
![]()
See the 中文文档 for Chinese readme.
- What problems does XPipe solve
- System Overview
- Quick Start with Docker
- In-Depth Understanding
- Technical Exchange
- License
Redis is widely used within Ctrip, with client data statistics showing a total of 20 million read and write requests per second across all Redis instances at Ctrip. Among them, write requests are approximately 1 million per second. Many businesses even use Redis as a persistent in-memory database. This creates a significant demand for Redis in a multi-data-center environment, primarily to enhance availability and address Data Center Disaster Recovery (DR) issues and improve access performance. In response to these needs, XPipe was developed.
For convenience in description, DC (Data Center) is used to represent a data center.
The overall architecture diagram is as follows:
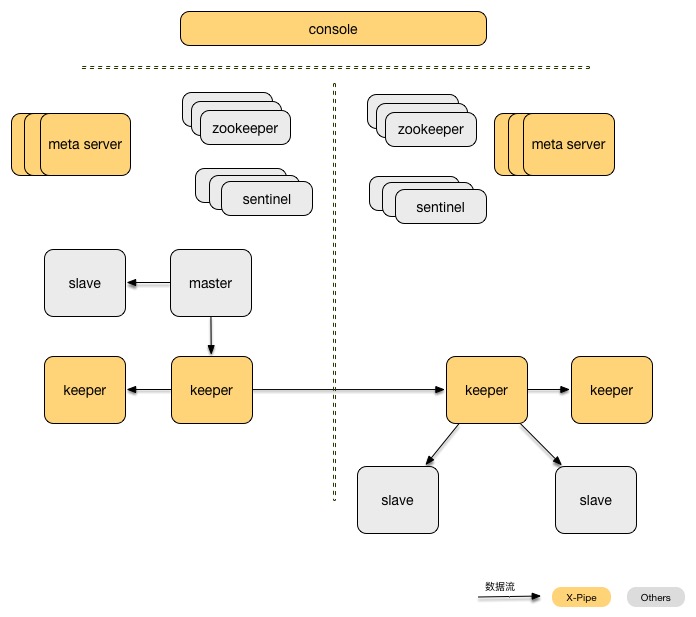
- Console is used to manage metadata for multiple data centers and provides a user interface for configuration and DR switching operations.
- Keeper is responsible for caching Redis operation logs and processing cross-data-center transfers, including compression and encryption.
- Meta Server manages the status of all keepers within a single data center and corrects abnormal states.
The primary challenge in a multi-data-center environment is data replication—how to transfer data from one DC to another. The decision was made to adopt a pseudo-slave approach, implementing the Redis protocol to masquerade as a Redis slave, allowing the Redis master to push data to the pseudo-slave, referred to as a keeper. The following diagram illustrates this:
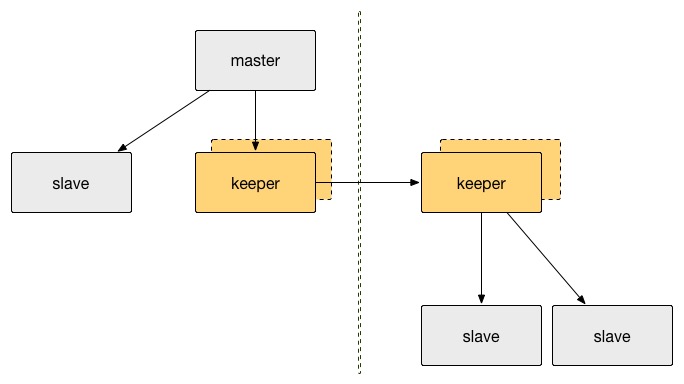
Advantages of using keeper:
- Reduces master full synchronization: Keeper caches RDB and replication log, allowing remote DC slaves to obtain data directly from the keeper, enhancing master stability.
- Reduces cross-data-center network traffic: Data between two data centers only needs to be transmitted through the keeper once, and the keeper-to-keeper transmission protocol can be customized for compression support (not currently supported).
- Reduces full synchronization in case of network issues: Keeper caches Redis log data to disk, enabling the caching of a large amount of log data, ensuring log data transmission even during prolonged network outages between data centers.
- Enhanced security: Data transmission between multiple data centers often occurs over public networks, making data security crucial. Keeper-to-keeper data transmission can also be encrypted (not yet implemented), increasing security.
- Check if DR switching can be performed: Similar to the 2PC protocol, the process starts with preparation to ensure a smooth flow.
- Disable writes in the original master data center: This step ensures that during migration, only one master is present, addressing potential data loss issues during migration.
- Promote the new master in the target data center.
- Other data centers synchronize with the new master.
Rollback and retry functionalities are provided. The rollback feature can revert to the initial state, while the retry feature allows fixing abnormal conditions and continuing the switch under DBA intervention.
If a keeper goes down, data transmission between multiple data centers may be interrupted. To address this, each keeper has a primary and backup node. The backup node constantly replicates data from the primary node. If the primary node goes down, the backup node is promoted to the primary node to continue service. This promotion operation is performed through a third-party node called MetaServer, responsible for transitioning keeper states and storing internal metadata for the data center. MetaServer also ensures high availability: each MetaServer is responsible for a specific Redis cluster, and when a MetaServer node goes down, another node takes over its Redis cluster. If a new node joins the cluster, an automatic load balancing occurs, transferring some clusters to the new node.
Redis itself provides a Sentinel mechanism to ensure cluster high availability. However, in versions prior to Redis 4.0, promoting a new master results in other nodes performing full synchronization upon connection to the new master. This leads to slave unavailability during full synchronization, reduced master availability due to RDB export, and instability in the overall system due to the large-scale data (RDB) transfer within the cluster.
As of the time of writing, Redis 4.0 has not been released, and the internal version used at Ctrip is 2.8.19. To address this, optimizations were made based on Redis 3.0.7, implementing the psync2.0 protocol for incremental synchronization. The Redis author's introduction to the protocol can be found here.
Internal Ctrip Redis address link
The testing method is illustrated in the following diagram. Data is sent from the client to the master, and the slave notifies the client through keyspace notification. The total test latency is the sum of t1, t2, and t3.
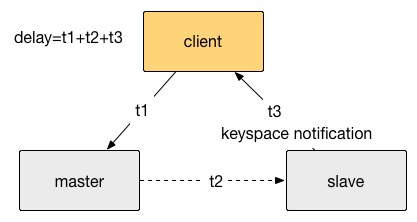
First, the latency test was conducted for direct replication from Redis master to slave, resulting in a latency of 0.2ms. Then, adding a layer of keeper between the master and slave increased the overall latency by 0.1ms to 0.3ms.
In production testing at Ctrip, where the round-trip time (RTT) between two data centers was approximately 0.61ms, the average latency with two layers of cross-data-center keepers was around 0.8ms, with a 99.9 percentile latency of 2ms.
Detailed reference - cross-public network deployment and architecture
Detailed reference - docker quick start
- [If you have any questions, please read] XPipe Wiki
- [Current user questions compilation] XPipe Q&A
- [Article] Ctrip Redis Multi-Data Center Solution - XPipe
- [Article] Ctrip Redis Overseas Data Synchronization Practice
- [PPT] Introduction to XPipe Usage within Ctrip

The project is licensed under the Apache 2 license.