilization\n",
+ " - Ideally, we would like to see the GPU utilization at 100% for the duration of the embedding process\n",
+ "- The GPU memory (GRAM) percentage\n",
+ " - We would like to see the GPU memory utilization at 100% for the duration of the embedding process\n",
+ "- The time spent on io and network by different tasks\n",
+ "\n",
+ "We can then use this information to optimize our pipeline."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6f68b208",
+ "metadata": {},
+ "source": [
+ "##### Inspecting the output\n",
+ "\n",
+ "We check to see if the embeddings were written to disk."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "60f381af-8c34-4e08-9014-c916f8ac3687",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "!ls -llh {DATA_DIR / \"full_scale\" / \"03_embeddings\"}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a24e368b",
+ "metadata": {},
+ "source": [
+ "### Recap of the pipeline\n",
+ "\n",
+ "Here is our entire pipeline so far:\n",
+ "\n",
+ "```python\n",
+ "(\n",
+ " ray.data.read_json(\n",
+ " DATA_DIR / \"full_scale\" / \"02_sections\",\n",
+ " )\n",
+ " .flat_map(chunk_row)\n",
+ " .map_batches(\n",
+ " EmbedBatch,\n",
+ " concurrency=num_workers,\n",
+ " batch_size=200,\n",
+ " num_gpus=1,\n",
+ " )\n",
+ " .write_parquet(\n",
+ " path=DATA_DIR / \"full_scale\" / \"03_embeddings_tuning\",\n",
+ " )\n",
+ ")\n",
+ "```\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "bda2771a",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "### Activity: Tuning the pipeline\n",
+ "\n",
+ "Proceed to tune your pipeline by changing the batch size on `map_batches` and see what effect it has on the GPU memory (GRAM) percentage.\n",
+ "\n",
+ "```python\n",
+ "ds_sections_embedded = ds_sections_chunked.map_batches(\n",
+ " EmbedBatch,\n",
+ " concurrency=num_workers,\n",
+ " batch_size=200, # Hint: Check how GRAM changes when you change the batch size\n",
+ " num_gpus=1,\n",
+ ")\n",
+ "\n",
+ "ds_sections_embedded.materialize()\n",
+ "```\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "288d98a6",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Write your solution here\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3ea228c6",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3ce8b0c3",
+ "metadata": {},
+ "source": [
+ "### Upserting embeddings to a vector database\n",
+ "\n",
+ "We will use [chroma](https://www.trychroma.com/) to index our document embeddings in a vector store. Chroma is an open-source vector database optimized for similarity search and is user-friendly. We chose Chroma for its ease of use and its free tier, which meets our needs.\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c88b8083",
+ "metadata": {},
+ "source": [
+ "#### 1. Create a chroma client \n",
+ "\n",
+ "We create a chroma client using the `PersistentClient` class to connect to the chroma server against a persistent file store."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a3594d40",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "chroma_client = chromadb.PersistentClient(path=\"/mnt/cluster_storage/vector_store\")\n",
+ "chroma_client"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b815e31d",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "chroma_client.list_collections()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "04ed9863",
+ "metadata": {},
+ "source": [
+ "#### 2. Create a chroma collection\n",
+ "\n",
+ "Next, we create a collection in chroma to store our embeddings. A collection provides a vector store index for our embeddings.\n",
+ "\n",
+ "We specify `hnsw:space` to use the \"Hierarchical Navigable Small World\" algorithm for similarity search using cosine similarity."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "134c2d70",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "collection = chroma_client.get_or_create_collection(name=\"ray-docs\", metadata={\"hnsw:space\": \"cosine\"})\n",
+ "collection"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ff80c116",
+ "metadata": {},
+ "source": [
+ "#### 3. Load the embeddings from disk \n",
+ "\n",
+ "We will load the embeddings from disk using `ray.data.read_parquet` to initiate a distributed upsert of the embeddings to chroma."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "14a3f696",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ds_embeddings = ray.data.read_parquet(DATA_DIR / \"full_scale\" / \"03_embeddings/\")\n",
+ "ds_embeddings"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d883bcb2",
+ "metadata": {},
+ "source": [
+ "#### 4. Transform the embeddings into chroma index format \n",
+ "\n",
+ "We construct an `id` column to uniquely identify each embedding."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "168a85f1",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "def compute_id(row):\n",
+ " row_hash = joblib.hash(row)\n",
+ " page_name = row[\"page_url\"].split(\"/\")[-1]\n",
+ " section_name = row[\"section_url\"].split(\"#\")[-1]\n",
+ " row[\"id\"] = f\"{page_name}#{section_name}#{row_hash}\"\n",
+ " return row\n",
+ "\n",
+ "ds_embeddings_with_id = ds_embeddings.map(compute_id)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "154edf44",
+ "metadata": {},
+ "source": [
+ "We fetch back the data as a collection of objects and then upsert them into chroma."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "42c6730f",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "chroma_data = ds_embeddings_with_id.to_pandas().drop_duplicates(subset=[\"id\"]).to_dict(orient=\"list\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a91cf418",
+ "metadata": {},
+ "source": [
+ "Here is how to upsert documents into a collection in chroma:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2d749632",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "collection.upsert(\n",
+ " ids=chroma_data[\"id\"],\n",
+ " embeddings=[arr.tolist() for arr in chroma_data[\"embeddings\"]],\n",
+ " documents=chroma_data[\"text\"],\n",
+ " metadatas=[\n",
+ " {\n",
+ " \"section_url\": section_url,\n",
+ " \"page_url\": page_url,\n",
+ " }\n",
+ " for section_url, page_url in zip(chroma_data[\"section_url\"], chroma_data[\"page_url\"])\n",
+ " ],\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "05f2dee6",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "
\n",
+ "\n",
+ "Click here to see the solution
\n", + "\n", + "```python\n", + "ds_sections_embedded = ds_sections_chunked.map_batches(\n", + " EmbedBatch,\n", + " concurrency=num_workers,\n", + " batch_size=350, # Optimal batch size for GRAM\n", + " num_gpus=1,\n", + ")\n", + "\n", + "ds_sections_embedded.materialize()\n", + "```\n", + "\n", + "\n",
+ "\n",
+ "Note we can further parallelize the upsert using a `map_batches` operation. This is left as an exercise for the reader.\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a9fb5d69",
+ "metadata": {},
+ "source": [
+ "### Querying the chroma collection\n",
+ "\n",
+ "Given we have indexed our embeddings, we can now query the index to retrieve the most similar documents to a given query."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "23a48944",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "query = \"What is the default number of maximum replicas for a Ray Serve deployment?\""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "742abec1",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "model = SentenceTransformer('thenlper/gte-large')\n",
+ "query_embedding = model.encode(query).tolist()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6828281f",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "result = collection.query(\n",
+ " query_embeddings=[query_embedding],\n",
+ " n_results=5,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "be32a627",
+ "metadata": {},
+ "source": [
+ "Here is the most relevant text we found:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e58a34e8",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(result[\"documents\"][0][0])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c2ad9e4c",
+ "metadata": {},
+ "source": [
+ "It was fetched from this page of the documentation"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e0b9b6be",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "result[\"metadatas\"][0][0][\"page_url\"]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "cf59bf49",
+ "metadata": {},
+ "source": [
+ "We can additionally retrieve the similarity score in case we want to only retrieve results with a score above a certain threshold."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "db08e14d",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "scores = [1- distance for distance in result[\"distances\"][0]]\n",
+ "scores"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f4e9c74f",
+ "metadata": {},
+ "source": [
+ "## Key Takeaways\n",
+ "\n",
+ "With Ray and Anyscale we are able to achieve very fast and efficient embeddings generation at scale. See this [blog](https://www.anyscale.com/blog/rag-at-scale-10x-cheaper-embedding-computations-with-anyscale-and-pinecone) showcasing how we were able to achieve 10x cheaper embeddings generation of billions of documents using Ray and Pinecone.\n",
+ "\n",
+ "Ray Data's Lazy and Streaming execution model allows us to:\n",
+ "- Efficiently scale our pipeline to large datasets\n",
+ "- Avoid having to fully materialize the dataset in a store (memory/disk)\n",
+ "- Easily saturate GPUs by scaling preprocessing across CPU nodes\n",
+ " \n",
+ "Anyscale provides:\n",
+ "- Access to spot instances with fallback to on-demand to run the pipeline in the most cost-efficient manner\n",
+ "- Incremental metadata fetching of very large parquet datasets avoiding long \"boot times\" and idling instances\n"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/templates/ray-summit-rag/03_Build_RAG.ipynb b/templates/ray-summit-rag/03_Build_RAG.ipynb
new file mode 100644
index 000000000..5eb413289
--- /dev/null
+++ b/templates/ray-summit-rag/03_Build_RAG.ipynb
@@ -0,0 +1,652 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "c39cccf9",
+ "metadata": {},
+ "source": [
+ "# Brief \n",
+ "\n",
+ "Having indexed the data, we can now build our RAG system. We will start by building the retriever, which will be responsible for finding the most relevant documents to a given query and then we will build an LLM client to generate the response.\n",
+ "\n",
+ "\n",
+ "\n",
+ " Here is the roadmap for this notebook:\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "79ef871a",
+ "metadata": {},
+ "source": [
+ "## Setup\n",
+ "\n",
+ "### Imports"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "aef7fe4d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "import json\n",
+ "import shutil\n",
+ "from typing import Any, Iterator\n",
+ "\n",
+ "import openai\n",
+ "import chromadb\n",
+ "from openai.resources.chat.completions import ChatCompletion\n",
+ "from pathlib import Path\n",
+ "from sentence_transformers import SentenceTransformer"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e171a305",
+ "metadata": {},
+ "source": [
+ "## Pre-requisite setup\n",
+ "\n",
+ "- \n",
+ "
- Part 1: RAG Application Overview \n", + "
- Part 2: Building Retriever components \n", + "
- Part 3: Building Response Generation \n", + "
- Part 4: Putting it all together into a QA Engine \n", + "
Important if you want to run this notebook: \n",
+ "\n",
+ "This RAG notebook requires having a running LLM Anyscale service. To deploy an LLM as an Anyscale service, you can follow the step-by-step instructions in this [Deploy an LLM workspace template](https://console.anyscale.com/v2/template-preview/endpoints_v2). Make sure to choose the `mistralai/Mistral-7B-Instruct-v0.1` model when deploying.\n",
+ "\n",
+ "
\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "22a1e90f",
+ "metadata": {},
+ "source": [
+ "### Constants"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "dbbf9771",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ANYSCALE_SERVICE_BASE_URL = \"replace-with-my-anyscale-service-url\"\n",
+ "ANYSCALE_API_KEY = \"replace-with-my-anyscale-api-key\""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "dc53d896",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "if os.environ.get(\"ANYSCALE_ARTIFACT_STORAGE\"):\n",
+ " DATA_DIR = Path(\"/mnt/cluster_storage/\")\n",
+ " shutil.copytree(Path(\"./data/\"), DATA_DIR, dirs_exist_ok=True)\n",
+ "else:\n",
+ " DATA_DIR = Path(\"./data/\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "57d3af8e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Embedding model we used to build the search index on chroma\n",
+ "EMBEDDING_MODEL_NAME = \"thenlper/gte-large\"\n",
+ "# The chroma search index we built\n",
+ "CHROMA_COLLECTION_NAME = \"ray-docs\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6c257a14",
+ "metadata": {},
+ "source": [
+ "## 0. RAG Application Overview\n",
+ "\n",
+ "We are building a simple RAG application that can answer questions about [Ray](https://docs.ray.io/). \n",
+ "\n",
+ "As a recap, see the diagram below for a visual representation of the components required for RAG.\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "59e3516c",
+ "metadata": {},
+ "source": [
+ "## 1. Building Retriever components\n",
+ "Retrieval is implemented in the following steps:\n",
+ "\n",
+ "1. Encode the user query\n",
+ "2. Search the vector store\n",
+ "3. Compose a context from the retrieved documents"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d3ac27aa",
+ "metadata": {},
+ "source": [
+ "### 1. Encode the user query\n",
+ "To encode the query, we will use the same embedding model that we used to encode the documents. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "aa4db779",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class QueryEncoder:\n",
+ " def __init__(self):\n",
+ " self.embedding_model_name = EMBEDDING_MODEL_NAME\n",
+ " self.model = SentenceTransformer(self.embedding_model_name)\n",
+ "\n",
+ " def encode(self, query: str) -> list[float]:\n",
+ " return self.model.encode(query).tolist()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "62ce0b02",
+ "metadata": {},
+ "source": [
+ "We try out our QueryEncoder by encoding a sample query relevant to our domain."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "eb4c7627",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "query_encoder = QueryEncoder()\n",
+ "query = \"How can I deploy Ray Serve to Kubernetes?\"\n",
+ "embeddings_vector = query_encoder.encode(query)\n",
+ "\n",
+ "type(embeddings_vector), len(embeddings_vector)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ca5b790f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "embeddings_vector[:5]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "73087086",
+ "metadata": {},
+ "source": [
+ "### 2. Search the vector store\n",
+ "Next, we will search the vector store to retrieve the closest documents to the query.\n",
+ "\n",
+ "We implement a `VectorStore` abstraction that reiles on the chroma client to search the vector store."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "56e07e22",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class VectorStore:\n",
+ " def __init__(self):\n",
+ " chroma_client = chromadb.PersistentClient(\n",
+ " path=\"/mnt/cluster_storage/vector_store\"\n",
+ " )\n",
+ " self._collection = chroma_client.get_collection(CHROMA_COLLECTION_NAME)\n",
+ "\n",
+ " def query(self, query_embedding: list[float], top_k: int) -> dict:\n",
+ " \"\"\"Retrieve the most similar chunks to the given query embedding.\"\"\"\n",
+ " if top_k == 0:\n",
+ " return {\"documents\": [], \"usage\": {}}\n",
+ "\n",
+ " response = self._collection.query(\n",
+ " query_embeddings=[query_embedding],\n",
+ " n_results=top_k,\n",
+ " )\n",
+ "\n",
+ " return {\n",
+ " \"documents\": [\n",
+ " {\n",
+ " \"text\": text,\n",
+ " \"section_url\": metadata[\"section_url\"],\n",
+ " }\n",
+ " for text, metadata in zip(\n",
+ " response[\"documents\"][0], response[\"metadatas\"][0]\n",
+ " )\n",
+ " ],\n",
+ " }"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2141b44c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "vector_store = VectorStore()\n",
+ "vector_store_response = vector_store.query(\n",
+ " query_embedding=embeddings_vector,\n",
+ " top_k=3,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "32ae23d4",
+ "metadata": {},
+ "source": [
+ "We can inspect the retrieved document URLs given our query"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "33e0e6be",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "for doc in vector_store_response[\"documents\"]:\n",
