Design Doc: Split HTML Rewriter
Rahul Bansal, 2012-10-07
- Prioritize above the fold HTML on both network and browser for faster rendering of user visible content.
- Reconcile the critical line information used by the various filters - LazyloadImages, Inline, InlinePreview and Blink.
Blink caches a split version of origin HTML comprising of above the fold (ATF) and below the fold (BTF) content. It also sends ATF HTML first resulting in faster rendering. In Blink, publisher HTML is passed async to the headless browser which does the split. With Split HTML rewriter, we want to get the benefits of prioritizing ATF HTML without caching so that it can be turned on without publisher input.
Today Blink and other filters which use headless browsers have different interpretations of what is ATF. A direct implication is that Blink can’t use the other filters directly. We also want all the filters to use one source of truth for this information.
We’ll run WPT measurements to figure out exactly how much gains this rewriter would provide, but the following are the scenarios it could improve:
- We could execute scripts in ATF HTML early, could benefit ads and other scripts which render content above the fold.
- Background images in css for BTF content won’t compete with ATF content.
- The browser (we’ve seen this to be true in Chrome) tries to parse as much HTML as possible in one shot, hence a smaller DOM would lead to early paint.
- Browser wouldn’t need to parse and render the HTML which appears in the beginning of HTML but affects only BTF content. It can also be de-prioritized on the network.
In Split HTML rewriter, we’ll pass the HTML to the headless browser which will then spit out a config that describes the critical line information, as a set of XPaths. We’ll cache the config for some time (say an hour). In the line of the request, we’ll use this config to split the HTML into ATF HTML and BTF JSON. We’ll send out above the fold HTML first and hold back below the fold content. The ATF HTML will have stubs where the corresponding BTF content will be bound by javascript. After all the ATF HTML has been sent, the BTF content will be sent.
The critical line information that the headless browser spits out will also have set of critical images. This set will be used by filters like LazyloadImages, InlinePreview to determine what images to act upon.
In case we don’t find XPath in the html, we’ll backoff applying this filter and log those cases. We’ll figure out a more appropriate solution once we analyze those cases.
DeferJavaScript is a prerequisite to this filter. When we set BTF JSON as innerHtml, the scripts won’t get executed and we’ll use DeferJavascript to execute those scripts.
message Panel {
// XPath identifying the start instance for the panel.
// There may be multiple instances, each with its own start instance node.
required string start_xpath = 1;
// XPath identifying the marker which terminates this panel
// The marker can be text/comment/tag
// The marker is not part of the panel.
optional string end_marker_xpath = 2;
}
message PanelSet {
repeated Panel panels = 1;
};
message CriticalImages {
repeated string image_url;
}
Take panel XPath as start of panel and continue processing as part of panel until panel end marker is reached or container ends or another panel starts. That means all the siblings from the start of the panel will be considered a part of the panel until end marker is reached.
The exact XPath syntax needs to be iterated upon. For the initial version, we are plan to start with a limited XPath which would be XPath relative to the nearest parent with an id or from the body, if the element has no parent with an id.
<!-- ATF HTML -->
<html>
<head></head>
<body>
<!-- panel-id-1 -->
<script src="cutstom.js”></script>
<!-- BTF JSON data -->
<script>loader.loadNonCritical({"panel-id-1:non_critical_json"});</script>
<!-- FOOTER -->
</body>
</html>
<script>loader.loadNonCritical({"panel-id-1:non_critical_json"});</script>
If critical line information is not present, the filters will use a background render filter to register for a headless browser request. An extension js will be passed to the headless browser which will compute the critical line information. The critical line information will then be put into pcache.
Filters like LazyLoadImages will use the critical line information from pcache for their processing. Split HTML writer filter will be the last in the chain. It will split the incoming HTML based on the config, prioritize sending ATF HTML and then send BTF content.
We’ll store the original HTML (with non-cacheable stripped) into the property cache. There are multiple reasons to store it in property cache:
- With non-cacheable portions stripped out, this is not really input HTML but more a property of the page.
- We don’t have to explicitly do cache lookups for this data since property cache lookup happens as a part of the request in parallel with the proxy fetch flow.
- With HTML diff detection, it is much easier to purge out stale copies with this being stored only in L2 cache.
- This data doesn’t have any expiration semantics since its deleted explicitly on HTML diff detection.
