Herein can be found the above-named generated novel, along with the code for generating it, the both of which were produced for NaNoGenMo 2019.
The generator is written as a collection of command-line programs written in Python 3.6. The only Python dependency is Beautiful Soup, used to extract the text from a source HTML file.
After downloading the HTML version of Anne of Green Gables
from Project Gutenberg and saving it as 45-h.htm, the novel
was generated by running the following command:
./build.py aogg 45-h.htm --random-seed=6010 --markov-order=1 --title "Anne of Green Garbles"
According to wc -w, the resulting novel,
Anne of Green Garbles,
comprises 54,638 words.
The software versions used were cPython 3.6.2, with beautifulsoup4 4.6.0, on Ubuntu 16.04.
The main goal of this project was to see how additional grammatical structure could be imposed on a Markov chain.
The main result is that, if the desired additional structure can be captured by a regular grammar, then, observing that both the regular grammar and the Markov chain can be thought of as probabilistic finite automata (with the probabilities in the regular grammar being always either 0% or 100%), we can apply the standard product construction on these two automata to obtain an automaton that represents a language which is the intersection of the two original languages.
{kind=link}
As a concrete example, if the Markov chain is obtained from analyzing Lucy Maud Montgomery's Anne of Green Gables, and the regular grammar is one which describes some basic rules of punctuation in English writing, as shown below (in the form of the corresponding finite automaton):
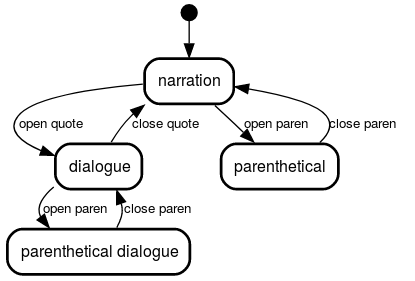
...then the resulting automaton is a Markov chain based on the word frequencies in Anne of Green Gables but restricted to producing only those strings which correctly follow the given rules of punctuation, generating text from it produces paragraphs like
“Well now that was overcome it much, of it was redder,” said Miss Barry kept the rake and starry eyes at the lane, the dismissal of being a middle of June evening at once in from being something to nobody either question. “I was born to the rest and good girl.” said. Once, with a boy at him on Anne’s eager-looking, hunting out into the way—their brown beard which, one of the tears and then to studying it, “Yes,” protested Anne walked home through the self-haired Shirley at least. “This is the worst.”
We might call the automaton resulting from this construction a "tagged Markov chain", because each token is tagged with the state of the regular grammar in which it was encountered. The construction is compatible with higher-order Markov chains; the tokens which precede a token can be thought of as additional tags on that token. Conversely, the state of the regular grammar could be thought of as a kind of abstract, "long-distance" higher-order factor in the Markov chain.
Just like when a conventional higher-order Markov chain is constructed, the result of this construction is itself a Markov chain; it retains the Markov property. This would not be the case if the grammar we wished to combine with the Markov chain was not a regular grammar (e.g. if it was a context-free grammar), as then we would need to "remember" how many levels of nesting we had entered previously.
The programs that comprise this generator are written in a style that is amenable
to usage in shell pipelines. However, for normal usage, running them via
the supplied build.py script is recommended.
Scripts whose names start with extract gather usable information from some
corpus or human-readable source, such as a web page downloaded from
Project Gutenberg, and output it in an intermediate format.
Scripts whose names start with xform are transformer filters
which read in a file (usually on stdin) and produce another
file (usually on stdout); these file are both in intermediate
formats, usually the same intermediate format.
Scripts whose names start with render are filters which
take a file in intermediate format and produce a file in
some human-readable output format, such as Markdown.
Some formats used by these tools are:
Intended as an input format only, this is any sort of HTML that BeautifulSoup can make sense of.
Intended as an output format only; as the final step of the pipeline the text is rendered as Markdown. (It can then be converted to HTML, etc., by various other tools.)
An intermediate format.
A text file in UTF-8 encoding, with LF line endings, with one token per line. A token is a lexeme, a sequence of characters that we treat as a "unit": a word or a bit of punctuation which is not part of some other word.
A tokenstream is merely a special case of tagged tokenstream (see below) where there are no tags on any tokens.
An intermediate format.
Like a tokenstream, but the token is preceded by a space and
zero or more tags; each tag is a string of the form A=B
where A and B can be any tokens which do not contain spaces
or =s.
Some meaningful tags are: state, the state of the automaton
representing the regular grammar; and prev1, the previous
token, for constructing an order-2 Markov chain.
If every token in the stream has the same set of tags, only potentially with different values for each tag, we call it a homogenous tagged tokenstream. The tagged tokenstreams used in this generator are homogenous.
An intermediate format.
A JSON file containing a map from tagged tokens to maps from tagged tokens to frequencies.
The generator here has some capabilities that, in the end, were not used in the generation of Anne of Green Garbles.
The build.py script supports being given multiple input
files (HTML documents), and builds a Markov chain model
as if this were a single long input text.
The xform-tag-with-prev-tokens.py filter implements an
order-2 Markov chain, by tagging each token with the
token immediately preceding it. This was to confirm that
the intersection construction works with higher-order
Markov chains.