+ " print(doc[\"section_url\"])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b50af105",
+ "metadata": {},
+ "source": [
+ "### 3. Compose a context from the retrieved documents\n",
+ "\n",
+ "We put together a `Retriever` that encapsulates the entire retrieval process so far.\n",
+ "\n",
+ "It also composes the context from the retrieved documents by simply concatenating the retrieved chunks."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2e0a5a9c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class Retriever:\n",
+ " def __init__(self, query_encoder, vector_store):\n",
+ " self.query_encoder = query_encoder\n",
+ " self.vector_store = vector_store\n",
+ "\n",
+ " def _compose_context(self, contexts: list[str]) -> str:\n",
+ " sep = 100 * \"-\"\n",
+ " return \"\\n\\n\".join([f\"{sep}\\n{context}\" for context in contexts])\n",
+ "\n",
+ " def retrieve(self, query: str, top_k: int) -> dict:\n",
+ " \"\"\"Retrieve the context and sources for the given query.\"\"\"\n",
+ " encoded_query = self.query_encoder.encode(query)\n",
+ " vector_store_response = self.vector_store.query(\n",
+ " query_embedding=encoded_query,\n",
+ " top_k=top_k,\n",
+ " )\n",
+ " contexts = [chunk[\"text\"] for chunk in vector_store_response[\"documents\"]]\n",
+ " sources = [chunk[\"section_url\"] for chunk in vector_store_response[\"documents\"]]\n",
+ " return {\n",
+ " \"contexts\": contexts,\n",
+ " \"composed_context\": self._compose_context(contexts),\n",
+ " \"sources\": sources,\n",
+ " }"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e6a32543",
+ "metadata": {},
+ "source": [
+ "We run the retriever to check it is working as expected\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c3b5997c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "retriever = Retriever(query_encoder=query_encoder, vector_store=vector_store)\n",
+ "retrieval_response = retriever.retrieve(\n",
+ " query=query,\n",
+ " top_k=3,\n",
+ ")\n",
+ "retrieval_response"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e350b905",
+ "metadata": {},
+ "source": [
+ "We inspect the retrieved context"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b3438a51",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(retrieval_response[\"composed_context\"])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6687d2a7",
+ "metadata": {},
+ "source": [
+ "## 2. Building Response Generation\n",
+ "\n",
+ "We will generate a response using an LLM server offering an openai-compatible API.\n",
+ "\n",
+ "To do so we implement a simple LLM client class that encapsulates the generation process."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8969eb0b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class LLMClient:\n",
+ " def __init__(self):\n",
+ " # Initialize a client to perform API requests\n",
+ " self.client = openai.OpenAI(\n",
+ " base_url=ANYSCALE_SERVICE_BASE_URL,\n",
+ " api_key=ANYSCALE_API_KEY,\n",
+ " )\n",
+ "\n",
+ " def generate(self, user_prompt: str, model=\"mistralai/Mistral-7B-Instruct-v0.1\", temperature: float = 0, **kwargs: Any) -> ChatCompletion:\n",
+ " \"\"\"Generate a completion from the given user prompt.\"\"\"\n",
+ " # Call the chat completions endpoint\n",
+ " chat_completion = self.client.chat.completions.create(\n",
+ " model=model,\n",
+ " messages=[\n",
+ " # Prime the system with a system message - a common best practice\n",
+ " {\"role\": \"system\", \"content\": \"You are a helpful assistant.\"},\n",
+ " # Send the user message with the proper \"user\" role and \"content\"\n",
+ " {\"role\": \"user\", \"content\": user_prompt},\n",
+ " ],\n",
+ " temperature=temperature,\n",
+ " **kwargs,\n",
+ " )\n",
+ "\n",
+ " return chat_completion"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "470e493a",
+ "metadata": {},
+ "source": [
+ "Note we are currently making use of an already deployed open-source LLM running on Anyscale.\n",
+ "\n",
+ "In case you want to deploy your own LLM, you can follow the instructions in the [Anyscale documentation](https://docs.anyscale.com/)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "29ca2e50",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "llm_client = LLMClient()\n",
+ "response = llm_client.generate(\"What is the capital of France?\")\n",
+ "print(response.choices[0].message.content)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3f1b49c6",
+ "metadata": {},
+ "source": [
+ "## 3. Putting it all together into a QA Engine\n",
+ "Given a user query we will want our RAG based QA engine to perform the following steps:\n",
+ "\n",
+ "1. Retrieve the closest documents to the query\n",
+ "2. Augment the query with the context\n",
+ "3. Generate a response to the augmented query"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "10197527",
+ "metadata": {},
+ "source": [
+ "We decide on a simple prompt template to augment the user's query with the retrieved context. The template is as follows:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "668f5d82",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "prompt_template_rag = \"\"\"\n",
+ "Given the following context:\n",
+ "{composed_context}\n",
+ "\n",
+ "Answer the following question:\n",
+ "{query}\n",
+ "\n",
+ "If you cannot provide an answer based on the context, please say \"I don't know.\"\n",
+ "Do not use the term \"context\" in your response.\"\"\"\n",
+ "\n",
+ "\n",
+ "def augment_prompt(query: str, composed_context: str) -> str:\n",
+ " \"\"\"Augment the prompt with the given query and contexts.\"\"\"\n",
+ " return prompt_template_rag.format(composed_context=composed_context, query=query)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "100fabee",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "augmented_prompt = augment_prompt(\n",
+ " query=query,\n",
+ " composed_context=retrieval_response[\"composed_context\"],\n",
+ ")\n",
+ "print(augmented_prompt)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a380ede7",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "**Considerations for building a prompt-template for RAG:**\n",
+ "\n",
+ "Prompt engineering techniques can be used need to be purpose built for the usecase and chosen model. For example, if you want the model to still use its own knowledge in certain cases, you might want to use a different prompt template than if you want the model to only use the retrieved context.\n",
+ "\n",
+ "For comparison, here are the links to popular third-party library prompt templates which are fairly generic in nature:\n",
+ "- [LangChain's default RAG prompt template](https://smith.langchain.com/hub/rlm/rag-prompt)\n",
+ "- [LlamaIndex's RAG prompt template](https://github.com/run-llama/llama_index/blob/main/llama-index-core/llama_index/core/prompts/default_prompts.py#L99)\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d23ad902",
+ "metadata": {},
+ "source": [
+ "We implement our question answering `QA` class below that composed all the steps together."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e476362f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class QA:\n",
+ " def __init__(self, retriever: Retriever, llm_client: LLMClient):\n",
+ " self.retriever = retriever\n",
+ " self.llm_client = llm_client\n",
+ "\n",
+ " def answer(\n",
+ " self,\n",
+ " query: str,\n",
+ " top_k: int,\n",
+ " include_sources: bool = True,\n",
+ " ) -> Iterator[str]:\n",
+ " \"\"\"Answer the given question and provide sources.\"\"\"\n",
+ " retrieval_response = self.retriever.retrieve(\n",
+ " query=query,\n",
+ " top_k=top_k,\n",
+ " )\n",
+ " prompt = augment_prompt(query, retrieval_response[\"composed_context\"])\n",
+ " response = self.llm_client.generate(\n",
+ " user_prompt=prompt,\n",
+ " stream=True,\n",
+ " )\n",
+ " for chunk in response:\n",
+ " choice = chunk.choices[0]\n",
+ " if choice.delta.content is None:\n",
+ " continue\n",
+ " yield choice.delta.content\n",
+ "\n",
+ " if include_sources:\n",
+ " yield \"\\n\" * 2\n",
+ " sources_str = \"\\n\".join(set(retrieval_response[\"sources\"]))\n",
+ " yield sources_str\n",
+ " yield \"\\n\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "147c965b",
+ "metadata": {},
+ "source": [
+ "We now test out our `QA` implementation"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6f18fd23",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "qa_agent = QA(retriever=retriever, llm_client=llm_client)\n",
+ "response = qa_agent.answer(query=query, top_k=3)\n",
+ "for r in response:\n",
+ " print(r, end=\"\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "354b4a73",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "#### Activity: Prompt the QA agent with different top_k values\n",
+ "\n",
+ "Prompt the same QA agent with the question \"How to deploy Ray Serve on Kubernetes?\" with `top_k=0` - is the answer still helpful and correct? \n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3c34d61e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Write your solution here\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f4b610d1",
+ "metadata": {},
+ "source": [
+ "\n",
+ "
\n"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/templates/ray-summit-rag/04_Deploy_RAG.ipynb b/templates/ray-summit-rag/04_Deploy_RAG.ipynb
new file mode 100644
index 000000000..ef5e3600c
--- /dev/null
+++ b/templates/ray-summit-rag/04_Deploy_RAG.ipynb
@@ -0,0 +1,1074 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "c39cccf9",
+ "metadata": {},
+ "source": [
+ "# Brief \n",
+ "\n",
+ "Having built a basic RAG application, we now need to deploy it. This guide will walk you through deploying the Retriever and Generation models on a server.\n",
+ "\n",
+ "\n",
+ "
\n",
+ "\n",
+ "\n",
+ "Click here to see the solution
\n", + "\n", + "\n", + "If you prompt the QA agent with `top_k=0`, the answer will not be meaningful. This is because the RAG application will not be able to retrieve any documents from the search index and therefore will not be able to generate an answer.\n", + "\n", + "```python\n", + "qa_agent = QA(model=\"mistralai/Mixtral-8x7B-Instruct-v0.1\")\n", + "response = qa_agent.answer(query=query, top_k=0)\n", + "for r in response:\n", + " print(r, end=\"\")\n", + "```\n", + "\n", + "This will now produce a hallucinated answer about using a helm chart that does not exist.\n", + "\n", + "\n", + "\n",
+ "\n",
+ " Here is the roadmap for this notebook:\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "79ef871a",
+ "metadata": {},
+ "source": [
+ "## Setup\n",
+ "\n",
+ "### Imports"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "aef7fe4d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "import json\n",
+ "import shutil\n",
+ "from fastapi import FastAPI\n",
+ "from fastapi.responses import StreamingResponse\n",
+ "from typing import Any, Iterator\n",
+ "\n",
+ "import openai\n",
+ "import requests\n",
+ "import chromadb\n",
+ "from ray import serve\n",
+ "from openai.resources.chat.completions import ChatCompletion\n",
+ "from pathlib import Path\n",
+ "from sentence_transformers import SentenceTransformer"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "96e82c45",
+ "metadata": {},
+ "source": [
+ "## Pre-requisite setup\n",
+ "\n",
+ "- \n",
+ "
- Part 1: RAG Backend Overview \n", + "
- Part 2: Deploying the Retriever components \n", + "
- Part 3: Deploying the Response Generation \n", + "
- Part 4: Putting it all together into a QA Engine \n", + "
- Part 5: Key Takeaways \n", + "
- Part 6: Bonus: Adding HTTP Ingress \n", + "
- Part 7: Bonus: Enabling streaming of response \n", + " \n", + "
Important if you want to run this notebook: \n",
+ "\n",
+ "This RAG notebook requires having a running LLM Anyscale service. To deploy an LLM as an Anyscale service, you can follow the step-by-step instructions in this [Deploy an LLM workspace template](https://console.anyscale.com/v2/template-preview/endpoints_v2). Make sure to choose the `mistralai/Mistral-7B-Instruct-v0.1` model when deploying.\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "22a1e90f",
+ "metadata": {},
+ "source": [
+ "### Constants"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2e5bc559",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ANYSCALE_SERVICE_BASE_URL = \"replace-with-my-anyscale-service-url\"\n",
+ "ANYSCALE_API_KEY = \"replace-with-my-anyscale-api-key\""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "dc53d896",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "if os.environ.get(\"ANYSCALE_ARTIFACT_STORAGE\"):\n",
+ " DATA_DIR = Path(\"/mnt/cluster_storage/\")\n",
+ " shutil.copytree(Path(\"./data/\"), DATA_DIR, dirs_exist_ok=True)\n",
+ "else:\n",
+ " DATA_DIR = Path(\"./data/\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "57d3af8e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Embedding model we used to build the search index on chroma\n",
+ "EMBEDDING_MODEL_NAME = \"thenlper/gte-large\"\n",
+ "# The chroma search index we built\n",
+ "CHROMA_COLLECTION_NAME = \"ray-docs\"\n",
+ "\n",
+ "ANYSCALE_SERVICE_BASE_URL = os.environ[\"ANYSCALE_SERVICE_BASE_URL\"]\n",
+ "ANYSCALE_API_KEY = os.environ[\"ANYSCALE_API_KEY\"]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6c257a14",
+ "metadata": {},
+ "source": [
+ "## 0. RAG Backend Overview\n",
+ "\n",
+ "Here is the same diagram from the previous notebook, but with the services that we will deploy highlighted.\n",
+ "\n",
+ "All the services will be deployed as part of a single QA engine application.\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "Note: delineating which components are built as separate deployments is a design decision. It depends whether you want to scale them independently or not. \n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "57455ffe",
+ "metadata": {},
+ "source": [
+ "## 1. Building Retriever components\n",
+ "\n",
+ "As a reminder, Retrieval is implemented in the following steps:\n",
+ "\n",
+ "1. Encode the user query\n",
+ "2. Search the vector store\n",
+ "3. Compose a context from the retrieved documents"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8d6fd59b",
+ "metadata": {},
+ "source": [
+ "### 1. Encode the user query\n",
+ "\n",
+ "To convert our QueryEncoder into a Ray deployment, simply need to wrap it with a `serve.deployment` decorator. \n",
+ "\n",
+ "Each deployment is a collection of replicas that can be scaled up or down based on the traffic.\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "The `autoscaling_config` parameter specifies the minimum and maximum number of replicas that can be created. \n",
+ "\n",
+ "The `ray_actor_options` parameter specifies the resources allocated to each replica. In this case, we allocate 1/10th (0.1) of a GPU to each replica."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f8b846b0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@serve.deployment(\n",
+ " ray_actor_options={\"num_gpus\": 0.1},\n",
+ " autoscaling_config={\"min_replicas\": 1, \"max_replicas\": 2},\n",
+ ")\n",
+ "class QueryEncoder:\n",
+ " def __init__(self):\n",
+ " self.embedding_model_name = EMBEDDING_MODEL_NAME\n",
+ " self.model = SentenceTransformer(self.embedding_model_name, device=\"cuda\")\n",
+ "\n",
+ " def encode(self, query: str) -> list[float]:\n",
+ " return self.model.encode(query).tolist()\n",
+ "\n",
+ "\n",
+ "query_encoder = QueryEncoder.bind()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9ae07650",
+ "metadata": {},
+ "source": [
+ "To send a gRPC request to the deployment, we need to:\n",
+ "1. start running the deployment and fetch back its handle using `serve.run`\n",
+ "2. send a request to the deployment using the handle using `.remote()`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "eb6db68e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "query_encoder_handle = serve.run(query_encoder, route_prefix=\"/query-encoder\")\n",
+ "query = \"How can I deploy Ray Serve to Kubernetes?\"\n",
+ "embeddings_vector = await query_encoder_handle.encode.remote(query)\n",
+ "\n",
+ "type(embeddings_vector), len(embeddings_vector)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a9a3528c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "embeddings_vector[:5]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "67ce46aa",
+ "metadata": {},
+ "source": [
+ "### 2. Search the vector store\n",
+ "\n",
+ "Next we would wrap the vector store with a `serve.deployment`. \n",
+ "\n",
+ "Note, we resort to a hack to ensure the vector store is running on the head node. This is because we are running a local chromadb in development mode which does not allow for concurrent access across nodes."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e314b9d7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@serve.deployment(\n",
