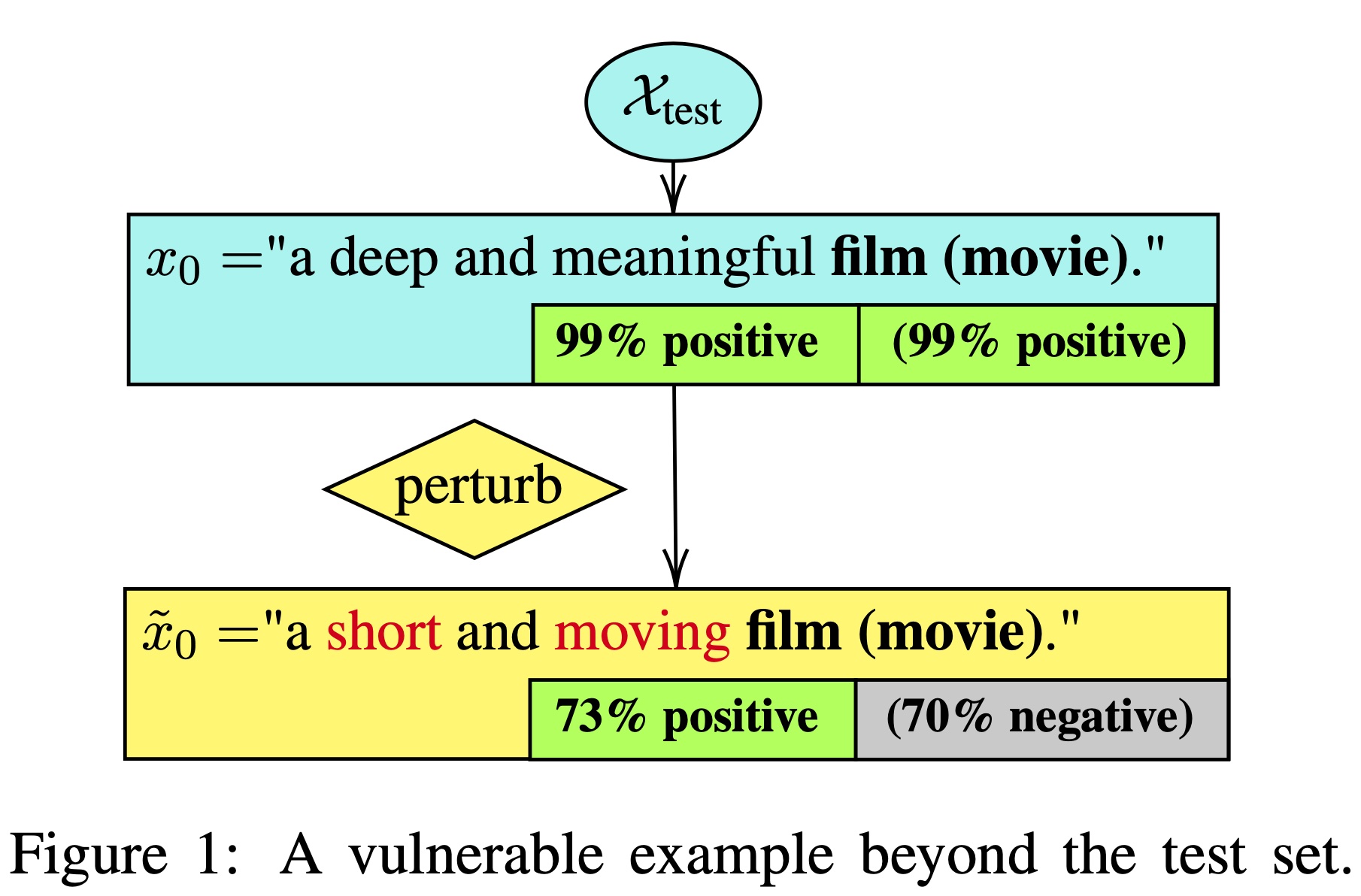
Robustness and counterfactual bias are usually evaluated on a test dataset. However, are these evaluations robust? If the test dataset is perturbed slightly, will the evaluation results keep the same? In this paper, we propose a "double perturbation" framework to uncover model weaknesses beyond the test dataset. The framework first perturbs the test dataset to construct abundant natural sentences similar to the test data, and then diagnoses the prediction change regarding a single-word substitution. We apply this framework to study two perturbation-based approaches that are used to analyze models' robustness and counterfactual bias in English. In the experiments, our method attains high success rates (96.0%-99.8%) in finding vulnerable examples and is able to reveal the hidden model bias. More details can be found in our paper:
Chong Zhang, Jieyu Zhao, Huan Zhang, Kai-Wei Chang, and Cho-Jui Hsieh, "Double Perturbation: On the Robustness of Robustness and Counterfactual Bias Evaluation", NAACL 2021 [demo notebook] [video] [slides] [poster] [proceeding]
Verified Environment:
- Ubuntu 20.04
- NVIDIA GeForce RTX 3090
- CUDA Version: 11.2
Clone the repo:
git clone --recurse-submodules git@github.com:chong-z/nlp-second-order-attack.git
cd nlp-second-order-attack
Create a clean environment in Conda or through your favorite virtual environments:
conda create --name SOAttack-3.8 python==3.8.3
conda activate SOAttack-3.8
Run the setup for PyTorch 1.7 and RTX 30xx GPU.
