![]()
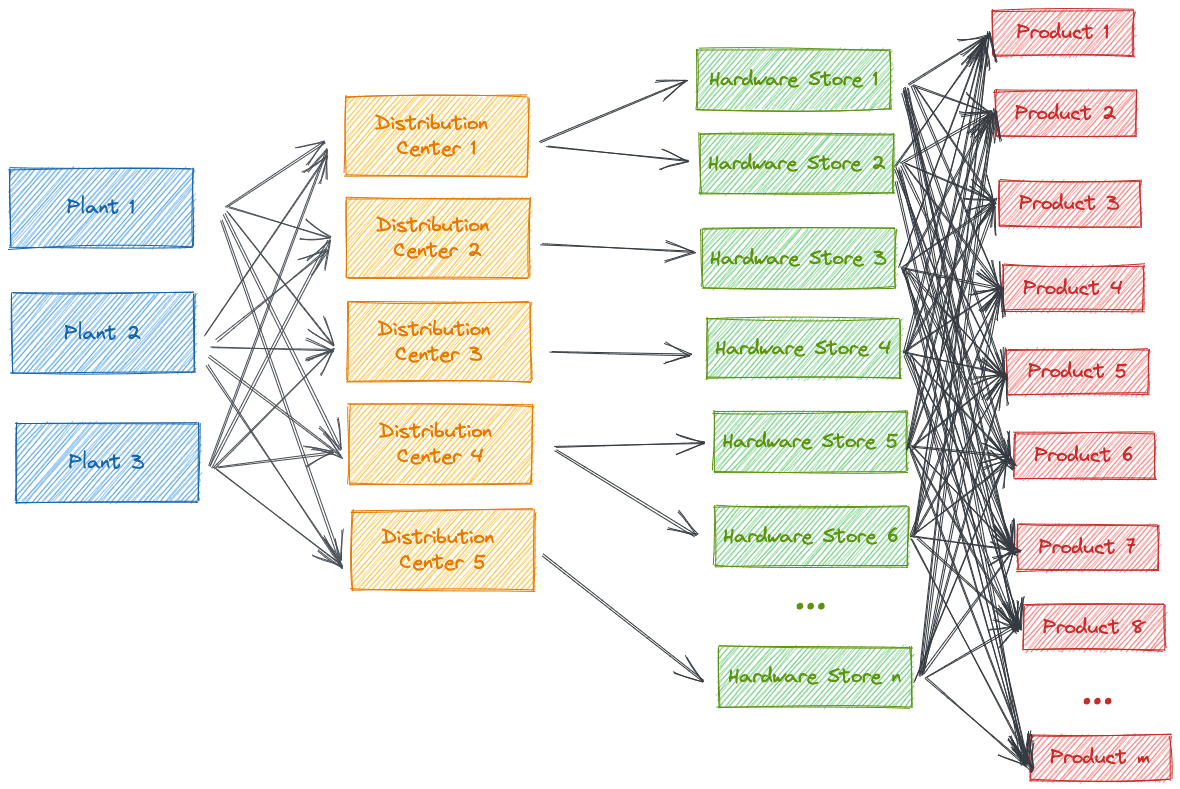
Situation: A manufacturer for power tools has 3 plants and delivers a set of 30 products to 5 distribution centers. Each distribution center is assigned to a set of between 40 and 60 hardware stores. Each store has a demand series for each of the products.
What's given:
- We have the demand series for each product in each hardware store
- We have a mapping table that uniquely assigns each distribution center to a hardware store. This assumption is a simplification as it is possible that one hardware store obtains products from different distribution centers
- We have a table that assignes the costs of shipping a product from each plant to each distribution center
- We have a table of the maximum quantities that can be produced by and shipped from each plant to each of the distribution centers
We proceeed in 2 steps:
- Demand Forecasting: Derive next week's demand for each product and distribution center:
- For the demand series for each product within each store we generate a one-week-ahead forecast
- For distribution center, we derive next week's estimated demand for each product
- Minimization of transportation costs: From the cost and constraints tables of producing by and shipping from a plant to a distribution center we derive cost-optimal transportation.
Author Max Köhler max.kohler@databricks.com
© 2022 Databricks, Inc. All rights reserved. The source in this notebook is provided subject to the Databricks License [https://databricks.com/db-license-source]. All included or referenced third party libraries are subject to the licenses set forth below.
| library | description | license | source |
|---|---|---|---|
| pulp | A python Linear Programming API | https://github.com/coin-or/pulp/blob/master/LICENSE | https://github.com/coin-or/pulp |
Although specific solutions can be downloaded as .dbc archives from our websites, we recommend cloning these repositories onto your databricks environment. Not only will you get access to latest code, but you will be part of a community of experts driving industry best practices and re-usable solutions, influencing our respective industries.

To start using a solution accelerator in Databricks simply follow these steps:
- Clone solution accelerator repository in Databricks using Databricks Repos
- Attach the
RUNMEnotebook to any cluster and execute the notebook via Run-All. A multi-step-job describing the accelerator pipeline will be created, and the link will be provided. The job configuration is written in the RUNME notebook in json format. - Execute the multi-step-job to see how the pipeline runs.
- You might want to modify the samples in the solution accelerator to your need, collaborate with other users and run the code samples against your own data. To do so start by changing the Git remote of your repository to your organization’s repository vs using our samples repository (learn more). You can now commit and push code, collaborate with other user’s via Git and follow your organization’s processes for code development.
The cost associated with running the accelerator is the user's responsibility.
Please note the code in this project is provided for your exploration only, and are not formally supported by Databricks with Service Level Agreements (SLAs). They are provided AS-IS and we do not make any guarantees of any kind. Please do not submit a support ticket relating to any issues arising from the use of these projects. The source in this project is provided subject to the Databricks License. All included or referenced third party libraries are subject to the licenses set forth below.
Any issues discovered through the use of this project should be filed as GitHub Issues on the Repo. They will be reviewed as time permits, but there are no formal SLAs for support.