+ " ray_actor_options={\"num_cpus\": 0, \"resources\": {\"is_head_node\": 1}},\n",
+ ")\n",
+ "class VectorStore:\n",
+ " def __init__(self):\n",
+ " chroma_client = chromadb.PersistentClient(\n",
+ " path=\"/mnt/cluster_storage/vector_store\"\n",
+ " )\n",
+ " self._collection = chroma_client.get_collection(CHROMA_COLLECTION_NAME)\n",
+ "\n",
+ " async def query(self, query_embedding: list[float], top_k: int) -> dict:\n",
+ " \"\"\"Retrieve the most similar chunks to the given query embedding.\"\"\"\n",
+ " if top_k == 0:\n",
+ " return {\"documents\": [], \"usage\": {}}\n",
+ "\n",
+ " response = self._collection.query(\n",
+ " query_embeddings=[query_embedding],\n",
+ " n_results=top_k,\n",
+ " )\n",
+ "\n",
+ " return {\n",
+ " \"documents\": [\n",
+ " {\n",
+ " \"text\": text,\n",
+ " \"section_url\": metadata[\"section_url\"],\n",
+ " }\n",
+ " for text, metadata in zip(\n",
+ " response[\"documents\"][0], response[\"metadatas\"][0]\n",
+ " )\n",
+ " ],\n",
+ " }\n",
+ "\n",
+ "vector_store = VectorStore.bind()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f1b7ebeb",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "vector_store_handle = serve.run(vector_store, route_prefix=\"/vector-store\")\n",
+ "vector_store_response = await vector_store_handle.query.remote(\n",
+ " query_embedding=embeddings_vector,\n",
+ " top_k=3,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9381166d",
+ "metadata": {},
+ "source": [
+ "We can inspect the retrieved document URLs given our query"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d91c7f69",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "for doc in vector_store_response[\"documents\"]:\n",
+ " print(doc[\"section_url\"])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d5310c44",
+ "metadata": {},
+ "source": [
+ "### 3. Compose a context from the retrieved documents\n",
+ "\n",
+ "We put together a `Retriever` that encapsulates the entire retrieval process so far.\n",
+ "\n",
+ "It also composes the context from the retrieved documents by simply concatenating the retrieved chunks."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "842765a1",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@serve.deployment(\n",
+ " ray_actor_options={\"num_cpus\": 0.1},\n",
+ ")\n",
+ "class Retriever:\n",
+ " def __init__(self, query_encoder, vector_store):\n",
+ " self.query_encoder = query_encoder\n",
+ " self.vector_store = vector_store\n",
+ "\n",
+ " def _compose_context(self, contexts: list[str]) -> str:\n",
+ " sep = 100 * \"-\"\n",
+ " return \"\\n\\n\".join([f\"{sep}\\n{context}\" for context in contexts])\n",
+ "\n",
+ " async def retrieve(self, query: str, top_k: int) -> dict:\n",
+ " \"\"\"Retrieve the context and sources for the given query.\"\"\"\n",
+ " encoded_query = await self.query_encoder.encode.remote(query)\n",
+ " vector_store_response = await self.vector_store.query.remote(\n",
+ " query_embedding=encoded_query,\n",
+ " top_k=top_k,\n",
+ " )\n",
+ " contexts = [chunk[\"text\"] for chunk in vector_store_response[\"documents\"]]\n",
+ " sources = [chunk[\"section_url\"] for chunk in vector_store_response[\"documents\"]]\n",
+ " return {\n",
+ " \"contexts\": contexts,\n",
+ " \"composed_context\": self._compose_context(contexts),\n",
+ " \"sources\": sources,\n",
+ " }\n",
+ "\n",
+ "\n",
+ "retriever = Retriever.bind(query_encoder=query_encoder, vector_store=vector_store)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f916b83c",
+ "metadata": {},
+ "source": [
+ "We run the retriever to check it is working as expected"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a4496e4b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "retriever_handle = serve.run(retriever, route_prefix=\"/retriever\")\n",
+ "retrieval_response = await retriever_handle.retrieve.remote(\n",
+ " query=query,\n",
+ " top_k=3,\n",
+ ")\n",
+ "retrieval_response"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ed7c0228",
+ "metadata": {},
+ "source": [
+ "We inspect the retrieved context"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8664a00a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(retrieval_response[\"composed_context\"])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f28bd2bf",
+ "metadata": {},
+ "source": [
+ "## 2. Building Response Generation\n",
+ "\n",
+ "Next we will wrap the LLM client as its own deployment. Here we showcase that we can also make use of fractional CPUs for this client deployment. \n",
+ "\n",
+ "Note: Separating the client as its own deployment is optional and could have been included in the QA engine deployment."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0c7dfe52",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@serve.deployment(\n",
+ " ray_actor_options={\"num_cpus\": 0.1},\n",
+ ")\n",
+ "class LLMClient:\n",
+ " def __init__(self):\n",
+ " # Initialize a client to perform API requests\n",
+ " self.client = openai.OpenAI(\n",
+ " base_url=ANYSCALE_SERVICE_BASE_URL,\n",
+ " api_key=ANYSCALE_API_KEY,\n",
+ " )\n",
+ "\n",
+ " def generate(\n",
+ " self,\n",
+ " user_prompt: str,\n",
+ " model=\"mistralai/Mistral-7B-Instruct-v0.1\",\n",
+ " temperature: float = 0,\n",
+ " **kwargs: Any,\n",
+ " ) -> ChatCompletion:\n",
+ " \"\"\"Generate a completion from the given user prompt.\"\"\"\n",
+ " # Call the chat completions endpoint\n",
+ " chat_completion = self.client.chat.completions.create(\n",
+ " model=model,\n",
+ " messages=[\n",
+ " # Prime the system with a system message - a common best practice\n",
+ " {\"role\": \"system\", \"content\": \"You are a helpful assistant.\"},\n",
+ " # Send the user message with the proper \"user\" role and \"content\"\n",
+ " {\"role\": \"user\", \"content\": user_prompt},\n",
+ " ],\n",
+ " temperature=temperature,\n",
+ " **kwargs,\n",
+ " )\n",
+ "\n",
+ " return chat_completion\n",
+ "\n",
+ "\n",
+ "llm_client = LLMClient.bind()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "36142cb0",
+ "metadata": {},
+ "source": [
+ "Note we are currently making use of an already deployed open-source LLM running on Anyscale.\n",
+ "\n",
+ "In case you want to deploy your own LLM, you can follow this [ready-built Anyscale Deploy LLMs template](https://console.anyscale.com/v2/template-preview/endpoints_v2)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b22be87b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "llm_client_handle = serve.run(llm_client, route_prefix=\"/llm\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "adde280d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "llm_response = await llm_client_handle.generate.remote( \n",
+ " user_prompt=\"What is the capital of France?\",\n",
+ ")\n",
+ "llm_response.choices[0].message.content"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fcab6183",
+ "metadata": {},
+ "source": [
+ "### Putting it all together\n",
+ "Given a user query we will want our RAG based QA engine to perform the following steps:\n",
+ "\n",
+ "1. Retrieve the closest documents to the query\n",
+ "2. Augment the query with the context\n",
+ "3. Generate a response to the augmented query"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "34304b2f",
+ "metadata": {},
+ "source": [
+ "We decide on a simple prompt template to augment the user's query with the retrieved context. The template is as follows:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "95d24422",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "prompt_template_rag = \"\"\"\n",
+ "Given the following context:\n",
+ "{composed_context}\n",
+ "\n",
+ "Answer the following question:\n",
+ "{query}\n",
+ "\n",
+ "If you cannot provide an answer based on the context, please say \"I don't know.\"\n",
+ "Do not use the term \"context\" in your response.\"\"\"\n",
+ "\n",
+ "\n",
+ "def augment_prompt(query: str, composed_context: str) -> str:\n",
+ " \"\"\"Augment the prompt with the given query and contexts.\"\"\"\n",
+ " return prompt_template_rag.format(composed_context=composed_context, query=query)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b2e67b56",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "augmented_prompt = augment_prompt(\n",
+ " \"How can I deploy Ray Serve to Kubernetes?\",\n",
+ " retrieval_response[\"composed_context\"],\n",
+ ")\n",
+ "print(augmented_prompt)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "78e56f6a",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "**Considerations for building a prompt-template for RAG:**\n",
+ "\n",
+ "Prompt engineering techniques can be used need to be purpose built for the usecase and chosen model. For example, if you want the model to still use its own knowledge in certain cases, you might want to use a different prompt template than if you want the model to only use the retrieved context.\n",
+ "\n",
+ "For comparison, here are the links to popular third-party library prompt templates which are fairly generic in nature:\n",
+ "- [LangChain's default RAG prompt template](https://smith.langchain.com/hub/rlm/rag-prompt)\n",
+ "- [LlamaIndex's RAG prompt template](https://github.com/run-llama/llama_index/blob/main/llama-index-core/llama_index/core/prompts/default_prompts.py#L99)\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b0058b28",
+ "metadata": {},
+ "source": [
+ "We follow a similar pattern and wrap the `QA` engine with a `serve.deployment` decorator. We update all calls to the retriever and generator to use the respective `remote` calls."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "63931704",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@serve.deployment(autoscaling_config=dict(min_replicas=1, max_replicas=3))\n",
+ "class QA:\n",
+ " def __init__(self, retriever, llm_client):\n",
+ " self.retriever = retriever\n",
+ " self.llm_client = llm_client\n",
+ "\n",
+ " async def answer(\n",
+ " self,\n",
+ " query: str,\n",
+ " top_k: int,\n",
+ " include_sources: bool = True,\n",
+ " ):\n",
+ " \"\"\"Answer the given question and provide sources.\"\"\"\n",
+ " retrieval_response = await self.retriever.retrieve.remote(\n",
+ " query=query,\n",
+ " top_k=top_k,\n",
+ " )\n",
+ " prompt = augment_prompt(query, retrieval_response[\"composed_context\"])\n",
+ " llm_response = await self.llm_client.generate.remote(user_prompt=prompt)\n",
+ " response = llm_response.choices[0].message.content\n",
+ "\n",
+ " if include_sources:\n",
+ " response += \"\\n\" * 2\n",
+ " sources_str = \"\\n\".join(set(retrieval_response[\"sources\"]))\n",
+ " response += sources_str\n",
+ " response += \"\\n\"\n",
+ "\n",
+ " return response\n",
+ "\n",
+ "\n",
+ "qa_engine = QA.bind(\n",
+ " retriever=retriever,\n",
+ " llm_client=llm_client,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "23af113f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "qa_handle = serve.run(qa_engine)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "154f06dc",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "qa_response = await qa_handle.answer.remote(\n",
+ " query=\"How can I deploy Ray Serve to Kubernetes?\",\n",
+ " top_k=3,\n",
+ " include_sources=True,\n",
+ ")\n",
+ "print(qa_response)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e68aae16",
+ "metadata": {},
+ "source": [
+ "## Key Takeaways\n",
+ "\n",
+ "With Ray and Anyscale, we can easily deploy complex applications with multiple components.\n",
+ "\n",
+ "Ray Serve is:\n",
+ "* **Flexible:** unlike other ML based serving platforms, Ray Serve is general purpose and allows for implementing complex logic which is almost always the case for production settings where multiple models need to be composed.\n",
+ "* **Lightweight:** Much simpler than a micro-services set up where each service has to be containerized - doesn't require additional tooling enabling a simple python native approach to deploying apps\n",
+ "* Offers **intuitive autoscaling** configuration instead of using proxies like CPU and network utilization.\n",
+ "* Enables **fractional resource allocation**: allows for efficient resource utilization by allowing for fractional resource allocation to each replica.\n",
+ "\n",
+ "The Anyscale Platform allows us to deploy Ray serve applications with ease. It offers:\n",
+ "* **Canary deployments**: to test new versions of the model\n",
+ "* **Versioned Rollouts/Rollbacks** to manage deployments\n",
+ "* **Replica compaction**: to reduce the number of replicas in a deployment\n",
+ "\n",
+ "To learn how to deploy an anyscale service, you can refer to the [Anyscale Services documentation](https://docs.anyscale.com/platform/services/)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1c287c8e",
+ "metadata": {},
+ "source": [
+ "## Bonus: Adding HTTP Ingress\n",
+ "\n",
+ "FastAPI is a modern web framework for building APIs.\n",
+ "\n",
+ "Ray Serve offers an integration with FastAPI to easily expose Ray Serve deployments as HTTP endpoints and get benefits like request validation, OpenAPI documentation, and more."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "11bee09d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "app = FastAPI()\n",
+ "\n",
+ "@serve.deployment(autoscaling_config=dict(min_replicas=1, max_replicas=3))\n",
+ "@serve.ingress(app)\n",
+ "class QAGateway:\n",
+ " def __init__(self, qa_engine):\n",
+ " self.qa_engine = qa_engine\n",
+ "\n",
+ " @app.get(\"/answer\")\n",
+ " async def answer(\n",
+ " self,\n",
+ " query: str,\n",
+ " top_k: int = 3,\n",
+ " include_sources: bool = True,\n",
+ " ):\n",
+ " return await self.qa_engine.answer.remote(\n",
+ " query=query,\n",
+ " top_k=top_k,\n",
+ " include_sources=include_sources,\n",
+ " )\n",
+ "\n",
+ "gateway = QAGateway.bind(qa_engine=qa_engine)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0befdcf6",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "gateway_handle = serve.run(gateway)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5f525e6f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "params = dict(\n",
+ " query=\"How can I deploy Ray Serve to Kubernetes?\",\n",
+ " top_k=3,\n",
+ ")\n",
+ "\n",
+ "response = requests.get(\"http://localhost:8000/answer\", params=params)\n",
+ "print(response.json())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7167a477",
+ "metadata": {},
+ "source": [
+ "## Bonus: Streaming Responses\n",
+ "\n",
+ "Assuming we want to stream directly from our client, we can use the `StreamingResponse` from FastAPI to stream the response as it is generated.\n",
+ "\n",
+ "We first simplify to only deploy the LLM client and then stream the response."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3a49cc3d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "app = FastAPI()\n",
+ "\n",
+ "@serve.deployment(\n",
+ " ray_actor_options={\"num_cpus\": 0.1},\n",
+ ")\n",
+ "@serve.ingress(app)\n",
+ "class LLMClient:\n",
+ " def __init__(self):\n",
+ " # Initialize a client to perform API requests\n",
+ " self.client = openai.OpenAI(\n",
+ " base_url=ANYSCALE_SERVICE_BASE_URL,\n",
+ " api_key=ANYSCALE_API_KEY,\n",
+ " )\n",
+ " \n",
+ " @app.get(\"/generate\")\n",
+ " async def generate(\n",
+ " self,\n",
+ " user_prompt: str,\n",
+ " model: str = \"mistralai/Mistral-7B-Instruct-v0.1\",\n",
+ " temperature: float = 0,\n",
+ " ) -> ChatCompletion:\n",
+ " \"\"\"Generate a completion from the given user prompt.\"\"\"\n",
+ " return StreamingResponse(\n",
+ " self._generate(\n",
+ " user_prompt=user_prompt, model=model, temperature=temperature\n",
+ " ),\n",
+ " media_type=\"text/event-stream\",\n",
+ " )\n",
+ "\n",
+ " def _generate(\n",
+ " self,\n",
+ " user_prompt: str,\n",
+ " model: str,\n",
+ " temperature: float,\n",
+ " **kwargs: Any,\n",
+ " ) -> Iterator[str]:\n",
+ " \"\"\"Generate a completion from the given user prompt.\"\"\"\n",
+ " # Call the chat completions endpoint\n",
+ " response = self.client.chat.completions.create(\n",
+ " model=model,\n",
+ " messages=[\n",
+ " # Prime the system with a system message - a common best practice\n",
+ " {\"role\": \"system\", \"content\": \"You are a helpful assistant.\"},\n",
+ " # Send the user message with the proper \"user\" role and \"content\"\n",
+ " {\"role\": \"user\", \"content\": user_prompt},\n",
+ " ],\n",
+ " temperature=temperature,\n",
+ " stream=True,\n",
+ " **kwargs,\n",
+ " )\n",
+ "\n",
+ " for chunk in response:\n",
+ " choice = chunk.choices[0]\n",
+ " if choice.delta.content is None:\n",
+ " continue\n",
+ " yield choice.delta.content\n",
+ "\n",
+ "llm_client = LLMClient.bind()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4c899089",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "llm_client_handle = serve.run(llm_client, name=\"streaming-llm\", route_prefix=\"/stream\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b131e056",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "params = dict(\n",