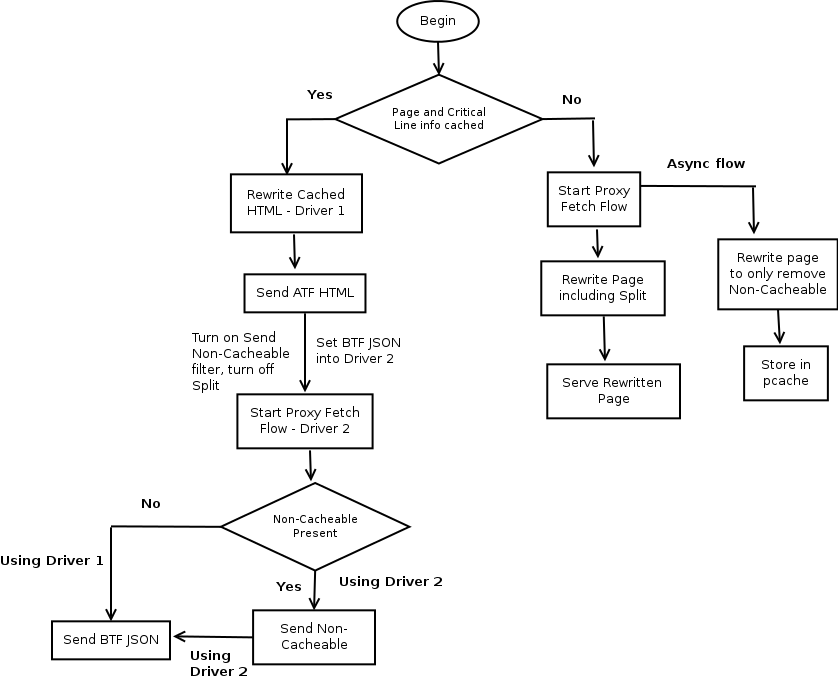
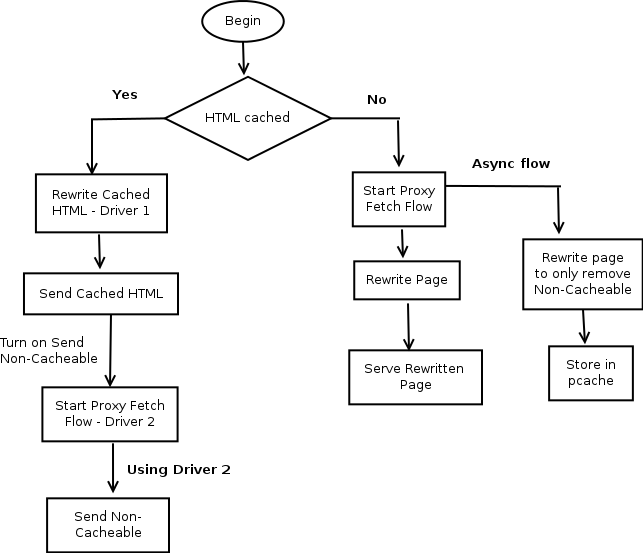
Design goal: Both Cache Filter and Split Filter can be enabled independent of each other
- In Cache Hit case, there will be two rewrite drivers for serving the request
- Rewriting cached HTML - driver 1
- Rewriting HTML the in proxy fetch flow - driver 2
- In Cache Miss case
- HTML will be rewritten in the proxy fetch flow and served to the user.
- In background, we'll store HTML into pcache with non-cacheable parts stripped off. That'll be the only rewriting done before storing input HTML into cache.
- We'll change the rewrite options for the proxy fetch driver based on cache lookup
- If HTML is cached, we'll do the split in driver 1, send ATF HTML and set BTF JSON in driver 2. For driver 2, split filter will be disabled and send non-cacheable filter will be the last filter.
- If HTML is not cached, we'll split in the proxy fetch flow. In this case for driver 2, send non-cacheable filter will be disabled and split filter will be the last filter in the chain.
- To keep things simple, driver 1 and driver 2 will operate serially. Only once the rewriting in driver 1 finishes, we'll trigger proxy fetch flow. We can later try to make these two in parallel.
Render cohort: The critical line information will be stored in render cohort. Whenever we do a headless render, the entire config will be re-computed and stored irrespective of which filter invoked the render. This will ensure that there are no races.
Co-exist with FixReflowFilter: Fix reflow filter also passes an extension, we’ll need to make both the extensions work together. We’ll worry about the co-existence once we have the initial prototype in place.
We’ll use a smaller viewport to compute critical images while a larger viewport to determine above the fold HTML so that the effectiveness of filters like LazyloadImages and InlinePreview remains the same
- Any spec that we use will need to be robust to changes in HTML. If we split incorrectly, the user might see only see part of the content on the screen first, followed by the remaining. At the moment we are thinking of following ways to mitigate this:
- Take a more conservative split. We could base the split on a larger screen size say 1920 * 1200. If the HTML doesn’t change significantly, hopefully the split should still be correct.
- In Blink, we are working on a smart diff which could detect changes to publisher HTML. This is still work in progress but if we can get this working the diff could be the basis for determining when to recompute the critical line.
- Impact on Page Load Time: Since we are splitting HTML, we’ll reduce the parallelism with which the scripts / other resources could be downloaded. We could potentially end up degrading the PLT.
- XPaths taken directly from the headless browser may cause problems when interpreting with PSA parser. Initially we’ll start off with this and if needed we can move the XPath generation logic to PSA parser.
- Have multiple split versions based on user’s viewport.