Welcome to the Heart Disease Prediction GitHub repository! This project is designed to help beginners learn the fundamentals of machine learning in a hands-on and interactive way. Whether you're completely new to machine learning or looking to refresh your knowledge, this repository has something for you.
Machine learning is a fascinating and rapidly growing field that involves building algorithms and models that can learn from data and make predictions or decisions. This repository is aimed at beginners who want to dive into the world of machine learning. Here, you'll find a collection of beginner-friendly tutorials, code examples, and resources to help you understand the core concepts of machine learning.
Before you dive into the tutorials and examples in this repository, make sure you have the following prerequisites:
- Basic programming knowledge (preferably in Python).
- Understanding of fundamental mathematical concepts (linear algebra, calculus, probability).
- Python 3.x installed on your system.
This repository is organized into the following sections:
-
Tutorials: Step-by-step tutorials that cover fundamental machine learning concepts. These tutorials include code examples and explanations to help you grasp the concepts.
-
Code Examples: A collection of standalone code examples that demonstrate various machine learning techniques and algorithms. These examples serve as building blocks for your own projects.
-
Datasets: Sample datasets that you can use to practice and experiment with machine learning algorithms.
-
Resources: Additional resources, including books, courses, and articles, to further your understanding of machine learning.
- Clone the Repository: Start by cloning this repository to your local machine using
git clone.
git clone https://github.com/chayandatta/Heart_disease_prediction.git-
Explore Tutorials and Code Examples: Browse the
TutorialsandCode Examplesdirectories to learn and experiment with different machine learning concepts. Each folder contains its own README file with instructions. -
Practice with Datasets: If you want to practice on real data, check out the
Datasetsdirectory for sample datasets that you can use in your machine learning projects. -
Check Resources: Explore the
Resourcessection for links to books, online courses, and articles to deepen your knowledge of machine learning. -
Contribute: If you have your own machine learning examples or resources that you'd like to share, feel free to contribute to this repository. See the Contributing section for guidelines.
contributions from the community is welcomed! If you'd like to contribute to this project, please follow these guidelines:
- Fork this repository.
- Create a new branch for your contribution.
- Make your changes and improvements.
- Test your changes thoroughly.
- Create a pull request (PR) with a clear description of your contribution.
I appreciate your help in making machine learning more accessible to beginners.
This project is licensed under the MIT License. You can find the full license details in the LICENSE file.
I hope you find this repository helpful on your journey to learning machine learning. If you have any questions or encounter issues, please feel free to open an issue, and I'll be happy to assist you. Happy learning! 🚀
Heart Disease prediction using 5 algorithms
- Logistic regression,
- Random forest,
- Naive Bayes,
- KNN(K Nearest Neighbors),
- Decision Tree
then improved accuracy by adjusting different aspect of algorithms.
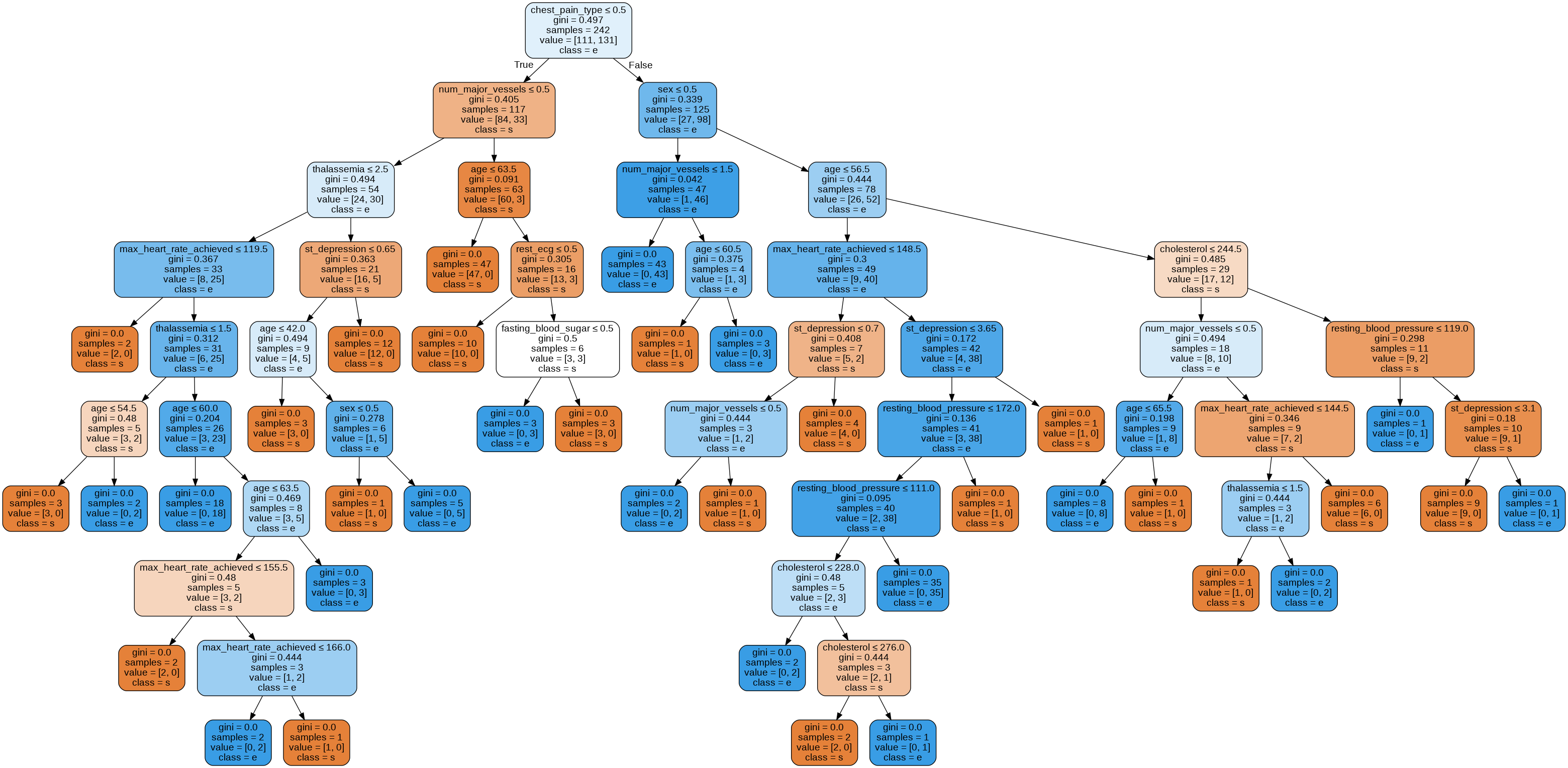
Final Decision tree
Dataset source (link)
Dataset Creators:
- Hungarian Institute of Cardiology. Budapest: Andras Janosi, M.D.
- University Hospital, Zurich, Switzerland: William Steinbrunn, M.D.
- University Hospital, Basel, Switzerland: Matthias Pfisterer, M.D.
- V.A. Medical Center, Long Beach and Cleveland Clinic Foundation: Robert Detrano, M.D., Ph.D.
Data Set Information:
This database contains 76 attributes, but all published experiments refer to using a subset of 14 of them. In particular, the Cleveland database is the only one that has been used by ML researchers to this date. The "goal" field refers to the presence of heart disease in the patient. It is integer valued from 0 (no presence) to 4. Experiments with the Cleveland database have concentrated on simply attempting to distinguish presence (values 1,2,3,4) from absence (value 0).