+ " user_prompt=\"What is the capital of France?\",\n",
+ ")\n",
+ "\n",
+ "response = requests.get(\"http://localhost:8000/stream/generate\", stream=True, params=params)\n",
+ "for chunk in response.iter_content(chunk_size=None, decode_unicode=True):\n",
+ " print(chunk, end=\"\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0a9e787d",
+ "metadata": {},
+ "source": [
+ "Next, we update the QA deployment to use the streaming LLM client.\n",
+ "\n",
+ "We start out by re-defining the `LLMClient`, this time just stripping the ingress decorator."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a3e56cd0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@serve.deployment(\n",
+ " ray_actor_options={\"num_cpus\": 0.1},\n",
+ ")\n",
+ "class LLMClient:\n",
+ " def __init__(self):\n",
+ " # Initialize a client to perform API requests\n",
+ " self.client = openai.OpenAI(\n",
+ " base_url=ANYSCALE_SERVICE_BASE_URL,\n",
+ " api_key=ANYSCALE_API_KEY,\n",
+ " )\n",
+ " \n",
+ " async def generate(\n",
+ " self,\n",
+ " user_prompt: str,\n",
+ " model: str = \"mistralai/Mistral-7B-Instruct-v0.1\",\n",
+ " temperature: float = 0,\n",
+ " ) -> Iterator[str]:\n",
+ " \"\"\"Generate a completion from the given user prompt.\"\"\"\n",
+ " # Call the chat completions endpoint\n",
+ " response = self.client.chat.completions.create(\n",
+ " model=model,\n",
+ " messages=[\n",
+ " # Prime the system with a system message - a common best practice\n",
+ " {\"role\": \"system\", \"content\": \"You are a helpful assistant.\"},\n",
+ " # Send the user message with the proper \"user\" role and \"content\"\n",
+ " {\"role\": \"user\", \"content\": user_prompt},\n",
+ " ],\n",
+ " temperature=temperature,\n",
+ " stream=True,\n",
+ " )\n",
+ "\n",
+ " for chunk in response:\n",
+ " choice = chunk.choices[0]\n",
+ " if choice.delta.content is None:\n",
+ " continue\n",
+ " yield choice.delta.content\n",
+ "\n",
+ "llm_client = LLMClient.bind()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "63a52743",
+ "metadata": {},
+ "source": [
+ "Next, we'll update the QA deployment to use the streaming LLM client."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d81e863d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@serve.deployment(autoscaling_config=dict(min_replicas=1, max_replicas=3))\n",
+ "@serve.ingress(app)\n",
+ "class QA:\n",
+ " def __init__(self, retriever, llm_client):\n",
+ " self.retriever = retriever\n",
+ " # Enable streaming on the deployment handle\n",
+ " self.llm_client = llm_client.options(stream=True)\n",
+ "\n",
+ " @app.get(\"/answer\")\n",
+ " async def answer(\n",
+ " self,\n",
+ " query: str,\n",
+ " top_k: int,\n",
+ " include_sources: bool = True,\n",
+ " ):\n",
+ " return StreamingResponse(\n",
+ " self._answer(\n",
+ " query=query,\n",
+ " top_k=top_k,\n",
+ " include_sources=include_sources,\n",
+ " ),\n",
+ " media_type=\"text/event-stream\",\n",
+ " )\n",
+ "\n",
+ " async def _answer(\n",
+ " self,\n",
+ " query: str,\n",
+ " top_k: int,\n",
+ " include_sources: bool = True,\n",
+ " ) -> Iterator[str]:\n",
+ " \"\"\"Answer the given question and provide sources.\"\"\"\n",
+ " retrieval_response = await self.retriever.retrieve.remote(\n",
+ " query=query,\n",
+ " top_k=top_k,\n",
+ " )\n",
+ " prompt = augment_prompt(query, retrieval_response[\"composed_context\"])\n",
+ "\n",
+ " # async for instead of await\n",
+ " async for chunk in self.llm_client.generate.remote(user_prompt=prompt):\n",
+ " yield chunk\n",
+ "\n",
+ " if include_sources:\n",
+ " yield \"\\n\" * 2\n",
+ " sources_str = \"\\n\".join(set(retrieval_response[\"sources\"]))\n",
+ " yield sources_str\n",
+ " yield \"\\n\"\n",
+ "\n",
+ "\n",
+ "qa_client = QA.bind(retriever=retriever, llm_client=llm_client)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5a7f8cbd",
+ "metadata": {},
+ "source": [
+ "Note, we left out the gateway to reduce the complexity of the example."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "12cfa908",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# we shutdown the existing QA deployment\n",
+ "serve.shutdown()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8962f26d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "qa_client_handle = serve.run(qa_client, name=\"streaming-qa\", route_prefix=\"/\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1fe0986a",
+ "metadata": {},
+ "source": [
+ "Let's request the streaming QA service in streaming mode:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "92e70e76",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "params = dict(\n",
+ " query=query,\n",
+ " top_k=3,\n",
+ ")\n",
+ "\n",
+ "response = requests.get(\n",
+ " \"http://localhost:8000/answer\", stream=True, params=params\n",
+ ")\n",
+ "for chunk in response.iter_content(chunk_size=None, decode_unicode=True):\n",
+ " print(chunk, end=\"\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4b662661",
+ "metadata": {},
+ "source": [
+ "## Cleanup\n",
+ "\n",
+ "We shutdown the existing QA deployment"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "fe984d27",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "serve.shutdown()"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/templates/ray-summit-rag/README.md b/templates/ray-summit-rag/README.md
new file mode 100644
index 000000000..37fc150fe
--- /dev/null
+++ b/templates/ray-summit-rag/README.md
@@ -0,0 +1,16 @@
+# RAG Applications - From Quickstart to Scalable RAG
+
+Retrieval-Augmented Generation (RAG) is transforming how AI systems interact with data, offering a powerful approach to enhance information retrieval and generation. This workshop is designed for AI practitioners who want to build and deploy RAG-powered applications from the ground up, leveraging Ray's capabilities for scalability and efficiency.
+
+You'll be guided through the entire lifecycle of a RAG system, starting with constructing and encoding a knowledge base using Ray Data. From there, you'll learn to deploy retrieval and generation endpoints with Ray Serve, ensuring your application can handle real-world queries effectively.
+
+By the end of this training, you will have a comprehensive understanding of the RAG application lifecycle and the skills to design, and deploy RAG systems. Join us to enhance your AI toolkit and master the art of creating scalable, high-quality RAG applications with Ray.
+
+## Prerequisites:
+This is beginner friendly training, you will learn about RAG from first principles. However, you are expected to have:
+- Basic understanding of LLMs-enabled use cases.
+- Intermediate-level experience with Python.
+
+## Ray Libraries:
+- Ray Data
+- Ray Serve
\ No newline at end of file
diff --git a/templates/ray-summit-rag/data/small_sample/sample-input.jsonl b/templates/ray-summit-rag/data/small_sample/sample-input.jsonl
new file mode 100644
index 000000000..7954921d3
--- /dev/null
+++ b/templates/ray-summit-rag/data/small_sample/sample-input.jsonl
@@ -0,0 +1,4 @@
+{"text":"\n\n\nConfiguring Environments#\n\n\nYou can pass either a string name or a Python class to specify an environment. By default, strings will be interpreted as a gym environment name.\nCustom env classes passed directly to the algorithm must take a single env_config parameter in their constructor:\n\n\nimport gymnasium as gym\nimport ray\nfrom ray.rllib.algorithms import ppo\n\nclass MyEnv(gym.Env):\n def __init__(self, env_config):\n self.action_space = \n",
+ " Here is the roadmap for this notebook:\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Imports"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "import uuid\n",
+ "import json\n",
+ "from typing import Any\n",
+ "\n",
+ "import matplotlib.pyplot as plt\n",
+ "import numpy as np\n",
+ "import ray\n",
+ "import torch\n",
+ "from art import text2art\n",
+ "from diffusers import DiffusionPipeline"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## A simple data pipeline\n",
+ "\n",
+ "Let's begin with a very simple data pipeline which converts text into ASCII art. \n",
+ "\n",
+ "We start with a simple dataset of items:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "items = [\n",
+ " \"Astronaut\", \"Cat\"\n",
+ "]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can then apply a transformation to each item in the dataset to convert the text into ASCII art:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def artify(item: str) -> str:\n",
+ " return text2art(item)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We will sequentially apply the `artify` function to each item in the dataset:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "data = []\n",
+ "for item in items:\n",
+ " data.append({\"prompt\": item, \"art\": artify(item)})"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can now inspect the results:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "data[0][\"prompt\"]"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(data[0][\"art\"])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Finally, we can write the data to a JSON file:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "with open(\"ascii_art.json\", \"w\") as f:\n",
+ " json.dump(data, f)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 2. Introduction to Ray Data\n",
+ "\n",
+ "\n",
+ "Ray Data is a scalable data processing library for ML workloads, particularly suited for the following workloads:\n",
+ "\n",
+ "\n",
+ "\n",
+ "Ray Data is particularly useful for streaming data on a heterogenous cluster:\n",
+ "\n",
+ "- \n",
+ "
- Part 1: A simple data pipeline \n", + "
- Part 2: Introduction to Ray Data \n", + "
- Part 3: Batch Inference with Stable Diffusion \n", + "
- Part 4: Stable Diffusion under the hood \n", + "
\n",
+ "\n",
+ "Your production pipeline for generating images from text could require:\n",
+ "1. Loading a large number of text prompts\n",
+ "2. Generating images using large scale diffusion models\n",
+ "3. Inferencing against guardrail models to remove low-quality and NSFW images\n",
+ "\n",
+ "You will want to make the most efficient use of your cluster to process this data. Ray Data can help you do this."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Ray Data's API\n",
+ "\n",
+ "Here are the steps to make use of Ray Data:\n",
+ "1. Create a Ray Dataset usually by pointing to a data source.\n",
+ "2. Apply transformations to the Ray Dataset.\n",
+ "3. Write out the results to a data source.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Loading Data\n",
+ "\n",
+ "Ray Data has a number of [IO connectors](https://docs.ray.io/en/latest/data/api/input_output.html) to most commonly used formats.\n",
+ "\n",
+ "For purposes of this introduction, we will use the `from_items` function to create a dataset from a list of items."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds_items = ray.data.from_items(items)\n",
+ "ds_items"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Transforming Data\n",
+ "\n",
+ "Datasets can be transformed by applying a row-wise `map` operation. We do this by providing a user-defined function that takes a row as input and returns a row as output."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def artify_row(row: dict[str, Any]) -> dict[str, Any]:\n",
+ " row[\"art\"] = text2art(row[\"item\"])\n",
+ " return row\n",
+ "\n",
+ "ds_items_artified = ds_items.map(artify_row)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Lazy execution\n",
+ "\n",
+ "By default, `map` is lazy, meaning that it will not actually execute the function until you consume it. This allows for optimizations like pipelining and fusing of operations.\n",
+ "\n",
+ "To inspect a few rows of the dataset, you can use the `take` method:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sample = ds_items_artified.take(2)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's inspect the sample:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(sample[0][\"item\"])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(sample[0][\"art\"])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Writing Data\n",
+ "\n",
+ "We can then write out the data to disk using the avialable [IO connector methods](https://docs.ray.io/en/latest/data/api/input_output.html).\n",
+ "\n",
+ "Here we will write the data to a JSON file to a shared storage location."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds_items_artified.write_json(\"/mnt/cluster_storage/ascii_art\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can now inspect the written files:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!ls /mnt/cluster_storage/ascii_art"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Recap of our Ray Data pipeline\n",
+ "\n",
+ "Here is our Ray data pipeline condensed into the following chained operations:\n",
+ "\n",
+ "```python\n",
+ "(\n",
+ " ray.data.from_items(items)\n",
+ " .map(artify_row)\n",
+ " .write_json(\"/mnt/cluster_storage/ascii_art\")\n",
+ ")\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Batch Inference with Stable Diffusion\n",
+ "\n",
+ "Now that we have a simple data pipeline, let's use Stable Diffusion to generate actual images from text.\n",
+ "\n",
+ "This will follow a very similar pattern. Let's say we are starting out with the following prompts:\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "prompts = [\n",
+ " \"An astronaut on a horse\",\n",
+ " \"A cat with a jetpack\",\n",
+ "] * 12"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We create a Ray Dataset from the prompts"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds_prompts = ray.data.from_items(prompts)\n",
+ "ds_prompts"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We now apply want to apply a DiffusionPipeline to the dataset. \n",
+ "\n",
+ "We first define a function that creates and applies the pipeline to a single row."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def apply_stable_diffusion(row: dict[str, Any]) -> dict[str, Any]:\n",
+ " # Create the stable diffusion pipeline\n",
+ " pipe = DiffusionPipeline.from_pretrained(\n",
+ " pretrained_model_name_or_path=\"stabilityai/stable-diffusion-2\",\n",
+ " torch_dtype=torch.float16,\n",
+ " use_safetensors=True,\n",
+ " variant=\"fp16\",\n",
+ " ).to(\"cuda\")\n",
+ " prompt = row[\"item\"]\n",
+ " # Apply the pipeline to the prompt\n",
+ " output = pipe(prompt, height=512, width=512)\n",
+ " # Extract the image from the output and construct the row\n",
+ " return {\"item\": prompt, \"image\": output.images[0]}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can now apply the function to each row in the dataset using the `map` method."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds_images_generated_mapping_by_row = ds_prompts.map(\n",
+ " apply_stable_diffusion,\n",
+ " num_gpus=1, # specify the number of GPUs per task\n",
+ ") "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Instead of parallelizing the inference per row, we can parallelize the inference per batch.\n",
+ "\n",
+ "Mapping over batches instead of rows is useful when we can benefit from vectorized operations on the batch level. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def apply_stable_diffusion_batch(batch: dict[str, np.ndarray]) -> dict[str, np.ndarray]:\n",
+ " pipe = DiffusionPipeline.from_pretrained(\n",
+ " pretrained_model_name_or_path=\"stabilityai/stable-diffusion-2\",\n",
+ " torch_dtype=torch.float16,\n",
+ " use_safetensors=True,\n",
+ " variant=\"fp16\",\n",
+ " ).to(\"cuda\")\n",
+ " # Extract the prompts from the batch\n",
+ " prompts = batch[\"item\"].tolist()\n",
+ " # Apply the pipeline to the prompts\n",
+ " outputs = pipe(prompts, height=512, width=512)\n",
+ " # Extract the images from the outputs and construct the batch\n",
+ " return {\"item\": prompts, \"image\": outputs.images}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We now apply the function to each batch in the dataset using the `map_batches` method."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds_images_generated_mapping_by_batch = ds_prompts.map_batches(\n",
+ " apply_stable_diffusion_batch,\n",
+ " batch_size=24, # specify the batch size per task to maximize GPU utilization\n",
+ " num_gpus=1, \n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "The current implementation requires us to load the pipeline for each batch we process.\n",
+ "\n",
+ "We can avoid reloading the pipeline for each batch by creating a stateful transformation, implemented as a callable class where:\n",