./setup.sh
Train a certified CNN model:
python libs/jia_certified/src/train.py classification cnn \
--out-dir model_data/cnn_cert_test -T 60 \
--full-train-epochs 20 -c 0.8 --random-seed 1234567 \
-d 100 --pool mean --dropout-prob 0.2 -b 32 \
--data-cache-dir .cache --save-best-only
Attack 10 examples from the SST2 dataset. Note that cnn_cert_test is a pre-defined variable in models/jia_certified.py, and you need to modify the file if you are using a different --out-dir.
./patched_textattack attack --attack-from-file=biasattack.py:SOBeamAttack \
--dataset-from-nlp=glue:sst2:validation --num-examples=10 --shuffle=False \
--model=models/jia_certified.py:cnn_cert_test
Train a certified 3-layer Transformers:
export PYTHONPATH=$PYTHONPATH:libs/xu_auto_LiRPA
python libs/xu_auto_LiRPA/examples/language/train.py \
--dir=model_data/transformer_cert --robust \
--method=IBP+backward_train --train --max_sent_length 128 \
--num_layers 3
Attack 10 examples from the SST2 dataset.
./patched_textattack attack --attack-from-file=biasattack.py:SOBeamAttack \
--dataset-from-nlp=glue:sst2:validation --num-examples=10 --shuffle=False \
--model=models/xu_auto_LiRPA.py:transformer_cert
Our code is general and can be used to evaluate custom models. Similar to models/jia_certified.py, you will need to create a wrapper models/custom_model.py and implement two classes:
class CustomTokenizerdef encode():- Optional:
def batch_encode():
class ModelWrapperdef __call__():def to():
And then the model and tokenizer can be specified with --model=models/custom_model.py:model_obj:tokenizer_obj, where model_obj and tokenizer_obj are the variables of the corresponding type.
Our code is built upon Qdata/TextAttack and thus shares the similar API.
Attack a pre-trained model lstm-sst2 in TextAttack Model Zoo:
./patched_textattack attack --attack-from-file=biasattack.py:SOBeamAttack \
--dataset-from-nlp=glue:sst2:validation --num-examples=10 --shuffle=False \
--model=lstm-sst2
Train a LSTM with the textattack train command:
./patched_textattack train --model=lstm \
--batch-size=32 --epochs=15 --learning-rate=1e-4 --seed=42 \
--dataset=glue:sst2 --max-length=128 --save-last
The resulting model can be found under model_data/sweeps/lstm_pretrained_glue:sst2_None_2021-04-10-17-23-38-819530. To attack:
./patched_textattack attack --attack-from-file=biasattack.py:SOBeamAttack \
--dataset-from-nlp=glue:sst2:validation --num-examples=10 --shuffle=False \
--model=model_data/sweeps/lstm_pretrained_glue:sst2_None_2021-04-10-17-23-38-819530
attack-from-file: Seebiasattack.pyfor a list of algorithms.SOEnumAttack: The brute-force SO-Enum attack that enumerates all neighborhood within distancek=2.SOBeamAttack: The beam search based SO-Beam attack that searches within the neighborhood of distancek=6.RandomBaselineAttack: The random baseline method mentioned in Appendix.BiasAnalysisChecklist: The enumeration method used for evaluating the counterfactual bias on protected tokens from Ribeiro et al. (2020).BiasAnalysisGender: The enumeration method used for evaluating the counterfactual bias on gendered pronounces from Zhao et al. (2018a).
dataset-from-nlp: The name of the HuggingFace dataset. It's also possible to load a custom dataset with--dataset-from-file=custom_datasets.py:sst2_simple.model: The target model for the attack. Can be a custom model in the form ofmodel_wrapper.py:model_obj:tokenizer_obj, or the name/path of the TextAttack model.- Additional parameters: Pleaser refer to
./patched_textattack --helpand./patched_textattack attack --help.
We use wandb to collect metrics for both training and attacking. To enable wandb, please do the following:
- Sign up for a free account through
wandb login, or go to the sign up page. - Append
--enable-wandbto the training and attacking commands mentioned previously.
Please refer to https://docs.wandb.ai/quickstart for detailed guides.
TextAttack: https://github.com/QData/TextAttack.libs/jia_certified: https://github.com/robinjia/certified-word-sub.libs/xu_auto_LiRPA: https://github.com/KaidiXu/auto_LiRPA.- See paper for the full list of references.