The reason Anne of Green Garbles was produced using only Anne of Green Gables as its input text, with a Markov chain of order 1, was for aesthetic purposes -- I found the contrast of orderly dialogue/narration structure against the decidedly gibberishy output of the order-1 chain on a single work, to be more striking. (More Jess-esque, perhaps.)
In addition, the regular grammar used in this generator also handles parenthetical remarks (as you can see from the diagram above.) This literary device is, however, used only rarely in Lucy Maud Montgomery's works. Lucky for us though, Sax Rohmer wasn't shy about putting in a few parentheses here and there. So, to demonstrate all three of these features, here is an excerpt from The Incoherent Dr. Fu Manchu, which uses an order-2 Markov chain on several of Sax Rohmer's works, some of which do employ parenthetical phrases.
It wanted only three minutes or more above the nauseating odor of burning Indian hemp; and despite the wide, so characteristic of the one to arrest with the marked changes (corresponding with phases of the one who watched him proved too potent for his elusive courage. He wrote on). This was still unreal to me, and began very slowly, “This marks a new toy it does make you understand?” he declared. “It was not until I realized that he hoped to lure us.”
I should say that I have no real idea if this is a standard technique in statistics or what. All I know is that I'd been idly wondering, on and off, about how one might "teach a Markov chain a bit of grammar", since probably 2015; that I've never, to my knowledge, seen this method applied in the area of generative text or elsewhere; and that, when I decided to actually sit down and try it for NaNoGenMo 2019, it wasn't immediately obvious to me that the resulting stochastic model was still a Markov chain. See this comment and this comment in particular for my thoughts while I was working it out.
Shortly after I started working on this I was reminded of a similar project from a previous NaNoGenMo, and hunted for it. I wanted to find it, if only to satisfy myself that this wasn't just repeating an existing technique. In a short time I did find it; it was The Quantum Supposition of Oz by @spc476, for NaNoGenMo 2014. It is definitely similar in one respect: it treats punctuation and words in the input text as separate tokens in the Markov model. This is something that definitely makes sense to do when some of those tokens (punctuation) trigger state changes in a state machine.
In the issue for QSoO, I also mention a tool for cleaning up punctuation. That tool eventually became T-Rext. There was a certain (large) amount of punctuation cleanup in this project, as well; however, the cleanup here comes before creating the model, whereas T-Rext was intended to be run over basically-arbitrary text after it has already been generated. (See below for more about cleaning up punctuation.)
That year I was doing a lot of extracting source texts from
Project Gutenberg; I started out using a tool called gutenizer
for this purpose but, unsatisfied with it, I wrote my own tool called
Guten-gutter. Since writing it, however, I've come to the
conclusion that it takes the wrong approach. Guten-gutter extracts
text from plain text files provided by PG, but plain text files
obscure the structure of the text. In this project I instead used
Beautiful Soup to extract text from PG's HTML files, which capture
more structure. In particular, a paragraph of text is almost always
an HTML <p> element, which is much simpler than keeping track of
interstitial blank lines. This also makes it more versatile, as it
can be used to extract text from other HTML-based sources such as
WikiSource.
I should also say a few words about the architecture. As I was building this, the structure that fell out was to have a set of small programs, each with a specific dedicated task, usually to transform an intermediate format to another intermediate format, and to set them up as a pipeline (though with intermediate files instead of shell pipes.) In the world of programming language technology, this architecture is sometimes called a "micropass compiler" (see, for example, this paper by Sarkar, Waddell, and Dybvig) and coincides with another previous project, Lexeduct, in which text-processing is organized along basically the same lines. The pipeline architecture used here could well become the next major version of Lexeduct, if fortune dictates that my interests swing back in that direction in the future.
A lesson learned in this project: if you plan to retain some structure from the input text, you need to be pretty sure the input text has that structure in the first place.
Since we've defined a regular language for the rules of punctuation (see diagram in "Theory of Operation", above), we can also use it to check if the input text already conforms to those rules.
But for that purpose, the diagram is not complete. We'd also like to show what happens when you encounter something that violates the rules. The diagram for that is a wee bit more complex:

Then we need to decide what we will do if the input text does in fact violate the rules, and we end up in the "reject" state.
A basic approach is to process the input in units (paragraphs, say) and just throw out any units that don't adhere to the structure. If there are enough total units, this suffices.
But I wanted to do slightly better, so in a couple of filters in this generator, the code makes one or more attempts to "fix" the structure of the text before giving up. For example, a paragraph that starts with an opening double-quotation mark, but has no other double-quotation marks, probably indicates a monologue that will continue in the next paragraph, so a closing double-quotation mark is added to the end of the paragraph, and the program tries again.
And can I just close by saying that, in this context, the ' symbol is
absolutely murderous to handle. You can first see if it is a contraction
by checking common cases like ["don", "'", "t"], but the set of
contractions is not something that is fixed for every text ("'phone",
"s'pose", etc.) and some words have even undergone multiple contractions
("'tweren't"). Then you have to consider that it is also used for
posessives, and quotes within double-quotes, leading to the possibility
of sentences like
"To which she replied, 'Aunt Pris' marbles'," said Anne.
For that reason, this generator doesn't even try to interpret these
as single quotes; it will just assume that all the instances of '
in the above sentence are contractions. It's certainly possible to do
better, but in my estimation, outside the scope of NaNoGenMo 2019.