+ "- `__init__`: initializes worker processes that will load the pipeline once and reuse it for transforming each batch.\n",
+ "- `__call__`: applies the pipeline to the batch and returns the transformed batch."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class StableDiffusion:\n",
+ " def __init__(self, model_id: str = \"stabilityai/stable-diffusion-2\") -> None:\n",
+ " self.pipe = DiffusionPipeline.from_pretrained(\n",
+ " model_id, torch_dtype=torch.float16, use_safetensors=True, variant=\"fp16\"\n",
+ " ).to(\"cuda\")\n",
+ "\n",
+ " def __call__(\n",
+ " self, batch: dict[str, np.ndarray], img_size: int = 512\n",
+ " ) -> dict[str, np.ndarray]:\n",
+ " prompts = batch[\"item\"].tolist()\n",
+ " batch[\"image\"] = self.pipe(prompts, height=img_size, width=img_size).images\n",
+ " return batch"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can now apply the class to each batch in the dataset using the same `map_batches` method."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds_images_generated_by_stateful_transform = ds_prompts.map_batches(\n",
+ " StableDiffusion,\n",
+ " batch_size=24,\n",
+ " num_gpus=1, \n",
+ " concurrency=1, # number of workers to launch\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "### Activity: Visualize the generated images\n",
+ "\n",
+ "Lets fetch a batch of the generated images to the driver and visualize them.\n",
+ "\n",
+ "Use the `plot_images` function to visualize the images.\n",
+ "\n",
+ "```python\n",
+ "def plot_images(batch: dict[str, np.ndarray]) -> None:\n",
+ " for item, image in zip(batch[\"item\"], batch[\"image\"]):\n",
+ " plt.imshow(image)\n",
+ " plt.title(item)\n",
+ " plt.axis(\"off\")\n",
+ " plt.show()\n",
+ "\n",
+ "# Hint: Implement the code below to fetch a batch from \n",
+ "# ds_images_generated_by_stateful_transform\n",
+ "batch = ...\n",
+ "plot_images(batch)\n",
+ "```\n",
+ "\n",
+ "
\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Write your solution here\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "
\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Reading/Writing to a Data Lake\n",
+ "\n",
+ "In a production setting, you will be building a Ray Dataset lazily by reading from a data source like a Data Lake (S3, GCS, HDFS, etc). \n",
+ "\n",
+ "To do so, let's make use of the artifact path that Anyscale provides."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "uuid_str = str(uuid.uuid4())\n",
+ "artifact_path = f\"/mnt/cluster_storage/stable-diffusion/{uuid_str}\"\n",
+ "artifact_path"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We start out by writing the prompts to a JSON directory:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds_prompts.write_json(artifact_path + \"/prompts\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can inspect the written files:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!ls {artifact_path}/prompts/ --human-readable "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Now here is how the pipeline would look like if we want to read the prompts from S3, generate images and store the images back to S3:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "(\n",
+ " ray.data.read_json(artifact_path + \"/prompts\")\n",
+ " .map_batches(StableDiffusion, batch_size=24, num_gpus=1, concurrency=1)\n",
+ " .write_parquet(artifact_path + \"/images\")\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "
Click to expand/collapse
\n", + "\n", + "```python\n", + "def plot_images(batch: dict[str, np.ndarray]) -> None:\n", + " for item, image in zip(batch[\"item\"], batch[\"image\"]):\n", + " plt.imshow(image)\n", + " plt.title(item)\n", + " plt.axis(\"off\")\n", + " plt.show()\n", + "\n", + "size = 12\n", + "batch = ds_images_generated.take_batch(batch_size=size)\n", + "plot_images(batch)\n", + "```\n", + "\n", + "\n",
+ "\n",
+ "Note how there is no need to explicitly materialize the dataset, instead the data will get streamed through the pipeline and written to the specified location. \n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!ls {artifact_path}/images/ --human-readable"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Stable Diffusion pipeline components\n",
+ "\n",
+ "Let's take a quick look at the components of the Stable Diffusion pipeline.\n",
+ "\n",
+ "First we load the pipeline on our local workspace node:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "model_id = \"stabilityai/stable-diffusion-2\"\n",
+ "pipeline = DiffusionPipeline.from_pretrained(\n",
+ " model_id, torch_dtype=torch.float16, use_safetensors=True, variant=\"fp16\"\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Inspecting the text tokenizer and encoder shows how the text will be preprocessed:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "type(pipeline.tokenizer), type(pipeline.text_encoder)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Inspecting the feature extractor and VAE shows how the images will be preprocessed:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "type(pipeline.feature_extractor), type(pipeline.vae)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Here is our main model that predicts the noise level"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "type(pipeline.unet)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "While the U-net will be used to predict which part of the image is noise, a scheduler needs to be used to sample the noise level.\n",
+ "\n",
+ "By default, diffusers will use the following scheduler, but other schedulers can be used as well."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "type(pipeline.scheduler)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Here is the inference data flow of the Stable Diffusion model simplified for generating an image of \"A person half Yoda and half Gandalf\":\n",
+ "\n",
+ "\n",
+ " \n",
+ " Here is the roadmap for this notebook:\n",
+ "
\n",
+ "\n",
+ "Note you don't need to understand the architecture specifics of each component to build the pre-training pipeline. "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 1. Pre-training of a Stable Diffusion V2 Model\n",
+ "\n",
+ "Below is a diagram of the data flow in the pre-training of the Stable Diffusion V2 model. \n",
+ "\n",
+ "- \n",
+ "
- Part 1: Pre-training of a Stable Diffusion Model \n", + "
- Part 2: Data pre-processing in more detail \n", + "
- Part 3: Compute requirements for pre-processing and training \n", + "
\n",
+ " \n",
+ "\n",
+ "The U-Net model improves at predicting and removing noise from images using text descriptions. This iterative process, involving noise prediction and subtraction, ultimately yields an image matching the text input.\n",
+ "\n",
+ "Below is the reverse diffusion process visualized, which generates the final image:\n",
+ "\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 2. Data pre-processing in more detail\n",
+ "\n",
+ "### Encoding the input images and text prompts\n",
+ "\n",
+ "Below is a diagram showing the how the VAE encodes/decodes the input images.\n",
+ "\n",
+ "\n",
+ " \n",
+ " \n",
+ "\n"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "base",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "name": "python",
+ "version": "3.11.9"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 2
+}
diff --git a/templates/ray-summit-stable-diffusion/03_Preprocessing.ipynb b/templates/ray-summit-stable-diffusion/03_Preprocessing.ipynb
new file mode 100644
index 000000000..5897634a6
--- /dev/null
+++ b/templates/ray-summit-stable-diffusion/03_Preprocessing.ipynb
@@ -0,0 +1,812 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "beda561e",
+ "metadata": {},
+ "source": [
+ "# Pre-processing for Stable Diffusion V2\n",
+ "\n",
+ "Let's build a scalable preprocessing pipeline for the Stable Diffusion V2 model.\n",
+ "\n",
+ "\n",
+ " Here is the roadmap for this notebook:\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "583b9839",
+ "metadata": {},
+ "source": [
+ "## Imports"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b2459683",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "import gc\n",
+ "import uuid\n",
+ "import io\n",
+ "import logging\n",
+ "from typing import Optional, Any\n",
+ "\n",
+ "import matplotlib.pyplot as plt\n",
+ "import numpy as np\n",
+ "import pyarrow as pa # type: ignore\n",
+ "import ray.data\n",
+ "import torch\n",
+ "import torchvision # type: ignore\n",
+ "from diffusers.models import AutoencoderKL\n",
+ "from PIL import Image\n",
+ "from transformers import CLIPTextModel, CLIPTokenizer # type: ignore"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ec837f75-fefd-42c5-b614-e435f8de7432",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "# 0. High-level overview of the preprocessing pipeline\n",
+ "\n",
+ "Here is a high-level overview of the preprocessing pipeline:\n",
+ "\n",
+ "- \n",
+ "
- Part 0: High-level overview of the preprocessing pipeline \n", + "
- Part 1: Reading in the data \n", + "
- Part 2: Transforming images and captions \n", + "
- Part 3: Encoding of images and captions \n", + "
- Part 4: Writing out the preprocessed data \n", + "
\n",
+ "\n",
+ "Ray Data loads the data from a remote storage system, then streams the data through two processing main stages:\n",
+ "1. **Transformation**\n",
+ " 1. Cropping and normalizing images.\n",
+ " 2. Tokenizing the text captions using a CLIP tokenizer.\n",
+ "2. **Encoding**\n",
+ " 1. Compressing images into a latent space using a VAE encoder.\n",
+ " 2. Generating text embeddings using a CLIP model.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2a2e8517-65f9-4c41-9144-57df326f6c02",
+ "metadata": {},
+ "source": [
+ "### 1. Reading in the data\n",
+ "\n",
+ "We're going to preprocess part of the LAION-art-8M dataset. To save time, we have provided a sample of the dataset on S3.\n",
+ "\n",
+ "We'll read this sample data and create a Ray dataset from it."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "fb3c85d9-1e00-492d-b119-fca467a42f8c",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "schema = pa.schema(\n",
+ " [\n",
+ " pa.field(\"caption\", getattr(pa, \"string\")()),\n",
+ " pa.field(\"height\", getattr(pa, \"float64\")()),\n",
+ " pa.field(\"width\", getattr(pa, \"float64\")()),\n",
+ " pa.field(\"jpg\", getattr(pa, \"binary\")()),\n",
+ " ]\n",
+ ")\n",
+ "\n",
+ "ds = ray.data.read_parquet(\n",
+ " \"s3://anyscale-public-materials/ray-summit/stable-diffusion/data/raw/\",\n",
+ " schema=schema,\n",
+ ")\n",
+ "\n",
+ "ds"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5fa9aad4-f273-4e8c-9fcf-8346fbff09a8",
+ "metadata": {},
+ "source": [
+ "We know that when we run that step, we're not actually processing the whole dataset -- that's the whole idea behind lazy execution of the data pipeline.\n",
+ "\n",
+ "But Ray does sample the data to determine metadata like the number of files and data schema."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "101b2899-13ae-4063-8dab-fb9e47b51e5c",
+ "metadata": {},
+ "source": [
+ "### 2. Transforming images and captions\n",
+ "\n",
+ "#### 2.1 Cropping and normalizing images\n",
+ "We start by preprocessing the images: \n",
+ "\n",
+ "We need to perform these two operations on the images:\n",
+ "1. Crop the images to a square aspect ratio.\n",
+ "2. Normalize the pixel values to the distribution expected by the VAE encoder.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3d2c77f4",
+ "metadata": {},
+ "source": [
+ "#### Step 1. Cropping the image"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d5d56d06-0546-4e40-9107-bb683e43fe95",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "class LargestCenterSquare:\n",
+ " \"\"\"Largest center square crop for images.\"\"\"\n",
+ "\n",
+ " def __init__(self, size: int) -> None:\n",
+ " self.size = size\n",
+ "\n",
+ " def __call__(self, img: Image.Image) -> Image.Image:\n",
+ " \"\"\"Crop the largest center square from an image.\"\"\"\n",
+ " # First, resize the image such that the smallest\n",
+ " # side is self.size while preserving aspect ratio.\n",
+ " img = torchvision.transforms.functional.resize(\n",
+ " img=img,\n",
+ " size=self.size,\n",
+ " )\n",
+ "\n",
+ " # Then take a center crop to a square.\n",
+ " w, h = img.size\n",
+ " c_top = (h - self.size) // 2\n",
+ " c_left = (w - self.size) // 2\n",
+ " img = torchvision.transforms.functional.crop(\n",
+ " img=img,\n",
+ " top=c_top,\n",
+ " left=c_left,\n",
+ " height=self.size,\n",
+ " width=self.size,\n",
+ " )\n",
+ " return img"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "55618e3f-f60f-456d-ab0c-edabca9c87b1",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "resolution = 512\n",
+ "crop = LargestCenterSquare(resolution)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "32f1eabd",
+ "metadata": {},
+ "source": [
+ "Let's take a simple example to understand visualize how the crop function works."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "920fec45",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds_example = ds.filter(lambda row: row[\"caption\"] == 'strawberry-lemonmousse-cake-3')\n",
+ "example_image = ds_example.take(1)[0]\n",
+ "image = Image.open(io.BytesIO(example_image[\"jpg\"]))\n",
+ "image"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "18cf17c5",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "crop(image)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "66cee5af",
+ "metadata": {},
+ "source": [
+ "#### Step 2. Normalizing the image\n",
+ "\n",
+ "We need to normalize the pixel values to the distribution expected by the VAE encoder. \n",
+ "\n",
+ "The VAE encoder expects pixel values in the range [-1, 1]\n",
+ "\n",
+ "Our images are in the range [0, 1] with an approximate mean of 0.5 in the center. \n",
+ "\n",
+ "To normalize the images, we'll subtract 0.5 from each pixel value and divide by 0.5"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "98f54b3f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "normalize = torchvision.transforms.Compose(\n",
+ " [\n",
+ " torchvision.transforms.ToTensor(),\n",
+ " torchvision.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),\n",
+ " ]\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2d34b6a7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "normalized = normalize(crop(image))\n",
+ "\n",
+ "normalized.min(), normalized.max()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0961204b",
+ "metadata": {},
+ "source": [
+ "#### Putting it together into a single transform function"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "86cef17d",
+ "metadata": {},
+ "source": [
+ "We build a `transform_images` below to crop and normalize the images."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a27d0a0d-260e-4782-bd7d-848228147cff",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def convert_tensor_to_array(tensor: torch.Tensor, dtype=np.float32) -> np.ndarray:\n",
+ " \"\"\"Convert a torch tensor to a numpy array.\"\"\"\n",
+ " array = tensor.detach().cpu().numpy()\n",
+ " return array.astype(dtype)\n",
+ "\n",
+ "\n",
+ "def transform_images(row: dict[str, Any]) -> np.ndarray:\n",
+ " \"\"\"Transform image to a square-sized normalized tensor.\"\"\"\n",
+ " try:\n",
+ " image = Image.open(io.BytesIO(row[\"jpg\"]))\n",
+ " except Exception as e:\n",
+ " logging.error(f\"Error opening image: {e}\")\n",
+ " return []\n",
+ "\n",
+ " if image.mode != \"RGB\":\n",
+ " image = image.convert(\"RGB\")\n",
+ "\n",
+ " image = crop(image)\n",
+ " normalized_image_tensor = normalize(image)\n",
+ "\n",
+ " row[f\"image_{resolution}\"] = convert_tensor_to_array(normalized_image_tensor)\n",
+ " return [row]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "780d98a8",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "Note how we reference `crop` and `normalize` functions in the `transform_images` function. Those outer-scope objects are serialized and shipped along with the remote function definition.\n",
+ "\n",
+ "In this case, they are tiny, but in other cases -- say, we have a 16GB model we're referencing -- we would not want to rely on this scope behavior but would want to use other mechanisms to make those objects availabe to the workers.\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "28973d35",
+ "metadata": {},
+ "source": [
+ "Now we call `flat_map` to apply the `transform_images` function to each row in the dataset."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "097ebdef",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds_img_transformed = ds.flat_map(transform_images)\n",
+ "\n",
+ "ds_img_transformed"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b279cd81-1ad5-4c3d-8d83-393f3dcca767",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "What happened to our schema?\n",
+ "\n",
+ "* `flat_map` is purely lazy ... applying didn't physically process any data at all, and since `flat_map` might have changed the schema of the records, Ray doesn't know what the resulting schema is\n",
+ "\n",
+ "If we want (or need) to inspect this behavior for development or debugging purposes, we can run the pipeline on a small part of the data using `take`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ba7b6346",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "image_transformed = ds_img_transformed.take(2)[1]\n",
+ "(\n",
+ " image_transformed[\"image_512\"].shape,\n",
+ " image_transformed[\"image_512\"].min(),\n",
+ " image_transformed[\"image_512\"].max(),\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8fe61534",
+ "metadata": {},
+ "source": [
+ "### 3. Tokenize the text captions\n",
+ "\n",
+ "Now we'll want to tokenize the text captions using a CLIP tokenizer."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "27eee876",
+ "metadata": {},
+ "source": [
+ "Let's load a text tokenizer and inspect its behavior."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9912591d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "text_tokenizer = CLIPTokenizer.from_pretrained(\n",
+ " \"stabilityai/stable-diffusion-2-base\", subfolder=\"tokenizer\"\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7b20f409",
+ "metadata": {},
+ "source": [
+ "Let's call the tokenizer on a simple string to get the token ids and tokens."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9e844989",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "token_ids = text_tokenizer(\"strawberry-lemonmousse-cake-3\")[\"input_ids\"]\n",
+ "token_ids"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6a83f7cc",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "tokens = text_tokenizer.convert_ids_to_tokens(token_ids)\n",
+ "tokens"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "da404a21",
+ "metadata": {},
+ "source": [
+ "We can now define a function that will tokenize a batch of text captions"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "073e0632",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def tokenize_text(batch: dict[str, np.ndarray]) -> dict[str, np.ndarray]:\n",
+ " \"\"\"Tokenize the caption.\"\"\"\n",
+ " batch[\"caption_ids\"] = text_tokenizer(\n",
+ " batch[\"caption\"].tolist(),\n",
+ " padding=\"max_length\",\n",
+ " max_length=text_tokenizer.model_max_length,\n",
+ " truncation=True,\n",
+ " return_tensors=\"np\",\n",
+ " )[\"input_ids\"]\n",
+ " return batch"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "36ee2c83",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds_img_txt_transformed = ds_img_transformed.map_batches(tokenize_text)\n",
+ "example_txt_transformed = ds_img_txt_transformed.filter(\n",
+ " lambda row: row[\"caption\"] == \"strawberry-lemonmousse-cake-3\"\n",
+ ").take(1)[0]\n",
+ "print(example_txt_transformed[\"caption\"])\n",
+ "example_txt_token_ids = example_txt_transformed[\"caption_ids\"]\n",
+ "example_txt_token_ids"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "eedc6833",
+ "metadata": {},
+ "source": [
+ "#### Understanding Ray Data's Operator Fusion\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4cddaf93",
+ "metadata": {},
+ "source": [
+ "Inspecting the execution plan of the dataset so far we see:\n",
+ "\n",
+ "```\n",
+ "Execution plan of Dataset: \n",
+ "InputDataBuffer[Input] \n",
+ "-> TaskPoolMapOperator[ReadParquet]\n",
+ "-> TaskPoolMapOperator[FlatMap(transform_images)->MapBatches(tokenize_text)]\n",
+ "-> LimitOperator[limit=2]\n",
+ "```\n",
+ "\n",
+ "Note how `transform_images` and `tokenize_text` functions are fused into a single operator.\n",
+ "\n",
+ "This is an optimization that Ray Data performs to reduce the number of times we need to serialize and deserialize data between Python processes.\n",
+ "\n",
+ "If Ray Data did not do this then it would have been advised to construct a `transform_images_and_text` transformation that combines the image and text transformations into a single function to reduce the number of times we need to serialize and deserialize data."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6dfe6dab-3cc2-455e-83d6-f5c634b5d8f4",
+ "metadata": {},
+ "source": [
+ "### 4. Encode images and captions\n",
+ "\n",
+ "We'll compress images into a latent space using a VAE encoder and generate text embeddings using a CLIP model."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2c9fcc5e-1e64-4670-ad39-3af591983eb9",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "class SDImageEncoder:\n",
+ " def __init__(self, model_name: str, device: torch.device) -> None:\n",
+ " self.vae = AutoencoderKL.from_pretrained(\n",
+ " model_name,\n",
+ " subfolder=\"vae\",\n",
+ " torch_dtype=torch.float16 if device == \"cuda\" else torch.float32,\n",
+ " ).to(device)\n",
+ " self.device = device\n",
+ "\n",
+ " def encode_images(self, images: np.ndarray) -> np.ndarray:\n",
+ " input_images = torch.tensor(images, device=self.device)\n",
+ " if self.device == \"cuda\":\n",
+ " input_images = input_images.half()\n",
+ " latent_dist = self.vae.encode(input_images)[\"latent_dist\"]\n",
+ " image_latents = latent_dist.sample() * 0.18215\n",
+ " return convert_tensor_to_array(image_latents)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5a37d934",
+ "metadata": {},
+ "source": [
+ "Let's run the image encoder against the sample image we have."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "54ef7ac7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "image_encoder = SDImageEncoder(\"stabilityai/stable-diffusion-2-base\", \"cpu\")\n",
+ "image_latents = image_encoder.encode_images(transform_images(example_image)[0][\"image_512\"][None])[0]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b76ab8c2",
+ "metadata": {},
+ "source": [
+ "Let's plot the image latents."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "aa3de5e2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nchannels = image_latents.shape[0]\n",
+ "fig, axes = plt.subplots(1, nchannels, figsize=(10, 10))\n",
+ "\n",
+ "for idx, ax in enumerate(axes):\n",
+ " ax.imshow(image_latents[idx], cmap=\"gray\")\n",
+ " ax.set_title(f\"Channel {idx}\")\n",
+ " ax.axis(\"off\")\n",
+ "\n",
+ "fig.suptitle(\"Image Latents\", fontsize=16, x=0.5, y=0.625)\n",
+ "plt.show()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "023b5ba8",
+ "metadata": {},
+ "source": [
+ "Next, let's encode the text using the CLIP model."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e314a8a5",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class SDTextEncoder:\n",
+ " def __init__(self, model_name: str, device: torch.device) -> None:\n",
+ " self.text_encoder = CLIPTextModel.from_pretrained(\n",
+ " model_name,\n",
+ " subfolder=\"text_encoder\",\n",
+ " torch_dtype=torch.float16 if device == \"cuda\" else torch.float32,\n",
+ " ).to(device)\n",
+ " self.device = device\n",
+ "\n",
+ " def encode_text(self, caption_ids: np.ndarray) -> np.ndarray:\n",
+ " \"\"\"Encode text captions into a latent space.\"\"\"\n",
+ " caption_ids_tensor = torch.tensor(caption_ids, device=self.device)\n",
+ " caption_latents_tensor = self.text_encoder(caption_ids_tensor)[0]\n",
+ " return convert_tensor_to_array(caption_latents_tensor)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a396bdb5",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "encoder = SDTextEncoder(\"stabilityai/stable-diffusion-2-base\", \"cpu\")\n",
+ "example_text_embedding = encoder.encode_text([example_txt_token_ids])[0]\n",
+ "example_text_embedding.shape"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "73088e0d",
+ "metadata": {},
+ "source": [
+ "Given Ray Data doesn't support operator fusion between two different stateful transformations, we define a single `SDLatentSpaceEncoder` transformation that is composed of the image and text encoders."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "78405e49",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class SDLatentSpaceEncoder:\n",
+ " def __init__(\n",
+ " self,\n",
+ " resolution: int = 512,\n",
+ " device: Optional[str] = \"cuda\",\n",
+ " model_name: str = \"stabilityai/stable-diffusion-2-base\",\n",
+ " ) -> None:\n",
+ " self.device = torch.device(device)\n",
+ " self.resolution = resolution\n",
+ "\n",
+ " # Instantiate image and text encoders\n",
+ " self.image_encoder = SDImageEncoder(model_name, self.device)\n",
+ " self.text_encoder = SDTextEncoder(model_name, self.device)\n",
+ "\n",
+ " def __call__(self, batch: dict[str, np.ndarray]) -> dict[str, np.ndarray]:\n",
+ " with torch.no_grad():\n",
+ " # Step 1: Encode images.\n",
+ " input_images = batch[f\"image_{self.resolution}\"]\n",
+ " image_latents = self.image_encoder.encode_images(input_images)\n",
+ " batch[f\"image_latents_{self.resolution}\"] = image_latents\n",
+ "\n",
+ " del batch[f\"image_{self.resolution}\"]\n",
+ " gc.collect()\n",
+ "\n",
+ " # Step 2: Encode captions.\n",
+ " caption_ids = batch[\"caption_ids\"]\n",
+ " batch[\"caption_latents\"] = self.text_encoder.encode_text(caption_ids)\n",
+ "\n",
+ " del batch[\"caption_ids\"]\n",
+ " gc.collect()\n",
+ "\n",
+ " return batch"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4e8e05b1",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "Note how we are deleting the original image and caption_ids from the batch to free up memory. This is important when working with large datasets.\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fc547a90",
+ "metadata": {},
+ "source": [
+ "We apply the encoder to the dataset to encode the images and text captions."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "cc8c31e3-1289-4f1e-9dbc-e320125cc6a3",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ds_encoded = ds_img_txt_transformed.map_batches(\n",
+ " SDLatentSpaceEncoder,\n",
+ " concurrency=2, # Total number of workers\n",
+ " num_gpus=1, # number of GPUs per worker\n",
+ " batch_size=24, # Use the largest batch size that can fit on our GPUs - depends on resolution\n",
+ ")\n",
+ "\n",
+ "ds_encoded"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f50f3178-3f33-436f-92f5-b2f0c4ad4802",
+ "metadata": {},
+ "source": [
+ "### 5. Write outputs to parquet"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "13bfdd3c-d8af-4442-8e60-ffe9e12b6918",
+ "metadata": {},
+ "source": [
+ "Finally, we can write the output.\n",
+ "\n",
+ "We use the artifact store to write the output to a parquet file."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ebceecfc",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "uuid_str = str(uuid.uuid4())\n",
+ "artifact_path = f\"/mnt/cluster_storage/stable-diffusion/{uuid_str}\"\n",
+ "artifact_path"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6cb8de52",
+ "metadata": {},
+ "source": [
+ "This operation requires physically moving the data, so it will trigger scheduling and execution of all of the upstream tasks."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ea15e02d-8f63-4347-af1b-66e064c89045",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "ds_encoded.write_parquet(artifact_path)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b994a8ea",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/templates/ray-summit-stable-diffusion/04_Pretraining.ipynb b/templates/ray-summit-stable-diffusion/04_Pretraining.ipynb
new file mode 100644
index 000000000..b78a32d5a
--- /dev/null
+++ b/templates/ray-summit-stable-diffusion/04_Pretraining.ipynb
@@ -0,0 +1,892 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "7078ab58-6ca4-4255-8050-b7c5fe7eae1c",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "# Distributed Training for Stable Diffusion\n",
+ "\n",
+ "This notebook demonstrates how to train a Stable Diffusion model using PyTorch Lightning and Ray Train. \n",
+ "\n",
+ "\n",
+ "\n",
+ "Here is the roadmap for this notebook:\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "765f5851",
+ "metadata": {},
+ "source": [
+ "## Imports"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e9ecea11-fc44-4bc2-af6d-09db4753d78e",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "\n",
+ "import lightning.pytorch as pl\n",
+ "import numpy as np\n",
+ "import torch\n",
+ "import torch.nn.functional as F\n",
+ "from diffusers import DDPMScheduler, UNet2DConditionModel\n",
+ "from lightning.pytorch.utilities.types import OptimizerLRScheduler\n",
+ "from transformers import PretrainedConfig, get_linear_schedule_with_warmup\n",
+ "\n",
+ "import ray.train\n",
+ "from ray.train.lightning import (\n",
+ " RayDDPStrategy,\n",
+ " RayLightningEnvironment,\n",
+ " RayTrainReportCallback,\n",
+ ")\n",
+ "from ray.train.torch import TorchTrainer, get_device"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7c1537cf",
+ "metadata": {},
+ "source": [
+ "- \n",
+ "
- Part 1: Load the preprocessed data into a Ray Dataset \n", + "
- Part 2: Define a stable diffusion model \n", + "
- Part 3: Define a PyTorch Lightning training loop \n", + "
- Part 4: Migrate the training loop to Ray Train \n", + "
- Part 5: Create and fit a Ray Train TorchTrainer \n", + "
- Part 6: Fault Tolerance in Ray Train \n", + "
\n",
+ "\n",
+ "The preceding architecture diagram illustrates the training pipeline for Stable Diffusion. \n",
+ "\n",
+ "It is primarily composed of three main stages:\n",
+ "1. **Streaming data from the preprocessing stage**\n",
+ "2. **Training the model**\n",
+ "3. **Storing the model checkpoints**\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ae7c50ba",
+ "metadata": {},
+ "source": [
+ "## 1. Load the preprocessed data into a Ray Dataset\n",
+ "\n",
+ "Let's start by specifying the datasets we want to use. We'll use `parquet` data that was generated using the same preprocessing pipeline."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "40392506-334f-4b05-9bb0-f2815daff428",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "columns = [\"image_latents_256\", \"caption_latents\"]\n",
+ "\n",
+ "train_data_uri = (\n",
+ " \"s3://anyscale-public-materials/ray-summit/stable-diffusion/data/preprocessed/256/\"\n",
+ ")\n",
+ "train_ds = ray.data.read_parquet(train_data_uri, columns=columns, shuffle=\"files\")\n",
+ "train_ds"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e4e9f3a7",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "NOTE: We make use of column pruning by setting `columns=columns` in `read_parquet` to only load the columns we need. Column pruning is a good practice to follow when working with large datasets to reduce memory usage.\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "37fec75d",
+ "metadata": {},
+ "source": [
+ "Given pyarrow and in turn parquet does not support saving float16, we need to add a step to convert the float32 columns to float16. \n",
+ "\n",
+ "Halving the precision of the data helps us reduce the memory usage and speed up the training process."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "86bd6050",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def convert_precision(batch: dict[str, np.ndarray]) -> dict[str, np.ndarray]:\n",
+ " for k, v in batch.items():\n",
+ " batch[k] = v.astype(np.float16)\n",
+ " return batch\n",
+ "\n",
+ "train_ds = train_ds.map_batches(convert_precision, batch_size=None)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "686c3c91",
+ "metadata": {},
+ "source": [
+ "We form a dictionary of the datasets to eventually pass to the trainer."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b6962ef7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ray_datasets = {\"train\": train_ds}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "41f8be2a",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "NOTE: We did not create a validation dataset in the preprocessing step. Validation can consume valuable GPU hours and resources that could be better utilized for training, especially on high-performance GPUs like the A100. Thoughtful scheduling of validation can help optimize resource usage.\n",
+ "\n",
+ "
\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ae0d8b57-ded8-42c2-84a1-60e8102d17ba",
+ "metadata": {},
+ "source": [
+ "## 2. Define a stable diffusion model\n",
+ "\n",
+ "This \"standard\" LightningModule does not explicitly refer to Ray or Ray Train, which makes migrating workloads easier."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d8b7e93d-4e8f-4053-86d0-0fd5f44b5f86",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "class StableDiffusion(pl.LightningModule):\n",
+ " def __init__(\n",
+ " self,\n",
+ " lr: float,\n",
+ " resolution: int,\n",
+ " weight_decay: float,\n",
+ " num_warmup_steps: int,\n",
+ " model_name: str,\n",
+ " ) -> None:\n",
+ " self.lr = lr\n",
+ " self.resolution = resolution\n",
+ " self.weight_decay = weight_decay\n",
+ " self.num_warmup_steps = num_warmup_steps\n",
+ " super().__init__()\n",
+ " self.save_hyperparameters()\n",
+ " # Initialize U-Net.\n",
+ " model_config = PretrainedConfig.get_config_dict(model_name, subfolder=\"unet\")[0]\n",
+ " self.unet = UNet2DConditionModel(**model_config)\n",
+ " # Define the training noise scheduler.\n",
+ " self.noise_scheduler = DDPMScheduler.from_pretrained(\n",
+ " model_name, subfolder=\"scheduler\"\n",
+ " )\n",
+ " # Setup loss function.\n",
+ " self.loss_fn = F.mse_loss\n",
+ " self.current_training_steps = 0\n",
+ "\n",
+ " def on_fit_start(self) -> None:\n",
+ " \"\"\"Move cumprod tensor to GPU in advance to avoid data movement on each step.\"\"\"\n",
+ " self.noise_scheduler.alphas_cumprod = self.noise_scheduler.alphas_cumprod.to(\n",
+ " get_device()\n",
+ " )\n",
+ "\n",
+ " def forward(\n",
+ " self, batch: dict[str, torch.Tensor]\n",
+ " ) -> tuple[torch.Tensor, torch.Tensor]:\n",
+ " \"\"\"Forward pass of the model.\"\"\"\n",
+ " # Extract inputs.\n",
+ " latents = batch[\"image_latents_256\"]\n",
+ " conditioning = batch[\"caption_latents\"]\n",
+ " # Sample the diffusion timesteps.\n",
+ " timesteps = self._sample_timesteps(latents)\n",
+ " # Add noise to the inputs (forward diffusion).\n",
+ " noise = torch.randn_like(latents)\n",
+ " noised_latents = self.noise_scheduler.add_noise(latents, noise, timesteps)\n",
+ " # Forward through the model.\n",
+ " outputs = self.unet(noised_latents, timesteps, conditioning)[\"sample\"]\n",
+ " return outputs, noise\n",
+ "\n",
+ " def training_step(\n",
+ " self, batch: dict[str, torch.Tensor], batch_idx: int\n",
+ " ) -> torch.Tensor:\n",
+ " \"\"\"Training step of the model.\"\"\"\n",
+ " outputs, targets = self.forward(batch)\n",
+ " loss = self.loss_fn(outputs, targets)\n",
+ " self.log(\n",
+ " \"train/loss_mse\", loss.item(), prog_bar=False, on_step=True, sync_dist=False\n",
+ " )\n",
+ " self.current_training_steps += 1\n",
+ " return loss\n",
+ "\n",
+ " def configure_optimizers(self) -> OptimizerLRScheduler:\n",
+ " \"\"\"Configure the optimizer and learning rate scheduler.\"\"\"\n",
+ " optimizer = torch.optim.AdamW(\n",
+ " self.trainer.model.parameters(),\n",
+ " lr=self.lr,\n",
+ " weight_decay=self.weight_decay,\n",
+ " )\n",
+ " # Set a large training step here to keep lr constant after warm-up.\n",
+ " scheduler = get_linear_schedule_with_warmup(\n",
+ " optimizer,\n",
+ " num_warmup_steps=self.num_warmup_steps,\n",
+ " num_training_steps=100000000000,\n",
+ " )\n",
+ " return {\n",
+ " \"optimizer\": optimizer,\n",
+ " \"lr_scheduler\": {\n",
+ " \"scheduler\": scheduler,\n",
+ " \"interval\": \"step\",\n",
+ " \"frequency\": 1,\n",
+ " },\n",
+ " }\n",
+ "\n",
+ " def _sample_timesteps(self, latents: torch.Tensor) -> torch.Tensor:\n",
+ " return torch.randint(\n",
+ " 0, len(self.noise_scheduler), (latents.shape[0],), device=latents.device\n",
+ " )"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "822926ee-bd2b-4977-8ffd-725881160da3",
+ "metadata": {},
+ "source": [
+ "## 3. Define a PyTorch Lightning training loop\n",
+ "\n",
+ "Here is a training loop that is specific to PyTorch Lightning.\n",
+ "\n",
+ "It performs the following steps:\n",
+ "1. **Model Initialization:**\n",
+ " - Instantiate the diffusion model.\n",
+ "2. **Trainer Setup:**\n",
+ " - Instantiate the Lightning Trainer with a `DDPStrategy` to perform data parallel training.\n",
+ "3. **Training Execution:**\n",
+ " - Run the trainer using the `fit` method."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "503c914e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def lightning_training_loop(\n",
+ " train_loader: torch.utils.data.DataLoader,\n",
+ " storage_path: str,\n",
+ " model_name: str = \"stabilityai/stable-diffusion-2-base\",\n",
+ " resolution: int = 256,\n",
+ " lr: float = 1e-4,\n",
+ " max_epochs: int = 1,\n",
+ " num_warmup_steps: int = 10_000,\n",
+ " weight_decay: float = 1e-2,\n",
+ ") -> None:\n",
+ " # 1. Initialize the model\n",
+ " torch.set_float32_matmul_precision(\"high\")\n",
+ " model = StableDiffusion(\n",
+ " model_name=model_name,\n",
+ " resolution=resolution,\n",
+ " lr=lr,\n",
+ " num_warmup_steps=num_warmup_steps,\n",
+ " weight_decay=weight_decay,\n",
+ " )\n",
+ "\n",
+ " # 2. Initialize the Lightning Trainer\n",
+ " trainer = pl.Trainer(\n",
+ " accelerator=\"gpu\",\n",
+ " devices=\"auto\",\n",
+ " precision=\"bf16-mixed\",\n",
+ " max_epochs=max_epochs,\n",
+ " default_root_dir=storage_path\n",
+ " )\n",
+ "\n",
+ " # 3. Run the trainer\n",
+ " trainer.fit(model=model, train_dataloaders=train_loader)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6423b358",
+ "metadata": {},
+ "source": [
+ "Here is how we would run the lightning training loop on a single GPU."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5575eac4",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "pl_compatible_data_loader = train_ds.limit(128).iter_torch_batches(batch_size=8)\n",
+ "storage_path = \"/mnt/local_storage/lightning/stable-diffusion-pretraining/\"\n",
+ "lightning_training_loop(train_loader=pl_compatible_data_loader, storage_path=storage_path)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "770a09b6",
+ "metadata": {},
+ "source": [
+ "Let's inspect the storage path to see what files were created."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e70a3ac9",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!ls {storage_path} --recursive"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1e2c2063-8988-4687-b1d4-b24e0a5a3d66",
+ "metadata": {},
+ "source": [
+ "# 4. Migrate the training loop to Ray Train\n",
+ "\n",
+ "Let's start by migrating the training loop to Ray Train to achieve distributed data parallel training."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c49711c5",
+ "metadata": {},
+ "source": [
+ "### Distributed Data Parallel Training\n",
+ "Here is a diagram showing the standard distributed data parallel training loop.\n",
+ "\n",
+ "\n",
+ "\n",
+ "Note how the model state is initially synchronized across all the GPUs before the training loop begins.\n",
+ "\n",
+ "Then after each backward pass, the gradients are synchronized across all the GPUs. "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6c9f8204",
+ "metadata": {},
+ "source": [
+ "### Ray Train Migration\n",
+ "\n",
+ "Here are the changes we need to make to the training loop to migrate it to Ray Train."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6b42be9f-fad5-4f3f-8a1c-5812c5573eca",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "def train_loop_per_worker(\n",
+ " config: dict, # Update the function signature to comply with Ray Train\n",
+ "): \n",
+ " # Prepare data loaders using Ray\n",
+ " train_ds = ray.train.get_dataset_shard(\"train\")\n",
+ " train_dataloader = train_ds.iter_torch_batches(\n",
+ " batch_size=config[\"batch_size_per_worker\"],\n",
+ " drop_last=True,\n",
+ " prefetch_batches=config[\"prefetch_batches\"],\n",
+ " )\n",
+ "\n",
+ " # Same model initialization as vanilla lightning\n",
+ " torch.set_float32_matmul_precision(\"high\")\n",
+ " model = StableDiffusion(\n",
+ " lr=config[\"lr\"],\n",
+ " resolution=config[\"resolution\"],\n",
+ " weight_decay=config[\"weight_decay\"],\n",
+ " num_warmup_steps=config[\"num_warmup_steps\"],\n",
+ " model_name=config[\"model_name\"],\n",
+ " )\n",
+ "\n",
+ " # Same trainer setup as vanilla lightning except we add Ray Train specific arguments\n",
+ " trainer = pl.Trainer(\n",
+ " max_steps=config[\"max_steps\"],\n",
+ " max_epochs=config[\"max_epochs\"],\n",
+ " accelerator=\"gpu\",\n",
+ " precision=\"bf16-mixed\",\n",
+ " devices=\"auto\", # Set devices to \"auto\" to use all available GPUs\n",
+ " strategy=RayDDPStrategy(), # Use RayDDPStrategy for distributed data parallel training\n",
+ " plugins=[\n",
+ " RayLightningEnvironment()\n",
+ " ], # Use RayLightningEnvironment to run the Lightning Trainer\n",
+ " callbacks=[\n",
+ " RayTrainReportCallback()\n",
+ " ], # Use RayTrainReportCallback to report metrics and checkpoints\n",
+ " enable_checkpointing=False, # Disable lightning checkpointing\n",
+ " )\n",
+ "\n",
+ " # 4. Same as vanilla lightning\n",
+ " trainer.fit(model, train_dataloaders=train_dataloader)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ae5328b5",
+ "metadata": {},
+ "source": [
+ "Here is the same diagram as before but with the Ray Train specific components highlighted.\n",
+ "\n",
+ "\n",
+ "\n",
+ "We made use of:\n",
+ "- `ray.train.get_dataset_shard(\"train\")` to get the training dataset shard.\n",
+ "- `RayDDPStrategy` to perform distributed data parallel training.\n",
+ "- `RayLightningEnvironment` to run the Lightning Trainer.\n",
+ "- `RayTrainReportCallback` to report metrics and checkpoints."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "242d8ccb-30c2-4491-a381-63ac3330bc2e",
+ "metadata": {},
+ "source": [
+ "## 5. Create and fit a Ray Train TorchTrainer\n",
+ "\n",
+ "Let's first specify the scaling configuration to tell Ray Train to use 2 GPU training workers."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "86459a71",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "scaling_config = ray.train.ScalingConfig(num_workers=2, use_gpu=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "27b32a89",
+ "metadata": {},
+ "source": [
+ "We then specify the run configuration to tell Ray Train where to store the checkpoints and metrics"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f441b156",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "storage_path = \"/mnt/cluster_storage/\"\n",
+ "experiment_name = \"stable-diffusion-pretraining\"\n",
+ "\n",
+ "run_config = ray.train.RunConfig(name=experiment_name, storage_path=storage_path)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7c1d2f69",
+ "metadata": {},
+ "source": [
+ "Now we can create our Ray Train `TorchTrainer`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "052fa684",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "train_loop_config = {\n",
+ " \"batch_size_per_worker\": 8,\n",
+ " \"prefetch_batches\": 2,\n",
+ " \"lr\": 0.0001,\n",
+ " \"num_warmup_steps\": 10_000,\n",
+ " \"weight_decay\": 0.01,\n",
+ " \"max_steps\": 550_000,\n",
+ " \"max_epochs\": 1,\n",
+ " \"resolution\": 256,\n",
+ " \"model_name\": \"stabilityai/stable-diffusion-2-base\",\n",
+ "}\n",
+ "\n",
+ "trainer = TorchTrainer(\n",
+ " train_loop_per_worker,\n",
+ " train_loop_config=train_loop_config,\n",
+ " scaling_config=scaling_config,\n",
+ " run_config=run_config,\n",
+ " datasets=ray_datasets,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1dac0bcd",
+ "metadata": {},
+ "source": [
+ "Here is a high-level architecture of how Ray Train works:\n",
+ "\n",
+ "\n",
+ "\n",
+ "Here are some key points:\n",
+ "- The scaling config specifies the number of training workers.\n",
+ "- A trainer actor process is launched that oversees the training workers."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "81045b35",
+ "metadata": {},
+ "source": [
+ "We call `.fit()` to start the training job."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ebc0bc5d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "result = trainer.fit()\n",
+ "result"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "675ad286-7eb5-4692-a999-9d8159814ceb",
+ "metadata": {},
+ "source": [
+ "## 6. Fault Tolerance in Ray Train\n",
+ "\n",
+ "Ray Train provides two main mechanisms to handle failures:\n",
+ "- Automatic retries\n",
+ "- Manual restoration\n",
+ "\n",
+ "Here is a diagram showing these two primary mechanisms:\n",
+ "\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4e381954",
+ "metadata": {},
+ "source": [
+ "### Modifying the Training Loop to Enable Checkpoint Loading\n",
+ "\n",
+ "We need to make use of `get_checkpoint()` in the training loop to enable checkpoint loading for fault tolerance.\n",
+ "\n",
+ "Here is how the modified training loop looks like."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "77d432a3",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def train_loop_per_worker_with_checkpoint_loading(config: dict):\n",
+ " # Same data loading as before\n",
+ " train_ds = ray.train.get_dataset_shard(\"train\")\n",
+ " train_dataloader = train_ds.iter_torch_batches(\n",
+ " batch_size=config[\"batch_size_per_worker\"],\n",
+ " drop_last=True,\n",
+ " prefetch_batches=config[\"prefetch_batches\"],\n",
+ " )\n",
+ "\n",
+ " # Same model initialization as before\n",
+ " torch.set_float32_matmul_precision(\"high\")\n",
+ " model = StableDiffusion(\n",
+ " lr=config[\"lr\"],\n",
+ " resolution=config[\"resolution\"],\n",
+ " weight_decay=config[\"weight_decay\"],\n",
+ " num_warmup_steps=config[\"num_warmup_steps\"],\n",
+ " model_name=config[\"model_name\"],\n",
+ " )\n",
+ "\n",
+ " # Same trainer setup as before\n",
+ " trainer = pl.Trainer(\n",
+ " max_steps=config[\"max_steps\"],\n",
+ " max_epochs=config[\"max_epochs\"],\n",
+ " accelerator=\"gpu\",\n",
+ " precision=\"bf16-mixed\",\n",
+ " devices=\"auto\",\n",
+ " strategy=RayDDPStrategy(),\n",
+ " plugins=[RayLightningEnvironment()],\n",
+ " callbacks=[RayTrainReportCallback()],\n",
+ " enable_checkpointing=False,\n",
+ " )\n",
+ "\n",
+ " # Load the latest checkpoint if it exists\n",
+ " checkpoint = ray.train.get_checkpoint()\n",
+ " if checkpoint:\n",
+ " # Continue training from a previous checkpoint\n",
+ " with checkpoint.as_directory() as ckpt_dir:\n",
+ " ckpt_path = os.path.join(ckpt_dir, \"checkpoint.ckpt\")\n",
+ "\n",
+ " # Call .fit with the ckpt_path\n",
+ " # This will restore both the model weights and the trainer states (optimizer, steps, callbacks)\n",
+ " trainer.fit(\n",
+ " model,\n",
+ " train_dataloaders=train_dataloader,\n",
+ " ckpt_path=ckpt_path,\n",
+ " )\n",
+ " \n",
+ " # If no checkpoint is provided, start from scratch\n",
+ " else:\n",
+ " trainer.fit(model, train_dataloaders=train_dataloader)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "878adcd0",
+ "metadata": {},
+ "source": [
+ "### Configuring Automatic Retries\n",
+ "\n",
+ "Now that we have enabled checkpoint loading, we can configure a failure config which sets the maximum number of retries for a training job."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "fd6d3cdb",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "failure_config = ray.train.FailureConfig(max_failures=3)\n",
+ "\n",
+ "trainer = TorchTrainer(\n",
+ " train_loop_per_worker_with_checkpoint_loading,\n",
+ " train_loop_config=train_loop_config,\n",
+ " scaling_config=ray.train.ScalingConfig(num_workers=2, use_gpu=True),\n",
+ " run_config=ray.train.RunConfig(\n",
+ " name=experiment_name,\n",
+ " storage_path=storage_path,\n",
+ " failure_config=failure_config, # Pass the failure config\n",
+ " ),\n",
+ " datasets=ray_datasets,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "164a57d3",
+ "metadata": {},
+ "source": [
+ "Now we can proceed to run the training job as before."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0d6f6bf9",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "trainer.fit()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "84437cfd",
+ "metadata": {},
+ "source": [
+ "### Performing a Manual Restoration\n",
+ "\n",
+ "In case the retries are exhausted, we can perform a manual restoration using the `TorchTrainer.restore` method. \n",
+ "\n",
+ "We can first check that we can still restore from a failed experiment by running the `can_restore` method."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "81176b07",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "can_restore = TorchTrainer.can_restore(path=os.path.join(storage_path, experiment_name))\n",
+ "can_restore"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "326d1b54",
+ "metadata": {},
+ "source": [
+ "This is mainly checking if the `trainer.pkl` file exists so we can re-create the TorchTrainer object."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "febde28d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!ls {storage_path}/{experiment_name}/trainer.pkl"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "552b77f1",
+ "metadata": {},
+ "source": [
+ "Let's restore the trainer using the `restore` method. We will however override the `train_loop_per_worker` function to perform the proper checkpoint loading."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2ca64d0d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "restored_trainer = TorchTrainer.restore(\n",
+ " path=os.path.join(storage_path, experiment_name),\n",
+ " datasets=ray_datasets,\n",
+ " train_loop_per_worker=train_loop_per_worker_with_checkpoint_loading,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1ab08cae",
+ "metadata": {},
+ "source": [
+ "Here is a view of our restored trainer."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d55e3907",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "restored_trainer"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "08c3a730",
+ "metadata": {},
+ "source": [
+ "Running the `fit` method will resume training from the last checkpoint. \n",
+ "\n",
+ "Given we already have completed all epochs, we expect the training to terminate immediately."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0f65deff",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "result = restored_trainer.fit()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5eb2e18c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "result"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "33b73ce0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "result.checkpoint"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "396caa4a",
+ "metadata": {},
+ "source": [
+ "## Clean up \n",
+ "\n",
+ "Let's clean up the storage path to remove the checkpoints and artifacts we created during this notebook."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "373ad2bd",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!rm -rf /mnt/cluster_storage/stable-diffusion-pretraining"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/templates/ray-summit-stable-diffusion/Bonus/04b_Advanced_Pretraining.ipynb b/templates/ray-summit-stable-diffusion/Bonus/04b_Advanced_Pretraining.ipynb
new file mode 100644
index 000000000..400e89d38
--- /dev/null
+++ b/templates/ray-summit-stable-diffusion/Bonus/04b_Advanced_Pretraining.ipynb
@@ -0,0 +1,456 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "7078ab58-6ca4-4255-8050-b7c5fe7eae1c",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "# Distributed Training Optimizations for Stable Diffusion\n",
+ "\n",
+ "This notebook demonstrates certain optimizations that can be applied to the training process to improve performance and reduce costs.\n",
+ "\n",
+ "\n",
+ "\n",
+ "Here is the roadmap for this notebook:\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "765f5851",
+ "metadata": {},
+ "source": [
+ "## Imports"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e9ecea11-fc44-4bc2-af6d-09db4753d78e",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "\n",
+ "import lightning.pytorch as pl\n",
+ "import numpy as np\n",
+ "import torch\n",
+ "import torch.nn.functional as F\n",
+ "from diffusers import DDPMScheduler, UNet2DConditionModel\n",
+ "from transformers import PretrainedConfig, get_linear_schedule_with_warmup\n",
+ "from lightning.pytorch.utilities.types import OptimizerLRScheduler\n",
+ "\n",
+ "import ray.train\n",
+ "from torch.distributed.fsdp import BackwardPrefetch\n",
+ "from ray.train.lightning import RayLightningEnvironment, RayTrainReportCallback, RayFSDPStrategy\n",
+ "from ray.train.torch import TorchTrainer, get_device"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ae7c50ba",
+ "metadata": {},
+ "source": [
+ "## 1. Setup\n",
+ "\n",
+ "Let's begin with the same code as in the basic pretraining notebook.\n",
+ "\n",
+ "We first load the dataset and convert the precision to float16."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "40392506-334f-4b05-9bb0-f2815daff428",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "def convert_precision(batch: dict[str, np.ndarray]) -> dict[str, np.ndarray]:\n",
+ " for k, v in batch.items():\n",
+ " batch[k] = v.astype(np.float16)\n",
+ " return batch\n",
+ "\n",
+ "\n",
+ "columns = [\"image_latents_256\", \"caption_latents\"]\n",
+ "\n",
+ "train_data_uri = (\n",
+ " \"s3://anyscale-public-materials/ray-summit/stable-diffusion/data/preprocessed/256/\"\n",
+ ")\n",
+ "train_ds = ray.data.read_parquet(train_data_uri, columns=columns, shuffle=\"files\")\n",
+ "train_ds = train_ds.map_batches(convert_precision, batch_size=None)\n",
+ "\n",
+ "ray_datasets = {\"train\": train_ds}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d3f22554",
+ "metadata": {},
+ "source": [
+ "We then define the model."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "86bd6050",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class StableDiffusion(pl.LightningModule):\n",
+ "\n",
+ " def __init__(\n",
+ " self,\n",
+ " lr: float,\n",
+ " resolution: int,\n",
+ " weight_decay: float,\n",
+ " num_warmup_steps: int,\n",
+ " model_name: str,\n",
+ " ) -> None:\n",
+ " self.lr = lr\n",
+ " self.resolution = resolution\n",
+ " self.weight_decay = weight_decay\n",
+ " self.num_warmup_steps = num_warmup_steps\n",
+ " super().__init__()\n",
+ " self.save_hyperparameters()\n",
+ " # Initialize U-Net.\n",
+ " model_config = PretrainedConfig.get_config_dict(model_name, subfolder=\"unet\")[0]\n",
+ " self.unet = UNet2DConditionModel(**model_config)\n",
+ " # Define the training noise scheduler.\n",
+ " self.noise_scheduler = DDPMScheduler.from_pretrained(\n",
+ " model_name, subfolder=\"scheduler\"\n",
+ " )\n",
+ " # Setup loss function.\n",
+ " self.loss_fn = F.mse_loss\n",
+ " self.current_training_steps = 0\n",
+ "\n",
+ " def on_fit_start(self) -> None:\n",
+ " \"\"\"Move cumprod tensor to GPU in advance to avoid data movement on each step.\"\"\"\n",
+ " self.noise_scheduler.alphas_cumprod = self.noise_scheduler.alphas_cumprod.to(\n",
+ " get_device()\n",
+ " )\n",
+ "\n",
+ " def forward(\n",
+ " self, batch: dict[str, torch.Tensor]\n",
+ " ) -> tuple[torch.Tensor, torch.Tensor]:\n",
+ " \"\"\"Forward pass of the model.\"\"\"\n",
+ " # Extract inputs.\n",
+ " latents = batch[\"image_latents_256\"]\n",
+ " conditioning = batch[\"caption_latents\"]\n",
+ " # Sample the diffusion timesteps.\n",
+ " timesteps = self._sample_timesteps(latents)\n",
+ " # Add noise to the inputs (forward diffusion).\n",
+ " noise = torch.randn_like(latents)\n",
+ " noised_latents = self.noise_scheduler.add_noise(latents, noise, timesteps)\n",
+ " # Forward through the model.\n",
+ " outputs = self.unet(noised_latents, timesteps, conditioning)[\"sample\"]\n",
+ " return outputs, noise\n",
+ "\n",
+ " def training_step(\n",
+ " self, batch: dict[str, torch.Tensor], batch_idx: int\n",
+ " ) -> torch.Tensor:\n",
+ " \"\"\"Training step of the model.\"\"\"\n",
+ " outputs, targets = self.forward(batch)\n",
+ " loss = self.loss_fn(outputs, targets)\n",
+ " self.log(\n",
+ " \"train/loss_mse\", loss.item(), prog_bar=False, on_step=True, sync_dist=False\n",
+ " )\n",
+ " self.current_training_steps += 1\n",
+ " return loss\n",
+ "\n",
+ " def configure_optimizers(self) -> OptimizerLRScheduler:\n",
+ " \"\"\"Configure the optimizer and learning rate scheduler.\"\"\"\n",
+ " optimizer = torch.optim.AdamW(\n",
+ " self.trainer.model.parameters(),\n",
+ " lr=self.lr,\n",
+ " weight_decay=self.weight_decay,\n",
+ " )\n",
+ " # Set a large training step here to keep lr constant after warm-up.\n",
+ " scheduler = get_linear_schedule_with_warmup(\n",
+ " optimizer,\n",
+ " num_warmup_steps=self.num_warmup_steps,\n",
+ " num_training_steps=100000000000,\n",
+ " )\n",
+ " return {\n",
+ " \"optimizer\": optimizer,\n",
+ " \"lr_scheduler\": {\n",
+ " \"scheduler\": scheduler,\n",
+ " \"interval\": \"step\",\n",
+ " \"frequency\": 1,\n",
+ " },\n",
+ " }\n",
+ "\n",
+ " def _sample_timesteps(self, latents: torch.Tensor) -> torch.Tensor:\n",
+ " return torch.randint(\n",
+ " 0, len(self.noise_scheduler), (latents.shape[0],), device=latents.device\n",
+ " )"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f720ec43",
+ "metadata": {},
+ "source": [
+ "## 2. Using Fully Sharded Data Parallel (FSDP)\n",
+ "\n",
+ "Ray Train also supports Fully Sharded Data Parallel (FSDP) for distributed training.\n",
+ "\n",
+ "FSDP is a new training paradigm that is designed to improve the performance of large-scale training by reducing the memory footprint of the model by sharding the model parameters across different GPUs.\n",
+ "\n",
+ "Here is a diagram to help illustrate how FSDP works.\n",
+ "\n",
+ "- \n",
+ "
- Part 1: Setup \n", + "
- Part 2: Using Fully Sharded Data Parallel (FSDP) \n", + "
- Part 3: Online (end-to-end) preprocessing and training \n", + "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "cfebb6c6",
+ "metadata": {},
+ "source": [
+ "### FSDP configuration:\n",
+ "\n",
+ "#### Sharding strategy:\n",
+ "\n",
+ "There are three different modes of the FSDP sharding strategy:\n",
+ "\n",
+ "1. `NO_SHARD`: Parameters, gradients, and optimizer states are not sharded. Similar to DDP.\n",
+ "2. `SHARD_GRAD_OP`: Gradients and optimizer states are sharded during computation, and additionally, parameters are sharded outside computation. Similar to ZeRO stage-2.\n",
+ "3. `FULL_SHARD`: Parameters, gradients, and optimizer states are sharded. It has minimal GRAM usage among the 3 options. Similar to ZeRO stage-3.\n",
+ "\n",
+ "#### Auto-wrap policy:\n",
+ "\n",
+ "Model layers are often wrapped with FSDP in a layered fashion. This means that only the layers in a single FSDP instance are required to aggregate all parameters to a single device during forwarding or backward calculations.\n",
+ "\n",
+ "Depending on the model architecture, we might need to specify a custom auto-wrap policy.\n",
+ "\n",
+ "For example, we can use the `transformer_auto_wrap_policy` to automatically wrap each Transformer Block into a single FSDP instance.\n",
+ "\n",
+ "#### Overlap communication with computation:\n",
+ "\n",
+ "You can specify to overlap the upcoming all-gather while executing the current forward/backward pass. It can improve throughput but may slightly increase peak memory usage. Set `backward_prefetch` and `forward_prefetch` to overlap communication with computation.\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "bc993de5",
+ "metadata": {},
+ "source": [
+ "Let's update our training loop to use FSDP."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ed963f6f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def train_loop_per_worker_fsdp(config):\n",
+ " train_ds = ray.train.get_dataset_shard(\"train\")\n",
+ " train_dataloader = train_ds.iter_torch_batches(\n",
+ " batch_size=config[\"batch_size_per_worker\"],\n",
+ " drop_last=True,\n",
+ " )\n",
+ "\n",
+ " torch.set_float32_matmul_precision(\"high\")\n",
+ " model = StableDiffusion(\n",
+ " lr=config[\"lr\"],\n",
+ " resolution=config[\"resolution\"],\n",
+ " weight_decay=config[\"weight_decay\"],\n",
+ " num_warmup_steps=config[\"num_warmup_steps\"],\n",
+ " model_name=config[\"model_name\"],\n",
+ " )\n",
+ "\n",
+ " trainer = pl.Trainer(\n",
+ " max_steps=config[\"max_steps\"],\n",
+ " max_epochs=config[\"max_epochs\"],\n",
+ " accelerator=\"gpu\",\n",
+ " devices=\"auto\",\n",
+ " precision=\"bf16-mixed\",\n",
+ " strategy=RayFSDPStrategy( # Use RayFSDPStrategy instead of RayDDPStrategy\n",
+ " sharding_strategy=\"SHARD_GRAD_OP\", # Run FSDP with SHARD_GRAD_OP sharding strategy\n",
+ " backward_prefetch=BackwardPrefetch.BACKWARD_PRE, # Overlap communication with computation in backward pass\n",
+ " ),\n",
+ " plugins=[RayLightningEnvironment()],\n",
+ " callbacks=[RayTrainReportCallback()],\n",
+ " enable_checkpointing=False,\n",
+ " )\n",
+ "\n",
+ " trainer.fit(model, train_dataloaders=train_dataloader)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4c8ecabd",
+ "metadata": {},
+ "source": [
+ "Let's run the training loop with FSDP."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "152c6749",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "storage_path = \"/mnt/cluster_storage/\"\n",
+ "experiment_name = \"stable-diffusion-pretraining-fsdp\"\n",
+ "\n",
+ "train_loop_config = {\n",
+ " \"batch_size_per_worker\": 8,\n",
+ " \"prefetch_batches\": 2,\n",
+ " \"every_n_train_steps\": 10, # Report metrics and checkpoints every 10 steps\n",
+ " \"lr\": 0.0001,\n",
+ " \"num_warmup_steps\": 10_000,\n",
+ " \"weight_decay\": 0.01,\n",
+ " \"max_steps\": 550_000,\n",
+ " \"max_epochs\": 1,\n",
+ " \"resolution\": 256,\n",
+ " \"model_name\": \"stabilityai/stable-diffusion-2-base\",\n",
+ "}\n",
+ "\n",
+ "run_config = ray.train.RunConfig(name=experiment_name, storage_path=storage_path)\n",
+ "\n",
+ "scaling_config = ray.train.ScalingConfig(\n",
+ " num_workers=2,\n",
+ " use_gpu=True,\n",
+ ")\n",
+ "\n",
+ "trainer = TorchTrainer(\n",
+ " train_loop_per_worker_fsdp,\n",
+ " train_loop_config=train_loop_config,\n",
+ " scaling_config=scaling_config,\n",
+ " run_config=run_config,\n",
+ " datasets=ray_datasets,\n",
+ ")\n",
+ "\n",
+ "result = trainer.fit()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9ab5d955",
+ "metadata": {},
+ "source": [
+ "Let's load the model from the checkpoint and inspect it."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c69903e5",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "with result.checkpoint.as_directory() as checkpoint_dir:\n",
+ " ckpt_path = os.path.join(checkpoint_dir, \"checkpoint.ckpt\")\n",
+ " model = StableDiffusion.load_from_checkpoint(ckpt_path, map_location=\"cpu\")\n",
+ " print(model)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3d1c4b82",
+ "metadata": {},
+ "source": [
+ "## 3. Online (end-to-end) preprocessing and training\n",
+ "\n",
+ "Looking ahead at more challenging Stable Diffusion training pipelines, we will need to handle data in a more sophisticated way.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9f79ea61",
+ "metadata": {},
+ "source": [
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0ac4c6e1",
+ "metadata": {},
+ "source": [
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "df44c586",
+ "metadata": {},
+ "source": [
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9a89b951",
+ "metadata": {},
+ "source": [
+ "### Resources for online preprocessing and training\n",
+ "\n",
+ "Check out the following resources for more details:\n",
+ "\n",
+ "- [Reducing the Cost of Pre-training Stable Diffusion by 3.7x with Anyscale](https://www.anyscale.com/blog/scalable-and-cost-efficient-stable-diffusion-pre-training-with-ray)\n",
+ "- [Pretraining Stable Diffusion (V2) workspace template](https://console.anyscale.com/v2/template-preview/stable-diffusion-pretraining)\n",
+ "- [Processing 2 Billion Images for Stable Diffusion Model Training - Definitive Guides with Ray Series](https://www.anyscale.com/blog/processing-2-billion-images-for-stable-diffusion-model-training-definitive-guides-with-ray-series)\n",
+ "- [We Pre-Trained Stable Diffusion Models on 2 billion Images and Didn't Break the Bank - Definitive Guides with Ray Series](https://www.anyscale.com/blog/we-pre-trained-stable-diffusion-models-on-2-billion-images-and-didnt-break-the-bank-definitive-guides-with-ray-series)\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ac62329a",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/templates/ray-summit-stable-diffusion/README.md b/templates/ray-summit-stable-diffusion/README.md
new file mode 100644
index 000000000..32f5e6de3
--- /dev/null
+++ b/templates/ray-summit-stable-diffusion/README.md
@@ -0,0 +1,17 @@
+# Scalable Generative AI with Stable Diffusion Models - From Pre-Training to Production
+
+Text-to-image generative AI models, like Stable Diffusion, are transforming the creative industry by generating high-quality images from text descriptions. In this workshop, you'll learn how to build scalable systems for these models by creating an end-to-end pipeline for pre-training a Stable Diffusion model on a billion-scale dataset using Ray Data and Ray Train.
+
+You'll explore how to efficiently stream data preprocessing and conduct distributed training across multiple GPUs. Additionally, you'll gain practical experience in deploying and scaling a Stable Diffusion model using Ray Serve, allowing you to deliver real-time, high-quality generative outputs.
+
+By the end of this session, you'll have a solid understanding of how to implement a complete generative AI pipeline with Ray. You'll leave with the skills to pre-train, deploy, and scale Stable Diffusion models, ready to handle large-scale generative tasks and produce impressive results.
+
+## Prerequisites:
+- Basic familiarity with computer vision tasks, including common challenges with data processing, training, and inference.
+- Intermediate programming skills with Python.
+- Basic understanding of text-to-image use cases.
+
+## Ray Libraries:
+- Ray Data
+- Ray Train
+- Ray Serve
\ No newline at end of file